Я расскажу, как мы создаём визуализации и каких придерживаемся принципов: в общем и на примере каждой визуализации. Все примеры включают ссылки на интерактивные прототипы, где можно самостоятельно «пощупать» данные и сделать собственные выводы.
Общие принципы
Мы начинаем работу над визуализацией с выделения «кирпичика», минимальной неделимой единицы информации, затем строим из кирпичиков наглядную макрокартину и усиливаем результат интерактивностью.
Кирпичик — это атом данных, чтобы выделить его необходимо изучить данные под микроскопом. Тривиальный пример кирпичика — тысяча погибших во впечатляющей визуализации потерь Второй мировой войны (автор: Neil Halloran). После выделения кирпичика мы выбираем наглядный способ визуализации его свойств таким образом, чтобы кирпичики отличались между собой (сравнимость) и визуально «складывались» друг с другом (аддитивность). В упомянутой визуализации кирпичик обозначается человечком с ружьём или без, национальность кодируется цветом. Немецкого солдата легко отличить от советского мирного жителя:

А складывая фигурки получаем суммарные потери — в конкретной битве, или определённой страны, или всех стран за время войны:

Качественная визуализация отражает структуру данных. Мы группируем, сортируем и складываем кирпичики с учётом особенностей данных, выводим на первый план важные измерения. Благодаря сравнимости и аддитивности кирпичиков, на макроуровне проявляются закономерности и аномалии, присущие данным в целом.
Секрет мощной визуализации — интерактивность. Подсказки при наведении и всплывающие блоки обогащают визуализацию дополнительной информацией. Фильтры, слайдеры, выпадающие списки управляют выборкой и позволяют сравнивать разные срезы. Срезы строятся из исходных кирпичиков и обладают той же достоверностью и полнотой, что и макрокартина в целом.
Обратимся к нашим экспериментам.
Танки
Задача: сравнить характеристики танков в игре World of Tanks. Источник данных: tanks-vs.com
