
ClickHouse позволяет выполнять аналитические запросы в интерактивном режиме по данным, обновляемым в реальном времени. Система способна масштабироваться до десятков триллионов записей и петабайт хранимых данных. Использование ClickHouse открывает возможности, которые раньше было даже трудно представить: вы можете сохранять весь поток данных без предварительной агрегации и быстро получать отчёты в любых разрезах. ClickHouse разработан в Яндексе для задач Яндекс.Метрики — второй по величине системы веб-аналитики в мире.
В этой статье мы расскажем, как и для чего ClickHouse появился в Яндексе и что он умеет; сравним его с другими системами и покажем, как его поднять у себя с минимальными усилиями.
Где находится ниша ClickHouse
Зачем кому-то может понадобиться использовать ClickHouse, когда есть много других технологий для работы с большими данными?
Если вам нужно просто хранить логи, у вас есть много вариантов. Вы можете загружать логи в Hadoop, анализировать их с помощью Hive, Spark или Impala. В этом случае вовсе не обязательно использовать ClickHouse. Всё становится сложнее, если вам нужно выполнять запросы в интерактивном режиме по неагрегированным данным, поступающим в систему в реальном времени. Для решения этой задачи, открытых технологий подходящего качества до сих пор не существовало.
Есть отдельные области, в которых могут быть использованы другие системы. Их можно классифицировать следующим образом:
- Коммерческие OLAP СУБД для использования в собственной инфраструктуре.
Примеры: HP Vertica, Actian Vector, Actian Matrix, EXASol, Sybase IQ и другие.
Наши отличия: мы сделали технологию открытой и бесплатной.
- Облачные решения.
Примеры: Amazon Redshift и Google BigQuery.
Наши отличия: клиент может использовать ClickHouse в своей инфраструктуре и не платить за облака.
- Надстройки над Hadoop.
Примеры: Cloudera Impala, Spark SQL, Facebook Presto, Apache Drill.
Наши отличия:
- в отличие от Hadoop, ClickHouse позволяет обслуживать аналитические запросы даже в рамках массового сервиса, доступного публично, такого как Яндекс.Метрика;
- для функционирования ClickHouse не требуется разворачивать Hadoop инфраструктуру, он прост в использовании, и подходит даже для небольших проектов;
- ClickHouse позволяет загружать данные в реальном времени и самостоятельно занимается их хранением и индексацией;
- в отличие от Hadoop, ClickHouse работает в географически распределённых датацентрах.
- Open-source OLAP СУБД.
Примеры: InfiniDB, MonetDB, LucidDB.
Разработка всех этих проектов заброшена, они никогда не были достаточно зрелыми и, по сути, так и не вышли из альфа-версии. Эти системы не были распределёнными, что является критически необходимым для обработки больших данных. Активная разработка ClickHouse, зрелость технологии и ориентация на практические потребности, возникающие при обработке больших данных, обеспечивается задачами Яндекса. Без использования «в бою» на реальных задачах, выходящих за рамки возможностей существующих систем, создать качественный продукт было бы невозможно.
- Open-source системы для аналитики, не являющиеся Relational OLAP СУБД.
Примеры: Metamarkets Druid, Apache Kylin.
Наши отличия: ClickHouse не требует предагрегации данных. ClickHouse поддерживает диалект языка SQL и предоставляет удобство реляционных СУБД.
В рамках той достаточно узкой ниши, в которой находится ClickHouse, у него до сих пор нет альтернатив. В рамках более широкой области применения, ClickHouse может оказаться выгоднее других систем с точки зрения скорости обработки запросов, эффективности использования ресурсов и простоты эксплуатации.

