 NGINX вполне заслуженно является одним из лучших по производительности серверов, и всё это благодаря его внутреннему устройству. В то время, как многие веб-серверы и серверы приложений используют простую многопоточную модель, NGINX выделяется из общей массы своей нетривиальной событийной архитектурой, которая позволяет ему с легкостью масштабироваться до сотен тысяч параллельных соединений.
NGINX вполне заслуженно является одним из лучших по производительности серверов, и всё это благодаря его внутреннему устройству. В то время, как многие веб-серверы и серверы приложений используют простую многопоточную модель, NGINX выделяется из общей массы своей нетривиальной событийной архитектурой, которая позволяет ему с легкостью масштабироваться до сотен тысяч параллельных соединений. Инфографика Inside NGINX сверху вниз проведет вас по азам устройства процессов к иллюстрации того, как NGINX обрабатывает множество соединений в одном процессе. Данная статья рассмотрит всё это чуть более детально.
Подготавливаем сцену: модель NGINX процессов
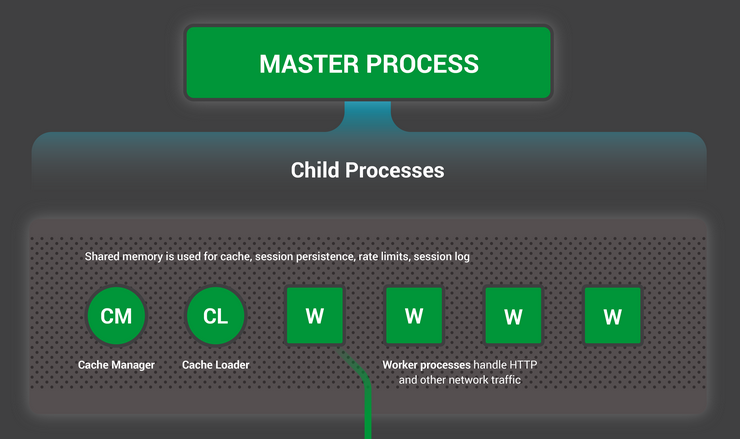
Чтобы лучше представлять устройство, сперва необходимо понять как NGINX запускается. У NGINX есть один мастер-процесс (который от имени суперпользователя выполняет такие операции, как чтение конфигурации и открытие портов), а также некоторое количество рабочих и вспомогательных процессов.
# service nginx restart
* Restarting nginx
# ps -ef --forest | grep nginx
root 32475 1 0 13:36 ? 00:00:00 nginx: master process /usr/sbin/nginx -c /etc/nginx/nginx.conf
nginx 32476 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
nginx 32477 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
nginx 32479 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
nginx 32480 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
nginx 32481 32475 0 13:36 ? 00:00:00 \_ nginx: cache manager process
nginx 32482 32475 0 13:36 ? 00:00:00 \_ nginx: cache loader processНа 4-х ядерном сервере мастер-процесс NGINX создает 4 рабочих процесса и пару вспомогательных кэш-процессов, которые управляют содержимым кэша на жестком диске.
Почему архитектура всё же важна?
Одна из фундаментальных основ любого Unix-приложения — это процесс или поток (с точки зрения ядра Linux процессы и потоки практически одно и то же — вся разница в разделении адресного пространства). Процесс или поток — это самодостаточный набор инструкций, который операционная система может запланировать для выполнения на ядре процессора. Большинство сложных приложений параллельно запускают множество процессов или потоков по двум причинам:
- Чтобы одновременно задействовать больше вычислительных ядер;
- Процессы и потоки позволяют проще выполнять параллельные операции (например обрабатывать множество соединений одновременно).
Процессы и потоки сами по себе расходуют дополнительные ресурсы. Каждый такой процесс или поток потребляет некоторое количество памяти, а кроме того они постоянно подменяют друг друга на процессоре (т. н. переключение контекста). Современные серверы могут справляться с сотнями активных процессов и потоков, но производительность сильно страдает, как только заканчивается память или огромное количество операций ввода-вывода приводит к слишком частой смене контекста.