В качестве кирпичика мы выбрали танк, самый наглядный и естественный способ визуализации — изображение танка (см. пример с автомобилями). Главные характеристики танков — это мобильность, «атака» и «защита». Покажем крепость разных участков брони цветом, так сразу виден и уровень защиты танка в целом, и слабые места. Скорость и атаку проявим на двумерном графике:
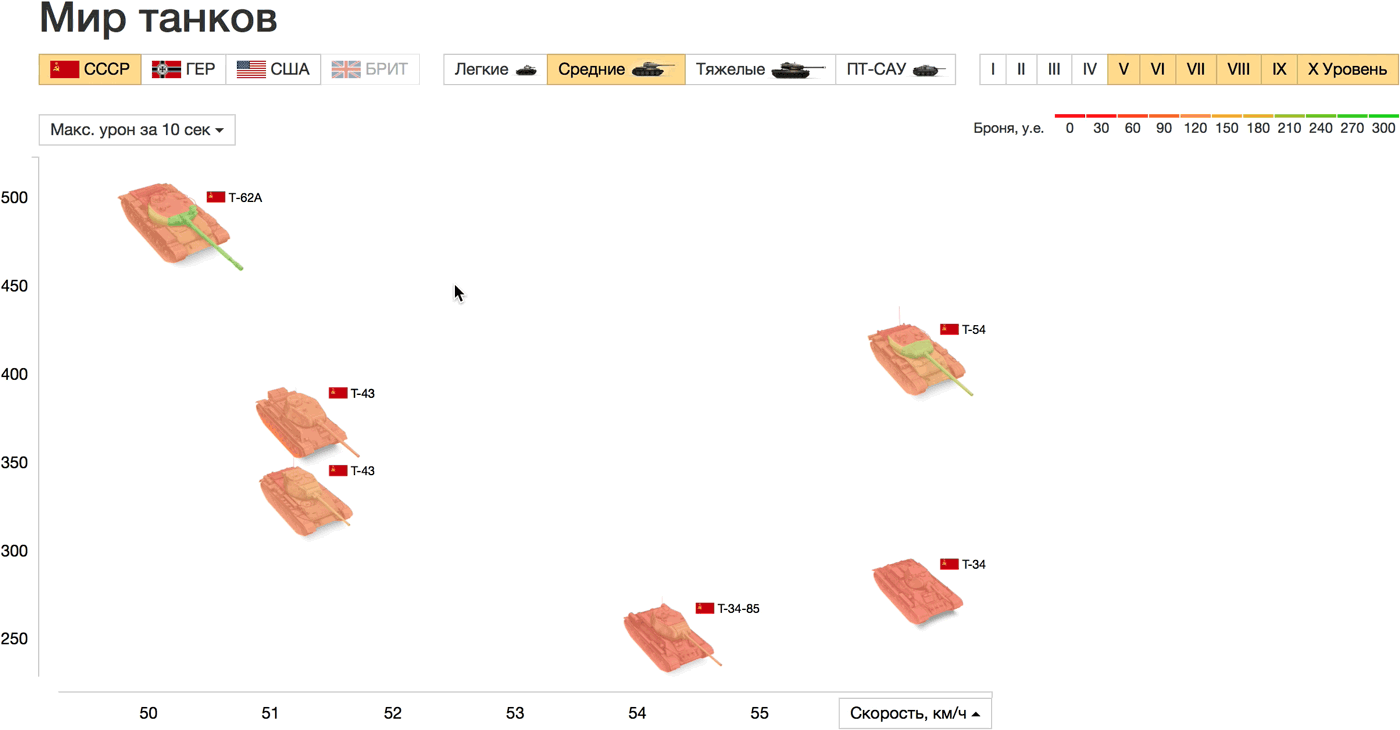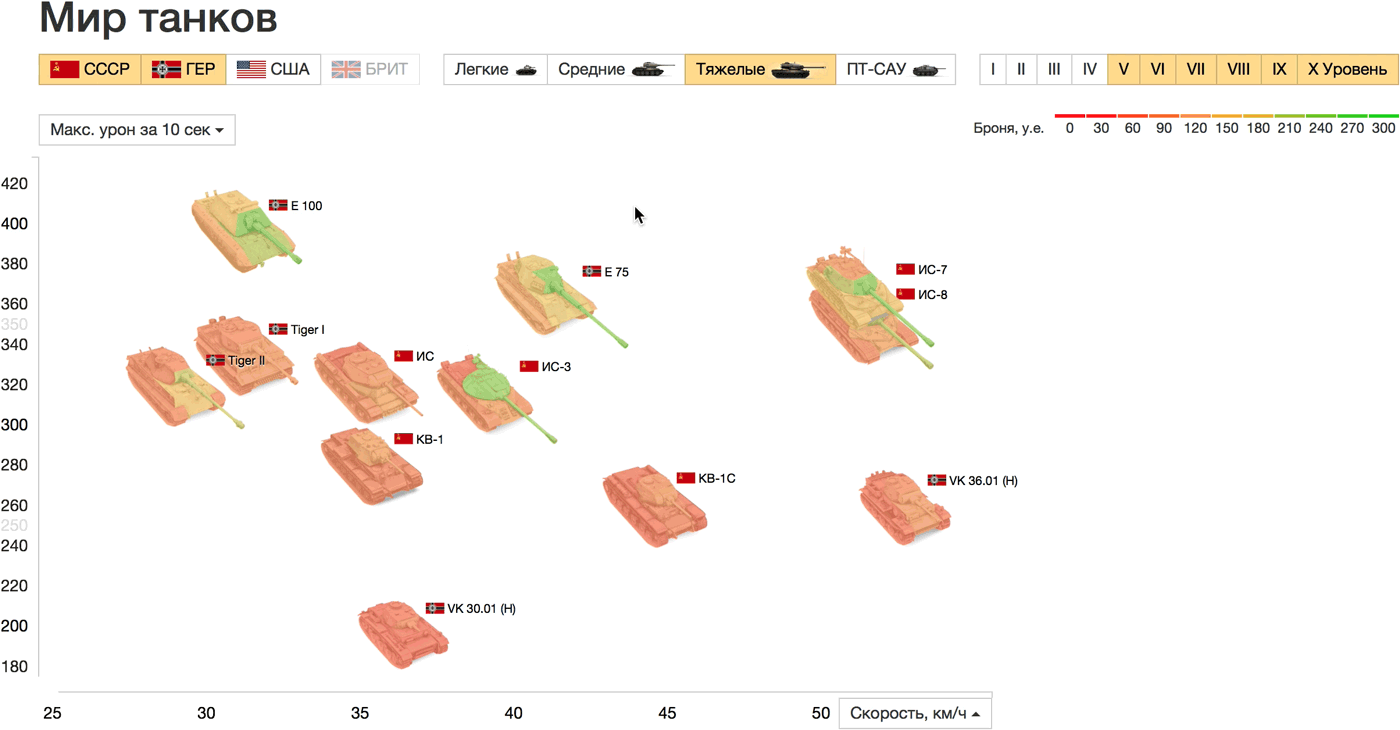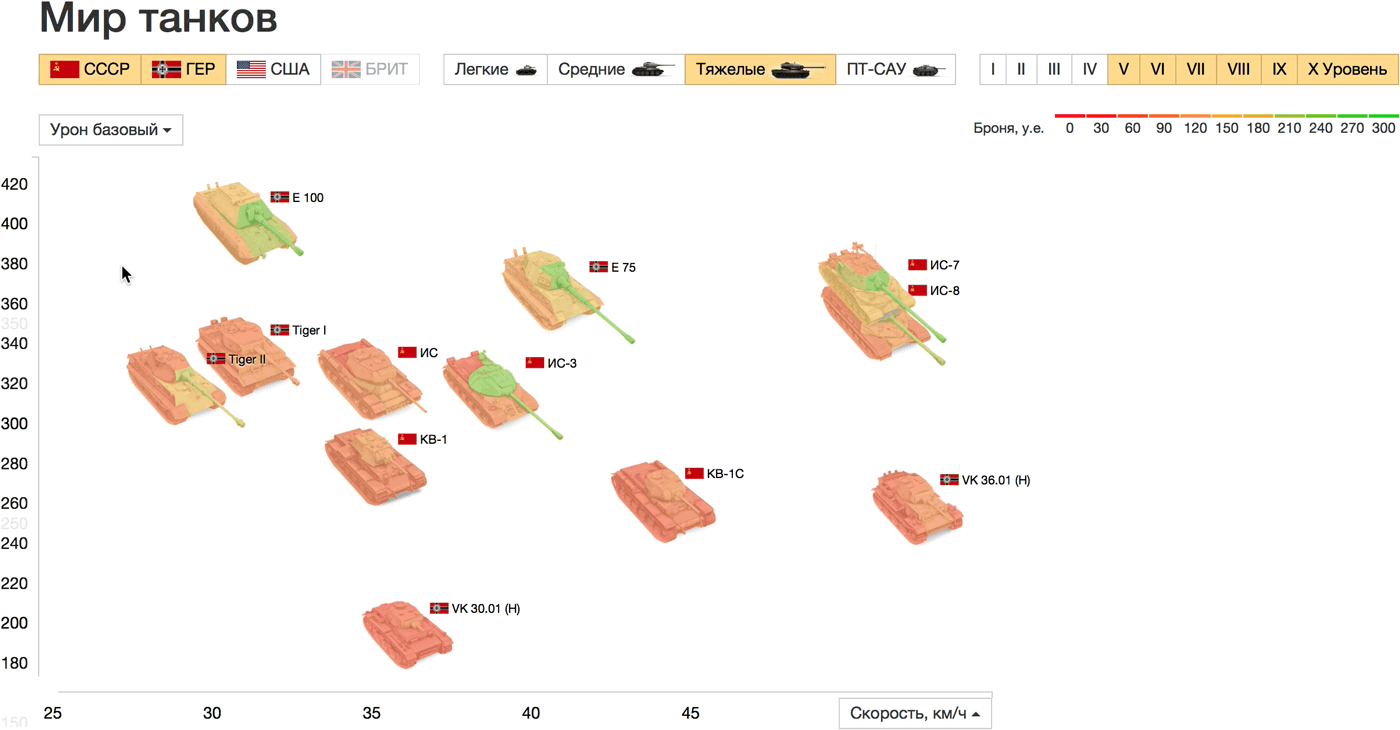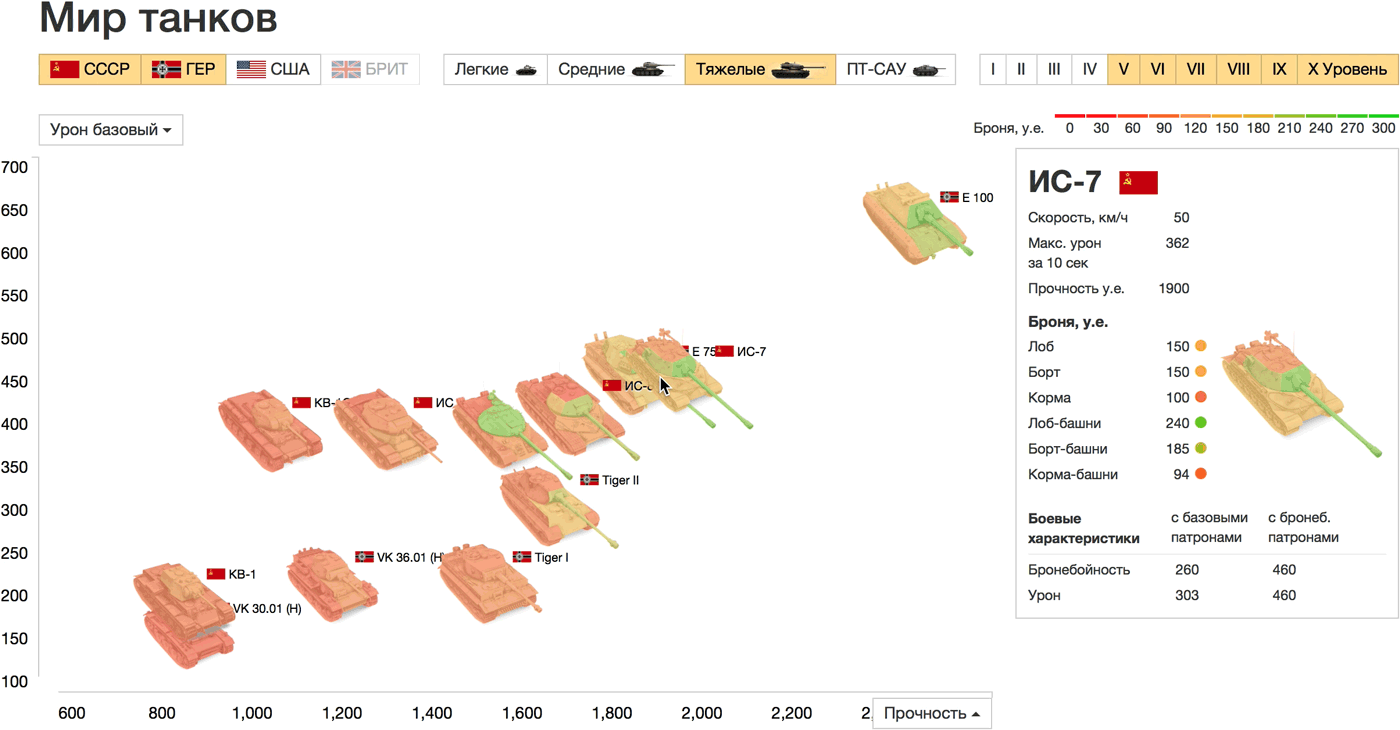
Живой прототип: http://tanks.datalaboratory.ru/
Скорость отложена по горизонтали, а максимальный урон за 10 сек., который был выбран в качестве параметра атаки, по вертикали. Точки на графике — танки на поле боя, можно сравнить их внешний вид, размер и ключевые характеристики. Ещё одна прямая аналогия: чем дальше от начала координат танк расположен по горизонтали, тем он быстрее (дальше уедет) в жизни. Страны, типы и уровни танков настраиваются в фильтрах над графиком, на осях можно выбрать любые другие параметры. При наведении на танки показаны все характеристики списком.
