ААБ-тест или ABA-тест — это когда трафик делят на три части: первую и вторую направляют на сайт без изменений, а третью с изменениями.
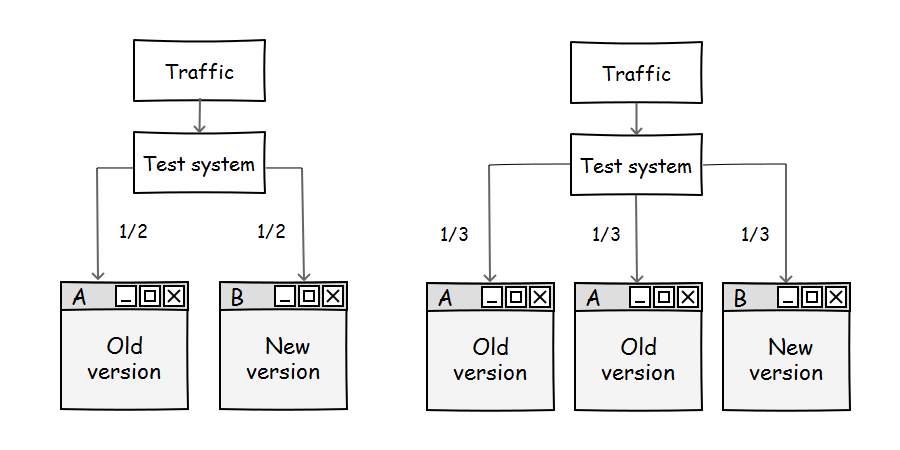
Что это дает?
- Выше точность теста. Считаем, что Б дает относительно достоверный результат только когда А и А сравняются.
- Видны резкие колебания значений А и А, легче понять какой из факторов, искажающих тест в этот момент повлиял.
- Получаем время и количество данных необходимое для будущих тестов.
Факторы, искажающие результаты тестов
1. Недостаточное количество трафика/операций
Вывод делается рано, высокая погрешность.
2. Некорректная ротация
Система или скрипт, который занимается ротацией не дает произвольного и равномерного распределения между блоками теста.
3. Неполная кроссбраузерность
В каком-то из браузеров изменения работаю неправильно. Группа пользователей данного браузера может иметь особенности. Исключение их из теста искажает его результат.
4. Влияние устройств
На разных устройствах изменения могут выглядеть по-разному. Например, на больших экранах небольшие детали не так заметны.
5. Эффект новизны
Пользователи заметили новый элемент на сайте или его изменение, больше на это обращают внимание и он в первое время работает лучше.
6. Эффект привыкания
Пользователи привыкли к каком-то элементу и не замечают его изменение, работают с ним как со старым.
7. Непопадание в покупательский цикл
Во время оценки конверсии период теста может не совпасть с циклом, в который происходит покупка. Другие факторы могут сработать раньше, а на время теста пользователи уже будут подготовленными, тест покажет некорректный результат. Также, у покупательского цикла может быть длительный или отложенный эффект и он не попадет в результаты теста.
8. Другие изменения
Чистого теста добиться очень сложно, во время его проведения могут произойти другие изменения на сайте. На первый взгляд может показаться, что они не связаны, но это косвенно повлияет на тест.
9. Сезонные факторы, распродажи и изменение товарных остатков и другие.
Что можно сделать, чтобы уменьшить эти влияния?
- проводить сплит-тест только на новых пользователях или на новых и старых отдельно.
- использовать несколько систем для контроля.
- выделить на тест отдельный источник трафика.
- делать AAБ-тесты.
Минимальные значения для тестов
По моему опыту это:
для рекламных кампаний 500.000, срок 2 недели.
для конверсии сайта: 500 транзакций, 2 месяца.
для оценки небольших изменений на сайте: 3 тысячи сеансов, неделя.
У каждого проекта цифры свои и определить их поможет как раз ААБ-тест.
А что делать, если нет такого количества на сайте?
- Смириться, что сплит-тесты пока у вас не работают.
- Оставить тесты работающими, пусть набирают статистику.
- Использовать другие способы проверки гепотез (опросы, изучение конкурентов, оценка поведения пользователей).
- Работать над минимизацией искажений в будущих тестах. Когда-то придет их время, а вы уже готовы.
Классическое АБ-тестирование
По этому поводу написано много, не вижу смысла повторяться. Пожалуй, имеет смысл дать ссылки на сервисы, с помощью которых можно делать тесты в том числе многовариантные:
Эксперименты в Google Analitycs — отличный вариант для новичка.
Changeagain.me, Convert.com, Vwo.com, Optimizely.com — мощные, платные сервисы с интеграцией с аккаунтом в Google Analytics.
