 Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест Стьюдента к любым данным без проверки их нормальности. Такая небрежность способна порождать серьёзные ошибки и превращать «поклонников» теста Стьюдента в ненавистников статистики. Попробуем поставить токи над i и разобраться, какие модели случайных величин должны использоваться для описания тех или иных явлений и какая между ними существует генетическая связь.
Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест Стьюдента к любым данным без проверки их нормальности. Такая небрежность способна порождать серьёзные ошибки и превращать «поклонников» теста Стьюдента в ненавистников статистики. Попробуем поставить токи над i и разобраться, какие модели случайных величин должны использоваться для описания тех или иных явлений и какая между ними существует генетическая связь.В первую очередь, данный материал будет интересен студентам, изучающим теорию вероятностей и статистику, хотя и «зрелые» специалисты смогут его использовать в качестве справочника. В одной из следующих работ я покажу пример использования статистики для построения теста оценки значимости показателей биржевых торговых стратегий.
В работе будут рассмотрены дискретные распределения:
- Бернулли;
- биномиальное;
- геометрическое;
- Паскаля (отрицательное биномиальное);
- гипергеометрическое;
- Пуассона,
а также непрерывные распределения:
- Гаусса (нормальное);
- хи-квадрат;
- Стьюдента;
- Фишера;
- Коши;
- экспоненциальное (показательное) и Лапласа (двойное экспоненциальное, двойное показательное);
- Вейбулла;
- гамма (Эрланга);
- бета.
В конце статьи будет задан вопрос для размышлений. Свои размышления по этому поводу я изложу в следующей статье.
Некоторые из приведённых непрерывных распределений являются частными случаями распределения Пирсона.
Дискретные распределения
Дискретные распределения используются для описания событий с недифференцируемыми характеристиками, определёнными в изолированных точках. Проще говоря, для событий, исход которых может быть отнесён к некоторой дискретной категории: успех или неудача, целое число (например, игра в рулетку, в кости), орёл или решка и т.д.
Описывается дискретное распределение вероятностью наступления каждого из возможных исходов события. Как и для любого распределения ( в том числе непрерывного) для дискретных событий определены понятия матожидания и дисперсии. Однако, следует понимать, что матожидание для дискретного случайного события — величина в общем случае нереализуемая как исход одиночного случайного события, а скорее как величина, к которой будет стремиться среднее арифметическое исходов событий при увеличении их количества.
В моделировании дискретных случайных событий важную роль играет комбинаторика, так как вероятность исхода события можно определить как отношение количества комбинаций, дающих требуемый исход к общему количеству комбинаций. Например: в корзине лежат 3 белых мяча и 7 чёрных. Когда мы выбираем из корзины 1 мяч, мы можем сделать это 10-ю разными способами (общее количество комбинаций), но только 3 варианта, при которых будет выбран белый мяч (3 комбинации, дающие требуемый исход). Таким образом, вероятность выбрать белый мяч:
Следует также отличать выборки с возвращением и без возвращения. Например, для описания вероятности выбора двух белых мячей важно определить, будет ли первый мяч возвращён в корзину. Если нет, то мы имеем дело с выборкой без возвращения (гипергеометрическое распределение) и вероятность будет такова:
наверх
Распределение Бернулли

(взято отсюда)
Если несколько формализовать пример с корзиной следующим образом: пусть исход события может принимать одно из двух значений 0 или 1 с вероятностями
По сложившейся традиции, исход со значением 1 называется «успех», а исход со значением 0 — «неудача». Очевидно, что получение исхода «успех или неудача» наступает с вероятностью
Матожидание и дисперсия распределения Бернулли:
наверх
Биномиальное распределение

(взято отсюда)
Количество
где
По другому можно сказать, что биномиальное распределение описывает сумму из
Матожидание и дисперсия:
Биномиальное распределение справедливо только для выборки с возвращением, то есть, когда вероятность успеха остаётся постоянной для всей серии испытаний.
