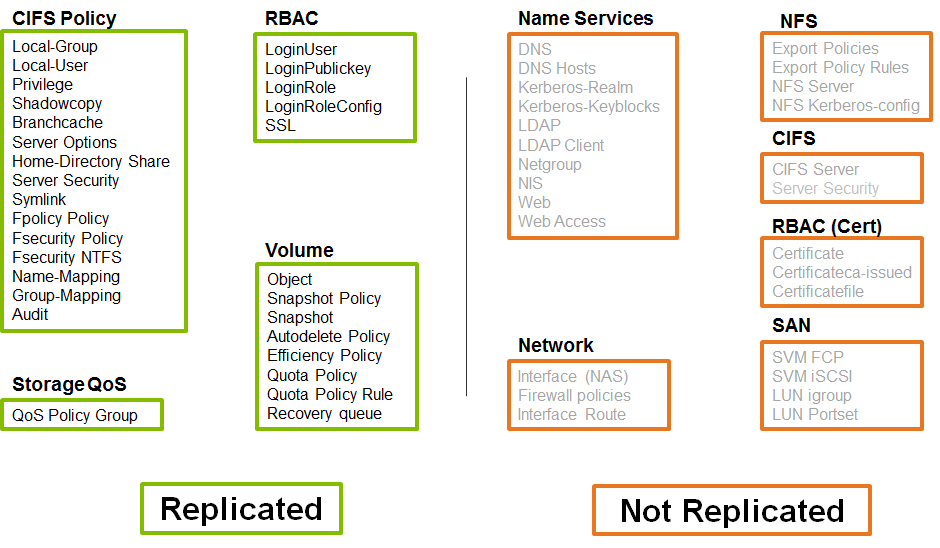
Чтобы мочь запустить все ваши сервисы на резервной системе, логично чтобы основная и запасная системы были более-менее одинаковые по производительности. Если же на резервной площадке система слабее, стоит заранее задаться вопросом, какие самые критичные сервисы необходимо будет запустить, а какие остануться не запущены. Можно реплицировать как весь SVM со всеми его вольюмами, так и исключить из реплики часть вольюмов и сетевых интерфейсов (начиная с ONTAP 9).
Существует два режима работы SnapMirror for SVM: Identity Preserve и Identity Discard.
Что такое NetApp SVM?
SVM — это что-то на подобии виртуальных машин на серверах, но предназначены для СХД. Пускай эта аналогия не введет вас в заблуждение, на СХД не получится запускать ваши виртуальные машины с Windows, Linux и так далее. SVM — это виртуальная машина (очень часто одна единственная, но при желании можно развернуть много) в кластере СХД. Кластер СХД с софтом (прошивкой) ONTAP может состоять из одной или более нод, на данный момент максимум 24 ноды в кластере. Каждая SVM «логически», это одна сущность, которая видна администратору, как одно целое. SVM живёт сразу на всём кластере, но физически, на самом деле, «под капотом» СХД, это набор виртуальных машин, по одной машине на каждой ноде всего кластера, которые объединены специальным образом и представляются администратору как как единая точка управления.
Смысл SVM в кластере ONTAP, с одной стороны, в том, что для администратора СХД она видна как одна точка управления всего кластера, и при необходимости мигрирует объекты (вольюмы, луны, сетевые адреса), по нодам кластера, без какой-либо специальной настройки (SVM берет всю заботу по миграции на себя).
С другой стороны смысл SVM также в том, чтобы красиво, изощренным способом, обманывать хосты, чтобы 2, 4,8, или даже 24 ноды кластера были видны для конечного хоста, как единое устройство, а миграция данных или сетевых адресов из одной ноды на другую, для хостов происходила прозрачно.
Все эти возможности SVM в кластере называют «Single Namespace».
Identity Preserve для NAS (IP)
Режим Identity Preserve предназначен для NAS, который сохраняет сетевые параметры и адреса, может использоваться с несколькими схемами:
- Когда имеется растянутый L2 домен между площадками
- Когда между сайтами есть L3 связность (маршрутизация)
- Когда вообще нет необходимости реплицировать настройки сетевых IP адресов -тогда их нужно будет настраивать вручную после переключения на резервную площадку.

