В продолжение статей про устройство таблицы маршрутизации и про реализацию протокола BGP в Quagga, в настоящей статье я разберу как работает протокол OSPF. Я ограничусь случаем для одной OSPF зоны без редистрибъюции маршрутов из других протоколов маршрутизации.
Как обычно, я не стану подробно описывать работу и настройку протокола OSPF, и сошлюсь где можно более подробно про него почитать. Ограничусь лишь наиболее важными для дальнейшего понимания статьи сведениями.
В отличие от протоколов RIP или BGP, которые сравнивают пришедшие маршруты от разных соседей и выбирают лучшие из них по каким-либо критериям, протокол OSPF строит топологическую карту сети и прокладывает по ней кратчайшие маршруты до соответствующих ip-сетей. Чтобы собрать информацию о топологии сети, маршрутизаторы обмениваются между собой кусочками информации о directly connected сетях и своих соседях OSPF. Данные кусочки топологической информации называются LSA (Link State Advertisement) и из них, как пазл, можно собрать полную топологическую карту сети. Как устроены LSA мы рассмотрим чуть позже, а сейчас перейдем к алгоритму нахождения кратчайшего пути.
Для нахождения кратчайшего пути используется алгоритм Дейкстры, работу которого рассмотрим на следующем примере. У нас имеется пять маршрутизаторов, соединенных между собой линками, как показано на рисунке:

R1 является корневым маршрутизатором, на котором выполняется алгоритм нахождения кратчайшего пути. Цифры на линках показывают стоимость (cost) данного линка. Задача состоит в том, чтобы найти от маршрутизатора R1 до каждого из остальных маршрутизаторов кратчайший путь, т.е. путь у которого суммарная стоимость линков минимальна.
В результате для каждого маршрутизатора мы должны вычислить две вещи:
Эта информация необходима, чтобы R1 смог правильно составить таблицу маршрутизации. Внутри каждого маршрутизатора мы будем указывать текущую стоимость до него. Рядом будем указывать текущий next-hop, который использует R1, чтобы достичь данный маршрутизатор. Зеленым цветом будем отмечать маршрутизаторы, до которых кратчайший путь вычислен.
Таким образом, на начальном этапе мы имеем кратчайший путь только до самого маршрутизатора R1, равный 0. До остальных маршрутизаторов стоимости равны бесконечности, а next-hop неизвестны.
Сейчас мы будем делать последовательность шагов, каждый из которых будет улучшать стоимость путей до маршрутизаторов, а в конечном счете мы вычислим кратчайшие пути до всех из них.
Соседями корневого маршрутизатора R1 являются маршрутизаторы R2 и R3. Для каждого из них устанавливаем стоимость пути равным стоимости соответствующего линка и next-hop равным самому маршрутизатору R2 или R3, как показано на рисунке:
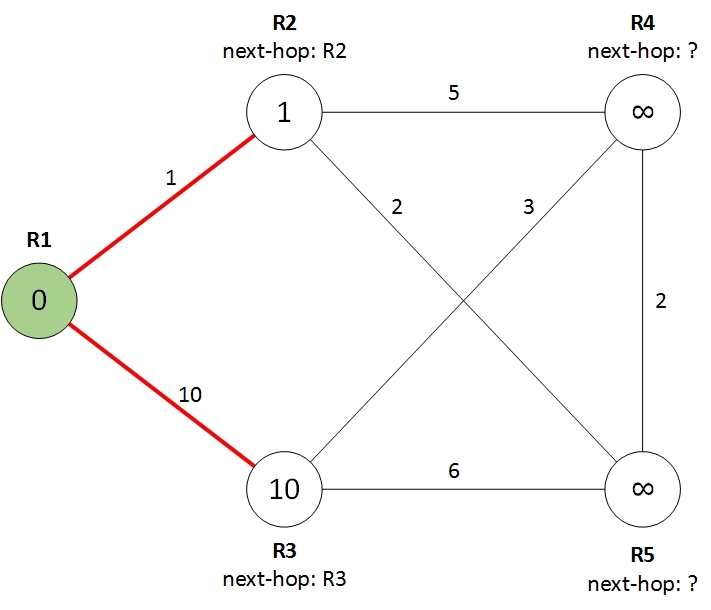
На данном шаге мы смотрим все оставшиеся маршрутизаторы, т.е. маршрутизаторы до которых кратчайший путь еще не найден (белого цвета) и выбираем из них маршрутизатор с наименьшей стоимостью пути до него. В нашем случае это маршрутизатор R2 со стоимостью 1. Этот маршрутизатор мы смело можем перекрасить в зеленый цвет, более короткого пути для него не существует.

