SO_REUSEPORT, которая доступна в современных версиях операционных систем, таких как DragonFly BSD и Linux (ядра 3.9 и новее). Данная опция разрешает открывать сразу несколько слушающих сокетов на одном и том же адресе и порту. При этом, ядро будет распределять входящие соединения между ними.(В NGINX Plus эта функциональность появится в выпуске 7, который выйдет позже в этом году.)
У опции
SO_REUSEPORT есть множество потенциальных вариантов применения для решения различных задач. Так, некоторые приложения могут использовать её для обновления исполняемого кода на лету (NGINX всегда имел такую возможность с незапамятных времен, используя иной механизм). В NGINX включение данной опции увеличивает производительность в отдельных случаях за счет уменьшения блокировок на локах.Как показано на рисунке, без
SO_REUSEPORT один слушающий сокет разделен между множеством рабочих процессов и каждый из них пытается принимать от него новые соединения:
С опцией
SO_REUSEPORT у нас есть множество слушающих сокетов, по одному на каждый рабочий процесс. Ядро операционной системы распределяет в какой из них попадет новое соединение (а тем самым какой из рабочих процессов его в итоге получит):
Это позволяет на многоядерных системах уменьшить блокировку, когда множество рабочих процессов одновременно принимают соединения. Однако, это также означает, что когда один из рабочих процессов заблокировался на какой-нибудь долгой операции, то это скажется не только на соединениях, которые им уже обрабатывает, но также и на тех, что еще ожидают в очереди.
Конфигурация
Для включения
SO_REUSEPORT в модулях http или stream достаточно указать параметр reuseport директивы listen, как показано в примере:http {
server {
listen 80 reuseport;
server_name example.org;
...
}
}
stream {
server {
listen 12345 reuseport;
...
}
}
Указание
reuseport при этом автоматически отключает accept_mutex для данного сокета, поскольку в данном режиме мьютекс не нужен.Тестируем производительность с reuseport
Измерения производились с помощью wrk, используя 4 рабочих процесса NGINX на 36 ядерном AWS инстансе. Чтобы свести к минимуму сетевые издержки клиент и сервер работали через loopback-интерфейс, а NGINX был сконфигурирован для отдачи строки
OK. Сравнивались три конфигурации: с accept_mutex on (default), c accept_mutex off и с reuseport. Как видно на диаграмме, включение reuseport в 2-3 раза увеличивает количество запросов в секунду и уменьшает задержки, а также их флуктуацию.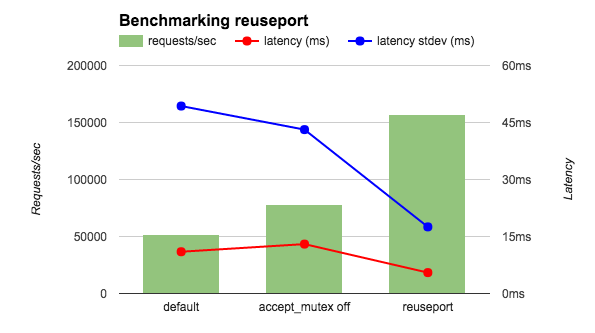
Также были проведены замеры, когда клиент и сервер были запущены на разных машинах и запрашивался html-файл. Как видно из таблицы, с
reuseport происходит снижение задержек, аналогичное предыдущему замеру, а их разброс снижается еще сильнее (почти на порядок). Другие тесты также демонстрируют хорошие результаты от использования опции. С использованием reuseport нагрузка распределялась равномерно по рабочим процессам. С включенной директивой accept_mutex наблюдался дисбаланс в начале теста, а в случае отключения все рабочие процессы занимали больше процессорного времени.| Latency (ms) | Latency stdev (ms) | CPU Load | |
|---|---|---|---|
| Default | 15.65 | 26.59 | 0.3 |
| accept_mutex off | 15.59 | 26.48 | 10 |
| reuseport | 12.35 | 3.15 | 0.3 |
В данных тестах частота запросов была крайне высокой, при этом они не требовали какой-либо сложной обработки. Различные наблюдения подтверждают, что наибольший эффект от применения опции
reuseport достигается когда нагрузка отвечает данному паттерну. Таким образом, опция reuseport не доступна для модуля mail, поскольку почтовый трафик однозначно не удовлетворяет данным условиям. Мы рекомендуем всем производить собственные замеры, чтобы убедиться в наличии эффекта от reuseport, а не слепо включать опцию везде, где только это возможно. Некоторые советы по тестированию производительности NGINX вы можете почерпнуть из выступления Константина Павлова на конференции nginx.conf 2014.Благодарности
Спасибо Sepherosa Ziehau и Yingqi Lu, каждый из которых предложил собственное решение для работы
SO_REUSEPORT в NGINX. Команда NGINX использовала их идеи для реализации, которую мы считаем идеальной.
