 Это будет длиннопост. Я давно хотел написать этот обзор, но sim0nsays меня опередил, и я решил выждать момент, например как появятся результаты ImageNet’а. Вот момент настал, но имаджнет не преподнес никаких сюрпризов, кроме того, что на первом месте по классификации находятся китайские эфэсбэшники. Их модель в лучших традициях кэгла является ансамблем нескольких моделей (Inception, ResNet, Inception ResNet) и обгоняет победителей прошлого всего на полпроцента (кстати, публикации еще нет, и есть мизерный шанс, что там реально что-то новое). Кстати, как видите из результатов имаджнета, что-то пошло не так с добавлением слоев, о чем свидетельствует рост в ширину архитектуры итоговой модели. Может, из нейросетей уже выжали все что можно? Или NVidia слишком задрала цены на GPU и тем самым тормозит развитие ИИ? Зима близко? В общем, на эти вопросы я тут не отвечу. Зато под катом вас ждет много картинок, слоев и танцев с бубном. Подразумевается, что вы уже знакомы с алгоритмом обратного распространения ошибки и понимаете, как работают основные строительные блоки сверточных нейронных сетей: свертки и пулинг.
Это будет длиннопост. Я давно хотел написать этот обзор, но sim0nsays меня опередил, и я решил выждать момент, например как появятся результаты ImageNet’а. Вот момент настал, но имаджнет не преподнес никаких сюрпризов, кроме того, что на первом месте по классификации находятся китайские эфэсбэшники. Их модель в лучших традициях кэгла является ансамблем нескольких моделей (Inception, ResNet, Inception ResNet) и обгоняет победителей прошлого всего на полпроцента (кстати, публикации еще нет, и есть мизерный шанс, что там реально что-то новое). Кстати, как видите из результатов имаджнета, что-то пошло не так с добавлением слоев, о чем свидетельствует рост в ширину архитектуры итоговой модели. Может, из нейросетей уже выжали все что можно? Или NVidia слишком задрала цены на GPU и тем самым тормозит развитие ИИ? Зима близко? В общем, на эти вопросы я тут не отвечу. Зато под катом вас ждет много картинок, слоев и танцев с бубном. Подразумевается, что вы уже знакомы с алгоритмом обратного распространения ошибки и понимаете, как работают основные строительные блоки сверточных нейронных сетей: свертки и пулинг.Переход от нейрофизиологии к компьютерному зрению
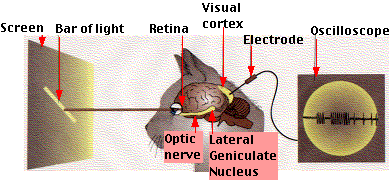
 Начать рассказ следовало бы с пионеров области нейронных сетей (не только искусственных) и их вклада: формальной модели нейрона МакКаллока — Питтса, теории обучения Хебба, персептрона Розенблатта, экспериментов Пола Бах-и-Риты и других, но, пожалуй, я оставлю это читателям для самостоятельной работы. Так что предлагаю сразу перейти к Дэвиду Хьюбелу и Торстену Визелю, нобелевским лауреатам 1981 года. Они получили премию за работу, проведенную в 1959 году (в то же время Розенблатт ставил свои эксперименты). Формально премия выдана за «работы, касающиеся принципов переработки информации в нейронных структурах и механизмов деятельности головного мозга». Стоит сразу предостеречь чувствительных читателей: далее будет описан эксперимент над котиками. Модель эксперимента изображена на рисунке ниже: коту на темном экране под различными углами демонстрируется яркий вытянутый движущийся прямоугольник; электрод осциллографа подсоединен к затылочной части головного мозга, где у млекопитающих находится центр обработки визуальной информации. В процессе эксперимента ученые наблюдали следующие эффекты (вы легко найдете аналогии с современными сверточными сетями и рекуррентными сетями):
Начать рассказ следовало бы с пионеров области нейронных сетей (не только искусственных) и их вклада: формальной модели нейрона МакКаллока — Питтса, теории обучения Хебба, персептрона Розенблатта, экспериментов Пола Бах-и-Риты и других, но, пожалуй, я оставлю это читателям для самостоятельной работы. Так что предлагаю сразу перейти к Дэвиду Хьюбелу и Торстену Визелю, нобелевским лауреатам 1981 года. Они получили премию за работу, проведенную в 1959 году (в то же время Розенблатт ставил свои эксперименты). Формально премия выдана за «работы, касающиеся принципов переработки информации в нейронных структурах и механизмов деятельности головного мозга». Стоит сразу предостеречь чувствительных читателей: далее будет описан эксперимент над котиками. Модель эксперимента изображена на рисунке ниже: коту на темном экране под различными углами демонстрируется яркий вытянутый движущийся прямоугольник; электрод осциллографа подсоединен к затылочной части головного мозга, где у млекопитающих находится центр обработки визуальной информации. В процессе эксперимента ученые наблюдали следующие эффекты (вы легко найдете аналогии с современными сверточными сетями и рекуррентными сетями):- определенные области зрительной коры активируются только тогда, когда линия проецируется на определенную часть сетчатки;
- уровень активности нейронов области изменяется при изменении угла наклона прямоугольника;
- некоторые области активируются только тогда, когда объект движется в определенном направлении.
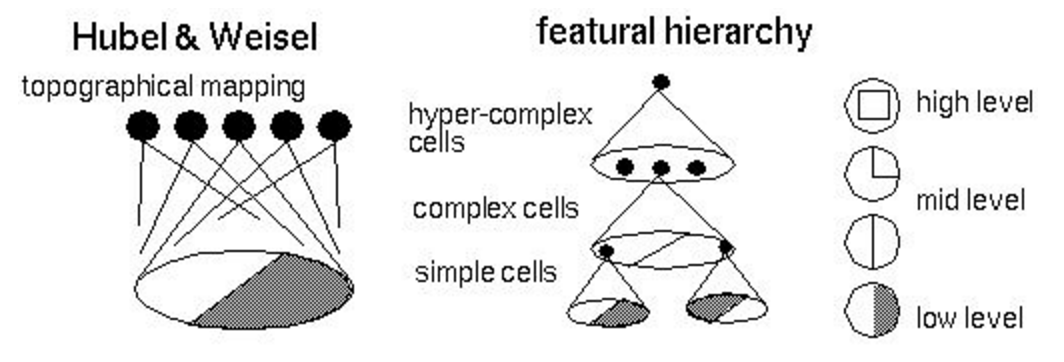
Одним из результатов исследования стала модель зрительной системы, или топографическая карта, со следующими свойствами:
- соседние нейроны обрабатывают сигналы с соседних областей сетчатки;
- нейроны образуют иерархическую структуру (изображение ниже), где каждый следующий уровень выделяет все более и более высокоуровневые признаки (сегодня мы уже умеем эффективно манипулировать этими признаками);
- нейроны организованы в так называемые колонки — вычислительные блоки, которые трансформируют и передают информацию от уровня к уровню.
Первым, кто попытался переложить идеи Хьюбела и Визеля в программный код, был Кунихико Фукусима, который в период с 1975 по 1980 годы предложил две модели: когнитрон и неокогнитрон. Эти модели почти повторяли биологическую модель, сегодня простые клетки (simple cells) мы называем свертками, а комплексные клетки (complex cells) — пулингом: это все еще основные строительные блоки современных сверточных нейронных сетей. Модель обучалась не алгоритмом обратного распространения ошибки, а оригинальным эвристическим алгоритмом в режиме без учителя. Можно считать, что именно эта работа стала началом нейросетевого компьютерного зрения.
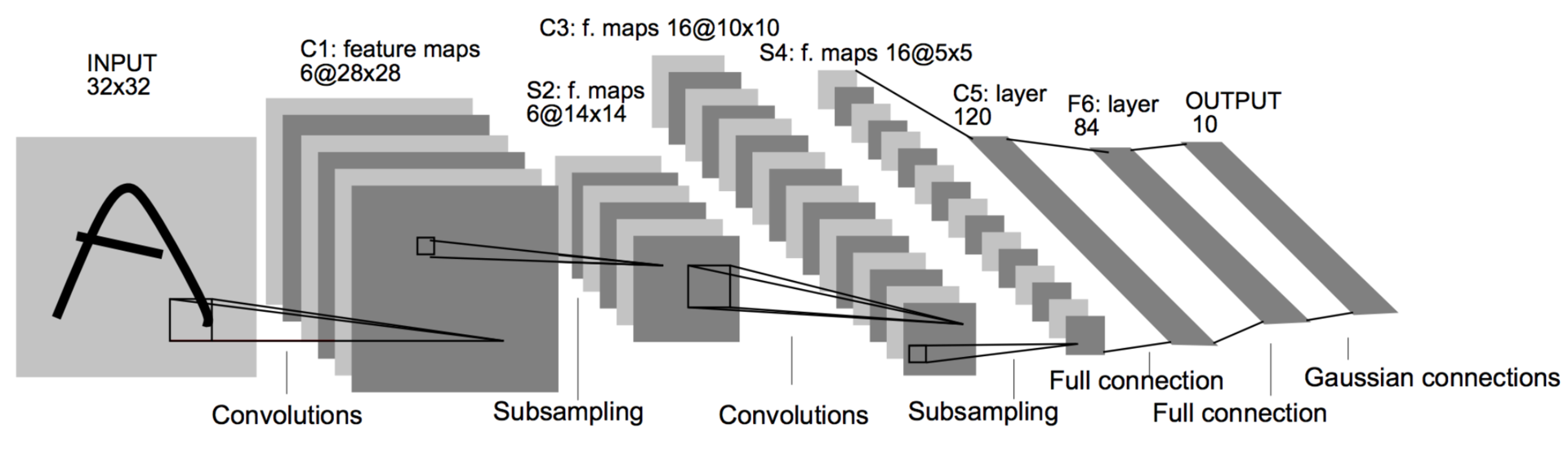
Gradient-based learning applied to document recognition (1998)
Спустя много лет настал 1998 год. Зима прошла. Ян ЛеКунн, который уже давно побывал постдоком одного из авторов статьи об алгоритме обратного распространения ошибки, публикует работу (в соавторстве с другими корифеями нейронных сетей), в которой смешивает идеи сверток и пулинга с бекпропом, в итоге получая первую работающую сверточную нейронную сеть. Ее внедрили в почту США для распознавания индексов. Эта архитектура была стандартным шаблоном для построения сверточных сетей вплоть до недавнего времени: свертка чередуется с пулингом несколько раз, затем несколько полносвязных слоев. Такая сеть состоит из 60 тысяч параметров. Основные строительные блоки — свертки 5 ? 5 со сдвигом 1 и пулинг 2 ? 2 со сдвигом 2. Как вы уже знаете, свертки играют роль детекторов признаков, а пулинг (или сабсемплинг) используют для уменьшения размерности, эксплуатируя тот факт, что изображения обладают свойством локальной скоррелированности пикселей — соседние пиксели, как правило, не сильно отличаются друг от друга. Таким образом, если из нескольких соседних получить какой-либо агрегат, то потери информации будут незначительными.
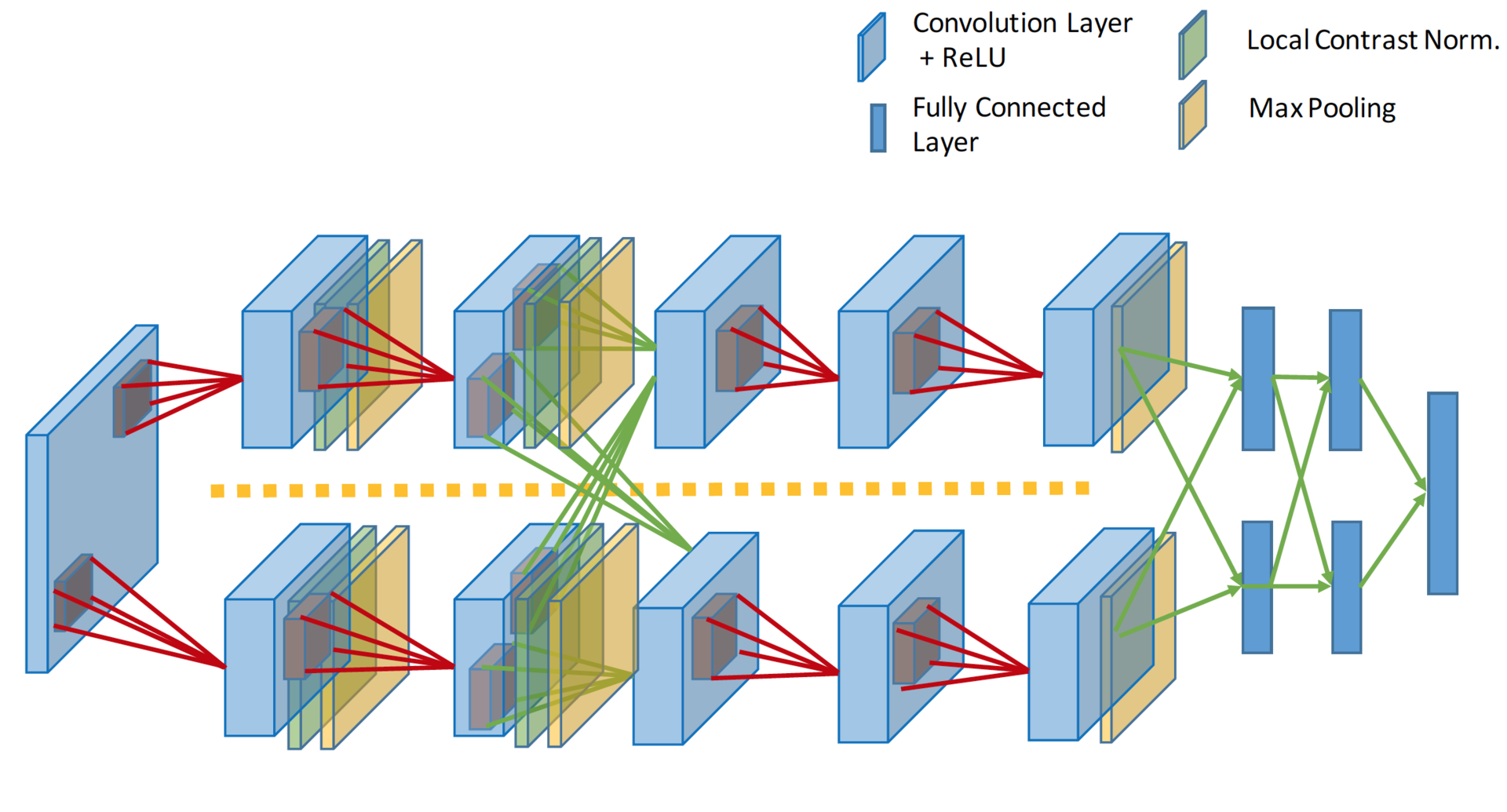
ImageNet Classification with Deep Convolutional Neural Networks (2012)
Прошло еще 14 лет. Алекс Крижевский из той же лаборатории, где был постдоком ЛеКун, добавил последние ингредиенты к формуле. Глубокое обучение = модель + теория обучения + большие данные + железо. GPU позволило значительно увеличить количество обучаемых параметров. Модель содержит 60 миллионов параметров, на три порядка больше, для обучения такой модели использовалось два графических ускорителя.
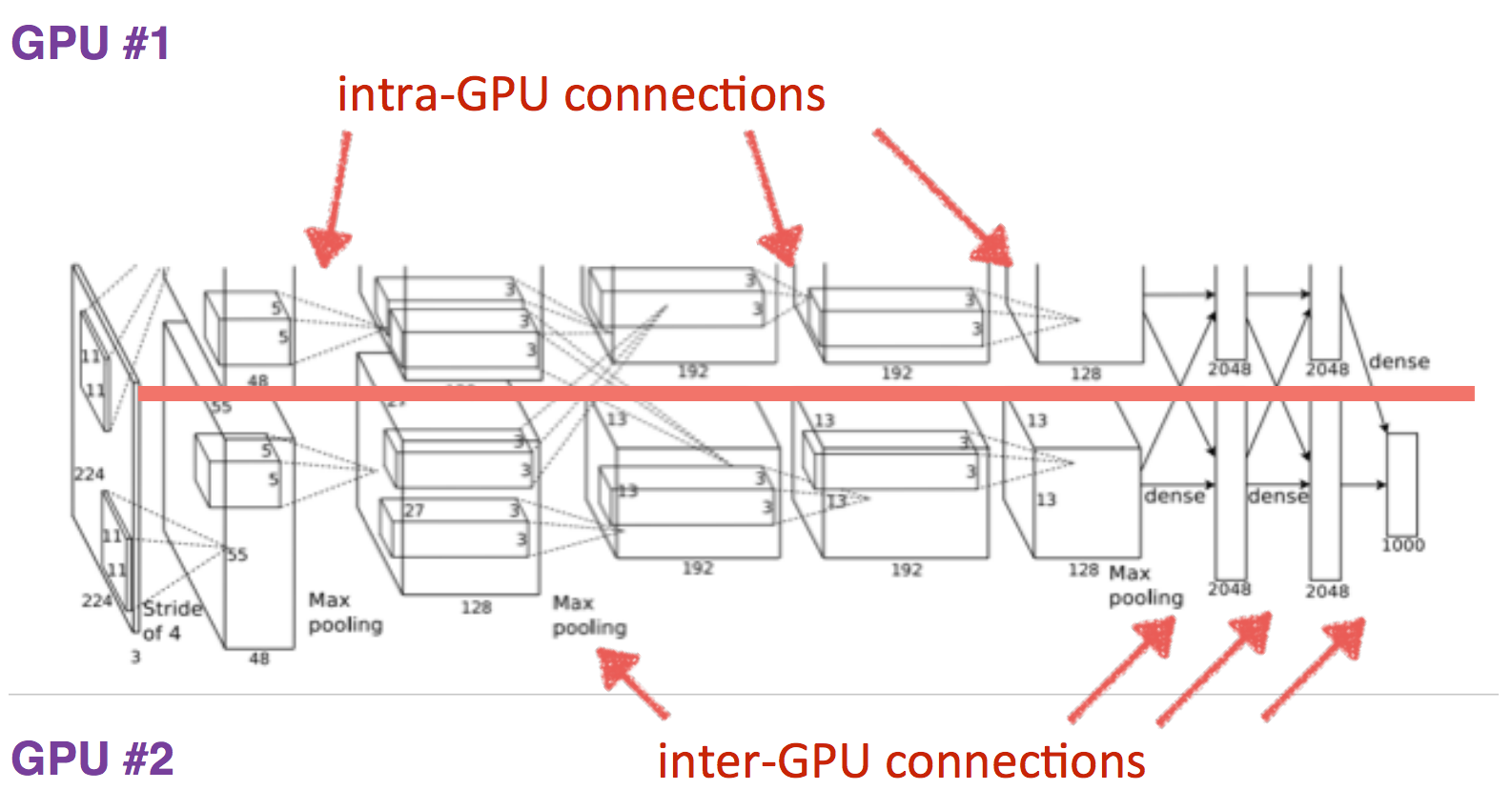
Размеры слоев
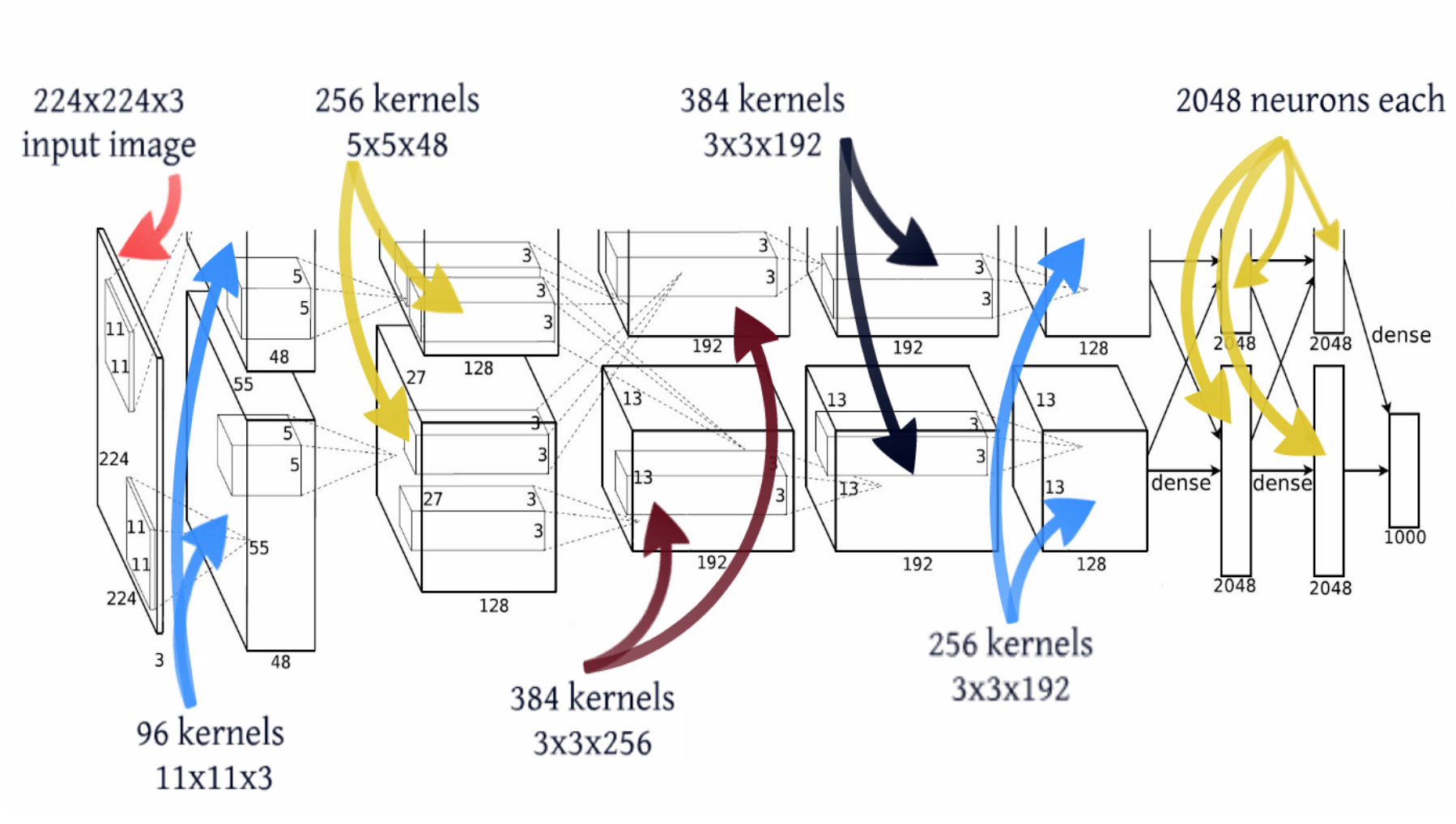
С точки зрения топологии сети это почти тот же LeNet, просто увеличенный в тысячу раз. Добавились еще несколько сверточных слоев, а размер ядер свертки уменьшается от входа сети к выходу. Это объясняется тем, что в начале пиксели сильно скоррелированы, и рецепторную область можно смело брать большую, мы все равно теряем мало информации. Далее мы применяем пулинг, тем самым увеличивая плотность некоррелированных участков. На следующем уровне логично взять чуть меньшую рецепторную область. В итоге у авторов получилась такая вот пирамида из сверток 11 ? 11 –> 5 ? 5 –> 3 ? 3…
Также были применены другие трюки для избежания переобучения, и некоторые из них сегодня являются стандартными для глубоких сетей: DropOut (RIP), Data Augmentation и ReLu. Мы не будем заострять внимание на этих трюках, сосредоточимся на топологии модели. Добавлю только, что с 2012 года не нейросетевые модели больше не побеждали в имаджнете.
