Дисклеймер: в посте много ascii-графики. Не стоит его читать с мобильного устройства — вас разочарует форматирование текста.
Сегодня мы узнаем всё о структурах данных.
«Оооооой как интересно...», да?
Да уж, не самая сочная тема на сей день, однако крайне важная. Не для того, чтобы сдавать курсы наподобие CS101, а чтобы лучше разбираться в программировании.
Знание структур данных поможет вам:
- Управлять сложностью своих программ, делая их доступней для понимания.
- Создавать высокопроизводительные программы, эффективно работающие с памятью.
Я считаю, что первое важнее. Правильная структура данных может кардинально упростить код, устраняя запутанную логику.
Второй пункт тоже важен. Когда учитываются производительность или память программы, правильный выбор структуры данных значительно сказывается на работе.
Чтобы познакомиться со структурами данных, мы реализуем некоторые из них. Не беспокойтесь, код будет лаконичен. На самом деле, тут больше комментариев, а кода между ними — раз, два и обчёлся.
============================================================================
,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'
============================================================================
Что такое структуры данных?
По сути, это способы хранить и организовывать данные, чтобы эффективней решать различные задачи. Данные можно представить по-разному. В зависимости от того, что это за данные и что вы собираетесь с ними делать, одно представление подойдёт лучше других.
Чтобы понять, почему так происходит, сперва поговорим об алгоритмах.
/*** ===================================================================== *** * *
* ,--,--. ,--,--. *
* ,----------. | | | | | | _____ *
* |`----------'| | | | | | | | | ,------. *
* | | | | | | | | ,--. | o o | |`------'| *
* | | ,| +-|-+ | | +-|-+ |` | | |_____| | | *
* | | ,:==| | |###|======|###| | |====#==#====#=,, | | *
* | | || `| +---+ | | +---+ |' ,,=#==#====O=`` ,| | *
* | | || | | | | | | ``=#==#====#=====|| | *
* `----------' || | | | | | | |__| `| | *
* | | ``=| |===`` `--,',--` `--,',--` /||\ `------' *
** \_/ \_/ / / \ \ / / \ \ //||\\ |_| |_| **
\*** ===================================================================== ***/
Алгоритмы
Алгоритм — такое хитроумное название для последовательности совершаемых действий.
Структуры данных реализованы с помощью алгоритмов, алгоритмы — с помощью структур данных. Всё состоит из структур данных и алгоритмов, вплоть до уровня, на котором бегают микроскопические человечки с перфокартами и заставляют компьютер работать. (Ну да, у Интела в услужении микроскопические люди. Поднимайся, народ!)
Любая данная задача реализуется бесконечным количеством способов. Как следствие, для решения распространённых задач изобрели множество различных алгоритмов.
Например, для сортировки неупорядоченного множества элементов существует до смешного большое количество алгоритмов:
Сортировка вставками, Сортировка выбором, Сортировка слиянием, Сортировка пузырьком, Cортировка кучи, Быстрая сортировка, Сортировка Шелла, Сортировка Тима, Блочная сортировка, Поразрядная сортировка...
Некоторые из них значительно быстрее остальных. Другие занимают меньше памяти. Третьи легко реализовать. Четвёртые построены на допущениях относительно наборов данных.
Каждая из сортировок подходит лучше других для определённой задачи. Поэтому вам надо будет сперва решить, какие у вас потребности и критерии, чтобы понять, как сравнивать алгоритмы между собой.
Для сравнения производительности алгоритмов используется грубое измерение средней производительности и производительности в худшем случае, для обозначения которых используется термин «О» большое.
/*** ===================================================================== *** * a b d *
* a b O(N^2) d *
* O(N!) a b O(N log N) d c *
* a b d c *
* a b d c O(N) *
* a b d c *
* a b d c *
* a b d c *
* ab c O(1) *
* e e e e ec d e e e e e e e e *
* ba c d *
* ba c d f f f f f f f *
** cadf f d f f f f f O(log N) **
\*** ===================================================================== ***/
О большое
«О» большое — обозначение способа приблизительной оценки производительности алгоритмов для относительного сравнения.
О большое — заимствованное информатикой математические обозначение, определяющее, как алгоритмы соотносятся с передаваемым им некоторым количеством N данных.
О большое характеризует две основные величины:
Оценка времени выполнения — общее количество операций, которое алгоритм проведёт на данном множестве данных.
Оценка объёма — общее количество памяти, требующееся алгоритму для обработки данного множества данных.
Оценки делаются независимо друг от друга: одни алгоритмы могут производить меньше операций, чем другие, занимая при этом больше памяти. Определив свои требования, вы сможете выбрать соответствующий алгоритм.
Вот некоторые распространённые значения О большого:
Имя Нотация Что вы скажете, припрись они к вам на вечеринку
----------------------------------------------------------------------------
Константная O(1) ОХРЕНЕННО!!
Логарифмическая O(log N) КРУТО!
Линейная O(N) НОРМАС.
Линейно-
логарифмическая O(N log N) БЛИИИН...
Полиномиальная O(N ^ 2) ОТСТОЙ
Экспоненциальная O(2 ^ N) ОТВРАТИТЕЛЬНО
Факториальная O(N!) ТВОЮЖМАТЬЧтобы дать представление, о каких порядках чисел мы говорим, давайте взглянем, что это будут за значения в зависимости от N.
N = 5 10 20 30
-----------------------------------------------------------------------
O(1) 1 1 1 1
O(log N) 2.3219... 3.3219... 4.3219... 4.9068...
O(N) 5 10 20 30
O(N log N) 11.609... 33.219... 84.638... 147.204...
O(N ^ 2) 25 100 400 900
O(2 ^ N) 32 1024 1,048,576 1,073,741,824
O(N!) 120 3,628,800 2,432,902,0... 265,252,859,812,191,058,636,308,480,000,000
Как видите, даже при относительно небольших числах можно сделать *дофига* дополнительной работы.
Структуры данных позволяют производить 4 основных типа действий: доступ, поиск, вставку и удаление.
Замечу, что структуры данных могут быть хороши в одном из действий, но плохи в другом.
Доступ Поиск Вставка Удаление
------------------------------------------------------------------------
Массив O(1) O(N) O(N) O(N)
Связный список O(N) O(N) O(1) O(1)
Двоичное дерево поиска O(log N) O(log N) O(log N) O(log N)
Или даже…
Доступ Поиск Вставка Удаление
------------------------------------------------------------------------
Массив ОХРЕНЕННО НОРМАС НОРМАС НОРМАС
Связный список НОРМАС НОРМАС ОХРЕНЕННО ОХРЕНЕННО
Двоичное дерево поиска КРУТО КРУТО КРУТО КРУТОКроме того, некоторые действия имеют разную «среднюю» производительность и производительность в «самом худшем случае».
Идеальной структуры данных не существует. Вы выбираете самую подходящую, основываясь на данных и на том, как они будут обрабатываться. Чтобы сделать правильный выбор, важно знать различные распространённые структуры данных.
