Arrays, Collections: Алгоритмический минимум
Массивы и списки
Недавно на собеседовании в крупную компанию на должность Java разработчика меня попросили реализовать стандартный алгоритм сортировки. Поскольку я никогда не реализовывал самописные алгоритмы сортировки, а пользовался всегда готовыми решениями, у меня возникли затруднения с реализацией. После собеседования я решил разобраться в вопросе и подготовить список основных алгоритмов сортировки и поиска, которые используются в стандартном пакете java — Java Collections Framework (JCF). Для этого я изучил исходники JDK 7.80.
В самом обобщенном виде результат изучения представлен на рисунке. Подробности — в основном тексте.
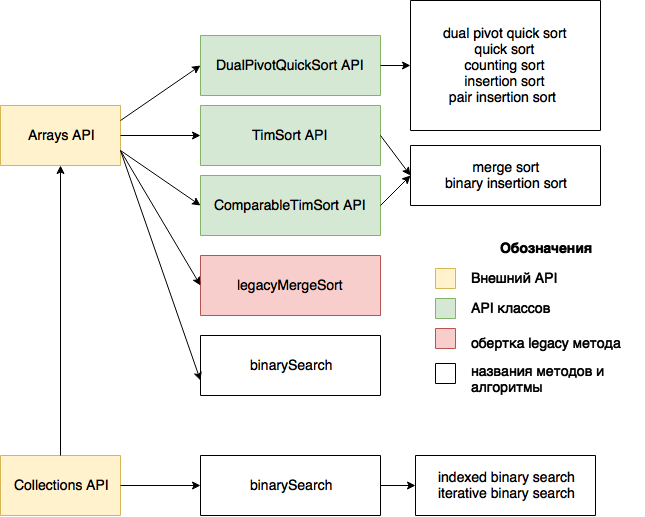
Рисунок 1. Методы Arrays, Collections и реализуемые ими алгоритмы
Первое, что поразило меня в алгоритмах, реализованных в Arrays и Collections — то, что их можно буквально по пальцам пересчитать — по большому счету, это два алгоритма сортировки и один алгоритм поиска.
Второе — то, что сортировка списков «под капотом» использует сортировку массивов.
Третье — то, что один из алгоритмов сортировки портирован с python.
Алгоритм быстрой сортировки с двумя опорными элементами разработан нашим соотечественником Владимиром Ярославским и реализован при содействии Джона Бентли и Джошуа Блоха.
Алгоритм сортировки слиянием, который является основным для сортировки массивов ссылочных типов, буквально назван по имени своего создателя Tim Peters — TimSort. Этот алгоритм был адаптирован Джошуа Блохом с алгоритма сортировки списков, реализованном на python Тимом Петерсом.
Кратко излагая результаты, стоит отметить, что:
- Можно условно выделить три слоя методов:
- Методы API
- Методы базовых (основных) алгоритмов
- Методы (блоки) дополнительных алгоритмов
- Основных алгоритмов используется три. Два алгоритма сортировки: быстрая сортировка, сортировка слиянием. Один алгоритм поиска: бинарный поиск.
- Для оптимизации «основные» алгоритмы заменяются на более подходящие в данный момент “дополнительные” алгоритмы (полный список алгоритмов и условий переключения приведен в конце)
- Для определения того, какой из «дополнительных» алгоритмов будет задействован, могут использоваться:
- сигнатуры методов (типы аргументов, булевы переменные)
- флаги VM
- пороговые значения длины массива/списка, хранящиеся в приватных переменных классов
В пакете util для работы с массивами и коллекциями предназначены классы Arrays и Collections соответственно. Как основной сервис, они предоставляют методы для сортировки и поиска. Для совместимости API Collections и API Arrays унифицированы. Пользователю предоставляются статические перегруженные методы sort и binarySearch. Разница заключается в том, что методы Arrays API принимают массивы примитивных и ссылочных типов, в то время как методы sort и binarySearch Collections API принимают только списки.
Итак, для того, чтобы выяснить, какие основные и дополнительные алгоритмы используются в пакете util, нужно разобрать реализацию 4-х методов из API Collections и API Arrays.
Таблица 1. API Arrays vs API Collections
| Метод | Arrays API | Collections API |
|---|---|---|
| Sort method | Arrays.sort | Collections.sort |
| Search method | Arrays.binarySearch | Collections.binarySearch |
Arrays.sort
Массивы примитивных типов
Основной алгоритм сортировки для массивов примитивных типов в Arrays — быстрая сортировка. Для реализации этой сортировки выделен финальный класс DualPivotQuickSort, который предоставляет публичные методы sort для сортировки массивов всех примитивных типов данных. Методы Arrays API вызывают эти методы и пробрасывают в них ссылку на массив. Если требуется отсортировать определенный диапазон массива, то передаются еще и индексы начала и конца диапазона.
