В этой статье мы продолжим рассказывать о похождениях нашей программы распознавания паспорта: теперь паспорт отправится на Эльбрус!

Итак, что же мы знаем про архитектуру Эльбрус?
Эльбрус — высокопроизводительная и энергоэффективная архитектура процессоров, отличающаяся высокой безопасностью и надежностью. Современные процессоры архитектуры Эльбрус могут применяться в качестве серверов, настольных компьютеров и даже встраиваемых вычислителей. Они способны удовлетворить повышенным требованиям по информационной безопасности, рабочему диапазону температур и длительности жизненного цикла продукции. Процессоры архитектуры Эльбрус, как говорят нам публикации МЦСТ [1, 2], предназначены для решения задач обработки сигналов, математического моделирования, научных расчетов, а также других задач с повышенными требованиями к вычислительной мощности.
Мы в Smart Engines попробовали убедиться, правда ли производительности Эльбруса достаточно, чтобы реализовать распознавание паспорта без значительных потерь в скорости работы.
Обзорно-описательная часть: особенности архитектуры Эльбрус
Архитектура Эльбрус отностися к категории архитектур, использующих принцип широкого командного слова (Very Long Instruction Word, VLIW). На процессорах с VLIW-архитектурой компилятор формирует последовательности групп команд (широкие командные слова), в которых отсутствуют зависимости между командами внутри группы и сведены к минимуму зависимости между командами в разных группах. Эти группы команд исполняются параллельно, что обеспечивает высокий уровень параллелизма на уровне операций.

Распараллеливание на уровне команд целиком обеспечивается оптимизирующим компилятором, что позволяет значительно упростить аппаратуру для исполнения команд, поскольку теперь она не решает задач распараллеливания, как в случае, например, с архитектурой x86. Энергопотребление системы снижается: от процессора больше не требуется анализировать зависимости между операндами или переставлять операции, поскольку все эти задачи возложены на компилятор. Компилятор располагает значительно большими вычислительными и временными ресурсами, чем аппаратные анализораторы бинарного кода, и поэтому может выполнять анализ тщательнее, находить больше независимых операций, и в результате формировать широкие командные слова, исполняющиеся более эффективно.
Наряду с использованием параллелизма операций в архитектуре Эльбрус заложена реализация и других видов параллелизма, свойственных вычислительному процессу: векторного параллелизма, параллелизма потоков управления на общей памяти, параллелизма задач в многомашинном комплексе.
Кроме того, архитектура Эльбрус обладает бинарной совместимостью с архитектурой Intel x86, реализованной на базе динамической бинарной трансляции.
Еще одной важной особенностью архитектуры Эльбрус является аппаратная поддержка защиты программ и данных при исполнении. Программы исполняются в едином виртуальном пространстве, реализованном на аппаратном уровне, что минимизирует возможность исполнения вредоносного кода и позволяет выявлять труднообнаруживаемые на других архитектурах ошибки.
Таким образом, основные особенности архитектуры процессоров Эльбрус [3, 4]:
- параллельная энергетически эффективная архитектура ядра;
- автоматическое распараллеливание потока команд с помощью компилятора;
- повышение надежности и безопасности создаваемого программного обеспечения за счет наличия защищенного режима;
- совместимость с распространенными микропроцессорными архитектурами.
Наше знакомство с Эльбрусом
Конкретной машиной, с которой мы работали, был Эльбрус 4.4, объединяющий четыре 4-ядерных процессора Эльбрус 4С с 3 контроллерами памяти, 3 каналами межпроцессорного обмена, 1 каналом ввода-вывода и 8 Мбайтным кэшем 2-го уровня (по 2 Мб на ядро). Рабочая тактовая частота Эльбрус 4С составляет 800 МГц, технологическая норма 65 нм, средняя рассеиваемая мощность — 45 Вт. Операционная система — ОС "Эльбрус", созданная на основе Linux. Вот что нам отобразила команда uname -a:

Оптимизирующий компилятор под Эльбрус называется lcс. На нашем сервере был установлен lcc версии 1.20.09 от 27 августа 2015 года, совместимый с gcc 4.4.0. lcc работает со стандартными флагами gcc, а также определяет некоторые дополнительные. Из стандарных флагов мы обратили внимание на -ffast и -ffast-math. Данные опции выключены по умолчанию, поскольку включают преобразования с вещественной арифметикой, которые могут приводить к некорректным результатам работы программ, предполагающих строгое соблюдение стандартов IEEE или ISO для вещественных операций и функций. Кроме того, они включают некоторые потенциально опасные оптимизации, которые в редких случаях могут приводить к некорректному поведению программ, вольно жонглирующих указателями. Оба флага дополнительно включают -fstdlib, -faligned, -fno-math-errno, -fno-signed-zeros, -ffinite-math-only, -fprefetch, -floop-apb-conditional-loads, -fstrict-aliasing. Их использование заметно влияет на производительность программы.
Кроме того, lcc позволяет довольно тонко настраивать оптимизации, например для настройки параметров подстановки функций есть целый набор флагов:
Таблица 1. Флаги lcc, позволяющие управлять параметрами подстановки функций.
| Флаг lcc | Назначение |
|---|---|
| -finline-level=<f> | Задает коэффициент увеличения интенсивности подстановки [0.1-20.0] |
| -finline-scale=<f> | Задает коэффициент увеличения основных ресурсных ограничений [0.1-5.0] |
| -finline-growfactor=<f> | Задает максимальное увеличение размера процедуры после подстановки [1.0-30.0] |
| -finline-prog-growfactor=<f> | Задает максимальное увеличение размера программы после подстановки [1.0-30.0] |
| -finline-size=<n> | Задает максимальный размер подставляемой процедуры |
| -finline-to-size=<n> | Задает максимальный размер процедуры, в которую может быть произведена подстановка |
| -finline-part-size=<n> | Задает максимальный размер вероятного региона процедуры для частичной подстановки |
| -finline-uncond-size=<n> | Задает максимальный размер безусловно подставляемой процедуры |
| -flib-inline-uncond-size=<n> | Задает максимальный размер безусловно подставляемой библиотечной процедуры |
| -finline-probable-calls=<f> | Запрещает подстановку процедур, счетчик вызова которых меньше, чем (аргумент * max_call_count), где max_call_count — максимальный счетчик операции вызова на всей задаче. |
| -fforce-inline | Включает безусловную подстановку функций со спецификатором inline. |
| -finline-vararg | Включает подстановку функций с переменным числом аргументов. |
| -finline-only-native | Выполняет подстановку только для функций с явным модификатором inline |
Также можно настраивать межпроцедурные оптимизации, анализ указателей, подкачку данных и т. д.
Для профилирования на Эльбрусе доступны привычный многим perf, а также куда менее известный dprof. Кроме того, для dprof доступно расширение, позволяющее перевести профиль в valgrind-совместимый формат.
Итак, нашей целью было запустить консольную версию программы распознавания паспорта. Она целиком написана на С/С++, местами с использованием С++11. Несмотря на то, что поддержки С++11 не заявлено, на самом деле lcc понимает его, хотя и весьма избирательно. Полная поддержка С++11 планируется в новых версиях lcc.
Точно не поддерживаются:
- std::default_random_engine. К сожалению, здесь можно только посоветовать использовать сторонние генераторы псевдослучайных чисел.
- nullptr_t. В тех случаях, когда nullptr действительно нужен, приходится использовать вместо него какое-то специально выделенное значение объекта.
- std::begin и std::end. Для объектов STL можно использовать методы begin() и end(), а вот для С/С++ объектов придется искать адреса вручную.
- std::chrono::steady_clock. Мы использовали std::chrono::high_resolution_clock вместо него, хотя, конечно, отсутствие std::chrono::steady_clock может внести погрешности в измерения времени работы.
- Отсутствует метод std::string::pop_back(). Но вместо него спокойно можно использовать std::string::erase(size()-1, 1).
- std::to_string не определен для аргумента типа double. Эта проблема решается преобразованием, например, к long double, который поддерживается.
- В стандартных контейнерах STL не предусмотрены спецификации для std::unique_ptr в качестве хранимого объекта с операцией перемещения вместо копирования, то есть, к примеру, создать std::map<int, std::uniqie_ptr> нельзя.
При этом сами по себе std::unique_ptr, std::shared_ptr поддерживаются.
Кроме того, lcc расстраивает gcc-расширение __uint128_t, а также файлы исходного кода в кодировке UTF-8 с BOM.
После переписывания неподдерживаемых кусков кода мы смогли успешно скомпилировать наш проект. Однако просто взять и запустить программу распознавания паспорта нам не удалось: при попытке запуска мы получили ошибку Bus error. После консультации со специалистами МЦСТ было выяснено, что проблема заключается в невыровненном доступе в память, который возникает внутри библиотеки Eigen, которой мы пользуемся.
Eigen — оптимизированная header-only библиотека линейной алгебры, написанная на С++ [5]. Она может использоваться для различных операций над матрицами и векторами, а также включает оптимизации под x86 SSE, ARM NEON, PowerPC AltiVec и даже IBM S390x.
Поскольку разработчики Eigen вряд ли предполагали, что их библиотеку когда-либо будут использовать на Эльбрусе, они не предусмотрели его в списке поддерживаемых архитектур, и режим выровненного доступа в память был попросту отключен. Наши коллеги из МЦСТ оперативно помогли нам исправить эту проблему, показав, как следует модифицировать :

В результате этого дополнения необходимая нам функциональность Eigen заработала. Надо заметить, это была единственная несовместимость Eigen с Эльбрусом, причем проявляющаяся только при включенных оптимизациях.
Однако на этом наши злоключения не закочились. Ошибка Bus error никуда не делась, однако теперь она возникала при исполнении кода уже наших библиотек. После небольшого исследования мы выяснили, что невыровненный доступ в память периодически возникал при инициализации дополнительных контейнеров изображений в процессе распознавания.
