Много ядер не бывает
Атомарные операции (atomics), например, Compare-and-Swap (CAS) или Fetch-and-Add (FAA) широко распространены в параллельном программировании.
Мульти- или многоядерные архитектуры установлены одинаково как в продуктах настольных и серверных компьютеров, так и в крупных центрах обработки данных и суперкомпьютерах. Примеры конструкций включают Intel Xeon Phi с 61 ядрами на чипе, который установлен в Tianhe-2, или AMD Bulldozer с 32 ядрами на узле, развернутых в Cray XE6. Кроме того, количество ядер на кристалле неуклонно растет и процессоры с сотнями ядер, по прогнозам, будут изготовлены в обозримом будущем. Общей чертой всех этих архитектур является растущая сложность подсистем памяти, характеризующаяся несколькими уровнями кэш-памяти с разными политиками включения, различными протоколами когерентности кэш-памяти, а также различными сетевыми топологиями на чипе, соединяющими ядра и кэш-память.
Практически все такие архитектуры обеспечивают атомарные операции, которые имеют многочисленные применения в параллельном коде. Многие из них (например, Test-and-Set) могут быть использованы для реализации блокировок и других механизмов синхронизации. Другие, например, Fetch-and-Add и Compare-and-Swap позволяют строить разные lock-free и wait-free алгоритмы и структуры данных, которые имеют более прочные гарантии прогресса, чем блокировки на основе кода. Несмотря на их важность и повсеместное употребление, выполнение атомарных операций полностью не проанализировано до сих пор. Например, по общему мнению, Compare-and-Swap идет медленнее, чем Fetch-and-Add. Тем не менее, это всего лишь показывает, что семантика Compare-and-Swap вводит понятие «wasted work», в результате – более низкая производительность некоторого кода.
Compare-and-Swap
Вспомним, что из себя представляет CAS (в процессорах Intel он осуществляется группой команд cmpxchg) – Операция CAS включает 3 объекта-операнда: адрес ячейки памяти (V), ожидаемое старое значение (A) и новое значение (B). Процессор атомарно обновляет адрес ячейки (V), если значение в ячейке памяти совпадает со старым ожидаемым значением(A), иначе изменения не зафиксируется. В любом случае, будет выведена величина, которая предшествовала времени запроса. Некоторые варианты метода CAS просто сообщают, успешно ли прошла операция, вместо того, чтобы отобразить само текущее значение. Фактически, CAS только сообщает: «Наверное, значение по адресу V равняется A; если так оно и есть, поместите туда же B, в противном случае не делайте этого, но обязательно скажите мне, какая величина — текущая.»
Самым естественным методом использования CAS для синхронизации будет чтение значения A со значением адреса V, проделать многошаговое вычисление для получения нового значения B, и затем воспользоваться методом CAS для замены значения параметра V с прежнего, A, на новое, B. CAS выполнит задание, если V за это время не менялось. Что, собственно говоря, наблюдается в JDK 7:
public final int incrementAndGet() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return next;
}
}
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
Где сам метод — unsafe.compareAndSwapInt является native, выполняется на процессоре атомарно и на ассемблере выглядит следующим образом, если включить распечатку ассемблерного кода:
lock cmpxchg [esi+0xC], ecx
Инструкция выполняется следующим образом: читается значение из области памяти, указанное первым операндом и блокировка шины после чтения не снимается. Затем происходит сравнение значения по адресу памяти с регистром eax, где хранится ожидаемое старое значение, и если они были равны, то процессор записывает значение второго операнда (регистр ecx) в область памяти, указанную первым операндом. По завершении записи блокировка шины снимается. Особенности x86 в этом, что запись происходит в любом случае, за тем небольшим исключением, что если значения были не равны, то в область памяти заносится значение, которое было получено на этапе чтения из этой же области памяти.
Таким образом мы получаем работу в цикле с проверкой переменной, причем которая может окончиться неудачей и всю работу в цикле до проверки необходимо начинать заново.