Карта кликов в Яндекс.Метрике и соответствующий запрос в ClickHouse
Изначально мы разрабатывали ClickHouse исключительно для задач Яндекс.Метрики — чтобы строить отчёты в интерактивном режиме по неагрегированным логам пользовательских действий. В связи с тем, что система является полноценной СУБД и обладает весьма широкой функциональностью, уже в начале использования в 2012 году, была написана подробная документация. Это отличает ClickHouse от многих типичных внутренних разработок — специализированных и встраиваемых структур данных для решения конкретных задач, таких как, например, Metrage и OLAPServer, о которых я рассказывал в предыдущей статье.
Развитая функциональность и наличие детальной документации привели к тому, что ClickHouse постепенно распространился по многим отделам Яндекса. Неожиданно оказалось, что система может быть установлена по инструкции и работает «из коробки», то есть не требует привлечения разработчиков. ClickHouse стал использоваться в Директе, Маркете, Почте, AdFox, Вебмастере, в мониторингах и в бизнес-аналитике. ClickHouse позволял либо решать задачи, для которых раньше не было подходящих инструментов, либо решать задачи на порядки эффективнее, чем другие системы.
Постепенно возник спрос на использование ClickHouse не только во внутренних продуктах Яндекса. Например, в 2013 году, ClickHouse применялся для анализа метаданных о событиях эксперимента LHCb в CERN. Система могла бы использоваться более широко, но в то время этому мешал закрытый статус. Другой пример: open-source технология Яндекс.Танк внутри Яндекса использует ClickHouse для хранения данных телеметрии, тогда как для внешних пользователей в качестве базы данных был доступен только MySQL, который плохо подходит для данной задачи.
По мере расширения пользовательской базы, возникла необходимость тратить на разработку чуть больше усилий, хоть и не очень много по сравнению с трудозатратами на решение задач Метрики. Зато в награду мы получаем повышение качества продукта, особенно в плане юзабилити.
Расширение пользовательской базы позволяет рассматривать примеры использования, которые без этого едва ли пришли бы в голову. Также это позволяет быстрее находить баги и неудобства, которые имеют значение в том числе и для основного применения ClickHouse — в Метрике. Без сомнения, всё это повышает качество продукта. Поэтому нам выгодно сделать ClickHouse открытым сегодня.
Как перестать бояться и начать использовать ClickHouse
Давайте попробуем работать с ClickHouse на примере «игрушечных» открытых данных — информации об авиаперелётах в США с 1987 по 2015 год. Это нельзя назвать большими данными (всего 166 млн. строк, 63 GB несжатых данных), зато вы можете быстро скачать их и начать экспериментировать. Скачать данные можно отсюда.
Данные можно также скачать из первоисточника. Как это сделать, написано здесь.
Для начала, установим ClickHouse на один сервер. Ниже также будет показано, как установить ClickHouse на кластер с шардированием и репликацией.
На Ubuntu и Debian Linux вы можете установить ClickHouse из готовых пакетов. На других Linux-системах, можно собрать ClickHouse из исходников и установить его самостоятельно.
Пакет clickhouse-client содержит программу clickhouse-client — клиент ClickHouse для работы в интерактивном режиме. Пакет clickhouse-server-base содержит бинарник clickhouse-server, а clickhouse-server-common — конфигурационные файлы к серверу.
Конфигурационные файлы сервера находятся в /etc/clickhouse-server/. Главное, на что следует обратить внимание перед началом работы — элемент path — место хранения данных. Необязательно модифицировать непосредственно файл config.xml — это не очень удобно при обновлении пакетов. Вместо этого можно переопределить нужные элементы в файлах в config.d директории.
Также имеет смысл обратить внимание на настройки прав доступа.
Сервер не запускается самостоятельно при установке пакета и не перезапускается сам при обновлении.
Для запуска сервера, выполните:
sudo service clickhouse-server startЛоги сервера расположены по-умолчанию в директории /var/log/clickhouse-server/.
После появления сообщения Ready for connections в логе, сервер будет принимать соединения.
Для подключения к серверу, используйте программу clickhouse-client.
clickhouse-client
clickhouse-client --host=... --port=... --user=... --password=...
Включить многострочные запросы:
clickhouse-client -m
clickhouse-client --multiline
Выполнение запросов в batch режиме:
clickhouse-client --query='SELECT 1'
echo 'SELECT 1' | clickhouse-client
Вставка данных в заданном формате:
clickhouse-client --query='INSERT INTO table VALUES' < data.txt
clickhouse-client --query='INSERT INTO table FORMAT TabSeparated' < data.tsv
Создаём таблицу для тестовых данных
$ clickhouse-client --multiline
ClickHouse client version 0.0.53720.
Connecting to localhost:9000.
Connected to ClickHouse server version 0.0.53720.
:) CREATE TABLE ontime
(
Year UInt16,
Quarter UInt8,
Month UInt8,
DayofMonth UInt8,
DayOfWeek UInt8,
FlightDate Date,
UniqueCarrier FixedString(7),
AirlineID Int32,
Carrier FixedString(2),
TailNum String,
FlightNum String,
OriginAirportID Int32,
OriginAirportSeqID Int32,
OriginCityMarketID Int32,
Origin FixedString(5),
OriginCityName String,
OriginState FixedString(2),
OriginStateFips String,
OriginStateName String,
OriginWac Int32,
DestAirportID Int32,
DestAirportSeqID Int32,
DestCityMarketID Int32,
Dest FixedString(5),
DestCityName String,
DestState FixedString(2),
DestStateFips String,
DestStateName String,
DestWac Int32,
CRSDepTime Int32,
DepTime Int32,
DepDelay Int32,
DepDelayMinutes Int32,
DepDel15 Int32,
DepartureDelayGroups String,
DepTimeBlk String,
TaxiOut Int32,
WheelsOff Int32,
WheelsOn Int32,
TaxiIn Int32,
CRSArrTime Int32,
ArrTime Int32,
ArrDelay Int32,
ArrDelayMinutes Int32,
ArrDel15 Int32,
ArrivalDelayGroups Int32,
ArrTimeBlk String,
Cancelled UInt8,
CancellationCode FixedString(1),
Diverted UInt8,
CRSElapsedTime Int32,
ActualElapsedTime Int32,
AirTime Int32,
Flights Int32,
Distance Int32,
DistanceGroup UInt8,
CarrierDelay Int32,
WeatherDelay Int32,
NASDelay Int32,
SecurityDelay Int32,
LateAircraftDelay Int32,
FirstDepTime String,
TotalAddGTime String,
LongestAddGTime String,
DivAirportLandings String,
DivReachedDest String,
DivActualElapsedTime String,
DivArrDelay String,
DivDistance String,
Div1Airport String,
Div1AirportID Int32,
Div1AirportSeqID Int32,
Div1WheelsOn String,
Div1TotalGTime String,
Div1LongestGTime String,
Div1WheelsOff String,
Div1TailNum String,
Div2Airport String,
Div2AirportID Int32,
Div2AirportSeqID Int32,
Div2WheelsOn String,
Div2TotalGTime String,
Div2LongestGTime String,
Div2WheelsOff String,
Div2TailNum String,
Div3Airport String,
Div3AirportID Int32,
Div3AirportSeqID Int32,
Div3WheelsOn String,
Div3TotalGTime String,
Div3LongestGTime String,
Div3WheelsOff String,
Div3TailNum String,
Div4Airport String,
Div4AirportID Int32,
Div4AirportSeqID Int32,
Div4WheelsOn String,
Div4TotalGTime String,
Div4LongestGTime String,
Div4WheelsOff String,
Div4TailNum String,
Div5Airport String,
Div5AirportID Int32,
Div5AirportSeqID Int32,
Div5WheelsOn String,
Div5TotalGTime String,
Div5LongestGTime String,
Div5WheelsOff String,
Div5TailNum String
)
ENGINE = MergeTree(FlightDate, (Year, FlightDate), 8192);
Мы создали таблицу типа MergeTree. Таблицы семейства MergeTree рекомендуется использовать для любых серьёзных применений. Такие таблицы содержат первичный ключ, по которому данные инкрементально сортируются, что позволяет быстро выполнять запросы по диапазону первичного ключа.
Например, если у нас есть логи рекламной сети и нам нужно показывать отчёты для конкретных клиентов-рекламодателей, то первичный ключ в таблице должен начинаться на идентификатор клиента, чтобы для получения данных для одного клиента, достаточно было прочитать лишь небольшой диапазон данных.
Загружаем данные в таблицу
xz -v -c -d < ontime.csv.xz | clickhouse-client --query="INSERT INTO ontime FORMAT CSV"Запрос INSERT в ClickHouse позволяет загружать данные в любом поддерживаемом формате. При этом на загрузку данных расходуется O(1) памяти. На вход запроса INSERT можно передать любой объём данных. Вставлять данные всегда следует пачками не слишком маленького размера. При этом вставка блоков данных размера до max_insert_block_size (= 1 048 576 строк по умолчанию), является атомарной: блок данных либо целиком вставится, либо целиком не вставится. В случае разрыва соединения в процессе вставки, вы можете не знать, вставился ли блок данных. Для достижения exactly-once семантики, для реплицированных таблиц, поддерживается идемпотентность: вы можете вставить один и тот же блок данных повторно, возможно на другую реплику, и он будет вставлен только один раз. В данном примере мы вставляем данные из localhost, поэтому мы не беспокоимся о формировании пачек и exactly-once семантике.
Запрос INSERT в таблицы типа MergeTree является неблокирующим, равно как и SELECT. После загрузки данных или даже во время процесса загрузки мы уже можем выполнять SELECT-ы.
В данном примере некоторая неоптимальность состоит в том, что в таблице используется тип данных String тогда, когда подошёл бы Enum или числовой тип. Если множество разных значений строк заведомо небольшое (пример: название операционной системы, производитель мобильного телефона), то для максимальной производительности, мы рекомендуем использовать Enum-ы или числа. Если множество строк потенциально неограничено (пример: поисковый запрос, URL), то используйте тип данных String.
Во-вторых, отметим, что в рассматриваемом примере структура таблицы содержит избыточные столбцы Year, Quarter, Month, DayOfMonth, DayOfWeek, тогда как достаточно одного FlightDate. Скорее всего, это сделано для эффективной работы других СУБД, в которых функции для манипуляций с датой и временем, могут работать недостаточно быстро. В случае ClickHouse в этом нет необходимости, так как соответствующие функции хорошо оптимизированы. Впрочем, лишние столбцы не проблема: так как ClickHouse — это столбцовая СУБД, вы можете позволить себе иметь в таблице достаточно много столбцов. Сотни столбцов — это нормально для ClickHouse.
Примеры работы с загруженными данными
- какие направления были самыми популярными в 2015 году;
SELECT OriginCityName, DestCityName, count(*) AS flights, bar(flights, 0, 20000, 40) FROM ontime WHERE Year = 2015 GROUP BY OriginCityName, DestCityName ORDER BY flights DESC LIMIT 20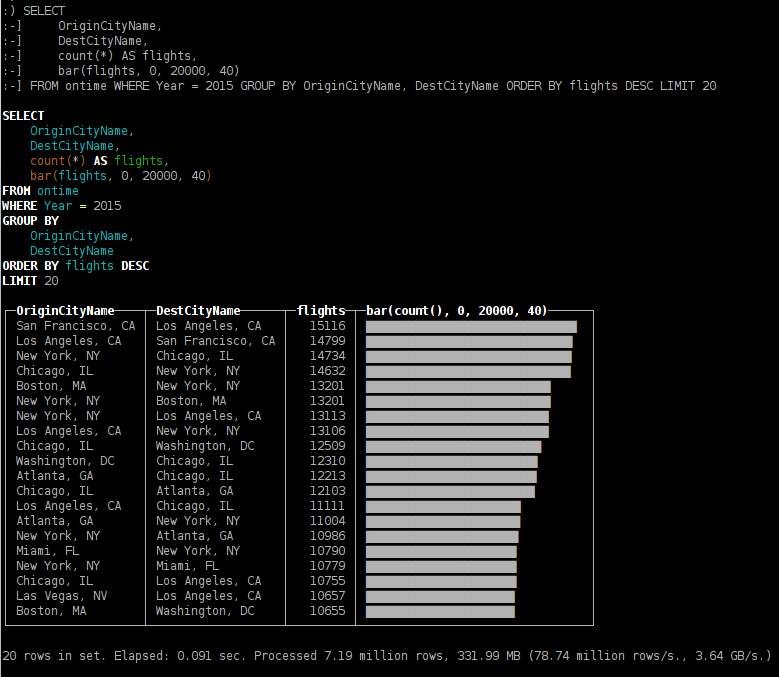
SELECT OriginCityName < DestCityName ? OriginCityName : DestCityName AS a, OriginCityName < DestCityName ? DestCityName : OriginCityName AS b, count(*) AS flights, bar(flights, 0, 40000, 40) FROM ontime WHERE Year = 2015 GROUP BY a, b ORDER BY flights DESC LIMIT 20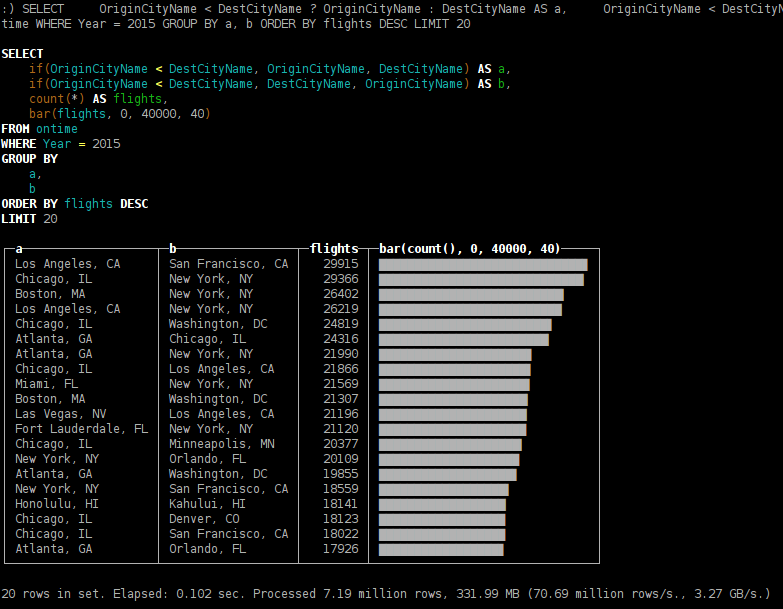
- из каких городов отправляется больше рейсов;
SELECT OriginCityName, count(*) AS flights FROM ontime GROUP BY OriginCityName ORDER BY flights DESC LIMIT 20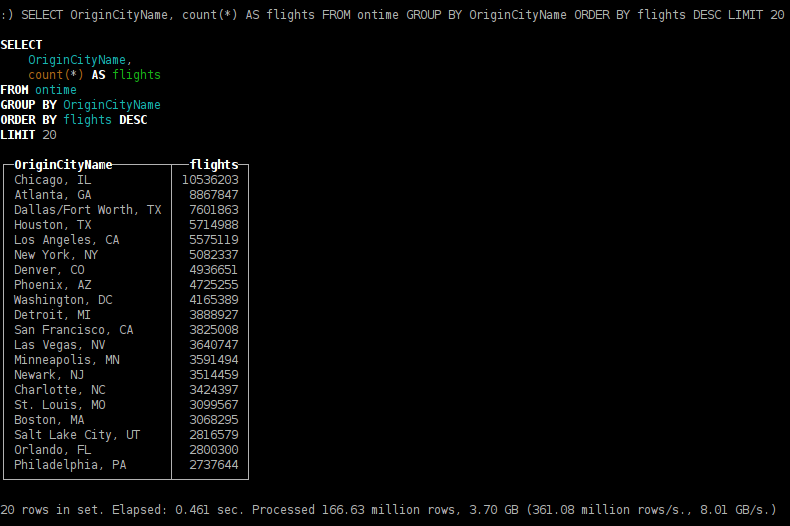
- из каких городов можно улететь по максимальному количеству направлений;
SELECT OriginCityName, uniq(Dest) AS u FROM ontime GROUP BY OriginCityName ORDER BY u DESC LIMIT 20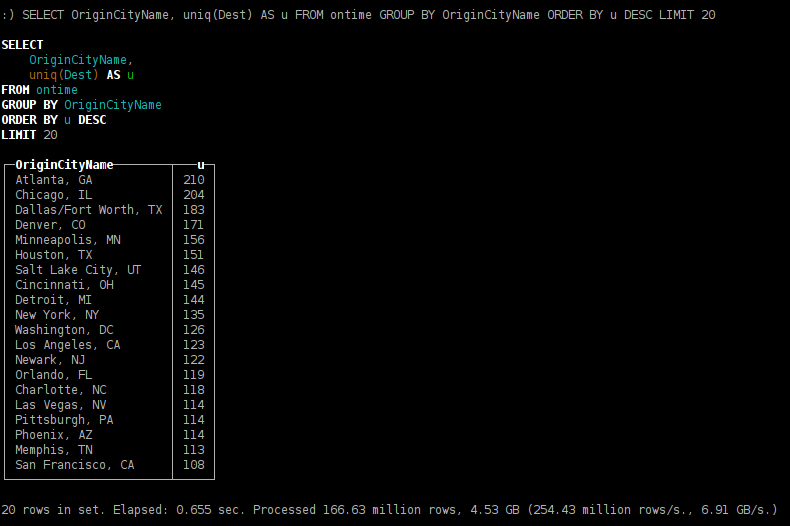
- как зависит задержка вылета рейсов от дня недели;
SELECT DayOfWeek, count() AS c, avg(DepDelay > 60) AS delays FROM ontime GROUP BY DayOfWeek ORDER BY DayOfWeek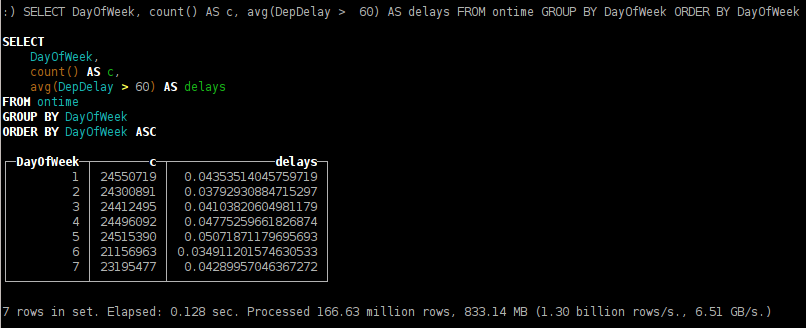
- из каких городов, самолёты чаще задерживаются с вылетом более чем на час;
SELECT OriginCityName, count() AS c, avg(DepDelay > 60) AS delays FROM ontime GROUP BY OriginCityName HAVING c > 100000 ORDER BY delays DESC LIMIT 20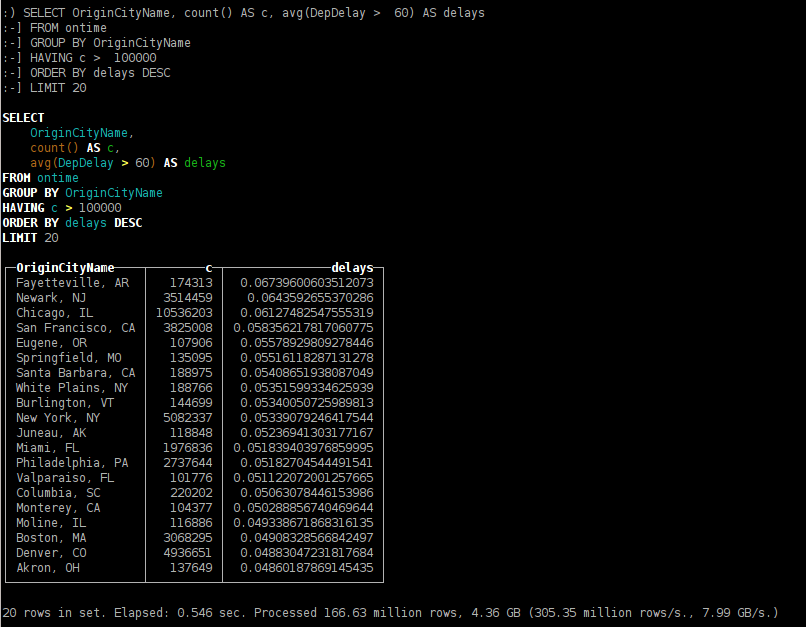
- какие наиболее длинные рейсы;
SELECT OriginCityName, DestCityName, count(*) AS flights, avg(AirTime) AS duration FROM ontime GROUP BY OriginCityName, DestCityName ORDER BY duration DESC LIMIT 20
- распределение времени задержки прилёта, по авиакомпаниям;
SELECT Carrier, count() AS c, round(quantileTDigest(0.99)(DepDelay), 2) AS q FROM ontime GROUP BY Carrier ORDER BY q DESC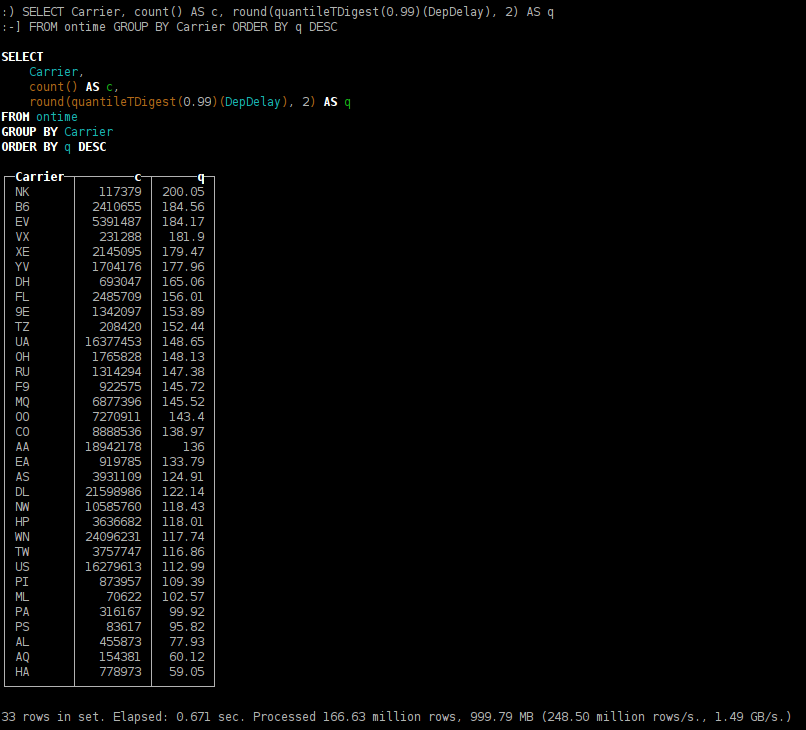
- какие авиакомпании прекратили перелёты;
SELECT Carrier, min(Year), max(Year), count() FROM ontime GROUP BY Carrier HAVING max(Year) < 2015 ORDER BY count() DESC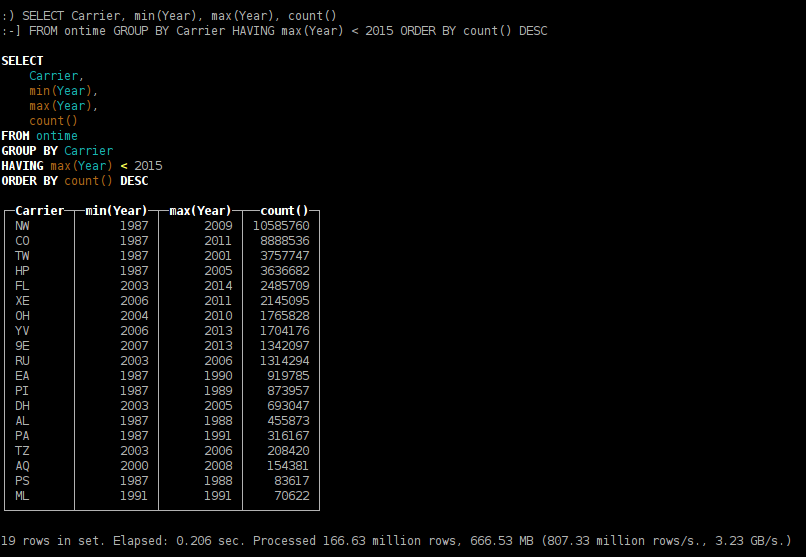
- в какие города стали больше летать в 2015 году;
SELECT DestCityName, sum(Year = 2014) AS c2014, sum(Year = 2015) AS c2015, c2015 / c2014 AS diff FROM ontime WHERE Year IN (2014, 2015) GROUP BY DestCityName HAVING c2014 > 10000 AND c2015 > 1000 AND diff > 1 ORDER BY diff DESC
- перелёты в какие города больше зависят от сезонности.
SELECT DestCityName, any(total), avg(abs(monthly * 12 - total) / total) AS avg_month_diff FROM ( SELECT DestCityName, count() AS total FROM ontime GROUP BY DestCityName HAVING total > 100000 ) ALL INNER JOIN ( SELECT DestCityName, Month, count() AS monthly FROM ontime GROUP BY DestCityName, Month HAVING monthly > 10000 ) USING DestCityName GROUP BY DestCityName ORDER BY avg_month_diff DESC LIMIT 20
Как установить ClickHouse на кластер из нескольких серверов
С точки зрения установленного ПО кластер ClickHouse является однородным, без выделенных узлов. Вам надо установить ClickHouse на все серверы кластера, затем прописать конфигурацию кластера в конфигурационном файле, создать на каждом сервере локальную таблицу и затем создать Distributed-таблицу.
Distributed-таблица представляет собой «вид» на локальные таблицы на кластере ClickHouse. При SELECT-е из распределённой таблицы запрос будет обработан распределённо, с использованием ресурсов всех шардов кластера. Вы можете объявить конфигурации нескольких разных кластеров и создать несколько Distributed-таблиц, которые смотрят на разные кластеры.
<remote_servers>
<perftest_3shards_1replicas>
<shard>
<replica>
<host>example-perftest01j.yandex.ru</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<host>example-perftest02j.yandex.ru</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<host>example-perftest03j.yandex.ru</host>
<port>9000</port>
</replica>
</shard>
</perftest_3shards_1replicas>
</remote_servers>
Создание локальной таблицы:
CREATE TABLE ontime_local (...) ENGINE = MergeTree(FlightDate, (Year, FlightDate), 8192);Создание распределённой таблицы, которая смотрит на локальные таблицы на кластере:
CREATE TABLE ontime_all AS ontime_local ENGINE = Distributed(perftest_3shards_1replicas, default, ontime_local, rand());Вы можете создать Distributed-таблицу на всех серверах кластера — тогда для выполнения распределённых запросов, можно будет обратиться на любой сервер кластера. Кроме Distributed-таблицы вы также можете воспользоваться табличной функцией remote.
Для того, чтобы распределить таблицу по нескольким серверам, сделаем INSERT SELECT в Distributed-таблицу.
INSERT INTO ontime_all SELECT * FROM ontime;Отметим, что для перешардирования больших таблиц, такой способ не подходит, вместо этого следует воспользоваться встроенной функциональностью перешардирования.
Как и ожидалось, более-менее долгие запросы работают в несколько раз быстрее, если их выполнять на трёх серверах, а не на одном.
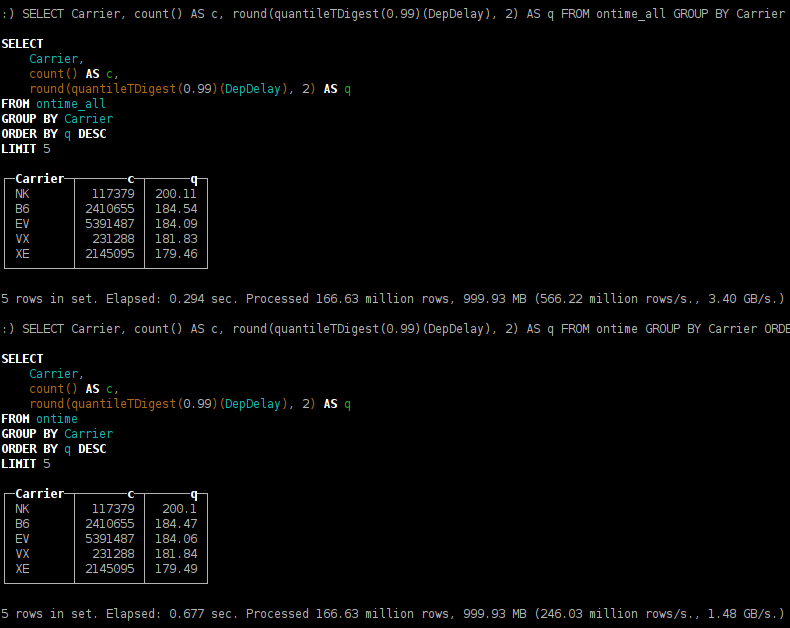
Можно заметить, что результат расчёта квантилей слегка отличается. Это происходит потому, что реализация алгоритма t-digest является недетерминированной — зависит от порядка обработки данных.
В данном примере мы использовали кластер из трёх шардов, каждый шард которого состоит из одной реплики. Для реальных задач в целях отказоустойчивости каждый шард должен состоять из двух или трёх реплик, расположенных в разных дата-центрах. (Поддерживается произвольное количество реплик.)
<remote_servers>
...
<perftest_1shards_3replicas>
<shard>
<replica>
<host>example-perftest01j.yandex.ru</host>
<port>9000</port>
</replica>
<replica>
<host>example-perftest02j.yandex.ru</host>
<port>9000</port>
</replica>
<replica>
<host>example-perftest03j.yandex.ru</host>
<port>9000</port>
</replica>
</shard>
</perftest_1shards_3replicas>
</remote_servers>
Для работы репликации (хранение метаданных и координация действий) требуется ZooKeeper. ClickHouse будет самостоятельно обеспечивать консистентность данных на репликах и производить восстановление после сбоев. Рекомендуется расположить кластер ZooKeeper на отдельных серверах.
На самом деле использование ZooKeeper не обязательно: в самых простых случаях вы можете дублировать данные, записывая их на все реплики вручную, и не использовать встроенный механизм репликации. Но такой способ не рекомендуется — ведь в этом случае ClickHouse не сможет обеспечивать консистентность данных на репликах.
<zookeeper-servers>
<node>
<host>zoo01.yandex.ru</host>
<port>2181</port>
</node>
<node>
<host>zoo02.yandex.ru</host>
<port>2181</port>
</node>
<node>
<host>zoo03.yandex.ru</host>
<port>2181</port>
</node>
</zookeeper-servers>
Также пропишем подстановки, идентифицирующие шард и реплику — они будут использоваться при создании таблицы.
<macros>
<shard>01</shard>
<replica>01</replica>
</macros>
Если при создании реплицированной таблицы других реплик ещё нет, то создаётся первая реплика, а если есть — создаётся новая реплика, которая клонирует данные существующих реплик. Вы можете либо сразу создать все таблицы-реплики и затем загрузить в них данные, либо сначала создать часть реплик, а затем добавить другие — уже после загрузки или во время загрузки данных.
CREATE TABLE ontime_replica (...)
ENGINE = ReplicatedMergeTree(
'/clickhouse_perftest/tables/{shard}/ontime',
'{replica}',
FlightDate,
(Year, FlightDate),
8192);
Здесь видно, что мы используем тип таблицы ReplicatedMergeTree, указывая в качестве параметров путь в ZooKeeper, содержащий идентификатор шарда, а также идентификатор реплики.
INSERT INTO ontime_replica SELECT * FROM ontime;Репликация работает в режиме multi-master. Вы можете вставлять данные на любую реплику, и данные автоматически разъезжаются по всем репликам. При этом репликация асинхронная, и в заданный момент времени, реплики могут содержать не все недавно записанные данные. Для записи данных, достаточно доступности хотя бы одной реплики. Остальные реплики будут скачивать новые данные и восстанавливать консистентность как только станут активными. Такая схема допускает возможность потери только что вставленных данных.
Как повлиять на развитие ClickHouse
Если у вас возникли вопросы, можно задать их в комментариях к этой статье либо на StackOverflow с тегом «clickhouse». Также вы можете создать тему для обсуждения в группе или написать своё предложение на рассылку clickhouse-feedback@yandex-team.ru. А если вам хочется попробовать поработать над ClickHouse изнутри, приглашаем присоединиться к нашей команде в Яндексе. У нас открыты вакансии и стажировки.
Комментарии (171)

