Материал, рассказанный нашим коллегой Константином Лахманом, обобщает историю развития нейросетей, их основные особенности и принципиальные отличия от других моделей, применяемых в машинном обучении. Также речь пойдёт о конкретных примерах применения нейросетевых технологий и их ближайших перспективах. Лекция будет полезна тем, кому хочется систематизировать у себя в голове все самые важные современные знания о нейронных сетях.
Константин klakhman Лахман закончил МИФИ, работал исследователем в отделе нейронаук НИЦ «Курчатовский институт». В Яндексе занимается нейросетевыми технологиями, используемыми в компьютерном зрении.
Под катом — подробная расшифровка со слайдами.
Нейронные сети
Всем привет. Меня зовут Костя Лахман, и тема сегодняшней лекции – это «Нейронные сети». Я работаю в «Яндексе» в группе нейросетевых технологий, и мы разрабатываем всякие прикольные штуки, основанные на машинном обучении, с применением нейронных сетей. Нейронные сети – это один из методов машинного обучения, к которому сейчас приковано достаточно большое внимание не только специалистов в области анализа данных или математиков, но и вообще людей, которые никак не связаны с этой профессией. И это связано с тем, что решения на основе нейронных сетей показывают самые лучшие результаты в самых различных областях человеческого знания, как распознавание речи, анализ текста, анализ изображений, о чем я попытаюсь в этой лекции рассказать. Я понимаю, что, наверное, у всех в этой аудитории и у тех, кто нас слушает, немножко разный уровень подготовки – кто-то знает чуть больше, кто-то чуть меньше, – но можете поднять руки те, кто читал что-нибудь про нейронные сети? Это очень солидная часть аудитории. Я постараюсь, чтобы было интересно и тем, кто вообще ничего не слышал, и тем, кто что-то все-таки читал, потому что большинство исследований, про которые я буду рассказывать – это исследования этого года или предыдущего года, потому что очень много всего происходит, и буквально проходит полгода, и те статьи, которые были опубликованы полгода назад, они уже немножко устаревают.

Давайте начнем. Я очень быстро просто расскажу, в чем заключается задача машинного обучения в целом. Я уверен, что многие из вас это знают, но, чтобы двигаться дальше, хотелось бы, чтобы все понимали. На примере задачи классификации как самой понятной и простой.
Пусть у нас есть некоторое U – множество объектов реального мира, и к каждому из этих объектов мы относим какие-то признаки этих объектов. А также у каждого из этих объектов есть какой-то класс, который мы бы хотели уметь предсказывать, имея признаки объекта. Давайте рассмотрим эту ситуацию на примере изображений.

Объекты – это все изображения в мире, которые могут нас интересовать.

Самые простые признаки изображений – это пиксели. За последние полвека, в течение которых человечество занимается распознаванием образов, были придуманы значительно более сложные признаки изображений – но это самые простые.

И класс, который мы можем отнести к каждому изображению, – это, например, человек (это фотография Алана Тьюринга, например), птица, дом и так далее.

Задачей машинного обучения в данном случае является построение решающей функции, которая по вектору признаков объекта будет говорить, к какому классу она принадлежит. У вас была лекция, насколько я знаю, Константина Воронцова, который про это все рассказывал значительно глубже меня, поэтому я только по самой верхушке.
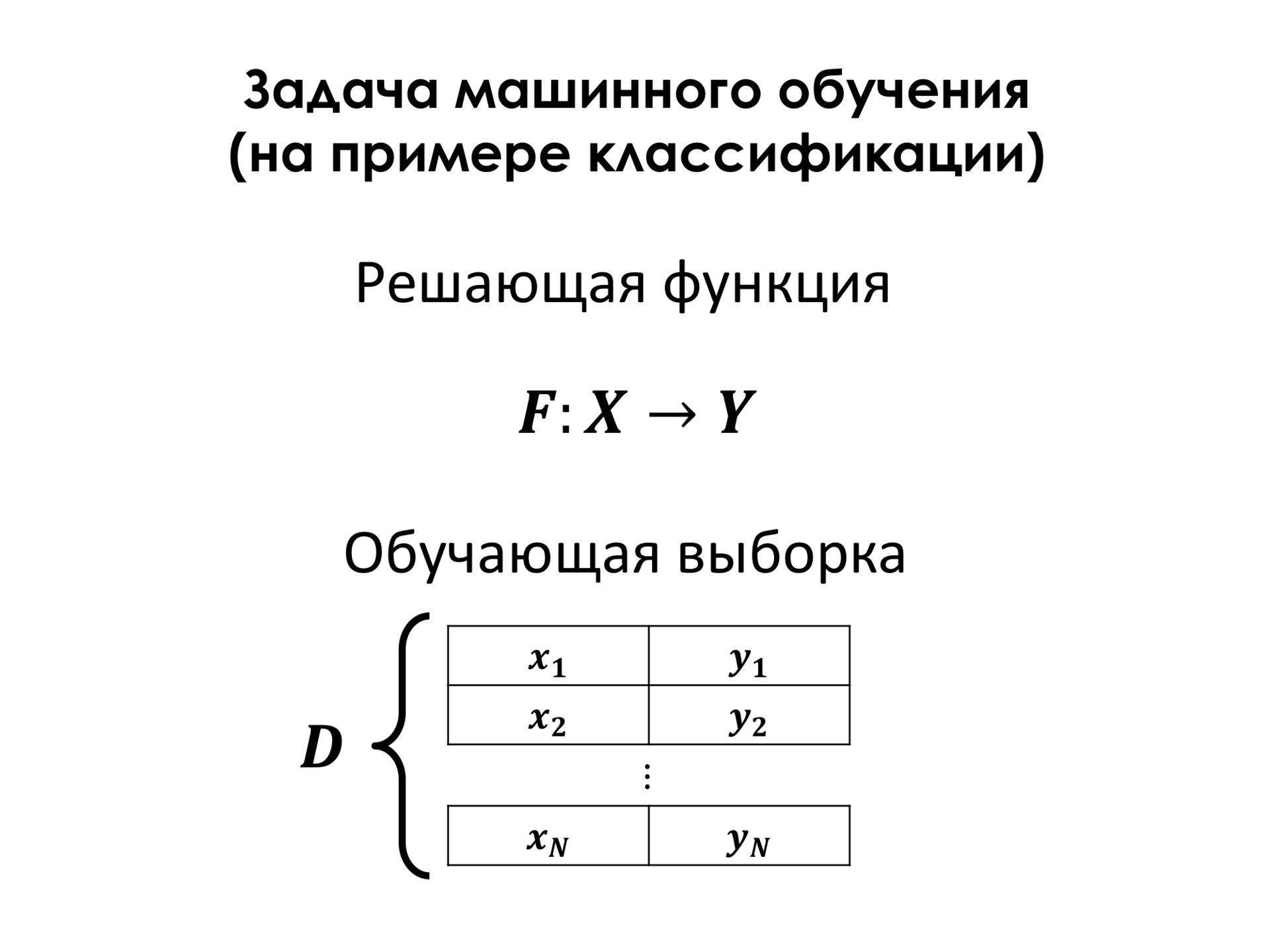
В большинстве случаев необходима так называемая обучающая выборка. Это набор примеров, про которые нам точно известно, что у этого объекта такой класс. И на основе этой обучающей выборки мы можем построить эту решающую функцию, которая как можно меньше ошибается на объектах обучающего множества и, таким образом, рассчитывает, что на объектах, которые не входят в обучающее множество, у нас будет тоже хорошее качество классификаций.

Для этого мы должны ввести некоторую функцию ошибки. Здесь D – это обучающее множество, F – это решающая функция. И в самом простом случае функция ошибки – это просто количество примеров, на которых мы ошибаемся. И, для того чтобы найти оптимальную решающую функцию, нам надо понять. Обычно мы выбираем функцию из какого-то параметрического множества, то есть это просто какой-то, например, полином уравнения, у которого есть какие-то коэффициенты, и нам их надо как-то подобрать. И параметры этой функции, которые минимизируют эту функцию ошибки, функцию потерь, и являются нашей целью, то есть мы хотим найти эти параметры.
Существует множество методов того, как искать эти параметры. Я не буду сейчас в это углубляться. Один из методов – это когда мы берем один пример этой функции, смотрим, правильно ли мы его классифицировали или неправильно, и берем производную по параметрам нашей функции. Как известно, если мы пойдем в сторону обратной этой производной, то мы, таким образом, уменьшим ошибку на этом примере. И, таким образом, проходя все примеры, мы будем уменьшать ошибку, подстраивая параметры функции.
То, о чем я сейчас рассказывал, относится ко всем алгоритмам машинного обучения и в той же степени относится к нейросетям, хотя нейросети всегда стояли немножко в стороне от всех остальных алгоритмов.

Сейчас всплеск интереса к нейросетям, но это один из старейших алгоритмов машинного обучения, который только можно придумать. Первый формальный нейрон, ячейка нейронный сети была предложена, его первая версия, в 1943 году Уорреном Маккалоком и Уолтером Питтсом. Уже в 1958 году Фрэнк Розенблатт предложил первую самую простую нейронную сеть, которая уже могла разделять, например, объекты в двухмерном пространстве. И нейронные сети проходили за всю эту более чем полувековую историю взлеты и падения. Интерес к нейронным сетям был очень большой в 1950–1960-е годы, когда были получены первые впечатляющие результаты. Затем нейронные сети уступили место другим алгоритмам машинного обучения, которые оказались более сильными в тот момент. Опять интерес возобновился в 1990-е годы, потом опять ушел на спад.

И сейчас в последние 5–7 лет оказалось, что во многих задачах, связанных с анализом естественной информации, а все, что нас окружает – это естественная информация, это язык, это речь, это изображение, видео, много другой самой разной информации, – нейронные сети лучше, чем другие алгоритмы. По крайней мере, на данный момент. Возможно, опять ренессанс закончится и что-то придет им на смену, но сейчас они показывают самые лучшие результаты в большинстве случаев.
Что же к этому привело? То что нейронные сети как алгоритм машинного обучения, их необходимо обучать. Но в отличие от большинства алгоритмов нейронные сети очень критичны к объему данных, к объему той обучающей выборки, которая необходима для того, чтобы их натренировать. И на маленьком объеме данных сети просто плохо работают. Они плохо обобщают, плохо работают на примерах, которые они не видели в процессе обучения. Но в последние 15 лет рост данных в мире приобретает, может быть, экспоненциальный характер, и сейчас это уже не является такой большой проблемой. Данных у нас очень много.
Второй такой краеугольный камень, почему сейчас ренессанс сетей – это вычислительные ресурсы. Нейронные сети – один из самых тяжеловесных алгоритмов машинного обучения. Необходимы огромные вычислительные ресурсы, чтобы обучить нейронную сеть и даже чтобы ее применять. И сейчас такие ресурсы у нас есть. И, конечно, новые алгоритмы были придуманы. Наука не стоит на месте, инженерия не стоит на месте, и теперь мы больше понимаем о том, как обучать подобного рода структуры.
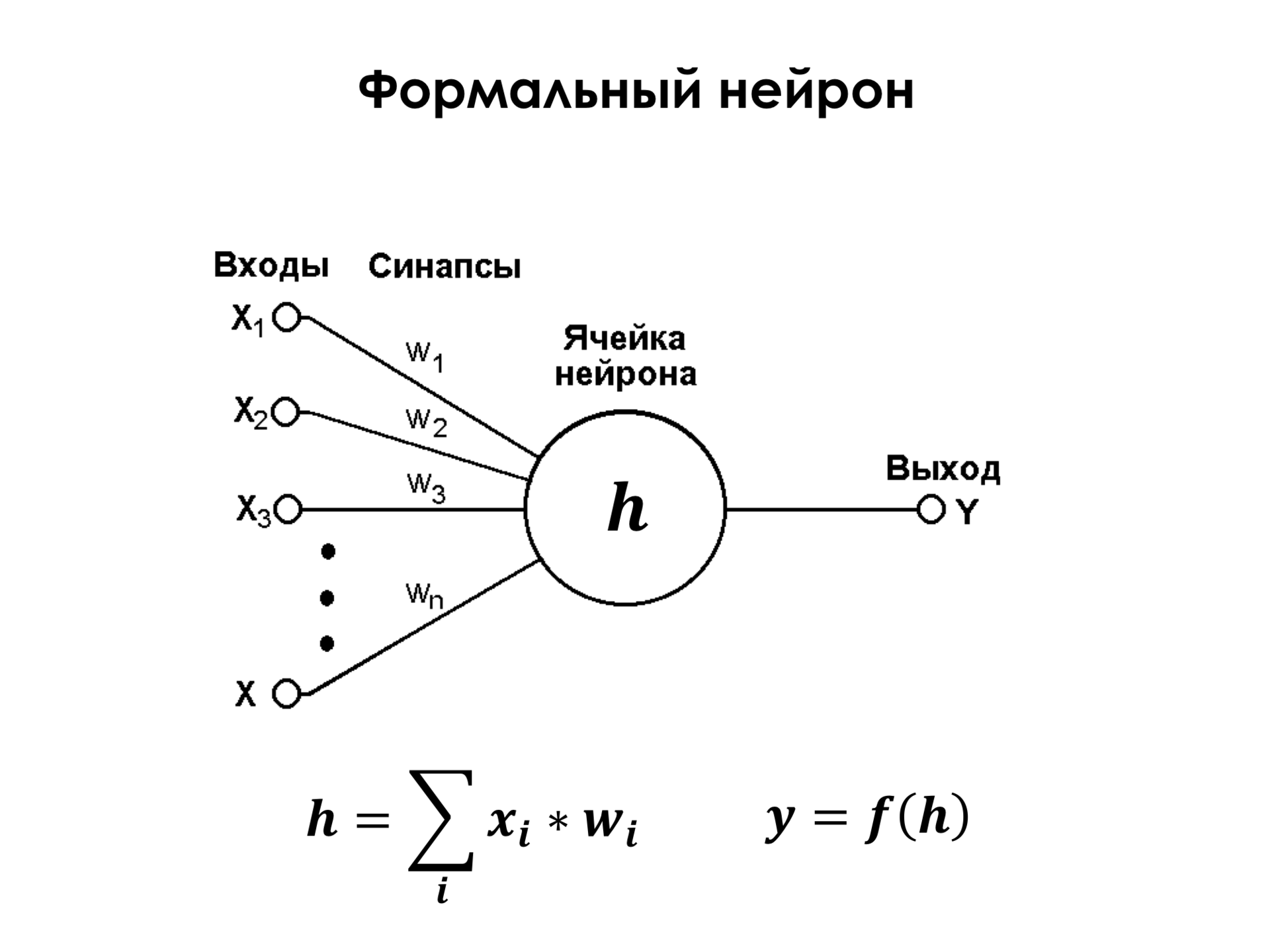
Что такое формальный нейрон? Это очень простой элемент, у которого есть какое-то ограниченное количество входов, к каждому из этих входов привязан некоторый вес, и нейрон просто берет и осуществляет взвешенную суммацию своих входов. На входе могут быть, например, те же самые пиксели изображения, про которые я рассказывал раньше. Представим себе, что X1 и до Xn – это просто все пиксели изображения. И к каждому пикселю привязан какой-то вес. Он их суммирует и осуществляет некоторое нелинейное преобразование над ними. Но даже если не касаться линейного преобразования, то уже один такой нейрон является достаточно мощным классификатором. Вы можете заменить этот нейрон и сказать, что это просто линейный классификатор, и формальный нейрон им и является, это просто линейный классификатор. Если, допустим, в двухмерном пространстве у нас есть некоторое множество точек двух классов, а это их признаки X1 и X2, то есть, подобрав эти веса V1 и V2, мы можем построить разделяющую поверхность в этом пространстве. И, таким образом, если у нас эта сумма, например, больше нуля, то объект относится к первому классу. Если эта сумма меньше нуля, то объект относится ко второму классу.
И все бы хорошо, но единственное, что эта картинка очень оптимистичная, тут всего два признака, классы, что называется, линейно разделимые. Это означает, что мы можем просто провести линию, которая правильно классифицирует все объекты обучающего множества. На самом деле так бывает не всегда, и практически никогда так не бывает. И поэтому одного нейрона недостаточно, чтобы решать подавляющее большинство практических задач.