Very Deep Convolutional Networks for Large-Scale Image Recognition (12 Apr 2014)
В этом году вышли две интересные статьи, эта и Google Inception, которую мы рассмотрим ниже. Работа же Оксфордской лаборатории — это последняя работа, придерживающаяся паттерна топологии, заложенного ЛеКуном. Их модель VGG-19 состоит из 144 миллионов параметров и добавляет в архитектуру, помимо 84 миллионов параметров, еще одну простую идею. Возьмем для примера свертку 5 ? 5, это отображение
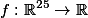 , оно содержит 25 параметров. Если заменить ее стеком из двух слоев со свертками 3 ? 3, то мы получим такое же отображение, но количество параметров будет меньше: 3 ? 3 + 3 ? 3 = 18, а это на 22 % меньше. Если же заменить 11 ? 11 на четыре свертки 3 ? 3, то это уже на 70 % меньше параметров.
, оно содержит 25 параметров. Если заменить ее стеком из двух слоев со свертками 3 ? 3, то мы получим такое же отображение, но количество параметров будет меньше: 3 ? 3 + 3 ? 3 = 18, а это на 22 % меньше. Если же заменить 11 ? 11 на четыре свертки 3 ? 3, то это уже на 70 % меньше параметров.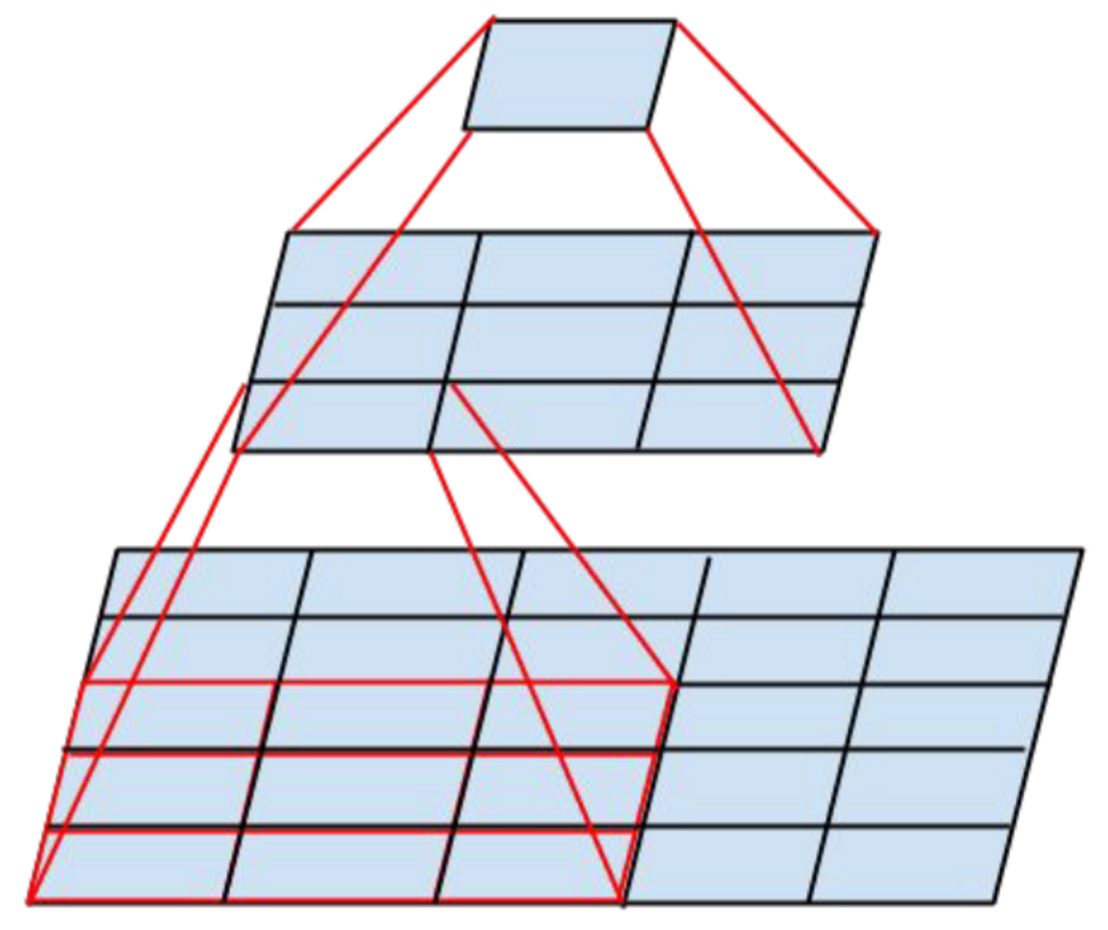
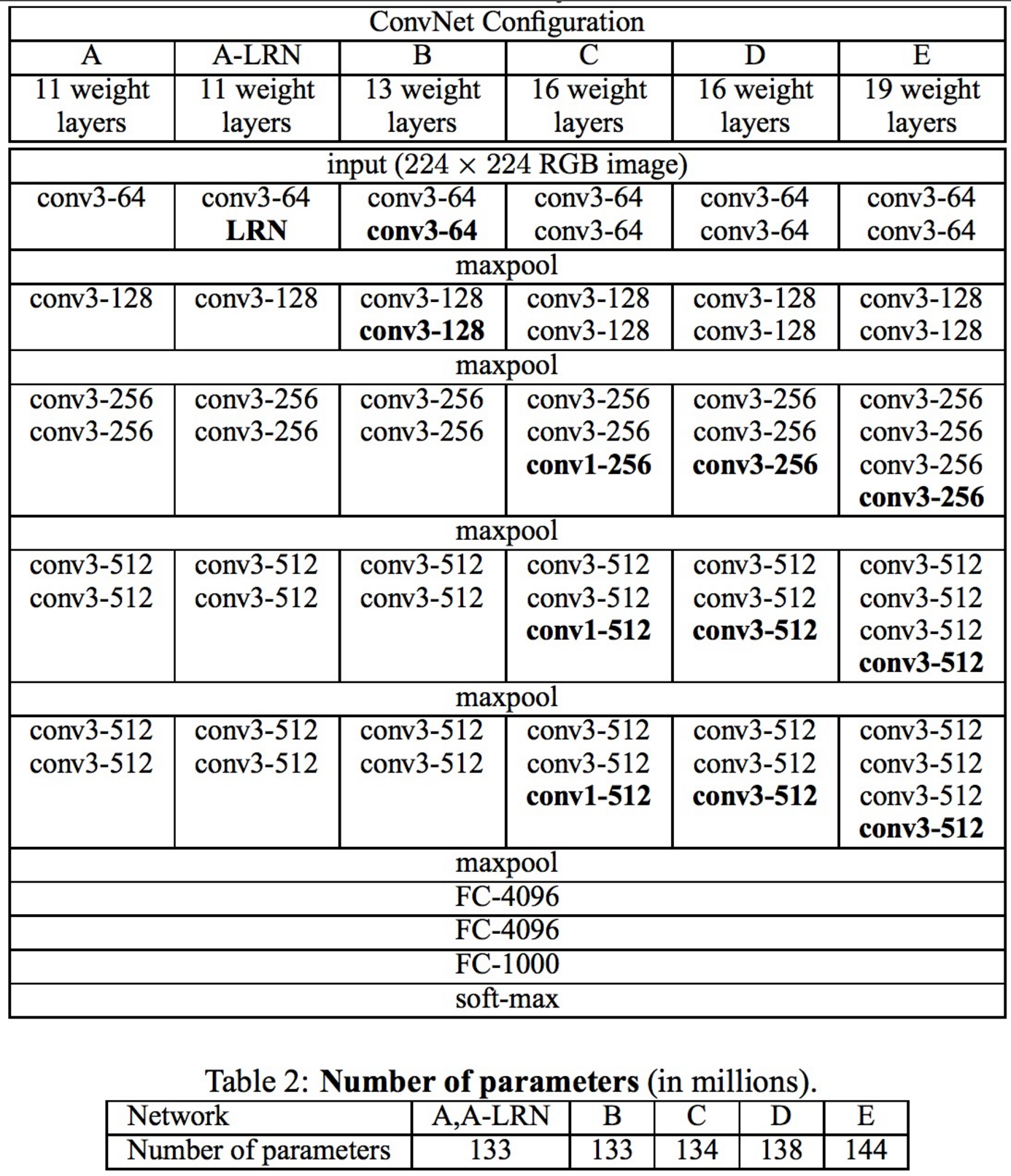
Network in Network (4 Mar 2014)

А вот тут начинаются танцы с бубном. Такой вот картинкой проиллюстрировал автор публикации свой пост в блоге, где рассказал о Сascaded Сross Сhannel Parameteric pooling. Рассмотрим основные идеи этой статьи. Очевидно, что операция свертки — это линейное преобразование патчей изображения, тогда сверточный слой — это обобщенная линейная модель (GLM). Предполагается, что образы линейно разделимы. Но почему же тогда CNN работает? Все просто: используется избыточное представление (большое количество фильтров), чтобы учесть все вариации одного образа в пространстве признаков. Чем больше фильтров на одном слое, тем больше вариаций нужно учесть следующему слою. Что делать? Давайте заменим GLM чем-нибудь поэффективнее, а самое эффективное, что есть, — однослойный персептрон. Это позволит нам эффективнее разделять пространство признаков, тем самым сократив их количество.
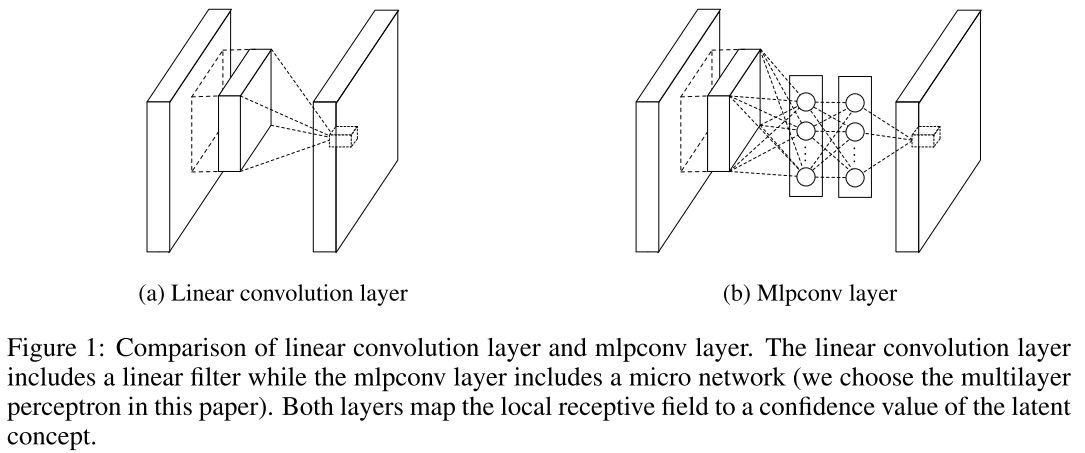
Уверен, что вы уже начали сомневаться в целесообразности такого решения, мы и вправду уменьшим количество признаков, но значительно увеличим количество параметров. Авторы говорят, что СССР решит эту проблему. Работает это следующим образом: на выходе из сверточного слоя мы получаем куб размером W ? H ? D. Для каждой позиции (w, h) возьмем все значения по D, Cross Channel, и посчитаем линейную комбинацию, Parametric pooling, и так будем делать несколько раз, тем самым создавая новый объем, и так несколько раз — Cascade. Оказывается, что это просто свертки 1 ? 1 с последующей нелинейностью. Этот трюк идейно такой же, как и в статье VGG про свертки 3 ? 3. Получается, что сначала мы предлагаем заменить обычную свертку на MLP, но так как MLP очень дорог, то заменим каждый его полносвязный слой на сверточный слой — такой вот сингапурский трюк. Получается, что NIN — это глубокая сверточная нейронная сеть, а вместо сверток в ней — небольшие сверточные нейронные сети с ядром 1 ? 1. В общем, пока они еще не подозревали, какого джинна выпустили.
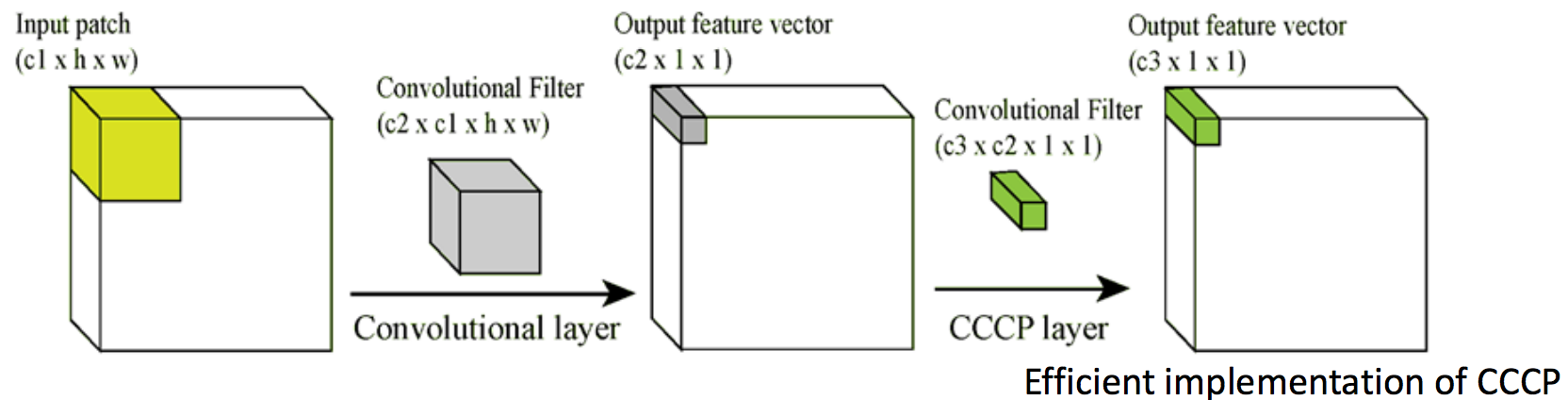
Следующая идея, еще более интересная, заключается в полном отказе от полносвязных слоев — global average pooling. Такую сеть называют fully convolutional network, так как она больше не требует на вход какого-либо определенного размера изображения и состоит только из сверток/пулингов. Допустим, есть задача классификации на N классов, тогда вместо полносвязных слоев используется свертка 1 ? 1, для того чтобы из куба W ? H ? D сделать куб W ? H ? N, т. е. сверткой 1 ? 1 можно изменять произвольно глубину куба признаков. Когда у нас есть N плашек W ? H, мы можем вычислить среднее значение плашки и посчитать softmax. Чуть более глубокая идея заключена в утверждении авторов, что раньше сверточные слои выступали просто как механизмы извлечения признаков, а дискриминаторами были полносвязные слои (оттуда и такой паттерн, заданный ЛеКунном). Авторы утверждают, что свертки — это тоже дискриминаторы, так как сеть состоит только из сверток и решает задачу классификации. Стоит заметить, что в сверточных сетях формата LeNet 80 % вычислений приходится на сверточные слои, а 80 % потребления памяти — на полносвязные.
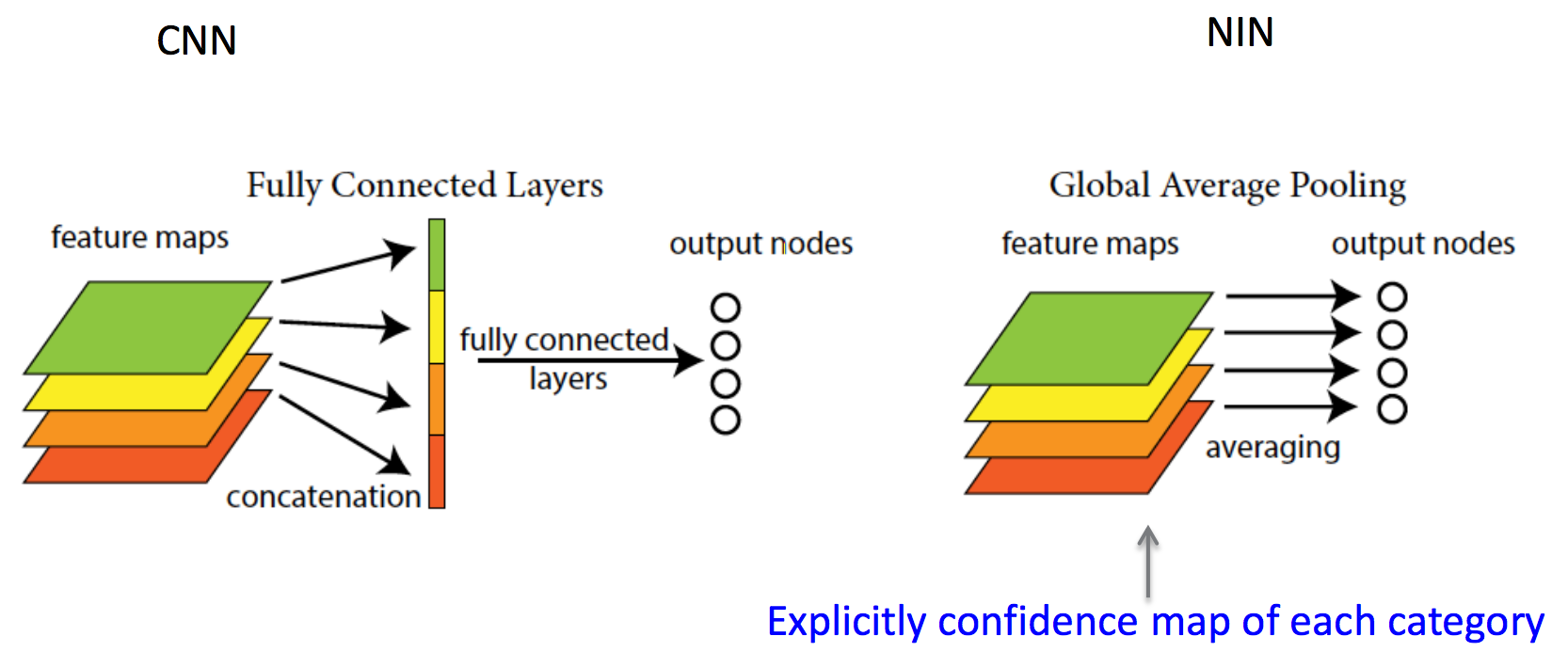
Позже ЛеКун напишет у себя в фейсбуке:
In Convolutional Nets, there is no such thing as «fully-connected layers». There are only convolution layers with 1 ? 1 convolution kernels and a full connection table.
Жаль только, что авторы, придумавшие столько новых идей, не участвовали в имаджнете. Зато Google вовремя подсуетился и использовал эти идеи в следующей публикации. В итоге гугл разделил призовые места 2014 года с командой из Оксфорда.
Going Deeper with Convolutions (17 Sep 2014)

В игру вступает гугл, свою сеть они назвали Inception, название выбрано не случайно, оно как бы продолжает идеи предыдущей работы про «Сеть внутри Сети», а также известного мема. Вот что пишут авторы:
In this paper, we will focus on an efficient deep neural network architecture for computer vision, codenamed Inception, which derives its name from the Network in network paper by Lin et al [12] in conjunction with the famous “we need to go deeper” internet meme [1]. In our case, the word “deep” is used in two different meanings: first of all, in the sense that we introduce a new level of organization in the form of the “Inception module” and also in the more direct sense of increased network depth. In general, one can view the Inception model as a logical culmination of [12] while taking inspiration and guidance from the theoretical work by Arora et al [2].
Произвольное увеличение ширины (количество нейронов в слоях) и глубины (количество слоев) имеет ряд недостатков. Во-первых, увеличение количества параметров способствует переобучению, а увеличение количества слоев добавляет еще и проблему затухания градиента. Кстати, последнее утверждение разрешится ResNet’ом, о которой речь пойдет дальше. Во-вторых, увеличение количества сверток в слое приводит к квадратичному увеличению вычислений в этом слое. Если же новые параметры модели используются неэффективно, например многие из них становятся близки к нулю, тогда мы просто впустую тратим вычислительные мощности. Несмотря на эти проблемы, первый автор статьи хотел поэкспериментировать с глубокими сетями, но со значительно меньшим количеством параметров. Для этого он обратился к статье «Provable Bounds for Learning Some Deep Representations», в которой доказывают, что если вероятностное распределение данных можно представить в виде разреженной, глубокой и широкой нейронной сети, тогда можно построить оптимальную нейронную сеть для данного датасета, анализируя корреляции нейронов предыдущего слоя и объединяя коррелированные нейроны в группы, которые будут нейронами следующего слоя. Таким образом, нейроны поздних слоев «смотрят» на сильно пересекающиеся области исходного изображения. Напомню, как выглядят рецепторные области нейронов на разных уровнях и какие признаки они извлекают.
