
На сегодняшний день, джентльменский набор по ускорению сайта включает в себя всё от минификации и оптимизации файлов до кеширования, CDN, разделения кода и так называемого tree shaking. Но даже если вы не знакомы с этой терминологией, значительного ускорения можно добиться и парой ключевых слов с продуманной структурой кода.
В Firefox скоро появится новый веб стандарт
<link rel="preload">, который позволит загружать важные ресурсы быстрее. Его уже можно опробовать в версиях Firefox Nightly и Developer Edition, а пока это прекрасный повод вспомнить основы работы браузера и глубже понять о производительности при работе с DOM.Самое важное для веб разработчика — это понимание того, что происходит под капотом браузера. В статье, мы рассмотрим как браузер интерпретирует код страницы и как он помогает загружать их быстрее при помощи спекулятивного парсинга, а дальше разберёмся с
defer, async и как можно использовать новый стандарт preload.По кирпичикам
HTML описывает структуру страницы. Для того, чтобы браузер смог извлечь из HTML хоть какую то пользу, его надо конвертировать в понятный браузерам формат — Document Object Model или попросту DOM. У браузера есть специальная функция парсер, позволяющая конвертировать из одного формата в другой. HTML парсер конвертирует HTML в DOM.
Связи различных элементов в HTML определяются вложенностью тегов. В DOM, эти же связи образуют древовидную структуру данных. У каждого тега HTML в DOM есть своя вершина (вершина DOM).
Шаг за шагом браузер строит DOM. Как только первые строки кода становятся доступными, браузер начинает парсить HTML, добавляя вершины в дерево.

У DOM две роли: объектная репрезентация HTML документа и в то же время DOM служит интерфейсом, связывая страницу с внешним миром, например с JavaScript. Если, например, вызвать
document.getElementById() то функция вернёт вершину DOM. Для манипуляции с вершиной и тем как её видит пользователь у вершины есть множество функций.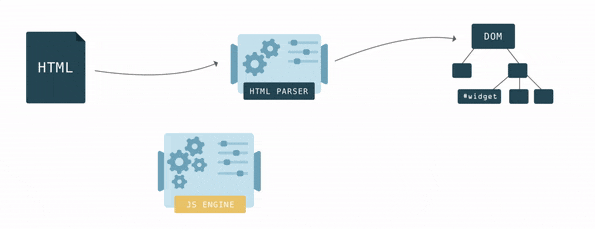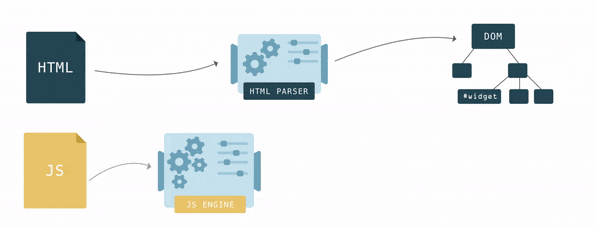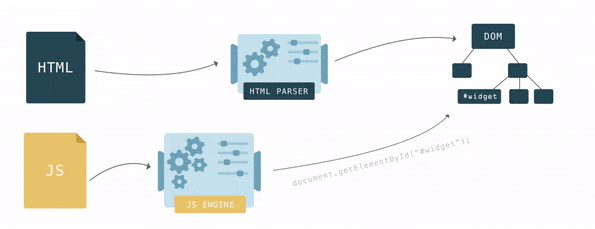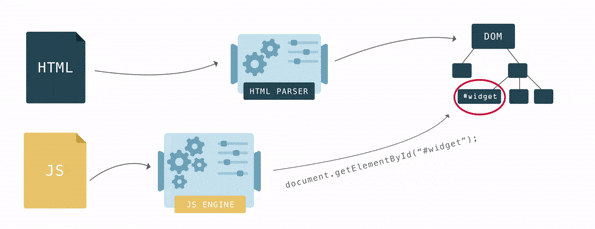
CSS стили на странице отображаются в модель CSSOM — CSS Object Model. Очень похож на DOM, но для CSS, а не HTML. В отличии от DOM, CSSOM нельзя построить пошагово, т.к. стили в CSS могут переопределять друг друга. Браузеру приходится значительно потрудится чтобы применить CSS к DOM.
История тега <script>
Если при постройке DOM браузер встречает в HTML коде тег
<script>...</script>, то он должен незамедлительно его выполнить, при этом скачав, если он из внешнего источника. Раньше, чтобы запустить скрипт, нужно было приостановить парсинг и продолжить его только после выполнения скрипта JavaScript’ом.