Это нелинейное преобразование, которое осуществляет каждый нейрон над этой суммой, оно критически важно, потому что, как мы знаем, если мы, например, осуществим такую простую суммацию и скажем, что это, например, какой-то новый признак Y1 (W1x1+W2x2=y1), а потом у нас есть, например, еще второй нейрон, который тоже суммирует те же самые признаки, только это будет, например, W1'x1+W2'x2=y2. Если мы потом захотим применить опять линейную классификацию в пространстве этих признаков, то это не будет иметь никакого смысла, потому что две подряд примененные линейные классификации легко заменяются на одну, это просто свойство линейности операций. А если мы осуществим над этими признаками некоторое нелинейное преобразование, например, самое простое… Раньше применяли более сложные нелинейные преобразования, такие, как эта логистическая функция, она ограничена нулем и единицей, и мы видим, что здесь есть участки линейности. То есть она около 0 по x ведет себя достаточно линейно, как обычная прямая, а дальше она ведет себя нелинейно. Но, как оказалось, чтобы эффективно обучать подобного рода классификаторы, достаточно самой простой нелинейности на свете – просто урезанной прямой, когда на положительном участке это прямая, а на отрицательном участке это всегда 0. Это самая простая нелинейность, и оказывается, что даже ее уже достаточно, чтобы эффективно обучать классификацию.
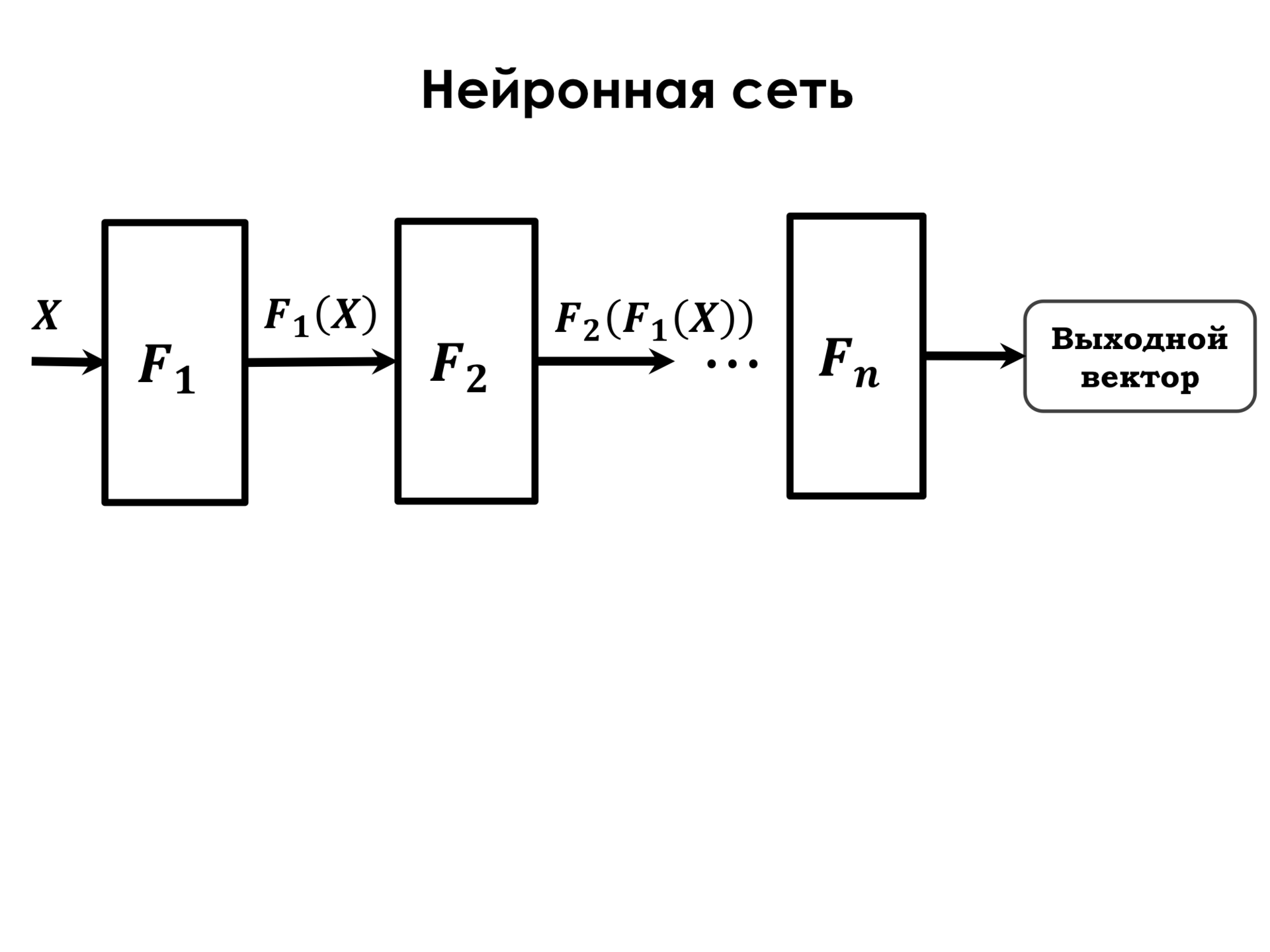
Что представляет из себя нейронная сеть? Нейронная сеть представляет из себя последовательность таких преобразований. F1 – это так называемый слой нейронной сети. Слой нейронной сети – это просто совокупность нейронов, которые работают на одних и тех же признаках. Представим, что у нас есть исходные признаки x1, x2, x3, и у нас есть три нейрона, каждый из которых связан со всеми этими признаками. Но у каждого из нейронов свои веса, на которых он взвешивает такие признаки, и задача обучения сети в подборе таких весов у каждого из нейронов, которые оптимизируют эту нашу функцию ошибки. И функция F1 – это один слой таких нейронов, и после применения функция у нас получается некоторое новое пространство признаков. Потом к этому пространству признаков мы применяем еще один такой слой. Там может быть другое количество нейронов, какая-то другая нелинейность в качестве преобразующей функции, но это такие же нейроны, но с такими весами. Таким образом, последовательно применяя эти преобразования, у нас получается общая функция F – функция преобразования нейронной сети, которая состоит из последовательного применения нескольких функций.

Как обучаются нейронные сети? В принципе, как и любой другой алгоритм обучения. У нас есть некоторый выходной вектор, который получается на выходе сети, например, класс, какая-то метка класса. Есть некоторый эталонный выход, который мы знаем, что у этих признаков должен быть, например, такой объект, или какое число мы должны к нему привязать.

И у нас есть некоторая дельта, то есть разница между выходным вектором и эталонным вектором, и дальше на основе этой дельты здесь есть большая формула, но суть ее заключается в том, что если мы поймем, что эта дельта зависит от Fn, то есть от выхода последнего слоя сети, если мы возьмем производную этой дельты по весам, то есть по тем элементам, которые мы хотим обучать, и еще применим так называемое правило цепочки, то есть когда у нас производные сложной функции – это произведение от производной по функции на произведение функции по параметру, то получится, что таким нехитрым образом мы можем найти производные для всех наших весов и подстраивать их в зависимости от той ошибки, какую мы наблюдаем. То есть если у нас на каком-то конкретном обучающем примере нет ошибки, то, соответственно, производные будут равны нулю, и это означает, что мы его правильно классифицируем и нам ничего не надо делать. Если ошибка на обучающем примере очень большая, то мы должны что-то с этим сделать, как-то изменить веса, чтобы уменьшить ошибку.
Сверточные сети
Сейчас было немножко математики, очень поверхностно. Дальше большая часть доклада будет посвящена крутым вещам, которые можно сделать с помощью нейронных сетей и которые делают сейчас многие люди в мире, в том числе и в Яндексе.