Если величины
наверх
Геометрическое распределение
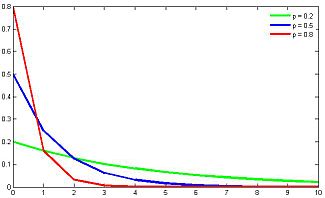
(взято отсюда)
Представим ситуацию, что мы вытягиваем мячи из корзины и возвращаем обратно до тех пор, пока не будет вытянут белый шар. Количество таких операций описывается геометрическим распределением. Иными словами: геометрическое распределение описывает количество испытаний
Матожидание и дисперсия геометрического распределения:
Геометрическое распределение генетически связано с экспоненциальным распределением, которое описывает непрерывную случайную величину: время до наступления события, при постоянной интенсивности событий. Геометрическое распределение также является частным случаем отрицательного биномиального распределения.
наверх
Распределение Паскаля (отрицательное биномиальное рспределение)

(взято отсюда)
Распределение Паскаля является обобщением геометрического распределения: описывает распределение количества неудач
где
Матожидание и дисперсия отрицательного биномиального распределения:
Сумма независимых случайных величин, распределённых по Паскалю, также распределена по Паскалю: пусть
наверх
Гипергеометрическое распределение
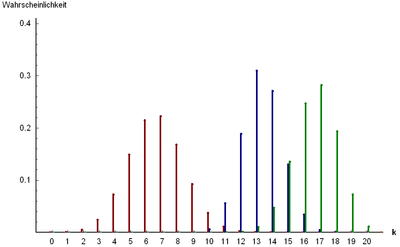
(взято отсюда)
До сих пор мы рассматривали примеры выборок с возвращением, то есть, вероятность исхода не менялась от испытания к испытанию.
Теперь рассмотрим ситуацию без возвращения и опишем вероятность количества успешных выборок из совокупности с заранее известным количеством успехов и и неудач (заранее известное количество белых и чёрных мячей в корзине, козырных карт в колоде, бракованных деталей в партии и т.д.).
Пусть общая совокупность содержит
где
Матожидание и дисперсия:
наверх
Распределение Пуассона
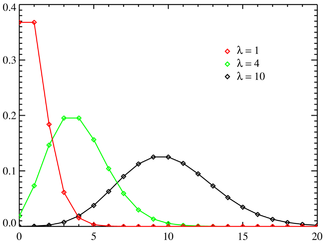
(взято отсюда)
Распределение Пуассона значительно отличается от рассмотренных выше распределений своей «предметной» областью: теперь рассматривается не вероятность наступления того или иного исхода испытания, а интенсивность событий, то есть среднее количество событий в единицу времени.
Распределение Пуассона описывает вероятность наступления
Матожидание и дисперсия распределения Пуассона:
Дисперсия и матожидание распределения Пуассона тождественно равны.
Распределение Пуассона в сочетании с экспоненциальным распределением, описывающим интервалы времени между наступлениями независимых событий, составляют математическую основу теории надёжности.
наверх
Непрерывные распределения
Непрерывные распределения, в отличие от дискретных, описываются функциями плотности (распределения) вероятности
Если известна плотность вероятности для величины
при условии однозначности и дифференцируемости
Плотность вероятности
Если распределение суммы случайных величин принадлежит к тому же распределению, что и слагаемые, такое распределение называется бесконечно делимым. Примеры бесконечно делимых распределений: нормальное, хи-квадрат, гамма, распределение Коши.
Плотность вероятности
Некоторые из приведённых ниже распределений являются частными случаями распределения Пирсона, которое, в свою очередь, является решением уравнения:
где
Распределения, которые будут рассмотрены в этом разделе, имеют тесные взаимосвязи друг с другом. Эти связи выражаются в том, что некоторые распределения являются частными случаями других распределений, либо описывают преобразования случайных величин, имеющих другие распределения.
На приведённой ниже схеме отражены взаимосвязи между некоторыми из непрерывных распределений, которые будут рассмотрены в настоящей работе. На схеме сплошными стрелками показано преобразование случайных величин (начало стрелки указывает на изначальное распределение, конец стрелки — на результирующее), а пунктирными — отношение обобщения (начало стрелки указывает на распределение, являющееся частным случаем того, на которое указывает конец стрелки). Для частных случаев распределения Пирсона над пунктирными стрелками указан соответствующий тип распределения Пирсона.