Комментарии (27)

sebres
03.06.2015 13:36+3включение reuseport в 2-3 раза увеличивает количество запросов в секунду
Подтверждаю, пробовал на siege, в моем случае не в 2-3 раза, но на реальном тесте, а не«OK»«hello, world» — мелкий (1,5K) и быстрый реквест, 15 tester, 6 nginx-worker, 4x2 core cpu:
with reuseportTransactions 5099 hits Availability 100.00 % Elapsed time 2.97 secs Data transferred 7.86 MB Response time 0.00 secs Transaction rate 1716.83 trans/sec Throughput 2.65 MB/sec Concurrency 14.90 Successful transactions 5099 Failed transactions 0 Longest transaction 0.11 Shortest transaction 0.00
zhovner
03.06.2015 14:45nginx: [emerg] reuseport is not supported on this platform
Ядро 3.18.5-x86_64
nginx/1.9.1 из официальных deb репозиториевsebres
03.06.2015 15:19оно просто собрано там без
SO_REUSEPORT
#if (NGX_HAVE_REUSEPORT) ... #else log("reuseport is not supported on this platform, ignored"); #endif

VBart Автор
03.06.2015 15:49А какой дистрибутив? Вероятно в нём старая версия glibc.

evnuh
03.06.2015 16:15+1Вы, скорее всего, в курсе. За счёт чего такой выйгрыш? Я так понимаю, чтобы засигналить один воркер, а не все сразу, ОС должна линеаризовать доступ к порту. То есть. по сути, то, что раньше делал accept_mutex, сейчас делает сама ОС. Почему перекладывание ответственности дало такой выйгрыш? Неужели синхронизация nginx была тяжелее, чем ос?
VBart Автор
03.06.2015 17:05+2Чтобы положить соединение в очередь или забрать из очереди ядро берет лок на сокете. Один единственный сокет на множество процессов при высокой частоте поступления новых соединений становится бутылочным горлышком. Получается так, что за один лок конкурирует ядро с множеством процессов.
Имея отдельный сокет на каждый процесс, мы также имеем отдельную очередь и отдельный лок, за который конкурирует только ядро и всего один процесс. Соответственно lock contention снижается в разы на многоядерных системах с множеством рабочих процессов.
accept_mutex тут не причем, это просто еще один лок, который не вносит ничего нового, потому что у нас все равно есть лок в ядре.evnuh
04.06.2015 18:35Вы меня не поняли, или я вас не понимаю. Физически то данные, пришедшие на один порт, хранятся в одном месте в ядре (не уверен, что это так, не силён в сетях), А сокетов много. И тут опять проблема сериализации доступа, только уже сокетов. А раньше был один сокет, но много слушателей, всё та же проблема сериализации, только уже слушателей. Или я где-то ошибаюсь? Если я прав, то проблема, по факту, не исчезла, просто теперь её решает ядро, а не nginx. Вот я и спрашиваю, почему стало быстрее.
sebres
04.06.2015 19:29Это вы не поняли, или фраза про бутылочное горлышко вам ничего не говорит? Один listener (с локом) при большом количестве входящих соединений на него — означает неоправданную конкуренцию, т.е. множественное переключение контекста и иже с ним.
«Клонирование» же listener соответственно и очередей (для каждого процесса-воркера по одной) позволяет избавится как минимум от контекст-свича между всеми воркерами (за лок борется только ядро и сам воркер, а не другие).
А то, что вы имеете ввиду под «переложением работы на ядро» — это совершенно другая история.
Во первых, у ядра гораздо больше возможностей организовать оптимальное распределение входящих соединений, да и сам «проброс» установления соединения до каждого listener. А некоторые вещи в принципе можно и нужно организовать только в ядре. А то так и до написания собственного tcp-стека недалеко.
Во вторых, как оно собственно сделано в ядре вы на досуге можете в исходниках оного глянуть — головную боль до завтра я вам гарантирую.
