
Александр Календарев ( akalend )
Здравствуйте, уважаемые коллеги! Мой доклад будет про вещь, без которой не обходится ни один HighLoad-проект — про сервера очередей, и если успею, то расскажу про блокировки (примечание расшифровщика — успел :).

О чем будет доклад? Я расскажу про то, где и как используются очереди, зачем это все нужно, расскажу чуть-чуть про протоколы.
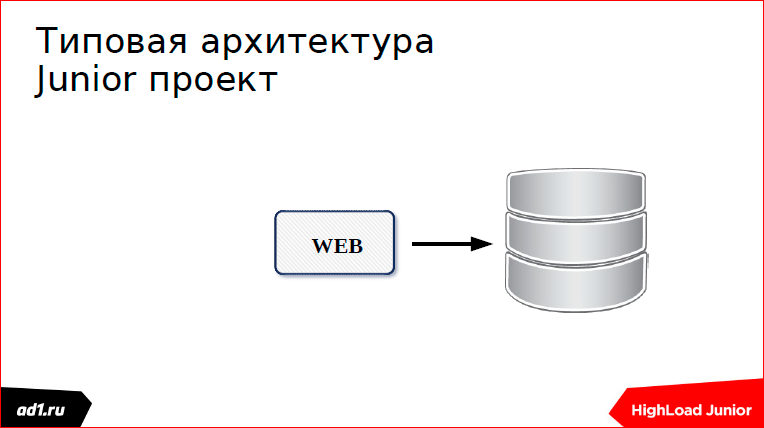
Т.к. наша конференция называет HighLoad Junior, я хотел бы пойти от Junior-проекта. Есть у нас типичный Junior-проект — это какая-то веб-страница, которая обращается к базе. Может быть, это электронный магазин или еще что-то там. И вот, к нам пошли-пошли пользователи, и на каком-то этапе мы получили ошибочку (может быть и другая ошибка):

Мы полезли в Интернет, стали исследовать, как можно масштабироваться, решили достать бэкендов.
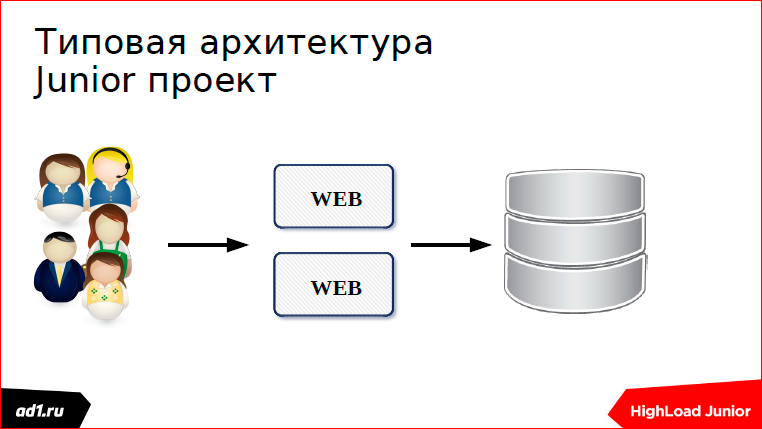
Пошли еще пользователи, и еще пользователи, и у нас появилась еще одна ошибочка:

Тогда мы полезли в логи, посмотрели, как можно отмасштабировать SQL-сервер. Нашли и сделали репликацию.
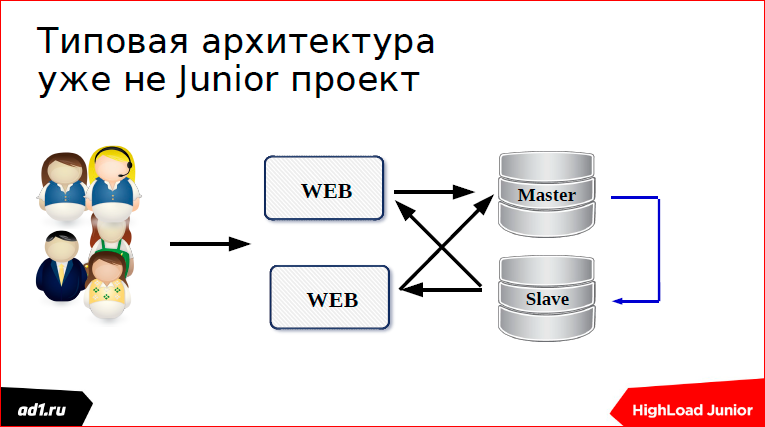
Но тут у нас в MySQL полезли ошибки:

Ну, ошибки могут быть и в более простых конфигурациях, это я тут образно показал.
И в этот момент мы начинаем задумываться о нашей архитектуре.

Мы нашу архитектуру рассматриваем «под микроскопом» и выделяем две вещи:

Первая — какие-то критические элементы нашей логики, которые нужно сделать; и вторая — какие-то медленные и ненужные вещи, которые можно отложить на потом. И эту архитектуру мы пытаемся разделить:

Мы разделили ее на две части.
Одну часть мы стараемся положить на один сервер, а другую — на другой. Такой паттерн я называю «хитрый ученик».

Сам когда-то этим «страдал»: говорил родителям, что я уже сделал уроки и бежал гулять, а на следующий день эти уроки читал перед уроками и рассказывал учителям за две минуты.
Есть более научное название этого паттерна:

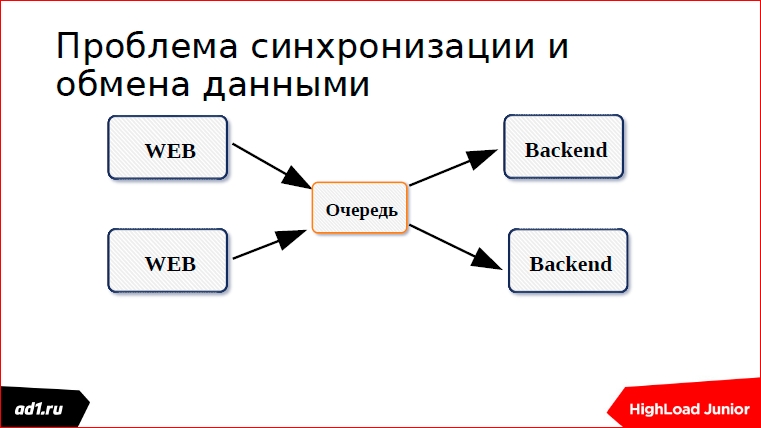
И в итоге мы приходим вот к такой архитектуре, где есть веб-сервер и бэкенд-сервер:

Между собой их надо как-то связать. Когда это два сервера, это делается проще. Когда их несколько, это чуть сложнее. И мы задумываемся, как их связать? И одно из решений общения между этими серверами — это очередь.
Что же такое очередь? Очередь — это список.