Наиболее типичный подход к построению сетевого приложения — это выделять для каждого соединения отдельный процесс или поток. Такая архитектура проста для понимания и легка в реализации, но при этом плохо масштабируется когда приложению приходится работать с тысячами соединений одновременно.
Как же работает NGINX?
NGINX использует модель с фиксированным числом процессов, которая наиболее эффективно задействует доступные ресурсы системы:
- Единственный мастер-процесс выполняет операции, которые требуют повышенных прав, такие, как чтение конфигурации и открытие портов, а затем порождает небольшое число дочерних процессов (следующие три типа).
- Загрузчик кэша запускается на старте чтобы загрузить данные кэша, расположенные на диске, в оперативную память, а затем завершается. Его работа спланирована так, чтобы не потреблять много ресурсов.
- Кэш-менеджер просыпается периодически и удаляет объекты кэша с жесткого диска, чтобы поддерживать его объем в рамках заданного ограничения.
- Рабочие процессы выполняют всю работу. Они обрабатывают сетевые соединения, читают данные с диска и пишут на диск, общаются с бэкенд-серверами.
Документация NGINX рекомендует в большинстве случаев настраивать число рабочих процессов равное количеству ядер процессора, что позволяет использовать системные ресурсы максимально эффективно. Вы можете задать такой режим с помощью директивы worker_processes auto в конфигурационном файле:
worker_processes auto;Когда NGINX находится под нагрузкой, то в основном заняты рабочие процессы. Каждый из них обрабатывает множество соединений в неблокирующемся режиме, минимизируя количество переключений контекста.
Каждый рабочий процесс однопоточен и работает независимо, принимая новые соединения и обрабатывая их. Процессы взаимодействуют друг с другом используя разделяемую память для данных кэша, сессий и других общих ресурсов.
Внутри рабочего процесса

Каждый рабочий процесс NGINX инициализируется с заданной конфигурацией и набором слушающих сокетов, унаследованных от мастер-процесса.
Рабочие процессы начинают с ожидания событий на слушающих сокетах (см. также accept_mutex и разделяемые сокеты). События извещают о новых соединениях. Эти соединения попадают в конечный автомат — наиболее часто используемый предназначен для обработки HTTP, но NGINX также содержит конечные автоматы для обработки потоков TCP трафика (модуль stream) и целого ряда протоколов электронной почты (SMTP, IMAP и POP3).
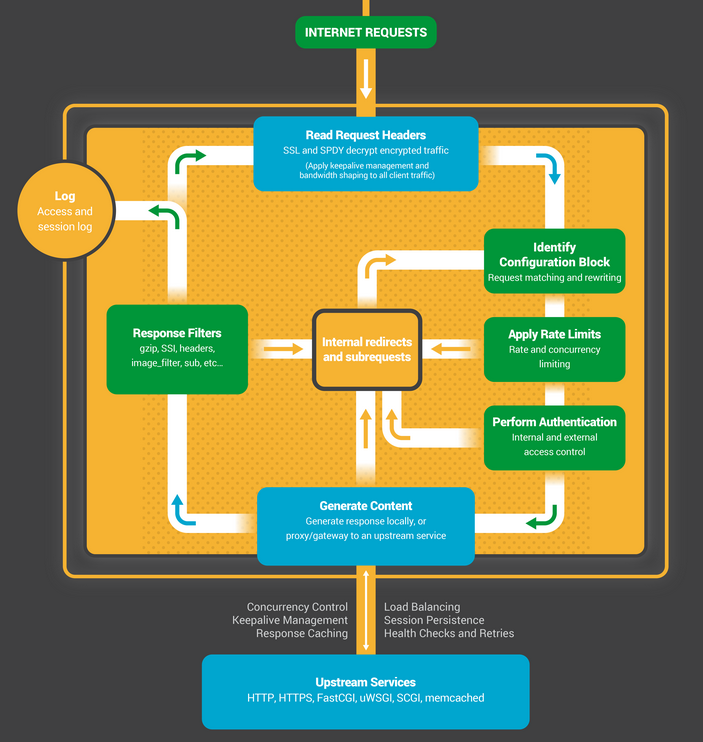
Конечный автомат в NGINX по своей сути является набором инструкций для обработки запроса. Большинство веб-серверов выполняют такую же функцию, но разница кроется в реализации.
