Это приблизительная расшифровка лекции о предсказании переходов (предсказании ветвлений) на localhost, новом цикле лекций, организованном RC. Выступление состоялось 22 августа 2017 года в Two Sigma Ventures.
Кто из вас использует ветвления в своём коде? Можете поднять руку, если применяете операторы if или сопоставление с образцом?
Сейчас я не буду просить вас подымать руки. Но если я спрошу, сколько из вас думают, что хорошо понимают действия CPU при обработке ветвления и последствия для производительности, и сколько из вас может понять современную научную статью о предсказании ветвлений, то руки подымет меньше людей.
Цель моего выступления — объяснить, как и почему процессоры осуществляют предсказание переходов, а затем вкратце объяснить классические алгоритмы предсказания переходов, о которых вы можете прочитать в современных статьях, чтобы у вас появилось общее понимание темы.
Перед тем как обсуждать предсказание переходов, поговорим о том, зачем вообще процессоры это делают. Для этого нужно немного знать о работе CPU.
В раках этой лекции можете воспринимать компьютер как CPU плюс немного памяти. Инструкции живут в памяти, а CPU выполняет последовательность инструкций из памяти, где сами инструкции имеют вид вроде «сложить два числа», «перенести фрагмент данных из памяти в процессор». Обычно после выполнения одной инструкции CPU выполняет инструкцию со следующим по порядку адресом. Однако есть инструкции типа «переходы», которые позволяют изменить адрес следующей инструкции.
Вот абстрактная диаграмма CPU, выполняющего некоторые инструкции. По горизонтальной оси отложено время, а по вертикальной — отличия между разными инструкциями.

Здесь мы сначала выполняем инструкцию A, затем инструкции B, C и D.
Один способ проектирования CPU — делать всю работу по очереди. Здесь нет ничего плохого; многие старые CPU так работают, как и некоторые современные очень дешёвые процессоры. Но если вы хотите сделать более быстрый CPU, то нужно превратить его в подобие конвейера. Для этого вы разбиваете процессор на две части, так что первая половина находится на фронтенде работы с инструкциями, а вторая половина — в бэкенде, как на конвейере. Это обычно называют конвейерным процессором (pipelined CPU).
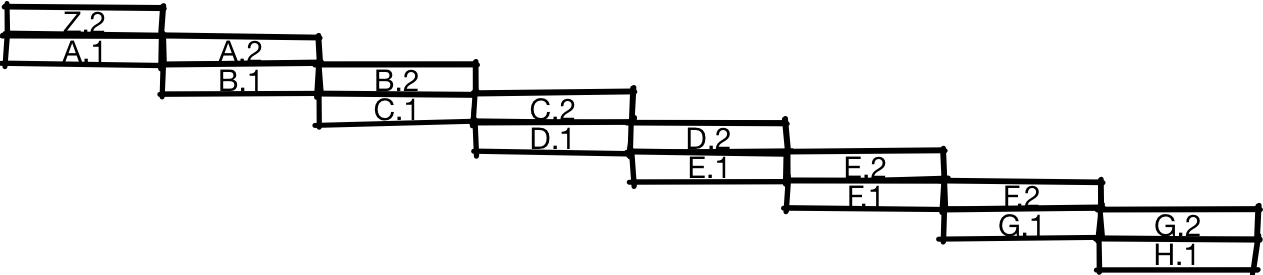
Если вы сделаете так, то выполнение инструкций будет происходить примерно как на иллюстрации. После выполнения первой половины инструкции A процессор начинает работать над второй половиной инструкции A одновременно с первой половиной инструкции B. А когда завершается выполнение второй половины A, процессор может одновременно начать вторую половину B и первую половину C. На этой диаграмме вы видите, что конвейерный процессор способен выполнять за промежуток времени вдвое больше инструкций, чем обычный процессор, показанный ранее.
Нет никакой причины разделять CPU всего на две части. Мы можем разделить его на три части и получить трёхкратный прирост производительности или на четыре части для четырёхкратного прироста. Хотя это не совсем верно и на самом деле обычно прирост не будет трёхкратным для трёхступенчатого конвейера или четырёхкратным для четырёхступенчатого конвейера, потому что есть определённые накладные расходы при разделении CPU на части.
Один источник накладных расходов — то, как обрабатываются ветвления. Первым делом CPU должен получить инструкцию. Для этого он должен знать, где она находится. Например, возьмём следующий код:
Его можно перевести в ассемблер:
В этом примере мы сравниваем x с нулём. Если он не равен нулю (
Для конвейера проблематичной является конкретная последовательность инструкций:
Процессор не знает, что будет дальше:
или
Он не знает этого, пока не завершилось (или почти завершилось) выполнение ветви. Одним из первых действий CPU должно быть извлечение инструкции из памяти, а мы даже не знаем, какой будет инструкция
Ранее мы говорили, что получаем почти трёхкратное ускорение при использовании трёхступенчатого конвейера или почти 20-кратное при использовании 20-ступенчатого. Предполагалось, что на каждом цикле вы можете начинать выполнение новой инструкции, но в данном случае две инструкции практически сериализованы.

Один из вариантов решения проблемы — использовать предсказание переходов. Когда появляется ветвь, CPU будет предполагать, взята эта ветвь или нет.

В этом случае процессор предсказывает, что ветвь не будет занята, и начинает выполнение первой половины

Если предсказание ошибочно, то после завершения выполнения ветви CPU отбросит результаты

Каково влияние на производительность? Чтобы оценить его, нужно смоделировать производительность и нагрузку. Для этой лекции возьмём карикатурную модель конвейерного CPU, где не-ветвления отрабатываются примерно одной инструкцией за цикл, непредсказанные или неправильно предсказанные переходы занимают 20 циклов, а правильно предсказанные — один цикл.
Если взять самый популярных бенчмарк для целочисленных нагрузок на «рабочую станцию» SPECint, то распределение может быть 20% ветвей и 80% других операций. Без предсказания переходов мы ожидаем, что «средняя» инструкция займёт
Посмотрим, что можно с этим сделать. Начнём с самых простых вещей, и постепенно выработаем решение получше.
Вместо случайных предсказаний мы можем посмотреть на все ветви выполнения всех программ. В этом случае мы увидим, что взятые и невзятые ветви неодинаково сбалансированы — взятых ветвей гораздо больше, чем невзятых. Одной из причин являются ветви цикла, которые часто выполняются.
Если предсказывать взятие каждой ветви, то мы можем выйти на уровень точности предсказаний 70%, так что будем оплачивать только неверно предсказанные 30% переходов, что снижает стоимость средней инструкции до

Предсказывать взятие всех ветвей хорошо работает для циклов, но не для других ветвей. Если посмотреть на процент выполнения переходов вперёд по программе или назад по программе (возвращение к предыдущему коду), то мы увидим, что переходы назад выполняются гораздо чаще, чем переходы вперёд. Поэтому можно попробовать предиктор, который предсказывает взятие всех переходов назад и невзятие всех переходов вперёд (BTFNT, backwards taken forwards not taken). Если мы реализуем эту схему на аппаратном уровне, то компиляторы подстроятся под нас и начнут организовывать код таким образом, чтобы ветви с наибольшими шансами выполнения становились переходами назад, а ветви с наименьшими шансами выполнения становились переходами вперёд.
Если это сделать, то можно добиться точности предсказаний около 80%, что снижает стоимость выполнения инструкции до

Кто использует:
До сих пор мы рассматривали схемы, которые не сохраняют никакого состояния, то есть такие схемы, где предиктор игнорирует историю выполнения программы. В литературе они называются статическими методами предсказания переходов. Их преимущество в простоте, но они плохо справляются с предсказанием переходов, которые изменяются со временем. Вот пример такого перехода:
В ходе выполнения программы на одном этапе флаг может быть установлен и переход осуществлён, а на другом этапе флага нет и переход не происходит. Статические методы никак не могут хорошо предсказывать ветвления вроде этого, так что рассмотрим динамические методы, где предсказание может изменяться в зависимости от истории выполнения программы.
Одна из простейших вещей — предсказывать на основе последнего результата, то есть предсказывать переход в том случае, если в прошлый раз он состоялся, и наоборот.
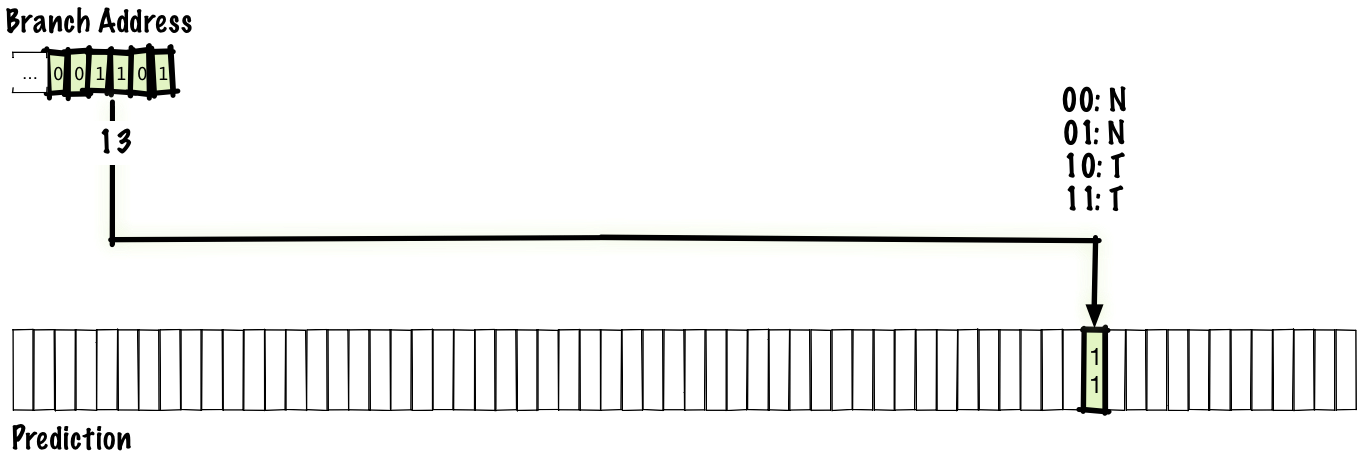
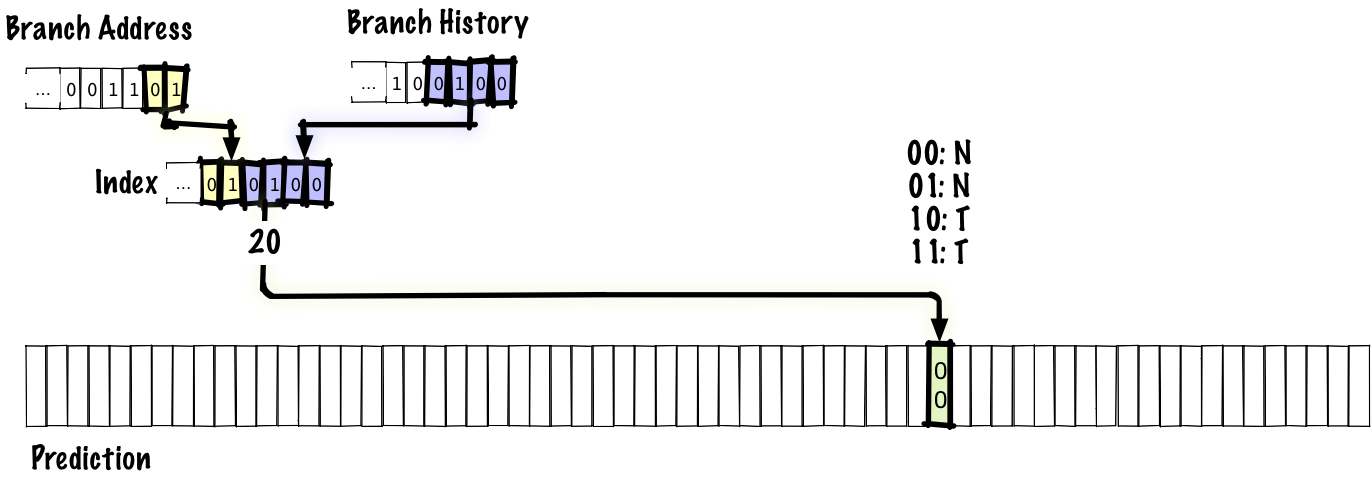
Поскольку назначать по биту на каждый переход — слишком много для разумного хранения, то сделаем таблицу для некоторого количества переходов, которые состоялись в последнее время. Для этой лекции предположим, что отсутствию перехода соответствует 0, а взятие ветви — 1.