/*** ===================================================================== *** * _.-.. *
* ,'9 )\)`-.,.--. *
* `-.| `. *
* \, , \) *
* `. )._\ (\ *
* |// `-,// *
* ]|| //" *
** hjw "" "" **
\*** ===================================================================== ***/
Память
Компьютерная память — довольно скучная штука. Это группа упорядоченных слотов, в которых хранится информация. Чтобы получить к ней доступ, вы должны знать её адрес в памяти.
Фрагмент памяти можно представить так:
Значения: |1001|0110|1000|0100|0101|1010|0010|0001|1101|1011...
Адреса: 0 1 2 3 4 5 6 7 8 9 ...
Если вы задумывались, почему в языках программирования отсчёт начинается с 0 — потому, что так работает память. Чтобы прочитать первый фрагмент памяти, вы читаете с 0 до 1, второй — с 1 до 2. Адреса этих фрагментов соответственно равны 0 и 1.
Конечно же, в компьютере больше памяти, чем показано в примере, однако её устройство продолжает принцип рассмотренного шаблона.
Просторы памяти — как Дикий Запад. Каждая работающая на компьютере программа хранится внутри одной и той же *физической* структуры данных. Использование памяти — сложная задача, и для удобной работы с ней существуют дополнительные уровни абстракции.
Абстракции имеют два дополнительных назначения:
— Сохраняют данные в памяти таким образом, чтобы с ними было эффективно и/или быстро работать.
— Сохраняют данные в памяти так, чтобы их было проще использовать.
/*** ===================================================================== *** * * _______________________ *
* ()=(_______________________)=() * *
* * | | *
* | ~ ~~~~~~~~~~~~~ | * * *
* * | | *
* * | ~ ~~~~~~~~~~~~~ | * *
* | | *
* | ~ ~~~~~~~~~~~~~ | * *
* * | | *
* * |_____________________| * * *
* ()=(_______________________)=() *
** **
\*** ===================================================================== ***/
Списки
Для начала реализуем список, чтобы показать сложности взаимодействия между памятью и структурой данных.
Список — представление пронумерованной последовательности значений, где одно и то же значение может присутствовать сколько угодно раз.
Начнём с пустого блока памяти, представленного обычным JavaScript-массивом. Также нам понадобится хранить значение длины списка.
Заметьте, что мы хотим хранить длину отдельно, поскольку в реальности у «памяти» нет значения length, которое можно было бы взять и прочитать.
class List {
constructor() {
this.memory = [];
this.length = 0;
}
//...
}Первым делом нужно получать данные из списка. Обычный список позволяет очень быстро получить доступ к памяти, поскольку вы уже знаете нужный адрес.
Сложность операции доступа в список — O(1) — «ОХРЕНЕННО!!»
get(address) {
return this.memory[address];
}
У списков есть порядковые номера, поэтому можно вставлять значения в начало, середину и конец.
Мы сфокусируемся на добавлении и удалении значений в начало или конец списка. Для этого понадобятся 4 метода:
- Push — Добавить значение в конец.
- Pop — Удалить значение из конца.
- Unshift — Добавить значение в начало.
- Shift — Удалить значение из начала.
Начнём с операции «push» — реализуем добавление элементов в конец списка.
Это настолько же легко, как добавить значение в адрес, следующий за нашим списком. Поскольку мы храним длину, вычислить адрес — проще простого. Добавим значение и увеличим длину.
Добавление элемента в конец списка — константа O(1) — «ОХРЕНЕННО!!»
push(value) {
this.memory[this.length] = value;
this.length++;
}
Комментарии хабра: poxu не согласен с автором и объясняет, что существует операция расширения памяти, увеличивающая сложность добавления элементов в список.
Далее, реализуем метод «pop», убирающий элемент из конца нашего списка. Аналогично push, всё, что нужно сделать — убрать значение из последнего адреса. Ну, и уменьшить длину.
Удаление элемента из конца списка — константа O(1) — «ОХРЕНЕННО!!»
pop() {
// Нет элементов — ничего не делаем.
if (this.length === 0) return;
// Получаем последнее значение, перестаём его хранить, возвращаем его.
var lastAddress = this.length - 1;
var value = this.memory[lastAddress];
delete this.memory[lastAddress];
this.length--;
// Возвращаем значение, чтобы его можно было использовать.
return value;
}
«Push» и «pop» работают с концом списка, и в общем-то являются простыми операциями, поскольку не затрагивают весь остальной список.
Давайте посмотрим, что происходит, когда мы работаем с началом списка, с операциями «unshift» и «shift».
Чтобы добавить новый элемент в начало списка, нужно освободить пространство для этого значения, сдвинув на один все последующие значения.
[a, b, c, d, e]
0 1 2 3 4
? ? ? ? ?
1 2 3 4 5
[x, a, b, c, d, e]
Чтобы сделать такой сдвиг, нужно пройтись по каждому из элементов и поставить на его место предыдущий.
Поскольку мы вынуждены пройтись по каждому из элементов списка:
Добавление элемента в начало списка — линейно O(N) — «НОРМАС.»
unshift(value) {
// Cохраняем значение, которое хотим добавить в начало.
var previous = value;
// Проходимся по каждому элементу...
for (var address = 0; address < this.length; address++) {
// заменяя текущее значение «current» на предыдущее значение «previous»,
// и сохраняя значение «current» для следующей итерации.
var current = this.memory[address];
this.memory[address] = previous;
previous = current;
}
// Добавляем последний элемент на новую позицию в конце списка.
this.memory[this.length] = previous;
this.length++;
}
Осталось написать функцию сдвига списка в противоположном направлении — shift.
Мы удаляем первое значение и затем сдвигаем каждый элемент списка на предшествующий адрес.
[x, a, b, c, d, e]
1 2 3 4 5
? ? ? ? ?
0 1 2 3 4
[a, b, c, d, e]
Удаление элемента из начала списка — линейно O(N) — «НОРМАС.»
shift() {
// Нет элементов — ничего не делаем.
if (this.length === 0) return;
var value = this.memory[0];
// Проходимся по каждому элементу, кроме последнего
for (var address = 0; address < this.length - 1; address++) {
// и заменяем его на следующий элемент списка.
this.memory[address] = this.memory[address + 1];
}
// Удаляем последний элемент, поскольку значение теперь в предыдущем адресе.
delete this.memory[this.length - 1];
this.length--;
return value;
}
Списки отлично справляются с быстрым доступом к элементам в своём конце и работой с ними. Однако, как мы увидели, для элементов из начала или середины они не слишком хороши, так как приходится вручную обрабатывать адреса памяти.
Давайте посмотрим на иную структуру данных и её методы по добавлению, доступу и удалению значений без необходимости знать адреса элементов.
/*** ===================================================================== *** * ((\ *
* ( _ ,-_ \ \ *
* ) / \/ \ \ \ \ *
* ( /)| \/\ \ \| | .'---------------------'. *
* `~()_______)___)\ \ \ \ \ | .' '. *
* |)\ ) `' | | | .'-----------------------------'. *
* / /, | '...............................' *
* ejm | | / \ _____________________ / *
* \ / | |_) (_| | *
* \ / | | | | *
* ) / | | | | *
** / / (___) (___) **
\*** ===================================================================== ***/
Хеш-таблицы
Хеш-таблица — неупорядоченная структура данных. Вместо индексов мы работаем с «ключами» и «значениями», вычисляя адрес памяти по ключу.