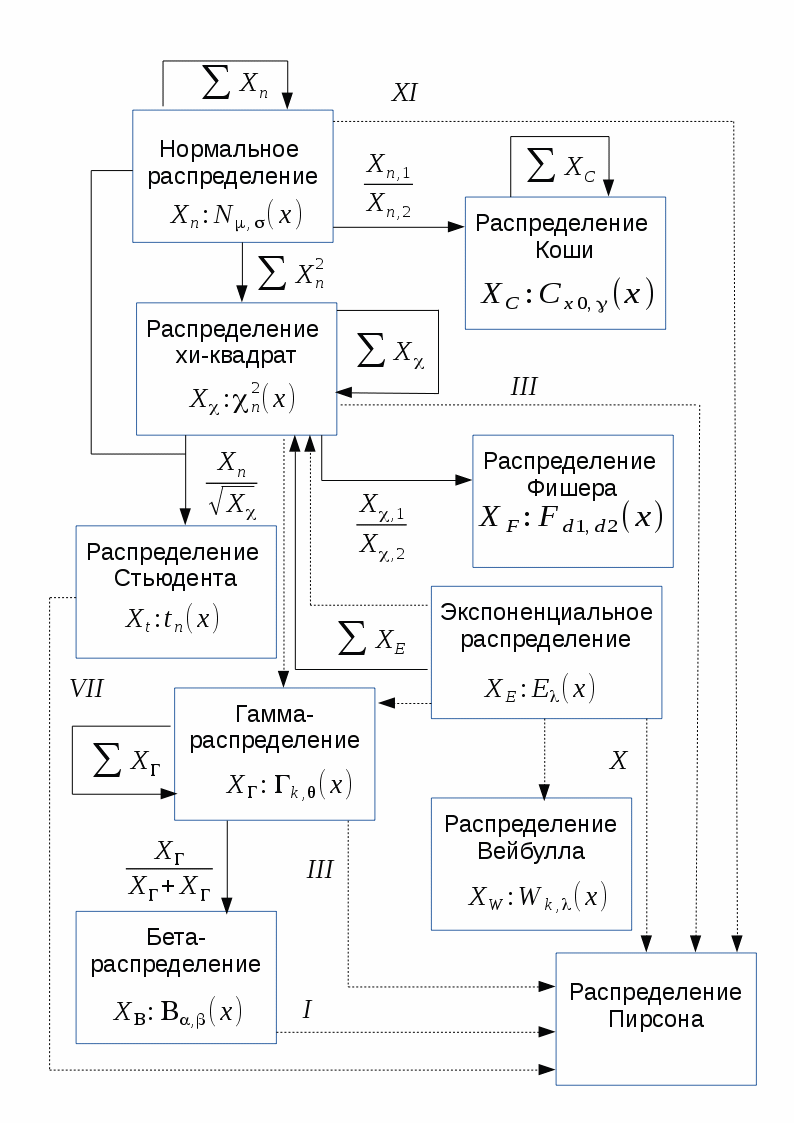
Предложенный ниже обзор распределений охватывает многие случаи, которые встречаются в анализе данных и моделировании процессов, хотя, конечно, и не содержит абсолютно все известные науке распределения.
наверх
Нормальное распределение (распределение Гаусса)
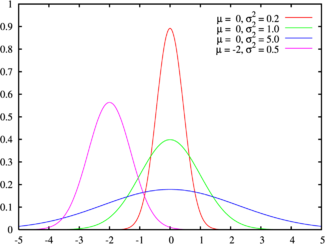
(взято отсюда)
Плотность вероятности нормального распределения
Если
Матожидание и дисперсия нормального распределения:
Область определения нормального распределения — множество дествительных чисел.
Нормальное распределение является распределение Пирсона типа VI.
Сумма квадратов независимых нормальных величин имеет распределение хи-квадрат, а отношение независимых Гауссовых величин распределено по Коши.
Нормальное распределение является бесконечно делимым: сумма нормально распределенных величин
Нормальное распределение хорошо моделирует величины, описывающие природные явления, шумы термодинамической природы и погрешности измерений.
Кроме того, согласно центральной предельной теореме, сумма большого количества независимых слагаемых одного порядка сходится к нормальному распределению, независимо от распределений слагаемых. Благодаря этому свойству, нормальное распределение популярно в статистическом анализе, многие статистические тесты рассчитаны на нормально распределенные данные.