Устройство конечного автомата
Конечный автомат можно представить себе в виде правил для игры в шахматы. Каждая HTTP транзакция — это шахматная партия. С одной стороны шахматной доски веб-сервер — гроссмейстер, который принимает решения очень быстро. На другой стороне — удаленный клиент, браузер, который запрашивает сайт или приложение по относительно медленной сети.
Как бы то ни было, правила игры могут быть очень сложными. Например, веб-серверу может потребоваться взаимодействовать с другими ресурсами (проксировать запросы на бэкенд) или обращаться к серверу аутентификации. Сторонние модули способны ещё сильнее усложнить обработку.
Блокирующийся конечный автомат
Вспомните наше определение процесса или потока, как самодостаточного набора инструкций, выполнение которых операционная система может назначать на конкретное ядро процессора. Большинство веб-серверов и веб-приложений используют модель, в которой для «игры в шахматы» приходится по одному процессу или потоку на соединение. Каждый процесс или поток содержит инструкции, чтобы сыграть одну партию до конца. Все это время процесс, выполняясь на сервере, проводит большую часть времени заблокированным в ожидании следующего хода от клиента.

- Процесс веб-сервера ожидает новых соединений (новых партий инициированных клиентами) на слушающих сокетах.
- Получив новое соединение, он играет партию, блокируясь после каждого хода в ожидании ответа от клиента.
- Когда партия сыграна, процесс веб-сервера может находиться в ожидании желания клиента начать следующую партию (это соответствует долгоживущим keepalive-соединениям). Если соединение закрыто (клиент ушел или наступил таймаут), процесс возвращается к встрече новых клиентов на слушающих сокетах.
Важный момент, который стоит отметить, заключается в том, что каждое активное HTTP-соединение (каждая партия) требует отдельного процесса или потока (гроссмейстера). Такая архитектура проста и легко расширяема с помощью сторонних модулей (новых «правил»). Однако, в ней существует огромный дисбаланс: достаточно легкое HTTP-соединение, представленное в виде файлового дескриптора и небольшого объема памяти, соотносится с отдельным процессом или потоком, достаточно тяжелым объектом в операционной системе. Это удобно для программирования, но весьма расточительно.
NGINX, как настоящий Гроссмейстер
Вероятно вы слышали о сеансах одновременной игры, когда один гроссмейстер играет на множестве шахматных полей сразу с десятками противников?

Кирил Георгиев на турнире в Болгарии сыграл параллельно 360 партий. Его итоговый результат составил: 284 победы, 70 вничью и 6 поражений.
Таким же образом рабочий процесс NGINX «играет в шахматы». Каждый рабочий процесс (помните — обычно всего один на вычислительное ядро) является гроссмейстером, способным играть сотни (а на самом деле сотни тысяч) партий одновременно.

- Рабочий процесс ожидает событий на слушающих сокетах и сокетах соединений.
- На сокетах происходят события и процесс их обрабатывает:
- Событие на слушающем сокете означает, что пришел новый клиент для начала игры. Рабочий процесс создает новый сокет соединения.
- Событие на сокете соединений сигнализирует, что клиент сделал ход. Рабочий процесс ему мгновенно отвечает.
Рабочий процесс, обрабатывая сетевой трафик, никогда не блокируется, ожидая очередного хода от оппонента (клиента). После того как процесс сделал свой ход, он немедленно переходит к другим доскам, на которых игроки ожидают хода, или встречает новых у двери.
Почему так получается быстрее, чем блокирующаяся многопоточная архитектура?
Каждое новое соединение создает файловый дескриптор и потребляет небольшой объем памяти в рабочем процессе. Это очень малые накладные расходы на соединение. Процессы NGINX могут оставаться привязанными к конкретным ядрам процессора. Переключения контекста происходят достаточно редко и в основном когда не осталось больше работы.