На рисунке он покрашен в более темный зеленый цвет, поскольку этот маршрутизатор пригодится нам на шаге 3.
Этот шаг похож на шаг 1, только вместо маршрутизатора R1 мы смотрим на соседей выбранного на предыдущем этапе темно-зеленого маршрутизатора. Для каждого соседа мы вычисляем стоимость пути через выбранный маршрутизатор. Если стоимость такого пути получается меньше, чем текущая стоимость, то соседу присваиваем новую стоимость, а next-hop просто копируем от выбранного маршрутизатора. Получается такая картина:

Теперь повторяем шаги 2 и 3 до тех пор, пока все маршрутизаторы не станут зелеными. На этапе 2 у нас один маршрутизатор обязательно зеленеет, так что такой процесс рано или поздно закончится.
Итак, выбираем лучший из оставшихся, перекрашиваем в зеленый цвет (маршрутизатор R5):

Смотрим на соседей выбранного маршрутизатора, улучшаем стоимости, копируем next-hop:

Видно, что у R3 сменился next-hop, который был скопирован от R5. Выбираем лучшего:
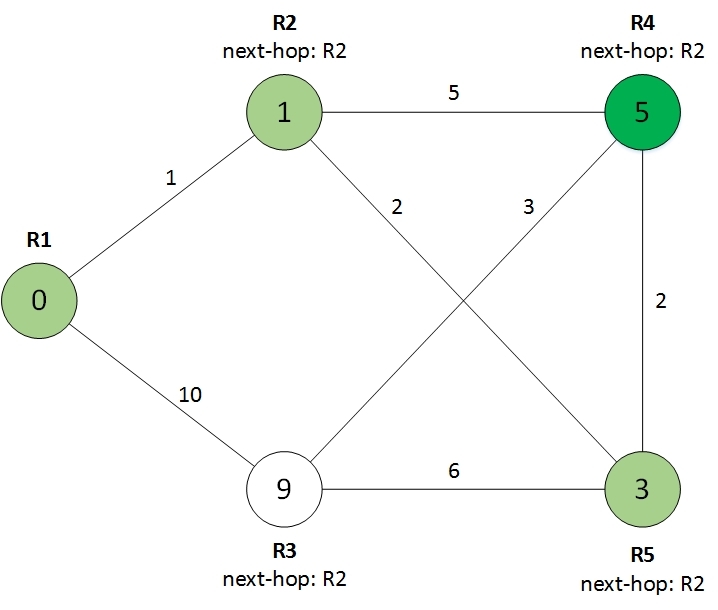
Смотрим на оставшегося соседа:

И получаем окончательный результат:

Теперь у нас есть стоимости путей до каждого из маршрутизаторов, а также какие next-hop использовать на корневом маршрутизаторе для их достижения. Т.е. мы практически готовы составить таблицу маршрутизации. Однако для непосредственного применения в сетях рассмотренный выше алгоритм требует некоторой модернизации.
Вышеописанный алгоритм работает только с линками типа точка-точка, когда каждый линк соединяет два маршрутизатора. Реальные же маршрутизаторы, могут подключаться между собой через сеть Ethernet, которая допускает подключения к одному сегменту более 2-х маршрутизаторов, как показано на рисунке.
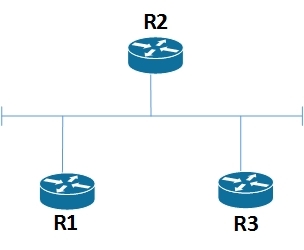
В протоколе OSPF такая сеть называется транзитной. Для решения данной проблемы в OSPF каждая транзитная сеть представляется отдельным узлом в графе. Т.е. при вычислении кратчайшего пути топология будет выглядеть так:

Узел N1 как раз и обозначает транзитную сеть. Теперь у нас каждый линк соединяет только два узла и можно применять алгоритм нахождения кратчайшего пути. При расчете стоимости пути учитывается только стоимость линка от маршрутизатора до транзитной сети, а от транзитной сети до маршрутизатора она считается равной 0.