Есть более длинный и нудный, но это просто список, куда мы пишем элементы, а потом читаем их и вычеркиваем, исполняем. Список длится дальше, элементы уменьшаются, очередь так регулируется.
Переходим ко второй части — где и как она используется? Когда-то я работал в таком проекте:

Этот аналог Яндекс.Маркета. В этом проекте крутится очень много разных сервисов. И эти сервисы как-то должны были синхронизироваться. Синхронизировались они через базу данных.
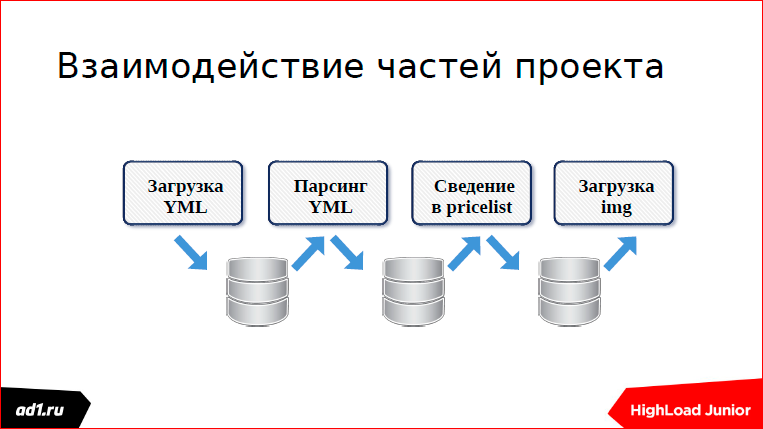
Как устроена очередь на базе данных?

Есть некий счетчик — в MySQL это автоинкремент, в Postgress это через сиккенс реализуется; есть какие-то данные.
Записываем данные:

Читаем данные:

Удаляем из очереди, но для полного счастья нужны lock’и.

Хорошо это или плохо?
Это медленно. Мой данный паттерн для этого не существует, но в некоторых случаях очередь через базу данных многие делают.

Во-первых, через базу данных можно хранить историю. Тогда добавляется поле deleted, оно может быть как флаговым, так и timestamp писать. Мои коллеги через очередь делают общение, которое через партнерскую сеть идет, они баннеры записывают — сколько было кликов, потом у них аналитика на Вертике находит кластеры, какие группы пользователей на какие баннеры больше откликаются.
Мы же для этого используем MongoDb.

В принципе, все то же самое, только используется какая-то коллекция. Пишем в эту коллекцию, читаем из этой коллекции. С удалением — прочитали элемент, он автоматически удалился.

Это также медленно, но все-таки быстрее, чем DB. Для наших потребностей, мы это в статистике используем, это нормально.
Дальше, я работал в таком проекте, это социальная игрушка была — «однорукий бандит»:

Все знают, нажимаешь кнопочку, крутятся у нас барабанчики, выпадают совпадения. Игрушка была реализована на PHP, но меня попросили ее отрефактурить, потому что база данных наша не справлялась.

Я для этого использовал Tarantool. Tarantool в двух словах — это key value хранилище, оно сейчас уже ближе к документно-ориентированным базам данным. Был реализован у меня на Tarantool оперативный кэш, это только чуть-чуть помогло. Решили все это организовать через очередь. Все прекрасно работало, но однажды у нас это все упало. Упал бэкенд-сервер. И в Tarantool начали накапливаться очереди, накапливаться пользовательские данные, и память переполнилась, потому что это Memory Only хранилище.

Память переполнилась, все упало, данные пользователей за полдня потерялись. Пользователи немножко недовольны, где-то чего-то играли, проиграли, выиграли. Кто проиграл, тому хорошо, кто выиграл — тому хуже. Вывод какой? Нужно делать мониторинг.
Что тут надо мониторить? Длину очереди. Если мы видим, что она превышает среднюю длину раз в 5 или 10, 20 раз, то должны слать SMS — у нас такой сервис сделан на Telegram’е. Telegram бесплатный, SMS все-таки денег стоит.
Что еще нам дает Tarantool? Tarantool — хорошее решение, там есть шардинг из коробки, репликация из коробки.

Еще в Tarantool есть замечательный пакет с Queue.

То, что я реализовывал — это было еще 4-5 лет назад, тогда такого пакета еще не было. Сейчас появился очень хороший API у Tarantool, если кто пользуется Python, у них API, вообще заточенный под очереди. Я сам на PHP с 2002-го года, 15 лет уж как. Разрабатывал модуль под Tarantool на PHP, поэтому PHP мне чуточку ближе.
Тут есть две операции: запись в очередь и чтение из очереди. Хочу обратить внимание на эту циферку (0,1 синим на слайде) — это у нас timeout. И, вообще, при подходе к написанию бэкендовских скриптов, которые разбирают очередь, есть два подхода: синхронный и асинхронный.

Что такое синхронный подход? Это когда мы читаем из очереди и, если есть данные, то мы их обрабатываем, если данных нет, то мы встаем в блокировочку и ждем, пока данные придут. Данные пришли, мы поехали читать дальше.

Асинхронный подход, как и понятно, когда данных нет, мы поехали дальше — либо читаем из другой очереди, либо делаем какие-то другие операции. Если нужно, подождем. И снова идем в начало цикла. Всем понятно, все очень просто.

Какие плюшки даем нам пакет Queue? Там есть очереди с приоритетами, такого я больше не встречал нигде среди других серверов очередей. Там еще можно задать жизнь элементу очереди — иногда это очень полезно. Подтверждение доставки — и это все есть. О синхронности и асинхронности я говорил.
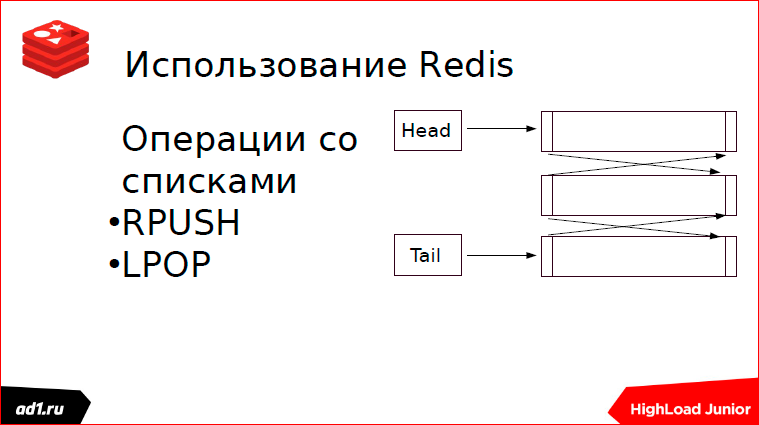
Redis. Это у нас зоопарк, где есть много разных структур данных. Очередь реализуется на списках. Чем хороши списки? Они хороши тем, что время доступа к первому элементу списка или к последнему происходит за постоянное время. Как реализуется очередь? С начала списка пишем, с конца списка читаем. Можно делать наоборот, это не принципиально.

Работал я в такой игрушке. Эта игрушка была под ВКонтакте написана. Классическая реализация была, игрушка работала быстро, флэшка общалась с веб-сервером.