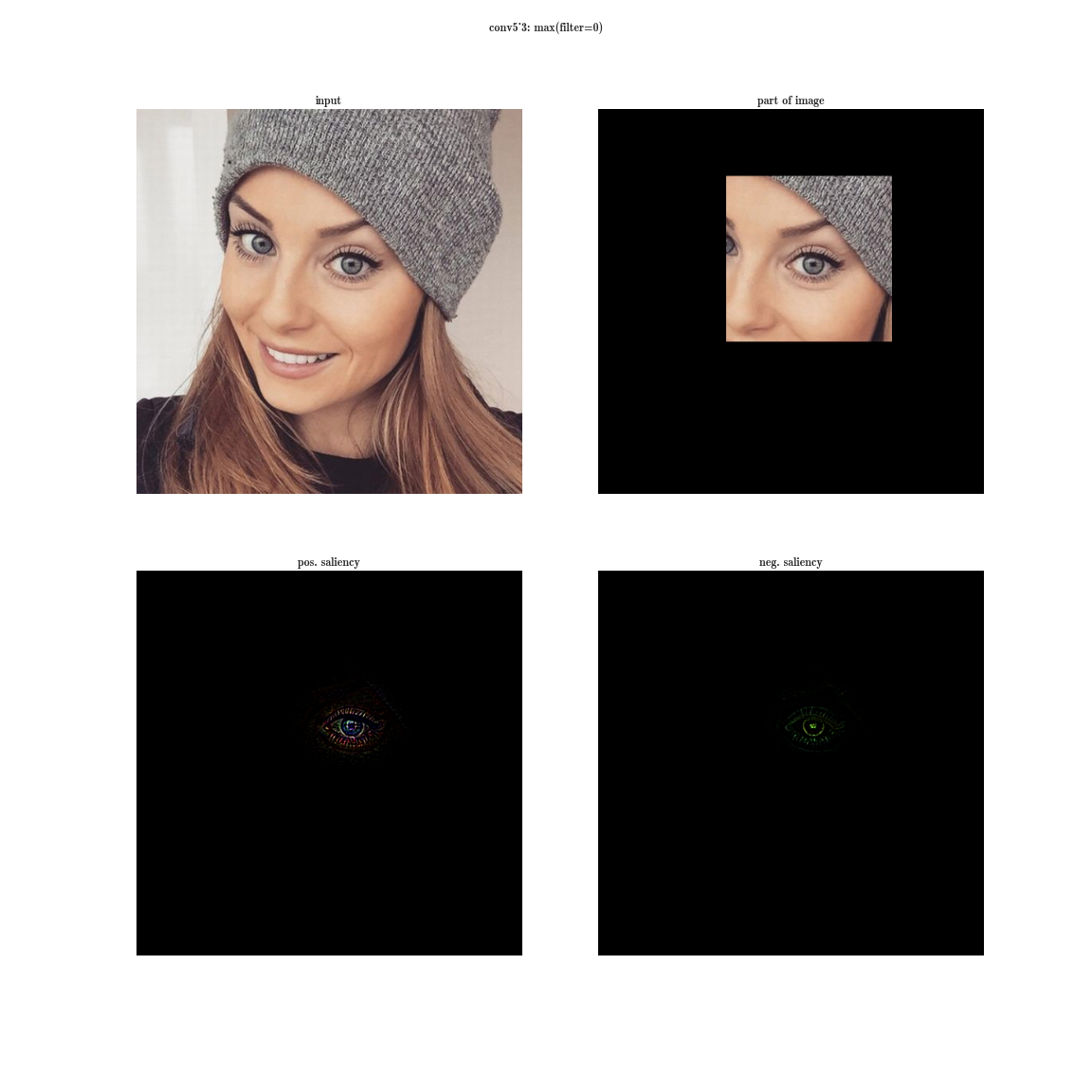
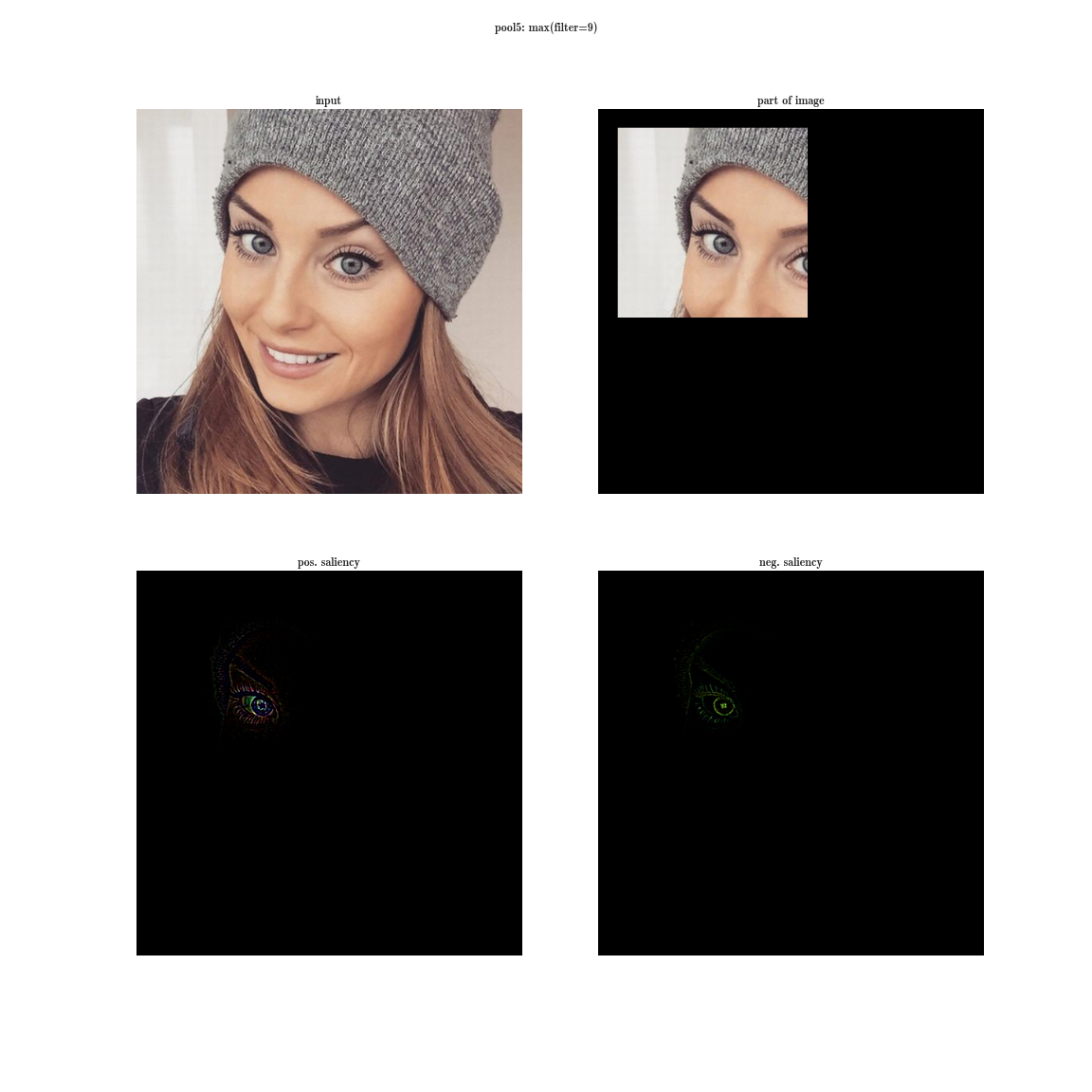
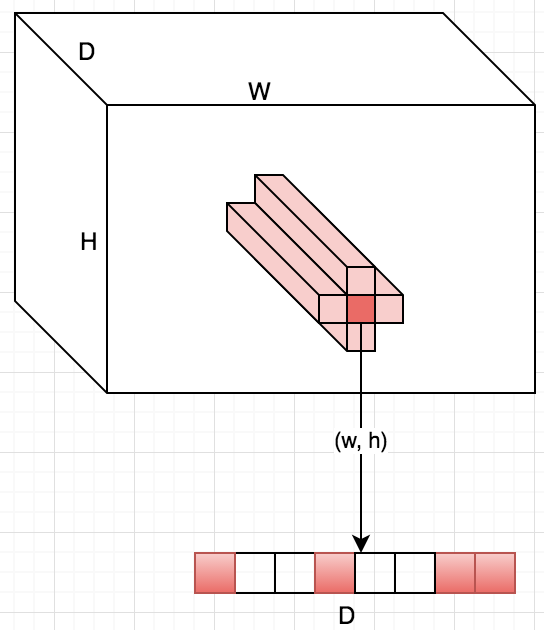
На ранних слоях (ближе к входу) коррелированные нейроны будут концентрироваться в локальных областях. Это значит, что если несколько нейронов в одной координате (w, h) на плашке могут выучить примерно одно и то же, то в тензоре после первого слоя их активации будут располагаться на небольшом регионе в районе некоторой точки (w, h), а распределены будут вдоль размерности банка фильтров — D. Примерно так:
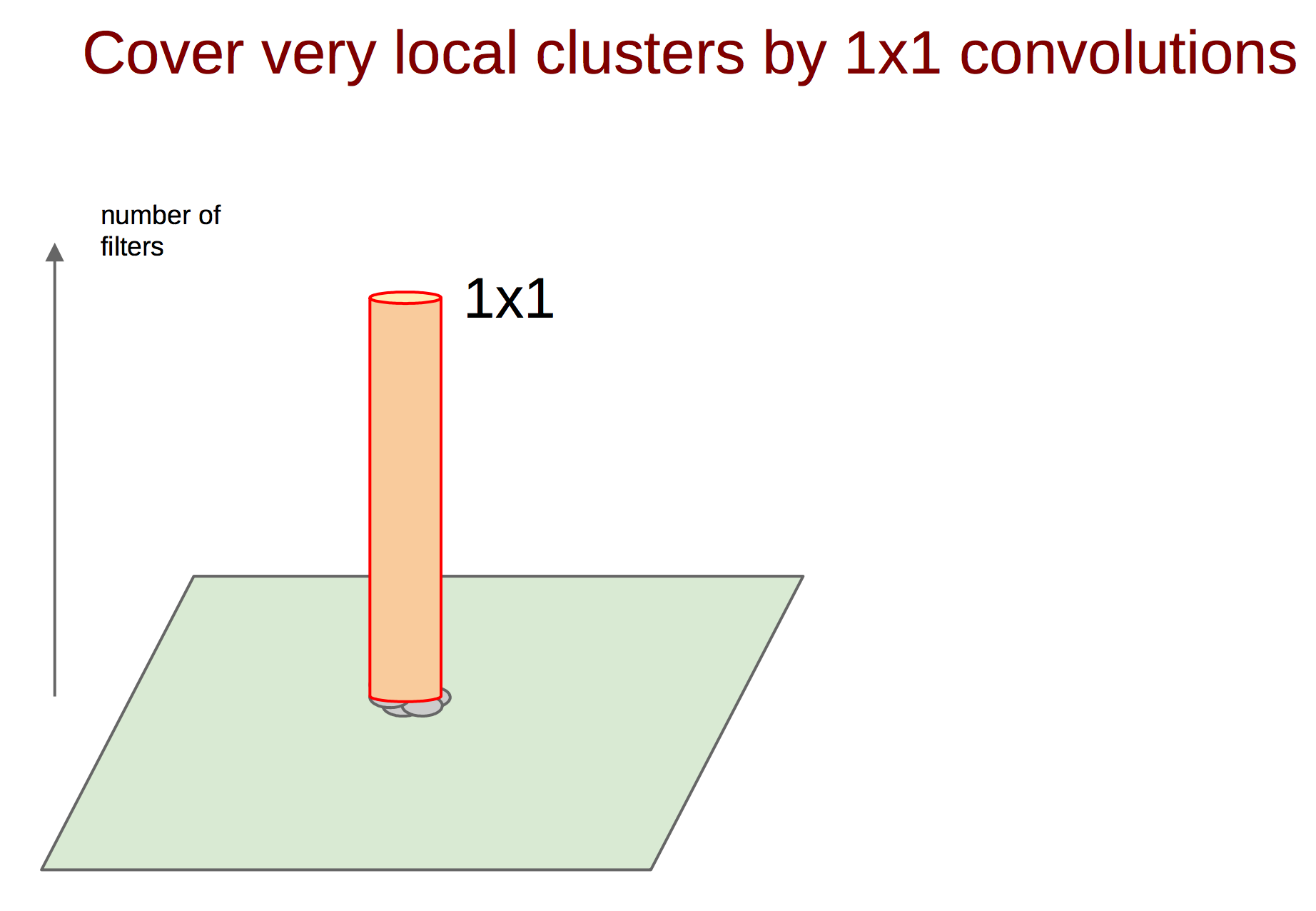
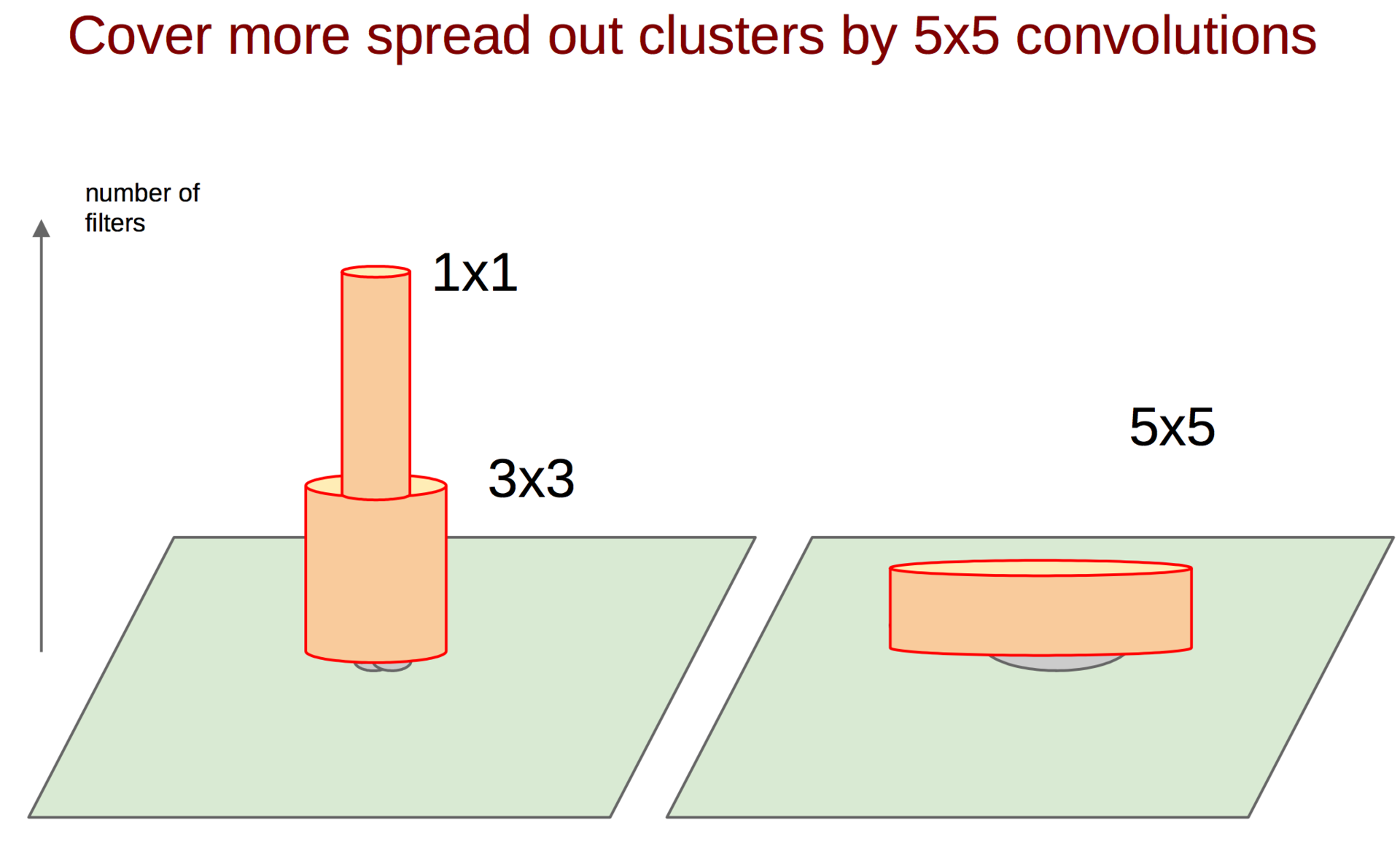
Каким же образом поймать такие корреляции и превратить их в один признак? На помощь приходит идея сверток 1 ? 1 из предыдущей работы. Продолжая эту идею, можно предположить, что чуть меньшее количество коррелированных кластеров будет чуть большего размера, например 3 ? 3. То же самое справедливо для 5 ? 5 и т. д., но гугл решил остановиться на 5 ? 5.
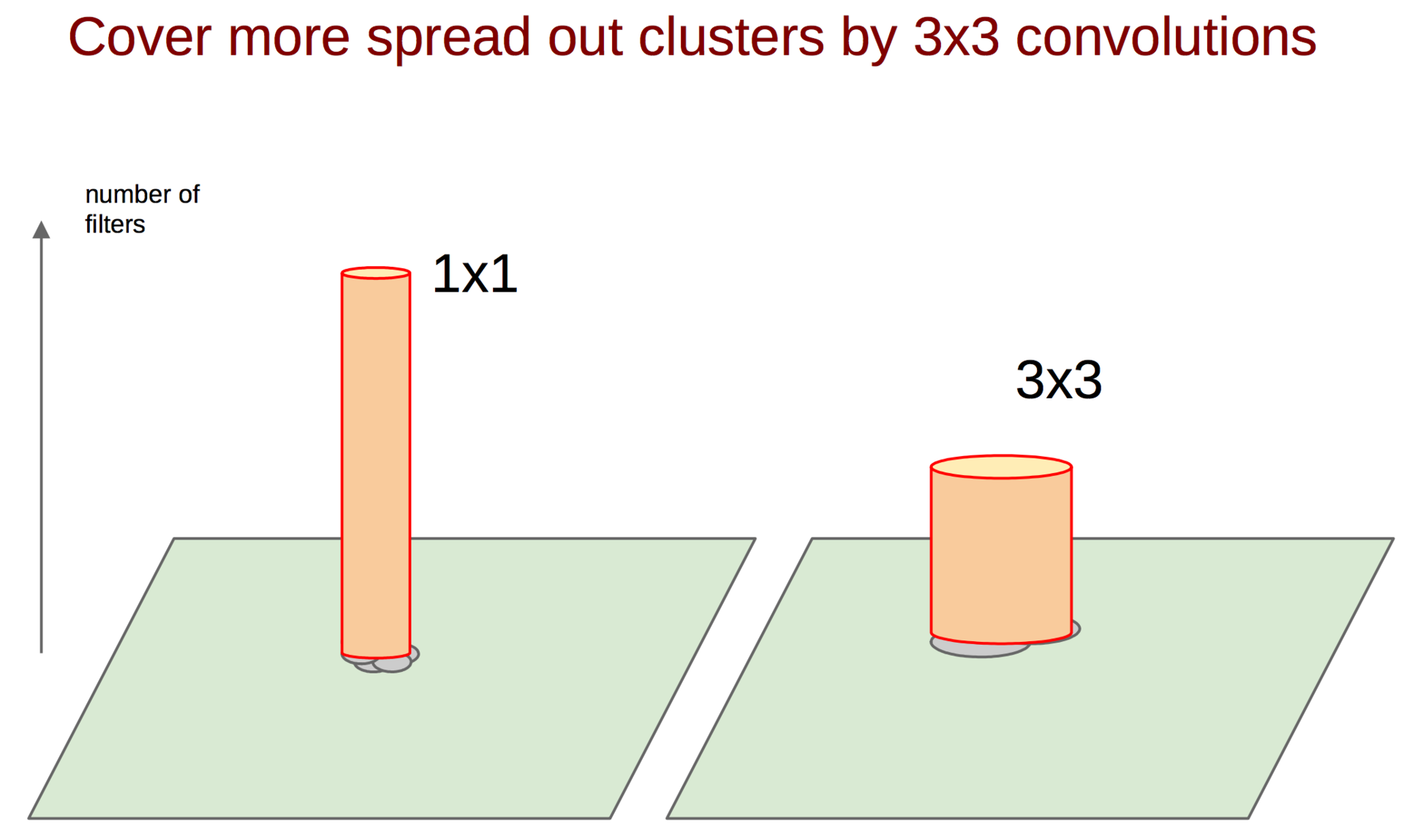
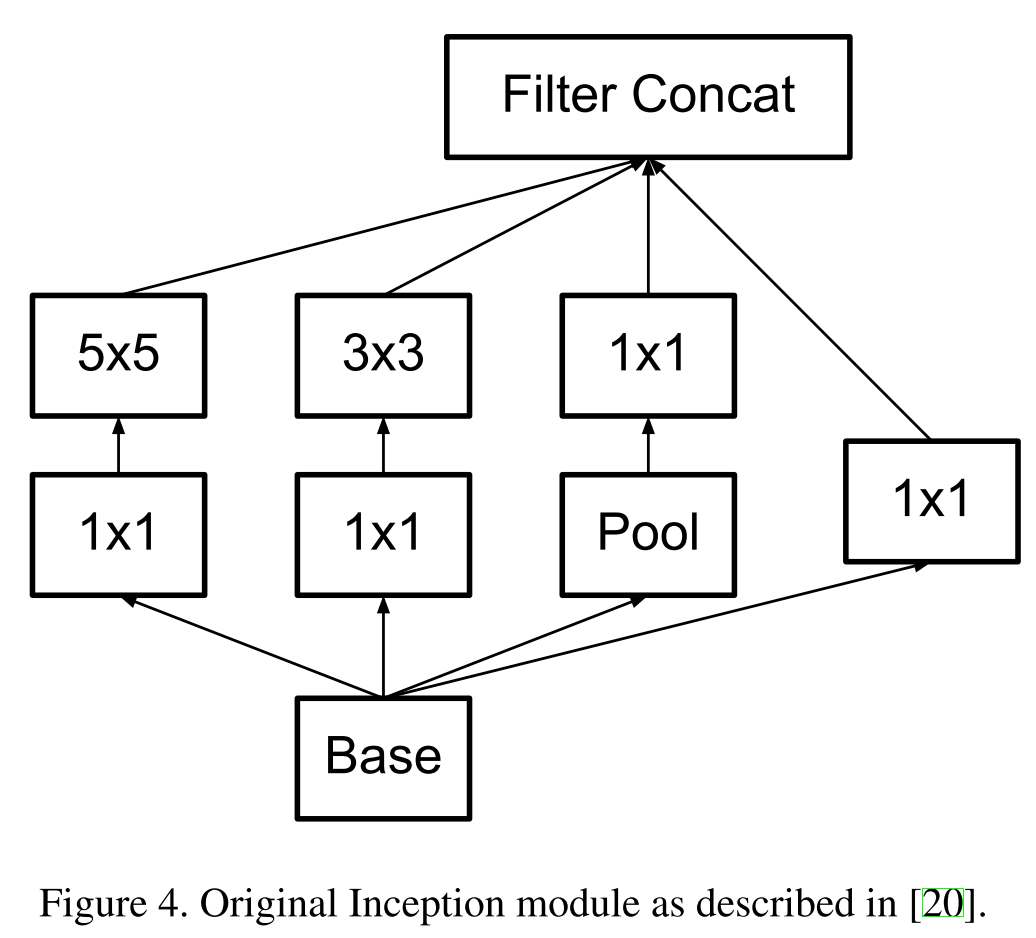
После вычисления карт признаков для каждой свертки их необходимо каким-либо способом агрегировать, например конкатенировать фильтры.
