На этот вопрос мы попытались найти ответ, написав java-приложение, использующее Non-Blocking I/O технологию обмена. В итоге появился NIOBench, с помощью которого можно получить бенчмарки магнитных и твердотельных носителей с различными интерфейсами, а фактически – любого внешнего накопителя (за исключением, разве что, устройств с дисциплиной доступа Read Only, но и на них есть свои планы).
В процессе разработки возник ряд ситуаций, когда нужно было определяться со сценариями тестирования. Оставим рабочие моменты в стенах лаборатории, остановимся подробно на таком важном аспекте, как выбор тестового паттерна. Использовать эвристические методы, как это реализовано, например, в AS SSD, не было резона: по сути, — это повторение пройденного. Решено было искать свой вариант. Прежде, чем перейти к его изложению, немного нудных воспоминаний.
Фактор нулей и единиц
Современные микросхемы энергонезависимой Flash-памяти, применяемые в твердотельных накопителях располагают собственным встроенным автоматом записи, оптимально управляющим процессом программирования запоминающей матрицы. Внутри такой микросхемы находится основная часть логики программатора постоянного запоминающего устройства (ПЗУ). Это обстоятельство не только делает электронное устройство компактным, но и охраняет интеллектуальную собственность производителя, превращая чип в «черный ящик».
Поэтому, для наглядности, рассмотрим «антикварные» микросхемы с электрическим программированием, ультрафиолетовым стиранием и объемом 2 килобайта. Очевидно, устройства 30-летней давности существенно отличаются от современных, тем не менее, ряд физических принципов и эффектов, сохранили свою актуальность.
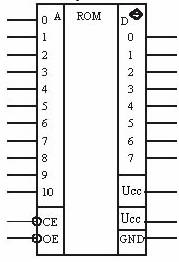
Рис. 1. Интерфейс микросхем содержит линии адреса, данных, управления и питания
Как известно, после стирания такой микросхемы, ячейки памяти устанавливаются в состояние 0FFh или «все единицы». Байты, значение которых должно быть 0FFh можно просто не записывать. Кроме того, количество и(или) длительность программирующих импульсов, необходимых для записи байта, зависит от соотношения количества нулей и единиц в этом байте. Таким образом, налицо зависимость времени записи от данных. Отметим, что если в записываемых данных нулей значительно больше, чем единиц, разработчик устройства может принять решение хранить данные в инверсном виде, сэкономив не только время записи, но и ресурс микросхемы и даже некоторую (пусть и микроскопическую) часть потребляемой мощности.
Фактор сжатия
Накопитель, архивирующий информацию неизбежно должен использовать алгоритм, анализирующий и преобразующий потоки данных, курсирующие между хост-интерфейсом и матрицей Flash-памяти.
А это означает, что время обработки данных будет различным, в зависимости от энтропии, если, конечно, разработчик устройства не нивелирует этот эффект намеренно.
Тест NIOBench
В версии v0.42 бенчмарка NIOBench реализован сценарий заполнения тестовых паттернов (копируемых файлов) псевдослучайными данными. По умолчанию в качестве заполнителя используются нули.
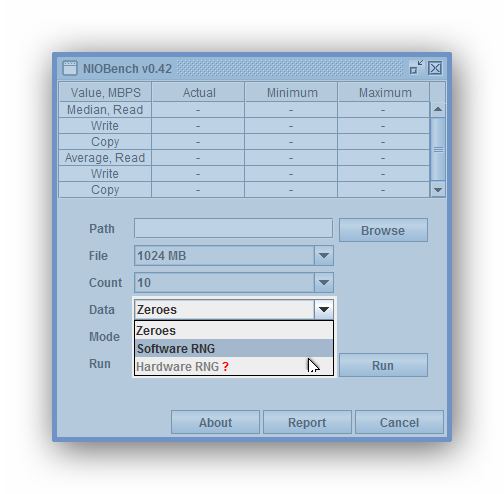
Поддерживается два вида генераторов случайных чисел:
- Программный, методы класса java.util.Random
- Аппаратный, инструкция RDRAND, опционально поддерживаемая процессорами
Если инструкция RDRAND не поддерживается, либо отсутствует нативная библиотека под данную ОС, опция Hardware RNG не активируется — бенчмарки можно выполнить в режиме заполнения нулями либо c программной генерацией тестового паттерна псевдослучайными числами. Опция Data, выбирает один из трех методов тестирования:
- Zeroes — заполнение тестовых файлов нулями
- Software RNG (Random Number Generator) — заполнение тестовых файлов псевдослучайными данными, полученными программно, методами класса java.util.Random
- Hardware RNG — заполнение тестовых файлов псевдослучайными данными, полученными аппаратно, с помощью машинной инструкции RDRAND
Режимы 1 и 2 поддерживаются на всех платформах. Режим 3 поддерживается при условии поддержки процессором инструкции RDRAND и наличия нативной библиотеки для данной ОС. В этой версии присутствуют нативные библиотеки для Windows 32/64. Планируется поддержка инструкции RDRAND и под Linux.