Все было прекрасно, но однажды нам сказали сверху: «Давайте использовать статистику, наши партнеры хотят знать, сколько у нас куплено юнитов, какие наиболее покупаемые юниты, сколько у нас ушло и с какого уровня пользователей и т.п.». И предложили нам не изобретать велосипед и использовать внешние скрипты статистики. И все было замечательно.
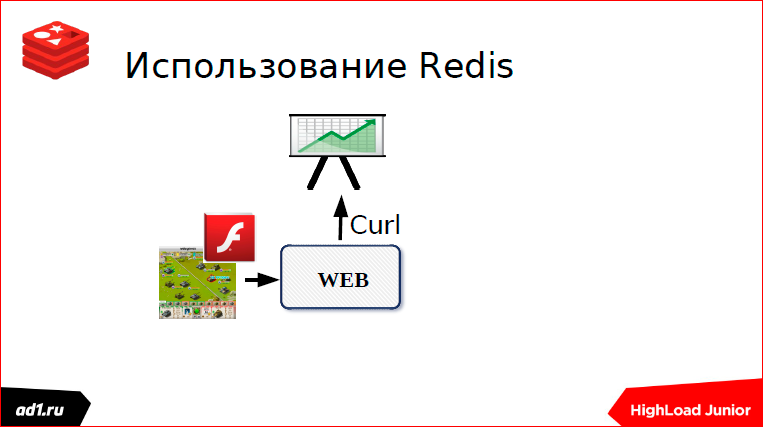
Только мой скрипт отрабатывал 50 мс, а когда обращались к внешнему скрипту, там была какая-то Америка, это 250 мс минимум, а то и 2 с лишним секунды ping туда шел. Соответственно, вся игрушка зависла.
Мы применили такую вот схему:

И все у нас было хорошо, все работало быстро. Но однажды наш админ ушел в отпуск. Админ ушел в отпуск, все было хорошо первую неделю, а через неделю мы узнали, что Redis течет. Redis течет, админа нет, мы приходим, смотрим с утра на консоль, смотрим, сколько осталось памяти, сколько до swap’а еще осталось, вздыхали: «Ох, как хорошо, пронесло на сегодня». В пятницу к нам пришло много пользователей, особенно после обеда, памяти не хватило.

Выводы те же, что и с Tarantool. Другой проект, ошибки те же. Память нужно мониторить. Длину очереди нужно мониторить. Про мониторинг много все говорят, повторяться не буду.

В Redis можно также выполнять как блокирующие, так и неблокирующие операции чтения; операция Count нужна, как раз, именно для мониторинга.
Как-то еще я удаленно работал в проекте загрузки видео с популярных видеохостингов:

В чем проблема этого проекта? В том, что если мы загружаем видео, то мы его конвертируем, если видео чуть длиннее, веб-клиент просто отваливается. Применили такую схему:

Все у нас хорошо. Закачали файл. Но очередь работает у нас только в одну сторону, а мы должны проинформировать наш веб-скрипт — файл-то уже закачан.
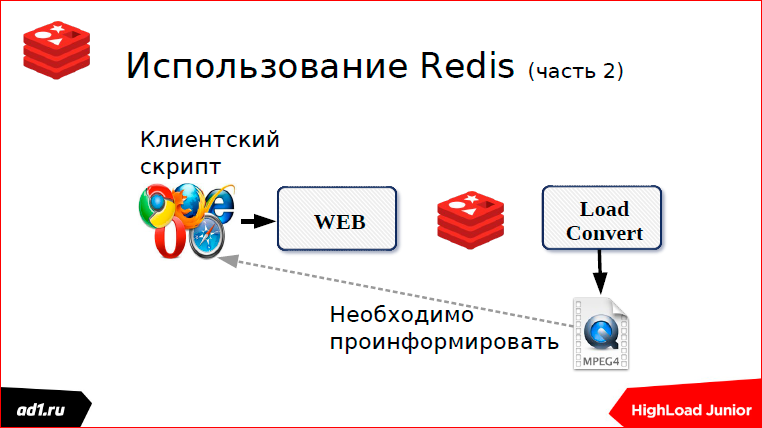
Как это делается? Это делается двумя способами.
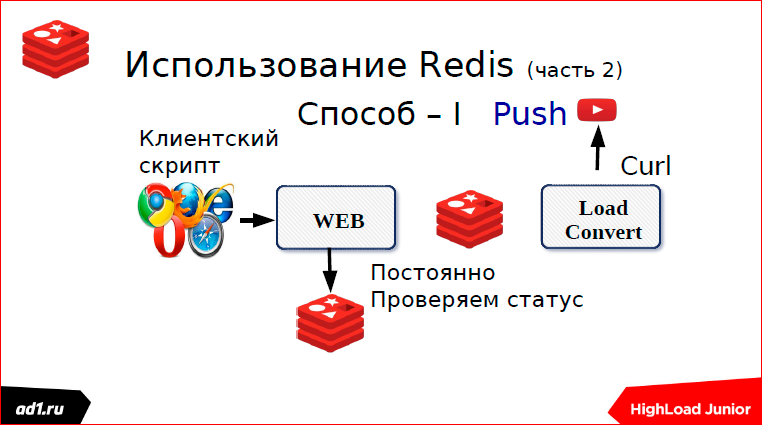
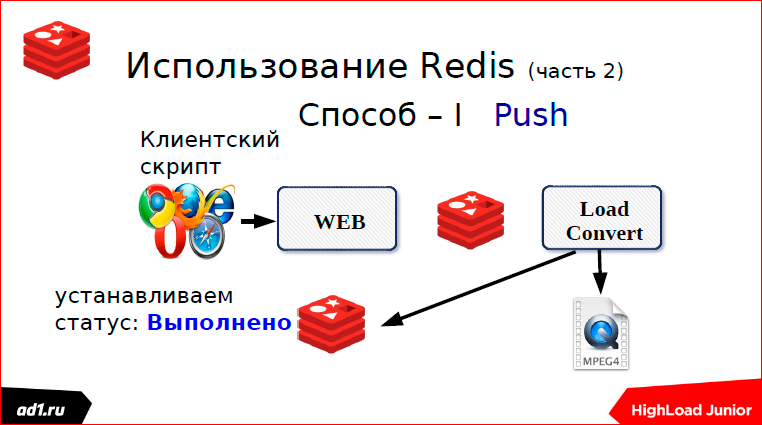

