
В этом году статическому анализатору PVS-Studio исполнилось 10 лет. Правда, стоит уточнить, что 10 лет назад он назывался Viva64. И есть ещё одна интересная дата: прошло 5 лет с момента предыдущей проверки кода проекта Notepad++. С тех пор PVS-Studio был очень сильно доработан: добавлено около 190 новых диагностик, усовершенствованы старые. Впрочем, ожидать огромного количества ошибок в Notepad++ не стоит. Это небольшой проект, состоящий всего из 123 файлов с исходным кодом. Тем не менее, в коде найдены ошибки, которые будет полезно исправить.
Введение
Notepad++ — свободный текстовый редактор с открытым исходным кодом для Windows, с подсветкой синтаксиса большого количества языков программирования и разметки. Базируется на компоненте Scintilla, написан на C++ с использованием STL, а также Windows API и распространяется под лицензией GNU General Public License.
На мой взгляд, Notepad++ отличный текстовой редактор. Я сам его использую для всего, кроме написания кода. Для анализа исходников я воспользовался статическим анализатором PVS-Studio 6.15. Проект Notepad++ уже проверялся в 2010 и 2012 годах. Сейчас нашлось 84 предупреждения уровня High, 124 предупреждения уровня Medium и 548 предупреждений уровня Low. Уровни предупреждений указывают на достоверность найденных ошибок. Так, из 84-х наиболее достоверных предупреждений (High), 81, на мой взгляд, указывают на настоящие дефекты в коде — их стоит сразу исправить, не вникая глубоко в логику программы, т.к. проблемы очевидны.
Примечание. Кроме обработки результатов статического анализатора, будет полезно улучшить код, определившись: использовать для отступов пробелы или табы. Абсолютно весь код выглядит примерно так:
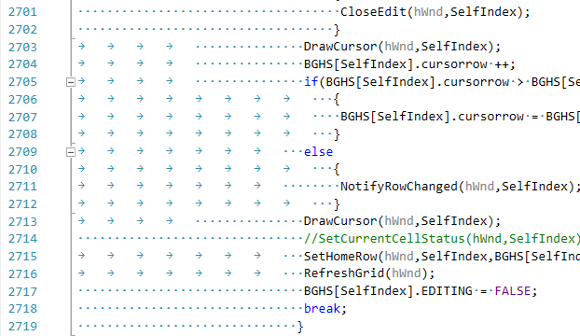
Рисунок 1 — Разные отступы в коде.
Давайте рассмотрим некоторые ошибки, которые показались мне наиболее интересными.
Проблемы наследования

V599 The virtual destructor is not present, although the 'FunctionParser' class contains virtual functions. functionparser.cpp 39
class FunctionParser
{
friend class FunctionParsersManager;
public:
FunctionParser(....): ....{};
virtual void parse(....) = 0;
void funcParse(....);
bool isInZones(....);
protected:
generic_string _id;
generic_string _displayName;
generic_string _commentExpr;
generic_string _functionExpr;
std::vector<generic_string> _functionNameExprArray;
std::vector<generic_string> _classNameExprArray;
void getCommentZones(....);
void getInvertZones(....);
generic_string parseSubLevel(....);
};
std::vector<FunctionParser *> _parsers;
FunctionParsersManager::~FunctionParsersManager()
{
for (size_t i = 0, len = _parsers.size(); i < len; ++i)
{
delete _parsers[i]; // <=
}
if (_pXmlFuncListDoc)
delete _pXmlFuncListDoc;
}Анализатором была найдена серьёзная ошибка, приводящая к неполному разрушению объектов. У базового класса FunctionParser присутствует виртуальная функция parse(), но отсутствует виртуальный деструктор. В иерархии наследования от этого класса присутствуют такие классы, как FunctionZoneParser, FunctionUnitParser и FunctionMixParser:
class FunctionZoneParser : public FunctionParser
{
public:
FunctionZoneParser(....): FunctionParser(....) {};
void parse(....);
protected:
void classParse(....);
private:
generic_string _rangeExpr;
generic_string _openSymbole;
generic_string _closeSymbole;
size_t getBodyClosePos(....);
};
class FunctionUnitParser : public FunctionParser
{
public:
FunctionUnitParser(....): FunctionParser(....) {}
void parse(....);
};
class FunctionMixParser : public FunctionZoneParser
{
public:
FunctionMixParser(....): FunctionZoneParser(....), ....{};
~FunctionMixParser()
{
delete _funcUnitPaser;
}
void parse(....);
private:
FunctionUnitParser* _funcUnitPaser = nullptr;
};Для наглядности я составил схему наследования для этих классов:
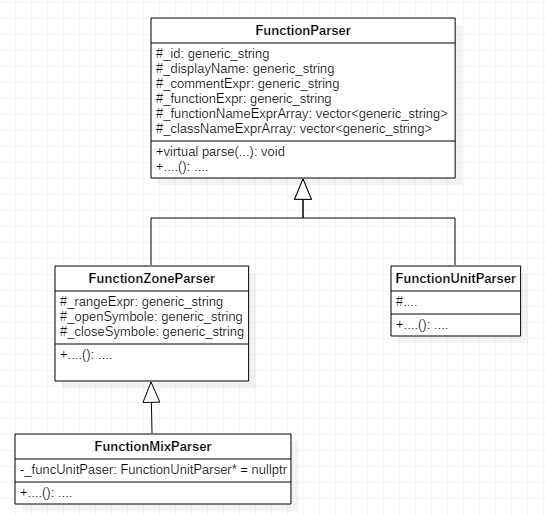
Рисунок 2 — Схема наследования от класса FunctionParser
Таким образом, созданные объекты будут разрушаться не полностью. Это приведёт к неопределённому поведению программы. Нельзя сказать как будет вести себя программа после того, как в ней возникнет UB, но на практике в данном случае, как минимум, произойдёт утечка памяти, так как код «delete _funcUnitPaser» не будет выполнен.
Рассмотрим следующую ошибку.
V762 It is possible a virtual function was overridden incorrectly. See first argument of function 'redraw' in derived class 'SplitterContainer' and base class 'Window'. splittercontainer.h 61
class Window
{
....
virtual void display(bool toShow = true) const
{
::ShowWindow(_hSelf, toShow ? SW_SHOW : SW_HIDE);
}
virtual void redraw(bool forceUpdate = false) const
{
::InvalidateRect(_hSelf, nullptr, TRUE);
if (forceUpdate)
::UpdateWindow(_hSelf);
}
....
}
class SplitterContainer : public Window
{
....
virtual void display(bool toShow = true) const; // <= good
virtual void redraw() const; // <= error
....
}В коде Notepad++ найдено несколько проблем с перегрузкой функций. В классе SplitterContainer, унаследованного от класса Window, метод display() перегружен правильно, а при перегрузке метода redraw() допустили ошибку.
Ещё несколько неправильных мест:
- V762 It is possible a virtual function was overridden incorrectly. See third argument of function 'create' in derived class 'UserDefineDialog' and base class 'StaticDialog'. userdefinedialog.h 332
- V762 It is possible a virtual function was overridden incorrectly. See third argument of function 'create' in derived class 'FindReplaceDlg' and base class 'StaticDialog'. findreplacedlg.h 245
- V762 It is possible a virtual function was overridden incorrectly. See third argument of function 'create' in derived class 'GoToLineDlg' and base class 'StaticDialog'. gotolinedlg.h 45
- V762 It is possible a virtual function was overridden incorrectly. See third argument of function 'create' in derived class 'FindCharsInRangeDlg' and base class 'StaticDialog'. findcharsinrange.h 52
- V762 It is possible a virtual function was overridden incorrectly. See third argument of function 'create' in derived class 'ColumnEditorDlg' and base class 'StaticDialog'. columneditor.h 45
- V762 It is possible a virtual function was overridden incorrectly. See third argument of function 'create' in derived class 'WordStyleDlg' and base class 'StaticDialog'. wordstyledlg.h 77
- V762 It is possible a virtual function was overridden incorrectly. See first argument of function 'redraw' in derived class 'WordStyleDlg' and base class 'Window'. wordstyledlg.h 99
- V762 It is possible a virtual function was overridden incorrectly. See third argument of function 'create' in derived class 'PluginsAdminDlg' and base class 'StaticDialog'. pluginsadmin.h 107
Утечки памяти

V773 The function was exited without releasing the 'pXmlDocProject' pointer. A memory leak is possible. projectpanel.cpp 326
bool ProjectPanel::openWorkSpace(const TCHAR *projectFileName)
{
TiXmlDocument *pXmlDocProject = new TiXmlDocument(....);
bool loadOkay = pXmlDocProject->LoadFile();
if (!loadOkay)
return false; // <=
TiXmlNode *root = pXmlDocProject->FirstChild(TEXT("Note...."));
if (!root)
return false; // <=
TiXmlNode *childNode = root->FirstChildElement(TEXT("Pr...."));
if (!childNode)
return false; // <=
if (!::PathFileExists(projectFileName))
return false; // <=
....
delete pXmlDocProject; // <= free pointer
return loadOkay;
}Интересным примером утечки памяти является вот такая функция. Под указатель pXmlDocProject выделяется динамическая память, но освобождается она только при выполнении функции до конца. Что, скорее всего, является недоработкой, приводящей к утечкам памяти.
V773 Visibility scope of the 'pTextFind' pointer was exited without releasing the memory. A memory leak is possible. findreplacedlg.cpp 1577
bool FindReplaceDlg::processReplace(....)
{
....
TCHAR *pTextFind = new TCHAR[stringSizeFind + 1];
TCHAR *pTextReplace = new TCHAR[stringSizeReplace + 1];
lstrcpy(pTextFind, txt2find);
lstrcpy(pTextReplace, txt2replace);
....
}Функция processReplace() вызывается при каждой замене некой подстроки в документе. В коде выделяется память под два буфера: pTextFind и pTextReplace. В один буфер копируется искомая строка, а в другой — строка для замены. Тут присутствует несколько ошибок, следствием которых является утечка памяти:
- Буфер pTextFind не очищается и вообще не используется в функции. Для замены используется исходный буфер txt2find.
- Буфер pTextReplace в дальнейшем используется, но память тоже не освобождается.
Вывод: каждая операция автозамены приводит к утечке нескольких байт. Чем больше искомая строка и чем больше совпадений, тем больше течёт память.
Ошибки с указателями

V595 The 'pScint' pointer was utilized before it was verified against nullptr. Check lines: 347, 353. scintillaeditview.cpp 347
LRESULT CALLBACK ScintillaEditView::scintillaStatic_Proc(....)
{
ScintillaEditView *pScint = (ScintillaEditView *)(....);
if (Message == WM_MOUSEWHEEL || Message == WM_MOUSEHWHEEL)
{
....
if (isSynpnatic || makeTouchPadCompetible)
return (pScint->scintillaNew_Proc(....); // <=
....
}
if (pScint)
return (pScint->scintillaNew_Proc(....));
else
return ::DefWindowProc(hwnd, Message, wParam, lParam);
}В одном месте пропустили проверку указателя pScint на валидность.
V713 The pointer _langList[i] was utilized in the logical expression before it was verified against nullptr in the same logical expression. parameters.h 1286
Lang * getLangFromID(LangType langID) const
{
for (int i = 0 ; i < _nbLang ; ++i)
{
if ((_langList[i]->_langID == langID) || (!_langList[i]))
return _langList[i];
}
return nullptr;
}Автор кода допустил ошибку при записи условного выражения. Он сначала обращается к полю _langID, используя указатель _langList[i], а потом сравнивает этот указатель с нулём.
Скорее всего, правильный код должен быть таким:
Lang * getLangFromID(LangType langID) const
{
for (int i = 0 ; i < _nbLang ; ++i)
{
if ( _langList[i] && _langList[i]->_langID == langID )
return _langList[i];
}
return nullptr;
}Разные ошибки

V501 There are identical sub-expressions to the left and to the right of the '!=' operator: subject != subject verifysignedfile.cpp 250
bool VerifySignedLibrary(...., const wstring& cert_subject, ....)
{
wstring subject;
....
if ( status && !cert_subject.empty() && subject != subject)
{
status = false;
OutputDebugString(
TEXT("VerifyLibrary: Invalid certificate subject\n"));
}
....
}Помнится, в Notepad++ была найдена уязвимость, позволяющая подменять компоненты редактора на модифицированные. В код были добавлены проверки целостности. Я точно не знаю, этот код был написан для закрытия уязвимости или нет, но по названию функции можно судить, что служит она для важной проверки.
На фоне этого проверка:
subject != subjectвыглядит крайне подозрительно, скорее всего, правильно должно быть так:
if ( status && !cert_subject.empty() && cert_subject != subject)
{
....
}V560 A part of conditional expression is always true: 0xff. babygrid.cpp 711
TCHAR GetASCII(WPARAM wParam, LPARAM lParam)
{
int returnvalue;
TCHAR mbuffer[100];
int result;
BYTE keys[256];
WORD dwReturnedValue;
GetKeyboardState(keys);
result = ToAscii(static_cast<UINT>(wParam),
(lParam >> 16) && 0xff, keys, &dwReturnedValue, 0); // <=
returnvalue = (TCHAR) dwReturnedValue;
if(returnvalue < 0){returnvalue = 0;}
wsprintf(mbuffer, TEXT("return value = %d"), returnvalue);
if(result!=1){returnvalue = 0;}
return (TCHAR)returnvalue;
}Всегда истинные или всегда ложные условные выражения выглядят очень подозрительно. Константа 0xff всегда истинна. Возможно, допустили опечатку в операторе и параметр функции ToAscii() должен был быть таким:
(lParam >> 16) & 0xffV746 Type slicing. An exception should be caught by reference rather than by value. filedialog.cpp 183
TCHAR* FileDialog::doOpenSingleFileDlg()
{
....
try {
fn = ::GetOpenFileName(&_ofn)?_fileName:NULL;
if (params->getNppGUI()._openSaveDir == dir_last)
{
::GetCurrentDirectory(MAX_PATH, dir);
params->setWorkingDir(dir);
}
} catch(std::exception e) { // <=
::MessageBoxA(NULL, e.what(), "Exception", MB_OK);
} catch(...) {
::MessageBox(NULL, TEXT("....!!!"), TEXT(""), MB_OK);
}
::SetCurrentDirectory(dir);
return (fn);
}Перехватывать исключения лучше по ссылке. Проблема такого кода заключается в том, что будет создан новый объект, что приведёт к потере информации об исключении при перехвате. Всё, что хранилось в унаследованных от Exception классах, будет недоступно.
V519 The 'lpcs' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 3116, 3117. babygrid.cpp 3117
LRESULT CALLBACK GridProc(HWND hWnd, UINT message,
WPARAM wParam, LPARAM lParam)
{
....
case WM_CREATE:
lpcs = &cs;
lpcs = (LPCREATESTRUCT)lParam;
....
}Сразу перетёрли старое значение новым. Похоже на ошибку. Если сейчас всё работает правильно, то следует оставить только вторую строчку с присваиванием, а первую удалить.
V601 The 'false' value becomes a class object. treeview.cpp 121
typedef std::basic_string<TCHAR> generic_string;
generic_string TreeView::getItemDisplayName(....) const
{
if (not Item2Set)
return false; // <=
TCHAR textBuffer[MAX_PATH];
TVITEM tvItem;
tvItem.hItem = Item2Set;
tvItem.mask = TVIF_TEXT;
tvItem.pszText = textBuffer;
tvItem.cchTextMax = MAX_PATH;
SendMessage(...., reinterpret_cast<LPARAM>(&tvItem));
return tvItem.pszText;
}Возвращаемым значением функции является строка, но вместо пустой строки кто-то решил сделать «return false».
Чистка кода