Fetch-and-Add
Fetch-and-Add работает проще и не содержит никаких циклов (в архитектуре Intel осуществляется группой команд xadd). Также он включает 2 объекта-операнда: адрес ячейки памяти (V) и значение (S), на которое следует увеличить старое значение, хранимое по адресу памяти (V). Так, FAA можно описать в таком виде: получить значение, располагаемое по указанному адресу (V) и сохранить его временно. Затем в указанный адрес (V) занести сохраненное ранее значение, увеличенное на значение, которое из себя представляет 2 объект-операнд (S). Причем, все указанные выше операции выполняются атомарно и реализованы на аппаратном уровне.
В JDK 8 код выглядит так:
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
«Ноо, — скажете Вы, — чем данная реализация отличается от 7 версии»?
Тут приблизительно такой же цикл и все выполняется схожим образом. Однако, тот код, который вы видите и написан на Java не выполняется в конечном итоге на процессоре. Тот код, который связан с циклом и установкой нового значения заменяется в конечном итоге на одну операцию ассемблера:
lock xadd [esi+0xC], eax
Где, соответственно, в регистре eax хранится значение, на которое нужно будет увеличить старое значение, хранимое по адресу [esi+0xC]. Повторюсь, все выполняется атомарно. Но такой фокус сработает, если у Вас 8 версия JDK, иначе выполнится обычный CAS.
Что бы я еще хотел бы добавить...
Хочу тут отметить, что здесь упоминается протокол MESI, о котором можно почитать в очень хорошем цикле статей: Lock-free структуры данных. Основы: откуда пошли быть барьеры памяти.
Спасибо kmu1990 за уточнение перевода с англ.
- CAS является «оптимистичным» алгоритмом и допускает невыполнение операции, в то время как FAA нет. У FAA нет явной лазейки в виде уязвимости из-за удаленного вмешательства, следовательно, нет необходимости в цикле для повторных попыток.
- Если вы применяете стандартный CAS подход, предполагая, что ваша система использует наиболее популярную реализацию когерентности через snoop-base или «подслушивание», то это может вызвать read-to-share транзакцию, чтобы получить основную строку кэша или состояние E. CAS операция, по сути, переводит кэш линию в состояние M (Modified), для чего может потребоваться дополнительная транзакция. Таким образом, в самом худшем случае стандартный CAS подход может подвергнуть шину двум транзакциям, но реализация Fetch-And-Add будет стремиться провести передачу линии непосредственно до M состояния. В процессе вы бы могли спекулировать значениями и получать короткий путь без предварительных загрузок, как это пытается получить «голый» CAS. К тому же, это возможно при сложных реализациях процессора для выполнения согласованных операций и целевого исследования линии в M состоянии. Наконец, в некоторых случаях можно успешно вставить инструкцию предвыборки-для-записи (PREFETCHW) перед выполнением операций, чтобы избежать транзакции обновления. Но этот подход должен быть применен с особым вниманием, так как в некоторых случаях это может принести больше вреда, чем пользы. Учитывая все это, FAA, где это возможно, имеет преимущество. Другими словами (спасибо за подсказку jcmvbkbc) — что для того, чтобы сделать CAS нужно загрузить старое значение из памяти, что даёт два обращения к памяти, а чтобы сделать xadd старое значение загружать не нужно, и обращение к памяти нужно только одно.