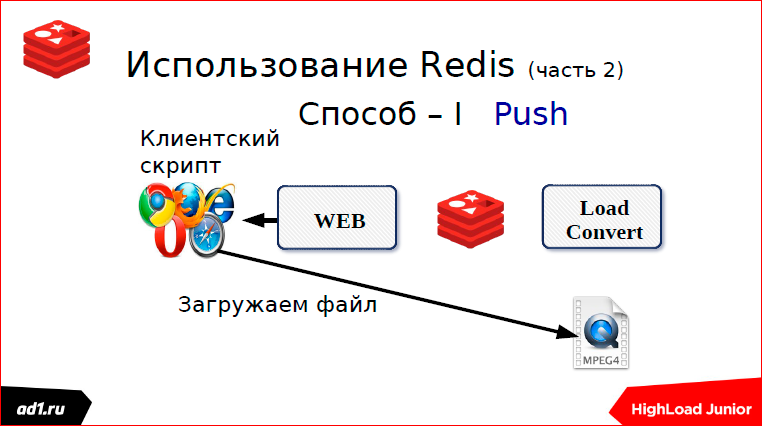
Первый — мы через какой-то определенный timeout проверяем статус. Что может быть статусом? Это keyvalue хранилище — лучше уже взять тот же Redis. Key может послужить какой-нибудь MD5 хэш от URL’а нашего. И после того, как мы сконвертировали, мы в keyvalue пишем статус. Статус может быть: «выполнено», «конвертируется», «не найдено» или еще чего-нибудь. Через секунду, через какой-то timeut, скрипт запросит статус, увидит, что выполнено или не выполнено, покажет все клиенту. Все понятно. Это первый способ, мы использовали пулинг.
Второй — веб-сокеты.
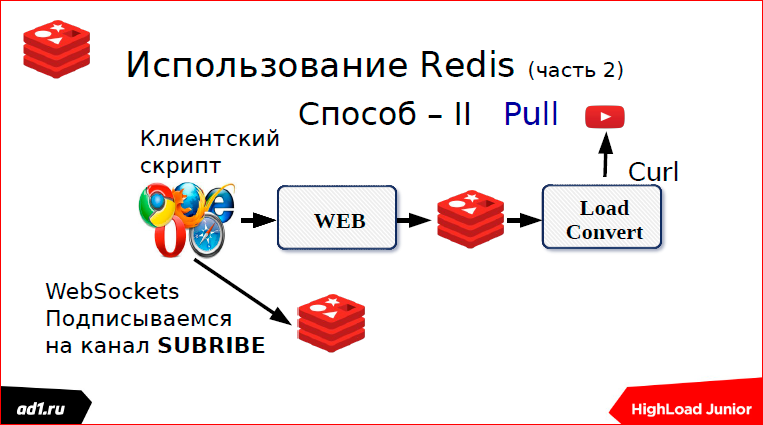

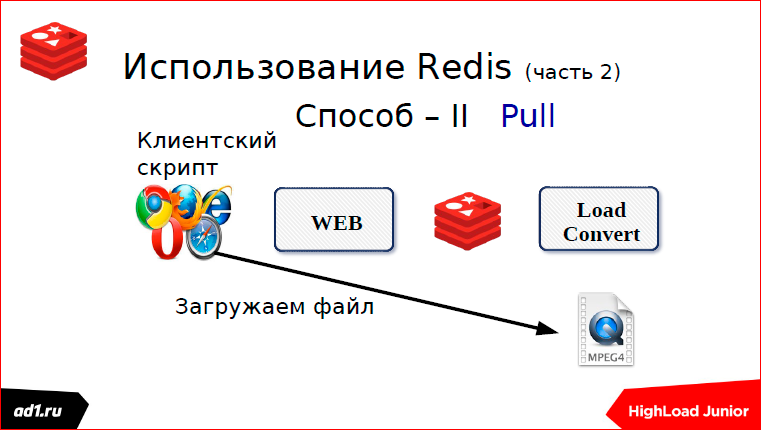
Мы загружаем файл — это второй способ. Это подписки. Здесь, как раз, использовали веб-сокеты.
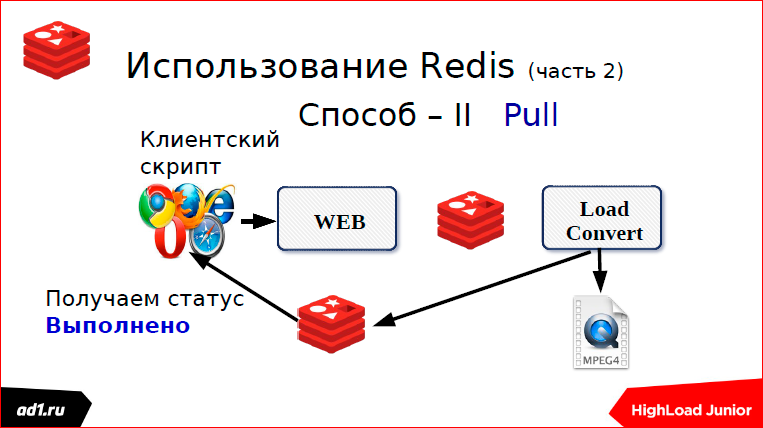
Как это делается? Как только мы начали загрузочку, мы сразу подписываемся на канал в Redis. Если там можно было, допустим, memcaсhed использовать или еще что-нибудь, если мы Redis не использовали, то здесь к Redis привязано. Подписываемся на какой-то канал, имя канала. Грубо говоря, тот же MD5 хэш от URL’а.
Как только мы загрузили файл, мы берем и пушим в канал, что у нас статус «выполнено» или статус «не найдено». И сразу же мгновенно у нас Push отдает статус на веб-скрипт. После этого загружаем файл, если он найден.

Не совсем напрямую, приблизительно такая схема.

Как это делается? Есть некий источник данных — температура вулкана, количество звезд, видимых в телескопы, направленные НАСА, количество сделок по конкретным акциям… Мы принимаем эти данные, и наш скрипт бэкграундовский, который принял эти данные, пушит их в некий канал. Наш веб-скрипт через веб-сокет, обычно используются ноды JS, подписывается на определенный канал, как только там данные получаются, он через веб-сокет эти данные передает на клиентский скрипт, и они там отображаются.

Есть такое решение — MamecachedQ. Это довольно старое решение, я бы сказал, одно из первых. Оно было порождено использованием Mamecached и BerkeleyDb, это встраиваемое, одно из ранних, keyvalue хранилище.
Чем достопримечательно это решение? Тем, что используется протокол Mamecached.

В чем большой минус — мы здесь никак не отмониторим длину очереди. О чем я говорил — мониторинг нужен, а здесь этого мониторинга нет.
Говоря об очередях, нельзя не сказать о Zerro MQ.

Zerro MQ — хорошее и быстрое решение, но это не брокер очередей, это надо понимать. Это просто API, т.е. мы соединяем одну точку с другой точкой. Или одну точку с множеством точек. Но здесь нет никаких очередей, если одна из точек пропадет, то какие-то данные потеряются. Я, конечно, могу на том же Zerro MQ написать того же брокера и его реализовать…

Apache Kafka. Как-то я пытался это решение использовать. Это решение из стека hadoop. Оно, в принципе, хорошее, высокопроизводительное решение, но оно нужно там, где есть большой поток данных и нужно его обработать. А так, я бы более легкие решения использовал.

Его нужно еще очень долго настраивать, синхронизировать через Zookepek и т.д.
Протоколы. Что такое протоколы?

Я вам показал кучу всяких решений. Сообщество IT подумало и сказало: «Чего мы все изобретаем велосипеды, давайте мы все это дело застандартизируем». И придумало протоколы. Один из наиболее ранних протоколов — это STOMP.