Делать рефакторинг ради рефакторинга не стоит, в любом проекте есть много других полезных задач. Но избавляться от бесполезного кода однозначно нужно.
V668 There is no sense in testing the 'source' pointer against null, as the memory was allocated using the 'new' operator. The exception will be generated in the case of memory allocation error. notepad_plus.cpp 1149
void Notepad_plus::wsTabConvert(spaceTab whichWay)
{
....
char * source = new char[docLength];
if (source == NULL)
return;
....
}Вот зачем здесь эта проверка? Согласно современному стандарту C++, оператор new бросает исключение при нехватке памяти, а не возвращает nullptr.
Эта функция зовётся при замене всех символов табуляции на пробелы во всём документе. Взяв большой текстовый документ, я убедился, что нехватка памяти в этом месте действительно приводит к краху программы.
Если корректировать проверку, то при нехватке памяти будет происходить отмена операции замены символов, и редактором можно пользоваться дальше. Все такие места следует исправить, и их так много, что пришлось вынести список в отдельный файл.
V713 The pointer commentLineSymbol was utilized in the logical expression before it was verified against nullptr in the same logical expression. notepad_plus.cpp 3928
bool Notepad_plus::doBlockComment(comment_mode currCommentMode)
{
....
if ((!commentLineSymbol) || // <=
(!commentLineSymbol[0]) ||
(commentLineSymbol == NULL)) // <= WTF?
{ .... }
....
}Таких странных и бесполезных проверок найдено десять штук:
- V713 The pointer commentLineSymbol was utilized in the logical expression before it was verified against nullptr in the same logical expression. notepad_plus.cpp 3928
- V713 The pointer commentStart was utilized in the logical expression before it was verified against nullptr in the same logical expression. notepad_plus.cpp 3931
- V713 The pointer commentEnd was utilized in the logical expression before it was verified against nullptr in the same logical expression. notepad_plus.cpp 3931
- V713 The pointer commentStart was utilized in the logical expression before it was verified against nullptr in the same logical expression. notepad_plus.cpp 4228
- V713 The pointer commentEnd was utilized in the logical expression before it was verified against nullptr in the same logical expression. notepad_plus.cpp 4228
- V713 The pointer commentLineSymbol was utilized in the logical expression before it was verified against nullptr in the same logical expression. notepad_plus.cpp 4229
- V713 The pointer commentStart was utilized in the logical expression before it was verified against nullptr in the same logical expression. notepad_plus.cpp 6554
- V713 The pointer commentEnd was utilized in the logical expression before it was verified against nullptr in the same logical expression. notepad_plus.cpp 6554
- V713 The pointer commentLineSymbol was utilized in the logical expression before it was verified against nullptr in the same logical expression. notepad_plus.cpp 6555
V601 The 'true' value is implicitly cast to the integer type. pluginsadmin.cpp 603
INT_PTR CALLBACK PluginsAdminDlg::run_dlgProc(UINT message, ....)
{
switch (message)
{
case WM_INITDIALOG :
{
return TRUE;
}
....
case IDC_PLUGINADM_RESEARCH_NEXT:
searchInPlugins(true);
return true;
case IDC_PLUGINADM_INSTALL:
installPlugins();
return true;
....
}
....
}Функция run_dlgProc() и так возвращает значение далеко не логического типа, так ещё в коде возвращают то true/false, то TRUE/FALSE. Хотел написать, что в функции хотя бы отступы одного типа, но нет: из 90 строк функции в одной строке все равно присутствует смесь из табуляций и пробелов. В остальных строках используются символы табуляции. Да, это всё не критично, но код выглядит для меня, как стороннего наблюдателя, неаккуратным.
V704 '!this' expression in conditional statements should be avoided — this expression is always false on newer compilers, because 'this' pointer can never be NULL. notepad_plus.cpp 4980
void Notepad_plus::notifyBufferChanged(Buffer * buffer, int mask)
{
// To avoid to crash while MS-DOS style is set as default
// language,
// Checking the validity of current instance is necessary.
if (!this) return;
....
}К бесполезному коду я бы ещё отнёс такие проверки. Как видно из комментария, раньше проблема разыменования нулевого this была. Согласно же современному стандарту языка C++, такая проверка является лишней.
Список всех таких мест:
- V704 'this && type == DOCUMENT' expression should be avoided: 'this' pointer can never be NULL on newer compilers. tinyxmla.h 505
- V704 'this && type == ELEMENT' expression should be avoided: 'this' pointer can never be NULL on newer compilers. tinyxmla.h 506
- V704 'this && type == COMMENT' expression should be avoided: 'this' pointer can never be NULL on newer compilers. tinyxmla.h 507
- V704 'this && type == UNKNOWN' expression should be avoided: 'this' pointer can never be NULL on newer compilers. tinyxmla.h 508
- V704 'this && type == TEXT' expression should be avoided: 'this' pointer can never be NULL on newer compilers. tinyxmla.h 509
- V704 'this && type == DECLARATION' expression should be avoided: 'this' pointer can never be NULL on newer compilers. tinyxmla.h 510
- V704 'this && type == DOCUMENT' expression should be avoided: 'this' pointer can never be NULL on newer compilers. tinyxml.h 505
- V704 'this && type == ELEMENT' expression should be avoided: 'this' pointer can never be NULL on newer compilers. tinyxml.h 506
- V704 'this && type == COMMENT' expression should be avoided: 'this' pointer can never be NULL on newer compilers. tinyxml.h 507
- V704 'this && type == UNKNOWN' expression should be avoided: 'this' pointer can never be NULL on newer compilers. tinyxml.h 508
- V704 'this && type == TEXT' expression should be avoided: 'this' pointer can never be NULL on newer compilers. tinyxml.h 509
- V704 'this && type == DECLARATION' expression should be avoided: 'this' pointer can never be NULL on newer compilers. tinyxml.h 510
- V704 'this' expression in conditional statements should be avoided — this expression is always true on newer compilers, because 'this' pointer can never be NULL. nppbigswitch.cpp 119
Заключение
Были найдены и другие ошибки, которые не вошли в статью. При желании авторы Notepad++ могут самостоятельно проверить проект и внимательно изучить предупреждения. Мы готовы предоставить им для этого временную лицензию.
Конечно, обычному пользователю описанные проблемы не видны. Модули оперативной памяти сейчас больших объёмов и дешёвые :). Тем не менее, развитие проекта продолжается, а качество кода, как и удобство его поддержки, можно значительно улучшить, исправив найденные ошибки и удалив пласты устаревшего кода.
По моим расчётам, на 1000 строк кода анализатор PVS-Studio выявлял 2 настоящие ошибки. Конечно, это не все ошибки. Думаю, на самом деле их будет где-то 5-10 на 1000 строк кода, что соответствует небольшой плотности ошибок. Размер проекта Notepad++ составляет 95 KLoc, а значит типичная плотность ошибок для проектов этого размера: 0-40 ошибок на 1000 строк кода. Впрочем, источник этих чисел стар, и я считаю, что, в среднем, качество кода сейчас стало выше.
Ещё раз хочу поблагодарить авторов Notepad++ за их работу над крайне полезным инструментом и желаю им всевозможных успехов.

Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Svyatoslav Razmyslov. Checking Notepad++: five years later
Комментарии (168)

kravtsov_dim
07.06.2017 10:26-44Я извиняюсь, мог пройти мимо, но не удержался.
Кому-то до сих пор интересно читать обзоры проверок программ?
Может стоить подумать над другим форматом подачи PVS?
я не знаю каким.
Поначалу читал такие обзоры, потом понял, что они почти все однообразные.
Gradarius
07.06.2017 11:58+20А может стоит учесть что представляет из себя PVS? Лучшей подачи и быть не может. Кроме того что идет реклама продукта, можно насладиться интересным разбором с отличным оформлением.
Cenzo
08.06.2017 10:40Согласен, очень правильная подача материала, как говорится умный учится на чужих ошибках, а дурак на своих. Тем более повторение всегда полезно для того что освежить знания. Мы стали пользоваться PVS как только вышла тестовая версия под Linux.
mayorovp
08.06.2017 10:46Я читал такой вариант: "Мудрый учится на чужих ошибках, умный — на своих, а дурак повторяет их из раза в раз"
lany
07.06.2017 19:39+3Эк заминусовали-то. Мне в целом интересно почитать, что ещё накопали, но в чём-то kravtsov_dim прав. Например, разделы про "The 'pScint' pointer was utilized before it was verified against nullptr" я пролистываю, потому что такое реально в каждой статье есть и в каждой программе с 10-15-летней историей можно отыскать подобное. Это скучно. Но есть интересные ошибки и особенности C++, о которых я не знал (потому что не пишу на нём). Например, про ловлю исключений по значению. Пара интересных ошибок — уже не зря статью прочитал :-)

PenguiN560
07.06.2017 20:41+1… разделы про «The 'pScint' pointer was utilized before it was verified against nullptr» я пролистываю ...
… Но есть интересные ошибки и особенности C++, о которых я не знал ...
У всех скил разный, то что знает один может быть интересно другим.lany
08.06.2017 03:36У всех скил разный, но о первом нельзя не знать, если вы видели хотя бы пару предыдущих статей в таком формате от PVS-Studio. Конечно, каждая статья может для кого-то оказаться первой.
PenguiN560
08.06.2017 09:07+1Можно тоже самое сказать про утечки памяти(все, я думаю, знают, что перед любым return'ом в функции/методе стоит удалять все динамические объекты/выделенную память, указатели на которые были локальными в функции/методе), и многие другие банальные ошибки. На мой взгляд отображение таких ошибок в статьях позволяет понять, что какими бы глупыми не казались ошибки, это не спасает от их появления в продакшене любых проектов.
Но согласитесь приятно смотреть на чужую глупость, пока у себя подобное однажды не найдешь)




zedalert
07.06.2017 13:25+8Пробелы или табуляция? Конечно табуляция!
Silicon Valley - S03E06varnav
07.06.2017 15:35+7Статистика GitHub говорит что пробелы гораздо популярнее
BratSinot
07.06.2017 17:26+5А знаете почему? Из-за отсутствия стандартизации. Вот пишет автор код с выравниваем, поставил две табуляции, а остальное догнал пробелами, у него все красиво и аккуратно. Откроет этот файл другой человек в другом редакторе, а у него табуляция отображается как 5-ть пробелов, а не 4-ре как у автора и все форматирование поплыло. Или бывают редакторы которые табуляцию отображают не просто в виде N-пробелов, а в виде N-пробелов с учетом сроки выше / ниже.
Если с шириной символов уже проблем в 99% случаев нет (ибо моноширинный это стандарт де-факто), а вот с табуляцией будут проблемы, если код публичный, а не в рамках одной компании и одного инструментария.khim
07.06.2017 17:36-11Откроет этот файл другой человек в другом редакторе, а у него табуляция отображается как 5-ть пробелов, а не 4-ре как у автора и все форматирование поплыло.
Вот из-за таких как вы всё и ломается. Табуляция — это 8 пробелов.BratSinot
07.06.2017 17:42А я тут при чем? У меня в medit тоже 8, в какой-то IDE 4 видел. Это значения по умолчанию были.
Splo1ter
07.06.2017 18:06+101-н таб состоит из 4-х пробелов.
khim
07.06.2017 18:45-4Это у кого они из 4-х пробелов состоят? Изначально (на пишущих машинках) они 5 пробелов занимали, когда их адаптировали для компьютеров, то принтеры в течение десятилетей поддерживали только и исключительно восемь (до восьми считать удобнее). А 4 — это как раз и есть «начало конца», когда «всё смешалось».
Так как мы, всё-таки, работаем с компьютерами, а не с ремингтоновскими машинками, то в табе — 8 пробелов.
pavel_pimenov
07.06.2017 19:00+2«до восьми считать удобнее» — это почему?
в Visual Studio по дефолту 4 пробела
https://stackoverflow.com/questions/14167033/visual-studio-replace-tab-with-4-spaceskhim
07.06.2017 19:28«до восьми считать удобнее» — это почему?
Транзисторов/реле меньше нужно (да-да — этот старднарт появился в эпоху электромеханических устройств, в частности вот таких вот принтеров).
в Visual Studio по дефолту 4 пробела
В этом, собственно, и проблема: Microsoft, как обычно, проигнорировал то, что десятилетиями делалось до появления Visual Studio и изобрёл свой стандарт.
AllexIn
07.06.2017 20:02+68 пробелов — это жесть жестяная. Поддерживаю майкрософт. 4 пробела, а лучше — 2.
khim
07.06.2017 20:29Размер отступа не имеет никакого отношения к размеру таба. Размер таба в 8 символов — это просто свойство текстового формата.
Возьмите какой-нибудь язык, где отступы важны (скажем Python) — там у вас отступ из одного таба будет считаться больше, чем из семи пробелов, но меньше, чем из девяти — вот и всё.
А уж какой отступ вам нравится — это ваше личное дело.
PenguiN560
07.06.2017 20:57Поправьте меня, но в VS вместо табуляции срабатывает автозамена на 4 пробела, а тут речь, как я понимаю, идет о размере самой табуляции в редакторах…
К слову: именно из-за таких неожиданных поворотов я и перестал использовать табуляцию и перешел на пробелы. Особенно было проблемно смотреть файлы с табуляцией в том же Vim'e в консоли, когда 4 уровень уползал почти на половину экрана.

