Дело было так.
Одна маленькая организация государственных масштабов решила обновить во владении своем местном оборудование серверное. И обратились ее мужи к нашим доблестным менеджерам, мол, хотим мы серверов с дисками для сервисов наших важных. И узнали они от менеджеров о виртуализации заморской, отказоустойчивой да с кластеризацией.
Собственно, долго сказка сказывается, да быстро дело делается.
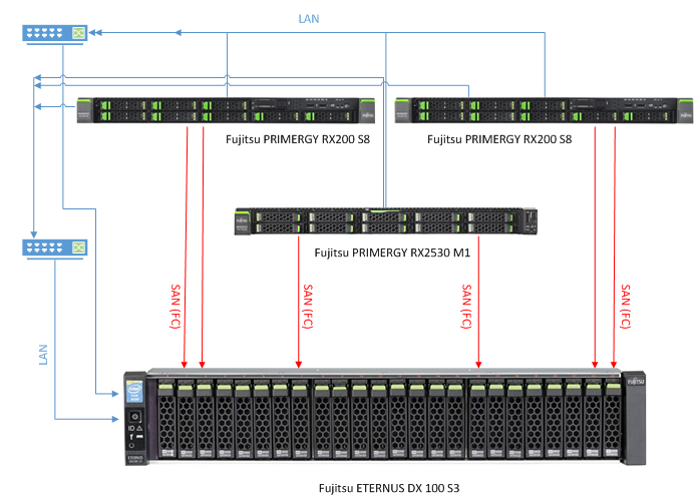
Так и появилась у организации той связка из двух серверов Fujitsu PRIMERGY RX 200 S8 и системы хранения данных ETERNUS DX 100 S3. И никто на тот момент не думал, что очень скоро ресурсов серверов тех не станет хватать. А наоборот, посчитали и были уверены, что хватит, и надолго. Но быстро машины виртуальные плодится стали и прожорливы они были да тучны. И тогда расширенно было пространство дисковое, а к двум RX 200 подселился брат их юный Fujitsu PRIMERGY RX2530 M1.
О подселении нового сервера в кластер, а также о добавлении в контроллерные блоки новых карт расширения с дополнительными FC-интерфейсами мы и расскажем. А вернее, о простоте, безопасности и удобстве всех этих и других инженерных манипуляций, которые возможны (в нашем случае) с виртуализацией VMware и оборудованием Fujitsu. Те, кто уже имеет СХД и ту или иную реализацию виртуализации серверов (или просто в теме) не удивятся и, наверное, не почерпнут ничего нового из этого текста. Но есть еще много организаций, где какие-либо действия с оборудованием, его перезагрузкой и остановкой вызывают ужас и заставляют скрупулезно планировать и минимизировать предстоящий downtime.
О системе хранения данных
Как известно, для того чтобы добавить или убрать какой-либо компонент (не поддерживающий «горячую» замену) в уже работающем устройстве, предоставляющем сервисы и постоянно обменивающимся данными, это устройство требуется выключить. В случае с сервером такая остановка неизбежна, в случае с современными СХД, имеющими два контроллера, все делается без остановок и пауз. Действительно, помимо отказоустойчивости посредством многопутевого ввода-вывода (MultiPathing – каждый из хостов (серверов) имеет по несколько каналов передачи данных от своих I/O портов к портам каждого из контроллеров СХД), современные системы хранения данных (в частности, речь идет о Fujitsu ETERNUS DX 100 S3) умеют распределять/распараллеливать передачу данных по этим каналам, уменьшая нагрузку на канал и увеличивая пропускную способность. Время простоя при отказе одного из каналов сведено к нулю (active / active режим) либо минимизировано при автоматическом переключении с активного (но «потерянного») канала на пассивный – «ожидающий» (active / passive режим). Собственно, эти возможности, а также особенности операционной системы позволяют нам вносить изменения в контроллерные блоки (либо заменять их полностью) без простоев и перезагрузок.
С DX 100 S3 это легко и просто выполняется следующим образом, отражающим всю безопасность и продуманность манипуляций:
Войдя в GUI под учетной записью сервисного инженера (f.ce), всю систему переводим в режим обслуживания
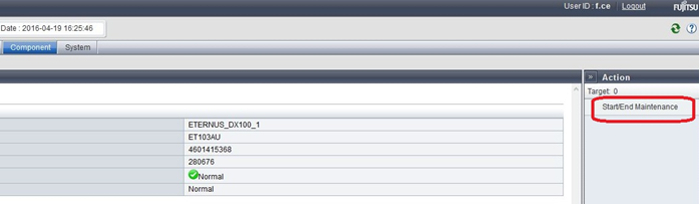
- Далее, выбрав нужный нам контроллерный модуль, переводим его в режим обслуживания