Его описание покрывает все, что можно делать с очередями.
Второй протокол, MQTT — это Message Queue Telemetry Transport протокол.

Он бинарный, в отличие от STOMP, покрывает, в принципе, всю ту же функциональность, что и STOMP, но более быстро за счет того, что бинарный.
Вот наиболее яркие представители, брокера очередей, которые работают с протоколами:

ActiveMQ все три протокола использует, даже четыре (есть еще один). RabbitMQ использует три протокола; Qpid использует Q и P.
Теперь коротко об AMQP — Advanced Message Queuing Protocol.

Если про него долго рассказывать, то можно часа полтора, не меньше, говорить про его особенности. Я кратко. Мы брокер представим как некий идеальный почтовый сервис. Exchange — это будет почтовый ящик отправителя, куда приходит сообщение.

Этот Exchange имеет тип, свойства.

Здесь на PHP написано, как его объявлять. Кстати, этот драйвер тоже я разрабатывал.
Раз есть ящик отправителя, у нас должен быть ящик получателя. Ящик получателя имеет такую особенность, что мы за одно обращение можем взять только одно письмо. Ящик получателя также имеет имя, свойство. Приблизительно так его надо объявлять:

Между ящиком отправителя и ящиком получателя нужно проложить некий маршрут, по которому будут бегать почтальоны и носить наши письма.

Этот маршрут определяется ключом маршрутизации.

Когда мы объявляем связь, то мы обязательно указываем ключ маршрутизации. Это один из путей объявления связи.
Есть второй подход. Мы можем объявить Exchange и с него сделать Bind на очередь, т.е. это наоборот — мы можем с очереди сделать связь на Exchange или с Exchange на очередь, это без разницы.
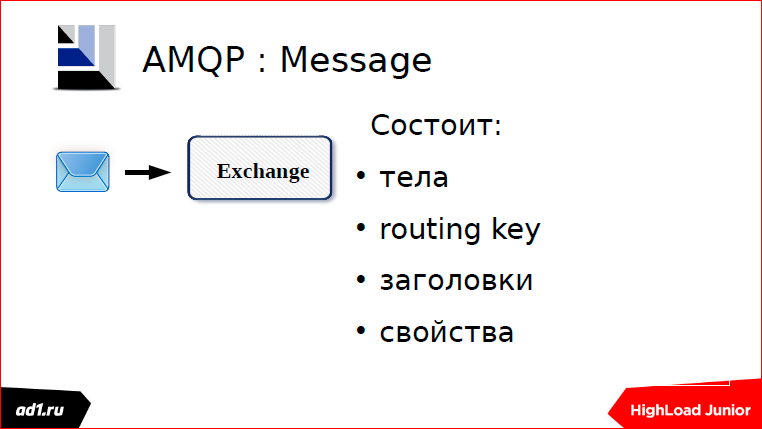
Есть у нас сообщение. В сообщении должен быть обязательно указан routingKey, т.е. это тот ключ, по которому маршруту побежит наш почтальон.

Наши почтальоны могут быть трех типов:

- Первый тип — это слепые почтальоны. Они не могут прочитать ключ, они бегут только по тому маршруту, который мы им проложили. Эти почтальоны бегут, и это
самые быстрые почтальоны.
- Почтальоны второго типа могут немного читать, они сверяют буковки, только не знают, как чего… Сверили буковки, что совпадает ключ нашего сообщения и
соответствующей тропинки, по которой бежать, и бегут по той тропинке. Т.е. наш получатель идет чисто по ключу совпадения.
- И третий вид почтальонов — это Topic. Мы можем задать маску, маска такая же, как в файловой системе, и по этой маске почтальончики наши относят письма.
Приблизительно так выглядит, как отправляются сообщения:

Какие у нас типичные ошибочки бывают?

Типичные ошибочки бывают в том, что люди часто забывают определять связь. Сейчас третий Rabbit — он более-менее приличный, у него есть веб-интерфейс, можно через веб-интерфейс все посмотреть: что там объявлено, какие очереди, какой у них тип, какие там exchange, какие у них типы.
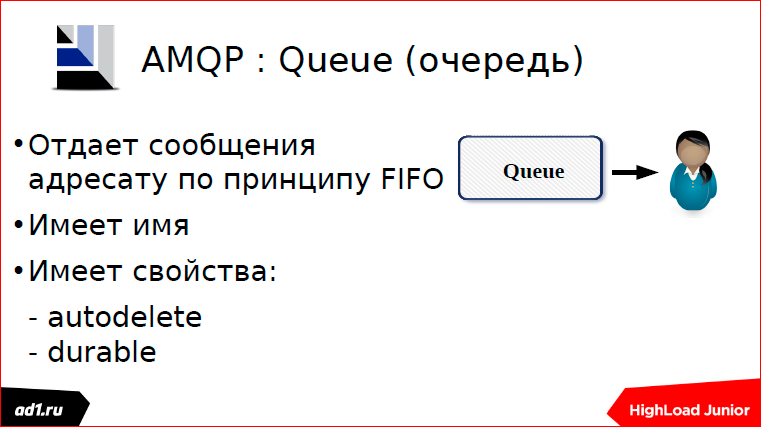
Вторая типичная ошибочка. Когда мы объявляем очередь или exchange, они у нас по умолчанию autodelete — закончилась сессия, очередь убилась. Поэтому ее нужно каждый раз переобъявлять. В принципе, это нежелательно делать, а лучше сделать постоянную очередь и еще назначить durable. Durable — это такой признак, что если у нас очередь durable, то после перезагрузки RabbitMQ у нас эта очередь будет жить.

Что можно сказать про RabbitMQ? Он не очень приятен в администрировании, зато его можно расширить, если мы знаем Erlang. Он очень требователен по памяти. RabbitMQ работает через эрланговское встраиваемое решение, но оно очень много памяти ест. Есть некоторые плагины, которые работают с другими хранилищами, но я, честно говоря, с ними не работал.

Вот в таком журнале «Системный администратор» я написал статью «Кролик в песочнице» — там, в принципе, то же самое, что я вам тут рассказал.

