Современные компьютерные системы, от обычного ноутбука до вычислительного кластера, рассчитаны на параллельную обработку данных. Поэтому, чем полнее программы задействуют эту возможность, тем больше у них шансов раскрыть потенциал существующих аппаратных решений. Однако, прежде чем переходить к параллельной схеме исполнения кода, этот код должен максимально эффективно работать в однопоточном режиме. Иначе увеличение числа потоков не даст ожидаемого роста производительности.
Оптимизации, которые влияют на скорость вычислений при использовании любого числа потоков, сводятся к учёту в коде особенностей процессорных архитектур, наборов инструкций, к поиску наиболее рациональных способов работы с разными видами памяти. Помощь в подобной оптимизации способен оказать, например, подход к исследованию производительности методом «сверху вниз» с использованием низкоуровневых данных о системных событиях, которые преобразуются в доступные для анализа и практического применения высокоуровневые показатели.

Здесь мы рассмотрим методику оптимизации вычислений, связанных с моделированием течений многофазных жидкостей в пористых средах по методике, предложенной в этой работе. Речь идёт о численном методе решения дифференциальных уравнений гиперболического типа в частных производных.
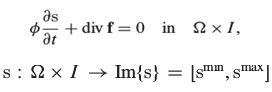
Моделирование течений многофазных жидкостей в пористых средах
Данная задача находит применение во многих сферах. Например, в области добычи нефти и газа, в промышленности, экологии.
Мы рассмотрим методики векторизации кода, расскажем о переходе от последовательного к параллельному исполнению, проведём ряд экспериментов. Эксперименты проводились на платформах Intel, для анализа и оптимизации приложения применялись различные программные средства, в частности, Intel VTune Amplifier.
Материал состоит из трёх основных разделов:
Здесь, в качестве аппаратной платформы для экспериментов, используется система на Ubuntu 14.04 с установленным процессором Intel Core i5-4350U (1.4 ГГц, 2 ядра, 4 потока) с 3 Мб кэш-памяти и 4 Гб RAM. Наша экспериментальная среда построена на процессоре, принадлежащем к семейству Intel Haswell, которое отличается полной поддержкой набора инструкций Intel AVX2. Использование возможностей этого набора инструкций, в частности, улучшенная поддержка векторизации, позволяет повысить производительность приложений, предназначенных для широкого спектра платформ, среди них – серверные решениях на базе Intel Xeon и Intel Xeon Phi.
При разработке для Intel AVX2 используется та же модель программирования, что использовалась в предыдущей версии, Intel AVX, однако, новые инструкции расширяют то, что было, предлагая большинство 128-битных целочисленных SIMD инструкций с возможностью обработки 256-битных чисел. Векторизация кода позволяет раскрыть потенциал однопоточного варианта программы, что крайне важно перед переходом к следующему шагу – параллельному исполнению.
Для анализа производительности и оценки качества оптимизации здесь использована Intel Parallel Studio XE 2015.
Для того, чтобы понять, как оптимизировать код, нужно его проанализировать и найти блоки программы, исполнение которых можно ускорить за счёт векторизации и параллелизации. Для того, чтобы этого достичь, можно воспользоваться инструментами Intel, такими, как Intel VTune Amplifier и Intel Parallel Advisor. Весьма полезны в этом плане и отчёты, которые генерирует компилятор.
Подобные инструментальные средства позволяют анализировать исходный код приложения и исполняемые файлы, давая подсказки о направлениях оптимизации. Исследованию, в основном, подвергаются узкие места производительности в конвейере процессора.
Современные микропроцессоры реализуют конвейерное исполнение инструкций, и, вместе с этим подходом, используют другие техники, такие, как аппаратные потоки, выполнение команд с изменением их очерёдности, параллелизм на уровне инструкций. Делается всё это для того, чтобы наиболее полно использовать ресурсы системы.
Перед программистом, который занимается оптимизацией кода, стоит непростая задача. Главная сложность здесь в том, что ему нужно как можно эффективнее использовать аппаратные возможности компьютера, а они находятся на уровне микроархитектуры вычислительной системы, который расположен довольно далеко от уровня абстракции, предоставляемого современными языками программирования, такими, как C, C++ и Fortran.
Инструменты Intel могут помочь в оптимизации кода, анализируя компиляцию и компоновку приложения, давая сведения о временных параметрах исполнения программы для определения того, как именно используются аппаратные ресурсы. Среди этих инструментов – отчёты компилятора, Intel VTune, Intel Parallel Advisor. Вот как можно организовать работу с ними.
Программист, скомбинировав данные, полученные с помощью вышеперечисленных средств, может изменить исходный код программы и параметры компиляции для того, чтобы достичь целевых показателей оптимизации.
Современные компиляторы способны векторизовать исполняемый код. В частности, для этого устанавливают параметр оптимизации в значение -
В двух словах, векторизация – это такое преобразование программы, после которого одна инструкция способна выполнять некоторые действия с несколькими наборами данных. Рассмотрим в качестве примера обработку нижеприведённого цикла.
Если этот цикл не подвергся векторизации, то использование регистров при его исполнении выглядит примерно так, как показано на рисунке ниже.
Использование регистров при исполнении цикла, который не подвергся векторизации
Если тот же самый цикл векторизовать, будут задействованы дополнительные регистры, как результат, можно будет выполнять четыре операции сложения, используя одну инструкцию. Это называют «один поток команд – много потоков данных» (Single Instruction Multiple Data, SIMD).
Исполнение векторизованного цикла
Подобный подход обычно позволяет повысить производительность, так как одна инструкция обрабатывает несколько наборов данных вместо одного.
В приложении моделирования потока в пористых средах, оптимизацией которого мы занимаемся, автоматическая векторизация позволила повысить производительность в два раза на процессоре семейства Haswell, который поддерживает набор инструкций Intel AVX2.
Параметр -
На рисунке ниже показан сводный отчёт Intel VTune Amplifier по программе, скомпилированной без использования параметра -
Отчёт VTune Amplifier, параметр -xHost не используется
Основная цель оптимизации в данном случае заключается в уменьшении времени исполнения кода и увеличении CPI, который, в идеале, должен составлять 0.75, что означает полное использование возможностей конвейера.
На рисунке ниже показан список модулей приложения, отсортированный по эффективно используемому машинному времени.

Список модулей приложения
Обратите внимание на то, что функция
Обратите внимание на то, что CPI очень плох у функции
Вот фрагмент исходного кода функции

Фрагмент ассемблерного кода линейной реконструкции
В этом фрагменте кода можно видеть следующие инструкции: MULSD, MOVSDQ, SUB, IMUL, MOVSXD, MOVL, MOVQ, ADDQ. Все они из набора инструкций Intel Streaming SIMD Extensions 2 (Intel SSE2). Эти «старые» инструкции появились с выходом в ноябре 2000-го года процессора Intel Pentium 4.
Скомпилировав тот же самый код с параметром
Отчёт VTune Amplifier, параметр -xHost используется
А именно, время исполнения кода теперь составило 65.6 секунд, CPI – 0.62, что гораздо лучше, чем было раньше и ближе к идеальному значению 0.75.
Для того, чтобы понять причину подобного роста производительности, можно взглянуть на ассемблерный код. Там обнаружатся инструкции из набора команд Intel AVX2. Кроме того, сравнивая отчёты VTune Amplifier, можно заметить, что при использовании Intel AVX2 число выполненных инструкций гораздо меньше, чем в случае с применением SSE2 в невекторизованной версии кода.
Это происходит из-за того, что в итоговых данных не учитываются инструкции, исполнение которых было отменено, так как они находились в ветке, по которой не должно было пойти исполнение кода из-за неверного предсказания ветвлений. Меньшее число подобных ошибок так же объясняет улучшение параметра CPI.
Вот тот же фрагмент исходного кода, который мы рассматривали выше, но теперь его ассемблерное представление получено после включения параметра -
Фрагмент векторизованного ассемблерного кода линейной реконструкции
Обратите внимание на то, что большинство инструкций здесь – векторные, из набора Intel AVX2, а не из SSE2. Имена векторных инструкций начинаются с префикса
Например, использование инструкции VMOV вместо MOV указывает на то, что мы имеем дело с векторизованным кодом.
На рисунке ниже вы можете видеть сравнение регистров для наборов инструкций Intel SSE2, AVX и AVX2.

Регистры и наборы инструкций
Простой в применении подход с включением автоматической векторизации позволяет достичь трёхкратного роста производительности.
В системе, с которой мы экспериментируем, на двух физических ядрах могут исполняться 4 потока. Сейчас единственное сделанное улучшение кода – это автоматическая векторизация, выполненная компилятором. Мы пока далеки от программы, которая способна работать на пределе возможностей системы, код ещё можно оптимизировать. Для того, чтобы продолжить улучшение кода, нужно выявить его узкие места. Например, в исходном варианте нашего приложения имеется множество строк, где используется деление.
Опция
Вот фрагмент исходного кода, где часто используется операция деления. Этот код находится внутри функции

Множество операций деления в важном участке кода
Однако, у опции
Вот ещё одна важная проблема, которую можно решить с помощью инструментов Intel. В нашем случае она заключается в том, что множество модулей приложения написано на Fortran, что усложняет их оптимизацию. Для того, чтобы при подготовке кода к исполнению была выполнена межпроцедурная оптимизация, используется опция
С использованием опций

Результат использования опций –ipo, -xHost и –no-prec-div
Для того, чтобы лучше понять вклад в производительность программы, который вносит использование опции
Ещё одно испытание, на этот раз с отключённой опцией
Intel VTune Amplifier может не только сообщать о времени, затраченном на исполнение программы, о CPI, и о том, сколько инструкций было выполнено. Используя его профиль General Exploration, можно получить сведения о поведении программы внутри конвейера процессора и выяснить, можно ли улучшить производительность, если учесть ограничения процессора и памяти.
Ограничения вычислительного ядра (Core Bounds) относятся к проблемам, не связанным с передачей данных в памяти и воздействуют на производительность при исполнении инструкций с изменением их порядка или при перегрузке операционных блоков. Ограничения памяти (Memory Bounds) способны вызвать неэффективную работу конвейера из-за необходимости ожидания завершения инструкций загрузки/сохранения данных. Вместе два этих параметра определяют то, что называют Back-End Bounds, этот показатель можно воспринимать как ограничения, возникающие внутри конвейера.
Если же простои конвейера вызваны незаполненными слотами, то есть, тем фактом, что микрокоманды не успевают поступать в него по каким-либо причинам, и часть конвейера не выполняет полезной работы только потому что ей нечего обрабатывать, перед нами уже так называемые Front-End Bounds – внешние по отношению к конвейеру ограничения.
Вот схема типичного современного конвейера, поддерживающего исполнение кода с изменением последовательности команд.
Конвейер процессора Intel, поддерживающий исполнение инструкций с изменением их порядка
Внутренние структуры, back-end конвейера, представляют собой порты для доставки инструкций к ALU, к блокам загрузки и сохранения. Несбалансированное использование этих портов обычно плохо сказывается на производительности, так как некоторые блоки могут либо простаивать, либо использоваться не так равномерно, как другие, которые оказываются перегруженными.
Для приложения, которое мы здесь рассматриваем, анализ показал, что даже при использовании автоматической векторизации, выполняемой компилятором, имеются проблемы при исполнении кода. А именно – высокое значение показателя Core Bound из-за несбалансированного распределения инструкций по портам.
Ограничения вычислительного ядра
Результаты анализа, показанные на рисунке выше, указывают на высокий уровень тактовых циклов (0.203, или 20.3%), в которых не задействован ни один порт. Это говорит о неэффективном использовании ресурсов процессора. Кроме того, заметен высокий уровень циклов (0.311, или 31.1%), когда задействованы три или более порта. Такая ситуация приводит к перегрузке. Очевидно, перед нами несбалансированное использование ресурсов.
Результаты анализа ситуации, выполненные в Intel VTune Amplifier и показанные на рисунке ниже, позволяют обнаружить причины вышеописанных проблем. В данном случае видны четыре функции (
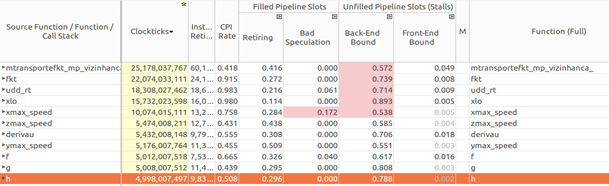
Анализ показателей Back-End Bound и Bad Speculation
Следующий шаг наших изысканий заключается в использовании Intel VTune Amplifier в качестве инструмента для анализа выявленных проблем. Мы собираемся тщательно изучить каждую отмеченную выше функцию для того, чтобы найти участки кода, из-за которых процессорное время тратится впустую.
Анализируя каждую функцию, которая имеет высокий показатель в графе Back-End Bound, можно выяснить, где именно возникают проблемы. На нескольких рисунках, приведённых ниже, можно видеть, что Intel VTune Amplifier показывает исходный код и соответствующие метрики для каждой строки. Среди них – успешно завершённые инструкции (Retiring), ошибки предсказаний (Bad Speculation), такты (Clockticks), CPI, ограничения внутри конвейера (Back-End Bound). В общем случае, высокое значение показателя Clockticks указывает на ответственные строки кода и VTune выделяет соответствующие им значения.
Вот анализ функции
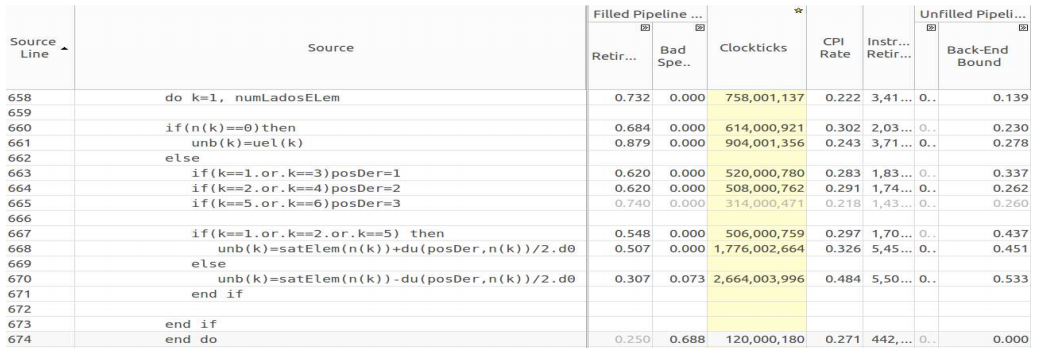
Анализ причин высокого значения показателя Back-End Bound в функции transport
Функцию
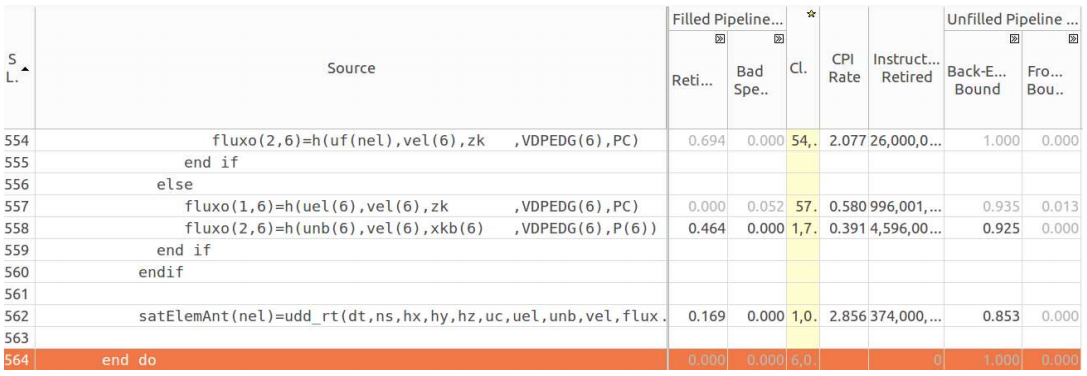
Анализ функции fkt
Вот код функций
Здесь важно обратить внимание на то, что здесь идёт речь о двумерных компонентах вектора