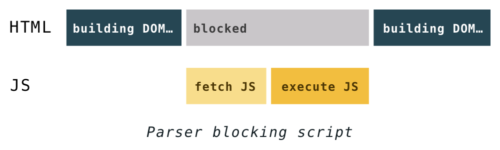
Почему нужно останавливать парсинг? Скрипты могут изменять и HTML, и DOM. Структуру DOM можно изменить при помощи функции
document.createElement(). А печально известная функция document.write() может менять и HTML. Дурную славу эта функция заработала тем, что она может изменить HTML, усложняя последующий парсинг. Например, с помощью этой функции можно вставить открывающий тег комментария, тем самым ломая HTML.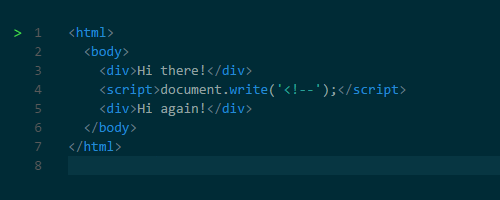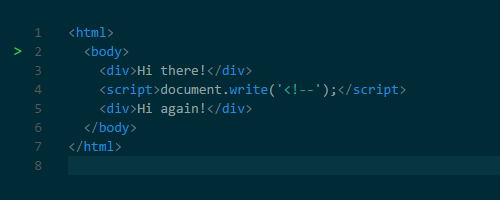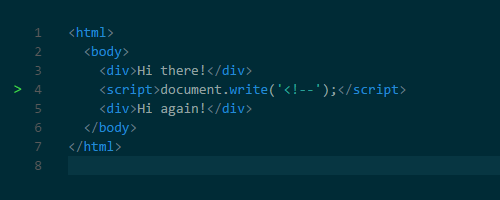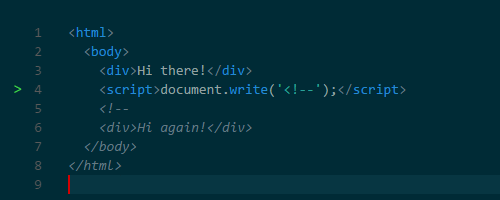
Скрипты также могут отправлять запросы в DOM и если это происходит во время постройки DOM, результат может оказаться непредсказуемым.
document.write() — функция-наследие, которая может сломать страницу самым неожиданным образом, поэтому лучше её не использовать, даже если браузеры будут её поддерживать. По этим причинам в браузерах были разработаны хитрые методы обхода проблем с производительностью, вызванных блокированием скриптов, о них чуть ниже. А что с CSS?
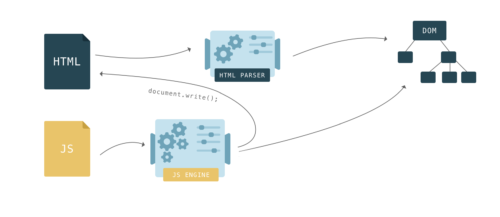
JavaScript приостанавливает парсинг HTML, т.к. скрипты могут менять страницу. CSS не может изменить страницу, поэтому причин останавливать процесс парсинга у него нет, так?
Но что если скрипт запросит информацию о стиле элемента, который ещё не парсился? Браузер не имеет ни малейшего понятия, что будет выполняться в скрипте — в нём может оказаться запрос вершине DOM о свойстве
background-color, зависящего от таблицы стилей, либо же может находиться прямое обращение к CSSOM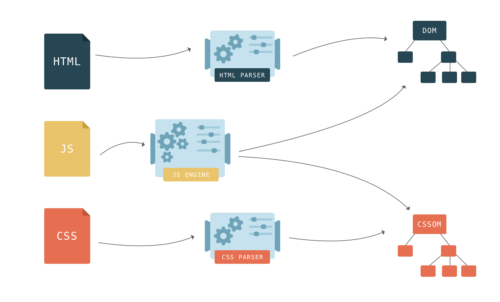
Из-за этого CSS может блокировать парсинг в зависимости от порядка подключения скриптов и стилей на странице. Если внешние таблицы стилей находятся до скриптов, то создание DOM и CSSOM может мешать друг другу. Когда парсер доходит до скрипта, постройка DOM не может продолжаться до тех пор, пока JavaScript не выполнит скрипт, а JavaScript в свою очередь не может быть запущен, пока CSS не скачается, распарится и CSSOM станет доступным.
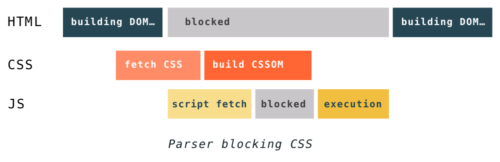
Ещё один момент, о котором не стоит забывать. Даже если CSS не будет блокировать постройку DOM, он блокирует процесс рендеринга. Браузер ничего не покажет пока у него не будет готовых DOM и CSSOM. Это потому, что зачастую страницы без CSS непригодны для использования. Если браузер покажет кривую страницу без CSS, а потом через мгновение полную стилизованную страницу, то у пользователя возникнет когнитивный диссонанс.