При заполнении строчки 8-битной картинки фиксированным значением в целях ускорения находилась часть строчки, кратная 4 байтам, и заполнялась 32-битными значениями (созданными копированием исходного 8-битного), а остаток строчки заполнялся уже по одному байту. Однако при аллокации 8-битной картинки выравнивание в памяти гарантируется только до одного байта, и при попытке записать по такому адресу 32-битное значение возникала ошибка.
Для решения проблемы мы добавили в начале обработки строчки вычисление ближайшего адреса, кратного нужному количеству байт (в описанном случае — четырём) и заполнение до этого адреса по одному байту, а заполнение по 4 байта сделали уже с этого адреса.
После исправления этой ошибки наша программа не просто запустилась, но и продемонстрировала правильную работу!


Это уже была маленькая победа, но мы двинулись дальше. Следующим шагом мы перешли непосредственно к оптимизации нашей системы. Наша программа может работать в двух режимах: распознавание произвольно расположенного разворота паспорта на фотографии или отсканированном изображении (anywhere-режим), а также распознавание паспорта на видеоролике (mobile-режим). Во втором случае предполагается, что паспорт занимает большую часть кадра, от кадра к кадру его положение меняется слабо, и обработка одного кадра включает значительно упрощенные алгоритмы поиска документа.
Распознавание одного тестового изображения в anywhere-режиме, идущее в 1 поток, “из коробки” работало на Эльбрусе около 100 (!) секунд.
Сначала мы попробовали задействовать все 16 ядер Эльбрус 4.4. Задействовать эффективно все 16 потоков оказалось возможным только примерно в трети нашей программы. Остальные вычисления удалось распараллелить на 2 потока. В результате время распознавания сократилось до 7.5 секунд. Воодушевленные, мы посмотрели в профайлер. К нашему удивлению, мы увидели там что-то такое:

Оказалось, внутри основного цикла программы было замечательное место:
std::vector<Object> candidates;
for (int16_t x = x_min; x < x_max; x += x_step)
for (int16_t y = y_min; y < y_max; y += y_step)
candidates.emplace_back(x, y, 0.0f);В результате многократного выполнения этого кода накладные расходы на изменение размера вектора чудовищно растут и достигают 16% времени распознавания. На других архитектурах это место не было заметно, однако на Эльбрусе реаллокация памяти оказалась неожиданно медленной. После исправления этой досадной оплошности время работы сократилось практически на 1 секунду.
Затем мы перешли к увеличению параллелизма внутри каждого потока — основной “фишке” VLIW. Для этого мы использовали самый короткий путь — уже оптимизированную специалистами МЦСТ библиотеку EML.
Высокопроизводительная библиотека EML
Для микропроцессоров архитектуры Эльбрус разработана библиотека EML — библиотека, предоставляющая пользователю набор разнообразных функций для высокопроизводительной обработки сигналов, изображений, видео, а также математические функций и операции [4, 6].
EML включает в себя следующие группы функций:
- Vector — функции для работы с векторами (массивами) данных;
- Algebra — функции линейной алгебры;
- Signal — функции обработки сигналов;
- Image — функции обработки изображений;
- Video — функции обработки видео;
- Volume — функции преобразования трехмерных структур;
- Graphics — функции для рисования фигур.
Библиотека EML предназначена для использования в программах, написанных на языках С/С++.
Низкоуровневые функции обработки изображений или поддерживаются EML напрямую, или представимы через основные ариметические функции EML над векторами (в нашем случае — строками изображения).
Например, поэлементное сложение двух массивов 32-битных вещественных чисел:
for (int i = 0; i < len; ++i)
dst[i] = src1[i] + src2[i];можно выполнить с помощью функции EML:
eml_Status eml_Vector_Add_32F(const eml_32f *pSrc1, const eml_32f *pSrc2, eml_32f *pDst, eml_32s len)где
pSrc1— Указатель на вектор первого операндаpSrc2— Указатель на вектор второго операндаpDst— Указатель на вектор результатаlen— Количество элементов в векторах
Возвращает она
EML_OK, если функция отработала успешноEML_INVALIDPARAMETER, если один из указателей равен NULL или длина векторов меньше или равна 0.
Всего перечисление eml_Status может принимать 4 значения:
EML_OK— Нет ошибокEML_INVALIDPARAMETER— Некорректный аргумент или вне допустимого диапазонаEML_NOMEMORY— Нет свободной памяти для операцииEML_RUNTIMEERROR— Некорректные данные, ошибка в процессе исполнения
Определены основные типы данных:
typedef char eml_8s;
typedef unsigned char eml_8u;
typedef short eml_16s;
typedef unsigned short eml_16u;
typedef int eml_32s;
typedef unsigned int eml_32u;
typedef float eml_32f;
typedef double eml_64f;Аналогично устроена функция для поэлементного умножения 32-битных вещественных чисел:
eml_Status eml_Vector_Mul_32F(const eml_32f *pSrc1, const eml_32f *pSrc2, eml_32f *pDst, eml_32s len)А вот для целых чисел определены только функции поэлементного сложения и умножения со сдвигом, которые выполняют такие операции:
// Addition
for (int i = 0; i < len; ++i)
dst[i] = SATURATE((src1[i] + src2[i]) << shift);
// Multiplication
for (int i = 0; i < len; ++i)
dst[i] = SATURATE((src1[i] * src2[i]) << shift); И собственно функции EML:
// int16_t addition
eml_Status eml_Vector_AddShift_16S(const eml_16s *pSrc1, const eml_16s *pSrc2, eml_16s *pDst, eml_32s len, eml_32s shift)
// int32_t addition
eml_Status eml_Vector_AddShift_32S(const eml_32s *pSrc1, const eml_32s *pSrc2, eml_32s *pDst, eml_32s len, eml_32s shift)
// uint8_t addition
eml_Status eml_Vector_AddShift_8U(const eml_8u *pSrc1, const eml_8u *pSrc2, eml_8u *pDst, eml_32s len, eml_32s shift)
// int16_t multiplication
eml_Status eml_Vector_MulShift_16S(const eml_16s *pSrc1, const eml_16s *pSrc2, eml_16s *pDst, eml_32s len, eml_32s shift)
// int32_t multiplication
eml_Status eml_Vector_MulShift_32S(const eml_32s *pSrc1, const eml_32s *pSrc2, eml_32s *pDst, eml_32s len, eml_32s shift)
// uint8_t multiplication
eml_Status eml_Vector_MulShift_8U(const eml_8u *pSrc1, const eml_8u *pSrc2, eml_8u *pDst, eml_32s len, eml_32s shift)Такие фунции могут пригодиться, например, для целочисленной арифметики.
В EML определена структура для изображения:
typedef struct {
void * data; /**< Указатель на начало данных */
eml_image_type type; /**< Тип данных изображения */
eml_32s width; /**< Ширина изображения в пикселях, ось x */
eml_32s height; /**< Высота изображения в пикселях, ось y */
eml_32s stride; /**< Расстояние между строками в элементах формата */
eml_32s channels; /**< Число каналов (элементов) в пикселе */
eml_32s flags; /**< Вспомогательные признаки */
void * state; /**< Указатель на внутреннюю структуру */
eml_32s bitoffset;/**< Смещение в битах от начала буфера данных до первого пикселя */
eml_format format; /**< Формат пикселя */
eml_8u addition[32 - 2 * sizeof (void *)]; /**< выравнивание размера структуры до 64 байт */
} eml_image;Поддерживаемые типы данных eml_image_type для изображений:
- EML_BIT — 1-битные беззнаковые целые данные
- EML_UCHAR — 8-битные беззнаковые целые данные
- EML_SHORT — 16-битные знаковые целые данные
- EML_INT — 32-битные знаковые целые данные
- EML_FLOAT — 32-битные данные с плавающей точкой
- EML_DOUBLE — 64-битные данные с плавающей точкой
- EML_USHORT — 16-битные безнаковые целые данные
EML поддерживает и другие функции, нужные для обработки изображений. Например, часто нужная для эффективной реализации сепарабельных фильтров функция транспонирования:
eml_Status eml_Image_FlipMain(const eml_image *pSrc, eml_image *pDst)Эта функция накладывает центр исходного изображения на центр результирующего изображения и выполняет транспонирование. Ее работу можно описать формулой:
dst[width_dst/2 + (y - height_src/2), height_dst/2 + (x - width_src/2)] = src[x, y], где x = [0, width-1], y = [0, height-1]Изображения должны иметь одинаковый тип данных (EML_UCHAR, EML_SHORT, EML_FLOAT или EML_DOUBLE) и иметь одинаковое число каналов (1, 3 или 4).
Эксперименты и результаты
В Таблице 2 показаны времена выполнения сложения и умножения для разных типов данных. В данном эксперименте мы 50 раз замеряли время выполнения 1000 итераций сложения/умножения двух массивов длины 105 и брали медиану из полученных значений. В таблице приведено среднее время выполнения одной итерации. Можно видеть, что использование EML позволяет заметно ускорить вычисления в вещественных 32-битных числах и 8-битных беззнаковых целых числах. Это важно, поскольку эти типы данных очень часто используются в оптимизированном тракте обработки изображений.