В нашем случае, чтобы всё поместилось на иллюстрации, возьмём таблицу на 64 записи. Такое количество записей позволяет проиндексировать таблицу 6 битами, так что мы используем нижние 6 бит адреса перехода. После выполнения перехода мы обновляем состояние в таблице предсказаний (выделено внизу), а следующий раз по индексу используем уже обновлённое состояние.

Возможно, произойдёт наложение и две ветки из разных мест укажут на один и тот же адрес. Схема не идеальна, но это компромисс между скоростью работы таблицы и её размером.
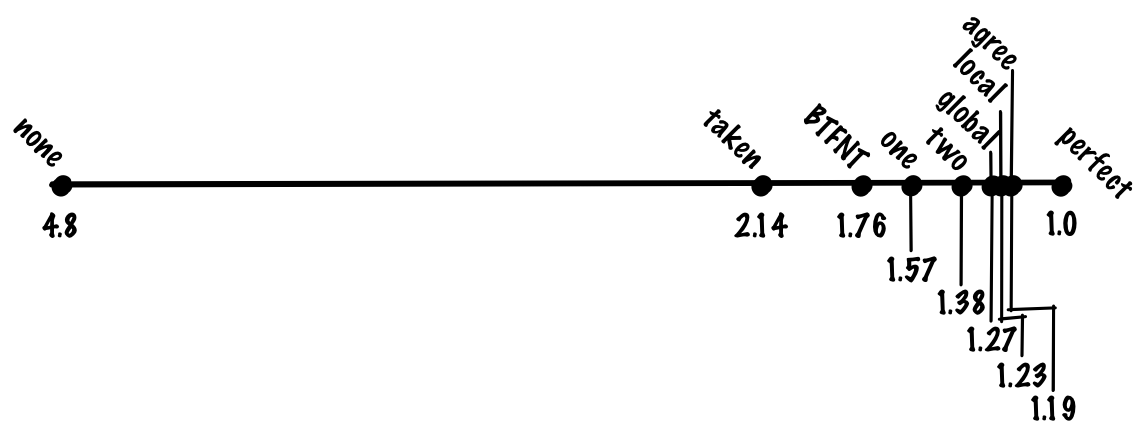
Если использовать однобитную схему, то мы можем добиться точности 85%, что соответствует в среднем
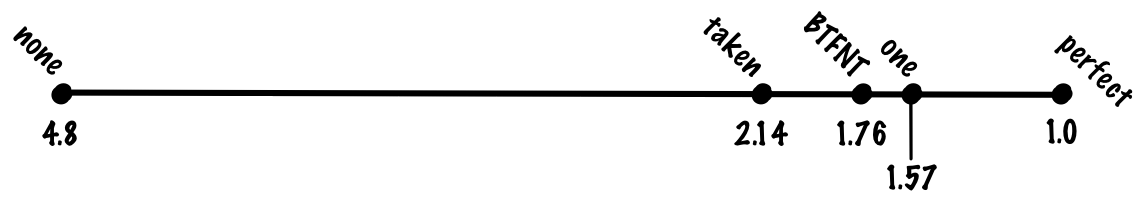
Кто использует:
Однобитная схема хорошо работает для шаблонов вида
«Насыщающая» часть счётчика означает, что если мы досчитаем до 00, то остаёмся на этом значении. Точно так же, если досчитаем до 11, то остаёмся на нём. Эта схема идентична однобитной, но только вместо одного бита в таблице предсказаний мы используем два бита.
По сравнению с однобитной схемой в двухбитной может быть вдвое меньше записей при тех же размере и стоимости (если мы учитываем только стоимость хранения, но не учитываем стоимость логики счётчика). Но даже так для любого разумного размера таблицы двухбитная схема обеспечивает лучшую точность.
Несмотря на свою простоту, схема работает довольно успешно, и мы можем ожидать повышения точности в двухбитном предикторе примерно до 90%, что соответствует 1,38 цикла на инструкцию.
Кажется логичным обобщить схему для n-битного счётчика с насыщением, но оказывается, что увеличение битности практически не влияет на точность. Мы не обсуждали цену предсказателя ветвлений, но переход с двух на три бита увеличивает размер таблицы в полтора раза ради незначительной выгоды. В большинстве случаев это не стоит того. Самые простые и наиболее распространённые случаи, которые мы не сможем хорошо предсказывать двухбитным предиктором — это шаблоны вроде
Кто использует:
Если подумать о таком коде
То он генерирует шаблон ветвлений вроде
Если мы знаем три предыдущих результата ветвления, то можем предсказать четвёртый:
Предыдущие схемы использовали адрес ветвления для помещения индекса в таблицу, которая сообщала, состоится ли с большей вероятностью переход или нет, в зависимости от истории выполнения программы. Она говорит, в каком направлении скорее произойдёт ветвление, но не способна угадать, что мы находимся в середине повторяющегося шаблона. Чтобы исправить это, будем хранить историю большинства последних переходов, а также таблицу предсказаний.
В этом примере мы связываем четыре бита истории переходов с двумя битами адреса перехода для помещения индекса в таблицу предсказаний. Как и раньше, источником предсказания является двухбитный счётчик с насыщением. Здесь мы не хотим использовать для индекса только историю переходов. Если так сделать, то любые две ветви с одинаковой историей будут ссылаться на одну и ту же запись в таблице. В настоящем предикторе у нас, вероятно, была бы таблица большего размера и больше битов для адреса перехода, но чтобы вместить таблицу в слайд, мы вынуждены использовать шестибитный индекс.
Ниже мы видим, какое значение обновляется при осуществлении перехода.
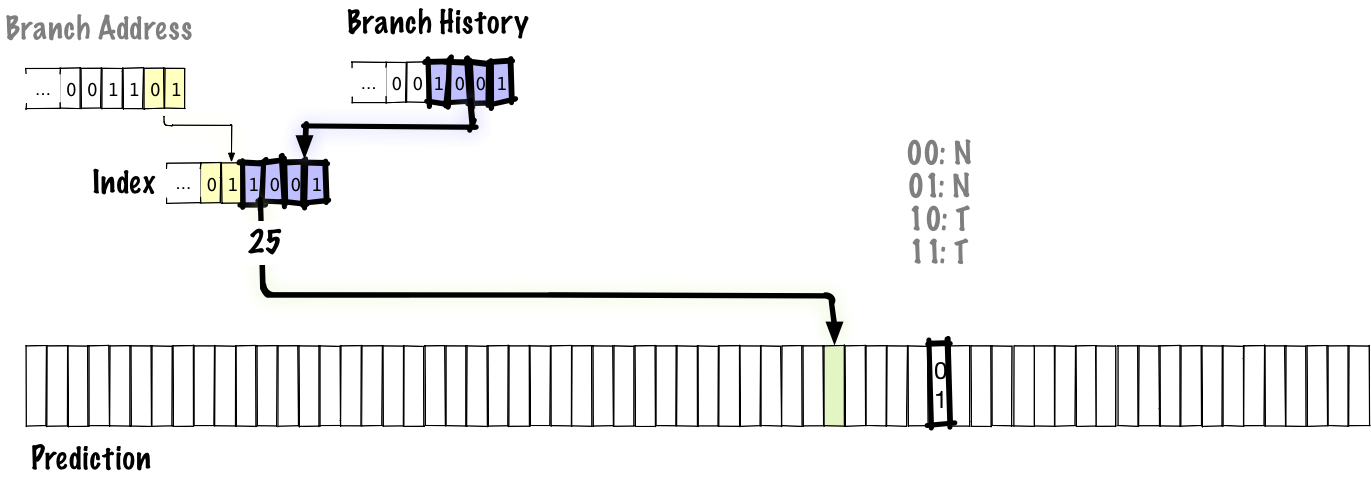
Жирным выделены обновляемые части. На этой диаграмме мы сдвигаем новые биты истории переходов справа налево, обновляя историю ветвлений. Поскольку история обновлена, нижние биты индекса в таблице предсказаний тоже обновляются, так что в следующий раз, когда столкнёмся с этой ветвью, мы используем другое значение из таблицы для предсказания перехода, в отличие от предыдущих схем, где индекс был зафиксирован в адресе перехода.
Поскольку в этой схеме хранится глобальная история, то она правильно предскажет шаблоны вроде
Если произойдёт переход по первой или второй ветви, то третья определённо останется незадействованной.
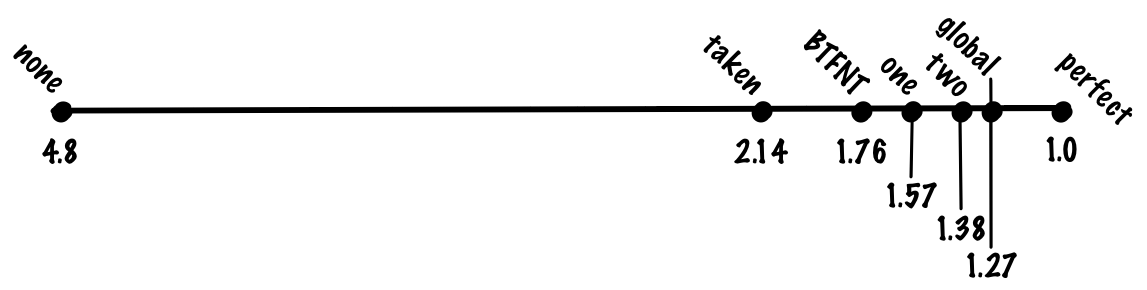
С этой схемой мы можем добиться точности 93%, что соответствует 1,27 цикла на инструкцию.
Кто использует:
Как упомянуто выше, у схемы с глобальной историей есть проблема, что история локальных ветвлений засоряется другими ветвями.
Хороших локальных предсказаний можно добиться, если отдельно хранить историю локальных ветвлений.

Вместо хранения единой глобальной истории мы сохраняем таблицу локальных историй, проиндексированную по адресу перехода. Такая схема идентична глобальной схеме, которую мы только что рассматривали, за исключением хранения историй нескольких ветвлений. Можно представить глобальную историю как частный случай локальной истории, где количество хранимых историй равно 1.