Поскольку транзитная сеть является логическим объектом, то какой-то из маршрутизаторов должен взять на себя обязанность по созданию необходимой топологической информации, описывающей транзитную сеть. Для этого в OSPF в каждой транзитной сети выбирается Designated Router (DR), который помимо информации о себе также имеет обязанность анонсировать информацию о транзитной сети.
Кроме того, в таблице маршрутизации находятся маршруты не до маршрутизаторов, а до ip-сетей. Вопрос с транзитными сетями решается просто. Поскольку транзитные сети представляются вершинами в графе, то стоимость маршрутов до транзитных сетей вычисляется в процессе работы алгоритма поиска кратчайшего пути. Остальные сети, например, сети к которым подключен только один маршрутизатор OSPF, считаются конечными (stub) сетями и анонсируются маршрутизаторами, к которым они подключены. Зная стоимость кратчайшего пути до каждого маршрутизатора можно легко вычислить и стоимость маршрута до всех подключенных к нему конечных сетей.
Как я уже говорил, для того, чтобы каждый маршрутизатор мог составить топологию сети и применить к ней алгоритм поиска кратчайшего пути, маршрутизаторы обмениваются между собой небольшими кусочками информациями, называемыми Link State Advertisement LSA. LSA бывают разных типов и передают разную информацию. Для нашего случая с единственной зоной важны два типа LSA — LSA тип 1 и LSA тип 2. Каждая LSA тип 1 описывает маршрутизатор. LSA тип 2 описывает транзитную сеть. Если опустить различную служебную информацию, то эти LSA схематично можно представить так:
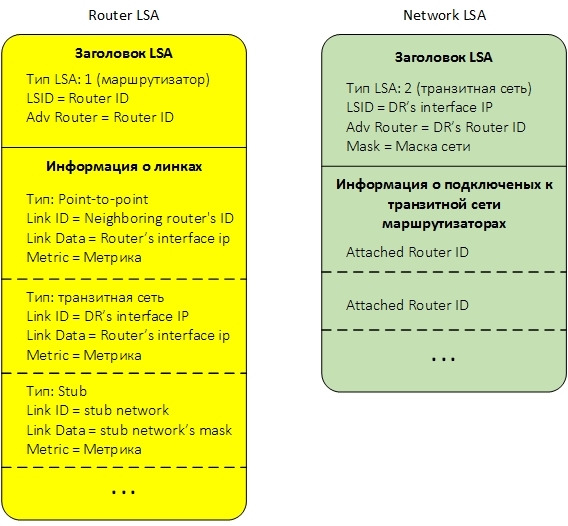
Ниже дано краткое описание полей LSA.
В заголовке LSA нам важны три поля:
Ниже идет информация о линках нашего маршрутизатора. От типа линка зависит и передаваемая о линке информация. Маршрутизатор может иметь линки трех различных типов:
Транзитная сеть. Для линка данного типа передается следующая информация:
Точка-точка. Для линка типа точка-точка передается:
Конечная (Stub) сеть. Для нее передается:
LSA тип 2 передает информацию о транзитной сети и анонсируется специально выбранным для каждой транзитной сети Designated Router.
В заголовке LSA находятся четыре важных поля:
Далее идет информация о маршрутизаторах, подключенных к транзитной сети. Для каждого такого маршрутизатора указывается его Router ID.
Каждая LSA соответствует узлу графа и, в зависимости от типа, представляет либо маршрутизатор, либо транзитную сеть. Имея все LSA теперь легко создать топологию сети. Для этого достаточно заметить, что Link ID транзитного линка маршрутизатора соответствует LSID транзитной сети, и наоборот, Attached Router ID транзитной сети соответствует LSID подключенного к транзитной сети маршрутизатора.