Временная сложность алгоритма быстрой сортировки в лучшем случае и в среднем случае составляет O(n log n). В некоторых случаях (например, на малых массивах) алгоритм быстрой сортировки обладает не лучшей производительностью, деградирует до квадратичной сложности. Поэтому имеет смысл вместо него применять другие алгоритмы, которые в общем случае проигрывают, но в конкретных случаях могут дать выигрыш. В качестве дополнительных алгоритмов были выбраны сортировка вставками, “обычная” быстрая сортировка (с одной опорной точкой), сортировка подсчетом.
Инженеры Oracle эмпирическим путем вычислили оптимальные размерности массивов для задействования каждого дополнительного алгоритма сортировки. Эти значения записаны в приватных полях класса DualPivotQuickSort. Для наглядности я свел их в таблицу 2.
Таблица 2. Дополнительные алгоритмы в DualPivotQuickSort.sort
| Типы данных | Размер массива, n | Предпочитаемый алгоритм | Временная сложность в лучшем случае |
|---|---|---|---|
| int, long, short, char, float, double | n < 47 | insertion sort, pair insertion sort |
O(n) |
| int, long, short, char, float, double | n < 286 | quick sort | O(n log n) |
| byte | 29 < n | counting sort | O(n+k) |
| short, char | 3200 < n | counting sort | O(n+k) |
В теле методов DualPivotQuickSort.sort производятся проверки на длину массива, и в зависимости от результата применяется либо основной, либо дополнительный алгоритм.
Массивы примитивных типов. Выбор алгоритма и булев параметр leftmost
Параметр leftmost при необходимости передается в метод sort и показывает, является ли указанная часть самой левой в диапазоне. Если да, то применяется алгоритм “обычной” сортировки вставками. Если нет, то применяется парная сортировка вставками.
Еще одно объяснение о выборе дополнительных алгоритмов можно почитать
здесь.
Массивы ссылочных типов
Для массивов ссылочных типов в качестве основного предусмотрен алгоритм сортировки слиянием, он реализован в трех вариациях. Две актуальные реализации вынесены в специальные классы: TimSort, ComparableTimSort. TimSort предназначена для сортировки объектов с использованием компараторов. ComparableTimSort — это версия TimSort, предназначенная для сортировки объектов, поддерживающих Comparable. Подробности реализации сортировки TimSort смотрите в посте на хабре.
Класс TimSort содержит единственную пороговую величину, при сравнении с которой принимается решение о переключении на дополнительный алгоритм. Это величина называется MIN_MERGE и хранит минимальную длину массива, при которой будет производиться сортировка слиянием. Если же длина массива будет меньше MIN_MERGE, т.е. 32, то будет задействована бинарная сортировка вставками. Как сказано в документации, это мини-TimSort, т.е. без использования слияний.
Таблица 3. Дополнительные алгоритмы в TimSort.sort и ComparableTimSort.sort
| Тип данных | Размер массива, n | Предпочитаемый алгоритм | Временная сложность в лучшем случае |
|---|---|---|---|
| T[] | n < 32 | binary insertion sort | O(n) |
Третья реализация сортировки слиянием является legacy и оставлена для сохранения обратной совместимости с версией JDK 1.6 и более ранними. Legacy сортировка обернута в метод legacyMergeSort и непосредственно реализована в методе Arrays.mergeSort. Для того, чтобы ее использовать, необходимо выставить флаг -Djava.util.Arrays.useLegacyMergeSort=true перед запуском виртуальной машины. Для хранения значения этой переменной в Arrays имеется внутренний статический класс LegacyMergeSort (см. Листинг. 1).
Листинг 1. Статический внутренний класс LegacyMergeSort в Arrays
static final class LegacyMergeSort {
private static final boolean userRequested =
java.security.AccessController.doPrivileged(
new sun.security.action.GetBooleanAction(
"java.util.Arrays.useLegacyMergeSort")).booleanValue();
}
При вызове Arrays.sort с массивом ссылочного типа происходит проверка, выставлен ли флаг на применение legacy сортировки. Тогда происходит вызов либо legacy сортировки, либо одной из базовых (см. Листинг 2).
Листинг 2. Реализация метода Arrays.sort для массива ссылочного типа с компаратором
public static <T> void sort(T[] a, Comparator<? super T> c) {
if (LegacyMergeSort.userRequested)
legacyMergeSort(a, c);
else
TimSort.sort(a, c);
}
Arrays.binarySearch
Для массивов как примитивных, так и ссылочных типов предусмотрен бинарный поиск. Перед поиском массив должен быть отсортирован. Сложность алгоритма бинарного поиска в среднем и в худшем случае составляет O(log n). Дополнительных алгоритмов не предусмотрено.