TheShock
07.06.2017 19:48+4Так как мы, всё-таки, работаем с компьютерами, а не с ремингтоновскими машинками, то в табе — 8 пробелов.
Глупости пишете. В табе нету пробелов. Таб — это таб, один символ и неважно, какая у него ширина.khim
07.06.2017 19:52-1Это — новомодное изобретение и попытка «переосмыслить» старую добрую концепцию, которой скоро сто лет исполнится.
Не надо так. Хотите ввести какие-нибудь «элестичные табы» — вводите. Тоько не стоит их с традиционными путать.TheShock
07.06.2017 19:59+3Я что-то не вижу в вашей концепции ничего про ширину. В том же Ворде ширина табов точно так же эластична.
В печатном деле ширина табов была неэластична исключительно в силу механических ограничений. Отталкиваться от того, что там было в эпоху печатных машинок не имеет смысла, потому что сейчас это не так.
Таб — один символ, всё. Попытки захаркодить его с пробелами — это просто глупость. Это не может быть предметом холивара, потому что это вкусовщина и каждый настраивает его ширину по своему. Я вот люблю табуляцию шириной в три пробела. Но на любой ширине мой код будет выглядеть корректно.khim
07.06.2017 20:15В том же Ворде ширина табов точно так же эластична.
Нет. Она зафиксирована для конкретного документа. Даже в ворде.
Отталкиваться от того, что там было в эпоху печатных машинок не имеет смысла, потому что сейчас это не так.
Это и сейчас так. Вот вы тут подняли Ворд. Ok. Где там можно выставить размер таба? Не для конкретного документа, а «вообще» — так, чтобы он действовал на все документы?
Это не может быть предметом холивара, потому что это вкусовщина и каждый настраивает его ширину по своему.
Формат текстовых файлов, увы и ах, не предусматривает места, где это можно указать. HTML — предусматривает, но даже там — это свойство документа (вернее наложенного на него стиля), а не «хотелки» читателя. И умолчание — там всё равно 8, а не 5, 4, или, прости госсподи, 2.
Я вот люблю табуляцию шириной в три пробела.
Это ваше право. Любите. Но не в текстовых документах, пожалуйтста.
Но на любой ширине мой код будет выглядеть корректно.
Это ваше прово — тратить время и силы на то, чтобы картины «из рисовых зёрнышек» складывать. Мне этим заниматься, если честно, лень. За меня это clang-format делает — в нём есть опция UseTab.TheShock
07.06.2017 20:28Видите ли, мы говорим о рабочем инструменте. Он выполняет определенные функции. И должен соответствовать определенным условиям — удобству, семантике и т.п, а не тому, как хочет какой-то Кхим, потому что где-то в другом месте табы используются иначе.
Жаль вас огорчать, но правила верстки печатных текстов не распространяются на правила оформления кода.khim
07.06.2017 20:36-1Видите ли, мы говорим о рабочем инструменте.
Видите ли — но мы говорим, прежде всего, о некотором формате файла. В данном случае — текстовом. В нём — табы имеют фиксированную ширину. 8 символов.
Всё что вы хотите «навернуть» сверху, сбоку, справа, слева — следует уже после этого.
Он выполняет определенные функции.
Именно.
И должен соответствовать определенным условиям — удобству, семантике и т.п, а не тому, как хочет какой-то Кхим, потому что где-то в другом месте табы используются иначе.
Первое и самое главное требование — он должен быть интерепретирован каким-то определённым способом. И так исторически сложилось, что в текстовых файлах таб стопы расставлены через 8 символов и также исторически сложилось, что многие языки программирования используют текстовые файлы для хранения текста. Всё остальное — навешивается над этой конструкцией «сверху».
Жаль вас огорчать, но правила верстки печатных текстов не распространяются на правила оформления кода.
А вот требования к форматам файлам — распространяются. Python — хороший тому пример.encyclopedist
08.06.2017 02:20+6Вы так любите на докомпьютерную историю ссылаться. Так вот, к вашему сведению, на печатных машинках как раз табы были "эластичными". Там были линейки по которым можно было двигать стопоры. И таб сдвигал каретку до следующего стопора.
encyclopedist
08.06.2017 02:23+3Что касается питона, то вы тоже неправы:
Indentation is rejected as inconsistent if a source file mixes tabs and spaces in a way that makes the meaning dependent on the worth of a tab in spaces; a TabError is raised in that case.
TheShock
08.06.2017 10:04+5В данном случае — текстовом. В нём — табы имеют фиксированную ширину. 8 символов.
Ошибаетесь. В нем таб — это один символ \t и у него нету ширины.
так исторически сложилось, что в текстовых файлах таб стопы расставлены через 8 символов и также исторически сложилось
Вы вот раз за разом это повторяете. Но ваша проблема в том, что вы путаете понятия. Так не «исторически сложилось», а «так когда-то было». Сейчас объясню.
Да, возможно, когда-то давным-давно табы были 8 символов и ими удобно было выравнивать таблицы, но… (а теперь внимание)… так исторически сложилось, что теперь в разных редакторах разные настройки. Кто-то ставит себе таб 8 символов, кто-то 4, кто-то 3, кто-то 2. Вот именно это «исторически сложилось».
И теперь, учитывая этот факт можно понять, что даже если когда-то было, что таб использовался для выравнивания таблиц, то теперь его уже так нельзя использовать, потому что так исторически сложилось, что у разных людей на разных устройствах ширина будет совершенно разной.
А вот использование таба как я предлагаю — никак не зависит от «исторически сложенного» плавающего размера таба. Так как при любом размере таба будет только изменяется ширина отступа, но не будет ломаться его логическая структура.
При вашем же использовании, увы, но на разных настройках будет сбиваться структура и ваша таблица будет превращаться в кашу. Потому вариантов нету и необходимо выравнивать ее пробелами. А ваша захардкодженность на настройки по-умолчанию в некоторых редакторах — это жуткий, плохо работающий костыль.
iCpu
08.06.2017 06:54+4Нет. Она зафиксирована для конкретного документа. Даже в ворде.
Откройте ворд и посмотрите на поведение табуляции. Откроете много нового для себя. Например, что табуляция хранится в виде <w:tab/>(действительно, 8 символов =\ ) и выставляется в сантиметрах. Или что табуляция состоит из 4 букв «Ш», но из семи символов "!". А при изменении размера шрифта — из 4 единиц и 2 букв «Ш». При этом, в табуляцию помещается не целое число символов. Или что табуляция — не синоним сноски слева, которая является параметром абзаца. Или что после удаления стилей из документа отображение документа зависит от настроек Word'а.
И самое страшное, текстовые процессоры не открывают файлы .cpp\.java\.py\.css. Импортируют текст, да, но не открывают. Вот и не надо нам натягивать правила какой-то левой среды. Мы код пишем не для того, чтобы его на принтерах печатать, а для чтения нами же. И у нас табуляция — один символ 0x09, а как его отображать — целиком зависит от контекста.
А то, что в допотопных матричных принтерах табуляция была 8 символов, так это тоже выставлялось в параметрах драйвера принтера, и далеко не у всех были именно 8 по умолчанию.
vagran
07.06.2017 20:26+1Не будет, если смешано с пробелами, а смешивать приходится, если нужно выравнивать, например, под скобки для аргументов функции, а без выравнивания опять же некрасиво. За пробелы!
mayorovp
07.06.2017 18:45+2Вот из-за редакторов, чьи авторы считают так же, я и разлюбил табы. Какие-то пять уровней вложенности (а это всего лишь пространство имен, класс, метод, цикл и условный оператор) — и строки кода уже с середины экрана начинаются...
lany
07.06.2017 19:43Почему-то все про 4, 5 и 8 говорят. По-моему, идеальный отступ — два пробела. Один можно не заметить в некоторых случаях, а два в глаза бросается и при этом драгоценное место на экране не тратится.
khim
07.06.2017 19:56-4Потому что табы — не отступы. Они предназначены для создания таблиц (даже из названия ясно). Изначально — они были в 5 символов (на механических пишущих машинках), потом их решили расширить до 8 символов.
И только уже ближе к XXI веку разработчики некоторых редакторов решили всё «учучшить» и сотворили «чудо-юдо» в 4 символа.
Два символа на таб смысла не имеют — проще два пробела поставить.
vagran
07.06.2017 20:29Это, кстати, тема для отдельного холивара — отступы на неймспейс и внешний класс, если он один в файле. Не понимаю, зачем бесполезно тратить два отступа практически на весь код файле. Считаю, что это отдельный котёл и всё такое.

VEG
07.06.2017 18:26Потому что для отступов нужно использовать табы (чтобы показать уровень вложенности), а для выравнивания — пробелы. В итоге и не плывёт ничего ни у кого, и настроить комфортный размер отступов можно.
AllexIn
07.06.2017 20:03Я не понимаю что вы подразумеваете под выравниванием.
VEG
07.06.2017 20:09Первое что попалось под руку в качестве примера:

То есть уровни вложенности делаем табами, а внутри строки если что-то надо выровнять что-то — то уже пробелы. В некоторых редакторах такое поведение можно сделать автоматическим, чтобы в зависимости от места в строке кнопка tab вставляла или табы, или пробелы.
vagran
07.06.2017 20:33+4Только обычно никто не соблюдает, и большую часть выравнивания забивают табами, а остаток добивается пробелами. В результате и получается… Не понимаю, почему нельзя использовать просто пробелы. В современных IDE при редактировании разницы не увидишь, экономить байты в исходниках в наше время — смешно.
khim
07.06.2017 20:37-3В современных IDE при редактировании разницы не увидишь
Ага-ага. Попробуйте в Makefile заменить табы на пробелы — а я над вами посмеюсь.quwy
08.06.2017 00:26+3Makefile — велосипедный анахроизм, написанный на коленке по принципу «лишь бы один раз отработало, все равно на выброс». Так себе аргумент, короче.
khim
08.06.2017 02:00-3Makefile — велосипедный анахроизм, написанный на коленке по принципу «лишь бы один раз отработало, все равно на выброс»
Ну да, конечно. Программу, пережившую многих тут дискутирующих, оказывается на «лишь бы отработало, всё равно на выброс» писали.
На самом деле в те времена в этом был очень даже практический смысл: устройствами ввода-вывода служили телетайпы, скорость передачи данных была 300 (или уже 600?) бод и разница в использовании табов и пробелов вполне себе была видна «невооруженным глазом».
Однако в сегодняшних реалиях, соглашусь, вариант использования пробелов везде и всюду — вполне имеет право на жизнь. А вот устраивать чёрт знает что с переменными размерами табуляций — не стоит.lany
08.06.2017 03:39+2Программу, пережившую многих тут дискутирующих, оказывается на «лишь бы отработало, всё равно на выброс» писали.
Не вижу противоречия. В жизни часто так бывает.
quwy
08.06.2017 14:06+1A great anecdote I often like to quote, and which has been confirmed as truthful by
someone who was there at the time, is that Stuart Feldman, the original author of “Make”
in Unix v7, was asked to change the dependence of the Makefile syntax on hard tab char-
acters. His response was something along the lines that he agreed tab was a problem, but
that it was too late to fix since there were already a dozen or so users.
Даже автор этого вашего make признал, что табы — фуфло, но менять ничего не захотел потому что Makefile уже начали использовать полтора анонимуса. Так что повторяю: пример ваш скорее аргумент против табуляции.
masai
08.06.2017 09:39+2Попробуйте в Makefile заменить табы на пробелы — а я над вами посмеюсь.
В GNU make это настраивается, кстати.
TheShock
07.06.2017 20:44-6Только обычно никто не соблюдает
Это уже недостатки программистов, а не табов.
Табы лучше, ибо:
1. Удобнее перемещение стрелочками
2. Нельзя поставить курсор в середину отступа
3. Семантика
4. Возможность каждому программисту настроить под свой вкус
5. Возможность в IDE включить отображение табов и видеть реальную глубину отступа