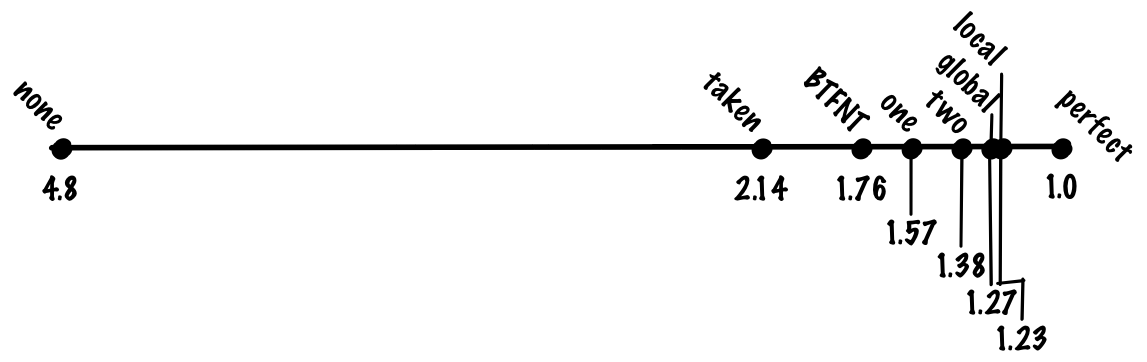
С этой схемой мы можем добиться точности 94%, что соответствует 1,23 цикла на инструкцию
Кто использует:
В глобальной двухуровневой схеме приходится идти на компромисс: в таблице предсказаний фиксированного размера биты должны соответствовать или истории переходов, или адресу перехода. Мы хотели бы выделить больше бит под историю переходов, потому что это позволит отслеживать корреляции на большем «расстоянии», а также отслеживать более сложные паттерны. Но мы также хотим отдать больше бит под адрес, чтобы избежать взаимных помех между несвязанными ветвями.
Можно попробовать решить обе задачи, применив одновременное хеширование, а не сцепление истории переходов и адреса перехода. Это одна из самых простых и разумных вещей, которые мы можем сделать, и первым кандидатом на роль механизма для этой операции приходит
С этой схемой мы можем повысить точность примерно до 94%. Это такая же точность, как в локальной схеме, но в gshare не нужно хранить большую таблицу локальных историй. То есть мы получаем такую же точность при меньших затратах, что является существенным улучшением.
Кто использует:
Одна из причин неправильного предсказания переходов — помехи между разными ветвями, которые ссылаются на один адрес. Есть много способов уменьшить помехи. На самом деле, в этой лекции мы рассматриваем схемы 90-х годов именно потому, что с тех пор предложено большое количество схем устранения помех, и их слишком много, чтобы уложиться в полчаса.
Посмотрим на одну схему, которая даёт общее представление о том, как может выглядеть устранение помех — это предсказатель “agree”. Когда происходит коллизия двух пар история-переход, то предсказания или совпадают, или нет. Если совпадают, мы называем это нейтральной интерференцией, а если нет, то отрицательной интерференцией. Идея в том, что большинство ветвей имеют сильный уклон в какую-то сторону (то есть если мы используем двухбитные записи в таблице предсказаний, то ожидаем, что без интерференции большинство записей бoльшую часть времени будет равняться
Если посмотреть, как это работает, то здесь предиктор идентичен предиктору gshare, за исключением изменения, которое мы сделали — предсказание теперь выглядит как agree/disagree (согласен или не согласен), а не taken/not-taken (переход осуществлён или не осуществлён), и у нас есть бит “bias”, который проиндексирован в адресе перехода, что даёт нам материал для принятия решения agree/disagree. Авторы оригинальной научной статьи предлагают использовать “bias” непосредственно, но другие специалисты выдвинули идею определять “bias” путём оптимизации, основанной на профилировании (по существу, когда работающая программа передаёт данные обратно компилятору).
Заметьте, что если мы выполняем переход, а затем возвращаемся назад к тому же ветвлению, то мы будем использовать тот же бит “bias”, потому что он проиндексирован адресом перехода, но мы будем использовать другую запись в таблице предсказаний, потому что она проиндексирована одновременно и адресом перехода, и историей переходов.

Если вам кажется странным, что такое изменение имеет значение, рассмотрим его на конкретном примере. Скажем, у нас есть два ветвления, ветвь A, по которой происходит переход с вероятностью 90%, и ветвь B, по которой происходит переход с вероятностью 10%. Если предположить, что вероятности переходов по каждой ветке независимы друг от друга, то вероятность принятия решения disagree и отрицательной интерференции составляет
Если мы используем схему agree, мы можем повторить этот расчёт, но вероятность принятия решения disagree для двух ветвей и отрицательной интерференции составляет
С этой схемой мы можем добиться точности 95%, что соответствует 1,19 цикла на инструкцию.
Кто использует:
Как мы видели, локальные предикторы могут хорошо предсказывать некоторые типы ветвлений (например, встроенные циклы), а глобальные предикторы хорошо справляются с другими типами (например, с некоторыми коррелированными ветвями). Можно попробовать совместить преимущества обоих предикторов и получить мета-предиктор, который предсказывает, использовать локальный или глобальный предиктор. Простой способ — использовать для мета-предиктора такую же схему, как в вышеописанном двухбитном предикторе, но только вместо предсказания
Также как существует много схем для устранения помех, одна из которых — вышеупомянутая схема agree, также много существует гибридных схем. Мы можем использовать любые два предиктора, а не только локальный и глобальный, и количество предикторов даже бывает больше двух.
Если использовать глобальный и локальный предикторы, мы можем добиться точности 96%, что соответствует 1,15 цикла на инструкцию.
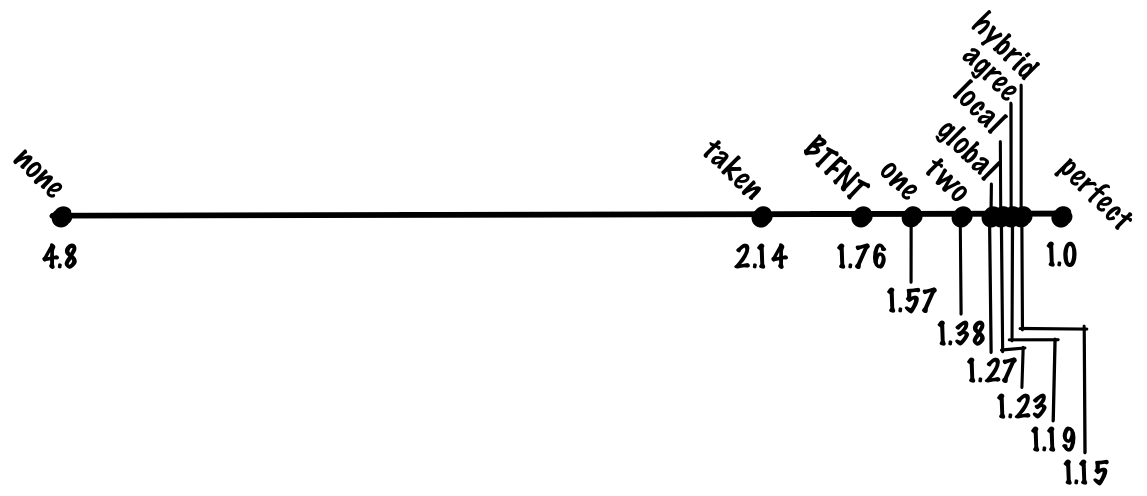
Кто использует:
В этой лекции мы о многом не рассказали. Как вы могли ожидать, объём пропущенного материала гораздо больше, чем того, о котором мы рассказали. Я кратко упомяну некоторые пропущенные темы со ссылками, так что вы можете почитать о них, если хотите знать больше.
Одна важная вещь, о которой мы не говорили — как предсказать целевой адрес перехода. Обратите внимание, что это нужно делать даже для некоторых безусловных переходов (то есть для переходов, которые не нуждаются в специальном предсказании, потому что они происходят в любом случае), потому что у (некоторых) безусловных переходов есть неизвестные цели.
Предсказание цели перехода настолько дорого обходится, что у некоторых ранних CPU политикой предсказания переходов было «всегда предсказывать отсутствие перехода», потому что целевой адрес перехода не потребуется, если переход отсутствует! У постоянного предсказания отсутствия переходов низкая точность, но она всё равно выше, чем если вообще не делать предсказаний.
Среди предикторов со снижением помех, которые мы не обсудили, bi-mode, gskew и YAGS. Если очень кратко, bi-mode похож на agree в том, что пытается разделить переходы по направлению, но здесь используется другой механизм: мы ведём несколько таблиц предсказаний, а третий предиктор на основе адреса перехода используется для предсказания, какую таблицу использовать для определённой комбинации перехода и истории переходов. Bi-mode кажется более успешным, чем agree, поскольку получил более широкое использование. В случае с gksew мы ведём минимум три таблицы предсказаний и отдельные хеши для внесения индекса в каждую таблицу. Идея в том, что если два перехода накладываются друг на друга в индексе, то это происходит лишь в одной таблице, так что мы можем провести голосование и результатом из двух других таблиц перекрыть потенциально плохой результат из таблицы с наложением. Я не знаю, как очень кратко описать схему YAGS :-).
Поскольку мы не говорили о скорости (задержке), то не говорили о такой стратегии предсказания как использование маленького/быстрого предиктора, результат которого может быть перекрыт более медленным и точным предиктором.
У некоторых современных CPU совершенно иные предсказатели переходов; в процессорах AMD Zen (2017) и AMD Bulldozer (2011) вроде бы используются предикторы переходов на перцептронах. Перцептроны — это одноуровневые нейронные сети.
Как утверждается, в процессоре Intel Haswell (2013) используется разновидность предиктора TAGE. TAGE означает тегированный геометрический (TAgged Geometric) предиктор с размером истории. Если изучить описанные нами предикторы и посмотреть на реальное выполнение программ — какие переходы там предсказываются неправильно, то среди них есть один большой класс: это переходы, которым нужна большая история. Значительному количеству переходов нужны десятки или сотни бит истории, а некоторым требуется даже более тысячи бит истории переходов. Если у нас единственный предиктор или даже гибридный, который сочетает несколько разных предикторов, будет неэффективным хранить тысячу бит истории, поскольку это снижает качество предсказаний для переходов, которым нужна относительно небольшая история (снижает особенно относительно цены), а таких переходов большинство. Одна из идей, заложенных в предиктор TAGE, состоит в том, чтобы сохранять геометрические длины размеров историй, и тогда каждый переход будет использовать соответствующую историю. Это объяснение части GE в аббревиатуре. Часть TA означает, что переходы помечаются тегами. Мы не обсуждали этот механизм, предиктор использует его для определения, какая история соответствует каким переходам.
В современных CPU часто используются специализированные предикторы. Например, предсказатель циклов может точно предсказывать переходы в циклах там, где общий предсказатель переходов не способен хранить разумный размер истории для идеального предсказания каждой итерации цикла.
Мы вообще не говорили о компромиссе между использованием объёма памяти и лучшими предсказаниями. Изменение размера таблицы не только меняет эффективность предиктора, но и меняет расстановку сил в том, какой предиктор лучше по сравнению с другими.
Мы также вообще не говорили о том, как разные задачи влияют на производительность предикторов разного типа. Их эффективность зависит не только от размера таблицы, но также от того, какая конкретно программа запущена.
Ещё мы обсуждали стоимость неправильного предсказания перехода так, будто это постоянная величина, но это не так, и в этом отношении стоимость инструкций без переходов тоже сильно отличается, в зависимости от типа выполняемой задачи.
Я пытался избежать непонятной терминологии где возможно, так что если будете читать литературу, там терминология немного другая.
Мы рассмотрели ряд классических предсказателей переходов и очень кратко обсудили пару более новых предикторов. Некоторые из рассмотренных нами классических предикторов до сих пор используются в процессорах, и если бы у меня был час времени, а не полчаса, мы могли бы обсудить самые современные предикторы. Думаю, у многих людей есть мысль, что процессор — это загадочная и трудная для понимания вещь, но по моему мнению, процессоры на самом деле проще для понимания, чем программное обеспечение. Я могу быть не объективен, потому что раньше работал с процессорами, но всё-таки мне кажется, что дело не моей необъективности, а это нечто фундаментальное.
Если подумать о сложности софта, то единственным ограничивающим фактором этой сложности будет ваше воображение. Если вы можете вообразить нечто в такой подробной детализации, что это можно записать, то вы можете это сделать. Конечно, в некоторых случаях ограничивающим фактором является нечто более практичное (например, производительность крупномасштабных приложений), но я думаю, что большинство из нас проводит бoльшую часть времени за написанием программ, где ограничивающий фактор — это способность создавать и управлять сложностью.