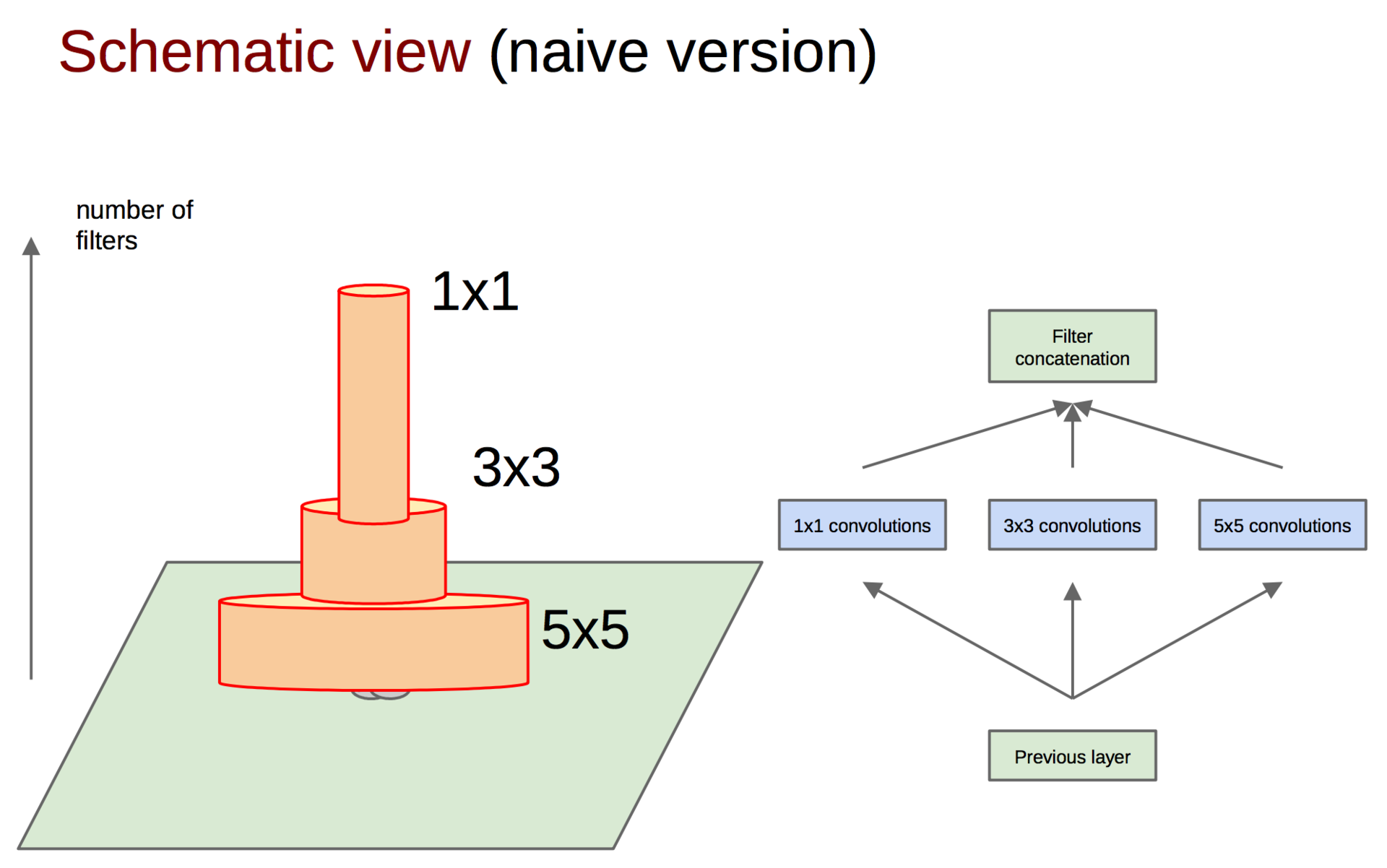
Кстати, для того чтобы не терять оригинальный образ из предыдущего слоя, помимо сверток добавляются еще пулинг-признаки (мы же помним, что операция пулинга не влечет больших потерь информации). Да и вообще, все юзают пулинг — нет причин от него отказываться. Вся группа из нескольких операций называется Inception block.
Additionally, since pooling operations have been essential for the success in current state of the art convolutional networks, it suggests that adding an alternative parallel pooling path in each such stage should have additional beneficial effect, too.
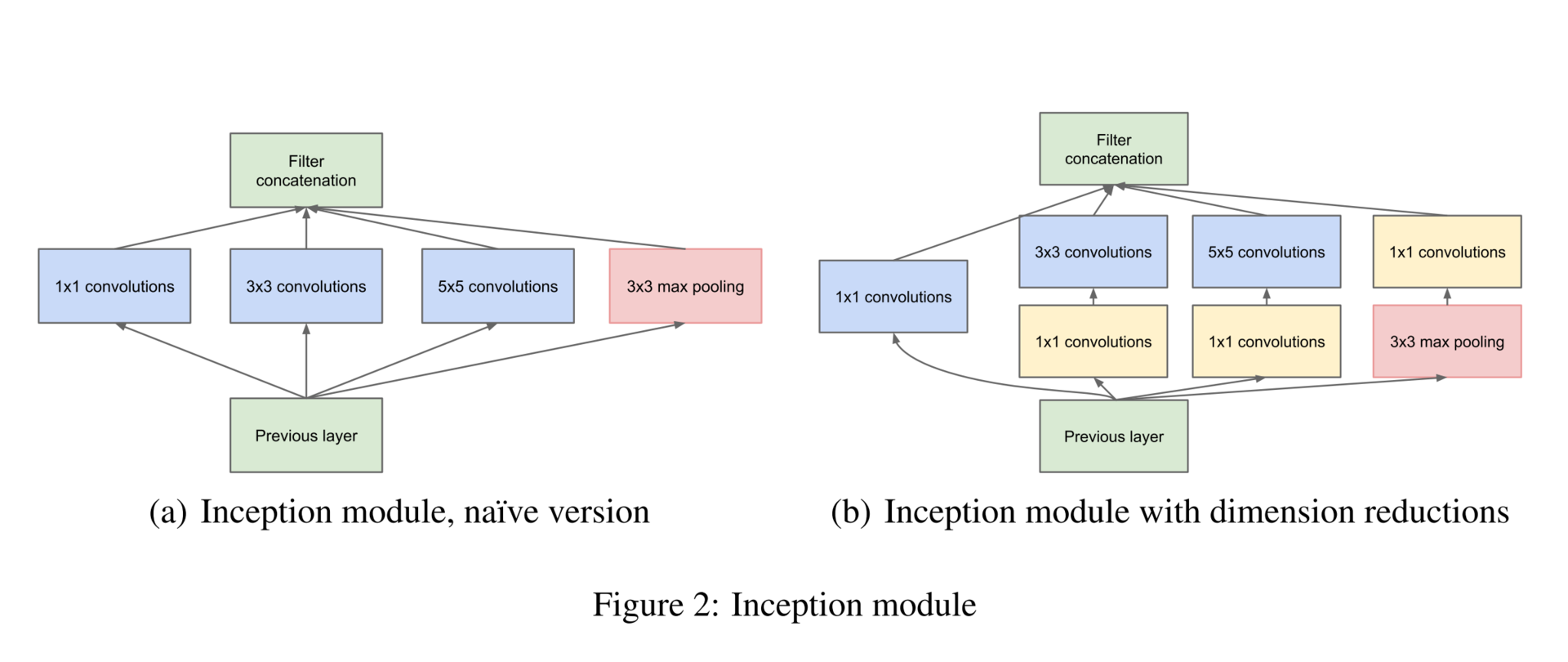
Чтобы выравнять размер выходных тензоров, предложено также использовать свертку 1 ? 1, это вы можете видеть на рисунке справа после операции пулинга. Помимо этого, свертки 1 ? 1 используются еще и для уменьшения размерности перед энергозатратными операциями свертки. Как вы можете заметить, гугл использует 1 ? 1 свертки для достижения таких целей (следующие поколения сетей будут также эксплуатировать эти приемы):
- увеличения размерности (после операции);
- уменьшения размерности (до операции);
- группировки коррелированных значений (первая операция в блоке).
Итоговая модель выглядит следующим образом:
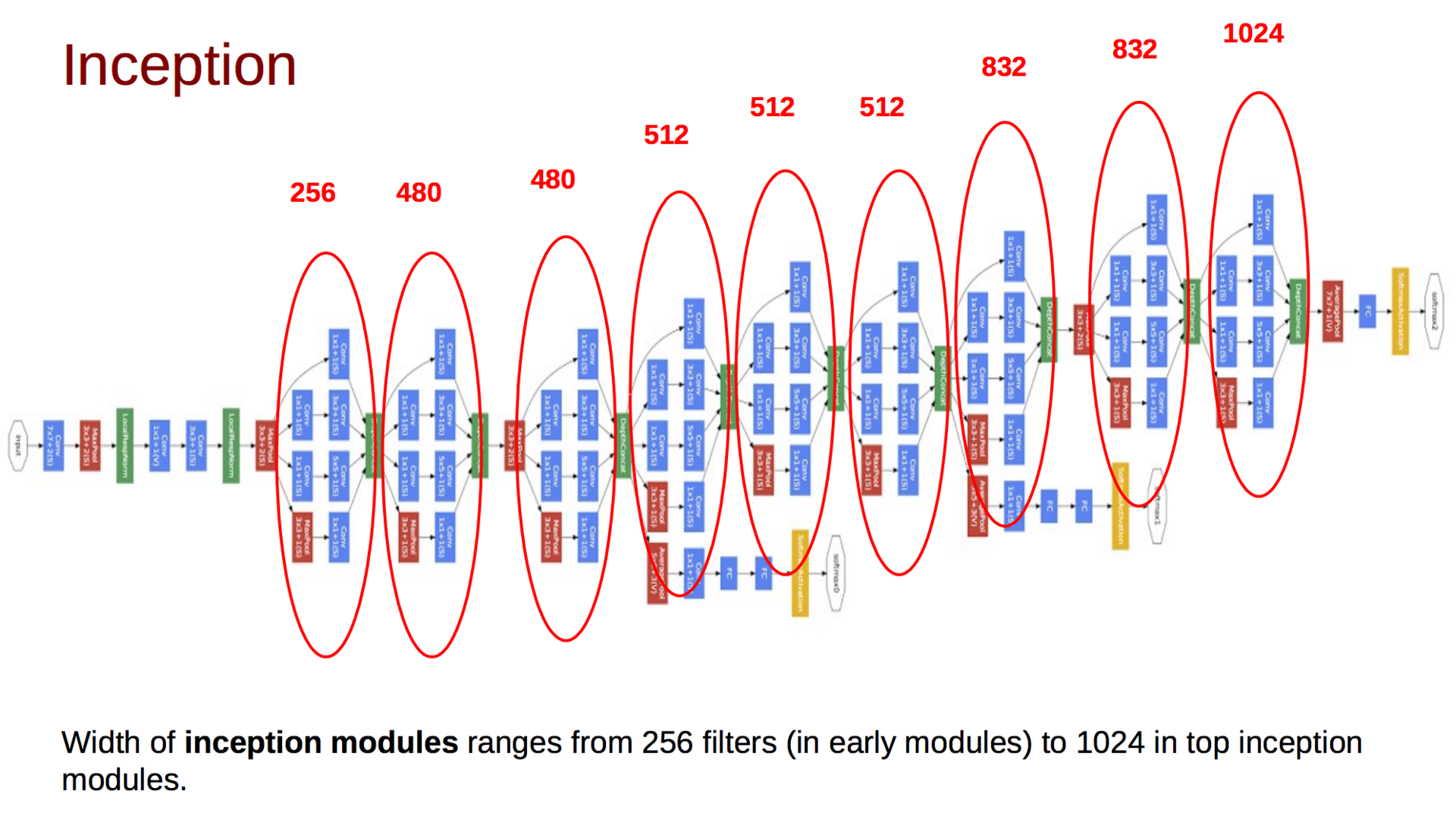
Помимо описанного выше, вы можете заметить еще и несколько дополнительных классификаторов на разных уровнях. Первоначальная идея была в том, что такие классификаторы позволят «протолкнуть» градиенты к ранним слоям и тем самым уменьшить эффект затухания градиента. Позже гугл от них откажется. Сама же сеть постепенно увеличивает глубину тензора и уменьшает пространственную размерность. В конце статьи авторы оставляют открытым вопрос об эффективности такой модели, а также намекают на то, что будут исследовать возможность автоматической генерации топологий сетей, используя вышеприведенные принципы.
Rethinking the Inception Architecture for Computer Vision (11 Dec 2015)
Спустя год гугл хорошо подготовился к имаджнету, переосмыслил архитектуру инсептрона, но проиграл совершенно новой модели, о которой пойдет речь в следующей части. В новой статье авторы исследовали на практике различные архитектуры и разработали четыре принципа построения глубоких сверточных нейронных сетей для компьютерного зрения:
- Избегайте representational bottlenecks: не стоит резко снижать размерность представления данных, это нужно делать плавно от начала сети и до классификатора на выходе.
- Высокоразмерные представления следует обрабатывать локально, увеличивая размерность: недостаточно плавно снижать размерность, стоит использовать принципы, описанные в предыдущей статье, для анализа и группировки коррелированных участков.
- Пространственные сверки можно и нужно факторизовывать на еще более мелкие: это позволит сэкономить ресурсы и пустить их на увеличение размера сети.
- Необходимо соблюдать баланс между глубиной и шириной сети: не стоит резко увеличивать глубину сети отдельно от ширины, и наоборот; следует равномерно увеличивать или уменьшать обе размерности.
Помните идею VGG в 2014 году, что свертки большего размера можно факторизовать в стек сверток 3 ? 3? Так вот, гугл пошел еще дальше и факторизовал все свертки в N ? 1 и 1 ? N.
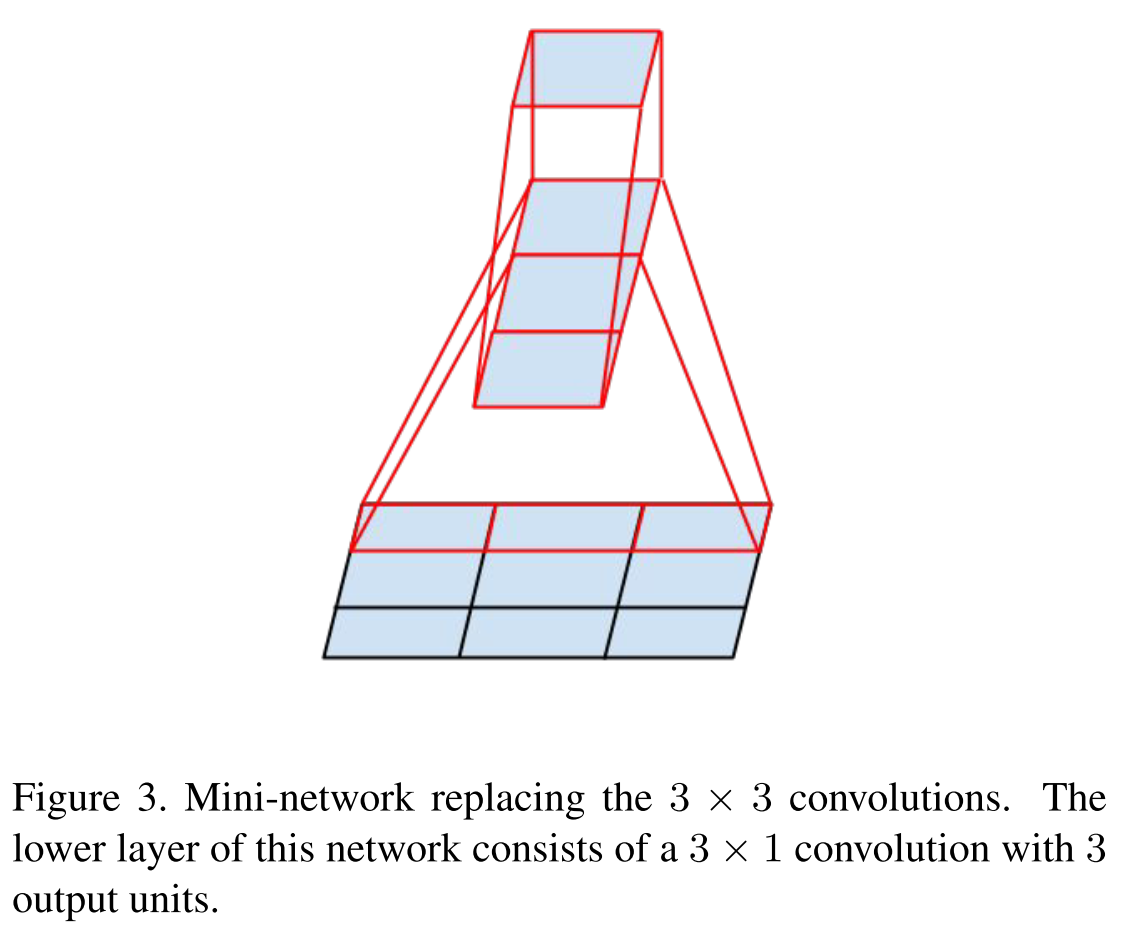
Первая факторизованная по принципу VGG.
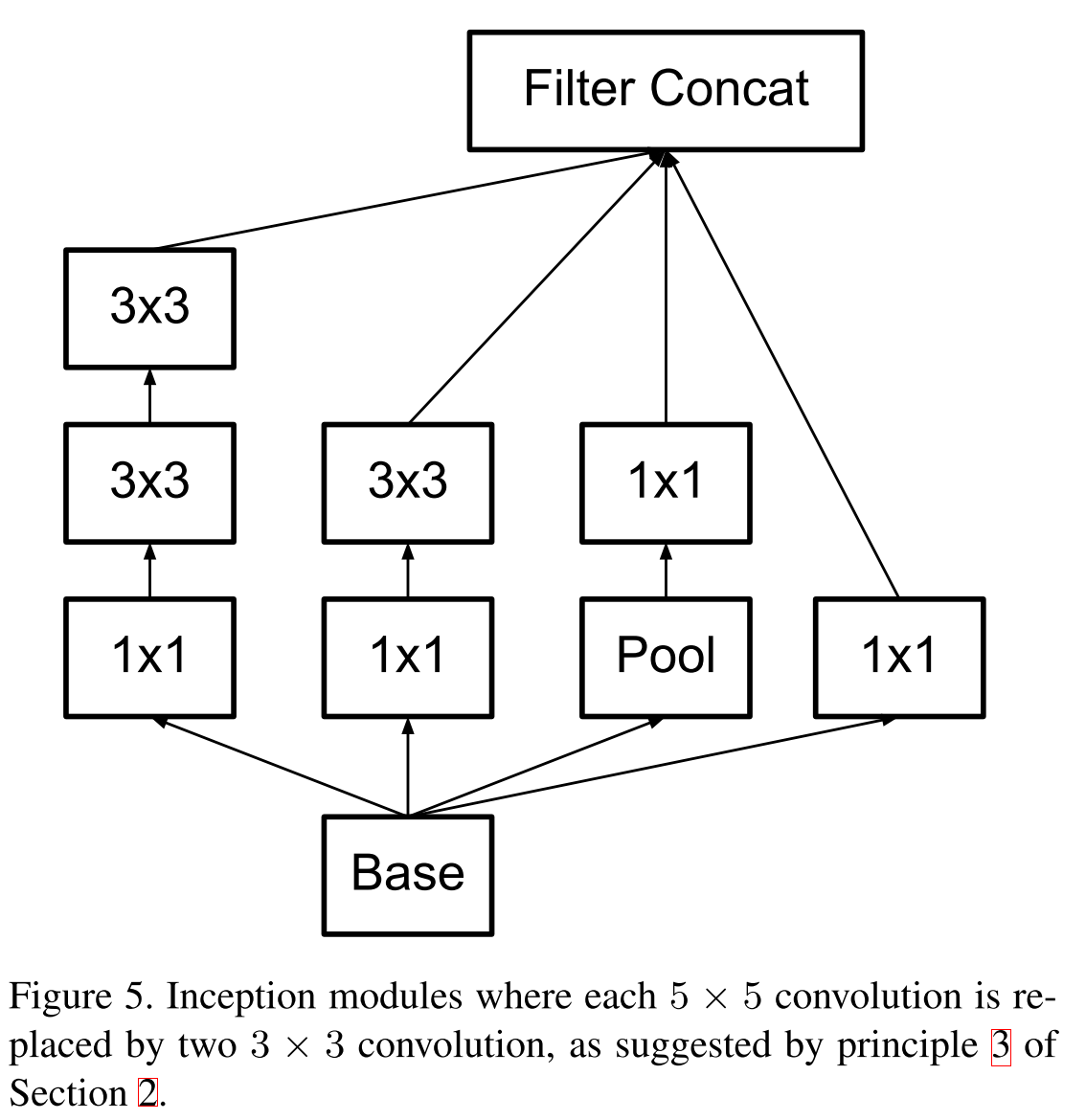
Новая модель блока.