На бесконечной делимости нормального распределении основан z-тест. Этот тест используется для проверки равенства матожидания выборки нормально распределённых величин некоторому значению. Значение дисперсии должно быть известно. Если значение дисперсии неизвестно и рассчитывается на основании анализируемой выборки, то применяется t-тест, основанный на распределении Стьюдента.
Пусть у нас имеется выборка объёмом n независимых нормально распределенных величин
Благодаря широкой распространённости распределения Гаусса, многие, не очень хорошо знающие статистику исследователи забывают проверять данные на нормальность, либо оценивают график плотности распределения «на глазок», слепо полагая, что имеют дело с Гауссовыми данными. Соответственно, смело применяя тесты, предназначенные для нормального распределения и получая совершенно некорректные результаты. Наверное, отсюда и пошла молва про статистику как самый страшный вид лжи.
Рассмотрим пример: нам надо измерить сопротивления набора резистров некоторого номинала. Сопротивление имеет физическую природу, логично предположить, что распределение отклонений сопротивления от номинала будет нормальным. Меряем, получаем колоколообразную функцию плотности вероятности для измеренных значений с модой в окрестности номинала резистров. Это нормальное распределение? Если да, то будем искать бракованные резистры используя тест Стьюдента, либо z-тест, если нам заранее известна дисперсия распределения. Думаю, что многие именно так и поступят.
Но давайте внимательнее посмотрим на технологию измерения сопротивления: сопротивление определяется как отношение приложенного напряжения к протекающему току. Ток и напряжение мы измеряли приборами, которые, в свою очередь, имеют нормально распределенные погрешности. То есть, измеренные значения тока и напряжения — это нормально распределенные случайные величины с матожиданиями, соответствующими истинным значениям измеряемых величин. А это значит, что полученные значения сопротивления распределены по Коши, а не по Гауссу.
Распределение Коши лишь напоминает внешне нормальное распределение, но имеет более тяжёлые хвосты. А значит предложенные тесты неуместны. Надо строить тест на основании распределения Коши или вычислить квадрат сопротивления, который в данном случае будет иметь распределение Фишера с параметрами (1, 1).
к схеме
наверх
Распределение хи-квадрат

(взято отсюда)
Распределение
где
Матожидание и дисперсия распределения
Область определения — множество неотрицательных натуральных чисел.
На распределении
Предположим, что у нас имеется выборка некоторой случайной величины
Приведем
где
Полученные величины
Сравнивая значение
к схеме
наверх
Распределение Стьюдента (t-распределение)

(взято отсюда)
Распределение Стьюдента используется для проведения t-теста: теста на равенство матожидания выборки стандартно нормально распределённых случайных величин некоторому значению, либо равенства матожиданий двух нормальных выборок с одинаковой дисперсией (равенство дисперсий необходимо проверять f-тестом). Распределение Стьюдента описывает отношение нормально распределённой случайной величины к величине, распределённой по хи-квадрат.
T-тест является аналогом z-теста для случая, когда дисперсия или стандартное отклонение выборки неизвестно и должно быть оценено на основании самой выборки.
Рассмотрим пример проверки равенства матожидания нормальной выборки некоторому значению: пусть нам дана выборка
Рассчитаем величину
где
Полученное значение можно сравнивать с квантилями распределения Стьюдента и принимать либо отклонять гипотезу о равенстве маотожидания значению
Матожидание и дисперсия распределения Стьюдента:
при
к схеме
наверх
Распределение Фишера
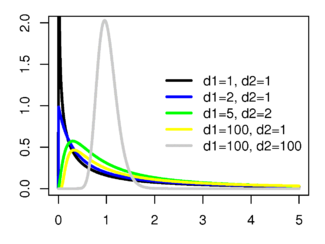
(взято отсюда)
Пусть
Распределение Фишера определено для действительных неотрицательных аргументов и имеет плотность вероятности:
Матожидание и дисперсия распределения Фишера:
Матожидание определено для
На распределении Фишера основан ряд статистических тестов, таких как оценка значимости параметров регрессии, тест на гетероскедастичность и тест на равенство дисперсий нормальных выборок (f-тест, следует отличать от точного теста Фишера).