Экономия байтов — это скорее может применятся как шуточный аргумент, в том числе в сериале.
В то время, как у пробелов из преимуществ — только «есть программисты, которые не могут осознать простые правила». Но это легко обходится code-review за один день.
Так что я не понимаю, почему нельзя просто использовать табы)khim
07.06.2017 21:06-41. Удобнее перемещение стрелочками
Кто тут говорил об ограничениях инструментов? Да даже в каком-нибудь убогом Midnight Commander'е есть режим когда всё это работает с пробелами, менять понятие понятия «таб» для этого не нужно. А вот если вы выравниваете текст в серединие, то вам удобнее, чтобы табы имели размную ширину — 8 вполне годится.
2. Нельзя поставить курсор в середину отступа
3. Семантика
4. Возможность каждому программисту настроить под свой вкус
Не работает. Экран, увы и ах, имеет фиксированную ширину, потому невозможно вписать в него текст не зафиксировав размер таба. Зафиксировав же размер таба мы обнаружим, что нам неважно — каков он конкретно. И тогда непонятно — почему не использовать умолчальное значение в 8 пробелов, а пытаться совершить никому ненужную революцию.
5. Возможность в IDE включить отображение табов и видеть реальную глубину отступа
Опять-таки — непонятно зачем для этого менять формат файла. IDEA вполне может рисовать вертикальные линии, которые ну никак не хуже табов.
Так что я не понимаю, почему нельзя просто использовать табы)
Я тоже. Я их регулярно использую, когда размешаю в комментариях таблицы, например. Редактировать — реально удобнее.
TheShock
07.06.2017 21:37+2А вот если вы выравниваете текст в серединие, то вам удобнее, чтобы табы имели размную ширину — 8 вполне годится.
А еще сгодится 2, 3 или 4.
Экран, увы и ах, имеет фиксированную ширину, потому невозможно вписать в него текст не зафиксировав размер таба
Глупость
почему не использовать умолчальное значение в 8 пробелов
Потому что это неважно. Можно использовать любое.
Опять-таки — непонятно зачем для этого менять формат файла
Формат файла не меняется. Вы сегодня прям в ударе.khim
07.06.2017 22:20-3А еще сгодится 2, 3 или 4.
4 ещё, может быть, сгодился бы, но 2-3 — слишком мало. Очень узкие колонки получаются. Нет большого выигрыша по сравнению с пробелами.
Глупость
О, уже на личности переходим.
Потому что это неважно. Можно использовать любое.
Для того, чтобы выравгивать текст в несколько колонок? Ню-ню.
Формат файла не меняется.
Как это «не меняется»? Вы «забрали» один символ и вместо значения, которое у него было последние полвека (с середины 60х) начинаете упорно навязывать ему какие-то другие варианты.TheShock
07.06.2017 22:44+2О, уже на личности переходим.
Это не личности, я оценил вполне определенную фразу, а не вас.
Остальное — уже нный круг.khim
07.06.2017 23:04-1Остальное — уже нный круг.
Где конкретно вы обьяснили как жить с не умещающимся на экран кодом? Кроме я открываю в редакторах, которыми пользуюсь, а там всё нормально настроено я ничего не приминаю, как бы. А этот подход — равносилен поражению, так как единственное неоспоримое «преимущество» подхода «indent with tabs, align with spaces» — это возможность использовать такой отступ, какой вам хочется… но если это не работает (а это не работает) — то какой вообще во всей это конструкции смысл?
Все остальные псевдопреимущества достижимы в рамках модификации IDE и не требуют переосмысленного трактования понятия «текстовый файл».
PenguiN560
07.06.2017 21:36+41. Удобнее перемещение стрелочками
Для начала убираем подальше мышь, и вспоминаем о волшебной клавише Ctrl.
2. Нельзя поставить курсор в середину отступа
3. Семантика
Секунду, мы код пишем или семантически грамотно используем знак табуляции для отображения табличных данных?
4. Возможность каждому программисту настроить под свой вкус
Сомнительное «преимущество» учитывая сколько проблем за собой несет.
5. Возможность в IDE включить отображение табов и видеть реальную глубину отступа
Как уже ответили часть IDE прекрасно отображает уровни вложенности при использовании пробелов.
К слову о стандартах: у PHP'шников есть такая штука как PSR. В PSR-2 четко регламентируется стиль оформления кода:Code MUST use 4 spaces for indenting, not tabs.
О пробелах и табуляции. Попробуйте открыть тот же cpp файл в различных текстовых редакторах/ide особенно когда дело доходит до глубокой вложенности и вся эта табуляция переносит код на средину окна редактора. Вот и вспоминаешь потом людей добрыми словами. Что мешает использовать пробелы? К тому же большинство ide прекрасно умеют при нажатии на Tab ставить 4 пробельных символа.TheShock
07.06.2017 21:41-1Для начала убираем подальше мышь, и вспоминаем о волшебной клавише Ctrl.
Зачем убирать мышь? Удобный дополнительный инструмент. Из-за кризины использования пробелов?
Сомнительное «преимущество» учитывая сколько проблем за собой несет.
Нисколько.
К слову о стандартах: у PHP'шников есть такая штука как PSR. В PSR-2 четко регламентируется стиль оформления кода:
Сочувствую пхпшникам.
Попробуйте открыть тот же cpp файл в различных текстовых редакторах/ide особенно когда дело доходит до глубокой вложенности и вся эта табуляция переносит код на средину окна редактора
Что? Я открываю в редакторах, которыми пользуюсь, а там всё нормально настроено.
Что мешает использовать пробелы?
Вы повторяетесь.
К тому же большинство ide прекрасно умеют при нажатии на Tab ставить 4 пробельных символа.
Или ставить символ табуляции.PenguiN560
07.06.2017 21:55+1Зачем убирать мышь? Удобный дополнительный инструмент. Из-за кризины использования пробелов?
Я не буду Вас призывать освоить столь чудные инструменты как командные текстовые редакторы(к примеру Vim), которые позволяют при должном навыке писать код быстрее. Но даже в ide я не вижу смысла убирать вторую руку с клавиатуры для позиционирования курсора(к слову Вы сами про стрелки разговор начали, Ctrl+стрелки позволяют быстрее позиционировать, чем использование табуляции и просто стрелок).
Что? Я открываю в редакторах, которыми пользуюсь, а там всё нормально настроено.
Я рад за Вас, но иногда для редактирования пары строк легче открыть даже примитивный блокнот, чем загружать ради этой цели тяжелую IDE.
Или ставить символ табуляции.
теперь уже Вы повторяетесь.TheShock
07.06.2017 22:48-1Но даже в ide я не вижу смысла убирать вторую руку с клавиатуры для позиционирования курсора
Есть моменты, когда удобнее использовать клавиатуру, а есть моменты, когда удобнее использовать мышь. Это инструменты для слегка разных целей.
Я рад за Вас, но иногда для редактирования пары строк легче открыть даже примитивный блокнот, чем загружать ради этой цели тяжелую IDE.
Открою вам секрет, но есть непримитивные блокноты и, при они с настройками и даже работаю быстрее примитивного. Мне вообще непонятно, как кто-то ещё может пользоваться блокнотом по-умолчанию
теперь уже Вы повторяетесь.
Ну да, мы замкнулись)PenguiN560
07.06.2017 23:22-1Есть моменты, когда удобнее использовать клавиатуру, а есть моменты, когда удобнее использовать мышь. Это инструменты для слегка разных целей.
Есть, не спорю, но началось то все с:1. Удобнее перемещение стрелочками
Стрелками удобнее с Ctrl передвигаться(хотя о вкусах не спорят), а ему все равно 1 знак табуляции или 2-4-8-16(или сколько там набралось) пробельных символов подряд.
2. Нельзя поставить курсор в середину отступа
Открою вам секрет, но есть непримитивные блокноты и, при они с настройками и даже работаю быстрее примитивного. Мне вообще непонятно, как кто-то ещё может пользоваться блокнотом по-умолчанию
Блокнот был назван со словами «легче открыть даже примитивный блокнот», что подразумевало использование блокнота в качестве примера. Для просмотра/внесения мелких правок исходников достаточно простого текстового редактора, и далеко не каждый текстовый редактор готов отображать символ табуляции так, как хотел бы пользователь.
Я не сторонник использования табуляции для отображения уровней вложенности кода. Табуляция всегда использовалась для табличных данных и мне не хотелось бы видеть как один текстовый редактор отображает данный символ по своему, а другой — по своему.
Ну да, мы замкнулись)
Предлагаю закончить этот спор: мне не понять Ваше желание иметь возможность редактировать размер табуляции, Вам не понять моей нелюбви к отступам в виде символа табуляции.
michael_vostrikov
07.06.2017 23:00-1Но даже в ide я не вижу смысла убирать вторую руку с клавиатуры для позиционирования курсора
Команды главного меню, контекстного меню, выделение строки в списках типа git log или в окне результатов поиска, прокрутка колесиком или перетаскиванием вместо PgUp/PgDown, переключение через трей или панель задач. Когда рука уже на мышке, удобнее сразу тыкнуть куда надо.
PenguiN560
07.06.2017 23:28Не отрицаю, мы просто ушли от первоначального высказывания, на которое я сослался выше.
Учитывая контекст Вы хотите сказать, что позиционируя курсор мышкой при использовании пробелов, есть большая доля вероятности поставить его в середину отступа?michael_vostrikov
08.06.2017 10:48+2Так часто бывает, когда надо поставить курсор в начало текста в другой строке. С пробелами надо целиться точнее.
mayorovp
08.06.2017 11:17В VS постановка курсора сразу после отступа делается нажатием Home. Удобнее чем табы.
michael_vostrikov
08.06.2017 14:07Так много где делается. А если курсор уже попал в нужную позицию, то Home на начало переходит. Тоже следить надо, а туда ли я ткнул, а надо Home нажимать или можно сразу печатать. Это все мелочи конечно, просто с табами их меньше.
lany
08.06.2017 03:42-1Как перемещение может быть удобнее? Вот у меня курсор стоит в
<|footer>и я хочу его перевести в<|/footer>. Я нажимаю четыре раза кнопку вниз, а курсор начинает при этом ещё влево-вправо скакать, отвлекая меня от сути моего действия. Это удобно?TheShock
08.06.2017 10:14Да, вполне. Вот пример из Notepad++:

Основное преимущество, что при таком способе курсор не может стать в середину символа.lany
08.06.2017 13:13Так я и говорю, что скачет влево-вправо. И на вашей гифке именно влево-вправо и скачет, а не только идёт вверх-вниз. Что вы мне хотите этим показать из того, что я ещё не сказал?
TheShock
08.06.2017 13:15+1Главное, что он стает туда, куда необходимо. Да, не отвлекает, да удобно. Значительно менее удобно и больше отвлекало бы, если бы он внезапно оказывался посреди символа, вот это действительно отвлекает.
lany
08.06.2017 13:23Когда я просто прохожу мимо этого места мне как-то наплевать, есть там табуляция или нет, я просто мимо проходил. Как это может действительно отвлекать?
TheShock
08.06.2017 13:35-1Вы же сами сказали, что вас там что-то отвлекает:
курсор начинает при этом ещё влево-вправо скакать, отвлекая меня от сути моего действия
Вы очень непоследовательны.khim
08.06.2017 18:30-1На самом деле lany вполне последователен. Но проблема в другом: есть редакторы, которые вполне могут делать то, чего вы хотите, в файлах, отформатированных с помощью пробелов, можно представить себе редактор, который будет вести себя так, как хочет lany в файлах, где используются табы (вставляя при необходимости нужное число пробелов), менять ради этого весь мир, как предлагаете вы, для этого не требуется.
TheShock
08.06.2017 18:36+1менять ради этого весь мир
Вы — не мир, слишком много на себя берете.
Менять мне ничего не надо. Мир уже давно живет по двойственным правилам.khim
08.06.2017 19:01-1Вы — не мир, слишком много на себя берете.
Я — нет, но если сложить вместе разработчиков Android'а и GCC, Ghome и Notepad++, вот этих вот всех проектов, где «поставил две табуляции, а остальное догнал пробелами, у него все красиво и аккуратно» — то примерно так и наберётся если не весь мир, то полмира точно.
Менять мне ничего не надо. Мир уже давно живет по двойственным правилам.
Возможно ваш мирок и живёт по «двойственным правилам», но я не видел ни одного проекта достаточно большого размера, где бы практиковался продвигаемый вами «новаторский подход». Я когда писал расскажите уж о проектах с числом разработчиков от тысячи и числом строк от 10 миллионов где используется ваша технология — это без сарказма делал.
Ибо пока что я реально встречал ваш «новаторский» подход только в мелких проектах — притом, что, якобы, смысл заключается именно в том, что позволяет привлечь кучу народу… так почему же этого не происходит?
VEG
07.06.2017 20:49-3Потому что вам нравятся отступы в 2 символа, мне нравятся в 4 символа, Пете нравятся отступы в 8 символов, а кому-то подавай 3 символа. Именно поэтому пробелы для отступов — это отстой. Потому что они лишают возможности смотреть код так, как удобно именно вам.
khim
07.06.2017 21:09-1Потому что вам нравятся отступы в 2 символа, мне нравятся в 4 символа, Пете нравятся отступы в 8 символов, а кому-то подавай 3 символа.
Это такая же вкусовщина как Camel Case против Snake Case и прочего. Автор кода решает.
Потому что они лишают возможности смотреть код так, как удобно именно вам.
Ага. Давайте ещё CSS к текстовым файлам прикрутим. Тестовые файлы хороши своей простотой и однозначностью. Не нужно их усложнять без необходимости.michael_vostrikov
08.06.2017 10:57+3Ага. Давайте ещё CSS к текстовым файлам прикрутим.
Внезапно, подсветка кода в редакторе это применение стилей к тексту. Ширина таба это тоже дополнительный стиль отображения, как например размер шрифта.
khim
08.06.2017 18:32-1Внезапно, подсветка кода в редакторе это применение стилей к тексту.
Хорошая аналогия.
Ширина таба это тоже дополнительный стиль отображения, как например размер шрифта.
И так же, как считается дурным тоном менять размер шрифта в:hover, также и не стоит менять размер таба без крайней на то необходимости в текстовых файлах.michael_vostrikov
08.06.2017 20:56В hover менять не стоит, а у себя в IDE я могу поставить тот размер шрифта, который мне надо.
TheShock
07.06.2017 20:05поставил две табуляции, а остальное догнал пробелами
Стоп-стоп-стоп, вот тут ложный посыл, а дальше уже из него все глупости и пошли. Проблема в вашем примере не в использовании табов, а в использовании пробелов. Смотрите, ничего не едет:
2 пробела на таб:

5 пробелов на таб:

9 пробелов на таб:

mayorovp
07.06.2017 20:18+1К сожалению, мало кто делает так же аккуратно.
Видел проект, где отступ первого уровня делался 4 пробелами, а отступ второго уровня — одним табом...
TheShock
07.06.2017 20:20Ну это ведь проблемы не табов и не пробелов, а людей.
khim
07.06.2017 20:25-5Нельзя обвинять людей в том, что они суп едят ложкой, а землю копают лопатой.
TheShock
07.06.2017 20:36+1Я понимаю, что обезьяны всю жизнь только били палками окружающих, но люди из палок сделали инструменты и используют их не только так, как раньше. Я использую палку как рычаг и осуждаю вас за то, что вы бьете палками окружающих. Хоть оно исторически только так и было.