Аппаратное обеспечение тут заметно отличается, потому что есть силы, которые противостоят сложности. Каждый кусок железа, которое вы внедряете, стоит денег, так что вы хотите использовать минимум оборудования. Вдобавок, для большинства железа важна производительность (будь то абсолютная производительность или производительность на доллар, или на ватт, или на другой ресурс), а увеличение сложности замедляет работу железа, что ограничивает производительность. Сегодня вы можете купить серийный CPU за $300, который разгоняется до 5 ГГц. На 5 ГГц одна единица работы выполняется за одну пятую наносекунды. Для информации, свет проходит примерно 30 сантиметров за одну наносекунду. Ещё один сдерживающий фактор — то, что люди весьма расстраиваются, если CPU не работает идеально всё время. Хотя у процессоров есть баги, количество багов гораздо меньше, чем почти в любом программном обеспечении, то есть стандарты для их проверки/тестирования гораздо выше. Увеличение сложности затрудняет тестирование и проверку. Поскольку процессоры придерживаются более высокого стандарта точности, чем большинство программного обеспечения, то увеличение сложности добавляет слишком тяжёлое бремя тестирования/проверки для CPU. Таким образом, одинаковое усложнение намного дороже обходится для железа, чем для софта, даже без учёта других факторов, которые мы обсуждали.
Побочный эффект этих факторов, которые противостоят усложнению микросхемы состоит в том, что каждая «высокоуровневая» функция процессора общего назначения обычно достаточно концептуально проста, чтобы описать её в получасовой или часовой лекции. Процессоры проще, чем думают многие программисты! Кстати, я сказал «высокоуровневая», чтобы исключить всякие штуки вроде устройства транзисторов и схемотехники, для понимания которых нужен определённый низкоуровневый бэкграунд (физика или электроника).
Кто из вас использует ветвления в своём коде? Можете поднять руку, если применяете операторы if или сопоставление с образцом?
Большинство присутствующих в аудитории поднимают руки Сейчас я не буду просить вас подымать руки. Но если я спрошу, сколько из вас думают, что хорошо понимают действия CPU при обработке ветвления и последствия для производительности, и сколько из вас может понять современную научную статью о предсказании ветвлений, то руки подымет меньше людей.
Цель моего выступления — объяснить, как и почему процессоры осуществляют предсказание переходов, а затем вкратце объяснить классические алгоритмы предсказания переходов, о которых вы можете прочитать в современных статьях, чтобы у вас появилось общее понимание темы.
Перед тем как обсуждать предсказание переходов, поговорим о том, зачем вообще процессоры это делают. Для этого нужно немного знать о работе CPU.
В раках этой лекции можете воспринимать компьютер как CPU плюс немного памяти. Инструкции живут в памяти, а CPU выполняет последовательность инструкций из памяти, где сами инструкции имеют вид вроде «сложить два числа», «перенести фрагмент данных из памяти в процессор». Обычно после выполнения одной инструкции CPU выполняет инструкцию со следующим по порядку адресом. Однако есть инструкции типа «переходы», которые позволяют изменить адрес следующей инструкции.
Вот абстрактная диаграмма CPU, выполняющего некоторые инструкции. По горизонтальной оси отложено время, а по вертикальной — отличия между разными инструкциями.
Здесь мы сначала выполняем инструкцию A, затем инструкции B, C и D.
Один способ проектирования CPU — делать всю работу по очереди. Здесь нет ничего плохого; многие старые CPU так работают, как и некоторые современные очень дешёвые процессоры. Но если вы хотите сделать более быстрый CPU, то нужно превратить его в подобие конвейера. Для этого вы разбиваете процессор на две части, так что первая половина находится на фронтенде работы с инструкциями, а вторая половина — в бэкенде, как на конвейере. Это обычно называют конвейерным процессором (pipelined CPU).
Если вы сделаете так, то выполнение инструкций будет происходить примерно как на иллюстрации. После выполнения первой половины инструкции A процессор начинает работать над второй половиной инструкции A одновременно с первой половиной инструкции B. А когда завершается выполнение второй половины A, процессор может одновременно начать вторую половину B и первую половину C. На этой диаграмме вы видите, что конвейерный процессор способен выполнять за промежуток времени вдвое больше инструкций, чем обычный процессор, показанный ранее.
Нет никакой причины разделять CPU всего на две части. Мы можем разделить его на три части и получить трёхкратный прирост производительности или на четыре части для четырёхкратного прироста. Хотя это не совсем верно и на самом деле обычно прирост не будет трёхкратным для трёхступенчатого конвейера или четырёхкратным для четырёхступенчатого конвейера, потому что есть определённые накладные расходы при разделении CPU на части.
Один источник накладных расходов — то, как обрабатываются ветвления. Первым делом CPU должен получить инструкцию. Для этого он должен знать, где она находится. Например, возьмём следующий код:
if (x == 0) {
// Do stuff
} else {
// Do other stuff (things)
}
// Whatever happens laterЕго можно перевести в ассемблер:
branch_if_not_equal x, 0, else_label
// Do stuff
goto end_label
else_label:
// Do things
end_label:
// whatever happens laterВ этом примере мы сравниваем x с нулём. Если он не равен нулю (
if_not_equal), то мы переходим к else_label и выполняем код в блоке else. Если это сравнение не выполняется (то есть если x равен нулю), то мы проваливаемся, выполняем код в блоке if, а затем перепрыгиваем к end_label, чтобы избежать выполнения кода в блоке else.Для конвейера проблематичной является конкретная последовательность инструкций:
branch_if_not_equal x, 0, else_label
???Процессор не знает, что будет дальше:
branch_if_not_equal x, 0, else_label
// Do stuffили
branch_if_not_equal x, 0, else_label
// Do thingsОн не знает этого, пока не завершилось (или почти завершилось) выполнение ветви. Одним из первых действий CPU должно быть извлечение инструкции из памяти, а мы даже не знаем, какой будет инструкция
??? и не можем с ней работать, пока предыдущая инструкция почти не закончена.Ранее мы говорили, что получаем почти трёхкратное ускорение при использовании трёхступенчатого конвейера или почти 20-кратное при использовании 20-ступенчатого. Предполагалось, что на каждом цикле вы можете начинать выполнение новой инструкции, но в данном случае две инструкции практически сериализованы.
Один из вариантов решения проблемы — использовать предсказание переходов. Когда появляется ветвь, CPU будет предполагать, взята эта ветвь или нет.
В этом случае процессор предсказывает, что ветвь не будет занята, и начинает выполнение первой половины
stuff, одновременно заканчивая выполнение второй половины ветви. Если предсказание верно, то CPU выполнит вторую половину stuff и может начать выполнение ещё одной инструкции, работая со второй половиной stuff, как мы видели на первой диаграмме конвейера.Если предсказание ошибочно, то после завершения выполнения ветви CPU отбросит результаты
stuff.1 и начнёт выполнение правильных инструкций вместо неправильных. Поскольку в отсутствие предсказания переходов мы бы остановили процессор и не выполнили бы никаких инструкций, мы ничего не теряем в такой ситуации (по крайней мере, на том уровне приближения, с которым рассматриваем ситуацию).Каково влияние на производительность? Чтобы оценить его, нужно смоделировать производительность и нагрузку. Для этой лекции возьмём карикатурную модель конвейерного CPU, где не-ветвления отрабатываются примерно одной инструкцией за цикл, непредсказанные или неправильно предсказанные переходы занимают 20 циклов, а правильно предсказанные — один цикл.
Если взять самый популярных бенчмарк для целочисленных нагрузок на «рабочую станцию» SPECint, то распределение может быть 20% ветвей и 80% других операций. Без предсказания переходов мы ожидаем, что «средняя» инструкция займёт
branch_pct * 1 + non_branch_pct * 20 = 0.8 * 1 + 0.2 * 20 = 0.8 + 4 = 4.8 цикла. При идеальном на 100% точном предсказании переходов средняя инструкция займёт 0.8 * 1 + 0.2 * 1 = 1 цикл, что означает ускорение в 4,8 раза! Другими словами, если у нас конвейер со «штрафом» в 20 циклов за непредсказанный переход, то мы получаем почти пятикратные издержки по сравнению с идеальным конвейером, только за счёт предсказания ветвлений.Посмотрим, что можно с этим сделать. Начнём с самых простых вещей, и постепенно выработаем решение получше.
Берём все переходы
Вместо случайных предсказаний мы можем посмотреть на все ветви выполнения всех программ. В этом случае мы увидим, что взятые и невзятые ветви неодинаково сбалансированы — взятых ветвей гораздо больше, чем невзятых. Одной из причин являются ветви цикла, которые часто выполняются.
Если предсказывать взятие каждой ветви, то мы можем выйти на уровень точности предсказаний 70%, так что будем оплачивать только неверно предсказанные 30% переходов, что снижает стоимость средней инструкции до
(0.8 + 0.7 * 0.2) * 1 + 0.3 * 0.2 * 20 = 0.94 + 1.2. = 2.14. Если сравнить обязательное предсказание всех переходов с отсутствием предсказания и с идеальным предсказанием, то обязательное предсказание отыгрывает бoльшую часть преимущества идеального предсказания, хотя это очень простой алгоритм.Берём переходы назад, не берём переходы вперёд (BTFNT)
Предсказывать взятие всех ветвей хорошо работает для циклов, но не для других ветвей. Если посмотреть на процент выполнения переходов вперёд по программе или назад по программе (возвращение к предыдущему коду), то мы увидим, что переходы назад выполняются гораздо чаще, чем переходы вперёд. Поэтому можно попробовать предиктор, который предсказывает взятие всех переходов назад и невзятие всех переходов вперёд (BTFNT, backwards taken forwards not taken). Если мы реализуем эту схему на аппаратном уровне, то компиляторы подстроятся под нас и начнут организовывать код таким образом, чтобы ветви с наибольшими шансами выполнения становились переходами назад, а ветви с наименьшими шансами выполнения становились переходами вперёд.
Если это сделать, то можно добиться точности предсказаний около 80%, что снижает стоимость выполнения инструкции до
(0.8 + 0.8 * 0.2) * 1 + 0.2 * 0.2 * 20 = 0.96 + 0.8 = 1.76 цикла.Кто использует:
- PPC 601 (1993): также использует советы компилятора в виде сгенерированных переходов
- PPC 603
Один бит
До сих пор мы рассматривали схемы, которые не сохраняют никакого состояния, то есть такие схемы, где предиктор игнорирует историю выполнения программы. В литературе они называются статическими методами предсказания переходов. Их преимущество в простоте, но они плохо справляются с предсказанием переходов, которые изменяются со временем. Вот пример такого перехода:
if (flag) {
// things
}В ходе выполнения программы на одном этапе флаг может быть установлен и переход осуществлён, а на другом этапе флага нет и переход не происходит. Статические методы никак не могут хорошо предсказывать ветвления вроде этого, так что рассмотрим динамические методы, где предсказание может изменяться в зависимости от истории выполнения программы.
Одна из простейших вещей — предсказывать на основе последнего результата, то есть предсказывать переход в том случае, если в прошлый раз он состоялся, и наоборот.
Поскольку назначать по биту на каждый переход — слишком много для разумного хранения, то сделаем таблицу для некоторого количества переходов, которые состоялись в последнее время. Для этой лекции предположим, что отсутствию перехода соответствует 0, а взятие ветви — 1.
В нашем случае, чтобы всё поместилось на иллюстрации, возьмём таблицу на 64 записи. Такое количество записей позволяет проиндексировать таблицу 6 битами, так что мы используем нижние 6 бит адреса перехода. После выполнения перехода мы обновляем состояние в таблице предсказаний (выделено внизу), а следующий раз по индексу используем уже обновлённое состояние.
