Этот релизный цикл был очень важным — удалось многое из того, что нас долго просили сделать: поддержка триггеров, поиск использований внутри представлений и функций, отложенное редактирование таблиц. Благодарим тех, кто не стесняется тестировать наши инструменты и пробует новые версии задолго до релиза.
Итак, DataGrip 2016.3!

Хранилище исходников
Использования таблицы или представления ищутся не только в исходном коде, но и внутри других объектов базы данных: функциях, процедурах и других представлениях.
Это работает так: DataGrip выгружает исходники объектов в хранилище, куда и обращается при надобности. По умолчанию загружаются коды из всех схем, кроме системных. Настроить это можно в свойствах источника данных, вкладка Options.
Для включения хранилища запустите Forget Schemas из контекстного меню, а потом обновите источник данных — нажмите на Synchronize в панели инструментов.
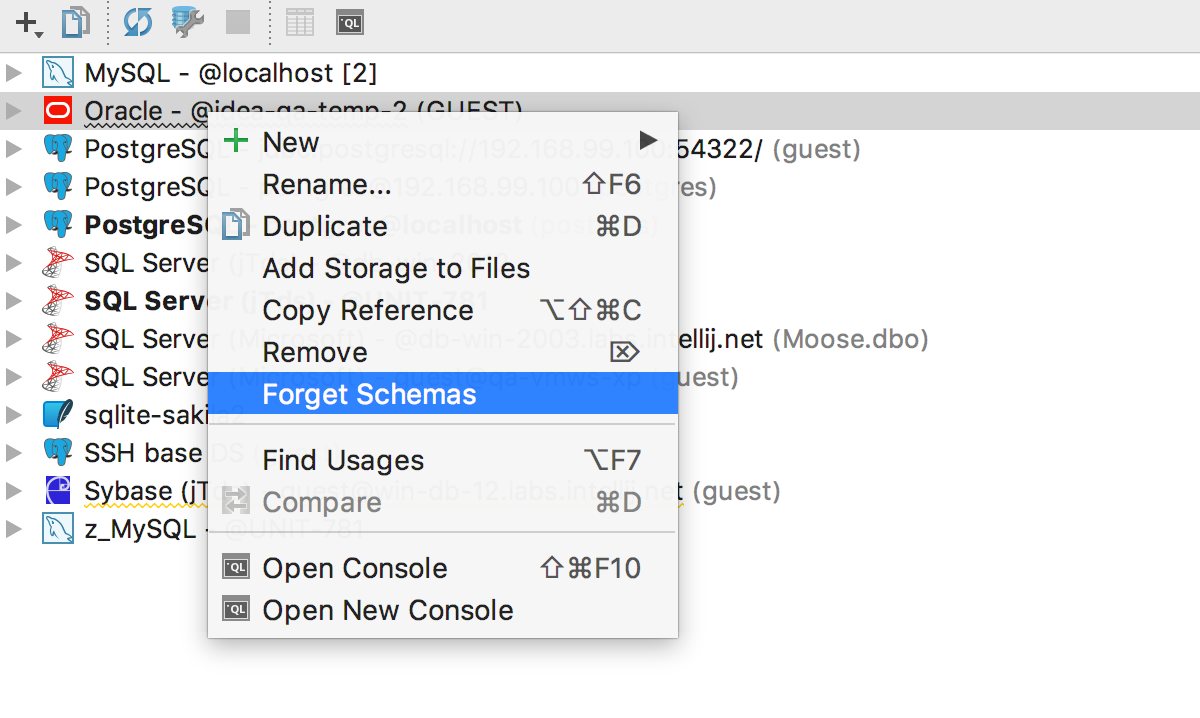
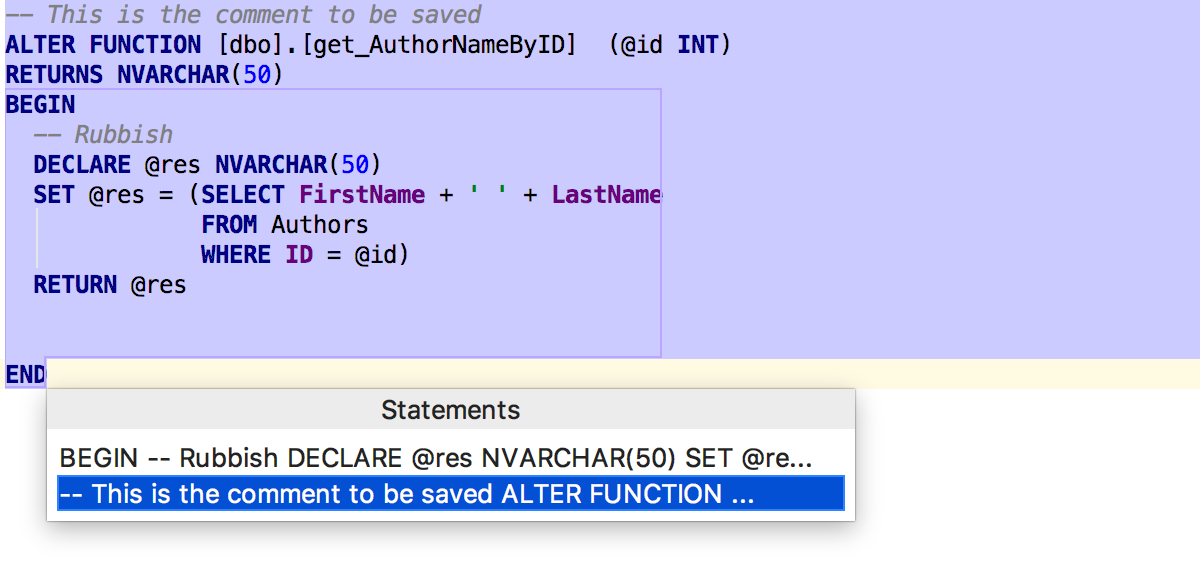
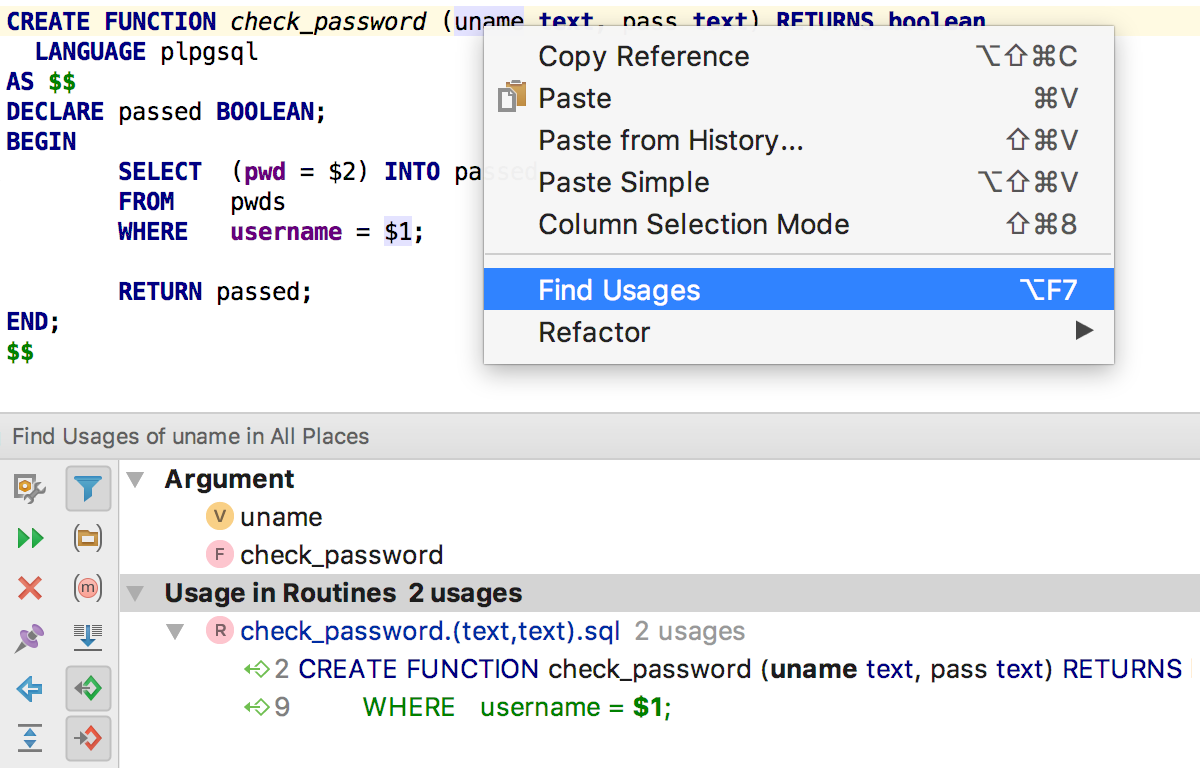
Пробуем: как всегда, Alt+F7 найдёт использования текущего объекта в скриптах. А теперь и внутри других объектов. Справа видно, в каком месте кода нашлось вхождение.
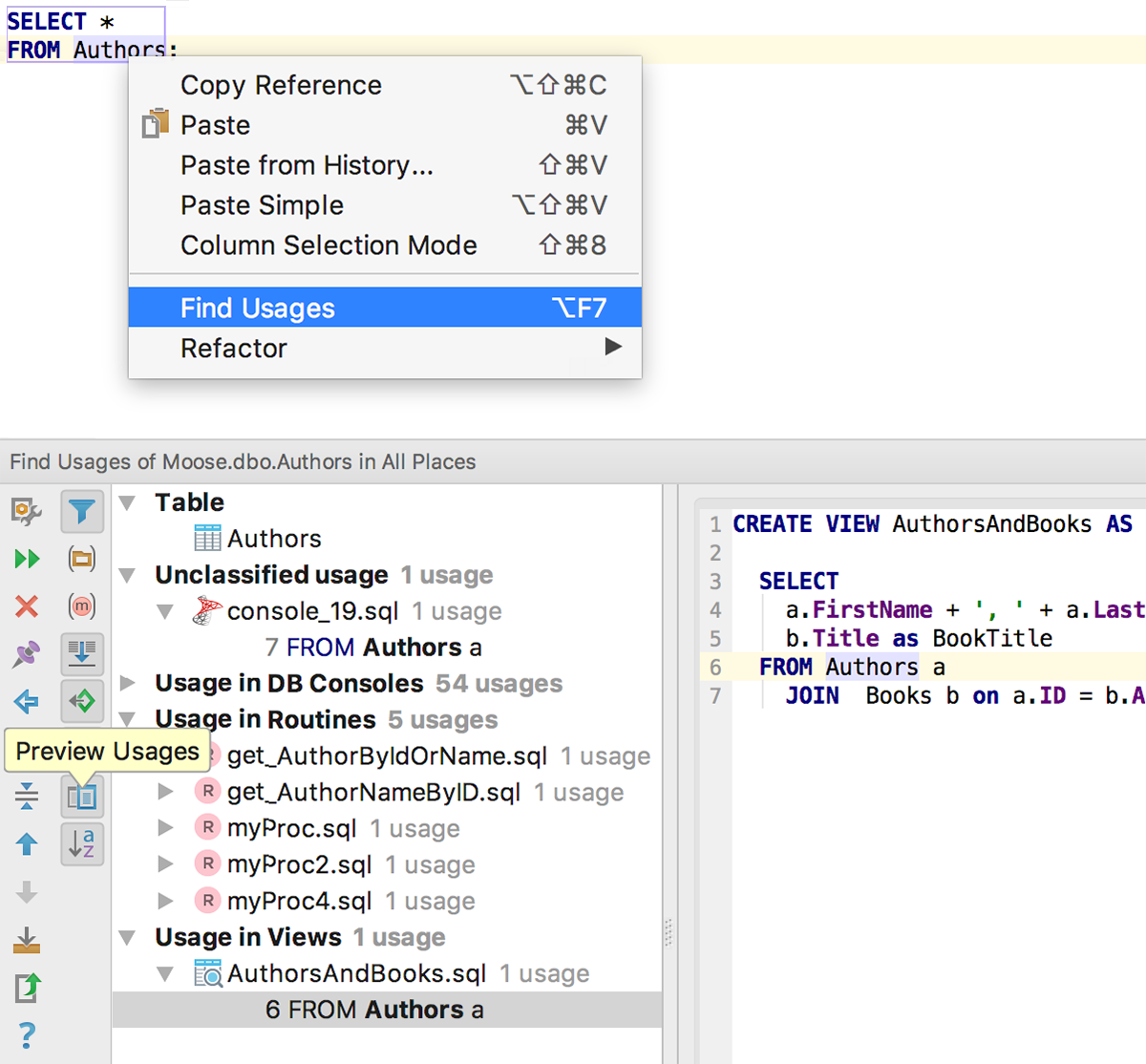
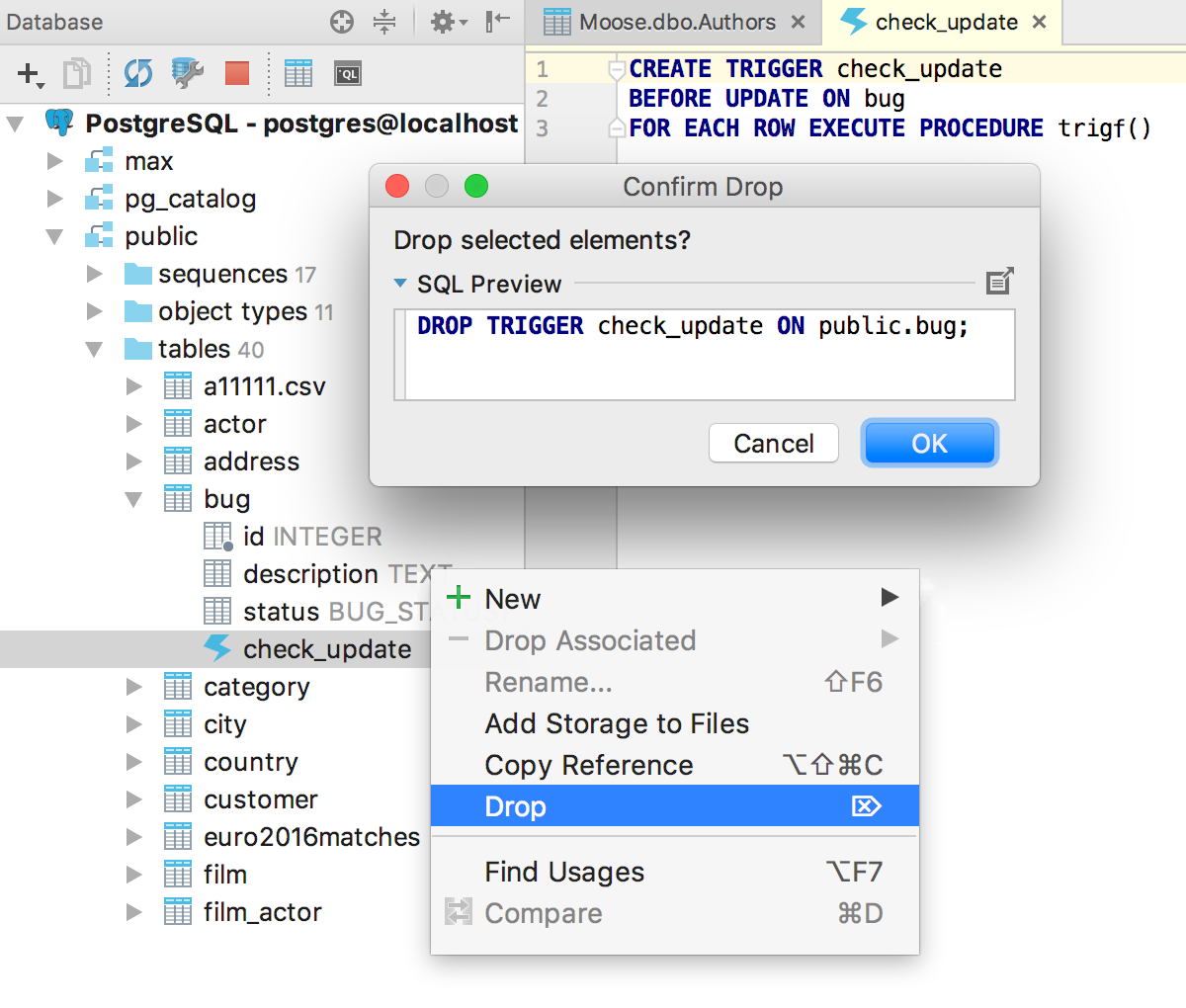
Как я уже написал, мы загружаем исходники триггеров для популярных СУБД: MySQL, PostgreSQL, SQL Server, Oracle и Sybase. А для PostgreSQL ещё и исходники правил. Теперь можно удалить триггер из контекстного меню.
