 Intel начинает поставки двухчиповой платформы для разработки, состоящей из процессора Xeon E5-2600 v4 (Broadwell) и FPGA Altera Arria 10 — такую информацию озвучила вице-президент Intel Diane Bryant в своей речи на конференции IDF 2016 в Китае. Предполагается, что с помощью подобного гибрида удастся получить 70% прирост производительности при том же энергопотреблении и частоте. Плоды сотрудничества Intel и Altera, которое продолжается далеко не первый год, мы уже видели в лице прототипа платформы 5G — там скрещивались FPGA и Intel Core. И вот теперь — новый дуэт. В планах на будущее — полная интеграция обоих компонентов на одном кристалле. Первыми потребителями гибрида станут крупнейшие облачные сервисы и дата-центры. По прогнозам Intel, к 2020 году до 30% серверов в дата-центрах будут иметь процессоры с FPGA.
Intel начинает поставки двухчиповой платформы для разработки, состоящей из процессора Xeon E5-2600 v4 (Broadwell) и FPGA Altera Arria 10 — такую информацию озвучила вице-президент Intel Diane Bryant в своей речи на конференции IDF 2016 в Китае. Предполагается, что с помощью подобного гибрида удастся получить 70% прирост производительности при том же энергопотреблении и частоте. Плоды сотрудничества Intel и Altera, которое продолжается далеко не первый год, мы уже видели в лице прототипа платформы 5G — там скрещивались FPGA и Intel Core. И вот теперь — новый дуэт. В планах на будущее — полная интеграция обоих компонентов на одном кристалле. Первыми потребителями гибрида станут крупнейшие облачные сервисы и дата-центры. По прогнозам Intel, к 2020 году до 30% серверов в дата-центрах будут иметь процессоры с FPGA.Тут уместно упомянуть, что в прошлом году стартовал совместный проект компаний Intel и eASIC по созданию платформы Xeon + ASIC для кастомизации процессоров под конкретные предварительно оговоренные нагрузки. Воистину, больше Xeon'ов, хороших и разных!
Под катом — немного информации о FPGA Altera Arria 10.
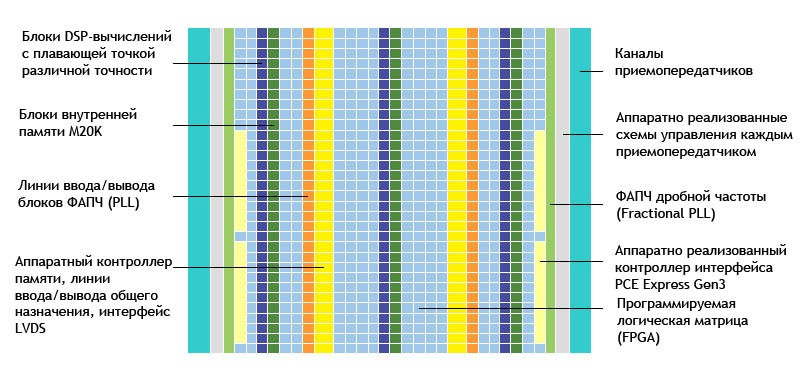
Устройство FPGA семейства Arria 10
Новые ПЛИС FPGA семейства Arria 10 выполнены по технологическим нормам 20 нм. Устройства семейства Arria 10 отличаются на 40% меньшим энергопотреблением, чем ПЛИС FPGA предыдущего поколения, и являются единственными в отрасли программируемыми логическими схемами с аппаратно реализованными блоками цифровой обработки сигналов с плавающей точкой с производительностью 1500 GFLOPS (млрд. операций с плавающей точкой).
- Пропускная способность интегрированных приемопередатчиков до 28.3 Гбит/с
- Высокопроизводительный интерфейс внешней памяти с пропускной способностью 2666 Мбит/с
- Аппаратные блоки DSP-вычислений с плавающей точкой, соответствующие требованиям спецификации IEEE 754
- До 96 каналов приемопередатчиков обеспечивают тракт последовательной передачи данных с пропускной способностью до 3.6 Тбит/с
Программное использование возможностей FPGA будет осуществляться посредством Altera OpenCL SDK
Комментарии (28)

liptipton
27.04.2016 16:59+2Теперь можно поставлять процессоры без AES, а потом заливать прошивку на месте.