0x0FFF
15.06.2016 11:21+8Что примечательно, практически вся СУБД была создана одним человеком
В целом же молодцы, что открыли исходники! Очень интересно посмотреть, как оно работает изнутри
Hertz
15.06.2016 11:40Вклад Алексея колоссален, но часть истории изменений, кажется, была потеряна при переезде на внешний GitHub.
o6CuFl2Q
15.06.2016 12:30Я специально проследил, чтобы история изменений не потерялась.
Посмотреть авторов коммитов можно так:
git log --format='%aN %aE' | sort | uniq -c | sort -rn
Проблема в том, что Github не связывает твой email с твоим аккаунтом.
Это можно исправить… напишу через пару часов лично.
vics001
15.06.2016 13:52+6Не согласен, двумя. Вы смотрите по частоте комитов. Alexey: LOC +2MM -1MM, PCartavyi: +1MM.
Конечно, возможно, что Алексей просто удалял все, что написал другой человек :)

alexrett
15.06.2016 11:30+1Действитель очень круто, но я видимо слепой и не нашел интерфейсов к ЯП, неужели все только через HTTP\CLI\TCP?
o6CuFl2Q
15.06.2016 12:35+2Только эти интерфейсы документированы и ими можно пользоваться.
Есть также ODBC и JDBC драйверы.
ODBC драйвер находится в разработке. Он работает во многих случаях, но сейчас лучше им не пользоваться, если только вы не собираетесь самостоятельно его дорабатывать. Если очень надо, то можете найти его в исходниках.
JDBC драйвер находится в отдельном репозитории и на данный момент не выложен (это будем решать).
elcamlost
15.06.2016 13:27+1Очень интересует возможность обращаться к базе из разных языков программирования (Perl, Scala, etc). В документации написано, что для этого сейчас используется HTTP интерфейс и у вас есть готовые модули для этого.
Что хочется узнать
1) Планируется ли эти модули отдать в open source так же как и сам ClickHouse?
2) Планируется ли документировать TCP интерфейс, а то сейчас мы видимРодной интерфейс используется в клиенте командной строки clickhouse-client, при межсерверном взаимодействии для распределённой обработки запроса, а также в программах на C++. Будет рассмотрен только клиент командной строки.
o6CuFl2Q
15.06.2016 15:06+31) Планируется ли эти модули отдать в open source так же как и сам ClickHouse?
Не уверен. Например, для Python есть несколько разных модулей в виде простых обёрток над HTTP интерфейсом. Может быть, какой-то из них автор захочет выложить, пусть даже просто ради примера. Но они все не представляют большой ценности.
2) Планируется ли документировать TCP интерфейс, а то сейчас мы видим
Пока нет — TCP интерфейс и внутрений C++ интерфейс специально не документирован для того, чтобы не бояться ломать совместимость протокола и ABI. Поэтому, для внешних программ только HTTP интерфейс.
kshvakov
15.06.2016 14:43Может быть стоит сделать описание протокола взаимодействия между клиентом и сервером, чтоб дать возможность разрабатывать сторонние клиенты?
o6CuFl2Q
15.06.2016 15:13Для сторонних клиентов проще всего использовать HTTP интерфейс. Например, API Яндекс.Метрики использует именно его для построения отчётов.
kormushin
15.06.2016 12:37+2Да, jdbc драйвер необходим. Это реально блоккер для использования со всякими olap системами.