Одним из методов, который первым показал практическую пользу, являются так называемые сверточные нейронные сети. Что такое сверточные нейронные сети? Допустим, у нас есть изображение Альберта Эйнштейна. Эту картину, наверное, многие из вас тоже видели. И эти кружочки – это нейроны. Мы можем подсоединить нейрон ко всем пикселям входного изображения. Но тут есть большая проблема, что если подсоединить каждый нейрон ко всем пикселям, то, во-первых, у нас получится очень много весов, и это будет очень вычислительно емкая операция, очень долго будет вычислять такую сумму для каждого из нейронов, а во-вторых, весов получится так много, что этот метод будет очень неустойчив к переобучению, то есть к эффекту, когда на обучающем множестве мы все хорошо предсказываем, а на множестве примеров, которые не входят в обучающие, мы работаем очень плохо, просто потому, что мы перестроились на обучающее множество. У нас слишком много весов, слишком много свободы, мы можем очень хорошо объяснить любые вариации в обучающем множестве. Поэтому придумали другую архитектуру, в которой каждый из нейронов подсоединен только к небольшой окрестности на изображении. Кроме всего прочего все эти нейроны обладают одними и теми же весами, и такая конструкция называется сверткой изображения.
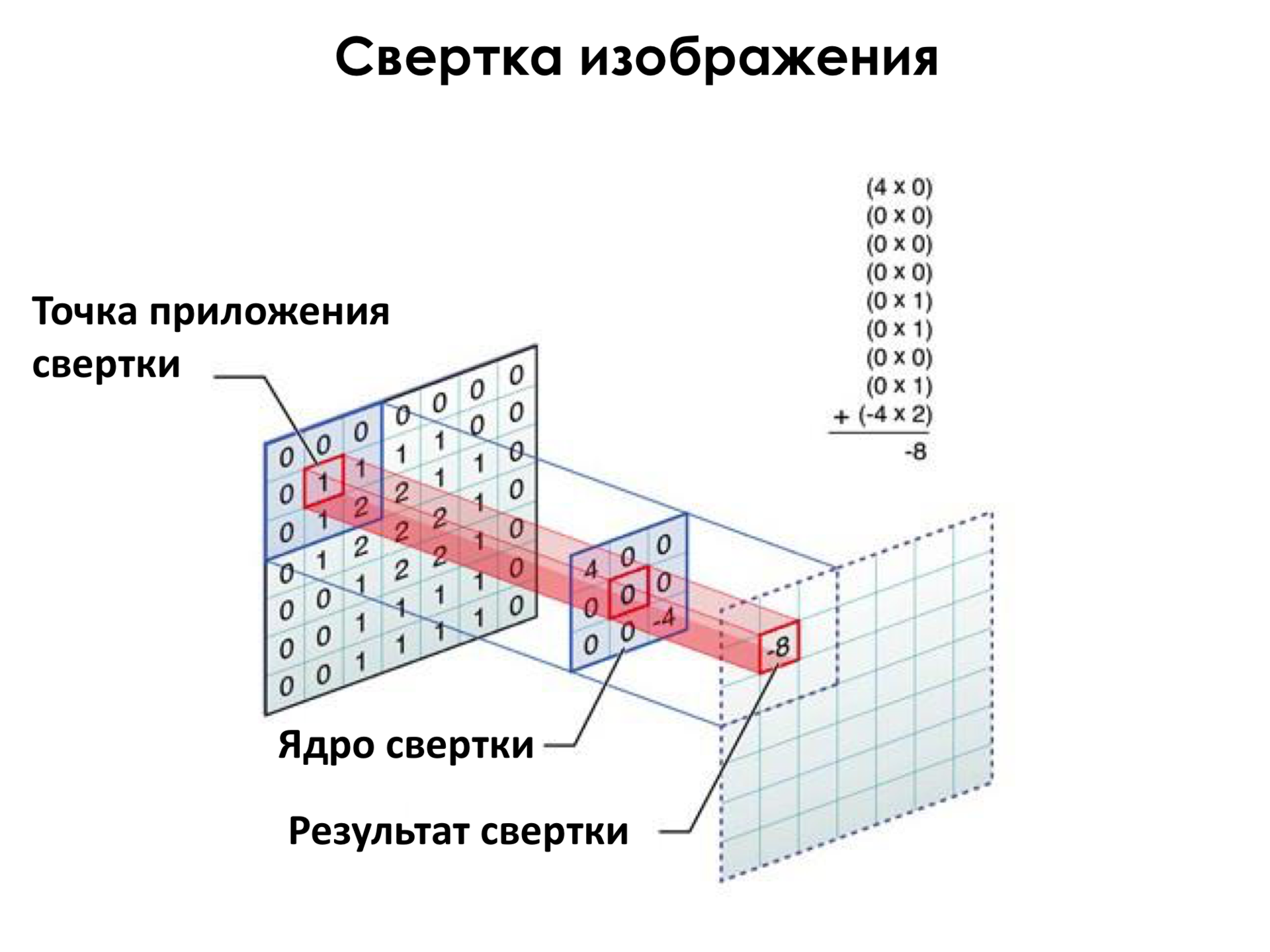
Как она осуществляется? У нас тут в центре есть так называемое ядро свертки – это совокупность весов этого нейрона. И мы применяем это ядро свертки во всех пикселях изображения последовательно. Применяем – это означает, что мы просто взвешиваем пиксели в этом квадрате на веса, и получаем некоторое новое значение. Можно сказать, что мы преобразовали картинку, прошлись по ней фильтром. Как в Photoshop, например, существуют какие-то фильтры. То есть самый простой фильтр – как можно из цветной картинки сделать черно-белую. И вот мы прошлись таким фильтром и получили некоторое преобразованное изображение.
В чем здесь плюс? Первый плюс, что меньше весов, быстрее считать, меньше подвержены к переобучению. С другой стороны, каждый из этих нейронов получается некоторым детектором, как я покажу это дальше. Допустим, если где-то у нас на изображении есть глаз, то мы одним и тем же набором весов, пройдясь по картинке, определим, где на изображении глаз.

Здесь должно быть видео.
И одной из первых вещей, к чему применили подобную архитектуру – это распознавание цифр, как самых простых объектов.
Применил это где-то в 1993 году Ян Лекун в Париже, и здесь сейчас будет практически архивная запись. Качество так себе. Здесь сейчас они предоставляют рукописные цифры, нажимают некоторую кнопочку, и сеть распознает эти рукописные цифры. В принципе, безошибочно она распознает. Ну, эти цифры, естественно, проще, потому что они печатные. Но, например, на этом изображении цифры уже значительно сложнее. А эти цифры, честно сказать, даже я не совсем могу различить. Там, кажется, четверка слева, но сеть угадывает. Даже такого рода цифры она распознает. Это был первый успех сверточных нейронных сетей, который показал, что они действительно применимы на практике.
В чем заключается специфика этих сверточных нейронных сетей? Эта операция свертки элементарная, и мы строим слои этих сверток над изображением, преобразовывая все дальше и дальше изображения. Таким образом, мы на самом деле получаем новые признаки. Наши первичные признаки – это были пиксели, а дальше мы преобразовываем изображение и получаем новые признаки в новом пространстве, которые, возможно, позволят нам более эффективно классифицировать это изображение. Если вы себе представите изображение собак, то они могут быть в самых разных позах, в самых разных освещениях, на разном фоне, и их очень сложно классифицировать, непосредственно опираясь только на пиксели. А последовательно получая иерархию признаков новых пространств, мы это сделать можем.
Вот в чем основное отличие нейронных сетей от остальных алгоритмов машинного обучения. Например, в области компьютерного зрения, в распознавании изображений до нейронных сетей был принят следующий подход.
Когда вы берете предметную область, например, нам нужно между десятью классами определять, к какому из классов принадлежит объект – дом, птица, человек, люди очень долго сидели и думали, какие бы признаки можно было найти, чтобы отличать эти изображения. Например, изображение дома легко отличить, если у нас много геометрических линий, которые как-то пересекаются. У птиц, например, бывает очень яркий окрас, поэтому если у нас есть сочетание зеленых, красных, других признаков, то, наверное, это больше похоже на птицу. Весь подход заключался в том, чтобы придумать как можно больше таких признаков, а дальше подать их на какой-нибудь достаточно простой линейный классификатор, примерно такой, который состоит на самом деле из одного слоя. Есть еще и сложнее методы, но, тем не менее, они работали на этих признаках, которые придуманы человеком. А с нейронными сетями оказалось, что вы можете просто сделать обучающую выборку, не выделять никакие признаки, просто подать ей на вход изображения, и она сама обучится, она сама выделит те признаки, которые критичны для классификации этих изображений за счет этой иерархии.
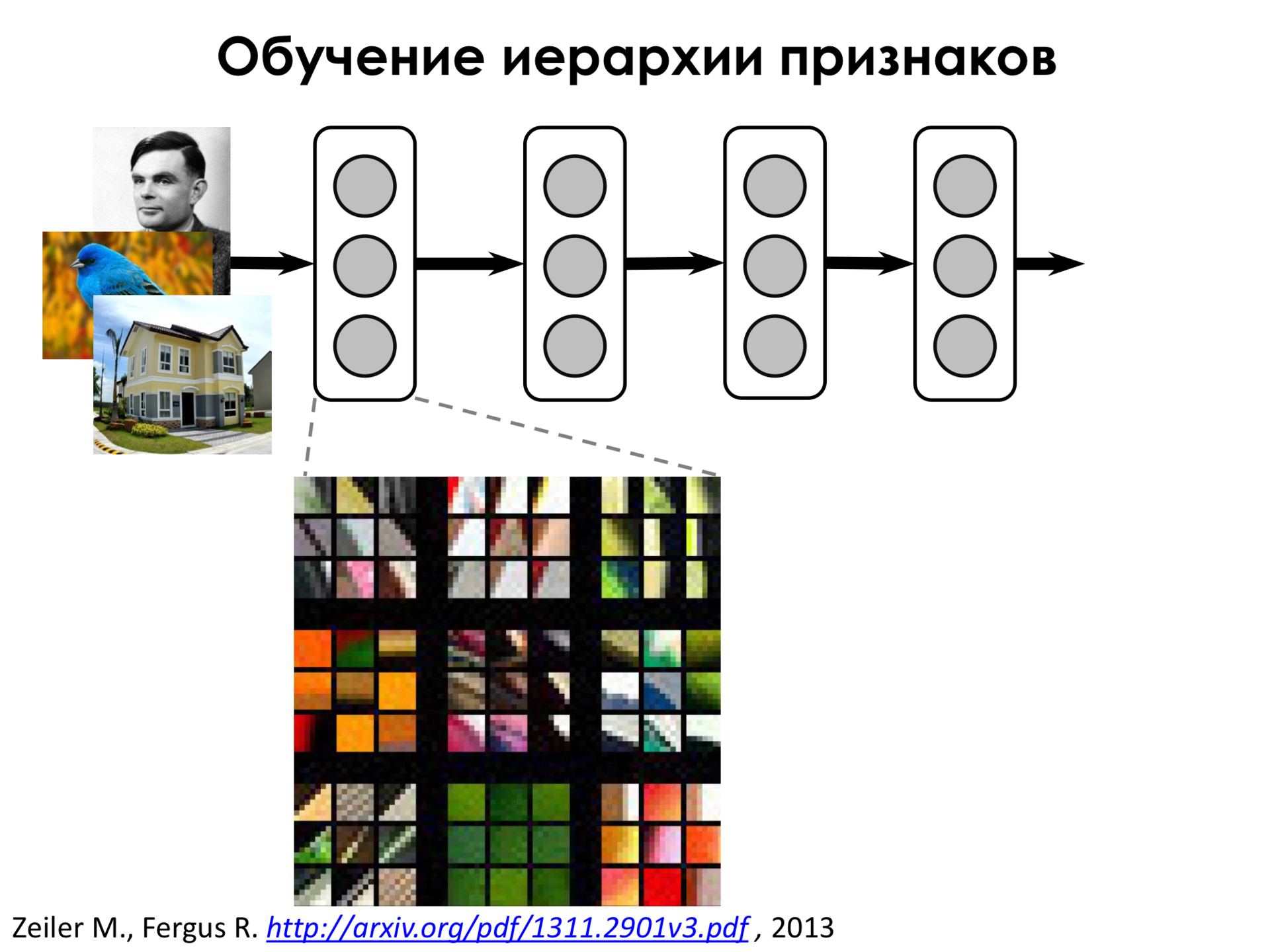
Давайте посмотрим на то, какие признаки выделяет нейронная сеть. На первых слоях такой сети оказывается, что сеть выделяет очень простые признаки. Например, переходы градиентов или какие-то линии под разным углом. То есть она выделяет признаки – это означает, что нейрон реагирует, если примерно такой кусок изображения он видит в окне своего ядра свертки, в области видимости. Эти признаки не очень интересны, мы бы и сами их могли придумать.
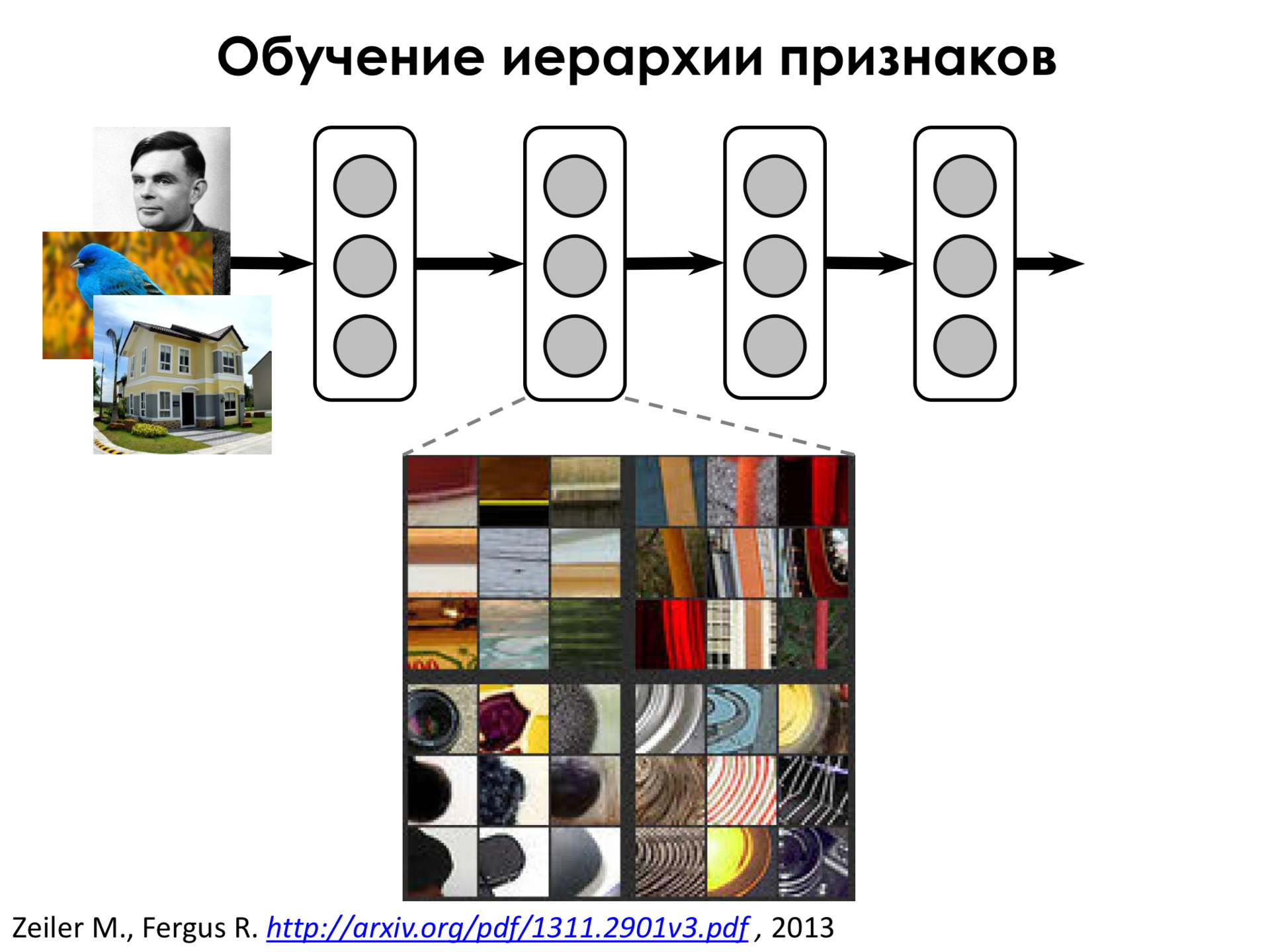
Переходя глубже, мы видим, что сеть начинает выделять более сложные признаки, такие, как круговые элементы и даже круговые элементы вместе с какими-то полосками.
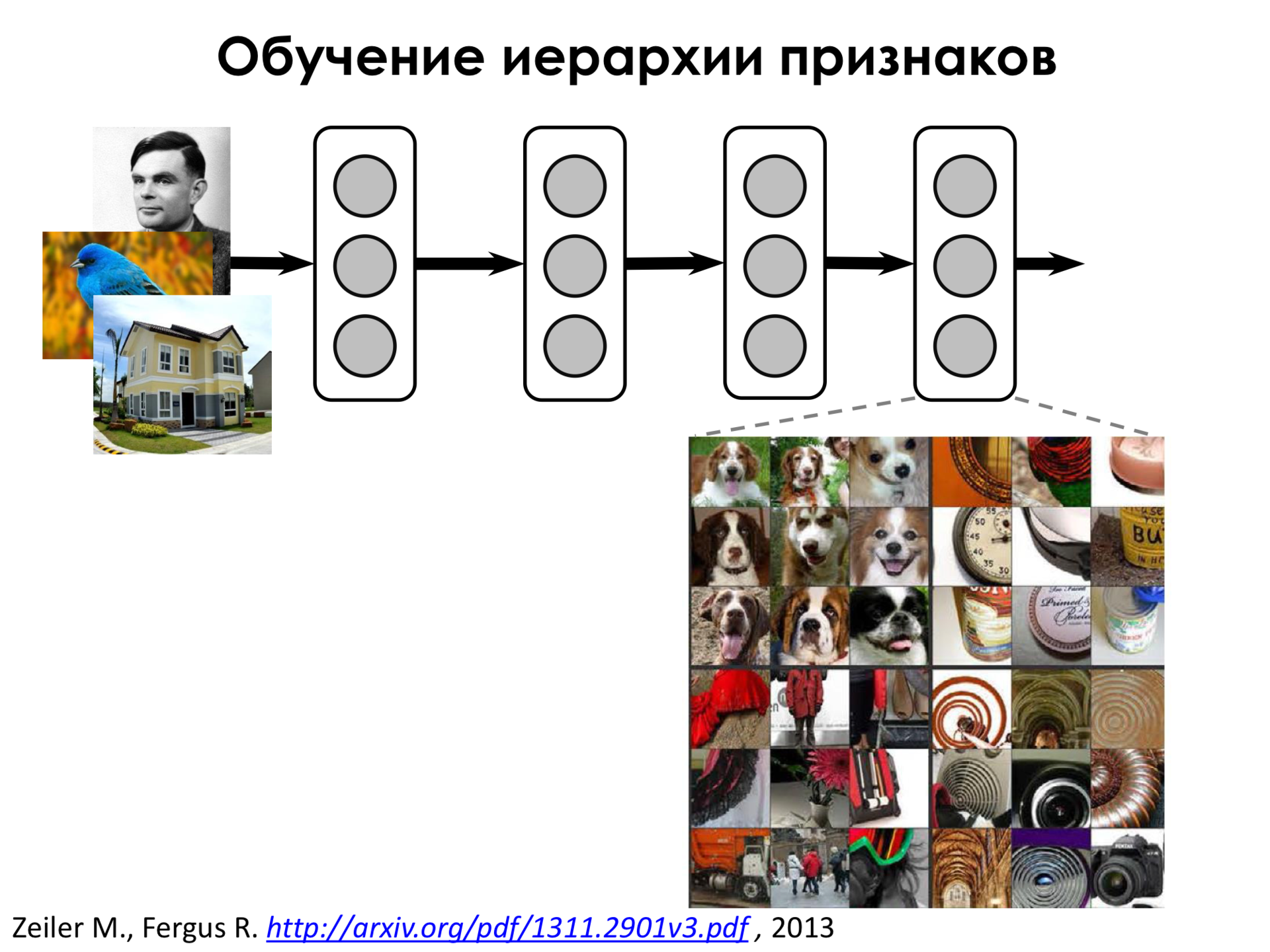
И чем дальше мы идем по нейронной сети, чем дальше мы от входа, тем более сложными становятся признаки. То есть, например, этот нейрон уже может реагировать на лицо собаки, то есть он зажигается, когда видит в части изображения лицо собаки, банку, часы, еще что-то такое.