Возможно, произойдёт наложение и две ветки из разных мест укажут на один и тот же адрес. Схема не идеальна, но это компромисс между скоростью работы таблицы и её размером.
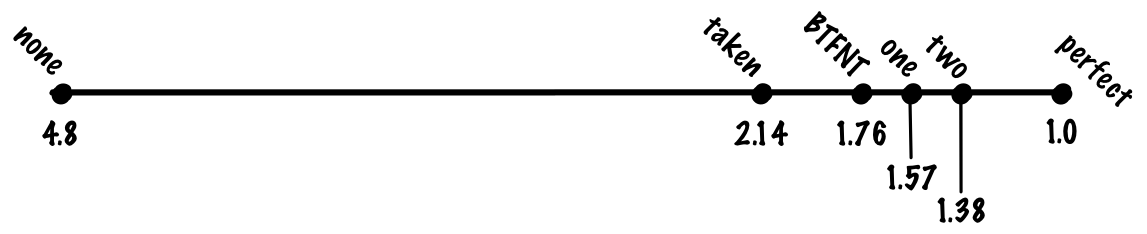
Если использовать однобитную схему, то мы можем добиться точности 85%, что соответствует в среднем
(0.8 + 0.85 * 0.2) * 1 + 0.15 * 0.2 * 20 = 0.97 + 0.6 = 1.57 цикла на инструкцию.Кто использует:
- DEC EV4 (1992)
- MIPS R8000 (1994)
Два бита
Однобитная схема хорошо работает для шаблонов вида
TTTTTTTT… или NNNNNNN…, но будет выдавать неправильные предсказания для потока ветвлений, где происходит большинство переходов, но один из них не происходит, ...TTTNTTT.... Это можно исправить, добавив к каждому адресу второй бит и внедрив счётчик, реализующий арифметику с насыщением. Например, будем отнимать единицу, если переход не состоялся, и добавлять единицу, если он состоялся. Результаты в двоичном виде будут такими:00: predict Not
01: predict Not
10: predict Taken
11: predict Taken «Насыщающая» часть счётчика означает, что если мы досчитаем до 00, то остаёмся на этом значении. Точно так же, если досчитаем до 11, то остаёмся на нём. Эта схема идентична однобитной, но только вместо одного бита в таблице предсказаний мы используем два бита.
По сравнению с однобитной схемой в двухбитной может быть вдвое меньше записей при тех же размере и стоимости (если мы учитываем только стоимость хранения, но не учитываем стоимость логики счётчика). Но даже так для любого разумного размера таблицы двухбитная схема обеспечивает лучшую точность.
Несмотря на свою простоту, схема работает довольно успешно, и мы можем ожидать повышения точности в двухбитном предикторе примерно до 90%, что соответствует 1,38 цикла на инструкцию.
Кажется логичным обобщить схему для n-битного счётчика с насыщением, но оказывается, что увеличение битности практически не влияет на точность. Мы не обсуждали цену предсказателя ветвлений, но переход с двух на три бита увеличивает размер таблицы в полтора раза ради незначительной выгоды. В большинстве случаев это не стоит того. Самые простые и наиболее распространённые случаи, которые мы не сможем хорошо предсказывать двухбитным предиктором — это шаблоны вроде
NTNTNTNTNT... или NNTNNTNNT…, но переход на большее количество бит тоже не улучшит точность в этих случаях!Кто использует:
- LLNL S-1 (1977)
- CDC Cyber? (начало 80-х)
- Burroughs B4900 (1982): состояние хранится в потоке инструкций; на аппаратноми уровне инструкция перезаписывается для обновления состояния перехода
- Intel Pentium (1993)
- PPC 604 (1994)
- DEC EV45 (1993)
- DEC EV5 (1995)
- PA 8000 (1996): в действительности реализовано в виде трёхбитного регистра сдвига с большинством голосов
Двухуровневое адаптивное глобальное предсказание переходов (1991)
Если подумать о таком коде
for (int i = 0; i < 3; ++i) {
// code here.
}То он генерирует шаблон ветвлений вроде
TTTNTTTNTTTN....Если мы знаем три предыдущих результата ветвления, то можем предсказать четвёртый:
TTT:N
TTN:T
TNT:T
NTT:T Предыдущие схемы использовали адрес ветвления для помещения индекса в таблицу, которая сообщала, состоится ли с большей вероятностью переход или нет, в зависимости от истории выполнения программы. Она говорит, в каком направлении скорее произойдёт ветвление, но не способна угадать, что мы находимся в середине повторяющегося шаблона. Чтобы исправить это, будем хранить историю большинства последних переходов, а также таблицу предсказаний.
В этом примере мы связываем четыре бита истории переходов с двумя битами адреса перехода для помещения индекса в таблицу предсказаний. Как и раньше, источником предсказания является двухбитный счётчик с насыщением. Здесь мы не хотим использовать для индекса только историю переходов. Если так сделать, то любые две ветви с одинаковой историей будут ссылаться на одну и ту же запись в таблице. В настоящем предикторе у нас, вероятно, была бы таблица большего размера и больше битов для адреса перехода, но чтобы вместить таблицу в слайд, мы вынуждены использовать шестибитный индекс.
Ниже мы видим, какое значение обновляется при осуществлении перехода.
Жирным выделены обновляемые части. На этой диаграмме мы сдвигаем новые биты истории переходов справа налево, обновляя историю ветвлений. Поскольку история обновлена, нижние биты индекса в таблице предсказаний тоже обновляются, так что в следующий раз, когда столкнёмся с этой ветвью, мы используем другое значение из таблицы для предсказания перехода, в отличие от предыдущих схем, где индекс был зафиксирован в адресе перехода.
Поскольку в этой схеме хранится глобальная история, то она правильно предскажет шаблоны вроде
NTNTNTNT… во внутренних циклах, но может не всегда правильно предсказывать высокоуровневые ветвления, потому что у глобальная история засорена информацией из других ветвлений. Однако здесь компромисс в том, что хранить глобальную историю дешевле, чем таблицу локальных историй. Вдобавок, использование глобальной истории позволяет корректно предсказывать коррелированные ветви. Например, у нас может быть что-то подобное:if x > 0:
x -= 1
if y > 0:
y -= 1
if x * y > 0:
foo()Если произойдёт переход по первой или второй ветви, то третья определённо останется незадействованной.
С этой схемой мы можем добиться точности 93%, что соответствует 1,27 цикла на инструкцию.
Кто использует:
- Pentium MMX (1996): 4-битная глобальная история переходов
Двухуровневое адаптивное локальное предсказание переходов (1992)
Как упомянуто выше, у схемы с глобальной историей есть проблема, что история локальных ветвлений засоряется другими ветвями.
Хороших локальных предсказаний можно добиться, если отдельно хранить историю локальных ветвлений.
Вместо хранения единой глобальной истории мы сохраняем таблицу локальных историй, проиндексированную по адресу перехода. Такая схема идентична глобальной схеме, которую мы только что рассматривали, за исключением хранения историй нескольких ветвлений. Можно представить глобальную историю как частный случай локальной истории, где количество хранимых историй равно 1.
С этой схемой мы можем добиться точности 94%, что соответствует 1,23 цикла на инструкцию
Кто использует:
- Pentium Pro (1996): 4-битная история локальных ветвлений, нижние биты используются для индекса. Обратите внимание, что насчёт этого вопроса ведутся споры, а Эндрю Фог заявляет, что в PPro и последующих процессорах используется 4-битная глобальная история
- Pentium II (1997): такое же, как в PPro
- Pentium III (1999): такое же, как в PPro
gshare
В глобальной двухуровневой схеме приходится идти на компромисс: в таблице предсказаний фиксированного размера биты должны соответствовать или истории переходов, или адресу перехода. Мы хотели бы выделить больше бит под историю переходов, потому что это позволит отслеживать корреляции на большем «расстоянии», а также отслеживать более сложные паттерны. Но мы также хотим отдать больше бит под адрес, чтобы избежать взаимных помех между несвязанными ветвями.
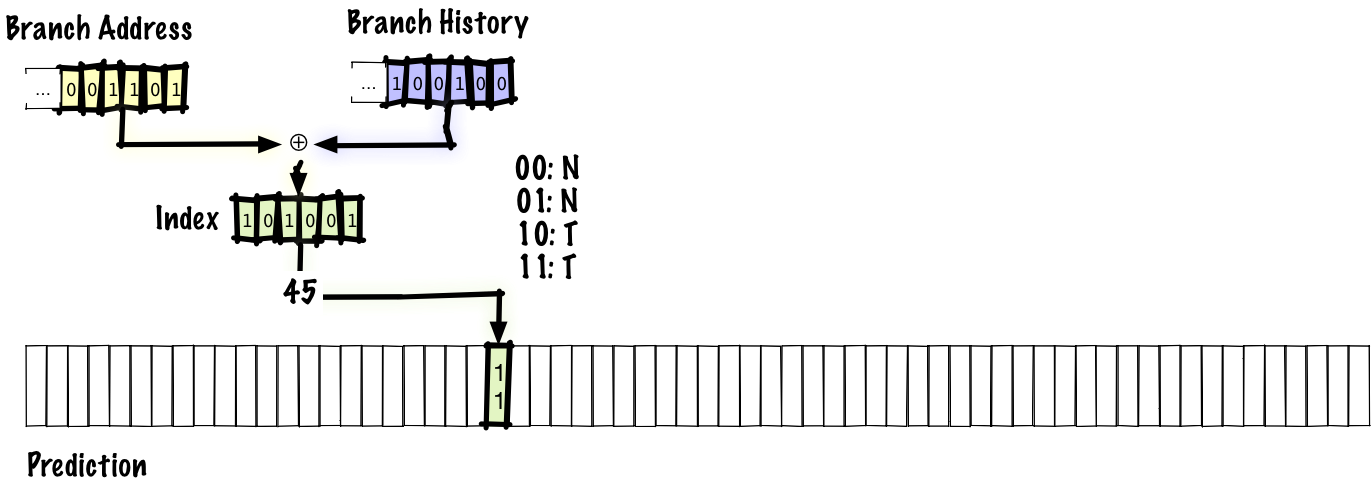
Можно попробовать решить обе задачи, применив одновременное хеширование, а не сцепление истории переходов и адреса перехода. Это одна из самых простых и разумных вещей, которые мы можем сделать, и первым кандидатом на роль механизма для этой операции приходит
xor. Такая двухуровневая адаптивная схема, где мы применяем xor, называется gshare.С этой схемой мы можем повысить точность примерно до 94%. Это такая же точность, как в локальной схеме, но в gshare не нужно хранить большую таблицу локальных историй. То есть мы получаем такую же точность при меньших затратах, что является существенным улучшением.
Кто использует:
- MIPS R12000 (1998): 2K записей, 11 бит PC, 8 бит истории
- UltraSPARC-3 (2001): 16K записей, 14 бит PC, 12 бит истории
agree (1997)
Одна из причин неправильного предсказания переходов — помехи между разными ветвями, которые ссылаются на один адрес. Есть много способов уменьшить помехи. На самом деле, в этой лекции мы рассматриваем схемы 90-х годов именно потому, что с тех пор предложено большое количество схем устранения помех, и их слишком много, чтобы уложиться в полчаса.