PsyHaSTe
09.06.2017 17:53+1Но можно, если они суп едят лопатой, а копают — ложкой.
khim
09.06.2017 23:18-3Тут нам как раз и предлагается копать ложкой.
Табы (как следует, собственно, из названия) предназначены для создания таблиц (тут и картинки приводили) — а «табы переменной, заранее неизвестной ширины» для этого, в общем, непригодны (за исключением, пожалуй, elastic tabstops — но вот как раз их-то мало кто поддерживает).
Но тот факт, что этот подход вступает вразрез с тем, как табы используются в миллионах уже существующих документов — уже достаточен для отказа от него.
khim
07.06.2017 20:23-4Видел проект, где отступ первого уровня делался 4 пробелами, а отступ второго уровня — одним табом...
То есть в этом проекте табы использовались по их прямому назначению — в чём проблема?
khim
07.06.2017 21:24-2Собственно это — то, как почти все проекты в которых участвуют сотни и тысячи разработчиков устроены.
Вот вам gcc. А вот вам Linux — тут вообще написано просто и жёстко: There are heretic movements that try to make indentations 4 (or even 2!) characters deep, and that is akin to trying to define the value of PI to be 3.
Задолбали ужеэсперантистылюбители резиновых табов. Просто секта какая-то.VEG
08.06.2017 01:08+2Совсем недавно вы написали:
То есть ваша претензия к тому, что если в редакторе по умолчанию таб 8 символов (кстати, в обсуждаемом Notepad++, если мне не изменяет память, по умолчанию 4), то при таких отступах код очень быстро уползает вправо. И тут же вы ссылаетесь на документ, который говорит:Моя технология работает при ЛЮБЫХ настройках, что я и показал.
При настройках по умолчанию текст начинает очень быстро уползать за правую границу экрана.
Tabs are 8 characters, and thus indentations are also 8 characters. There are heretic movements that try to make indentations 4 (or even 2!) characters deep, and that is akin to trying to define the value of PI to be 3.
То есть теперь уже отступы по 8 символов ок и код уже не убегает вправо слишком быстро? И вообще другие размеры отступов придумали еретики? Вы уж определитесь с аргументацией и не используйте аргументы, которые противоречат друг другу.
Now, some people will claim that having 8-character indentations makes the code move too far to the right, and makes it hard to read on a 80-character terminal screen. The answer to that is that if you need more than 3 levels of indentation, you’re screwed anyway, and should fix your program.
Чтобы решить вопрос «какие отступы вам нравятся» и было придумано использовать табы для отступов. И это реально работает. Мне нравятся отступы размером в 4 пробела. Вам нравятся отступы в 8 пробелов (предположим, что вы поклонник Торвальдса и когда сказали, что код слишком быстро убегает вправо — это вы погорячились и забыли что говорил гуру против этого аргумента). Общий знаменатель для нас обоих — использовать табы для отсутпов. И вам будет приятно читать и дописывать этот код, и мне будет приятно делать то же саме. И Пете, который хочет отступы размером в 2 пробела. Всё что для этого нужно — это настроить в своём основном инструменте комфортный размер табов. Если где-нибудь на стороне вы увидите код с табами, размер которых вам не нравится — душевная травма от этого будет невелика. Вы знаете, что вы можете взять этот код, и не изменяя в нём ни символа — он в вашем основном софте покажется именно так, как вам нужно. И то маленькое неудобство от того, что вы где-нибудь в левой софтине случайно мельком увидели не такой размер таба не идёт ни в какое сравнение с печалью, когда вам нужно дорабатывать код, который использует по 2 пробела для отступов, а вам привычно 4 или вообще 8 (как Торвальдсу).
То есть пробелы — это постоянная боль при работе с кодом, если принятый в коде отступ не совпадает с вашим предпочитаемым. А он часто не совпадает. Мне не раз приходилось дорабатывать код с отступом в 2 пробела — и это была перманентная боль и ненависть. А ведь кто-то это писал, и наверняка он скажет, что ему 4 пробела — это как мне 8 пробелов. Слишком много. То что вы можете увидеть свой код где-нибудь мельком, где будет не такой размер отступов, как вам нравится — такая мелочь, по сравнению с этим. Тем более, что все свои инструменты вы сможете настроить, чтобы больше не огорчаться по этому поводу (и все адекватные инструменты имеют такую настройку). Даже в CSS добавили настройку размера таба. Просто потому что он не фиксирован. Он может быть любым. По умолчанию (в большинстве случаев в обычных редакторах, не предназначенных для кода) — как 8 пробелов, но это не обязательно.khim
08.06.2017 01:42-2То есть ваша претензия к тому, что если в редакторе по умолчанию таб 8 символов (кстати, в обсуждаемом Notepad++, если мне не изменяет память, по умолчанию 4), то при таких отступах код очень быстро уползает вправо.
Моя претензия в том, что если делать отступы с помощью символа табуляции и не учитывать тот факт, что стандартный его размер — 8 символов, то текст быстро уползает вправо.
То есть теперь уже отступы по 8 символов ок и код уже не убегает вправо слишком быстро?
Если код структурирован так, что у него отступы по 8 символов и при этом он не уползает вправо — то почему нет? Для меня не так важно — как конкретно размечен код, важно чтобы при стандартных настройках его можно было читать.
Чтобы решить вопрос «какие отступы вам нравятся» и было придумано использовать табы для отступов.
Откуда вообще взялась эта проблема? Какая мне, в сущности, разница — отступы в 2, 4, или 8 символов вы используете? Я непривередлив. Для меня главное — чтобы текст был нормально читаем при стандартных настройках системы — то есть когда таб стопы расставлены через 8 символов. Но вот собственно только этому, простому и естественному, требованию — указанный подход и не удовлетворяет! Только если одновременно с использованием табуляции для отступов сами отступы не принимаются размером в 8 символов (как в ядре Linux'а) — с соответствующим форматированием кода. Но если вы уже приняли такие отступы — то зачем вам нужна гибкость с переменной шириной табов?
И то маленькое неудобство от того, что вы где-нибудь в левой софтине случайно мельком увидели не такой размер таба не идёт ни в какое сравнение с печалью, когда вам нужно дорабатывать код, который использует по 2 пробела для отступов, а вам привычно 4 или вообще 8 (как Торвальдсу).
Вот не вижу вообще никакой печали от того, что в каком-то коде отступы в 2 символа, а в другом — 8 символов. А вот от того, что я не могу нормально работать с кодом при стандартных настройках — печаль таки вижу.
Мне не раз приходилось дорабатывать код с отступом в 2 пробела — и это была перманентная боль и ненависть.
Отчего вдруг? Какая вообще разница — сколько там пробелов? На фоне всего остальное (названия переменных и общая структура кода) — это мелочи.
Тем более, что все свои инструменты вы сможете настроить, чтобы больше не огорчаться по этому поводу (и все адекватные инструменты имеют такую настройку).
В том-то и дело, что не смогу. Я пользуюсь сейчас тремя системами ревью кода, несколькими программами для слияния файлов, да, в конце-концов могу иногда просто текст скрипта какого-нибудь распечатать с помощью «adb shell cat filename»! Это если не считать разных инструментов, с которым я сталкиваюсь раз в месяц. У меня нет ни времени, ни сил для настройки всего этого зоопарка. Потому единственное требования у меня простое и незатейливое: всё должно нормально выглядеть при стандартных настройках всех этих инструментов.
Но вот ровно этому требованию предложенный «гибкий» подход как раз и не удовлетворяет.
Даже в CSS добавили настройку размера таба.
Заметьте — в CSS, не в GUI браузера!
Просто потому что он не фиксирован.
Для текстовых файлов — фиксирован. 8 символов. Что там у вас в Word'е или QuarkXPress — меня мало волнует.VEG
08.06.2017 11:13+1Для меня не так важно — как конкретно размечен код, важно чтобы при стандартных настройках его можно было читать.
И таки код с отступами на табах вы сможете нормально читать. Просто отступы будут 8 символов, как в коде ядра Linux. На современных размерах мониторов вообще не проблема даже если не ограничиваться тремя уровнями вложенности.
Откуда вообще взялась эта проблема? Какая мне, в сущности, разница — отступы в 2, 4, или 8 символов вы используете? Я непривередлив. Для меня главное — чтобы текст был нормально читаем при стандартных настройках системы — то есть когда таб стопы расставлены через 8 символов. Но вот собственно только этому, простому и естественному, требованию — указанный подход и не удовлетворяет!
Так забавно видеть «я непривередлив», и следом — очень привередливое требование :)
Вот не вижу вообще никакой печали от того, что в каком-то коде отступы в 2 символа, а в другом — 8 символов. А вот от того, что я не могу нормально работать с кодом при стандартных настройках — печаль таки вижу.
То что у вас табы отображаются не с таким размером, как у автора, никак не мешает вам работать с этим кодом на стандартных настройках. Код с отступами на табах будет выглядеть нормально с любым размером таба: хоть 2, хоть 8. И работать с ним сможет любой программист, независимо от того, какой размер таба ему удобен. Использовать пробелы для отступов — это своего кода эгоизм «мне так удобно, а вы привыкайте к моим отступам».
Отчего вдруг? Какая вообще разница — сколько там пробелов? На фоне всего остальное (названия переменных и общая структура кода) — это мелочи.
Не выдавайте субъективное за объективное. Меня вот гораздо меньше напрягают странные имена переменных, чем плохие отступы. (Я комфортно чувствую себя в ассемблере, где имена почти всех инструкций — это сокращения из пары-тройки символов.)
Для текстовых файлов — фиксирован. 8 символов. Что там у вас в Word'е или QuarkXPress — меня мало волнует.
Вы видите только то что хотите увидеть. Какой-то прям религиозный подход :) Я выше упомянул, что в обсуждаемом Notepad++ по умолчанию размер таба — 4 пробела. А это именно что редактор обычных текстовых файлов. И многие другие редакторы также имеют соответствующую настройку, именно потому, что размер таба не фиксирован — он настраиваем. И если в каком-то редакторе нет такой настройки (например, notepad.exe из стандартной поставки Windows) — то это проблема этого редактора. Впрочем, notepad.exe и \n не понимает, ему \r\n подавай. Тем не менее, \n без \r часто используется в текстовых файлах. Беда же! На самом деле нет.khim
08.06.2017 19:31На современных размерах мониторов вообще не проблема даже если не ограничиваться тремя уровнями вложенности.
Разместите три копии кода для тройного слияния — и вы поймёте что даже «на современных размерах мониторов» таки «размер имеет значение»…
Использовать пробелы для отступов — это своего кода эгоизм «мне так удобно, а вы привыкайте к моим отступам».
А все эти соглашения по тому куда расставлять скобочки и как называть переменные — это не эгоизм?
Меня вот гораздо меньше напрягают странные имена переменных, чем плохие отступы.
И потому вы хотите тысячи (хотя, скорее, миллионы) разработчиков изменить их правила, передалеть используемые ими инстроументы и вообще совершить революцию ради вашего удобства. Это — не эгоизм?
Я выше упомянул, что в обсуждаемом Notepad++ по умолчанию размер таба — 4 пробела.
И вот именно это — и является проблемой, как я уже говорил. Пока вы работает с кодом со стандарными табами — у вас нет проблем. Как только вы начинаете использовать разные варианты — у вас проблемы. И ратовать нужно не за «гибкие схемы», а за постепенный отказ от самодеятельности и переход на стандартный размер. Microsoft достаточно дров наломал со своими табами в 4 символа — незачем это продолжать.VEG
08.06.2017 19:54вообще совершить революцию ради вашего удобства
Нет революции в использовании табов. Большинство разработчиков использует кнопку tab для вставки отступов. Просто в моду вошла автоматическая вставка пробелов вместо таба средствами IDE или блокнота. При этом важно заметить, что она идёт всё равно до табстопа, то есть имитирует поведение таба.
Это — не эгоизм?
Это попытка показать, что существует компромиссное решение, которое могло бы устраивать всех. Кроме крайних случаев, когда это не подходит по религиозным соображениям, конечно же.
И вот именно это — и является проблемой, как я уже говорил. Пока вы работает с кодом со стандарными табами — у вас нет проблем. Как только вы начинаете использовать разные варианты — у вас проблемы.
Переделать кучу уже существующих инструментов, где размер табов меняется — не представляется возможным. И если вы опираетесь на фиксированный размер таба — это и является проблемой. Потому что изменяемый размер таба — это уже давным давно данность, от которой вам никуда не деться.khim
08.06.2017 21:27-1Это попытка показать, что существует компромиссное решение, которое могло бы устраивать всех.
А ещё мы могли бы использовать в качестве языка международного общения эсперанто вместо английского.
Переделать кучу уже существующих инструментов, где размер табов меняется — не представляется возможным.
И не нужно. Если в них размер таба меняется — нужно выставить там 8 и всё.
Та же самая история, что и с UTF-8: нужно просто потихоньку отказаться от использования всего остального — и всё.
Потому что изменяемый размер таба — это уже давным давно данность, от которой вам никуда не деться.
Ага. А кодировки — это ужас с которым нам придётся жить столетиями. Ага-ага.VEG
08.06.2017 22:45Если в них размер таба меняется — нужно выставить там 8 и всё.
Почему 8? Хоть один разумный довод кроме «так было полвека назад». Серьёзно, этот аргумент выглядит так же, как «так написано в Библии». Да не важно как там было, важно как сейчас. Таб не имеет фиксированного размера. Он может быть любым. Смиритесь.
К слову, при просмотре текстовых файлов шрифт не обязан быть моноширным (вот только не надо говорить, что в полвека назад только такие и были). И в данном случае тот же notepad.exe (где таб только «стандартный» и нет настроек) выводит таб размером с 18 пробелов, если шрифт Times New Roman, и 14 пробелов, если шрифт — Arial. Нет и намёка на 8.khim
08.06.2017 23:50-2Хоть один разумный довод кроме «так было полвека назад».
А вам нужен ещё какой-то довод? В IT индустрии (да и в любой другой, если копнуть) «ширина лошадиной задницы» определяет если не всё, то очень многое (если не читали байку — просветитесь). По той же самой причине мы на телефоне используем далеко не оптимальную QWERTY (и слегка более оптимальный ЙЦУКЕНГ).
Да не важно как там было, важно как сейчас.
Он и сейчас полагается равным 8 символам в массе инструментов и массе самых разных проектов.
Таб не имеет фиксированного размера. Он может быть любым. Смиритесь.
Извините, но… смириться придётся вам. Потому просто, что людей, рассчитывающих на табы фиксированной ширины банально больше — и они не будут всё на свете переделывать чтобы вам угодить.
Максимум, чего вы сможете добиться — отказа от использования табов вообще. Это — да, популярная опция и со временем становится всё популярнее.
Если введение настрийки «ширины таба» преследовало целью именно это — то да, можете праздновать победу, мы туда движемся уверенно.
Добиться того, чтобы люди подстраивались под «резиновые табы», вы не сможете, не стоит даже и пытаться.
К слову, при просмотре текстовых файлов шрифт не обязан быть моноширным (вот только не надо говорить, что в полвека назад только такие и были).
Не полвека. Лет 10 назад народ пытался прикрутить к разнообразным IDE пропорциональные шрифты. Не прижилось. Опять-таки, потому что большинство писало программы с рассчётом на моноширинные шрифты и их не волновало — смогут ли на них смотреть любители пропорциональных…
michael_vostrikov
08.06.2017 21:09+1Разместите три копии кода для тройного слияния — и вы поймёте что даже «на современных размерах мониторов» таки «размер имеет значение»…
Да, действительно, чё-то не помещается. Вот было бы клёво таб на время поменьше сделать, чтобы этот файл без горизонтальной прокрутки просматривать.
khim
08.06.2017 21:30-1Вот было бы клёво таб на время поменьше сделать, чтобы этот файл без горизонтальной прокрутки просматривать.
Но… Зачем? Ширина текста, который человек нормально может воспринимать — не так велика, это уже давным-давно ещё при разработке форматов для газет и журналов прощитывали. Достаточно подобрать размер шрифта, подходящее ограничение на ширину строки (80 символов или там 100) — и всё.michael_vostrikov
08.06.2017 22:04+1Как зачем? Чтобы код за край окна не уезжал. Шрифт меньше делать? Нет уж, спасибо.
khim
07.06.2017 20:22-2Стоп-стоп-стоп, вот тут ложный посыл
Какой, нафиг, «ложный посыл»? Табы — это способ выровнять текст на определённые вертикальные линии. Не больше, не меньше. Эти линии для каждого документа фиксированы. Если нужно попасть куда-то ещё — есть пробелы. В более сложных форматах, чем тестовый файлб есть возможность эти позиции переставить, в текстовом документе — такого способа нет. И всё.
Я, в частности, использую отступы в два символа (так мне удобнее и вообще — корпоративный стандарт) и табы в 8 симоволов (так как — стандартное значение для текстовых файлов, HTML и т.п.)
Ваша технология при стандартных настройках — не работает. Всё.TheShock
07.06.2017 20:31Эти линии для каждого документа фиксированы
Сначала сами придумали себе ненужные ограничения, а потом стараетесь ими аргументировать. Не надо так.
в текстовом документе — такого способа нет
А в любом вменяемом редакторе кода — есть. Если вы пишете в блокноте — это проблемы людей, которые с вами работают и это уже их дело переубедить вас или смириться с вашими тараканами.
Ваша технология при стандартных настройках — не работает. Всё.
Моя технология работает при ЛЮБЫХ настройках, что я и показал.khim
07.06.2017 20:42-2Сначала сами придумали себе ненужные ограничения, а потом стараетесь ими аргументировать.
Добро пожаловать в мир IT-индустрии.
Не надо так.
А как надо? Почему у нас все процессоры little endian при том, что big endian безопаснее? Ответ: потому что так исторически сложлось. То же самое и здесь.
А в любом вменяемом редакторе кода — есть.
Кроме редакторов кода есть много других инструментов, которые могут работать с кодом. Всевозможные веб-сайты, системы контроля версий и прочее, прочее, прочее. Потому код должен нормально выглядеть, прежде всего, при использовании настроек по умолчанию.
Моя технология работает при ЛЮБЫХ настройках, что я и показал.
При настройках по умолчанию текст начинает очень быстро уползать за правую границу экрана.TheShock
07.06.2017 20:50Добро пожаловать в мир IT-индустрии.
Нет, это лишь ваш воображаемый мир, который вы хотите представить, как всеобщий мир. К счастью я живу в ином мире.
А как надо? Почему у нас все процессоры little endian при том, что big endian безопаснее? Ответ: потому что так исторически сложлось. То же самое и здесь.
Если что-то исторически сложилось, то этому не обязательно теперь слепо следовать, особенно если легко можно не следовать. Если бы мы могли везде так легко менять «исторически сложилось» как можем это сделать с табами — наша жизнь была бы только лучше.
При настройках по умолчанию текст начинает очень быстро уползать за правую границу экрана.
1. Это не означает, что оно работает неправильно
2. Настройки по-умолчанию легко меняются на любые другие.khim
07.06.2017 21:17Если что-то исторически сложилось, то этому не обязательно теперь слепо следовать, особенно если легко можно не следовать.
Легко можно не следовать — это поменять тысячи программ на миллионах компьютнеров? Нифига себе «легко».
Если бы мы могли везде так легко менять «исторически сложилось» как можем это сделать с табами — наша жизнь была бы только лучше.
Проблема в том, что вы сильно недооцениваете сложность замены размера таба. У вас есть уютный мирок, где вы себе всё подстроили — и вы в нём живёте. А я общаюсь с кучей разных инструментов на разных платформах и менять в них всех понятие таба — «себе дороже». Особенно ради сомнительного выигрыша.
2. Настройки по-умолчанию легко меняются на любые другие.
Это вам к эсперантистам. Это они рассказывают сказки, что если вдруг все перестанут использовать ужасный английский для мендународной переписки — так сразу всем щастя настанет. Не надо так. Ваш файл должен хороши читаться прижде всего с настройками по умолчанию. Чего большинство апологетов «резиновых табов» таки не достигают. Увы. Всё остальное — уже неважно.
1. Это не означает, что оно работает неправильно
Это обозначет что использовать ваш стиль — неудобно если вам небходимо работать с большой командой. А если вы не работаете с большой командой и пишите текст только «для себя» — то так ли важно какие там отступы?TheShock
07.06.2017 21:44Все команды, с которыми я работал прекрасно управлялись с табами. Пробовали работать с более профессиональными разработчиками? Ну чисто так, для разнообразия.
Легко можно не следовать — это поменять тысячи программ на миллионах компьютнеров?
Опять глупость какая-то. Вы сегодня решили пойти на рекорд? Зачем менять код там, где он уже написан? Тем более уже написанный код есть и с табами, и с пробелами.
Проблема в том, что вы сильно недооцениваете сложность замены размера таба
У таба нету размера, потому переоценивать тут нечего.
khim
07.06.2017 22:33+1Пробовали работать с более профессиональными разработчиками?
Как определяется профессионализм? Если по количеству пользователей — то речь идёт о разработчиках, продукцией которых пользуются миллиарды.
Ну чисто так, для разнообразия.
А вы расскажите уж о проектах с числом разработчиков от тысячи и числом строк от 10 миллионов где используется ваша технология — тож для разнообразия. Вы ж говорите что это важно, когда разраработчики разные, то есть из много.
Зачем менять код там, где он уже написан?
А вот ради этого: я открываю в редакторах, которыми пользуюсь, а там всё нормально настроено.
Мы очень рады за то, что вы открываете код только в редакторах, в которых «всё нормально настроено». А я открываю код не только редакторах, но и в системах контроля версий, в разнообразных web-инструментах, да, черт побери, мало ли где может оказаться мой код? В логах разнообразных, к примеру. В выдаче сообщений об ошибках и прочем.
И вы предлагаете вот это вот всё подстраивать под ваше «видение мира»? Спасибо, но… спасибо не надо.
У таба нету размера, потому переоценивать тут нечего.
У таба есть размер. Иначе в нём бы не было никакого смысла вообще. В текстовых файлах это — 8 символов.EvilFox
07.06.2017 23:03+2А что, есть стандарт который как-то регламентирует сколько знакомест должен взять на себя байт 0x09 при отображении в каком-либо ПО?
Зря тащите пережитки прошлого и несовершенство отдельного взятого ПО которое не позволяет вам выставить произвольный размер табуляции.
Это как если бы запрещали использовать юникод потому что какие-то недоредакторы его не поддерживают.
пЕАЪРЮ, ДЮБЮИРЕ ФХРЭ ДПСФМН!khim
07.06.2017 23:32-1А что, есть стандарт который как-то регламентирует сколько знакомест должен взять на себя байт 0x09 при отображении в каком-либо ПО?
Отдельного стандарта я не припомню, но как часть разных стандартов оно встречается. Вот тут, например, или здесь (таблица совместимости с браузерами). Да, там указывается и возможность его поменять, но это, как правило, опция. У текстовых файлов никаких CSS нету и, соответственно, как менять и где задавать tab-size — непонятно. А у питона это в спецификации языка прописано.
Это как если бы запрещали использовать юникод потому что какие-то недоредакторы его не поддерживают.
Какую проблему решает переход на юникод — я понимаю. Какую проблему решает отказ от стандартного трактования табуляции как перехода к о чередной «позиции табуляции» выставленной через каждые 8 символов — нет.
Вреда от попыток изменить трактовку символа табуляции — куда больше, чем пользы. Хотите искать приключений на свою задницу — заведите символ в PUA — и трактуйте его как хотите.
пЕАЪРЮ, ДЮБЮИРЕ ФХРЭ ДПСФМН!
Ага. Юникод нас спас от указания кодировок — вернём проблему?EvilFox
08.06.2017 00:42Стало быть стандарта нет, тем более оправдывающего нужды такого размера в современных реалиях. Есть просто какие-то отдельно взятые нормы аля стили кодирования. Традиция тянущаяся со времён печатных машинок.
Так же как и CR+LF в винде просто традиция унаследованная от DOS/DEC, ранее тянущаяся тоже с печатных машинок.
где задавать tab-size — непонятно
Очевидно в настройках ПО. Любой адекватный текстовый редактор или IDE позволяет указать желаемый размер табуляции и все остальное ПО тоже должно это уметь, это же просто отображение и ничего более, настройка добавляется программистом очень просто и никаких проблем.
Какую проблему решает отказ от стандартного трактования табуляции
Но стандартного трактования же нет, есть просто традиционное о котором всерьёз не думали.
А решает проблему удобства читаемости без переформатирования исходника, на разных устройствах я могу настроить более оптимальные отступы и не маяться с костылями. У меня включено отображение этих символов в редакторе и подменять отображение самообманываясь лично я не желаю, как и не желаю видеть пробелы вместо табуляции для отступов, попадать мимо границы отступа и хранить лишний мусор на диске.khim
08.06.2017 01:55+1Любой адекватный текстовый редактор или IDE позволяет указать желаемый размер табуляции и все остальное ПО тоже должно это уметь, это же просто отображение и ничего более, настройка добавляется программистом очень просто и никаких проблем.
А выбор кодировки — это тоже указание желаемого набора символов и ничего более, «настройка добавляется программистом очень просто и никаких проблем».
Но стандартного трактования же нет, есть просто традиционное о котором всерьёз не думали.
POSIX — это таки стандарт, CSS — это проект стандарта, VT102 — тоже вполне себе задокументирован. Почему вы считаете что стандарт — это только что-то, принятое ISO? Если так подходить — то у нас вообще никаких стандартов нет, ни на ECMAScript, ни на C#, ни на Java'у.
У меня включено отображение этих символов в редакторе и подменять отображение самообманываясь лично я не желаю, как и не желаю видеть пробелы вместо табуляции для отступов, попадать мимо границы отступа и хранить лишний мусор на диске.
Это ваш выбор. Если вы при всём при этом ещё и будете использовать символы табуляции размером 8 пробелов — то мне вообще будет пофигу. Но я использую символы табуляции для выравнивание текстов — и потому для меня важно, чтобы вы не устраивали чёрт знает что.
Вы тут сами подняли Юникод как «всеобщее благо» — а ведь он всего-навсего сделал так, чтобы символы с одними и теми же кодами не отображались по разному на разных машинах… так почему вы в отношении одного конкретного символа, с которым в 60е и 70е годы ни у кого не было никаких разночтений в трактовании сделать шаг назад и сделать так, чтобы он вёл себя по разному на разных системах? Где логика?abyrkov
08.06.2017 11:07POSIX — это таки стандарт, CSS — это проект стандарта
Формата текстовых документов?
Если уже и считать все подряд «стандартом», в кодстайле Google написано, что выравнивание должно быть 2мя пробелами. Т.е. я могу смело утверждать, что таб — это 2 пробела, а не 8.
так почему вы в отношении одного конкретного символа, с которым в 60е и 70е годы ни у кого не было никаких разночтений в трактовании сделать шаг назад и сделать так, чтобы он вёл себя по разному на разных системах? Где логика?
Ну, многим, я уверен, абсолютно пофиг, на сколько таб там 8, 4 или 2. А от стандартизации мы получим сомнительную выгоду. Очень сомнительную. А все ваше нытье про то, что будет уезжать, ехать или еще что-то сомнительны. Если вас не устраивать текущее ПО, то почему вы его не меняете или не настраиваете? Времени нет? Лень? А холивар устроить не лень? Или проще стандартизировать таб(причем делать этого сами не хотите)?
Вашу проблему можно решить куда проще — использовать пробелы вместо табов и не так много. А если на выходе или входе табы — достаточно обработать исходник регулярным выражением, заменяя табы на N пробелов и наоборот. Уверен, что такой функционал уже даже кто-то делал. И проблемы с нестадартизированостью табов как-то исчезнут.khim
08.06.2017 18:21-4Если уже и считать все подряд «стандартом», в кодстайле Google написано, что выравнивание должно быть 2мя пробелами.
Совершенно верно. И Google старается этого правила придерживаться. Даже в заимствованном и «переработанном» коде.
Т.е. я могу смело утверждать, что таб — это 2 пробела, а не 8.
Вы идиот? Или просто играете роль идиота на Хабре? Возьмите это файл из кодбазы Google и посмотрите — как и для чего там используются табы. Отступы там стандартные, 2 пробела, как и написано в кодстайле.
А все ваше нытье про то, что будет уезжать, ехать или еще что-то сомнительны.
Откройте вышеупомянутый файл у себя в редакторе — и посмотрите как он будет выглядеть. А потом сравните с тем, как он выглядит при стандартных настройках. Ну или исходники Notepad++ откройте.
Если вас не устраивать текущее ПО, то почему вы его не меняете или не настраиваете?
Кто вам сказал, что меня не устораивает текущее ПО? Меня оно вполне устраивает. У меня нет файлов ненормально выглядящих при стандартных настройках (а если есть — то они правятся и всё становится снова в порядке).
Это вы хотите меня заставить менять ПО — только лишь ради того, чтобы я смог читать ваши замечательные файлы. Типичный случай, когда весь мир шагает не в ногу, а ты — в ногу. Не будет весь мир под вас перестраиваться, просто не будет, вот и всё.
Или проще стандартизировать таб(причем делать этого сами не хотите)?
Проще работать с стандартными табами. Холивар решили устроить вы — в попытке заставить меня сломать то, что не сломано. Зачем это мне? А стандиртозовать как бы ничего не нужно: все известные мне инструменты либо обрабатывают стандартные табы, либо позволяют переключаться на работу с ними (и вот тут-то как раз исключений я не знаю: программ, в которые жёстко зашито, что таб имеет размер в 8 символов я-таки знаю, начиная с Python'а, а вот программ, которые используют по умолчанию что-то другое и не позволяют это менять — не видел).
Вашу проблему можно решить куда проще — использовать пробелы вместо табов и не так много.
Угу. На том же сайте, на который вы ссылаетесь есть такое правило (правда для другого языка): Do not use tabs in your code. You should set your editor to emit spaces when you hit the tab key.
Однако, заметьте, правила «если вы открыли файл с табами, то немедленно замените их все на пробелы» — нету. И табы в файлах вполне себе живут и здравствуют, как я показал выше.
А если на выходе или входе табы — достаточно обработать исходник регулярным выражением, заменяя табы на N пробелов и наоборот.
Это не так-то просто: табы могут оказаться в исходнике не просто так. А в языках, в которых до исходника функции можно добраться (скажем тот же JavaScript) подобное действие может просто всё сломать.
Уверен, что такой функционал уже даже кто-то делал.
Конечно. clang-format так умеет, к примеру. Но никто его не будет напускать на кодбазу в миллионы строк только для того, чтобы вас стало «приятнее на душе». Обычно он применяется только к изменённым строкам (смотреть в сторону git-clang-format).
Это вообще две ортогональные задачи: избавление от табов в исходниках и определения размера таба. Типичное решение нормальных людей просто и незатейливо: фетиша из этого не делать, табы использовать такими, какие они есть, но стараться, по возможности, не использовать их в коде.
Вы же предлагаете совершить непонятную революцию для того, чтобы людей, у которых и без неё есть чам заняться и у которых проблем нет они появились. Зачем оно им?TheShock
08.06.2017 18:34+3Вы идиот? Или просто играете роль идиота на Хабре?
А вот вы уже перешли на личности. И очень грубо и оскорбительно, кстати.khim
08.06.2017 19:10Извиняюсь, не сдержался. Просто думал, что уж кодстайл-то Google я хорошо знаю, благо они похожи (отступы — 2 символа что в C++, что в Java, табы — не используются ни здесь, ни там и так далее), но вы правы — перечитав JavaScript-стайл Google стайл-гайд и взглянув на него с точки зрения вашей религии можно действительно заподозрить, что в Google используется двухсимвольные табы… но голова-то на плечах есть? Кода, порождённого в соответствии с этим гайдом — в интеренете полно, можно же посмотреть и увидеть, что никакими табами там и не пахнет…
abyrkov
08.06.2017 22:51Вы идиот? Или просто играете роль идиота на Хабре? Возьмите это файл из кодбазы Google и посмотрите — как и для чего там используются табы.
Это всего лишь был сарказм, не ожидал, что вы примете его за чистую монету. Извиняюсь.
Я вообще к тому это сказал, что любую стороннюю спецификацию можно использовать для трактовки размера таба. Как вы сами сказали,
Отдельного стандарта я не припомню
и на этом тему «таб должен отображаться как 8 символов/пробелов» можно закрыть.
Это вы хотите меня заставить менять ПО — только лишь ради того, чтобы я смог читать ваши замечательные файлы. Типичный случай, когда весь мир шагает не в ногу, а ты — в ногу. Не будет весь мир под вас перестраиваться, просто не будет, вот и всё.
Типичное решение нормальных людей просто и незатейливо: фетиша из этого не делать
Может вам стоит перечитать перед добрыми 2/3 оставшегося ответа? Я же написал:
Ну, многим, я уверен, абсолютно пофиг, на сколько таб там 8, 4 или 2
Т.е. лично я ваш код перестраивать под себя не буду. И код на миллион строк тоже. А что делать с моим кодом(если он вам конечно попадется xD) решать вам.
На этом можно закончить, но вот вам еще забавный момент:
Вы же предлагаете совершить непонятную революцию для того, чтобы людей, у которых и без неё есть чам заняться и у которых проблем нет они появились. Зачем оно им?
А я написал:
А от стандартизации мы получим сомнительную выгоду. Очень сомнительную.
Опять-таки я только против какой-то революции таба на 8 проблемов.khim
09.06.2017 00:01и на этом тему «таб должен отображаться как 8 символов/пробелов» можно закрыть.
Почему вдруг? Потому что стандарты не озаглавленные «Ширина таба, как она есть» «некошерны»?
Опять-таки я только против какой-то революции таба на 8 проблемов.
Какая «революция»? О чём вы? Таб имел ширину в 8 символов в 70е, таб имер ширину 8 симполов в 80е, только в 90е Microsoft с сотоварищами начал «мутить воду». Ну так кончится Microsoft — кончится и эта истерия. Нужно только подождать. VAX'ы продержались 23 года, Windows оказалась покрепче, но тоже уже видно что рано или поздно это безумие кончится. Всему своё время.abyrkov
09.06.2017 23:35+1Почему вдруг? Потому что стандарты не озаглавленные «Ширина таба, как она есть» «некошерны»?
Нет. Потому, что вы утверждаете, что таб должен отображаться как 8 пробелов в текстовом формате. Linux и Python и все остальные примеры — всего лишь отдельные случаи, которые регулируют соответствующие сферы. Ни о каком общем правиле не может идти речь.
Допускаю, какие-то неписаные правила того, что таб равен 8ми пробелам, вообщем то, существуют. Однако это как best practise: хочешь — используй, а хочешь — нет. Отстаивать с пеной у рта не стоит.
Microsoft с сотоварищами начал «мутить воду»
Гнать на Microsoft бочку про неканонические табы… Интересно, откуда. Если мы именно о символе табуляции — то с ним у Microsoft'овского Блокнота все по канону. А если брать в расчет VS — а там замена на пробелы, если не ошибаюсь — тогда кодстайл Google очень даже аргумент*autistic eheheh*.
Cenzo
08.06.2017 22:00А как надо? Почему у нас все процессоры little endian при том, что big endian безопаснее? Ответ: потому что так исторически сложлось. То же самое и здесь.
Ворвусь в холивар про табы vs пробелы с замечанием, что little endian таки безопаснее, в нём при неявном кастинге указателя на другой (меньший) тип не нужно менять значение указателя. А это гораздо безопаснее чем иметь вероятность считать старшую половину слова при кастинге например uint32->uint16. Даже большинство ARMов на Linux/Android уже в LE режиме, несмотря на допзатраты по разворачиванию заголовков в TCP/IP.khim
08.06.2017 22:36-1Ворвусь в холивар про табы vs пробелы с замечанием, что little endian таки безопаснее, в нём при неявном кастинге указателя на другой (меньший) тип не нужно менять значение указателя
…и именно это делает его более опасным.
А это гораздо безопаснее чем иметь вероятность считать старшую половину слова при кастинге например uint32->uint16.
s/безопаснее/опаснее/
Что происходит на Big Endian, если вы перепутали размеры? Правильно: программа получает в качестве входных данных мусор, падает, программист ругается матом, чинит проблему — и на этом всё кончается.
Что происходит на Little Endian, если вы перепутали размеры? Тесты проходят, программа сдана заказчику, exploit написан, весь мир на ушах.
Так какой мир более безопасен? Тот в котором Джо (…или Иван… или Ляо) потратил два лишних часа на отладку программы? Или тот, в котором необнаруженная ошибка просочилась на миллиарды компьютеров и привела к потерям измеряющимся в десятках и сотнях миллионах долларов?
Даже большинство ARMов на Linux/Android уже в LE режиме, несмотря на допзатраты по разворачиванию заголовков в TCP/IP.
И это очень хорошо показывает во что IT-индустрия ценит безопасность. Ни во что. Совместимость важнее — а они с безопасностью очень частно «на ножах». Вот и вы их спутали, хотя казлось бы — всё очевидно.Cenzo
09.06.2017 01:04Что происходит на Big Endian, если вы перепутали размеры? Правильно: программа получает в качестве входных данных мусор, падает, программист ругается матом, чинит проблему — и на этом всё кончается.
Неправильно, по двум причинам:
1. Компилятор C при явном приведении типа uint32->uint16 на BE правильно обрежет данные, он достаточно умный в этом плане. Ну а если программист сам читает данные побайтно и/или вручную кастует указатели не понимая различия LE/BE, то он сам себе буратино и проблем огребёт независимо от платформы.
2. Если бы все ветки кода и варианты его использования попадали в test coverage, то PVS Studio, в блоге которого мы сидим, был бы не нужен, не так ли? Граничных условий море и я не видел проектов, где хотя бы бОльшая часть покрывается тестами. Так что в общем случае, тесты пройдут и ничего не будет заметно, пока не выстрелит та самая ветка кода.
Что происходит на Little Endian, если вы перепутали размеры? Тесты проходят, программа сдана заказчику, exploit написан, весь мир на ушах.
До переполнения типа не происходит ничего, в остальных случаях происходит классический случай переполнения типа, что мешает переполнить переменную типа uint16/uint32 и получить то же самое поведение? Эта проблема не имеет отношения к endianness.
Вот и вы их спутали, хотя казлось бы — всё очевидно.
Совершенно неочевидно, особенно про то как связан buffer overflow в EternalBlue с различиями в BE/LE, поделитесь деталями, если не секрет. При обрезании индекса буфера на little endian мы можем получить только buffer underflow.khim
09.06.2017 01:33Компилятор C при явном приведении типа uint32->uint16 на BE правильно обрежет данные, он достаточно умный в этом плане.
При работе с регистрами разницы между BigEndian и LittleEndian нет вообще. Она появляется при обращении в память.
Ну а если программист сам читает данные побайтно и/или вручную кастует указатели не понимая различия LE/BE, то он сам себе буратино и проблем огребёт независимо от платформы.
Правда — вот только на BE он «огребёт себе проблем» практически моментально и будет вынужден проблемы как-то чинить, а на LE — они доживут не только до релиза, но и, скорее всего, до момента, когда софт будет использовать на миллиардах компьютеров по всему миру.
Если бы все ветки кода и варианты его использования попадали в test coverage, то PVS Studio, в блоге которого мы сидим, был бы не нужен, не так ли?
Правда ваша — в коде, который вызывается редко (скажем обработчик ошибок, ага) — проблема может сидеть сколь угодно долго. Так что PVS-Studio без работы не останется. Однако шансов выжить у ошибки, подобной той, которую использовал WannaCry на BE было бы очень мало. Даже если бы тесты этот код не покрывали — скорее всего он бы у пользователей «выстрелил» и они багрепорты начали бы слать.
Я не говорю о том, что мир LE — ужасен, а мир BE — абсолютно безопасен. Это не так. Но то, что мир BE безопаснее, так как ошибки обнаруживаются раньше — это однозначно.
До переполнения типа не происходит ничего, в остальных случаях происходит классический случай переполнения типа, что мешает переполнить переменную типа uint16/uint32 и получить то же самое поведение?
А если в код посмотреть вместо того, чтобы исходить из предположения о том, что вы всё знаете и так? Я вам даже этот кусочек могу прям сюда скопировать:
In vulnerable SrvOs2FeaListSizeToNt() function, there is a important change from WinNT4 (to fix OOB read) in for loop.
Как вы думаете — долго бы программа прожила на BE-системе если бы к переменной типа DWORD лазили бы через указатель на WORD? А на LE-системе — она дожила до всемирной эпидемии.
The psuedo code is here.if (nextFea > lastFeaStartLocation) { // this code is for shrinking FeaList->cbList because last fea is invalid. // FeaList->cbList is DWORD but it is cast to WORD. *(WORD *)FeaList = (BYTE*)fea - (BYTE*)FeaList; return size; }
При обрезании индекса буфера на little endian мы можем получить только buffer underflow.
Только если мы правильно его пишем и читаем. В противном случае мы легко можем прочитать младший байт от 0x100, интерпретировать его как нуль и разрешить буферу расти дальше, например.
Совершенно неочевидно, особенно про то как связан buffer overflow в EternalBlue с различиями в BE/LE
buffer overflow там случился, если вы почитаете детали, из-за того, что один и тот же указатель интерптетировали то как указатель на слово, то как указатель на байт, а в памяти там, на самом деле, вообще двойное слово лежало. И всё это — работало до поры до времени, пока не придумали как через это дело систему взломать. Попытка устроить подобную же «гремучую смесь» на BE-системе привела бы к тому что при первом же попадании туда чего-то, отличного от нуля, вся конструкция бы немедленно сломалась и её пришлось бы чинить, так что до никакиго buffer overflow код бы просто не дожил.Cenzo
09.06.2017 02:45При работе с регистрами разницы между BigEndian и LittleEndian нет вообще. Она появляется при обращении в память.
Регистры тут совершенно ни при чем, при присвоении переменных по значению компилятор делает всё работу правильно по приведению типа.
Я не говорю о том, что мир LE — ужасен, а мир BE — абсолютно безопасен. Это не так. Но то, что мир BE безопаснее, так как ошибки обнаруживаются раньше — это однозначно.
Вот это утверждение для меня неоднозначно, есть статистика на эту тему? Еще один пример кривой игры с указателями не статистика, как я и говорил в своем комментарии, такие кодописатели сами себе буратины, огребут проблем независимо от BE или LE.
Как вы думаете — долго бы программа прожила на BE-системе если бы к переменной типа DWORD лазили бы через указатель на WORD? А на LE-системе — она дожила до всемирной эпидемии.
Да, долго. На BE платформах так же лазят к переменным типа DWORD через указатели на WORD, только по немного другим смещениям, не находите? Если бы Windows был только под BE, то приведённый вами код добили бы похожими хаками до рабочего состояния именно на этой платформе. При попытке собрать код под LE, оно бы предсказуемо рассыпалось.
вся конструкция бы немедленно сломалась и её пришлось бы чинить
У них именно всё сломалось (заметьте, на LE платформе, а не на BE), а программист починил «как смог», смотрите их описание:
there is a important change from WinNT4 (to fix OOB read)
Почему вы уверены, что когда ломается код на BE платформе, его внезапно починят правильно а не напихают подобных кривых хаков с выборочной загрузкой байтов из памяти?khim
09.06.2017 03:25На BE платформах так же лазят к переменным типа DWORD через указатели на WORD, только по немного другим смещениям, не находите?
Не нахожу. Наиболее популярное смещение (на любой платформе) — это нуль. То есть указатель прямо указывает на переменную. На LE попытка использовать этот указатель с неправильным типом может работать довольно долго (пока кто-нибудь exploit не напишет). На BE практически любая попытка исполнить подобный код приводит к катастрофе, разбирательствам и, соответственно, исправлению программы.
Если бы Windows был только под BE, то приведённый вами код добили бы похожими хаками до рабочего состояния именно на этой платформе.
Там не было хаков. Там было банальное рассогласование типов. Так вот на BE — подобная проблема обнаруживается почти сразу, а на LE — живёт годами, пока не «выстрелит».
Почему вы уверены, что когда ломается код на BE платформе, его внезапно починят правильно а не напихают подобных кривых хаков с выборочной загрузкой байтов из памяти?
Потому что для получения проблемы вам нужно сделать не одну ошибку (грубо говоря перепутатьWORD PTR [%EAX]иDWORD PTR [%EAX]), а две (нужно будет умудриться случайно превратитьDWORD PTR [%EAX]вWORD PTR [%EAX+2]) — что, согласитесь, сделать гораздо сложнее.
То же самое с OOB: на LE вы можете взять — и просто читать два байта вместо четырёх, чтобы не вылазить за границы массива, а на BE — не можете, нужных вам байтов вы в этом случае не прочитаете.
Можно себе представить альтернативный мир, где указатели указывают не на первый байт многобайтового целого, а на последний и строки растут в сторону уменьшения адресов, а не увеличения — там LE будет безопаснее BE. Но в нашем мире этот подход, как бы, не прижился, указатели указывают на начало целого, а строки расширяются «вверх», а не «вниз»…
Кстати в этом «альтернативном» мире как раз BE обладал бы «ценным» свойством, которое вы рекламируете — и именно поэтому он был бы небезопасным.Cenzo
09.06.2017 04:13Не нахожу. Наиболее популярное смещение (на любой платформе) — это нуль
… потому что вы привыкли приводить типы указателей на LE платформе? Замечательно, особенно если вы пропускаете такое в ваш код.
На BE практически любая попытка исполнить подобный код приводит к катастрофе, разбирательствам и, соответственно, исправлению программы.
Как я уже сказал, особенно замечательно, если этот код поселится в ветке, которая не покрывается вашими тестами (нет, не обработчик ошибок, а функциональность при определённой комбинации фич). +10 к надежности. И еще, вы уверены что любая попытка исполнить подобный код приведёт к крашу а не к потенциальному эксплоиту?
Там не было хаков. Там было банальное рассогласование типов. Так вот на BE — подобная проблема обнаруживается почти сразу, а на LE — живёт годами, пока не «выстрелит».
Опять же, повторюсь, если вы считаете «не хаками» приведение типов указателей, которое разваливается при сборке на платформе с другой endianness, то мне здесь добавить нечего.khim
09.06.2017 07:20… потому что вы привыкли приводить типы указателей на LE платформе?
Нет — потому что подобное происходит автоматически при ошибке в описании типа и использовании «свободных» указателей, которых в типичной программе больше, чем структур. Они возникают при передаче параметров по значению (соответствено — и при возврате их из функции), при захвате одного параметра лямбдой (а тут, также, один — гораздо популярнее любых других значений… кроме нуля, пожалуй) и в куче других мест.
И еще, вы уверены что любая попытка исполнить подобный код приведёт к крашу а не к потенциальному эксплоиту?
Почти любая. Вы «забираете» из памяти «старшую» половину числа и интерпретируете её как если бы это было всё число. Иногда — это может сработать (для чисел, которые состоят из одинаковых половин). Но на практике — это случается гораздо реже, чем «маленькие» числа, когда всё отрабатывает «на ура» в LE.
Как я уже сказал, особенно замечательно, если этот код поселится в ветке, которая не покрывается вашими тестами (нет, не обработчик ошибок, а функциональность при определённой комбинации фич). +10 к надежности.
А с безопасностью часто так.
Опять же, повторюсь, если вы считаете «не хаками» приведение типов указателей, которое разваливается при сборке на платформе с другой endianness, то мне здесь добавить нечего.
А вы — считате? Вот как видитеvoid*— и сразу верёвку и мыло готовите? Да чёрт с ним, cvoid*, рассмотрите какую-нибудь функцию подобную ReadFile и подумайте что будет если в один прекрасный момент вы решите перейти от 4х-байтовых длин файлов к 8-байтовым — а одну из библиотек забудете пересобрать. Думаете так никогда не бывает?
Если вы немножко подумаете над тем, как устроены типичные API — то увидите, что там масса мест, где вы можете обратиться к переменной через указатель «не того» типа. И почти во всех этих местах программа на LE-системе будет какое-то время работать, а на BE-системе — упадёт почти сразу. Может ли быть обратное? Да, разумеется — вот только все примеры будут черезвычайно странными и вычурно выглядящими, не похожими и близко на простую ошибку при использовании pthread_create или чего-нибудь подобного.
TheShock
07.06.2017 19:44-1Статистика GitHub говорит что пробелы гораздо популярнее
Это ложное утверждениеTheShock
07.06.2017 19:55На всякий случай сразу кину пруф. Оригинальная статья — лживая манипуляция, не имеющая ничего общего с реальностью. Я описывал там в комментариях, что большинство проектов с табами они записали в «пробельные» из-за кода, составленного с ошибкой… Возможно, ошибка допущенна специально — она слишком глупая и очевидная.