В блокирующемся подходе, с отдельным процессом на каждое соединение, требуется сравнительно большой объем дополнительных ресурсов, и переключения контекста с одного процесса на другой происходят гораздо чаще.
Дополнительную информацию по теме можно также узнать из статьи об архитектуре NGINX от Андрея Алексеева, вице-президента по развитию и сооснователя компании NGINX, Inc.
С адекватной настройкой системы, NGINX прекрасно масштабируется до многих сотен тысяч параллельных HTTP cоединений на каждый рабочий процесс и уверенно поглощает всплески трафика (толпы новых игроков).
Обновление конфигурации и исполняемого кода
Архитектура NGINX с малым количеством рабочих процессов позволяет достаточно эффективно обновлять конфигурацию и даже его собственный исполняемый код на лету.

Обновление конфигурации NGINX — очень простая, легковесная и надежная процедура. Она заключается в простой отправке мастер-процессу сигнала SIGHUP.
Когда рабочий процесс получает SIGHUP, он производит несколько операций:
- Перезагружает конфигурацию и порождает новый набор рабочих процессов. Эти новые рабочие процессы сразу начинают принимать соединения и обрабатывать трафик (используя новые настройки).
- Сигнализирует старые рабочие процессы о плавном завершении. Они перестают принимать новые соединения. Как только завершается обработка текущих HTTP-запросов, соединения закрываются (никаких затянувшихся keep-alive соединений). Как только все соединения закрыты, рабочий процесс завершается.
Данная процедура может вызвать небольшой всплеск нагрузки на процессор и память, но в общем это практически незаметно на фоне затрат на обработку активных соединений. Вы можете перезагружать конфигурацию несколько раз в секунду (и есть немало пользователей NGINX, кто так делает). В редких случаях могут возникнуть проблемы, когда слишком много поколений рабочих процессов NGINX ожидают закрытия соединений, но они быстро разрешаются.
Обновление исполняемого кода NGINX — это Святой Грааль высокой доступности сервисов. Вы можете обновлять сервер на лету, без потери соединений, простоя ресурсов и каких-либо перерывов в обслуживании клиентов.

Процесс обновления исполняемого кода использует схожий с перезагрузкой конфигурации подход. Новый мастер-процесс NGINX запускается параллельно со старым и получает от него дескрипторы слушающих сокетов. Оба процесса загружены и их рабочие процессы обрабатывают трафик. Затем вы можете отдать команду старому мастер-процессу на плавное завершение.
Вся процедура подробно описана в документации.
Подведем итоги
Мы дали поверхностный обзор того, как функционирует NGINX. Под этими простыми описаниями скрывается более чем десятилетний опыт разработки и оптимизации, который позволяет NGINX демонстрировать выдающуюся производительность на широком спектре оборудования и реальных задачах, оставаясь надежным и безопасным, как того требуют современные веб-приложения.
Если вы хотите узнать больше по данной теме, то рекомендуем для ознакомления:
Комментарии (32)

robert_ayrapetyan
11.06.2015 17:51Какой самый эффективный способ прицепить свои обработчики на C\C++ к nginx?
Если через написание модуля — то планируется ли какая-либо вменяемая документация \ API, кроме известной статьи 10-летней давности?
Если через fcgi — насколько данное решение будет уступать модулю по производительности?
ntfs1984
11.06.2015 18:02По идее, через fcgi+сокет — и скорость работы будет равна скорости вашего ОЗУ.
Ну а остальное зависит от вашего скрипта.

VBart Автор
11.06.2015 18:06*CGI/HTTP должно хватить для большинства задач. Едва ли вы упретесь в протокол, зато получится гибко, стабильно и это будет на порядок легче поддерживать.
Планы были, но пока отсутствует понятный, формализованный, стабильный и безопасный API для сторонних модулей, любая такая документация будет неполноценной и быстро устаревать. На данный момент самая вменяемая документация — исходный код.
evnuh
11.06.2015 18:25Наверное, если делать API для модулей, то совсем без копирования в памяти, а иначе-то оно и по fcgi неплохо.
robert_ayrapetyan
12.06.2015 00:30Какой из зоопарка решений (https://blog.inventic.eu/2013/11/fastcgi-c-library-for-all-platforms-windows-mac-and-linux/) порекомендуете? Нужно, чтоб была мульти-платформенная обработка асинхр. событий (не харкоднутый select) и желательно не Boost.ASIO. Есть такие?