Таблица 2. Время выполнения сложения и умножения массивов чисел длины 105 на Эльбрус 4.4.
| Сложение | ||
|---|---|---|
| Тип данных | uint8_t | float |
| Без EML, мкс | 16.7 | 148.8 |
| EML, мкс | 8.0 | 83.6 |
| Умножение | ||
|---|---|---|
| Тип данных | uint8_t | float |
| Без EML, мкс | 31.4 | 108.9 |
| EML, мкс | 27.6 | 73.5 |
Затем, мы решили проверить, как EML работает с изображениями и исследовали транспонирование, поскольку это довольно востребованная операция при обработке изображений. Зависимость времени транспонирования от размера для квадратных изображений разных типов:
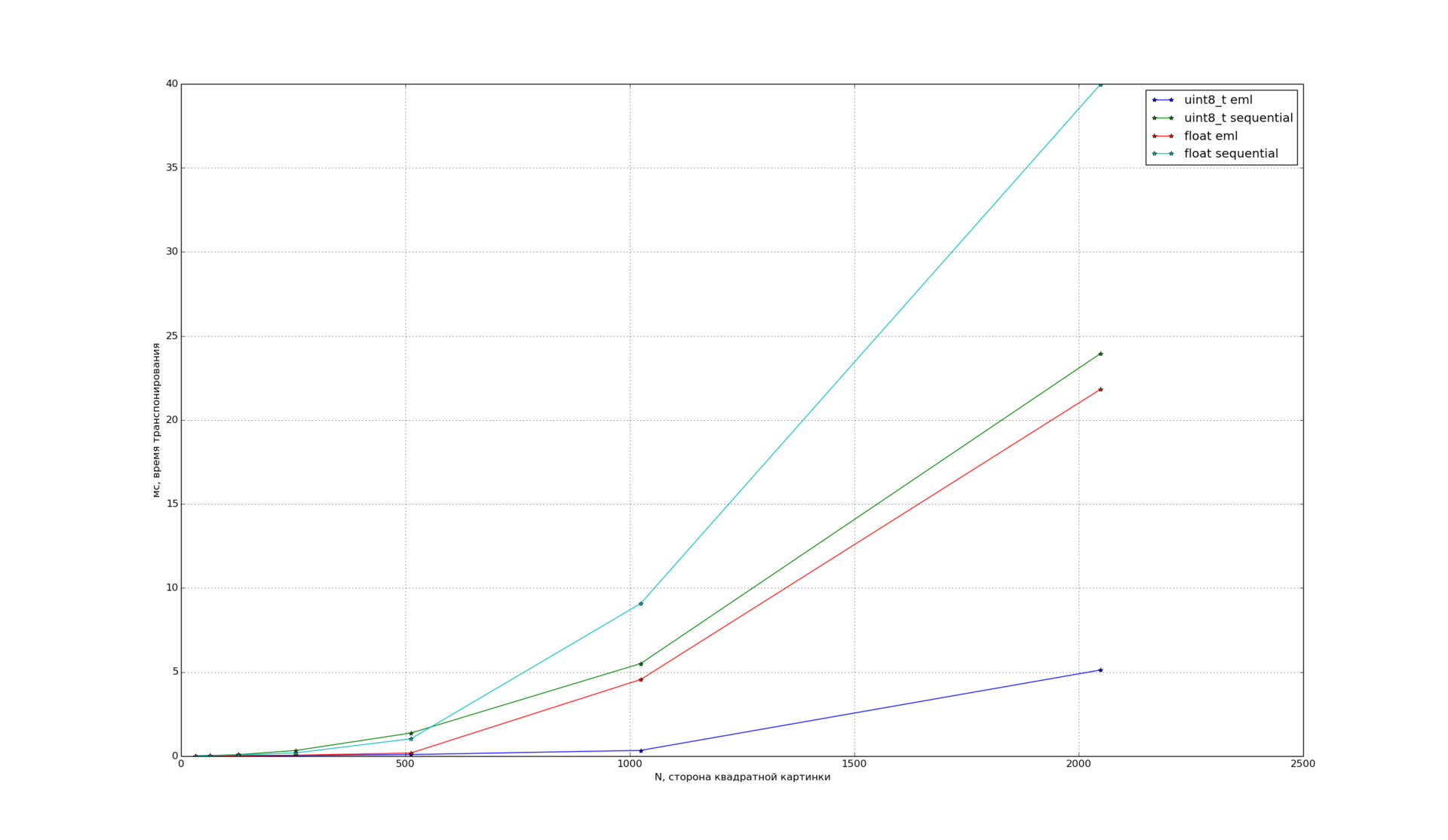
Можно видеть, что EML демонстрирует хорошее ускорение для типов uint8_t и float.
Результаты по ускорению программы распознавания паспорта (тестовое изображение, anywhere-режим) приведены в Таблице 3. Они были получены за первые 3 месяца работы с Эльбрусом и, разумеется, мы планируем работать над оптимизацией системы дальше.
Таблица 3. Процесс оптимизации программы распознавания паспорта на Эльбрус 4.4.
| Версия | Время работы, с |
|---|---|
| 1 поток | ~100 |
| 16 потоков, О3 | 6.2 |
| 16 потоков, O4 | 5.4 |
| 16 потоков, O4, транспонирование (EML) | 5.0 |
| 16 потоков, O4, транспонирование, матричные операции (EML) | 4.5 |
| 16 потоков, O4, транспонирование, матричные операции, арифметические операции (EML) | 3.4 |
Для оценки времени работы оптимизированной версии мы проанализировали время работы на 1000 входных изображений для каждого из режимов. В Таблице 4 приведены минимальное, максимальное и среднее времена распознавания одного кадра для anywhere- и mobile-режимов.
Таблица 4. Время работы распознавания паспорта на Эльбрус 4.4.
| Режим | Минимальное время, c | Максимальное время, с | Среднее время, с |
|---|---|---|---|
| anywhere | 0.9 | 8.5 | 2.2 |
| mobile | 0.2 | 1.5 | 0.6 |
Мы не стали сравнивать производительность с Intel или ARM: оптимизация наших библиотек для этих процессоров заняла у нас несколько лет и было бы некорректно проводить сравнение сейчас, всего лишь после 3 месяцев работы.
Заключение
В этой статье мы постарались поделиться своим опытом портирования программы на такую необычную архитектуру, как Эльбрус. “Этого точно не может случиться с нами!” — думали мы, рассуждая о некоторых видах программных ошибок, однако от глупых ляпов не застрахован никто. Стоит признать, что работа с платформой Эльбрус действительно помогла нам найти как минимум два проблемных места в нашем коде, поэтому обещания производителя можно считать выполненными.
Всего за несколько месяцев нам удалось не только добиться правильной работы распознавания, но и значительного ускорения нашей системы на Эльбрусе. Сейчас производительность нашей программы распознавания паспорта на Эльбрус 4.4 и на x86 отличается уже не на порядок, что является очень неплохим результатом. И мы не намерены останавливаться на достигнутом. Мы верим, что его все еще можно значительно улучшить.
Что ж, все это означает, что наши первые шаги в путешествии на Эльбрус можно считать вполне успешными!
Большое спасибо компании МЦСТ и ее сотрудникам за предоставление аппаратной платформы и консультаций по архитектуре и оптимизации.
Использованные источники
[1] А.К. Ким, И.Н. Бычков и др. Архитектурная линия “Эльбрус” сегодня: микропроцессоры, вычислительные комплексы, программное обеспечение // Современные информационные технологии и ИТ-образование. Сборник докладов, с. 21–29.
[2] A.К. Ким. Российские универсальные микропроцессоры и вычислительные комплексы высокой производительности: результаты и взгляд в будущее. Вопросы радиоэлектроники серия ЭВТ, Т. 3, c. 5–13, 2012.
[3] А.К. Ким и И.Н. Бычков. Российские технологии “Эльбрус” для персональных компьютеров, серверов и суперкомпьютеров.
[4] В.С. Волин и др. Микропроцессоры и вычислительные комплексы семейства "Эльбрус". Учебное пособие. Питер, 2013.
[5] Eigen, C++ template library for linear algebra: matrices, vectors, numerical solvers, and related algorithms, http://eigen.tuxfamily.org.
[6] П.А. Ишин, В.Е. Логинов, and П.П. Васильев. Ускорение вычислений с использованием высокопроизводительных математических и мультимедийных библиотек для архитектуры Эльбрус.
Комментарии (83)

SHVV
05.07.2016 13:26+4Мы не стали сравнивать производительность с Intel или ARM
Вот так, на самом интересном месте облом.
Кстати, а EML таки задействует встроенный в процессор DSP, или она работает на основных ядрах, но написана оптимально под архитектуру?
Agat-Aquarius
05.07.2016 14:14+1EML таки задействует встроенный в процессор DSP, или она работает на основных ядрах? Судя по документации, EML таки не задействует DSP; и вообще, компиляция для DSP — это особое дело. В любом случае, процессор «Эльбрус-4С», на основе которого построен используемый авторами сервер «Эльбрус-4.4», не имеет DSP-ядер.
SmartEngines
05.07.2016 16:51Все верно, на этом сервере нет DSP, выигрыш достигается за счет более эффективной загрузки АЛУ.
RomanArzumanyan
05.07.2016 17:18Как соотносится достигнутая вами производительность к теоретической? Во что упёрлись после оптимизации?
SmartEngines
05.07.2016 18:24В данный момент мы перешли на следующий этап оптимизации и пока явных барьеров не видим. Вопрос времени и более глубокого изучения возможностей. Мы хотим довести время распознавания до 1 секунды и дальше уже снижать число потоков. А пока что уперлись в лето :)
RomanArzumanyan
05.07.2016 19:14Честно говоря, хотелось узнать, сколько Гфлопс и/или Гб/с было достигнуто (если не коммерческая тайна). Может, вы уже 80% ресурсов исчерпали, и дальше расти особенно некуда.

Ivan_83
05.07.2016 21:20100500 Гфлопс и/или Гб/с.
Вопрос то не оч корректный.
Авторы измеряют в штука/сек, при этом 1 штука это интегральная величина от времени выполнения дохрена инструкций.
Время выполнения различных инструкций различается, как и их количество. Плюс сюда нужно добавить взаимное расположение инструкций и особенности расположения обрабатываемых данных.
Завтра они заменят деление на умножение или того хуже вычитание/сдвиг и у них 100500% прироста сразу образуется, при тех же условных 80% использованных ресурсов.
А после завтра кого то осенит и он перепишет алгоритм получив ещё 100500% прироста.
Я, как и авторы, тоже сейчас по работе всякими тестами с алгоритмами на OpenCV занят, алгоритмы делают одно и тоже с видео, но сильно разными способами с сильно разными результатами и сильно разной загрузкой проца, и у каждого алгоритма есть ещё минимум 5 крутилок которые часто сильно влияют на результат/скорость/ресурсы.
Вы же сейчас просите какую то универсальную метрику производительности, а её просто не существует.
Те же гигафлопсы — у видюх их полно и за дёшего, но CPU они даже не конкуренты, ибо решаемые задачи в основном сильно разные.