Для чего это все нужно? Есть по современным меркам не очень большая, но три года это была самая большая размеченная база изображений в мире Image.net. В ней есть чуть больше миллиона изображений, которые разделены на тысячу классов. И необходимо добиться наибольшей точности распознавания на этой выборке.

Эта выборка совсем непростая. Надо просто понять, что, например, хаски и сибирский хаски – это два разных класса там. Если мне показать два эти изображения, я не отличу, где хаски, а где сибирский хаски, а сеть может отличить. Там, по-моему, больше 300 пород собак разных классов и пара десятков только видов терьеров. То есть человек, наверное, обладающий каким-то специфическим знанием в области кинологии, но обычный человек не может.

Применили нейронную сеть к этой выборке изображений, и оказалось, что она очень неплохо с ней справляется. Например, здесь показана картинка, под картинкой показан правильный класс, а здесь показаны столбиками предсказания сети. И чем больше столбик, тем больше сеть уверена, что это предсказание правильно. И мы видим, что она правильно предсказывает леопарда, предсказывает скутер, несмотря на то что здесь кроме скутера еще люди есть на изображении. Но она видит, что скутер – это доминирующий объект на изображении, и предсказывает именно его. Допустим, она даже предсказывает клеща, несмотря на то что все изображение состоит просто из однородного фона, и клещ только где-то в самом-самом углу. Но она понимает, что клещ является основой этой сцены. При этом анализ ошибок нейронной сети тоже очень интересен и позволяет выявить, например, ошибки в обучающем множестве, потому что это множество размечали люди, и люди всегда ошибаются. Допустим, есть картинка с далматином и вишней, на которую нейронная сеть с огромной уверенностью отвечает, что это далматин. Ну, правда, мы смотрим на это изображение и видим, что основной объект – далматин. Но на самом деле на переднем фоне здесь есть вишня, и человек, который размечал это изображение в процессе подготовки выборки, почему-то решил, что вишня – это доминирующий объект на этом изображении. И получается, что нейронная сеть ошиблась по нашей метрике.
С другой стороны, например, здесь есть некоторое животное справа внизу. Я не знал, что это за животное. В разметке написано, что это мадагаскарская кошка. Поверим разметке. Но сеть делает очень резонное предположение о том, что это может быть. Она говорит, что это какой-то вид обезьяны. Мне кажется, что эти ошибки они очень разумны. То есть я тоже мог бы предположить, что это какой-то вид обезьяны, очень нераспространенный и экзотический.
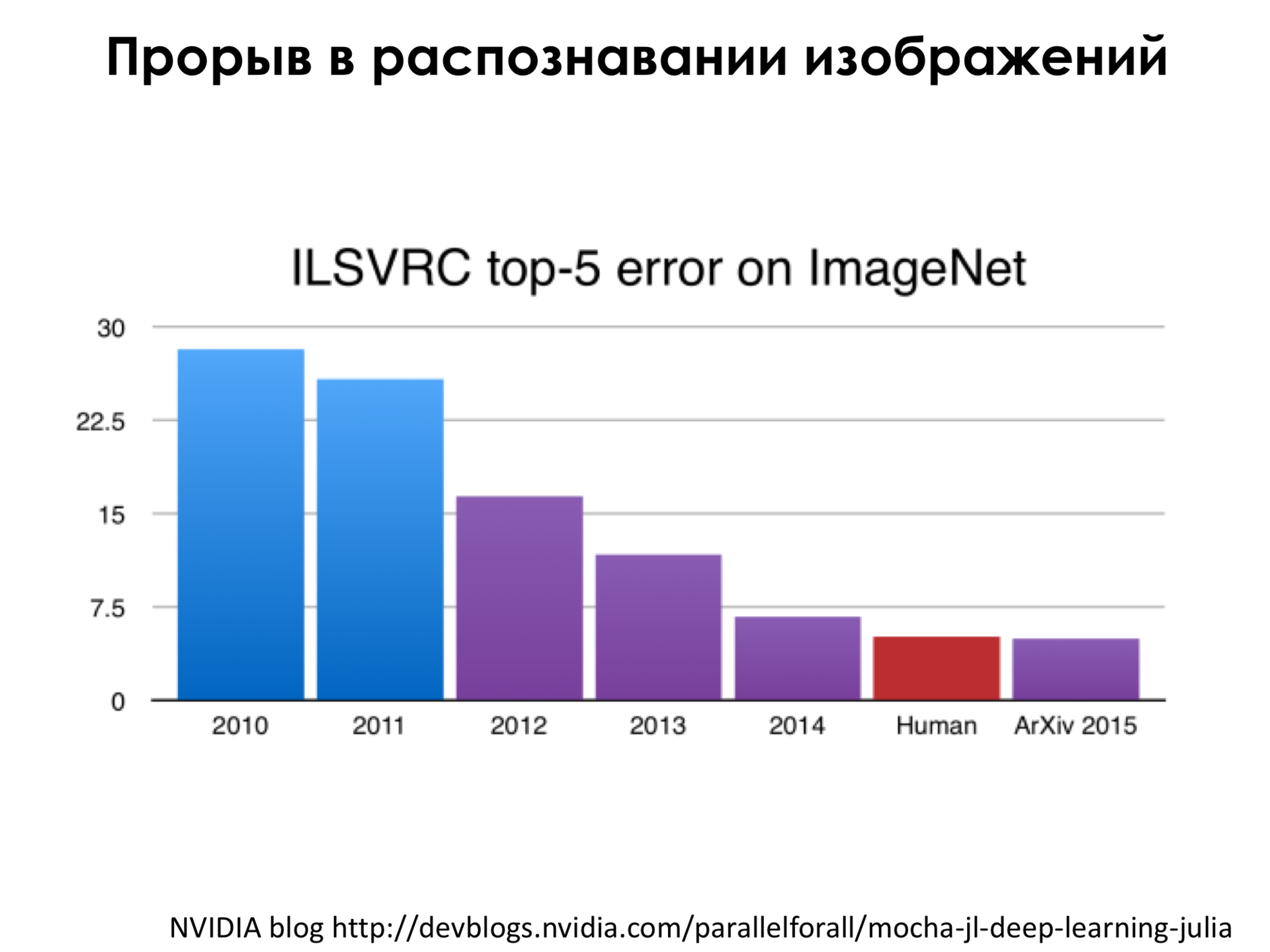
Основной метрикой ошибки на этой базе является так называемая Топ-5 ошибка. Это когда мы берем Топ-5 предсказаний, первые пять предсказаний нашей сети, в которых она наиболее уверена, и если правильный класс из разметки попал в эти пять предсказаний, то мы говорим, что сеть права. И ошибка – это когда у нас в первые пять предсказаний не попал правильный класс. И до эры нейронной сети (это 2010-2011 год, это до эры сверточных нейронных сетей) мы видим, что ошибка, конечно, уменьшалась, была чуть ниже 30%, а в 2011 году еще чуть ниже, но, например, в 2012 году, когда впервые применили сверточную нейронную сеть к этой задаче, оказалось, что мы можем снизить ошибку радикально, то есть все остальные методы были на это неспособны, а нейронная сеть была на это способна, и дальше по мере роста интереса к нейронным сетям оказалось, что мы можем снизить эту ошибку – это сейчас будет некоторая спекуляция – на уровень, которого может достичь человек на этой базе. Было проведено некоторое исследование, оно было не очень глобальное, там было пять человек, которые несколько дней готовились распознавать подобного рода изображения, и у них получилась ошибка где-то в районе 4,5% на этой выборке, и нейронная сеть на момент весны или лета 2015 года этот рубеж побила, что всех очень поразило, было очень много новостных заметок по этом поводу, и так далее.