Collections.sort
В Collections сортировка предусмотрена только для списков. Интересно, что сначала производится преобразование списка в массив с последующим применением сортировки слиянием для массивов ссылочных типов. Сортировка осуществляется вызовом метода Arrays.sort.
Collections.binarySearch
Как и в случае с сортировкой, в Collections бинарный поиск реализован только для списков. Переменная BINARYSEARCH_THRESHOLD устанавливает ограничение на размер списка в 5000 элементов.
Списки поддерживают либо произвольный доступ, либо последовательный. Если список поддерживает произвольный доступ, то он будет обрабатываться алгоритмом индексированного бинарного поиска. Если список поддерживает последовательный доступ, то он будет обрабатываться алгоритмом итеративного бинарного поиска. Как видно, и в том, и в другом случае будет применяться бинарный поиск.
Всего интерфейс List в JDK 7.8 реализуют 10 классов, 2 из которых — абстрактные AbstractList и AbstractSequentialList. Последовательный доступ реализует только LinkedList и все потомки AbstractSequentialList. Поэтому они будут обрабатываться алгоритмом iteratorBinarySearch. Остальные списки, такие как ArrayList, CopyOnWriteArrayList, будут обрабатываться алгоритмом indexedBinarySearch.
UPD. Как стало понятно из личной дискуссии с Zamyslov, необходимо уточнить, каким образом BINARYSEARCH_THRESHOLD участвует в определении типа алгоритма сортировки. Это пороговое значение имеет влияние только на списки с последовательным доступом.
Cписок, поддерживающий произвольный доступ, будет всегда обрабатываться Collections.indexedBinarySearch. А список, поддерживающий последовательный доступ, будет обрабатываться Collections.iteratorBinarySearch только если он будет превышать значение BINARYSEARCH_THRESHOLD (см. листинг 3), в противном случае он также будет обрабатываться Collections.indexedBinarySearch.
Листинг 3. Влияние типов списков и константы BINARYSEARCH_THRESHOLD на определение алгоритмов обработки списка
int binarySearch(List<? extends Comparable<? super T>> list, T key) {
if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD)
return Collections.indexedBinarySearch(list, key);
else
return Collections.iteratorBinarySearch(list, key);
} Обобщаем изученное
Теперь, когда рассмотрены основные методы и условия перехода к дополнительным методам, можно обобщить полученные данные. Для максимальной наглядности детализируем рисунок 1, выделив на нем основные методы и добавим условия перехода к дополнительным методам.

Рисунок 2. Основные и дополнительные алгоритмы Arrays, Collections