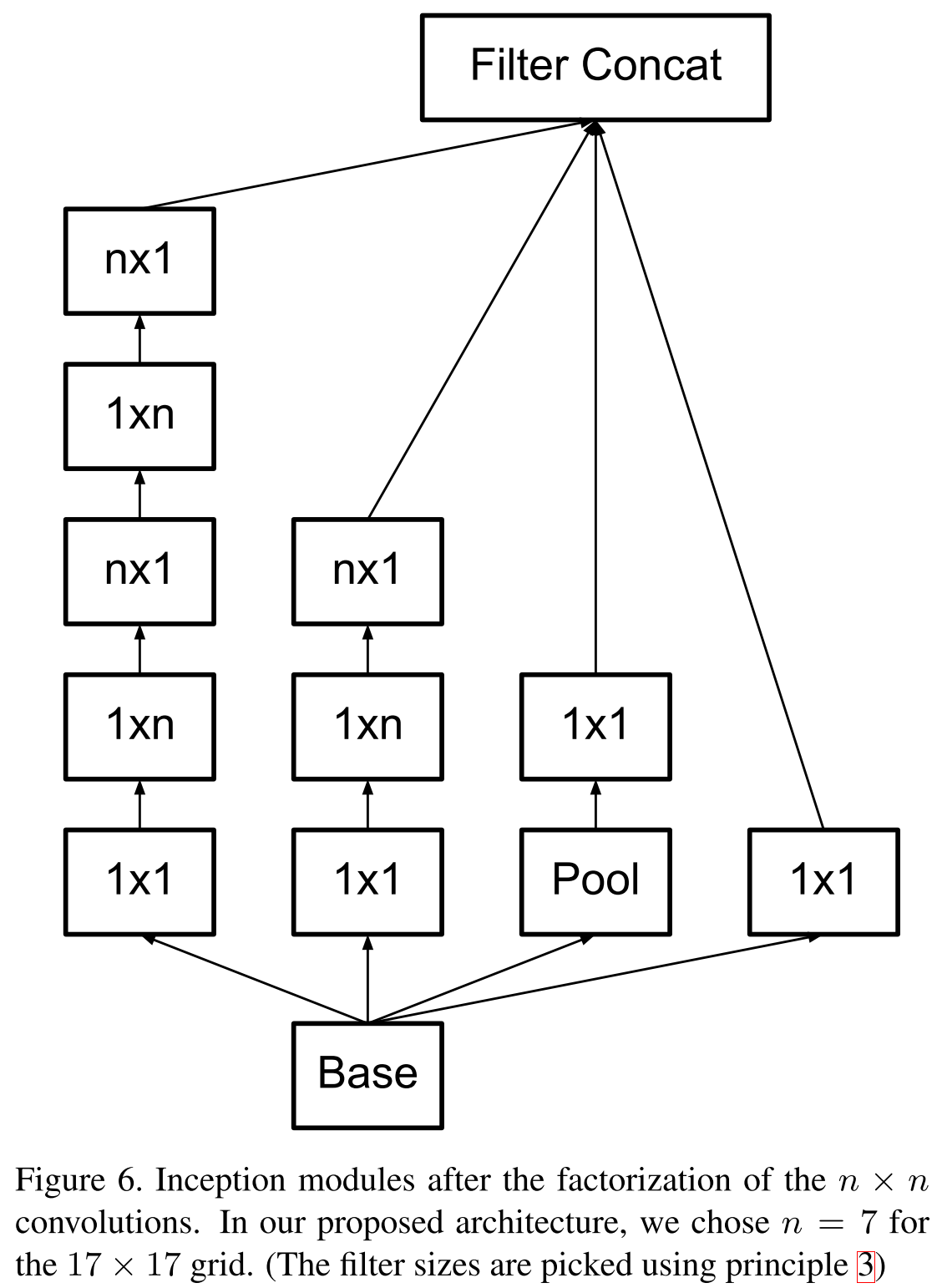
Что же касается бутылочных горлышек, то предлагается следующая схема. Допустим, если входная размерность
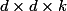 , а мы хотим получить
, а мы хотим получить 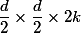 , то мы сначала применяем свертку из
, то мы сначала применяем свертку из 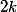 фильтров с шагом 1 и затем делам пулинг. Итоговая сложность такой операции
фильтров с шагом 1 и затем делам пулинг. Итоговая сложность такой операции 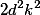 . Если делать сначала пулинг, а затем свертку, то сложность упадет до
. Если делать сначала пулинг, а затем свертку, то сложность упадет до 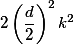 , но тогда будет нарушен первый принцип. Предлагается увеличивать количество параллельных веток, делать свертки с шагом 2, но в то же время увеличивать количество каналов в два раза, тогда репрезентативная сила представления уменьшается «плавнее». А для манипулирования глубиной тензора используются свертки 1 ? 1.
, но тогда будет нарушен первый принцип. Предлагается увеличивать количество параллельных веток, делать свертки с шагом 2, но в то же время увеличивать количество каналов в два раза, тогда репрезентативная сила представления уменьшается «плавнее». А для манипулирования глубиной тензора используются свертки 1 ? 1. 
Новую модель называют Inception V2, а если добавить batch normalization, то будет Inception V3. Кстати, убрали дополнительные классификаторы, так как оказалось, что они особо не увеличивают качество, но могут выступать регуляризатором. Но к этому моменту уже были более интересные способы регуляризации.
Deep Residual Learning for Image Recognition (10 Dec 2015)
Пришло время изучить работу китайского подразделения Microsoft Research, которому проиграл гугл в 2015 году. Давно было замечено, что если просто стекать больше слоев, то качество такой модели растет до некоторого предела (смотрите VGG-19), а затем начинает падать. Эту проблему называют degradation problem, а сети, полученные стеканием большего количества слоев, — plain, или плоские сети. Авторы смогли найти такую топологию, при которой качество модели растет при добавлении новых слоев.
Достигается это простым, на первый взгляд, трюком, хотя и приводит к неожиданным математическим результатам. Благодаря Арнольду и Колмогорову мы и они в курсе, что нейросеть может аппроксимировать почти любую функцию, например некоторую сложную функцию
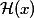 . Тогда справедливо, что такая сеть легко выучит residual-функцию (по-русски будем называть ее остаточной функцией):
. Тогда справедливо, что такая сеть легко выучит residual-функцию (по-русски будем называть ее остаточной функцией): 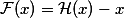 . Очевидно, что наша первоначальная целевая функция будет равна
. Очевидно, что наша первоначальная целевая функция будет равна 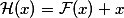 . Если мы возьмем некоторую сеть, например VGG-19, и пристекаем к ней еще слоев двадцать, то нам хотелось бы, чтобы глубокая сеть вела себя как минимум не хуже своего неглубокого аналога. Проблема деградации подразумевает, что сложная нелинейная функция
. Если мы возьмем некоторую сеть, например VGG-19, и пристекаем к ней еще слоев двадцать, то нам хотелось бы, чтобы глубокая сеть вела себя как минимум не хуже своего неглубокого аналога. Проблема деградации подразумевает, что сложная нелинейная функция 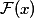 , полученная стеканием нескольких слоев, должна выучить тождественное преобразование, в случае если на предыдущих слоях был достигнут предел качества. Но этого не происходит по каким-то причинам, возможно, оптимизатор просто не справляется с тем, чтобы настроить веса так, чтобы сложная нелинейная иерархическая модель делала тождественное преобразование. А что, если мы поможем ей добавить shortcut-соединение, и, возможно, оптимизатору будет легче сделать все веса близкими к нулю, нежели создавать тождественное преобразование. Наверняка это вам очень напоминает идеи бустинга.
, полученная стеканием нескольких слоев, должна выучить тождественное преобразование, в случае если на предыдущих слоях был достигнут предел качества. Но этого не происходит по каким-то причинам, возможно, оптимизатор просто не справляется с тем, чтобы настроить веса так, чтобы сложная нелинейная иерархическая модель делала тождественное преобразование. А что, если мы поможем ей добавить shortcut-соединение, и, возможно, оптимизатору будет легче сделать все веса близкими к нулю, нежели создавать тождественное преобразование. Наверняка это вам очень напоминает идеи бустинга.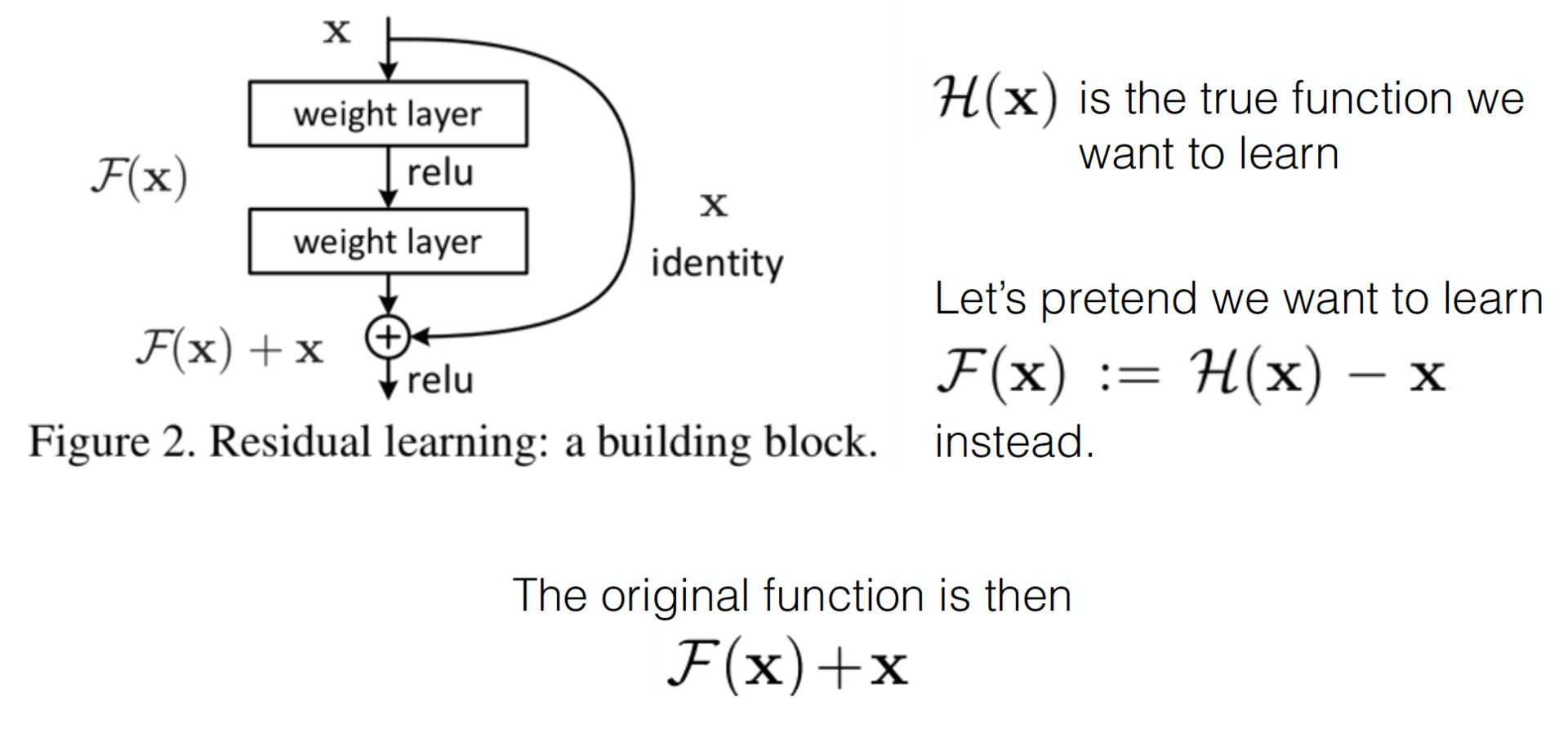
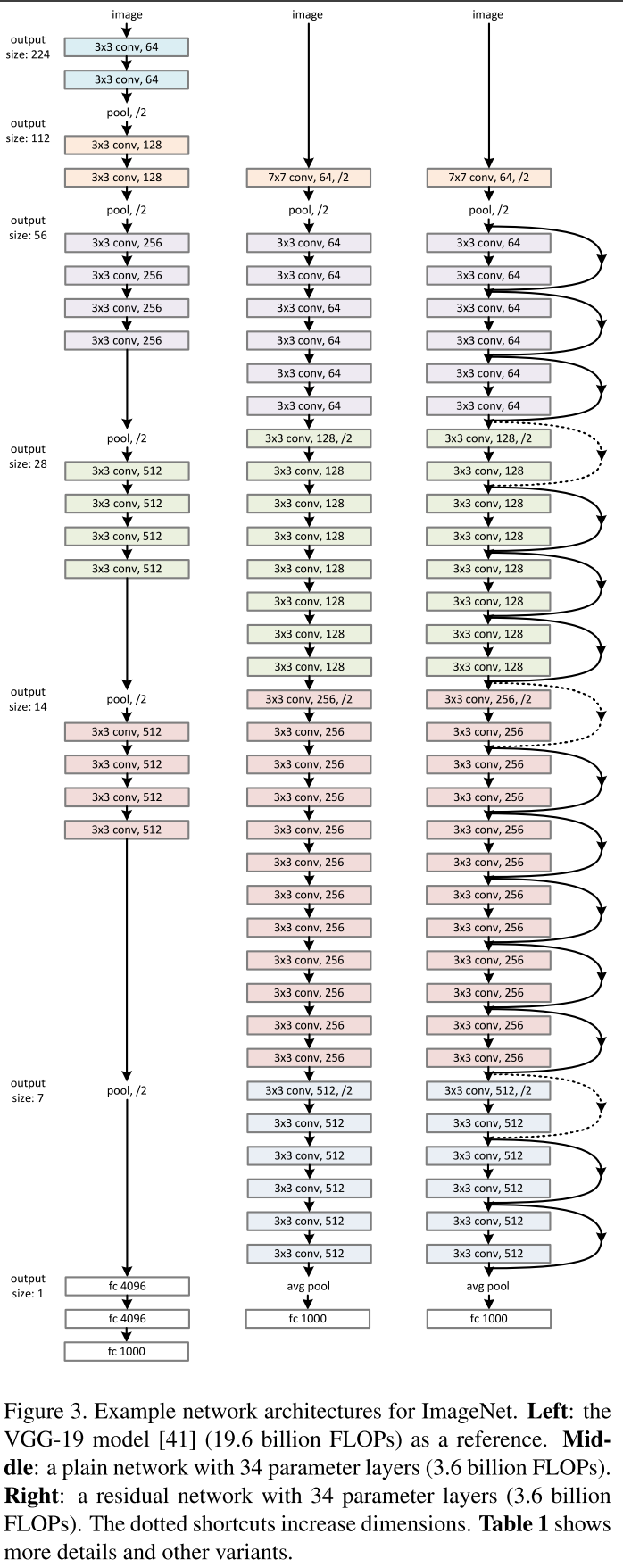
Детали построения ResNet-52 на theano/lasagne описаны тут, здесь же упомянем лишь то, что 1 ? 1 свертки эксплуатируются для увеличения и уменьшения размерности, как и завещал гугл. Сеть является fully convolution.
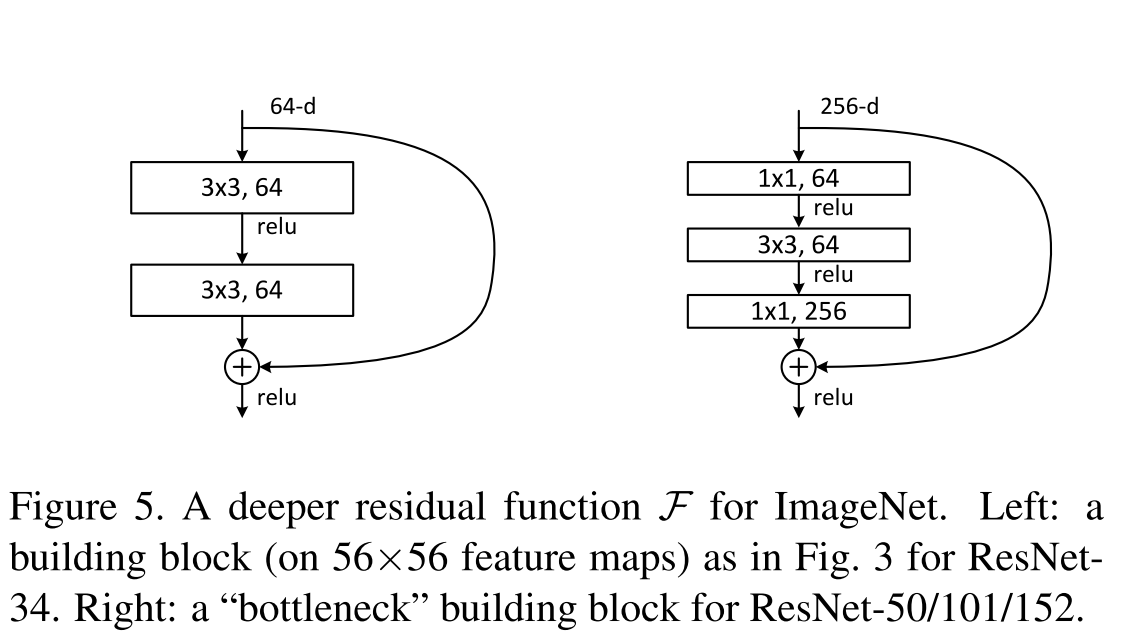
В качестве одного из обоснований своей гипотезы о том, что остаточные функции будут близки к нулю, авторы приводят график активаций остаточных функций в зависимости от слоя и для сравнения активации слоев в плоских сетях.
А выводы из всего этого примерно такие:

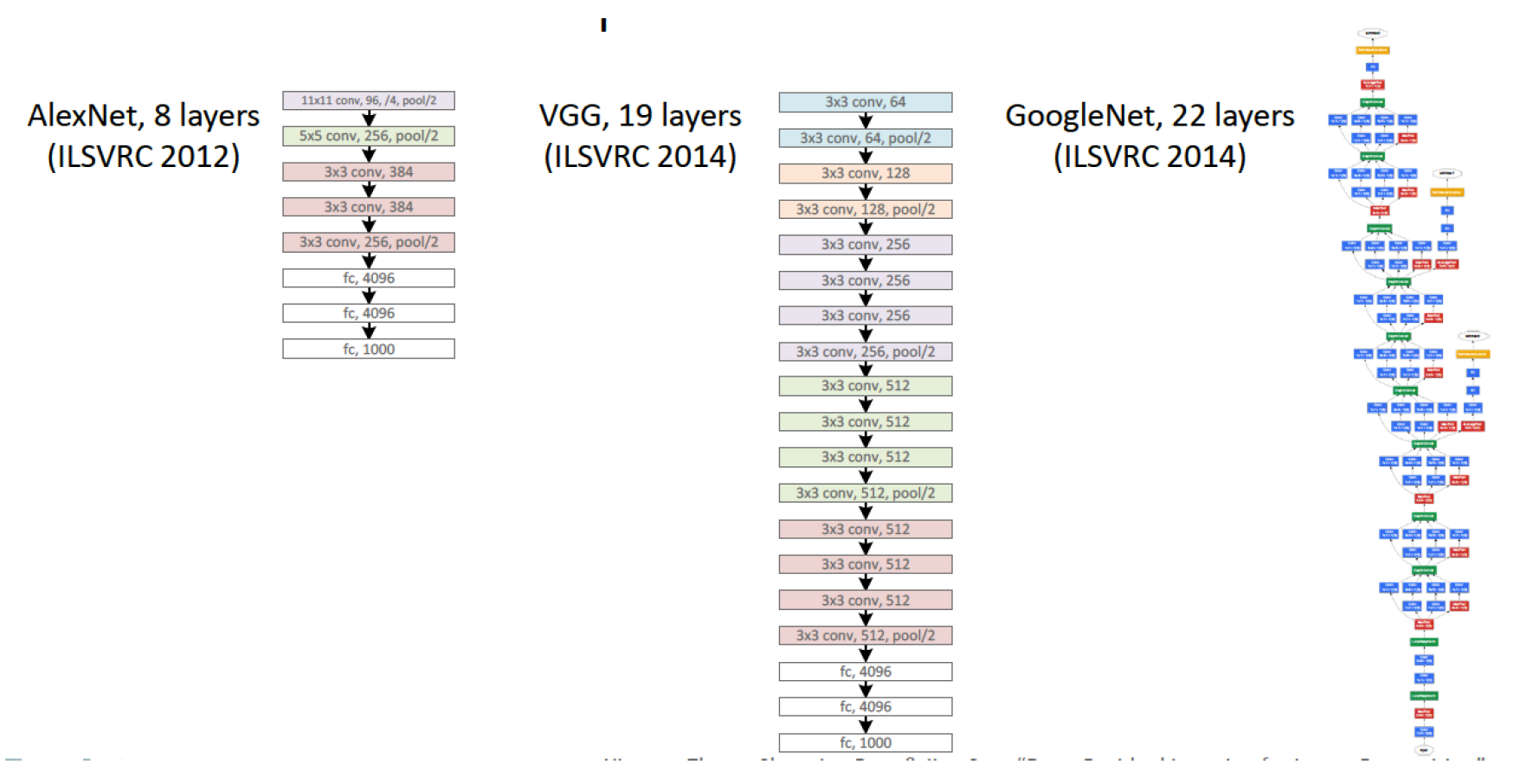

Еще один интересный слайд авторов показывает, что они сделали прорыв в глубине/качестве сетей. Модель, с которой они победили на имаджнете, содержит меньше параметров, чем 19-слойный VGG, при глубине 152 слоя.
