
О сложности.
Простота — это противоположность сложности.
Сложность разработки ПО — тема, давно волновавшая умы инженеров и ученых, и один из наиболее концептуальных подходов к вопросу был оформлен автором известнейшей книги “Мифический человеко-месяц”, Фредериком Бруксом, в виде отдельного труда - “Серебрянной пули нет” (“No Silver Bullet”). Этот труд написан в 1987 году, но концептуальный взгляд на тему делает его актуальным и через 30 лет.
В частности, Брукс проводит важное разделение сложности на “неотъемлемую”(essential) и “привнесенную”(или “случайную” — accidental). Неотъемлемая сложность — это та сложность, которая происходит из самой области проблемы, от её природы. Скажем, если вам нужно имплементировать протокол FTP — неважно, какой язык или инструментарий вы выберете для этого, у вас все равно есть набор команд, действий, кодов возврата и логики, которую придется реализовать. Нет такого способа, чтобы упростить задачу до имплементации в одну строчку. Сложность вам даётся как данное (в данном случае из спецификации протокола), и способа повлиять на эту составляющую у вас, в общем случае, нет.
Привнесенная сложность — напротив, это сложность, которая происходит от тех инструментов, которые мы используем. Это та сложность, которую мы создаём себе сами. На неё мы можем влиять и уменьшать.
История развития индустрии разработки ПО сводится к уменьшению именно этой, accidental, сложности.
Почему сложность это плохо?
Все должно быть сделано так просто, как это возможно. Но не проще.
Альберт Эйнштейн
Ответ на вопрос — “хорошо” или “плохо”? — лежит исключительно в области признания или не признания хороших и плохих практик. Нет формального способа доказать, что, скажем, “глобальные переменные” — это хорошо или плохо. Рассматривая частные примеры, сторонники каждой из сторон найдут вам сотню убедительных аргументов и “за”, и “против”. Но собрав, хотя бы частично, опыт многих и многих разработчиков ПО, работающих с самыми разными программистами и языками, вы так или иначе будете слышать утверждения про “хорошие практики” или “плохие практики”.
Только с коллективным эмпирическим опытом многих тысяч инженеров и программистов, изложивших свои мысли на бумаге, приходит понимание, что “сложность” — это то, чего стоит избегать настолько, насколько это возможно. Сложность ведёт к целой лавине не сразу очевидных эффектов, которые также зачастую сложно формально доказать и которые измеряются вероятностями — большая вероятность появления ошибок, большее время на понимание кода, большее время и усилия, необходимые для изменения дизайна ПО в случае необходимости (рефакторинг), которые, в свою очередь, порождают стимул не производить эти изменения, которые, в свою очередь, приводят к тому, что разработчики начинают искать обходные пути и так далее.
В конце концов, код — это всего лишь инструмент решения задач, и в итоге главным критерием, отделяющим «хорошее» от «плохого» является продуктивность — скорость и качество решения этих самых задач. Сложность является убийцей продуктивности, и именно потому вся индустрия разработки движется в сторону уменьшения сложности.
Причем тут языки программирования?
Управление сложностью — квинтэссенция программирования.
Брайан Керниган
Выбор языка программирования — это очень удачный, если не лучший, пример “привнесённой сложности” в мире разработки ПО. Сами по себе языки программирования — это тоже инструменты для уменьшения сложности разработки. И каждый виток их развития, так или иначе решает один из аспектов сложности разработки ПО, но тем самым и привносит новые элементы сложности.
Вся история их развития — история поиска более простого инструмента для реалий того времени. Теория языков программирования — такая же развивающаяся наука, как и, допустим, нейробиология, и нет единого канонического знания, каким должен быть язык программирования. Это стохастический процесс, замешанный на законах рынка, удачных решениях, хорошего бэкапа в виде крупной компании (почти все популярные языки имели за спиной крупную компанию) и массе других факторов.
И этот процесс не стоит на месте, новые концепции порождают новые проблемы и новые уровни абстракций, растет коллективный опыт и понимание, вместе с тем, развивается и стремительно меняется экосистема железа и софта, меняются приоритеты в вопросах компромиссов и экономии ресурсов, и всё это плотно завязано на инерционности человеческого мозга и систем образования. Другими словами — это очень сложная махина. Простого и одного решения тут нет и быть не может.
Но что можно утверждать наверняка — что одни языки привносят больше сложности в общий пул сложности, а другие меньше. Одни практики и паттерны (“паттерны — это багрепорт на ваш язык”), которые навязываются языками, увеличивают суммарную сложность разработки, другие — уменьшают.
И мы, как инженеры, должны стремиться в итоге, к тому, чтобы избегать этой “привнесенной сложности”.
Сложность в Go
Go родился, как ответ на повышенную “привнесенную” сложность существующих языков. По крайней мере, той предметной области, которая волновала Google — разработки системного, сетевого и серверного софта. Его главной целью изначально было уменьшить эту сложность любой ценой. Это был главный приоритет с самого начала.
Немалую роль тут сыграл колоссальный практический опыт авторов Go — Пайка, Томпсона и компании — людей, стоявших у истоков Unix, языка C и UTF-8, а сейчас работающих над ключевыми продуктами Google. Так или иначе, но Go явился в некоторой степени радикальным языком, который качнул маятник сложности в другую сторону, пытаясь выровнять существующий ландшафт мира разработки ПО.
И это именно то, что подразумевается под термином “простота” в контексте Go. Уменьшение сложности. Уменьшение времени необходимое среднестатическому программисту для понимания среднестатического проекта, написанного другими людьми. Уменьшение рисков ошибок. Уменьшение времени и затрат на «хорошие практики». Уменьшение шансов писать код плохо и некрасиво. Уменьшение времени на освоение языка. И так далее, и тому подобное.
Цифры
Но довольно слов, давайте и в самом деле попробуем оценить сложность, привносимую языками. В комментариях к предыдущим статьям, отсутствие «формального доказательства» было причиной бурных споров. Сразу скажу, что осознаю сложность этой задачи. Реальная оценка лежит в плоскости субъективного практического опыта и трудноизмеряемых вероятностей. Простого способа свести всё к одной цифре и сказать «сложность языка А больше, чем языка Б» — нет. Но тем не менее, если вы хорошо знаете какие-либо два или больше языка, вы для себя достаточно легко можете решить, какой язык для вас проще. Ваш мозг как-то умеет оценить и решить, какой из языков сложнее.
Поэтому, за неимением лучшего варианта, я попробую взять несколько методик, и посмотреть какую картину они нарисуют. У каждой методики есть серъезные недостатки, но если их результаты не будут сильно различаться, можно будет считать, что это что-то большее, чем случайное распределение.
При этом я буду анализировать языки, которые достаточно универсальны для решения большого круга задач, имеют достаточно большое сообщество и информация о них доступна. Экзотику вроде Brainfuck мы не рассматриваем.
Метод 1.
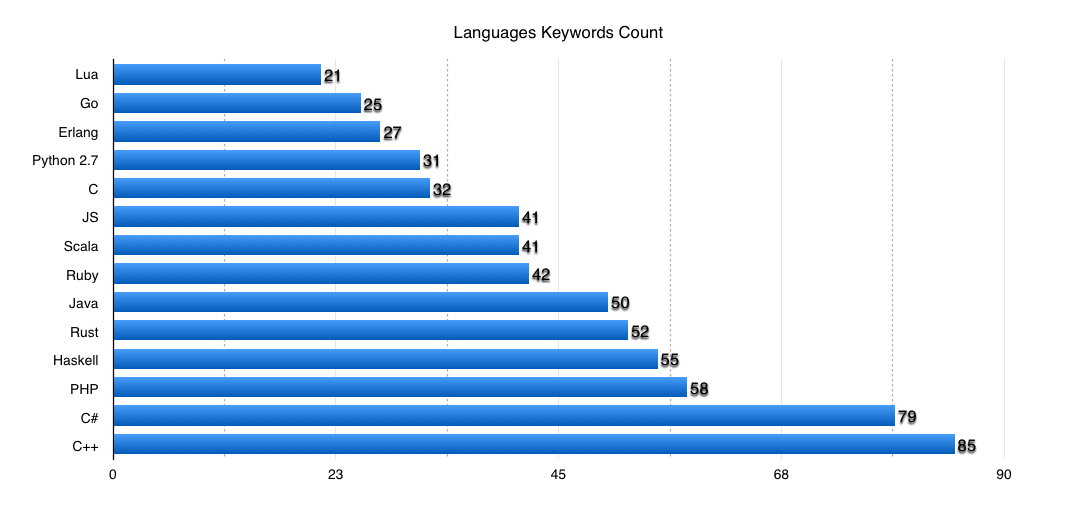
Одной из таких простейших методик является подсчет ключевых слов (keywords) языка. На самом деле точнее будет оценивать концепты, которые привносит язык — но это сложнее считается, и при этом кореллирует с количеством ключевых слов. Оценка будет очень грубая, но достаточно показательная и логичная. Логичная, потому что меньшее количество знаний равно меньшей когнитивной нагрузке на мозг.
Вот что мы имеем:
| Python 2.7 | 31 | docs.python.org/2.7/reference/lexical_analysis.html |
| Python 3 | 33 | docs.python.org/3.4/reference/lexical_analysis.html |
| Lua | 21 | www.lua.org/manual/5.1/manual.html |
| C (C99) | 32 | en.wikipedia.org/wiki/C_syntax#Reserved_keywords |
| C (C11) | 37 | en.wikipedia.org/wiki/C_syntax#Reserved_keywords |
| C++11 | 85 | en.cppreference.com/w/cpp/keyword |
| Go | 25 | golang.org/ref/spec |
| JS (ECMAScript 5.1) | 41 | www.ecma-international.org/ecma-262/5.1/#sec-7.6.1 |
| Haskell | 55 | www.haskell.org/haskellwiki/Keywords |
| Java | 50 | en.wikipedia.org/wiki/List_of_Java_keywords |
| C# | 79 | msdn.microsoft.com/en-us/library/x53a06bb.aspx |
| PHP | 58 | www.php.net/manual/en/reserved.keywords.php |
| Ruby 1.9 | 42 | ruby-doc.org/docs/keywords/1.9 |
| Scala | 41 | www.scala-lang.org/files/archive/spec/2.11/01-lexical-syntax.html |
| Erlang | 27? | erlang.org/doc/reference_manual/introduction.html |
То же самое, в виде графика:
Метод 2
Можно попробовать оценить грамматики языка, многие из которых описаны с помощью Формы Бэкуса-Наура. Грамматики в этом формате (BNF/EBNF) есть не ко всем языкам, но в сети есть немало различных грамматик, составленных полуавтоматически. К примеру, я брал несколько грамматик отсюда: slps.github.io/zoo/index.html. Оценивать количество правил я буду простыми однострочниками. К примеру, для Go извлечь ENBF-правила очень просто прямо с официальной страницы со спецификацией языка:
$ curl -s http://golang.org/ref/spec | grep pre.*ebnf | wc -lХотя в других спецификациях иногда не сильно просто подсчитать количество правил. На всякий случай, привожу команду, которой считал.
| Язык | Количество правил |
|---|---|
| C | 65 |
| Go | 58 |
| Python | 83 |
| Haskell | 78 |
| JS (ECMAScript 5.1) | 128 |
| Ruby (для 1.4) | 37 |
| Java (JRE 1.9) | 216 |
| C++ (2008) | 159 |
| C# 4.0 | 314 |
| Lua 5.1 | 25 |
| PHP | 146 |
| Rust | 115 |
| Erlang | 219 |
| Scala | 143 |
curl -s http://www.cs.man.ac.uk/~pjj/bnf/c_syntax.bnf | grep ": " | wc -lGo
curl -s http://golang.org/ref/spec | grep pre.*ebnf | wc -lPython
manually copy text from https://docs.python.org/2/reference/grammar.html, then “cat py.bnf | grep ": " | wc-l”Haskell www.haskell.org/onlinereport/haskell2010/haskellch10.html#x17-17500010
JS (ECMAScript 5.1)
curl -s http://www.ecma-international.org/ecma-262/5.1/ | grep '<div class="lhs"><span class="nt">.*::'| tr -d ' ' | sort -u | wc -lRuby (для 1.4)
curl -s http://docs.huihoo.com/ruby/ruby-man-1.4/yacc.html | grep ": " | wc -lJava (JRE 1.9)
curl -s http://docs.oracle.com/javase/specs/jls/se8/html/jls-19.html | grep '<div class="lhs">' | wc -lC++ (2008)
curl -s http://slps.github.io/zoo/cpp/iso-n2723.bnf | egrep ":$" | wc -lC# 4.0
curl -s http://slps.github.io/zoo/cs/csharp-msft-ls-4.0.bnf | egrep ":$" | wc -lLua 5.1
curl -s http://wiki.luajit.org/Extended-BNF | grep "::=" | wc -lPHP
curl -s http://slps.github.io/zoo/php/cordy.bnf | egrep ":$" | wc -lRust
curl -s https://doc.rust-lang.org/grammar.html | grep "[a-z_]* :" | wc -lErlang
curl -s https://raw.githubusercontent.com/ignatov/intellij-erlang/master/grammars/erlang.bnf | grep "::=" | wc -lScala
curl -s http://www.scala-lang.org/files/archive/spec/2.11/13-syntax-summary.html | grep "::=" | wc -lВ виде графика:
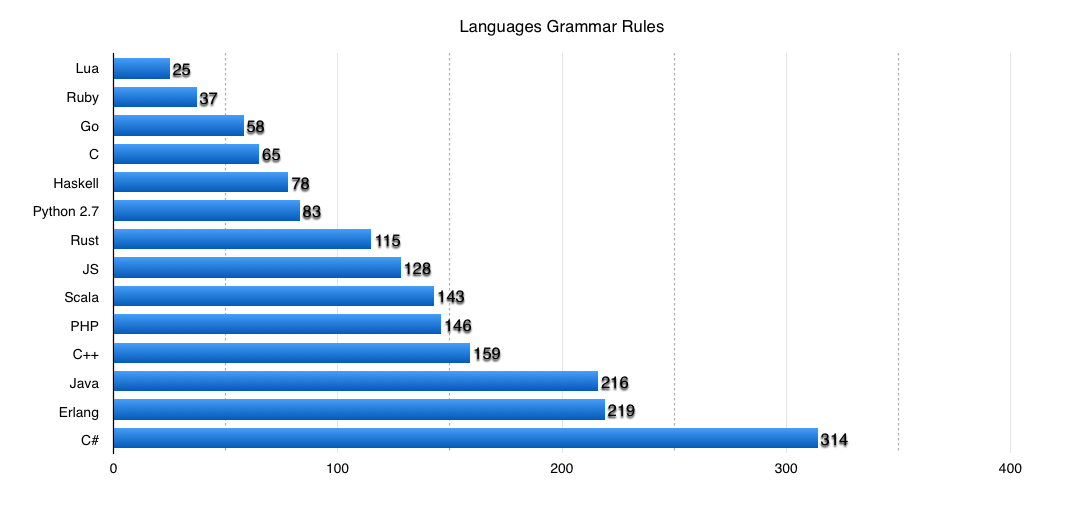
Еще раз повторюсь, эти методики не дают объективной картины и чисел, но дают грубую оценку одному из факторов сложности языка.
Метод 3.
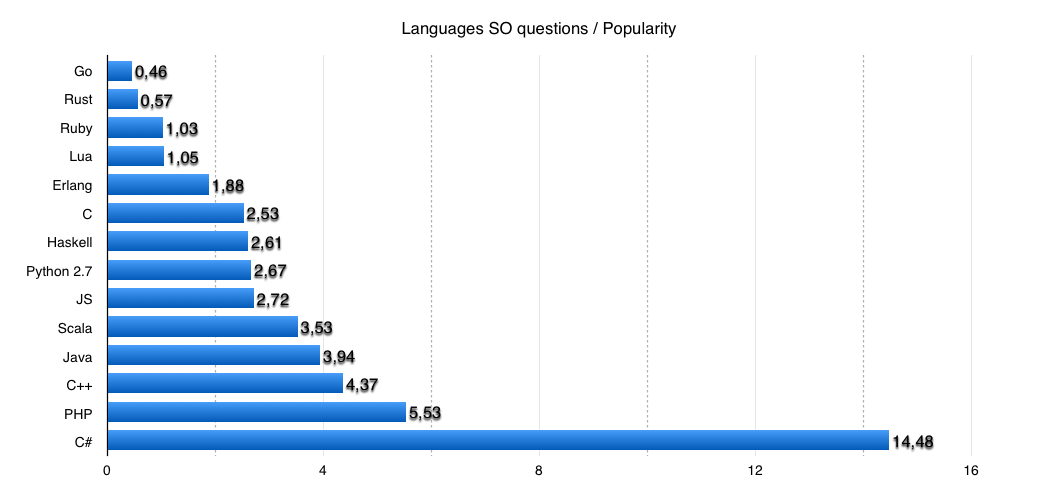
Третья методика оценить практическую сложность языка будет основана на статистических данных — количестве вопросов на StackOverflow с учетом коэффициента популярности языка. Предвижу критику о спорности методики, но на самом деле она имеет смысл, и ребята из RedMonk даже ведут такую статистику уже некоторое время: redmonk.com/sogrady/2015/01/14/language-rankings-1-15
StackOverflow хорош тем, что, благодаря модерации, теги по языкам проставлены достаточно аккуратно, и это, как ни крути, сейчас место, куда многие идут за вопросами даже раньше, чем на официальный сайт — даже термин такой придумали — SODD, Stack-Overflow Driven Development. Поэтому логично предположить, что чем больше вопросов — тем непонятнее, тем сложнее (хотя, безусловно, еще масса факторов влияет). Количество вопросов по тегам StackOverflow удобно предоставляет вот тут: stackoverflow.com/tags?page=2&tab=popular
При этом, разумеется, нужно учитывать абсолютное количество пишущих на том или ином языке, и для этого я возьму рейтинг по репозиториям GitHub за последний квартал 2014, доступный в замечательной форме вот тут: githut.info и количество активных репозиториев буду считать за кореллирующий показатель количества активно использующих язык.
А дальше схема простая — делим количество вопросов на StackOverflow на количество активных репозиториев на Github. Чем больше число, тем сложнее язык.
Вот что получается:
| Язык | Репозиториев на GitHub | Вопросы на SO | Соотношение |
|---|---|---|---|
| Go | 22264 | 10272 | 0,46 |
| Ruby | 132848 | 136920 | 1,03 |
| Lua | 8123 | 8502 | 1,04 |
| Rust | 4383 | 2478 | 1,76 |
| C | 73075 | 184984 | 2,53 |
| Haskell | 8789 | 22930 | 2,60 |
| Python 2.7 | 164852 | 439994 | 2,66 |
| JS | 323938 | 880188 | 2,71 |
| Java | 222852 | 879064 | 3,94 |
| C++ | 86505 | 377834 | 4,36 |
| PHP | 138771 | 768018 | 5,53 |
| C# | 56062 | 811952 | 14,48 |
| Erlang | 2961 | 5571 | 1,88 |
| Scala | 10853 | 38302 | 3,52 |
График:
Выводы
Предвосхищая комментарии, ещё раз напишу, что я прекрасно понимаю минусы и недостатки всех вышеописанных методик оценивания, но их потому и несколько, чтобы иметь возможность составить суммарную картину, минимизируя эффекты минусов всех этих подходов. Погрешность тут может быть очень большой (к примеру грамматика Руби тут проще грамматики Go, но тот скрипт однострочник лишь считает количество правил, но не их сложность — и весь синтаксический сахар Ruby, который добавляет достаточно сложности, тут не учтен). Если у кого-то есть ещё идеи, как можно оценивать объективно сложность языков программирования — пишите, буду рад услышать и обсудить.
В целом, по этим графикам видно, что данные достаточно совпадают, и сильных расхождений нет — четко видны группы “сложных”, “простых” и “средних” языков. Немного удивил результат Rust-а в последнем графике — как никак, Rust отнюдь не относится к простым языкам: скорее всего такой результат связан с молодостью языка (версия 1.0 вышла пару месяцев как), и, как следствие, высокой средней квалификации rust-девелоперов — отсюда и низкая относительная активность на Stack Overflow. В целом эти цифры у меня подкрепляются личными наблюдениями, по крайней мере в тех языках, которые я знаю лично. А те, которые не знаю, оцениваю достаточно близко.
Я предвижу критику по поводу методов выше и заявления о их несостоятельности. Поэтому сразу задаю два вопроса, ответы на которые можно прямо в комментарии с критикой оставлять:
а) какой есть метод лучше, для оценки сложности языка (в терминологии сложности данной статьи)?
б) как можно объяснить достаточно очевидную корелляцию результатов у всех трех методик, если они несостоятельны и их результаты — результат случайного распределения?
Ну и последнее — сложность языка — это лишь один из факторов успеха. Хотя статья и посвящена простоте Go, это далеко не единственная причина его успеха, хотя и одна из важных. Будь Go таким же простым, но не имей богатой стандартной библиотеки и отличного тулинга — скорее всего его путь был совсем иным.
Заключение
После описания важности простоты инструментов разработки, и попытки формально доказать простоту Go относительно других популярных языков, важно напомнить, что это не случайность, а намеренное решение авторов языка. Это задумывалось вопреки популярному мнению — “чем сложнее, тем лучше” — и это принесло ожидаемый эффект. Количество людей и проектов, которые подхватили Go растёт большими темпами (сегодня без графиков, ссори)), и многие делают акцент именно на этом “освежающем” качестве Go — его простоте.
В конце концов, простота даёт людям возможность концентрироваться на логике программы, а не на управлении памятью, борьбе с компилятором и расшифровке витиеватых синтаксических конструкций языка. И это делает программирование снова интересным и увлекающим, как, возможно, в первые разы вашего знакомства с программированием вообще. Возможно вы еще помните тот фан, когда вы писали свои первые программы. Большинство отзывов людей, которые начали писать на Go заканчивается словами “Go makes programming fun again”. Но при этом вы пишете не Hello, World, а качественный современный софт, быстрый, кроссплатформенный, многопоточный и безопасный.
У каждого языка своя ниша, свои компромиссы и свои плюсы и минусы. Но если круг ваших задач пересекается с той областью, в которой Go уже доказал свою состоятельность — скорее всего вы получите большой плюс от простоты Go и тех эффектов, которые она оказывает на продуктивность и качество.
Ссылки
No Silver Bullet — faculty.salisbury.edu/~xswang/Research/Papers/SERelated/no-silver-bullet.pdf
Less Is Exponentially More — commandcenter.blogspot.com/2012/06/less-is-exponentially-more.html
Less is more — lambda-the-ultimate.org/node/4852
Комментарии (202)

