В этой статье мы расскажем о методе выявления доменных имен, сгенерированных с использованием Domain Generation Algorithm. Например, moqbwfijgtxi.info, nraepfprcpnu.com, ocfhoajbsyek.net, pmpgppocssgv.biz, qwujokiljcwl.ru, bucjbprkflrlgr.org, cqmkugwwgccuit.info, pohyqxdedbrqiu.com, dfhpoiahthsjgv.net, qdcekagoqgifpq.biz. Подобные доменные имена часто даются сайтам, связанным с незаконной деятельностью.
Один из сценариев использования DGA можно наблюдать в случае заражения компьютерной системы вредоносной программой. Вредоносное ПО на скомпрометированной машине будет пытаться подключиться к системам под управлением злоумышленника, чтобы получать команды или отправить обратно собранную информацию.
Злоумышленники используют DGA для вычисления последовательности доменных имен, к которым будут пытаться подключиться зараженные машины. Это делается, чтобы предотвратить потерю контроля над взломанной инфраструктурой в тех случаях, когда домены или IP-адреса злоумышленника, прописанные прямо в коде, блокируются системами безопасности.
Решить проблему определения зловредного DGA-домена с помощью черного списка не получится, здесь требуется иной подход. Об одном из таких подходов и пойдет речь.
Основная идея состоит в том, что последовательности символов, используемые в легитимных доменных именах, отличаются от последовательностей символов доменных имен, полученных с помощью DGA, т. к. легитимный домен часто является человекочитаемым и несет смысловую нагрузку.
Для решения задачи было использовано машинное обучение и N-грамм-анализ. В качестве обучающей выборки был взят топ-миллион от alexa (белые домены) и 700 тысяч от bambenekconsulting.com (зловредные домены).
Для начала все множество доменов разбивается на обучающую и тестовую выборку. На основе обучающей выборки доменов строится множество N-грамм с учетом их уникальности. В качестве N-граммы берется подстрока доменного имени фиксированной длины.
Рассмотрим на примере DGA-домена Cryptolocker vzdzrsensinaix.com. Из него получится 11 N-грамм длиной 4 символа.

Рис. 1. Разбиение домена на N-граммы
Множество уникальных N-грамм, построенное на основе обучающей выборки, разбивается на три части: множество невредоносных N-грамм (встречаются только в легитимных доменах), множество вредоносных N-грамм (встречаются только в зловредных доменах) и множество нейтральных N-грамм (встречаются в доменах обоих типов). Каждой уникальной N-грамме ставится в соответствие числовой коэффициент:
Под обученной моделью мы будем понимать множество пар
Для данной задачи мы разработали специфический метод разбиения выборки. Основная его идея состоит в том, что в качестве обучающей выборки из множества зловредных и белых доменов составляется множество, содержащее в себе максимум информации о всех имеющихся доменах. По сути это означает, что для любого домена из тестовой выборки в модели существует как минимум k N-грамм, принадлежащих этому домену, где k — наперед заданное натуральное число.
В данном случае для обучения мы, в сущности, берем в качестве модели ядро нашей выборки. Это позволяет на этапе обучения избежать ситуаций, когда у очередного домена из тестовой выборки нет ни одного совпадения с моделью и, соответственно, нельзя принять решение о его принадлежности к тому или иному классу.
Такой способ разбиения выборки позволил улучшить точность классификации доменов — по сравнению, например, со случайным разбиением. Результаты тестирования обоих методов будут представлены ниже.