Функция

Функция xlo
Вот анализ функции
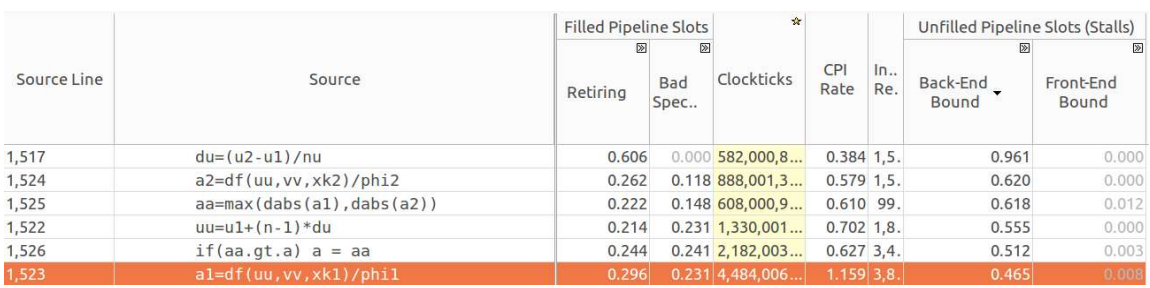
Функция xmax_speed
Intel VTune Amplifier использует данные о функциях, анализ которых мы провели выше, для нахождения итогового показателя Back-End Bound.
Как уже было сказано, причиной возникновения такого рода ограничений может являться неэффективное использование процессора или памяти. Так как автоматическая векторизация уже была применена к нашему коду, весьма вероятно, что причина возникшей ситуации – в памяти. Дальнейший анализ, а именно, рассмотрение показателя Memory Bound, данные по которому приведены ниже, позволяет говорить о том, что программа неэффективно использует кэш первого уровня (показатель L1 Bound).

Показатель Memory Bound
Поскольку в приложении имеется большое количество структур данных, таких, как векторы, необходимых во множестве различных функций, их нужно тщательно исследовать для того, чтобы найти подходы к улучшению производительности за счёт уменьшения задержек, связанных с памятью. Кроме того, стоит обратить внимание на выравнивание данных для того, чтобы помочь векторизации кода.
Для того, чтобы обнаружить больше возможностей оптимизации кода посредством векторизации, следует воспользоваться отчётами компилятора, так как в них можно найти сведения о циклах, которые можно векторизовать. Модуль
Некоторые внешние циклы не векторизуются из-за того, что соответствующие внутренние циклы уже векторизованы благодаря описанной выше методике автоматическое векторизации. В подобной ситуации компилятор выдаёт такое сообщение:
В некоторых случаях компилятор указывает разработчику на то, что для векторизации цикла ему следует воспользоваться директивой SIMD, но, когда это сделано, цикл всё равно не векторизуется из-за того, что в нём выполняется присвоение скалярной переменной:
Вот соответствующее сообщение компилятора:
Большая часть циклов была автоматически векторизована компилятором, и в некоторых случаях потенциальный рост производительности, оценённый компилятором, варьировался от 1.4 (большинство циклов) до 6.5 (такой показатель получен лишь для одного цикла).
Когда компилятор обнаруживает, что после векторизации производительность падает (то есть, рост производительности составляет меньше, чем 1.0), векторизацию он не проводит. Вот один из примеров сообщения компилятора в подобной ситуации.
Реально же производительность после автоматической векторизации выросла примерно в три раза, в соответствии с оценённым компилятором средним значением.
Анализ причин, по которым компилятор не выполняет векторизацию некоторых циклов, следует провести до применения других методов оптимизации.
Все тесты, которые проводились до настоящего момента, выполнялись в применении к решению задачи, пространство которой представляет собой сетку размером 100x20x100, при этом проводится 641 шаг вычислений с использованием одного вычислительного потока.
Здесь мы взглянем на работу с сетками других размеров для того, чтобы сравнить общий прирост производительности, полученный благодаря автоматической векторизации. Вот это сравнение.
Эти испытания показали, что чем больше сетка – тем больше и рост производительности, достигаемый благодаря автоматической векторизации. Это важный вывод, так как реальные задачи требуют большей точности, а значит, и больших сеток.
Ниже мы рассмотрим сетки большего размера для того, чтобы проверить эту гипотезу.
После того, как код векторизован, к нему применены автоматические, и, если это возможно, полуавтоматические методы оптимизации, можно заняться рассмотрением вопроса о том, насколько ускорится работа приложения при исполнении его в многопоточной среде. Для этой цели в данном разделе представлены результаты эксперимента по сравнению производительности приложения при использовании одного и двух потоков. Изучать приложение мы будем с помощью Intel VTune Amplifier.
Тесты, о которых здесь пойдёт речь, выполнены на системе, которая отличается от той, с которой мы экспериментировали ранее. На этом компьютере установлена Ubuntu 14.04.3 LTS, он оснащён процессором Intel Core i7-5500U (2.4 ГГц, 4 Мб кэш-памяти) с двумя ядрами и с поддержкой технологии HT (до четырёх одновременно исполняемых потоков). Этот процессор принадлежит к семейству Intel Broadwell, он полностью поддерживает набор инструкций Intel AVX2. В компьютере имеется 7.7 Гб оперативной памяти.
Процессоры семейства Broadwell производятся с использованием 14-нанометрового техпроцесса, развивая микроархитектуру Haswell. В стратегии «тик-так» («tick-tock»), которую использует Intel, это семейство относится к фазе «тик», то есть, это шаг, на котором уменьшен техпроцесс и произведены некоторые улучшения микроархитектуры, представленной ранее.
Для анализа производительности программы воспользуемся Intel VTune XE 2016. Первый эксперимент заключается в однопоточном исполнении кода, скомпилированного с использованием параметров
Расчёты с выполнением 641 шага для той же самой сетки размером 100x20x100, заняли 39.259 секунд, что означает рост производительности в сравнении с процессором семейства Haswell примерно в 1.4 раза. Вот часть отчёта об этом эксперименте из Intel VTune Amplifier.
Отчёт Intel VTune Amplifier
Анализируя эти данные, важно учитывать, что получены они на процессоре, который примерно в 1.7 раза быстрее, нежели тот, с которым мы экспериментировали ранее. А то, что при этом прирост в производительности составляет лишь около 1.4, говорит о неэффективном использовании вычислительных ресурсов.
Из отчёта видно, что показатель Back-End Bound оставляет 0.375. Это указывает на то, что даже увеличение тактовой частоты процессора не спасает в ситуации, когда причины неэффективного использования ресурсов системы не устранены.
На следующем рисунке показаны развёрнутые данные по показателю Back-End Bound.

Анализ отчёта Intel VTune Amplifier
Здесь видно, что причиной высокого значения обобщённого показателя Back-End Bound являются ограничения ядра (показатель Core Bound), а именно – задержки в блоке деления (Divider). Есть и другие проблемы, не связанные с блоком деления, на них указывает показатель Port Utilization. Этот показатель позволяет понять, насколько эффективно используются порты исполнения внутри ALU. Высокое значение Core Bound – это отражение последовательности запросов к модулю исполнения или следствие недостатка параллелизма на уровне инструкций в коде. Задержки в работе процессора могут указывать, кроме прочего, на неоптимальное использование порта исполнения. Например, операция деления, довольно ресурсоёмкая, может задержать исполнение, увеличивая потребность в порте, который обслуживает специфические типы микрокоманд. Это, как следствие, это приведёт к малому числу портов, задействованных в тактовом цикле.
Вышесказанное указывает на то, что код должен быть улучшен для того, чтобы избежать зависимости от данных. Здесь нужно применить более эффективный подход, нежели уже использованная автоматическая векторизация.
На рисунке ниже показан один из этапов анализа причин высокого значения показателя Back-End Bound, в частности, функции, которые вносят наибольший вклад в падение производительности, находятся в верхней части списка и выделены. Мы уже сталкивались с этими функциями.
Анализ в Intel VTune Amplifier
Сейчас можно сделать вывод о том, что даже при увеличении частоты процессора узкие места кода никуда не деваются, или проявляются в новых участках программы из-за исполнения команд с изменением их очерёдности и более высокой потребности в вычислительных ресурсах из-за более высокой скорости расчётов.
В деле оптимизации очень важно проанализировать воздействие параллелизма на ускорение работы приложения с использованием двух и большего количества потоков OpenMP.
Наша аппаратная платформа оснащена процессором, обладающим двумя физическими ядрами с поддержкой технологии Hyper-Threading, поэтому тесты были выполнены с использованием двух потоков для того, чтобы понять, какой вклад исполнение каждого потока на собственном физическом ядре способно внести в уменьшение времени исполнения программы.
Вот сводный отчёт Intel VTune после проведения эксперимента.

Отчёт Intel VTune
Здесь исполняется тот же код, который мы рассматривали выше, единственная разница заключается в том, что переменная среды OMP_NUM_THREADS была установлена в значение 2. Код работает примерно в 1.8 раза быстрее, но показатель Back-End Bound всё ещё высок и у данной ситуации те же причины, о которых мы говорили выше.
Вот подробный анализ происходящего. Здесь видны те же узкие места, что и ранее, к ним, кроме того, добавился высокий уровень параметра Bad Speculation у функции
Анализ в Intel VTune Amplifier
Высокий уровень показателя Bad Speculation указывает на то, что слоты вычислений используются неэффективно из-за неудачных предсказаний ветвления. Подобное может быть вызвано двумя разными причинами. Во-первых, слоты могут быть задействованы в исполнении микрокоманд, выполнение которых отменяется. Во-вторых, слоты могут быть заблокированы из-за восстановления после произошедшего ранее неудачного предсказания.
Когда увеличивается число потоков, начинают проявляться зависимости по данным между ними, что может вызвать неудачные предсказания. Это ведёт к отмене исполнения в ходе работы конвейера, который реализует методику исполнения команд с изменением порядка. Увеличение показателя CPI Rate в функции
Вот трафарет, который задействован в применяемом численном методе решения уравнений, его использование и ведёт к зависимости по данным между потоками при параллельном исполнении программы.