- Допустим, вы пытаетесь увеличить переменную (например, инкрементировать) с помощью CAS цикла. Когда CAS начинает сбиваться достаточно часто, можно обнаружить, что ветвь для выхода из цикла (обычно возникает при отсутствии или легкой нагрузке) начинает прогнозировать ошибочные пути, которые прогнозируют нам, что мы останемся в петле. Поэтому, когда CAS в конечном счете достигнет цели, вы словите branch mispredict (ошибочное предположение ветви) при попытке выйти из цикла. Это может быть болезненно на процессорах с глубоким конвейером и привести к целому вороху out-of-order (внеочередные исполнения) спекуляций машины. Как правило, вы не хотите, чтобы этот кусок кода приводил к потерям скорости. В связи с выше сказанным, когда CAS начинает часто терпеть неудачу, ветвь начинает прогнозировать, что управление остается в цикле и в свою очередь, цикл работает быстрее за счет удачного предсказания. Как правило, мы хотим некоторого back-off в цикле. И при легкой нагрузке с нечастыми неудачами branch mispredict служит в качестве потенциального неявного back-off. Но при более высокой нагрузке мы теряем преимущество back-off, вытекающих из branch mispredict. У FAA нет циклов и никаких проблем.
Тесты
Ну и напоследок я написал простенький тест, который иллюстрирует работу атомарного инкрементирования в JDK 7 и 8:
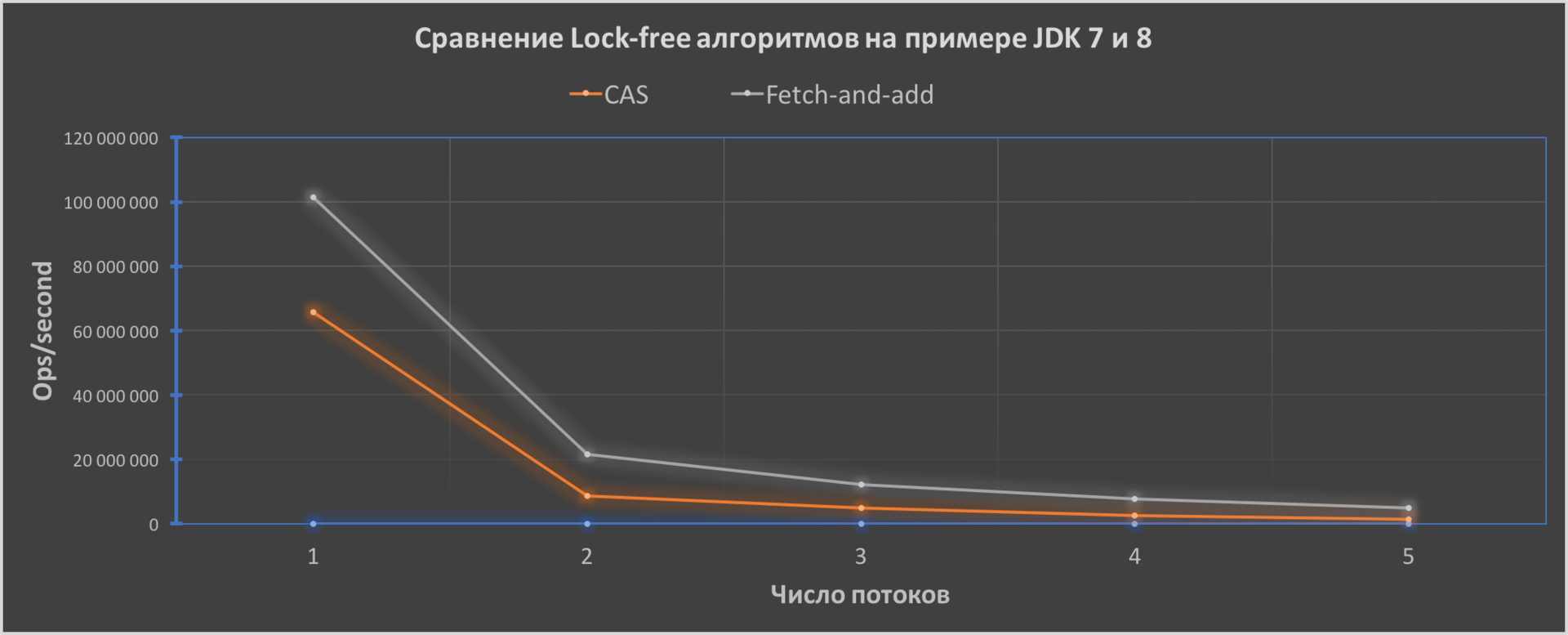
Как мы видим, производительность кода у FAA будет лучше и его эффективность увеличивается с увеличением числа потоков от 1.6 раза до приблизительно 3.4 раза.