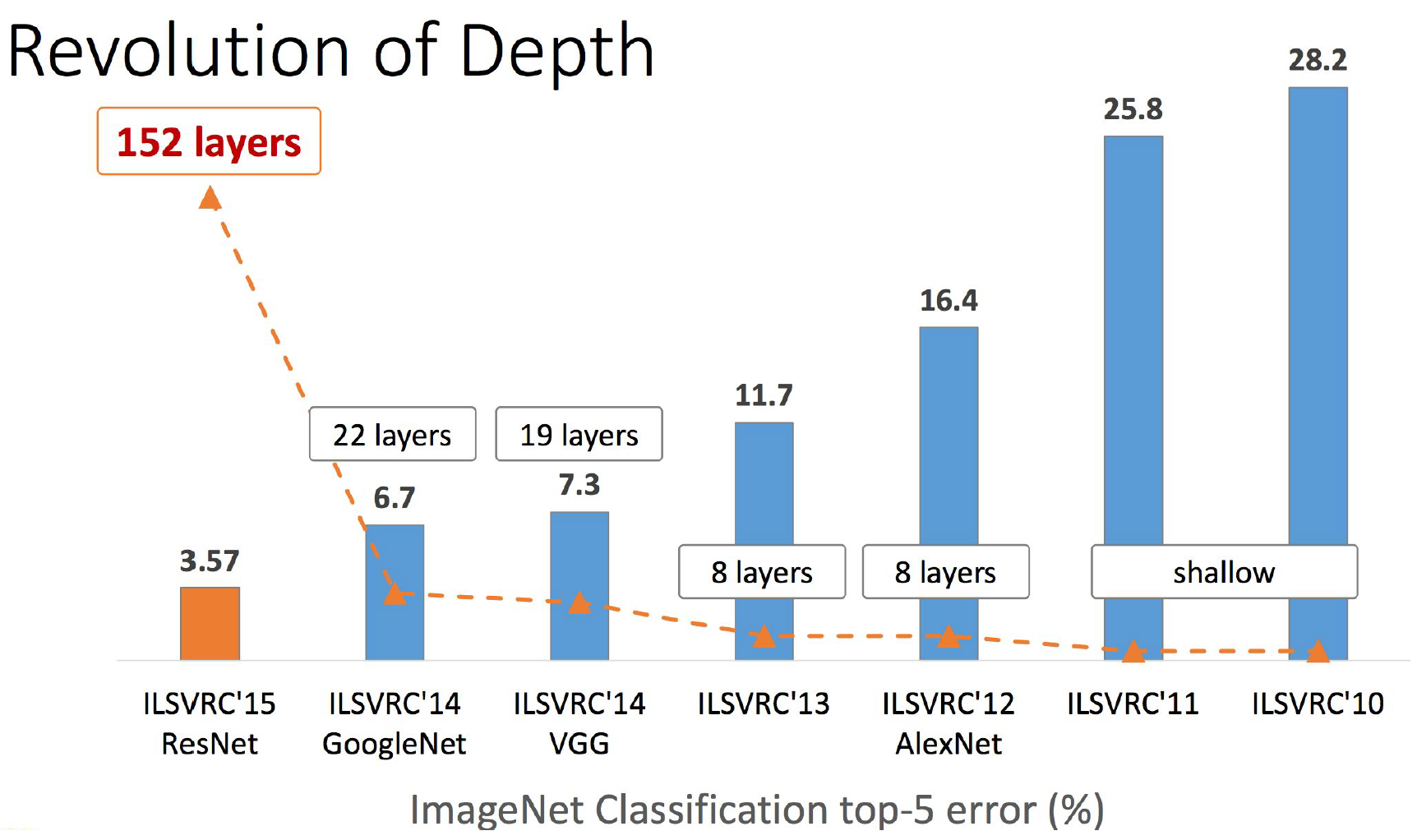
А что же насчет обещанной математической неожиданности, спросите вы. А об этом у них отдельная статья, и вообще в 2016 году вышло множество статей, в которых рассматриваются остаточные сети с разных точек зрения. Некоторые из них действительно с очень неожиданными выводами.
Несколько вариантов визуализации ResNet:
Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning (23 Feb 2016)
Спустя несколько месяцев гугл публикует статью, в которой задается вопросом, а будет ли лучше работать их модель Inception, если позаимствовать идеи ResNet’а. И внезапно оказывается, что да, если добавить тождественных связей, то и их модель улучшится. Далее в статье идет множество картинок, которые еще больше подтверждают то, что их модель строится в полуавтоматическом режиме. Результатом статьи становятся модели Inception V4 и Inception ResNet.
Inception V4 не особо отличается от предыдущих поколений, здесь они поэкспериментировали с паддингом и упростили Inception-блоки. Честно говоря, мне кажется, версия 4 здесь присутствует только для того, чтобы увеличилось количество страниц, а основная цель — это просто сказать, что резнет и у них работает.

Stem-блок.
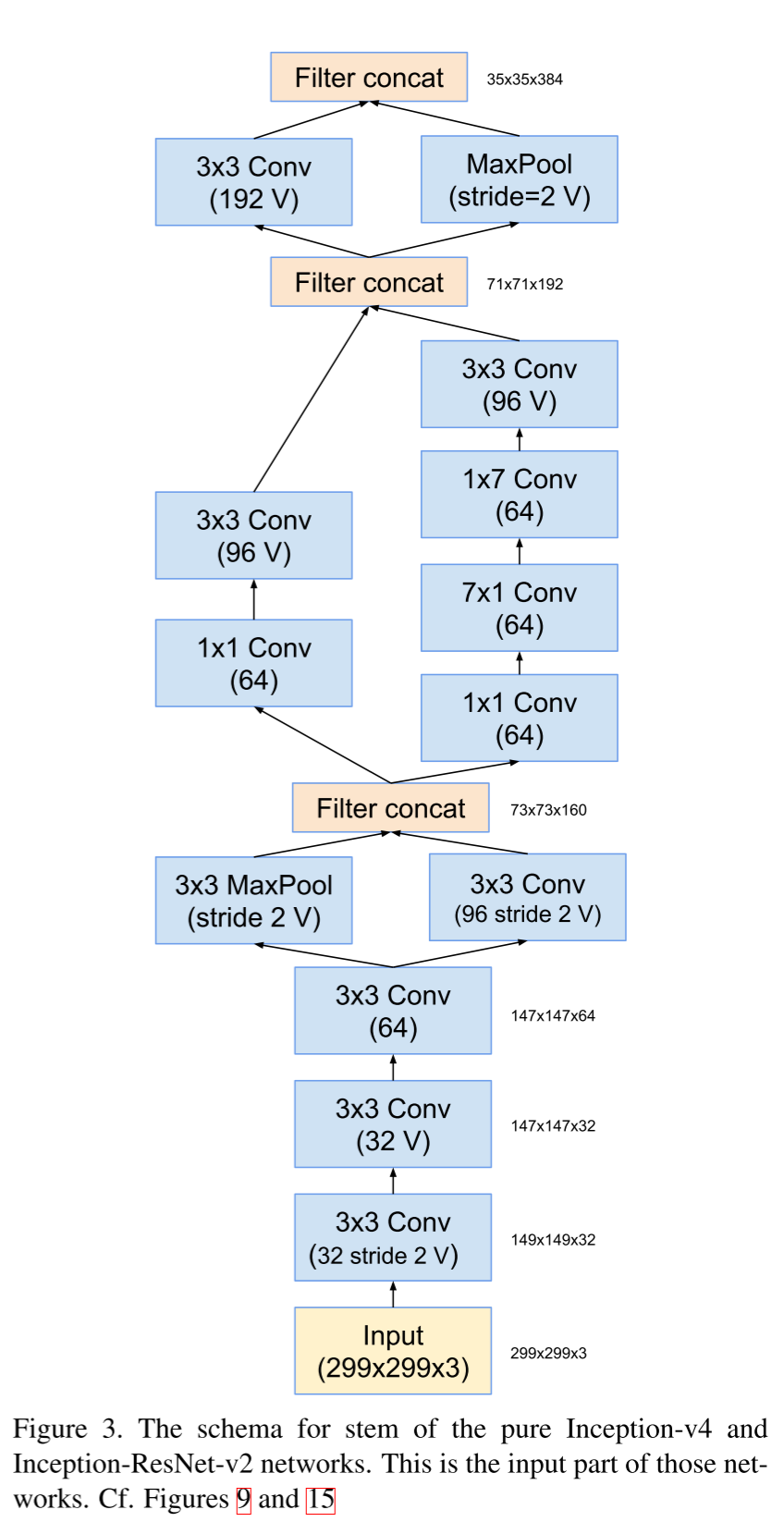
Inception блок А.
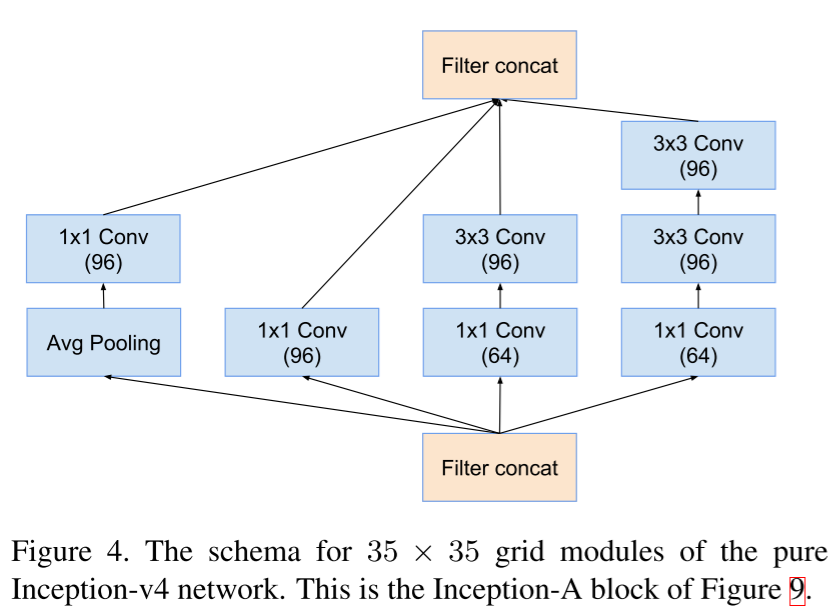
Если же в общей схеме Inception V4 заменить Inception-блоки на аналогичные, но с shortcut-связью, то получится Inception ResNet.
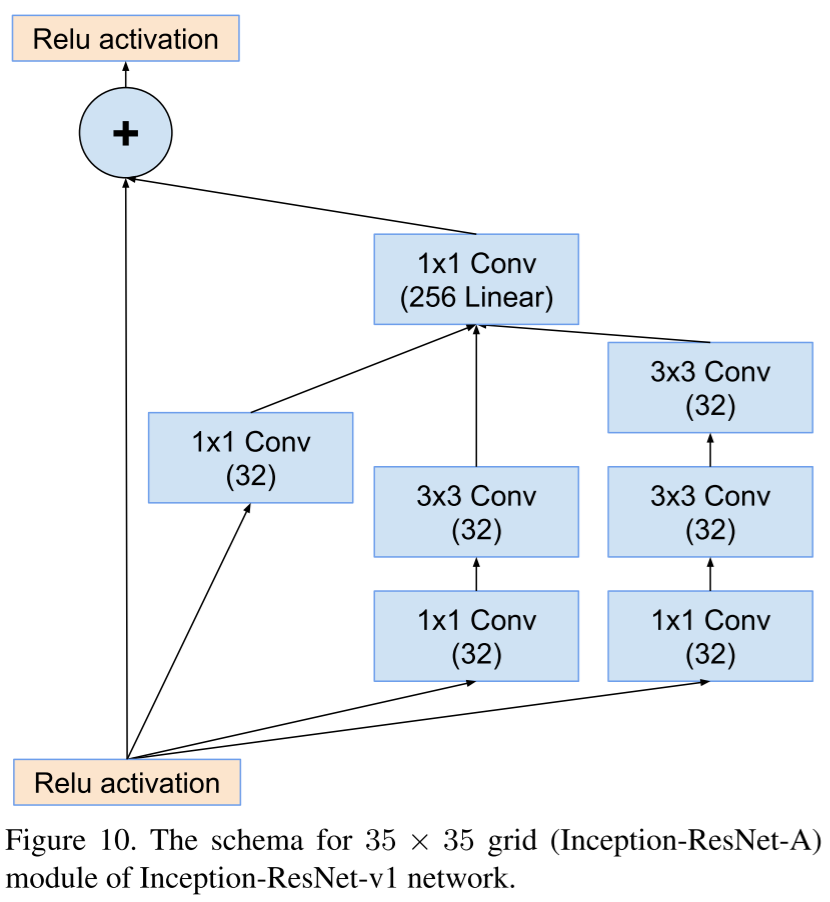
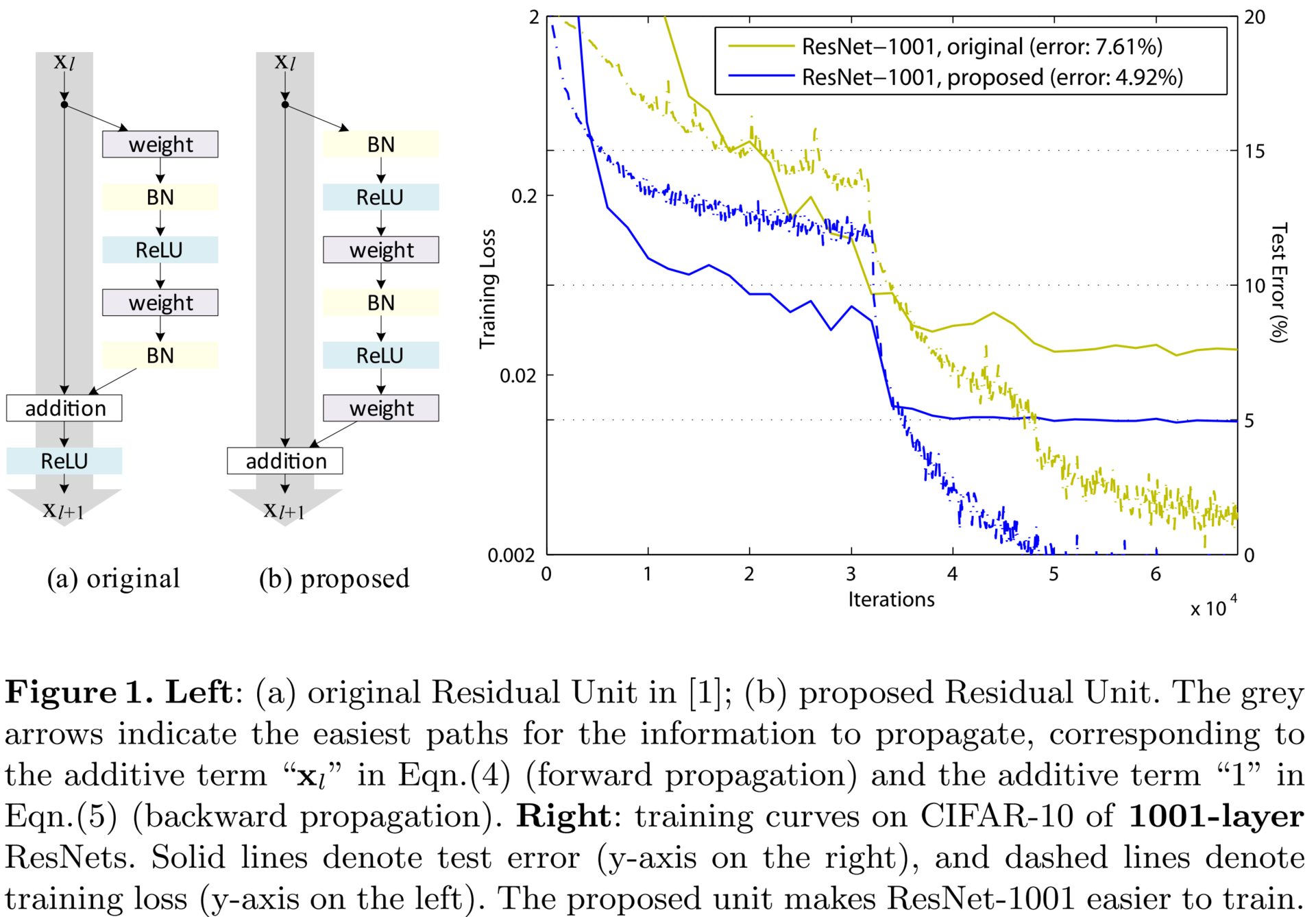
Identity Mappings in Deep Residual Networks (12 Apr 2016)
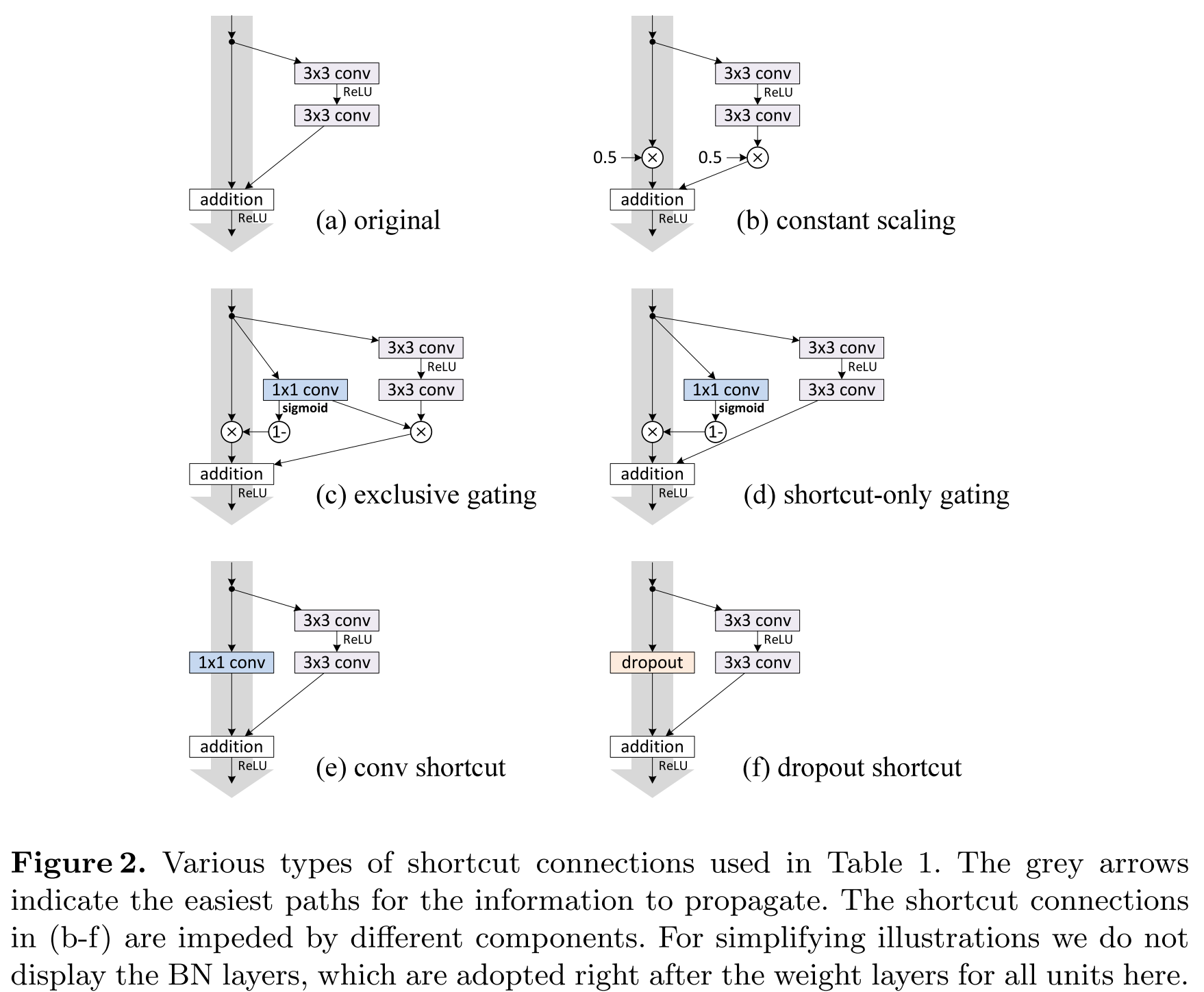
Если вы заглянули в детали реализации оригинального ResNet, то могли заметить, что нелинейность берется после агрегирования двух ветвей: остаточной функции и тождественной связи. Авторы заявляют, что это не совсем правильная техника и лучше вообще не брать нелинейность после агрегации. Лучше как бы сдвинуть все нелинейности на один шаг назад по остаточным ветвям. Таким образом выход из блока подается на тождественную связь следующего, где он неизмененным доходит до своего выхода; а также на остаточную сеть следующего, где над выходом текущего уже применяется нелинейность. Так удалось обучить сверхглубокую нейронную сеть, состоящую из 1001 слоя. Сравните, еще в 2014 году 19-слойная нейронная сеть считалась «very deep convolutional neural networks».
В статье приводится небольшой математический анализ такого трюка. Пусть
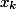 — вход текущего слоя;
— вход текущего слоя; 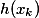 — shortcut connection, в нашем случае это просто тожественное преобразование
— shortcut connection, в нашем случае это просто тожественное преобразование 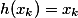 ;
; 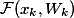 — residual network;
— residual network; 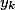 — агрегированный выход двух ветвей блока;
— агрегированный выход двух ветвей блока; 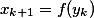 — вход следующего блока равен некоторому преобразованию от агрегации двух ветвей предыдущего блока.
— вход следующего блока равен некоторому преобразованию от агрегации двух ветвей предыдущего блока.
Тогда можно рассмотреть две ситуации, в первой
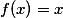 — это как раз вариант, предложенный в текущей статье. Обозначим любой слой сети K, тогда его значение можно вывести как сумму всех предыдущих плюс некоторое начальное значение. Напомню, что для градиентного спуска нам необходимо вычислять частную производную целевой функции по входам в каждый слой. Если продифференцировать целевую функцию по какому-либо слою k, то получим, что градиент декомпозируется в сумму двух членов: производной целевой функции по последнему слою и суммы частных производных. Это отличается от формулы для плоской сети тем, что в плоской сети формула градиента состоит из серии матрично-векторных произведений. Мы можем видеть, что градиент целевой функции доходит до каждого слоя внутри сети, а чтобы наблюдался vanishing gradients, необходимо, чтобы все
— это как раз вариант, предложенный в текущей статье. Обозначим любой слой сети K, тогда его значение можно вывести как сумму всех предыдущих плюс некоторое начальное значение. Напомню, что для градиентного спуска нам необходимо вычислять частную производную целевой функции по входам в каждый слой. Если продифференцировать целевую функцию по какому-либо слою k, то получим, что градиент декомпозируется в сумму двух членов: производной целевой функции по последнему слою и суммы частных производных. Это отличается от формулы для плоской сети тем, что в плоской сети формула градиента состоит из серии матрично-векторных произведений. Мы можем видеть, что градиент целевой функции доходит до каждого слоя внутри сети, а чтобы наблюдался vanishing gradients, необходимо, чтобы все 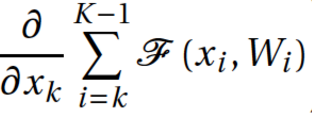 были равны –1. Авторы считают, что это крайне маловероятно. Таким образом, проблему затухания градиентов можно больше не брать в расчет.