raydac
27.04.2016 16:59+1жаль Иван Макарченко не дожил, он в конце 90-х сращивал Z84 и Altera FPGA, на базе чего была построена платформа Sprinter 97 которая могла менять аппаратную конфигурацию до 2х раз в секунду, своего рода Domain Specific Platform, похоже что через 20 лет Intel набрел на путь
vilgeforce
27.04.2016 17:04А как FPGA будет конфигурироваться? Будут специальные инструкции процессора?

mikhanoid
27.04.2016 19:18+1А зачем? Просто будет обычная FPGA на кристалле. Вряд ли слишком тесная интеграция CPU и FPGA оправдана. Хотя бы по той причине, что частоты у CPU намного выше. Просто буде ещё одно устройство в системе, как сейчас это с IGP.
nckma
28.04.2016 13:50+1Слишком тесная интеграция вряд ли получится у Интел уже был Атом с FPGA Альтеры — там связь была через PCIe. Думаю и здесь будет так же.
PS: кстати Интел таки купила Альтеру в конце прошлого года.

ishevchuk
27.04.2016 17:24+4- Есть ли (где) даташит на этот чип от Интела? Сколько там ресурсов у FPGA? Сколько там трансиверов, если есть?
- Cокет не поменялся? Я могут этот чип просто взять и вставить себе в старый сервер?
- Поставки идут для абстрактых кастомеров с инжерерными образцами, или реально пошел масспродакт?
- Когда чип можно будет купить в США/Европе/России в «обычном» магазине? Можно ли как-то записаться в очередь на получение чипов?

GennPen
27.04.2016 19:22+2Аппаратно изменяемый процессор — я думаю, это будет новый виток.
dmitry_ch
28.04.2016 08:51+2«Вы не оплатили стоимость аренды расширенных функцйй вашего процессора на следующий период. Расширенные функции были отключены, и теперь вместо Xeon 32 ядра 3 Ггц вы используете процессор, эквивалентный i3 1 ядро 1 Ггц, рекомендуем учитывать это при расчетах нагрузочной способности вашего серверного оборудования»
mikhanoid
27.04.2016 19:32Занятно, конечно, но зачем это нужно? Почему это будет эффективнее обычных GPU, которые весьма неплохо под OpenCL заточены? Или gpu-технологии все уже запатентованы, а Intel-у надо что-то делать, чтобы быть на уровне?

kosmos89
27.04.2016 20:01+2Вы не знаете, что такое FPGA?
boblenin
27.04.2016 22:05А где можно ознакомиться, чтобы доступным языком?

istui
27.04.2016 22:20крайне грубое объяснение — это программируемая матрица вентилей, из которых можно собрать любую схему, которая вам нужна, решающую конкретную задачу в разы быстрее (т.к. ее исполнение будет реализовываться не процессорами, а напрямую «в железе»). + Возможно сформировать необходимое аппаратное обеспечение на ходу (условно: на одних и тех же выводах формировать то VGA, то LPT-интерфейс).
P.S. Я не специалист, поэтому возможны некоторые расхождения…GennPen
27.04.2016 22:31А кто в курсе, с какой частотой современные ПЛИС могут «пересобираться»?