Для примера на рисунке показана небольшая сеть:
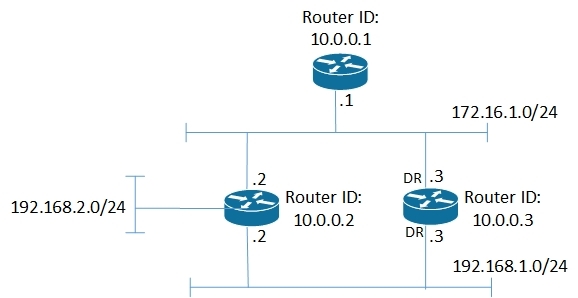
соответствующие ей LSA:
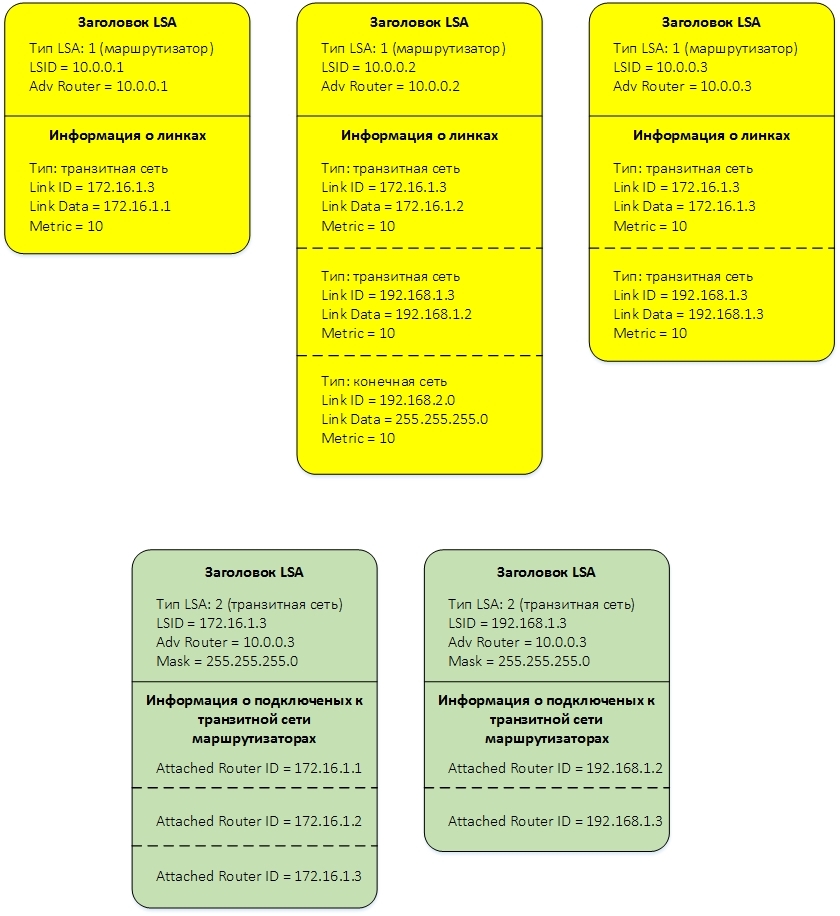
и топология:
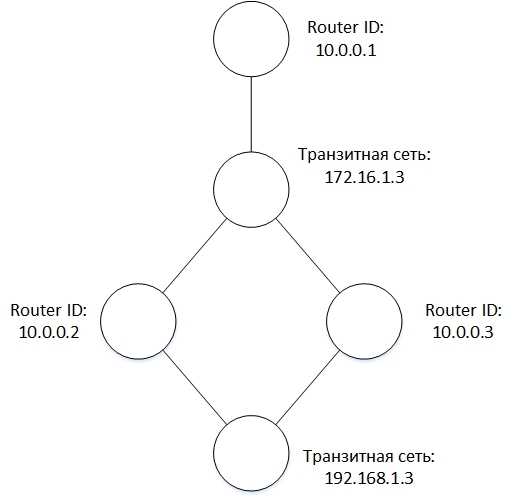
Все созданные и принятые LSA хранятся в базе, называемой LSDB (LSA Database). Основное, что нужно от этой базы – это иметь возможность добавлять в нее LSA, перебирать все LSA определенного типа и искать LSA по ключевым полям из заголовка LSA.
Посмотреть список всех LSA в LSDB и их поля можно при помощи команд show ip ospf database (выводит заголовки всех LSA), show ip ospf database route (выводит полную информацию по LSA тип Router) и show ip ospf database network (выводит полную информацию по LSA тип Network).