были равны –1. Авторы считают, что это крайне маловероятно. Таким образом, проблему затухания градиентов можно больше не брать в расчет.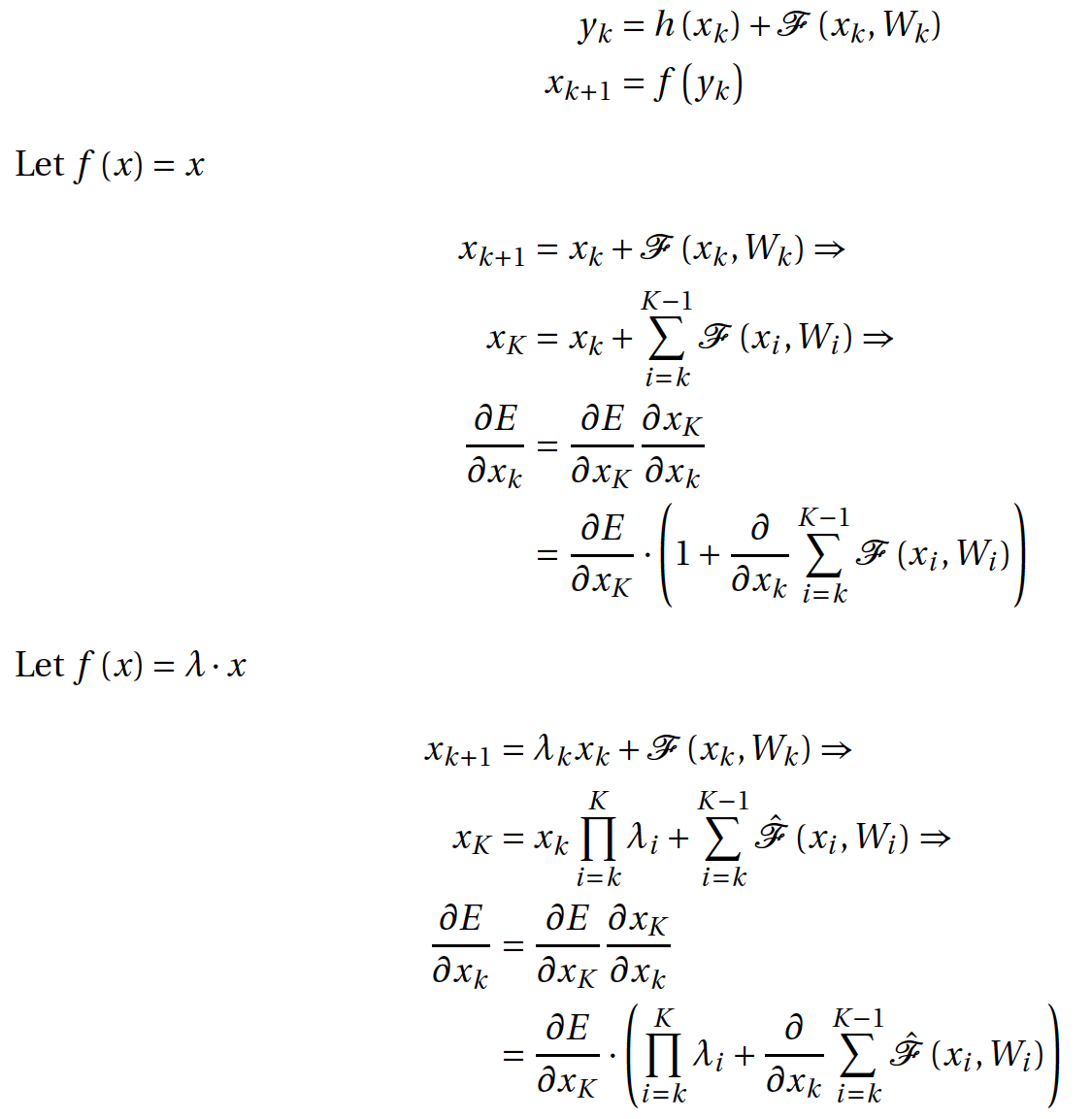
А что будет, если все-таки брать не тождественную функцию от агрегации двух ветвей блока? Давайте рассмотрим простейший случай, когда
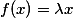 . Тогда вместо единицы мы получим произведение лямбд. Если лямбда больше единицы, то это может привести к экспоненциальному росту значений градиента. Если же лямбда меньше единицы, тогда градиент целевой функции будет затухать. А эти свойства как раз нам и хотелось бы устранить.
. Тогда вместо единицы мы получим произведение лямбд. Если лямбда больше единицы, то это может привести к экспоненциальному росту значений градиента. Если же лямбда меньше единицы, тогда градиент целевой функции будет затухать. А эти свойства как раз нам и хотелось бы устранить.На самом деле авторы исследовали различные конфигурации residual-блока и пришли к выводу, что именно предложенная простая конструкция, со сдвигом нелинейности на шаг назад, самая лучшая.
Тут стоит упомянуть отца глубоких рекуррентных сетей — Юргена Шмидхубера (Jurgen Schmidhuber). Если вы знакомы с его LSTM-моделью, опубликованной еще в 1997 году, то вы легко заметите, что ResNet в предложенной версии — это не что иное, как развернутый LSTM, где скрытые состояния соединены друг с другом по оси времени фиксированной необучаемой связью с весом 1. И неудивительно, что Юрген работал в это же время над очень похожей моделью — Highway Network. Но, похоже, они переусложнили модель, добавив несколько вентилей (gate), и не смогли получить результатов лучше, чем вариант из текущей статьи.
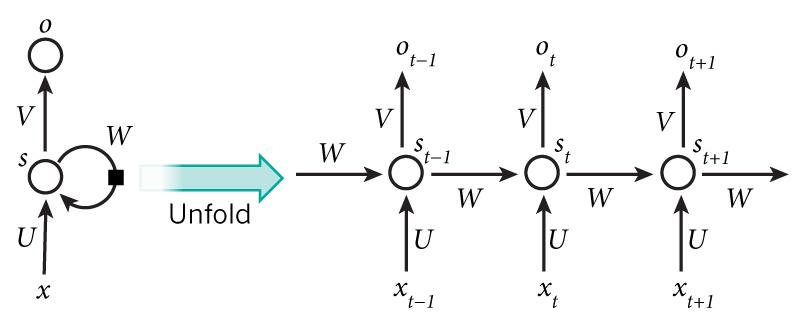
Bridging the Gaps Between Residual Learning, Recurrent Neural Networks and Visual Cortex (13 Apr 2016)
На следующий день появляется статья, в которой авторы сравнивают ResNet и обычные RNN. Одну мысль из этой статьи считаю нужным упомянуть. Авторы утверждают, что успехи глубоких нейронных сетей объясняются тем, что глубокие сети аппроксимируют рекуррентные сети, которые, в свою очередь, аппроксимируют динамические системы и вообще ближе к тому, как работает мозг.
The dark secret of Deep Networks: trying to imitate Recurrent Shallow Networks?
A radical conjecture would be: the effectiveness of most of the deep feedforward neural networks, including but not limited to ResNet, can be attributed to their ability to approximate recurrent computations that are prevalent in most tasks with larger t than shallow feedforward networks. This may offer a new perspective on the theoretical pursuit of the long-standing question “why is deep better than shallow”.
Residual Networks are Exponential Ensembles of Relatively Shallow Networks (20 May 2016)
Уверен, почти все из вас знакомы с DropOut, стратегией обучения, которая до недавнего времени являлась стандартом при обучении глубоких сетей. Было показано, что такая стратегия эквивалентна обучению экспоненциально большого числа моделей и усреднению результата прогнозирования. Получается построение ансамбля алгоритмом обучения. Авторы данной статьи показывают, что ResNet — это ансамбль по своей конструкции. Показывают они это серией интересных экспериментов. Для начала посмотрим на развернутый вариант ResNet, который получается, если считать два подряд идущих shortcut-соединения как одно ребро flowing graph’а.
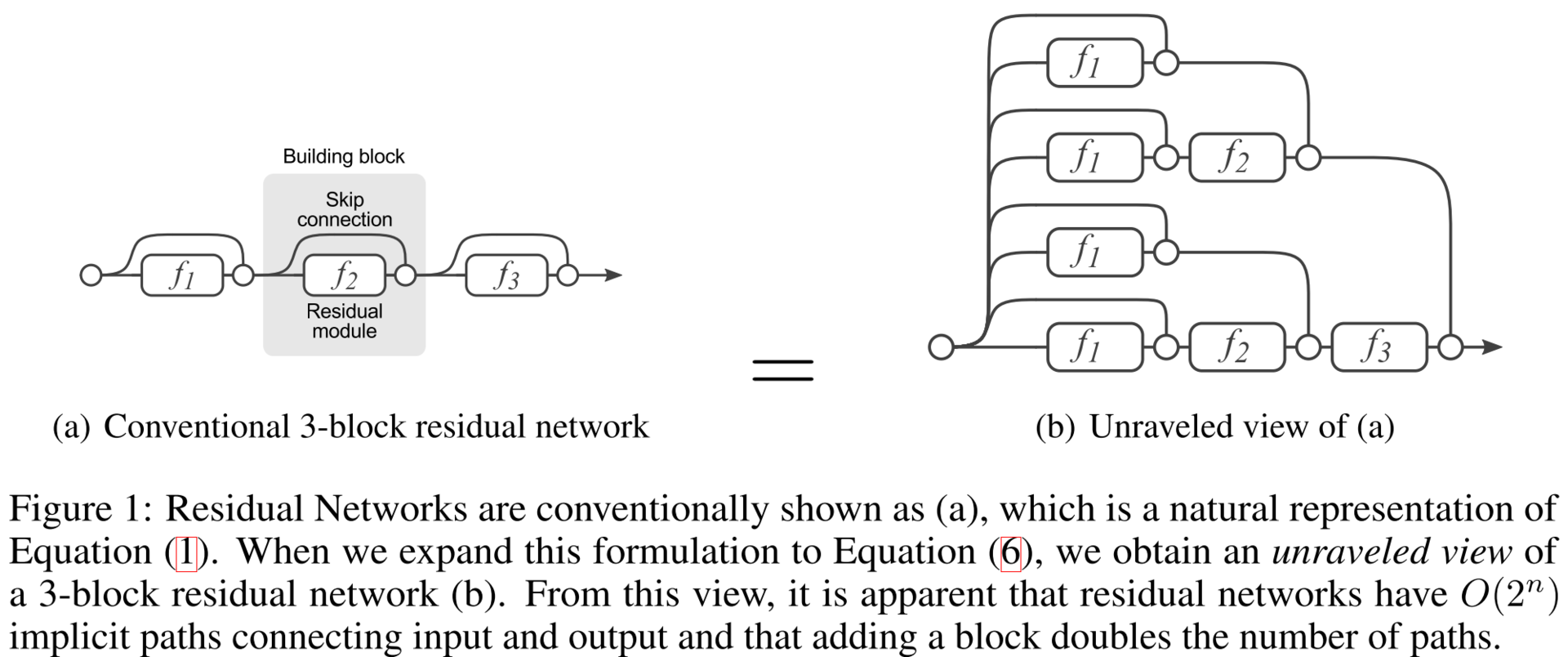
Проверить это можно простым разложением формулы последнего слоя:
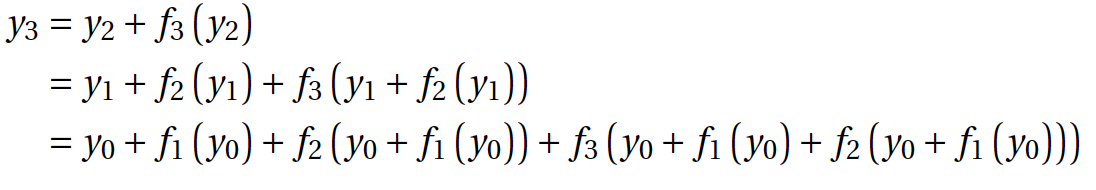
Как видите, сеть выросла еще по одной размерности, помимо ширины и глубины. Авторы говорят, что это новая третья размерность, и называют ее multiplicity, по-русски, наверное, ближе всего будет — многообразие. Получается, что благодаря Арнольду и Колмогорову мы знаем, что сеть нужно растить в ширину (доказано). Благодаря Хинтону мы знаем, что добавление слоев улучшает нижнюю вариационную границу правдоподобия модели, в общем, тоже хорошо (доказано). И вот предлагается новое измерение, что нужно делать модели многообразными, хотя это еще стоит доказать.
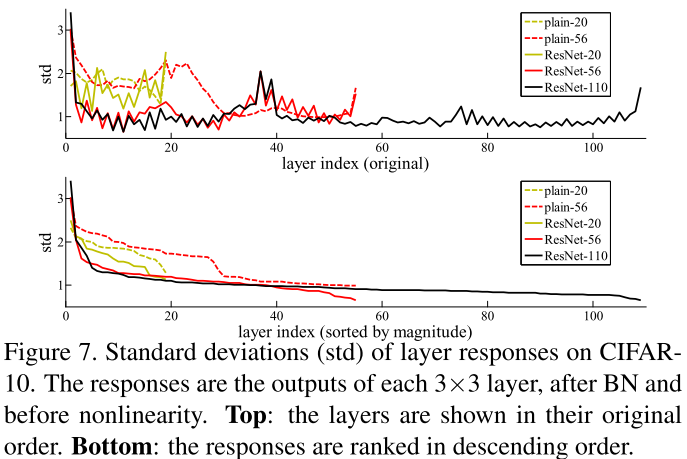
Пока же нет доказательства, авторы предлагают следующие доводы. После обучения, в режиме прогнозирования, мы удалим несколько слоев из сети. Очевидно, что все сети до ResNet после такой операции просто перестанут работать.
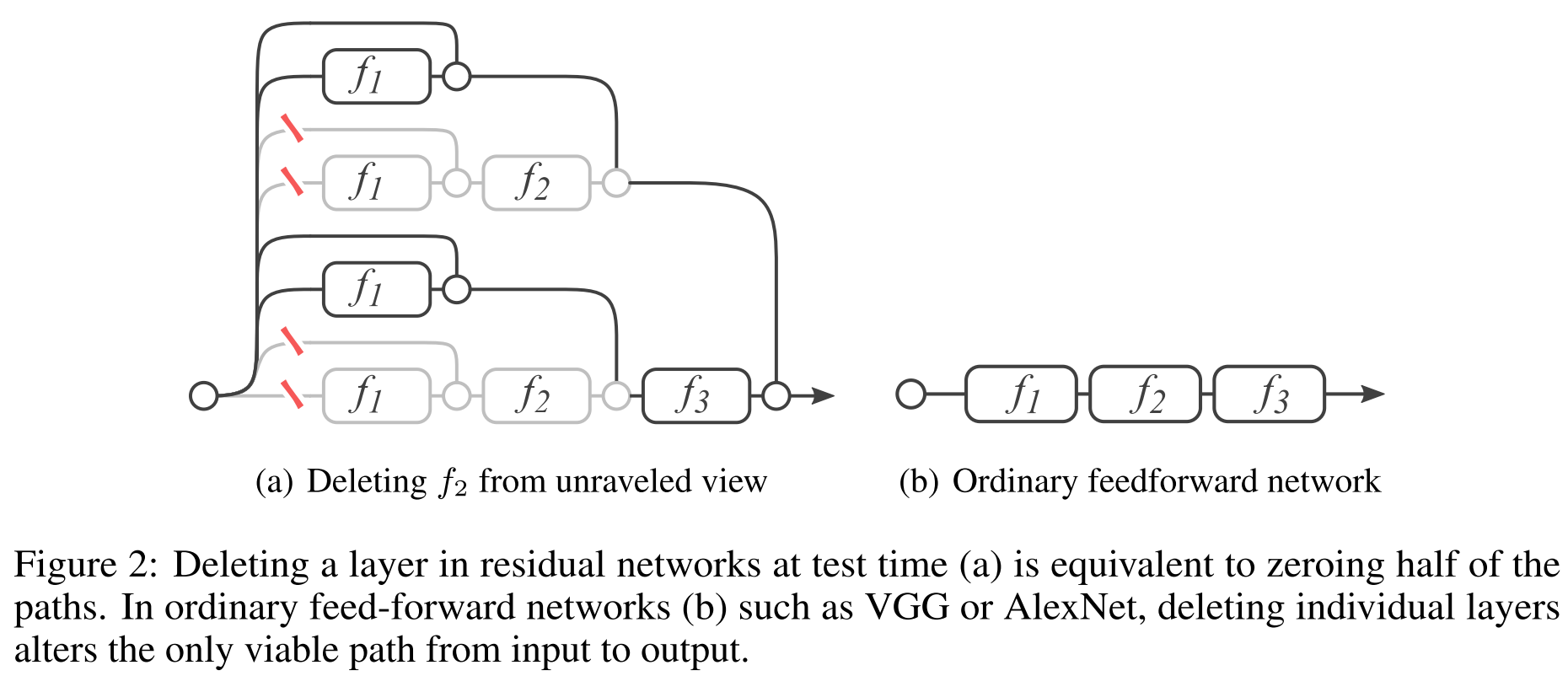
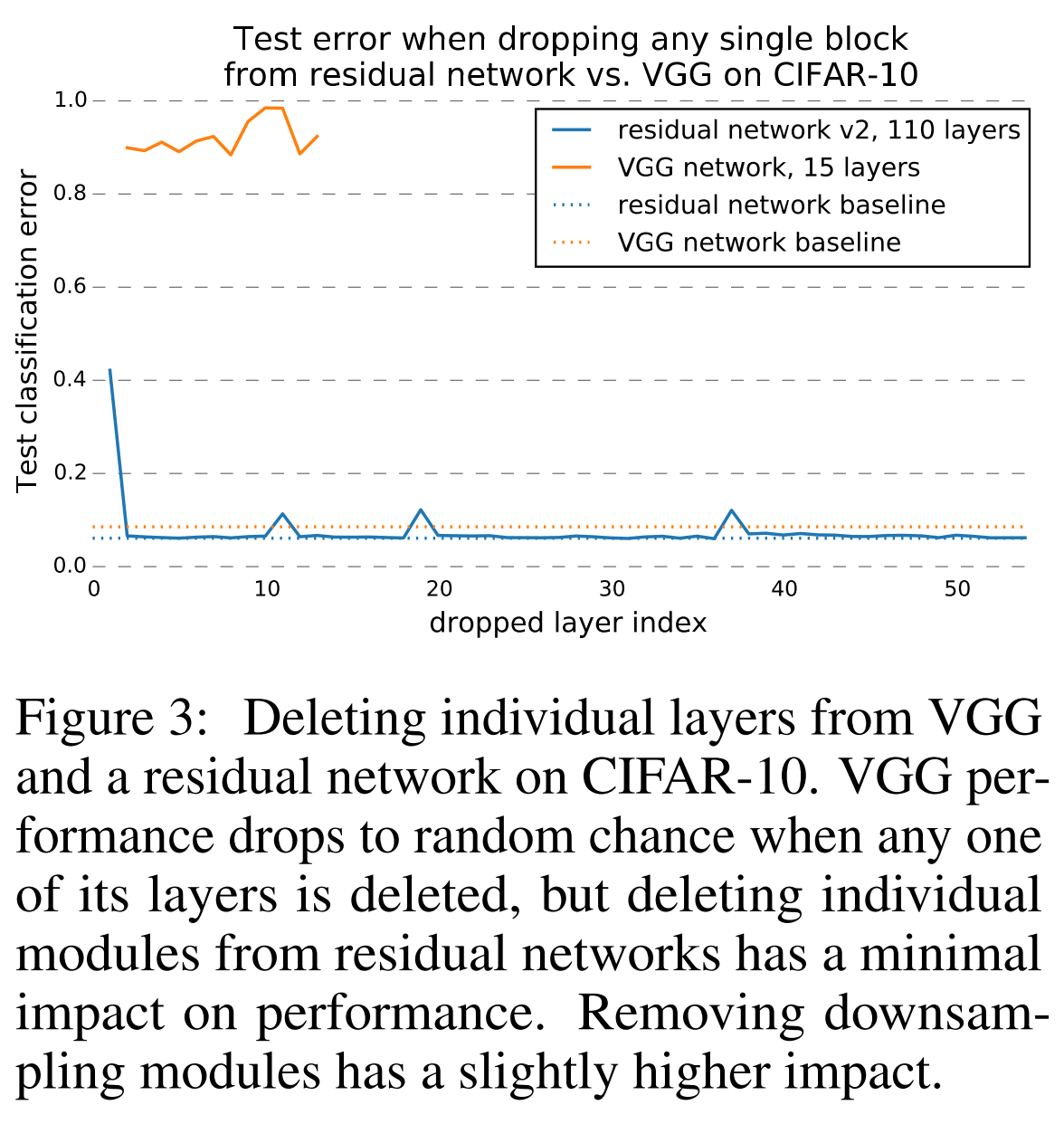
Оказывается, что качество прогнозирования у ResNet плавно ухудшается при увеличении количества удаленных слоев. Скажем, если удалить половину слоев, то качество падает не так драматично.
Похоже, ради троллинга авторы удаляют несколько слоев из VGG и из ResNet и сравнивают качество.