Если же сравнивать среднюю температуру по больнице в виде «комфорт работы как на десктопе» то эльбрус так себе, но там ещё много куда есть расти, в частности и х86 транслятор выкинуть (я видел работу через него) и компилятор и софт пооптимизировать.RomanArzumanyan
05.07.2016 21:28+1Оптимизация программы под архитектуру = насколько сильно ты загружаешь железо расчётами. Не путайте с оптимизацией алгоритмов. Так что вопрос — нормальный.
Ivan_83
06.07.2016 00:44Оно и в такой формулировке смысла не имеет.
«Расчёты» могут быть бесполезными, загрузка будет 100%, при производительности эквивалентной загрузке на 5% с другим алгоритмом.
Более того, если речь про распараллеливание расчётов по ядрам, то это не всегда просто, и часто это накладно.
Простой пример: собрал сегодня прогу, в один поток давала 12 фпс и грузила одно ядро в полку. Собрал её же с OpenMP, стала грузить в полку все 4 ядра и давать 20 фпс.
Или вот возился я с собственной реализацией ECDSA, оно совершенно не параллелится, в принципе, там все расчёты по цепочке идут. И выдавало оно мне одну подпись за 0,9 сек, потом за 0,6… потом я поменял алгоритм и стало 0,06 сек (если правильно помню).RomanArzumanyan
06.07.2016 01:25Проц от Intel решает некую эталонную задачу за время Х. Эльбрус решает ту же задачу за время 5Х. Проц от Intel выдаёт 85% теоретической производительности (софт давно написан, отлажен, оптимизирован). Эльбрус выдаёт 30% (мало что оптимизировали? упёрлись в память? медленный процессор? молодой компилятор?)
Меня интересует качество реализации (насколько эффективно используется вычислительный ресурс), а не качество алгоритмов. В статье прямо так и написано — кодовая база (то есть алгоритмы) для разных платформ одинаковые, поменяли 100 строчек под условной компиляцией. Если команда автора быстро выжала из Эльбруса все соки, то оптимизировать под него условно легко. Если не выжала — оптимизировать под него условно нелегко.
Теперь ясно?Ivan_83
06.07.2016 10:51+1Скорость решения «эталонной» задачи очень сильно зависит от того как она реализована под данную платформу.
Например, под х86 для обнуления регистра сейчас компиляторы генерируют код:
xor eax, eax
хотя раньше было:
mov eax, 0
а могло бы быть вообще:
sub eax, eax
результат один и тот же но за разное время.
Те для любой задачи сложнее пары инструкций получаем производительность проца в «эталонных задач»/сек.
В случае пары инструкций — смотрим в справочник, там написано за сколько тактов оно выполнится, дальше смотрим на мегагерцы.
В случае сложных задач на х86 можно получать пенальти (простои) за работу с не выравненной памятью, отсутствием данных в кеше, и некоторые инструкции когда рядом могут параллельно выполнятся, плюс есть ещё предсказание переходов и вообще переходы могут очищать конвеер, а это опять простои…
Даже результаты бенчей memcpy(), memset() оптимизированных под платформу трудно однозначно интерпретировать.
Оптимизировать легко когда время выполнения команд предсказуемое, на х86 с его прибамбасами это не так, и один и тот же код может исполнятся в разы и порядки быстрее/медленее на разных процах.
Чтобы понять как с этим в эльбрусе нужно читать доку на проц и смотреть есть там какие то факторы влияющие на задержки выполнения или нет. Вот сейчас там написано что можно выполнять команды параллельно, но не во всех алгоритмах это допустимо…RomanArzumanyan
06.07.2016 15:31Уже теплее. Поэтому сначала смотрим на то, сколько данных мы читаем и пишем (не упёрлись ли мы в память и не голодают ли АЛУ), а затем — сколько арифметики в секунду делаем (flops, ipc и прочее). И только потом лезем на уровень ассемблера (не факт, что придётся, может intrinsic'ами отделаемся).
Таким образом, полученный bandwidth и flops (ipc) дают поверхностную, но очень важную оценку. Возвращаемся к первому вопросу.
firsttimecxx
06.07.2016 19:23>>результат один и тот же но за разное время.
Не верно. х86 умеет распознавать паттерны для зануления регистров и sub/xor ничем друг от друга не отличается, как и прямое зануление через присваивание.
>>В случае пары инструкций — смотрим в справочник, там написано за сколько тактов оно выполнится, дальше смотрим на мегагерцы.
Что есть «выполняется»? Это когда результат будет получен, когда можно исполнить следующую? Если первое, то где основание для определения суммы этого времени как результирующие время исполнения набора инстуркций опять же в трактовке номер один.
Время можно получить только эмуляцией потока исполнения — никак иначе.
>>В случае сложных задач на х86 можно получать пенальти (простои)
Это не простои а дополнительная латенси для доступа к данным/а в следствии и результатам инструкиций, либо сами результатам.
Опять же это пайплайн и без контекста в котором летенси что-то определяет это ничего не стоит.
>>отсутствием данных в кеше
Отсутствие данных в кеше стоит доступа их из памяти к пенальти не имеет никакого отношения.
>>и некоторые инструкции когда рядом могут параллельно выполнятся
Не верно. Это утверждение не имеет смысла. По определению при out-of-order execution нет такого понятия как «рядом».
Да и вообще нет такого понятия. В х86 есть «каналы»/пайплайны по амд/порты по штеуду исполнения.
Каждый порт объединяет доступ к набору исполнителей( либо там заморочки более сложны — неизвестно). Они абсолютно независимы. Там есть свои заморочки с пенальти между переключениями исполнителей, но опять же — это +летенси к самой операции, а не лок исполнителя.
Исполнятся параллельно инструкции могут как в рамках одного пайплайна, так и в рамках разных «портов». Рядом/не рядом — от этого ничего не зависит.
Пайплайн — это трупут 1оп/такт, когда в мануале написано 0.5 — это значит, что эту операцию может исполнять 2порта.
>>плюс есть ещё предсказание переходов и вообще переходы могут очищать конвеер
Переход просто инвалидирует те инструкции, которые начали исполнятся/исполнились спекулятивно.
Переходы — это алгоритмические заморочки. Если он есть — он будет всегда. Другое дело, что у него может быть разная цена на разных процессорах, только в этом и есть смысл сравнения.
>>Даже результаты бенчей memcpy(), memset() оптимизированных под платформу трудно однозначно интерпретировать.
Просто. Только надо понимать что ты и зачем измеряешь. Что ты и для чего используешь.
Надо просто в голове иметь модель рабочую, с разными уровнями «памяти»(уровни кешей, уровни оперативной памяти, уровни иной памяти), а не пихать всё в одну кучу.
>>Оптимизировать легко когда время выполнения команд предсказуемое
Оно всегда предсказуемое — написано в мануалах, либо измеряется.
>>и один и тот же код может исполнятся в разы и порядки быстрее/медленее на разных процах.
Можно увидеть примеры? Единственные примеры, которые можно сюда притянуть за уши — это сложные инструкции, но они используются редко и ими можно пренебречь.

Aquarius-Michael
05.07.2016 21:51+1ГФлопс — это числовая математика вещественных чисел. Не всё меряется относительно чисел. Важно ещё и смотреть, сколько операций за такт / в секунду может выполнить.
PerlPower
05.07.2016 13:51Ну хорошо, по скорости Эльбрус отличается от других акрхитектур, но с точки зрения конечного продукта/сервиса смогли бы вы предоставить решение на базе Эльбрусов на коммерческой основе или нет? В смысле возможно ли при желании это окупить?
SmartEngines
05.07.2016 14:19В данный момент мы предлагаем всю нашу линейку продуктов по распознаванию и у нас есть совместный продукт с МЦСТ.
PerlPower
05.07.2016 13:53+1Можете хотя бы в общих чертах расписать алгоритм распознавания и его основные этапы, и что у вас получилось эффективно запараллелить?
SmartEngines
05.07.2016 16:23В очень общих чертах алгоритм таков: поиск документа и наведение зон, поиск полей, распознавание полей. Наибольший эффект был достигнут на первом этапе. Про оптимизацию отдельных алгоритмов мы планируем часть 2.
sim3x
05.07.2016 15:06+4Всего за несколько месяцев нам удалось не только добиться правильной работы распознавания
А можно в человекочасах?
И какая квалификация персонала потребовалась для адаптации?
И на какой кодовой базе все происходило (кол строк измененных для совместимости/общее кол строк кода)?
И как вообще верифицировалась правильность?
И насколько все изменения совместимы между платформами (не нужно ли поддерживать два репозитория с кодом)?SmartEngines
05.07.2016 16:47+31. Правильность распознавания проверяется прогоном на референтном датасете (1000 изображений паспортов).
2. Первая рабочая версия — 3 дня работы одного человека, после чего началась оптимизация производительности (3 ч.м.).
3. Для адаптации заменили порядка 100 строчек кода из ~20 мегабайт кода, все изменения обратно совместимы.
4. Оптимизированный код в том же репозитории, вызовы EML под условной компиляцией.
5. Квалификация: студенты и аспиранты, для нас — обычная.sim3x
06.07.2016 14:31-3Я правильно понял, что юнит и модульных тестов на проекте нет? Только функциональные
Квалификация — студент/аспирант мне не знакома. Если нет возможности оценить с точки зрения тайтлов, то хотя б, какой примерный опыт работы в коммерческой разработке софта в данной области знания?SmartEngines
06.07.2016 16:52Первая рабочая версия — опыт работы 4 года.
Оптимизация — опыт работы 2 и 4 года.
Тесты есть, проходят.

nikitasius
05.07.2016 17:53+4Распознавание паспорта РФ на платформе Эльбрус. Часть 1
Представил на секунду следующую картину: оператору эльбруса на экран выводится скан паспорта и оператор начинает его распознавать…

BalinTomsk
05.07.2016 21:54Ожидал увидеть строку — из 25,000 юнит тестов сломалось 300.
firsttimecxx
06.07.2016 00:12Зачем нужны «25000 юнит тестов» одной операции, которая может либо работать, либо не работать?
2PAE
06.07.2016 07:17От всей статьи, ждал одного слова. Да или Нет.