Нативные библиотеки упакованы в составе выполняемого JAR-архива. Подключение к java приложению, процедур, написанных на ассемблере, базируется на спецификации JNI (Java Native Interface).
О результатах
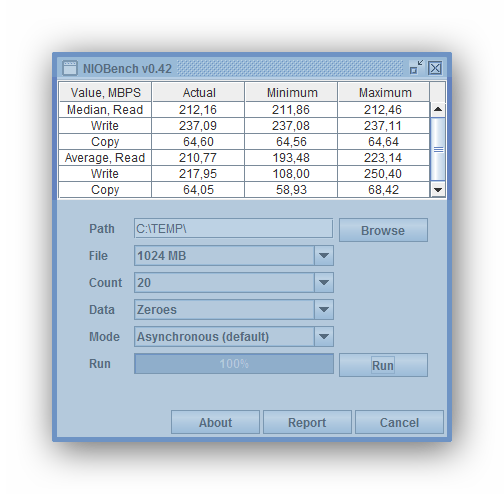
В ходе тестовых операций таблица в верхней части окна утилиты NIOBench заполняется полученными результатами. По столбцам разнесена статистика бенчмарок: средняя, минимальная и максимальная скорости. Построчно выводятся медианы чтения, записи и копирования, а затем — средние значения, полученные в процессе выполнения этих же операций.
Пользователь может сохранить текстовый рапорт выполнения бенчмарок. В нем детально представлены результаты по каждой из итераций, заданных в поле Count. Данные, участвующие в вычислениях медиан, отмечены литерой «M».
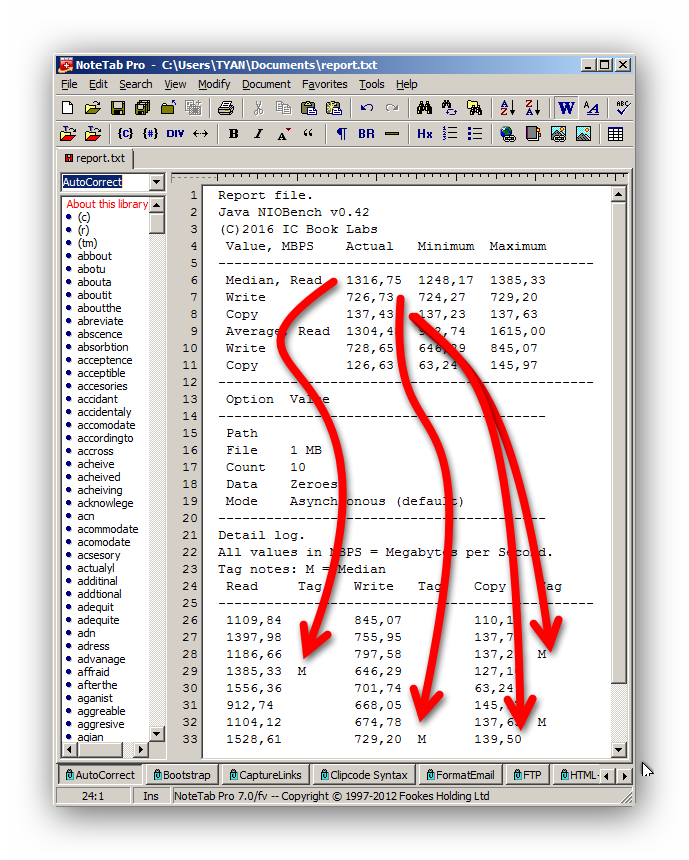
При разработке сценария теста, поставлена задача измерить исключительно производительность накопителя (либо схем архивации данных, работающих на уровнях, ниже файловых API, что возможно в некоторых системах хранения данных) и ее зависимость от данных. При этом необходимо исключить зависимость результатов от производительности самого генератора случайных чисел. Поэтому массивы тестовых данных заполняются один раз при старте приложения, а не во время выполнения измерительной операции. В зависимости от состояния опции Data, выбирающей метод тестирования, используется один из трех заранее подготовленных массивов (нули, soft-RNG, hard-RNG). Тестовые данные повторяются с периодом 1 мегабайт.
