Естественно, что растет число пользователей, желающих работать с бэкапами виртуальных и физических машин, используя единую консоль. Поэтому наши инженеры решили реализовать такую возможность в Veeam Backup & Replication, не откладывая в долгий ящик, а я вам сегодня про нее расскажу. За подробностями добро пожаловать под кат.

Начну с внешнего вида. Поскольку Veeam Backup & Replication теперь будет работать и с виртуальными, и с физическими машинами, то решено было вынести ранее живший в представлении VMs раздел Inventory в отдельное представление. В нем будут отображаться все машины, защищаемые Veeam, будь то Veeam Backup & Replication или любой из Veeam Agents.
Логические контейнеры Protection Groups
Для того, чтобы обеспечить возможность управления и настройки защиты через консоль, нужно создать соответствующие логические контейнеры – так называемые Protection Groups (защитные группы) – а затем уже туда будут помещаться нужные объекты.
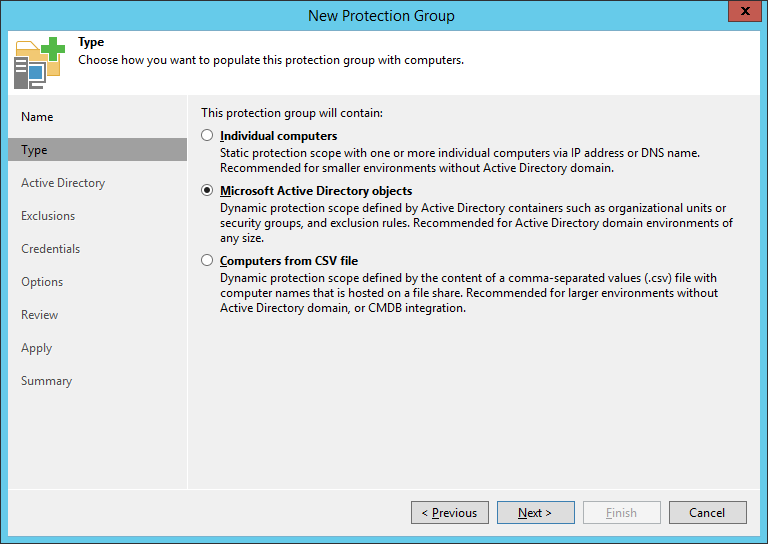
Прежде всего, разбираемся с типом объектов, для которых будем настраивать защиту. На шаге Type мастера создания защитной группы есть несколько вариантов:
- Если хотим помещать в контейнер (группу) отдельно взятые компьютеры – назначаем группе тип Individual computers. Получим статическое объединение (изменения не подхватываются «на лету»), в который компьютеры можно добавить, указав их IP адрес или доменное имя. Такие группы рекомендуется использовать для небольших инфраструктур, где не настроен домен Active Directory.
- Если хотим иметь динамическую группу, куда будем помещать объекты Microsoft Active Directory – назначаем группе тип Microsoft Active Directory objects. Это контейнер динамического типа, куда объекты будут попадать автоматически после включения их, например, в Active Directory OU или security group. Рекомендуется использовать такие группы для инфраструктур любого размера, работающих с Active Directory.
- Если у вас немаленькая инфраструктура, но Active Directory вы не используете, либо у вас настроена интеграция с CMDB, то рекомендуется использовать защитные группы, пополняемые через список компьютеров, импортируемый из файла CSV – Computers from CSV file.
Поскольку в организациях чаще всего будут, видимо, использоваться группы для объектов Active Directory, остановимся поподробнее сначала на них.
Если был выбран тип защитной группы Microsoft Active Directory objects, то сервер Veeam Backup & Replication автоматически запросит информацию о структуре Active Directory своего домашнего домена и отобразит ее.