Timrael
15.06.2016 11:46+5Всё становится сложнее, если вам нужно выполнять запросы в интерактивном режиме по неагрегированным данным, поступающим в систему в реальном времени. Для решения этой задачи, открытых технологий подходящего качества до сих пор не существовало.
GreenPlum?o6CuFl2Q
15.06.2016 14:53+1Спасибо! Стыдно сказать, я видел новость про open-source Greenplum и хотел изучить его подробнее, но потом забыл про это.
Надо будет уделить этому больше внимания. Возможно, утверждение «до сих пор не существовало» придётся пересмотреть.



Halt
15.06.2016 12:12+2Не умаляю ценности проекта, но все же странно иметь в коде комментарии на русском языке.
Неужели в Яндексе нет гайдлайнов относительно комментирования кода?
Viacheslav01
15.06.2016 12:20+3А в чем проблема комментариев на русском языке, в свете рускоязычного проекта?
Я в текущем проекте тоже все комментирую на русском, более того коментарии к комитам тоже пишу на русском, т.к. читатели 100% русские.Halt
15.06.2016 12:28+14Если ориентироваться только на русскоязычную аудиторию — нет проблем. Просто я предполагал, что проект такого уровня является достаточно значимым, чтобы публиковать его на весь мир.

skor
15.06.2016 12:46+4Может быть изначально не предполагалось выкладывать в опен-сорс.
Может быть руки ещё до перевода не дошли.o6CuFl2Q
15.06.2016 15:26+7Да, совершенно верно. Изначально у нас не было цели разработать open-source СУБД.
Я понимаю, что использование русского языка для комментариев — это минус для open-source продукта.
При этом к самому факту наличия подробных комментариев на русском языке следует отнестись позитивно: это лучше, чем если бы комментариев не было или если бы они были бы менее понятными для основных разработчиков.

mrstrictly
15.06.2016 12:28+9Не вижу абсолютно никаких минусов в использовании русскоязычных комментариев в проекте, который изначально не создается под open source и активно используется в бизнес-задачах русскоязычной компании. И нет большого смысла заставлять разработчиков переводить свою мысль на английский в ущерб продуктивности отдельно взятой команды. Честно говоря, не припоминаю, чтобы где-либо в гайдлайнах встречал что-либо касательно требований к английскому языку в комментариях.
Если вас действительно это смущает, то сделайте пул-реквест. Это же теперь open source. :)
Kadae
15.06.2016 14:44+4Почему вас не смущает, что в космосе пишут на российских приборах на русском, даже работающие в международной станции? Китайцы тоже пишут на китайском. В своем языке нет ничего плохо и даже наоборот, так и надо делать — свой язык надо отстаивать.
lirq
15.06.2016 15:10+11>>, так и надо делать — свой язык надо отстаивать.
Опенсорс — место для коллаборации, но никак не до отстаивания языка.
georgevp
15.06.2016 22:39+2Космос — тоже место для сотрудничества. И..?

ivaschenko
16.06.2016 15:32-9Названия, например, «Союз», можно и на русском написать, но комментарии — это часть технической документации. Я сомневаюсь, что инструкции на МКС на русском.

phprus
18.06.2016 13:11+1Мало того, что на русском (как и многие обозначения на приборах), так еще и знание русского языка является обязательным требованием для работы на МКС.
georgevp
16.06.2016 01:45+5ООН, признающая русский язык своим официальным (одним из шести) языком, немного не согласна с таким постулатом. Предвосхищая возможное возражение, что программистский мир — особая среда со своими традициями и канонами, отмечу, что мир может меняться, потому как не заспиртован ;-).