Версии Java для тестов: Oracle JDK7u80 и JDK8u111 — 64-Bit Server VM. CPU — Intel Core i5-5250U поколения Broadwell, OS — macOS Sierra 10.12.2, RAM — 8-Gb.
Ну и если интересно, ссылка на код теста — исходники теста.
Жду замечаний, улучшений и прочее.
Комментарии (30)

lany
06.01.2017 19:03+2Тесты не пробовали в JMH делать? Снимает многие вопросы к методологии.
И, кстати, для полноты обзора может в LongAdder ещё поглядеть? Если надо много добавлять и редко считывать общую сумму (частый сценарий при наборе всякой статистики), то должно быть существенно быстрее.
И про MESI бы пару общих слов. Не все знают, что такое "состояние E", и гуглить по букве E трудно.

jcmvbkbc
07.01.2017 15:50Если вы используете типичную нагрузку CAS идиомы, предполагая нормальный snoop-base когерентности кэша (подслушивание или snooping, это часто употребимая реализация когерентности в многоядерных системах), то нагрузка может вызывать read-to-share транзакцию, чтобы получить основную строку кэша в S или состояние E. CAS, который имеет эффективную память семантик в отношении протоколов когерентности кэшей, может вызвать другую транзакцию шины, чтобы обновить линию для M состояния. Таким образом, в самом худшем случае идиома может подвергнуть шину двум транзакциям, но реализация XADD будет стремиться провести передачу линии непосредственно в M состоянии. В процессе вы могли бы спекулировать значениями и получать короткий путь, который пытается получить «голый» CAS без предварительных загрузок. К тому же, это возможно для сложных реализаций процессора для выполнения согласованных спекуляций и целевого исследования линии в M состоянии. Наконец, в некоторых случаях можно успешно вставить инструкцию предвыборка-для-записи (PREFETCHW) до нагрузки, чтобы избежать транзакции обновления. Но этот подход должен быть применен с тщательностью, так как в некоторых случаях это может принести больше вреда, чем пользы. Учитывая все это, XADD, где это возможно, имеет преимущество.
Вы не могли бы перевести этот текст до конца на русский? Действительно ли сказанное здесь вытекает из вышесказанного?
Priest512
07.01.2017 16:56Вы имеете введу внести больше ясности в терминологию — про snoop-base, про MESI и прочее?
kmu1990
07.01.2017 17:16Дело не в терминологии, ваш перевод просто некорректен грамматически. И вообще по хорошему стоит приводить ссылку на оригинал.
Priest512
07.01.2017 17:24Придерживаюсь вашего мнения, к сожалению среди знакомых нет людей с хорошим опытом перевода, чтобы корректировать недочеты. Поэтому, если есть возможность, прошу оказать мне помощь в столь деликатном деле))
kmu1990
07.01.2017 17:27+1Во-первых, если вы не можете переводить, то зачем беретесь.
Во-вторых, не нужно быть знатоком языков, чтобы увидеть, что текст из цитаты выше выглядит очень странно, достаточно более или менее знать русский.
В-третьих, не нужно переводить, если вы понимаете смысл, достаточно этот смысл описать своим языком.
jcmvbkbc
07.01.2017 18:00+1Я имею в виду вот что: над списком, второй пункт которого я процитировал, вы написали: «Из выше сказанного. В результате, что мы имеем:». Но до этого вы ни разу не упоминали детали реализации такого низкого уровня. Я не вижу, как этот пункт вытекает из сказанного вами выше.
Если вы хотели сказать, что для того, чтобы сделать CAS нужно загрузить старое значение из памяти, что даёт два обращения к памяти, а чтобы сделать xadd старое значение загружать не нужно, и обращение к памяти нужно только одно, то можно было так и сказать.