Identity Preserve: L2 домен для NAS
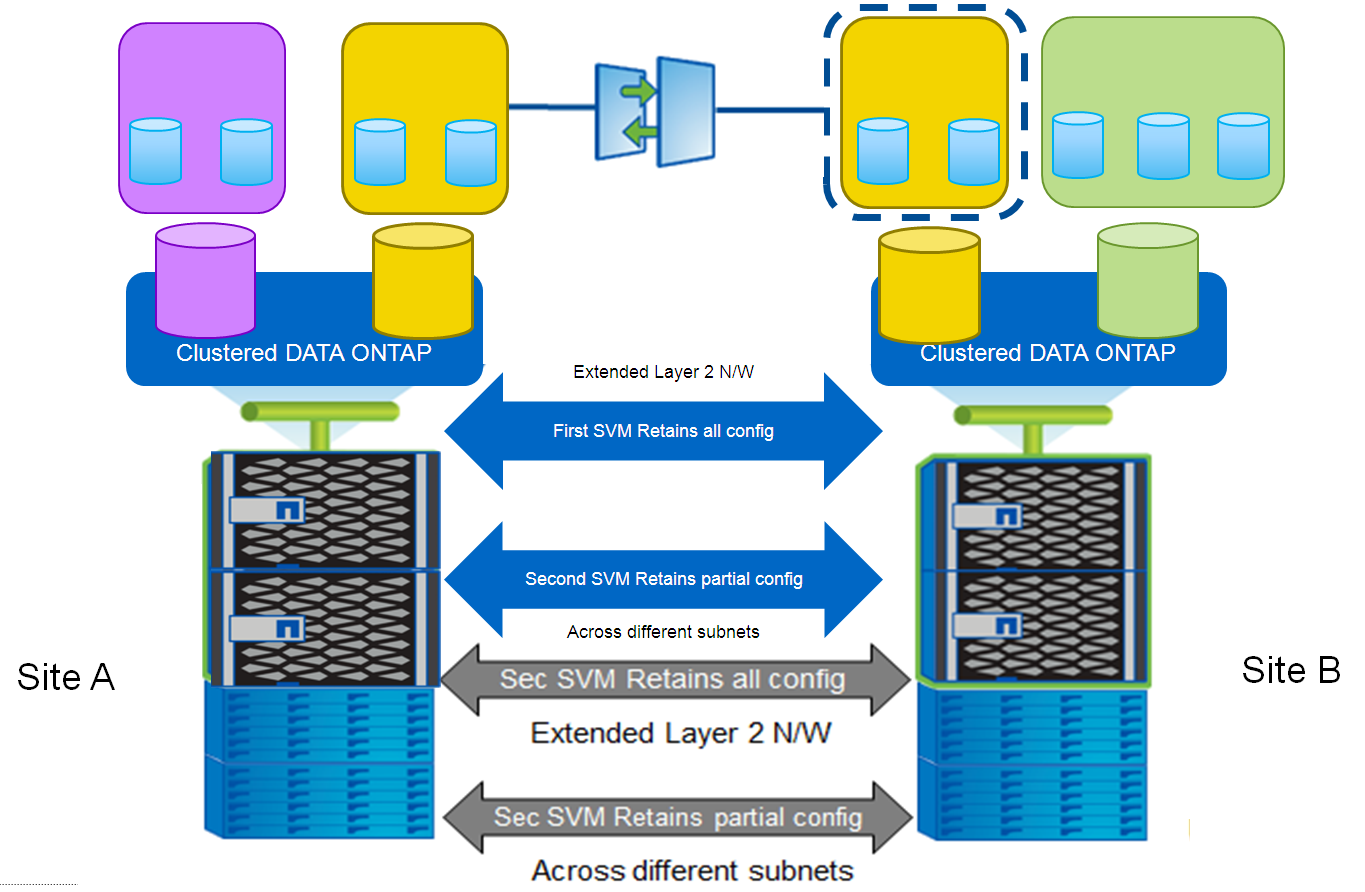
L2 домен между площадками требует соответствующего сетевого оборудования и каналов. Представьте себе две площадки с двумя СХД, которые реплицируют данные с первой на вторую, в случае аварии администратор выполняет переключение на резервный сайт, и на второй СХД поднимаются теже самые сетевые IP адреса, что и были на основной площадке, и вообще всё, что было настроено на первой СХД тоже переезжает. В свою очередь когда переехавшие сервера (со старыми настройками подключения к СХД) использующие ранее первую (основную) СХД, поднимаются на второй (запасной, DR) площадке, они видят те же адреса, куда они подключались ранее, но по-факту это резервная площадка, а они об этом просто не знают, и подключаются ко второй СХД, как будто к основной, что очень упрощает и ускоряет процесс переключения на резервную площадку. Требуемое оборудование и каналы могут себе позволить крупные компании, с другой стороны этот режим существенно ускоряет переключение на резервную площадку.