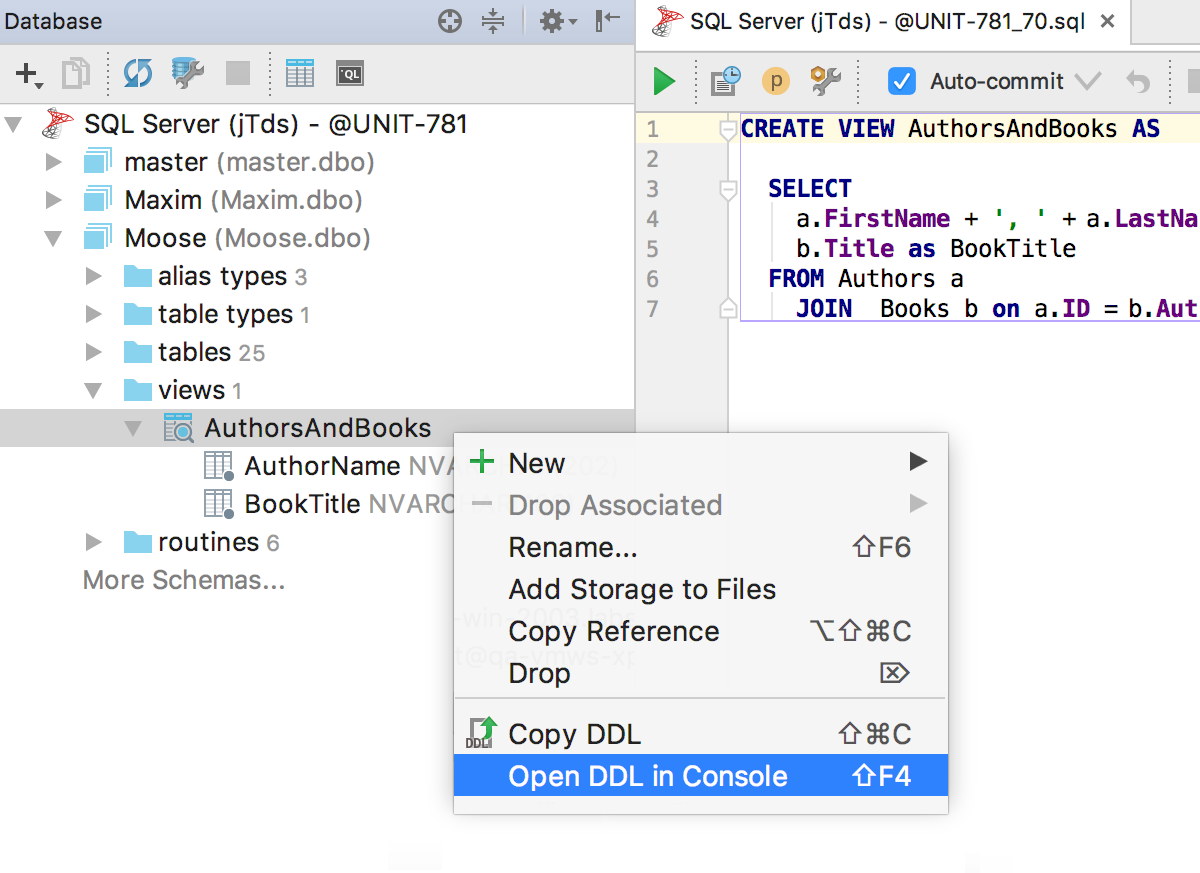
Починили баги с исходными кодами представлений — теперь они показываются верно во всех местах. Для каждого объекта, исходники которого мы записали в хранилище, доступно Open DDL In Console в контекстном меню.
Не забыли и о материализованных представлениях в PostgreSQL. Загружайте исходные коды, обновляйте данные в них из контекстного меню.
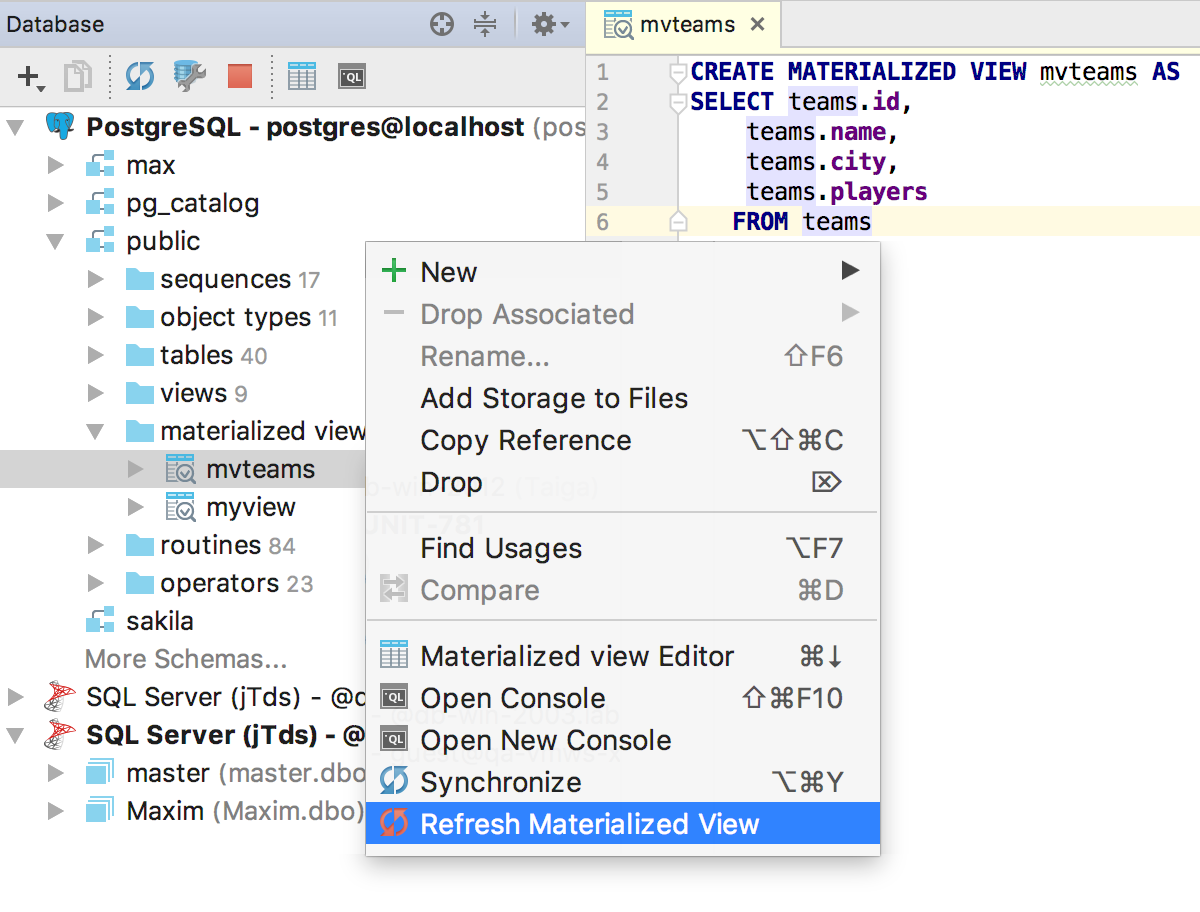
Когда вы редактируете исходные коды объектов из хранилища, DataGrip отслеживает изменения и подсвечивает их на лету в боковой панели.
Важно понимать, что редактор процедур, функций и представлений показывает локальную версию исходного кода, которая хранится у вас всегда, даже если вы перезапустите IDE. Проще говоря, если вы напишите и выполните здесь запросы, не относящиеся к объекту, они всё равно сохранятся и будут отображаться каждый раз, когда вы редактируете объект. Так что лучше ничего лишнего здесь не запускать :)
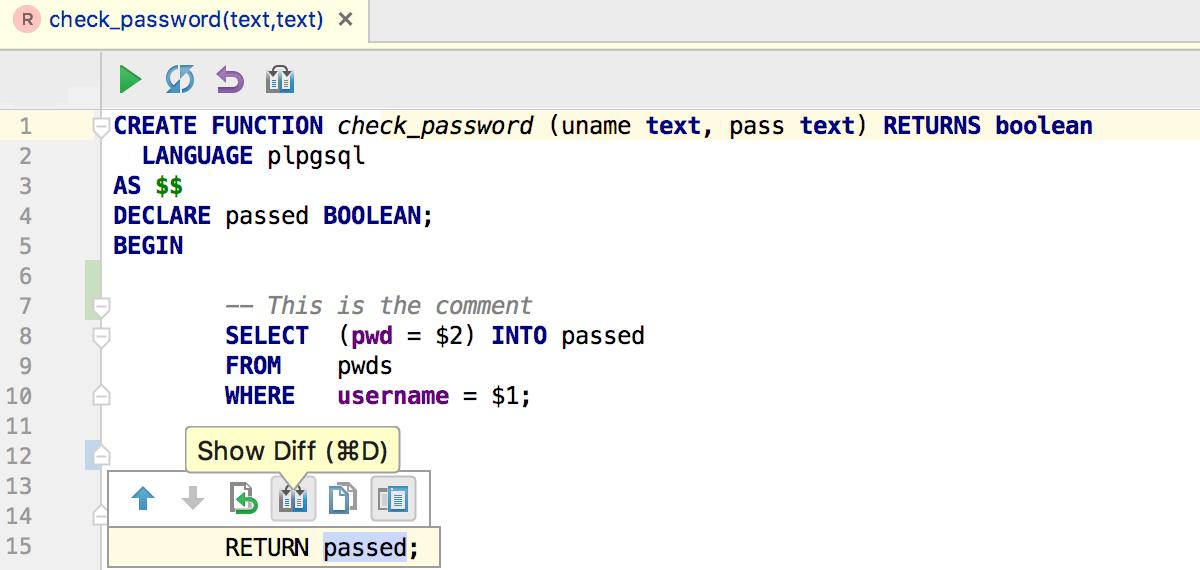
А если таких изменений много, и они все ещё не отправлены в базу, то их список ищите в Tools > DataBase changes. Внимание! Этого окна в других наших IDE нет, только в DataGrip.