igordata
29.06.2015 00:50+12*с дальних рядов* А добавьте пожалуйста в графики Brainfuck! Спасибо.

divan0 Автор
29.06.2015 00:51При этом я буду анализировать языки, которые достаточно универсальны для решения большого круга задач, имеют достаточно большое сообщество и информация о них доступна. Экзотику вроде Brainfuck мы не рассматриваем.
igordata
29.06.2015 02:15+2Так-то оно понятно, что крайности не показатель, и во всём важен баланс. Но интересно же. Для чистоты эксперимента, так сказать. А то ведь подстройка выборки под результат не есть гуд.
divan0 Автор
29.06.2015 03:22-3Да нет, подстройки выборки тут нет — я изучил всё что осилил о том, как можно оценивать сложность языков, и это три методики, к которым я реально пришёл. Серьезно, если кто-то тут предложит реально выполнимую методику получше (чем составная оценка по разным более грубым методам), я буду только рад.
Да и речь на самом деле о небольшой группе «универсальных» языков. Это не только с точки зрения здравого смысла и контекста статьи важно, но и для статистических данных.
Brainfuck не подходит, потому что это не язык общего назначения и кроме как ради фана или академического инструмента не используется. А так, взять его, чтобы доказать, что вышеиспользованные методы приблизительных оценок имеют очень ограниченную область применения и обладают массой минусов — не интересно, и так же понятно )igordata
29.06.2015 13:18+1Зато это было бы весьма по-научному. Читайте про фальсифицируемость. Сейчас вы эмпирически предполагаете, что теория не работает на Брейнфаке. А если вы его измерите и попугаями, и удавами, то можно будет уже предметно от цифр отталкиваться. И с умным видом заявить, что на нём теория сползла до уровня погрешности, и применяться не может.
divan0 Автор
29.06.2015 15:17Я не знаю, откуда вы взяли, что я считаю «оценку количества keyword-ов» универсиальной теорией расчет сложности языков, применимую ко всем языкам, но я несколько раз это явно дал понять — единственный реальный метод _оценить_ сложность я вижу в совокупности нескольких оценочных методик, и проследить корелляцию.
И столько же раз написал, что да, прекрасно понимаю, насколько примитивной и грубой оценкой является первая методика, но при этом я, да, считаю что она не лишена оснований для группы императивных языков. Вы же не будете мне доказывать, что количество ключевых слов в C++ чисто случайно больше, чем в Go, и чисто случайно Go субъективно называется более простым?
Но если вы хотите гнуть свою линию «нет брейнфака — никакой взаимосвязи быть не может» — продолжайте, но мне странны такие доводы от логически мыслящих людей.
nsinreal
29.06.2015 16:45+2Вы же не будете мне доказывать, что количество ключевых слов в C++ чисто случайно больше, чем в Go, и чисто случайно Go субъективно называется более простым?
Я могу попробовать. Сравните велосипед и мотоцикл по количеству деталей и необходимых навыков для управления. А потом сравните их же по простоте преодоления больших дистанций.
И почему вы сравниваете Go и C++? Вот, возьмите из вашего графика Scala & JS с одинаковым количеством keywordов. Или Haskell и C# (первый считается более сложным, во втором больше keywordов по вашему графику). Вы подтасовываете теорию под то, что хотите видеть вы сами.divan0 Автор
29.06.2015 16:50Нет-нет, я пытаюсь этими графиками попробовать дать ответ на вопрос «А докажи, что Go проще C++ или Java?» людям, которые не пробовали Go, и считают все утверждения о простоте — выдумкой. То, сколько и кто и как едет — это уже тем отдельного холивара :)
nsinreal
29.06.2015 16:59+2Ну госпади, какая разница сколько keywordов учить — 25 или 50? Людей не волнует как долго им придется учить язык до уровня владения «ниндзя»; их волнует то, как быстро они смогут написать что-то на нем. Если для написания «hello %username%» им придется призывать последний круг ада и танцевать голышом на канате, то сомневаюсь что им поможет факт, что в языке всего 10 keywords.
Не, как аргумент для дебилов — это конечно покатит.divan0 Автор
29.06.2015 17:01-1Всё, я устал писать одинаковые комменты ) Признаю это как свой фейл.
Речь не в том, «сколько keyword-ов учить», а в том, что это кое-как коррелирует со сложностью языка, и это легко подсчитать, поэтому годится как одну из методик. Аргументы про «просто случайное распределение» я выслушал, понял, и не согласен.nsinreal
29.06.2015 17:16+1Речь не в том, «сколько keyword-ов учить», а в том, что это кое-как коррелирует со сложностью языка, и это легко подсчитать
Да ну, это коррелирует со сложностью разработки компилятора и IDE для данного языка. У тебя нету никакого графика «сложности» языка и ты рассуждаешь о корреляции между сложностью и количеством чего-нибудь? Че, правда? Дай сводный график твоих трех методик и реальный график сложности языков и сравни.
Аргументы про «просто случайное распределение» я выслушал, понял, и не согласен.
Да бля, ты сам-то на график посмотри. Ты смотришь на Go и C++, я смотрю на JS & Scala & C#. Какое еще нахер случайное распределение (мы до него еще тупо не дошли), если ты тупо игнорируешь свой график и чужое мнение?
У тебя ни keywordы не были посчитаны правильно, ни bnf-грамматики. Сначала нужна нормализация, приведение к общему виду. А то получается так, что в одном языке медленный глючный компилятор и три правила в грамматике, а в другом языке быстрый оттестированный компилятор и пятьсот правил грамматики.
Какой еще блин анализ на необработанных данных?
nsinreal
29.06.2015 16:51Ой, простите. Haskell же функциональный, да. Поглядите на C и C# в рамках какого-нибудь написания какого-нибудь хабра.

areht
05.07.2015 18:21> но мне странны такие доводы от логически мыслящих людей.
ru.wikipedia.org/wiki/Чучело_(логическая_уловка)
ЗЫ. Вы сразу в конце статьи дописывайте «кто не согласен — тот дурак»

sferrka
29.06.2015 01:16habrahabr.ru/post/259279/#comment_8445561
Наконец-то кто-то это начал. Но повторюсь, в идеале сравнивать количество сущностей нужно на конкретных типовых задачах, тогда это будет иметь смысл, ведь никто не будет изучать все конструкции языка сразу, а изучив их это становится скорее преимуществом.
Т.е. нужно что-то вроде кучи таких вещей todomvc.com, где каждый представитель языка (сообщество) решает задачу оптимальным способом. А в итоге имеем график сравнения сложностей для этой задачи и комплексный график по всем задачам.divan0 Автор
29.06.2015 01:21Да, было бы точнее, но я не вижу способа как это сделать реальным. Есть проект сравнения языков на основе задач с Rosetta Code — Go там, кстати, тоже жжот — arxiv.org/pdf/1409.0252v4.pdf — но, сложность таких сравнений мне не под силу, увы.
sferrka
29.06.2015 01:32+2Без реальных задач, любой ассемблер, в вашем сравнении, будет очень крут, однако уже на банальной математике проиграет.

deniskreshikhin
29.06.2015 01:22-5О да, Rust проще чем C++!
Ох, уж этот С++ со своими шаблонами!!! Взгляните какую портянку подсовывают нам в качестве итератора:
template <class Category, class T, class Distance = ptrdiff_t, class Pointer = T*, class Reference = T&> struct iterator { typedef T value_type; typedef Distance difference_type; typedef Pointer pointer; typedef Reference reference; typedef Category iterator_category; };
Дауж, очевидно что давно пора утереть нос этому зарвавшимуся датскому профессору.
То ли дело итераторы в Rust:
Ооооо нет! Rust прекрати!pub trait Iterator { type Item; fn next(&mut self) -> Option<Self::Item>; fn size_hint(&self) -> (usize, Option<usize>) { ... } fn count(self) -> usize { ... } fn last(self) -> Option<Self::Item> { ... } fn nth(&mut self, n: usize) -> Option<Self::Item> { ... } fn chain<U>(self, other: U) -> Chain<Self, U::IntoIter> where U: IntoIterator<Item=Self::Item> { ... } fn zip<U>(self, other: U) -> Zip<Self, U::IntoIter> where U: IntoIterator { ... } fn map<B, F>(self, f: F) -> Map<Self, F> where F: FnMut(Self::Item) -> B { ... } fn filter<P>(self, predicate: P) -> Filter<Self, P> where P: FnMut(&Self::Item) -> bool { ... } fn filter_map<B, F>(self, f: F) -> FilterMap<Self, F> where F: FnMut(Self::Item) -> Option<B> { ... } fn enumerate(self) -> Enumerate<Self> { ... } fn peekable(self) -> Peekable<Self> { ... } fn skip_while<P>(self, predicate: P) -> SkipWhile<Self, P> where P: FnMut(&Self::Item) -> bool { ... } fn take_while<P>(self, predicate: P) -> TakeWhile<Self, P> where P: FnMut(&Self::Item) -> bool { ... } fn skip(self, n: usize) -> Skip<Self> { ... } fn take(self, n: usize) -> Take<Self> { ... } fn scan<St, B, F>(self, initial_state: St, f: F) -> Scan<Self, St, F> where F: FnMut(&mut St, Self::Item) -> Option<B> { ... } fn flat_map<U, F>(self, f: F) -> FlatMap<Self, U, F> where U: IntoIterator, F: FnMut(Self::Item) -> U { ... } fn fuse(self) -> Fuse<Self> { ... } fn inspect<F>(self, f: F) -> Inspect<Self, F> where F: FnMut(&Self::Item) -> () { ... } fn by_ref(&mut self) -> &mut Self { ... } fn collect<B>(self) -> B where B: FromIterator<Self::Item> { ... } fn partition<B, F>(self, f: F) -> (B, B) where F: FnMut(&Self::Item) -> bool, B: Default + Extend<Self::Item> { ... } fn fold<B, F>(self, init: B, f: F) -> B where F: FnMut(B, Self::Item) -> B { ... } fn all<F>(&mut self, f: F) -> bool where F: FnMut(Self::Item) -> bool { ... } fn any<F>(&mut self, f: F) -> bool where F: FnMut(Self::Item) -> bool { ... } fn find<P>(&mut self, predicate: P) -> Option<Self::Item> where P: FnMut(&Self::Item) -> bool { ... } fn position<P>(&mut self, predicate: P) -> Option<usize> where P: FnMut(Self::Item) -> bool { ... } fn rposition<P>(&mut self, predicate: P) -> Option<usize> where Self: ExactSizeIterator + DoubleEndedIterator, P: FnMut(Self::Item) -> bool { ... } fn max(self) -> Option<Self::Item> where Self::Item: Ord { ... } fn min(self) -> Option<Self::Item> where Self::Item: Ord { ... } fn min_max(self) -> MinMaxResult<Self::Item> where Self::Item: Ord { ... } fn max_by<B, F>(self, f: F) -> Option<Self::Item> where F: FnMut(&Self::Item) -> B, B: Ord { ... } fn min_by<B, F>(self, f: F) -> Option<Self::Item> where B: Ord, F: FnMut(&Self::Item) -> B { ... } fn rev(self) -> Rev<Self> where Self: DoubleEndedIterator { ... } fn unzip<A, B, FromA, FromB>(self) -> (FromA, FromB) where Self: Iterator<Item=(A, B)>, FromA: Default + Extend<A>, FromB: Default + Extend<B> { ... } fn cloned<'a, T>(self) -> Cloned<Self> where T: 'a + Clone, Self: Iterator<Item=&'a T> { ... } fn cycle(self) -> Cycle<Self> where Self: Clone { ... } fn reverse_in_place<'a, T>(&mut self) where Self: Iterator<Item=&'a mut T> + DoubleEndedIterator, T: 'a { ... } fn sum<S = Self::Item>(self) -> S where S: Add<Self::Item, Output=S> + Zero { ... } fn product<P = Self::Item>(self) -> P where P: Mul<Self::Item, Output=P> + One { ... } }
splav_asv
29.06.2015 01:39+8Собственно, и что? Просто это разного уровня сущности.
deniskreshikhin
29.06.2015 01:42Просто это разного уровня сущности.
Пояснитеsplav_asv
29.06.2015 08:22+3В C++ это способ пробежаться по коллекции, а в Rust это еще реализация стандартных алгоритмов над коллекцией по умолчанию.
The iteration protocol is defined by the Iterator trait in the std::iter module. The minimal implementation of the trait is a next method, yielding the next element from an iterator object.
The Iterator trait provides many common algorithms as default methods.
Т.е. для создания своего надо только next реализовать. Для остальных методов есть дефолтная реализация.deniskreshikhin
29.06.2015 13:51-3Теперь понятнее что вы хотели сказать) Но нет, это не так.
Итератор это эквивалентные сущности в C++ и Rust. Единственное в чем моя ложь, в том то что в C++ к итераторам прилагается ещё библиотечка в которой и находятся большинство методов которые внесены в трейт из Rust'а.
С другой стороны, если кастомный итератор хоть немного нетривиален придётся приложить немало усилий, что бы подхватились все эти методы. Хотя такая же проблема существует и в C++.
Но суть не в этом, Rust это язык по сложности сопоставимый с C++, который требует усилий по отслеживанию времени жизни, декомпозиции на трейты и т.п. непростые вещи. Это не говоря про бюрократию Rust, вроде списка из почти ста возможных ошибок компляции doc.rust-lang.org/error-index.html.
Поэтому то, что он оказался рядом с Ruby и Go это вообще оксюморон.splav_asv
29.06.2015 14:22+2Не совсем — подходы слегка отличаются. В Rust Iterator это что-о близкое к концепции iterable в Python, только статически организованное. В С++ библиотека висит снаружи, опираясь на абстракцию итератора, в Rust включена в этот самый итератор.
Зато в C++ есть зачем-то поле distance… Какое отношение оно имеет к абстрактному итератору?
И, кстати, если сильно всё переделывать — снаружи использование данной коллекции ничем не будет
отличаться, а как в C++ — не уверен. Не приходилось такое проделывать.
Но суть не в этом, Rust это язык по сложности сопоставимый с C++, который требует усилий по отслеживанию времени жизни, декомпозиции на трейты и т.п. непростые вещи.
Согласен, но способов выстрелить себе в ногу в runtime убавилось — этого и добивались.
Да и отсутствия наследия конца 90х благотворно сказывается на стройность языка.
Это не говоря про бюрократию Rust, вроде списка из почти ста возможных ошибок компляции doc.rust-lang.org/error-index.html.
Опять же, на мой вкус, это не страшно. Размер стандарта C++ последних версий — вот где бюрократия.
Ставить в ряд с Ruby и Go естественно не стоит — ниши и цели разные. Но вот сравнить с близкими альтернативами по предложенным параметрам — почему нет. Собстенно это автор и предлагает, вроде бы.
P.S. кто-то похоже обиделся на один из моих комментариев выше и теперь нормально цитаты не отображаются — прошу прощения.