Identity Preserve: L3 домен для NAS
При отсутствии растянутой L2 сети между основной и резервной площадками, понадобится наличие нескольких разных IP подсетей и маршрутизации. Если бы данные были доступны по старым адресам, на второй (резервной, DR) площадке, то приложения не смогли бы к ним получить доступ, ведь на резервной площадке другие подсети. В этом случае также приходит на помощь функция Identity Preserve с сохранением сетевых адресов — ведь вы можете заранее указать новые сетевые IP адреса для DR площадки (которые поднимутся на DR площадке в момент переключения на вторичную СХД), по которым будут доступны данные на резервной СХД. Если просто мигрировать хосты, то их сетевые адреса тоже потребуется перенастроить: вручную или при помощи скриптов на резервной площадке, чтобы они увидели свои данные, со своих новых IP адресов подключаясь, опять таки, на новые IP адреса СХД. Этот режим работы будет больше интересен не большим компаниям, которые могут себе позволить более длительное время переключения в случае катастрофы или аварии при этом, не тратясь на дорогостоящее оборудование и каналы.
Identity Discard для SAN или NAS
Иногда есть необходимость полностью отказаться от старых настроек, при переключении на резервную площадку, к примеру отказаться от настроек NFS экспорта, настроек CIFS сервера, DNS и т.д. Также бывает необходимо обеспечить возможность чтения данных на удаленной площадке или когда есть необходимость реплицировать луны для SAN окружения. Во всех таких ситуациях приходит на помощь функция Identity Discard (Identity Preserve = False).
Как и в случае с Identity Preserve L3 конфигурацией, на удалённом сайте, после переключения необходимо будет перенастроить сетевые IP или FC адреса (и другие настройки, которые небыли были реплицированны, согласно режима Identity Discard), по которым будут доступны старые данные на вторичной СХД. Если просто мигрировать хосты, то их сетевые адреса тоже потребуется перенастроить: вручную или при помощи скриптов на резервной площадке, чтобы они увидели свои данные. Этот режим работы будет больше интересен для заказчиков которым необходимо иметь возможность реплицировать LUN'ы для SAN инфраструктуры или для тех кто хочет выполнять чтение данных на резервной площадке (к примеру каталогизация). Также этот режим будет интересен для проверки резервной копии на возможность к ней восстановится, а также для разнообразных тестироващиков и разработчиков.
SnapMirror Toolkit
Clustered Data ONTAP SnapMirror Toolkit — это бесплатный набор Perl скриптов, которые позволят ускорить и наладить процесс автоматизации проверки, подготовки, настройки, инициализации, обновления, переключения на резервную площадку и обратно репликации SnapMirror.
Скачать SnapMirror Toolkit.
NetApp-PowerShell Commandlets
Для Windows машин доступен NetApp PowerShell Toolkit, который позволит создавать скрипты управления NetApp.