Смысл в том, что ключи «хешируются» и позволяют эффективно работать с памятью — добавлять, получать, изменять и удалять значения.
var hashTable = new HashTable();
hashTable.set('myKey', 'myValue');
hashTable.get('myKey'); // >> 'myValue'
Вновь используем обычный JavaScript-массив, представляющий память.
class HashTable {
constructor() {
this.memory = [];
}
// ...
}
Чтобы сохранять пары ключ-значение из хеш-таблицы в память, нужно превращать ключи в адреса. Этим занимается операция «хеширования».
Она принимает на вход ключ и преобразовывает его в уникальное число, соответствующее этому ключу.
hashKey("abc") => 96354
hashKey("xyz") => 119193
Такая операция требует осторожности. Если ключ слишком большой, он будет сопоставляться несуществующему адресу в памяти.
Следовательно, хеш-функция должна ограничивать размер ключей, т.е. ограничивать число доступных адресов памяти для неограниченного количества значений.
Любая реализация хеш-таблиц сталкивается с этой проблемой.
Однако, поскольку мы собираемся рассмотреть лишь устройство их работы, предположим, что коллизий не случится.
Давайте определим функцию «hashKey».
Не вдавайтесь во внутреннюю логику, просто поверьте, что она принимает на вход строку и возвращает (практически всегда) уникальный адрес, который мы будем использовать в остальных функциях.
hashKey(key) {
var hash = 0;
for (var index = 0; index < key.length; index++) {
// Ма-а-а-агия.
var code = key.charCodeAt(index);
hash = ((hash << 5) - hash) + code | 0;
}
return hash;
}
Теперь определим функцию «get», получающую значение по ключу.
Сложность чтения значения из хеш-таблицы — константа O(1) — «ОХРЕНЕННО!!»
get(key) {
// Сперва получим адрес по ключу.
var address = this.hashKey(key);
// Затем просто вернём значение, находящееся по этому адресу.
return this.memory[address];
}
Перед тем, как получать данные, неплохо бы их сперва добавить. В этом нам поможет функция «set».
Сложность установки значения в хеш-таблицу — константа O(1) — «ОХРЕНЕННО!!»
set(key, value) {
// И вновь начинаем с превращения ключа в адрес.
var address = this.hashKey(key);
// Затем просто записываем значение по этому адресу.
this.memory[address] = value;
}
Наконец, нужен способ удалять значения из хеш-таблицы. Сложность удаления значения из хеш-таблицы — константа O(1) — «ОХРЕНЕННО!!»
remove(key) {
// Как обычно, хешируем ключ, получая адрес.
var address = this.hashKey(key);
// Удаляем значение, если оно существует.
if (this.memory[address]) {
delete this.memory[address];
}
}
============================================================================
,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'
============================================================================
Теперь мы прекратим работать с памятью напрямую: все последующие структуры данных будут реализовываться через другие структуры данных.
Новые структуры фокусируются на двух вещах:
- Организовывают данные, исходя из особенностей их применения
- Абстрагируют детали реализации
Цель таких структур данных — организовать информацию для применения в программах различного типа. Они предоставляют язык, позволяющий выражать более сложную логику. При этом абстрагируются детали реализации, т.е. можно изменить реализацию, сделав её быстрее.
/*** ===================================================================== *** * _ . - - -- .. _ *
* |||| .-' /```\ `'-_ /| *
* |||| ( /`` \___/ ```\ ) | | *
* \__/ |`"-//..__ __..\\-"`| | | *
* || |`"||...__`````__...||"`| | | *
* || |`"||...__`````__...||"`| \ | *
* || _,.--|`"||...__`````__...||"`|--.,_ || *
* || .'` |`"||...__`````__...||"`| `'. || *
* || '. `/ |...__`````__...| \ .' || *
* || `'-..__ `` ````` `` __..-'` || *
* `""---,,,_______,,,---""` *
** **
\*** ===================================================================== ***/
Стеки
Стеки похожи на списки. Они также упорядочены, но ограничены в действиях: можно лишь добавлять и убирать значения из конца списка. Как мы увидели ранее, это происходит очень быстро, если обращаться к памяти напрямую.
Однако стеки могут быть реализованы через другие структуры данных, чтобы получить дополнительную функциональность.
Наиболее общий пример использования стеков — у вас есть один процесс, добавляющий элементы в стек и второй, удаляющий их из конца — приоритизируя недавно добавленные элементы.
Нам вновь понадобится JavaScript-массив, но на этот раз он символизирует не память, а список, вроде реализованного выше.
class Stack {
constructor() {
this.list = [];
this.length = 0;
}
// ...
}Нам понадобится реализовать два метода, функционально идентичных методам списка — «push» и «pop».
Push добавляет элементы на верхушку стека.
push(value) {
this.length++;
this.list.push(value);
}
Pop удаляет элементы из верхушки.
pop() {
// Нет элементов — ничего не делаем.
if (this.length === 0) return;
// Возьмём последний элемент списка и вернём значение.
this.length--;
return this.list.pop();
}
Кроме того, добавим функцию peek, показывающую элемент на верхушке стека без его удаления. Прим. переводчика: peek – взглянуть.
peek() {
// Возвращаем последний элемент, не удаляя его.
return this.list[this.length - 1];
}
/*** ===================================================================== *** * /:""| ,@@@@@@. *
* |: oo|_ ,@@@@@`oo *
* C _) @@@@C _) *
* ) / "@@@@ '= *
* /`\\ ```)/ *
* || | | /`\\ *
* || | | || | \ *
* ||_| | || | / *
* \( ) | ||_| | *
* |~~~`-`~~~| |))) | *
* (_) | | (_) |~~~/ (_) *
* | |`""....__ __....""`| |`""...._|| / __....""`| | *
* | |`""....__`````__....""`| |`""....__`````__....""`| | *
* | | | ||``` | | ||`|`` | | *
* | | |_||__ | | ||_|__ | | *
* ,| |, jgs (____)) ,| |, ((;:;:) ,| |, *
** `---` `---` `---` **
\*** ===================================================================== ***/
Очереди
Теперь создадим очередь — структуру, комплементарную стеку. Разница в том, что элементы очереди удаляются из начала, а не из конца, т.е. сначала старые элементы, потом новые.
Как уже оговаривалось, поскольку функциональность ограничена, существуют разные реализации очереди. Хорошим способом будет использование связного списка, о котором мы поговорим чуть позже.
И вновь мы призываем на помощь JavaScript-массив! В случае с очередью мы опять рассматриваем его как список, а не как память.
class Queue {
constructor() {
this.list = [];
this.length = 0;
}
// ...
}
Аналогично стекам мы определяем две функции для добавления и удаления элементов из очереди.