То, о чем я говорил раньше, что глубина этой сети, то есть количество этих функций, которые мы последовательно применяем к входному изображению, имеет значение. Например, в 2013 году победила такая сеть, которая имела порядка, по-моему, 8 или 9 слоев последовательного преобразования изображения. А, например, в 2014 году победила такая сеть, в которой очень много слоев и архитектура в целом значительно сложнее, но главное, что она глубже, то есть это означает, что мы больше применяем нелинейности к нашему входному изображению, и за счет этого мы получаем прорыв в качестве.

Для чего все это нужно? Не только распознавать изображения, но и как мы можем применить это на практике? Например, так как мы с вами уже знаем, что на каждом слое мы получаем некоторые новые признаки, то мы можем взять с какого-нибудь одного из последних слоев нейронной сети выходы и считать что-то, допустим, это некоторые новые признаки изображения, и искать похожие изображения на основе этих признаков, то есть, грубо говоря, попробовать найти изображения с такими же признаками, как у входного. Например, есть такая картинка, ребята играют в баскетбол, NBA, все дела, и мы хотим найти похожие изображения.
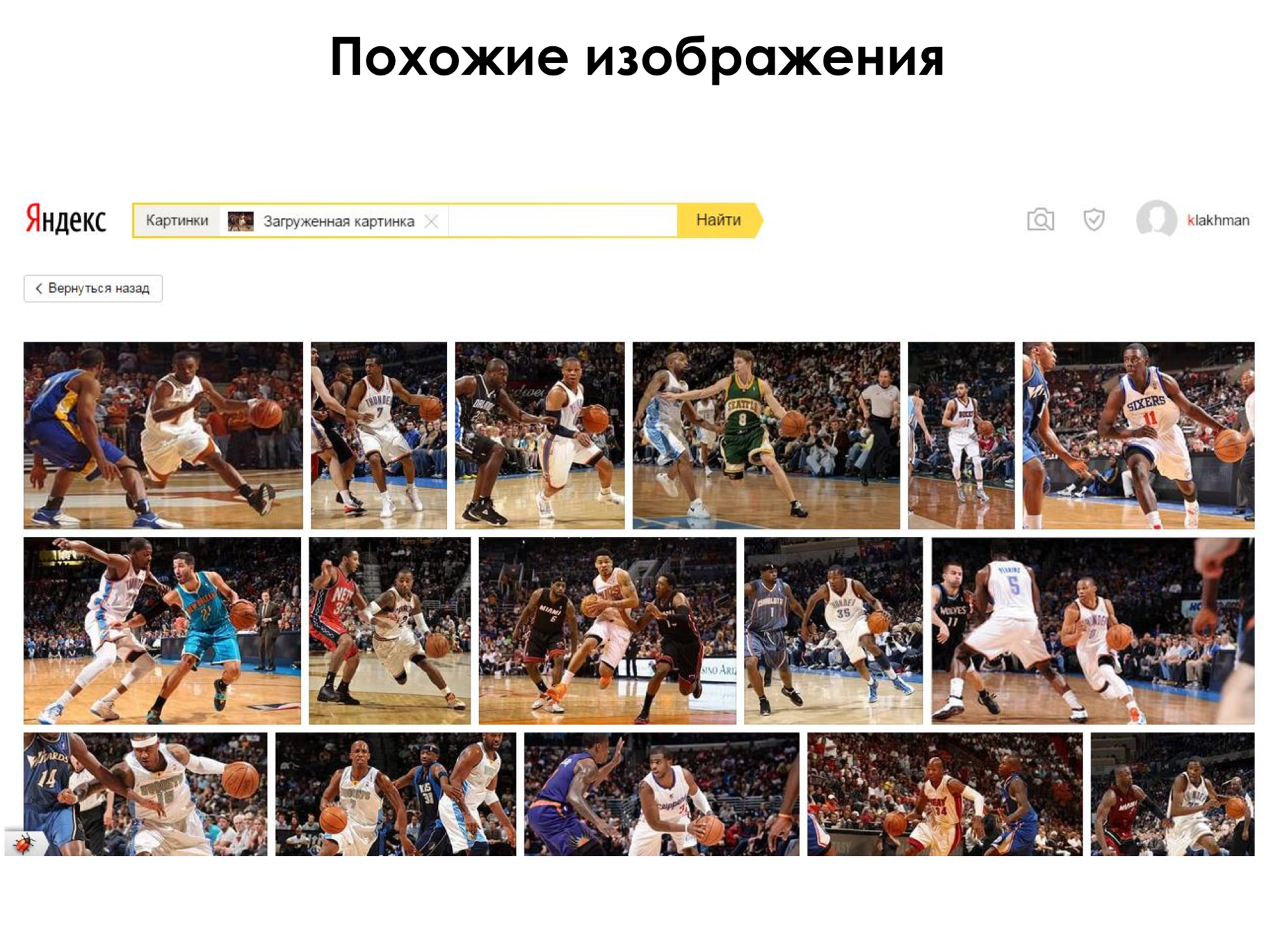
Кидаем эту картинку в сервис похожих изображений и, действительно, находим другие изображения. Это другие игроки, другие команды. Но мы видим, что все они относятся к тому, как игрок ведет мяч на площадке.

На самом деле, у того, о чем я сейчас рассказываю – у алгоритмов компьютерного зрения – есть очень много применений, но есть также очень много применений в реальном мире, такие, как поиск таких изображений, распознавание. Но есть очень много и анекдотичных применений. Например, группа исследователей попробовала взять достаточно простую картинку, она здесь слева в верхнем ряду изображения, и научить сеть стилизовывать это изображение под картины разных великих художников, таких, как Пабло Пикассо, Кандинский, Винсент Ван Гог. Фактически они подавали на вход обычные изображения и картину и говорили, что «Мы хотим, чтобы, с одной стороны, выходное изображение было похоже на исходное, но также чтобы в нем присутствовал некоторый стиль этого художника». И, как мы видим, оно достаточно интересным образом преобразует картинки. И, с одной стороны, мы можем узнать исходное изображение, а также черты автора. Как видите, большинство статей, про которые рассказываю, – это где-то 2014-2015 год, и вы тоже можете зайти и посмотреть более подробно.
Рекуррентные нейронные сети
В последний год приобретают популярность другие модели нейронных сетей: не сверточные, которые мы применяем к изображениям, а так называемые рекуррентные модели нейронных сетей. Что это такое?
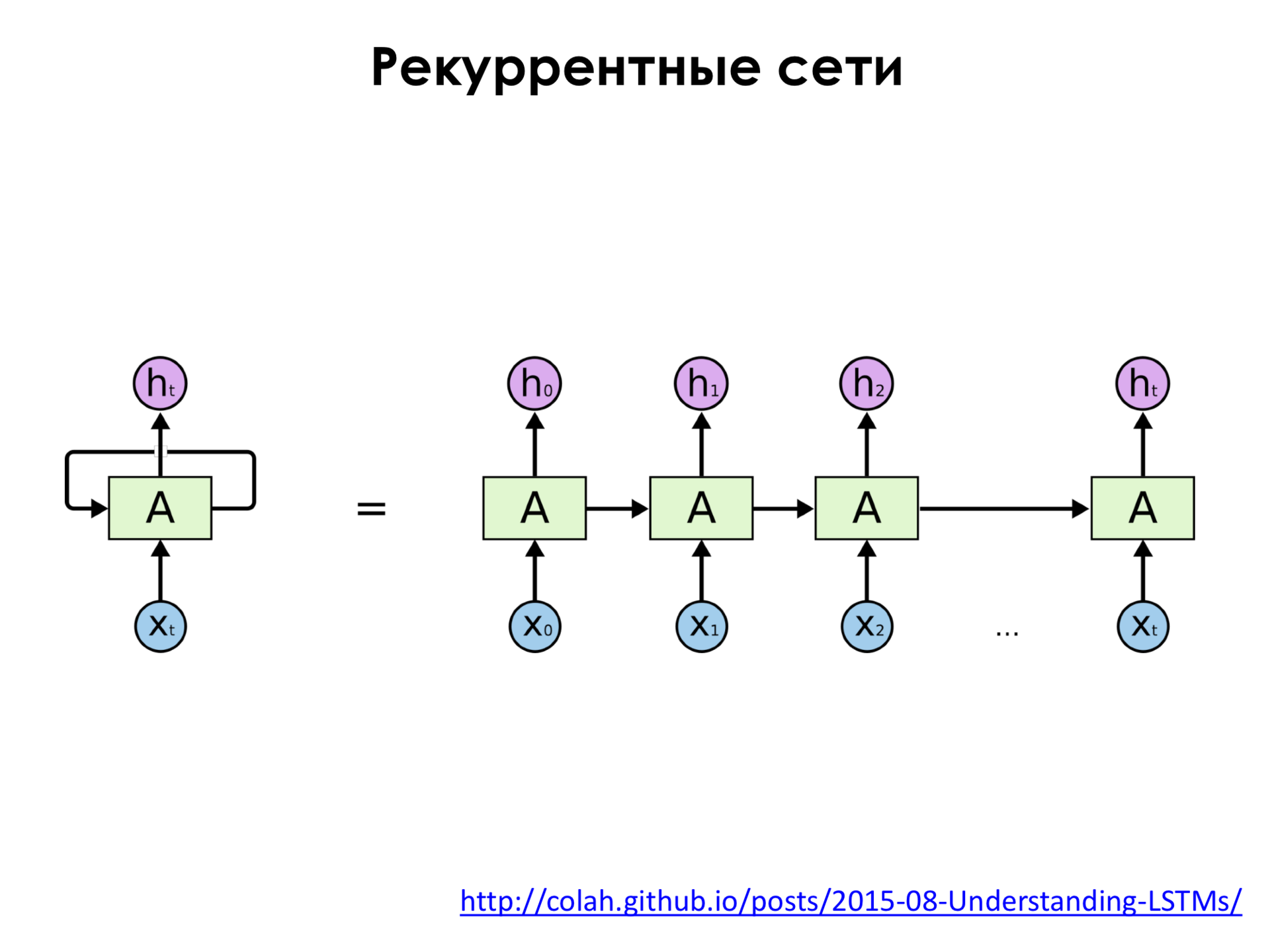
Обычно такая сеть – сеть прямого распространения – не имеет в себе никакой памяти. То есть, допустим, мы подали изображение на эту сеть, она что-то распознала, мы подали следующее изображение, и она ничего про предыдущее изображение уже не помнит. То есть она никак не связывает последовательность изображений между собой. Во множестве задач такой подход не очень применим, потому что если мы, например, возьмем какой-нибудь текст, допустим, текст на естественном языке, какая-нибудь глава книжки, то этот текст состоит из слов, и эти слова образуют некоторую последовательность. И нам бы хотелось, чтобы мы, например, подавали это слово на сеть, потом подавали на следующее слово, но чтобы она не забыла про предыдущее слово, чтобы она помнила про него, помнила, что оно было, и анализировала каждое следующее слово с учетом предыдущей истории. И для этого существуют рекуррентные нейронные сети. Как здесь видно, кроме того, что у нас есть путь от входных признаков к некоторому выходу нейронной сети, мы также учитываем сигналы из этих внутренних слоев с предыдущих временных шагов, то есть мы как бы запоминаем информацию, подаём её на вход опять самим себе. И такую рекуррентную нейронную сеть можно развернуть.
Справа – это просто развертка по времени. x0, x1, x2 и так далее. И сеть еще помнит свое предыдущее состояние. И то, как она анализирует каждый входной объект, зависит не только от этого объекта, но и от предыдущей истории.

Для чего это применяется? Одно из интересных применений – например, мы хотим генерировать тексты просто по букве. Допустим, мы сначала инициализируем эту сеть некоторой последовательностью, например, словом, и дальше хотим, чтобы на каждом следующем временном шаге она нам выплевывала просто букву, то есть какую следующую букву она хочет написать. Это статья в LaTeX, которая позволяет одновременно писать, то есть это такой язык программирования для написания статей по большому счету. Если натренировать сеть таким образом и позволить ей генерировать текст, то получаются осмысленные, по крайней мере, слова. То есть слова она не путает. Кажется, что даже синтаксис предложений тоже получается осмысленным. То есть у нас есть глагол, есть подлежащее, сказуемое в английском языке, но семантика этих предложений, то есть их смысл, не всегда присутствует. Вроде с точки зрения построения все выглядит хорошо, а смысла там бывает иногда немного. Но это очень простая модель, она генерирует по одному символу за проход. И, например, она еще даже пытается рисовать какие-то диаграммы здесь справа наверху. Так как язык разметки LaTeX позволяет не только писать, но и рисовать, то она пытается еще что-то рисовать.

Или, например, мы можем непосредственно генерировать исходный код программ. Эта сеть была обучена на исходном коде ядра операционной системы Linux, и мы можем видеть, что, кажется, она генерирует, по крайней мере, похожий на осмысленный код. То есть у нас есть, например, функции, есть разные условные выражения, циклы и так далее. Кажется, что это выглядит осмысленно. Скоро сети будут сами писать за нас программы, кажется, но, я думаю, что до этого еще далеко, и программисты будут нам еще нужны, не только сети.