Workflow Automation
Workflow Automation — это бесплатная графическая утилита позволяющая создавать наборы или связки задач, для автоматизации процессов управления ONTAP. К примеру через неё можно настроить создание новых разрешений для файловых шар или iGroup, добавить в неё отреплицированные вольюмы и новых хостов-инициаторов с DR площадки, поднять новые LIF интерфейсы и многое другое (создать Broadcast Domain, создать Failover Groups, Firewall Policies, Routes, DNS, и т.д.). Всё это можно автоматизировать так, чтобы это было выполнено сразуже, после выполнения разрыва репликации, практически по одному клику мыши. Workflow Automation будет более полезен для режимов Identity Preserve L3 и Identity Discard, так как в этих режимах после переключения на резервную площадку необходимо будет выполнить дополнительную настройку СХД и серверов. Также Workflow Automation будет крайне полезен для тестировщиков и разработчиков, которые могут клонировать огромные наборы данных средствами СХД за секунды и автоматизировать их подготовку для своей работы.
Snap-to-Cloud
Репликация данных может быть выполнена как на физическую FAS платформу, так и на их виртуальных братьев: Data ONTAP Edge, ONTAP Select или Cloud ONTAP в публичное облако. Последний вариант получил название Snap-to-Cloud. Если быть более точным то Snap-to-Cloud это набор (бандл) определенных моделей FAS платформ + Cloud ONTAP с установленными лицензиями репликации для бэкапа в облако.

Disaster Recovery не High Avalability
Чтобы обеспечить 0 время переключения, понадобится ещё большие затраты на каналы, ещё больше и ещё дороже сетевое оборудование. По-этому часто более целесообразно использовать DR, а не HA. В случае DR простой при переключении на резервную площадку неизбежен, RPO и RTO может быть достаточно небольшим, но он не равняются 0, как в случае с HA.
Исключение вольюма из DR реплики
Чтобы исключить вольюм/лун из DR реплики всего SVM, необходимо на источнике выполнить:
source_cluster::> volume modify -vserver vs1 -volume test_vol1 -vserver-dr-protection unprotected
Вторым применением SnapMirror может служить Test/Dev
Использование запасной площадки как среды разработки при помощи тонкого клонирования (Data Protection вольюма) снижает нагрузку на основную СХД, при этом тестировщики и разработчики могут иметь более новую информацию (по сравнению с традиционным подходом FullBackup из-за того что снепы снимаются и реплицируются намного быстрее и как правило из-за этого чаще) для своей работы, отреплицированную из основной СХД. Для тонкого клонирования понадобится лицензия FlexClone на соответствующей площадке.
Традиционный бекап vs Snap*
Cнепшоты NetApp вообще никак не виляют на производительность всей системы так устроено архитектурно. Благодаря чему снепшоты удобно использовать для репликации — передавать только изменения. Это более эффективно по сравнению с Full Backup/Restore так как при операциях резервного копирования читаются/пишутся только эти изменения, а не каждый раз всё по-новой. Использовать аппаратную репликацию средствами СХД более эффективно ещё и потому, что CPU хоста и его сетевые порты не задействуются во время бекапа. Это позволяет более часто выполнять резервное копирование, а возможность моментально снимать снепшоты позволит снимать их прямо посреди рабочего дня.
Хочу отметить, что репликация на основе нетаповских снепшотов, пускай и на много меньше, чем традиционая схема бекапирования или традиционных CoW снепшотов, грузит СХД, но всё-равно репликация её дополнительно грузит. Во-первых для репликации порождаются дополнительные операции чтения собственно новых изменений, генерируя дополнительную задачи чтения с дисковой подсистемы. Во-вторых операции чтения проходят через CPU СХД. Магии не происходит: мы можем существенно снизить и оптимизировать нагрузку от процесса резервного копирования, но нельзя его полностью нивилировать.
Выводы
Технология SnapMirror тонко реплицирует и восстанавливает данные, используя снепшоты. Это позволяет уменьшить нагрузку на сеть и дисковую подсистему по сравнению с Full Backup/Restore и выполнять реплики даже посреди рабочего дня, благодаря чему увеличить число резервных копий и таким образом существнно уменьшить окно резервного окпирования. Функционал SnapMirror for SVM обеспечивает удобный способ создания DR схемы восстановления всей СХД. Кроме DR второй сайт может быть использован для Test/Dev, снимая эти задачи с основной СХД.