Первым будет «enqueue» — добавление элемента в конец списка.
enqueue(value) {
this.length++;
this.list.push(value);
}
Далее — «dequeue». Элемент удаляется не из конца списка, а из начала.
dequeue() {
// Нет элементов — ничего не делаем.
if (this.length === 0) return;
// Убираем первый элемент методом shift и возвращаем значение.
this.length--;
return this.list.shift();
}
Аналогично стекам объявим функцию «peek», позволяющую получить значение в начале очереди без его удаления.
peek() {
return this.list[0];
}
Важно заметить, что, поскольку для реализации очереди использовался список, она наследует линейную производительность метода shift (т.е. O(N) — «НОРМАС.»).
Как мы увидим позже, связные списки позволяют реализовать более быструю очередь.
============================================================================
,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'
============================================================================
С этого места и далее мы будем работать со структурами данных, где значения ссылаются друг на друга.
+- Структура данных -------------------------------------+
| +- Элемент A ------------+ +- Элемент B ------------+ |
| | Значение: 1 | | Значение: 2 | |
| | Ссылка на: (Элемент B) | | Ссылка на: (Элемент A) | |
| +------------------------+ +------------------------+ |
+--------------------------------------------------------+
Элементы структуры данных становятся сами по себе министруктурами, содержащими значение и дополнительную информацию — ссылки на другие элементы родительской структуры.
Сейчас вы поймёте, что я имею ввиду.
/*** ===================================================================== *** * *
* | RICK ASTLEY'S NEVER GONNA... *
* | +-+ *
* | +-+ |-| [^] - GIVE YOU UP *
* | |^| |-| +-+ [-] - LET YOU DOWN *
* | |^| |-| +-+ |*| [/] - RUN AROUND AND DESERT YOU *
* | |^| |-| +-+ |\| |*| [\] - MAKE YOU CRY *
* | |^| |-| |/| |\| +-+ |*| [.] - SAY GOODBYE *
* | |^| |-| |/| |\| |.| |*| [*] - TELL A LIE AND HURT YOU *
* | |^| |-| |/| |\| |.| |*| *
* +-------------------------------- *
** **
\*** ===================================================================== ***/
Графы
На самом деле граф — совсем не то, о чём вы подумали, увидев ascii-график.
Граф — структура наподобие этой:
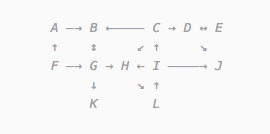
У нас есть множество «вершин» (A, B, C, D, ...), связанных линиями.
Эти вершины можно представить вот так:
Node {
value: ...,
lines: [(Node), (Node), ...]
}
А весь граф будет выглядеть вот так:
Graph {
nodes: [
Node {...},
Node {...},
...
]
}
Представим список вершин JavaScript-массивом. Массив используется не с целью специально упорядочить вершины, а как место для хранения вершин.
class Graph {
constructor() {
this.nodes = [];
}
// ...
}
Начнём добавлять значения в граф, создавая вершины без каких-либо линий.
addNode(value) {
this.nodes.push({
value: value,
lines: []
});
}
Теперь нужен способ искать вершины в графе. Обычно для ускорения поиска делается ещё одна структура данных поверх графа.
Но в нашем случае мы просто переберём все вершины, чтобы найти соответствующую значению. Способ медленный, но работающий.
find(value) {
return this.nodes.find(function(node) {
return node.value === value;
});
}
Теперь мы можем связать две вершины, проведя «линию» от одной до другой (прим. переводчика: дугу графа).
addLine(startValue, endValue) {
// Найдём вершины для каждого из значений.
var startNode = this.find(startValue);
var endNode = this.find(endValue);
// Ругнёмся, если не нашли одной или другой.
if (!startNode || !endNode) {
throw new Error('Обе вершины должны существовать');
}
// В стартовую вершину startNode добавим ссылку на конечную вершину endNode.
startNode.lines.push(endNode);
}
Полученный граф можно использовать вот так:
var graph = new Graph();
graph.addNode(1);
graph.addNode(2);
graph.addLine(1, 2);
var two = graph.find(1).lines[0];
Кажется, что для такой мелкой задачи сделано слишком много работы, однако это мощный паттерн.
Он часто применяется для поддержания прозрачности в сложных программах. Это достигается оптимизацией взаимосвязей между данными, а не операций над самими данными. Если вы выберете одну вершину в графе, невероятно просто найти связанные с ней элементы.
Графами можно представлять уйму вещей: пользователей и их друзей, 800 зависимостей в папке node_modules, даже сам интернет, являющийся графом связанных друг с другом ссылками веб-страниц.
/*** ===================================================================== *** * _______________________ *
* ()=(_______________________)=() ,-----------------,_ *
* | | ," ", *
* | ~ ~~~~~~~~~~~~~ | ,' ,---------------, `, *
* | ,----------------------------, ,----------- *
* | ~ ~~~~~~~~ | | | *
* | `----------------------------' `----------- *
* | ~ ~~~~~~~~~~~~~ | `, `----------------' ,' *
* | | `, ,' *
* |_____________________| `------------------' *
* ()=(_______________________)=() *
** **
\*** ===================================================================== ***/
Связные списки
Давайте теперь посмотрим, как графоподобная структура может оптимизировать упорядоченный список данных.
Связные списки — распространённая структура данных, зачастую используемая для реализации других структур. Преимущество связного списка — эффективность добавления элементов в начало, середину и конец.
Связный список по своей сути похож на граф: вы работаете с вершинами, указывающими на другие вершины. Они расположены таким образом:
1 -> 2 -> 3 -> 4 -> 5
Если представить эту структуру в виде JSON, получится нечто такое:
{
value: 1,
next: {
value: 2,
next: {
value: 3,
next: {...}
}
}
}
В отличие от графа, связный список имеет единственную вершину, из которой начинается внутренняя цепочка. Её называют «головой», головным элементом или первым элементом связного списка.
Также мы собираемся отслеживать длину списка.
class LinkedList {
constructor() {
this.head = null;
this.length = 0;
}
// ...
}
Первым делом нужен способ получать значение по данной позиции.
В отличие от обычных списков мы не можем перепрыгнуть на нужную позицию. Вместо этого мы должны перейти к ней через отдельные вершины.
get(position) {
// Выведем ошибку, если искомая позиция превосходит число вершин в списке.
if (position >= this.length) {
throw new Error('Позиция выходит за пределы списка');
}
// Начнём с головного элемента списка.
var current = this.head;
// Пройдём по всем элементам при помощи node.next,
// пока не достигнем требуемой позиции.
for (var index = 0; index < position; index++) {
current = current.next;
}
// Вернём найденную вершину.
return current;
}
Теперь необходим способ добавлять вершины в выбранную позицию.
Создадим метод add, принимающий значение и позицию.
add(value, position) {
// Сначала создадим вершину, содержащую значение.
var node = {
value: value,
next: null
};
// Нужно обработать частный случай, когда вершина вставляется в начало.
// Установим поле «next» в текущий головной элемент и заменим
// головной элемент нашей вершиной.
if (position === 0) {
node.next = this.head;
this.head = node;
// Если мы добавляем вершину на любую другую позицию, мы должны вставить её
// между текущей вершиной current и предыдущей previous.