VBart Автор
12.06.2015 00:59Если вопрос ко мне, то не могу ничего порекомендовать, поскольку нет такого опыта, не пользовался. Вообще протокол в самом базовом виде достаточно простой и можно свое написать за день.
И мне кажется обработкой событий не fastcgi библиотека должна заниматься.
Mercury13
11.06.2015 22:25Хорошо, есть вопрос.
Допустим, я хочу сделать игровой сервер (несколько игроков в общем мире). Игра нединамичная и потому протокол TCP. Как лучше реализовать обмен, чтобы потоков было поменьше?VBart Автор
11.06.2015 22:30Так же, как это делает nginx, асинхронно обрабатывая сокеты в неблокирующемся режиме.
Mercury13
11.06.2015 22:38В моей архитектуре было два потока на игрока: один занимается отправкой, второй — приёмом. Почему два? А потому, что сообщение с игрока А, после того, как обработается, будет разослано всем. Но всё равно многовато. Может, от второго потока удастся избавиться асинхронным вводом-выводом? — всё равно разбираться и разбираться.
Потому я и написал это в статью про NGINX, что у него есть чему научиться.А вот с чего начать?
Ivan_83
11.06.2015 23:50+3Каша!
1. Асинхронный в/в — он в винде при использовании CompletionIO (порта завершения ввода/вывода), и кажется там ещё какой механизм был, оба требуют заранее передавать буфера откуда/куда поступят данные и заполнять OVERLAPPED структуру.
Те вы говорим ОС: нужно принять/отправить данные вот из этого буфера, в вот тот сокет (для файлов там ещё и смещения в файле нужно указывать куда читать/писать), и забываем про это. Когда всё будет готово нам приходит уведомление.
Так работает IIS и всё новодное типа хайлоад в мс. С 2к винды начиная они всё на это переносят.
2. Неблокирующий в/в это в BSD/Linux и винде (вроде, давно уже не кодил/читал) когда ты выставляешь на сокет/файл O_NONBLOCK и после этого каждый раз когда делаешь read()/write()/send()/recv()/… то тебе может вернутся 0 (-1 см доки по апи) и код ошибки обозначающий что операция не завершена. При этом нужно быть готовым что когда ты пытаешься записать 10мб то у тебя запишется 64к, и тебе вернётся что записано 64к, и нужно будет вызывать запись ещё еи ещё но самому сдвигать оффсет в буфере и уменьшать размер.
Или когда ты вызываешь recv() а данных в сокете нет он не залипнет, а сразу вернёт 0 байт прочитанных и код ошибки выставит что операция в процессе.
Для неблокирующего режима в BSD есть kqueue а в линухе epoll. (Кто начинал с kqueue будет плеватся от epoll, ибо огрызок)
Привязываешь дескриптор сокета/файла к этой хрени и задашь какие уведомления тебе интересны: можно прочитать, можно записать, или всё сразу.
Потом поток отправляешь ждать событий (сон) на соотвествующей функции: kevent() или epoll_wait(), когда они отпустят поток то у тебя будет как минимум void* (для epoll) привязанный к соотвествующему дескриптору. И флаги отдельно для чтения и записи что это уже можно делать (данные пришли/место в буфере появилось/приконектились).
В случае kqueue() будет и void* для данных отдельно для чтения и отдельно для записи, и сам int с дескриптором, и размер сколько можно прочитать/записать и EOF если соединение закрыто/конец файла и код ошибки.
Есть ещё select() — он везде доступен, но у него куча ограничений и неприятных моментов.
В винде неблокирующий режим можно ещё получить с помощью оконных сообщений (сокеты привязывать к окну).
Тебе нужен всего один поток, все сокеты засовываешь в kqueue/epoll и тупо отрабатываешь события на них.