В третьих, использовать reuseport на самом деле очень просто — главная проделанная работа, заключалась в «правильном» вписывании его в nginx, чтобы значит усе стабильно было, например reuseport с reload на лету (когда воркеры перезагружаются для новой конфигурации) и т.д.VBart Автор
04.06.2015 19:55у ядра гораздо больше возможностей организовать оптимальное распределение входящих соединений
Не совсем так. Точнее даже совсем не так. Ядро понятия не имеет, когда тот или иной рабочий процесс освободится и сможет забрать соединение. Сейчас Linux просто раскладывает их псевдослучайно. Такое распределение хорошо только в том случае, если у нас все соединения одинаковые с точки зрения ресурсов, которые потребуются для их обработки. Но это более-менее так только в синтетических тестах. В реальности все сложнее. И какому-то из рабочих процессов могут в итоге насыпать тяжелых запросов в то время, как другой будет простаивать.sebres
04.06.2015 20:08Я имел ввиду оптимальные в смысле архитектуры проброса от порта до listener, не в смысле оптимизации распределения как такового. Про псевдослучайность последнего знаю, но пока по другому никак. Хотя видел как-то один алгоритм, если не ошибаюсь в solaris, там вводилось понятие веса очереди, «перемещением» в топ «ложились» очереди наименее полные. Т.е. как бы не совсем псевдослучайное, а с учетом «веса» очереди в топе.
evnuh
04.06.2015 21:27Я теперь понял, что никакой сериализации сокетов больше нет, грубо говоря, epoll() и т.д. так же больше не нужны? Теперь ядро само пробуждает потоки по очереди?
Как было:
все воркеры спят -> new socket data -> notification всех воркеров -> все воркеры вступают в борьбу за лок -> один захватывает лок и принимает коннект, остальные засыпают
Как стало:
воркеры спят в accept() -> new socket data -> ядро выбирает любой воркер, пробуждает и т.д.
В связи с этим, распределение коннектов теперь делает ядром, которое не в курсе, что воркер занят. Посему может напихать ему коннектов, так? Тогда штука реально опасная, особенно учитывая политику распределения коннектов. Какой-нибудь залогиненный пользователь для которого страница генерируется гораздо дольше чем для анонимного всегда будет попадать на один и тот же воркер, забивая его.
UPD: увидел новые комментарии, стало понятно, что правsebres
04.06.2015 21:34nginx — асинхронный сервер, т.е. будет у какого либо воркера «очередь» длиннее и только. Реально же нужно оценивать совокупность всех вместе…
VBart Автор
04.06.2015 22:56Я теперь понял, что никакой сериализации сокетов больше нет, грубо говоря, epoll() и т.д. так же больше не нужны? Теперь ядро само пробуждает потоки по очереди?
Epoll никуда не делся, он всегда был отдельный в каждом рабочем процессе. Помимо принятия новых соединений, рабочие процессы делают много другой работы: читают запросы, отправляют ответы, обрабатывают таймауты, устанавливают соединения с бекендами. Рабочий процесс не может ждать на accept(), ему нужно работать с другими событиями, мониторить другие дескрипторы. Поэтому нужен механизм уведомления о событиях.
Как было:
Если интенсивность поступления новых соединения маленькая — то да. Для борьбы с этим эффектом как раз и существует accept_mutex, который отключает нотификацию у отдельных процессов в этом случае. Это можно видеть во втором бенчмарке, его включение снижает нагрузку на CPU.
все воркеры спят -> new socket data -> notification всех воркеров -> все воркеры вступают в борьбу за лок -> один захватывает лок и принимает коннект, остальные засыпают
Если нагрузка большая, как в первом бенчмарке в статье, то там всегда в общем-то есть новые соединения в очереди. И ситуаций когда рабочий процесс не получает соединения — практически не бывает. В этом случае accept_mutex скорее вредит, поэтому без него RPS получает немного выше. Тем не менее, лок в ядре никуда не девается, и когда несколько процессов одновременно зовут accept() на одном и том же сокете, то часть из них в итоге тратит на это больше времени, поскольку блокируются и вынуждены в ядре ждать своей очереди на получение лока.
Как стало:
См. выше. Воркерам не позволительно ждать на accept(), им нужно другие соединения обрабатывать.
воркеры спят в accept() -> new socket data -> ядро выбирает любой воркер, пробуждает и т.д.
Но то, что теперь будет уведомляться только один воркер, поскольку он мониторит только свои собственные дескрипторы, а не общие на все процессы — это верно. Но спать он по-прежнему будет в epoll_wait().
Тогда штука реально опасная, особенно учитывая политику распределения коннектов. Какой-нибудь залогиненный пользователь для которого страница генерируется гораздо дольше чем для анонимного всегда будет попадать на один и тот же воркер, забивая его.
Не настолько на самом деле. Псевдослучайное распределение будет раскидывать новые подключения от него случайным образом. С тем же успехом и раньше, установив keepalive соединение, можно было нагрузить запросами один рабочий процесс больше другого. Но в масштабах десятков и сотен тысяч соединений — все это довольно незначительные эффекты.