Пояснения к цифрам на стрелках рисунка 2 содержатся в Сводной таблице. Цифры обозначают условия перехода. Серым выделены основные алгоритмы. Они применяются по умолчанию. В Сводной таблице строки, описывающие основные алгоритмы, выделены темно-серым.
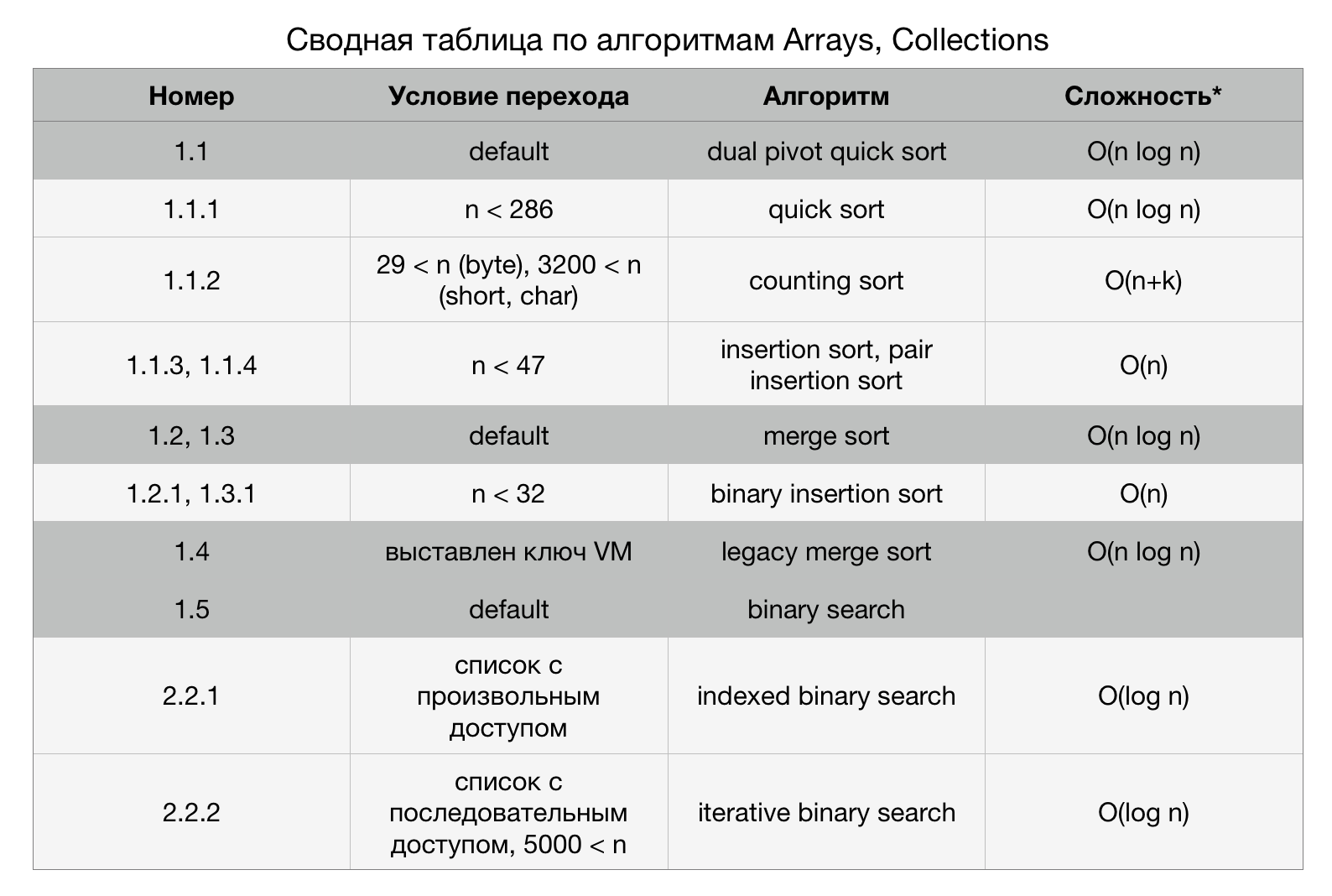
*Сложности для основных алгоритмов приведены «в среднем случае», а сложности дополнительных алгоритмов приведены «в лучшем случае».
Заключение
Целью заметки было составить полный список алгоритмов, применяющихся для поиска и сортировки массивов и списков в пакете java.util. Итак, для того, чтобы в полной мере понимать, что происходит “под капотом” при использовании API Arrays и API Collections достаточно владеть следующими алгоритмами:
- быстрая сортировка с двумя опорными точками
- быстрая сортировка с одной опорной точкой
- сортировка подсчетом
- «простая» сортировка вставками
- бинарная сортировка вставками
- парная сортировка вставками
- сортировка слиянием (версия Тима Петерса)
- бинарный поиск
- индексированный бинарный поиск
- итеративный бинарный поиск
Разбор алгоритмов и их свойств можно найти по ссылкам:
Комментарии (47)

Kiselioff Автор
09.12.2017 23:32Вы правы, спасибо за замечание! Я привожу среднюю сложность для «основных» алгоритмов и сложность в лучшем случае для дополнительных. Я исходил из того, что имеет смысл применять дополнительный алгоритм, если он показывает производительность лучше основного. А с алгоритмами insertion sort и binary insertion sort это происходит только в лучшем случае. Поэтому и указал такие параметры. Я собирался сделать сноску об этом, видимо что-то отвлекло. Спасибо, что заметили.
khim
10.12.2017 00:38Я исходил из того, что имеет смысл применять дополнительный алгоритм, если он показывает производительность лучше основного.
Совершенно верно, но если посмотрите на условия, когда происходит переход, то поймёте, что к Big O всё это отношения не имеет.
Переход на «вспомогательные» алгоритмы происходит не тогда, когда у них лучшая сложность (как мы это вообще можем узнать заранее???), а когда, несмотря на то, что в терминах Big O сложность велика, в терминах элементарных операций она невелики — за счёт константы, очевидно. Которая у «вспомогательных» алгоритмов, очевидно, меньше…

fzn7
10.12.2017 00:31-2Я думаю за просьбу «реализовать стандартный алгоритм сортировки» нужно увольнять. Сразу и без сожалений. Это же армейский тупняк, зачем работать с такими людьми?
khim
10.12.2017 00:49Ну как бы это. Это типичный случай ситуации «кто на что учился».