Рекомендую по одному потоку на один kqueue/epoll, если потоков хочется моного то лучше расширить модель просто запустив потоки и обменивась между ними сообщениями. В kqueue это можно делать с помощью «пользовательских» фильтров (оч просто).
В epoll нужно будет использовать pipe() и просто писать в нужные, а поток их получит как будто из файла/сокета.
Так сделано в msd_lite: www.netlab.linkpc.net/wiki/ru:software:msd:lite и ещё паре программ по соседству, типа ssdpd.
В nginx примерно также, только у них потоки вынесены в отдельные процессы, и не уверен что процессы могут посылать друг другу сообщения/данные.
Модель один kqueue/epoll и пачка потоков — имеет много подводных камней, нужно 100 раз подумать прежде чем воспользоватся ей.
Например очень трудно отправить сообщение конкретному потому, сложности с общими данными, необходимость блокировок.
Те использовать это можно, но нужно чётко понимать что это даёт и насколько сильно ограничивает.
МС рекомендует (по крайней мере рекомендоавала в начале 200х) эту модель совместно со своим портов завершения в/в, притом в книжке было всё красиво, но был нюанс: там оно было в псевдокоде с предложением реализовать getcpuusge() и HasThreadIO() (есть ли у потока не завершённые задания которые он ставил) самостоятельно. Первое было относительно легко, а второе это уровень ядра или довольно экзотический код с интерлокед которое не дешевое. Лет через 5 эта функция появилась официально в PlatformSDK для ХР с каким то сп, а до того её энтузиасты откопали в 2к (или ХР без сп). Те мс сделало и придержало для себя.
crea7or
12.06.2015 03:33IOCP в связке с пулом потоков работает. Для игр вот как раз статейка про него.

waleks
12.06.2015 01:31а почему бы вам не попробовать связку nginx->node.js->websocket? возможно, вам подойдет это решение…
lexore
12.06.2015 18:04+1А вот с чего начать?
Начать можно вот с этого: www.gnu.org/software/libc/manual/html_node/Server-Example.html
Очень простая штука на самом деле.
Простая, портабельная и эффективная, как топор.
Я с ней ещё 15 лет назад баловался, когда писал сетевые программки.
Для двух игроков вам этого хватит за глаза.
Когда освоите её и захочется стильного, быстрого и современного, легко сможете переключиться на это:
banu.com/blog/2/how-to-use-epoll-a-complete-example-in-c
Это в случае, если у вас сервер linux only.
ntfs1984
11.06.2015 23:01-4Просто висеть в памяти, ловить соединения на порту, и давать ответ.
Мой пример на ПоХаПэ<?php set_time_limit(0); error_reporting(0); $socket = stream_socket_server("tcp://0.0.0.0:8000", $errno, $errstr); if (!$socket) {echo 'test';} else { while ($conn = stream_socket_accept($socket,9999999)) { $pool=fgetss($conn,1024); echo "Это выведется в консоль отладки: $pool\n"; fwrite($conn,"А это улетит в ответ клиенту, сделавшему запрос: $pool"); fclose($conn); } fclose($socket); } ?>
UA3MQJ
13.06.2015 01:24Буду тем парнем, который скажет про Erlang.

bARmaleyKA
14.06.2015 17:58+1Ну Nitrogen не всем по зубам, как и Cowboy. Там думать надо много да по иному. Функциональщина. Одни log-файлы бывают чего стоят. Есть, правда, не такой мозгодробильный Yaws, только его тоже мало жалуют.
Бывает для души с CMS Zotonic вожусь. Ух и забористая штука временами.

vazic
15.06.2015 08:07+1Как раз недавно использовал NGINX для нанрузочного тестирования F5 LTM, где объект этой статьи выступал в роли backend. Без тонкой настройки сетевых параметров ядра, каждый легко обрабатывал 50000 запросов в секунду на статике. (уперся в способности сетевой карты)
Нащупать потолок у F5 не получилось только на чистом http трафике (на 500к запросов он даже не потел). С TLS и всякими IDP функциями все оказалось прозаичнее

nckma
Для меня это была интересная статья.