Сетка конечных элементов
Каждый элемент «O» в сетке, используемый в этом методе, зависит от данных, поступающих от четырёх соседних элементов: левого, правого, верхнего и нижнего. Участки, выделенные светло-серым цветом – это области, используемые и элементом, и его соседями. Тёмно-серый цвет указывает на области, используемые элементом и другими двумя его соседями. Точки xl, xln, xlc, xr, xrn, xrc, yun, yu, yuc, ydc, yd и ydn – это данные, которыми пользуются расположенные рядом элементы и здесь видно возможное узкое место для параллельного исполнения, так как данные приходится пересылать между параллельными потоками, а это значит, что в транспортном модуле должны быть реализованы методы синхронизации с помощью барьеров OpenMP.
Для того, чтобы узнать, влияет ли размер задачи на ускорение, вызванное параллельным исполнением, были проверены другие размеры сеток. Вот результаты испытаний.
В ходе эксперимента не было обнаружено значительной разницы в однопоточной и двухпоточной производительности для маленьких сеток. Однако, здесь особо выделяется самая маленькая сетка, 10x2x10, которая отличается очень малым объёмом вычислений. Время, необходимое на проведение расчётов при использовании двух потоков, выше, чем в однопоточном варианте. Здесь, учитывая малый размер задачи, проявляются дополнительные затраты времени на работу механизмов OpenMP, в частности, на создание и уничтожение потоков.
Вот отчёт Intel VTune Amplifier, касающийся исполнения задачи с самой маленькой сеткой в однопоточном режиме.

Отчёт Intel VTune, 1 поток
Вот – тот же анализ, но уже для двух потоков.

Отчёт Intel VTune, 2 потока
Обратите внимание на то, что в однопоточном режиме показатель Front-End Bound равен нулю, а Back-End Bound – единице. А при использовании двух потоков первый равняется единице, а второй – нулю.
Intel Parallel Advisor – это полезный инструмент, который помогает предсказывать и анализировать воздействие на программу распараллеливания. Это средство находит наиболее нагруженные фрагменты кода и оценивает ускорение, которого можно достичь при многопоточном исполнении программы.
Использование Intel Parallel Advisor состоит из четырёх шагов:
Обзорный анализ позволяет выявить наиболее нагруженные участки кода, которые могут быть кандидатами на распараллеливание. На рисунке ниже показан отсортированный список модулей программы, где самый верхний элемент,

Intel Parallel Advisor
Intel Parallel Advisor выводит такие сведения, как время, проведённое в каждой функции, тип цикла (векторный или скалярный), используемый набор инструкций (Intel AVX, AVX2, SSE и так далее). Те же сведения выводятся в нижней части рисунка, но уже в виде древовидной структуры, показывающей взаимоотношения между вызывающими и вызываемыми модулями. Это даёт возможность оценить поведение модулей, даёт сведения о возможных проблемах на уровне микроархитектуры процессора, помогает выявить наиболее нагруженные циклы, от распараллеливания которых можно получить серьёзный прирост производительности. В данном случае главный цикл функции
После того, как выявлены циклы, на которые приходится основная вычислительная нагрузка, в исходный код программы добавляются аннотации. Они предназначены для выделения участков в последовательно исполняемой программе, которые Intel Advisor должен воспринимать как те, в которых будет происходить параллельное исполнение и синхронизация. Позже программа модифицируется для подготовки её к параллельному исполнению с помощью замены аннотаций на код потокового API, после чего отмеченные участки кода будут исполняться в параллельном режиме.
На данном этапе нужно выявить части циклов или функций, которые используют значительное количество процессорного времени, особенно те, которые могут работать независимо, и обработку которых можно распределить по нескольким ядрам. Аннотации – это, в зависимости от используемого языка программирования, либо вызовы функций, либо макросы, которые могут быть обработаны компилятором. Сами по себе, аннотации не влияют на исполнение программы, с ними она будет работать так же, как и без них.
Добавляемые в код аннотации позволяют отметить области, которые предлагается распараллелить. Эти области Parallel Advisor подвергнет подробному анализу. Вот три основных типа аннотаций.
Вот какие аннотации были добавлены в наш код.
Первая выделенная область включает в себя вызов функции
После размещения аннотаций можно проанализировать возможный прирост производительности при исполнении кода в многопоточной среде, выполнив анализ эффективности. На рисунке ниже показана оценка производительности кода из первой выделенной области (помеченной как

Анализ эффективности исполнения области principal в Intel Parallel Advisor
Вот такой же анализ для области

Анализ эффективности исполнения области loop2 в Intel Parallel Advisor
В результате, для четырёх параллельных потоков OpenMP (параметр CPU Count установлен в значение 4) Intel Parallel Advisor предсказал возможный рост производительности в 2.47 раза для области «principal» и в 2.5 раза для «loop2». Нужно заметить, что для того, чтобы получить оценку, справедливую для всего приложения, следует аннотировать другие нагруженные части кода.
Для того, чтобы узнать, насколько быстро может исполняться наш код, мы провели испытания на узле кластера, состоящего из четырёх процессоров Intel Xeon E5-2698 V3 (2.3 ГГц, 40 Мб кэш-памяти).
Мы исследовали задачу с размером сетки 100x20x100 и 200x40x200 для того, чтобы выяснить, как производительность разных вариантов приложения зависит от числа потоков. Выше мы анализировали код в Intel Parallel Advisor, который предсказал, что линейного роста производительности можно ожидать при использовании до 32-х потоков. Здесь же мы это предсказание проверим на практике.
Наш код может нормально работать до тех пор, пока для его исполнения используются до 47 потоков. Если их больше, возникает ошибка сегментации. Причина возникновения этой ошибки пока не найдена.
Задача с первой сеткой (100x20x100) показывала линейную зависимость производительности от числа потоков до тех пор, пока их число не превысило 25. Это можно видеть на рисунке ниже. После этого наблюдается падение производительности, а дальше рост продолжается, и на 32-х потоках показатель производительности достигает той же величины, что и на 25. После 32-х потоков производительность ведёт себя похожим образом – сначала падает, потом снова растёт.

Зависимость производительности от числа потоков, сетка 100x20x100
В результате на графике зависимости производительности от числа потоков можно выделить три области: от 1 до 25 потоков, от 26 до 32, и от 33 до 47. Подобное поведение, вероятнее всего, может быть вызвано двумя причинами. Первая – особенности многопоточного исполнения кода и технологии Intel Hyper-Threading. Вторая – так называемый NUMA-эффект.
Способ организации памяти NUMA (Non Uniform Memory Access) предлагает решение задачи масштабирования в архитектуре SMP, но, из-за проблем с доступом к памяти, способен стать узким местом производительности.
Архитектура NUMA предусматривает применение распределённой модели памяти. При этом на NUMA-платформе у каждого процессора есть доступ ко всей имеющейся памяти, так же, как и на платформе SMP. Однако, каждый процессор напрямую соединён только с некоторой частью доступной физической памяти.
Процессору, для того, чтобы получить доступ к тем частям памяти, с которыми он не связан напрямую, нужно использовать специальные быстрые каналы связи, однако, доступ к памяти, подключённой к процессору напрямую, осуществляется быстрее, нежели к удалённым участкам. В результате, для эффективной и стабильной работы в NUMA-среде, при создании приложений и операционных систем, нужно учитывать особенности подсистемы памяти, необычное поведение которой может влиять на производительность.

Архитектура NUMA
Узел кластера, на котором проводятся испытания, включает в себя четыре процессора, каждый из них подключён к собственному блоку памяти. Как результат, в подобной среде возможно возникновение NUMA-эффекта.
Как было сказано выше, одна из причин необычного поведения программы в многопоточной среде заключается в особенностях технологии Intel Hyper-Threading.

Intel Hyper-Threading
Эта технология позволяет одному физическому ядру одновременно исполнять два потока, используя пару наборов регистров. Когда поток исполняет операцию, допускающую простой блока исполнения, второй поток способен задействовать свободные ресурсы, что повышает пропускную способность процессора. Выглядит это примерно так, как показано на рисунке ниже.

Intel Hyper-Threading
Итак, мы имеем два потока, но физическое ядро всего одно, поэтому прирост производительности в приложениях, интенсивно использующих процессор, не будет двукратным.
Вот, что по этому поводу, с использованием в качестве демонстрации вышеприведённого рисунка, говорится в данном материале. «Перед нами – пример того, как можно улучшить производительность вычислений с использованием технологии Intel HT. 64-битные процессоры Intel Xeon имеют по четыре исполнительных блока на ядро. Если технология Intel HT выключена, ядро может выполнять только инструкции из потока №1 или из потока №2. Как и ожидается, в течение многих тактовых циклов некоторые исполнительные блоки простаивают. Если же включить HT, процессор может обрабатывать инструкции из двух потоков одновременно. В данном примере использование HT позволило сократить требуемое число тактовых циклов с 10 до 7».
Сокращение необходимых тактовых циклов с 10 до 7 даёт прирост производительности примерно в 1.5 раза.
Вот результаты испытаний второй сетки (200x40x200). Здесь выполняется расчёт 1281 шага, эта задача в 1000 раз больше предыдущей (с сеткой 100x20x100), что делает её гораздо более ресурсоёмкой.
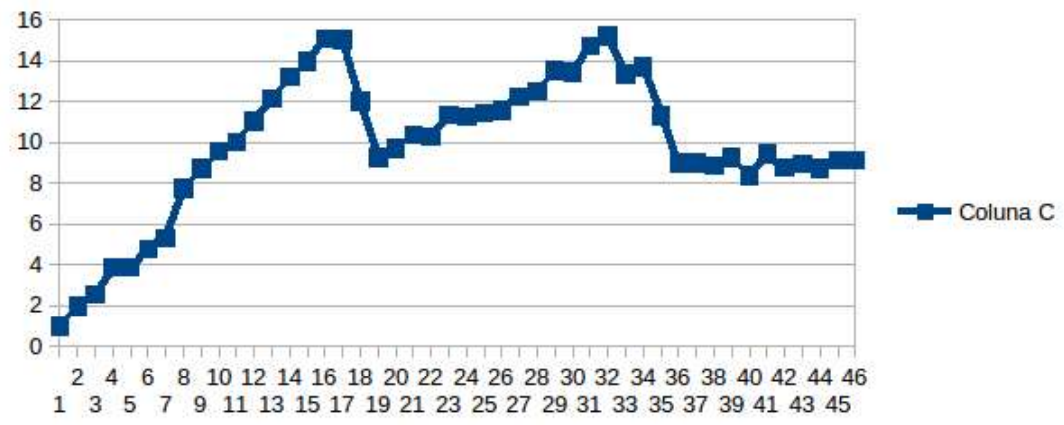
Зависимость производительности от числа потоков, сетка 200x40x200
График показывает, что зависимость производительности от числа потоков близка к линейной лишь до тех пор, пока это число не превысит 16. Как и в предыдущем случае, на графике можно выделить три области. При использовании от 1 до 16 потоков и от 19 до 32-х наблюдается рост производительности при увеличении числа потоков. Последующее увеличение числа потоков прироста в производительности почти не даёт.
Вне зависимости от разницы в процессорном времени, необходимом для двух вышеописанных тестов, важно обратить внимание на общие черты этих расчётов, так как они указывают на то, что во втором случае добиться линейной зависимости производительности от числа потоков, предсказанной Intel Parallel Advisor, не удаётся по тем же причинам, что и в первом: это NUMA-эффект и особенности технологии Hyper-Threading.
Вот сведения о времени в секундах, необходимом для решения наших задач с использованием разного числа потоков.

Задача с сеткой 100x20x100
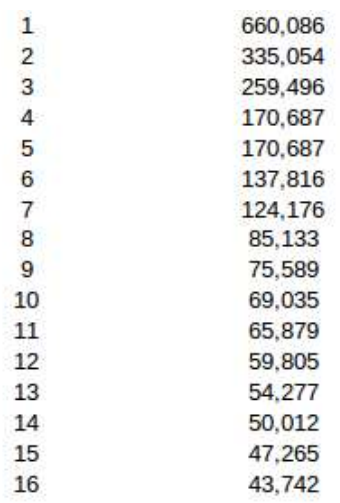
Задача с сеткой 200x40x200
Для достижения большего выигрыша в производительности можно провести другие испытания, с более высокой нагрузкой. Закон Амдала указывает на то, что ускорение программы, возможное от её распараллеливания, ограничено размером той её части, которая исполняется последовательно. Это означает, что вне зависимости от количества областей программы, которые можно исполнять параллельно и количества потоков, общий рост производительности ограничен той частью программы, которую распараллелить не удаётся.
В нашем случае, для испытаний, о которых речь пойдёт ниже, число расчётных шагов было увеличено благодаря уменьшению числа Куранта (Cr) c 0.125 до 0.0125. Это привело к тому, что общее время расчётов составило более 19 часов. Для задачи с сеткой 100x20x100 число шагов возросло с 641 до 6410, для задачи размера 200x40x200 – с 1281 до 12810. Объём вычислений, и в том и в другом случае, возрос в 10 раз, так как Cr было уменьшено в 10 раз.
Вот каковы результаты испытаний для меньшей задачи.