VBart Автор
04.06.2015 19:39С точки зрения приложения — слушающий сокет это дескриптор, по сути идентификатор, который передают в системном вызове. Со стороны ядра — это структура с данными, в частности с очередью соединений ожидающих accept'a. Поскольку к этой структуре могут обращаться одновременно из разных потоков, то она защищена локом.
Вот когда у нас был один сокет, то у нас была одна очередь и была ситуация, как вы назвали «данные, пришедшие на один порт, хранятся в одном месте». И была проблема сериализации доступа к этой очереди.
С множеством сокетов у ядра много очередей, причем к каждой отдельной очереди со стороны юзерспейса теперь обращается всего один процесс nginx. Меньше параллельного доступа — меньше блокировок на ожидании лока.
Да, множество сокетов с SO_REUSEPORT создают множество точек хранения данных пришедших на один адрес-порт.
«просто теперь её решает ядро, а не nginx»
У nginx не было проблемы, проблема всегда была в ядре и её всегда решало ядро. Теоретически разработчики ядра могли бы решить её и без необходимости вносить какие-либо изменения в приложения, но было проще сделать так, как сейчас сделали.

robert_ayrapetyan
03.06.2015 17:38Однако, это также означает, что когда один из рабочих процессов заблокировался на какой-нибудь долгой операции, то это скажется не только на соединениях, которые им уже обрабатывает, но также и на тех, что еще ожидают в очереди.
Можно поподробнее этот момент расписать, что тут имелось ввиду? По-вашему, ОС ждет завершения обработки запроса от процесса?
Кстати, в FreeBSD при REUSE распределение запросов на процессы не равномерное, а «лесенкой». Интересно, как с этим обстоят дела в других ОС.VBart Автор
03.06.2015 17:52+1В случае одного сокета на все рабочие процессы, мы имеем одну очередь соединений, ожидающих accept()-а. Когда один рабочий процесс заблокировался на долгой операции, другой освободившийся процесс может тем временем accept()-ить новые поступившие соединения.
Когда у нас много сокетов, то ядро разбрасывает соединения по их очередям (в Linux в этом месте используется псевдослучайное распределение). Поскольку каждая из этих очередей выстраивается к отдельному рабочему процессу, то когда тот блокируется, то увеличивается время ожидания всех находящихся в этой очереди, они уже не могут быть приняты другим воркером.
Во FreeBSD опция SO_REUSEPORT работает иначе, мы ее там не поддерживаем.

1it
03.06.2015 23:18В tengine эта фича где-то полгода назад появилась.
VBart Автор
03.06.2015 23:31+2Тут есть большая разница. Одно дело реализовать функцинальность и все будет работать, а другое дело реализовать функциональность и при этом сломать что-нибудь еще, например, релоад на лету без потери соединений. В tengine второй случай.
Тяп-ляп можно сделать быстро всё что угодно, просто у нас другой подход.1it
03.06.2015 23:38Согласен, у вас хороший подход. Но, честно говоря не заметил того бага про который вы сказали.
VBart Автор
03.06.2015 23:52+1Я код смотрел. Они просто открывают и закрывают сокеты прямо в рабочих процессах. Все соединения, которые ядро между последним accept()-ом и close() успеет сложить в этот сокет — будут дропнуты.
В nginx перезагрузка конфигурации и обновление на лету без потери соединений возможна только благодаря тому, что при всех этих процессах он никогда не закрывает сокеты. В нашей реализации все сокеты для каждого рабочего процесса открываются в мастере, а затем он форкается и рабочие процессы их наследуют. После этого мы можем сколько угодно раз обновить конфигурацию и форкнуть новые рабочие процессы все с тем же набором открытых сокетов, что и у процессов предыдущего поколения.
Просто вы не тестировали достаточно тщательно. Можете запустить Tengine, включить там SO_REUSEPORT, подать на него достаточную нагрузку с помощью wrk, а затем под этой нагрузкой поотдавать команды на обновление конфига или на обновление бинарника, посмотреть как он это переживет. Вот nginx при этом не потеряет ни одного запроса.

hostmaster
04.06.2015 13:07+1Ну вот, теперь каждая статья из серии «оптимизация производительности блога на wordpress» будет включать упоминание SO_REUSEPORT
UUSER
При добавлении этой опции начинает ругаться на:
Других директив listen нет.
VBart Автор
Посмотрите в других блоках server. Директива задает слушающий сокет, который может разделяться множеством виртуальных серверов, поэтому его параметры можно указывать только единожды.
UUSER
Понятно, то есть так делать нельзя:
Странноватенько.