А в этой статье, я расписал более такие интересные паттерны, как можно использовать RabbitMQ, какие там можно делать перенаправления очередей, например, как сделать так, что если очередь не прочиталась, то эти данные пишутся в другую очередь, в запасную, которую потом может прочитать другой скрипт. Если есть возможность, то почитайте.
Блокировочки

Рассказывал я про такой проект в самом начале. Если бы я делал этот проект сегодня, то использовал бы микросервисы.
А микросервисы требуют синхронизации как взаимодействия. В качестве синхронизации у нас используется такой инструмент, как Apache Zookeeper.
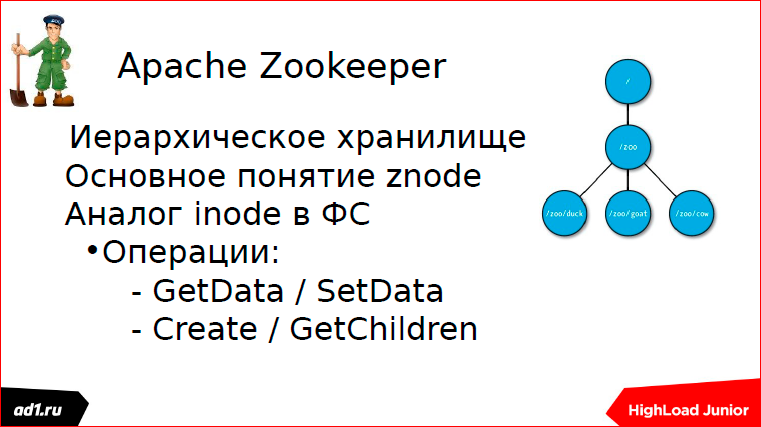
В основу философии Apache Zookeeper лежит znode. Znode по аналогии с элементом файловой системы имеет некий путь. И есть у нас операция создания ноды, создания детей ноды, получение детей, получение данных и запись чего-то в данные.
Znode бывают двух типов: простые и эфемерные.

Эфемерные — это такие znode, которые, если у нас пользовательская сессия умерла, то znode уничтожилась, autodelete.
Последовательности — это автоинкрементные znode, т.е. это znode, которые имеют некое имя и числовой префикс автоинкрементный.
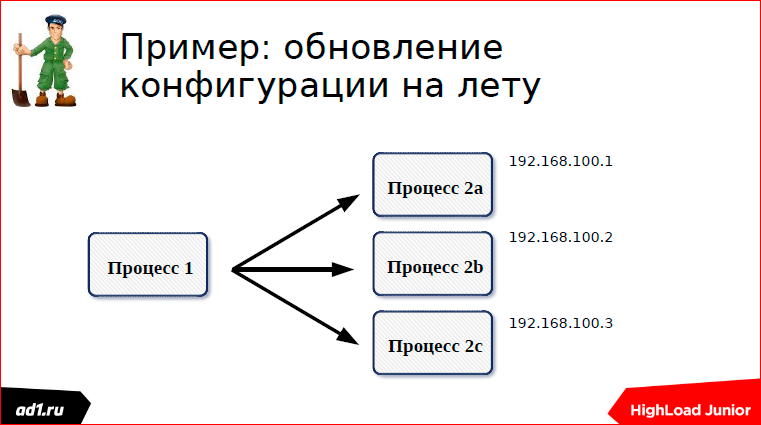
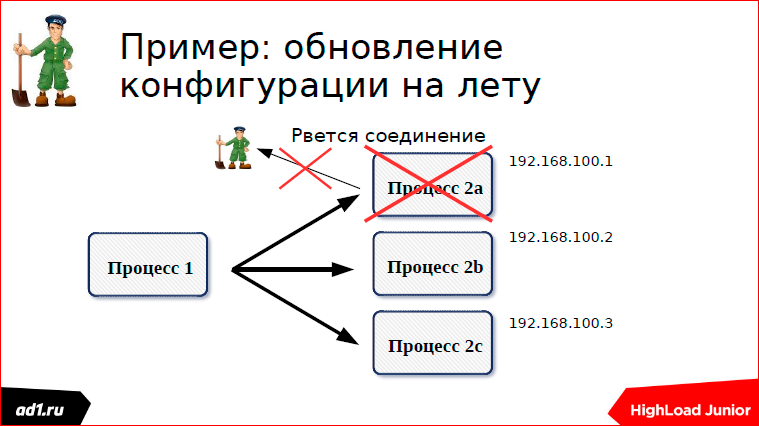
На примере конфигурации на лету расскажу, как приблизительно это все работает. Есть у нас две группы процессов — группа процессов a и группа процессов b. Процессы 1 коннектятся к процессам 2 и как-то взаимодействуют. Процессы 2, когда запускаются, пишут свою конфигурацию в Zookeeper.
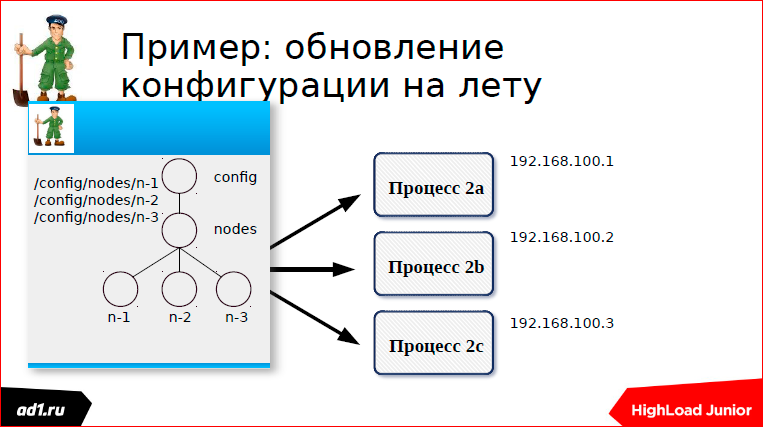
Каждый процесс создает свою znode — первый процесс, второй, третий.
И вот мы один из процессов остановили или, например, запустили. У меня тут на примере остановки процессов показано:

У нас процесс остановлен, соединение порвалось, znode у нас удалилась, посылается event, что мы слушали эту znode, что в ней одна znode пропала.
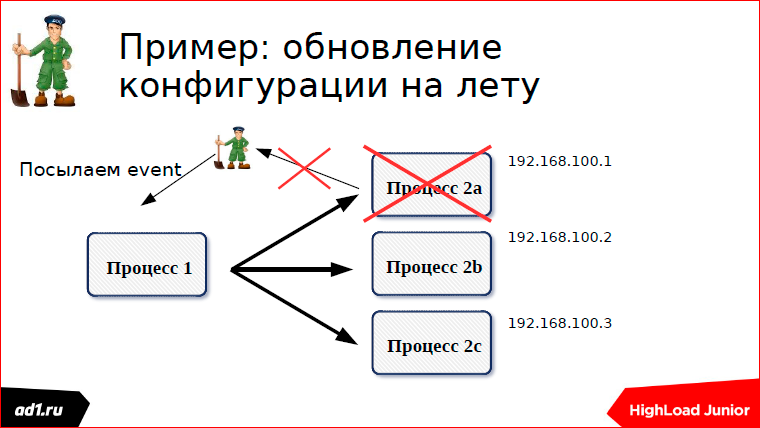

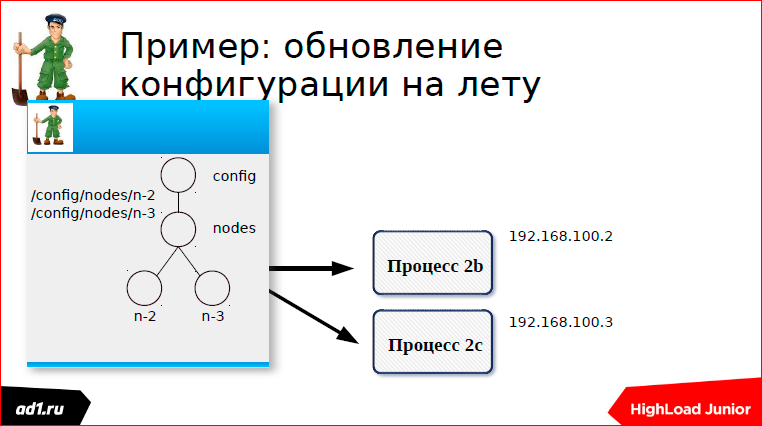
Посылается event, мы пересчитываем конфигурацию. Все очень красиво работает.