Технология разработки и отладки
Написание и отладка java-приложения выполнены в среде NetBeans 8.1. Ассемблерные библиотеки написаны в среде FASM Editor 2.0, оттранслированы с помощью Flat Assembler 1.71.49. Отладка 32-битного ассемблерного кода выполняется в OllyDbg v2.01. Отладка 64-битного ассемблерного кода выполняется в FDBG v0025.
Комментарии (19)

grossws
03.10.2016 12:04+1И зачем, если есть fio? Там вполне есть:
fio job paramszero_buffers
Initialize buffers with all zeros. Default: fill buffers with random data.
refill_buffers
If this option is given, fio will refill the IO buffers on every submit. The default is to only fill it at init time and reuse that data. Only makes sense if zero_buffers isn't specified, naturally. If data verification is enabled, refill_buffers is also automatically enabled.
scramble_buffers=bool
If refill_buffers is too costly and the target is using data deduplication, then setting this option will slightly modify the IO buffer contents to defeat normal de-dupe attempts. This is not enough to defeat more clever block compression attempts, but it will stop naive dedupe of blocks. Default: true.
buffer_compress_percentage=int
If this is set, then fio will attempt to provide IO buffer content (on WRITEs) that compress to the specified level. Fio does this by providing a mix of random data and a fixed pattern. The fixed pattern is either zeroes, or the pattern specified by buffer_pattern. If the pattern option is used, it might skew the compression ratio slightly. Note that this is per block size unit, for file/disk wide compression level that matches this setting. Note that this is per block size unit, for file/disk wide compression level that matches this setting, you'll also want to set refill_buffers.
buffer_compress_chunk=int
See buffer_compress_percentage. This setting allows fio to manage how big the ranges of random data and zeroed data is. Without this set, fio will provide buffer_compress_percentage of blocksize random data, followed by the remaining zeroed. With this set to some chunk size smaller than the block size, fio can alternate random and zeroed data throughout the IO buffer.
buffer_pattern=str
If set, fio will fill the IO buffers with this pattern. If not set, the contents of IO buffers is defined by the other options related to buffer contents. The setting can be any pattern of bytes, and can be prefixed with 0x for hex values. It may also be a string, where the string must then be wrapped with "".
icbook
03.10.2016 13:08Хороший вопрос! Подскажите, пожалуйста, fio поддерживает аппаратные источники энтропии?
grossws
03.10.2016 14:59+1Если правильно помню, там были только prng, но достаточно хорошие. А зачем вам там hardware rng? Это тут же убивает возможность воспроизводимого теста (
fioподдерживает явное указание seed'а для этого.icbook
03.10.2016 20:18Hardware RNG (в частности процессорная инструкция RDRAND) дает достаточно высокое качество случайных чисел. А если это на некоторых накопителях приведет к нарушению воспроизводимости, то выявление такого факта тоже неплохой результат. Хотя не думаю, что упаковщик в SSD диске настолько интеллектуальный, ведь он должен успевать отрабатывать в темпе чтения и записи данных, у него нет времени на детальный анализ этих данных. Что и проверим с помощью RDRAND.
Программный генератор псевдо-случайных чисел также поддерживается, режим всегда можно выбрать в соответствии с задачей.grossws
04.10.2016 13:56Hardware RNG (в частности процессорная инструкция RDRAND) дает достаточно высокое качество случайных чисел. ...snip... Хотя не думаю, что упаковщик в SSD диске настолько интеллектуальный, ведь он должен успевать отрабатывать в темпе чтения и записи данных, у него нет времени на детальный анализ этих данных. Что и проверим с помощью RDRAND.
Вы оценивали разницу, которую даёт использование hw rng по сравнению с нормальным prng? Если да, то с какими prng вы сравнивали? И насколько велика эта разница при сравнении с нормальными prng, оправдывает ли использование hw rng?
icbook
05.10.2016 15:32Мы используем RDRand, как один из многих путей в области рандомизации, и берем его в надежде улучшить саму рандомизацию.