Оказывается, что тренировать такие рекуррентные сети, если мы будем просто представлять их так слоями нейронов, достаточно сложно. Сложно потому, что они очень быстро забывают информацию о предыдущих объектах, которые мы им подавали до текущего. А иногда нам нужно, чтобы они помнили взаимосвязи между объектами, которые очень отдалены на расстоянии. Допустим, если мы себе представим «Войну и мир», чудесное произведение Льва Толстого, то там некоторые предложения занимают по несколько строчек. И я помню, что когда я их читал, то к концу предложения я уже забывал о том, что там было вначале. И такая же проблема наблюдается у рекуррентных сетей, они тоже забывают, что было в начале последовательности, а не хотелось бы. И для этого придумали более сложную архитектуру. Здесь важно то, что у нас в центре есть один нейрон, который подает свой выход себе же на вход. Мы видим такую рекуррентную связь. Кроме всего прочего у нас есть еще отдельные нейроны, которые контролируют, они являются вентилями, то есть определяют, нужно ли нам воспринимать текущую входящую информацию. Есть вентиль на входе, то есть у нас есть некоторый вход, и мы определяем, нужно его пропустить дальше или не нужно. Или нам нужно его игнорировать и просто сохранить свои воспоминания. Точно также здесь есть вентиль на воспоминания: стоит ли нам сохранять наши воспоминания в текущий момент времени о предыдущих, или нам стоит их обнулить и сказать, что мы стираем нашу память.
— Откуда берется число нейронов, и что они из себя представляют?
— Нейрон – это просто такой сумматор, у которого есть какие-то входы и есть веса, с которыми он их взвешенно суммирует. Это очень простой элемент.
А количество – это хороший вопрос, вопрос экспериментального подхода. В разных задачах нам может быть необходимо разное число слоев этих нейронов и разное количество нейронов в слоях. Это очень сильно зависит от задачи. Каждый раз, когда вы сталкиваетесь с какой-то задачей, которую вы хотите решить с помощью нейронных сетей, нужно провести какое-то количество экспериментов, чтобы понять, что, если у вас 100 нейронов – этого недостаточно. Она плохо обучается, высокая ошибка на обучающем множестве, надо больше нейронов. Например, 100 тыс нейронов – слишком много, у нас нет таких вычислительных ресурсов, чтобы все обсчитать, ее обучить. Она переобучается на множестве. Поэтому правда где-то посредине. Давайте возьмем 50 тыс., например, и получим оптимальное качество распознавания.
Подобные сети, которые могут контролировать вентилями, нужно ли воспринимать текущий вход и нужно ли забывать некоторую память, которая у нас на текущий момент есть, они сейчас и применяются. И типичная архитектура такой сети выглядит следующим образом.
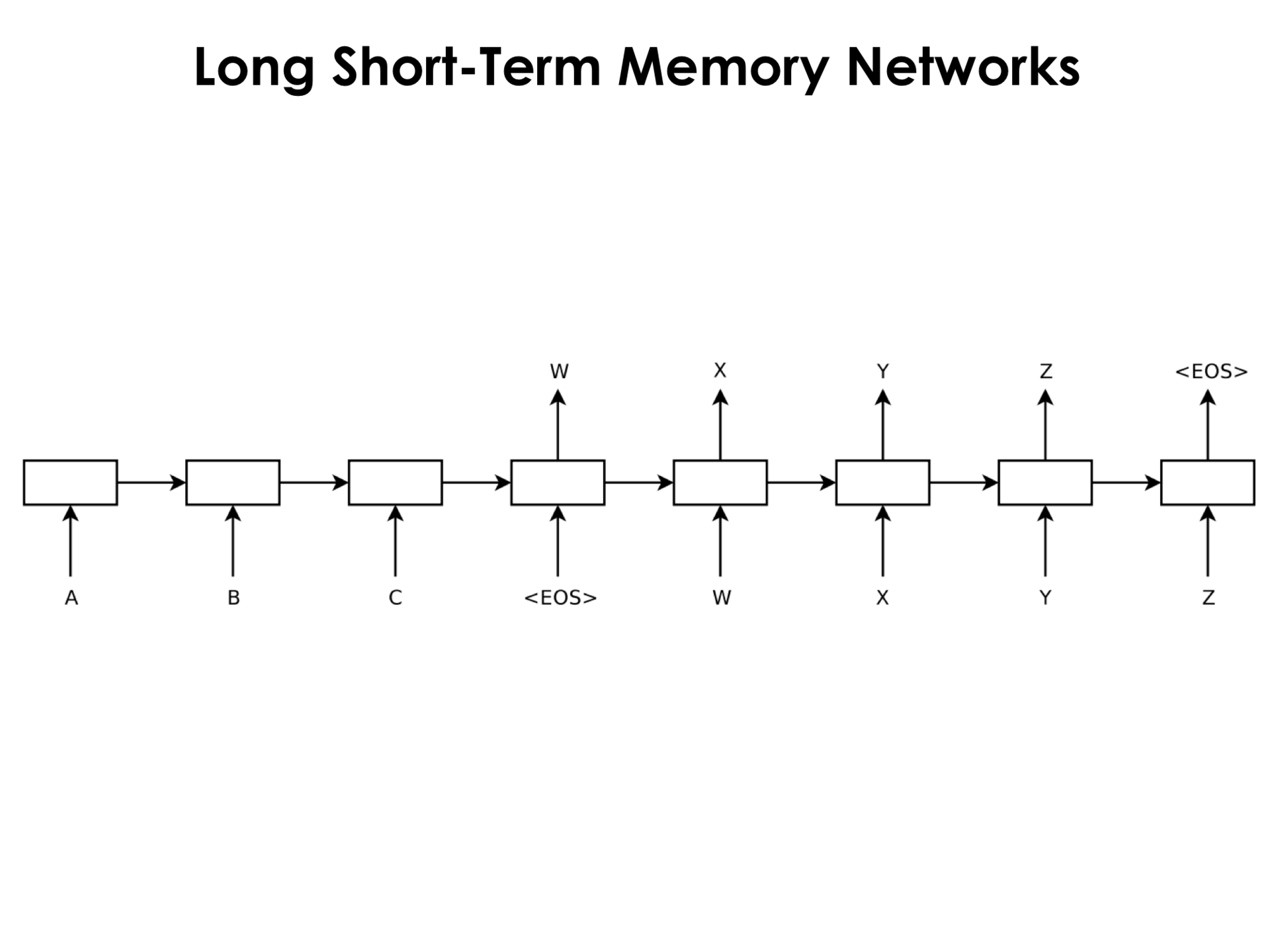
У нас на вход этой сети подается входная последовательность, например, некоторые предложения, и на выходе мы тоже можем с помощью такой же рекуррентной сети генерировать слова. То есть мы сворачиваем входящую последовательность и генерируем выходящую последовательность.
Для чего это нужно? Применений очень много, поэтому я про все из них не буду рассказывать. Одно из применений, которые активно исследуются, – это, например, перевод. То есть на входе у нас предложение из одного языка, например, из русского, а на выходе мы пытаемся сгенерировать перевод этого предложения на другой язык, например, на английский. Другое приложение немножко фантастическое – это когда у нас есть некоторая статья, которую нам написал какой-то журналист, а мы хотим некую краткую выжимку из этой статьи, abstract. И мы подаем на вход этой сети всю эту статью, а дальше она нам некоторое краткое содержание этой статьи выплевывает на выводе.

Или, например, мы можем обучить некоторую систему, которая будет вести диалог и разговаривать с ней. Например, мы можем взять большие логи общения людей с командой техподдержки, то есть людей, которые решают некоторые проблемы пользователя, связанные с IT, натренировать такую сеть и попробовать пообщаться с ней. Например, здесь у пользователя возникла проблема, что он не может подключиться по сети к удаленному терминалу, и пользователь спрашивает, что ему делать, и машина пытается решить его проблему. Она сначала пытается понять некоторые входные данные, то есть какая операционная система у пользователя, что он видит на экране, пытается проводить разные диагностические тесты и предлагает какие-то решения. И все это сделано с помощью этой простой сети, которая состоит просто из взвешивания различных входов, которые ей подаются на вход. Здесь нет никаких тайных знаний, или люди не сидели долго-долго и не думали, что «Давайте попробуем как-нибудь, если у нас есть одно слово в начале предложения, другое слово в конце, как бы нам их связать, проанализировать?». Нет, все это подали на нейронную сеть, она обучилась и генерирует такие замечательные диалоги с человеком.

В конце концов, нейронная сеть решает проблему человека. Она ему говорит, что нужно получить другой сертификат, еще что-то, ввести пароль, и человек остается доволен.
Сверточные + рекуррентные сети
Мы можем попробовать связать сверточные сети с рекуррентными. Я рассказывал отдельно про одни, отдельно про другие, но мы можем попробовать их связать.

Например, задача «картинка в текст». Допустим, у нас есть картинка на входе, и мы применяем сверточную нейронную сеть, чтобы получить некоторое сжатое представление этой картинки, некоторые признаки. Дальше мы подаем эти признаки на вход рекуррентной сети, и она нам генерирует описание этого изображения. Допустим, три года назад такое казалось просто невозможным, а сейчас нейронные сети просто описывают изображение, что на них изображено, какие объекты. И не просто говорят, что на картинке есть такой объект, а описывают это связным предложением.
Здесь должно быть еще одно видео. Оно называется «Прогулка с нейронной сетью». Оно было опубликовано буквально недели две-три назад. Один из поклонников нейронных сетей, назовем его так, решил применить технологию «картинка в текст», просто пройдясь по своему родному городу Амстердаму с телефоном и снимая что-то на камеру, и пытался понять, что же сеть будет говорить на предметы окружающего мира. То есть не на те картинки в академических коллекциях, которые, возможно, не очень близки к реальности, а просто снимая то, что вокруг него происходит. Здесь будет не очень хорошо видно, но я надеюсь, что мы увидим.
Здесь слева наверху ответ сети на то, что она видит. Это она говорит «какой-то человек в кофте». Генерирует какие-то фразы. Здесь она говорит, что это какой-то знак, она не понимает, что на нем написано, но она понимает, что это знак. Говорит, что это человек гуляет по улице, какие-то здания вокруг, окно или дверь, переулок, говорит, что много велосипедов (но это Амстердам, там много велосипедов, поэтому она часто говорит, что везде велосипеды). Говорит, что припаркована белая лодка. И так далее. Я бы не сказал, что это специально подготовленное изображение, человек просто ходит и снимает, и в реальном времени получается, что нейросеть справляется с распознаванием того, что человек снимает.
— А с какой скоростью она это распознает? А если человек бежит, а не идет, как быстро она понимает?
— Мне кажется, просто частота кадров задана.
— Да. На самом деле, я вас немножко обманул, потому что, насколько я помню, это видео было снято с постобработкой, то есть он его снял, а потом прогнал уже локально на компьютере через распознавание этой сети. Но сейчас в очень многих мобильных телефонах есть графические видеокарточки, которые есть в компьютере, только они меньше, менее мощные, но более мощные, чем процессоры. И в целом можно практически с какой-то дискретизацией кадров в режиме реального времени что-нибудь распознавать какой-нибудь небольшой сетью, даже когда вы бежите, то есть пытаться это делать. В целом это возможно, и я думаю, что этот вопрос будет менее актуален еще через несколько лет, потому что, как мы знаем, вычислительные возможности растут, и, наверное, когда-нибудь станет возможным в режиме реального времени с самыми большими сетями что-нибудь распознавать.
— На деле смысл этой технологии распознавания по картинке? То есть я сам вижу.
— Тут мне подсказывают — для людей с ограниченными возможностями это имеет большой смысл. Во-вторых, представьте себе, как происходит поиск по изображениям в Интернете. Как?
— Вы рассказывали, по этим самым.
— Это поиск похожих изображений. А, например, если вы зайдете на какой-нибудь сервер типа «Яндекс.Картинки»…
— По ключевым словам.
— Да. И в этот момент, если мы можем генерировать эти ключевые слова из картинки, то поиск будет просто более качественным. То есть мы можем находить картинки… Сейчас поиск по картинкам в большинстве своем идет по прикартиночным текстам. То есть вокруг картинки есть какой-то текст. Когда мы кладем картинку в наш индекс, то говорим, что у нас у картинки такой текст. Когда пользователь вводит запрос, то мы пытаемся сопоставлять слова и запросы со словами в тексте. Но прикартиночный текст – это очень сложная штука, она бывает не всегда релевантна картинке, рядом с которой она расположена. Очень многие людей пытаются оптимизировать свой заработок в Интернете, например, или еще что-то такое, и поэтому это не всегда надежная информация.
А если мы сможем надежно говорить, что на картинке, то это будет очень полезно.

В том видео были достаточно сухие и короткие описания, то есть мы говорили, что «Вот лодка припаркована где-то» или «Вот груда велосипедов лежит на асфальте», но мы можем натренировать сеть немножко другой выборке, например, на выборке приключенческих романов, и тогда она будет генерировать очень живые описания к любым картинкам. Они будут не совсем релевантны этим картинкам, то есть не до конца, но, по крайней мере, они будут очень смешные. Например, здесь человек просто спускается на лыжах, и сеть говорит о том, что был такой человек, который жил сам по себе, и он не знал, как далеко он может зайти, и он гнался, не показывал никаких признаков слабости. То есть такой приключенческий роман по одной картинке. Это сделала тоже группа исследователей в ответ на то, что говорили, что «У вас какие-то очень сухие предсказания по картинке, как-то сеть не жжет». Но сделали так, чтобы сеть генерировала интересные описания.