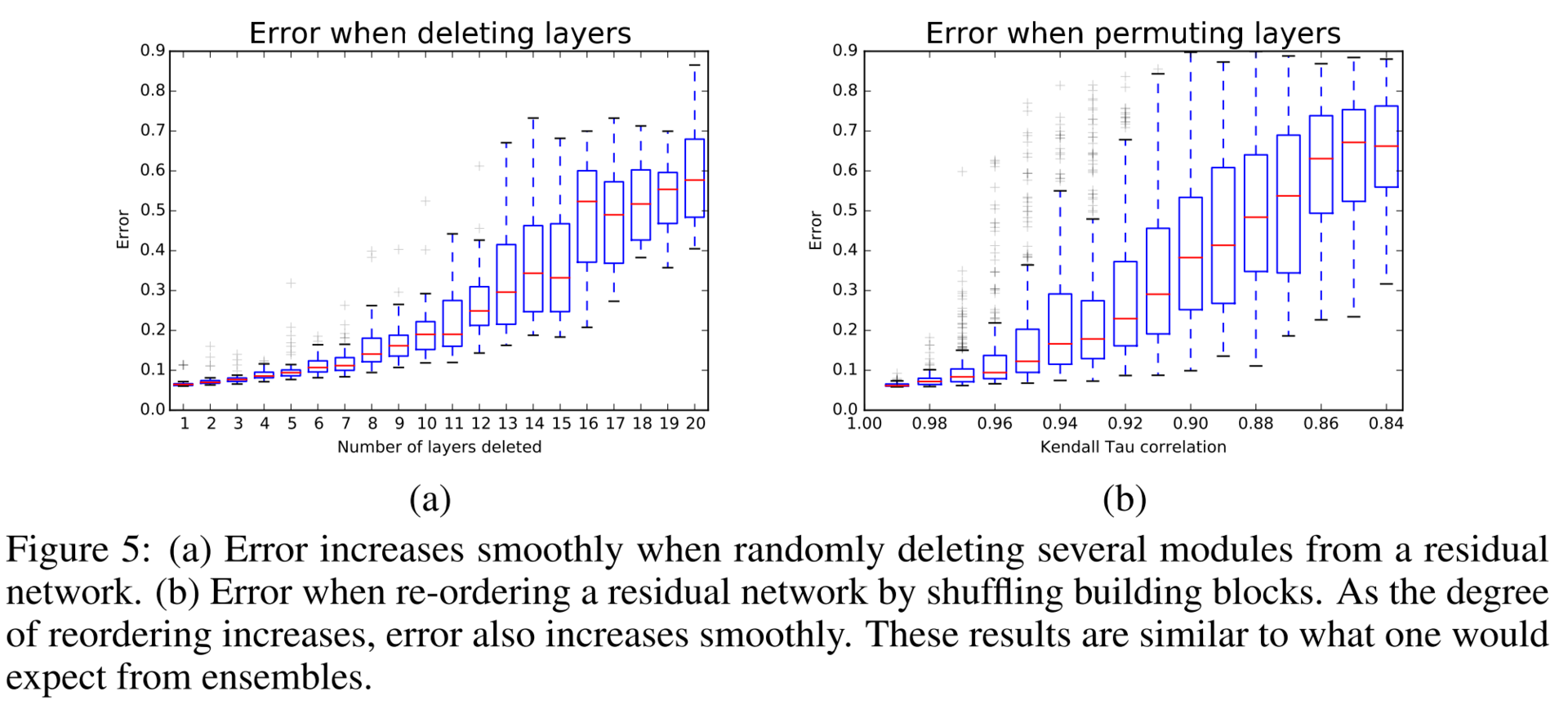
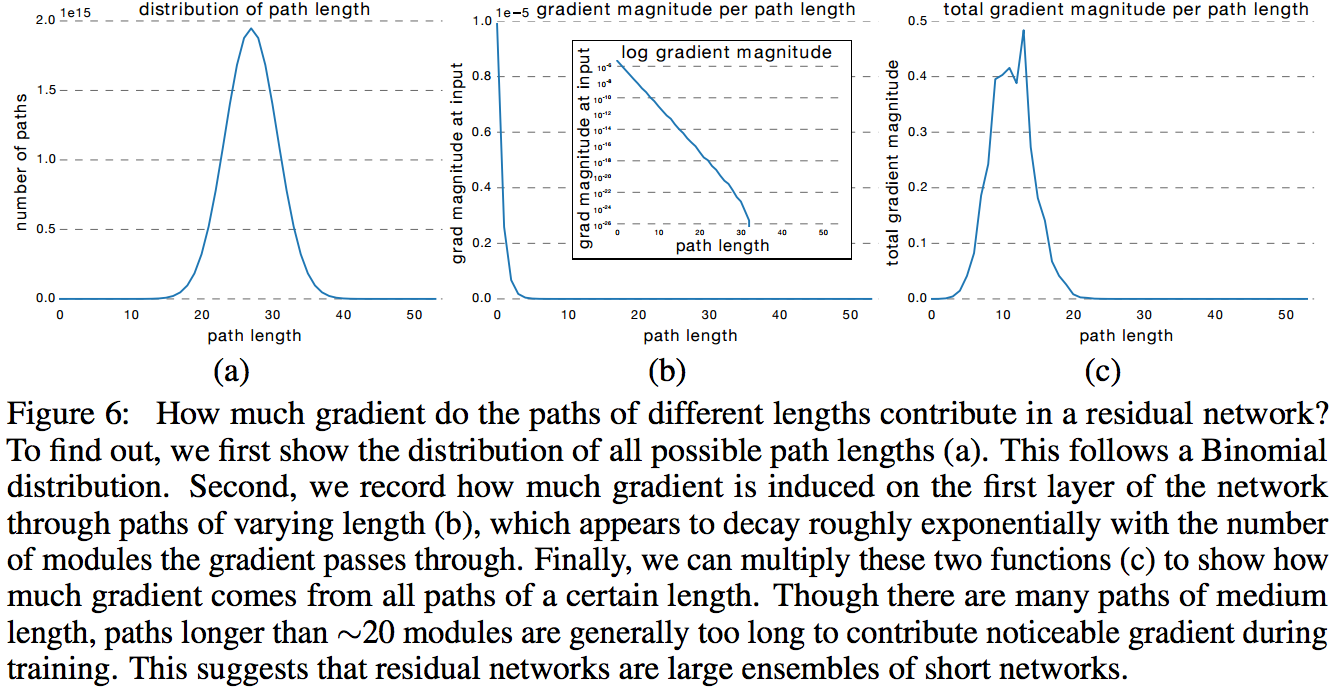
В следующем эксперименте авторы строят распределение абсолютных значений градиента, полученных из подсетей разной длины. Оказывается, что для ResNet-50 эффективная длина подсети — от 5 до 17 слоев, на их долю приходится почти весь вклад в обучение всей модели, хотя они занимают всего 45 % от всех длин путей.
Заключение
ResNet продолжает активно развиваться, и различные группы как пробуют что-то новое, так и применяют проверенные паттерны из прошлого. Например, создают ResNet in ResNet.
- Convolutional Residual Memory Networks (14 Jul 2016)
- Wide Residual Networks (23 May 2016)
- Depth Dropout: Efficient Training of Residual Convolutional Neural Networks
- Resnet in Resnet: Generalizing Residual Architectures (25 Mar 2016)
- Residual Networks of Residual Networks: Multilevel Residual Networks (9 Aug 2016)
- Multi-Residual Networks (24 Sep 2016)
- Deep Learning with Separable Convolutions (7 Oct 2016)
- Deep Pyramidal Residual Networks (10 Oct 2016)
Если вы прочитали что-то, не упомянутое в данном обзоре, расскажите в комментариях. Уследить за всем при таком потоке новых статей просто не реально. Пока данный пост проходил модерацию в блоге, я успел добавить в список еще две новых публикации. В одной гугл рассказывает про новую версию инсептрона — Xception, а во второй — пирамидальный ResNet.
Если спросить у кого-либо, немного разбирающегося в нейронных сетях, какие виды сетей бывают, он скажет обычные (полносвязные и сверточные) и рекуррентные. Похоже, что вскоре появится теоретическая база, в рамках которой все типы нейросетей будут принадлежать к одному классу. Есть теорема универсальной аппроксимации, в которой говорится, что любую (почти) функцию можно приблизить нейросетью. В аналогичной теореме для RNN говорится, что любую динамическую систему можно приблизить рекуррентной сетью. А сейчас оказывается, что и RNN может быть приближена обычной сетью (осталось это доказать, правда). В общем, в интересное время живем.

Комментарии (44)

ZlodeiBaal
12.10.2016 19:27+2Ещё бы видюхи поспевали с объёмом памяти за этими новыми сетями)
Взял себе домой 1080, так даже её частенько не хватает. Приходиться что-то на рабочих тэслах считать:)Idot
13.10.2016 12:07Старые компьютеры вполне тянули в реальном времени Creatures в которой были десятки норнов, гренделей и эттинов на нейронных сетях. Они были способны к самообучению, и даже разговаривали на несложном языке.
Интересно как их нейронные сети были устроены?

Dark_Daiver
12.10.2016 20:31+3А для непосвященных, почему DropOut RIP?
А статья классная, побольше бы таких
mephistopheies
12.10.2016 20:39+2так появился batch normalization
дропаут — это штука для регуляризации по средствам добавления шума в сеть
бн — это штука для ускорения обучения, но тк он все таки нормализует батчи, а не весь датасет, то и шума он тоже добавляет, получается он еще немного и регулризатор
в больших датасетах вариации данных и так достаточно, так что бн важнее
есть статьи где используется и то и то, но суда по конкурсам — все перешли на бн вместо дропаута
ну и еще обратите внимание, что с появлением резнета сеть стала сама по себе как ансамбль, а дропаут вообще говоря и есть ансамбль, но не по построению, а изза алгоритма обучения, получается что резнет с бн и так обладает всем, что дает дропаутDark_Daiver
12.10.2016 20:41+1Понял, спасибо!
Просто опыта у меня совсем мало, со всем зоопарком приемов для fine-tuning сетей я не знаком.

supersonic_snail
13.10.2016 11:04Для больших датасетов и сверточных сетей все, что вы написали, верно. Но если данных мало, а использовать что-то предобученное хочется, то дропаут вполне себе помогает, хотя и не сильно — переход с googlenet на inception-resnet даст результат лучше, чем включение дропаута в googlenet.
Для рекурентных сетей bn не очень удобно использовать, поэтому там недавно появился layer normalization (ln). ln это почти то же, самое, что и bn, только они считают среднее и отклонение по всем нейронам, а не по батчу. Для рекурентных сетей работает получше и в целом удобнее, чем bn. Вместе с этим ln вполне можно использовать дропаут и в рекурентных, и в нерекурентных соединениях. Но опять же, если данных немного — на огромных сложных датасетах дропаут не используется. Как пример — недавно выходила статья от гуглбрейн, в которой они поставили несколько state-of-the-art результатов на широко используемых небольших бенчмарках с дропаутом. В той же статье есть результаты на больших наборах, так там уже никакого дропаута.
Так что рано говорить, что dropout is dead, имхо.mephistopheies
13.10.2016 11:06ну я согласен, что еще не умер, но думаю на пути туда; учитывая как быстро сейчас все развивается, то и бн не долго пробудет, там же тоже все на соплях держится, слишком много предположений
Dark_Daiver
12.10.2016 20:36+1>Оказывается, что качество прогнозирования у ResNet плавно ухудшается при увеличении количества удаленных слоев
Если ResNet это что-то типа каскада, то такой результат довольно ожидаем. Каждый следующий уровень каскада просто улучшает результат предыдущего.mephistopheies
12.10.2016 20:41интересно, что не только предыдущего, но и всех вообще вариантов «предыдущего», тк если взять произвольный блок в середине сети, то если развернуть — получится несколько «предыдущих»
посмотрите на блок f2, у него есть одно предыдущее связанное с f1, а есть другое связанное с входом в сеть

DistortNeo
13.10.2016 01:10+1Чем мне не нравятся нейросети — они задвинули собой целый зоопарк различных методов в определённых областях обработки изображений. Большое количество библиотек и пакетов позволяет эффективно решать задачи при минимальном понимании предметной области. Всё, что нужно от программиста — это предобработать данные и засунуть в алгоритм машинного обучения.
Единственный недостаток нейросетей — это их высокая вычислительная сложность, поэтому спрос на более простые методы, не основанные на нейросетях, пока ещё есть, но и он сойдёт нет с развитием вычислительной техники.mephistopheies
13.10.2016 08:55+1>они задвинули собой целый зоопарк различных методов
мне вот кажется, что отлично, что и задвинули; компьютерное зрение стагнировало, из него выжали все что можно; и тут появляются модели которые «изобретают» все хэндкрафт методы сами
особенно мне например нравится подход R-CNN для детектирования, и то как сейчас делается сегментация
Хинтон давно писал "To Recognize Shapes, First Learn to Generate Images", и именно к этому мы и пришли со всеми современными нейрогенеративными моделямиDark_Daiver
13.10.2016 11:03Кстати интересный вопрос, как ведут себя DL подходы в ситуациях, когда у нас очень мало примеров (200-1000), и при этом очень большое пространство признаков (20к-60к), и нет возможности синтетически увеличить датасет или использовать transfer learning?
mephistopheies
13.10.2016 11:10+2пока нейросети работают хорошо только там, где данные обладают одним свойством — локальная корреляция: картинки, текст, звук
на остальных данных лучше работает xgboost пока
так что это еще не паханное поле и еще дип лернингу туда предстоит зайти
если же примеров мало, и это картинки, то все вполне решаемо, но зависит от контекста задачи
Arseny_Info
13.10.2016 18:36Раскройте, пожалуйста, тему чуть подробнее — что такое локальная корреляция?
mephistopheies
13.10.2016 20:03+2примеры:
- соседние пиксели не сильно отличаются друг от друга в изображении
- соседние значения звуковой волны голоса на оси времени не сильно отличаются друг от друга
- текст — это поток токенов, выстроенных в определенном порядке, и по корпусу текстов всегда можно вычислить какие слова более вероятно встретить после других и до, в каком то смысле это тоже корреляция локальная, тк мы больше знаем информации о соседних словах при данном слове, чем о других словах более удаленных от данного
konar
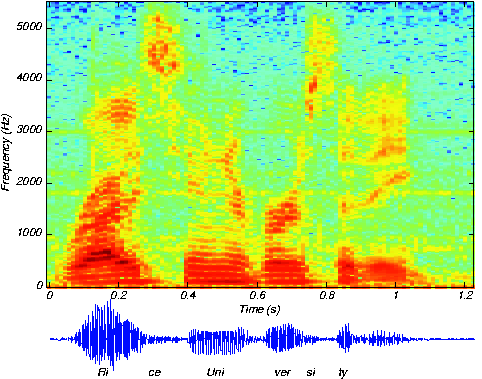
14.10.2016 01:02Может я ошибаюсь, но насколько я знаю — голосовую запись никто напрямую в методы ML и DL не подает. А вычисляются MFCC, которые декоррелированы между собой. При этом большинство современных систем интеллектуальной обработки речи (распознавание речи, идентификация диктора и тд.) строятся именно на нейронных сетях (на харбе был пример алгоритма от яндекса).и отлично работают. По этому со звуком — не совсем удачный пример.
mephistopheies
14.10.2016 01:05+2все верно, напрямую вроде не подают, но если сделать оконное Фурье преобразование, то можно обрабатывать полученную спектрограмму сверточной сетью например

ternaus
14.10.2016 01:58+1Для тех, кто хочет поиграться с этим подходом приведу ссылку на соревнование, которое проходит прямо сейчас.
Многие участники как раз и преобразуют временные ряды в спектрограммы, CNN на нижних слоях и рекурентные слои сверху.
https://www.kaggle.com/c/melbourne-university-seizure-prediction
vfdev-5
13.10.2016 02:31+1Напомню, как выглядят рецепторные области нейронов на разных уровнях и какие признаки они извлекают.
А можно для забывчивых ссылку на то, как вычисляются эти картинки? Спасибо
mephistopheies
13.10.2016 09:01вот тут я описывал несколько способов как визуализировать свертки https://habrahabr.ru/company/mailru/blog/306916/
kraidiky
13.10.2016 12:30Большое спасибо, интререснейшая статья! И язык достаточно человеческий чтобы поняли не только те, кто пишет на той же библиотеке. Правда позабавило вот этот:
полученная стеканием нескольких слоев, должна выучить тождественное преобразование, в случае если на предыдущих слоях был достигнут предел качества. Но этого не происходит по каким-то причинам,
Если задуматься над простой аналогией, то от сети, с не остаточной архитектуры, в которой следующий слой соединён только с предыдущими, ожидать увеличения качества с ростом количества слоёв — примерно то же самое, что ожидать лучшего результата от Ряда Тейлора, который раньше состоял из 4 членов, а теперь из шести начиная со второго.
По сути это то же самое, что вы сказали: «возможно, оптимизатор просто не справляется с тем, чтобы настроить веса так, чтобы сложная нелинейная иерархическая модель делала тождественное преобразование». Но только гораздо интуитивно проще и понятнее и требует меньше мат.подготовки чтобы понять.
Это, конечно, не так математически точно, зато позволяет дойти до идеи остаточных сетей на много быстрее и по более прямому пути.mephistopheies
13.10.2016 13:01примерно то же самое, что ожидать лучшего результата от Ряда Тейлора, который раньше состоял из 4 членов, а теперь из шести начиная со второго.
вот мне кажется ошибочно рассуждать о residual сети в аналогии с рядом Тейлора, каждый член разлодения в ряде Тейлора уточняет значение в смысле О(x^n), выкинув некий член мы сильно просядем в точности на выкинутом уровне
в то время как в резидуал сети каждый член он как бы уточняет весь ансамбль https://habrahabr.ru/company/mailru/blog/311706/#comment_9856086kraidiky
13.10.2016 13:21Я не говорю, что это точная аналогия. Это просто способ прийти к тому же результату сильно быстрее на интуитивном уровне. В картинке из моей статьи двухгодичной давности на 36 нейронов приходится 27 слоёв, и никакой сетью без прокидки сопоставимого размера, такого же качества добиться не получится. Рискну предположить что и в десять раз большегго размера сетью глубиной в 5 слоёв результат будет если и лучше, то не на много.
Если человек будет думать о нелинейном слое не только как о апроксиматоре произвольной функции делающем всё лучше, но и как о изгибателе добавляющем изогнутости абсолютно всем признакам, выявленным слоем ниже, до него идея скипающихся слоёв дойдёт сильно быстрее. Потому что он будет понимать что в некоторых случаях он делает хуже, и даже интуитивно понятно в каких.
Vjatcheslav3345
13.10.2016 12:46Также были применены другие трюки для избежания переобучения, и некоторые из них сегодня являются стандартными для глубоких сетей: DropOut (RIP), Data Augmentation и ReLu.
А что этим трюкам в сетях из живых нейронов соответствует?
kraidiky
13.10.2016 12:52Дропаут в явном виде присутствует, у ребёнка синапсов в мозге на порядок больше чем у взрослого. ДатаАугментейшен это сны и проигрывание гипокампом запомненого опыта. А вот с ReLu сложнее.
mephistopheies
13.10.2016 13:18тут вот во второй части они описывают биологические предпосылки дропаута
ReLu не помню в какой статье, но сравнивают с осцилляциями и спайками в реальных нейронах, и показывают что РеЛу как бы лучше описывает динамику одного нейрона нежели другие
в общем в какой то лекции Салакхудинов, вроде, говорил, что бывает они что то придумывают и им биологи говорят, типа все так, и они вписывают в статью био обоснование; а бывает биологи смотрят на статью и говорят что нифига не так в мозге, а им математики говорят — ну и ладно, главное работаетDistortNeo
13.10.2016 13:50Про ReLU я уже оставлял свои соображения:
https://habrahabr.ru/post/309508/#comment_9795718
Если вкратце: использование ReLU обусловлено существованием эффективных методов оптимизации коэффициентов свёрточных сетей, основанных на теории разреженных представлений. Ну а сравнение с осцилляциями и спайками — типичный случай, когда сначала идёт практика, а затем под неё подгоняется теория.mephistopheies
13.10.2016 13:55использование ReLU обусловлено существованием эффективных методов оптимизации коэффициентов свёрточных сетей, основанных на теории разреженных представлений. Ну а сравнение с осцилляциями и спайками — типичный случай, когда сначала идёт практика, а затем под неё подгоняется теория.
так там же обычный бекпроп, нельзя сказать что это новый метод эффективной оптимизации именно сверточных сетей; релу решает важную проблему — он отменяет понятие насыщенного нейрона, которое ведет к затуханию градиента, но добавляет еще больше шансов на exploding, что например в статье Mikolov'a решается методом cliping gradients; а все остальное про спарсность и спайки можно списать на «подтянутое за уши»DistortNeo
13.10.2016 14:16так там же обычный бекпроп, нельзя сказать что это новый метод эффективной оптимизации именно сверточных сетей… а все остальное про спарсность и спайки можно списать на «подтянутое за уши»
Я и не заявляю, что свёрточные нейросети имеют аналог в спарсе. Задача оптимизации коэффициентов нейросети — это просто задача минимизации функционала. В случае ReLU — задача L1-минимизации.
Просто в последнее десятилетие произошёл большой прогресс в области минимизации функционалов с L1-нормой благодаря теории разреженных представлений. Так что спасибо спарсу и товарищу Нестерову за то, что мы имеем сейчас эффективные математические методы обучения нейросетей, которые теперь называются «обычный бекпроп».mephistopheies
13.10.2016 14:28а, вы вероятно про метод момента при обновлении параметров модели?
DistortNeo
13.10.2016 14:45возможно
mephistopheies
13.10.2016 14:51интересно тогда как он связан с L1 оптимизацией, метод момента это же немного другое; если найдете ссылки на то что вы имеете в виде, в смысле как связаны РеЛу, л1 и Юрий Нестеров то делитесь такими ссылками, это всегда интересно понимать такие связи -)
DistortNeo
13.10.2016 15:54Метод Нестерова (ключевые слова для поиска: Nesterov Accelerated Gradient) — метод асимптотически оптимальной минимизации выпуклых функционалов. Предлагается как альтернатива обычному методу градиентного спуска. Конкретно для задач L1-минимизации, которыми и являются задачи обучения нейросетей с ReLU, оказался очень хорош.
Ссылок полно, легко гуглятся по ключевым словам:
1. Просто Нестеров в Deep Learning (~400 цитирований):
http://www.jmlr.org/proceedings/papers/v28/sutskever13.pdf
2. Альтернативы методу Нестерова:
https://arxiv.org/pdf/1412.6980.pdf
3. Регуляризация:
http://cs231n.github.io/neural-networks-2/#reg
barmaley_exe
14.10.2016 13:01+1NAG и Momentum – это разные вещи. Более того, значительная доля того, что придумал Нестеров, не очень полезна в глубоком обучении, т.к. функционалы там невыпуклые.
Dark_Daiver
13.10.2016 19:08Кстати интересный вопрос, если я делаю сеть с ReLU в скрытом слое и сигмоидой на выходе и оптимизирую все это дело с использованием квадратов в качестве функции ошибки, это разве будет L1 оптимизация?
Yane
13.10.2016 13:09Благодаря Арнольду и Колмогорову мы и они в курсе, что нейросеть может аппроксимировать почти любую функцию
что за теорема имеется ввиду?

sergeypid
13.10.2016 13:59+4Вот вам пара новинок после residual nets:
Deep Networks with Stochastic Depth
http://arxiv.org/pdf/1603.09382v1.pdf
Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra, Kilian Weinberger
Берут за основу Residual net, и пропускают при обучении целые слои аналогично dropout. Обычный dropout выполняется для отдельных связей или активаций, а здесь выкидываются целые фрагменты сети (слои) выбранные случайным образом, для каждого минибатча. При тестировании используются все слои, но их выходы модифицируются — умножаются на вероятность использования этого слоя при обучении.
Точность и скорость превосходят residual net, до 1202 слоев пробовали.
Фактически обучается ансамбль сетей 2^L т.к. возможно такое число комбинаций включенных и пропущенных слоев (L-общее число слоев).
FractalNet: Ultra-Deep Neural Networks without Residuals
http://arxiv.org/pdf/1605.07648v1.pdf
Gustav Larsson, Michael Maire, Gregory Shakhnarovich
Отказываются от residuals и конструируют “фрактальные” сети (структура самоподобная) эквивалентные очень большому числу слоев, и получают конкурентоспособную точность работы сети.
Очень хороший краткий обзор новых архитектур сетей с их недостатками.
Операция объединения у них — покомпонентное усреднение (объединяемых каналов). Это похоже на сложение в residual net, но способно работать при дропауте отдельных ветвей, вынуждая каждый канал обучаться надежному представлению данных.
mephistopheies
13.10.2016 14:41спасибо за ссылки, я как то натыкался на них в rss арксива, но как то пролистал, теперь раз советуете то есть повод почитать подробнее -)
а вы не пробовали сами фрактальные сети применять? вообще идея мне кажется красивая, интересно рабочая ли
babylon
Спасибо, отличная статья!