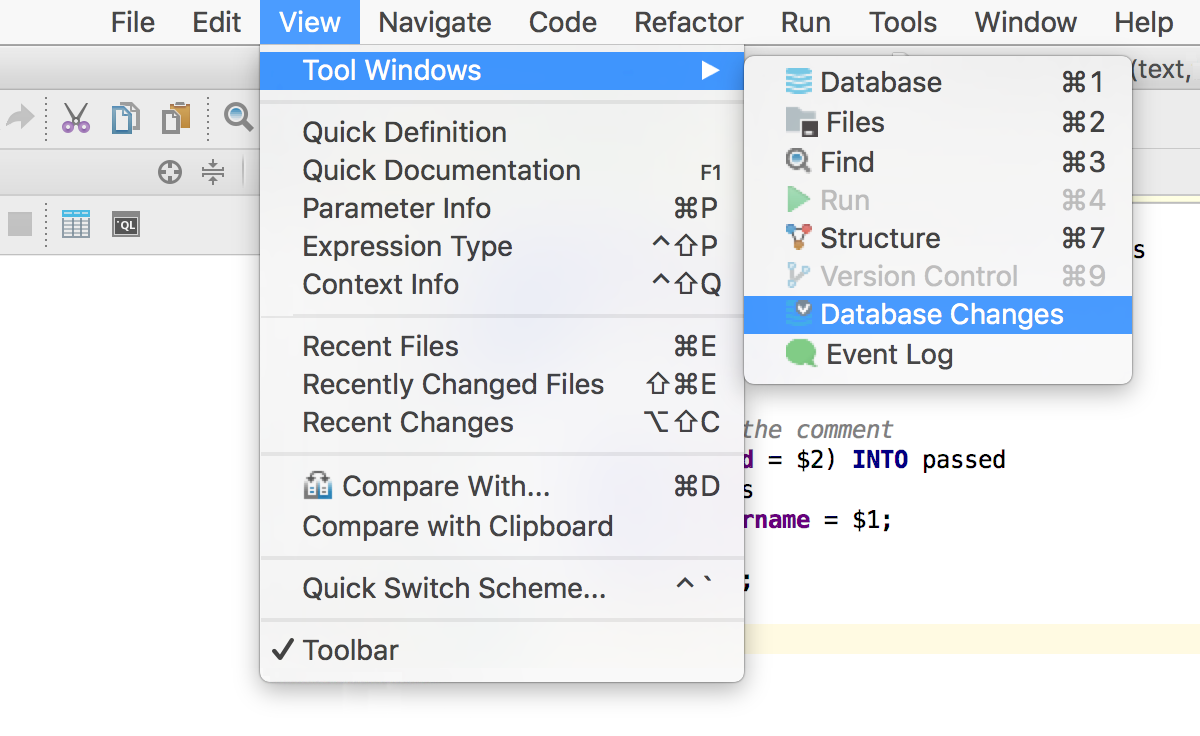
Инструмент сравнения поможет узнать, что поменялось для каждого из объектов.
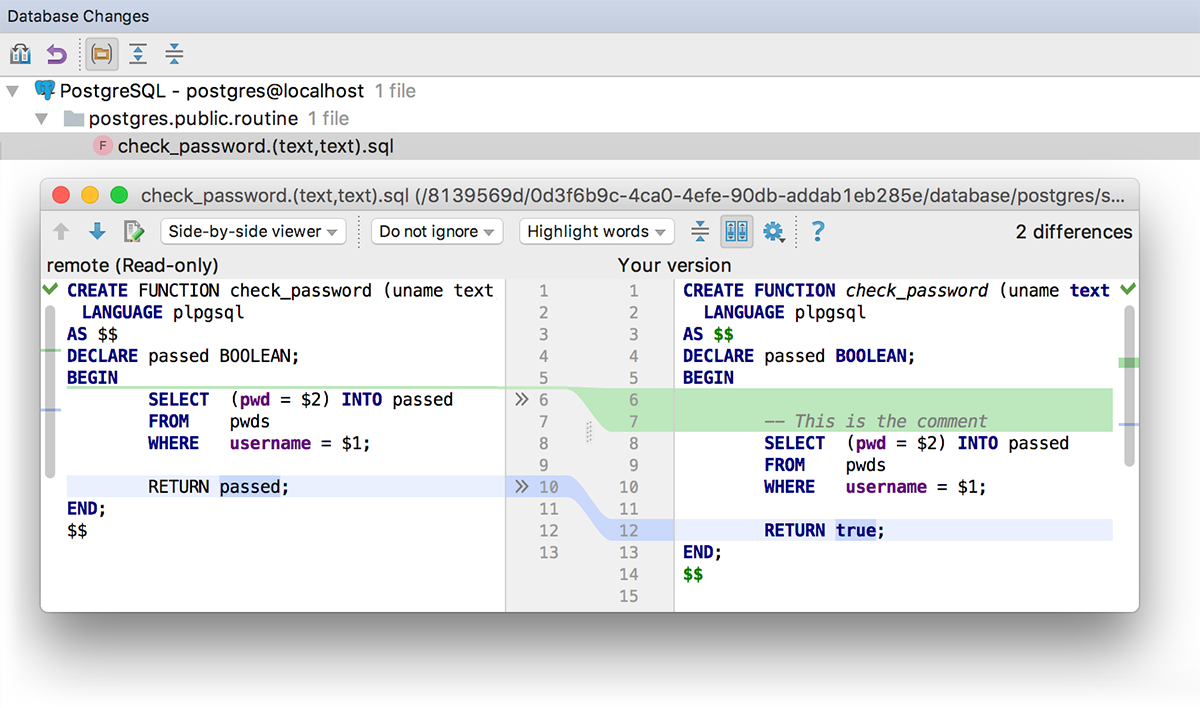
Комментарии при создании процедур сохраняются в базе.
Редактор данных
Редактор данных постепенно превращается в мощный инструмент: умеет то, чего обычно от него в IDE для баз данных не ждут.
Главное нововведение в этой версии — отложенное редактирование: ваши изменения хранятся локально и подсвечиваются, пока вы не отправите их в базу по Ctrl+Enter (Cmd+Enter для OSX). Пока изменения не отправлены, их можно откатить: Ctrl+Z (Cmd+Z для OSX) отменит только те изменения, которые выделены. Соответственно, прежде, чем отменить всё, нажмите Ctrl+A (Cmd+A для OSX) .
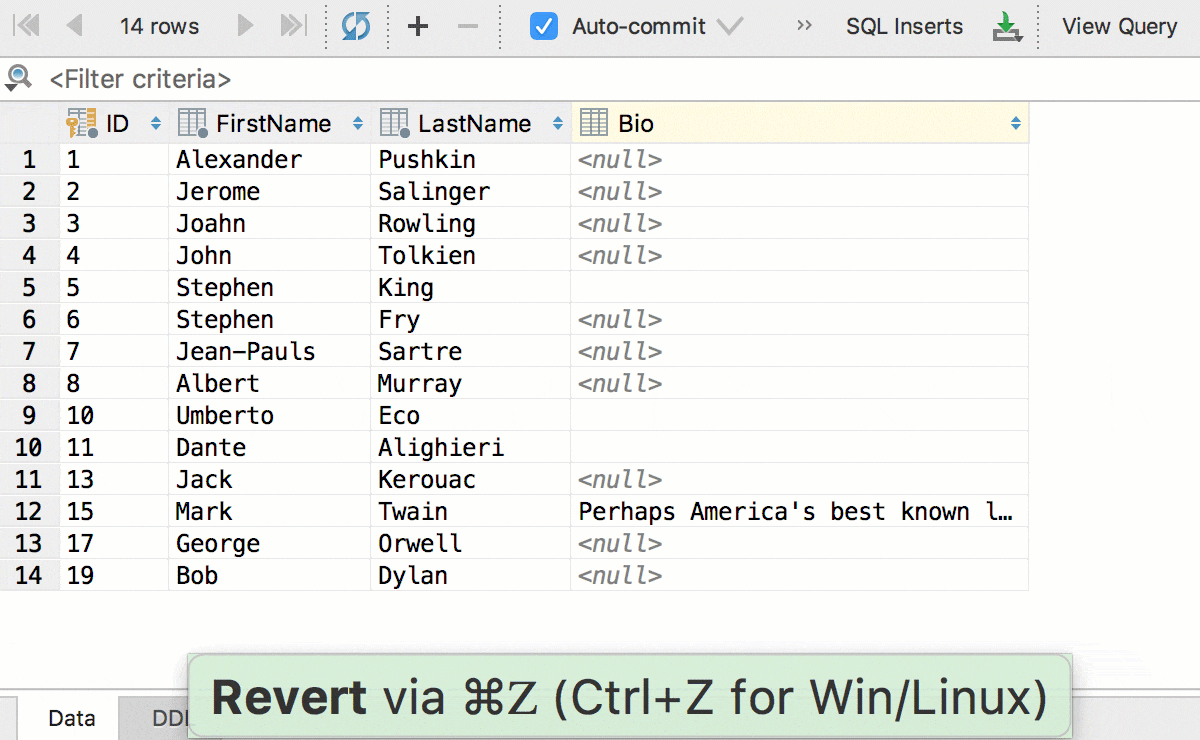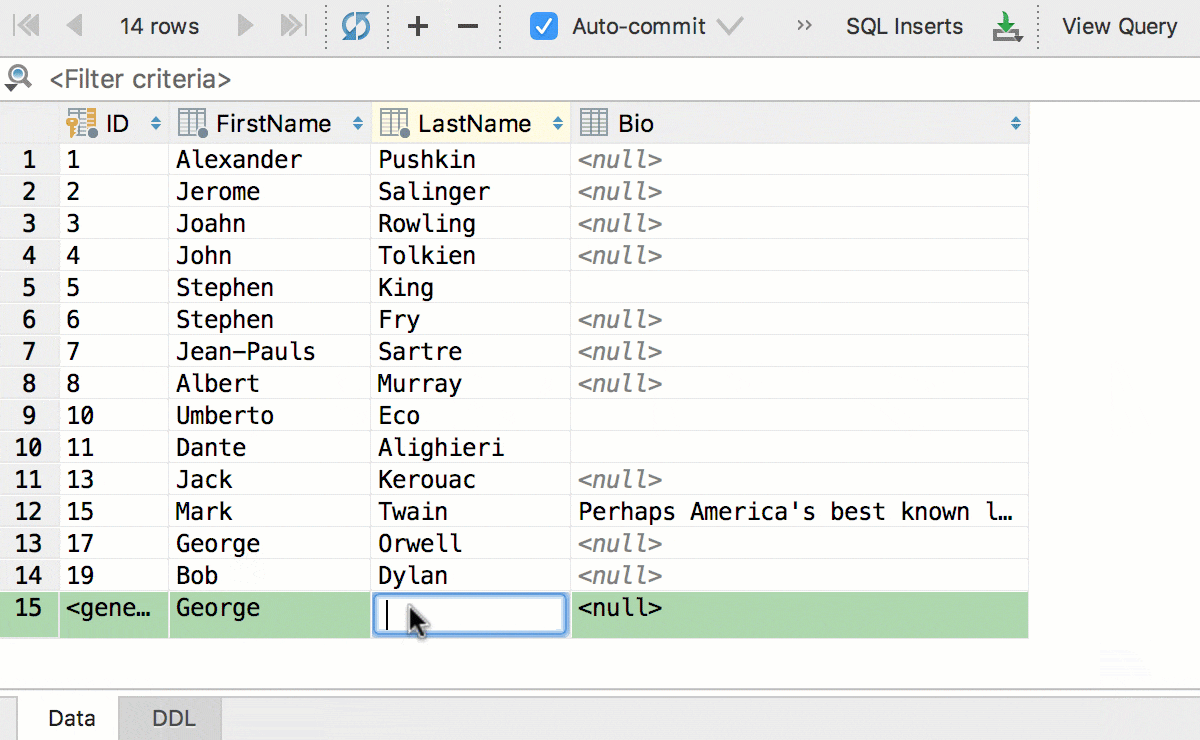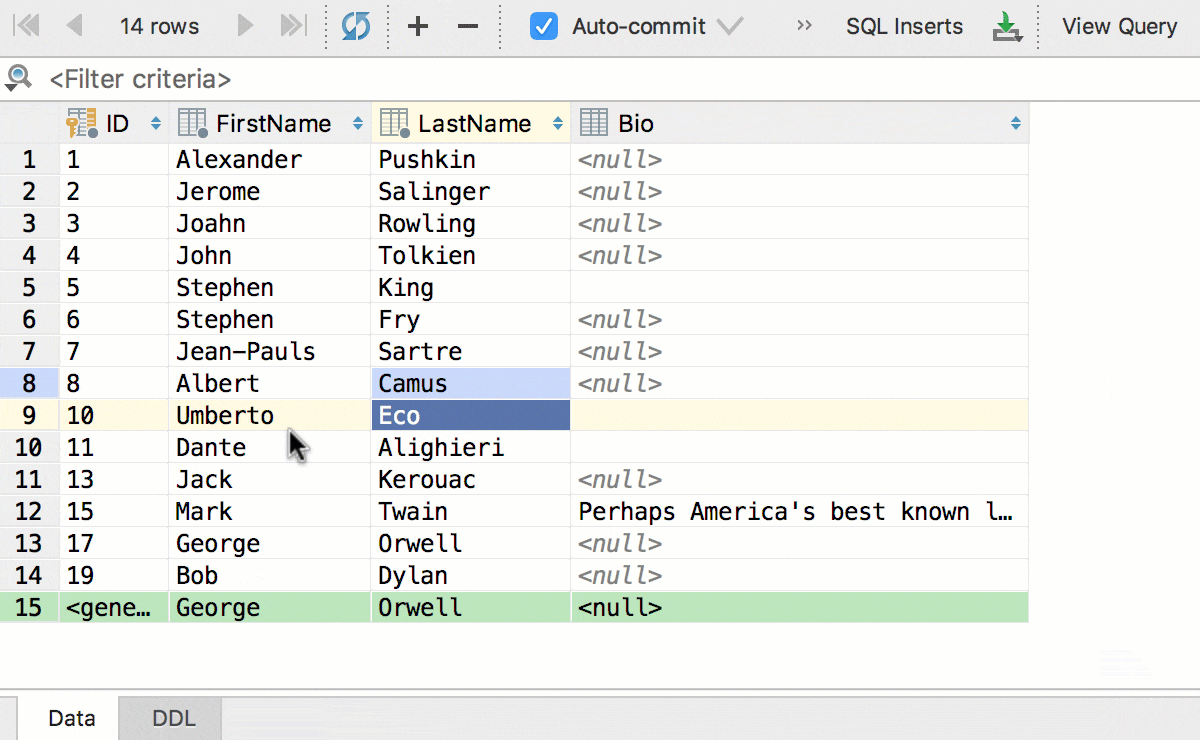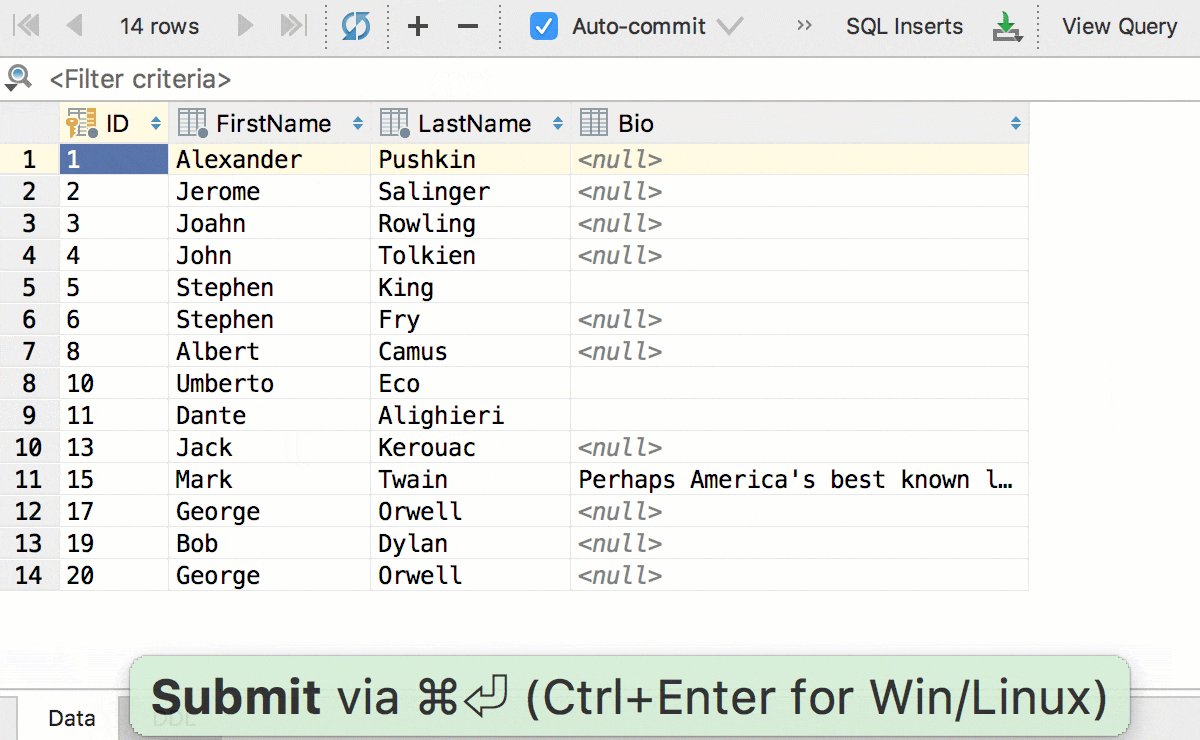
Редактируйте несколько ячеек одновременно. Конечно, это работает, если они все одного типа и не имеют ограничений по уникальности.