В Quagga вся база для хранения LSA (LSDB) разбита на несколько баз, отдельных для каждого типа LSA, как показано на рисунке:

Каждая база для хранения LSA отдельного типа устроена одинаково и хранит содержащиеся в ней LSA в виде описанного в предыдущей статье префиксного дерева. В качестве префикса используется комбинация LSID и Adv Router. Комбинация этих полей уникальна для каждой LSA определенного типа в пределах зоны.
При получении новой LSA данная LSA добавляется в LSDB и запускается процесс вычисления кратчайшего маршрута. Процесс начинается с LSA, соответствующей самому маршрутизатору. На основе содержащейся в ней информации в памяти создается новый узел, соответствующий корневому узлу в топологии. Далее, из LSDB последовательно достаются LSA, соответствующие соседним узлам в топологии, создаются новые узлы и вычисляются кратчайшие пути и next-hop до них, как было описано в алгоритме кратчайшего пути. Параллельно, для обработанных узлов, в таблицу маршрутизации OSPF добавляются маршруты до транзитных сетей.
После окончания построения топологии и вычисления кратчайших путей, просматриваются все узлы, соответствующие маршрутизаторам, и в таблицу маршрутизации OSPF добавляются все их конечные (stub) сети. Маршруты до транзитных сетей в таблицу маршрутизации были уже добавлены ранее.
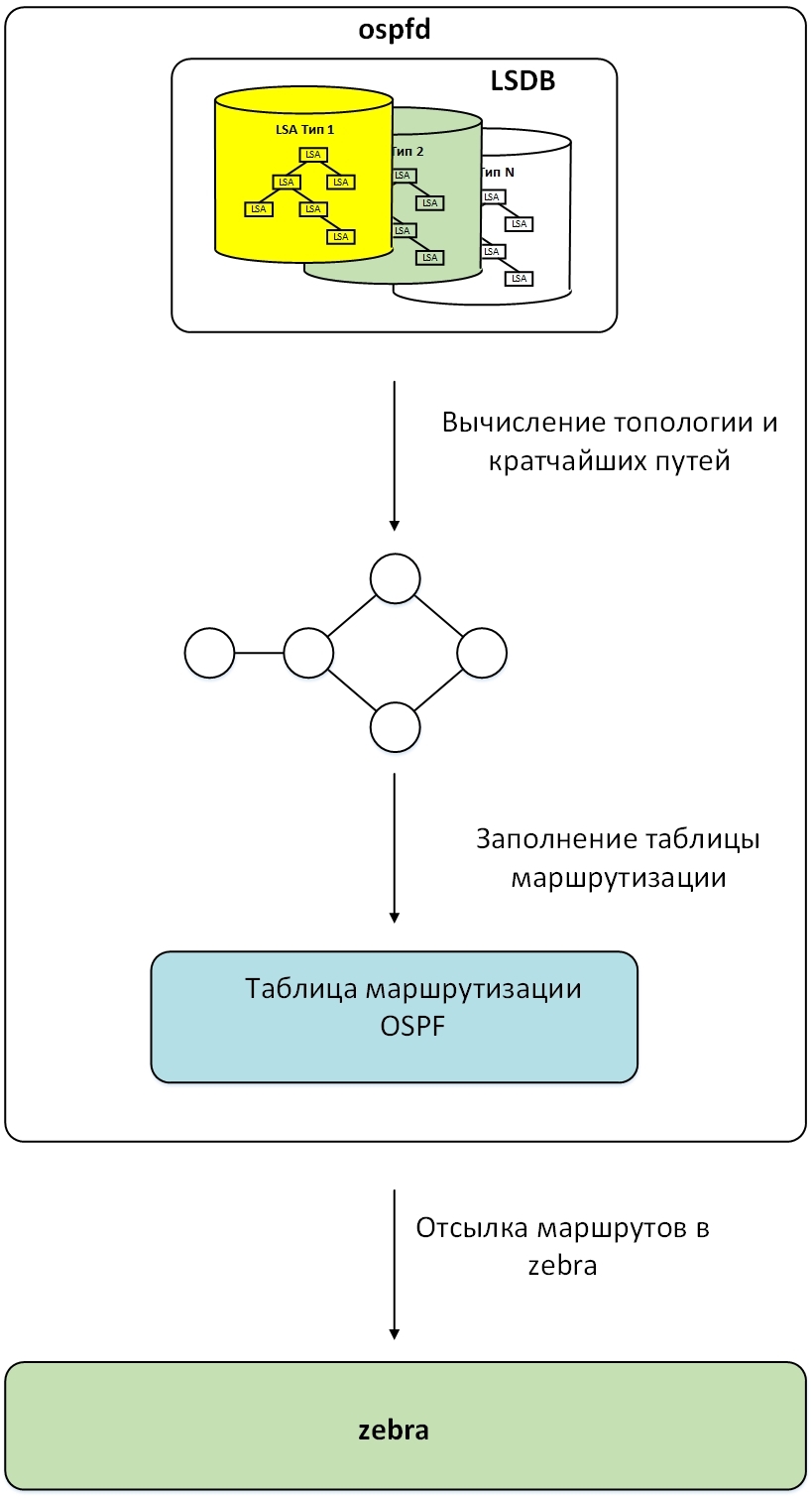
На последнем этапе все узлы в топологии удаляются из памяти, а маршруты из таблицы маршрутизации OSPF передаются в демон zebra. Схема данного процесса показана на рисунке.