KvanTTT
07.06.2017 19:40+1Я всегда включаю опцию "Отображать пробельные символы" во всех редакторах и придерживаюсь стиля проекта. Поэтому у меня нет проблем :)
michael_vostrikov
08.06.2017 14:19Отступ в коде 4 пробела. Отступ в коде. Отступ. Среди всех символов кода мы выделяем отдельную сущность. Логично использовать для нее отдельный символ, а не заменять другими, всегда подразумевая что N пробелов это на самом деле не N пробелов, а один отступ, причем только в начале строки.
khim
08.06.2017 18:37-1Логично использовать для нее отдельный символ, а не заменять другими, всегда подразумевая что N пробелов это на самом деле не N пробелов, а один отступ, причем только в начале строки.
Логично. Нелогично брать символ с уже существующей семантикой и пытаться эту семантику менять для того, чтобы использовать его под эту вашу «сущность». Хотите сделать спецсимол для отступов — да ради бога, в PUA достаточно места. Зачем табы-то уродовать?michael_vostrikov
08.06.2017 21:21+1А вот кстати для табов с "обычным" назначением (для разметки таблиц в текстовых файлах) было бы неплохо сделать несколько новых табов шириной 8, 16, 24 пробела. Раньше-то ладно, однобайтовые кодировки, символов мало, форматов текста мало, а сейчас-то кто таблицы текстом размечает. Но если уж надо, то лучше чтоб таблица не ехала при добавлении 9-го символа в текст ячейки.