Nagg
29.06.2015 02:07Такие же штуки в Java (stream) и C# (linq) выглядят ни разу не лучше. Вы сравнили теплое с мягким.
deniskreshikhin
29.06.2015 02:20Во-первых C#, Java идут почти рядышком в графике. Rust же получается проще Ruby, JS, C. Типа прост почти как Go) Комментарий об этом если что)
Во-вторых, в Java и C# есть итераторы, и они определяются так же просто как и в обычных языках, зачем вы stream и linq приплели — не понятно.Nagg
29.06.2015 02:26Я так понимаю вас испугал в Rust список шаблонных методов типа skip,take, max, zip — почти 1 в 1 тоже самое что содержиться в классе Enumerable С# (и stream для java) который linq. Так после реализации их в том же Enumerable они не кажутся мне страшными в итераторе в Rust.
deniskreshikhin
29.06.2015 02:55Да ничего меня не пугает) Я программирую на rust'е уже больше года, а C++ так вообще 5 лет)
Просто что касается C++ есть относительно элегантное объяснение почему эта структура выглядит именно так. (На самом деле это тоже трейт, а не структура, в терминологии Страуструпа)
В rust'е же каждое решение это почти «a riddle wrapped in a mystery inside an enigma: but perhaps there is a key», и этот ключ может быть тоже не менее загадочным для новичка понятием вроде — заимствования, времени жизни и т.п. С другой стороны, огромное значение имеют не только абстракции, но низкоуровневые нюансы. Так числа типа int считаются упорядоченным множеством (Ord), а типа float частично упорядоченным (PartialOrd) в соответствии с IEEE 754 )))
Итератор я привел как пример, т.к. в современных языках очень многое строится вокруг этой концепции вне зависимости от того является язык ООП или не совсем.
Опять же — я не писал ничего про Java или C# в комментарии. Я писал про Rust и C++, и они совершенно не в том отношении находятся в списке, как оно должно быть.
Каким образом ваши linq и stream это опровергают для меня загадка если честно.
senia
29.06.2015 02:30Во-вторых, в Java и C# есть итераторы, и они определяются так же просто как и в обычных языках, зачем вы stream и linq приплели — не понятно.
В Java и C# данные операции отдельно по историческим причинам. Изначально их там вообще не было. В той же scala, где библиотека коллекций писалась сразу высокоуровневой, похожий набор методов есть в Iterable.areht
05.07.2015 18:33-2Во-первых, в C# итератор — это не коллекция.
И причины у этого не исторические, а просто потому, что итератор — это не коллекция.
withkittens
05.07.2015 19:27Так никто не утверждал, что итератор — коллекция.
Речь шла про «голый» итератор и набор ништяков в виде Linq.
Мол, в Rust итератор — этоmove_nextплюс функциональные ништяки.
А в C# — отдельноMoveNext, а потом отдельно появился Linq.areht
05.07.2015 19:591) Скажите, в Rust
(1..1000)
.filter(|&x| 1 == 1)
.filter(|&x| 1 == 1)
.first()
создаст 3 копии коллекции в памяти (надеюсь в синтаксисе не наврал)? и по каждой из них сделает проход?
в C#.
Enumerable.Range(1,1000)
.Where(x => 1 == 1)
.Where(x => 1 == 1)
.First();
— нет и нет, потому, что Where возвращает не коллекцию.
Итератор — это не коллекция, функциональные ништяки тут ни при чём.
2) habrahabr.ru/post/147363 — а в Rust как «функциональные ништяки» добавляют?senia
05.07.2015 20:36Да причем тут вообще коллекции? Вы среагировали на «библиотека коллекций»? Ну уж извините, так это называется в scala.
Сам интерфейс Iterator (Iterable, etc) ничего не говорит о создании промежуточных коллекций. Также как он ничего не говорит про однопоточность/многопоточность обработки.
Вопрос номер 1 некорректен. Ибо с таким интерфейсом итератора всегда можно написать какой-нибудь LazyRange, не создающий промежуточных коллекций.
В той же scala, где весь набор таких методов прямо в Iterable (на самом деле в еще более общем интерфейсе — Traversable),
(1 to 1000) .filter(x => 1 == 1) .filter(x => 1 == 1) .head()
создаст 2 промежуточные коллекции, а
(1 to 1000).view .filter(x => 1 == 1) .filter(x => 1 == 1) .head()
промежуточных коллекций не создаст.areht
05.07.2015 21:00> Ибо с таким интерфейсом итератора всегда можно написать какой-нибудь LazyRange, не создающий промежуточных коллекций.
Формально — да.
Вопрос не в том, что можно создать, а в том, как с этим работать. Если мне приходит IEnumerable — я знаю, например, что Count() может быть достаточно долгим, а пытаться обойти больше 1 раза — плохая идея. И это принципиально влияет на выбранные алгоритмы.
LazyRange написать вы можете, но выставив его как абстракцию Iterator вы подложите грабли любому, использующему ваш код.splav_asv
05.07.2015 21:03+1LazyRange написать вы можете, но выставив его как абстракцию Iterator вы подложите грабли любому, использующему ваш код.
В Python так вполне живут.areht
05.07.2015 21:13ну как… Может и живут. Если клепать сайтики с полусотней записей на страничку — без разницы, конечно. Python в энтерпрайзе, с переколбашиванием миллионов записей, мне не попадался.
Только C# писался для других целей, поэтому там так не делают.senia
05.07.2015 21:24Linq в C# это, несомненно, гениальная библиотека. Но это именно гениальное дополнение к жутковатому легаси, а не нечто, идеальное во всех отношениях. Не стоит рассматривать ее как единственно возможный путь.
areht
05.07.2015 21:38а это не совсем про Linq. Или совсем не про Linq.
IEnumerable и ICollection (IQueryable) — это не часть Linq, это абстракции структур данных, поддерживающие (располагающие) к разным кейсам использования.
в Rust этого разделения нет.
Linq не идеален, но лучшего (для моих задач) я пока не видел. И я не считаю его дополнением к легаси.senia
05.07.2015 21:51Обратит внимание на коллекции в scala. На мой взгляд это пока один из лучших подходов, хоть и не без недостатков.
Коллекции в scala сохраняют как можно большую часть исходного контракта и при этом очень хорошо расширяются. Например
"abc".filter(_ != 'b') // "ac"areht
05.07.2015 22:33Надо посмотреть поближе, но именно такой extension метод написать на C# не сложно.
Ну, то есть буквально
new String(«abc».Where(_ => _ != 'b').ToArray()); // вот это уже легасиsenia
05.07.2015 22:44В scala один из принципиальных моментов — отсутствие этих «ToArray». То есть они там есть (есть даже обобщенный метод to: «abc».to[Vector]), но использовать их обычно не надо.
Ну и да, строка в scala — это как раз легаси строка из java.
Огромное преимущество подхода scala перед Linq — возможность работы с персистентными коллекциями благодаря переопределению методов, чего не добиться с extension methods.areht
05.07.2015 22:57Я не могу сказать почему конструктор строки не принимает enumerable, но это точно не проблема linq
senia
05.07.2015 23:00Вы где-то видите в моем коде конструктор строки?
areht
05.07.2015 23:25> отсутствие этих «ToArray»
Я думаю вы про мой кодsenia
05.07.2015 23:48Именно. В моем коде не было «mkString». Вот тут нет «toArray»:
Array('a', 'b', 'c').filter(_ != 'b') // Array(a, c)areht
06.07.2015 00:43«abc».filter(_ != 'b') — возвращает строку «ac»?
«abc».view.filter(_ != 'b') — уже не вернёт строку(должно же быть ленивым?)? И не массив? А как получить строку/массив?senia
06.07.2015 00:58«abc».view.filter(_ != 'b').force
areht
06.07.2015 01:17> .force
Тот же ToArray(), вид сбоку. Хотя строками через Linq работать не очень красиво (но в общем то и не надо).
А вот идея отделить ленивое от неленивого мне нравится.senia
06.07.2015 01:25На все типы данных ToType не напасешься. Сам Linq довольно беден на методы ToType. ToSet, например, нет.
Да и сам код с force не упоминает конкретный тип, что позволяет при необходимости сменить тип только в одном месте.areht
06.07.2015 01:42> На все типы данных ToType не напасешься. ToSet, например, нет.
Внезапно, мне почему-то объекты нужны в правильном порядке. Я не помню когда Set в последний раз использовал.
> Да и сам код с force не упоминает конкретный тип
Разницы между ToArray и ToList с практической стороны тоже немного. Я себе не представляю, что бы метод принимал Array, перемылывал, возвращал Array, а потом я вдруг захотел бы что бы он принимал List и возвращал List.
И оба они реализуют IList.
Ну, наверное неплохо, но и бесполезно.
Да что хорошего мне бы мог вернуть
new Dictionary<int, int>().Select(x => x.Value).force
или
new HashSet().OrderBy(x => x.Value).force
?senia
06.07.2015 01:52Внезапно, мне почему-то объекты нужны в правильном порядке. Я не помню когда Set в последний раз использовал.
У вас какой-то очень специфичный узкий круг задач, что вам не нужен Set.
new Dictionary<int, int>().Select(x => x.Value).force
Зачем тут force? Тут же нет ленивых коллекций.areht
06.07.2015 01:55new Dictionary<int, int>().Select(x => x.Value) — это IEnumerable<`Int>
senia
06.07.2015 02:00И? force — метод исключительно ленивых коллекций, позволяющий превращать их в неленивые.
У Iterable его просто нет.areht
06.07.2015 02:14> У Iterable его просто нет.
о как…
А new HashSet().OrderBy(x => x.Value) — это на ленивый HashSet потянет?
> У вас какой-то очень специфичный узкий круг задач, что вам не нужен Set.
Возможно. Наверное на нашем workflow его заменяет ToDictionary() и
.Select(x => x.prop)
.Distinct()
И результат — immutable, строить для него Set — это как-то…senia
06.07.2015 02:24это на ленивый HashSet потянет
У Set нет orderBy. Хотите сортировку — приводите к Seq: mySet.seq
Distinct
distinct и в scala есть (в Seq).
Но мне Set обычно для быстрой проверки нужен. В C# я его тоже Dictionaty заменял, но это не от хорошей жизни. Выкрутиться-то всегда можно.
И результат — immutable
В scala все коллекции неизменяемые по умолчанию. Мутабельные коллекции еще импортировать надо. Их стараются без необходимости не использовать.
senia
05.07.2015 21:13Какая связь с Count вообще? Используйте наследника Iterable с гарантированной сложностью Size.
Iterable — самый базовый контракт. Хотите дополнительных условий — используйте наследников.
Какие еще грабли? Контракт не нарушен. Более того, как ниже уже отметили, в расте по умолчанию эти операции ленивые.areht
05.07.2015 21:22> Контракт не нарушен
а у вас контракт подразумевает ограничение Count() по сложности?
в C# разумно предполагать, что он отличается для Enumerable и коллекции.
в Rust — видимо, «хрен его знает».
Это просто более слабый контракт.
> Используйте наследника Iterable с гарантированной сложностью Size.
А есть стандартный?withkittens
05.07.2015 21:53Есть Iterator, где есть
count()с O(n) иsize_hint()(предполагаемая верхняя граница; может быть неизвестна).
И есть ExactSizeIterator — An iterator that knows its exact length.areht
05.07.2015 22:48Толково. А ExactSumIterator есть?
Ну то есть мне надо посчитать среднее по данным из чужого кода.
В c# я могу написать функцию, хорошо работающую примерно в 100% случаев, даже если данных — терабайт. Примерно так(да, я знаю что int не бесконечен):
public int Avg(IEnumerable enumerable)
{
var collection = enumerable as ICollection;
if (collection != null)
{
return collection.Sum() / collection.Count;
}
var query = enumerable as IQueryable;
if (query != null)
{
return query.Sum()/query.Count();
}
var sum = 0;
var count = 0;
foreach (var i in enumerable)
{
sum += i;
count++;
}
return sum/count;
}
что мне делать с ExactSizeIterator я пока не понял (только не надо упоминать, что считалка среднего где-то встроена. Это пример)withkittens
05.07.2015 23:14Не очень удачный пример:
Sum()— O(n), а коли так, мне видется, можно заодно и посчитатьcount.
Вот пример на Rust.areht
06.07.2015 00:20Я этим примером хочу показать, что вы не знаете, когда выгоднее collection.Sum(), а когда foreach. Поэтому мало показать 2 варианта, надо показать как вы выбираете какой применить.
foreach эквивалентен вашему avg2, худший случай.
collection.Sum() — O(n), но коллекция по смыслу неленива (для ленивых есть другие интерфейсы), поэтому всё в оперативной памяти, никаких LazyRange оберток вокруг терабайтного файла тут быть не должно. ExactSizeIterator же подобного не обещает? То есть Avg1() не лучше foreach/avg2, можно выкинуть (или надеяться, что у ExactSizeIterator sum() как-то оптимизирован, что наивно).
query.Sum() — выполняется, скорее всего, на стороне БД (возможно O(1)) и мне не надо терабайт данных вычитывать. Вот тут Sum — очень выиграет, даже если в БД это O(n).splav_asv
06.07.2015 10:12Всё равно, если ваш источник данных/коллекция не позволяют получить нужную сложность — ничего не поможет. Если поддерживают — в любом случае будет использоваться оптимизированный конкретный вариант.
Ничто не мешает доопределить свои варианты Iterator, обязывающие иметь нужную сложность конкретных методов, если вам хочется статически это гаратнтировать.
Из коробки есть только наиболее общие. По понятным причинам, все возможные сочетания засунуть в std просто не реально.areht
06.07.2015 12:00В общем случае я не могу сделать итератор, который посчитает collection.Sum() / collection.Count() за один проход, для этого нужен foreach. Вы предлагаете 2 раза проходить или не пользоваться оптимизированы вариантами?
С подходом ExactSizeIterator в стд добавить все комбинаторные комбинации действительно нельзя (хотя и в шарпе тут не сильно удобно).
И я не хочу никого обязывать иметь сложность, для этого придется предрасчитывать показатели под мой алгоритм извне (а фактически реализовать на 99% подсчет среднего в итераторе). А если алгоритм поменяется — вызывающий код переписывать?nsinreal
06.07.2015 12:53+1В общем случае я не могу сделать итератор, который посчитает collection.Sum() / collection.Count() за один проход, для этого нужен foreach
Да что вы такое говорите.
collection.Aggregate(new { sum = 0, count = 0 }, (item, total) => new { sum = total.sum + item, count = total.count + 1 })
lair
06.07.2015 13:03На больших объемах GC расстраивается от такого, кстати. Спасает нормальный класс и изменяемые свойства.
areht
06.07.2015 18:04> Да что вы такое говорите.
1) я про Rust и итератор, а не про Linq
2) я про collection.Sum() / collection.Count(), а не про (item, total) => new { sum = total.sum + item, count = total.count + 1 }.
3) Aggregate не оптимизируется вообще никак.
withkittens
05.07.2015 20:401. Коллекция останется в единственном экземпляре. Методы filter создают маленькие структурки с двумя ссылками на коллекцию-источник и предикат.
2. Я под «функциональными ништяками» имел в виду набор методов вроде filter, map, fold, first, nth, sum и т.д.
Если в C# — это «надстройка» над IEnumerable, то в Rust набор входит в трейт Iterator, наравне с move_next.
По ссылке монада Maybe. Аналог в Rust — тип Option.withkittens
05.07.2015 20:521. Должен дополнить: в Rust iterator adaptors (к коим как раз относится filter и проч.) ленивые. Их нужно пнуть, например, собрать в другую коллекцию или проитерировать (for… in ..). Иначе фактически ничего не произойдёт, а Rust покажет warning.
areht
05.07.2015 21:08> Методы filter создают маленькие структурки с двумя ссылками на коллекцию-источник и предикат.
Посмотрите ответ выше про LazyRange.
> Аналог в Rust — тип Option.
нене, я спросил «как расширять», а не «есть ли аналог». Потому что Maybe то «наравне», а в Rust — фиксированный интерфейс.senia
05.07.2015 21:22То, что описано в статье, это не функциональные ништяки, а extension methods. Причем их использование там крайне неудачное.
В даном случае стоило бы использовать Option/Maybe, а не неявную возможность null.areht
05.07.2015 21:27Это просто пример под руками. Весь Linq — это extension methods.
Ещё раз, новые функциональные ништяки в Rust добавить нельзя?senia
05.07.2015 21:34Весь Linq — это extension methods.
Для Linq-подобных интерфейсов extension methods не нужны. Нужны они только если надо навесить это поверх легаси.