Как обычно, я не стану подробно описывать работу и настройку протокола OSPF, и сошлюсь где можно более подробно про него почитать. Ограничусь лишь наиболее важными для дальнейшего понимания статьи сведениями.
В отличие от протоколов RIP или BGP, которые сравнивают пришедшие маршруты от разных соседей и выбирают лучшие из них по каким-либо критериям, протокол OSPF строит топологическую карту сети и прокладывает по ней кратчайшие маршруты до соответствующих ip-сетей. Чтобы собрать информацию о топологии сети, маршрутизаторы обмениваются между собой кусочками информации о directly connected сетях и своих соседях OSPF. Данные кусочки топологической информации называются LSA (Link State Advertisement) и из них, как пазл, можно собрать полную топологическую карту сети. Как устроены LSA мы рассмотрим чуть позже, а сейчас перейдем к алгоритму нахождения кратчайшего пути.
Алгоритм нахождения кратчайшего пути
Для нахождения кратчайшего пути используется алгоритм Дейкстры, работу которого рассмотрим на следующем примере. У нас имеется пять маршрутизаторов, соединенных между собой линками, как показано на рисунке:
R1 является корневым маршрутизатором, на котором выполняется алгоритм нахождения кратчайшего пути. Цифры на линках показывают стоимость (cost) данного линка. Задача состоит в том, чтобы найти от маршрутизатора R1 до каждого из остальных маршрутизаторов кратчайший путь, т.е. путь у которого суммарная стоимость линков минимальна.
В результате для каждого маршрутизатора мы должны вычислить две вещи:
- Стоимость пути от R1 до данного маршрутизатора.
- Какой next-hop использует R1, чтобы достичь данный маршрутизатор.
Эта информация необходима, чтобы R1 смог правильно составить таблицу маршрутизации. Внутри каждого маршрутизатора мы будем указывать текущую стоимость до него. Рядом будем указывать текущий next-hop, который использует R1, чтобы достичь данный маршрутизатор. Зеленым цветом будем отмечать маршрутизаторы, до которых кратчайший путь вычислен.
Таким образом, на начальном этапе мы имеем кратчайший путь только до самого маршрутизатора R1, равный 0. До остальных маршрутизаторов стоимости равны бесконечности, а next-hop неизвестны.
Сейчас мы будем делать последовательность шагов, каждый из которых будет улучшать стоимость путей до маршрутизаторов, а в конечном счете мы вычислим кратчайшие пути до всех из них.
Шаг 1. Смотрим соседей корневого маршрутизатора.
Соседями корневого маршрутизатора R1 являются маршрутизаторы R2 и R3. Для каждого из них устанавливаем стоимость пути равным стоимости соответствующего линка и next-hop равным самому маршрутизатору R2 или R3, как показано на рисунке:
Шаг 2. Выбираем лучшего из оставшихся.
На данном шаге мы смотрим все оставшиеся маршрутизаторы, т.е. маршрутизаторы до которых кратчайший путь еще не найден (белого цвета) и выбираем из них маршрутизатор с наименьшей стоимостью пути до него. В нашем случае это маршрутизатор R2 со стоимостью 1. Этот маршрутизатор мы смело можем перекрасить в зеленый цвет, более короткого пути для него не существует.
На рисунке он покрашен в более темный зеленый цвет, поскольку этот маршрутизатор пригодится нам на шаге 3.