} else {
// Сперва найдём предыдущую и текущую вершины.
var prev = this.get(position - 1);
var current = prev.next;
// Затем вставим новую вершину между ними, установив поле «next»
// на текущую вершину current,
// и поле «next» предыдущей вершины previous — на вставляемую.
node.next = current;
prev.next = node;
}
// И увеличим длину.
this.length++;
}
Последний метод, который нам понадобится — remove. Найдём вершину по позиции и выкинем её из цепочки.
remove(position) {
// Если мы удаляем головной элемент, просто переставим указатель head
// на следующую вершину.
if (position === 0) {
this.head = this.head.next;
// Для остальных случаев требуется найти предыдущую вершину и поставить
// в ней ссылку на вершину, следующую за текущей.
} else {
var prev = this.get(position - 1);
prev.next = prev.next.next;
}
// И затем уменьшим длину.
this.length--;
}
============================================================================
,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'`'-.,.-'
============================================================================
Две оставшиеся структуры данных относятся к семейству «деревьев».
Как и в жизни, существует множество различных древовидных структур данных.
Прим. переводчика: ну не-е-е-е, я пас…
Binary Trees:
AA Tree, AVL Tree, Binary Search Tree, Binary Tree, Cartesian Tree, left child/right sibling tree, order statistic tree, Pagoda,…
B Trees:
B Tree, B+ Tree, B* Tree, B Sharp Tree, Dancing Tree, 2-3 Tree,…
Heaps:
Heap, Binary Heap, Weak Heap, Binomial Heap, Fibonacci Heap, Leonardo Heap, 2-3 Heap, Soft Heap, Pairing Heap, Leftist Heap, Treap,…
Trees:
Trie, Radix Tree, Suffix Tree, Suffix Array, FM-index, B-trie,…
Multi-way Trees:
Ternary Tree, K-ary tree, And-or tree, (a,b)-tree, Link/Cut Tree,…
Space Partitioning Trees:
Segment Tree, Interval Tree, Range Tree, Bin, Kd Tree, Quadtree, Octree, Z-Order, UB-Tree, R-Tree, X-Tree, Metric Tree, Cover Tree,…
Application-Specific Trees:
Abstract Syntax Tree, Parse Tree, Decision Tree, Minimax Tree,…
Чего уж вы не ожидали, так это что будете изучать сегодня дендрологию… И это ещё не все деревья. Пусть они вас не смущают, большинство из них вообще не имеет смысла. Надо же было людям как-то защищать кандидатские степени и что-то для этого доказывать.
Деревья похожи на графы или связные списки, с той разницей, что они «однонаправленые». Это значит, что в них не может существовать циклических ссылок.

Если вы можете пройти круг по вершинам дерева… что ж, поздравляю, но это не дерево.
Деревья применяются во множестве задач. Они используются для оптимизации поиска или сортировки. Они могут лучше организовывать программу. Они могут создать представление, с которым проще работать.
/*** ===================================================================== *** * ccee88oo \ | / *
* C8O8O8Q8PoOb o8oo '-.;;;.-, ooooO8O8QOb o8bDbo *
* dOB69QO8PdUOpugoO9bD -==;;;;;==-aadOB69QO8PdUOpugoO9bD *
* CgggbU8OU qOp qOdoUOdcb .-';;;'-. CgggOU ddqOp qOdoUOdcb *
* 6OuU /p u gcoUodpP / | \ jgs ooSec cdac pdadfoof *
* \\\// /douUP ' \\\d\\\dp/pddoo *
* \\\//// \\ \\//// *
* |||/\ \\/// *
* |||\/ |||| *
* ||||| /||| *
** .............//||||\.......................//|||\\..................... **
\*** ===================================================================== ***/
Деревья
Начнём с простой древовидной структуры. В ней нет особых правил, и выглядит она примерно так:
Tree {
root: {
value: 1,
children: [{
value: 2,
children: [...]
}, {
value: 3,
children: [...]
}]
}
}
Дерево должно начинаться с единственного родителя, «корня» дерева.
class Tree {
constructor() {
this.root = null;
}
// ...
}
Нам нужен способ обходить наше дерево и вызывать определённую функцию в каждой его вершине.
traverse(callback) {
// Определим функцию обхода walk, которую можно рекурсивно вызывать
// в каждой вершине дерева.
function walk(node) {
// Сперва вызовем callback на самой вершине.
callback(node);
// Затем рекурсивно вызовем walk на всех её потомках.
node.children.forEach(walk);
}
// А теперь запустим процесс обхода.
walk(this.root);
}
Теперь нужен способ добавлять вершины в дерево.
add(value, parentValue) {
var newNode = {
value: value,
children: []
};
// Если корня не существует, установим в него новую вершину.
if (this.root === null) {
this.root = newNode;
return;
}
// В остальных случаях переберём внутреннее дерево, найдём вершину
// с соответствующим значением parentValue и добавим новую вершину
// к его потомкам.
this.traverse(function(node) {
if (node.value === parentValue) {
node.children.push(newNode);
}
});
}
Это простое дерево, возможно, полезное лишь в случае, когда отображаемые данные на него похожи.
Однако при наличии дополнительных правил деревья могут выполнять кучу различных задач.
/*** ===================================================================== *** * 0 0 1 0 1 0 0 1 0 1 1 1 0 1 ,@@@@@@@@@@@@@@, 0 0 1 0 1 0 0 1 0 1 1 1 0 *
* 0 1 0 1 0 1 0 1 1 0 1 1 0 @@` '@@ 0 1 0 1 0 1 1 0 1 0 1 0 *
* 1 1 0 0 0 1 0 0 1 1 1 0 @@` 8O8PoOb o8o '@@ 0 0 1 0 0 1 0 0 1 1 1 *
* 0 0 1 1 0 1 0 1 0 0 0 @@ dOB69QO8PdUgoO9bD @@ 1 0 1 1 0 1 0 1 0 0 *
* ===================== @@ CgbU8OU qOp qOdOdcb @@ 0 1 1 0 1 0 1 0 1 0 *
* @@ 6OU /p u gcoUpP @@ 1 0 1 1 0 1 0 0 1 1 *
* ===================== @@ \\// /doP @@ 0 1 1 0 0 1 0 0 1 0 *
* 1 1 0 0 1 1 0 1 1 0 0 @@ \\// @@ 1 0 1 0 0 1 1 0 1 1 *
* 0 1 1 0 1 0 1 1 0 1 1 0 @@, ||| ,@@ 0 1 1 0 1 1 0 0 1 0 1 *
* 1 0 1 0 1 1 0 0 1 0 0 1 0 @@, //|\ ,@@ 0 1 0 1 0 1 1 0 0 1 1 0 *
** 1 0 1 0 0 1 1 0 1 0 1 0 1 `@@@@@@@@@@@@@@' 0 1 1 1 0 0 1 0 1 0 1 1 **
\*** ===================================================================== ***/
Двоичные деревья поиска
Двоичные деревья поиска — распространённая форма деревьев. Они умеют эффективно читать, искать, вставлять и удалять значения, сохраняя при этом отсортированный порядок.