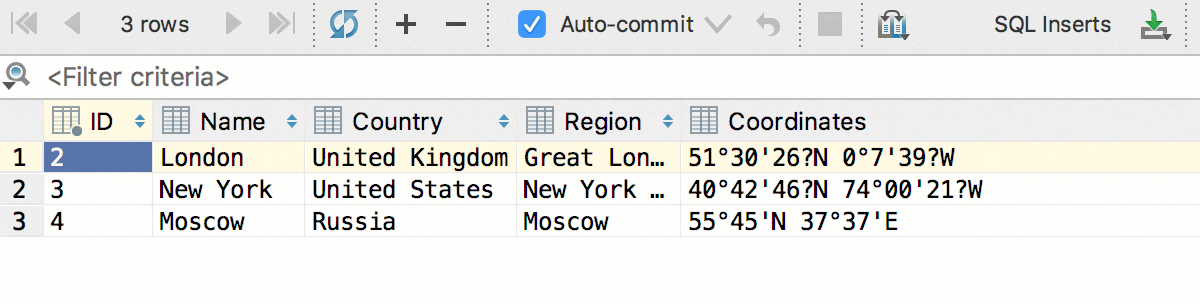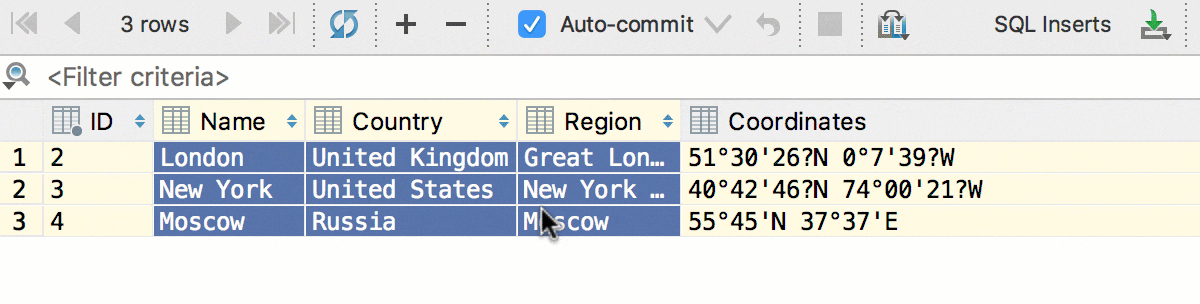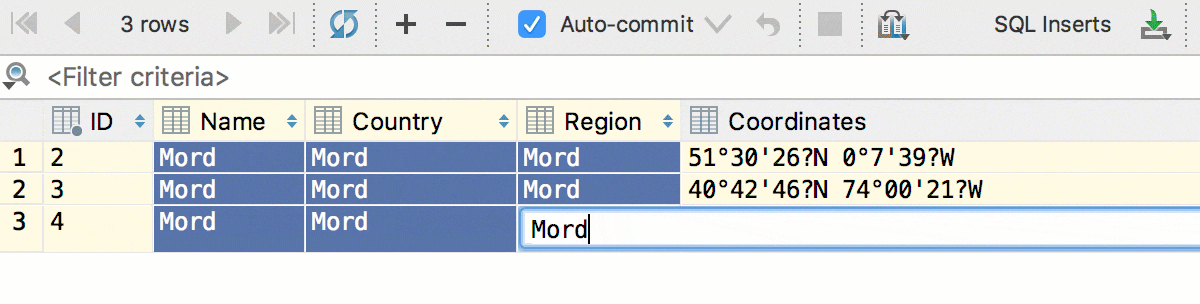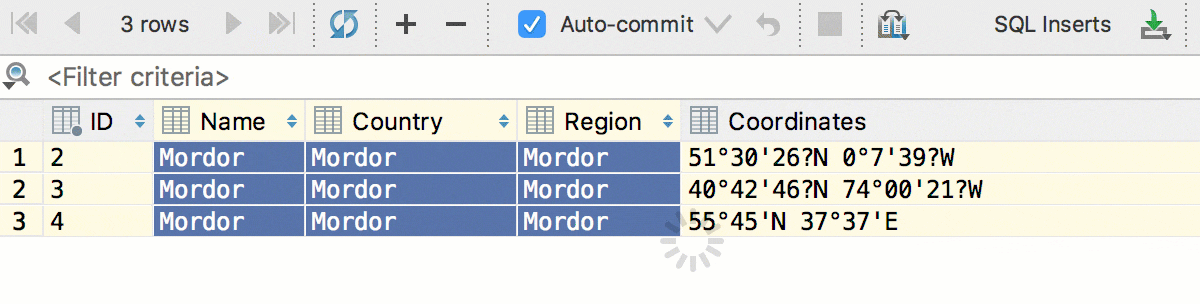
Кроме того, мы добавили конвертацию — теперь данные можно копировать из ячеек одного типа в другой. А с учётом предыдущего, копировать колонками: даты в строки, логические значения в числа и так далее. Это сработает, даже если исходная таблица и таблица назначения находятся в базах от разных СУБД.
И небольшие изменения: в редакторе данных, теперь, как и в тексте, работает Выделить следующее появление по Alt+J (Ctrl+G для OSX). Можно выделять несколько полей сразу.
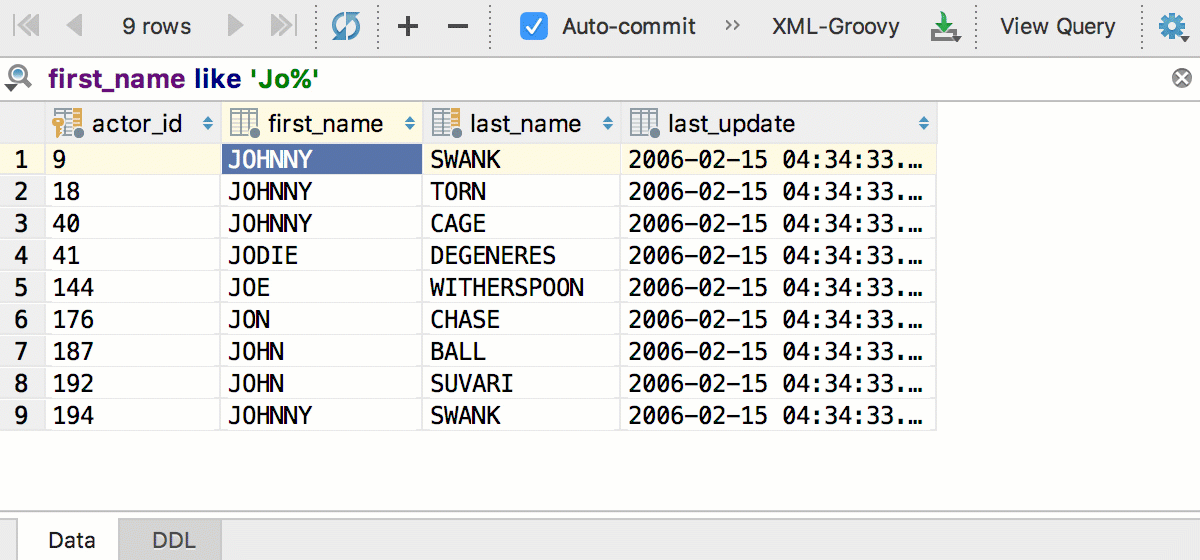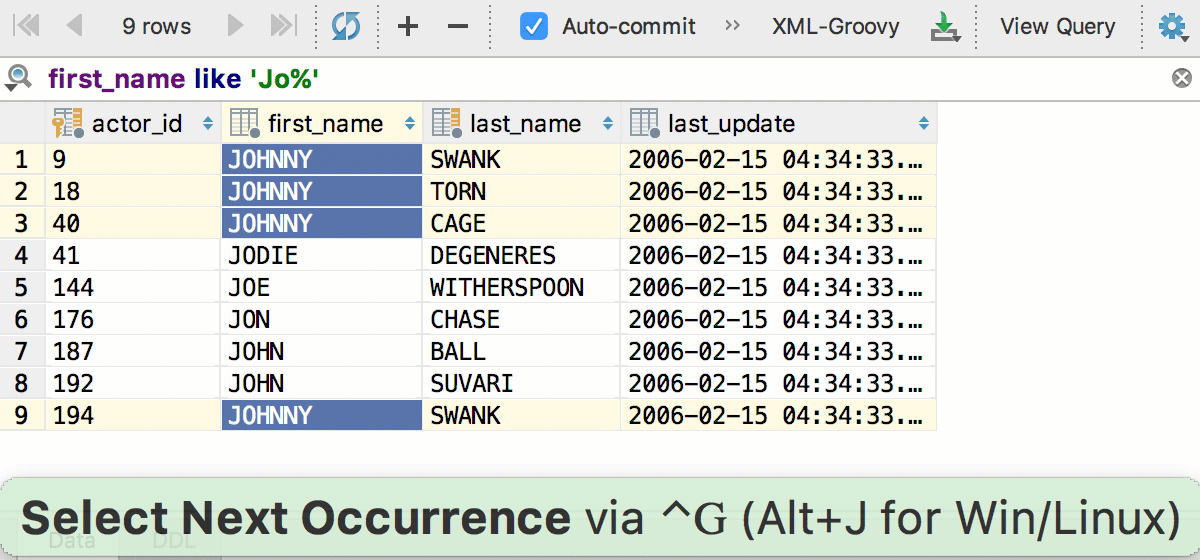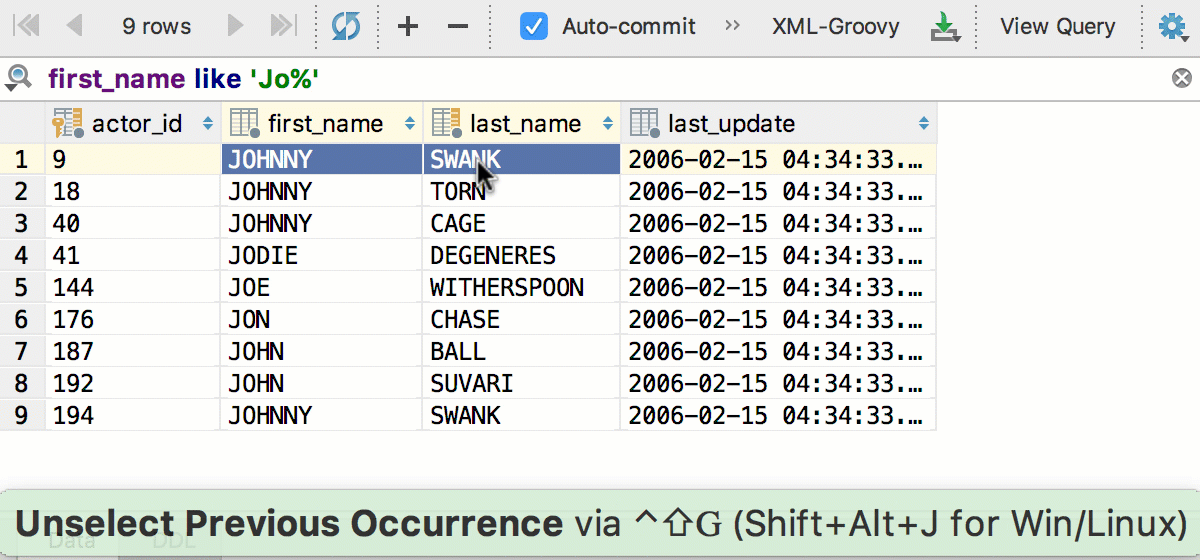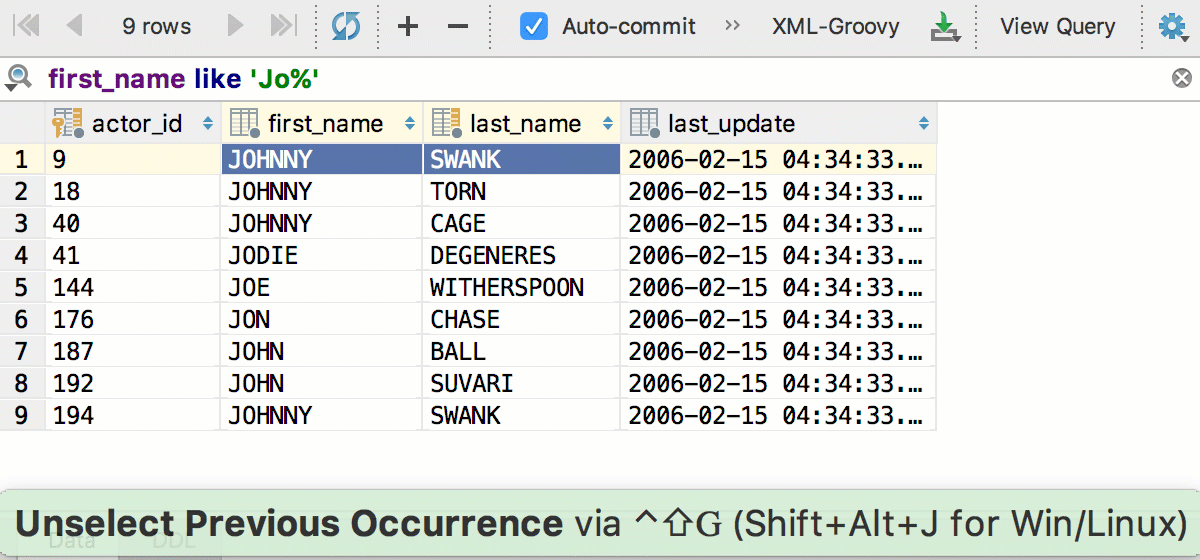
Ещё одна знакомая вещь из текстового редактора — так называемое «умное» выделение по Ctrl+W (Alt+Up для OSX) — в редакторе данных работает так: сначала выделяется активная колонка, потом активная строчка, потом всё.