F-тест: пусть имеются две независимые выборки
Рассчитаем величину
Сравнивая значение
к схеме
наверх
Распределение Коши
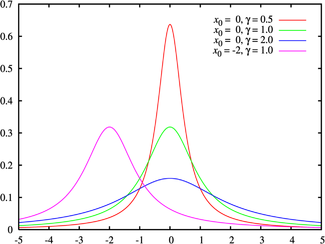
(взято отсюда)
Распределение Коши описывает отношение двух нормально распределенных случайных величин. В отличие от других распределений, для распределения Коши не определены матожидание и дисперсия. Для описания распределения используются коэффициенты сдвига
Распределение Коши является бесконечно делимым: сумма независимых случайных величин, распределённых по Коши, также распределена по Коши.
к схеме
наверх
Экспоненциальное (показательное) распределение и распределение Лапласа (двойное экспоненциальное, двойное показательное)
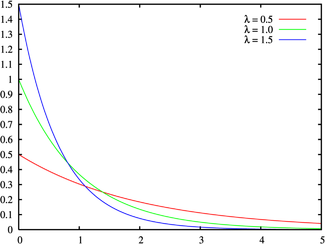
(взято отсюда)
Экспоненциальное распределение описывает интервалы времени между независимыми событиями, происходящими со средней интенсивностью
Кроме теории надёжности, экспоненциальное распределение применяется в описании социальных явлений, в экономике, в теории массового обслуживания, в транспортной логистике — везде, где необходимо моделировать поток событий.
Экспоненциальное распределение является частным случаем распределения хи-квадрат (для n=2), а следовательно, и гамма-распределения. Так-как экспоненциально распределённая величина является величиной хи-квадрат с 2-мя степенями свободы, то она может быть интерпретирована как сумма квадратов двух независимых нормально распределенных величин.
Кроме того, экспоненциальное распределение является честным случаем распределения Вейбулла.
Дискретный вариант экспоненциального распределения — это геометрическое распределение.
Плотность вероятности экспоненциально распределения:
определена для неотрицательных действительных значений
Матожидание и дисперсия экспоненциального распределения:
Если функцию плотности вероятностей экспоненциального распределения отразить зеркально в область отрицательных значений, то есть, заменить

(взято отсюда)
Для большего обобщения, вводится параметр сдвига, смещающий центр «соединения» левой и правой частей распределения вдоль оси абсцисс. В отличие от экспоненциального, распределение Лапласа, определено на всей действительной числовой оси.
где
Матожидание и дисперсия:
Благодаря более тяжёлым хвостам, чем у нормального распределения, распределение Лапласа используется для моделирования некоторых видов погрешностей измерения в энергетике, а также находит применение в физике, экономике, финансовой статистике, телекоммуникации и т.д.
к схеме
наверх
Распределение Вейбулла

(взято отсюда)
Распределение Вейбулла описывается функцией плотности вероятности следующего вида:
где
Таким образом, распределение Вейбулла — обобщение экспоненциального распределения на случай нестационарной интенсивности событий. Используется в теории надёжности, моделировании процессов в технике, в прогнозировании погоды, в описании процесса измельчения и т.д.
Матожидание и дисперсия распределения Вейбулла:
где
к схеме
наверх
Гамма-распределение (распределение Эрланга)
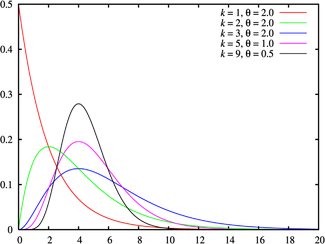
(взято отсюда)
Гамма-распределение является обобщением рапсределения хи-квадрат и, соответственно, экспоненциального распределения. Суммы квадратов нормально распределённых величин, а также суммы величин распределённых по хи-квадрат и по экспоненциальному распределению будут иметь гамма-распределение.
Гамма-распределение является распределением Пирсона III рода. Область определения гамма-распределения — натуральные неотрицательные числа.
Гамма-распределение определяется двумя неотрицательными параметрами
Гамма-распределение является бесконечно делимым: если величины
где
Матожидание и дисперсия:
Гамма распределение широко применяется для моделирования сложных потоков событий, сумм временных интервалов между событиями, в экономике, теории массового обслуживания, в логистике, описывает продолжительность жизни в медицине. Является своеобразным аналогом дискретного отрицательного биномиального распределения.