Здесь тоже, если прочитать, то целая драма о том, как человек садился в автобус, пытался куда-то доехать и потом менял маршруты, садился на машину, оказывался в Лондоне, и так далее.

Вообще-то мы можем поменять эти два блока в нашей архитектуре и сказать, что «А давайте мы сначала поставим на первое место рекуррентную сеть, которая будет воспринимать слова, а потом некоторое подобие сверточной сети, которое будет не сжимать наше изображение, а наоборот, разжимать его». То есть есть какой-то вектор признаков в каком-то пространстве, а мы по этому вектору признаков хотим сгенерировать изображение. И один мой коллега в «Яндексе» сказал, что «Будущее, оно здесь, только пока слегка размытое». И будущее действительно здесь, но слегка размытое. Здесь можно видеть, что мы генерируем изображение по описанию. Например, слева вверху желтый автобус припаркован на парковочное место. Здесь цвета сложно воспринимаются, к сожалению, но, тем не менее, если мы заменим, например, слово «желтый» на слово «красный» в этом же предложении, то действительно поменяется цвет этого пятна, которое представляет из себя автобус, то есть он станет красным. И то же самое, если мы зададим, что это зеленый автобус, то это пятно станет зеленым. Он действительно чем-то похож на автобус.
Здесь представлено то же самое, что если мы будем менять не только цвет, но и сами объекты, например, «шоколадка лежит на столе» или «банан лежит на столе», то мы непосредственно не задаем цвет объекта, но понятное дело, что шоколадка обычно коричневая, а банан обычно желтый, и поэтому, даже напрямую не задавая цвет объекта, наша сеть меняет некоторую цветность изображения.

Это примерно то же самое, о чем я говорил раньше. Например, стадо слонов гуляет по выжженному полю, по полю с сухой травой. И сухая трава обычно бывает оранжевой, а зеленая трава обычно бывает зеленой. И здесь видно, что какие-то существа, не очень различимые, гуляют по чему-то зеленому, а здесь по чему-то оранжевому. Обычно этих существ больше одного. Если встретимся с вами через год или через полгода, то мы сильно продвинемся в этой области вперед.
Нейронные сети + обучение с подкреплением
О чем я бы хотел рассказать в завершение – это очень интересная тема «Связка нейронных сетей с обучением с подкреплением». Кто-нибудь из вас читал, что такое обучение с подкреплением?
— В психологии есть такое.
— На самом деле это связано с психологией. Область «связка нейронных сетей с обучением с подкреплением» — это самая относящаяся к биологии и психологии область исследования нейронных сетей.

Представим себе, что у нас есть мышка и есть лабиринт. И мы знаем, что в концах этого лабиринта лежит сыр, вода, морковка и ничего в одном из концов лабиринта. И мы знаем, что каждый из этих предметов обладает некоторой полезностью для нашей мышки. Например, мышка очень любит сыр, но меньше любит морковку и воду, но любит их одинаково, а ничего она совсем не любит. То есть если она придет к концу лабиринта и не увидит ничего, то она будет очень расстроена.
Представьте себе, что у нас в этом простом лабиринте есть всего три состояния, в которых может находиться мышка – это S1. В состоянии S1 она может сделать выбор – пойти налево или пойти направо. И в состоянии S2 и S3 она тоже может сделать выбор пойти налево или пойти направо.
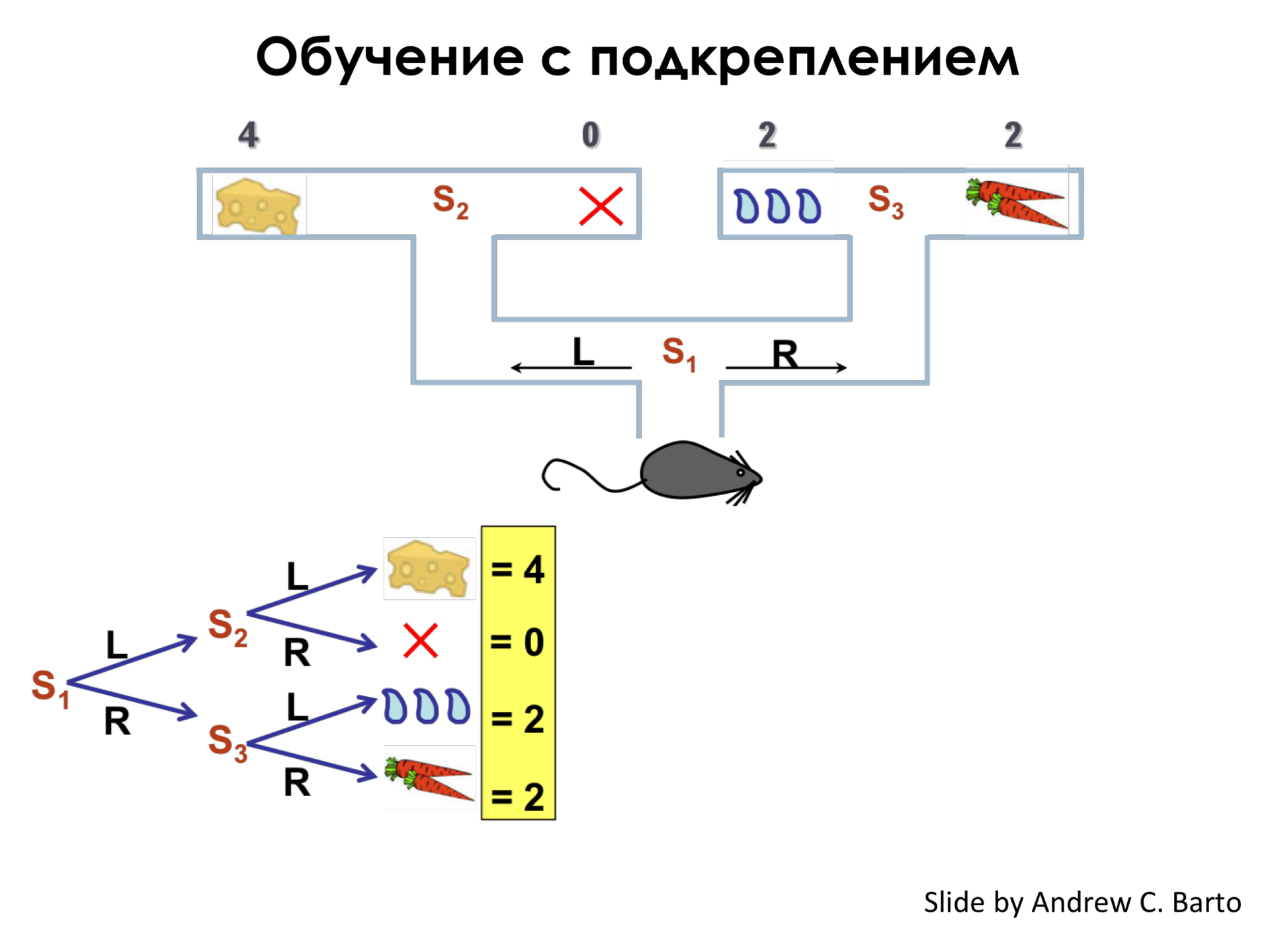
Мы можем задать такое чудесное дерево, которое говорит нам, что если мышка два раза пойдет налево, то она получит некоторую ценность, равную четырем условным единицам. Если она пойдет направо, а потом уже неважно, налево или направо, после того как первый раз она сходила направо, а получит ценность двойки.

И задача обучения с подкреплением в этом простейшем случае состоит в построении такой функции Q, которая для каждого состояния S в нашем лабиринте или в какой-то нашей среде будет говорить: «Если ты совершишь это действие, – например, пойдешь налево, — то ты сможешь получить такую-то награду». Нам важно, чтобы в состоянии S1, когда мы еще не знаем, что будет впереди, чтобы эта функция говорила, что «Если ты пойдешь налево в этом состоянии, ты сможешь получить награду 4». Хотя, если мы из S1 перейдем в S2, то мы можем получить и награду 0. Но максимальная награда, которую мы можем получить при правильной стратегии поведения, – это 4.

В этой формуле это и отображено. Представим себе, что для некоторого из состояний мы знаем для всех следующих состояний, в которые можно попасть из этого, оптимальную награду, то есть мы знаем оптимальную политику поведения. Тогда для текущего состояния мы очень легко можем сказать, какое действие нам надо совершать. Можем просто просмотреть все следующие состояния, сказать, в каком из следующих состояний мы приобретаем наибольшую награду – представим себе, что мы ее знаем, хотя это не так на самом деле, — и сказать, что нужно идти в то состояние, в котором ожидаемая награда больше.

Есть алгоритм этой функции, потому что мы же не знаем для следующих состояний оптимальную политику поведения.

И этот алгоритм достаточно простой, он итеративный. Представим себе, что у нас есть эта функция Q ( s, a).

У нас есть ее старое значение, и мы хотим некоторым образом ее обновить, чтобы она стала более правильно оценивать текущий реальный мир.

Что мы должны сделать? Мы должны для всех следующих состояний оценить, где мы наибольший максимум можем заработать, в каком из следующих состояний. Вы видите, что здесь это еще не оптимальная оценка, это просто какое-то приближение этой оценки. А это разница между оценкой награды в текущем состоянии и в следующем. Что это означает?
Представим себе, что у нас в каком-то состоянии нашей среды, например, возьмем просто, что это какой-то лабиринт, притом с такими клеточками, то есть мы находимся здесь в этом состоянии и мы хотим найти эту функцию Q (S, up), то есть найти, сколько мы сможем приобрести этой полезности, если пойдем наверх.
И, допустим, в текущий момент времени эта функция у нас равна трем. А в этом состоянии S, в которое мы переходим после того, как вышли из S, представим себе, что если мы возьмем maxa' Q(S',a'), то есть возьмем максимум, сколько мы можем получить из этого состояния S, оно равняется 5, например. У нас явно некоторая нестыковка. То есть мы знаем, что из этого состояния мы можем получить награду 5, а в этом состоянии мы почему-то этого еще не знаем, хотя если мы пойдем наверх, то мы сможем получить эту награду 5. И в таком случае мы пытаемся эту нестыковку устранить, то есть берем разницу между Q (S, up)=3 и max(a')? Q(S',a')=5 и, таким образом, на следующей итерации увеличиваем ценность этого действия в том состоянии. И так итеративно мы учимся.
Для чего все это надо? В этой задаче, к которой нейронные сети не имели никакого отношения изначально, это было обучение с подкреплением, где тоже использовались классические методы обучения, можно также их применить.