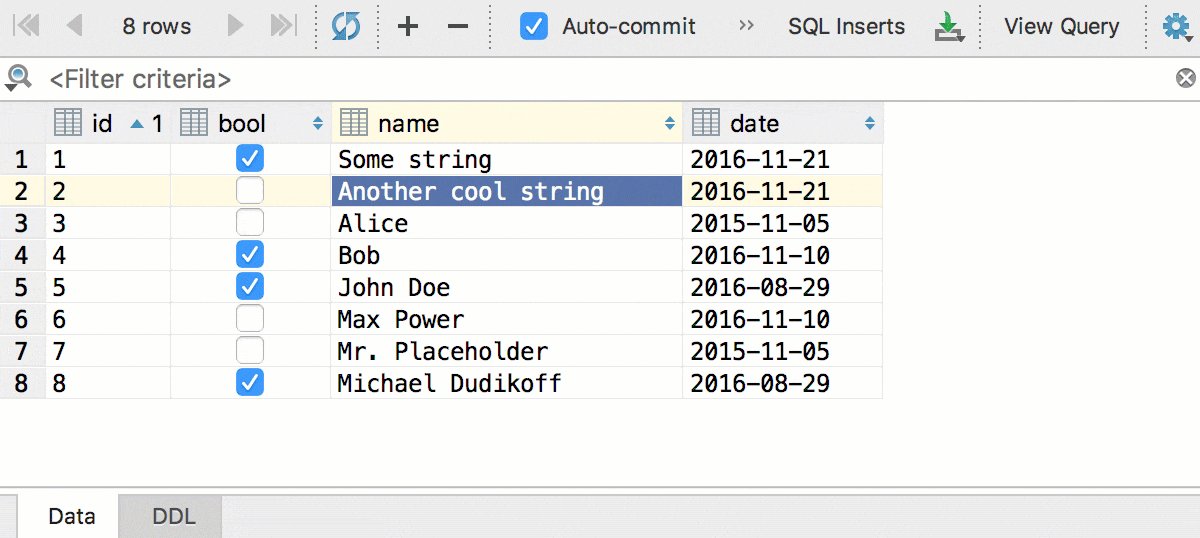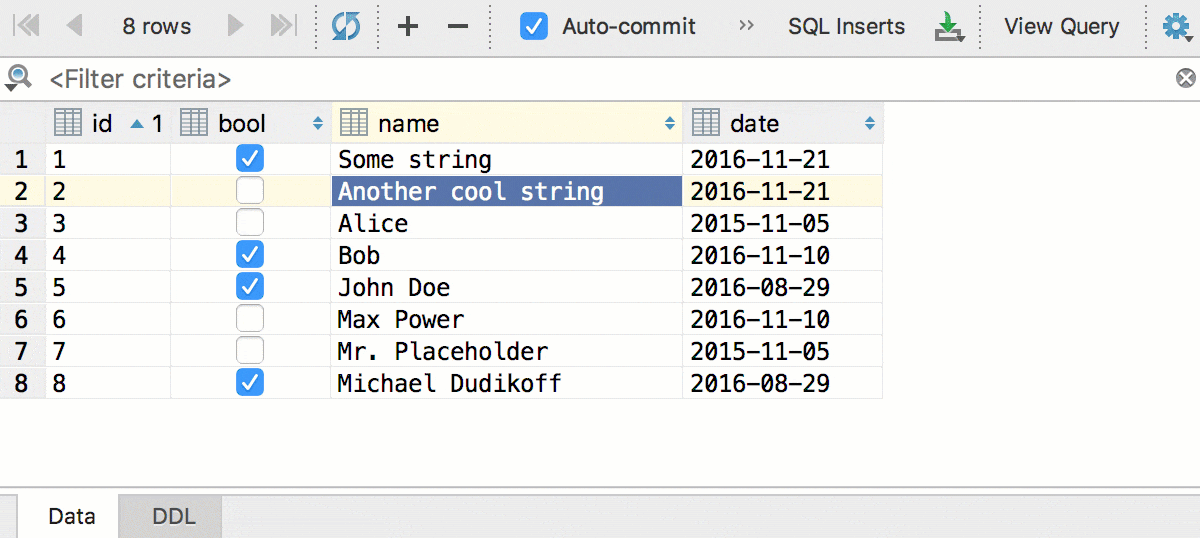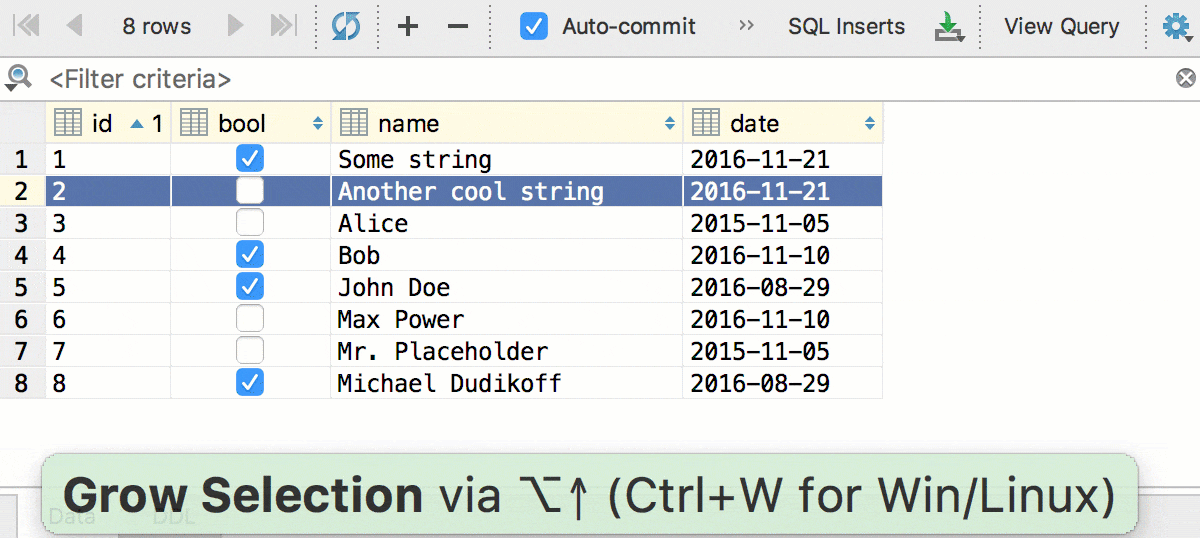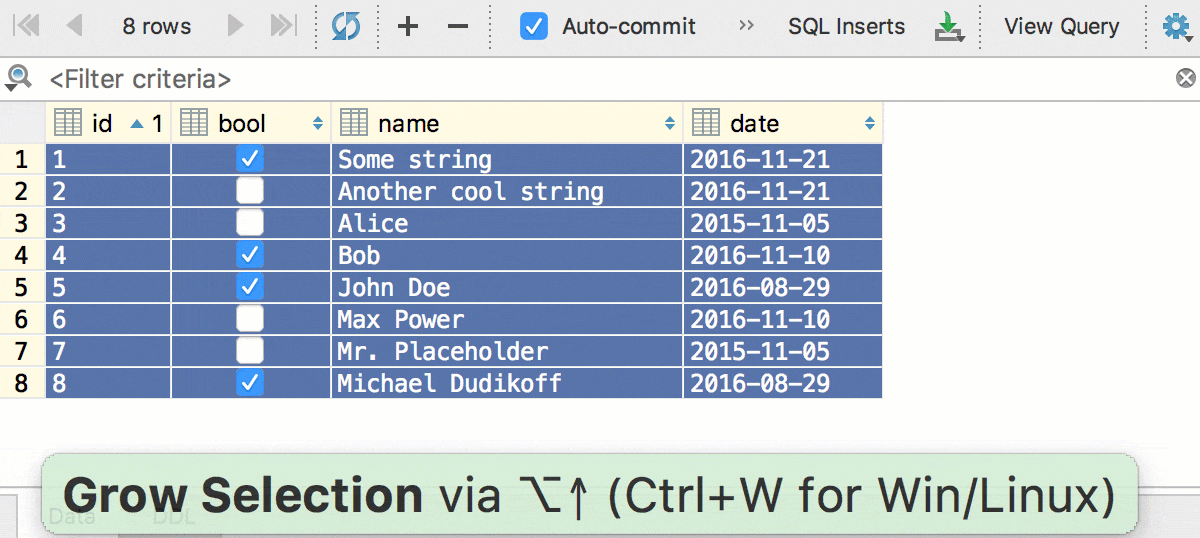
Поддержка SQL-кода
Автодополнение предложения INSERT предлагает в том числе вариант только с полями, у которых нет значения по умолчанию.
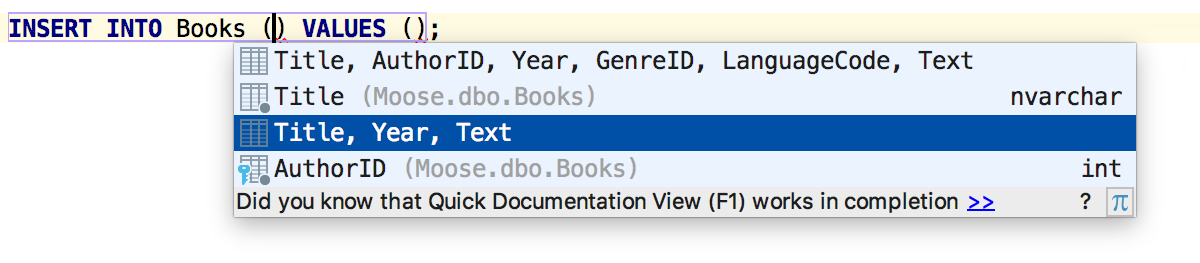
Если параметр или переменная не используются, вам сообщат.