Вы можете заниматься высокоинтеллектуальной деятельностью типа натягивания шаблонов на CMS типа Drupal'а. Или создания формочек в 1С или Excel'е. Тогда вам этот «армейский тупняк» действительно не нужен.
А можете — заниматься разной ерундой типа создания операцинок и браузеров, иструментов ИИ и распределённых систем — вот тут вам этот «армейский тупняк» таки понадобится.
А выбор, как всегда, за вами.
niamster
10.12.2017 01:40Если необходимо реализовать timsort на листочке на собеседовании в офисе — я согласен с fzn7 — ничего это задание не показывает.
Если это «домашнее задание» то почему бы и нет — покажет, что человек может в комфортной обстановке.
Так же в офисе могут попросить реализовать алгоритм на доске — вполне хорошее упражнение. Так как тут есть диалог между у частниками, даже если человек затрудняется реализовать алгоритм, видно как он мыслит (что в основном и должно быть целью собеседования).
А Вы, khim, можете тут вот реализовать все операции RB-tree или Radix-tree не заглядывая в wikipedia(или другие источники информации).khim
10.12.2017 02:31Если необходимо реализовать timsort на листочке на собеседовании в офисе — я согласен с fzn7 — ничего это задание не показывает.
В такой формулировке — таки нет. А в той формулировке, которая написана в статье — таки да.
Речь идёт не о фотографической памяти, а о понимании общих принципов. Если в качестве «стандартной сортировки» будет предьявлен MergeSort (как, собственно и было до Java7) — то можно будет поговорить про сложность и TimSort, если будет рассказано про TimSort — можно будет это обсудить тоже.
Так же в офисе могут попросить реализовать алгоритм на доске — вполне хорошее упражнение. Так как тут есть диалог между у частниками, даже если человек затрудняется реализовать алгоритм, видно как он мыслит (что в основном и должно быть целью собеседования).
Для этого, собственно, подобные вопросы и задаются.
А Вы, khim, можете тут вот реализовать все операции RB-tree или Radix-tree не заглядывая в wikipedia(или другие источники информации).
С первого раза безошибочно? Не факт. Особенно удаления. Но вы же сами указали на то, что этого, в общем, и не требуется. Важно посмотреть на то, как эта задача будет постепенно доводиться до ума. Все операции RB-tree сложнее, кстати, чем Timsort (про MergeSort я вообще молчу).
avost
12.12.2017 01:16А откуда вы берёте это "не заглядывая в википедию"? Как правило, такое условие никогда не ставится за бессмысленностью, а если вы боитесь задавать вопросы, то это очевидный преогромный минус вам, а не интервьюерам.
khim
12.12.2017 01:44+1А откуда вы берёте это «не заглядывая в википедию»?
На онлайновых интервью — это типичное требование.
Но почему-то все, кто слышит про подобные вещи считают, что от них ожидают фотографической памяти и умения воспроизвести 100-200-500 строк кода из Википедии «как стихи». Чего, в общем, и близко нет. Вот тут человек описывает — зачем такие вопросы задаются и чего хочется в результате увидеть.
а если вы боитесь задавать вопросы, то это очевидный преогромный минус вам, а не интервьюерам.
А вот это — не в бровь, а глаз.
Kiselioff Автор
10.12.2017 01:40Тут хочется вспомнить анекдот. Физику, математику и инженеру дали задание измерить объем красного резинового шара. Физик погрузил шар в воду и измерил объем вытесненной жидкости. Математик измерил длину окружности, вычислил радиус и взял тройной интеграл. Инженер достал из стола «Таблицу объемов красных резиновых мячей» и нашел нужное значение.
Иногда достаточно знать где посмотреть, иногда нужно уметь сделать руками.
fzn7
10.12.2017 10:32Поперхнулся чаем. Вы на java операционки и браузеры предлагаете писать
тов. прапорщик?
shishmakov
10.12.2017 14:34Писать на Java такие продукты как Hazelcast, Apache Ignite, Apache Cassandra и так далее. Чем вы недовольны?
fzn7
10.12.2017 15:48Может покажете, где в Hazelcast реализована копия стандартного алгоритма сортировки?
khim
10.12.2017 19:37+1А зачем вам реализовывать копию? Одна уже есть.
Понимать как устроена сортировка нужно для другого. Вы можете сортировать данные один раз — в конце. А можете засунуть из в TreeSet и иметь их сортированными всегда. И то и другое — O(N log N), но в некоторых случаях лучше делать одно, в некоторых — другое. А иногда — лучше и вообще без сортировки обойтись.
Как вы, например, делаете выбор? Не зная ничего то том, как у вас сортировка устроена?fzn7
10.12.2017 19:55+1А где я был против знания и понимания алгоритмов сортировки? Я против просьб написания реализации по памяти. Вы разницу видите или вам еще детальнее расписать?
khim
10.12.2017 20:32А где я был против знания и понимания алгоритмов сортировки?