QtRoS
16.06.2016 11:05-2Насчет гайдлайнов — открыл указанный файлик и увидел:
IColumn & column = *res;
Честно признаюсь, что секунд 15 пытался понять, что тут хотел сделать автор, и сначала в голову пришло побитовое «и» между переменной ICoumn и column… Никогда не видел, чтобы ссылки так объявлялись, обычно либо «IColumn &column», либо «IColumn& column». Это точно читабельный вариант? Да и вообще как-то мой личный опыт был таков, что явно ссылки не так уж часто объявляются…
P.S. Я знаю C++ довольно хорошо, но на практике больше на C# программирую, поэтому может отвык уже, одичал :)
Scf
15.06.2016 12:59Странно, что нигде нет сравнения с Solr/ElasticSearch. Они тоже активно используются в качестве аналитических БД.
o6CuFl2Q
15.06.2016 15:52Это продукты немного другого профиля.
Насколько я понимаю, основная задача Solr/ElasticSearch — работа с полнотекстовым индексом.
В ClickHouse нет полнотекстового индекса.
Основной характер нагрузки состоит в том, чтобы достать по диапазону первичного ключа какое-то, возможно весьма большое множество строк, и как можно быстрее выполнить над ним нужные операции: отфильтровать, агрегировать и т. п. При этом, сам индекс — первичный ключ, устроен достаточно примитивно, зато всегда требует немного оперативки (даже при наличии триллионов строк в таблице на одном сервере) и поддерживает локальность расположения данных на диске — для того, чтобы читать искомое множество данных с минимальным количеством seek-ов.
Короче говоря, в одних задачах важнее по-умному достать из базы небольшое количество данных, а в других — как можно эффективнее прочитать и обработать достаточно большое подмножество данных.
kshnurov
15.06.2016 16:12Отнюдь, у Elasticsearch сейчас отличные возможности по фильтрации, агрегации и вообще работе с большими объёмами постоянно поступающих данных. Скорость, надёжность и удобство на высоте. Для любой аналитики — самое то, у них на сайте можно посмотреть, сколько огромных систем на нем построено. Полнотекстовый поиск там лишь одна из сотен функций.
o6CuFl2Q
15.06.2016 16:51+5Это хорошо.
Вы не возражаете, если у меня будет к вам маленькая просьба?
Надо взять тестовые данные из этой статьи, загрузить их в Elasticsearch, и прогнать те запросы, которые приведены в качестве примеров.
Мне будет очень интересно посмотреть, как всё будет работать!
eigrad
15.06.2016 20:14Будет 3-4 часа на загрузку (на 2?E5-2630v3, 64Gb RAM, 2xSSD), но на запросы он должен по-шустрее clickhouse'а отвечать. Надо тестить… Но мы скорее будем на своих Едадиловских данных тестить clickhouse, потом с текущим эластиком сравнивать. Эластик на наши запросы, если данные на SSD или в оперативке, отвечает сравнимо с Druid'ом по скорости, не знаю как они это делают, ну не хранят агрегаты же? :-)
kshnurov
15.06.2016 22:06Про 3-4 часа на загрузку таких данных это вы загнули. Еще года 3 назад в моих экспериментах с ES 0.9x пара гигабайт XML-фидов превращалась в json и заливалась на одну ноду/индекс минут за 30ть, с сервером на HDD. В индексе при этом был полнотекстовый поиск с ngram'ами, вес индекса на выходе за 15GB. Сейчас все еще быстрее, а простые данные в простой индекс вообще грузятся близко к скорости самого SSD.
eigrad
15.06.2016 22:10В чем загнул? Пара гигабайт против 60 гб тут. На вышеприведенном конфиге можно примерно на 15к/с рассчитывать. 150кк документов — 10000 секунд, почти 3 часа.
kshnurov
15.06.2016 22:46У меня были ngram'ы. Без них все эти 60Гб загрузятся за считанные минуты.
У ES есть nightly benchmarks, на не самых простых данных с гео он загружает по 80к документов в секунду. Это всего 35 минут для данного набора, а скорее всего будет раза в 3 меньше в силу его простой структуры.
Кстати, o6CuFl2Q, сколько ClickHouse требуется времени на загрузку тестового набора?
o6CuFl2Q
16.06.2016 00:18+1Сейчас проверил — получилось 25 мин. 24 сек. — это 109 336 строк в секунду.
Время включает разжатие xz и парсинг CSV (команда для загрузки — точно как написано в статье).
eigrad
16.06.2016 15:44+1То есть ты не из практического опыта исходишь, а из бенчмарков версий которые даже не RC?) По бенчмаркам стабильных версий моя оценка справедлива. n-граммы добавят процентов 10-15% времени, но на этих данных они не нужны :-).
kshnurov
16.06.2016 15:55-3Не помню, чтобы мы на ты переходили. Предлагаю вам доказать справедливость оценки, сделанной на основании домыслов, и никчемность benchmarks, путем эксперимента.
eigrad
16.06.2016 17:04-4А я не заметил ни одного повода общаться с тобой на вы. Твое предложение мне не интересно — моя оценка это то что у меня реально на серверах происходит, а твоя оценка полностью описывается твоей фразой:
> У меня нет ни лишнего времени, ни лишней сотни гигабайт на SSD, чтобы провести описанный эксперимент с ES. Буду рад, если вы это сделаете хотя бы с той парой запросов, что я написал. Ставлю 10 к 1, что ES будет быстрее раз в 5.
Не видел предмет разговора в жизни, а лезешь к взрослым дядькам с советами. Фу таким быть.kshnurov
16.06.2016 21:34-1Взрослое быдло — все равно быдло.
eigrad
16.06.2016 21:46-3Было бы интересно почему ты пришел к выводу, что я быдло, но не вижу смысла продолжать дискуссию, потому что ты ещё в предыдущих сообщениях успел доказать то что твое слово ничего не стоит, а мнение подкрепляется личными эмоциональными фантазиями.
moknomo
16.06.2016 12:44+1Сравнивали ли вы производительность Druid с еластиком, если да, то какие получились результаты и почему выбрали еластик? И если будете тестить clickhouse, то расскажите общественности что у вас вышло.
eigrad
16.06.2016 16:15Выбрали эластик многим причинам (низкий порог вхождения, функциональность, автогенерация схемы, и т.п.), druid пока только тестим, для своих задач он хорош.
Пока нужные для запросов индексы в эластике влезают в оперативку — скорость выполнения аггрегаций в ES сравнима с выполнением запросов в Druid (где-то может быть хуже на порядок, а где-то даже лучше, зависит от данных и от запросов). Если данные не входят в оперативку, но лежат на SSD — у ES всё становится на порядок медленнее, как деградирует Druid мы пока не тестили, но есть подозрение что у него дела будут лучше.
Druid хорош тем, что он хранит собственно только данные необходимые для построения аггрегаций по заранее заданным измерениям и метрикам, и делает это эффективно. Собственно он создан для OLAP, ничего большего чем эффективно строить агрегации с его помощью не сделать, да и не нужно. У ES гораздо больше оверхед на размер индексов, следовательно большой объем данных потребует большего количества железа.
В нашем кейс — есть возможность снизить объем данных в ES с 2-3Тб в месяц до 100Гб в месяц. А по тем данным, которые в ES заливать не будем — достаточно Druid.
Эластик нам скорее всего будет нужен даже если основной объем данных перельем в clickhouse, так как пока не совсем понятно сможем ли на clickhouse'е реализовать некоторые свои потребности. Основное — span-запросы, мы через них делаем behaviour-matching. Ну и в паре мест fulltext-индексы нам тоже нужны. Но как хранилище и возможность исполнять sql-like запросы над полными данными clickhouse для нас может стать панацеей :-).
kshnurov
15.06.2016 21:41+1Без проблем, например вот это отдаст сразу из каких городов отправляется больше рейсов и распределение времени задержки прилёта, по авиакомпаниям в одном запросе, да еще и наверняка быстрее:
{ "aggs" : { "most_flights_from" : { "terms" : { "field" : "OriginCityName", "size" : 20 } }, "carriers" : { "terms" : { "field" : "Carrier", "size" : 0 }, "aggs" : { "avg_delays": { "percentiles": { "field" : "DepDelay" } } } } } }
Это 2 простейших агрегации (terms и квантили), все остальное тоже легко выполнимо — в ES три десятка разных агрегаций, которые спокойно накладываются, вкладываются и поворачиваются как угодно.
Более того, ES умеет еще и сам находить "выделяющиеся из общей массы" значения, например по каждой авиакомпании подсказать город, из которого она летает заметно чаще остальных авиакомпаний. Это настолько сложно, что надо всего-лишь добавить в последний
aggsперед/послеavg_delaysэто:
"significant_cities": { "significant_terms": {"field": "OriginCityName"} }
Я уж не говорю про невероятно удобную работу с датами и геолокацией — хочешь тебе агрегации и вычисления, хочешь — сортировка с экспоненциальным убыванием веса от расстояния, при этом, например, ближе 300м вес одинаковый, дальше 3км вообще всем ноль. Берите дистрибутив и пробуйте, документация там более чем понятная. ES очень активно используют Github, Foursquare, Twitter, Netflix и многие другие, вплоть до Cisco с Microsoft. Свой велосипед можете выбросить.
P.S. Если что — я как раз недавно написал систему аналитики форм, использующую ES и одним запросом считающую 2 десятка показателей вроде квантилей среднего времени, потраченного на каждое поле, % юзеров, взаимодействовавших/менявших это поле, средней длины вводимого в поле текста и т.д. Все это с группировкой/фильтрацией по чему угодно — хоть по ОС или урлу, хоть по css-классу формы (и дате, естественно). В базе сырые данные — события (click, focusin, change и т.д.) и время, десятки миллионов записей и 0.5GB данных для одного небольшого сайта, на котором все это обкатывается. Уровень вложенности агрегаций уходит за 10, все крутится на маленьком запасном сервере с HDD(!) и отдает все два десятка показателей с двойной группировкой и любой фильтрацией за 1 секунду уже в виде HTML. Если сильно интересно — могу дать посмотреть. С вашей штукой это превратилось бы в 30 отдельных запросов с кучей подзапросов и структуру данных из 3-4х таблиц, которые надо постоянно join'ить. Про скорость даже боюсь думать :)
o6CuFl2Q
15.06.2016 22:03+1Это весьма круто!
Спасибо за примеры.
одним запросом считающую 2 десятка показателей вроде квантилей среднего времени, потраченного на каждое поле, % юзеров, взаимодействовавших/менявших это поле, средней длины вводимого в поле текста и т.д. Все это с группировкой/фильтрацией по чему угодно — хоть по ОС или урлу, хоть по css-классу формы (и дате, естественно). В базе сырые данные — события (click, focusin, change и т.д.) и время
Вы прямо описываете sweet-spot сценарий для ClickHouse :)
все крутится на маленьком запасном сервере с HDD(!)
0.5 GB данных помещаются в page cache и поэтому запросы не должны упираться в дисковую подсистему.
С вашей штукой это превратилось бы в 30 отдельных запросов с кучей подзапросов и структуру данных из 3-4х таблиц, которые надо постоянно join'ить.
А может и не превратилось бы. Предположительно, будет одна «big flat table» с исходными событиями, и один или несколько запросов со всеми нужными агрегатными функциями. Возможно, с использованием такой функциональности.
На 10 млн. строк вряд ли время выполнения составит больше секунды.kshnurov
15.06.2016 22:38Вы прямо описываете sweet-spot сценарий для ClickHouse :)
Schema-less была обязательным условием, так что ClickHouse точно нет :)
0.5 GB данных помещаются в page cache и поэтому запросы не должны упираться в дисковую подсистему.
На этом сервере еще всякая фигня крутится, но да, может быть такой эффект. Тем не менее я еще на старых версиях ES экспериментировал с индексами размером в десятки GB и куда более простыми запросами (полнотекстовый поиск + 2-3 параметра) — ответ всегда укладывался в десятки миллисекунд.
Предположительно, будет одна «big flat table» с исходными событиями, и один или несколько запросов со всеми нужными агрегатными функциями.
Событие (event) относится к input'у, тот в свою очередь принадлежит form, которая относится к pageview. На один pageview, естественно, может быть несколько форм, сотни инпутов и десятки тысяч событий. Агрегация идет на всех уровнях — и по событиям, и по инпутам/их типам, и по формам, и по pageview. big flat точно не вариант, было бы огромное дублирование.
В случае с ES это один schema-less документ — pageview, в котором все вложено, и делать с ним можно все, что угодно — например посчитать общее число submit'ов отдельно для каждого встречающегося класса формы для pageview с OS = Windows и форм с action = /book, сортировка по количеству pageview для каждого класса формы. Занимает это строчек 20 и считается попутно со всем остальным. Попробуйте здесь такой же запрос для ClickHouse нарисовать ;)o6CuFl2Q
16.06.2016 03:35+1Если всё работает со schema-less данными, то это отлично.
Schema-less не подходит, если необходимо любой ценой максимизировать скорость сканирования данных.
Это различие примерно аналогично различию между статической и динамической типизацией.
Для примера, ClickHouse может на простых запросах обрабатывать более миллиарда строк в секунду на одном сервере. А скорость в несколько сотен миллионов строк в секунду видна даже на примерах из этой статьи. И это вряд ли возможно со schema-less данными.
big flat точно не вариант, было бы огромное дублирование
Как ни странно, это как раз может быть нормальным. Дело в том, что повторяющиеся значения хорошо сожмутся. Хотя имеет смысл сделать несколько таблиц, но в самой детальной (events) дублировать столбцы из input, form и т. п.
Для примера, в данных Метрики, столбец Title — заголовок страницы — может очень часто повторяться для одного сайта (при этом он занимает в среднем 94 байта в несжатом виде). Но хранить Title inplace в таблице гораздо лучше, чем пытаться сохранить уникальные Title в отдельной таблице и делать сложный JOIN.kshnurov
16.06.2016 16:09-4Schema-less не подходит, если необходимо любой ценой максимизировать скорость сканирования данных.
Это различие примерно аналогично различию между статической и динамической типизацией.
Мне кажется вы плохо понимаете, как устроен ES. Schema-less отнюдь не значит, что данных хранятся абы как и их структура каждый раз вычисляется заново.
In Elasticsearch, all data in every field is indexed by default. That is, every field has a dedicated inverted index for fast retrieval. And, unlike most other databases, it can use all of those inverted indices in the same query, to return results at breathtaking speed.
У меня нет ни лишнего времени, ни лишней сотни гигабайт на SSD, чтобы провести описанный эксперимент с ES. Буду рад, если вы это сделаете хотя бы с той парой запросов, что я написал. Ставлю 10 к 1, что ES будет быстрее раз в 5.
Но хранить Title inplace в таблице гораздо лучше, чем пытаться сохранить уникальные Title в отдельной таблице и делать сложный JOIN.
Вот тут то и чувствуется вся сила и удобство ES, ибо там этот геморрой вообще не нужен. Сжатие сжатием, но оверхэд в сотни процентов у вас все равно будет. А если вдруг понадобится достать еще одно поле, которое изначально не продублировали — лучше сразу застрелиться.o6CuFl2Q
16.06.2016 17:19+2У меня нет ни лишнего времени, ни лишней сотни гигабайт на SSD, чтобы провести описанный эксперимент с ES. Буду рад, если вы это сделаете хотя бы с той парой запросов, что я написал. Ставлю 10 к 1, что ES будет быстрее раз в 5.
Надо попробовать, если удастся найти время.
In Elasticsearch, all data in every field is indexed by default.
В этом случае будет проблемой размер индексов.
Это нужно считать. Часто для данных в ClickHouse средний размер строки в сжатом виде получается очень маленьким. При среднем размере строки в десятки байт, размер индекса становится проблемой.
В ClickHouse для уменьшения объёма, специально используется «разреженный» индекс — он не позволяет найти, где расположена конкретная строчка, а позволяет найти только начало диапазона из index_granularity строк (рекомендуется 8192 для почти всех приложений). То есть, при чтении будет читаться немного лишних данных, зато индекс будет занимать примерно нулевое количество места по сравнению с объёмом данных.
greevex
17.06.2016 14:07С одной оговоркой: field is indexed by default, но это отключаемо. В маппинге полю можно проставить параметр
index: "no"
Это, конечно, в случае, если известны все возможные поля, но не при абсолютном анархичном schema-less.eigrad
17.06.2016 16:31С помощью dynamic templates можно отключить индексацию для всех не заданных полей или по шаблону — https://www.elastic.co/guide/en/elasticsearch/reference/current/dynamic-templates.html.
Но какой смысл в эластике, если не индексировать поля? Как хранилище он не эффективен, проще монгу взять.greevex
17.06.2016 18:30Но какой смысл в эластике, если не индексировать поля? Как хранилище он не эффективен, проще монгу взять.
На основе какого опыта вы пришли к такому выводу?
Работаю активно с данным инструментарием(и с mongodb, и c elasticsearch) каждый день на достаточно больших данных и выводы могу сделать противоположные вашим.
Динамика данных: ~3.5млрд активных записей, средний размер 3КБ, с ежедневным замещением ~110млн (поступление новых, удаление старых). И на таких объемах у меня получилось следующее:
* монга хороша для очень быстрого доступа к данным (в том числе холодным), в этом плане она сильно выигрывает у эластика, и лучше держит резкие всплески нагрузки.
* эластик хорош для агрегации (она функциональнее и быстрее, нежели у монги), сэмпловой выборки по всем данным, а также для выполнения сложных запросов — делает это гораздо быстрее монги.
Основное, в чем эластик менее эффективен относительно монги — это объем хранимых данных и объем индексов, но, взвешивая профит работы с данными, по большинству критериев выигрывает эластик.eigrad
17.06.2016 20:29> монга хороша для очень быстрого доступа к данным (в том числе холодным), в этом плане она сильно выигрывает у эластика
> Основное, в чем эластик менее эффективен относительно монги — это объем хранимых данных и объем индексов
Я собственно это и имею ввиду. Опыт — построение сложных отчетов, когда агрегаций ES не достаточно и приходится выгружать миллионы документов в Python. Иногда эффективнее в hadoop'е по сырым сжатым данным пройтись, чем из эластика их достать. Выгрузка данных в JSON по HTTP из эластика сильно проигрывает выгрузке BSON по бинарному протоколу монги.
В текущем кейсе у меня таких выборок не много, ES — нормально, он в основном для агрегаций используется. Хотя иногда приходится выгрузки делать, и это боль. А на прошлом месте работы был вполне успешный опыт подобных выгрузок с монгой.
> взвешивая профит работы с данными, по большинству критериев выигрывает эластик
Согласен, в нашем кейсе для аналитики ES тоже лучше монги :-).
Но если данные не индексировать, то зачем их хранить в ES?.. Выборки по ним делать нельзя. Если для того чтобы просто доставать — лучше монгу взять.
Отдельный вопрос — поля метрик. Не знаю, влияет ли отключение их индексирования на производительность аггрегаций по ним? Какие-то агрегаты для индексов насчитываются, что будет если для метрик выключить индексирование? Да и иногда по метрикам тоже выборки хочется делать.greevex
17.06.2016 20:36Но если данные не индексировать, то зачем их хранить в ES?.. Выборки по ним делать нельзя. Если для того чтобы просто доставать — лучше монгу взять.
В этом случае идея заключается в другом: часть полей индексируется, по которым проходит агрегация и сама критерия при запросе, а некоторые поля — это данные, которые нужно получить в довесок. Вы ведь в базе данных тоже индексы не на все поля создаёте.
Отдельный вопрос — поля метрик. Не знаю, влияет ли отключение их индексирования на производительность аггрегаций по ним? Какие-то агрегаты для индексов насчитываются, что будет если для метрик выключить индексирование? Да и иногда по метрикам тоже выборки хочется делать.
К сожалению или к счастью не приходилось с этим сталкиваться, да и более интересных экспериментов и ресёрча хватает. Но если я правильно вас понял, то метрики — это в основном числовые значения. Почему вы их не индексируете? Они не так уж много места занимают.eigrad
17.06.2016 20:56> а некоторые поля — это данные, которые нужно получить в довесок
Кажется в случае elasticsearch таких полей обычно не много. А изначально мое замечание было про отключение индексации для всех полей. Хотя сейчас я уже понял что это вполне нормальная ситуация для стандартного сценария использования ES для full-text поиска — с одним analyzed полем, и набором не индексируемых полей данных, разным для разных документов, которые просто удобно сразу получать в результатах поиска.
> метрики — это в основном числовые значения. Почему вы их не индексируете? Они не так уж много места занимают.
Я не говорил что не индексирую метрики, просто отметил как отдельный случай в котором может быть допустимо выключить индекс.
bejibx
16.06.2016 15:23Подскажите, есть ли возможность в Elasticsearch сделать join по нескольких таблицам с возможностью сортировки по полям?
Пример: есть 2 таблицы — авторы и посты с лайками. Необходимо вывести информацию про авторов, отсортированную по суммарному количеству лайков в постах данного автора. Можно ли это сделать в один запрос?kshnurov
16.06.2016 15:40Конечно можно. В ES нет понятия таблиц, там индексы и документы. Сортировать их можно как угодно, хоть наизнанку — сами лайки по числу постов у автора. В доках как раз пример про посты, не поленитесь. В вашем случае автор и пост будут связаны как parent-child, а лайки можно просто вкладывать в пост. У нас заведения, например, сортируются в т.ч. (но не только, там целая формула) по числу подтвержденных броней за последние 2 месяца, все это внутри одного запроса.
eigrad
16.06.2016 17:20Не нужно использовать Elasticsearch как замену RDBMS, join'ы через parent-child там сделаны весьма спорно — весь словарь связей parent-child всегда хранится в памяти, целиком. Плюс с шардированием есть ньюансы.
Если говорить про аналитику, то в OLAP-топологии звезда Elasticsearch применим. Но в общем случае, хотите реляционку — возьмите реляционку.eigrad
17.06.2016 17:40> parent-child всегда хранится в памяти, целиком
Оказывается не совсем правда уже, но в любом случае вот правильный линк который необходимо прочитать при возникновении желания поделать JOIN'ы в ES — https://www.elastic.co/guide/en/elasticsearch/guide/current/parent-child-performance.html.