Представьте, что у вас есть последовательность чисел:
1 2 3 4 5 6 7
Развернём её в дерево, начинающееся из центра.
4
/ 2 6
/ \ / 1 3 5 7
-^--^--^--^--^--^--^-
1 2 3 4 5 6 7
Вот пример, как работает бинарное дерево. У каждой вершины есть два потомка:
- Левый — меньше, чем значение вершины-родителя.
- Правый – больше, чем значение вершины-родителя.
Замечание: для того, чтобы это работало, все значения в дереве должны быть уникальны.
Это делает обход дерева при поиске значения очень эффективным. Например, попробуем найти число 5 в нашем дереве.
(4) <--- 5 > 4, двигаемся направо.
/ 2 (6) <--- 5 < 6, двигаемся налево.
/ \ / 1 3 (5) 7 <--- Мы добрались до 5!
Заметьте, чтобы добраться до 5, потребовалось сделать лишь 3 проверки. А если бы дерево состояло из 1000 элементов, путь был бы таким:
500 -> 250 -> 125 -> 62 -> 31 -> 15 -> 7 -> 3 -> 4 -> 5
Всего 10 проверок на 1000 элементов!
Ещё одной важной особенностью двоичных деревьев поиска является их схожесть со связными списками — при добавлении или удалении значения вам нужно обновлять лишь непосредственно окружающие элементы.
Как и в прошлой секции, сперва нужно установить “корень” двоичного дерева поиска.
class BinarySearchTree {
constructor() {
this.root = null;
}
// ...
}
Чтобы проверить, находится ли значение в дереве, нужно провести поиск по дереву.
contains(value) {
// Начинаем с корня.
var current = this.root;
// Мы будем продолжать обход, пока есть вершины, которые можно посетить.
// Если мы достигнем левой или правой вершин, равных null, цикл закончится.
while (current) {
// Если значение value больше current.value, двигаемся вправо.
if (value > current.value) {
current = current.right;
// Если значение value меньше current.value, двигаемся влево.
} else if (value < current.value) {
current = current.left;
// Иначе значения должны быть равны и мы возвращаем true.
} else {
return true;
}
}
// Если мы не нашли ничего, возвращаем false.
return false;
}
Чтобы добавить элемент в дерево, нужно произвести такой же обход, как и раньше, перепрыгивая по левым и правым вершинам в зависимости от того, больше или меньше ли они по сравнению с добавляемым значением.
Однако теперь, когда мы доберёмся до левой или правой вершины, равной null,
мы добавим вершину в эту позицию.
add(value) {
// Для начала создадим вершину.
var node = {
value: value,
left: null,
right: null
};
// Частный случай, если не существует корневой вершины — добавим её.
if (this.root === null) {
this.root = node;
return;
}
// Начнём обход с корня.
var current = this.root;
// Мы собираемся циклически продолжать работу до тех пор, пока не добавим
// наш элемент или не обнаружим, что он уже находится в дереве.
while (true) {
// Если значение value больше current.value, двигаемся вправо.
if (value > current.value) {
// Если правая вершина не существует, установим её и закончим обход.
if (!current.right) {
current.right = node;
break;
}
// Иначе перейдём на правую вершину и продолжим.
current = current.right;
// Если значение value меньше current.value, двигаемся влево.
} else if (value < current.value) {
// Если левая вершина не существует, установим её и закончим обход.
if (!current.left) {
current.left = node;
break;
}
// Иначе перейдём на левую вершину и продолжим.
current = current.left;
// Если значение ни больше и не меньше, оно должно быть совпадать
// с текущим, значит ничего делать не надо.
} else {
break;
}
}
}
/*** ===================================================================== *** * .''. *
* .''. *''* :_\/_: . *
* :_\/_: . .:.*_\/_* : /\ : .'.:.'. *
* .''.: /\ : _\(/_ ':'* /\ * : '..'. -=:o:=- *
* :_\/_:'.:::. /)\*''* .|.* '.\'/.'_\(/_'.':'.' *
* : /\ : ::::: '*_\/_* | | -= o =- /)\ ' * *
* '..' ':::' * /\ * |'| .'/.\'. '._____ *
* * __*..* | | : |. |' .---"| *
* _* .-' '-. | | .--'| || | _| | *
* .-'| _.| | || '-__ | | | || | *
* |' | |. | || | | | | || | *
* _____________| '-' ' "" '-' '-.' '` |____________ *
** jgs~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ **
\*** ===================================================================== ***/
Конец
Надеюсь, вы получили хорошую дозу знаний. Если вам понравилось,
ставьте звездочки в репозитории и подписывайтесь на меня в твиттере.
Также можете прочитать другую мою статью, «The Super Tiny Compiler» github.com/thejameskyle/the-super-tiny-compiler
// Экспортируем модули для тестов...
module.exports = {
List: List,
HashTable: HashTable,
Stack: Stack,
Queue: Queue,
Graph: Graph,
LinkedList: LinkedList,
Tree: Tree,
BinarySearchTree: BinarySearchTree
};
Также эту статью можно прочитать на гитхабе.
Перевод: aalexeev, редактура: iamo0, Чайка Чурсина.
Комментарии (46)

A-Stahl
23.09.2016 16:58-7Вы уж простите, но из-за иллюстраций к статье я не могу удержаться от оффтопа (я развлекаюсь иногда написанием ASCII игрушек под андроид): http://asciigames.tk
P.S. И никакого ЯваСкрипта. Qt и, соответственно Си++.
P.P.S. Да, это по факту спам и я спамер. Презирайте меня, насмехайтесь надо мной. Можете даже кота забрать, я заслужил:)
gunlinux
23.09.2016 17:01+2Статье понадобилось 2 минуты, чтобы я понял профит от деревьев поиска. В универе это заняло кучу времени и не сказал бы, что отложилось в памяти. Спасибо.
Ddnn
25.09.2016 00:10Странно, мне, например, профит от деревьев поиска стал очень явно понятен как раз из университетской лабораторной — посчитать для каждого слова из файла, сколько раз оно употребляется, и записать все слова с посчитанной информацией в другой файл( тема работы, кстати, к деревьям вообще никак не относилась).
std::map из стандартной библиотеки С++ отлично показал, чем логарифмическое время вставки и поиска отличается от линейного, когда во входном файле оказалось 700 тысяч слов.



SilverFerrum
23.09.2016 18:09Спасибо за статью.
А мне нравятся nested tree.
Можно получить информацию о местоположении элемента в структуре, сделав только один запрос.

vlade11115
23.09.2016 19:21+1Классические книги по структурам данных легко гуглятся, но такие статьи редкость.
Для немного более глубокого погружения советую интерактивный учебник http://aliev.me/runestone/
Он на питоне, но язык простой и базовый минимум для понимания примеров есть во введении.


lookid
24.09.2016 07:17-4Это не для самых маленьких. Это вообще никак. Алгоритмы нужно учить через Problem Solving. Кормен должен осваиваться в полном объеме за 1-2 семестра 1 курса. Иначе вы будете плавать и тупить при решении задач, путаться в рекурсии и мемоизации, динамике и гриди,

iit
24.09.2016 07:39+1Отличный перевод статьи!