Сопоставима скорость работы реального приложения на Эльбрусе со схожим процессором х86 или нет?
ИМХО, на данный момент, это самый главный вопрос об Эльбрусе. Что процессор может на самом деле?
santey_tm
06.07.2016 09:47+4В статье вполне достаточно информации на этот счет. «Эльбрусы» с частотой 0.8ГГц и с 64-битными векторами отстают от Интелов менее, чем на порядок. А Интелы — это, надо полагать, Haswell с 256-битным AVX-2 и с 3+ ГГц. С учетом того, что, как упомянуто в статье, оптимизация кода под Эльбрусы только-только началась, а под Интел с АРМ этот процесс шел годами, результат вполне себе неплохой.
Понятно, что Эльбрус-4С на сегодня далек от вершин производительности. Производительность камня — на уровне Core2 Duo 2ГГц. Но это не вина Эльбруса и МЦСТ. Наоборот, с учетом тех крох, которые выделялись и выделяются на разработку новых процессоров, мцст-совцы совершили подвиг. Порядок этих крох примерно такой: на разработку Эльбруса-8С контрактом было выделено 25млн$ на 4 года. В то время как мировые производители процессоров средней руки тратят на НИОКР не менее 1 миллиарда$ _ежегодно_! (Интел — так все 10 ярдов). Что называется, почувствуйте разницу. При таком подходе наивно ожидать, что продукция МЦСТ будет на равных с мировыми конкурентами. Тем более, нет никаких оснований этого с праведным гневом требовать, как поступают некоторые.
А вот если бы у государства были здоровые приоритеты на развитие страны, следствием чего было бы надлежащее финансирование и размах работ, сейчас уже был бы в серии какой-нить 2ГГц Эльбрус-16С с 128-битными, и это как минимум.
Да, авторам — огромное спасибо за статью! Очень познавательно! Молодцы! Ждем продолженияsim3x
06.07.2016 14:36-1Странно производить продукт, если он никогда не выйдет на уровень конкурента
Странно продавать продукт своим за бешенные деньги, если свои и так уже заплатили за него из налоговsantey_tm
06.07.2016 16:06+1Странно ожидать выхода на «уровень конкурента» при уровне финансирования, который ниже на порядкИ.
Как альтернатива — разгон МЦСТ и закрытие отечественной школы проектирования процессоров.
Пока эта школа существует, есть надежда и на достижение «уровня конкурента», хотя бы теоретическая…
Плюс к этому, есть такая важная вещь, как независимость страны. В данном случае — по части создания процессоров (и чипсетов к ним).
Некоторым подобные вещи, конечно, глубоко побоку, но кому интересно их мнение?
Ну и потом, Интел и АРМ — это не те конкуренты, которые в состоянии предложить доверенную платформу российской разработки. Т.е. не все меряется исключительно быстродействием.
Что касается «бешеных денег», то все определяется величиной серии. Которая сейчас мизерная.
sim3x
06.07.2016 16:57+1Доверенность платформы никак не зависит от проектировщика или производителя.
Она зависит от открытости и наличия большого числа исследователей, которые не дадут положить закладку
Пока что разработка больше похожа на последствия синдрома NIH. Что впринице хорошо, если б оно было направлено на массовый, а не локальный рынок.
Серия всегда будет мизерная, если она ориентируется на мизерный рынок. Что никак не оправдывает цены за, по сути, опытные образцы
ПС: характерно, что «еллекторату» внушили, что есть только один способ решения проблемы —разгон МЦСТ
santey_tm
07.07.2016 09:48+1> Доверенность платформы никак не зависит от проектировщика или производителя.
Да ну?
> Она зависит от открытости и наличия большого числа исследователей, которые не дадут положить закладку
Степень открытости как раз целиком зависит от политики производителя.
Сомневающиеся могут попытаться получить исходники интеловских процессоров на уровне Verilog RTL
> Серия всегда будет мизерная, если она ориентируется на мизерный рынок.
На другой при текущих объемах финансирования замахиваться нет никакой возможности. Это понятно?
> Что никак не оправдывает цены за, по сути, опытные образцы
Одному из законов производства, в соответствии с которым себестоимость продукции обратно пропорциональна размеру серии, нет никакой необходимости оправдывать что-либо. Он просто объективно существует. Как таблица умножения.
Что насчет опытных образцов, то это не так. Они серийные, потому как камни отлажены и выпускаются серийно. Опытными можно назвать инженерные образцы, напечатанные в «шаттле». Но эту стадию Эльбрус-4С давно прошел.

georgevp
07.07.2016 19:28Подскажите, пожалуйста, название такого открытого производителя и хотя бы одну- две группы исследователей топологий микропроцессоров, работающих не на контрактной основе.
firsttimecxx
06.07.2016 19:42Выйти по какому критерию? По критерию производительности? Этому ничего не мешает.
Сила интела не в том, что он быстрый(хотя хасвел скакнул не слабо), а в том что он может исполнять плохой код с приемлемой производительностью. Естественно здесь с ним тягаться никто не может, да и не будет.
В данном случае вся «обвесочная» сложность была выпилена из процессора. Это дало возможность выпустить «быстрый» процессор без ресурсов интела.
Потенциально его слабость перед интелом можно решить сильным компилятором, при этом на уровне компилятора эта задача решается на порядки проще и оптимальней.
Сейчас же даже без компилятора производительность можно снять руками(прям как на интеле), а компилятор потихоньку пилится. Это решение намного лучше, нежели пытаться повторить достижения интел.
Продукт продаётся за бешеные деньги лишь потому, что стоит он бешеных денег.
Не понимаю почему они так противятся популяризации своего детища среди энтузиастов. Я не думаю что это прям очень дорого — заказать дополнительно, либо сделать версию ширпотребного качества. Хотя зная паникёров и всёпросральщиков в интернетах — я понимаю их мотивацию.
В целом, я не особо верю в то, что они, да и кто-либо вообще может сделать вменяемый компилятор С/С++ для данной архитектуры. Но пусть делаю — я рад за них.sim3x
06.07.2016 23:14Выйти по какому критерию?
по тому что указали выше
Понятно, что Эльбрус-4С на сегодня далек от вершин производительности.
Продукт продаётся за бешеные деньги лишь потому, что стоит он бешеных денег.
Деньги уже уплочены. Зачем брать второй раз?
firsttimecxx
06.07.2016 23:37>>по тому что указали выше
Я объяснил. Эльбрус не далёк до вершин — далёк от вершин конпелятор. Тем более под х86 они так же далеки от вершин и всё надо делать руками.
х86 выигрывает из-за того, что просто технологичней и своей архитектурой, которая более приспособлена для исполнения кода такого качества, который производят нынешние программисты, языки, их рантаймы и компиляторы.
Были бы у меня реальные спеки эльбруса — я бы мог сравнить, а так заявлять безосновательно о том, что он говно — я не готов.
>>Деньги уже уплочены. Зачем брать второй раз?
Откуда информация? За что уплочены — за разработку? За реализацию? За что?
Скорее всего оплачена только разработка и тестовые стенды/прочее железо. Далее дали чуть бабок на партию, а дальше крутись как хочешь.
Я не знаю сколько и что там стоит, но если нифа из сети верна и себестоимость самого чипа копейки, то почему они не заказали сразу большую партию — пусть бы продавали за столько же, но и выкатывали энтузиастам.
Возможно так нельзя и им надо отчитываться, возможно они не хотят, либо не знают как. Возможно обвязка стоит денег, но что мешает сделать партию материнок из ширпотреба?
Я так и не понял какие у вас претензии. Их можно ругать за многое, но явно не за то, за что ругаете вы.
Тем более цена у них как у серверных интелов. У обывателя пригорает только из-за сравнения с десктопным железом. Сколько флопсов в даблах выдаёт игровая видяшка? Как х86. Сколько там стоит e5-й хеон? Либо 2011 десктоп? У 2011 трупут рамы в 2раза выше, чем у 1055/6, либо какие там щас. Собственно как и у е5 по сравнению с е3.santey_tm
11.07.2016 10:32+1>Я объяснил. Эльбрус не далёк до вершин — далёк от вершин конпелятор. Тем более под х86 они так же далеки от вершин и всё надо делать руками.
Это в мемориз))
Как раз компилер в случае с VLIW — просто немерянно крут по сравнению с компилерами для Out-of-order процессоров.
>х86 выигрывает из-за того, что просто технологичней и своей архитектурой, которая более приспособлена для исполнения кода такого качества, который производят нынешние программисты, языки, их рантаймы и компиляторы.
Насчет архитектуры — набор бездоказательных утверждений. Как раз архитектура Эльбруса — гораздо гибче и гармоничней в сравнении с x86, потому как в ней отсутствуют многочисленные костыли x86, вроде SSE и AVX.
А вот насчет технологичности — в самую точку. С такой низкой ТЧ (0.8ГГц) мерятся с Интелами бесполезно. Проблема в том, что физдизайн Эльбрусов выполнен на основе standard cells, в то время как Интеловские камни — с использованием очень дорогостоящего full custom design. По этой причине, в основном, ТЧ Эльбрусов такая низкая (хотя на этот счет есть и ограничения самой архитектуры)
Ну и надо иметь в виду, что ядро Эльбруса-4С — это, по сути, E2K образца 1999г, только с б0льшими кэшами. Более-менее заметные изменения в архитектуре появились в Е8С, когда добавили 2 FPU. Хотя, по хорошему, давно бы пора ввести те же 128 векторы. Но это из серии «лучше быть богатым и здоровым»: все упирается в мизерное финансирование и недостаток людских ресурсов небольшой, по сути, конторы МЦСТ.
SmartEngines
06.07.2016 09:56+7Ответы, которые мы получили для себя:
1. Процессор — рабочий.
2. Набор инструментов для разработки — имеется.
3. Поддержка и консультации — имеются.
4. Документация — есть (по ГОСТу).
5. Нужная скорость работы нашего софта — достижима (при должной оптимизации).
6. Интересно — очень!
7. Идем ли дальше — да.
Кроме того, в процессе работы над Эльбрусом мы улучшили производительность и на других платформах.