Задача с сеткой 100x20x100, Cr = 0.0125
Можно заметить, что производительность линейно росла до тех пор, пока число потоков не достигло 34-х. Это близко к числу используемых физических ядер в узле кластера. А именно, здесь имеется 4 процессора с поддержкой технологии HT, в каждом задействованы 9 ядер. Здесь происходит то же самое, что и в ранее проведённых тестах: технология Hyper-Threading в задаче, выполняющей интенсивные вычисления, не может обеспечить дальнейший рост производительности.
Несмотря на это, что отличает данное испытание от предыдущего исследования той же задачи, здесь наблюдается практически линейный рост производительности до тех пор, пока число потоков не превысит число используемых физических ядер. Результаты указывают на то, что при более высоких рабочих нагрузках код эффективнее использует возможности многоядерной архитектуры, но здесь всё ещё остаётся один вопрос. Он относится к ранее проведённому испытанию задачи с сеткой 200x40x200, которая отличается более высокой рабочей нагрузкой, нежели задача меньшего размера, но при этом рост производительности происходил лишь до тех пор, пока число потоков не достигло 16. Какая именно нагрузка на процессор позволит занять его работой, при выполнении которой с добавлением новых потоков продолжится рост производительности?
Увеличить рабочую нагрузку, в применении к нашей задаче, можно двумя путями. Первый – использовать более плотную сетку, в которой имеется большее число точек, и, таким образом, больше конечных элементов внутри областей. Второй – использовать больше шагов вычислений, чего можно достигнуть за счёт большего времени проведения симуляции или благодаря уменьшению Cr. На предыдущем рисунке, для задачи с сеткой 100x20x100, объём вычислений возрос благодаря увеличению числа шагов по времени. При этом время, необходимое для решения задачи с использованием одного потока, составило 403,16 секунд, а при использовании 36 потоков – 14,22 секунды, что указывает на примерно 28-кратный рост производительности.
Другой подход, который заключается в том, что увеличивается и число шагов по времени, и плотность сетки, показан на рисунке ниже. Здесь общее время решения задачи с применением одного потока составило 6577,53 секунды. Когда в работу включились 36 потоков, время расчётов сократилось до 216,16 секунд, то есть, производительность выросла примерно в 30 раз.
С использованием этих двух подходов к повышению рабочей нагрузки, рост производительности идёт практически линейно при добавлении потоков, которые соответствуют физическим ядрам. Это указывает на то, что фактором, который помогает распараллеленной программе достичь более высокой производительности, является увеличение числа шагов по времени, а не плотности сетки.