Списки реализовывали еще в колледже на старом добром pascal, к сожалению про деревья рассказывали что они просто есть и ни одного сами не реализовывали.
Понимание принципов работы структур данных сильно упрощает жизнь разработчику. Вот по деревьям упоролся на совсем странной ситуации: делал сторонний проект суть которого — разбор xml файлов размером ~3гб.
Язык php (можете кинуть в меня камень, но не я такой — специфика заказчика).
Изначально работая с dom обработка файла с сохранением в базу занимала около 3 часов. Если посмотреть в сторону более легковесного simpleXML то уже 2.5 часа, сам объект simpleXmlElement компактнее серии объектов из dom.
Далее если изначально перегнать все данные из XML объектов в дерево на массивах то разбор обработка уже сократится до 20 минут (массивы куда более производительны чем объекты). Отказавшись от старого доброго mysql в пользу postgres с переносом некоторых операций разбора на саму базу время уже сократилось до 20-30 секунд.
Итог — понимание того как устроены структуры данных в конкретном языке сократило выполнение операции с 3 часов до 30 секунд, при этом еще и уменьшились затраты памяти и процессорного времени. Так что учите структуры данных и способы работы с ними — пригодиться в самый внезапный момент.G-M-A-X
24.09.2016 20:47Большие xml файлы никогда не парсил с помощью simpleXML, а тем более dom, для этого есть xml_parser_create и подобные ф-и.
Наверное, больше времени будет занимать сам парсинг файла, нежели обработка.iit
24.09.2016 21:37В сторону xml_parser_create и прочего пока не смотрел.
Само создание и обход xml древа выполняется достаточно быстро. Но вот dom и simpleXML как результат разбора возвращают объект. И вот обработка коллекции из более миллиона объектов средствами php вызывает просто дикие тормоза и нагрузку на память и процессор, если при разборе сразу перевести объекты в массивы и построить коллекцию уже из массивов — тогда обработка идет уже намного быстрее.G-M-A-X
25.09.2016 19:17Хм, а у меня тупил сам парсинг и памяти много жрало. :)
Поэтому и использовал xml_parser_create.
Это ж ООП.
Чего вы хотели :)
kuda78
24.09.2016 09:12Добавление элемента в конец списка — константа O(1) — «ОХРЕНЕННО!!»
А почему не учтена сложность на операцию увеличения размера списка (grow)? этом случае сложность становится O(N).
aalexeev
24.09.2016 12:51Приведите, пожалуйста, пример.
poxu
25.09.2016 22:28+6Собственно пример уже приведён — добавление элемента в конец списка.
Посмотрел внимательнее описание списка в статье — нет слов. С чего начинать критику — неясно. Понятно одно. Уверенно говорить о сложности добавления в конец списка из статьи вообще нельзя.
Пойдём по пунктам.
То, что в статье наызвают списком, обычно списком не называется
Списком обычно называют то, что в статье называется связным списком. Обычно список и связный список — синонимы. Это вопрос терминологии, но он очень путает, потому что добавление в конец связного списка — действительно O(1), и если не вчитываться — можно не понять где тут читателя кидают :)
Массивы из статьи — особые
уличныеджваскриптовые массивы
Дальше интереснее. Список из статьи реализован на основе массива. Этот массив — джаваскриптовый, что означает, что туда можно добавить элемент с любым индексом. Например, если в массиве один элемент, то можно добавить туда элемент с индексом 10 и джаваскрипт это скушает. Правда в массиве будет "дырка" на 9 элементов. Или можно, как в статье, добавить туда элемент с индексом 1 и тогда в массиве будет элемент с индексом 0 и с индексом 1 и дырки не будет. То есть, если в массиве 1 элемент — можно безо всяких проблем добавить второй — массив автоматом вырастет.
Обычные массивы сами по себе не растут
Во многих других языках программирования при создании массива надо задавать его размер, поменять который нельзя — можно только создать новый массив побольше и скопировать туда элементы старого.
Запись в массив по индексу стоит O(1)
Так вот — например у нас есть массив из 20 элементов и на его основе мы сделали список в который пока положили 10 элементов. То есть переменная length равна 10. И вот мы хотим добавить в список ещё один элемент. Тогда мы запишем новый элемент в массив по индексу 10 и увеличим переменную length на еденицу. Она теперь равна 11. Вот эта операция действительно стоит O(1).
Расширение массива стоит O(N)
Но если в списке, внутри которого массив из 20 элементов уже 20 элементов и есть (переменная length равна 20), то мы не можем записать новый элемент в индекс 20 и увеличить значение length, потому что массив слишком маленький. Теперь нам надо сделать новый массив из 40 элементов, скопировать туда элементы из предыдущего массива и уже потом записать новый элемент в новый массив по индексу 20 и увеличить переменную length до 21. И эта операция, как несложно догадаться, происходит за O(N), потому что надо скопировать N элементов.
Можно подумать, что вот этот случай с O(N) — не показателен, так как мы выращиваем массив 2 раза и потом ещё 20 элементов добавим за O(1). Потом нам, конечно, придётся скопировать массив в новый ещё раз. Но ведь после этого мы добавим за O(1) ещё 40 элементов.
Но это иллюзия. Допустим у нас есть пустой массив и мы хотим добавить в
конец 10 элементов. Тогда нам надо сделать следующую последовательность действий.
- Создаём новый массив на 2 элемента и записываем туда 1 элемент по индексу 0. 1 действие.
- Записываем в массив элемент по индексу 1. 1 действие.
- Создаём новый массив из 4 элементов и копируем туда 2 элемента из старого массива. Потом записываем туда элемент по индексу 2. 3 действия.
- Записываем в массив элемент по индексу 3. 1 действие.
- Создаём новый массив из 8 элементов и копируем туда 4 элемента из старого массива. Потом записываем туда элемент по индексу 4. 5 действий.
- Записываем в массив элементы по индексу 5, 6, 7. 3 действия.
- Создаём новый массив из 16 элементов и копируем туда 8 элементов из старого массива. Потом записываем туда элемент по индексу 8. 9 действий.
- Записываем в массив элементы по индексу 9. Одно действие.
Итак, нам понадобилось добавить в список 10 элементов.
И для этого нам понадобилось произвести 24 действия.
Посчитаем только операции копирования, из старого массива в новый. Получится 2 + 4 + 8 = 14. Вот где она линейная сложность, то есть O(N). N = 10, надо сделать 14 дополнительных копирований.
Джаваскриптовые массивы — вообще не массивы
В джаваскрипте за массивом стоит очень хитрая структура данных
и если вы делаете так
var memory = []; var length = 0; memory[length] = 2; ++length;
то для того, чтобы узнать O(1) у вас или O(N) или O(log(N)) — надо лезть в исходники интерпретатора. Возможно там не массив, а HashTable (чтобы можно было иметь нецифровые индексы и дырки), а может быть там гибридная структура, которая будет массивом, пока вы не начнёте добавлять нецифровые индексы и дырки, а потом распадётся на HashTable и обыкновенный массив. Сложно сказать наверняка, когда в ход идёт уличная магия и коварные оптимизации. Ну и сложность добавлений в конец списка, реализованного автором явным образом такая же как сложность добавления элемента в конец массива. То есть неизвестная.