У нас есть игры Atari. Я не уверен, что кто-нибудь из вас в них играл, потому что даже я в них не играл. Я в них играл, но уже во взрослом возрасте. Они самые разные. Самая известная из них, которая слева внизу расположена – это называется Space Invaders, это когда у нас есть некоторый шаттл, на нас надвигается группа жёлтых инопланетных захватчиков, а мы такая одинокая зеленая пушка, и мы пытаемся всех этих желтых захватчиков отстрелить и таким образом выиграть.
Есть совсем простые игры, как «Пинг-понг», когда нам надо пытаться не упустить мяч у своей половины и сделать так, чтобы соперник упустил мяч на своей половине.
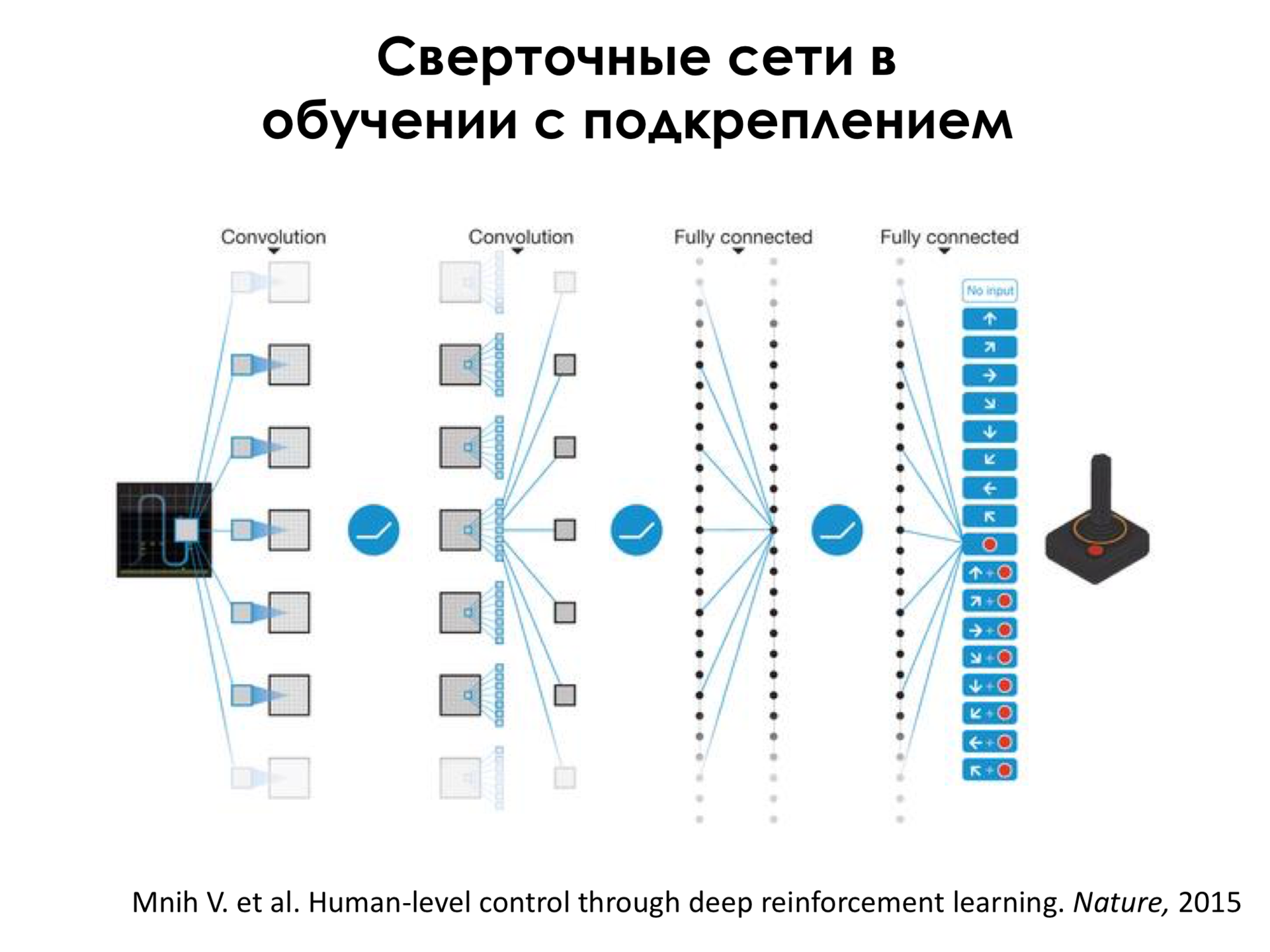
Что мы можем сделать? Мы можем опять взять сверточные нейронные сети, подать на вход этим сверточным нейронным сетям изображение игры и на выходе попробовать получить не класс этого изображения, а что мы должны сделать в этой игровой ситуации, то есть как мы должны поступить: уйти налево, выстрелить, ничего не делать и так далее.
И если мы сделаем такую достаточно стандартную сеть, то есть тут сверточные слои, слои просто с нейронами, и обучим ее, запустим ее в этой среде – а в этой среде надо правильно понимать, что у нас есть счет, и этот счет как раз и является наградой, — если мы запустим в этой игре и дадим ей немного обучиться, то мы получим систему, которая может, как я покажу дальше, даже обыгрывать человека.
То есть они сейчас на уровне, значительно превышающем топового человека, который играет в эту игру. И мы видим, что эта игра не очень простая, здесь нужно скрываться за этими красненькими штучками. Они защищают нас. И когда мы видим, что в нас летит бластер, то лучше уворачиваться, скрываться за ними, потом вылезать обратно и продолжать отстреливать эти жёлтые пиксели наверху. Выглядит не очень впечатляюще, я чувствую. Но, на самом деле, чтобы добиться такого прорыва, потребовалось достаточно много работы. И я попытаюсь рассказать, почему это действительно впечатляюще.
Еще до применения нейронных сетей в этой задаче существовало множество методов, которые создавались специально под каждую из этих игр, и они очень хорошо работали. Они тоже иногда обыгрывали человека и так далее. Но, как и с областью распознавания изображений, людям приходилось очень много работать, чтобы придумать те или иные выигрышные стратегии в этой игре.
Они брали каждую игру, например, Space Invaders или «Пинг-понг», долго думали, как нужно двигаться, придумывали какие-то признаки, говорили, что если мяч летит под таким углом и с такой скоростью, то мы должны развить такую скорость, чтобы принять его на противоположной стороне и чтобы он еще отскочил неудобно для противника. И так далее. И для каждой игры это приходилось придумывать отдельно. А теперь они взяли вообще одну и ту же архитектуру нейронной сети, запустили ее в разные игры, и на всех этих играх эта одна архитектура, правда с разными весами – в каждой игре были разные веса, но одна и та же архитектура – ей удалось обыграть практически большинство всех этих методов, которые придумывались на протяжении 10–20 лет.
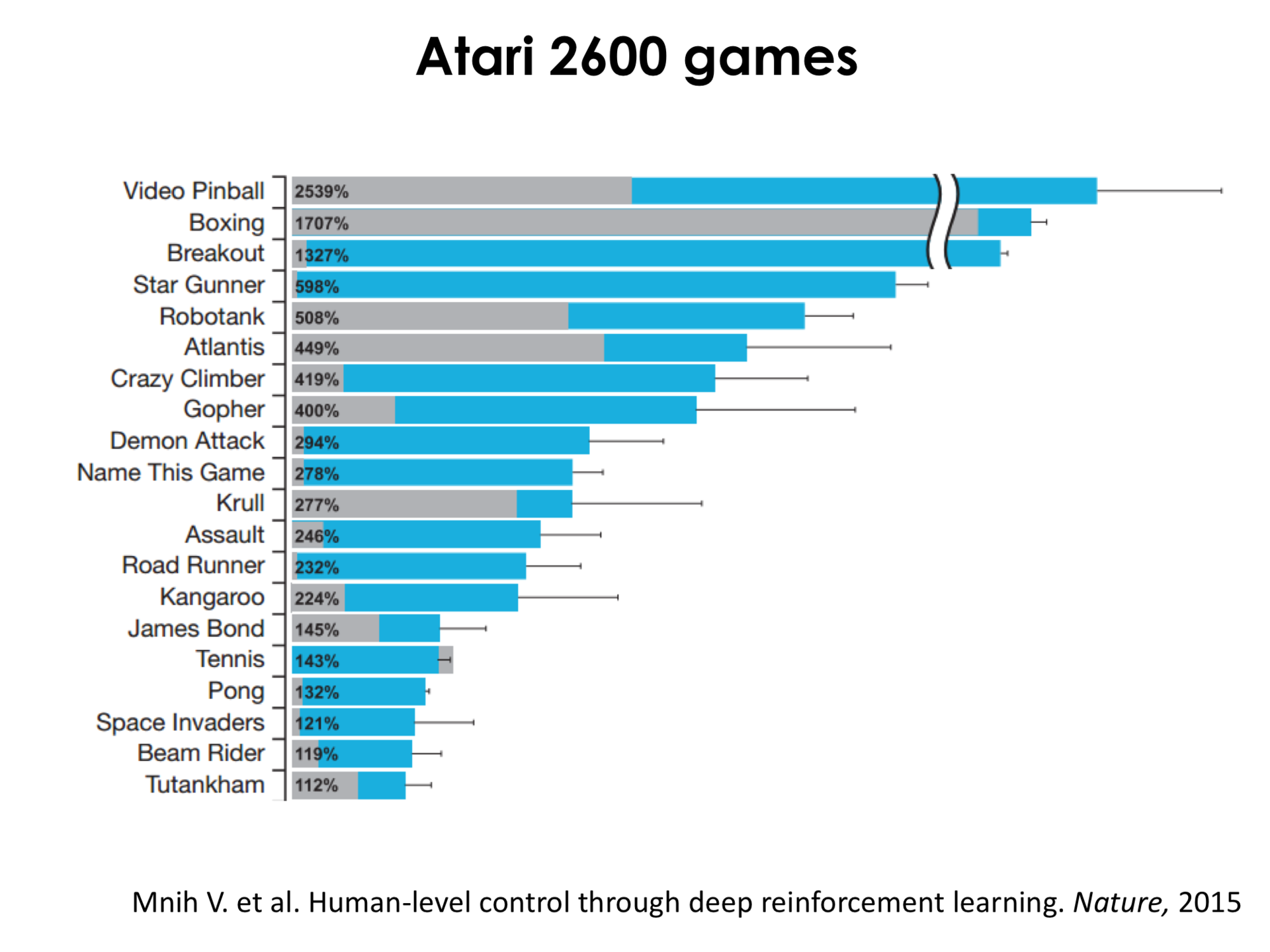
Здесь синее – это, грубо говоря, какое количество очко набирает нейронная сеть, серенькое – это state of the art может до нейронных сетей, а процентики в столбиках – это то, на сколько процентов нейронная сеть играет лучше, чем человек. То есть мы можем видеть, например, что в пинбол нейронная сеть играет на 2500% лучше, чем человек. В бокс, в самые разные игры, гонки, теннис, пинг-понг, даже в Space Invaders нейронная сеть играет лучше, чем человек. Притом надо понимать, что Space Invaders – это очень сложная игра. Если мы тут посмотрим, то она здесь находится, и это серенькое – это state of the art, который был до этого, грубо говоря. Скажем так, что он был очень плохой. Это означает, что эта игра очень сложная, и с помощью нейронных сетей можно не только обойти его, но и обойти человека.
На самом деле, я показываю только верхнюю часть этой диаграммы, там еще внизу есть некоторая часть этой диаграммы, где по убывающей идет успех нейронной сети, но сейчас на большинстве игр Atari с новыми результатами сеть выигрывает у человека.
Конечно, есть очень сложные игры для сети, где нужно обладать памятью, про которую я говорил, и туда тоже можно применить рекуррентные сети, и тогда результаты значительно улучшатся.
Спасибо за внимание. Надеюсь, у вас остались вопросы.
Единственное, что я хотел сказать, что в Интернете безумное количество различных материалов про нейронные сети, очень много материалов в виде научных статей, которые, наверное, тяжеловато будет воспринять с нуля. Но, тем не менее, есть очень хорошие туториалы. Они в большинстве случаев на английском. Есть очень хороший курс Виктора Лемпицкого во взрослом ШАД. Есть, например, вторая ссылка – так называемый Hackers guide to Neural Networks. Это такой туториал без математики, только с программированием. То есть там, например, на языке Python показано, как делать простейшие сети, как их обучать, как собирать выборки и так далее. Есть очень много программных средств, в которых реализованы нейронные сети, и ими очень просто пользоваться. То есть вы, грубо говоря, просто создаете нейроны, создаете слои, из кирпичиков собираете нейронную сеть и дальше ею пользуетесь. И я вас уверяю, это по силам каждому из вас – попробуйте поэкспериментировать. Это очень интересно, весело и полезно. Спасибо за внимание.
Комментарии (15)

Shablonarium
07.08.2016 22:31-10Нет, ну как можно околонаучную статью строить на обывательских мифах!? Мыши не любят сыр более всего, он просто очень пахуч и легче ими обнаруживается!

Randl
08.08.2016 02:37+3Если бы ссылки под слайдами были бы кликабельными, было бы еще круче. Спасибо за отличный материал.

alexey_vv
08.08.2016 11:51Чет намудрили со сверточными сетями. Не так они работают
lookid
08.08.2016 14:16Большинство рокет-саенсовых областей работает по принципу динамического программирования:
1) Мы не знаем, как решать конкретно эту задачу.
2) Давай разобьем её на более мелкие.
3) Берем задачу поменьше.
4) goto 1)

hellpirat
08.08.2016 11:55+1Очень интересная статья, все время хочу попробовать, но вся эта математика пугает.
khrisanfov
08.08.2016 11:55С чего начать изучать машинное обучение программисту без серьезной мат. подготовки? В универе нейросети тяжело давались. Сейчас закончил изучать R, основы descriptive statistics и inferential statistics, куда дальше двигаться?
myrov_vlad
08.08.2016 18:39+11) Теоретическая подготовка (курсы или учебники).
2) Практиковаться при решении задач. Берете какую-нибудь задачу, которая вам интересна, и пробуете ее решить. Так же очень полезно участие в различных контестах (тот же http://mlbootcamp.ru/, недавно открыли задачи в режиме песочницы).
Прямо серьезная мат.подготовка нужна в случае, если вы будете разрабатывать новые методы, а для использования в прикладных задачах хватает базовой линейной алгебры, статистики и мат.анализа.

yorko
09.08.2016 00:33+1Начинайте, как и все, с курса Andrew Ng. После него захочется порешать какое-то соревнование на Kaggle. Потом наверняка захочется понимать, что же все-таки происходит, и тогда можно браться за Хасти и Тибширани — "The Elements of Statistical Learning".

artinn
08.08.2016 11:55Это классическая картинка из https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf. Автор тут не причем.
Shablonarium
Что за тупой троллинг? Это же нифига не мадагаскарская кошка! Автор не владеет материалом, лень было чтоли загуглить как выглядит настоящая мадагаскарская кошка?
Shablonarium
Там изображен лемур, он вхожит в отряд приматов и поэтому действительно ближе к обезьянам, чем к кошкам.
Laytlas
Безусловно, это самый важный аспект лекции, без которого она абсолютно теряет смысл!
Shablonarium
В и так не точном пересказе Лекуна изначально смысла было мало.А за ошибками и вообще почти не осталось.