Если кратко, то вот так.
darkAlert
Извините, закидывайте меня чем угодно, но на любой конференции/семинаре после фраз:
«Эльбрус — высокопроизводительная и… архитектура процессоров»
И
«Сейчас производительность нашей программы распознавания паспорта на Эльбрус 4.4 и на x86 отличается уже не на порядок»
Вам бы заявили, что тезисы и выводы вашего доклада не совпадают.
Ivan_83
Сравнивать то с чем и как?
Со счётами? С арм? С самим собой? С GPU?
Средне-бюджетная видюха в некоторых применениях рвёт любой интел в клочья, те на порядки.
Хотя бы в тех же биткойнах.
Даже х86 трудно сравнивать между собой, даже среди интелов между собой.
У меня был вариант кода который на i7-4750 работал за 8 секунд, а на Е8400 за 50+, на амд 5350 за 100+, притом что не сильно отличающиеся другие варианты кода работали за 9, 12 и 20 секунд соответственно. (входные, выходные данные одни и те же, разница только в одной подпрограмме которая была ядром-обработчиком).
Опять же у х86 есть SSE, AVX а у эльбруса вроде DSP и какие то свои фичи, притом вряд ли их кто то использует кроме самого МЦСТ в своих либах.
darkAlert
Смотрите, я прихожу и слушаю доклад, в результате которого я должен увидеть и осознать, что вот этот самый эльбрус это то что нам сейчас нужно и мы поимеем такой то профит при переходе на его архитектуру.
В качестве примера, могу привести вам ту же GPU и CUDA в частности. Только когда свет увидел работы, показывающие реальное ускорение в 50-100 раз (не в 2 и не в 3, а на порядки!) на конкретных прикладных задачах, тогда и начался постепенный переход на GPU.
Сейчас же, после прочтения статьи, я ничего подобного по отношению к эльбрусу не увидел. Вы тут все сыпете множеством непонятных мне терминов, вроде как бы в теории все замечательно, но на деле мне — обычному разработчику, которому нужна максимум производительности при адекватных усилиях, не видно каких-либо этих преимуществ. Покажите мне многократный прирост (на порядки), который бы подтолкнул меня переходить на другую архитектуру (как это было с CUDA в свое время).
Ivan_83
Эльбрус берут не ради скорости, это же очевидно.
Его берут госы как доверенную платформу, в которой нет закладок.
При этом в статье показано что в целом он по производительности не сильно то и отстаёт после допиливания отдельно взятой софтины, или по крайней мере работать можно не сильно страдая.
У меня есть подозрения что сам компилятор так себе, если бы МЦСТ потратило время на clang пользы было бы больше.
zedalert
В которой нет зарубежных закладок. :)
VlK
Код clang или gcc, кстати говоря, вполне себе можно просто прочитать на предмет закладок. А вот железо — нельзя. Поэтому линукс сойдет для того же минобороны, а винда — нет.
Lcc использовали, вероятно, потому что это компилятор изначально разрабатывался для легкого добавления новых архитектур. Он вообще сознательно упрощен оригинальными авторами. Соответственно, в смысле оптимизации, тем более под редкую платформу, оставляет желать лучшего.
phprus
> Lcc использовали
Lcc, который «Local C Compiler» или «Little C Compiler» и Lcc в Эльбрусе не имеют ничего общего, кроме аббревиатуры.
Разработка МЦСТ полностью собственная, умеет С, С++ и Fortran, оптимизации, много чего еще и, если мне память не изменяет, является сокращением от «eLbrus CC».
VlK
Серьезно? Сами тянут компилятор?! Прошу прощения, я не в курсе, по очевидным причинам Эльбрус даже в глаза не видел.
А подумал я на другой LCC, т.к. перепутал Эльбрус с Мультиклетом (https://habrahabr.ru/post/302776/). Они вроде использовали именно тот LCC.
phprus
> Серьезно? Сами тянут компилятор?!
С учетом того, что это исторически в России одни из лучших компиляторщиков, то ничего в этом странного не вижу. Бекенд, который собственно занимается оптимизацией и кодогенерацией у них свой.
А фронтенд говорят, что от Edison Design Group, но эта меньшая часть компилятора.
P.S. На эту тему был подкаст http://eax.me/eaxcast-s01e06/ «EaxCast S01E06, о разработке компиляторов и Эльбрусах».
VlK
Признаться, я несколько не в курсе российской тусовки компиляторщиков. Можно чуть подробней..? Компиляторы ведь дело такое, серьезный проектов на весь мир не очень много.
Я издалека темой интересуюсь, но до сих пор, например, с соответствующей русскоязычной литературой не сталкивался.
vadimr
Вообще, на профильной программистской специальности, написание простейшего компилятора — это курсовая работа.
VlK
ТАКИХ компиляторов у меня самого полный Гитхаб :-)
vadimr
Ну, вряд ли именно таких, если Вы говорите, что не сталкивались с русскоязычной литературой. Так-то со времён Гриса в теории этого дела мало что изменилось. Тем более, что для языка Си всю платформеннонезависимую часть можно взять готовую. Работа по написанию промышленно используемого кодогенератора и платформеннозависимого оптимизатора, конечно, небанальна, но это далеко не самое сложное в разработке процессора.
Помнится, в 90-е годы Виталий Мирянов в одиночку и без финансирования написал одну из самых популярных сред разработки под OS/2, Virtual Pascal. Вполне сравнимая задача.
VlK
Ну, если по-честному, я сталкивался еще будучи студентом с парой русских книг по теории компиляторов. И да, конкретно парсер, тем более для несложного Си, найти в наши дни очень даже реально.
Более того, я точно знаю, что за три-четыре месяца полноценной дневной работы можно сделать парсер и генератор кода для небольшого языка и несложной архитектуры, реальной или виртуальной. Сам делал пару раз в качестве развлечения и один раз по работе.
Но я не уверен, что аналог GCC или Clang — дело столь же подъемное.
Впрочем, ладно. Процессор и собственная архитектура вообще — дело гораздо более широкое, как вы вполне резонно заметили.
Мне на самом деле интересно, какая есть литература от русских авторов на тему компиляторов, поэтому и спрашиваю. Разумеется, речь не только о парсере, но и об остальных аспектах задачи.
Может, подскажете..?
vadimr
Я знаю, что, например, Терехов (который Ланит-Терком) этим вопросом много занимается, в том числе и книжки пишет. Наверняка, и другие коллективы есть.
Что касается аналога gcc или clang, то ведь это и не нужно. Обычно народ делает просто свою собственную ветку gcc, в которой добавляет кодогенератор под свою архитектуру.
vadimr
Посмотрел – вот ещё такую книжку нашёл: http://www.twirpx.com/file/714408/ Я её, правда, не читал, но у авторов учился в институте.
VlK
Собственно, эта плюс еще одна политеховская и были у меня в универе (питерский политех). Это сугубо теоретическая книга по теории компиляторов.
Но компиляторы — не только теория парсеров. Собственно, про практические аспекты книг я никогда не видел, к огромному моему сожалению.
vadimr
Про практические вопросы мало пишут, как правило, это интеллектуальная собственность заказчика работ.
VlK
Пишут-пишут… У меня в читалке штук десять англоязычных книг про разные компиляторы, их архитекутуру, различные: lcc, gcc, LLVM, оптимизирующие компиляторы и т.д.
Вообще, в эпоху открытого кода этими вещами никого уже не удивить. Признаться, мое любопытство диктуется скорее уже коллекционными соображениями, чем недостатком материала на английском.
Тут выше кто-то заметил, что российская школа разработки компиляторов очень развита, ну мне и стало любопытно, какую литературу издают и читают.
vadimr
Ну на уровне открытого кода как бы и нет проблем с вопросом. Эти решения хорошо известны и более-менее неплохо описаны. А вот если вы захотите, например, почитать про архитектуру современных оптимизирующих компиляторов IBM, тот увидите только самые общие тезисы в каком-нибудь IBM Sys. J. Примерно в духе статей того же Терехова.
beeruser
Бывшие разработчики первой команды Эльбруса, писавшие компилятор под Эльбрус перебрались в Интел дописывать уже ICC под Itanium.
Agat-Aquarius
«У х86 есть SSE, AVX, а у Эльбруса вроде DSP и какие-то свои фичи; притом вряд ли их кто-то использует кроме самого МЦСТ в своих либах».
Позиция МЦСТ такова, что на платформе «Эльбрус» надо пользоваться высокоуровневыми языками C/C++ и Fortran и специальными библиотеками для них, а опускаться на уровень машинных команд можно разве что в исключительных случаях. Как бы то ни было, у их компилятора C/C++ есть флаги, включающие поддержку GCC-шных встроенных функций для работы с MMX, 3DNow, SSE вплоть до 4.2, XOP, AVX, FMA4, CLMUL, BMI, F16C, AES, — насколько я понимаю, некоторое из этого и так реализовано в железе (просто инструкции другие), а остальное эффективным образом конвертируется в нативные широкие команды.
firsttimecxx
«на платформе «Эльбрус» надо пользоваться высокоуровневыми языками C/C++ и Fortran» — странная позиция.
Подавляющие большинство операций в реальном мире не параллелятся, либо параллелятся слабо. Собственно поэтому для задействования этого параллелизма надо параллельно исполнять множество «потоков исполнения», а для того, чтобы их исполнять — они должны быть, но их нет.
Допустим, надо нам вычислить синус( вычислить полином) — его, конечно, расспараллелить можно, только это имеет мало смысла(90% нашего параллелизма будет простаивать из-за постоянных зависимостей по данным).
Решается это просто — надо считать не один отдельный синус, а много. Просто в теории. На практике эта задача сложнее векторизации, а даже векторизацию до сих ни один компилятор делать, кроме примитивных случаев, не умеет.
Да что там распараллеливание — даже банально зашедулить(раскидать инструкции по «каналам исполнения») один поток такая же непосильная для компилятора задача.
Проблема в самих языках и подходах к разработке/сборки.