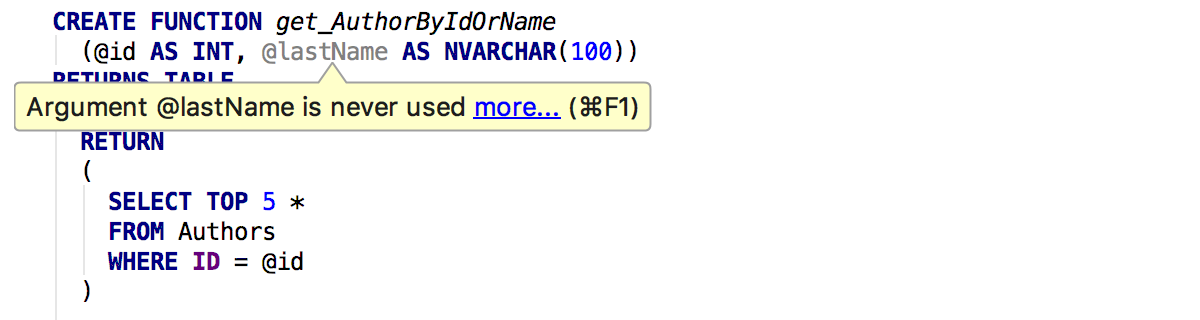
Также вас предупредят, если количество колонок при сочетании результатов запросов не совпадает.

Автодополнение для JOIN USING, основанное на поиске колонок с одинаковыми именами, теперь работает для PostgreSQL.
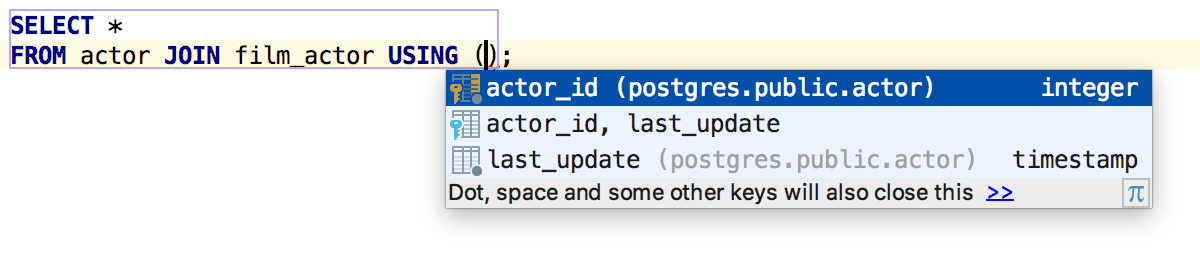
Поиск использования параметров по Alt+F7 в PostgreSQL понимает ссылки типа $n.
Навигация по методам, знакомая по другим нашим IDE, у нас стала навигацией по запросам. Сочетания клавиш: Alt+Up и Alt+Down (Ctrl+Down и Ctrl+Up для OSX).

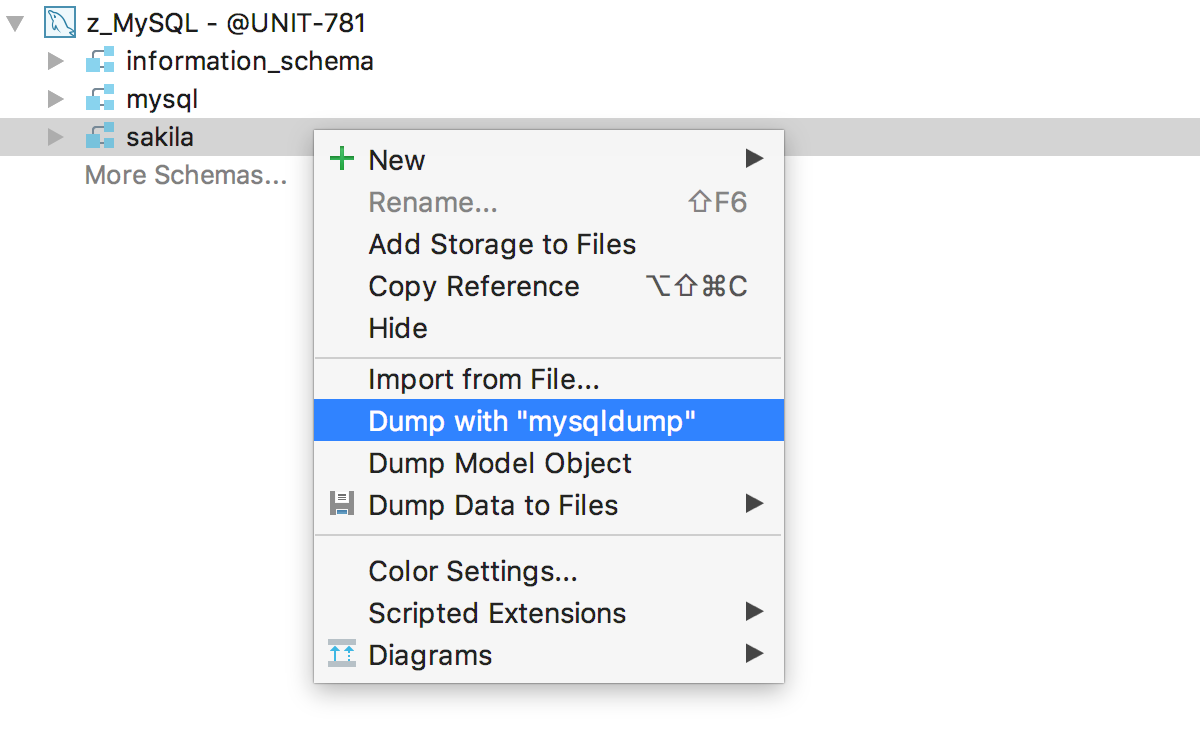
Интеграция с mysqldump и pg_dump
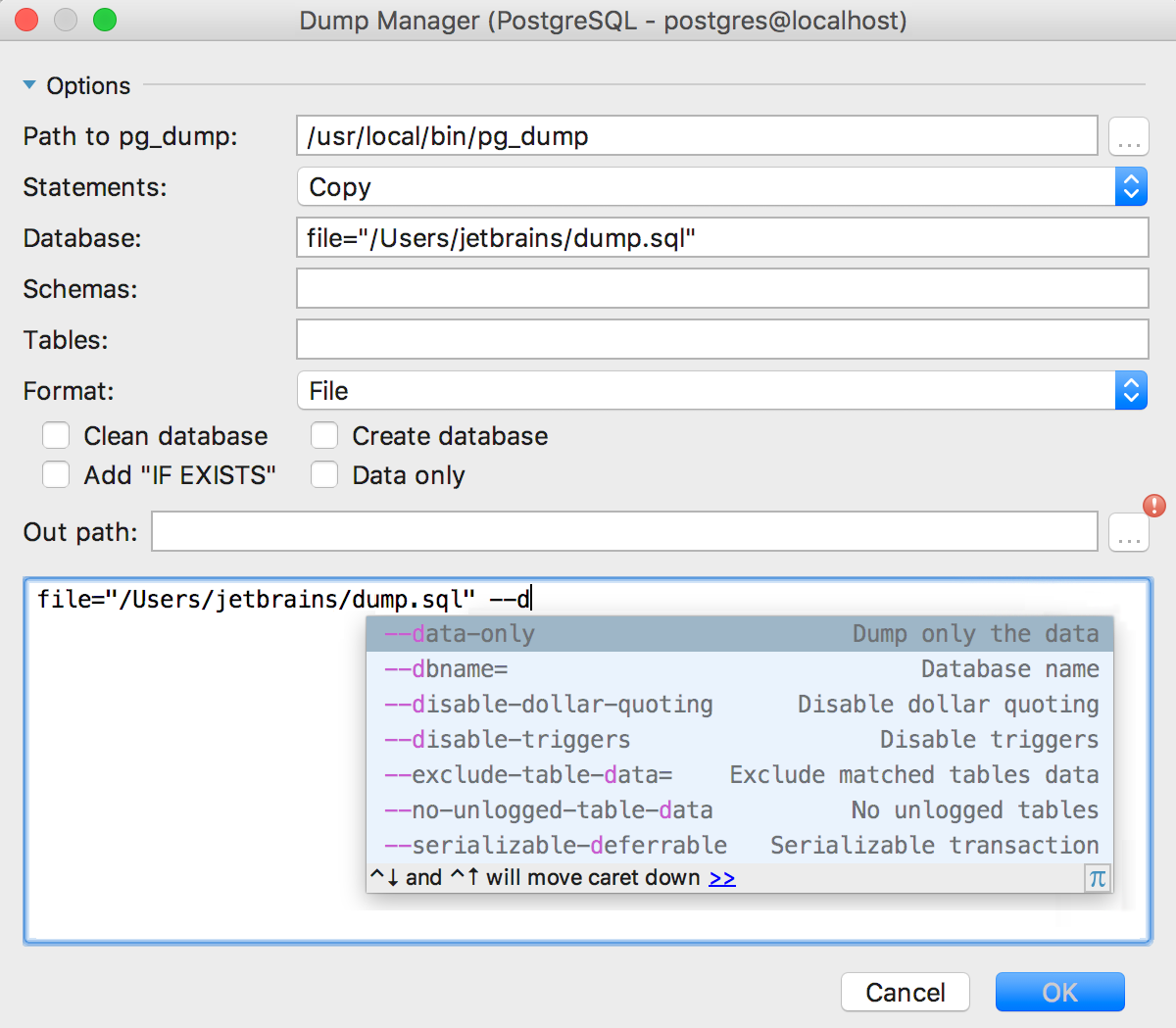
Для параметров работает дополнение по Ctrl+Space.
Разное
Ещё когда DataGrip назывался 0xDBE у нас был XML-экстрактор данных — любой набор данных экспортировался в XML. Мы его убрали, но многие просили вернуть обратно: вернули.
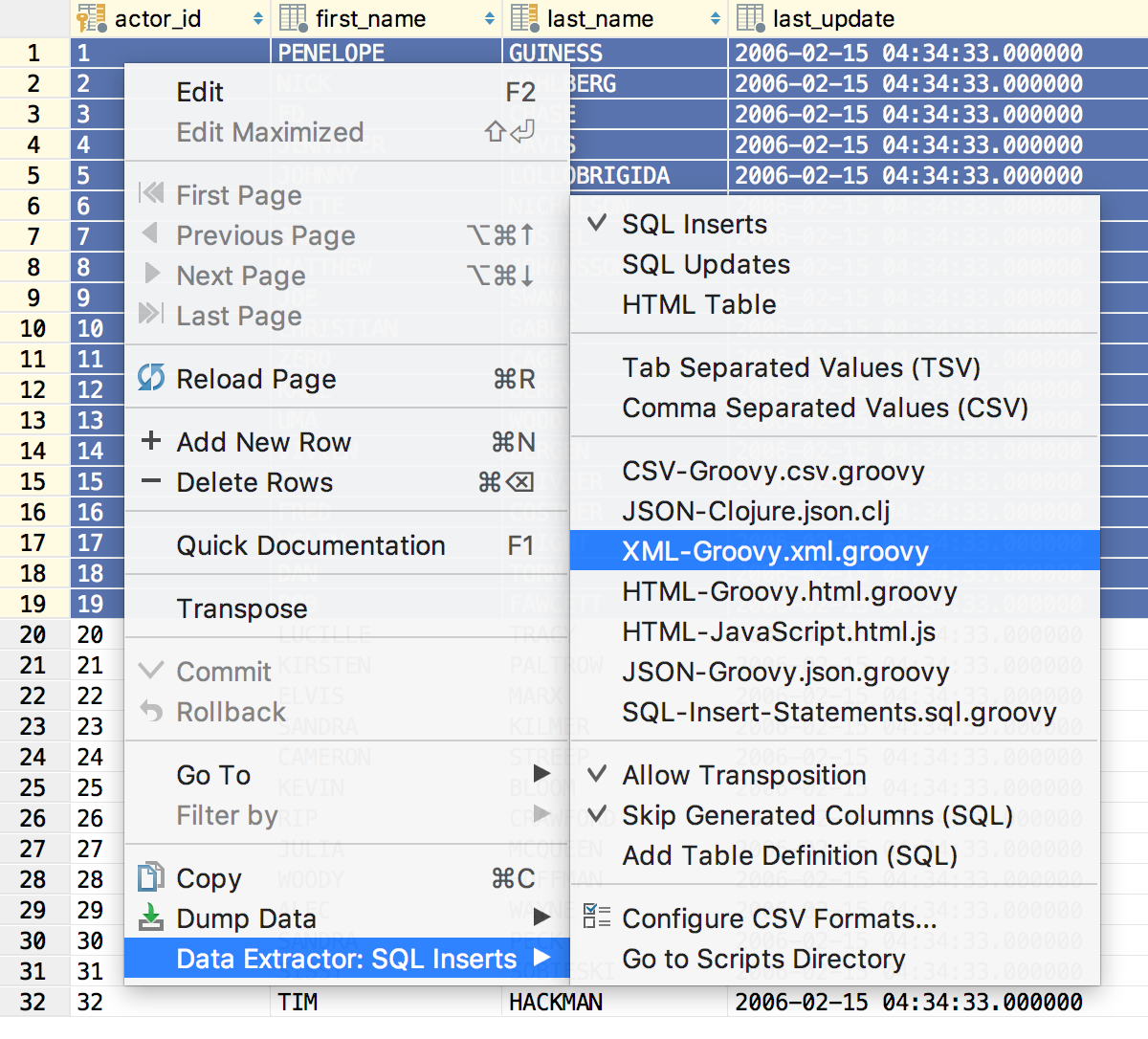
Получается вот что:
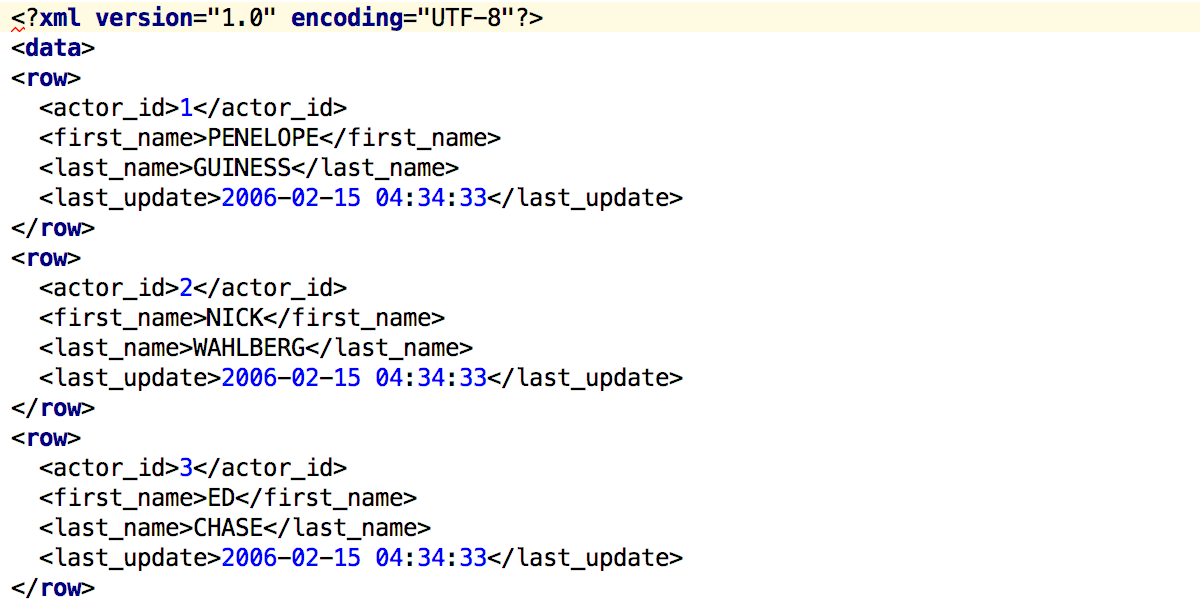
Ускорили запуск больших скриптов из контекстного меню — теперь мы отправляем запросы в базу не по одному, а пакетами.