Здесь могут содержаться ссылки на Habra-статьи, которые будут опубликованы позже.
Сообщения по ошибкам в тексте прошу направлять в ЛС.
Замечания, дополнения и вопросы по статье напротив, прошу в комментарии.
Комментарии (15)

nobletracer
16.07.2016 09:10Есть информация о том, по какому протоколу идет SnapMirror по сети? Очень интересно, но найти не смог.

bbk
16.07.2016 09:11SnapMirror работает по IP, сам протокол проприетарный нетаповский.
nobletracer
16.07.2016 13:36Вот как раз было интересно найти что за проприетарный протокол. Видимо в открытом доступе нет.

navion
21.07.2016 13:45-1По TCP, причем не очень хорошо оптимизированному, если судить по частоте упоминаний в рекламе WAN-оптимизаторов.
navion
21.07.2016 22:05Буду рад если поправите, но вот тема где чувак пытается разобарться в хэндшейке (видимо для IDS/IPS).
bbk
22.07.2016 10:50Обратите внимение что тема про 7-Mode, а в статье рассматривается функционал Cluatered ONTAP.
Также хочу отметить что SnapMirror, SnapMirror'у рознь. Одно дело «просто», другое для SVM.
navion
21.07.2016 13:57-1При нетаповские снепшоты забывают сказать одну важную штуку: они не заменяют обычные снепшты VMware, а работают параллельно с ними и придётся переделывать всю схему работы.
Это изменилось в VVOLs, но ими пока мало кто пользуется и у NetApp интеграция выполнена довольно хреново — VASA-провайдер ставивтся в виртуалку, а не интегрирован в контроллер как у 3PAR с EMC.bbk
22.07.2016 11:14Как-то у коментарии к моим постам всегда однобокие получаются.
Всё плохо, все не работает.
У вас используется TCP? Какой кашмар, сам факт использования TCP ужасен и говорит об ущербности ВСЕХ без исключения технологий NetApp, вы ещё скажите, не дай Бог, что SnapMirror работает поверх IP!
У вас можно использовать оптимизаторы WAN? Ужас, это прямое подтвержение первого утверждения!
Технологии снепшотов ущербынее некуда, вы посмотрите на эти снепшоты, не то что HP и EMC, они то знают что снепшоты это зло, именно по-этому у них их так долго небыло. И вообще «NetApp это на настотоящий SAN» ©!
Посмотрите на реализацию их vVol'ов, это сплошной технический беспредел, VASA провайдер вынесен из ONTAP. Только сам факт того что VASA вынесен наружу подтверждает ущербность реализации этой технологии и не важно, что NetApp был одним из главных дизайнеров этой технологии и самой первой её ревлизовал и внедрил в свои продукты! Да и вообще этот vVOL никто не использует потому что работает это отсойно, нето что в 3PAR и EMC.
navion
22.07.2016 12:39Я из тех, кто в первую очередь смотрит на недостатки и ограничения, потому что вендор рассказать про них забывает. Про NetApp есть прекрасная статья в блоге ТКС, жаль такое редко встречается.
bbk
22.07.2016 14:49Это прекрасный пример того как люди хотели сэкономить, получили больше чем конкуренты, но остались не давольны потому что хотели ещё больше.
bbk
22.07.2016 17:14Вы уже столько недостатков понаходили, ну прям недостаток на недостатке, вы меня снова поймали.
Не пойму как у вас интерес к нетапу ещё остался.
Я сам после ваших железобетонных аргументов подумываю бросить заниматься этим безобразием, на что я трачу свою жизнь? Одно сплошное разачарование.
bbk
22.07.2016 12:09+1А если отвечать не в вашем стиле, а по-факту, то:
Действительно используется TCP/IP, при необходимости снепмирор может передавать трафик используя компрессию Over the Wire, но эта компрессия ест мошность CPU СХД. Over the Wire это когда вы жмете данные перед отправкой и потом расжимаете, когда получаете на принимающей стороне. По-этому её можно отключить и использовать выделенный WAN оптимизатор, чтобы CPU СХД не нагружать, а вынести нагрузку по компрессии на отдельное устройство — оптимизатор.