к схеме
наверх
Бета-распределение

(взято отсюда)
Бета-распределение описывает долю суммы двух слагаемых, приходящуюся на каждое из них, если слагаемые являются случайными величинами, имеющими гамма-распределение. То есть, если величины
Очевидно, что область определения бета-распределения
где параметры
Матожидание и дисперсия:
к схеме
наверх
Вместо заключения
Мы рассмотрели 15 распределений вероятности, которые, на мой взгляд, охватывают большинство наиболее популярных приложений статистики.
Напоследок, небольшое домашнее задание: для оценки надёжности биржевых торговых систем используется такой показатель как профит-фактор. Профит-фактор рассчитывается как отношение суммарного дохода к суммарному убытку. Очевидно, что для системы, приносящей доход, профит-фактор больше единицы, и чем его значение выше, тем система надёжнее.
Вопрос: какое распределение имеет значение профит-фактора?
Свои размышления по этому поводу я изложу в следующей статье.
P.S. Если Вы захотите сослатья на нумерованные формулы из этой статьи, то можете использовать такую сслыку: ссылка_на_статью#x_y_z, где (x.y.z)- номер формулы, на которую Вы ссылаетесь.
Комментарии (27)


Lelushak
30.09.2016 18:48-1Зачем захламлять теги отдельным названием каждого распределения? У них другое предназначение.
ratatosk
30.09.2016 19:03+1Вот очень хорошая вводная статья про виды распределений: Common Probability Distributions: The Data Scientist’s Crib Sheet.

JamaGava
01.10.2016 14:52Название действительно провокационное, для привлечения внимания. В самой статье я пишу, что предложенные распределения используются в «наиболее часто встречающихся задачах».
Что касается «дз» это тизер готовящейся к публикации работы. Идея такова: мы не можем знать всё обо всех стратегиях, но может поступить по аналогии с тем, как строятся другие стат.тесты, а именно, построить распределение профитфактора для системы, торгующей случайно. Тогда значение профитфактора реальной системы должно быть таковым, чтобы случайное достижения такого значения являлось маловероятным.

smxfem
01.10.2016 14:59+1Название статьи провокационное. Получается, что сингулярные распределения — бесполезная альтернатива и создание этих распределений не продиктовано непригодностью описанных тут распределений к некоторым задачам — «случаям жизни»?
Домашнее задание смахивает на задачку с подвохом. Требуется смоделировать множество биржевых систем (тут требуются знания предметной области на уровне бога) и напрямую получить распределения аналитически или откуда-то взять статистику по биржевым системам, подобрать для нескольких дающих надежду распределений оптимальные параметры (оптимизационная задача) и выбрать среди полученных конкретных распределений наиболее точные?

ShashkovS
03.10.2016 00:37+4Я просто оставлю это здесь :)
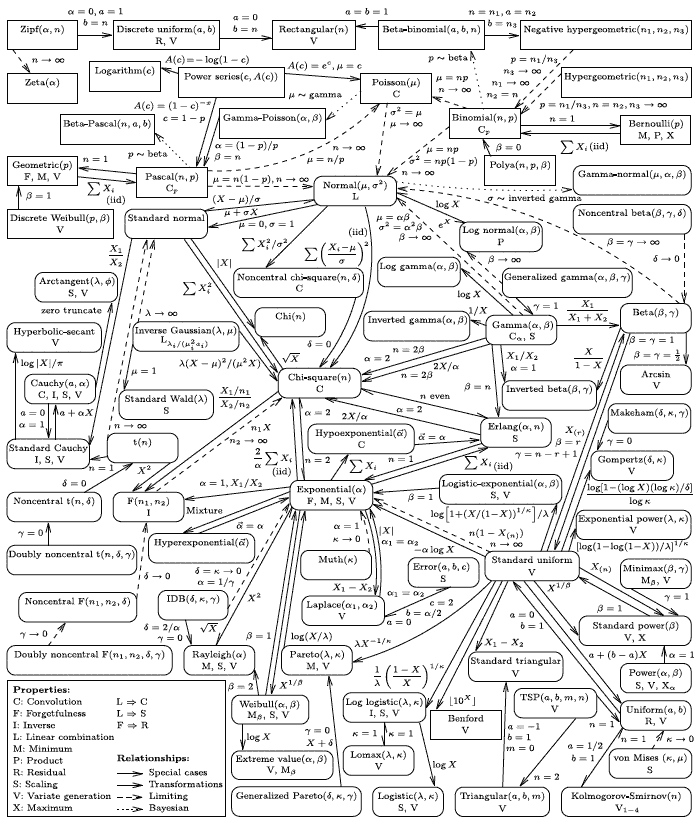
Ну, и с подробностями: http://www.math.wm.edu/~leemis/chart/UDR/UDR.htmlJamaGava
03.10.2016 01:19+1Вот это действительно: «Вау!» :)
Спасибо!JamaGava
03.10.2016 01:38У меня вообще подозрение, что почти все непрерывные распределения должны укладываться в форму
, где
и
— полиномы. Либо являться подстановкой функции (например, нецелой степени либо логарифма) от
вместо аргумента в эту формулу.