Сравним, например, тяжёлые танки СССР и Германии выше 5 уровня. Самые быстрые танки ИС-7, ИС-8 (СССР) и VK 36.01 (Германия), последний сильно проигрывает в максимальном уроне. E 100 хоть и медленный, зато чемпион по урону и прочности. На графике прочности и базового урона наблюдается почти линейная зависимость между параметрами. Только немецкий Tiger I (больше прочный, чем ударный) и советский КВ (больше ударный, чем прочный) отличаются по соотношению этих параметров от остальных танков выборки.
Для крепости брони мы использовали «светофорный» градиент: крепкая и надёжная — зелёная, слабая и опасная — красная. У некоторых читателей такой выбор цветов вызвал диссонанс: для них зелёный обозначает легко пробиваемую броню, а красный — сложную. Этот вопрос не кажется мне принципиальным и может быть решён любым способом при наличии однозначной легенды.
ПДД
Задача: извлечь пользу из статистики тренажера билетов по ПДД. Данные предоставлены тренажёром «Атрена»: pdd.atrena.org
В данных скрыт ответ на вопрос, сколько нужно тренироваться, чтобы успешно сдать экзамен. В этом их главный интерес и польза. Кирпичик в данном случае — это попытка, ответ конкретным пользователем на конкретный вопрос в N-й раз и результат («правильно» или «ошибка»). Чтобы оценить сложность конкретного вопроса, вычислим процент ошибок в зависимости от номера попытки.
Результаты закодируем «светофорным» градиентом и покажем на сетке сгруппированных по билетам вопросов. При наведении на вопрос, показываем содержание и варианты ответов, выделяя правильный. Вычислим среднее количество ошибок на человека в билете и добавим индикатор прохождения: две и менее ошибок — экзамен сдан, более двух — не сдан.

Живой прототип: pdd.datalaboratory.ru
Видим, что без подготовки сдать экзамен почти нереально, в каждом билете в среднем допущено от 3 до 5 ошибок. Зато после первого тренировочного круга ситуация сильно улучшается: 23 билета из 40 сданы со второй попытки. С третьей попытки не поддались только самые сложные: 11-й, 27-й и 38-й билеты, причём видно, какие именно вопросы вызывают наибольшие сложности. В 11-м и 27-м билетах, есть несколько вопросов, в которых совершаются ошибки. А в 38-м 13-й вопрос вызывает проблемы у трети студентов, из-за чего среднее количество ошибок на человека остаётся выше двух. Начиная с четвёртой попытки все билеты в среднем сданы, но 13-й вопрос 38-го билета вызывает затруднения у трети студенов вплоть до пятнадцатой попытки!
«Двойная галочка» отмечает билеты, среднее количество ошибок в которых падает ниже единицы, то есть которые сданы с большой вероятностью. К пятнадцатой попытке таких 11 из 40. Вообще, картина между пятой и пятнадцатой попыткой меняется незначительно. Самый заметный эффект от первого тренировочного круга, а проходить билеты более 5 раз практически бессмысленно.
Мы также добавили группировку по темам. Видно, что сложные и простые вопросы распределены по темам более-менее равномерно.
Погода
Задача: показать ежедневные температурные рекорды, чтобы было интересно их изучать. Источник данных: rp5.ru
Мы показали годовой график температур точечным графиком с «тепловым» градиентом, сделали акцент на сегодняшней температуре и рекордах, дополнили климатической сводкой (количество солнечных и пасмурных дней, годовые осадки) и населением города — это наш кирпичик. Акцент на сегодняшней температуре и рекордах добавляет релевантности: «Сейчас в Москве +22°С, а в 2014 в этот день было +10°С — ого!».