ValeriyS
28.04.2016 00:50+1Зависит от размера FPGA и ширины шины конфигурирования. Для FPGA, не встроенных в CPU, максимальная скорость конфигурирования 32 бит 100 MHz. Размер типичного конфигурационного файла — 30 МБайт. Получается около 80 миллисекунд.
Есть ещё такая технология как Partial Reconfiguration, т.е. можно переконфигурировать только часть FPGA. Если это 10% от размера FPGA, то время переконфигурирования будет в десять раз меньше.
lorc
27.04.2016 20:10+2FPGA — это более никий уровень, а значит на нём можно делать то, что GPU не под силу. Например обрабатывать сильно коррелированные данные (где одни ячейки данных зависят от других).
TimID
27.04.2016 23:05Напротив, FPGA — это более «высокий» уровень — это возможность добавить новую функцию прямо в «железо процессора». Например, нужно Вам аппаратно сложить два вектора с сотней разрядов, то не мучайтесь с битами переносов CPU, а просто реализуйте соответствующий модуль на ПЛИС.
mikhanoid
28.04.2016 00:30А точно будет эффективнее, чем с битами на GPU бороться? Ведь, вроде как, и у самой FPGA частота меньше, и ещё задержки будут, скорее всего, по log от размера схемы. Так что, не очевидно.
TimID
28.04.2016 01:00+1Как знать. Вот точно видел реализацию модуля стереореконструкции на FPGA. После калибровки «в железе» свёртки в один «щелк» считаются. Правда для каждой точки исходного изображения по-отдельности. Но для «большой» ПЛИСки можно ведь сразу для целой строки изображения считать. Получите всё облако точек всего за 1080 операций (построчно для HD), разве это плохо?
mikhanoid
28.04.2016 08:53+1Не плохо, конечно же. Но для ПЛИС вопросы масштабирования не так уж и просто решаются. Для той же стереореконструкции нужно рассматривать некие окрестности точек, для определения совпадений, значит, надо грузить данные некими пачками и раздавать эти пачки по трактам данных на различные схемы. И тут сразу возникает вопрос сложности топологии. Не любая топология успешно раскладывается на ПЛИС, и не любая успешно разложенная топология может работать с высокой частотой.
Поэтому, ПЛИС, вроде как на практике, выстреливают в двух случаях: когда можно организовать длинные конвейеры и грузить их данными без задержек, или когда есть параллелизм по данным с локальными зависимостями, примерно такой же, как в GPU. Если выполняются оба условия, то получается ещё лучше.
Но надо ещё учитывать, что частота работы ПЛИС всегда существенно меньше, чем частота работы ASIC, потому что вентили у ПЛИС организованы по гораздо более сложной схеме. Они занимают больше места, потребляют больше энергии и так далее, и тому подобное.
Microsoft в своё время озаботилась сравнением реализаций скалярного умножения, и у них получилось, что быстрее всего работает это умножение работает на CPU. Можно нагуглить информацию по microsoft gaxpy. По энергопотреблению ПЛИС выиграла прилично, но по скорости уступила процессорам. Если же ПЛИС разогнать до скорости процессора, то и энергопотребление вырастет существенно. В общем, как-то так всё. Существенно нетривиально.
Сейчас просто для Intel не очень приятная ситуация, видимо. AMD скоро выпускает свой Zen, вроде как, обещают, что cpu-ядра будут там выдавать приличную производительность, а с gpu-ядрами у AMD всегда было хорошо. Intel-у же сейчас нечего предложить подобного. Поэтому вот пробуют через ПЛИС зайти. Поэтому и пишут, что программировать можно будет на OpenCL.
Так что, запасаемся попкорном и ждём тестов производительности.
lorc
28.04.2016 14:14Ну вот именно потому это и низкий уровень — грубо говоря, можно напрямую коммутировать логические элементы.
GPU — это уровень повыше: логические элементы уже сконфигурированы в процессорные блоки, каждый из которых может выполнять один и тот же код. Где-то дальше по спектру лежат виртуальные машины типа Java VM: вычислитель, структура которого вообще никак не коррелирует со структурой нижележащего аппаратного обеспечения.
mikhanoid
28.04.2016 00:32А точно получится? Вроде как, большое количество трактов данных между разными ФУ протянуть сложновато может быть.
horlon
28.04.2016 08:41На мой взгляд, это нужно для увеличения продаж процессоров, т.к. FPGA имеет ресурс 3000 — 10000 циклов перезаписи, а дальше — выход из строя.
Disasm
28.04.2016 13:35+1> ресурс 3000 — 10000 циклов перезаписи
Пруфы, пожалуйста. Вы не путаете с мелкими CPLD, у которых своя память для постоянного хранения конфигурации?
valeriyk
28.04.2016 00:18ну это не сюрприз, и ежу понятно, что именно для этого интел альтеру и купил
alexkuzko
На десктопах это хоть как-то планируется? Или будет исключительно прерогативой серверного рынка?
darkAlert
кто вам сейчас мешает взять и поставить xeon у себя дома?
safari2012
цена на серверную материнку, имхо.