Задача с сеткой 200x40x200, Cr = 0.0125
В таблице ниже показано сравнение стратегий по увеличению рабочей нагрузки, которую создаёт задачу и указание на то, линейным или нет является рост производительности при увеличении числа потоков.
Как уже было сказано, выяснено, что увеличение числа расчётных шагов (за счёт уменьшения Cr) позволяет добиться лучшего роста производительности, уменьшая долю времени, затрачиваемого на доступ к кэш-памяти, к которой процессор не подключён напрямую, а значит – уменьшая NUMA-эффект. Этот результат позволяет спрогнозировать, какие задачи удастся эффективно решать на системах с многоядерными процессорами, такими, как Intel Xeon Phi.
Оптимизация кода и переход к параллельному исполнению способны дать значительный прирост в производительности программ. Как вы могли убедиться, задачи это непростые, но вполне решаемые.
На пути оптимизации приложений встают самые разные проблемы. Так, нередко в переработке нуждается код, который, например, не удаётся векторизовать или исполнять в параллельном режиме. Но, даже если код, в теории, кажется вполне готовым к параллельному исполнению, практические испытания способны выявить дополнительные сложности. Например, способы, которыми программа работает с данными, могут стать причиной недостаточно эффективного использования аппаратных ресурсов системы. Как результат, конвейер процессора оказывается либо перегруженным, либо простаивает, всё это сказывается на производительности не лучшим образом. К счастью, эти проблемы тоже можно решить.
Исследовав нашу программу с помощью инструментов Intel, мы выяснили, что размер задачи влияет на динамику производительности. Так, автоматическая векторизация уменьшает время исполнения примерно в 2.5 раза на небольших задачах, и примерно в 3 раза – на задачах более крупных.
Если говорить о дальнейшем развитии этого проекта, то улучшить код поможет полуавтоматическая векторизация, кроме того, может понадобиться рефакторинг для упрощения операций по работе со структурами данных и улучшения возможностей по векторизации циклов, которые компилятор не может векторизовать автоматически. Кроме того, надо отметить, что для расширения возможностей тестирования следует использовать более крупные задачи. Это позволит понять, каких показателей производительности можно достигнуть в решении реальных проблем.
Ещё один важный вывод, который сделан в ходе нашего исследования, относится к многопоточному (OpenMP) исполнению кода, который показал, что при использовании двух потоков можно достичь роста производительности примерно в 1.8 раз, даже несмотря на то, что код ещё можно оптимизировать.
Анализ с использованием Intel Parallel Advisor выявил, что, в потенциале, возможно 32-кратное ускорение кода, но тесты, проведённые на узле вычислительного кластера, показали, что линейный рост производительности при увеличении числа потоков наблюдается лишь при использовании 25 или 16 потоков в задачах разного размера. Эти различие между прогнозами Parallel Advisor и результатами испытаний, вероятнее всего, вызваны NUMA-эффектом и особенностями технологии Hyper-Threading.
Кроме того, интересные результаты получены при испытании модифицированной версии программы. В частности, модификация касалась увеличения количества расчётных шагов при неизменном размере сетки. Такой подход позволил свести вышеозначенные проблемы к минимуму, уменьшив долю времени, необходимого на доступ к кэш-памяти, не подключённой к процессору напрямую. В результате NUMA-эффект снизился, нам удалось добиться линейного роста производительности при увеличении числа потоков вплоть до количества, соответствующего числу доступных физических процессорных ядер.
Каждый программный проект индивидуален, поэтому невозможно предсказать, каким будет путь его оптимизации, как он поведёт себя в многопоточной среде. Однако, правильный подбор инструментов и методов работы способны помочь в улучшении любого кода. Надеемся, наш материал поможет разработчикам повысить производительность их приложений.
Оптимизации, которые влияют на скорость вычислений при использовании любого числа потоков, сводятся к учёту в коде особенностей процессорных архитектур, наборов инструкций, к поиску наиболее рациональных способов работы с разными видами памяти. Помощь в подобной оптимизации способен оказать, например, подход к исследованию производительности методом «сверху вниз» с использованием низкоуровневых данных о системных событиях, которые преобразуются в доступные для анализа и практического применения высокоуровневые показатели.
Здесь мы рассмотрим методику оптимизации вычислений, связанных с моделированием течений многофазных жидкостей в пористых средах по методике, предложенной в этой работе. Речь идёт о численном методе решения дифференциальных уравнений гиперболического типа в частных производных.
Моделирование течений многофазных жидкостей в пористых средах
Данная задача находит применение во многих сферах. Например, в области добычи нефти и газа, в промышленности, экологии.
Мы рассмотрим методики векторизации кода, расскажем о переходе от последовательного к параллельному исполнению, проведём ряд экспериментов. Эксперименты проводились на платформах Intel, для анализа и оптимизации приложения применялись различные программные средства, в частности, Intel VTune Amplifier.
Материал состоит из трёх основных разделов:
- В первом мы поговорим об автоматической векторизации кода и проведём эксперименты на системе с процессором Intel Core i5-4350U в однопоточном режиме.
- Второй раздел посвящён сравнению однопоточного и двухпоточного исполнения приложения. Здесь мы будем сравнивать скорость работы разных вариантов программы на процессоре Intel Core i7-5500U.
- Третий раздел посвящён подготовке приложения для исполнения в многопоточной среде. Он включает в себя рассказ об анализе и оптимизации приложения с применением Intel Parallel Advisor. Испытывать код будем на узле вычислительного кластера с 4-мя Intel Xeon E5-2698 v3.
Анализ и автоматическая векторизация кода
?Испытательная платформа и набор инструкций Intel AVX2
Здесь, в качестве аппаратной платформы для экспериментов, используется система на Ubuntu 14.04 с установленным процессором Intel Core i5-4350U (1.4 ГГц, 2 ядра, 4 потока) с 3 Мб кэш-памяти и 4 Гб RAM. Наша экспериментальная среда построена на процессоре, принадлежащем к семейству Intel Haswell, которое отличается полной поддержкой набора инструкций Intel AVX2. Использование возможностей этого набора инструкций, в частности, улучшенная поддержка векторизации, позволяет повысить производительность приложений, предназначенных для широкого спектра платформ, среди них – серверные решениях на базе Intel Xeon и Intel Xeon Phi.
При разработке для Intel AVX2 используется та же модель программирования, что использовалась в предыдущей версии, Intel AVX, однако, новые инструкции расширяют то, что было, предлагая большинство 128-битных целочисленных SIMD инструкций с возможностью обработки 256-битных чисел. Векторизация кода позволяет раскрыть потенциал однопоточного варианта программы, что крайне важно перед переходом к следующему шагу – параллельному исполнению.
Для анализа производительности и оценки качества оптимизации здесь использована Intel Parallel Studio XE 2015.
?О выявлении потенциала оптимизации
Для того, чтобы понять, как оптимизировать код, нужно его проанализировать и найти блоки программы, исполнение которых можно ускорить за счёт векторизации и параллелизации. Для того, чтобы этого достичь, можно воспользоваться инструментами Intel, такими, как Intel VTune Amplifier и Intel Parallel Advisor. Весьма полезны в этом плане и отчёты, которые генерирует компилятор.
Подобные инструментальные средства позволяют анализировать исходный код приложения и исполняемые файлы, давая подсказки о направлениях оптимизации. Исследованию, в основном, подвергаются узкие места производительности в конвейере процессора.
Современные микропроцессоры реализуют конвейерное исполнение инструкций, и, вместе с этим подходом, используют другие техники, такие, как аппаратные потоки, выполнение команд с изменением их очерёдности, параллелизм на уровне инструкций. Делается всё это для того, чтобы наиболее полно использовать ресурсы системы.
Перед программистом, который занимается оптимизацией кода, стоит непростая задача. Главная сложность здесь в том, что ему нужно как можно эффективнее использовать аппаратные возможности компьютера, а они находятся на уровне микроархитектуры вычислительной системы, который расположен довольно далеко от уровня абстракции, предоставляемого современными языками программирования, такими, как C, C++ и Fortran.
Инструменты Intel могут помочь в оптимизации кода, анализируя компиляцию и компоновку приложения, давая сведения о временных параметрах исполнения программы для определения того, как именно используются аппаратные ресурсы. Среди этих инструментов – отчёты компилятора, Intel VTune, Intel Parallel Advisor. Вот как можно организовать работу с ними.
- Анализ отчёта компилятора. Компилятор способен генерировать отчёт, из которого можно узнать, какие автоматические оптимизации были применены к коду, а какие – нет. Иногда, например, некий цикл может быть автоматически векторизован, а иногда этого не происходит. При этом и в том и в другом случае компилятор сообщает об этом, а подобные сведения полезны для программиста, так как они позволяют ему решить, нужно ли его вмешательство в код или нет.
- Анализ с использованием Intel VTune Amplifier. Это средство позволяет наблюдать за тем, как приложение исполняется на конвейере, как оно использует память. Кроме того, с помощью VTune Amplifier можно узнать, какое время занимает исполнение каждого модуля, и то, насколько эффективно при этом задействуются ресурсы системы. Intel VTune Amplifier создаёт высокоуровневую систему показателей, с помощью которых можно всё это анализировать. Среди таких показателей, например, количество тактовых циклов, необходимых на инструкцию.
- Анализ с помощью Intel Parallel Advisor. Этот инструмент может спрогнозировать ожидаемый рост производительности при переходе к параллелизму на уровне потоков. Кроме того, Parallel Advisor способно помочь в подготовке кода к параллельному исполнению.
Программист, скомбинировав данные, полученные с помощью вышеперечисленных средств, может изменить исходный код программы и параметры компиляции для того, чтобы достичь целевых показателей оптимизации.
?Автоматическая векторизация кода
Современные компиляторы способны векторизовать исполняемый код. В частности, для этого устанавливают параметр оптимизации в значение -
O2 или выше. Отключить автоматическую векторизацию можно, используя параметр компилятора –no-vec. Это может быть полезно для сравнения производительности разных вариантов исполняемого кода. В двух словах, векторизация – это такое преобразование программы, после которого одна инструкция способна выполнять некоторые действия с несколькими наборами данных. Рассмотрим в качестве примера обработку нижеприведённого цикла.
for (i=0; i<=MAX; i++) {
c[i] = b[i] + a[i];
}Если этот цикл не подвергся векторизации, то использование регистров при его исполнении выглядит примерно так, как показано на рисунке ниже.
Использование регистров при исполнении цикла, который не подвергся векторизации
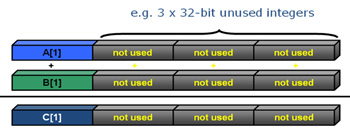
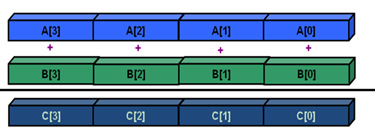
Если тот же самый цикл векторизовать, будут задействованы дополнительные регистры, как результат, можно будет выполнять четыре операции сложения, используя одну инструкцию. Это называют «один поток команд – много потоков данных» (Single Instruction Multiple Data, SIMD).
Исполнение векторизованного цикла
Подобный подход обычно позволяет повысить производительность, так как одна инструкция обрабатывает несколько наборов данных вместо одного.
В приложении моделирования потока в пористых средах, оптимизацией которого мы занимаемся, автоматическая векторизация позволила повысить производительность в два раза на процессоре семейства Haswell, который поддерживает набор инструкций Intel AVX2.
Параметр -
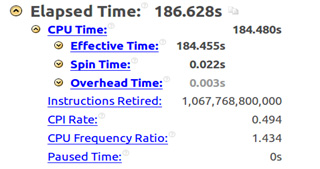
xHost указывает компилятору на то, что он должен генерировать исполняемый код, соответствующий архитектуре системы, на которой выполняется компиляция. В случае, когда такой системой является компьютер с процессором семейства Haswell, использование этого параметра гарантирует применение инструкций Intel AVX2. На рисунке ниже показан сводный отчёт Intel VTune Amplifier по программе, скомпилированной без использования параметра -
xHost. Здесь время исполнения составило 186,6 секунд, количество тактовых циклов на инструкцию (Clocks per Instruction, CPI) – примерно 0.5, число выполненных инструкций – 1.067.768.800.000.Отчёт VTune Amplifier, параметр -xHost не используется
Основная цель оптимизации в данном случае заключается в уменьшении времени исполнения кода и увеличении CPI, который, в идеале, должен составлять 0.75, что означает полное использование возможностей конвейера.
На рисунке ниже показан список модулей приложения, отсортированный по эффективно используемому машинному времени.
Список модулей приложения
Обратите внимание на то, что функция
vizinhanca создаёт максимальную нагрузку на систему, используя порядка 20% времени процессора. Эта функция занята пошаговым расчётом параметров пористости, проницаемости, скоростей, потока в каждом элементе и во всех его соседних элементах в моделируемой среде.Обратите внимание на то, что CPI очень плох у функции
fkt, которая занята расчётом параметров потока на заданном шаге по времени. Эта функция вызывает функцию vizinhanca.Вот фрагмент исходного кода функции
visinhanca. Здесь имеются сведения о времени, необходимом на выполнение каждой строки и выведен код на ассемблере для выделенной строки, которая занята линейной реконструкцией. Обратите внимание на то, что в коде нет инструкций Intel AVX2.Фрагмент ассемблерного кода линейной реконструкции
В этом фрагменте кода можно видеть следующие инструкции: MULSD, MOVSDQ, SUB, IMUL, MOVSXD, MOVL, MOVQ, ADDQ. Все они из набора инструкций Intel Streaming SIMD Extensions 2 (Intel SSE2). Эти «старые» инструкции появились с выходом в ноябре 2000-го года процессора Intel Pentium 4.
Скомпилировав тот же самый код с параметром
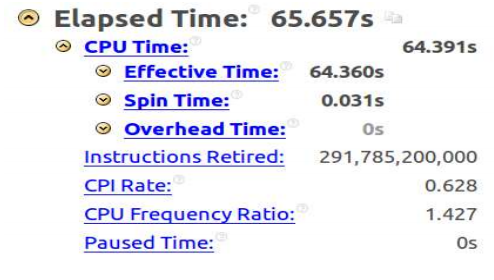
–xHost, который указывает компилятору на то, что нужно сгенерировать исполняемый код для архитектуры используемой системы, и проанализировав его исполнение с помощью Intel VTune Amplifier, мы получили следующее.Отчёт VTune Amplifier, параметр -xHost используется
А именно, время исполнения кода теперь составило 65.6 секунд, CPI – 0.62, что гораздо лучше, чем было раньше и ближе к идеальному значению 0.75.
Для того, чтобы понять причину подобного роста производительности, можно взглянуть на ассемблерный код. Там обнаружатся инструкции из набора команд Intel AVX2. Кроме того, сравнивая отчёты VTune Amplifier, можно заметить, что при использовании Intel AVX2 число выполненных инструкций гораздо меньше, чем в случае с применением SSE2 в невекторизованной версии кода.
Это происходит из-за того, что в итоговых данных не учитываются инструкции, исполнение которых было отменено, так как они находились в ветке, по которой не должно было пойти исполнение кода из-за неверного предсказания ветвлений. Меньшее число подобных ошибок так же объясняет улучшение параметра CPI.
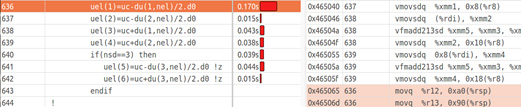
Вот тот же фрагмент исходного кода, который мы рассматривали выше, но теперь его ассемблерное представление получено после включения параметра -
xHost.Фрагмент векторизованного ассемблерного кода линейной реконструкции
Обратите внимание на то, что большинство инструкций здесь – векторные, из набора Intel AVX2, а не из SSE2. Имена векторных инструкций начинаются с префикса
V. Например, использование инструкции VMOV вместо MOV указывает на то, что мы имеем дело с векторизованным кодом.
На рисунке ниже вы можете видеть сравнение регистров для наборов инструкций Intel SSE2, AVX и AVX2.
Регистры и наборы инструкций
Простой в применении подход с включением автоматической векторизации позволяет достичь трёхкратного роста производительности.
?Поиск проблемных участков кода
В системе, с которой мы экспериментируем, на двух физических ядрах могут исполняться 4 потока. Сейчас единственное сделанное улучшение кода – это автоматическая векторизация, выполненная компилятором. Мы пока далеки от программы, которая способна работать на пределе возможностей системы, код ещё можно оптимизировать. Для того, чтобы продолжить улучшение кода, нужно выявить его узкие места. Например, в исходном варианте нашего приложения имеется множество строк, где используется деление.
Опция
–no-prec-div указывает компилятору на то, что операции деления нужно заменить на операции умножения на обратные величины. Этой возможностью мы воспользуемся в ходе оптимизации нашего приложения.Вот фрагмент исходного кода, где часто используется операция деления. Этот код находится внутри функции
udd_rt, которая, по данным ранее проведённого анализа, представляет собой одно из узких мест.Множество операций деления в важном участке кода
Однако, у опции
–no-prec-div имеется одна проблема. Иногда после этой оптимизации полученные значения не так точны, как при использовании обычного деления по стандарту IEEE. Если для целей приложения важна точность, используйте эту опцию для отключения оптимизации, что приведёт к более точным результатам с некоторым падением производительности.Вот ещё одна важная проблема, которую можно решить с помощью инструментов Intel. В нашем случае она заключается в том, что множество модулей приложения написано на Fortran, что усложняет их оптимизацию. Для того, чтобы при подготовке кода к исполнению была выполнена межпроцедурная оптимизация, используется опция
–ipo, которая указывает компилятору и компоновщику на то, что такую оптимизацию нужно провести. При этом некоторая часть действий по оптимизации кода производится на стадии компоновки.С использованием опций
–ipo, –xHost и –no-prec-div общее время исполнения программы снизилось ещё сильнее, до 53.5 секунд.Результат использования опций –ipo, -xHost и –no-prec-div
Для того, чтобы лучше понять вклад в производительность программы, который вносит использование опции
–no-prec-div, было проведено испытание с отключением этой опции. В результате время исполнения выросло до 84.324 с. Это означает, что данная опция даёт примерно 1.5-кратный прирост производительности.Ещё одно испытание, на этот раз с отключённой опцией
–ipo, показало, что время исполнения возросло до 69.003 с. Это позволяет говорить о том, что данная опция даёт примерно 1.3-кратный прирост производительности.?Использование Intel VTune Amplifier General Exploration для выявления ограничений процессора и памяти
Intel VTune Amplifier может не только сообщать о времени, затраченном на исполнение программы, о CPI, и о том, сколько инструкций было выполнено. Используя его профиль General Exploration, можно получить сведения о поведении программы внутри конвейера процессора и выяснить, можно ли улучшить производительность, если учесть ограничения процессора и памяти.
Ограничения вычислительного ядра (Core Bounds) относятся к проблемам, не связанным с передачей данных в памяти и воздействуют на производительность при исполнении инструкций с изменением их порядка или при перегрузке операционных блоков. Ограничения памяти (Memory Bounds) способны вызвать неэффективную работу конвейера из-за необходимости ожидания завершения инструкций загрузки/сохранения данных. Вместе два этих параметра определяют то, что называют Back-End Bounds, этот показатель можно воспринимать как ограничения, возникающие внутри конвейера.
Если же простои конвейера вызваны незаполненными слотами, то есть, тем фактом, что микрокоманды не успевают поступать в него по каким-либо причинам, и часть конвейера не выполняет полезной работы только потому что ей нечего обрабатывать, перед нами уже так называемые Front-End Bounds – внешние по отношению к конвейеру ограничения.
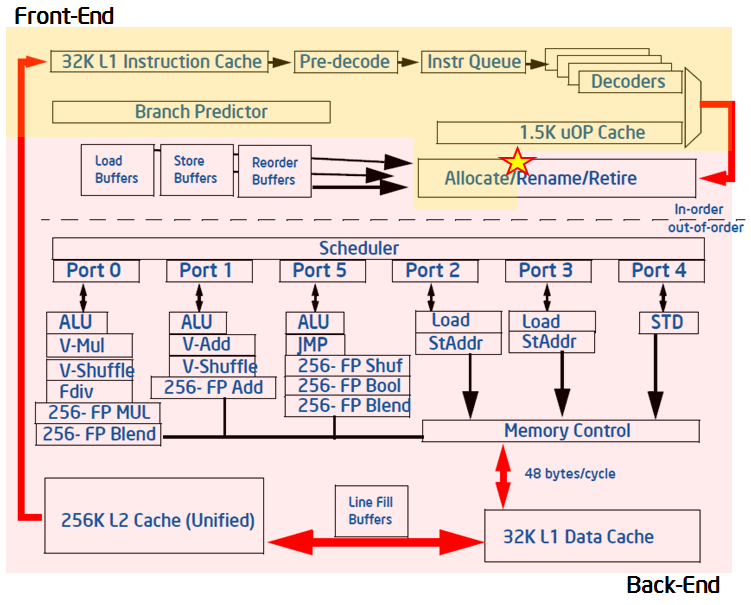
Вот схема типичного современного конвейера, поддерживающего исполнение кода с изменением последовательности команд.
Конвейер процессора Intel, поддерживающий исполнение инструкций с изменением их порядка
Внутренние структуры, back-end конвейера, представляют собой порты для доставки инструкций к ALU, к блокам загрузки и сохранения. Несбалансированное использование этих портов обычно плохо сказывается на производительности, так как некоторые блоки могут либо простаивать, либо использоваться не так равномерно, как другие, которые оказываются перегруженными.
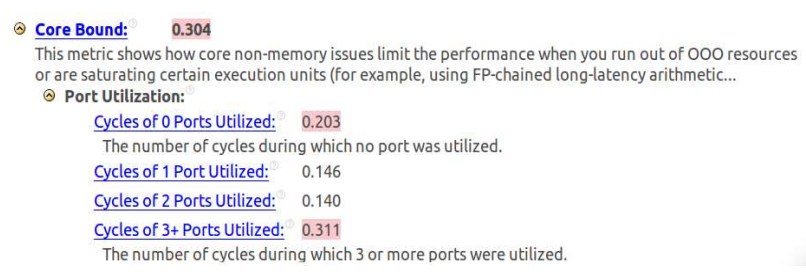
Для приложения, которое мы здесь рассматриваем, анализ показал, что даже при использовании автоматической векторизации, выполняемой компилятором, имеются проблемы при исполнении кода. А именно – высокое значение показателя Core Bound из-за несбалансированного распределения инструкций по портам.
Ограничения вычислительного ядра
Результаты анализа, показанные на рисунке выше, указывают на высокий уровень тактовых циклов (0.203, или 20.3%), в которых не задействован ни один порт. Это говорит о неэффективном использовании ресурсов процессора. Кроме того, заметен высокий уровень циклов (0.311, или 31.1%), когда задействованы три или более порта. Такая ситуация приводит к перегрузке. Очевидно, перед нами несбалансированное использование ресурсов.
Результаты анализа ситуации, выполненные в Intel VTune Amplifier и показанные на рисунке ниже, позволяют обнаружить причины вышеописанных проблем. В данном случае видны четыре функции (
fkt, udd_rt, xlo, и xmax_speed), у которых слишком высок показатель Back-End Bound. Кроме того, функция xmax_speed отличается слишком высоким уровнем неправильных предсказаний (показатель Bad Speculation). Не всё благополучно и в модуле transport.Анализ показателей Back-End Bound и Bad Speculation
Следующий шаг наших изысканий заключается в использовании Intel VTune Amplifier в качестве инструмента для анализа выявленных проблем. Мы собираемся тщательно изучить каждую отмеченную выше функцию для того, чтобы найти участки кода, из-за которых процессорное время тратится впустую.
Анализируя каждую функцию, которая имеет высокий показатель в графе Back-End Bound, можно выяснить, где именно возникают проблемы. На нескольких рисунках, приведённых ниже, можно видеть, что Intel VTune Amplifier показывает исходный код и соответствующие метрики для каждой строки. Среди них – успешно завершённые инструкции (Retiring), ошибки предсказаний (Bad Speculation), такты (Clockticks), CPI, ограничения внутри конвейера (Back-End Bound). В общем случае, высокое значение показателя Clockticks указывает на ответственные строки кода и VTune выделяет соответствующие им значения.
Вот анализ функции
transport, отличающейся высоким показателем Back-End Bound.Анализ причин высокого значения показателя Back-End Bound в функции transport
Функцию
fkt так же можно отнести к разряду ответственных. Она вызывает функции g и h для вычисления потока и функцию udd_rt для вычисления насыщения начального элемента сетки. Аналитические данные по этой функции показаны на рисунке ниже.Анализ функции fkt
Вот код функций
g и h, которые вызывает функция fkt.function g(uu,vv,xk,VDISPY,POROSITY)
!
!
вычисляет f в узле или объёме
!
use mPropGeoFisica, only: xlw,xlo,xlt,gf2,rhoo,rhow
implicit none
real(8) :: g,uu,vv,xk
REAL(8) :: VDISPY,POROSITY
real(8) :: fw
real(8) :: xlwu,xlou
real(8) :: xemp,xg
xlwu=xlw(uu)
xlou=xlo(uu)
fw=xlwu/(xlwu+xlou)
xg = gf2
xemp=fw*xg*xlou*xk*(rhoo-rhow)
g=fw*vv-xemp
end function
function h(uu,vv,xk,VDISPZ,POROSITY)
!
!
вычисляет f в узле или объёме
!
use mPropGeoFisica, only: xlw,xlo,xlt,gf3,rhoo,rhow
implicit none
real(8) :: h,uu,vv,xk
REAL(8) :: VDISPZ,POROSITY
real(8) :: fw
real(8) :: xlwu,xlou
real(8) :: xemp,xg
xlwu=xlw(uu)
xlou=xlo(uu)
fw=xlwu/(xlwu+xlou)
xg = gf3
xemp=fw*xg*xlou*xk*(rhoo-rhow)
h=fw*vv-xemp
end functionЗдесь важно обратить внимание на то, что здесь идёт речь о двумерных компонентах вектора
F, который представляет поток сохраняющейся величины s в соответствии со следующим выражением.Функция
xlo, которая находит общую подвижность, в соответствии с подвижностью воды и нефти, так же отличается высоким показателем Back-End Bound. Вот её анализ.Функция xlo
Вот анализ функции
xmax_speed, которая вычисляет максимальную скорость в направлении x. Эта функция так же вносит немалый вклад в общий уровень показателя Back-End Bound.Функция xmax_speed
Intel VTune Amplifier использует данные о функциях, анализ которых мы провели выше, для нахождения итогового показателя Back-End Bound.
Как уже было сказано, причиной возникновения такого рода ограничений может являться неэффективное использование процессора или памяти. Так как автоматическая векторизация уже была применена к нашему коду, весьма вероятно, что причина возникшей ситуации – в памяти. Дальнейший анализ, а именно, рассмотрение показателя Memory Bound, данные по которому приведены ниже, позволяет говорить о том, что программа неэффективно использует кэш первого уровня (показатель L1 Bound).
Показатель Memory Bound
Поскольку в приложении имеется большое количество структур данных, таких, как векторы, необходимых во множестве различных функций, их нужно тщательно исследовать для того, чтобы найти подходы к улучшению производительности за счёт уменьшения задержек, связанных с памятью. Кроме того, стоит обратить внимание на выравнивание данных для того, чтобы помочь векторизации кода.
?Применение отчётов компилятора для поиска дополнительных путей оптимизации
Для того, чтобы обнаружить больше возможностей оптимизации кода посредством векторизации, следует воспользоваться отчётами компилятора, так как в них можно найти сведения о циклах, которые можно векторизовать. Модуль
MTRANSPORT стал центральным объектом анализа, так как в нём сосредоточен значительный объём вычислений.Некоторые внешние циклы не векторизуются из-за того, что соответствующие внутренние циклы уже векторизованы благодаря описанной выше методике автоматическое векторизации. В подобной ситуации компилятор выдаёт такое сообщение:
remark #####: loop was not vectorized: inner loop was already vectorizedВ некоторых случаях компилятор указывает разработчику на то, что для векторизации цикла ему следует воспользоваться директивой SIMD, но, когда это сделано, цикл всё равно не векторизуется из-за того, что в нём выполняется присвоение скалярной переменной:
!DIR$ SIMD
do n=1,nstep+1
ss=smin+(n-1)*dsВот соответствующее сообщение компилятора:
LOOP BEGIN at ./fontes/transporte.F90(143,7)
remark #15336: simd loop was not vectorized: conditional
assignment to a scalar [ ./fontes/transporte.F90(166,23) ]
remark #13379: loop was not vectorized with "simd"Большая часть циклов была автоматически векторизована компилятором, и в некоторых случаях потенциальный рост производительности, оценённый компилятором, варьировался от 1.4 (большинство циклов) до 6.5 (такой показатель получен лишь для одного цикла).
Когда компилятор обнаруживает, что после векторизации производительность падает (то есть, рост производительности составляет меньше, чем 1.0), векторизацию он не проводит. Вот один из примеров сообщения компилятора в подобной ситуации.
LOOP BEGIN at ./fontes/transporte.F90(476,7)
remark #15335: loop was not vectorized: vectorization
possible but seems inefficient. Use vector always directive
or -vec-threshold0 to override
remark #15451: unmasked unaligned unit stride stores: 1
remark #15475: --- begin vector loop cost summary ---
remark #15476: scalar loop cost: 3
remark #15477: vector loop cost: 3.000
remark #15478: estimated potential speedup: 0.660
remark #15479: lightweight vector operations: 2
remark #15481: heavy-overhead vector operations: 1
remark #15488: --- end vector loop cost summary ---
LOOP ENDРеально же производительность после автоматической векторизации выросла примерно в три раза, в соответствии с оценённым компилятором средним значением.
Анализ причин, по которым компилятор не выполняет векторизацию некоторых циклов, следует провести до применения других методов оптимизации.
?Эксперименты с различными размерами сетки
Все тесты, которые проводились до настоящего момента, выполнялись в применении к решению задачи, пространство которой представляет собой сетку размером 100x20x100, при этом проводится 641 шаг вычислений с использованием одного вычислительного потока.
Здесь мы взглянем на работу с сетками других размеров для того, чтобы сравнить общий прирост производительности, полученный благодаря автоматической векторизации. Вот это сравнение.