Что вы подразумеваете под «новые функциональные ништяки»?areht
05.07.2015 21:49> Нужны они только если надо навесить это поверх легаси.
Соглашусь, всю эту фигню с наследованием, traits, mixins можно заменить на старый добрый god objectsenia
05.07.2015 21:54Почему вы считаете extension methods единственным подходом?
В скала есть stream api. Кстати, тоже над легаси. И никаких extension methods.
В scala есть аналог extension methods, но в коллекциях он не используется ибо не нужно.
В Rust эти методы тоже в Iterable.areht
05.07.2015 22:21Я не считаю его единственным подходом. Я считаю его подходом не хуже.
Хотя бы потому, что IEnumerable реализуется без наследования проще, чем интерфейс с полусотней методов. А «ибо не нужно» аргументом не считаю.senia
05.07.2015 22:27+1Чем же проще? У этого интерфейса всего 1 абстрактный метод.
Зато подход с extension methods не позволяет переопределять методы, например сделать sum по range константной сложности, как в Rust и Scala.
withkittens
05.07.2015 22:27Хотя бы потому, что IEnumerable реализуется без наследования проще, чем интерфейс с полусотней методов.
На всякий случай уточню, что в Rust эта полусотня методов бесплатна :) Из обязательных для реализации толькоnext().
withkittens
05.07.2015 21:35М, кажется, я вас понял.
trait AwesomeThing { // ... } impl<T: Iterator> AwesomeThing for T { // ... }
и всё, что «умеет итерироваться» — коллекции, адапторы и т.д. — будет поддерживать и новый ништяк.
PokimonFromGamedev
29.06.2015 01:37-7В чем Go проще C#?
Тем что в нем нет исключений? Как результат у вас будет весь код усеян проверками ошибок. Что несомненно сделает его сложнее.
Исключения упрощают обработку ошибок.
Тем, что там нет LINQ, который экономит мое время и делает код понятнее?
А что на счет метапрограммирования? Где шаблоны или дженерики? Где работа с кодом как с данными (деревья выражений)? Как создавать удобные, универсальные API интерфейсы в Go? Или по вашему хорошее Api это сложно и ненужно?
То что в Go вырезали циклы или скобочки, это вообще никого не волнует. Это не делает язык проще.
Java, C# не просто так имеют все свои возможности. Каждая из них направлена на то, чтобы сделать код проще.
Почему по вашему, вырезав все эти улучшения можно получить лучший язык?
Мои пункты описывающие «простой» современный язык:
* Простая и надежная обработка ошибок. (Лучше исключений ничего не придумали)
* Работа с данными как в памяти, так и в других источниках (Лучше LINQ ничего не придумали)
* Простое использование многопоточности и асинхронности (У C# это довольно сложно получилось не смотря на все старания)
* Выполнение правила: если программа скомпилировалась — она работает (к сожалению мы еще далеки до этого)
* Возможность писать большие проекты. Пока вы пишите HelloWorld — можете рассуждать о простоте сколько хотите. Но как только количество строк исчисляется миллионами или десятками миллионов, все модные «простые» языки сдуваются. Остается Java да C# и нет альтернативы.
* Наличие тулзов и библиотек. Что лучше, простой язык или кнопка «Создать приложение»?divan0 Автор
29.06.2015 01:50+6После вашего комментария я понял, что мой пост вобщем-то адресовался таким людям, как вы, у которых понятие «простота» кардинально расходится с моим.
Отвечу вам так — вы смотрите на вопрос «простоты» с позиции «простота для меня». Go смотрит на этот вопрос с позиции «простота для всех».
Вы можете как угодно сильно верить, что «исключения — самый простой способ обработки ошибок», но это будет справедливо лишь в рамках вашего опыта и вашей привычки. А уже для меня, к примеру, не справедливо — для меня код, написанный с исключениями, всегда сложнее читать и понимать где и как обрабатываются ошибки, и обрабатываются ли вообще. Не говоря уже о том, что 80% кода, который мне встречался, использует исключения не для обработки ошибок, а для «выкинуть и забыть об этом ненужном случае», что на практике приводит к некорректной и неправильной обработке последних.
Возможно у вас опыт работы сравним с опытом Кена Томпсона или Роба Пайка — тогда я не вправе дискутировать. Но авторы Go утверждают, что исключения и вправду имеют стимул к неверному их использованию, что приводит к увеличению накладной («привнесенной») сложности в результате. Я им верю, особенно учитывая то, что это 100% совпадает с моим личным опытом.
Но вообще да, я хотел написать пост, который бы людям с вот такими, как ваши, взглядами, немного делал понятнее, что подразумевается под «простотой» в Go. Но слишком мало конкретно этому посвятил внимания, мой промах.
Tiendil
29.06.2015 08:29-1Не говоря уже о том, что 80% кода, который мне встречался, использует исключения не для обработки ошибок, а для «выкинуть и забыть об этом ненужном случае», что на практике приводит к некорректной и неправильной обработке последних.
Отвечу вам так — вы смотрите на вопрос «простоты» с позиции «простота для меня». Go смотрит на этот вопрос с позиции «простота для всех».
Не попадайтесь на этот же крючёк.
Исключения и возвращаемые коды закрывают разные аспекты обработки ошибок. И те и те нужно уметь готовить. Я убеждён, что со временем исключения в Go появятся, когда будет осмысленна текущая философия языка.divan0 Автор
29.06.2015 09:20+1Я убеждён, что со временем исключения в Go появятся, когда будет осмысленна текущая философия языка.
Она более, чем осмыслена еще 5 лет назад.
Вы, видимо, безоговорочно считаете отсутствие исключений признаком незрелости языка и непонимания глубины темы, игнорируя все слова авторов Go на эту тему.Tiendil
29.06.2015 09:43Она более, чем осмыслена еще 5 лет назад.
5 лет назад Go только-только заявил о себе, он в принципе в то время не мог иметь законченный вид. Набор же нововведений в нём достаточно велик, чтобы требовать годы их проверки практикой.
Если Вы считаете, что можно на раз выдать идеальную большую систему без недостатков и недоработок, то Вы сильно ошибаетесь. Любая сложная система со временем эволюционирует. По-другому не бывает. И Go не раз ещё изменится.
В C нет исключений и я его считаю зрелым языком. Не читайте между строк.divan0 Автор
29.06.2015 09:49Извините, но философия Go была фактически заложена в первый же день, и первые три года обсуждался и оттачивался дизайн языка, а не его философия.
Tiendil
29.06.2015 09:56+3Критерий истинности любой идеи — практика.
Естественно, что любая вещь создаётся на основе некоторых идей. Но утверждать, что практика применения вещи не может изменить сами идеи — это несколько самонадеянно.divan0 Автор
29.06.2015 10:01Мне нравится, как вы умело манипулируете утверждениями, виден опыт )
А так, да, насчет практики согласен, и это именно то, где Go однозначно хорош.
khim
29.06.2015 12:22+15 лет назад Go только-только заявил о себе, он в принципе в то время не мог иметь законченный вид.
Некоторые его аспекты — может быть. Но вот конкретно исключения — нет, решение об их применении было принято чуть не двадцать лет назад людьми, которые работали как с языками «зараженными» исключениями (Java, Python), так и с языками, где был выбор (C++) — причём в последнем случае выбор был сознательно сделан в пользу неиспользования исключений.
Вывод по результатам более, чем десятилетнего эксперимента на кодовой базе в десятки миллинов строк и тысячах разработчиков вполне однозначен: исключения послали в *опу. Правильно это сделали или неправильно — можно обсуждать долго. И обсуждалось это тоже долго. Потому что все понимали, что это решение можно принять только один раз:For existing code, the introduction of exceptions has implications on all dependent code. If exceptions can be propagated beyond a new project, it also becomes problematic to integrate the new project into existing exception-free code. Because most existing C++ code at Google is not prepared to deal with exceptions, it is comparatively difficult to adopt new code that generates exceptions.
Замените здесь «C++» на «Go» и вы поймёте почему даже если вдруг Go появятся исключения (ну там, если разработку вдруг передадут в Микрософт, мало ли что) их в Гугле использовать не будут — а значит пока разработка Go контролируется людьми из Гугла их в языке не будет тоже.lair
29.06.2015 12:31+1Вот и прекрасная иллюстрация того, почему «простота в Go» — это не «простота для всех», а «простота для Google».
divan0 Автор
29.06.2015 15:25+1Google — это авангард разработки ПО, они рождают новые технологии и языки, сталкиваются с проблемами и масштабами, с которыми другие столкнутся через 10 лет. Поэтому да, те, кому хватает для всех своих задач Perl-а и «всего за 3 часика написать деплой скрипт на баше» — те, конечно, будут считать точку зрения Google на проблематику разработки странной.
lair
29.06.2015 15:28Google — это авангард разработки ПО, они рождают новые технологии и языки, сталкиваются с проблемами и масштабами, с которыми другие столкнутся через 10 лет.
Ну, мы же все понимаем, что это, гм, весьма тенденциозное заявление.
Но самое главное даже не в этом, а в том, что — даже если это так — большая часть разработчиков и через десять лет не столкнется с проблемами Google (потому что маленьких компаний больше чем больших), и, вероятно, им гугловский подход и не полезен?
lair
29.06.2015 09:41+1А откуда Go берет информацию о «всех»? Из вашего описания выходит только что это «простота как ее понимают авторы языка», что от «простоты для меня» отличается только авторитетом.
divan0 Автор
29.06.2015 09:45Из реального опыта, как из команд внутри Google, так из всего прошлого опыта Пайка, Томпсона и ко. Не знаю, я себя не ставлю выше них, и легко могу поверить, что они о «хороших» и «плохих» практиках понимают гораздо больше меня.
lair
29.06.2015 11:51А это все равно не имеет отношения ко всем, так же как олигократия и меритократия не имеет отношения к демократии. Это опыт конкретных людей в конкретном сообществе с конкретной культурой (точно так же как C# написан на основании реального опыта внутри MS). Дальше можно бесконечно обсуждать, правильно ли Пайк и Томпсон понимают простоту, или нет, но в итоге это сведется к апеляции к авторитету.
khim
29.06.2015 12:44Ясно «простота для меня» и «простота для всех» — достаточно сложно определяемые понятия, но разницу в подходах достаточно точно описывают слоганы Perl'а и Python'а. «Простота для меня» — это есть больше одного способа сделать это, а «простота для всех» — это Должен быть один — и желательно только один — очевидный способ сделать это. Грубо говоря «простота для меня» — это сложность написания программы, а сложность для всех — это сложность чтения исходников незнакомой программы.
Понятно, что всегда есть некоторый конфликт между этими двумя вещами (чем меньше у тебя понятий в языке, тем длиннее оказывается программа, что тоже усложняет её чтение) и понятно, что иногда способы оказываются неудачными и «только один способ» меняется со временем (тот же Python изначально предлагал только один способ обработки командной строки, потом появился более очевидный способ, а теперь есть ещё более очевидный… но потом от одного из трёх всё-таки отказались), но среднем — чем больше тебе дают свободы тем проще и понятнее программу писать и тем сложнее её читать.
Хорошим примером является отказ разработчиков Go от Style Guide: пробелы расставляются так, как их расставит gofmt (и это не обсуждаются), а более сложные вещи описываются в мануалах и туториалах, а не в отдельно существющем Style Guide.lair
29.06.2015 12:52+1чем больше тебе дают свободы тем проще и понятнее программу писать и тем сложнее её читать.
Это утверждение недоказуемо.
Понимаете ли, удивительный факт, но увеличение числа понятий в естественных языках почему-то не усложняет чтение литературы; более того, это увеличение, напротив, позволяет выражать более сложные вещи проще. Почему вы считаете, что в языках программирования наоборот? (мы, естественно, говорим о чтении человеком, а не анализе компьютером)
neolink
29.06.2015 12:54я думаю правильнее сравнивать с чтением литературы на не родном языке. Так вот это как минимум в среднем становится сложнее, чем больше там разных слов и по разному составленных предложений
lair
29.06.2015 12:56Так вот это как минимум в среднем становится сложнее, чем больше там разных слов и по разному составленных предложений
Только в том случае, если вы владеете языком ниже определенного уровня. Кстати, для родного языка тоже верно.khim
29.06.2015 13:06Только в том случае, если вы владеете языком ниже определенного уровня. Кстати, для родного языка тоже верно.
Вы всегда можете пропустить какое-нибудь двадцать пятое значение одного из сотен тысяч слов, а всякие идеомы легко пролетают мимо людей, даже если вы являетесь носителем.
Разбираться во всех этих аллегориях, смаковать их — интересное времяпровождение, но оно ну никак не делает чтение книг проще.
Наоборот, книги, которые написаны просто обычно считаются скучными, пресными и неинтересными. Потому что их задача — как раз занять ваш мозг. При чтении же программ ваш мозг и так достаточно занят, совершенно нет никакого смысла загружать ещё и аллегориями языка.lair
29.06.2015 13:10Наоборот, книги, которые написаны просто обычно считаются скучными, пресными и неинтересными.
Кем считаются? Я с таким суждением ранее не сталкивался.
khim
29.06.2015 13:01+1Понимаете ли, удивительный факт, но увеличение числа понятий в естественных языках почему-то не усложняет чтение литературы
Усложняет. Без вариантов. Сравните книжки для детей и взрослых.
Вам может быть приятнее читать книги, написанные богатым языком, интереснее, но «проще»? Ни в коем случае.lair
29.06.2015 13:17+2Сравните книжки для детей и взрослых.
Найти вам теорию относительности, изложенную в словах не длинее четырех букв?
Хотя, конечно, книжки для детей дошкольного (и иногда раннего школьного возраста) иногда используют упрощенный словарь, но вы правда хотите ориентироваться на программистов с таким уровнем развития?
Вам может быть приятнее читать книги, написанные богатым языком, интереснее, но «проще»? Ни в коем случае.
Именно проще. Введение нового понятия, более точно отражающего суть объекта или явления, упрощает изложение, а не усложняет его.
Попробуйте в книге по программированию заменить понятие «компилятор» на «программу, выполняющую перевод из языка высокого уровня в язык более низкого уровня». Везде. Количество понятий, несомненно, уменьшится, но упростится ли текст?
lair
29.06.2015 13:21увеличение числа понятий в естественных языках почему-то не усложняет чтение литературы
Я тут, конечно, излишне категоричен. Правильнее добавить «в определенных пределах».
lair
29.06.2015 12:02+2Ну давайте еще раз вернемся к обработке ошибок в Go.
- Есть ли в go механизм, гарантирующий невозможность скомпилировать код, не проверяющий возвращаемый
error, или хотя бы выдающий предупреждение об этом? - Правильно ли я понимаю, что ошибки «изнутри» языка (например, nil dereferencing) при этом кидаются как
panic, а не какerror?
(PS Хотя вотdefer— это круто)khim
29.06.2015 12:59Есть ли в go механизм, гарантирующий невозможность скомпилировать код, не проверяющий возвращаемый
Нет, так как задача — не заставить человека сделать что-то, а сделать так, чтобы ошибка была видна. «Просто так» проигнорировать ошибку не получится, так как у вас программа не скомпилируется с сообщением о неиспользованной переменной. Всегда можно использовать «blank identifier» (подчёркивание), чтобы «проглотить» ошибку без жалоб, но это оставляет «следы» в коде, что, собственно, и требуется.error, или хотя бы выдающий предупреждение об этом?
Правильно ли я понимаю, что ошибки «изнутри» языка (например, nil dereferencing) при этом кидаются как panic, а не как error?