Система перед вводом искомого блока в maintenance mod выполнит ряд тестов безопасности и реализует запрос только если второй контроллер и зависимые компоненты работают штатно и целостности данных ничего не угрожает. Все логические диски, для которых отключенный контроллер являлся «владельцем», перейдут в обслуживание второго контроллера практически мгновенно и бесшовно после синхронизации кэша и смены путей передачи данных.
- В графическом интерфейсе станет видно, что контроллер больше не доступен и может быть извлечен. По окончании манипуляций, так же в онлайн режиме возвращаем его на место, система автоматически, без перезагрузок самих контроллерных блоков, распознает и вернет прежнюю схему работы. Появившиеся новые устройства (у нас это FC-адаптеры) нужно задействовать, добавив в систему. Вот и все, воистину у ETERNUS DX операционная система «реального времени».
У линейки IBM (Lenovo) Storwize, например, данные манипуляции тоже проходят онлайн, но сами контроллеры выполняют цикл из нескольких поочередных перезагрузок после указания того, что это вовсе не ошибка и это мы добавили тот или иной компонент. И перезагрузки могут длиться, по показаниям системы, до 30 (!!!) минут каждая.

Хочется добавить еще несколько слов о реализованном здесь алгоритме безопасности, можно сказать, защите от необдуманных действий. А суть его проста и изящна: нельзя что-либо удалить нечаянным нажатием не туда, куда надо. Например, мы не можем удалить RAID-массив или логический диск пока не разберем всю цепочку взаимосвязей с самого «конца», а именно – сначала нужно изъять LUN-группы из настроек связи с хостом (Host Affinity), далее сами логические диски убрать из LUN-групп, удалить логические диски и только потом разрушить RAID. Согласитесь, сделать такое случайно и непреднамеренно практически невозможно.


Вкладки "Delete" LUN Group и RAID Group не активны до разрыва "связей"
Стоит оговориться, что из командной строки (SSH) при необходимости принудительное удаление любых элементов доступно сразу.
О серверах и виртуализации
Как уже упоминалось ранее, серверная часть кластера изначально состояла из 2-х серверов Fujitsu PRIMERGY RX200 S8, к которым в дальнейшем добавили аналогичное по классу и производительности устройство Fujitsu PRIMERGY RX 2530 M1. По сути, архитектурно устройства весьма схожи, но новая линейка процессоров Intel (как следствие и новые функции, инструкции, протоколы) в RX 2530 M1 сулила нам проблемы на уровне кластера VMware, а именно, проблемы с миграцией машин между хостами. Что и проявилось после внедрения: некоторые из уже имеющихся машин при миграции выдавали ошибку, связанную как раз с отличием CPU целевого сервера.
Конечно же, VMware предусмотрела решение для подобного рода проблем, ее функция EVC (Enhanced vMotion Compatibility) предназначена для «маскировки» различий в процессорах разных поколений. Увы, изначально кластер поднимался на пятой версии виртуальной сферы VMware (VMware vSphere 5.5), которая тогда еще «понятия не имела» о новых процессорах Intel. Однако суть в том, что для нашей ситуации эта беда – вовсе не беда. Имея отказоустойчивый кластер, обновление до версии VMware vSphere 6.0 (EVC которой имеет возможность работать со всеми версиями процессоров) занимает всего нескольких часов. При правильном использовании и планировании кластера любой из имеющихся в нем серверов можно свободно обслуживать, распределив его машины на оставшихся хостах, используя «живую» миграцию.
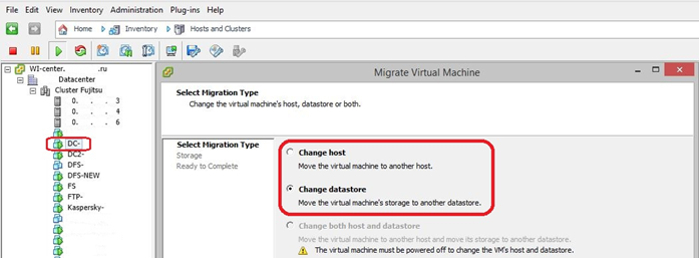
Миграция машины производилась со сменой не только хоста, но и хранилища данных, так как выполнялась реорганизация дискового пространства СХД. Данный процесс протекает путем полного клонирования машины, оригинал которой после синхронизации автоматически удаляется. Одновременная миграция (сервер и диск) возможна только при выключенной виртуальной машине.
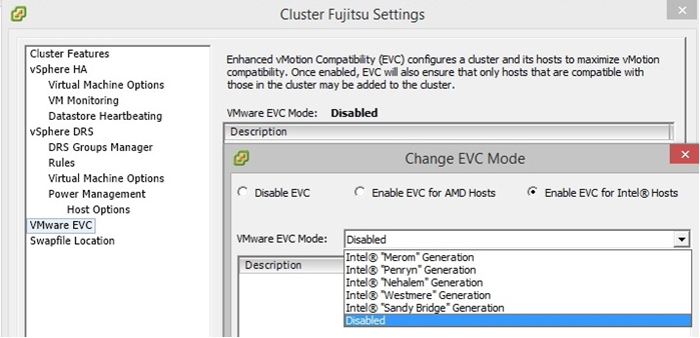
В VMware vSphere 5.5 поддержка процессоров заканчивается поколением "Sandy Bridge"