Из кирпичиков мы собрали макрокартину для городов-миллионников России и добавили Севастополь и Сочи для контраста:
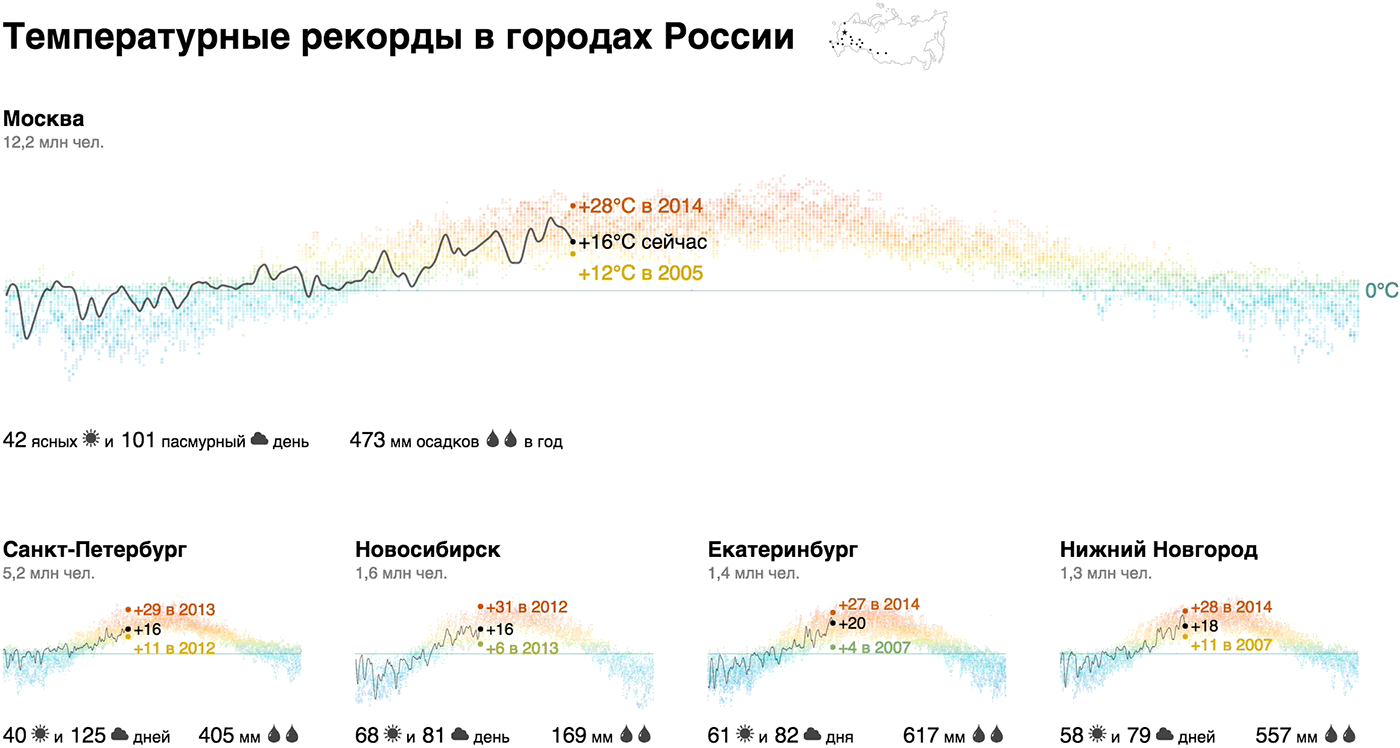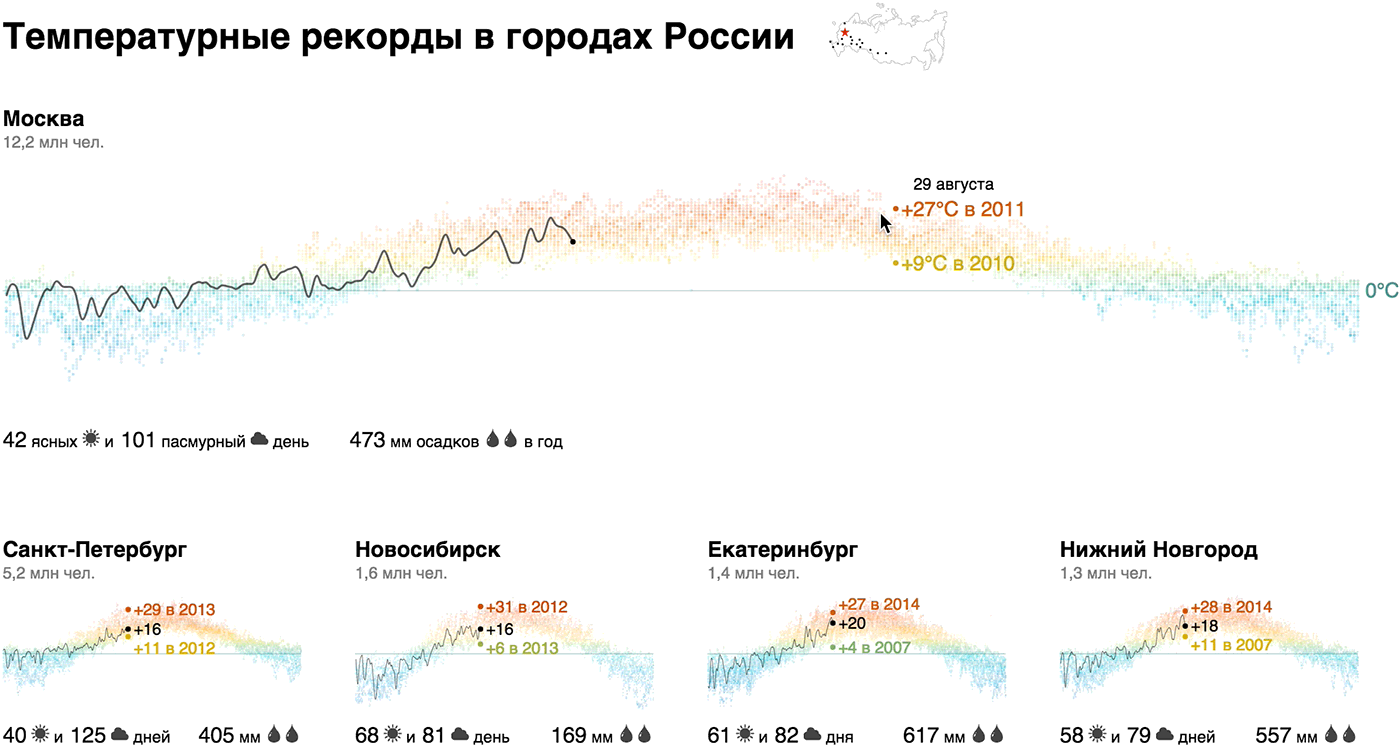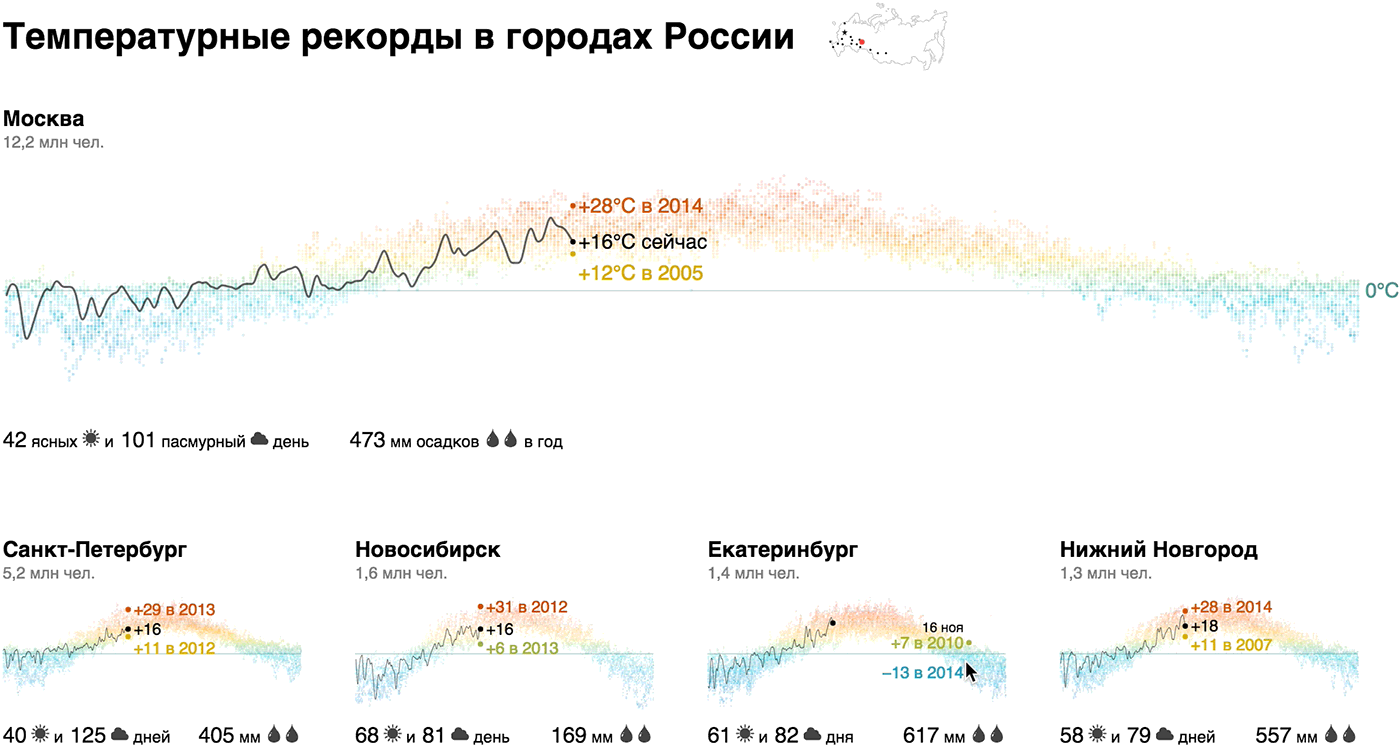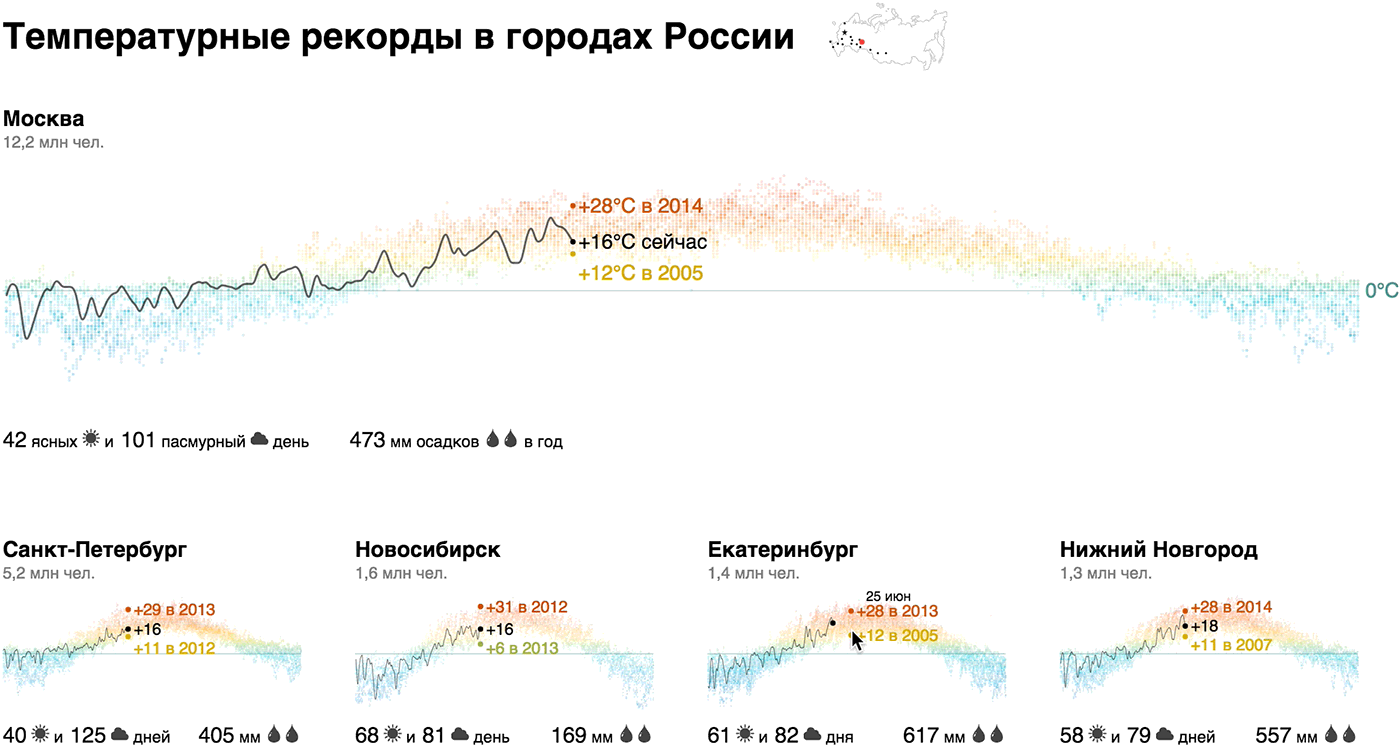
Живой прототип: weather-records.datalaboratory.ru
Оказывается, температурный профиль Новосибирска не так уж значительно отличается от Москвы. Зимой температура регулярно поднимается выше нуля в Ростове, Волгограде и Воронеже, в Севастополе разброс от +20 до -20, и только Сочи ниже нуля не опускается в принципе. Рекордсмены по солнечным дням — Севастополь, Сочи и, неожиданно, Омск, антирекордсмены — Питер, Москва, Воронеж и Челябинск. В Москве больше осадков, чем в Петербурге, в Омске в две раза больше, чем в Новосибирске, в Воронеже в три раза больше, чем в Волгограде.
Для тех, кто, как и я, плохо себе представляет взаимное расположение городов, мы «закрепили» над визуализацией микрокарту, на которой города подсвечиваются при наведении на соответсвующий кирпичик.