iroln
07.06.2017 13:31+5"Сапожник без сапог". Делают редактор, в котором есть функция замены табов на пробелы (и наоборот) во всём документе, а также замена вставки табуляции пробелами, при этом стиль своего собственного кода поправить не могут. Забавно.
AllexIn
07.06.2017 13:41+2Врядли они код пишут в самом notepad++.
Для начала — это просто неудобно.
Да к тому же сам npp не для того сделан.iroln
07.06.2017 13:52+1Я не приверженец идеи писать код не в IDE. Просто наблюдение и мне это показалось забавным.
Да к тому же сам npp не для того сделан.
И всё же они позиционируют его как "source code editor" (так на сайте написано :))
pavel_pimenov
07.06.2017 14:34+1IDE у разработчиков тоже могут быть настроены по разному.
в результате слияния pull request-ов от разных разработчиком — табы/пробелы перемешиваются.
Тут 2 варианта
* Вешать хуки на коммиты и заставлять править стиль руками.
* Использовать автоматический форматер типа http://astyle.sourceforge.net/ и периодически им причесывать код.
я уже много лет использую второй вариант — удобноUirandir
07.06.2017 15:21+2> Использовать автоматический форматер
Блин, спасибо вам за идею, вечно мучался от своей и чужой лени в конфигах nginx'а, прочитал про автоматический форматер и быстро нагуглил готовый https://github.com/1connect/nginx-config-formatter от которого мои конфиги шустро пришли в нормальный вид.
Комменты на хабре всегда полезней самой статьи.
iroln
07.06.2017 15:44+1Мы используем http://uncrustify.sourceforge.net/
Действительно, есть люди, которые просто не способны соблюдать code style.