Кто-нибудь встречал подобные обобщение?
smxfem
08.10.2016 10:33+2Есть обобщенное нормальное и обобщенное гиперболическое распределения, которые содержат многие распределения. Но обобщенный вид затрудняет оценку параметров (не критично), а полу-гуманитарные критерии применимости распределений к реальным задачам слабо распространены на такие виды. Попробуйте убедить, предположим, медиков, что какое-то обобщенное распределение лучше подходит для описания некоторой случайной величины, когда 100 лет уже её описывают в обширных исследованиях, которые считаются фундаментальными, более простым частным распределением. Хотя, если, после оценки, вклад всех параметров в распределение будет существенным, то никто не отвертится и придется принять обобщение.
Знакомый психолог публиковала в зарубежном журнале статью, где математических претензий не было, а отфутболивали именно из-за отсутствия обоснования применимости использованных распределений, пока не были найдены необходимые подтверждающие ссылки.


nickolaym
06.10.2016 02:00+1Для плотности f(x) и y=g(x), — формула плотности fy(y) справедлива, только если g-1(y) однозначна. То есть, g(x) биективна. А дифференцируемость g(x) не только недостаточное, но и необязательное условие: легко придумать кучу примеров как с разрывными отображениями
— например, пила вдоль линии y = int(x)-frac(x)
так и дифференцируемые отображения, для которых обратные не дифференцируемы
— например, с седловой точкой, y = x3 (при том, что оно биективно)JamaGava
06.10.2016 11:40Согласен с Вашим, замечанием: дифференцируемой должна быть обратная к g(x) (опечатка).
GeMir
Неплохо бы статью перед публикацией показать корректору, который почистит текст от остатков «(3/10) х (2/9)» и «Г(x)» (раз уж в большинстве случаев используется красивый TeX). Нумерация формул кажется лишней, а сама статья скорее похожа на цитату из скрипта лекции по вероятностному исчислению. Справочников по теме предостаточно и как студенты, так и «зрелые специалисты», думается мне, первым делом обратятся к ним, а не к поиску по Хабру.
JamaGava
Спасибо за комментарий. По поводу формул — согласен, буду дорабатывать.
А что касается тематики и нумерации формул: эта статья «база» для дальнейших более IT-шных статей по анализу данных (чтобы ставить ссылки на конкретные формулы, собранные вместе).
kxx
И есть небольшая неточность: биномиальный коэффициент записывается обычно либо как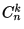 , либо как
, либо как  , но не как
, но не как  .
.
JamaGava
Это действительно ляп с моей стороны… Спасибо.
Уже исправлено.