| Сетка |
Время исполнения без векторизации |
Время исполнения с векторизацией |
Рост производительности |
Количество шагов |
| 100?20?100 |
186,628 |
53,590 |
3,4 |
641 |
| 50?10?50 |
17,789 |
5,277 |
3,4 |
321 |
| 25?5?25 |
0,773 |
0,308 |
2,5 |
161 |
| 10?2?10 |
0,039 |
0,0156 |
2,5 |
65 |
Эти испытания показали, что чем больше сетка – тем больше и рост производительности, достигаемый благодаря автоматической векторизации. Это важный вывод, так как реальные задачи требуют большей точности, а значит, и больших сеток.
Ниже мы рассмотрим сетки большего размера для того, чтобы проверить эту гипотезу.
Переход от одного потока к двум
?Испытательная платформа
После того, как код векторизован, к нему применены автоматические, и, если это возможно, полуавтоматические методы оптимизации, можно заняться рассмотрением вопроса о том, насколько ускорится работа приложения при исполнении его в многопоточной среде. Для этой цели в данном разделе представлены результаты эксперимента по сравнению производительности приложения при использовании одного и двух потоков. Изучать приложение мы будем с помощью Intel VTune Amplifier.
Тесты, о которых здесь пойдёт речь, выполнены на системе, которая отличается от той, с которой мы экспериментировали ранее. На этом компьютере установлена Ubuntu 14.04.3 LTS, он оснащён процессором Intel Core i7-5500U (2.4 ГГц, 4 Мб кэш-памяти) с двумя ядрами и с поддержкой технологии HT (до четырёх одновременно исполняемых потоков). Этот процессор принадлежит к семейству Intel Broadwell, он полностью поддерживает набор инструкций Intel AVX2. В компьютере имеется 7.7 Гб оперативной памяти.
Процессоры семейства Broadwell производятся с использованием 14-нанометрового техпроцесса, развивая микроархитектуру Haswell. В стратегии «тик-так» («tick-tock»), которую использует Intel, это семейство относится к фазе «тик», то есть, это шаг, на котором уменьшен техпроцесс и произведены некоторые улучшения микроархитектуры, представленной ранее.
?Однопоточное исполнение
Для анализа производительности программы воспользуемся Intel VTune XE 2016. Первый эксперимент заключается в однопоточном исполнении кода, скомпилированного с использованием параметров
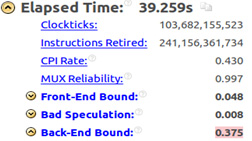
–ipo, –xHost и –no-prec-div. Такие настройки соответствуют тем, которые использовались ранее.Расчёты с выполнением 641 шага для той же самой сетки размером 100x20x100, заняли 39.259 секунд, что означает рост производительности в сравнении с процессором семейства Haswell примерно в 1.4 раза. Вот часть отчёта об этом эксперименте из Intel VTune Amplifier.
Отчёт Intel VTune Amplifier
Анализируя эти данные, важно учитывать, что получены они на процессоре, который примерно в 1.7 раза быстрее, нежели тот, с которым мы экспериментировали ранее. А то, что при этом прирост в производительности составляет лишь около 1.4, говорит о неэффективном использовании вычислительных ресурсов.
Из отчёта видно, что показатель Back-End Bound оставляет 0.375. Это указывает на то, что даже увеличение тактовой частоты процессора не спасает в ситуации, когда причины неэффективного использования ресурсов системы не устранены.
На следующем рисунке показаны развёрнутые данные по показателю Back-End Bound.
Анализ отчёта Intel VTune Amplifier
Здесь видно, что причиной высокого значения обобщённого показателя Back-End Bound являются ограничения ядра (показатель Core Bound), а именно – задержки в блоке деления (Divider). Есть и другие проблемы, не связанные с блоком деления, на них указывает показатель Port Utilization. Этот показатель позволяет понять, насколько эффективно используются порты исполнения внутри ALU. Высокое значение Core Bound – это отражение последовательности запросов к модулю исполнения или следствие недостатка параллелизма на уровне инструкций в коде. Задержки в работе процессора могут указывать, кроме прочего, на неоптимальное использование порта исполнения. Например, операция деления, довольно ресурсоёмкая, может задержать исполнение, увеличивая потребность в порте, который обслуживает специфические типы микрокоманд. Это, как следствие, это приведёт к малому числу портов, задействованных в тактовом цикле.
Вышесказанное указывает на то, что код должен быть улучшен для того, чтобы избежать зависимости от данных. Здесь нужно применить более эффективный подход, нежели уже использованная автоматическая векторизация.
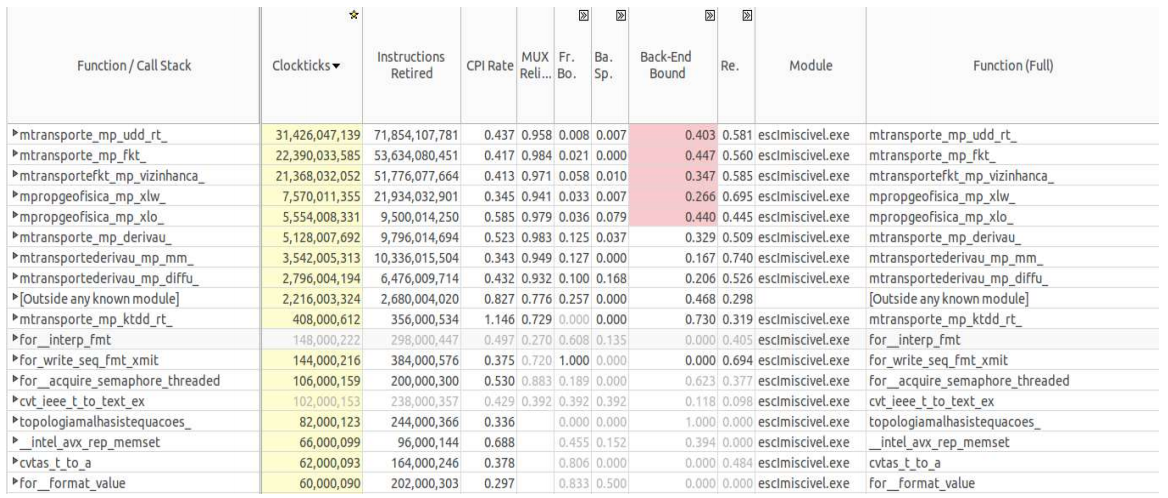
На рисунке ниже показан один из этапов анализа причин высокого значения показателя Back-End Bound, в частности, функции, которые вносят наибольший вклад в падение производительности, находятся в верхней части списка и выделены. Мы уже сталкивались с этими функциями.
Анализ в Intel VTune Amplifier
Сейчас можно сделать вывод о том, что даже при увеличении частоты процессора узкие места кода никуда не деваются, или проявляются в новых участках программы из-за исполнения команд с изменением их очерёдности и более высокой потребности в вычислительных ресурсах из-за более высокой скорости расчётов.
?Исполнение с использованием двух потоков
В деле оптимизации очень важно проанализировать воздействие параллелизма на ускорение работы приложения с использованием двух и большего количества потоков OpenMP.
Наша аппаратная платформа оснащена процессором, обладающим двумя физическими ядрами с поддержкой технологии Hyper-Threading, поэтому тесты были выполнены с использованием двух потоков для того, чтобы понять, какой вклад исполнение каждого потока на собственном физическом ядре способно внести в уменьшение времени исполнения программы.
Вот сводный отчёт Intel VTune после проведения эксперимента.
Отчёт Intel VTune
Здесь исполняется тот же код, который мы рассматривали выше, единственная разница заключается в том, что переменная среды OMP_NUM_THREADS была установлена в значение 2. Код работает примерно в 1.8 раза быстрее, но показатель Back-End Bound всё ещё высок и у данной ситуации те же причины, о которых мы говорили выше.
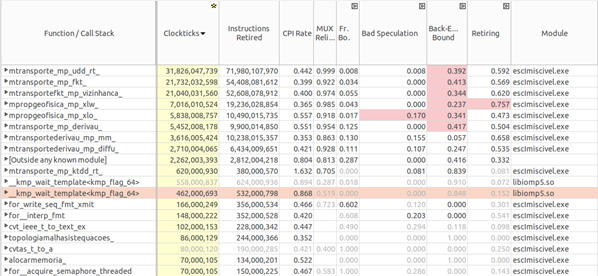
Вот подробный анализ происходящего. Здесь видны те же узкие места, что и ранее, к ним, кроме того, добавился высокий уровень параметра Bad Speculation у функции
xlo и высокий уровень показателя Retiring у функции xlw.Анализ в Intel VTune Amplifier
Высокий уровень показателя Bad Speculation указывает на то, что слоты вычислений используются неэффективно из-за неудачных предсказаний ветвления. Подобное может быть вызвано двумя разными причинами. Во-первых, слоты могут быть задействованы в исполнении микрокоманд, выполнение которых отменяется. Во-вторых, слоты могут быть заблокированы из-за восстановления после произошедшего ранее неудачного предсказания.
Когда увеличивается число потоков, начинают проявляться зависимости по данным между ними, что может вызвать неудачные предсказания. Это ведёт к отмене исполнения в ходе работы конвейера, который реализует методику исполнения команд с изменением порядка. Увеличение показателя CPI Rate в функции
xlw указывает на то, что параллелизм немного улучшил использование слотов.Вот трафарет, который задействован в применяемом численном методе решения уравнений, его использование и ведёт к зависимости по данным между потоками при параллельном исполнении программы.
Сетка конечных элементов
Каждый элемент «O» в сетке, используемый в этом методе, зависит от данных, поступающих от четырёх соседних элементов: левого, правого, верхнего и нижнего. Участки, выделенные светло-серым цветом – это области, используемые и элементом, и его соседями. Тёмно-серый цвет указывает на области, используемые элементом и другими двумя его соседями. Точки xl, xln, xlc, xr, xrn, xrc, yun, yu, yuc, ydc, yd и ydn – это данные, которыми пользуются расположенные рядом элементы и здесь видно возможное узкое место для параллельного исполнения, так как данные приходится пересылать между параллельными потоками, а это значит, что в транспортном модуле должны быть реализованы методы синхронизации с помощью барьеров OpenMP.
Для того, чтобы узнать, влияет ли размер задачи на ускорение, вызванное параллельным исполнением, были проверены другие размеры сеток. Вот результаты испытаний.
| Сетка |
Время исполнения, один поток |
Время исполнения, два потока |
Рост производительности |
Количество шагов |
| 100?20?100 |
39.259 |
21.429 |
1.83 |
641 |
| 50?10?50 |
2.493 |
1.426 |
1.74 |
321 |
| 25?5?25 |
0.185 |
0.112 |
1.65 |
161 |
| 10?2?10 |
0.014 |
0.015 |
0.94 |
65 |
В ходе эксперимента не было обнаружено значительной разницы в однопоточной и двухпоточной производительности для маленьких сеток. Однако, здесь особо выделяется самая маленькая сетка, 10x2x10, которая отличается очень малым объёмом вычислений. Время, необходимое на проведение расчётов при использовании двух потоков, выше, чем в однопоточном варианте. Здесь, учитывая малый размер задачи, проявляются дополнительные затраты времени на работу механизмов OpenMP, в частности, на создание и уничтожение потоков.
Вот отчёт Intel VTune Amplifier, касающийся исполнения задачи с самой маленькой сеткой в однопоточном режиме.
Отчёт Intel VTune, 1 поток
Вот – тот же анализ, но уже для двух потоков.
Отчёт Intel VTune, 2 потока
Обратите внимание на то, что в однопоточном режиме показатель Front-End Bound равен нулю, а Back-End Bound – единице. А при использовании двух потоков первый равняется единице, а второй – нулю.
Работа в многопоточной среде
?Рекомендации по многопоточному исполнению из Intel Parallel Advisor
Intel Parallel Advisor – это полезный инструмент, который помогает предсказывать и анализировать воздействие на программу распараллеливания. Это средство находит наиболее нагруженные фрагменты кода и оценивает ускорение, которого можно достичь при многопоточном исполнении программы.
Использование Intel Parallel Advisor состоит из четырёх шагов:
- Обзорный анализ.
- Анализ с добавлением аннотаций.
- Анализ эффективности.
- Анализ корректности.
Обзорный анализ позволяет выявить наиболее нагруженные участки кода, которые могут быть кандидатами на распараллеливание. На рисунке ниже показан отсортированный список модулей программы, где самый верхний элемент,
transport, является наиболее нагруженным. Это значит, что его параллельное исполнение на нескольких потоках, вероятнее всего, способно повысить производительность программы.Intel Parallel Advisor
Intel Parallel Advisor выводит такие сведения, как время, проведённое в каждой функции, тип цикла (векторный или скалярный), используемый набор инструкций (Intel AVX, AVX2, SSE и так далее). Те же сведения выводятся в нижней части рисунка, но уже в виде древовидной структуры, показывающей взаимоотношения между вызывающими и вызываемыми модулями. Это даёт возможность оценить поведение модулей, даёт сведения о возможных проблемах на уровне микроархитектуры процессора, помогает выявить наиболее нагруженные циклы, от распараллеливания которых можно получить серьёзный прирост производительности. В данном случае главный цикл функции
ktdd_rt, внутри модуля transport, который потребляет 98% процессорного времени, показан в верхней части рисунка.После того, как выявлены циклы, на которые приходится основная вычислительная нагрузка, в исходный код программы добавляются аннотации. Они предназначены для выделения участков в последовательно исполняемой программе, которые Intel Advisor должен воспринимать как те, в которых будет происходить параллельное исполнение и синхронизация. Позже программа модифицируется для подготовки её к параллельному исполнению с помощью замены аннотаций на код потокового API, после чего отмеченные участки кода будут исполняться в параллельном режиме.
На данном этапе нужно выявить части циклов или функций, которые используют значительное количество процессорного времени, особенно те, которые могут работать независимо, и обработку которых можно распределить по нескольким ядрам. Аннотации – это, в зависимости от используемого языка программирования, либо вызовы функций, либо макросы, которые могут быть обработаны компилятором. Сами по себе, аннотации не влияют на исполнение программы, с ними она будет работать так же, как и без них.
Добавляемые в код аннотации позволяют отметить области, которые предлагается распараллелить. Эти области Parallel Advisor подвергнет подробному анализу. Вот три основных типа аннотаций.
- Аннотации для выделения параллельных областей (parallel site) позволяют отметить границы участка кода, содержащего одну или несколько задач. Эти участки при переходе к распараллеленному коду будут исполняться в отдельных потоках.
- Аннотации для выделения параллельных задач (parallel task) используются для выделения отдельных задач внутри параллельной области. Каждая задача, встречающаяся в ходе исполнения параллельной области, воспринимается как код, который может быть исполнен одновременно с другими задачами и оставшимся в области кодом. При преобразовании программы к параллельному виду задачи будут исполняться одновременно. Другими словами, каждый экземпляр кода задачи может быть запущен параллельно на разных ядрах и множество экземпляров этого кода так же исполняется параллельно с множеством экземпляров любых других задач внутри той же самой параллельной области.
- Аннотации блокировки синхронизации (locking synchronization) позволяют защитить области программы, в которых требуется доступ нескольких экземпляров параллельно исполняемого кода к одним и тем же данным.
Вот какие аннотации были добавлены в наш код.
call annotate_site_begin("principal")
call annotate_iteration_task("maxder")
call maxder(numLadosELem,ndofV,numelReserv,vxmax,vymax,vzmax,vmax,phi,permkx,v)
call annotate_site_end
call annotate_site_begin("loop2")
do nel=1,numel
call annotate_iteration_task("loop_nelem")
[…]
end do
call annotate_site_endПервая выделенная область включает в себя вызов функции
maxder. Вторая – цикл, который занят расчётом поля скорости для каждого конечного элемента в сетке.После размещения аннотаций можно проанализировать возможный прирост производительности при исполнении кода в многопоточной среде, выполнив анализ эффективности. На рисунке ниже показана оценка производительности кода из первой выделенной области (помеченной как
principal) при использовании разного числа потоков. А именно, в левой части отчёта можно видеть графическое представление прогноза влияния числа потоков (до 32-х) на производительность. Здесь можно видеть, что предсказанная зависимость линейна.Анализ эффективности исполнения области principal в Intel Parallel Advisor
Вот такой же анализ для области
loop2, но уже выполненный для 64-х потоков.Анализ эффективности исполнения области loop2 в Intel Parallel Advisor
В результате, для четырёх параллельных потоков OpenMP (параметр CPU Count установлен в значение 4) Intel Parallel Advisor предсказал возможный рост производительности в 2.47 раза для области «principal» и в 2.5 раза для «loop2». Нужно заметить, что для того, чтобы получить оценку, справедливую для всего приложения, следует аннотировать другие нагруженные части кода.
?Испытательная платформа
Для того, чтобы узнать, насколько быстро может исполняться наш код, мы провели испытания на узле кластера, состоящего из четырёх процессоров Intel Xeon E5-2698 V3 (2.3 ГГц, 40 Мб кэш-памяти).
?Исследование приложения в многопоточной среде
Мы исследовали задачу с размером сетки 100x20x100 и 200x40x200 для того, чтобы выяснить, как производительность разных вариантов приложения зависит от числа потоков. Выше мы анализировали код в Intel Parallel Advisor, который предсказал, что линейного роста производительности можно ожидать при использовании до 32-х потоков. Здесь же мы это предсказание проверим на практике.
Наш код может нормально работать до тех пор, пока для его исполнения используются до 47 потоков. Если их больше, возникает ошибка сегментации. Причина возникновения этой ошибки пока не найдена.
Задача с первой сеткой (100x20x100) показывала линейную зависимость производительности от числа потоков до тех пор, пока их число не превысило 25. Это можно видеть на рисунке ниже. После этого наблюдается падение производительности, а дальше рост продолжается, и на 32-х потоках показатель производительности достигает той же величины, что и на 25. После 32-х потоков производительность ведёт себя похожим образом – сначала падает, потом снова растёт.
Зависимость производительности от числа потоков, сетка 100x20x100
В результате на графике зависимости производительности от числа потоков можно выделить три области: от 1 до 25 потоков, от 26 до 32, и от 33 до 47. Подобное поведение, вероятнее всего, может быть вызвано двумя причинами. Первая – особенности многопоточного исполнения кода и технологии Intel Hyper-Threading. Вторая – так называемый NUMA-эффект.
Способ организации памяти NUMA (Non Uniform Memory Access) предлагает решение задачи масштабирования в архитектуре SMP, но, из-за проблем с доступом к памяти, способен стать узким местом производительности.
Архитектура NUMA предусматривает применение распределённой модели памяти. При этом на NUMA-платформе у каждого процессора есть доступ ко всей имеющейся памяти, так же, как и на платформе SMP. Однако, каждый процессор напрямую соединён только с некоторой частью доступной физической памяти.
Процессору, для того, чтобы получить доступ к тем частям памяти, с которыми он не связан напрямую, нужно использовать специальные быстрые каналы связи, однако, доступ к памяти, подключённой к процессору напрямую, осуществляется быстрее, нежели к удалённым участкам. В результате, для эффективной и стабильной работы в NUMA-среде, при создании приложений и операционных систем, нужно учитывать особенности подсистемы памяти, необычное поведение которой может влиять на производительность.
Архитектура NUMA
Узел кластера, на котором проводятся испытания, включает в себя четыре процессора, каждый из них подключён к собственному блоку памяти. Как результат, в подобной среде возможно возникновение NUMA-эффекта.
Как было сказано выше, одна из причин необычного поведения программы в многопоточной среде заключается в особенностях технологии Intel Hyper-Threading.
Intel Hyper-Threading
Эта технология позволяет одному физическому ядру одновременно исполнять два потока, используя пару наборов регистров. Когда поток исполняет операцию, допускающую простой блока исполнения, второй поток способен задействовать свободные ресурсы, что повышает пропускную способность процессора. Выглядит это примерно так, как показано на рисунке ниже.
Intel Hyper-Threading
Итак, мы имеем два потока, но физическое ядро всего одно, поэтому прирост производительности в приложениях, интенсивно использующих процессор, не будет двукратным.
Вот, что по этому поводу, с использованием в качестве демонстрации вышеприведённого рисунка, говорится в данном материале. «Перед нами – пример того, как можно улучшить производительность вычислений с использованием технологии Intel HT. 64-битные процессоры Intel Xeon имеют по четыре исполнительных блока на ядро. Если технология Intel HT выключена, ядро может выполнять только инструкции из потока №1 или из потока №2. Как и ожидается, в течение многих тактовых циклов некоторые исполнительные блоки простаивают. Если же включить HT, процессор может обрабатывать инструкции из двух потоков одновременно. В данном примере использование HT позволило сократить требуемое число тактовых циклов с 10 до 7».
Сокращение необходимых тактовых циклов с 10 до 7 даёт прирост производительности примерно в 1.5 раза.
Вот результаты испытаний второй сетки (200x40x200). Здесь выполняется расчёт 1281 шага, эта задача в 1000 раз больше предыдущей (с сеткой 100x20x100), что делает её гораздо более ресурсоёмкой.
Зависимость производительности от числа потоков, сетка 200x40x200
График показывает, что зависимость производительности от числа потоков близка к линейной лишь до тех пор, пока это число не превысит 16. Как и в предыдущем случае, на графике можно выделить три области. При использовании от 1 до 16 потоков и от 19 до 32-х наблюдается рост производительности при увеличении числа потоков. Последующее увеличение числа потоков прироста в производительности почти не даёт.
Вне зависимости от разницы в процессорном времени, необходимом для двух вышеописанных тестов, важно обратить внимание на общие черты этих расчётов, так как они указывают на то, что во втором случае добиться линейной зависимости производительности от числа потоков, предсказанной Intel Parallel Advisor, не удаётся по тем же причинам, что и в первом: это NUMA-эффект и особенности технологии Hyper-Threading.
Вот сведения о времени в секундах, необходимом для решения наших задач с использованием разного числа потоков.
Задача с сеткой 100x20x100
Задача с сеткой 200x40x200
Для достижения большего выигрыша в производительности можно провести другие испытания, с более высокой нагрузкой. Закон Амдала указывает на то, что ускорение программы, возможное от её распараллеливания, ограничено размером той её части, которая исполняется последовательно. Это означает, что вне зависимости от количества областей программы, которые можно исполнять параллельно и количества потоков, общий рост производительности ограничен той частью программы, которую распараллелить не удаётся.
В нашем случае, для испытаний, о которых речь пойдёт ниже, число расчётных шагов было увеличено благодаря уменьшению числа Куранта (Cr) c 0.125 до 0.0125. Это привело к тому, что общее время расчётов составило более 19 часов. Для задачи с сеткой 100x20x100 число шагов возросло с 641 до 6410, для задачи размера 200x40x200 – с 1281 до 12810. Объём вычислений, и в том и в другом случае, возрос в 10 раз, так как Cr было уменьшено в 10 раз.
Вот каковы результаты испытаний для меньшей задачи.
Задача с сеткой 100x20x100, Cr = 0.0125
Можно заметить, что производительность линейно росла до тех пор, пока число потоков не достигло 34-х. Это близко к числу используемых физических ядер в узле кластера. А именно, здесь имеется 4 процессора с поддержкой технологии HT, в каждом задействованы 9 ядер. Здесь происходит то же самое, что и в ранее проведённых тестах: технология Hyper-Threading в задаче, выполняющей интенсивные вычисления, не может обеспечить дальнейший рост производительности.
Несмотря на это, что отличает данное испытание от предыдущего исследования той же задачи, здесь наблюдается практически линейный рост производительности до тех пор, пока число потоков не превысит число используемых физических ядер. Результаты указывают на то, что при более высоких рабочих нагрузках код эффективнее использует возможности многоядерной архитектуры, но здесь всё ещё остаётся один вопрос. Он относится к ранее проведённому испытанию задачи с сеткой 200x40x200, которая отличается более высокой рабочей нагрузкой, нежели задача меньшего размера, но при этом рост производительности происходил лишь до тех пор, пока число потоков не достигло 16. Какая именно нагрузка на процессор позволит занять его работой, при выполнении которой с добавлением новых потоков продолжится рост производительности?
Увеличить рабочую нагрузку, в применении к нашей задаче, можно двумя путями. Первый – использовать более плотную сетку, в которой имеется большее число точек, и, таким образом, больше конечных элементов внутри областей. Второй – использовать больше шагов вычислений, чего можно достигнуть за счёт большего времени проведения симуляции или благодаря уменьшению Cr. На предыдущем рисунке, для задачи с сеткой 100x20x100, объём вычислений возрос благодаря увеличению числа шагов по времени. При этом время, необходимое для решения задачи с использованием одного потока, составило 403,16 секунд, а при использовании 36 потоков – 14,22 секунды, что указывает на примерно 28-кратный рост производительности.
Другой подход, который заключается в том, что увеличивается и число шагов по времени, и плотность сетки, показан на рисунке ниже. Здесь общее время решения задачи с применением одного потока составило 6577,53 секунды. Когда в работу включились 36 потоков, время расчётов сократилось до 216,16 секунд, то есть, производительность выросла примерно в 30 раз.
С использованием этих двух подходов к повышению рабочей нагрузки, рост производительности идёт практически линейно при добавлении потоков, которые соответствуют физическим ядрам. Это указывает на то, что фактором, который помогает распараллеленной программе достичь более высокой производительности, является увеличение числа шагов по времени, а не плотности сетки.
Задача с сеткой 200x40x200, Cr = 0.0125
В таблице ниже показано сравнение стратегий по увеличению рабочей нагрузки, которую создаёт задачу и указание на то, линейным или нет является рост производительности при увеличении числа потоков.
| Сетка 100?20?100 |
Сетка 200?40?200 |
|
| Cr = 0.125 |
Нелинейный рост |
Нелинейный рост |
| Cr = 0.0125 |
Линейный рост |
Линейный рост |
Как уже было сказано, выяснено, что увеличение числа расчётных шагов (за счёт уменьшения Cr) позволяет добиться лучшего роста производительности, уменьшая долю времени, затрачиваемого на доступ к кэш-памяти, к которой процессор не подключён напрямую, а значит – уменьшая NUMA-эффект. Этот результат позволяет спрогнозировать, какие задачи удастся эффективно решать на системах с многоядерными процессорами, такими, как Intel Xeon Phi.
Итоги
Оптимизация кода и переход к параллельному исполнению способны дать значительный прирост в производительности программ. Как вы могли убедиться, задачи это непростые, но вполне решаемые.
На пути оптимизации приложений встают самые разные проблемы. Так, нередко в переработке нуждается код, который, например, не удаётся векторизовать или исполнять в параллельном режиме. Но, даже если код, в теории, кажется вполне готовым к параллельному исполнению, практические испытания способны выявить дополнительные сложности. Например, способы, которыми программа работает с данными, могут стать причиной недостаточно эффективного использования аппаратных ресурсов системы. Как результат, конвейер процессора оказывается либо перегруженным, либо простаивает, всё это сказывается на производительности не лучшим образом. К счастью, эти проблемы тоже можно решить.
Исследовав нашу программу с помощью инструментов Intel, мы выяснили, что размер задачи влияет на динамику производительности. Так, автоматическая векторизация уменьшает время исполнения примерно в 2.5 раза на небольших задачах, и примерно в 3 раза – на задачах более крупных.
Если говорить о дальнейшем развитии этого проекта, то улучшить код поможет полуавтоматическая векторизация, кроме того, может понадобиться рефакторинг для упрощения операций по работе со структурами данных и улучшения возможностей по векторизации циклов, которые компилятор не может векторизовать автоматически. Кроме того, надо отметить, что для расширения возможностей тестирования следует использовать более крупные задачи. Это позволит понять, каких показателей производительности можно достигнуть в решении реальных проблем.
Ещё один важный вывод, который сделан в ходе нашего исследования, относится к многопоточному (OpenMP) исполнению кода, который показал, что при использовании двух потоков можно достичь роста производительности примерно в 1.8 раз, даже несмотря на то, что код ещё можно оптимизировать.
Анализ с использованием Intel Parallel Advisor выявил, что, в потенциале, возможно 32-кратное ускорение кода, но тесты, проведённые на узле вычислительного кластера, показали, что линейный рост производительности при увеличении числа потоков наблюдается лишь при использовании 25 или 16 потоков в задачах разного размера. Эти различие между прогнозами Parallel Advisor и результатами испытаний, вероятнее всего, вызваны NUMA-эффектом и особенностями технологии Hyper-Threading.
Кроме того, интересные результаты получены при испытании модифицированной версии программы. В частности, модификация касалась увеличения количества расчётных шагов при неизменном размере сетки. Такой подход позволил свести вышеозначенные проблемы к минимуму, уменьшив долю времени, необходимого на доступ к кэш-памяти, не подключённой к процессору напрямую. В результате NUMA-эффект снизился, нам удалось добиться линейного роста производительности при увеличении числа потоков вплоть до количества, соответствующего числу доступных физических процессорных ядер.
Каждый программный проект индивидуален, поэтому невозможно предсказать, каким будет путь его оптимизации, как он поведёт себя в многопоточной среде. Однако, правильный подбор инструментов и методов работы способны помочь в улучшении любого кода. Надеемся, наш материал поможет разработчикам повысить производительность их приложений.
Поделиться с друзьями
Комментарии (10)