Приблизительно так все это синхронизируется. Есть другие примеры, как с бэкапами там кто-то синхронизировал.

На этом итоговом слайде я хотел бы продемонстрировать все возможности серверов очередей. Где у нас знаки вопросов — либо это спорный момент, либо просто не было данных. Например, база данных у нас масштабируется, правильно? Непонятно, но, в принципе, масштабируется. Но можно ли масштабировать очереди на них или нет? В принципе, нет. Поэтому у меня здесь вопрос. По ActiveMQ у меня просто нет данных. С Redis могу объяснить — ACL есть, но он не совсем правильный. Можно сказать, его нет. Масштабируется Redis? Через клиент масштабируется, таких каких-то элементов, коробочных решений, я не видел.

Такие вот выводы:
- Надо каждый инструмент использовать по назначению. Я много общался с разными разработчиками, RabbitMQ сейчас использует только неленивый, но в
большинстве случаев тот же RabbitMQ можно заменить Redis’ом.
- Скорость, умноженная на надежность. Что я хотел этим сказать? Чем быстрее работает инструмент, тем у него меньше надежность. Но с другой стороны,
величина этой константы может меняться — это мое личное наблюдение.
- Ну и, про мониторинг тут много говорили и до меня профессионалы.
Контакты
» akalend
» akalend@mail.ru
Этот доклад — расшифровка одного из лучших выступлений на обучающей конференции разработчиков высоконагруженных систем HighLoad++ Junior.
Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
Ну и главная новость — мы начали подготовку весеннего фестиваля "Российские интернет-технологии", в который входит восемь конференций, включая HighLoad++ Junior. Мы, конечно, жадные коммерсы, но сейчас продаём билеты по себестоимости — можно успеть до повышения цен :)
Комментарии (40)

mantyr
29.11.2016 20:09Вот тоже самое только переработанное под хабр хочется. Сам доклад не то что бы что-то новое хабру даёт.

olegbunin
29.11.2016 20:18+5Коллега, мы ведь с Вами это уже обсуждали? :)
У нас нет ресурсов на адаптацию, но есть ресурсы на расшифровку. Материалы хорошие, доклады выбраны пользователями. Мы честно пишем, что это расшифровка доклада, всё по-чесноку!
Scratch
29.11.2016 21:34Олег, приветствую ) А не проще давать видео, поделённое на экран с презентацией и самого презентера? Не вижу смысла в расшифровке, которую никто кроме поисковых роботов не будет до конца читать. Можно и сами слайды выкладывать, если уж на то пошло (pdf, ppt)

SKolotienko
29.11.2016 21:48+14Я, пожалуй, поддержу редкий вид человеков, которые предпочитают текстовый материал. Так что за расшифровку спасибо!

polarnik
29.11.2016 23:18Делал расшифровки выпусков телепередач. На слух запоминал речь в рамках эпизода, ставил на паузу, печатал, снова слушал. В результате натренировал память. Потом вторым проходом расставлял знаки препинания, в обнимку с сайтом грамота ру — натренировал пунктуацию. И то и другое не раз пригодилось. Смысл есть в самых неожиданных местах.
polarnik
29.11.2016 22:18Спрашивал активных пользователей RabbitMQ про надёжность, в каких ситуациях лучше использовать БД. Все говорили, что очередь надёжна, что записи никуда не пропадут, что очередь сбрасывается на диск, и даже перезапуск сервера ей не страшен.
А судя по слайдам, узким местом является требование к памяти, памяти надо много, и когда она заканчивается, как понимаю, работа сервера очередей может прекратиться. Протестировать очередь при недостатке памяти дело нехитрое, на ноутбуке памяти мало. Постараюсь протестировать.
Расшифровка — отличный формат. Спасибо.

novoxudonoser
29.11.2016 23:07+1Если говорить про RabbitMQ то она не супер супер надёжна, сохранение новых элементов очередей которые объявлены как персистентные (есть ещё менне надёжные очереди в памяти ) на диск не делает fsync (ради производительности), это значит что данные попадут в кеш дисковой подсистемы и только когда ядро соизволит сбросить данные на диск они будут надёжно сохранены, если в этот (обычно короткий) промежуток выключить сервер данные потеряются.

crazylh
30.11.2016 00:24Что мешает смонтировать файловую систему с флагом sync (или в контексте экстов data=journal)?
novoxudonoser
01.12.2016 19:02Немого не то. отсюда:
ОПИСАНИЕ
fsync копирует все части файла, находящиеся в памяти, на
устройство (диск) и ждет, пока устройство не доложит о
том, что все части нормально сохранены.
ЗАМЕЧАНИЯ
В случае, если на жестком диске включено кэширование при
записи, данных фактически может не быть на диске, хотя
fsync/fdatasync уже сообщит об их записи на диск и
завершит работу.
Это значит что опция sync вас не спасёт. Но не всё так плохо, в новой версии (3.5.5) кролика fsync происходит раз в 0.2с и ни что не мешает вам собрать из исходников свою версию с более коротким промежутком.
ВАЖНО для всех пользователей RabbitMQ
Обычно высокая надёжность достигается за счёт использование кластера из 2х и более машин (что кстати избавляет от необходимости рейда). И есть замечательный механизм — Acknowledgment. Если на пальцах — то при его использовании приходит асинхронное подтверждение согласованного надёжного сохранения сообщения в кластере или сообщение что отвергнуто. Ну соответственно прикладная программа должна уметь с этом работать. Вариантов как это использовать масса.

RPG18
30.11.2016 01:36fsync штука хорошая, но не спасет от выхода из строя самого диска.
В этой ситуации кеш можно перенести на SSD.novoxudonoser
01.12.2016 19:09В этой ситуации кеш можно перенести на SSD.
Либо я вас не понял либо насколько я знаю это не возможно использовать в *nix. Для защиты от отказа диска обычно используют рейд или в случае с RabbitMQ лучше использовать кластер.RPG18
01.12.2016 19:21Смотря какой *nix использовать. Прокачай свой жёсткий диск! Этот способ реально работает!. А в Кеширование данных на SSD с помощью EnhanceIO упоминаются еще парочка решений.
novoxudonoser
01.12.2016 19:54Так здесь кешируеться запись к диску а не кеш фс. Такое решение по надёжности аналогично (а скорее всего и менее надёжно) RAID 1 из одного hdd и одного ssd. В свою очередь RAID 1 это не самый хороший и надёжный рейд.
RPG18
01.12.2016 20:04Для некоторых решений нужно патчить ядро, можно на уровне ядра добавить принудительный сброс в ssd.
RAID разные бывают. fsync не гарантирует пробивку кеша рейда. Поэтому и появились RAID с батарейкой. Если туже батарейку не поменять, то можем потерять данные.
novoxudonoser
01.12.2016 20:11В ядре нет готового кода для принудительного сброса кеша фс на блочное устройство. И насколько я знаю нет и такого патча. Вам придётся писать его самостоятельно а это очень сложно и долго.
>RAID разные бывают
Я говорил исключительно про софтверный рейд. Про аппаратный рейд вы полностью правы.
Кстати очень забавно наблюдать когда люди покупают аппаратный без батарейки потому как дорого и не выключают кеш на нём.