Шаг 3. Смотрим на соседей выбранного маршрутизатора.
Этот шаг похож на шаг 1, только вместо маршрутизатора R1 мы смотрим на соседей выбранного на предыдущем этапе темно-зеленого маршрутизатора. Для каждого соседа мы вычисляем стоимость пути через выбранный маршрутизатор. Если стоимость такого пути получается меньше, чем текущая стоимость, то соседу присваиваем новую стоимость, а next-hop просто копируем от выбранного маршрутизатора. Получается такая картина:
Теперь повторяем шаги 2 и 3 до тех пор, пока все маршрутизаторы не станут зелеными. На этапе 2 у нас один маршрутизатор обязательно зеленеет, так что такой процесс рано или поздно закончится.
Итак, выбираем лучший из оставшихся, перекрашиваем в зеленый цвет (маршрутизатор R5):
Смотрим на соседей выбранного маршрутизатора, улучшаем стоимости, копируем next-hop:
Видно, что у R3 сменился next-hop, который был скопирован от R5. Выбираем лучшего:
Смотрим на оставшегося соседа:
И получаем окончательный результат:
Теперь у нас есть стоимости путей до каждого из маршрутизаторов, а также какие next-hop использовать на корневом маршрутизаторе для их достижения. Т.е. мы практически готовы составить таблицу маршрутизации. Однако для непосредственного применения в сетях рассмотренный выше алгоритм требует некоторой модернизации.
Модернизация алгоритма нахождения кратчайшего пути
Вышеописанный алгоритм работает только с линками типа точка-точка, когда каждый линк соединяет два маршрутизатора. Реальные же маршрутизаторы, могут подключаться между собой через сеть Ethernet, которая допускает подключения к одному сегменту более 2-х маршрутизаторов, как показано на рисунке.
В протоколе OSPF такая сеть называется транзитной. Для решения данной проблемы в OSPF каждая транзитная сеть представляется отдельным узлом в графе. Т.е. при вычислении кратчайшего пути топология будет выглядеть так:
Узел N1 как раз и обозначает транзитную сеть. Теперь у нас каждый линк соединяет только два узла и можно применять алгоритм нахождения кратчайшего пути. При расчете стоимости пути учитывается только стоимость линка от маршрутизатора до транзитной сети, а от транзитной сети до маршрутизатора она считается равной 0.
Поскольку транзитная сеть является логическим объектом, то какой-то из маршрутизаторов должен взять на себя обязанность по созданию необходимой топологической информации, описывающей транзитную сеть. Для этого в OSPF в каждой транзитной сети выбирается Designated Router (DR), который помимо информации о себе также имеет обязанность анонсировать информацию о транзитной сети.
Кроме того, в таблице маршрутизации находятся маршруты не до маршрутизаторов, а до ip-сетей. Вопрос с транзитными сетями решается просто. Поскольку транзитные сети представляются вершинами в графе, то стоимость маршрутов до транзитных сетей вычисляется в процессе работы алгоритма поиска кратчайшего пути. Остальные сети, например, сети к которым подключен только один маршрутизатор OSPF, считаются конечными (stub) сетями и анонсируются маршрутизаторами, к которым они подключены. Зная стоимость кратчайшего пути до каждого маршрутизатора можно легко вычислить и стоимость маршрута до всех подключенных к нему конечных сетей.
Link State Advertisement (LSA)
Как я уже говорил, для того, чтобы каждый маршрутизатор мог составить топологию сети и применить к ней алгоритм поиска кратчайшего пути, маршрутизаторы обмениваются между собой небольшими кусочками информациями, называемыми Link State Advertisement LSA. LSA бывают разных типов и передают разную информацию. Для нашего случая с единственной зоной важны два типа LSA — LSA тип 1 и LSA тип 2. Каждая LSA тип 1 описывает маршрутизатор. LSA тип 2 описывает транзитную сеть. Если опустить различную служебную информацию, то эти LSA схематично можно представить так:
Ниже дано краткое описание полей LSA.
LSA Тип 1 (Router LSA).
В заголовке LSA нам важны три поля:
- Тип. Указывает тип LSA. В нашем случае это тип 1, или Router LSA.
- LSID. Идентификатор LSA. В нашем случае LSID равен Router ID маршрутизатора, который создает LSA.