Такие дела.
Ddnn
26.09.2016 01:37+1Если я не ошибаюсь, то добавление элемента в конец массива корректнее рассматривать как амортизированное О(1), а не как «иногда О(1), иногда О(N)» — если под массивом понимать модифицированный сишный массив (или С++-ный вектор).
Учитывая, что максимальный размер массива ограничен, то ограничено и количество реаллокаций памяти под массив, и количество копирований элементов. Следовательно, можно ограничить сверху стоимость одного добавления константой С (для разных начальных размеров массива она будет разной). Время добавления в конец массива = О(С)= О(1). Конечно, стоит помнить, что это не совсем обычная константа, но О(N) является еще более грубой оценкой.
poxu
26.09.2016 09:45Это правда. Корректно говорить об O(1) в лучшем случае, O(N) в худшем и O(1) амортизированном. А то о чём написал я в предпоследней части — это дополнительная стоимость добавления первых N элементов. Надо было сделать дополнительнй заголовок.
Проблема статьи в том, что автор вообще никак не рассматривает момент, что массив надо выращивать и сколько это стоит в случае с джаваскриптом.

aktuba
26.09.2016 21:04А разве это не «фича» реализации? Если разговор идет о структурах данных — нет смысла обговаривать какую-либо реализацию и тогда получается именно О(1) для структуры. А для реализаций время и сложность будет различаться.
poxu
27.09.2016 06:42Нет, это не фича реализации. Это имманентное свойство структуры данных. В нашем случае списка на основе массива. Именно для такой структуры будет в лучшем случае O(1) и в худшем, когда надо увеличивать массив — O(N).
Для реализаций что-то действительно может меняться. Например, можно копировать элементы в другой массив не по одному, а блоками — это несколько улучшит ситуацию. Но в данном случае нам показывают не другую реализацию, а другую структуру данных — не список на основе массива, а список на основе джаваскриптового массива, который имеет совсем другие свойства. В том числе сам растёт и в том числе там не совсем понятно какова сложность даже доступа по индексу, не говоря уже о сложности увеличения размера.
aktuba
27.09.2016 11:36>В нашем случае списка на основе массива.
Ну я как-раз говорил о структуре «список», а не «список на основе массива». Про последнюю «структуру данных» слышу впервые)poxu
27.09.2016 12:37Вас путает тот факт, что структура данных, которую автор называет списком, обычно называется динамическим массивом. Ключевым различием тут является то, что массив обязательно предоставляет произвольный доступ к элементам, а список такого контракта не имеет.
Вообще когда мы говорим о структуре данных без реализации, то об алгоритмической сложности особенно то ничего и не скажешь. В случае с тем же списком операции добавления и удаления имеют разную сложность в зависимости от реализации, а теория, насколько я помню лишь определяет список как структуру данных, хранящую множество элементов в определённой последовательности. Один и тот же элемент может встречаться в списке больше одного раза.
aktuba
27.09.2016 20:23Хм… Согласитесь, реализация подобного списка отличается в зависимости от используемого языка, платформы, мозга программиста. Соответственно, алгоритмическая сложность каждой реализации будет индивидуальна. В то-же время, алгоритмическая сложность именно структуры данных (без реализации) — величина (достаточно) постоянная.
Видимо, пора перечитывать Кнута, а то какие-то сомнения поселились в голове…
aalexeev
26.09.2016 23:25Спасибо за развернутый и полезный комментарий.
Надеюсь, вы понимаете, что статья рассчитана на нулевой уровень знаний, и её цель — дать минимальные зачатки предмета. Здорово, что вы акцентировали внимание на неточностях и задали направление, в котором следует разбираться дальше.poxu
27.09.2016 07:07То, что статья рассчитана на нулевой уровень — не повод закрывать глаза на грубые ошибки. С таким же успехом можно в статье, посвящённой истории человечества рассказывать, что австралопитеки охотились с собаками и называть это неточностями.
В моем комментарии внимание акентировано не на неточностях, а именно на грубой ошибке — на том, что автор не написал, что кусок памяти нельзя просто расширить и что это расширение стоит O(N). Кроме того, создаётся впечатление, что автор и вправду считает джаваскриптовый массив просто пустым блоком памяти.
Я тут просмотрел статью ещё раз и списком то всё не исчерпывается. Описанная в статье хэш таблица просто напросто не работает. Что будет, если туда положить объект по какому-то ключу, а потом положить другой объект по другому ключу, у которого hashKey такой же как у первого ключа?
aalexeev
27.09.2016 10:21К сожалению, мне не хватает знаний, чтобы аргументированно спорить. Вероятно, автор ошибся. Вы можете написать ему об этом в оригинальный репозиторий.
Что касается хеш-таблиц, автор оговаривает, что коллизий не предполагается.
aalexeev
27.09.2016 10:32Пардон, выше неправильная ссылка.
https://github.com/thejameskyle/itsy-bitsy-data-structurespoxu
27.09.2016 11:15+1Я думаю автор не ошибся, а считает, что рассказывать про расширение массива просто не нужно и тут я с ним не согласен. Свои сомнения я ему уже высказал, посмотрим что он ответит.
С хэш таблицами ведь похожая история — большая часть алгоритмов для хэш таблиц — это алгоритмы разрешения коллизий. Но тут автор хотя бы прямо написал, что коллизий не будет :)

babylon
24.09.2016 10:48Лично мне понравилась подача материала. Конечно все примеры учебные и в рабочем проекте не прокатят. Если только не взять и сделать так как в статье. Что маловероятно.
guzoff
24.09.2016 14:13+2У Вас, как и у автора в оригинале, ошибка в методе List.shift():
// Проходимся по каждому элементу…
for (var address = 0; address < this.length; address++) {
// и заменяем его на следующий элемент списка.
this.memory[address] = this.memory[address + 1];
}
Во время последней итерации значение переменной address будет равно this.length-1, следовательно address+1 будет равно this.length — обратившись по этому адресу, мы выйдем за границы массива.
Поэтому цикл должен быть с такими параметрами:
for (var address = 0; address < (this.length-1); address++)
Разве не так?

poxu
26.09.2016 14:28-3Уважаемый переводчик, слово AWESOME не переводится, как ОХРЕНЕННО. Мальчик семи лет может сказать маме что It's AWESOME. А вот если мальчик семи лет скажет маме, что это ОХРЕНЕННО вообще, то не исключено, что его пороть будут.

nickolaym
26.09.2016 14:32+1Аски-арт, причём такой отвлечённый, в стиле «чавой-то мне скушно было, вам тоже небось скушно будет, поэтому давайте поприкалываемся» — только мешает.
не_надо_так.jpg

TimeCoder
28.09.2016 09:48Спасибо! а почему удаление из списка О(1)? ведь прежде, чем разорвать цепочку ссылок, элемент надо найти, хоть по индексу, хоть по значению. Или в оценках удалений всегда считают, что мы уже стоим на элементе?
babylon
Шедевр!