В этом посте изложены две недавно опубликованные идеи, как ускорить процесс обучения глубоких нейронных сетей при увеличении точности предсказания. Предложенные (разными авторами) способы ортогональны друг другу, и могут использоваться совместно и по отдельности. Предложенные здесь способы просты для понимания и реализации. Собственно, ссылки на оригиналы публикаций:
1. Ансамбль снимков: много моделей по цене одной
Обычные ансамбли моделей
Ансамбли — это группы моделей, используемых коллективно для получения предсказания. Идея проста: обучи несколько моделей с разными гиперпараметрами, и усредни их предсказания при тестировании. Эта методика дает заметный прирост в точности предсказания, большинство победителей соревнований по машинному обучению
Так в чем проблема?
Обучение N моделей потребует в N раз больше времени по сравнению с тренировкой одной модели.
Механика SGD
Стохастический градиентный спуск (SGD) — жадный алгоритм. Он перемещается в пространстве параметров в направлении наибольшего уклона. При этом, есть один ключевой параметр: скорость обучения. Если скорость обучения слишком высока, SGD игнорирует узкие лощины в рельефе гиперплоскости параметров (минимумы) и перескакивает через них как танк через окопы. С другой стороны, если скорость обучения мала, SGD проваливается в один из локальных минимумов и не может выбраться из него.
Однако, есть возможность вытащить SGD из локального минимума повысив скорость обучения.
Следим за руками...
Авторы статьи используют этот контролируемый параметр SGD для скатывания в локальный минимум и выхода оттуда. Разные локальные минимумы могут давать одинаковый процент ошибок при тестировании, но конкретные ошибки для каждого локального минимума будут разными!
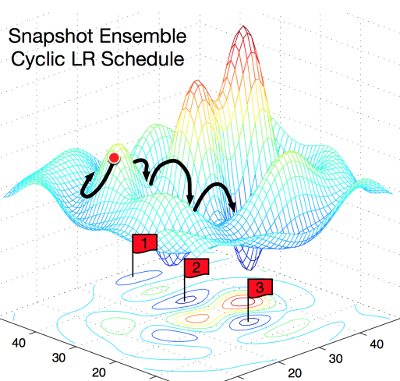
На этой картинке очень наглядно поясняется концепция. Слева показано, как работает обычный SGD, пытаясь найти локальный минимум. Справа: SGD проваливается в первый локальный минимум, делается снимок обученной модели, затем SGD выбирается из локального минимума и ищет следующий. Так вы получаете три локальных минимума с одинаковым процентом ошибок, но различающимися характеристиками ошибок.

Из чего состоит ансамбль?
Авторы эксплуатируют свойство локальных минимумов отражать различные «точки зрения» на предсказания модели. Каждый раз, когда SGD достигает локального минимума, сохраняют снимок модели, из которых при тестировании и составят ансамбль.
Циклический косинусный отжиг
Для автоматического принятия решения, когда погружаться в локальный минимум, и когда выходить из него, авторы используют функцию отжига скорости обучения:

Формула выглядит громоздко, но на самом деле довольно проста. Авторы используют монотонно убывающую функцию. Альфа — новое значение скорости обученя. Альфа-ноль — предыдущее значение. Т — общее число итераций, которое вы планируете использовать (размер батча Х число эпох). М — число снимков модели, которое хотите получить (размер ансамбля).
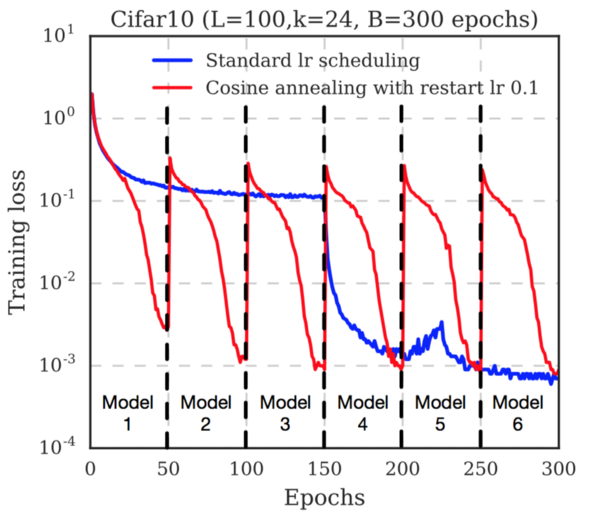
Обратите внимание, как быстро снижается функция потерь перед сохранением каждого снимка. Это потому, что скорость обучения непрерывно снижается. После сохранения снимка скорость обучения восстанавливают (авторы используют уровень 0.1). Это выводит траекторию градиентного спуска из локального минимума, и начинается поиск нового минимума.
Заключение
Авторы приводят результаты тестирования на нескольких датасетах (Cifar 10, Cifar 100, SVHN, Tiny IMageNet) и нескольких популярных архитектурах нейронных сетей (ResNet-110, Wide-ResNet-32, DenseNet-40, DenseNet-100). Во всех случаях ансамбль, обученный предложенным способом показал наименьший процент ошибок.
Таким образом, предложена полезная стратегия получения прироста точности без дополнительных вычислительных затрат при обучении моделей. О влиянии разных параметров, таких как Т и М на производительность, см. оригинал статьи.
2. Вымораживание: ускорение обучения путем последовательного замораживания слоёв
Авторы статьи продемонстрировали ускорение обучения путем замораживания слоёв без потери точности предсказания.
Что означает замораживание слоёв?
Замораживание слоя предотвращает изменение весовых коэффициентов слоя при обучении. Эта методика часто используется при обучении переносом (transfer learning), когда базовую модель, обученную на другом датасете, замораживают.
Как замораживание влияет на скорость модели?
Если вы не хотите изменять весовые коэффициенты слоя, обратный проход по этому слою можно полностью исключить. Это серьезно ускоряет процесс вычислений. Например, если половина слоев в вашей модели заморожена, для тренировки модели потребуется вдвое меньше вычислений.
С другой стороны, вам все-таки нужно обучить модель, так что если вы заморозите слои слишком рано, модель будет давать неточные предсказания.
В чем новизна?
Авторы показали способ, как замораживать слои один за другим как можно раньше, оптимизируя время обучения за счет исключения обратных проходов. В начале модель целиком обучаема, как обычно. После нескольких итераций первый слой модели замораживают, и продолжают обучать остальные слои. После еще нескольких итераций замораживают следующий слой, и так далее.
(Опять) отжиг скорости обучения
Авторы использовали отжиг скорости обучения. Важное отличие их подхода: скорость обучения изменяется от слоя к слою, а не для всей модели. Они использовали следующее выражение:

Здесь альфа — скорость обучения, t — номер итерации, i — номер слоя в модели.
Обратите внимание, поскольку первый слой модели будет заморожен первым, его тренировка продлится наименьшее количество циклов. Для компенсации этого авторы масштабировали начальный коэффициент обучения для каждого слоя:

В результате, авторы добились ускорения обучения на 20% за счет падения точности на 3%, либо ускорения на 15% без снижения точности предсказания.
Однако, предложенный метод не очень хорошо работает с моделями, в которых не используются пропуски слоёв (такими как VGG-16). В таких сетях ни ускорения, ни влияния на точность предсказания не обнаружено.
Комментарии (21)

sim0nsays
06.07.2017 19:51Спасибо за разбор, очень понятно и по делу!
Про первое — по мне, главная практическая проблема, что часто bottleneck — это скорость inference, а не тренировки, особенно финальной. А тут inference все еще в N раз медленней.
А они сравнивали качество ансамбля, которые получается их техникой, с тем, который достигается полной тренировкой несколько раз? Ну и да, если плохо тренировать бейзлайн, много пейперов написать можно…
Про второе — AFAIR, часто первые слои жрут намного больше вычислений, поэтому если первую половину выкинуть, то должно быть ускорение сильно больше, чем в два раза.
Тем не менее, из разряда идей «хозяйке на заметку» — обе статьи интересные.
sergeypid
07.07.2017 11:36+2Если скорость при тестировании для вас важнее, значит вы успешно внедряете технологию!
Все-таки скорость обучения тоже важна если данных много, GPU не топовый, модель сложная, идей много надо проверить…sim0nsays
09.07.2017 10:20Тоже важна, вопросов нет, но все же предполагаемая скорость Inference тоже имеет значение. Т.е. если понятно, что inference будет очень тормозной часто и экспериментировать в эту сторону не хочется. Впрочем, верю, что могут быть юзкейсы, где не так.
sergeypid
07.07.2017 12:03Почему у комментаторов сложилось впечатление, что авторы первой статьи плохо обучили baseline?
ResNet-110, Cifar-10
Оригинальная статья авторов архитектуры ResNet
Смотрим таблицу 6: ошибка классификации на CIFAR-10: 6.43 (6.61±0.16)
Статья про «отжиг» (ансамбль снимков модели): Фигура 1.2 — ошибки классификации CIFAR-10
Resnet-110 Single Model: 5.52 (по оригинальной статье)
Resnet-110 Snapshot Ensemble: 5.32
Остальные результаты тоже можно проверить.

RomanSt
07.07.2017 17:06Про первую. Мне кажется, было бы хорошо иметь возможность убедиться в том, что у нас нет одинаковых снэпшотов. Можно, конечно, веса посравнивать. Но без этого мы рискуем получить M клонов одной модели. Второе соображение состоит в том, что если время обучения одного снэпшота T/M сильно меньше обучения одной модели, то мы рискуем получать не локальные минимумы, что даст нам малополезные результаты. А если сравнимо, то итоговое время сравнимо со временем обучения всей модели.