maxru
15.06.2016 13:18+1Хотелось бы какую-либо информацию о минимальных ТТХ серверного юнита для запуска ClickHouse.
(документацию покурил, не нашёл, может мало курил)

fabi
15.06.2016 14:06+17Алексей! Спасибо Вам за такой грандиозный и ооочень нужный проект!
Яндекс! Спасибо за возможность пользоваться!
Документация\референс просто замечательный! Автор со всей любовью и профессиональным пониманием вопроса подошел к вопросу документации. Такое редко в каком проекте встретишь, и что бы было професионально все разложено по полочкам, и понятно, и читать просто приятно (на одном дыхании прочитал)! И еще бенчарки в придачу!!!
Алексей, Вам надо проект как то в массы продвигать, на конфы, статьи в english сообществах и ресурсах. Взять хотябы в качестве примера ребят из Mail.ru с их Tarantool.
Я надеюсь и хочу верить, что данный проект найдет широкий отклик у коммюнити и поможет многои и многим другим интерстным проектам :)
Светлого будущего проекту!!!

furyon
15.06.2016 14:32+4На docker hub бы еще все это.

bx23
15.06.2016 21:44+1Будет!
Сейчас приняли пулл-реквест с примерными Dockerfile'ами. Немного разберемся с версионированием и выложим на hub.docker.com/r/yandex.

clickfreak
16.06.2016 01:20+1clickfreak
16.06.2016 01:24Для теста хватит, если в бой — всё равно переписывать.
Ждём оффициального образа :)
pqgg7nwkd4
15.06.2016 15:10+2Добрый день. Можно вкратце и, желательно, популярно описать как он работает?
Скорости впечатляют, но чудес же не бывает.
Спасибо.o6CuFl2Q
15.06.2016 16:21+2Коротко это описано в самом начале документации.
Основа для скорости — это хранение данных по столбцам и векторный движок. По этим признакам, система не отличается, например, от Actian Vector (бывшая Vectorwise), которая может похвастаться сравнимой скоростью обработки запросов.
Дополнительные преимущества в производительности достигаются за счёт:
— алгоритмической оптимизации;
— низкоуровневой оптимизации;
— специализации и проработки частных случаев.
009b
15.06.2016 16:30+3Мне резануло название «столбцовая СУБД».
Разве не «колоночная СУБД»? Или есть разница, которую я не уловил?
Терминология («колоночная СУБД») встречается довольно часто, https://special.habrahabr.ru/kyocera/p/95181/, например.o6CuFl2Q
15.06.2016 16:56+2Действительно, чаще говорят «колоночная».
Почему-то у нас закрепилось именно выражение «столбцовая». Как-то приятнее произносить.
Никакой разницы нет.

afiskon
15.06.2016 16:54Мне кажется, вы немного поспешили с анонсом. Не хватает содержимого сабмодуля private:
https://github.com/yandex/ClickHouse/blob/master/.gitmodules
[submodule "private"]
path = private
url = git@github.yandex-team.ru:Metrika/ClickHouse_private.git
… и простым смертным его нельзя склонировать:
git clone git@github.yandex-team.ru:Metrika/ClickHouse_private.git
Cloning into 'ClickHouse_private'...
ssh: connect to host github.yandex-team.ru port 22: Network is unreachable
fatal: Could not read from remote repository.
Please make sure you have the correct access rights
and the repository exists.
В CMakeLists.txt этот сабмодуль числится как зависимость, без него ничего не соберется:
add_subdirectory (private)
o6CuFl2Q
15.06.2016 17:24+5Так как вы не можете скачать этот сабмодуль, у вас будет пустая директория private.
При этом, всё собирается нормально, так как у всех собираемых программ нет зависимости от содержимого private.
Упоминание пустой директории в CMakeLists тоже нормально работает.
Если нет — можете указать версию CMake и привести пример, как он не работает.

yusman
15.06.2016 17:19+2Яндекс, спасибо!
Сколько же аналитических МРР-систем вышло в Open-Source в последнее время!
В начале статьи вы не совсем правильно провели аналитику рынка, разделив его на 5 сегментов и противопоставив себя каждому.
Все перечисленные решения в сравнении плюс/минус тоже самое(кроме платных).
Геораспределенность в аналитической системе? зачем? «Надстройки над Hadoop» это полноценные аналитические МРР-системы и от вашего решения отличаются практически ничем, умеют делать такие же SQL запросы, имеют почти такое же колоночное хранилище, с сжатием. Приближенные вычисления — интересно.
Я не знаю конечно какие цели были у Яндекса, но конкурировать будет с кем.
А вы не думали сделать аналог BigQuery на его основе? Мне кажется было бы интересно, тем более у вас имеются преимущества.o6CuFl2Q
15.06.2016 21:43Геораспределённость нужна нам для обеспечения аптайма Яндекс.Метрики при недоступности датацентра. Особенно в связи с «учениями».
Все перечисленные решения в сравнении плюс/минус тоже самое(кроме платных).
В общих чертах, наверное, так и есть. Но если рассматривать детали, то будут видны тысячи отличий, многие из которых очень важны.
Для примера, некоторые системы не переупорядочивает данные постоянно по мере вставки. Вы не сможете одновременно постоянно загружать туда данные и эффективно доставать данные по диапазону первичного ключа. Но если для вас достаточно один раз загрузить данные, а затем все запросы сводятся к full scan, то это нормально.
А вы не думали сделать аналог BigQuery на его основе? Мне кажется было бы интересно, тем более у вас имеются преимущества.
Не могу сказать.

AlexeyKovyazin
15.06.2016 22:14Версию под Windows не планируете?
o6CuFl2Q
15.06.2016 22:30+5Пока нет, не планируем.
Так как у нас никто не использует Windows, обеспечить поддержку (автосборку, функциональные тесты, тесты производительности) под эту платформу нам довольно сложно.

erlyvideo
15.06.2016 22:21поясните, пожалуйста: речь идет о хранении сырых данных, но без индексов вообще?
o6CuFl2Q
15.06.2016 22:58+2Данные можно назвать сырыми, но не совсем.
В Метрике, в ClickHouse сохраняются неагрегированные (одна строка в базе — одно событие), но «чистые» и «обогащённые» данные.
То есть, перед загрузкой в ClickHouse, данные слегка обрабатываются (например, декодируются URL-ы); вычисляется и раскладывается в отдельные столбцы всё, что можно вычислить: поисковый запрос, регион, браузер и т. п.
Данные хранятся в таблице с первичным ключом.
Например, сейчас у нас в таблице hits, 8.2 триллиона строк. При каждой загрузке отчёта в интерфейсе Метрики (~2 млн. раз в сутки), делается запрос в ClickHouse. Ясно, что мы не могли бы показывать отчёты, если бы в таблице не было ключа.
Первичный ключ в таблицах Метрики начинается на идентификатор счётчика — то есть, клиента Метрики. Это позволяет быстро доставать данные по одному или по множеству счётчиков для отчёта.
При этом, также есть возможность выполнять глобальные запросы — по всем счётчикам сразу.
Для примера, запрос типа такого
SELECT CounterID, count() FROM hits_all WHERE EventDate = today() GROUP BY CounterID ORDER BY count() DESC LIMIT 20
Выполняется на кластере с такой скоростью:
20 rows in set. Elapsed: 0.815 sec. Processed 12.13 billion rows, 72.77 GB (14.87 billion rows/s., 89.25 GB/s.)

dedokOne
16.06.2016 00:15(~2 млн. раз в сутки) — какое железо и сколько? Если не секрет :)
23 запросов в секунду, так то можно и посгрю натюнить даже для больших данных )
Я просто пытаюсь понять чем это лучше Hive, ES, кластер посгри. Так что не воспринимай как тролинг )o6CuFl2Q
16.06.2016 03:40+1Железо всё-таки секрет.
23 запросов в секунду, так то можно и посгрю натюнить даже для больших данных )
Для аналитических баз данных, без указания дополнительной информации, сравнивать количество запросов в секунду не имеет смысл, так как сложность отдельных запросов может отличаться на порядки.
Если мы вдруг выясним, что можем обрабатывать запросы в два раза быстрее, то мы вместо этого предпочтём увеличить порог для срабатывания сэмплирования в Метрике — то есть увеличить объём данных для обработки и качество сервиса для пользователей.dedokOne
16.06.2016 11:09Я это все к чему, я представляю структуру select'ов + join|unio для ваших отчетов (с учетом семплирование), она достаточно фиксированная.
Вот почему pg cluster привожу как пример, если не делать прям совсем кастом-кастом по любым датам и диапазонам то, интуитивно, такой rps получить можно, при всех прочих равных.
Короче, заинтересовали, буду щупать :)
dedokOne
15.06.2016 23:46'Performance comparison of analytical DBMS' — а на каких конфигурациях (железо, оси) проводились тесты?
И правильно ли я понял: *MergeTree не поддерживает доп. индексы (точней только secondary Date)?
Я кстати не понял в чем радикальное отличие от Hive (если не считать скорости). Кстати как-то тюнили Hive или голый взяли?
Да и ваш map reduce ограничен оперативкой, верно я понял?o6CuFl2Q
16.06.2016 00:11+1а на каких конфигурациях (железо, оси) проводились тесты?
Железо такое: двухсокетный E5-2650 v2, 128 GiB RAM, RAID-5 из 8 дисков SATA 7200 RPM на 6 ТБ.
ОС — Ubuntu 14.04.
И правильно ли я понял: *MergeTree не поддерживает доп. индексы (точней только secondary Date)?
Да, правильно. Для этого есть причины.
Пусть у нас есть индекс, и, при обработке запроса, согласно этому индексу, необходимо прочитать из таблицы множество данных по некоторому множеству смещений. Если множество достаточно большое (например, хотя бы от 1000 записей), и если данные не помещаются в оперативку, то при использовании HDD, скорость чтения этого множества будет определяться локальностью его расположения на диске. Если множество расположено не локально, то для его чтения, придётся выполнить примерно столько seek-ов, сколько элементов есть во множестве. Обычно это говорит о том, что если данные расположены недостаточно локально, то аналитические запросы не будут работать с приемлимой скоростью. Подробнее об этом рассказывалось в предыдущей статье.
Если порядок данных по двум индексам независим, и данные расположены в одном экземпляре, то мы можем добиться хорошей локальности лишь по одному индексу. Замечание: на самом деле, не совсем — см. эту информацию для размышлений.
Поэтому, локальность по нескольким индексам, если она нужна, имеет смысл достигать путём дублирования данных. Например, так устроены проекции в Vertica.
Пример, когда это необходимо — рекламная сеть, в которой есть рекламодатели и рекламные площадки. Одна рекламная кампания может откручиваться на многих площадках, а одна площадка может показывать рекламу от многих рекламодателей. Если мы хотим сделать сервис с отчётами и для рекламодателей и для площадок, то имеет смысл хранить одни и те же данные в двух таблицах с разными первичными ключами.
Я кстати не понял в чем радикальное отличие от Hive (если не считать скорости). Кстати как-то тюнили Hive или голый взяли?
Не тюнили. Более того, у нас тестировался довольно старый Hive, надо будет обновить.
Главное отличие — ClickHouse подходит для «онлайн» запросов из веб-интерфейса. То есть, скорость выполнения запросов позволяет выполнять запросы прямо в момент загрузки страницы с отчётом. Трудно представить себе сервис, в котором при каждом переходе между страницами, пользователь должен ждать выполнения запроса в Hive.
Да и ваш map reduce ограничен оперативкой, верно я понял?
Недавно была добавлена возможность внешней агрегации — с сохранением временных данных на диск. Эта возможность ещё не документирована.dedokOne
16.06.2016 00:24Недавно была добавлена возможность внешней агрегации — с сохранением временных данных на диск. Эта возможность ещё не документирована.
Интересно! Жду доки, будет интересно огромную выборку попробовать.
Не тюнили. Более того, у нас тестировался довольно старый Hive, надо будет обновить.
Главное отличие — ClickHouse подходит для «онлайн» запросов из веб-интерфейса. То есть, скорость выполнения запросов позволяет выполнять запросы прямо в момент загрузки страницы с отчётом. Трудно представить себе сервис, в котором при каждом переходе между страницами, пользователь должен ждать выполнения запроса в Hive.
Вроде скоро из инкубатора выйдут новые проекты, ранее упоминали.
В hive'е добиться online можно, кешированием (горячие данные), hive (холодные), конечно доля online теряется, но и у вас не прям онлайн. Пока данные от счетчиков придут, пока зальется в кластер… это все латенси. Это я к чему, к тому что латенси в систему будет всегда.
dedokOne
16.06.2016 00:45Да, правильно. Для этого есть причины.
...
Отчасти согласен, можно по дискутировать )
Но, замечу, по опыту, избыточность может привести к куда более страшные последствиям.
К примеру, консистентность данных при связи один к многим нельзя гарантировать. Тригеров я у вас не нашел, что означает, все на совести разработчика.
Кстати, говоря о консистентность, а какой уровень изоляции транзакции? И есть ли какие-то известные проблемы c network partition?o6CuFl2Q
16.06.2016 03:00И есть ли какие-то известные проблемы c network partition?
При использовании ReplicatedMergeTree, в случае network partition, INSERT работает только в той части сети, из которой доступен кворум ZooKeeper. SELECT работает в обеих частях сети, но в одной из них будет возвращать устаревшие данные.
Обычно это означает, что при отключении от сети одного датацентра, в этом датацентре не будут записываться данные. В случае сценария использования для веб-аналитики это нормально, так как в этот датацентр не будут также поступать исходные данные (логи) из внешней сети, и записывать при этом нечего.
Кстати, говоря о консистентность, а какой уровень изоляции транзакции?
Транзакции не поддерживаются.
Запрос INSERT вставляет данные по блокам (не более 1 048 576 строк по-умолчанию). Вставка каждого блока атомарна.
(В случае таблиц семейства -MergeTree), запрос SELECT использует для выполнения snapshot данных, который захватывается на момент начала выполнения запроса.