Если же используется inline компрессия и дедуп, которая оптимизирована для CPU которая выполняет запись данных уже в сжатом виде, то Over the Wire включать смысла нет, так как данные уже сжаты и задедуплицированы передаются на получатель.
Что же касается vVOL, как было сказано, Нетапп является не только технологическим партнёром, но и дизайнером этой технологии. Первой реализовал этот функционал, первой реализовал фукционал vVOL для NFS, и вы всё ещё думаете что она «хреново работает», просто потому что VASA-провайдер ставивтся в виртуалку? Нетапп рассматривал возможность установки его в ONTAP, но остановился на таком решении. Это просто такой подход имеющий право на жизнь, никак не сказывающийся на том как работает vVOL. А драйвил тему с vVOL нетап, потому что у него снепы отлично работают и ВМваровский гипервизор тоже очень хорошая технология, но снепы плохо у него работают, по-этому в сочитании технологий нетаповских снепов и ВМваре гипервизора можно получить больше плюсов.
Что же касается снепов на виртуализации, опять таки не понимание, не договоки и манипуляции с целью приуменьшить значимость снепов:
- Во-первых, да есть такая схема которая использует снеп ВМваре, потом снимается снеп нетапа, потом снеп Вмваре удаляется. Разница с «просто снепами Вмваре» в том, что её снеп на много меньше живёт и соответственно вопрос проблемы консолидации Вмваровских снепов не стоит. Эта схема хорошо подходит для средних нагрузок.
- Во-вторых, есть и другая схема снепов в среде виртуализации — RDM (кстати vVOL очень много подчерпнул из этой схемы), когда луны пробрасываюся внутрь гостевой ОС, в таком случае устраняется необходимость в снепах ВМваре вовсе. Эта схема подходит для высоких нагрузок, к примеру с базами данных (десятки тысяч IOPS, террабайты данных).
- В третьих манипуляция в том что приуменьшается таким образом нетаповские снепы. В то время как нетаповским снепам уже 23 года (появились спустя год после выпуска WAFL — в 1993 г), которые отлажены и отлично работают как на NAS так и SAN, у конкурентов они появились только недавно и только в для SAN. Ситуация с WAFL вообще смешная, маркетинг конкурентов кричали что NetApp «это не настоящий SAN», там используется «файловая система», у которой «фрагментация из-за чего она медленно она работает», а сами техоничко пилитли тоже самое.
- В четвертых давайте посмотрим на ситуацию не «относительно», а «по факту», как это сейчас устроено у других: а там всё ещё хуже, вам нужно или использовать снепы ВМвары и пока идёт фулл-бекап хранить его, всё это время дельта снепа растёт, всё это время имеются накладные расходы по производительности и только потом, после окончания его можно удалить. Альтернатива этому — делать фул-бэкап из нутри гостевой ОС, опять таки имея дополнительную и длительное время на дисковую подсистему, пока идёт фул-бэкап. В обоих вариантах имеем дополнительную нагрузку на CPU гипервизора и сетевые порты — в противовес нетаповским снепам, где этого безобразия нет.
Теперь EMC сделала Unity, а HP купили 3PAR и вдруг они вспомнили что они «тоже умеют снепы как у нетап» и «тоже умеют SAN и NAS из одной коробки». Но чтобы сделать тоже самое, того же качества, интеграции и функционала им теперь нужно пройти теже 23 года. Именно по-этому у них столько «но» и столько ограничений связаных с снепами и NAS.
Всё познается в сравнении.
{kind=link}
freefd
EMC VPLEX, IBM SVC, NetApp SVM?
bbk
EMC VPLEX — Архитектура для HighAvalability
NetApp SVM — Архитектура DisasterRecovery
IBM SVC — SAN Volume Controller
Горячее, Синее и Твёрдое.
freefd
Ok.