Конечно. Как вы можете обработать nil dereference? И зачем? Это только разработчик может сделать увидев Stack Trace.lair
29.06.2015 13:08+1Нет, так как задача — не заставить человека сделать что-то, а сделать так, чтобы ошибка была видна. «Просто так» проигнорировать ошибку не получится, так как у вас программа не скомпилируется с сообщением о неиспользованной переменной. Всегда можно использовать «blank identifier» (подчёркивание), чтобы «проглотить» ошибку без жалоб, но это оставляет «следы» в коде, что, собственно, и требуется.
Я искренне подозреваю — поправьте меня, если это не так — что нет никакого способа отличить blank identifier на местеerrorот blank identifier на месте любого другого возвращаемого значения. Ведь так?
Конечно. Как вы можете обработать nil dereference? И зачем? Это только разработчик может сделать увидев Stack Trace.
Вот мы и пришли к тому, что в Go, фактически, два механизма обработки ошибок —errorиpanic. Выводы из этого занятны, но, в общем случае, сводятся к тому, что обработка ошибок в Go концептуально не отличается от аналогичной в других языках с поддержкой exceptions.divan0 Автор
29.06.2015 15:36Вот мы и пришли к тому, что в Go, фактически, два механизма обработки ошибок — error и panic. Выводы из этого занятны, но, в общем случае, сводятся к тому, что обработка ошибок в Go концептуально не отличается от аналогичной в других языках с поддержкой exceptions.
Спеку языка не читай, делай желаемые для себя выводы :) Ок.lair
29.06.2015 15:38Что в спеке языка противоречит сказанному мной? Механизм обработки ошибок один?
panicнельзя перехватить или бросить пользовательским кодом?
powerman
30.06.2015 09:45Технически Вы правы, их два. Но один (исключения) искусственно ограничен в возможностях (отсутствие try приводит к тому что минимальная единица убиваемая panic-ом это функция, требование вызывать recover непосредственно в defer-функции усложняет использование вспомогательных функций для обработки исключений, соглашение о том, что panic никогда не должен покидать пределы своего пакета приводит к тому что окружающий код в принципе совершенно не готов обрабатывать исключения выкинутые вашим кодом). В результате этих ограничений второй механизм обработки ошибок вроде бы и есть, но в реальном коде пользоваться им получается очень ограниченно. Авторы Go не стесняются и сами его использовать для обработки ошибок в случаях когда нужно по-проще раскрутить стек вызовов, например при рекурсивном парсинге. В общем и целом по факту реально механизмов обработки ошибок в Go… может и не один, но и никак не два — скажем, их 1?. :)
lair
30.06.2015 11:16Важно, что их больше одного — и теперь, вместо того, чтобы получить единообразную (и централизованную в нужных мне границах) обработку ошибок, я должен делать это двумя разными способами.
neolink
30.06.2015 11:22в Go разделены ошибки и исключения.
Ошибки это предусмотренные состояния, файл не открылся, сеть упала и т.п., то что можно обработать и жить дальше.
Паника, это что-то что не входит в нормальную работу и после нее возможно стоит вообще оставить выполнение программы: выход за границу массив, ошибка выделения памяти, дедлоки и т.п. то есть то что в месте непосредственного вызова не решается, а перехватывается каким то совсем абстракным кодом, который грубо говоря залогирует панику, сдампит что сможет на диск и завершит приложение.
ЗЫ панику бывает ещё используют для раскручивания стека, но вот гугл от этого уходит кстатиlair
30.06.2015 11:28Это все предположения и намерения. Фактически же для двух разных задач одно и то же поведение может быть как ожидаемой ошибкой, так и исключительной ситуацией. Это с одной стороны, а с другой, если мне по каким-то причинам нужно поймать все ошибочные состояния (исключительное состояние является ошибочным, но не обязательно наоборот), мне нужно обрабатывать n+1 разную ситуацию (где n — это количество потенциально ошибочных вызовов в скоупе).
neolink
30.06.2015 11:48в смысле предположения?
Если вы не обработаете err в случае открытия файла например программа все равно дальше упадет при обращении к nil, так что не вижу проблемы с разным поведением
в Go ошибки не ловят, ошибка это просто некое значение. Вот вы вызываете некий метод, у него есть error вы его обрабатываете, хотите выкинуть его наверх, выкидывайте.
Хотите возвращать прям свой объект ошибки (ну вот хотите), напишите defer который будет оборачивать err если он != nil
Я так понимаю вы хотели что-то такое:
func test() (b byte, err error)
{
if err = some_method; err != nil {
return
}
}
С одной стороны кода становится немного больше (на первый взгляд), но в коде сразу видно где бывают ошибки и что с ними происходит.
Ну и самое главное — «никто не обрабатывает исключения», именно для нивелирования этого и придумали всякие аннотации с информацией о том что метод что-то там генерирует и т.п.
А ещё в библиотеках нужно оборачивать исключения в свой тип исключений иначе его могут не правильно поймать. И в целом делать это правильно вызывая из своего кода чужой будет даже тяжелее чем обрабатывать error который приходит, как одно из значений.
В общем то как это сделано в Go не серебрянная пуля, собственно как и исключения, но причины у этого вполне обоснованные.lair
30.06.2015 11:58в смысле предположения?
В том смысле, что мы хотим, чтобы вызываемая библиотека работала так, и предполагаем, что программист так написал. Но в реальности мы не знаем, какие ситуации как он трактовал.
Если вы не обработаете err в случае открытия файла например программа все равно дальше упадет при обращении к nil, так что не вижу проблемы с разным поведением
Это если я результат использую, а не прокидываю дальше. Но даже если использую — я получу panic в другом месте, и happy debugging.
в Go ошибки не ловят, ошибка это просто некое значение.
В данном случае «ловить» = «обрабатывать».
Ну и самое главное — «никто не обрабатывает исключения», именно для нивелирования этого и придумали всякие аннотации с информацией о том что метод что-то там генерирует и т.п.
А это не надо нивелировать. Необработанное исключение долетит доверху и сложит приложение. Типичный fail early.
А ещё в библиотеках нужно оборачивать исключения в свой тип исключений иначе его могут не правильно поймать.
Зачем? Вы про какой-то конкретный язык говорите?
В общем то как это сделано в Go не серебрянная пуля, собственно как и исключения, но причины у этого вполне обоснованные.
Ну вот я этого обоснования пока не осознал. И, что важнее, я точно не считаю, что то, как сделано в Go — проще (или «меньше понятий», ага).neolink
30.06.2015 12:23> я получу panic в другом месте, и happy debugging.
я вам на конкретный вопрос отвечал про ожидаемую ошибку. не хотите обрабатывать, не обрабатывайте, оно все равно упадет
> Необработанное исключение долетит доверху и сложит приложение
Так. в том то и цель чтобы не было не обработанных ошибок, для складывания есть panic.
> Зачем? Вы про какой-то конкретный язык говорите?
затем, что вы должны понимать что происходит иначе когда у вас закончится память, у вас исключения повалятся например в том же блоке catch хотя по идее не должны.
> И, что важнее, я точно не считаю, что то, как сделано в Go — проще (или «меньше понятий», ага).
а я кстати не говорил, что это проще, вообще обработка ошибок это то что на самом деле мало кто делает, потому что это скучно, сложно и не интересно и такая явность их возврата как раз для мотивации этой обработки и делаласьlair
30.06.2015 12:43я вам на конкретный вопрос отвечал про ожидаемую ошибку. не хотите обрабатывать, не обрабатывайте, оно все равно упадет
Только не там, и не так, как ожидалось. Это плохо. А еще же бывают операции, которые никакого ожидаемого результата не возвращают.
Так. в том то и цель чтобы не было не обработанных ошибок, для складывания есть panic.
Это возвращает нас к вопросу «кто принимает решение о том, стоит ли складывать приложение или нет».
затем, что вы должны понимать что происходит иначе когда у вас закончится память
Так зачем для этого оборачивать исключения? Как раз наоборот, критические исключения трогать не надо, пусть летят себе вверх.
а я кстати не говорил, что это проще
Весь пост про это.
такая явность их возврата как раз для мотивации этой обработки и делалась
Вот только я не вижу, как это мотивирует обрабатывать ошибки. Всегда же можно поставить blank identifier.neolink
30.06.2015 13:15> Весь пост про это.
Ну так пост то не мой. В целом я тоже приходил к выводу, что Go простой в обучении язык. Но аргументация в посте мне нравится.
> Это возвращает нас к вопросу «кто принимает решение о том, стоит ли складывать приложение или нет».
это зависит от того что произошло, если вас вызывают не правильно, говорят выдели мне 200гб памяти, а столько нет или обратись к -2 элементу в массиве это паника, это не нормально, программа написана не правильно, ее нужно переписывать и т.п.
если вы не можете достучаться до сервиса погоды, это нормально это ситуация, которая должна быть предусмотрена и обработана, если у вас http библиотека, вы возвращаете error если сервис запроса погоды вы ее обрабатываете и можете скрыть внутри себя (например вернуть старые данные или ничего не вернуть, а в фоне повторять попытки)
Ну вы же сами выделил критические исключения, кто решает критическое это исключение или нет?
> Всегда же можно поставить blank identifier.
мотивировать != заставить (это кстати можно притянуть к простоте — несмотря на строгость типизации, писать программу ты можешь как хочешь)
error в Go не содержит информации о месте где его создали и т.п., даже больше error это обычно глобальный immutable объект. так что вы можете получать 10, 100к и т.п. ошибок в секунду и у вас приложение будет работать, а вот если вы попробуете сгенерировать столько же исключений, будет грустно.lair
30.06.2015 13:21это зависит от того что произошло, если вас вызывают не правильно, говорят выдели мне 200гб памяти, а столько нет [...] это не нормально, программа написана не правильно, ее нужно переписывать и т.п.
если вы не можете достучаться до сервиса погоды, это нормально это ситуация, которая должна быть предусмотрена и обработана,
Вот вы только что приняли два решения, которые ни на чем не основаны. Представьте, что у меня есть сервис, который раз в пять минут забирает погоду и обрабатывает ее. Так вот, я вполне могу считать, что ошибки «сервис погоды недоступен» и «на сервере не хватило памяти на обработку» эквивалентны — причем и в варианте «фиг с ним, через пять минут починится», и в варианте «критическая ситуация, падаем, зовем админа».
error в Go не содержит информации о месте где его создали и т.п., даже больше error это обычно глобальный immutable объект. так что вы можете получать 10, 100к и т.п. ошибок в секунду и у вас приложение будет работать, а вот если вы попробуете сгенерировать столько же исключений, будет грустно.
О, это внезапно performance-driven decision? Окей, я ничего не имею против такой аргументации, только что мне делать, если у меня никогда не будет столько ошибок (btw, если у вас столько ошибок — приложение надо класть, на мой вкус, почти в любой ситуации это флуд), зато мне важнее иметь стабильное приложение, которое при любой неожиданной ситуации падает и рестартует?neolink
30.06.2015 13:32> Так вот, я вполне могу считать, что ошибки «сервис погоды недоступен» и «на сервере не хватило памяти на обработку» эквивалентны
ну так есть recover я же не os.Exit в конце концов написал. внутри своей либы общения с погодой я не могу ничего сделать с тем что нет памяти, а вот на уровне приложения уже можно решить что делать.
то есть вы запустили горутины общения с погодой она упала по памяти, вы в recover решили что нужно делать и сделали. (panic кстати не закрывает приложение, он только раскручивает стек вызовов горутины и если дошел до конца завершает её, приложение может условно даже не заметить этого)
Собственно в случае исключений будет та же самая логика.
> О, это внезапно performance-driven decision?
внезапно в мире есть не только черное и белое, а решения не обязательно принимаются лишь из-за чего-то одного, но производительность тут сыграла не последнюю роль, это факт.
> только что мне делать, если у меня никогда не будет столько ошибок
Не использовать Go? Пишите на чем-то скриптовом, с точки зрения скорости написание это будет быстрее, я например пишу на PHP.
Ни один язык не заменяет здравый смысл.lair
30.06.2015 13:38ну так есть recover
Он работает только в одну сторону. И это два способа вместо одного.
Собственно в случае исключений будет та же самая логика.
… только в случае исключений у меня (почти никогда) нет альтернативных способо возврата ошибок, и я все обрабатываю единообразно.
Не использовать Go?
Вот и я об этом же.
- Есть ли в go механизм, гарантирующий невозможность скомпилировать код, не проверяющий возвращаемый
neolink
29.06.2015 02:41+2В том что ему не нужен .net framework?
Исключения не упрощают обработку ошибок, генерацию и игнорирование, да, а вот обработку нет. (ну и почитайте про panic)
Про дженерики вопрос давний, так скажем нет единого мнения как это должно выглядеть, сейчас это вполне решается кодогенерацией.
Больше чем в 10 языках из статьи нет LINQ, тоже самое про деревья выражений.
Вы путаете язык и «стандартную библиотеку», и тот же LINQ далеко не сразу появился.
Ну и чисто по букве правил — Go под них подходит
PS ну и это как-то странно, язык не простой, потому что в нем нет дженериков, динамической генерации кода во время выполнения и т.п.nsinreal
29.06.2015 12:12Исключения не упрощают обработку ошибок, генерацию и игнорирование, да, а вот обработку нет. (ну и почитайте про panic)
Ой да ну ладно вам. Это тот еще холивар: вы с легкостью найдете людей, которые считают что исключения это самый лучший способ; и с легкостью найдете людей, которые считают коды возврата ошибок замечательной штукой. Причем каждый, сука, встречается с обработкой ошибок в контексте разных задач и даже мозгами не думает, когда ему говорят что в другой задаче другой подход будет более адекватным.
Только вот в языке, в котором нету исключений нельзя их сделать руками; а вот в языке, в котором есть исключения можно легко сэмулировать коды возврата ошибок через тип Or[Result, Error]. Я лично встречался с обоими типами задач — там где оба подхода являются более адекватными.
Больше чем в 10 языках из статьи нет LINQ, тоже самое про деревья выражений.
LINQ — это довольно примитивная вещь. IQueryProvider — это уже далеко не примитивная вещь (по сути я ни разу не видел людей, которые умеют это писать, но через эту штуку и работает C# -> SQL).
А деревья выражений — это по сути кодогенерация в runtime с доступом к рефлексии. Если сравнивать с рефлексией и динамическими вызовами, то компиляция деревьев выражений позволяет добиться скорости руками написанного кода (даже больше, потому что весь синтаксический сахар сразу уходит и пишется максимально производительный код).
Если сравнивать с чистой кодогенерацией, то деревья выражений позволяют чуточку больше (легкий доступ к метаданным уже работающей программы) и одновременно чуточку меньше (в edit-time у вас нету информации о сгенерированном коде, т.е. вы не можете притвориться что вы вот сейчас сгенерируете код, а потом просто и легко переименуете поле).
Вы путаете язык и «стандартную библиотеку», и тот же LINQ далеко не сразу появился.
В C# язык и стандартная библиотека развиваются весьма параллельно, хотя разработчики компилятора предпочитают не завязываться на существование стандартной библиотеки.