У этого явления есть название — Проблеск Неоформленного Содержания, сокращённо ПнОС [Flash of Unstyled Content или FOUC]
Во избежание таких проблем нужно как можно быстрее предоставить CSS. Помните золотое правило «стили сверху, скрипты снизу»? Теперь вы в курсе почему это важно!
Назад в будущее. Спекулятивный парсинг
Приостанавливание парсера при каждой встрече со скриптом будет означать задержку в обработке остальных данных, подгружаемых в HTML.
Раньше, если взять несколько скриптов и изображений, подгрузив их, например, так:
<script src="slider.js"></script>
<script src="animate.js"></script>
<script src="cookie.js"></script>
<img src="slide1.png">
<img src="slide2.png">Процесс парсинга выглядел бы как показано ниже:
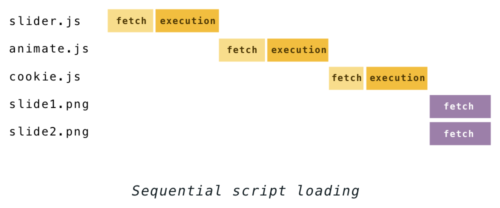
Такое поведение изменилось в 2008 годах, когда IE представил так называемый «опережающий загрузчик» [the lookahead downloader]. С помощью него файлы подгружались в фоновом режиме прямо во время выполнения скриптов. Вскоре этот метод переняли и Firefox, Chrome с Safari, используя его под разными названиями, равно как и большинство современных браузеров. У Chrome с Safari это «предварительный анализ» [the preload scanner], а у Firefox — спекулятивный парсер. Идея вот в чём, с учётом того, что постройка DOM во время выполнения скриптов весьма рискованна, можно всё ещё парсить HTML чтобы посмотреть какие ресурсы должны быть подгружены. Затем обнаруженные файлы добавляются в очередь на загрузку и скачиваются параллельно в фоновом режиме. И к моменту завершения скрипта, необходимые файлы могут быть уже готовы к использованию.
Таким образом с применением такого метода, процесс парсинга выше, выглядел бы так:
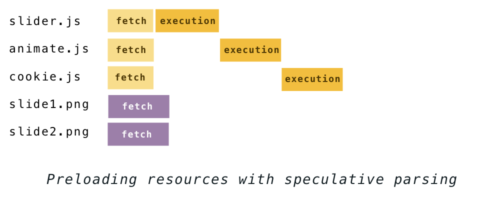
Такой процесс называется «спекулятивным», иногда «рискованным», потому что HTML всё ещё может меняться во время выполнения скрипта (напомню про
document.write), что может привести к работе проделанной впустую. Но несмотря что такой сценарий возможен, он крайне редок, именно поэтому спекулятивный парсинг даёт огромный прирост производительности.В то время как другие браузеры загружают таким способом только привязанные файлы, парсер Firefox ещё и продолжает строить DOM во время выполнения скриптов. Плюс этого в том что если спекуляция прошла, то часть работы в постройке DOM уже будет проделана. А вот в случае неудачной спекуляции работы будет затрачено больше.
(Пред)загрузка
При использовании такой техники загрузки можно значительно повысить скорость загрузки и никаких специальных навыков для этого не понадобится. Но если вы веб разработчик, то знание механизма спекулятивного парсинга поможет использовать его по максимуму.
Различные браузеры предзагружают различные типы ресурсов. Все основные браузеры обязательно предзагружают следующие:
- скрипты
- внешние CSS
- и изображения в теге
<img>
Firefox так же загружает атрибут
poster у видео элементов, в то время как Chrome и Safari загружают правила @import из inlined стилей.Количество файлов, которые могут быть загружены параллельно, ограничено и варьируется от браузера к браузеру. Это ещё зависит от множество факторов, таких как скачиваются ли файлы из одного сервера или из разных, используется протокол HTTP/1.1 или HTTP/2. Чтобы отрендерить страницу как можно быстрее, браузеры используют сложные алгоритмы и скачивают ресурсы с разными приоритетами, зависящие от типа ресурса, местоположения на странице и состояния самого процесса рендеринга.
При спекулятивном парсинге, браузер не запускает inline JavaScript блоки. Это означает, что если подгружать файлы в скриптах, то они наверняка окажутся последними в очереди на загрузку.
var script = document.createElement('script');
script.src = "//somehost.com/widget.js";
document.getElementsByTagName('head')[0].appendChild(script);Поэтому это очень важно упростить задачу браузера при загрузке важных ресурсов. Можно, например, вставить их в HTML теги или перенести скрипт загрузки в inline и как можно выше в коде страницы. Хотя иногда требуется наоборот, загрузить файлы как можно позже, т.к. они не столь важные. В таком случае, чтобы спрятать ресурс от спекулятивного парсера, его можно подключить как можно позже на странице через JavaScript. Чтобы узнать больше о том как оптимизировать страницу для спекулятивного парсера, можно пройти по ссылке MDN руководства [на русском].
defer и async
Но скрипты выполняющиеся последовательно остаются проблемой. И не все скрипты действительно важны для пользователя, такие как скприпты аналитики, например. Идеи? Можно загружать их асинхронно.