Ох.
Я против просьб написания реализации по памяти.
А кто просит вас «реализовать по памяти»? Если вы «знаете и понимаете» алгоритмы сортировки — то почему для вас такая проблема один из них написать?
Вы разницу видите или вам еще детальнее расписать?
Пожалуйста поподробнее. Потому как судя по вашему негодованию вы протестуете против просьбы написать код на тему, которую вы хорошо знаете и понимаете. Что, как по мне, является совершенно необходимым минимумом для того, чтобы можно было говорить о приёме на работу…
То есть получается такая цепочка:
1. Кандидат хорошо знает и понимает проблему (с этим вы вроде как не спорите).
2. Кандидат не помнит наизусть решение этой проблемы (тут как бы тоже всё хорошо: кто, действительно, в зравом уме и твёрдой памяти будет помнить все эти ньюансы?)
3. Однако при этом он неспособен написать решение задачи!'
Если обьеденить первый и третий пункты то это значит, что кандидат неспособен написать код для решения даже задачи, которую он хорошо знает и понимает! С которой он сталкивался 100 раз за время своей работы! Ну и нафига такой «работник» кому-то нужен?fzn7
10.12.2017 20:42Если у вас работник вместо использования библиотечной функции каждый раз пишет свой квиксорт, то забирайте себе инвалида. У меня он завалится на dry
khim
10.12.2017 19:25+1Операционка — это далеко не только ядро. Посмотрите на Android или Chrome for Android. И вы увидите там таки немало Java'ы.

vba
10.12.2017 01:43Неужели вам совершенно западло было бы ответить на такой запрос горячо любимым и таким пушистым
heapsort-ом. Вас же не просятwater trappingзадачу решить или замкнутый список поправить с помощью алгоритма Флойда для поиска зацикливаний.khim
10.12.2017 02:41HeapSort — это таки перебор. Кстати вопрос: почему HeapSort почти никогда не используется для «стандартных» сортировок, хотя часто используется для очередей с приоритетами — тоже хороший вопрос для собеседования.
vba
10.12.2017 11:02Перебор или нет а это таки уже
экзекуторуэкзаменатору тов Киселоффа решать. Попросили написать алгоритм сортировки на доске? Не помнишь QuickSort, но не хочешь позорится с пузырем, HeapSort таки для тебя.khim
10.12.2017 19:39+1С трудом представляю себе человека, способного написать HeapSort, но неспособного написать QuickSort, извините.
То есть могу поверить, что такие бывают, но… не видел. Концептуально — HeapSort на порядок сложнее. Хотя код и не очень сложный…vba
10.12.2017 21:48Если тебя попросили написать алгоритм сортировки без рекурсии но с использованием классических структур данных (без Sorted* разумеется) то HeapSort тут на много проще и будет. Да и сама куча не такая уж и сложная.
khim
11.12.2017 01:05+1А где написано «без рекурсии»? Это вы уже что-то из пальца высасывать начинаете.
Да, куча — штука относительно несложная. Но она заведомо сложнее примитивного QuickSort'а.
Сделать стек на массиве проще, чем «кучу», даже если рекурсия на уровне языка запрещена. Сделать так, чтобы размер этого стека не превысил O(log N) — тоже несложно (hint: хвостовая рекурсия).
P.S. Но на самом деле, открою маленький секрет, если вы напишите HeapSort вместо QuickSort'а — то это не будет большой проблемой. Материала для «поговорить во время интервью» это даст достаточно. Так что если вы фанат HeapSort'а — ну пишите его в качестве «стандартной сортировки». Проблемой будет изобретение 100500 причини «ничего не делать» по типу fzn7 — вот это действительно к отказу приведёт достаточно быстро.
fzn7
10.12.2017 10:37Было-бы не западло, если бы предоставили натуральный тикет, где удивительным образом, самым оптимальным решением является написание копии стандартной сортировки. Боюсь, что такого тикета в природе нет, поэтому это форма армейского тупняка и творческой импотенции.
vba
10.12.2017 11:13Да в том то и дело что естественных примеров вокруг нас миллионы. Вы доблестный защитник израильского неба от самопала палестинцев, разработайте систему способную
гаситьв сортирена подлете эти самые самодельные ракеты, в учет должны приниматься скорость и расстояние ракеты до потенциальной цели.