asm0dey
29.06.2015 07:48Жалко в сравнениях нету какого-нибудь clojure, который целиком почти сам на себе написан.
divan0 Автор
29.06.2015 09:21На самом деле я даже сомневался, включать ли Haskell. Методики сравнения, особенно первые две, всё же более адекватный результат покажут на схожих (итеративных) языках.
senia
29.06.2015 09:38Если вы пройдетесь по ключевым словам в scala, то увидите, что многие из них относятся к областям, не охваченным Go. Так что нет тут никакой «схожести». Есть только подгонка под результат. Ибо clojure настолько же императивный, как и scala.

i_user
29.06.2015 08:33+1Давайте возьмем, например, метрику «количество вопросов на SO по отношению к репам на GH»
Большинство приведенных в списке языков имеют такое большое число по одной очень простой причине — новички крайне редко пишут на Go, Rust, Haskell,… зато много пишут на Ruby, JS, C++, Java, C#,…
Вот если на Go появится много вакансий по миру, в него придут джуны, в общем, в случае успеха — через 5 лет можно будет еще раз посмотреть на эту метрику.
Говоря же о других метриках, по моему субъективному ощущению количество кейвордов говорит о том, что
1. Сколько же в этом языке кейвордов (удивительно)
2. К насколько широкому классу задач стараются приложить этот инструмент
3.… Привнесенная сложность
Да, Го действительно прост, но, на мой взгляд, он пока еще не прошел испытания злобным продакшеном в полной мере и хотя бы 3-4 мажорных версий. Возможно низкая сложность языка является следствием не окончательного понимания предметной области, не полной «вынужденной сложности»?
На данный момент ГО нерепрезентативен для таких вот исследований и его данные будут врать. Возможно даже в разы.divan0 Автор
29.06.2015 09:27Возможно низкая сложность языка является следствием не окончательного понимания предметной области, не полной «вынужденной сложности»?
Нет.
В этом и поинт статьи — сложность не является синонимом «продвинутости» или «зрелости», и в данном случае это ровно наоборот — действительно глубокое понимание предметной области.
Посмотрите видео выступлений Пайка на тему сложности Go — думаю, вы быстро перестанете считать авторов Go за недоучек )i_user
29.06.2015 09:30Ну что вы, я, разумеется, не считаю авторов Go за недоучек, напротив — опытнейшие и матерые ребята. Однако все остальные языки так же писались отнюдь не дураками, которые тоже читали Брукса. И они почему-то пошли другим путем. И пока я не понимаю до конца почему — я и отношусь с некоторым недоверием к тому, что простота Го окончательна.
divan0 Автор
29.06.2015 09:35И пока я не понимаю до конца почему
Именно потому что сложность других языков на практике имела негативные последствия для разработки, и они проявились лишь с годами практического использования.
Тоесть, не будь других языков («которые писались отнюдь не дураками») или будь они достаточно хороши, Go не появился бы. Я потому и написал про «Go качнул маятник в другую сторону».