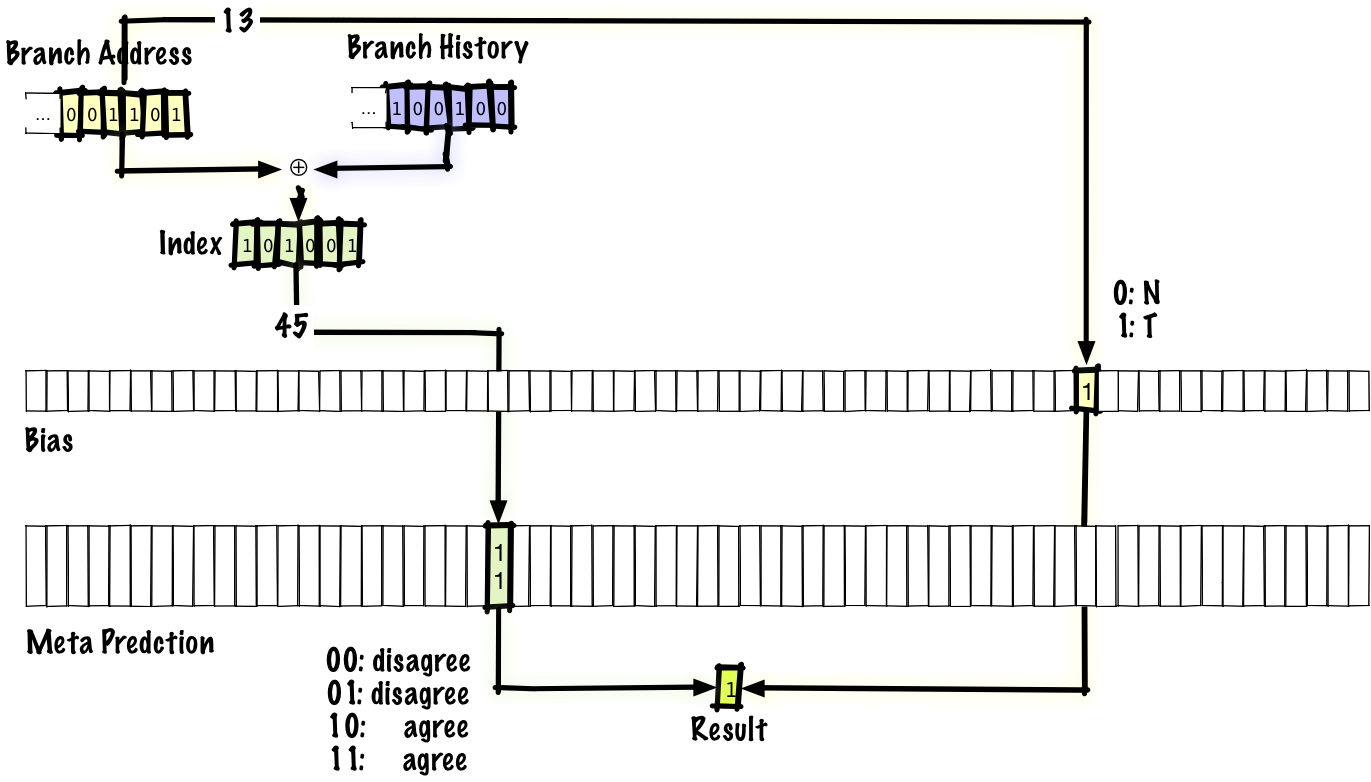
Посмотрим на одну схему, которая даёт общее представление о том, как может выглядеть устранение помех — это предсказатель “agree”. Когда происходит коллизия двух пар история-переход, то предсказания или совпадают, или нет. Если совпадают, мы называем это нейтральной интерференцией, а если нет, то отрицательной интерференцией. Идея в том, что большинство ветвей имеют сильный уклон в какую-то сторону (то есть если мы используем двухбитные записи в таблице предсказаний, то ожидаем, что без интерференции большинство записей бoльшую часть времени будет равняться
00 или 11, а не 01 или 10). Для каждого перехода в программе мы будем хранить один бит, который назовём “bias”. Вместо хранения абсолютных предсказаний переходов таблица будет хранить информацию о том, соответствует или не соответствует предсказание биту “bias”.Если посмотреть, как это работает, то здесь предиктор идентичен предиктору gshare, за исключением изменения, которое мы сделали — предсказание теперь выглядит как agree/disagree (согласен или не согласен), а не taken/not-taken (переход осуществлён или не осуществлён), и у нас есть бит “bias”, который проиндексирован в адресе перехода, что даёт нам материал для принятия решения agree/disagree. Авторы оригинальной научной статьи предлагают использовать “bias” непосредственно, но другие специалисты выдвинули идею определять “bias” путём оптимизации, основанной на профилировании (по существу, когда работающая программа передаёт данные обратно компилятору).
Заметьте, что если мы выполняем переход, а затем возвращаемся назад к тому же ветвлению, то мы будем использовать тот же бит “bias”, потому что он проиндексирован адресом перехода, но мы будем использовать другую запись в таблице предсказаний, потому что она проиндексирована одновременно и адресом перехода, и историей переходов.
Если вам кажется странным, что такое изменение имеет значение, рассмотрим его на конкретном примере. Скажем, у нас есть два ветвления, ветвь A, по которой происходит переход с вероятностью 90%, и ветвь B, по которой происходит переход с вероятностью 10%. Если предположить, что вероятности переходов по каждой ветке независимы друг от друга, то вероятность принятия решения disagree и отрицательной интерференции составляет
P(A taken) * P(B not taken) + P(A not taken) + P(B taken) = (0.9 * 0.9) + (0.1 * 0.1) = 0.82.Если мы используем схему agree, мы можем повторить этот расчёт, но вероятность принятия решения disagree для двух ветвей и отрицательной интерференции составляет
P(A agree) * P(B disagree) + P(A disagree) * P(B agree) = P(A taken) * P(B taken) + P(A not taken) * P(B taken) = (0.9 * 0.1) + (0.1 * 0.9) = 0.18. Другими словами, чтобы появилась деструктивная интерференция, одна из ветвей должна не согласиться с “bias”. По определению, если мы правильно определили этот бит, то вероятность этого события не может быть велика.С этой схемой мы можем добиться точности 95%, что соответствует 1,19 цикла на инструкцию.
Кто использует:
- PA-RISC 8700 (2001)
Hybrid (1993)
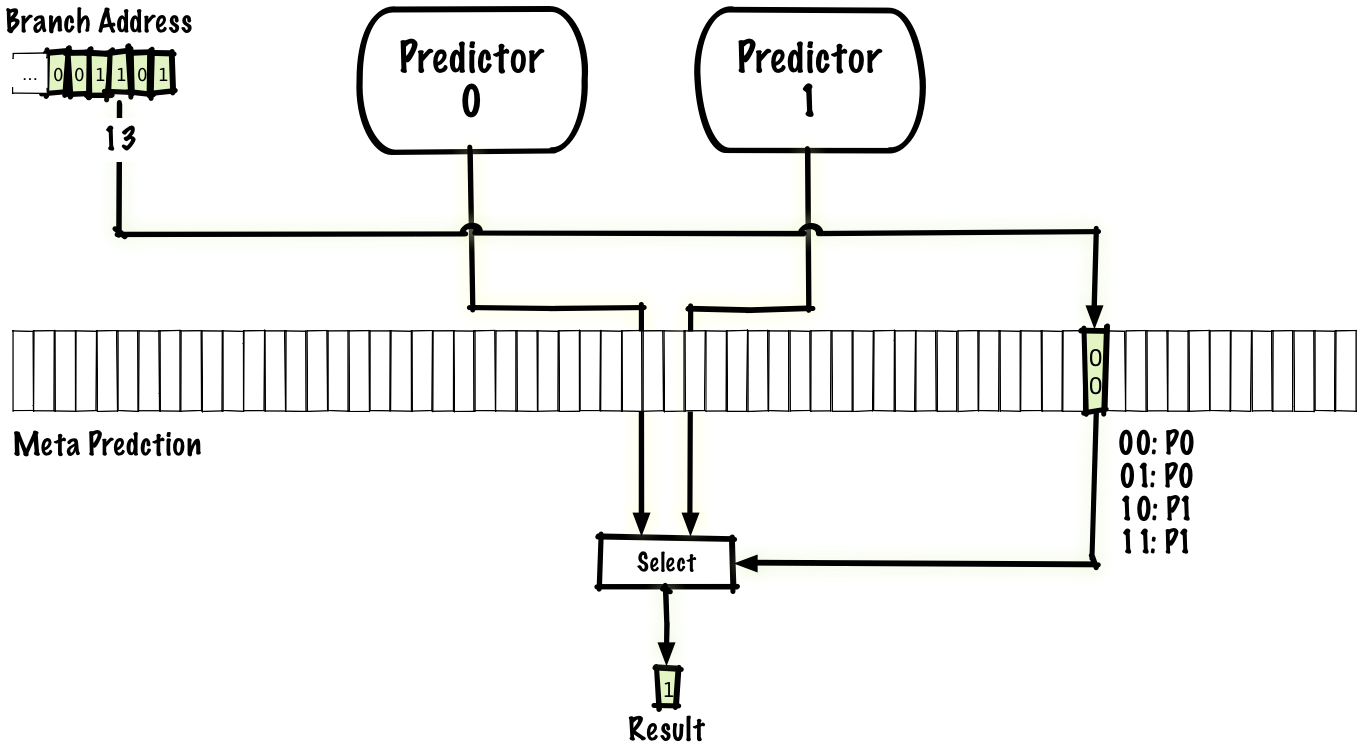
Как мы видели, локальные предикторы могут хорошо предсказывать некоторые типы ветвлений (например, встроенные циклы), а глобальные предикторы хорошо справляются с другими типами (например, с некоторыми коррелированными ветвями). Можно попробовать совместить преимущества обоих предикторов и получить мета-предиктор, который предсказывает, использовать локальный или глобальный предиктор. Простой способ — использовать для мета-предиктора такую же схему, как в вышеописанном двухбитном предикторе, но только вместо предсказания
taken или not taken он предсказывает локальный или глобальный предиктор.Также как существует много схем для устранения помех, одна из которых — вышеупомянутая схема agree, также много существует гибридных схем. Мы можем использовать любые два предиктора, а не только локальный и глобальный, и количество предикторов даже бывает больше двух.
Если использовать глобальный и локальный предикторы, мы можем добиться точности 96%, что соответствует 1,15 цикла на инструкцию.
Кто использует:
- DEC EV6 (1998): комбинация локального (1k записей, 10 бит истории, 3 бита на счётчик) и глобального (4k записей, 12 бит истории, 2 бита на счётчик) предикторов
- IBM POWER4 (2001): локальный (16k записей) и gshare (16k записей, 11 бит истории, xor с адресом перехода, таблица селекторов на 16k)
- IBM POWER5 (2004): сочетание бимодального (не освещён здесь) и двухуровневого адаптивного предикторов
- IBM POWER7 (2010)
Что мы пропустили
В этой лекции мы о многом не рассказали. Как вы могли ожидать, объём пропущенного материала гораздо больше, чем того, о котором мы рассказали. Я кратко упомяну некоторые пропущенные темы со ссылками, так что вы можете почитать о них, если хотите знать больше.
Одна важная вещь, о которой мы не говорили — как предсказать целевой адрес перехода. Обратите внимание, что это нужно делать даже для некоторых безусловных переходов (то есть для переходов, которые не нуждаются в специальном предсказании, потому что они происходят в любом случае), потому что у (некоторых) безусловных переходов есть неизвестные цели.
Предсказание цели перехода настолько дорого обходится, что у некоторых ранних CPU политикой предсказания переходов было «всегда предсказывать отсутствие перехода», потому что целевой адрес перехода не потребуется, если переход отсутствует! У постоянного предсказания отсутствия переходов низкая точность, но она всё равно выше, чем если вообще не делать предсказаний.