Примечание: Можно поменять настройку по умолчанию и отображать в качестве области выбора, например, поддомен или вообще другой домен. Также можно исключать из области выбора отдельные объекты – например, можно исключить учетки компьютеров, которые были выключены в течение последнего месяца, а можно исключить и целый OU.
Итак, мы указали, из какой области выбора будут наши объекты AD. На эти объекты Veeam установит исполняемый модуль Veeam Agent, который, собственно, будет выполнять резервное копирование. Разумеется, для установки агентов у учетной записи Veeam Backup Service должны быть соответствующие права.
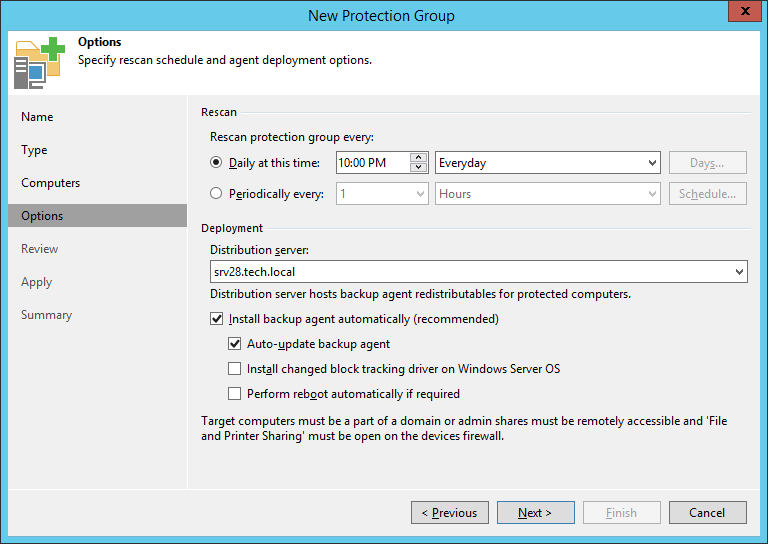
Затем нужно указать, с какой периодичностью мы хотим сканировать нашу область выбора – эта сущность динамическая, то есть как только при очередном скане будут обнаружены новые объекты, то они тут же будут автоматически включаться в свою защитную группу.
В опциях сканирования (шаг Options) для группы любого типа можно выбрать, хотим ли мы, чтобы на вновь обнаруженные объекты автоматически ставился Veeam Agent – если хотим, то зачекиваем галку Install backup agent automatically (recommended):
Резервное копирование
После того, как мы должным образом сгруппировали наши компьютеры, настраиваем для них резервное копирование с использованием агента. Для этого выбираем нужную защитную группу и для нее создаем новое задание (или включаем ее в уже имеющееся).
Тип задания
В зависимости от того, что за машины мы хотим процессить, выбираем тип задания. Это может быть:
- Рабочая станица – тогда выбираем опцию Workstation
- Сервер – выбираем, само собой, Server
- И – по многочисленным просьбам пользовательской аудитории! — Failover Cluster

Режим управления заданием
На этом же шаге необходимо определиться, в каком режиме будет работать агент, ответственный за резервное копирование. В зависимости от того, какой был выбран тип защищаемой машины, будут доступны либо оба, либо один из двух вариантов:
- Централизованный контроль со стороны сервера Veeam backup (Managed by backup server).
Если был выбран этот режим, то на машины будет установлена облегченная версия Veeam Agent – без GUI, без локальной базы данных конфигурации. Все настройки необходимо будет делать на сервере Veeam backup server.
В таком варианте сервер контролирует всю работу, включая удаленный запуск и остановку задания, просмотр статистики и т.д.
Такой режим удобен для бэкапа машин, которые всегда подключены к инфраструктуре. Он всегда будет назначаться для бэкапа кластеров, а также будет вариантом выбора для бэкапа серверов. - Контроль за заданием выполняется самим агентом (Managed by agent).
Если вы выбираете этот режим, то на машины будет установлена полная версия Veeam Agent.