0x0FFF
29.11.2016 22:53Плакал, читая вашу статью:
Нам понадобилась очередь, и мы решили использовать для ее организации СУБД. А там блокировки, да и хранит данные она на диске, непорядок! Решили использовать модный распределенный ObjectStore для организации очереди, он работает побыстрее, но все равно оверхед большой и управлять им сложно, не то. Затем для реализации очереди мы решили использовать распределенный in-memory key-value store (а почему бы и нет?). Затем не распределенный in-memory key-value store. Затем мы решили все-таки попробовать продукты, реализующие функционал очередей, но что-то у них настройка больно мудреная, и мы не осилили
Это же основы. ПО для организации очередей писалось не дураками, и писалось именно потому, что другие инструменты конкретно для задачи организации очередей подходят плохо. ActiveMQ, ZeroMQ, RabbitMQ, Kafka и многие другие — создавались именно для того, чтобы снизить оверхед на операции с очередями, гарантировать сохранность данных и их последующую обработку. По определению никакие СУБД, key-value store, object store и прочие не будут решать эту задачу лучше, за исключением ситуации, когда у вас одно сообщение в секунду и вам не важно, будет ли оно в итоге обработано или потеряно.novoxudonoser
29.11.2016 23:13вам не важно, будет ли оно в итоге обработано или потеряно
Не согласен, очереди в бд какрастаки и нужны для сверх надёжности, транзакционности и ACID + для произвольной выборки а не только из конца как в стандартных FIFO очередях. За это конечно приходиться платить меньшей производительностью.0x0FFF
29.11.2016 23:41Я утрировал. СУБД обычно не используются для организации очередей. Скорее СУБД можно использовать для регистрации событий исходной системы, для последующей их пакетной обработки (и, соответственно, хранения истории). Писатели и так не блокируют друг друга (параллельные insert уже давно исполняются СУБД без блокировки), а читателей при пакетной обработке не много и не нужно дикости вроде полной блокировки таблицы, как в примере автора. Для классического кейса с большим количеством параллельных читателей для распределения нагрузки, СУБД будет работать плохо
Что хорошо в очередях, и из-за чего появилось много решений для организации очередей — им не нужна полноценная ACID. А по поводу произвольной выборки — та же Kafka умеет читать из произвольного места в очереди.novoxudonoser
01.12.2016 19:31Полностью с вами согласен, но это как говориться детали.
А по поводу произвольной выборки — та же Kafka умеет читать из произвольного места в очереди.
Это верно но стоит добавить что это введено недавно в версии 9.0 и пока offset работает очень плохо — при стечений обстоятельств можно потерять много данныx (я бы пока не советовал для прода). Если хочется высокопроизводительную и надёжную очередь с произвольным чтением я бы советовал IBM MQ это конечно проприетарный и дорогой продукт но аналогов у него пока нет.
Что хорошо в очередях, и из-за чего появилось много решений для организации очередей — им не нужна полноценная ACID.
Блин это круто! Вам книги технические надо писать, вся суть одним предложением. Тут только могу добавить что «им» это не очередям, а задачам которые на них решают.
Кстати кластер на RabbitMQ практически почти обеспечивает ACID. Практически поскольку ACID классификация применима в случае очередей для всей системы в целом т.е. очередь + прикладные программы. Сответсвенно прикладные программы могут всё порушить.RPG18
01.12.2016 19:45ACID это требование к транзакционной системе, если нет транзакций, то и ACID не нужен.
novoxudonoser
01.12.2016 20:00Если говорить про RabbitMQ то там есть транзакции.
RPG18
01.12.2016 20:01Там много, что есть. Но всегда ли нужны транзакции?
novoxudonoser
01.12.2016 20:24В большинстве случаев ненужны, но если строить именно высоконадёжную систему то они не помешают.
RPG18
30.11.2016 00:03Сверх надежность обеспечивается дублированием систем. Как только мы будем собирать кластер БД, то мы столкнемся с CAP теоремой. Как не крути, грусть и печаль.
novoxudonoser
01.12.2016 19:46+1Если кластер географически не разделён (т.е. вероятность отказа коммуникаций очень низка) то устойчивость к разделению не нужна в подавляющем большинстве кейсов.
Кстати если всё же географическое разделение необходимо, то есть интересный подход — отказ от устойчивости к разделению через исключение разделяемых ресурсов. Это конечно не всегда возможно. Пример для лучшего понимания — нужно сделать количество денег на счёту пользователя не разделяемым. Тогда предварительно нужно разделить сумму на две части и предоставить каждую часть на пользование одной из двух нод, а потом раз в некоторое время перебалансировать два этих подбаланса. Конечно на время разделение чтение актуальной итоговой суммы по разделённому каналу не возможно но все операции по обработки в пределах разделения будут происходить не нарушая ACID.

akalend
04.12.2016 00:20-1Не хочу флейма, но смысл доклада в том, что есть очереди, их можно использовать для этого… и этого… и для реализации этого есть такие и такие инструменты… Это дают то..., а эти это…
как-то так…

Komei
30.11.2016 14:52Скажите пожалуйста, а вы случаем не планируете выкладывать расшифровки с HighLoad++ этого года? И если планируете, то есть ли какие-то ориентиры по срокам (лично я хотел бы глянуть несколько докладов оттуда, поэтому и интересуюсь)?
olegbunin
30.11.2016 14:53Мы не торопливые :)
Видео сейчас дорабатывается, на этой неделе или в начале следующей будет у участников.
Затем будет выложено в продажу.
В этот момент лучшие из записей будут выложены публично и мы пустим их на расшифровку.
В общем, в этом году расшифровок с HL++ 2016, скорее всего, не будет.


akalend
01.12.2016 10:23Спасибо за интересные комментарии, в общем для меня было сюрпризом, что доклад попал в лучшие…
как продолжение, есть слайды с митапа "10 рецептов готовки кролика"

Nashev
13.03.2017 22:46При проецировании на сетчатку можно динамически расстоянием фокусировки управлять! Наверняка научатся
RPG18
В случае реализации очередей на PostgreSQL следует упомянуть про PgQ из SkyTools написанный Skype, для реализации репликации Londiste.