Атрибуты defer и async были придуманы специально для этого, чтобы дать возможность разработчикам указать какие скрипты можно загружать асинхронно.
Оба этих атрибута подскажут браузеру, что он может продолжить парсить HTML и в тоже время загрузить эти скрипты в фоне. При таком раскладе, скрипты не будут блокировать постройку DOM и рендеринг, в результате чего, пользователь увидит страницу ещё до того, как все скрипты загрузятся.
Разница между
defer и async в том, что они начинают выполнять скрипты в разный момент времени. defer появился раньше async. Скрипты с этим атрибутом выполняются после того, как парсинг полностью завершён, но перед событием DOMContentLoaded. Они гарантировано будут запущены в порядке, в котором они находятся на странице и не будут блокировать парсер. 
Скрипты с
async же будут выполнены при первой же возможности после того как будут загружены и перед событием load у window. Это значит, что возможно (и скорее всего наверняка) скрипты с async будут выполнены не в порядке их появления в HTML. Это так же значит, что они могут блокировать постройку DOM. Где бы они не были указаны, скрипты с
async загружаются с низким приоритетом, зачастую после всех остальных скриптов, без блокирования постройки DOM. Но если скрипт с async загрузится быстрее, то его выполнение может заблокировать постройку DOM и все остальные скрипты, которым только предстоит загрузиться.
Замечание: атрибуты
async и defer работают только для внешних скриптов. Без параметра src они будут проигнорированы.preload
async и defer прекрасно подходят если вы не паритесь о некоторых скриптах, но что делать с ресурсами на странице, которые важны для пользователя? Спекулятивные парсеры полезны, но подходят только для горстки типов ресурсов и действуют по своей заложенной логике. В целом, нужно загружать CSS в первую очередь, потому что он блокирует рендеринг, последовательные скрипты должны всегда иметь приоритет выше чем асинхронные, видимые изображения должны быть доступны скорее и есть ещё шрифты, видео, SVG… короче говоря, всё сложно. Как автор, вам лучше знать какие именно ресурсы важны для рендеринга страницы. Некоторые из них часто погребенны в CSS или скриптах и браузеру придётся пройти сквозь дебри пока он хотя бы до них доберётся. Для таких важных ресурсов теперь можно использовать
<link rel="preload"> чтобы подсказать браузеру загрузить файл как можно скорее. Все что требуется написать это:
<link rel="preload" href="very_important.js" as="script">Список того, что можно загрузить весьма велик и атрибут
as скажет браузеру, какой именно контент он загружает. Возможные значения этого отрибута:- script
- style
- image
- font
- audio
- video
Более подробно можно узнать из MDN [на английском].
Шрифты, пожалуй, самый важный элемент для загрузки, который спрятан в CSS. Шрифты необходимы для рендеринга текста на странице, но они не будут загружены пока браузер не удостоверится что именно они будут использованы. А эта проверка происходит только после парсинга и применения CSS и когда стили уже применены к вершинам DOM. Это происходит достаточно поздно в процессе загрузки страницы и как правило приводит к неоправданной задержке рендеринга текста. Этого можно избежать, использовав атрибут
preload при загрузке шрифтов. Одна деталь на которую стоит обратить внимание при предзагрузке шрифтов, это то, что нужно устанавливать атрибут crossorigin, даже если шрифт находится на том же домене. <link rel="preload" href="font.woff" as="font" crossorigin>В данное время возможности предзагрузки ограничены и браузеры только начинают применять этот метод, но за прогрессом можно следить тут.
Заключение
Браузеры это сложные существа, которые эволюционируют с 90-х. Мы разобрали некоторые причуды из прошлого равно как и новейшие стандарты в веб разработке. Эти рекомендации помогут сделать сайты приятнее для пользователя.
Если вы хотите узнать больше о работе браузеров, то ниже пара статей, которые могут быть вам интересны:
> Quantum Up Close: What is a browser engine?
> Inside a super fast CSS engine: Quantum CSS (aka Stylo) (на хабре)
Комментарии (5)


Jackley
28.09.2017 12:13Спасибо за статью. Со скоростью загрузки страниц многое прояснилось. А можете рассказать в каком месте этого действа браузеру нужна гора памяти для отрисовки?
ArjLover
preload -это что-то новенькое? Уже пару лет на нем все ездим…
ghost404
Автор говорит что
preloadещё не работает в Firefox и судя по данным, Firefox не один отстающее звено.PaulMaly
Все это кто?