NeoCode
29.06.2015 09:53+2Сравнение конечно ни о чем, но забавное:)
Я бы еще добавил, что примитивная «простота» — не главное в языке. Это слишком однобокий критерий. Например, количество ключевых слов должно быть не большим и не маленьким, оно должно быть соответствующим внутренней логике языка. Количество роли не играет вообще. Применение одного и того же ключевого слова для разных целей (чем грешит тот же С++ ради «совмесимости с legacy кодом») не есть хорошо. Когда ключевыми словами обозначается все подряд — тоже плохо.
Главное в языке — внутренняя стройность и логичность, отсутствие «белых пятен» в плане фич. Я уже писал об этом здесь — если в языке чего-то нет, программисты все равно это сделают, но оно будет не органично встроено в язык, а прикручено сбоку изолентой (C++/Boost), что сильно отрицательно скажется на удобстве использования.divan0 Автор
29.06.2015 09:58Да, согласен, этот момент я не озвучил явно. Сравнение имеет смысл только языков, которые мы признаем как равнозначных по охвату и функционалу, принимая как данное, что на них решают достаточно схожий класс задач.
А «внутренняя стройность и логичность» — да, еще один критерий, но это ещё сложнее доказать и измерить )NeoCode
29.06.2015 10:18Автоматически конечно не измерить, но экспертная оценка вполне возможна. Языков много, и если мы рассматриваем равнозначные по охвату и функционалу — то и наборы возможностей у них вполне сравнимы.

gandjustas
29.06.2015 10:02+1Половина поста — рассуждения о сложности, а дальше графики, которые к сложности не имеют отношения, да еще и само понятие сложности никак не формализовано.
Более того, совершенно неочевидно как выбор языка влияет на сложность. И как-то странно сравнивать без контекста задачи. Например нужно делать запросы в бд из кода приложения, в c# есть linq и сложность написания запросов будет сильно ниже, чем на том же go.divan0 Автор
29.06.2015 10:06Да, уже понял, что стоило вообще на два поста разбить. )
Контекст задачи слишком обобщён, область — системное/сетевое/серверное программирование. Тут одним примером с БД не обойдешься, увы.