parpalak
Картинки, кстати, тоже можно сделать красивыми:
%3D(%5Cp%5E(%5Ck))*((1-%5Cp)%5E(%5Cn-%5Ck))*factorial(%5Cn)%2F(factorial(%5Cn-%5Ck)*factorial(%5Ck))%3B%7D%0A%5D%0A%5Caddlegendimage%7Bblue%7D%0A%5Caddlegendimage%7Bgreen%7D%0A%5Caddlegendimage%7Bred%7D%0A%5Cforeach%20%5Cn%2F%5Cp%2F%5Cc%20in%20%7B20%2F0.5%2Fblue%2C%2020%2F0.7%2Fgreen%2C%2040%2F0.5%2Fred%7D%20%7B%0A%20%20%20%20%5Cforeach%20%5Ck%20in%20%7B0%2C...%2C%5Cn%7D%20%7B%0A%20%20%20%20%20%20%20%20%5Cedef%5Ctemp%7B%5Cnoexpand%0A%20%20%20%20%20%20%20%20%20%20%20%20%5Caddplot%5B%5Cc%5D%20coordinates%20%7B(%5Ck%2C%7Bbinom(%5Ck%2C%20%5Cn%2C%20%5Cp)%7D)%7D%3B%0A%20%20%20%20%20%20%20%20%7D%5Ctemp%0A%20%20%20%20%7D%0A%20%20%20%20%5Cedef%5Ctemp%7B%5Cnoexpand%0A%20%20%20%20%20%20%20%20%5Caddlegendentry%7B%24p%3D%5Cp%2C%20n%3D%5Cn%24%7D%0A%20%20%20%20%7D%5Ctemp%0A%7D%0A%5Cend%7Baxis%7D%0A%5Cend%7Btikzpicture%7D)
Вот исходник:
tomzarubin
Непонятно почему вы считаете свой график лучше представленных выше. Точки тут неуместны— чтобы понять о чём график(а потом и форму распределения), надо напрячься.
parpalak
Согласен, конечно. Мы тут обсуждали оформление, а не содержание.
%3D(%5Cp%5E(%5Ck))*((1-%5Cp)%5E(%5Cn-%5Ck))*factorial(%5Cn)%2F(factorial(%5Cn-%5Ck)*factorial(%5Ck))%3B%7D%0A%5D%0A%5Caddlegendimage%7Bblue%7D%0A%5Caddlegendimage%7Bgreen%7D%0A%5Caddlegendimage%7Bred%7D%0A%5Cforeach%20%5Cn%2F%5Cp%2F%5Cc%20in%20%7B20%2F0.5%2Fblue%2C%2020%2F0.7%2Fgreen%2C%2040%2F0.5%2Fred%7D%20%7B%0A%20%20%20%20%5Cforeach%20%5Ck%20in%20%7B0%2C...%2C%5Cn%7D%20%7B%0A%20%20%20%20%20%20%20%20%5Cedef%5Ctemp%7B%5Cnoexpand%0A%20%20%20%20%20%20%20%20%20%20%20%20%5Caddplot%5Bybar%2Cfill%3D%5Cc%2Copacity%3D0.5%5D%20coordinates%20%7B(%5Ck%2C%7Bbinom(%5Ck%2C%20%5Cn%2C%20%5Cp)%7D)%7D%3B%0A%20%20%20%20%20%20%20%20%7D%5Ctemp%0A%20%20%20%20%7D%0A%20%20%20%20%5Cedef%5Ctemp%7B%5Cnoexpand%0A%20%20%20%20%20%20%20%20%5Caddlegendentry%7B%24p%3D%5Cp%2C%20n%3D%5Cn%24%7D%0A%20%20%20%20%7D%5Ctemp%0A%7D%0A%5Cend%7Baxis%7D%0A%5Cend%7Btikzpicture%7D)
В тексте была откуда-то скопированная png-картинка. Моя svg-картинка сделана в латехе с пакетом tikz. Способ не без проблем: человеку без опыта тяжело сразу готовить такие картинки. Зато исходник можно править на лету, не перерисовывая картинку. Я вот за 5 минут поменял точки на столбцы, и диаграмма стала понятнее:
tomzarubin
Постойте, так про оформление и речь. Пример выше, конечно, чище и понятней.
JamaGava
Такие диаграммы красивее. Я взял материал со страниц википедии (в тексте приведены ссылки). Если для кого-нибудь действительно совсем несложно переделать графики — Вы можете улучшить Вики.
Сам бы занялся, но не владею технологией построения настолько красивых диаграмм :)
(Хотя, уже захотелось освоить)
parpalak
Переделать — не сложно, но и не просто :)
Хотите освоить — посмотрите введение к официальной документации tikz. В нем последовательным усложнением строятся полноценные примеры графиков и диагамм. Это хорошая отправная точка.
JamaGava
Спасибо
tomzarubin
Я не в претензии)
Кстати, в R есть прекрасные библиотеки. Тот же «классический уже» ggplot2 или seaborn + несколько библиотек интерактивных графиков.
Ну и R, по ощущениям, очень прекрасен для статистики и EDA. Самое главное— побороть непонимание синтаксиса самого R.