ComodoHacker
16.06.2016 10:25при использовании HDD, скорость чтения этого множества будет определяться локальностью его расположения на диске. Если множество расположено не локально, то для его чтения, придётся выполнить примерно столько seek-ов, сколько элементов есть во множестве.
Сейчас понятия «локальность на диске» и «количество seek-ов» стали довольно эфемерными с учетом того, что в продакшене мы имеем RAID-ы, SAN-ы, SSD-кэши, «умное» железо, «умные» ФС и т.п., часто в комбинации. Ваши алгоритмы в ClickHouse как-то пытаются это учитывать? Или же целиком полагаются на то, что близкое смещение в файле обеспечит достаточно хорошую физическую локальность?
dedokOne
16.06.2016 00:29Еще такой вопрос, а нет ли у вас готового образа, ansible или чего-то такого чтобы я мог залить в AWS? Или только мне надо накатить ubuntu 14.* и поставить dep пакет?
o6CuFl2Q
16.06.2016 02:40Готового образа нет.
Но на Ubuntu 14.04 всё нормально ставиться несколькими командами, как в статье. В том числе, проверял на Amazon-е.
tomzarubin
16.06.2016 00:30>Карта кликов в Яндекс.Метрике и соответствующий запрос в ClickHouse
А можно посмотреть на результат исполнения запроса?o6CuFl2Q
16.06.2016 02:50Вы могли бы получить эти же данные по-другому: зайти на демо-счётчик в Метрике, открыть карту кликов; в браузере в отладчике открыть вкладку «сеть» и посмотреть, какие данные придут.
Результат:) SELECT EventDate, Path, X, Y, T FROM mouse_clicks_layer SAMPLE 32768 WHERE CounterID = 29761725 AND URLNormalizedHash = 11352313218531117537 AND EventDate >= '2016-05-28' AND EventDate <= '2016-06-03' LIMIT 50 SELECT EventDate, Path, X, Y, T FROM mouse_clicks_layer SAMPLE 32768 WHERE (CounterID = 29761725) AND (URLNormalizedHash = 11352313218531117537) AND (EventDate >= '2016-05-28') AND (EventDate <= '2016-06-03') LIMIT 50 ---EventDate-T-Path---------------T-----X-T-----Y-T----T-¬ ¦ 2016-05-28 ¦ ? ¦ 15420 ¦ 32767 ¦ 56 ¦ ¦ 2016-05-28 ¦ WA4AAAA1 ¦ 42802 ¦ 36408 ¦ 73 ¦ ¦ 2016-05-28 ¦ ;A2AA4AAAA1 ¦ 29285 ¦ 56797 ¦ 93 ¦ ¦ 2016-05-28 ¦ ;AAAA1AAA ¦ 28086 ¦ 26623 ¦ 33 ¦ ¦ 2016-05-28 ¦ ? ¦ 23130 ¦ 43007 ¦ 19 ¦ ¦ 2016-05-28 ¦ ;A2AAAA1 ¦ 4437 ¦ 35194 ¦ 111 ¦ ¦ 2016-05-28 ¦ ;AAA3AAAAA1AA1 ¦ 26214 ¦ 26214 ¦ 107 ¦ ¦ 2016-05-28 ¦ WA3AAAAA1AA1 ¦ 24341 ¦ 30246 ¦ 91 ¦ ¦ 2016-05-28 ¦ ;A2AAAAA1AA1 ¦ 22469 ¦ 37808 ¦ 44 ¦ ¦ 2016-05-28 ¦ ;AAA2AAAAA1AA1 ¦ 13107 ¦ 28398 ¦ 35 ¦ ¦ 2016-05-28 ¦ A;A2AAAAA1AA1 ¦ 36044 ¦ 35388 ¦ 25 ¦ ¦ 2016-05-28 ¦ WA5AAAAA1AA1 ¦ 18022 ¦ 31507 ¦ 28 ¦ ¦ 2016-05-28 ¦ ;A3AA4AAAAA1AA1 ¦ 20830 ¦ 4369 ¦ 62 ¦ ¦ 2016-05-28 ¦ WA4AAAAA1AA1 ¦ 20596 ¦ 32767 ¦ 47 ¦ ¦ 2016-05-28 ¦ PWWFA1AA1AAA ¦ 18766 ¦ 45196 ¦ 52 ¦ ¦ 2016-05-28 ¦ ?FA1AA1AAA ¦ 38228 ¦ 10239 ¦ 227 ¦ ¦ 2016-05-28 ¦ ;A1AAAAA1AA1 ¦ 37214 ¦ 23945 ¦ 203 ¦ ¦ 2016-05-28 ¦ ;A1AAAAA1AA1 ¦ 25043 ¦ 49151 ¦ 49 ¦ ¦ 2016-05-28 ¦ ;A1AAAAA1AA1 ¦ 15915 ¦ 21424 ¦ 45 ¦ ¦ 2016-05-28 ¦ AA2AA1 ¦ 31302 ¦ 47645 ¦ 163 ¦ ¦ 2016-05-28 ¦ WA3AAAAA1AA1 ¦ 22469 ¦ 26466 ¦ 40 ¦ ¦ 2016-05-28 ¦ WA3AA3AAAAA1AA1 ¦ 32533 ¦ 13107 ¦ 66 ¦ ¦ 2016-05-28 ¦ ;AAA3AAAAA1AA1 ¦ 35342 ¦ 45874 ¦ 86 ¦ ¦ 2016-05-28 ¦ Qd1A1AA2AA1 ¦ 11179 ¦ 29490 ¦ 98 ¦ ¦ 2016-05-28 ¦ ;A10AAAAA1AA1 ¦ 22703 ¦ 49151 ¦ 1068 ¦ ¦ 2016-05-28 ¦ WA5AAAAA1AA1 ¦ 38852 ¦ 24904 ¦ 74 ¦ ¦ 2016-05-28 ¦ ;A2AA5AAAAA1AA1 ¦ 17085 ¦ 22366 ¦ 158 ¦ ¦ 2016-05-28 ¦ AWA5AAAAA1AA1 ¦ 32767 ¦ 45874 ¦ 81 ¦ ¦ 2016-05-28 ¦ A;A2AAAAA1AA1 ¦ 32767 ¦ 58981 ¦ 135 ¦ ¦ 2016-05-28 ¦ AWA5AAAAA1AA1 ¦ 32767 ¦ 38010 ¦ 66 ¦ ¦ 2016-05-28 ¦ AWA4AAAAA1AA1 ¦ 16383 ¦ 39321 ¦ 96 ¦ ¦ 2016-05-28 ¦ AWA4AAAAA1AA1 ¦ 26214 ¦ 49151 ¦ 112 ¦ ¦ 2016-05-28 ¦ A;A2AAAAA1AA1 ¦ 32767 ¦ 43253 ¦ 122 ¦ ¦ 2016-05-28 ¦ AWA5AAAAA1AA1 ¦ 26214 ¦ 38010 ¦ 150 ¦ ¦ 2016-05-28 ¦ AWA5AAAAA1AA1 ¦ 40631 ¦ 29490 ¦ 172 ¦ ¦ 2016-05-28 ¦ AWA4AAAAA1AA1 ¦ 52428 ¦ 43253 ¦ 178 ¦ ¦ 2016-05-28 ¦ A;A3AA4AAAAA1AA1 ¦ 36044 ¦ 50243 ¦ 190 ¦ ¦ 2016-05-28 ¦ ;A8AA3AA4AAAAA1AA1 ¦ 10586 ¦ 23830 ¦ 213 ¦ ¦ 2016-05-28 ¦ ;SA2AA2AA1 ¦ 52123 ¦ 23130 ¦ 10 ¦ ¦ 2016-05-28 ¦ ;SA2AA2AA1 ¦ 53861 ¦ 30840 ¦ 11 ¦ ¦ 2016-05-28 ¦ ;A2AAAAA1AA1 ¦ 31597 ¦ 35288 ¦ 14 ¦ ¦ 2016-05-28 ¦ ;A7AA7AAAAA1AA1 ¦ 0 ¦ 0 ¦ 722 ¦ ¦ 2016-05-28 ¦ ;Qd1A1AA2AA1 ¦ 16920 ¦ 10922 ¦ 1650 ¦ ¦ 2016-05-28 ¦ ;AAA2AA1 ¦ 55295 ¦ 43007 ¦ 798 ¦ ¦ 2016-05-28 ¦ ;AAA2AA1 ¦ 40959 ¦ 36863 ¦ 503 ¦ ¦ 2016-05-28 ¦ ;S3A2AA2AA1 ¦ 38859 ¦ 36408 ¦ 275 ¦ ¦ 2016-05-28 ¦ ;AAA2AA1 ¦ 34815 ¦ 22527 ¦ 133 ¦ ¦ 2016-05-28 ¦ ;A1AAAAA1AA1 ¦ 31831 ¦ 36548 ¦ 112 ¦ ¦ 2016-05-28 ¦ dA2AA2AA1 ¦ 39648 ¦ 51881 ¦ 903 ¦ ¦ 2016-05-28 ¦ WA4AAAAA1AA1 ¦ 8659 ¦ 37808 ¦ 4198 ¦ L------------+--------------------+-------+-------+------- 50 rows in set. Elapsed: 0.032 sec.
GliX
16.06.2016 04:46Вы можете использовать сжатие при передаче данных. Формат сжатых данных нестандартный, и вам придётся использовать для работы с ним специальную программу compressor (sudo apt-get install compressor-metrika-yandex).
Строка из документации. Но такого пакета в репозитории нет. Где можно ознакомиться с форматом?o6CuFl2Q
16.06.2016 18:35+1Этот пакет ещё не выложили (постараемся добавить). Можно собрать программу самому — программа расположена здесь.
На самом деле, документация в этом месте чуть-чуть устарела, так как у нас есть поддержка обычного HTTP сжатия (gzip/deflate через заголовки Accept-Encoding при чтении и Content-Encoding при отправке).
Как её включить, написано в примере здесь.
Единственная особенность — необходимость выставить параметр enable_http_compression в 1.
Это сделано для того, чтобы готовые HTTP клиенты не стали непреднамеренно использовать сжатие, которое может привести к повышенному потреблению CPU.
Также, при запросе можно указать настройку http_zlib_compression_level. По-умолчанию — 3.
Стоит иметь ввиду, что gzip сжимает медленно (на тестеtime curl -sS 'http://localhost:8123/' -H 'Accept-Encoding: gzip' -d 'SELECT number FROM system.numbers LIMIT 10000000' | gzip -d | wc -c;получается всего 39 MB/sec.)