Anton_Menshov
25.09.2016 18:26Возник вопрос: почему CPI=0.75 сигнализирует о полном использовании возможностей конвейера для данной (?) архитектуры? Как это считается?
Anton_Menshov
25.09.2016 18:30Однако, у опции –no-prec-div имеется одна проблема. Иногда после этой оптимизации полученные значения не так точны, как при использовании обычного деления по стандарту IEEE. Если для целей приложения важна точность, используйте эту опцию для отключения оптимизации, что приведёт к более точным результатам с некоторым падением производительности.
Несколько странный абзац. Насколько я понимаю, опция -no-prec-div позволяет использовать доп. оптимизации с потерей точности. И, следовательно, наоборот: если для целей приложения важна точность, не нужно использовать эту опцию. Наоборот, можно поставить опцию -prec-div (идет по дефолту, вроде как).
Anton_Menshov
25.09.2016 18:39Эти испытания показали, что чем больше сетка – тем больше и рост производительности, достигаемый благодаря автоматической векторизации. Это важный вывод, так как реальные задачи требуют большей точности, а значит, и больших сеток.
Чуть-чуть позанудствую, скорее всего, имеется ввиду не больших сеток — а более плотных (dense) сеток. Дабы узлов для аппроксимации производных было больше. Большая сетка — я читаю больше как большая по физическому размеру.
И, вдобавок, для достижения большей точности — увеличение плотности сетки не единственный способ. Увеличение порядка аппроксимации производных часто приводит к большему эффекту. Хотя это вопрос не об оптимизации кода, а вопросы численного анализа.