Рис. 2. Каждое доменное имя содержит непустое пересечение с обучающей выборкой. Минимальное количество пересечений для каждого домена задается в параметрах алгоритма разбиения
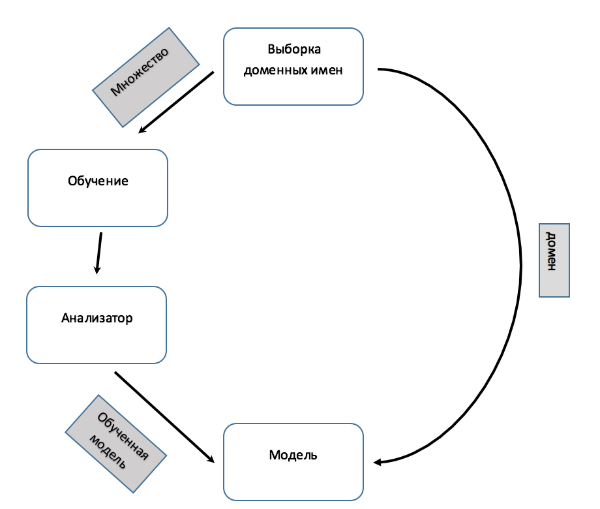
Рис. 3. Схема работы классификатора
Для определения вредоносности анализируемого домена алгоритм вычисляет рекурсивную функцию:
Проиллюстрируем работу анализатора на примере зловредного (pushdo bot) домена.
jrgxmwgwjz.com (? = 0,9; T = ?1,5)
Таблица 1. Пример работы анализатора:
?1,99 < T следовательно домен является зловредным. Пороговое значение T определено эмпирическим путем на основе проведенных исследований (см. рис. 4).
Теперь рассмотрим подробнее коэффициенты нейтральных N-грамм. Для получения этих коэффициентов используется эволюционный алгоритм (эволюционные алгоритмы — это семейство алгоритмов, предназначенных для решения задач оптимизации, основанных на принципах природной эволюции), в котором в качестве особи популяции берется вектор коэффициентов нейтральных N-грамм.
Задачей данной реализации эволюционного алгоритма является вычисление оптимальных числовых значений для нейтральных N-грамм. Решением, полученным в результате работы эволюционного алгоритма, является вектор значений коэффициентов нейтральных N-грамм, обеспечивающий наибольшую точность работы классификатора. Точность классификатора оценивается значением неубывающей целевой функции, выбранной в результате экспериментального тестирования:
Чем ближе значение Fitness к 2, тем выше точность классификации.
Для оценки эффективности нашего предложения была проведена серия экспериментов на выборке доменов. Все множество доменов было разделено на две части: обучающую и тестовую выборку.
Таблица 2. Размеры исследуемых выборок:

Рис. 4. Выбор оптимального порогового значения
Из графика на рис. 4 следует, что оптимальным пороговым значение является ?1,5, так как достигается баланс между false positive и false negative (обе ошибки порядка 1%).