Хотя бы теперь понятна принципиальная разница между apache и nginx.
Но у меня другой вопрос. А что если сделать аппаратный http сервер? Можно например зашить логику http сервера в ПЛИС. Я пытался так сделать и даже моя простейшая модель http сервера когда-то заработала:
marsohod.org/index.php/projects/marsohod2/290-websrv
Но как мне узнать вообще такие идеи кому интересны или нет?
Я знаю, что мир сейчас наоборот двигается в сторону виртуализации и всяких SDN (Software Defined Network), но может и чисто аппаратные решения имеют свои плюсы?
По крайней мере сделать в ПЛИС/FPGA web сервер, который будет отдавать статику по HTTP — я не думаю что это сильно сложно.
maksqwe
Думаю, тот же высокочастотный трейдинг? Где под конкретные протоколы делаются свои FPGA железки.
К примеру, хотя не совсем то: www.es.ele.tue.nl/mamps/web_server/files/report.pdf
zup
так ведь есть подобные решения на рынке — f5 networks ltm, citrix netscaler.
в том числе и для обеспечения low latency, что критично для трейдеров, но там сильно ограничены возможности анализа/модификации пэйлоада в угоду большей производительности.
ntfs1984
На самом деле «аппаратный» практически ничем не будет отличаться от программного.
У вас ведь тот же самый программный http-сервер, только работающий на другом устройстве вычисления.
Но порождает больше проблем, чем решений:
— Как себя поведет микроконтроллер, если страницу считают раз 500? Думаю никак. Он все 500 раз будет вытягивать ее с ресурса. Кэша там быть не может по определению.
— Как себя поведет микроконтроллер, если к странице обратятся одновременно 30 клиентов? Я думаю что скорость микроконтроллера не позволит отдать ее вовремя.
— Собственно HTTP это всего лишь протокол связи, он плюс минус идеален. Клиент запрашивает страницу, сервер ее отдает. Но ведь большинство проблем вызывает не отдача страницы, а ее создание. Как быть, если контент динамический?
— Можно попробовать отдавать статику этим контроллером, но как и куда тогда передавать динамику? Я думаю что на связь «http-сервер на микроконтроллере»->«PHP на Малинке», уйдет больше времени, чем на обработку http-PHP сразу на Малинке.
— Кстати с статическим контентом. Откуда он будет браться? Логично будет прикрутить внешний носитель, но это уже получится компьютер.
И таких вопросов очень много. Все таки основная проблема интернета — быстродействие связки «веб-сервер->генератор контента», чем сама отдача.
lexore
А какие плюсы у аппаратного решения, кроме скорости?
Имхо, у аппаратного решения много минусов:
* подбор кадров (сколько в мире специалистов по nginx, и сколько специалистов по этому решению?)
* нет стандартной реализации (нужно будет сделать и протестировать 1U железку)
* массовая замена железа (вместо стандартного сервера нужно будет ставить эту железку)
* соответствие по функционалу (нужно, чтобы аппаратное решение поддерживало весь требуемый функционал)
* объем настройки (нужно переделать все конфиги)
* сложность при правке конфига (перепрошивать железку?)
* сложность обновления (достаточно будет перепрошить железку, или нужно новую железку?)
Поэтому (опять же, имхо) «скорость» станет существенным фактором, если прирост будет не на 15-30%, а в 5-10 раз или больше.
Т.е. оно должно финансово переплюнуть все затраты на переход.
А ведь железо дешевеет, т.е. стандартный подход все дешевеет и дешевеет, а следовательно «профит» от железки должен быть все больше и больше, чтобы оправдать себя.
Лично мне не кажется, что будет большой плюс в скорости.
Сами по себе *nix+nginx добавляют очень маленькие накладные расходы, т.е. очень эффективно используют аппаратные ресурсы.
Вот если задействовать ресурсы GPU…
Но и при этом nginx — это же не просто отдача статики.
Это ещё куча логики + куча доп. модулей.
Чего стоит обработка запросов с использованием map и регулярок.
Ещё всякие fastcgi, uwsgi и прочие *gi, без которых nginx теряет половину привлекательности.