Высосано из пальца но для собеседования потянет. Кстати такое вот например у вас могут спросить на одном из 6 технических собеседований в Amazon.
fzn7
10.12.2017 11:38+1На java, систему ПРО писать? Почему бы не на, lua? Неужели не о чем больше поговорить на собеседовании, кроме обсуждения вещей, которые придумали не вы, которые в 99.999% уже везде реализованы лучше и оптимальнее? (подсказка — можно поговорить о реальных задачах)
vba
10.12.2017 13:55На псевдокоде. Накопившегося у человечества математического аппарата хватит на сто или двести лет вперед. Сегодняшние алгоритмы основаны на открытиях математиков 50, 100, 300 летней давности. Дейкстра свой алгоритм не за пол часа написал на каком нибудь собеседовании, на это иногда уходят годы.
Сегодня невероятное количество компаний работают над интереснейшими и очень реальными задачами. Что бы вас допустить до решения таковых задач такие компании должны быть в вас уверены, поэтому и прощупывают ваши знания на собеседованиях. Так устроен мир, увы.
fzn7
10.12.2017 15:39Вы написали настолько воодушевляющий комментарий, что пришлось его читать вслух и стоя )
Сегодня невероятное количество компаний работают над интереснейшими и очень реальными задачами.Что бы вас допустить до решения таковых задач такие компании должны быть в вас уверены, поэтому и прощупывают ваши знания на собеседованиях
Да кто спорит, что нужно быть уверенными, но как в этом деле поможет псевдокод с квиксортом? На месте компании логично дать реальную задачу, которую предстоит решать разработчику на позиции, вы не согласны?
Оценивать сантехника по умению решать гидродинамические уравнения в уме или боеспособность армии по умению тянуть носочек, конечно, красивая история. Вместе с тем, это попахивает проблемами с целеполаганием и в тяжелом случае, шизофренией.vba
10.12.2017 18:39+1Поверьте, я тоже исхожу из подобных убеждений. Мне тоже ближе к сердцу когда работодатель дает комплексное тестовое задание без отрыва от своего контекста. Это гораздо более качественный подход чем решение вот такой задачи по телефону за 30 мин.
Но большие конторы предпочитают другой подход, который может привести к вот таким вот результатам (Обсуждение того как Max Howell создатель Homebrew, которым пользуются 90 проц инженеров в гугле, не прошел собеседование в корпорацию добра). Так устроен мир, что тут можно сказать. Вопрос, на что готовы вы что бы работать на них...
fzn7
10.12.2017 20:10+1Зачем работать на них, если уже с порога эта компания не может предложить ничего, кроме унылых задач из сборника олимпиадных задачек 93 года, в не зависимости от того куда идет человек. Бодишопы за версту видно, в т.ч. по подобным вопросам
khim
10.12.2017 20:19Если вы так во всём этом уверены, то зачем вы тут в комментариях так стремитесь всем доказать, что «виноград — зелен, ну очень зелен… и кисл — прям почти горек»?
Если всё, как вы говорите — то Гугл скоро потяряет своё первое место среди работодателей и все успокоятся.
Вам-то какое дело?fzn7
10.12.2017 20:36Я считаю, что отсутствие нерелевантных фильтров при трудоустройстве позволит каждому разработчику занять более справедливое положение на рынке и получить более высокий оклад, а компаниям, осознание собственных целей и грамотный подбор персонала, позволит увеличить эффективность и сократить издержки
Возможно кто-то из коллег прочитает тред и сочтет мои доводы убедительными
Ответил на ваш вопрос?vba
10.12.2017 22:40Кстати про несоответствующие (простите нерелевантные не русское слово) фильтры. Я так понимаю это часть IT менталитета англосаксонского мира, поработав в нем я в этом убедился. Устраиваясь там на работу у вас всегда спросят какое-нибудь упражнение и довольно часто у доски во время собеседования. Мне казалось в России дела обстоят точно так же. А вот во Фр и Бельгии дела обстоят не так весело, там просто с вами побеседуют, зададут какие нибудь вопросы типа про алгоритмы сборки мусора в JVM и вроде все на этом, ибо голод кадров просто ужасающий.
fzn7
11.12.2017 13:12-1Думаю, что это не часть менталитета, а результат грамотной рекламной политики западных стран, создающих толпу кандидатов на входе. Если у вас есть большой выбор, можно в целом глумиться как угодно, найдутся те, кто будет терпеть (был свидетелем, как руки целуют начальству в соседних отраслях со сверхдоходами). Опять-же моя цель в том, чтобы таких штрейкбрехеров было как можно меньше
khim
11.12.2017 01:10+1Я считаю, что отсутствие нерелевантных фильтров при трудоустройстве позволит каждому разработчику занять более справедливое положение на рынке и получить более высокий оклад,
Если «каждый разработчик еа рынке начнёт получать более высокий оклад» — то за чей счёт будет банкет?