Ну и напоследок. Многие, наверное, заметили: у нас новые иконки!
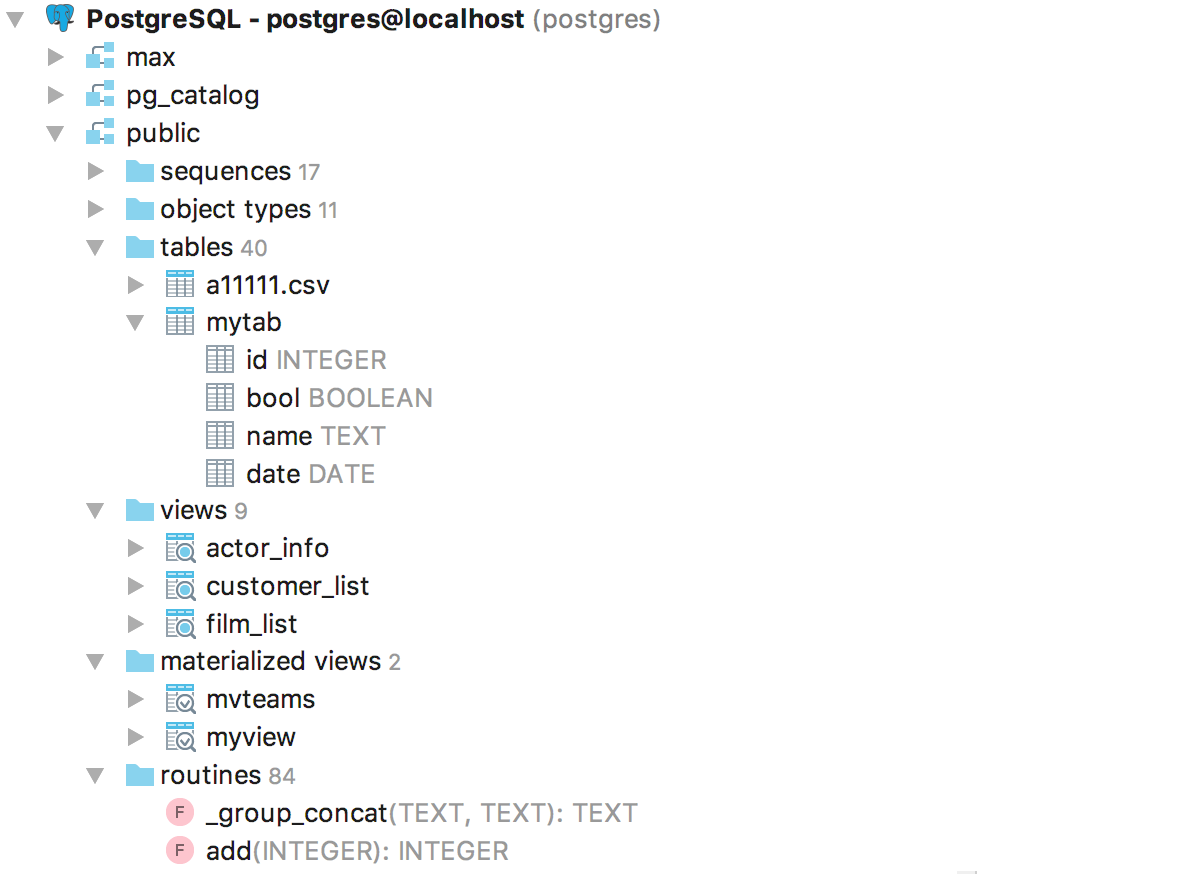
А также:
- Поддержка грамматик SQL Server 2016 и PostgreSQL 9.6
- Автоматическое определение, устарел ли драйвер
- Добавили Drop в контекстное меню многих объектов
- Шрифт FiraCode с лигатурами идёт из коробки
- Поддержка Auto-inc для таблиц в SQLite
- Поддержка Expression index в SQLite
Если понравилось, а вы ещё не пробовали DataGrip, скачайте бесплатную пробную версию и пишите нам здесь, в комментариях, что вы думаете. Ещё мы ведём и читаем твиттер, а об ошибках лучше сразу сообщать в треккер.
Часто оказывается, что о некоторых возможностях DataGrip люди просто не знают, так что не лишним будет и посетить наш сайт, где описано, что умеет DataGrip.
Спасибо!
Команда DataGrip
_
JetBrains
The Drive to Develop
Комментарии (63)



L0NGMAN
26.11.2016 00:59Мне вот всёравно неудобно использовать Database Manager в PHPStorm'е и приходится запускать HeidiSQL из под wine :(
@JetBrains посмотрите пожалуйста на HeidiSQL и сделайте такую же удобную Database Manager…
moscas
26.11.2016 16:29+3Мы же не можем и просто взять и копировать другие инструменты. У нас есть представление о том, как удобно, и как нет. Зачастую наша задача сделать удобно, потому что как раз у других неудобно :) Поэтому было бы круто, если бы вы написали, что вам так удобно в HeidiSQL, и мы с вами это обсудим.

zekohina
27.11.2016 01:44Разрешите я выскажусь. Лично мне в PHPStorm не удобно (для mysql):
1) нельзя создать базу, можно только открыть уже созданную
2) нельзя сделать дамп базы с данными
3) когда добавляешь новую запись, то для того чтобы она применилась нужно создать новую строку, потому удалить ее. Видимо нужна какая-то кнопка «apply»
4) Не исполняются много запросов за один раз.
И добавьте, пожалуйста, поддержку MongoDB. Очень не хватает.
Спасибо.moscas
27.11.2016 01:46+41) Из UI нельзя, только скриптом CREATE DATASBE — это действительно так неудобно?
2) На PostgreSQL и MySQL можно.
3) По Ctrl+Enter происходит отправка данных в базу. Вы точно пробовали 2016.3?
4) Приведите пример, пожалуйста. Потому что, вообще, исполняются.
5) Монги пока нет в ближайших планах.zekohina
27.11.2016 02:171) Не критично, но хорошо было бы.
2) Как это сделать? Не нашел такой строчки.
3) Спасибо, помогло.
Записал видео проблемы 4 и 2 пунктов.
https://cloud.mail.ru/public/AEEa/C5t5yrAsT
moscas
27.11.2016 19:02+12) Из контексного меню. Есть подозрение, судя по ваемшу видео, что это не 2016.3. Или всё-таки, последняя версия? :)
4) Ctrl+A > Ctrl+Enter запускает всё?

dedulik
26.11.2016 02:20Визард по созданию БД где-то есть? )
Пользуюсь ems много лет. у datagrip много крутых фишек, но каких-то самых используемых визардов не найти (moscas
26.11.2016 16:30+2Я вам честно скажу, мы вообще скептически относимся к идее визардов — вроде, продукт для разрабочтиков и мы ожидаем от них использования SQL. Но я согласен, что во многих случаях это просто убыстряет работу, вероятно этот — один из них.
VolCh
27.11.2016 08:36Создание базы точно один из них. Синтаксис в диалектах отличается сильно, легко забыть какую-то опцию типа кодировки и очень часто изменить толком нельзя уже, когда обнаруживаешь (часто далеко не сразу) что что-то забыл, только дропнуть с уже созданными схемами, таблицами, данными, может даже реальными, и создавать новую.
moscas
28.11.2016 20:13+1Как решение, здесь можно предложить Live Templates > вы создадите шаблон один раз, а затем просто нажатием пары клавиши будете его вызывать со всеми плейсхолдерами для имени базы/схемы и.т.д.
Settings > Editor > Live templates
Taragolis
26.11.2016 11:24+2Нравятся ваши продукты, особенно DG, как всегда есть нюанс — синхронизация огромных схем.
Работаю с базой, в одной схеме которой есть 50к+объектов: 6к таблиц, 12к представлений, 25к пакетов и остального понемножку. Полная синхронизация почти всегда заканчивается с одним результатом — DG зависнет на Applying Changes.
Но это полбеды, если начать синхронизироваться с другой схемой внутри одного подключения (к примеру SYS), то после завершения Intoinspector примется за полную синхронизацию той огромной
moscas
26.11.2016 16:31+1У вас одинаково медленно и в 2016.2 и в 2016.3?
Taragolis
26.11.2016 19:33Мне трудно судить по скорости работы, потому как сейчас работаю только с двумя базами, у одной простая структура, там изначально проблем не было, а вторая — эта вот эта:
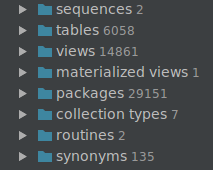
С ней трудно вести подсчеты по времени, полная синхронизация этой схемы прошла только один раз: на Win 10, 2016.3 (x64), Oracle JDK 8u111.
Вчера ночью запустил на Ubuntu 16.04, 2016.03, утром все еще выполнялся Applying Changes, после завершении работы "интраинспектора" интерфейс DG повис
moscas
27.11.2016 01:35+2Да, неплохо :) В вашем случае, вероятно стоит отключить загрузку исходников в хранилище. Делается это здесь:
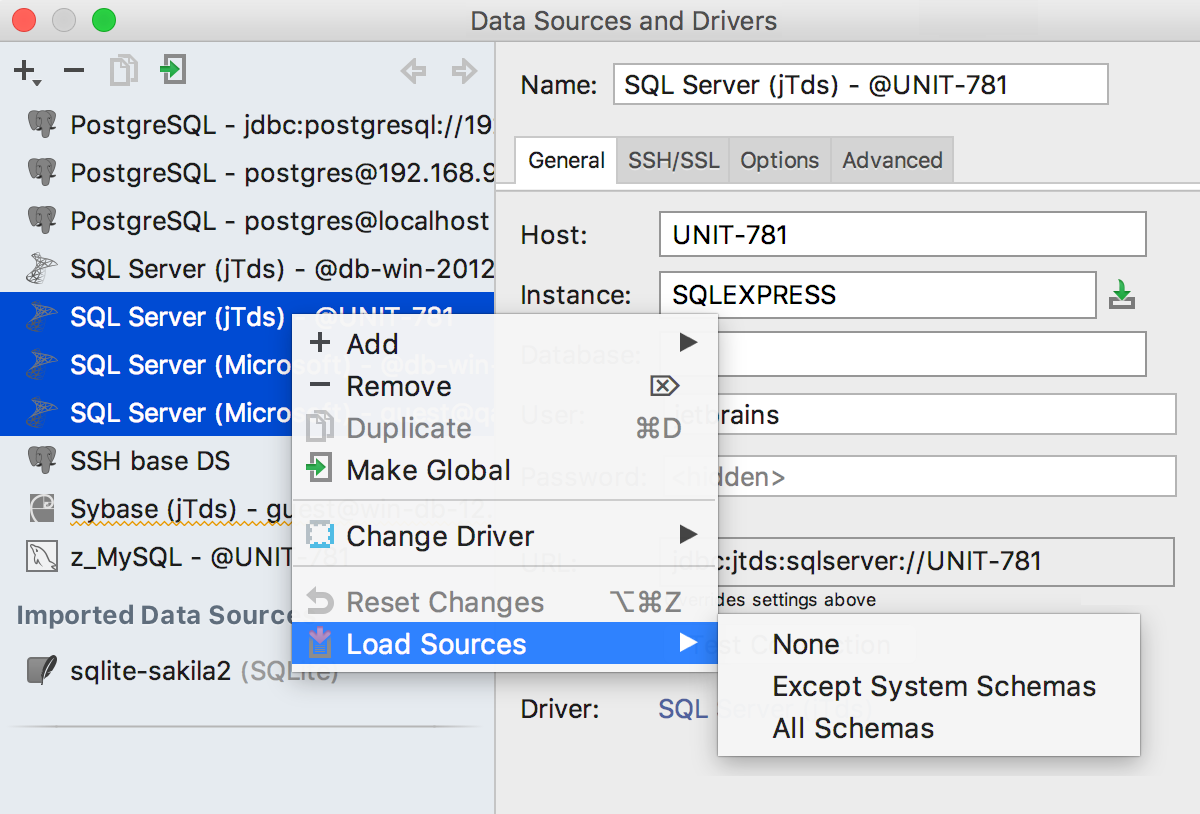
Напиши пожалуйста, помогло ли.Taragolis
27.11.2016 15:10+1Поигравшись с настройками:
Load Sources --> None
Auto Sync --> Снял чекбокс (почему сразу я не отключил — непонятно)
Запустил обновляться схему и… опять все повисло на этапе Applying Changes, полез в логи и обратил внимание, что раз в 5 секунд создаются файлы threadDump (пример)
В принципе рабочий workround уже для меня был:
- запустить синхронизацию
- остановить ее после индексов
Так как данная база — это коробочный продукт (АБС банка), в котором структура не так часто меняется, то меня вполне устроят подсказки по полям таблиц/представлений.