ooprizrakoo
По моему скромному мнению, довольно жестоко такую статью на Хабр вставлять, потому что от силы 0.05% посетителей её смогут понять.
Dark_Daiver
Разве не хардкорные статьи делают хабр тортом?
ooprizrakoo
Помимо возможности насыпать минусов в карму комментатору в знак несогласия с его мнением, тортом Хабр делают научпоп-статьи + хардкорные статьи написанные о какой-то вещи, знакомой и ковыряемой многими. Будь то ЯП или БД.
Ну либо чистый интеллект, алгоритмы и вот это всё. А в статье вышше чуть ли не RFC выложили — достатчно сухой технический текст, который реально может быть интересен и понятен сотрудникам Интела + нескольким чувакам из МЦСТ и СМ Варе.
Я понимаю что статья опубликована в блоге Интела, и размещать они имеют полное право — но вот не форматная она всё равно, это я и хочу сказать.
Anton_Menshov
Абсолютно не согласен. Эта статья очень полезна людям занимающимся высокопроизводительными вычислениями. Их не так уж мало.
Плюс. Даже если уравнения в частных производных — не то, чем человек занимается каждый день — на этом примере можно многое понять об используемых инструментах, стратегиях, возможных увеличениях производительности. О самой задаче здесь 5%. Анализ отчетов компилятора и вспомогательных инструментов — 95%.
ooprizrakoo
Ок, вам возможно и виднее.
Dark_Daiver
Ммм, статья вроде про то, как найти узкие места в коде, и выжать побольше производительности. Не всем это будет интересно, конечно, но в целом тема более чем актуальна.
И да, возможно статья «суховата», но лучше сухая статья чем очередная реклама гаджета или перевод очередного туториала по базовым структурам данных.