23derevo
и что? какие выводы вы предлагаете сделать читателям вашей статьи?
icbook
Это все-таки раздел «Разработка», идет процесс, после которого будут и выводы. Но уже сегодня с помощью NIOBench можно
23derevo
Вы проделали работу, из которой непонятно что следует. Зачем мне об этом знать? Зачем об этом знать другим читателям хабра? Что ваша работа им дает?
grossws
С использованием каких из доброго десятка низкоуровневых api для io? Или как повезёт и сравниваете удавов с попугаями?
icbook
Для Windows и Linux используются одни и те же методы пакета java.nio, создание прямых буферов методом java.nio.ByteBuffer.allocateDirect(); обеспечивает минимизацию транзитных операций. Это тот случай, когда кроссплатформенность действует.
Да, тест интегральный и зависит не только от ОС, но и JVM.
grossws
На это я и намекал. Какой метод io используется на конкретной версии jre — неизвестно, и измеряете вы, с большой вероятностью, неизвестно что, имеющее слабое отношение к реальной производительности io подсистемы.
Думаю, стоит скастовать amarao, может он что-нибудь расскажет хорошего ,)
amarao
А? Что? Какое java.nio.ByteBuffer.allocateDirect()? Оно libaio использует или просто O_DIRECT вешает на io? Даже при O_DIRECT запрос всё равно попадает в очередь устройства, дальше работает планировщик очереди — noop/deadline/cfq. Дальше там лимит на глубину команд в scsi стеке, количество свободных портов на enclosure, очередь устройства, плюс, разумеется, настройки кеширования устройства. Это если рейды не учитывать по дороге.
Сравнивать напрямую производительность блочных стеков linux/windows трудно, так как флаги и настройки решают очень много. Правильный вариант — iometer vs fio, а что тут java забыла… эм…
grossws
А это неведомо, т. к. в каждой JRE может быть своя реализация.
ByteBuffer.allocateDirectвыделяет память вне кучи и используется в nio для того, чтобы можно было избежать дополнительного копирования буферов между кучей и реальными буферами.На моей машине openjdk8 на linux при использовании
java.nio.channels.SeekableByteChannelиспользует обычныеopen/read/lseek.icbook
Вместо того чтобы конкретно сказать, что прямой буфер не улучшит ситуацию при взаимодействии с диском, разговор уходит в сторону.
В действительности, в дисковой операции есть два участника: диск и память. Прямой буфер не улучшит ситуацию с диском, но улучшит ситуацию с памятью, насколько это в данном случае можно разделять. Потому что java.nio.ByteBuffer.allocateDirect(), как метод создания буфера, минимизирует транзитные операции копирования данных между буферами JVM и нативными буферами ОС API. В идеале, при использовании этого метода, буфер, с которым работает Java-код, прямо соответствует буферу, с которым работает ОС API файловых операций. В системе команд x86 CPU тоже есть аналогичные, но «необязательные намеки», например, SSE prefetch hints для опережающей загрузки данных
В этом контексте опции файловых API (например, O_DIRECT) – это совсем другая тема, впрочем, также зависящая от реализации JVM. Но пользуясь всем набором опций нативных API по своему усмотрению, мы рискуем создать синтетические нетиповые сценарии.
Зависимость от JVM – нормальный и ожидаемый факт. Акцентируя внимания на особенностях той или иной реализации, мы упускаем из виду, что именно для оценки эффективности этих реализаций и разрабатывался NIOBench, как в общем-то и всякий другой тест.
JVM и NIO – это апробированные и респектабельные решения. Может, снимать метрики стоит с помощью тех профилей, которые они выбрали по умолчанию, а затем уже добавлять свои варианты, вплоть до NUMA-зависимого выделения памяти и прямой работы с регистрами AHCI/NVMe/SCSI?
> а что тут java забыла…
То же, что и здесь.
grossws
Спасибо, рассмешили. Это обёртка над обычным
sendfile(2).icbook
Ожидаемо, что JVM (и как следствие NIO) использует ОС API, а не собственный драйвер или другие экзотические методы. Это тривиально, а не смешно.
Если бы это был низкоуровневый тест, работающий с регистрами контроллера в обход ОС и без участия ОС, тогда бы точно не получилось сравнения Windows и Linux.
grossws
Ещё раз, этих api в рамках ОС выше крыши. Даже в рамках одной платформы. Не поленитесь заглянуть в man
fio(1).Задача, озвученная вами
не выполняется. Это не бенчмарки накопителей или io подсистемы ОС. Пока ваш NIOBench выглядит как попугаемерка.
icbook
Бенчмарки магнитных и твердотельных носителей с различными интерфейсами не существуют в отрыве от API в рамках современных ОС. Именно для интегральной оценки эффективности каждой из реализаций и может использоваться NIOBench. О этом уже сказано выше (Вы наши ответы читаете?)