A/Bingo — серверные фреймворки для Ruby.
В рекламной системе Google Adsense функция эксперименты тоже есть.
Отмечу также Онлайн-калькулятор критериев значимости сплит-теста

и сервис построения графиков по его результатам.
АА-тестирование
Для оценки корректного времени и необходимого количества данных иногда применяют АА-тесты, когда на тест ставят одно и то же, без изменений. Этот подход имеет право на жизнь, но он занимает отдельное время. Кроме того, с момента проведения АА до проведения АБ-теста что-то может измениться.
Плюсы и минусы AАБ
Подводя итоги можно сказать, что ААБ-тесты требуют больше ресурсов (трафика, времени, денег), но дают более точный и уверенный результат. Для его улучшения также применяют систему ААББ. В любом случае, для нового проекта или типа изменений стоит сделать один-два раза именно ААБ-тест, затем можно перейти на классические АБ.
Всем хороших тестов!
Смотрите также: Как получить максимальный доход с рекламных систем на своем сайте.
Комментарии (20)

TimurGilfanov
12.03.2017 17:30Идея вредная и показывает непонимание АБ–тестирования. Для принятия решения об остановки теста достаточно расчёта необходимой выборки, например с помощью этого калькулятора.
Если А1 и А2 сравнялись по показателям, то без достаточного числа выборки это не значит ничего. Это может быть временное случайное явление совпадения значений внутри очень больших доверительных интервалов. И наоборот, они могут отличаться на какое-то значение, но разница меньше доверительного интервала и следует считать их равными.
Если введением второй А вы пытаетесь решить проблему искажающих факторов то вы просто неправильно проводите тесты. В А и Б должны отличаться только проверяемся вещь, а все остальные факторы быть одинаковыми. Иначе непонятно какой из факторов дал отличие в метрике. Ну и непонятно каким образом введение второй А нейтрализует хотяб один из приведённых искажающих факторов.
izhanov
12.03.2017 18:12+3Идея вредная
Получить еще один инструмент, который поможет не сделать преждевременные выводы — вредно?
Для принятия решения об остановки теста достаточно расчёта необходимой выборки, например с помощью этого калькулятора.
Недостаточно. Калькулятор показал статистически значимую выборку. Практика показала, что А и А значительно расходятся. Смотрим, разбираемся где искажения.
Если А1 и А2 сравнялись по показателям, то без достаточного числа выборки это не значит ничего.
Да, если А1 и А2 сравнялись это не значит, что результат достоверный. Но если НЕ сравнялись — чрезвычайно высока вероятность, что он НЕдостоверный.
Фокус в том, что без достаточной выборки они могут сравняться только случайно. То есть, речь не об уменьшении выборки относительно калькулятора, скорее об увеличении.
Ну и непонятно каким образом введение второй А нейтрализует хотяб один из приведённых искажающих факторов.
Именно увеличением периода или объема для теста. Ну и дополнительным индикатором, который поможет выявить факторы влияния. В жизни их трудно избежать, идеальных условий для теста на реальном проекте не создать.
TimurGilfanov
12.03.2017 21:42+1По–моему, достаточно один раз запустить АА–тест чтобы проверить правильно ли вы делаете тесты. Но расходовать треть выборки на такую проверку в каждом тесте — это чрезмерная неуверенность в своей системе. Если вы ей настолько не доверяете — разберитесь как она работает и исправьте её.
izhanov
12.03.2017 22:11+3Странная ситуация с этим постом, Тимур.
В комментариях просто повторяю то, что уже написано в статье. Продолжу:
По поводу АА-теста.
Именно он — лишний расход времени и ресурсов. Вы трижды делаете А, вместо двух. Кроме того, что гораздо важнее, условия при АА тесте и при АБ могут быть разные (они делаются в разное время), чего нет при ААБ.
Про расходовать в каждом тесте:
В выводе писал, что можно ААБ каждый раз не делать, только пока не отладится тест.
Одно радует. Вы хотя бы не анонимный комментатор, что по моему наблюдению здесь редкость.TimurGilfanov
13.03.2017 14:42-1Этот вывод действительно пропустил. Често сказать, статью читать было тяжело, поэтому пробежался по диагонали. Возможно, поэтому вам приходится в ответах цитировать свою статью. Сама статья, взять даже название, про то что, ААБ лучше АБ, а выводе скромно написано, что может быть и не всегда.
izhanov
13.03.2017 15:26Ну прикольно, чо. Пастернака не читал, но осуждаю.