Динамическая линковка? Нерешаемая проблема — компилятор просто не может получить код того же синуса, не может его заинлайнить. На уровне процессора её решить можно — как решить на уровне компилятора?
Раздельная сборка, статическая линковка? Много ли компилятором имеют вменяемое lto+ipo? Один? Сколько к этому шли? 10лет? До сих пор не работает без подпорок. Когда это будет в эльбрусе?
В конечном итоге эти(да и любые другие) языки просто не могут в параллелизм — да, компилятор может взять эту работу на себя, но много ли умеет гцц/шланг для х86? Сколько от этого будет иметь эльбрус?
В конечном на х86 радуются ipc в районе 2, при потолке ~4/6(фронтенд/бекенд) — толку с теоретических 23(или сколько там?) на эльбрусе?
Почему бы не сделать dsl пусть на основе C, со своей логикой вычислений? Зачем цпу с такой архитектурой? На эти вопросы нет ответа.
Тот же интел с итаником не смог. Повторяем ошибку?
vadimr
Во многих реальных ресурсоёмких задачах основная вычислительная нагрузка приходится на реализацию нескольких стандартных операций. Условно говоря, если эльбрусовцы наваяли оптимизированную библиотеку матричных и векторных функций на ассемблере, то во многих прикладных областях этого вполне достаточно, чтобы обеспечить производительность, близкую к максимальной.
Хотя есть, конечно, задачи другого рода, именно алгоритмически запутанные, где значительную роль играет качество кодогенератора.
firsttimecxx
Спорное заявление. Я не знаю таких прикладных задач — возможно какие-то научные расчёты и строятся.
По поводу оптимизированной библиотеки — я описывал проблемы всех этих библиотек. Тем более эти библиотеки невозможно написать на асм — это всё должно быть машинная генерация. А зачем шедулить каждую операцию заново — проще написать дсл. А если есть дсл — зачем нужны эти языки? Только как скриптовая обёртка вокруг.
По поводу серебряных пуль. Тот же штеуд не может писать в память без nt, а nt собственно это обход кешей. Поэтому версия для работы в кешах не может работать вменяемое для данных больше кешей, а версия для памяти не может работать вменяемо для кешей.
ТС померил трупут л2(хотя и то навряд-ли, ибо 4/4GB/s даже для 600мггц смешно — это по ~два флоата лоад/стор на такт). И тут варианта два — либо библиотека от производителя слаба, либо процессор слаб сам по себе, либо ТС что-то не то померил.
По поводу операций. Функции с операциями — это тупиковый интерфейс. Допустим, нам надо сложить два массива, а потом как-то обработать. Нормализовать, отсеять, либо ещё что-то. Все эти операции для 10^5 упираются в llc, а значит мы просто так гоняем данные по кругу и греем воздух.
Делай мы это операцию не конвейерно, а параллельно — мы бы получили вторую, треть, десятую операцию бесплатно.
Т.е. вменяемый интерфейс это не просто функция — это паттерн доступа/обхода структуры данных + набор операций. Это не реализуемо, ибо опять же требует компилятор. Поэтому, собственно, это никто не использует.
Опять же — какая разница библиотека, либо нет. Реализациях этой самой библиотеки требует автоматических средств, иначе вменяемого качества не добиться. Если они есть — почему они не выкатываются, а если их нет — библиотеки не будет.
Agat-Aquarius
«Подавляющие большинство операций в реальном мире не параллелятся, либо параллелятся слабо. Собственно поэтому для задействования этого параллелизма надо параллельно исполнять множество потоков».
Если какая-то задача в принципе не распараллеливается, то при чём тут любой конкретно взятый процессор и компилятор? А если всё-таки распараллеливается для одной архитектуры, значит, можно как-нибудь распараллелить и для другой. Компилятор C/C++ помешает? Ну, если вы уже написали что-то для SSE, значит, вы пишете не совсем на C/C++, а на конкретном диалекте с использованием конкретных спецфункций, — этого добра и в МЦСТ-шном LCC хватает, как своего, так и GCC-совместимого.
«Надо считать не один отдельный синус, а много. На практике эта задача сложнее векторизации, а даже векторизацию до сих пор ни один компилятор делать, кроме примитивных случаев, не умеет».
Есть такая буква в библиотеке EML! Вычисление синуса элементов вектора — eml_Vector_Sin_32F, eml_Vector_Sin_64F. И, если верить утверждениям МЦСТ (я не проверял), компилятор в некоторых случаях может заменять обычный вызов скалярной функции sin() на вызов такой вот оптимизированной функции из библиотеки.
«Даже банально раскидать инструкции одного потока по каналам исполнения — такая же непосильная для компилятора задача».
Внезапно, именно этим LCC и занимается; собственно, на его оптимизациях всё и держится. Насколько он эффективен в среднестатистическом случае, судить не берусь, но сами МЦСТшники считают, что человеку не под силу с ним тягаться: если только вы не пишете ну очень критичный кусочек кода с большим потенциалом ручной оптимизации (для этого вы должны знать систему команд и учитывать тайминги каждой инструкции в составе широкой команды), не стоит даже пытаться смотреть в сторону ассемблера.
firsttimecxx
«Если какая-то задача в принципе не распараллеливается, то при чём тут любой конкретно взятый процессор и компилятор?»
Я уже рассказал как это делается. Её не надо паралеллелить — её надо коневеизировать( я не знаю как пишется это слово и есть ли он вообще).
Мы не может распараллелить одну операцию, но мы может параллельно делать много.
Штука в том, что любая обработка данных — это множество одинаковых, последовательных операций на разными данными.
Берём обычный цикл while() {...}, где тело независимо. Естественно он заанролится, но как? Любой компилятор, любой программист сделает просто набор последовательных блоков копипастой.
Собственно для этого и существует out of order execution. х86 сделает из этого множество независимых потоков исполнения.
Но проблема у х86 в том, чего его ооо существует только в рамках окна определённой длинных.
Т.е. если длинна тела цикла шире этого окна — ооо идёт в мусорку. Т.е. это актуально для х86. Эту проблему никто до сих пор в х86-компилятор не решает. Даже её подзадача векторизация не решена.
>>Компилятор C/C++ помешает?
Помешает сам язык и подходы к разработке. В рамках этого языка не таких понятий. Этим нельзя рулить. Даже передовые компиляторы эту проблему решить не могут, да и она не решаема в полной мере.
>>Ну, если вы уже написали что-то для SSE, значит, вы пишете не совсем на C/C++, а на конкретном диалекте с использованием конкретных спецфункций, — этого добра и в МЦСТ-шном LCC хватает, как своего, так и GCC-совместимого.
Ну это очередной подтверждение того, что эти(да и любые другие) языки не подходят. Да и их диалекты с набором интерфейсов к кастылям компилятора так же — об этом я то же писал.
Собственно поэтому и приходится кастылять на асм, ибо шедулер симдов в компиляторе никакой и ничем ты с этим не сделаешь. Ни язык, ни компилятор этому не способствует — на их уровне нет таких понятий. Всё это дети скалярной архитектуры.
«Есть такая буква в библиотеке EML! Вычисление синуса элементов вектора — eml_Vector_Sin_32F, eml_Vector_Sin_64F.»
А если мне нужен синус и косинус сразу, а если мне надо их на что-то помножить? Тупик. Но молодцы, что это сделали — нигде такого не видел.
>>И, если верить утверждениям МЦСТ (я не проверял), компилятор в некоторых случаях может заменять обычный вызов скалярной функции sin() на вызов такой вот оптимизированной функции из библиотеки.
Это имеет мало смысла. Если и может, то только для случая while() {b[i] = sin(a[i]);}. Даже если там будет паттерн сложнее и он в него сможет — это будет конвейер. Мы обойдём массив для записи в него синусов, потом для умножения их на что-то там.
Реально же это мало кому поможет.
>>Внезапно, именно этим LCC и занимается; собственно, на его оптимизациях всё и держится.
Я описывал основные проблемы — они решены? У ТС«а я не видел ни одного упоминания lto, ipo — без этого это не имеет смысла. Ваятели очень любят раскидывать всё по файликам, ибо раздельная компиляция. Это тупик для компилятора.
>>Насколько он эффективен в среднестатистическом случае, судить не берусь
Я уже объяснял — это задача, подзадачей которой является векторизация. Векторизация даже в передовых компиляторах в зачаточном состоянии. Они собираются переплюнуть гцц?
>>но сами МЦСТшники считают, что человеку не под силу с ним тягаться
Враньё.
Сила человека не в раскидывании, а в умении реализовать программу с учётом особенностей железяки. Это стоит много — само же раскидывание не стоит ничего.
Изначально это подлог. Вас пытаются обмануть подменой понятий. В этом сравнении предполагается, что человек будет решать ту же задачу что и компилятор в уме, но это не так. Никакой человек не пишет на ассблере считая тайминги на листочке. Всё это автоматизируется. Для частного случая, когда человек может подбить код под генератор — это задача не представляет никакой сложности и решается оптимально.
>>для этого вы должны знать систему команд и учитывать тайминги каждой инструкции в составе широкой команды
Эльбрус это вменяемая архитектура( жалко что мало пригодная в реальном мире), поэтому с нею не должно быть никаких проблем. Что я имею ввиду — в ней нет подводных камней, в ней не 16регистров и для неё есть вменяемая документация.
х86 в этом плане сложнее своей огороженностью. И для х86 ничего не мешает людям( в частности мне) писать оптимально на асм, а вот компилятор этого как не мог так и не может.
Agat-Aquarius
«Проблема у х86 в том, что его внеочередное исполнение существует только в рамках окна определённой длинны. Если длина тела цикла шире этого окна — ооо идёт в мусорку».
Эльбрус имеет гораздо более широкое окно, что в сочетании с большим количеством регистров позволяет замахиваться выше, чем x86, — как, например, в случае с шифром ГОСТ, тело которого удаётся полностью развернуть, из-за чего Э4С@800 оказывается вдвое быстрее i7-2600@3400.
«А если мне нужен синус и косинус сразу?»
Вы не поверите, но таки eml_Vector_SinCos_32F и eml_Vector_SinCos_64F. Вообще, там 60 страниц одного только перечисления названий функций. К тому же, они открыты для предложений: если функция объективно полезная, можно добавить новую.