dronnix
16.06.2016 08:25Спасибо!
Есть ли интеграция с какой-либо готовой системой визуализации типа Graphite?o6CuFl2Q
16.06.2016 18:42У нас внутри ClickHouse используется в качестве бэкенда к Graphite.
Для интеграции требуется отдельный код (патч для Graphite для чтения данных из ClickHouse; сервер для записи данных в ClickHouse пачками; для поиска имён метрик по шаблонам), который не выложен. Когда и как его выкладывать, будут решать авторы кода и их руководители, поэтому я пока ничего сказать не могу.
В самом ClickHouse есть domain-specific функциональность для поддержки Graphite — это GraphiteMergeTree. Посмотреть, что она делает, можно в исходниках.
Наверное, пока не выложена вся остальная «обвязка» над Graphite, самому пользоваться этим не стоит.
Ruslan_Y
16.06.2016 08:49А как в ClickHouse обработать такие кейсы:
- Авто-удаление исторических данных, скажем старше N дней (скажем 45 дней), как я понимаю в MergeTree данные партициируются за месяц и простого варианта нет? Или же создавать, таблицы одну на N дней и объединять их через MERGE и читать данные через неё, а если данные устарели удалять физические таблицы?
- Как быть, если в результате нужны все столбцы (строки из исходного лога)? Заводить отдельную колонку и хранить в ней строку лога без обработки?
o6CuFl2Q
16.06.2016 19:12Авто-удаление исторических данных, скажем старше N дней (скажем 45 дней), как я понимаю в MergeTree данные партициируются за месяц и простого варианта нет? Или же создавать, таблицы одну на N дней и объединять их через MERGE и читать данные через неё, а если данные устарели удалять физические таблицы?
Да, простое удаление только по месяцам. Мы хотим когда-нибудь сделать custom-партиционирование.
По одной таблице на день — тоже вариант (у нас такое используется для одной задачи), но не стоит делать таких таблиц слишком много.

dmrt
16.06.2016 14:04+1А для чего так много СУБД сейчас создается?
Они ведь все востребованы я так полагаю, в той или иной степени.
Нельзя обойтись старым, добрым MySQL или PostgreSQL?
flr
16.06.2016 16:12+5Как только вам надо будет сделать GROUP BY по триллиону записей за пару секунд, вы поймете, почему Яндекс написал свою бд.
m0ridin
16.06.2016 16:55+2Можно почитать предыдущую статью Алексея: там написано про причины создания кликхауса
strobegen
16.06.2016 15:03Странно что CLI не поддерживает автоматическое управление локальными таблицами (создание, удаление и тп) на всех серверах кластера при работе с Distributed таблицами? или все же можно?
o6CuFl2Q
16.06.2016 19:17Сейчас нельзя.
Например, DROP TABLE удаляет только локальную таблицу. Если написал DROP TABLE для Distributed-таблицы — удалится только сама Distributed-таблица («вид» на данные), а все данные останутся на месте.
Аналогично для Replicated-таблиц. Если сделал DROP TABLE — удалится одна реплика, и у таблицы станет на одну реплику меньше.
У нас есть задача «распределённые DDL», чтобы можно было одной командой манипулировать со всеми составляющими Distributed-таблиц. Но пока не очень спешим делать. К тому же, она, на всякий случай, будет работать только при каком-либо «снятом предохранителе».
eigrad
16.06.2016 18:57Сколько места для сборки release нужно?) Случайно забил все 10G в /home совмещенном с / :-).
Будут ли пакеты для xenial?o6CuFl2Q
16.06.2016 20:05Пакеты для Xenial, наверное, будут.
По крайней мере, поставлена задача.
Для запуска из корня./release --standalone, вроде бы, 10 GB должно впритык хватить.
А если собираются все таргеты, которые есть в репозитории, то около 30 GB.
iamoverit
16.06.2016 20:13Какой формат данных будет самым эффективным для загрузки данных в ClickHouse, кроме Native разумеется? Какой формат выбрать чтобы можно было самостоятельно подготавливать данные для загрузки?
o6CuFl2Q
16.06.2016 20:24TabSeparated формат как правило является приемлимым по эффективности, если только вы умеете эффективно эскейпить значения типа String. Иногда с этим бывают проблемы. CSV будет тоже нормальным или чуть хуже.
Форматы Native и RowBinary эффективнее, но они не описаны подробно в документации.
При записи в таблицу семейства MergeTree, узким местом является скорее не парсинг формата, а сортировка данных, которую сервер производит при записи. Если отправлять уже отсортированные по первичному ключу данные, то сервер это поймёт, и загрузка будет идти быстрее. (Но если данные изначально не отсортированы, то вряд ли их удастся отсортировать эффективнее, чем это делает сервер).
При записи в простые таблицы Log/TinyLog, узким местом по CPU будет именно формат данных.
Лучше сначала попробовать загружать, как удобно. Например, формат JSONEachRow, конечно, менее эффективен, но если он оказался удобен для вас, то лучше начать с него.
Ещё замечу, что если данные постоянно загружаются на кластер (в реальном времени) и никогда не удаляются, то постоянный throughput по записи в расчёте на один сервер будет совсем небольшим (так как иначе вы просто за несколько дней заполнили бы все серверы). И при этом, запись не будет упираться в CPU и диски.iamoverit
16.06.2016 21:51Меня интересует именно эффективность, «удобность» на втором плане. Таблицы имеют большое количество столбцов > 30 почти все данные hex(varbinary) или bigint или int, нужна именно производительность в скорости вставки данных, есть ли какие то показатели количества строк в секунду я конечно понимаю что все зависит от типа данных и количества столбцов но всеже я уверен что вы делали какие то бенчмарки)
o6CuFl2Q
16.06.2016 22:35Да. Это описано здесь.
Вставлять varbinary через TabSeparated формат довольно неудобно — надо будет эскейпить \t, \n, \\, что весьма неестественно для бинарных данных.
Можно рассмотреть формат RowBinary. Вкратце, он такой:
— числа пишутся в бинарном виде в little endian;
— String пишется в виде: длина в формате varint, затем байты строки;
— FixedString пишется просто как байты;
— Date пишется как UInt16 — число дней с unix эпохи, а DateTime как UInt32 — unix timestamp.
— все данные пишутся подряд, в порядке строк.
eigrad
17.06.2016 16:43Если говорить про удобные и эффективные форматы, то у Druid'а есть WOW-фича — указываешь ему класс со структурой Protobuf, и он читает данные через неё. Сложно ли будет вкрутить подобную функциональность в clickhouse-client?
o6CuFl2Q
17.06.2016 21:19Эта задача имеет среднюю сложность, если рассматривать только один из сценариев работы.
Можно сделать поддержку protobuf-формата так, что можно будет читать данные из таблицы в некотором protobuf-е, который однозначно ей соответствует, и записывать данные в таблицу, но только в этой, конкретной структуре protobuf-а.
Но здесь не рассматривается другой сценарий работы — сгенерировать структуру таблицы по уже существующему protobuf-у. Будет сложность с protobuf-ами, имеющими более один уровень вложенности.
У нас есть в продакшене программа, которая перекладывает данные из сложного protobuf-а в ClickHouse, но она ещё при этом делает денормализацию: исходный protobuf содержит сессию, которая состоит из множества событий; и на один такой protobuf, в таблицу вставляется много строчек-событий.
В связи с этим, этот, более сложный сценарий, лучше вообще не рассматривать.eigrad
17.06.2016 21:27Да, с такими сценариями проще отдельную программу написать, которая с вложенными данными будет разбираться. Но ведь это не специфично для Protobuf, как в случае того же JSON'а поступать?..
В документации описан тип данных Nested, будет ли работать вставка данных, если структура таблицы с Nested-полями и во входящем JSON совпадает? Или на вход поддерживается только JSON с плоской структурой?o6CuFl2Q
17.06.2016 22:04будет ли работать вставка данных, если структура таблицы с Nested-полями и во входящем JSON совпадает? Или на вход поддерживается только JSON с плоской структурой?
Nested будет представлен в виде отдельных массивов (одинаковых длин) для каждого элемента вложенной структуры.
Таким образом, прямое соответствие между иерархией в JSON и Nested типами не поддерживается.
iamoverit
17.06.2016 10:36А без SSE 4.2 вообще нет шансов завести?
o6CuFl2Q
17.06.2016 20:47Можно завести (по факту, запускали даже на AArch64 серверах). Для этого нужно найти все места в коде, где оно используется.
Найти их можно поиском по коду фрагмента _mm_ или __x86_64__.
Из SSE 4.2 используется совсем немного: crc32, строковые функции (в паре мест).
Это можно легко закрыть ifdef-ами.
o6CuFl2Q
17.06.2016 20:48И ещё: мы наблюдали, что на некоторых Openstack машинах, /proc/cpuinfo выдаёт неправильную информацию, хотя по факту, процессор выполняет нужные инструкции.
erlyvideo
17.06.2016 17:32Огромная вам просьба: соберите, пожалуйста, кег под homebrew.
30 гигов компилять — это отпаяет макбук от монитора =(
o6CuFl2Q
17.06.2016 22:18EAI_ADDRFAMILY -9 /* Address family for NAME not supported. */
Посмотрите вывод ifconfig.
Возможно, на сервере нет поддержки IPv6 (в принципе, даже link-local адреса), а для чего-то IPv6 нужен (в конфиге используется IPv6).
Может быть, стоит разобраться подробнее.georgas
17.06.2016 22:26Да, IPv6 нет. Без него вообще никак?
o6CuFl2Q
17.06.2016 22:35Пока не знаю. Само наличие IPv6 связности не требуется, система нормально работает по IPv4.
У вас IPv6 где-то явно выключен? (ядро собрано без IPv6, или какие-то настройки) Если да, то где?
Непонятно, зачем отключать IPv6.
Может быть, поможет убрать все адреса вида::из config.xml, users.xml, но скорее всего, не поможет.
И тогда помогла бы перекомпиляция, чтобы явно убрать IPv6 из DNS-запросов.georgas
17.06.2016 22:38Помог совет выше, но все-равно спасибо.
А IPv6 не отключал — просто такой вот сервер.

excoder
18.06.2016 09:34Спасибо за труд, ребята! Вопрос, почему же в benchmark нет join, ведь по отношению к остальным участникам, например Vertica, это нечестно?
o6CuFl2Q
18.06.2016 19:36Запросы для бенчмарка были выбраны осенью 2013, и тогда ClickHouse не поддерживал JOIN.
Нам надо бы серьёзно обновить бенчмарк.
— сделать его на основе открытых данных;
— сделать запросы более разнообразными.
В этой директории есть заготовки: инструкции, как загрузить некоторые открытые данные и выполнить некоторые запросы.
В частности, есть заготовка для AMPLab Big Data Benchmark. Правда там всего три запроса, так что он тоже не особо интересен.excoder
18.06.2016 23:33Понял, спасибо! В показательных целях очень стоит его добавить. Понятно что сканы сами по себе у вас быстрые, но вся мякотка аналитических (OLAP) движков именно вот в этих вот развесистых запросах. TPC-H load, условно говоря. Ну или взять ту же SAP HANA, которая (по крайней мере) утверждает, что никаких больше кубов и преагрегаций, все запросы прямо на колоночном движке с очень высокой скоростью.

masterOk
18.06.2016 20:29o6CuFl2Q Если не сложно расскажите пожалуйста в чем преимущества и недостатки ClickHouse vs Tarantool? Какую СУБД лучше использовать для хранения показаний датчиков и построения графиков по этим данным?
o6CuFl2Q
18.06.2016 20:49Это принципиально разные системы.
Используйте ClickHouse для аналитики, а Tarantool как Key-Value базу.
В том числе, можно использовать и то, и другое.
На примере рекламной сети:
В Tarantool кладёте:
— данные для короткой персонализации;
— данные для таргетинга;
— счётчики для антифрода.
И используете его для запросов непосредственно из крутилки.
В ClickHouse кладёте:
— логи показов рекламы, вместе со всеми данными, свойствами посетителя, факторами;
— логи торгов, аукциона;
— логи кликов;
— постклик данные.
И используете его для построения отчётов:
— для внутреннего использования, для исследований, для оптимизации;
— в сервисе отчётов для клиентов.
Какую СУБД лучше использовать для хранения показаний датчиков и построения графиков по этим данным?
Это зависит от того, что нужно делать с этими датчиками.
Два варианта:
— по определённой логике принимать решение на каждый сигнал или на основе данных за короткое окно времени;
— эффективно хранить все данные и строить графики за любое время.
lazil
21.06.2016 14:31Спасибо, очень интересно!
Одно замечание — что в этой статье, что в документации очень хромает грамматика, глаз спотыкается постоянно.o6CuFl2Q
21.06.2016 15:19Пишите, какие места следует исправить, и я постараюсь запомнить эти случаи.
lazil
21.06.2016 15:26Напимер:
Для решения этой задачи
,открытых
уже в начале использования в 2012 году
.,была написана
И в документации много, например:
при чтении
.,вынимается достаточно большое
С запятыми беда, в общем. Перебор )

facha
Kudu?
flr
Насколько я понимаю, Kudu вполне себе конкурент для ClickHouse.
Но надо понимать, что Kudu находится в Beta и не рекомендуется к использованию в production (хотя, разработчики, конечно, активно к этому призывают). В то же время ClickHouse используется в Метрике (и не только), что является очень серьёзным кейсом.
Опишу первые впечатления:
ClickHouse выглядит интереснее, чем Kudu в плане возможностей. Намного более дружелюбен для использования. Не надо ковырять Impala, можно использовать человеческий и довольно приятный на первый взгляд клиент. Однако Kudu более прост в организации кластера и репликаций. Там не нужно никаких телодвижений по этому поводу. По скорости не понятно — надо бы сравнить и потестировать.
В общем, Яндекс круты. Продукт очень востребован, на рынке действительно нет таких OpenSource проектов (опять же, Kudu еще молод). Будем тестировать и пробовать.