Однако интерес заставил поэкспериментировать, а именно поиграться с JDK. Поменял на версию от Oracle и о чудо — синхронизация завершилась. Решил продолжить:
- Снес подключение (для чистоты эксперимента)
- Создал новое подключение
- Настроил Load Sources / Auto Sync
- Добавил две схемы
- Нажал синхронизировать и ушел по делам
по возвращении в Event Log нашел следующую запись:
27.11.16 14:13 @TEST: Synchronization successful (25m 47s)
Информация о DG и JDKOracle JDK:
DataGrip 2016.3
Build #DB-163.7744.4, built on November 18, 2016
JRE: 1.8.0_112-b15 amd64
JVM: Java HotSpot(TM) 64-Bit Server VM by Oracle Corporation
Bundled openJDK
DataGrip 2016.3
Build #DB-163.7744.4, built on November 18, 2016
JRE: 1.8.0_112-release-408-b2 amd64
JVM: OpenJDK 64-Bit Server VM by JetBrains s.r.omoscas
29.11.2016 11:30Огромное спасибо за подробный ответ. Мы проведём расследвоание по итогам вашего сообщения :)
Если у вас будут ещё вопросы или проблемы, моежете писать мне прямо на почту maxim.sobolevskiy[at]jetbrains.com

the_unbridled_goose
26.11.2016 13:43+1Прочитал статью и оплатил. Животворящая сила гифок и подробностей о функционале.
ispcto
26.11.2016 16:31Мда. Эта штука не понимает, что типы можно создавать в схемах (хотя, конечно, низкий поклон, что вообще такую сущность еще не забыли). Эта штука как-то очень специфично работает с перегружаемыми процедурами, как бог на душу положит синхронизирует состояние с базами, она вообще не понимает, что под пользователем может быть доступно несколько баз. И это только на вскидку.
moscas
26.11.2016 16:33+1У вас PostgreSQL? Можно вас попросить немного подробней описать каждую из претензий? Можно по-разному трактовать «не понимает» и «специфично работает».
xioexception
27.11.2016 01:49А поддержка Database diagrams (MSSQL) планируется?
ref https://www.mssqltips.com/sqlservertip/1816/getting-started-with-sql-server-database-diagrams/
JSmitty
27.11.2016 15:04+1Я так понимаю, в шторме оно же используется? Мой лист претензий (основная база PostgreSQL):
- Нельзя выбрать коннект «по умолчанию» — вообще логика какая-то странная, по которой он выбирается;
- Очень плохой интерфейс для внешних ключей — строчки запрятаны в отдельную закладку, отображаются текстом, сам интерфейс просмотра структуры неудобный — например очень сложно найти, поле nullable или там unique; SQL скрипт структуры не показывается;
- Редактор хранимок в виде редактирования DDL — отвратителен. GUI должен облегчать исправление запроса. То что есть здесь — так, чуть расширенная версия psql.
- Права доступа ни назначить, ни посмотреть, аналогично с владельцем объекта;
- Объекты в базе не создаются, кроме таблиц — хранимку там, представление, последовательность, роль, схему — все это недоступно. Про создание новых баз — сказали выше. Если клиенту предлагается использовать DDL базы, то зачем вообще такой продукт?
Резюме — что-то небольшое поправить в данных или посмотреть — можно. Чуть задача пообъемнее, или лень на каждый чих лезть в мануал по DDL — то открываем pgAdmin III. Продукт пока уровнем чуть выше (местами) текстовой консоли psql. Местами кстати (встроенный help и сервисные функции) — ниже.moscas
28.11.2016 20:41Спасибо за фидбек!
Я не буду отвечать вам по пунктам — все ваши претензии обснованы. Единственное, что непонятно: про редактирвоание процедур «GUI должен облегчать исполнение запроса.». В любом GUI есть элемент «тело функции», в которой и находится сам запрос, как GUI должен помогать его исправлять?
Что касается возможностей по администрированию, мы знаем, что у нас сейчас их почти нет — надеемся заняться этим в будущем. Про GUI писал выше — отчасти здесь проблему решают Live Templates. Но мы обсуждаем возможность его создания для создания базовых объектов. Кстати, когда создаёте объекты, пробуйте в консоли Ctrl+N (Cmd+O на Маке) > IDE поможет вам сгенерировать простой код для начала.
Вы спрашиваете, зачем вообще такой продукт? У нас уже есть много возможностей, которых нет у многих других инструментов. Редактор данных умеет много, IDE позвоялет генерировать предложения INSERT, UPDATE, а самое главное — делает синтаксический анализ вашего кода и поэтому предлагает исправления и быстрое автодополнение. В этом посте, опять же, написано про то, что DataGrip (и все остальные наши IDE) научился искать вхождения внутри объектов. То есть он в первую очередь для того, кому эти фичи помогают в ежедневной работе. Сейчас это скорее SQL-программист, чем администратор БД. Но мы постараемся сделать так, чтобы продукт стал незаменинмым для всех.

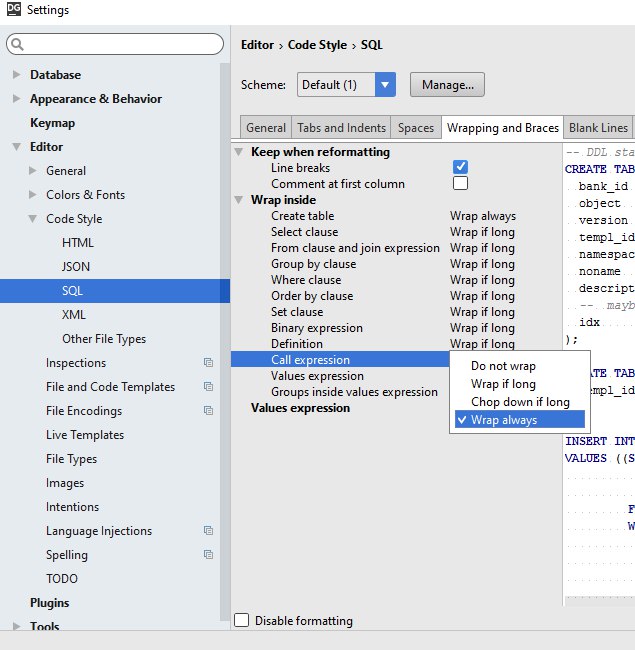
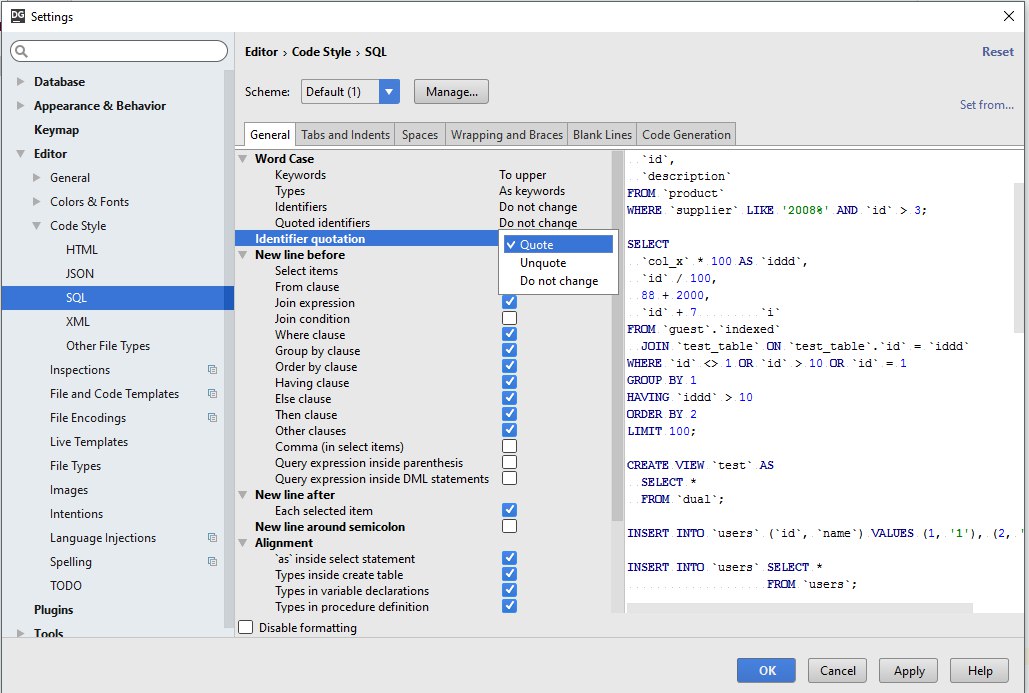
kxl
27.11.2016 18:42Можно ли настроить форматирование так, как у выражения MetallMass, а то Mass не читабельно:
SELECT ISNULL(-gdol.Mass, ISNULL(gdl.Mass, ISNULL(g1.Mass, ISNULL(sc.Mass, ISNULL(CASE WHEN pol.Operation = 0 THEN -gpol.Mass ELSE 0 END, 0))))) AS Mass, ISNULL(-gdol.MetallMass, ISNULL(gdl.MetallMass, ISNULL(g1.MetallMass, ISNULL(sc.MetallMass, ISNULL(CASE WHEN pol.Operation = 0 THEN -gpol.MetallMass ELSE 0 END, 0) ) ) ) ) AS MetallMass, FROM ...Taragolis
28.11.2016 12:22+1А не хотите попробовать "засахарить" с помощью COALESCE
SELECT COALESCE(-gdol.Mass, gdl.Mass, g1.Mass, sc.Mass, CASE WHEN pol.Operation = 0 THEN -gpol.Mass END, 0) , COALESCE(-gdol.MetallMass, gdl.MetallMass, g1.MetallMass, sc.MetallMass, CASE WHEN pol.Operation = 0 THEN -gpol.MetallMass END, 0) FROM ...kxl
28.11.2016 17:43Можно… В данном запросе, пожалуй, это не вызовет никаких накладок. А так я не очень люблю использовать COALESCE из-за двойного вычисления — где то забудешь и попадешь на неоптимальный план запроса…

kxxb
28.11.2016 08:58Добрый день!
Решил опробовать данный инструмент, и сразу воткнулся в проблему соединения с базой по ssh.
В поддержке нашел вот такой топик.
Скажите, есть ли какой-то туториал по этому поводу?
Спасибо!


Borz
28.11.2016 14:41если коротко:
на закладке "General" вы даёте настройки так, будто вы находитесь на сервере bastion. А на закладке "SSH/SSL" указываете настройки для входа по SSH на сервер bastion.
туннельный локальный порт DataGrip сам сгенерит случайныйkxxb
28.11.2016 16:27Совершенно верно, именно так всё и настроено.
По такому принципу у меня Toad работает.
В данном случае, сообщение об ошибке у меня исчезло и DataGrip начал работать по ssh, после перезапуска компьютера.
Возможно, где-то у меня в системе было что-то не так.
Как usercase:
1) Установил DataGrip
2) Настроил ssh-тонель, получил ошибку
3) Перезапустил систему
4) Соединение по ssh-тоннелю заработало

l_stoch
28.11.2016 20:43Выбивает ошибку, в случае если в именовании объекта присутствует #. У нас, к сожалению, таких объектов в базе валом. DbForge автоматом оборачивает имена объектов в гравис (`t#table_name`), а затем исполняет запрос. Можно ли это как-то настроить?
Не нашел, но было бы круто — распределение объектов по подпапкам, сейчас у нас решается костылями на уровне именования.
Velikodniy
29.11.2016 10:05Возможно это все уже озвучивалось, но для полноценной работы с Oracle не хватает управления грантами для таблиц/view/sequence/…, работы с partitions, управления юзерами, работы с check constraint-ами (сейчас они лишь отображаются в tree-view, но дропнуть, или изменить не понятно как), flashback-а и т. д… При всех достоинствах и преимуществах DataGrip пока приходится держать запущенный Oracle SQL Developer параллельно с DataGrip.
moscas
29.11.2016 16:35Спасибо! Всё справедливо, будем добиваться того, чтобы у вас была открыта всего одна программа. Наша :)

SXN
30.11.2016 15:30Доброго времени суток, очень приятно IDE часто улучшается но в этот раз в списке таблиц и sequence secuance расположена высшее чем остальные по сути список sequence не часто надо хотел предложить расположит группы () по частоте или сделать возможность настроить порядок.
Еще раз спасибо за хороший продукт.

Grief
Опять же, не злорадства ради, до сих пор нельзя sequence'ы по delete удалять, таблицы можно, причем каскадно, а ключи приходится через консоль и drop sequence: https://youtrack.jetbrains.com/issue/DBE-2750
Grief
Обратил внимание на упоминание об этом в статье: "Добавили Drop в контекстное меню многих объектов". Полез проверить еще раз и действительно — уже можно, значит этот тикет можно закрыть.
moscas
Да, мы добавили, просто баг не закрыли =) Закроем.
Borz
вот ещё тоже закройте :)