Все настройки расписания и управление заданием выполняются на стороне самого агента.
Такой режим удобен для бэкапа машин, для которых не всегда можно обеспечить постоянное подключение к инфраструктуре по хорошему каналу, но для которых, тем не менее, необходимо выполнять требования по RPO. Он всегда будет назначаться для бэкапа рабочих станций, а также будет вариантом выбора для бэкапа серверов.
Создание резервной копии с учетом работающих приложений
На шаге Guest Processing можно указать, что создание резервной копии должно выполняться с учетом работающих на машине приложений (application consistency). Поддерживаются следующие приложения:
- SQL Server, в том числе с поддержкой Always-On Groups,
- Oracle
- Exchange, в том числе с поддержкой DAG
- Active Directory
- SharePoint
Для восстановления объектов этих приложений из бэкапа можно будет задействовать инструменты из линейки Veeam Explorers.
Для баз данных SQL и Oracle будет поддержан бэкап журналов транзакций — для возможности восстановления на выбранный момент времени.
Приглашение на VeeamON Forum Russia 2017
Да-да, мы и в этом году приглашаем наших читателей и всех интересующихся к участию в форуме VeeamON Forum 2017 Russia, посвященном вопросам доступности данных. Мероприятие пройдет 26 октября, место проведения – Лотте Отель Москва.
В программе форума:
- рассказы экспертов Veeam о лучших практиках, анонсы новых версий наших продуктов
- выступления представителей компаний-производителей СХД (NEC, Quantum, Infinidat) с рассказом об интегрированных решениях
- сессии вопросов-ответов
- розыгрыши призов
- 4 потока лабораторных работ, которые будут идти параллельно с основной сессией
Кроме того, для всех, кто знает и умеет работать с Veeam Availability Suite 9.5, пройдут увлекательные соревнования LabWarz. Приз за победу – сертификат стоимостью 30 000 руб. на прохождение любого учебного курса в любом учебном центре, сертифицированном Veeam.
Участие в VeeamON Forum Russia 2017 бесплатное, нужно лишь предварительно зарегистрироваться. Рекомендую не откладывать регистрацию на последний момент, а уж тем более на день мероприятия, особенно желающим поучаствовать в лабораторных работах и в соревнованиях.
На сайте конференции можно также найти подробное описание программы и материалы с VeeamON Forum Russia 2016. Отчет о форуме-2015 был опубликован в нашем блоге на Хабре.
Дополнительные ссылки:
Комментарии (20)

puma34
10.10.2017 17:53+1Вы починили то что на windows server 2016 версия powershell новее и из-за этого при попытке снять снапшот базы была ошибка?

polarowl Автор
11.10.2017 14:12Насколько я понимаю, речь о процессинге гостевой ОС для ВМ на HV 2016?
Пожалуйста, можно немного подробнее о вашей ситуации?
Если был открыт кейс, можете прислать его номер в личном сообщении? Спасибо.

KorP
11.10.2017 09:18+1На этом же шаге необходимо определиться, в каком режиме будет работать агент, ответственный за резервное копирование.
А какой режим будет включен на уже подключенных серверах с агентами после обновления сервера до Update 3? А то у меня возникли сложности в своё время с удалением агента на CentOS 7 — процесс просто зависал и агент не удалялся, помнится даже кейс открывал, но саппорт мне так помочь и не смог.
Там в 10-ке не планируется кластеризация серверов Veeam то?strelec7
12.10.2017 13:52+1Зачем кластер? Отказоустойчивость можно организовать другими методами.
Лучше бы сделали серверную часть на линуксе или хотя-бы проксю на линуксе.KorP
12.10.2017 13:53Отказоустойчивость можно организовать другими методами.
С удовольствием послушаю ваш рассказ
mikkisse
12.10.2017 13:55+1Конечно же fault tolerance для Бэкап сервера. А вот серверная часть\прокси на линуксе — дело хорошее.