Маршрутки
Задача: визуализировать нарушения маршрутных такси (отклонения от расписание и превышения скорости). Данные предоставлены компанией Baseride: baseride.com
Как наглядно показать отклонения и превышения маршрутки за один рейс? Расположим остановки по горизонтали, сохранив пропорциональность растояний между ними. Отклонения от расписания при посещении конкретной остановки покажем кругом, площадь которого пропорциональна опозданию/опережению в минутах. Участки превышения скорости закрасим красным цветом: чем больше превышение, тем краснее участок. Рейсы без нарушений или с небольшими нарушениями выглядят нейтрально, чем больше нарушений, тем краснее рейс. Чтобы картина была нагляднее, оживим её временным слайдером:

Конкретные опоздания и превышения можно показать при наведении:

Такие рейсы легко сравнивать между собой. Например, можно одним взглядом окинуть все утренние рейсы, расположив их друг под другом (слева — время старта). Та же картина дня может быть свёрнута в одну линию с суммарным опозданиям по остановкам и суммарными (полупрозрачными) нарушениями на участках:

Живой прототип: minibus.datalaboratory.ru
Видим, что последние четыре остановки сильнее других страдают от нарушений расписания, а скорость превышают чаще всего в начале и на длинном перегоне в конце маршрута. Благодаря интерактивности видно, как маршрутки, стартовавшие в разное время дня, распределяются по маршруту: кто и где отстаёт и, наоборот, опережает общую массу.
Плюс такого подхода в том, что можно наглядно показать любой срез по рейсам: за определённую дату или время дня, для конкретного водителя, по определённым нарушениям, — а также сравнивать эти срезы между собой. Так можно показать все городские маршруты со статистикой за любой временной период на одном экране. При этом будет видна общая картина и каждый конкретный рейс в удобной для дальнейшего исследования форме.
Цены авиабилетов
Задача: показать изменения цен на авиабилеты в зависимости от даты вылета и даты покупки. Данные Туту.ру: tutu.ru
График цены билета на определённую дату вылета в зависимости от даты покупки — это наш кирпичик в данном случае. Именно такой тренд интересно изучать и сравнивать для разных дат и сезонов вылета, перевозчиков, направлений. Чтобы отличать графики между собой используем цветной градиент для разных дат вылета. На вертикально оси рисками показано распределение цен.
При наведении на временной слайдер и на график, подсвечиваем тренд с определённой датой вылета. Слайдер управляет выборкой: можно посмотреть летние, осенние, новогодние, весенние тренды, майские праздники и т.п.

Живой прототип: ticket-prices.datalaboratory.ru
В целом подтверждается гипотеза, что чем ближе вылет, тем дороже билеты: в правой части графика дорогих покупок больше, сеть плотнее. Но и исключений из этого правила — нисходящих графиков с заблаговременными дорогими покупками — довольно много.
Изучим внимательно наиболее подробные и однородные данные о перелёте Москва > Симферополь (только Аэрофлот):

Билеты в прошлом летнем сезоне покупались и заранее, и накануне вылета, в среднем за 5 тыс. руб со случайными отклонениями до 7—10 тыс. Осенью плотность «хвоста» слева уменьшилась, покупки совершались ближе к дате вылета, при этом ранняя цена в среднем чуть меньше поздней. Зимой билеты никто не покупал раньше, чем за полтора месяца до вылета, зато цены покупок в последние дни заметно скачут — до 10—15 тыс. Весной видны ярко выраженные ступеньки (фиксированные тарифы): синие мартовские ступеньки до снижения цен по указанию президента, зелёные апрельские — после.
Качественная визуализация проявляет закономерности и аномалии в данных, позволяет увидеть их невооружённым глазом. Это инструмент изучения данных без громоздкого софта и сложной математики. Мы уверены, что визуализация полезна в самых разных задачах, и наши эксперименты тому подтверждение. Чтобы поучаствовать в эксперименте, присылайте интересные данные на data@datalaboratory.ru с пометкой в рубрику «Вопрос-ответ».
Комментарии (5)


KoGor
20.06.2015 00:14+1Идея визуализации билетов ПДД очень классная, и главное полезная!
По танкам, согласен с «некоторыми» читателями — классическая «светофорная» шкала в данном случае вводит в заблуждение.

Iceg
20.06.2015 02:44Так круто, что не поленюсь внести несколько предложений :)
По маршруткам было бы лучше, если бы ползунок соответствовал эталонному времени, и расстояние между остановками на визуализации тоже соответствовало времени поездки между ними — тогда было бы нагляднее видно кто спешит/отстаёт. И, например, скорость отображать как аудиографики (расширяющиеся такие), а цветом закрашивать в местах превышения — от зелёного к красному.
Про погоду — жаль, что нельзя нужный город в большом размере посмотреть, как Москву (хотел проверить вас на предмет столичной болезни, когда москвичи игнорируют существование замкадья [мы тоже хотим удобно и подробно посмотреть про свои города!], но на сайте лаборатории данных не смог найти данные о месте дислокации, хм).
infotanka Автор
21.06.2015 10:25Спасибо! Про эталонное время классное предложение. Про «аудиографики» мы тоже думали, но они, на мой взгляд, слишком громоздкие для этой задачи.
Одним большим графиком в погоде обошлись, потому что в рамках экспериментов реализуем только функции, необходимые для демонстрации идеи (наш вариант MVP).
А Лаборатория сейчас равномерно распределена между Крымом, Питером, Ригой и Гуанчжоу :-)
Boomburum
Комментариев ещё нет, а плюсанул аж на +15 :) Очень круто! Больше всего понравилось про пдд — видно самые сложные вопросы (даже спустя 15 попыток) — посмотрел их и понял, что вопросы действительно непростые :)