А у многих ещё прикручены memcache/redis/lua/perl.
Если все это реализовывать в ПЛИС, то сколько будет стоить разработка?
ntfs1984
Простите, но у «аппаратного решения» нету ни одного повода быть быстрее.
Ну разве что если оно организуется на аналогичном неаппаратным решениям, железе.
lexore
Я в этом не специалист, но предположу, что там другой процессор.
А значит, его не следует сравнивать с x86/x64, как мы сравниваем i3 и i5.
Например, вспомним bitcoin.
Сравните Mhash/s у CPU и FPGA.
en.bitcoin.it/wiki/Non-specialized_hardware_comparison#CPUs.2FAPUs
en.bitcoin.it/wiki/Mining_hardware_comparison
ntfs1984
Я думаю, что процессор здесь сильно не поможет, поскольку таких процессоров просто не существует.
Любое «аппаратное» решение базируется только на исключении ненужных компонентов, и только за счет этого приближается по скорости к программным решениям.
Вот взять например тот же ARM. Уменьшенное количество команд, быстрое время выполнения, и все такое. Но на практике это оказывается до одного места, когда мы берем «кроссплатформенный линукс», «кроссплатформенный bash», пишем цикл от 1 до десяти миллионов, то на х86 2х1.5 ГГц он выполняется быстрее, чем на А20 2х1.5 ГГц. Хотя если мы возьмем ассемблер, напишем свой загрузчик и еще несколько прлцессов, то вышеупомянутый цикл будет выводиться так же, как и на х86, и даже быстрее.
Вот это называется «аппаратная платформа», но кроме цикла — она больше ничего не сможет.
Сам принцип работы системы веба не позволит использовать такие аппаратные решения. Сегодня мы выводим эту картинку, а завтра хотим другую. А послезавтра мы хотим не JPG, а PNG, но наш девайс этого не умеет, это умеет девайс более новой версии.
Впрочем, будущее у аппаратных серверов ЕСТЬ. Но для этого они должны быть размером с роутер, иметь вменяемую обновляемую прошивку, свой диск достаточно емких размеров (SSD 24Gb — вполне), гигабитный сетевой разъем, а главное — стоить 20 баксов.
zup
вот в целом вы правильно пишите, но тоже надо понимать, что вендоры прилагают массу усилий, чтобы создать некую экосистему вокруг своих продуктов.
я по работе часто сталкиваюсь и nginx и с «аппаратными» контроллерами доставки приложений. это целый сегмент рынка.
они жутко программируемы, в них используются криптоакселераторы и всяческие аппаратные прибамбасы для ускорения и оптимизации.
и каждый вендор зомбирует своими преимуществами — организуют тренинги и обучение, проводят вебексы и презентации для заказчиков.
у таких компаний есть свои клиенты и куча заказов, потому что не везде есть годные специалисты, способные обеспечить доступность приложений на кластере nginx, а после ухода из компании не каждый новый специалист будет способен всю эту инфраструктуру поддерживать.
а с таким вот «аппаратным» контроллером вы просто посылаете человека на курсы, он читает подробную документацию, которой сопровождается оборудование и без особых проблем инфраструктура продолжает жить.
чаще всего решает цена
lexore
Согласен.
Но для России, насколько я знаю, цена на такие аппаратные решения очень кусается.
А с падением курса рубля она стала кусаться только сильнее.
Т.е. сейчас стоимость специалистов упала по сравнению со стоимостью оборудования (в том числе и такого).
Могу предположить, что в других странах ситуация противоположна — оборудование дешевеет, специалисты дорожают.
И там выбор в сторону аппаратных решений реальнее.
VBart Автор
Она кусается не только для России. Многие клиенты с удовольствием отмечают, что NGINX Plus c поддержкой им обошелся буквально на порядок дешевле.
lexore
К своему ответу ещё хочу добавить, что сейчас сервер на nginx может отдавать, например 80 Гбит/с с себя.
А не с себя (т.е. просто проксировать) и того больше.
Поэтому нет вопроса «как бы это ускорить?», скорее стоит вопрос «чем все это нагрузить?».