navion
12.10.2017 13:55Как сделано в TSM: репликация на второй сервер и переключение клиентов на него при недоступности основного.
А датамуверы на линуксе действительно нужны (кластер AHV может быть вообще без лицензий на винду) и вряд ли портирование на .NET Core является невыполнимой задачей.KorP
12.10.2017 13:57А зачем мне репликация?
Или вот пример — хочу отказоустойчивый прокси физический, покупаю 2 сервака, подключаю к СХД и...? :)navion
12.10.2017 13:59Для DR при потере основного ЦОДа.
KorP
12.10.2017 14:04У меня продуктивная и резервная схд и так в разных цодах. Я привёл пример, который меня очень интересует :)
navion
12.10.2017 19:08КМК, бекап всё равно нужен на случай, если навернутся снепшоты СХД или данные в них и погибнет основной ЦОД.
А вот зачем нужен HA-кластер для сервера бекапа представить не могу. TSM так умеет, но даже на продвинутом курсе про это не рассказывают.KorP
12.10.2017 21:41У меня складывается впечатление, что я хочу чего то странного :)
Вот есть 2 цода, в каждом свой кластер vmware, продуктивная схд в одном цоде и схд для рк во втором (с нормальными дисками, которые выдержат запуск 85% вм с продуктива). Я делаю бекап вимом из цода в цод, те не реплика снепшотов, а именно бекап (каналы позволяют). И вот у меня виртуальный сервер вима (да хоть пусть и физический) в основном цоде. Если цод основной ложиться, у меня есть бекапы, но нет сервера, который их восстановит. В итоге был поднят кластер MSSQL, растянутый на 2 цода для вима, один виртуальный сервер на основной площадке и резервный на второй в выключенном состоянии :) Но это какие то грабли :) Другой схемы от ТП я так добиться вразумительно и не смог (как и отказоустойчивости прокси :)) Или я хочу чего то слишком странного? :)mikkisse
13.10.2017 05:05Коллега. Перенесите серевер BR на ваш DR Site. А в основном цод разместите прокси. При таком раскладе, при потере основного цод, у вас всегда будет готова система резервного копирования на удаленной площадке.
strelec7
13.10.2017 08:55В такой ситуации достаточно иметь во втором ЦОДе второй сервер, на котором будет смонтирован тот же репозиторий. Если навернется перый ЦОД или первый бэкап-сервер, то что-бы экстренно восстановить что-то достаточно импортировать .vbk на втором сервере и восстановить данные. Для дальнейшей работы (пока не будет восстановлен первый) на втором сервере можно накатить бэкап конфигурации VeeamConfigBackup.
Мне вот линуксовый сервер/прокси интересен исходя из экономии Win-лицензии и т.к. у нас на хостах имеются свободные* локальные сторажи, то на них созданы ВМ с линуксом, которые через iSCSI отдают эти свободные* пространства бэкап-серверу под бэкап-копи-репозитории. Так вот неплохо было бы этим ВМ дать еще роль прокси.
gotch
По многочисленным просьбам? В вашем агенте просто нет базовой функциональности, которая в других продуктах есть десятилетиями.
Как без этого вы представляете резервное копирование файлового кластера? Наугад? Или надо чтобы виртуальные сервисы обязательно съехали на предпочтительные узлы?
Так же вы примерно бекапите Exchange — с нулевым интеллектом. Нельзя просто взять и указать базу в DAG. Надо создать задание на конкретном сервере на уровне тома. Вариант, что в DAG на одном из узлов может и не быть некой базы, никому в голову не приходил? А если на томе вдруг RDB лежит, то ее не надо бекапить? А если логи и база на разных томах, то надо не забыть галочки проставить. Или то, что надо бекапить пассивные копии, выбрав из них ту, которая не lagged?
До полноценного бекапа серверной физики по состоянию на Update2 вам еще ой как далеко.