Среди предикторов со снижением помех, которые мы не обсудили, bi-mode, gskew и YAGS. Если очень кратко, bi-mode похож на agree в том, что пытается разделить переходы по направлению, но здесь используется другой механизм: мы ведём несколько таблиц предсказаний, а третий предиктор на основе адреса перехода используется для предсказания, какую таблицу использовать для определённой комбинации перехода и истории переходов. Bi-mode кажется более успешным, чем agree, поскольку получил более широкое использование. В случае с gksew мы ведём минимум три таблицы предсказаний и отдельные хеши для внесения индекса в каждую таблицу. Идея в том, что если два перехода накладываются друг на друга в индексе, то это происходит лишь в одной таблице, так что мы можем провести голосование и результатом из двух других таблиц перекрыть потенциально плохой результат из таблицы с наложением. Я не знаю, как очень кратко описать схему YAGS :-).
Поскольку мы не говорили о скорости (задержке), то не говорили о такой стратегии предсказания как использование маленького/быстрого предиктора, результат которого может быть перекрыт более медленным и точным предиктором.
У некоторых современных CPU совершенно иные предсказатели переходов; в процессорах AMD Zen (2017) и AMD Bulldozer (2011) вроде бы используются предикторы переходов на перцептронах. Перцептроны — это одноуровневые нейронные сети.
Как утверждается, в процессоре Intel Haswell (2013) используется разновидность предиктора TAGE. TAGE означает тегированный геометрический (TAgged Geometric) предиктор с размером истории. Если изучить описанные нами предикторы и посмотреть на реальное выполнение программ — какие переходы там предсказываются неправильно, то среди них есть один большой класс: это переходы, которым нужна большая история. Значительному количеству переходов нужны десятки или сотни бит истории, а некоторым требуется даже более тысячи бит истории переходов. Если у нас единственный предиктор или даже гибридный, который сочетает несколько разных предикторов, будет неэффективным хранить тысячу бит истории, поскольку это снижает качество предсказаний для переходов, которым нужна относительно небольшая история (снижает особенно относительно цены), а таких переходов большинство. Одна из идей, заложенных в предиктор TAGE, состоит в том, чтобы сохранять геометрические длины размеров историй, и тогда каждый переход будет использовать соответствующую историю. Это объяснение части GE в аббревиатуре. Часть TA означает, что переходы помечаются тегами. Мы не обсуждали этот механизм, предиктор использует его для определения, какая история соответствует каким переходам.
В современных CPU часто используются специализированные предикторы. Например, предсказатель циклов может точно предсказывать переходы в циклах там, где общий предсказатель переходов не способен хранить разумный размер истории для идеального предсказания каждой итерации цикла.
Мы вообще не говорили о компромиссе между использованием объёма памяти и лучшими предсказаниями. Изменение размера таблицы не только меняет эффективность предиктора, но и меняет расстановку сил в том, какой предиктор лучше по сравнению с другими.
Мы также вообще не говорили о том, как разные задачи влияют на производительность предикторов разного типа. Их эффективность зависит не только от размера таблицы, но также от того, какая конкретно программа запущена.
Ещё мы обсуждали стоимость неправильного предсказания перехода так, будто это постоянная величина, но это не так, и в этом отношении стоимость инструкций без переходов тоже сильно отличается, в зависимости от типа выполняемой задачи.
Я пытался избежать непонятной терминологии где возможно, так что если будете читать литературу, там терминология немного другая.
Заключение
Мы рассмотрели ряд классических предсказателей переходов и очень кратко обсудили пару более новых предикторов. Некоторые из рассмотренных нами классических предикторов до сих пор используются в процессорах, и если бы у меня был час времени, а не полчаса, мы могли бы обсудить самые современные предикторы. Думаю, у многих людей есть мысль, что процессор — это загадочная и трудная для понимания вещь, но по моему мнению, процессоры на самом деле проще для понимания, чем программное обеспечение. Я могу быть не объективен, потому что раньше работал с процессорами, но всё-таки мне кажется, что дело не моей необъективности, а это нечто фундаментальное.
Если подумать о сложности софта, то единственным ограничивающим фактором этой сложности будет ваше воображение. Если вы можете вообразить нечто в такой подробной детализации, что это можно записать, то вы можете это сделать. Конечно, в некоторых случаях ограничивающим фактором является нечто более практичное (например, производительность крупномасштабных приложений), но я думаю, что большинство из нас проводит бoльшую часть времени за написанием программ, где ограничивающий фактор — это способность создавать и управлять сложностью.
Аппаратное обеспечение тут заметно отличается, потому что есть силы, которые противостоят сложности. Каждый кусок железа, которое вы внедряете, стоит денег, так что вы хотите использовать минимум оборудования. Вдобавок, для большинства железа важна производительность (будь то абсолютная производительность или производительность на доллар, или на ватт, или на другой ресурс), а увеличение сложности замедляет работу железа, что ограничивает производительность. Сегодня вы можете купить серийный CPU за $300, который разгоняется до 5 ГГц. На 5 ГГц одна единица работы выполняется за одну пятую наносекунды. Для информации, свет проходит примерно 30 сантиметров за одну наносекунду. Ещё один сдерживающий фактор — то, что люди весьма расстраиваются, если CPU не работает идеально всё время. Хотя у процессоров есть баги, количество багов гораздо меньше, чем почти в любом программном обеспечении, то есть стандарты для их проверки/тестирования гораздо выше. Увеличение сложности затрудняет тестирование и проверку. Поскольку процессоры придерживаются более высокого стандарта точности, чем большинство программного обеспечения, то увеличение сложности добавляет слишком тяжёлое бремя тестирования/проверки для CPU. Таким образом, одинаковое усложнение намного дороже обходится для железа, чем для софта, даже без учёта других факторов, которые мы обсуждали.
Побочный эффект этих факторов, которые противостоят усложнению микросхемы состоит в том, что каждая «высокоуровневая» функция процессора общего назначения обычно достаточно концептуально проста, чтобы описать её в получасовой или часовой лекции. Процессоры проще, чем думают многие программисты! Кстати, я сказал «высокоуровневая», чтобы исключить всякие штуки вроде устройства транзисторов и схемотехники, для понимания которых нужен определённый низкоуровневый бэкграунд (физика или электроника).
Dreyk
хороший перевод, спасибо
claimc
В основном, каждое отдельное ветление часто срабатывают в одном направвлении, и очень редко в другом. Если каждый переход, еще на уровне компилятора, помечать в какую сторону он срабатывает чаще, то можно без сякого предсказания получать очень высокую вероятность правильного попадания.
Jamdaze
Компании столько тысяч человеко-лет инвестировали в патенты, а ты им предлогаеш всю эту лавочку похерить.
svr_91
В gcc на это есть __builtin_expect
qw1
Это не про предсказание переходов, а про группировку кода.
Чтобы редко используемые куски вынести подальше, чтобы они не перемешивались с «горячими» и не захламляли кеш L1.
qw1
Если «чаще» — это только 75%, то получаем проигрыш в сравнении с динамическими предикторами, которые дают 95%.
fukkit
Так себе гипотеза.
Igor_O
Почему вдруг? Гипотеза, что ветвления чаще всего срабатывают в одном направлении (назад, BTFNT), дает очень хороший прирост производительности, на фоне которого все остальные изыски — мелкие оптимизации.
fukkit
Так считали люди, для которых оптимизация на 30% — не мелкая.
Igor_O
Очевидным вариантом является, что при наличии пустых таблиц для оптимизации предсказаний — считать, что все переходы — назад. При накоплении некоторой достаточной статистики — плавно переключаться на более продвинутые методы. Что интересно, именно такой подход используется в Pentium и, видимо, более поздних процессорах…
Таким образом мы получаем начальный уровень успеха предсказания не 50:50, а 80:20. Что дает хорошую прибавку к пенсии, пока накапливается статистика для остальных предикторов.
DistortNeo
Почему же? Intel в старых процессорах её использовала. Переходы назад — likely, переходы вперёд — unlikely.
iehrlich
И отказалась от неё потому что… что?
DistortNeo
Видимо, Intel посчитала, что может лучше предсказывать переходы.
Igor_O
Потому что не отказалась?
Какая-та статическая модель предсказаний до сих пор используется в случаях, если таблицы для динамических предикторов пусты.
iehrlich
Не какая-то, а вполне конкретная — fallthrough likely. Собственно, это даже сложно назвать моделью, просто принимается самое простое решение из всех возможных. Однако это не полноценный статический предиктор, о котором мы говорили — выше по ветке речь шла про 2EH/3EH префиксы :)
4eyes
Скорее всего, этого можно достичь с PGO. Скорее всего, разработчики компиляторов в курсе, какие ветвления лучше предсказываются процессором, и строят код именно так, чтобы достичь минимума ошибок перехода для тестового случая.
DrZlodberg
Интересно, а как процессор контролирует изменение кода? Например при выгрузке/загрузке в своп. Или никак, просто некоторое время перезаполняет таблицу переходов с кучей промахов?
DistortNeo
При Page Fault происходит аппаратное прерывание, приводящее к сбросу конвейера.
Ничего страшного в этом нет: по сравнению с чтением из диска, разгон конвейера — мгновение.
DrZlodberg
А таблицы переходов являются частью конвейера или привязаны к оперативке? Или при каждом переключении задачи это всё сбрасываться в 0? Не очень понял этот момент. Или это какие-то внутренние регистры проца?
DistortNeo
Всё, что я могу сказать — никакой привязки к оперативке быть не должно: в инструкциях x86 просто не предусмотрено хранения соответстующего флага предпочтительной ветки, да и в случае ROM непонятно, как быть.
Скорее всего, в процессоре присутствует просто небольшая табличка на несколько значений (т.е. внутренние регистры процессора), содержащая в себе физический адрес инструкции перехода и статистические данные для неё.
А вообще, это нужно уже инженеров Intel спрашивать, потому что гадание на кофейной гуще получается.
RainM
Я боюсь, что даже те, кто знает ничего не скажут. Если интересно, есть хорошие мануалы от Agner Fog, которые лучше публичной документации некоторых компаний.
werevolff
Иными словами, хорошей практикой является упрощение ветвлений до такой степени, чтобы их ветки (по возможности) выполнялись всегда и без ошибок. Правильно?
DrZlodberg
GPU так и работают, поскольку условные переходы там весьма дороги (если получаются разные переходы в пределах одной группы потоков). Там куча встроенных инструкций (типа min, max, clamp), которые позволяют избавиться от очень большого количества условных переходов. А некоторые переходы бывает дешевле (и достаточно не сложно) свести к чуть более громоздким вычислениям, чем пихать лишний if. Например вместо
if( a < 10.) b = 20.; else b = 30.;
можно
b = 20. + step(a, 10.) * 10.;
valeriyk
обычно есть способ заинвалидировать таблицу переходов, чтобы избежать ложных срабатываний. Ядро операционки должно это делать при переключении контекста
DistortNeo
Не совсем так. В x86/amd64 архитектуре этого делать не нужно. А вот в ARM есть соответствующая команда.
MacIn
Думаю, здесь путаница с инвалидированием кеша.
DistortNeo
А зачем кэш инвалидировать? Внутренний кэш декодированных инструкций очистится сам. Кэш памяти же ещё пригодится, когда ОС вернёт управление процессу.
MacIn
Я лишь о том, что эта возможность есть.
marsianin
В случае x86 ни branch predictor ни кэш инвалид рожать не нужно. Что касается ARM, там инструкция branch predictor invalidate действительно присутствует, но с некоторых пор ничего не делает и оставлена в целях совместимости. Кэш же в ARM программист обязан инвалидировать в случае self-modified code, а именно, если код был перезаписан, программист обязан выполнить Data Cache Clean by VA at Point of Unification и Instruction Cache Invalidate by VA at Point of Unification. Связано это с тем, что в ARM кэш инструкций согласно архитектуре не является когерентным.
marsianin
Сорри, там не 'инвалид рожать', а инвалидировать. Это всё грёбаная автозамена в андроиде
Gryphon88
Можно ли перенести предсказание переходов с аппаратной части на программную (компилятор, стат.анализатор, правила написания кода) и будет ли это выгоднее с точки зрения скорости исполнения? Я имею в виду не взаимодействие с пользователем или оборудованием, а числомолотилки.