Рис. 5. Сравнение разбиений выборки
Эксперименты показали, что предложенный нами метод обладает достаточно высокой точностью классификации, которая дополнительно возрастает при применении разработанного метода разбиения.
Автор: Александр Колокольцев, Positive Technologies
Один из сценариев использования DGA можно наблюдать в случае заражения компьютерной системы вредоносной программой. Вредоносное ПО на скомпрометированной машине будет пытаться подключиться к системам под управлением злоумышленника, чтобы получать команды или отправить обратно собранную информацию.
Злоумышленники используют DGA для вычисления последовательности доменных имен, к которым будут пытаться подключиться зараженные машины. Это делается, чтобы предотвратить потерю контроля над взломанной инфраструктурой в тех случаях, когда домены или IP-адреса злоумышленника, прописанные прямо в коде, блокируются системами безопасности.
Решить проблему определения зловредного DGA-домена с помощью черного списка не получится, здесь требуется иной подход. Об одном из таких подходов и пойдет речь.
Основная идея состоит в том, что последовательности символов, используемые в легитимных доменных именах, отличаются от последовательностей символов доменных имен, полученных с помощью DGA, т. к. легитимный домен часто является человекочитаемым и несет смысловую нагрузку.
Для решения задачи было использовано машинное обучение и N-грамм-анализ. В качестве обучающей выборки был взят топ-миллион от alexa (белые домены) и 700 тысяч от bambenekconsulting.com (зловредные домены).
Описание метода
Для начала все множество доменов разбивается на обучающую и тестовую выборку. На основе обучающей выборки доменов строится множество N-грамм с учетом их уникальности. В качестве N-граммы берется подстрока доменного имени фиксированной длины.
Рассмотрим на примере DGA-домена Cryptolocker vzdzrsensinaix.com. Из него получится 11 N-грамм длиной 4 символа.
Рис. 1. Разбиение домена на N-граммы
Множество уникальных N-грамм, построенное на основе обучающей выборки, разбивается на три части: множество невредоносных N-грамм (встречаются только в легитимных доменах), множество вредоносных N-грамм (встречаются только в зловредных доменах) и множество нейтральных N-грамм (встречаются в доменах обоих типов). Каждой уникальной N-грамме ставится в соответствие числовой коэффициент:
- 1 — легитимные,
- ?1 — зловредные,
- число из {?1.0..1.0} — нейтральные.
Под обученной моделью мы будем понимать множество пар
{( q, Ng(q))}, где Ng(q) = p, p — числовой коэффициент N-граммы q, q принадлежит Q, Q — множество всех N-грамм в обучающей выборке.Разбиение выборки
Для данной задачи мы разработали специфический метод разбиения выборки. Основная его идея состоит в том, что в качестве обучающей выборки из множества зловредных и белых доменов составляется множество, содержащее в себе максимум информации о всех имеющихся доменах. По сути это означает, что для любого домена из тестовой выборки в модели существует как минимум k N-грамм, принадлежащих этому домену, где k — наперед заданное натуральное число.
В данном случае для обучения мы, в сущности, берем в качестве модели ядро нашей выборки. Это позволяет на этапе обучения избежать ситуаций, когда у очередного домена из тестовой выборки нет ни одного совпадения с моделью и, соответственно, нельзя принять решение о его принадлежности к тому или иному классу.
Такой способ разбиения выборки позволил улучшить точность классификации доменов — по сравнению, например, со случайным разбиением. Результаты тестирования обоих методов будут представлены ниже.
Рис. 2. Каждое доменное имя содержит непустое пересечение с обучающей выборкой. Минимальное количество пересечений для каждого домена задается в параметрах алгоритма разбиения
Обучение модели
Рис. 3. Схема работы классификатора
Для определения вредоносности анализируемого домена алгоритм вычисляет рекурсивную функцию:
I(i) = I(i-1) * ? + Ng(qi), где qi — i-я N-грамма домена, Ng(qi) — коэффициент рассматриваемой N-граммы, ? — смягчающий коэффициент, I(0) = 0. Для допустимых значений рекурсивной функции определена граница T. Как только результат вычисления очередной итерации рекурсивной функции становится меньше этой границы, соответствующий домен объявляется зловредным.Проиллюстрируем работу анализатора на примере зловредного (pushdo bot) домена.
jrgxmwgwjz.com (? = 0,9; T = ?1,5)
Таблица 1. Пример работы анализатора:
| Номер N-граммы | N-грамма | Коэффициент N-граммы из модели |
Значение рекурсивной функции |
|---|---|---|---|
| 1 | jrgx | -1 | ?1 |
| 2 | rgxm | 0 | ?0,9 |
| 3 | gxmw | 0 | ?0,81 |
| 4 | xmwg | 0 | ?0,73 |
| 5 | mwgw | 0,06 | ?0,6 |
| 6 | wgwj | ?0,92 | ?1,45 |
| 7 | gwjz | ?0,68 | ?1,99 |
?1,99 < T следовательно домен является зловредным. Пороговое значение T определено эмпирическим путем на основе проведенных исследований (см. рис. 4).
Теперь рассмотрим подробнее коэффициенты нейтральных N-грамм. Для получения этих коэффициентов используется эволюционный алгоритм (эволюционные алгоритмы — это семейство алгоритмов, предназначенных для решения задач оптимизации, основанных на принципах природной эволюции), в котором в качестве особи популяции берется вектор коэффициентов нейтральных N-грамм.
Задачей данной реализации эволюционного алгоритма является вычисление оптимальных числовых значений для нейтральных N-грамм. Решением, полученным в результате работы эволюционного алгоритма, является вектор значений коэффициентов нейтральных N-грамм, обеспечивающий наибольшую точность работы классификатора. Точность классификатора оценивается значением неубывающей целевой функции, выбранной в результате экспериментального тестирования:
Fitness = P/TP + N/TN + FP/P + FN/NЧем ближе значение Fitness к 2, тем выше точность классификации.
Результаты
Для оценки эффективности нашего предложения была проведена серия экспериментов на выборке доменов. Все множество доменов было разделено на две части: обучающую и тестовую выборку.
Таблица 2. Размеры исследуемых выборок:
| Количество зловредных доменов |
Количество легитимных доменов |
|
|---|---|---|
| Обучающая выборка |
60 000 | 70 000 |
| Тестовая выборка |
640 000 | 830 000 |
Рис. 4. Выбор оптимального порогового значения
Из графика на рис. 4 следует, что оптимальным пороговым значение является ?1,5, так как достигается баланс между false positive и false negative (обе ошибки порядка 1%).
Оценка качества метода
Рис. 5. Сравнение разбиений выборки
Эксперименты показали, что предложенный нами метод обладает достаточно высокой точностью классификации, которая дополнительно возрастает при применении разработанного метода разбиения.
Автор: Александр Колокольцев, Positive Technologies
Комментарии (3)

Noyer
25.04.2016 15:29student_ivan ещё можно добавить функцию > «чем длиннее тем хуже», и считывание по вордлисту простых слов англ. слов. Думаю, читаемые имена можно сразу исключить.

student_ivan
Круто, можно еще заведомо считать правильными домены короче 6 символов — среди них самая низкая вероятность вредных доменов.