waiwnf
10.07.2017 20:44+1Спасибо за разбор!
По первой статье не очень понятно, чем их схема принципиально лучше нескольких рестартов из разных начальных точек с одновременным уменьшением числа шагов на каждый рестарт (до периода косинуса). Судя по тому, что training loss каждый период всё равно раздергивается почти до исходного, по сути получаем те же рестарты, но рядом с предыдущим локальным минимумом. Есть соображения, почему так предпочтительнее?
brickerino
10.07.2017 21:47Суть в том, что каждая итерация сильно быстрее, чем полное обучение с нуля. Таким образом мы получаем ансамбль быстрее, чем если бы обучали каждый классификатор по отдельности.
waiwnf
11.07.2017 10:56+1Это понятно в качестве мотивации априори, но на их графике я не увидел «сильно быстрее», поэтому и спросил.
Синий график, где явно криво настроен learning rate, игнорируем, смотрим на их красный график. Там видно, что каждый раз, когда LR увеличивается (т.е. каждый период косинуса) training loss прыгает вверх до ~5e-1. По первому сегменту видно, что с нуля этот loss достигается за ~10 эпох при периоде косинуса в 50. То есть получаем от силы 30% ускорение, что на сильно быстрее на мой взгляд не тянет, особенно учитывая резервы по настройке learning rate.
Поэтому вопрос, что лучше (и главное почему) — их схема или, например, взять их LR schedule за первые 50 эпох, обучить 6 моделей по 50 эпох с нуля с разными инициализациями и сделать ансамбль из них, — остался открытым. Во втором случае индивидуальные модели будут похуже, но если за счет разных инициализаций они окажутся более разнообразными, то их ансамбль может сработать лучше.sergeypid
11.07.2017 11:55Только практика может ответить на этот вопрос. Проверьте свою схему и напишите статью на Архив.
Я бы применял их схему чуть попозже, после первоначального грубого обучения. Например, первые слои уже обучились типовым фильтрам Габора. Но это только мое предположение, все надо проверять. В этом и заключается эмпирический подход.
sergeypid
10.07.2017 21:49При «холодном» рестарте коэффициенты сети случайно инициализированы, и их надо долго обучать. При рестарте с локального минимума у нас уже в принципе обученная сеть, дальнейшее обучение будет только слегка изменять значения весов.
supersonic_snail
Что-то и то, и то какое-то странное. Первая статья еще нормальная, вторую даже статьей назвать сложно — скорее отчет о курсовом проекте.
Первая статья плохо настроила обучение — они берут плохие настройки sgd и потом говорят, что в то же время можно обучить много моделей, но с хорошими настройками. Ну как бы да, экспоненциальный decay — наше все, он сильно все ускоряет по сравнению с линейным. После чего они сохраняют N снэпшотов из одного запуска и делают тест в N раз медленнее.
Ко второй статье основная критика это что она 1 — не так то и ускоряет. 15-20% это ерунда, нужно ускорение на порядок как минимум, чтобы начать утверждать, что оно стоит того. см. batch normalization, там ускорение больше, чем на порядок. 2 — не везде работает. это значит, что просто взять и вставить нельзя — надо тюнить. Если надо тюнить, то надо больше запусков. Больше запусков — вся разработка дольше. Так что непонятно.
ПС — какой к черту «отжиг»? Переводить текст из довольно узкой области и вставляеть непонятные термины в гуглоперевод это как-то так себе.
sergeypid
Результаты второй статьи и мне показались слабоватыми. Что касается первой, то речь ведь не идет об ускорении обучения как такового. За время обучения одной модели формируют N моделей для ансамбля.
По поводу гуглоперевода, коллега, попросил бы не бросаться обвинениями.
Kaiser
Согласен с supersonic_snail по первой статье. Быть может метод и правда хорош, но подтверждений пока не так много.
В теории, если взять слишком малый шаг, нас мало выбьет из локального минимума и мы вновь скатимся к тому же. Как правильно выбратьправильный цикл? Не надёжнее ли на практике действовать как деды и просто снижать шаг? И сравнение берётся с заранее фиксированным временным бюджетом, быть может с другим бюджетом будет уже не так, это на совести авторов статьи, которую ещё предстоит проверить.
mbait
А что не так с термином "отжиг"?
emilmelnikov
По поводу второй статьи, автор на Reddit поясняет, что она была сделана за несколько дней в формате "индивидуального science-хакатона". Там же начали обсуждать, как быть с тенденцией публиковать и ссылаться на пусть и не до конца проверенные, но самые свежие идеи и результаты на arXiv: это плохо или хорошо?
Arastas
С моей точки зрения, это настолько "хорошо", что позволяет крупным издательствам не переживать за конкуренцию со стороны arXiv.
Xandrmoro
«отжиг» — вполне используемый термин для одного из классов алгоритмов, емнип, даже у банды четырёх был.
supersonic_snail
Можете показать? Я такого не видел, но может я что упустил.
В том контексте, в котором annealing используется в литературе про диплернинг, это явно не химический процесс отжига. С другой стороны, если он изначально был введен по аналогии с этим процессом, то да, я не прав.
sergeypid
Алгоритм имитации отжига
Гуглоперевод, говорите…
supersonic_snail
Хм, и правда.
Был неправ, извините.
sergeypid
Ничего, бывает.