а компаниям, осознание собственных целей и грамотный подбор персонала, позволит увеличить эффективность и сократить издержки.
А за счёт чего сократятся издежки при повышении оклада «каждому работнику»?
Возможно кто-то из коллег прочитает тред и сочтет мои доводы убедительными
Не виду доводов пока, вижу демагогию. Противоречащие друг другу отверждания в пределах одного предложения — да ещё и не следующие из всего остального.
khim
10.12.2017 20:13Но большие конторы предпочитают другой подход, который может привести к вот таким вот результатам (Обсуждение того как Max Howell создатель Homebrew, которым пользуются 90 проц инженеров в гугле, не прошел собеседование в корпорацию добра).
Слышал эту историю от разных людей, но так и не понял где подвох. То, что человек смог создать пакетный менеджер скорее говорит о том, что он может работать PM'ом, а не программистом, тот факт, что с решением простейшей задачи на доске возникли сложности — этот факт скорее подтверждает.
Не знаю конкретно насчёт Homebrew, но все системы управления пакетами, с которыми я разбирался, «в младенчесте» имели ужасный код (квадратичная, а то и кубическая, сложность вместо O(N log N), плохие интерфейсы и т.д. и т.п.) и если Homebrew хоть сколько-нибудь их напоминает, то я ни разу не удивлён тем, что его не взяли.
Более того, есть ощущение, что решение Макса не взять — было лучшим для обоих сторон.vba
10.12.2017 21:03Начнем с того что вас тов Ким там не было, и свечку другой держал. А что про качество кода и черезмерную сложность то этим, увы, могут похвастаться даже такие продукты как Windows или некоторые продукты корпорации добра. TensorFlow не всегда был таким привлекательным а про AngularJs я вообще молчу.
khim
11.12.2017 01:20+1Начнем с того что вас тов Ким там не было, и свечку другой держал.
Что не помешало вам приводить этот пример в качестве доказательство «плохого решения». Назвались груздем — полезайте в кузов. В смысле обьясняйте почему вы считаете, что оно плохое. Никто вас за язык не тянул и историю с Максом не навязывал.
А что про качество кода и черезмерную сложность то этим, увы, могут похвастаться даже такие продукты как Windows или некоторые продукты корпорации добра.
Совершенно с вами согласен — но это обозначает что, тем более, не стоит брать на работу людей, которые про них забывают или не знают, не так ли?vba
11.12.2017 13:46+1Что не помешало вам приводить этот пример в качестве доказательство «плохого решения». Назвались груздем — полезайте в кузов. В смысле обьясняйте почему вы считаете, что оно плохое. Никто вас за язык не тянул и историю с Максом не навязывал.
Я нигде не сказал что это было плохое решение. Все что вы тут указываете — полный бред, я ничего такого не говорил, вы лжец. Я лишь указал на вероятность появления таких ситуаций. К которой я совершенно никак не отношусь, в отличие от вас.
Совершенно с вами согласен — но это обозначает что, тем более, не стоит брать на работу людей, которые про них забывают или не знают, не так ли?
Это так же означает и обратное, не так ли?

Maccimo
10.12.2017 01:56Алгоритм быстрой сортировки с двумя опорными элементами разработан нашим соотечественником Владимиром Ярославским и реализован на python. Позже он был адаптирован на Java в классе DualPivotQuickSort
Кажется, вы что-то путаете. В статье Ярославского Python упоминается ровно ноль раз, а пример реализации как раз на Java.
Kiselioff Автор
10.12.2017 09:56Ваша правда. Python упоминается в документации дважды. Однако, оба раза по отношению к быстрой сортировке (исходный код Arrays, строки 454-455, исходный код TimSort, строки 37-40). Поправлю.
Kiselioff Автор
10.12.2017 11:55Кстати, коллеги, поделитесь пожалуйста опытом. Ситуация. Ты написал статью на Хабре (может и еще где-то). В ходе обсуждения выяснилось, что нужно что-то поправить. Есть тут какие-то best practice?
Просто бесследно перетереть переосмысленный кусок текста или как-то это оформить с указанием на то, что ранее было неверно, а верно так-то.
valemak
10.12.2017 13:12Другой вариант — исправить текст в статье, при этом ответить на комментарий в котором пользователь указал на неточность. В ответе поблагодарить за уточнение и сообщить что недочёт исправлен.
vba
Секундочку, какая то у вас сводная таблица по алгоритмам неверная. Например у алгоритма
Insertion Sortсред сложность пролегает стабильно вO(n^2), а вот лучший случай является?(n). Тоже самое, если не ошибаюсь можно сказать про сред сложность уBinary Insertion Sort. Интересное по теме.