В VMware vSphere 6.0 мы можем наблюдать "Ivy Bridge" и "Haswell"
Подводя итог этой небольшой истории о кластерной виртуализации, хочется процитировать строчку из песни – «Летать с тобой мне было трудно, но без тебя я не могу дышать!». Ибо решиться на это трудно, да и дорого. Но зато потом страшно представить, как раньше без всего этого обходились, вспоминая потраченные выходные, обеды и ночи, нервы, переживания и надежду успеть завершить задуманное до конца перерыва или начала рабочего дня.
Подготовлено по материалу Третьякова Вячеслава, инженера компании «Парадигма». Полную версию статьи смотрите здесь.
Комментарии (10)

NoOne
16.08.2016 09:33«Одновременная миграция (сервер и диск) возможна только при выключенной виртуальной машине.»
Такая миграция возможна, просто надо пользоваться не толстым клиентом, а всеми нелюбимым веб-клиентом.

brainfair
16.08.2016 12:00А почему не использовали SAN свичи? Ведь это и на будущее вас избавит от проблем с маштабированием, а не думаю что сильно дороже чем докупать карты в полку каждый раз.
«Одновременная миграция (сервер и диск) возможна только при выключенной виртуальной машине.» — привет люди из прошлого, данная фича уже доступна с 5.1, только не из толстого клиента, а из веб.
NoWE
16.08.2016 12:03Да FC коммутатор предлагался, но заказчик посчитал иначе, так как был уверен изначально что данной конфигурации хватит с головой и рост не предвидится, к тому же для отказоустойчивости SAN свича нужно было бы два.
NoWE
16.08.2016 13:48Мы в курсе что из web данная фича работает, забыли о этом упомянуть в статье. Спасибо что обратили внимание.

alexq2
16.08.2016 12:00+1А чем эта статья от полной версии отличается? И что-то технических подробностей мало. Что за фабрика? Что за сеть? Какая плотность вм? Как HA настроен? По слотам, по хостам, процентам? Умирали хосты или нет? Какие опции куплены для схд? Вайд страйпинг, дата тиринг, тонкие Луны? Почему именно сторвайзы упомянули? Если сравнить три сервера lenovo(IBM)+ storwize v3700 выходит дешевле аналогичной конфигурации фуджитсу, прайс из-за 30 минут повышается? И у какого вендора можно просто взять и раздел удалить?
NoWE
16.08.2016 12:02+1Описывать технические подробности не было целью статьи.
Ни какой фабрики, два коммутатора mikrotik (уже имелись, модель не припомню).
Плотность машин достигала на момент добавления третьего сервера 30 VM (в основном c Windows).
HA был настроен с резервированием по процентам, точных значений уже не помню.
Хосты не умирали (ну разве что только искусственно для проверки работы HA).
СХД работает с базовыми возможностями, ни какие опции пока не приобретались.
Тонкие диски не использовались (по решению заказчика).
В той же организации имелся и Storwize v3700, только еще от IBM. Его работа хоть и была не провальна, но и не вызывала особого доверия, при той же операции замены интерфейсных карт например, после перезагрузки стал недоступен как основной WEB интерфейс так и сервисный, в течении минут 20-30, что заставило понервничать в свое время заказчика, а так же второй storwize v3700 не рассматривался в виду внутренней 6 Gb SAS «петли» и довольно слабых процессоров (в будущем планировалось использование SSD для тиринга).
muon
Ну какой же это сказ, просто запись в корпоративном блоге. «Сказы» — они у админов компаний, в которых эти продукты используются. И сказы эти обычно про то, что несмотря на все шикарнейшие достижения науки и техники возникают ситуации, когда «все три стороны [админ, производитель СХД и дистрибутор] берутся за руки в произвольном порядке, и ходят то налево, то направо, поют песни разные. А в центре композиции огромный <...> И скрипит магнитная лента.»
Истина, как обычно, где-то посередине.
А это у вас были Ceph-хранилища? Как у них дела?
NoWE
Нет, в данном случае это были не Ceph-хранилища. Поэтому не знаем, как у них дела :-)
muon
В статье не они, это понятно, я имел в виду, что именно у вас где-то был Ceph. Если узнаете — обязательно сообщите :)
Fujitsu_Admin
Где то у нас он был тут :-)