Ну и про грамматику уже вам сказали.Priest512
07.01.2017 18:15Ага, подкорректировал) Насчет изменений, хотел по идее оставить по протоколу MESI изменения, которые происходят, но в целом Ваш вариант мне понравился. Спасибо
kmu1990
07.01.2017 18:25Compare-And-Swap имеет эффективную память семантик по отношению к протоколам когерентности кэшей, что может вызвать другую транзакцию шины, чтобы обновить линию до M состояния.
Нет не подкорректировали, в оригинале это предложение имеет следующий смысл: CAS операция, по сути, переводит кеш линию в состояние Modified, для чего может потребоваться дополнительная транзакция. Никакой эффективной памяти семантик в оригинальном тексте нет.Priest512
07.01.2017 18:41Ну как я понимаю это предложение, то тут подразумевается SMR — safe memory reclamation (отложенное физическое удаление) для решения проблем ABA-проблем? Поэтому использование «эффективное хранение семантики» не уместно? Или я что-то не так до конца понял?
kmu1990
07.01.2017 18:46The CAS, which effectively has store semantics with respect to the cache coherence protocol, may induce another bus transaction to upgrade the line to M state.
Это оргинальное предложение. В нем нет ни слова про SMR, ABA и прочее, так что вы, очевидно, совершенно не понимаете это предложение. Фраза «effectively has store semantics» дословно переводится как «по сути (effectively), имеет семантику (has semantics) сохранения (store)», никакого «эффективного хранения семантики» там нет.Priest512
07.01.2017 18:51-1Большое Вам спасибо за разъяснение! С английским туго, учил немецкий, приходится изучать на ходу все :)

kibb
07.01.2017 18:44x86 уже 20 лет, со времен Pentium Pro, не лочат шину, все делается в M состоянии строки кеша.
И x86 процессоров, которые поддерживают cmpxchg, но не умеют xadd, не бывает. Обе инструкции появились в 486.
kmu1990
Я не очень понял суть статьи, немогли бы вы разяснить зачем вы сравниваете Fetch-And-Add с Compare-And-Swap? Это не равнозначные операции, они не решают одну задачу — какой толк от этого сравнения?
Кроме того, используемые архитектуры не ограничиваются одним только x86, и атомарные операции не ограничваются CAS и FAA, есть еще например LL/SC (которые по общности, в отличие от FAA, на равне с CAS).
Priest512
В рамках реализации Java они делают к примеру, атомарные операции инкрементирования. Причем в разных версиях 7 и 8 соответственно используется CAS и FAA. То есть один и тот же код на разных версиях будет иметь разную производительность.
kmu1990
Перечитав статью я осознал, что вы сравниваеие не Fetch-And-Add с Compare-And-Swap, а две разные реализации Fetch-And-Add — моя ошибка, прошу прощения. Но все равно вопросы о ценности вашего сравнения остаются.
Во-первых, производительность одной атомарной операции совсем не обязательно значительно влияет на производительность всего алгоритма в целом.
Во-вторых, сама операция, которую вы тут измеряете в зависимости от условий будет иметь разную производительность даже на одной версии Java, например, если алгоритм использующий FAA (не важно как он реализован) спроектирован так идеально, что к атомарной переменной мы почти всегда обращаемся с одного CPU, то ее стоимость будет меньше, чем если за доступ к переменной одновременно борются много CPU.
В-третьих, как я уже писал, используемые архитектуры не ограничваются x86.
Отсюда вопрос, в чем ценность сравнения? В каком контексте ваши результаты окажутся применимыми?