Никакого «может быть» в моем выводе нет. ААБ лучше, чем просто АБ. И лучше, чем АА + АБ, да.TimurGilfanov
13.03.2017 15:32-1Пастернак хорошо писал, не сравнивайте.
izhanov
13.03.2017 15:55А вы, оказывается, не только статьи не читаете перед комментированием. Но и крылатые выражения не знаете. Оокей.
TimurGilfanov
13.03.2017 17:03-1Извините, я всю дорогу пытаюсь вам намекнуть, что статью никто не понял, потому что она плохо, путано и неинтересно написана. А не потому что все такие невнимательные. Но, видимо, без прямых как железная дорога слов это никак не сделать. Поэтому суть обсудить не получается, а всё скатывается к «я же вот тут писал».
izhanov
13.03.2017 17:38То есть, я сам виноват, что вы не прочли статью прежде, чем судить о ней и кидать громкие заявления. И вообще она неинтересная, поэтому в первый раз в этом году вы откомментировали именно ее из тысячи других.
Хорошо, хорошо, я же не спорю. Только остановитесь, пожалуйста, это какой-то сюр.TimurGilfanov
13.03.2017 20:26Я честно пытался понять, что написано в статье, но не смог. И да, вы в этом виноваты.

rhangelxs
Что я только что сейчас прочитал? При наличии корректно проведенной рандомизации двух групп (A и B) будет достаточно. Ключевое слово — корректно. Если, например, есть сомнение в самой системе которая занимается балансировкой пользователей по группам, то можно провести один раз A/A. Но не каждый же раз подмешивать вторую A группу…
Плюс, хочу обратить внимание на то, что такая схема может быть путой тратой мощности (power), ведь размер групп уже на старте предполагается не одинаковый.
izhanov
Вы прочитали мое личное мнение, выраженное и аргументированное в виде статьи.
Ответы на все вопросы, что вы написали в ней есть.
Недостаточно. Кроме некорректной рандомизации есть еще масса факторов, искажающих тест. Этому посвящен целый абзац.
Отдельно АА занимает время и ресурсы. С его проведения до последующего проведения АБ ситуация может измениться. Тоже написано.
Да, для ААБ тратятся ресурсы, это тоже написано в выводах. Почему это имеет смысл написано вначале.
Хотите одинаковый, сделайте ААББ. Хотя, как раз в этом особенного смысла нет.
amakhrov
Перечень факторов в статье действительно есть. Но статья не отвечает на вопрос, как ААБ помогает с этим бороться. Не могли бы вы раскрыть эту тему подробней?
Ну, то есть мне интуитивно понятно про факторы 1 и 2. А все остальные уже вызывают вопросы.
Спасибо.
izhanov
Не бороться, а скорее диагностировать и нивелировать.
Видим, что А и А не сходятся даже при достаточной выборке, это значит есть факторы искажения. Смотрим другой период, если А и А сошлись, значит факторы были в первый период, думаем что это могло быть.
А нивелируются так: Если просто со временем/объемом продолженного теста А и А сошлись, значит влияние факторов стало статистически незначительным и и тест уже более-менее достоверный.
Можно еще сравнивать насколько расходятся А и А в процентах (после достижения значимой выборки), колебания их разницы, чтобы понимать силу искажающих факторов. Условно, если А и А разнятся на 10%, а Б у нас дает лучше результат на 20%, то нельзя считать, что изменение дало положительный результат.
Всего этого простой АБ-тест не даст.
amakhrov
А как, допустим, фактор "эффект новизны" приведет к расхождению А и А? Они же идентично "новые" (или "старые" — смотря что мы берем за А).
С остальными факторами у меня такое же непонимание. Они же одинаково влияют на А и А — расхождения из-за них не будет. Расхождение будет только из-за проблем с рандомизацией или недостаточным объемом трафика (первые 2 фактора).
izhanov
Эффект новизны и эффект привыкания ААБ тестом не диагностируется, для этого надо делить старых пользователей и новых.
Весь фокус в том, что будет. Представим, что в ИЕ сайт работает некорректно, нельзя оформить заказ. А мы сравниваем и считаем конверсию. Юзер на ИЕ из группы А1 дошел до оформления и отвалился. Чтобы компенсировать эту ситуацию надо, чтобы другой юзер на ИЕ уже из А2 тоже не оформил заказ. Пока это не произошло возникает перекос, которого без этой проблемы с ИЕ не было бы.
Чем больше таких факторов, тем больше время/объем, которые необходимы для корректного теста.
amakhrov
А, теперь ясно.
По сути, это вариации на тему недостаточного трафика (первый фактор). Если для какой-то группы юзеров что-то не работает, грубо говоря считаем, что от них трафика нет. То есть ААБ говорит нам о недостаточности выборки, когда мы априорно считали, что выборка уже должна быть значимой.