«Никакой человек не пишет на ассемблере, считая тайминги на листочке».
Даже на x86 без учёта времени выполнения инструкций — почти никак (ну, как минимум надо себе представлять, какие инструкции предпочтительнее, и какие зависимости они создают), то на архитектурах с явным параллелизмом всё на этом же и держится. Как вы будете раскидывать [пусть даже независимые друг от друга] инструкции между широкими командами, если не знаете, насколько каждая из них будет задерживать выполнение всей команды?
firsttimecxx
>>Эльбрус имеет гораздо более широкое окно
Эльбрус не имеет окна — он не имеет out-of-order execution — он in-order.
>>что в сочетании с большим количеством регистров позволяет замахиваться выше,
Регистров у х86 на уровне архитектуры действительно мало — вот бы интел пробросил все сотни регистров на уровень архитектуры, которые внутри используются для ренейма.
На самом деле vex3 частично решает проблема малого кол-ва регистров и на вычислениях их хватает.
>>чем x86, — как, например, в случае с шифром ГОСТ, тело которого удаётся полностью развернуть, из-за чего Э4С@800 оказывается вдвое быстрее i7-2600@3400.
Проблема в том, что тело изначально не написанное под разворачивание развернуть не получится без lto и ipo — есть ли это в их компиляторе, работает ли оно?
По поводу госта. Можно мне увидеть сорцы под х86? Как я могу повторить результаты бенчмарка? Без всего этого это не более чем булшит.
>>Вы не поверите, но таки eml_Vector_SinCos_32F и eml_Vector_SinCos_64F
В глибц есть sincos — это можно так сказать «стандартная функция» и наличие её не достижение и меня никак не удивляет. Зачем передёргивать?
Мне надо записать синус в один массива — косинус в другой, либо в один. Помножить их на что-то. Ещё какие операции добавить нужные мне. Что делать?
В этом проблема — никто и никак не сможет сделать нужную мне функцию. Для этого придётся делать из них пайплайн, а это прощай производительность. Я уже объяснял почему.
>>если функция объективно полезная, можно добавить новую.
Нужна не функция, а возможность написания собственных операций, которые бы работали в один проход.
>>Даже на x86 без учёта времени выполнения инструкций — почти никак
Почему для вас отсутствие вычислений в блокноте есть отсутствие вычислений? Есть такая вещь как кодогенерация и программные вычисления. Я же уже отвечал на этот вопрос загодя. Написание такого генератора для примитивного случая(а случай там примитивен — вся обвязка си и не трогается. Остальное без ветвлений с минимумом операций) сложности не представляет.
Берём кусок написанный кое-как — строим дерево — раскидываем. Нету операций — размножаем деревья — сливаем. Порты простаивают — пытаемся руками ребалансировать код(замена шафлов на битопы, разные коверторы, реализация через разные типы операций и прочее). Мало регистров? Минимизируем руками. Эксплуатируем ренейм. Уперлись во фронтенд — бахаем побольше micro-fusion и прочих куллстори.
>>Как вы будете раскидывать [пусть даже независимые друг от друга] инструкции между широкими командами, если не знаете, насколько каждая из них будет задерживать выполнение всей команды?
Этот вопрос не имеет смысла — причины написал выше.
santey_tm
> Эльбрус не имеет окна — он не имеет out-of-order execution — он in-order.
На этапе исполнения скомпилированного кода — да
Однако на этапе компиляции — он именно out-of-order с «гораздо более широким окном», как упомянуто выше.
firsttimecxx
Во-первых об этом я выше писал, хотя может и не в этом ветке. Во-вторых это очередной подлог. Для х86 ничего не мешает на уровне компилятора делать какое угодно окно. Это не является плюсом.
В-третьих в х86 оно существует РЕАЛЬНО, а в эльбрусе ПОТЕНЦИАЛЬНО и именно о сложности реализации этого ПОТЕНЦИАЛЬНО я и говорю.
santey_tm
Более того, эльбрусовская архитектура, по сути, принадлежит к классу MIMD. Поэтому потенциально она гораздо более гибче, чем x86-шный SIMD.
firsttimecxx
Даже потенциально это маловероятно. Мало есть задач, где симд проигрывают.
Опять же — симд проигрывают в исполнении множества разных потоков команд одновременно, но это не реализуемая мечта на уровне компилятора. И опять же реально существующая в интеле в их гипертредах.
Как вы себе представляете слияние двух потоков команд на уровне языка(С/С++)? Как сделать слияние двух потоков разных тредов/процессов на уровне компилятора?
santey_tm
> Как вы будете раскидывать [пусть даже независимые друг от друга] инструкции между широкими командами, если не знаете, насколько каждая из них будет задерживать выполнение всей команды?
Это действительно могло бы стать проблемой, если бы не наличие конвейера выполнения команд. О котором многие почему-то забывают))
firsttimecxx
Летенси инструкций в любом случае нужно для снятия результата. Конвейер тут никак не помогает. Конвейер даёт возможность каждый такт накидывать инструкций не обращая внимание на другие, но опять же надо учитывать куда и что ты отправил ранее, ибо «конвейер» он не один.
santey_tm
> Как бы то ни было, у их компилятора C/C++ есть флаги, включающие поддержку GCC-шных встроенных функций для работы с MMX, 3DNow, SSE вплоть до 4.2, XOP, AVX, FMA4, CLMUL, BMI, F16C, AES, — насколько я понимаю, некоторое из этого и так реализовано в железе (просто инструкции другие), а остальное эффективным образом конвертируется в нативные широкие команды.
Насколько понимаю, эльбрусовская архитектура отменяет необходимость в таких интеловских костылях, как SSE и AVX. Хотя компилятор поддерживает «интринсинки» в целях совместимости с исходниками для x86
Эльбрус это не только SIMD, но и гораздо более гибкий MIMD
WayMax
> Даже х86 трудно сравнивать между собой, даже среди интелов между собой.
Почему же трудно? Тем более у вас все правильно написано Intel Core i7 4750HQ работает быстрее Intel Core2 Duo E8400, а Intel Core2 Duo E8400 работает быстрее AMD Athlon 5350. Или вас смущает что тактовая частота E8400 выше? Так «меряться» частотой перестали где-то после 4 пентиума. А AMD просто шлак :)
datacompboy
А если сравнивать AMD K6-2 3Dnow! с Cyrix Cayenne?
Ivan_83
Там выше есть пример, когда на 4750 скорость немного поднялась (с 9 сек до 8) зато на остальных сильно просела очень сильно.
Были и другие эксперименты с тем кодом, когда производительность на одном камне подрастала немного а на других падала, правда не в разы но заметно.
Правильное название проса не 4750 а i7-4770K, так что по частоте он немного больше Е8400, думаю если Е8400 догнать до такой же частоты то место 12 будет уже 11 секунд, и это будет более честное сравнение производительности кода на разных камнях.
Тактовая частота всё ещё один из весьма значимых факторов.
АМД весьма не плох, в синтетике — ubench у него производительность как у Е8400, понятно что это средняя температура по процу, но всё же. При сборке мира/ядра во фре он тоже не уступает по скорости. При этом он новый стоит дешевле/так же как б/у Е8400, и жрёт меньше и имеет приличное встроенное видео. (приличное всмысле достаточное чтобы работать, киношки смотреть и может гамать в старьё).
АМД Зен вообще обещает быть оч интересным, учитывая HBA память. Скайлек же вышел наоборот весьма унылым: нет AVX512 и контроллер памяти на 2133.
Mekras
Ну так автор же пишет, что оптимизация для Intel и ARM заняла несколько лет.
SmartEngines
Не можем оспорить ваше утверждение. Действительно, на любой конференции/семинаре после выступлений звучат самые разные заявления. Иногда верные, иногда безумные, иногда возникшие в результате недопонимания. Также ясно, что процитированная вами первая фраза может вызывать весьма эмоциональную реакцию. Однако составлялась она в здравом уме и твердой памяти, и она верна. А эмоциональный фон мог помешать увидеть, что объектом оценки в первой фразе выступает архитектура, а во второй приводятся экспериментальные данные о конкретной модели процессора. Производительность процессора определяется, помимо архитектуры, тактовой частотой (и не только, но не будем усложнять). Тактовая частота определяется в большой степени тех. процессом. Для нас представляется важным, что архитектура действительно является эффективной, как и обещал производитель. Это значит, что мы продолжим тратить своё время (а, следовательно, деньги) на освоение третьей основной для нас архитектуры (после Intel и ARM) в расчете на дальнейшее повышение производительности за счет смены тех. процесса. Догонять по тех. процессу всяко легче, чем усовершенствовать архитектуру. Поймите правильно — продукты мы делаем уже сейчас, производительности хватает. Но, как говорила Черная Королева, «здесь… приходится бежать со всех ног, чтобы только остаться на том же месте». И мы видим у МЦСТ приличный задел на этот самый бег.
TerraV
Прошу прощения, а каких единицах вы измеряете эффективность архитектуры? Вот для длины метры, для массы граммы. Меня бы устроило бы сравнение с Intel/ARM но именно эту информацию вы не даете. Какая разница сколько лет что вы оптимизируете. Сравнительные данные могли бы стать реперной точкой от которой можно было бы считать производительность через 3 месяца, через пол года. Пока извините выглядит как маркетинговый булшит. Благо что по Intel, что по ARM аналогичные дифирамбы по архитектуре можно нарыть вагон. И по оптимизации, и по энергоэффективности, и по много еще чему.
arcman
Архитектура и частота так же взаимосвязанных — на простом процессоре с длинным конвейером проще наращивать частоту. Для примера есть П4, который на старом тех процессе имел высокие частоты. А те же GPU даже на современных ТП не могут достичь высоких частот.
RomanArzumanyan
Разницу между архитектурой и производительностью программы улавливаете? Если хотите сравнить архитектуры — сравните их пиковую теоретическую производительность. Если хотите сравнить реализации неких алгоритмов — сравните скорости работы программ. Не надо смешивать всё в одну кучу.