kloppspb
07.06.2017 16:53+1я уже много лет использую второй вариант
А я — оба :) То есть AStyle висит на хуке. Ну и на хоткее, конечно же, для форматирования в процессе.

RussDragon
07.06.2017 15:08+1И всё же они позиционируют его как «source code editor» (так на сайте написано :))
Ну, для скриптовых/функциональных языков нормально подходит. В отличии от того же Сублайма, npp не стоит 70$ =)
Но там, где нужен нормальный дебаг/стак-трейс и прочие фишки IDE – конечно же, npp уступает.michael_vostrikov
07.06.2017 23:24

ViacheslavMezentsev
07.06.2017 15:59+2Мне интересно, а linux-проект из VS2017 можно проверить? Вообще, меня интересует проверка кросс-компиляторного проекта, но и такой вариант был бы не плох. Я пишу для embedded устройств на linux и я бы не против потестить анализатор.

SvyatoslavMC
07.06.2017 16:41+3Мы вышли на такой уровень, что проверяется всё, что компилируется.
а linux-проект из VS2017 можно проверить?
Если есть стандартный проектный файл для VIsual Studio 2010-2017 и хотя бы компиляция проходит успешно (линковка не обязательна), то можно.
Но предположу, что Вам проще сразу воспользоваться PVS-Studio для Linux. Работа с кросс-компиляторами описана в разделе "Быстрый старт/Если вы используете кросс-компиляторы".
Для тестирования Вы можете обратиться в поддержку для получения временного ключа. Смотрите также "Как использовать PVS-Studio бесплатно".
Vitalley
07.06.2017 17:12ReactOS когда проверите?
SvyatoslavMC
07.06.2017 17:26+5Проверка ReactOS (сентябрь 2011), вторая проверка (апрель 2013)
Есть много поводов проверить этот проект, но в следующем году можно сделать аналогичную «5 лет спустя...». Посмотрим. Наверняка в названии будет ещё что-нибудь про поиск уязвимостей.

MarinaGrom
08.06.2017 21:21как они могут править свой код если пишут его в другом редакторе, который без таких возможностей как notepad++, почему бы не писать в нем же? так они ж его и пишут :) замкнутый круг. Если серьезно, то хорошая программа, ошибки есть, есть куда улучшить, но по сути и с ними одни из лучших на мой взгляд.
zanac
14.06.2017 18:50-3Вот зачем здесь эта проверка? Согласно современному стандарту C++, оператор new бросает исключение при нехватке памяти, а не возвращает nullptr.
Не обязательно
Called by the non-throwing non-array new-expressions. The standard library implementation calls the version (1) and returns a null pointer on failure instead of propagating the exception.
Взял отсюда.SvyatoslavMC
14.06.2017 18:53+3Ну так здесь не nothrow оператор, да и код бы выглядел иначе, если явно указать. Не просто так же я написал:
Эта функция зовётся при замене всех символов табуляции на пробелы во всём документе. Взяв большой текстовый документ, я убедился, что нехватка памяти в этом месте действительно приводит к краху программы.

kostus1974
отличная статья! обычно у вас так себе объекты для проверок, а тут прям интересный объект взяли. отлично.
и авторы np++ тоже молодцы — ошибки прям такие… для учебника.
а вы отправили авторам полный список обнаруженных проблем?
SvyatoslavMC
Сейчас отправлю, мы всегда это делаем. Дополнительно пару мест сам поправлю для Pull Request'а.
oYASo
Без этого стабильного вопроса статья от авторов PVS-Studio была бы неполной.
vvzvlad
А ещё каждый раз интересно — проверяют ли они код анализатора своим анализатором.
SvyatoslavMC
Конечно проверяем. Поэтому нет и не может быть статьи о проверке C++ ядра анализатора, потому что анализатор с самого начала используется и количество предупреждений всегда должно быть равным нулю. Если разработчики что-то сами находят, то исправляют это до закладывания кода.
vvzvlad
В следующий раз буду поднимать табличку «сарказм» :)
SvyatoslavMC
Да я просто в работе, хотел быстро ответить :)
Но по опыту скажу, что на каждый такой сарказм находятся не знающие люди, задающиеся таким вопросом. Обычно их жестко минусуют.
vvzvlad
Да я знаю — мы тут коллективно читаем ваши статьи еще с того момента, когда у вас на хабре блога не было.
Первокомментатора не заминусовали, видимо потому, что там не только один вопрос был, а еще и немного по сути.
khim
Ну вы же не проверяет анализатором 2017го года код 2007го. Машины времени у вас нет.
Так что статья, рассказывающая, какие новые диагностики стриггерились на вашем кода, скажем, пятилетней давности — была бы интересна.
Понятно что она слишком многое расскажет о вашей кухне, так что, рассчитывать на неё не приходится… Но помечтать-то можно?
SvyatoslavMC
Статьи о старом коде будут крайне непопулярны.Есть много нового когда, где ещё никто не нашёл ошибки)
Когда была возможность, проверяли плагин PVS-Studio с помощью PVS-Studio.
EvgeniyRyzhkov
В статье об истории нашего продукта мы проверяли первую версию анализатора. Думаю это то, что нужно.