- Adv Router. Идентификатор маршрутизатора, создавшего LSA. В нашем случае он также равен Router ID маршрутизатора, который создает LSA, т.е. совпадает с LSID.
Ниже идет информация о линках нашего маршрутизатора. От типа линка зависит и передаваемая о линке информация. Маршрутизатор может иметь линки трех различных типов:
Транзитная сеть. Для линка данного типа передается следующая информация:
- Link ID — ip-адрес интерфейса Designated Router, подключенного к транзитной сети.
- Link Data — ip-адрес интерфейса самого маршрутизатора, подключенного к транзитной сети.
- Metric — стоимость линка.
Точка-точка. Для линка типа точка-точка передается:
- Link ID — ip-адрес интерфейса соседа.
- Link Data — ip-адрес интерфейса самого маршрутизатора.
- Metric — стоимость линка.
Конечная (Stub) сеть. Для нее передается:
- Link ID — собственно ip-адрес сети.
- Link Data — маска сети.
- Metric — стоимость линка.
LSA Тип 2 (Network LSA)
LSA тип 2 передает информацию о транзитной сети и анонсируется специально выбранным для каждой транзитной сети Designated Router.
В заголовке LSA находятся четыре важных поля:
- Тип. В нашем случае это тип 2, или Network LSA.
- LSID. Идентификатор LSA. В нашем случае LSID равен ip-адресу интерфейса Designated Router, подключенного к транзитной сети;
- Adv Router. Идентификатор маршрутизатора, создавшего LSA. В нашем случае он равен Designated Router ID.
- Mask. Маска сети.
Далее идет информация о маршрутизаторах, подключенных к транзитной сети. Для каждого такого маршрутизатора указывается его Router ID.
Каждая LSA соответствует узлу графа и, в зависимости от типа, представляет либо маршрутизатор, либо транзитную сеть. Имея все LSA теперь легко создать топологию сети. Для этого достаточно заметить, что Link ID транзитного линка маршрутизатора соответствует LSID транзитной сети, и наоборот, Attached Router ID транзитной сети соответствует LSID подключенного к транзитной сети маршрутизатора.
Для примера на рисунке показана небольшая сеть:
соответствующие ей LSA:
и топология:
Все созданные и принятые LSA хранятся в базе, называемой LSDB (LSA Database). Основное, что нужно от этой базы – это иметь возможность добавлять в нее LSA, перебирать все LSA определенного типа и искать LSA по ключевым полям из заголовка LSA.
Посмотреть список всех LSA в LSDB и их поля можно при помощи команд show ip ospf database (выводит заголовки всех LSA), show ip ospf database route (выводит полную информацию по LSA тип Router) и show ip ospf database network (выводит полную информацию по LSA тип Network).
Реализация в Quagga
В Quagga вся база для хранения LSA (LSDB) разбита на несколько баз, отдельных для каждого типа LSA, как показано на рисунке:
Каждая база для хранения LSA отдельного типа устроена одинаково и хранит содержащиеся в ней LSA в виде описанного в предыдущей статье префиксного дерева. В качестве префикса используется комбинация LSID и Adv Router. Комбинация этих полей уникальна для каждой LSA определенного типа в пределах зоны.
При получении новой LSA данная LSA добавляется в LSDB и запускается процесс вычисления кратчайшего маршрута. Процесс начинается с LSA, соответствующей самому маршрутизатору. На основе содержащейся в ней информации в памяти создается новый узел, соответствующий корневому узлу в топологии. Далее, из LSDB последовательно достаются LSA, соответствующие соседним узлам в топологии, создаются новые узлы и вычисляются кратчайшие пути и next-hop до них, как было описано в алгоритме кратчайшего пути. Параллельно, для обработанных узлов, в таблицу маршрутизации OSPF добавляются маршруты до транзитных сетей.
После окончания построения топологии и вычисления кратчайших путей, просматриваются все узлы, соответствующие маршрутизаторам, и в таблицу маршрутизации OSPF добавляются все их конечные (stub) сети. Маршруты до транзитных сетей в таблицу маршрутизации были уже добавлены ранее.
На последнем этапе все узлы в топологии удаляются из памяти, а маршруты из таблицы маршрутизации OSPF передаются в демон zebra. Схема данного процесса показана на рисунке.
Поделиться с друзьями