DistortNeo
В числомолотилках эта проблема не настолько актуальна.
Разворот циклов, условное выполнение операций (в SSE/AVX расширениях) — и ветвлений становится значительно меньше.
qw1
Возьмём, например, умножение матриц:
При n=3 динамический предиктор рано или поздно выявит паттерн, что во внутреннем цикле каждый 3-й переход не выполняется, а как это должен понять компилятор?
DistortNeo
На практике размер матриц, особенно небольших, редко является произвольным.
Поэтому n будет константой, и оптимизирующий компилятор просто развернёт цикл.
qw1
Это модельный пример. На практике может быть любой другой цикл обработки данных, который программист сделал параметризуемым, а параметр читается из конфига.
DistortNeo
Если производительность настолько важна, то в приложении можно сделать несколько веток: для n = 2, n = 3, n = 4 и произвольного n, где ошибки в предсказании ветвления для внутренних циклов уже не насколько критичны.
qw1
Вопрос выше был, что может сделать компилятор, а не программист вручную )))
RainM
Ну, теоретически, компилятор может сделать versioning. Т.е. несколько кусков кода под разные параметры.
qw1
Если только PGO.
Иначе откуда компилятор узнает, какой кусок кода наиболее критичен.
Gryphon88
Если n константное, то можно развернуть цикл. Если неконстантное, но вычислимое заранее, то тоже можно, если язык есть поддержка самомодифицирующегося кода. Можно попробовать векторизовать и раскидать на разные ядра, предвычислив i и/или j
PS Компиляторов не писал, процессоров не разрабатывал, так что все мои рассуждения сугубо теоретические
qw1
Цикл менее 1000 итераций, внутри которых пара арифметических действий, нет смысла раскидывать по ядрам. Больше потеряешь на создании потоков.
Насколько я видел (OpenMP, TPL и т.п.), везде программист даёт указания, что можно попробовать запараллелить. Поскольку программисты оптимизируют только горячие места, а не всё подряд, оптимизации всего остального лучше переложить на процессор.
Gryphon88
Подскажите, если не сложно, статью, где обобщенно (я понимаю, что серебряной пули нет) рекомендуется, начиная со скольки итераций/инструкций и какого объёма памяти раскидывание по ядрам или на GPU становится выгодным.
qw1
Ха, у процессора есть таймер с потактовой точностью замера (RDTSC).
Можете сами померять, сколько что стоит, и сделать соответствующие расчёты.
DistortNeo
Проверяется просто: создаёте поток в играете с ним в пинг-понг через средства синхронизации.
Вот одна из простейших реализаций parallel do: https://gist.github.com/e673/31b73495bfb83e818f226d2300568176
Варьируете N и смотрите, сколько итераций будет в зависимости от N.
Оптимальное значение N = числу логических ядер минус 1 (текущий поток тоже должен выполнять задачу).
Под Windows на 4-ядерном процессоре при N = 3 у меня получается 400к переключений в секунду (при N = 1, кстати, получается ~2 миллиона), т.е. ~10000 тактов уходит только на одну синхронизацию. Под Linux на 2-ядернике вдвое меньшей частоты при N = 1 — 80к переключений.
Чем на большее число потоков вы параллелите задачу, тем выше накладные расходы. Я даже боюсь представить, что будет твориться на Threadripper при 32 потоках, ведь блокировка шины при изменении атомарной переменной, за которую борется куча потоков — штука очень неприятная.
То есть, чтобы задачу вообще имело смысл параллелить, задача должна выполняться ощутимое время — несколько десятков микросекунд.
Кстати, низкая гранулярность тоже может оказаться не в фаворе, если будет страдать локальность доступа к памяти.
DistortNeo
Update: при использовании Windows-specific варианта при больших N (N = 8 и выше) накладные расходы становятся ниже, чем при кросс-платформенном варианте.
DrZlodberg
Кстати в командах x86 есть ведь и команды для цикла ( loop и иже с ними ). Нельзя ли их как-то оптимизировать и делать циклы по возможности на них. Правда для вложенных циклов необходимо, чтобы компилятор достаточно заранее восстанавливал CX, чтобы все ступени конвейера успели среагировать.
Gryphon88
Кстати, с VLIW-компиляторами как-то выкрутились, или по прежнему не получается выжать всё из архитектуры?
qw1
У меня ощущение, что они не нужны никому. Тот же Intel прекратил развитие Itanium.
Gryphon88
Есть ещё неподимый и легендарный Эльбрус, но документацию я одолеть не смог, она гораздо грустнее интеловской, и компилятор я не знаю, где скачать
valeriyk
В DSP активно используются. Вот, например, свежий 8-way VLIW для 5G модемов: www.ceva-dsp.com/product/ceva-xc12
valeriyk
Можно-то можно, но есть один нюанс. Дешифрация команды не происходит мгновенно, и сколько тактов пройдет, прежде чем процессор поймет, что он испольняет команду ветвления — одному Аллаху ведомо. А знать это процессору необходимо сразу, ибо следующую команду надо выбирать уже на следующем такте.
marsianin
Современные процессоры не читают по одной инструкции — они гребут код, что называется, «большой лопатой». В частности, мне приходилось видеть CPU, который читает по 2 кэшлайна кода за такт.
valeriyk
это никак не отменяет того, что я сказал
marsianin
Согласен. Только декодирование — процесс достаточно быстрый, и, соответственно, на out of order CPU о том, что инструкция является переходом, может быть известно сильно раньше, чем она реально начнёт исполняться. Что же касается двухстадийного конвейера, который нам упорно рисуют в статье, так в нём вообще можно обойтись без предсказания переходов — человечество изобрело такое понятие как delay slot.
DistortNeo
Довольно интересная ситуация, когда предсказание переходов можно пощупать на практике:
https://stackoverflow.com/questions/11227809/why-is-it-faster-to-process-a-sorted-array-than-an-unsorted-array
Задача: пробежаться по массиву байт и посчитать количество байт, больших 128.
Наблюдение: при случайном заполнении скорость работы алгоритма в 6 раз медленнее, чем при неслучайном (отсортированный массив).
homm
Я может быть глупость спрошу, но вот это предсказание нужно чтобы выбрать одну из двух ветвей выполнения. Если предсказание не сбылось, то результат работы с неверной веткой просто отбрасывается. Можно ли пойти сразу по двум веткам одновременно и отбросить результат работы той, что не сбылась?
DistortNeo
> Можно ли пойти сразу по двум веткам одновременно и отбросить результат работы той, что не сбылась?
Можно, но это дорого: в процессоре лишних вычислительных блоков под такое просто нет.
Возможно, это и используется, но очень ограничено: для выборки команд в кэш из обеих веток, например.
KursoRUS
По такому принципу кстати работают GPU. Но там это обусловлено тем, что блоки по 32 ядра (warpы в cuda) в один момент времени могут выполнять только одинаковые инструкции.
DrZlodberg
Не совсем по такому. Речь об одновременном выполнении обоих, а в GPU последовательное. Так что вместо выигрыша получаем наоборот проигрыш. Но там это частично решается кучей команд условных вычислений.
masterspline
Есть ли какой-то способ указать предсказателю переходов приоритетную ветку? Например, в этом коде я хочу, чтобы предсказатель всегда загружал в конвейер true ветку, потому что время, затрачиваемое на засыпание никого не интересует.
Насколько я понимаю, __builtin_expect лишь переупорядочивает код, но какая ветка будет загружена в конвейер процессора, решает предсказатель. Как бы ему объяснить, что в моем коде нужно всегда предсказывать определенную ветку?
qw1
В наборе x86/x64 нет такой инструкции.
С другой стороны, зачем? Если ветвление выполняется часто, оно будет запомнено и не вытеснится из буфера предсказаний. А если редко, потеря нескольких тактов не важна.
masterspline
В данном случае переход будет происходить в зависимости от данных, полученных из внешнего источника. Если они близки к случайным, то в половине случаев (!) предсказатель будет ошибаться и результат работы будет ужасный (выше есть пример, с проходом по сортированному и случайному массиву, который исправляется современным набором инструкций, но суть та же — если переходы рандомные, в половине случаев предсказатель ошибается). Вот поэтому и хочется иметь в дополнение к runtime предсказателю еще и статический (времени компиляции). Более того, в моем случае, нужно пометить ветку приоритетной, вне зависимости от частоты ее выполнения (может даже так сложиться, что именно вторая, малоприоритетная ветка станет выполняться чаще, что добавит тактов 10 на перезагрузку конвейера в случае, когда код должен быть максимально быстрым).
DistortNeo
Касательно процессоров Intel:
https://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-optimization-manual.pdf, раздел 3.4.1.
Про статическое предсказание (п. 3.4.1.3) вполне конкретно написано: The Intel Core microarchitecture does not use the static prediction heurist.
qw1
Что предлагается? Например, в цикле
Перед условным переходом вычислить i&1 и выполнить какую-то команду, которая подскажет по значению i, будет ли переход? Так такая команда — то же самое, что и ветвление, почему бы эти 2 команды не объединить в логику инструкции ветвления. На самом дела, нужно загрузить конвеер намного заранее до вычисления условия, а не прямо перед ним.
masterspline
> Статически — это значит один раз при компиляции, без возможности изменения.
Да, именно при компиляции я хочу указать, что ветка, в которой производится полезная работа должна всегда загружаться в конвейер, независимо от того, как часто условие вычисляется в true. Если в 90% будет промах (data == nullptr) и процессору понадобиться лишние 10 тактов, чтобы перезагрузить конвейер и пойти выполнять другую ветку (где go_to_sleep();), это нормально, для нее дополнительные накладные расходы не имеют значения. Нужно, чтобы при появлении данных (data != nullptr) их обработка всегда производилась максимально быстро, независимо от предыдущей истории переходов и без дополнительных накладных расходов.
> На самом дела, нужно загрузить конвеер намного заранее до вычисления условия, а не прямо перед ним.
Да, я хочу, чтобы __builtin_extect не только переупорядочивал код, но и генерировал такую инструкцию условного перехода (no_predict_jcc), которая отключает динамический предсказатель и грузит в конвейер инструкции, которые идут за ней. Но такой возможности на x64 нет.
sumanai
Архитектура х86 всё равно не подходит для задач реального времени, которые, видимо, вам нужно выполнять, раз у вас такие критические требования к предсказуемости скорости выполнения.
DrZlodberg
На самом деле не совсем. Например в циклах о том, будет ли переход часто известно ещё в начале цикла, что (теоретически) можно использовать. Кстати у x86 есть встроенная команда (loop и её вариации) которую можно было бы оптимизировать предсказанием, если бы были какие-то гарантии, что её рабочий регистр (CX для основного варианта) не используют подо что-то другое. Правда там ещё есть варианты, которые по флагам работаю, и тут уже ничего не предскажешь.
AndrewTishkin
А про 1 500 000 год до н.э. — это юмор?
AndrewTishkin
Допустим минус вопросу означает, что это не юмор. Тогда тем более не понимаю, к чему это было вынесено в заголовок и больше в тексте не упоминалось.
MacIn
Непонятна основа такого допущения.
mkostya
Мне кажется что лучше было бы использовать не «цель перехода», а «целевой адрес перехода». К слову «цель» напрашивается вопрос «зачем», но это совсем не то, что имелось в виду.
m1rko Автор
Хм, может быть.
vixs
Замените пожалуйста везде по тексту «подым(\S+)» на «подним$1». А то читать тяжело с самого начала.
vixs
Замените «в раках» на «в рамках».