Priest512
В 7 версии у нас используется цикл для атомарной установки нового значения переменной. Исходя из этого — в случае большой нагрузки и высокой конкурентности потоков мы будем ловить branch mispredict — ошибочное предсказание ветвления, который приводит, например, к перезагрузке конвейера процессора и всяким дополнительным издержкам, вроде out-of-order. В 8 версии мы полностью лишены цикла и всех связанных с ним издержек во время работы, таким образом получаем профит от использования новой версии и в моем понимании, все операции (то есть уже написанный код или системы), которые имеют атомарные операции с данными будут работать быстрее в каком-то определенном числе сценариев использования. Например, потокобезопасные коллекции иметь более высокую производительность. В моем понимании я вижу это так)) Поправьте, если я не так Вас понял)
kmu1990
Какой-то неопределенный ответ. Вы знаете хоть один конкретный алгоритм, который использует FAA и измеримо выиграет в производительности от перехода к Java 8 по причине изменения реализации FAA?
Кроме того, FAA все еще атомарная операция, так что для ее выполнения в архитектурах с когерентными кешами все равно придется повозиться, так что при высокой конкуренции совсем не факт что branch misprediction будет оказывать влияние по сравнению с накладными расходами на коммуникацию между CPU и поддержку когерентности. И эти расходы тем больше чем больше у вас ядер, а ваш low-voltage CPU из тестов не тянет на мощный CPU с кучей ядер (я абсолютно безосновательно предполагаю, что у вашего всего 2 настоящих ядра, каждое с HT). Т. е. на другой машине, возможно, и результаты другие.
Priest512
CounterMonitor или LinkedBlockingQueue, например, использует FAA в своей реализации. Это в исходниках самой Java. Затем, да, вы совершенно правы, физически у меня 2 ядра на машине)). Однако, на своем опыте замечал, что результат от перехода есть, когда тестил один и тот же код в в своей программе на разных версиях JDK, когда изменения счетчика происходили с частотой 100-200 раз за секунду и испытания проводились на серверном процессоре, результат был в целом хороший. Конечно, там было не так много потоков (2-3), соревнующихся между собой, однако профит все же был.
kmu1990
Во-первых, откуда вы знаете, что выигрышь именно от реализации FAA, а не от каких-то других изменений при переходе от Java 7 к Java 8.
Во-вторых, эти измерения и стоило привести, измерения отдельно взятой операции не наглядны.
Priest512
В целом на тот момент у меня производительность кода зависела как раз от FAA реализации. Это была часть системы (которую я сам полностью и писал) и для этой части у меня как раз был написан простой тест, который тупо отправлял данные в большом количестве и потом же забирал одновременно. По поводу измерений, в целом, возможно Вы и правы, но картина будет схожей, только пиковые значений выше. Но как появится возможность, я все же гляну на результаты на серверной машине ради интереса
kmu1990
Вы все воду льете, а я прошу конкретики. Конкретный код, конкретный сопособ измерения, конкретные результаты измерения. На каком основании был сделан вывод, что именно FAA — узкое место, или, как это часто бывает, «это было очевидно»?
Я не поверю ни в жизнь, что измерения реализации любого конкурентного алогритма, которой не посчастливилось использовать FAA будет давать схожую картину с измерениями отдельно взятой FAA. Так что хотелось бы таки услышать конкретики про то, где и как вы используете FAA, что она вдруг стала узким местом.
Priest512
Я согласен с Вами в том, что алгоритм, который стоит на FAA и отдельно взятый FAA не будут давать ну очень схожие результаты. По поводу конкретики, ждите после праздников как доберусь до рабочего места и сообщу Вам о результатах, потому как когда я готовил эту статью, я старался делать больше упор на общих вопросах и целью было донести разницу реализаций 7 и 8 версии и пытаться показать на очень простых примерах.
Priest512
Да, на 4-х ядерной машине (с физическими и 8 виртуальными) наблюдалась схожая картина
jcmvbkbc
LL/SC круче CAS, поскольку оно не страдает от проблемы ABA.
kmu1990
С практической точки зрения разница конечно есть, с теоретической точки зрения операции равномощны, т. е. CAS можно реализовать используя LL/SC и наоборот, LL/SC можно реализовать используя CAS, хотя практичность второй реализации вызывает вопросы.