beduin01
29.06.2015 10:03Где сравнение с D? Пока тот же подсчет слов на нем выглядит проще некуда. На Go такая же краткость и лаконичность возможна?
import std.stdio, std.string; void main() { uint[string] dictionary; foreach (line; stdin.byLine()) { foreach (word; splitter(strip(line))) { if (word in dictionary) continue; // Nothing to do auto newlD = dictionary.length; dictionary[word] = newlD; writeln(newlD, '\t', word); } } }divan0 Автор
29.06.2015 10:10D пропустил, каюсь.
В Go читабельность ставится выше краткости. Во многом принципы Go созвучны с Zen Of Python.
По вашему примеру, посмотрите на golang.org/pkg/bufio/#example_Scanner_linesbeduin01
29.06.2015 10:18А можно пример подсчета слов на Go? Просто сравнить читабельность хочется.
Или может это отдельной статьей лучше сделать? Я думаю многим было бы интересно.divan0 Автор
29.06.2015 10:19Чуть-чуть примером ошибся, там же, рядом: golang.org/pkg/bufio/#example_Scanner_words
beduin01
29.06.2015 10:43Пока что D и короче и читабельнее. Попробуйте добавить сортировку слов по их частоте. Думаю там в пару строк это не ну никак не получится сделать.
lair
29.06.2015 11:11+2Если говорить о читабельности, то тут DSL и функциональные языки радостно показывают гулю.

chemistmail
29.06.2015 10:22+5Поржал, крутая статистика.
Так на заметку, в том же haskell вы считаете все скобки, а если посчитать только слова, 22 получается (haskell98 lexical structure).
Язык и правда простой, только вот многовато понтов. Давно ждал релиза одной базы на go (influxdb), зарелизили, баг на баге багом погоняет, базового функционала, который кстати был заявлен, нет. Зато 5700 звезд, 560 форков, и 125 разработчиков, и в результате за год работы пшик(только над этой версией).
Задумка хорошая, исполнение пока на двоечку, уж подумываю не самому ли написать, а то ждать поднадоело.
Если убрать весь шум: для простых утилит, язык вполне себе, для больших и сложных проектов я пока сильно сомневаюсь.divan0 Автор
29.06.2015 10:33InfluxDB это да, ребята отожгли. Они его переписали чуть ли не с нуля, с 0.8 на 0.9, делая это в мастер ветке, причем.
Про большие и сложные проекты — посмотрите на Docker, достаточно большой.chemistmail
29.06.2015 12:32+1Большой, ну может быть.
Сложный, не уверен.
docker это по сути обвязка над набором утилит + работа с файлами (создать, удалить, изменить)
Ну да, еще хранилище образов, ну так а что в нем сложного?

datacompboy
29.06.2015 10:44+5А расскажите мне про функцию max(a,b) на Go пожалуйста?
divan0 Автор
29.06.2015 10:54Четыре строчки, напишете сами?
datacompboy
29.06.2015 11:05+7да-да, вот по 4 строчки в каждом проекте под каждый требуемый тип данных.
и смотри потом не перепутай.
а еще max(list) в десятке вариантов, правда, зачастую не работающий для пустого list.
f.e.:
github.com/search?utf8=%E2%9C%93&q=language%3Ago+max&type=Code&ref=searchresultsneolink
29.06.2015 11:51а зачем делать специальную функцию под каждый тип?
что мешаешь по месту написать max так как вам нужно, собственно по вашей же ссылке находятся такие примеры:
max := 0 if some > max { max = some }datacompboy
29.06.2015 12:03+5Действительно, зачем вообще нужны функции, если их функционал можно руками встроить в каждое место?
Зачем нужны inline'ы? Просто пишите инлайн!neolink
29.06.2015 12:12ну смотрите — на абстрактном max(a, b) вроде и правда всё плохо, но давайте что-то более жизненное:
например есть список неких структур, например заказов, нужно найти дату последнего заказа:
var maxDate uint = 0
for o := range orders {
maxDate := max(maxDate, o.createdAt)
}
или так:
var maxDate uint = 0
for o := range orders {
if o.createdAt > maxDate {
maxDate = o.createdAt
}
}
в читаемости как по мне даже несколько выиграло + в отличии от первого варианта, во втором кол-во присваиваний будет равно кол-ву заказов только в худшем случае. про формирование списка массива значений я думаю и говорить не стоит
PS сейчас с читаемостью всё плохо в обоих случаях т.к. хабр удаляет пробелы и не дает делать подсветку кодаdatacompboy
29.06.2015 12:17+1Вообще max() обычно для другого:
maxDate := max([ o.createdAt for o in orders ])
neolink
29.06.2015 12:30а можете указывать на каких языках это примеры? c# по maxBy я вроде опознал (только там результат без maxDate будет?)
по поводу сформировать массив для для max — на вскидку такое должно быть либо в компилятор встроено либо что-то с ленивыми вычислениями, иначе у нас мало того что массив создастся так ещё и кучу элементов туда надо добавить будет.lair
29.06.2015 12:33+2В C# нет
maxBy(и возврата туплов в мейнстриме). А в F#, где и то, и другое есть,maxByведет себя немного не так.

CAH4A
29.06.2015 11:40+4Интересная тема — метрики сложности ЯП.
Первые две метрики точно не годятся для поставленной задачи, ведь самый простой язык по ним — Brainfuck!
6 операторов, да 2 условных оператора — истинно самый простой язык.
А третья метрика, вообще непонятно от чего зависит.
От библиотек, от компиляторов, сред программирования, ленивости программистов, репозиториев с либами, и их удобства.
Ну и от языка, конечно, тоже. В общем совсем не понятно что означает то или иное число.
Вообще, я думаю, из-за того, что сложность бывает разных типов, хорошую метрику построить будет проблематично.
Какой бы простой Go или Lua не был, в решении математических задач WolframAlpha или Matlab надерут ему задницу по простоте.
Ставлю на Эмпирику. Так что продолжаем холиварить!divan0 Автор
29.06.2015 11:51Первый толковый комментарий :)
Первые две метрики точно не годятся для поставленной задачи, ведь самый простой язык по ним — Brainfuck!
Ну, нет, я вообще хотел в список включить только 3-4 схожих по охвату и подходам языка. Вот, согласитесь, сложность Go vs С++ неспроста кореллирует с количеством ключевых слов в Go и C++ :)
Ставлю на Эмпирику.
С эмпирикой всё понятно, но её не докажешь, аргументы «я чувствую это по своему опыту» не работают.NeoCode
29.06.2015 14:31+1C++ проектировался очень давно, на основе еще более древнего Си (который сам по себе содержит массу архитектурных решений, которые в современном мире выглядят как ошибки), метапрограмминг на шаблонах С++ получился «случайно» и только потом язык стали ориентировать на эту возможность (но все равно там очень много случайных по сути решений).
Go проектировался с нуля значительно позже С++, с учетом огромного опыта проектирования других языков. Но, как уже было сказано, в Go нет очень многих фич.
Тут некоторое время назад была серия статей про Оберон, где автор утверждал что минимум фич (и ключевых слов заодно) это хорошо. Хотя по факту там нет почти ничего, кроме старого процедурного программирования.
В общем, сравнивая количество ключевых слов, языки сравнивать совершенно некорректно. Нужно рассматривать семантику языков, их суть.
nsinreal
29.06.2015 11:49+1Где же lisp?
datacompboy
29.06.2015 12:04+5Лисперам некогда в холивар, они считают сколько скобочек закрыть надо.
nsinreal
29.06.2015 12:15+1Боюсь большинство лисперов уже давно пользуются rainbow brackets + highlight matching brackets. Кстати, весьма удобная штука даже для C#. Так что лисперы свободны для холивара.

datacompboy
29.06.2015 12:18Максимальная вложенность, насколько понимаю, ограничена 16,777,216. А что дальше-то делать?
nsinreal
29.06.2015 12:23Как что? Зацикливать! Очень хотелось бы посмотреть на то как будет выглядеть код с соответствующим количеством пробелов. Не, я конечно понимаю, что троллинг, но в лиспе не принято делать глубокую вложенность, вместо этого предпочитают выделять функции, да и вообще думать мозгами.
P.S.: ничего, некоторые люди живут с ограничением в 128 вложенных if else if

gbezyuk
29.06.2015 14:42+1Метод сравнения по Stack Overflow говорит скорее о средней по популяции использующих язык склонности искать решения самостоятельно и не задавать (простых и глупых) вопросов.
Kemet
29.06.2015 14:52Ты говоришь сложно о простых вещах и, создаётся впечатление, сам запутался в привнесённой тобой сложности.
Как мне кажется, понятия сложности и простоты в ЯП и программировании настолько субъективны, что неминуемо, стоит только задуматься над этой проблемой, появляются всё новые и новые языки программирования, призванные упростить сложность, неподвластную автору очередного шедевра.
Проблема, однако, в том, что упрощение в одном месте ведёт к ещё большему усложнению в других местах. Это хороший результат для исследовательского проекта — можно написать кучу диссертаций, но совершенно не пригодно для использования.
Поэтому, проблема понятна, но выбранная методика расчетов напоминает методику трёх «П» — пол, палец, потолок.
Лично я, для того, чтобы «определить сложность языка», да и чтобы изучить его, обычно переписываю на изучаемом языке какой-нибудь проект, например компилятор.
Чтобы изучить Активный Оберон, я переписал на нём Free Pascal Compiler, чтобы изучить Модулу-3 я переписал на ней компилятор Активного Оберона. Хотя на Go я не писал, но я переписывал компилятор для некоего подмножества языка на Активном Обероне, понятно, что читать исходный код на Go приходилось. Сейчас я начинаю переписывать компилятор Активного Оберона на C#, чтобы изучить его, использую для этого платформу Roslyn. И вот что я скажу по этому поводу — для меня код на C# читается и понимается легче, чем код на Go, да и пишется быстрее.
То есть C# как язык мне кажется проще Go. Более того, читая код Roslyn, мне показалось, что я читаю код на Активном Обероне.
То есть восприятие сложности/простоты языка снова упирается в субъективные ощущения.
sectronix
29.06.2015 19:19+2От вашей статьи веет популизмом и даже троллингом.
Я не понимаю, как можно сравнивать языки из разных областей применения и когда между релизами некоторых из них уже прошло более 30 лет?
Google выпустил молоток. Давайте теперь сравнивать его с отвёртками, пилами, гаечными ключами и рубанками. Количество запросов по работе с рубанком на StackOverflow больше чем с молотком («вау!» — слышен возглас удивлённой публики), значит молотком от Google действительно проще пользоваться. У молотка одна ручка, у пилы две и они с разных сторон («вау!» — публика в экстазе), тут молоток так же показал себя с лучшей стороны.
В этом и заключается ваш троллинг: возьмём инструменты, которые применяются к решению разных задач и будем их сравнивать.
— Что лучше выбрать: Go или C++? А может мне Java подойдёт? Или надо Haskell изучать?
— Выбирать нужно то, что подойдёт для решения твоей задачи.
И оценивать инструмент по кол-ву keyword-ов и вопросов на StackOverflow — не лучшая затея.divan0 Автор
29.06.2015 19:29Спасибо за критику по делу. Статья, конечно, популистская и холивары после тех графиков были неминуемы :) Но вообще, это ответ на комментарии из других статей, где меня доставали вопросами «а как ты докажешь, что Go проще C++». Впрочем, те же люди здесь сейчас вообще любое утверждение сводят к «а докажи? раз нет формального способа доказать 100% — значит ложь».
— Выбирать нужно то, что подойдёт для решения твоей задачи.
Это вы это понимаете, и я понимаю. Но реальность такова, что мне приходится сейчас увольняться из компании, потому что тим-лиды у нас ничего кроме С++ не знают, и знать не хотят, и пишут на нем всё — вопрос «выбора подходящего инструмента» там даже не стоит. Страдает продукт, страдает компания, страдают все. И судя, по комментариям, таких людей «одного языка» много.
Так что, даже если хотя бы один человек из-за таких популистских статей, решит взглянуть на Go и расширит круг своих познаний — я уже буду считать, что цель достигнута. Хотя, надоело конечно уже, план выполнен ))sectronix
29.06.2015 19:54Может оно и к лучшему что вы увольняетесь из этой компании, в которой «такие» тимлиды. Например, в островке правильно подошли к выбору инструмента для своей задачи оценив все за и против. Вот такие подходы к оценке инструмента мне нравятся.
sectronix
29.06.2015 20:01Upd. Раньше по ссылке было видео, а теперь куда-то исчезло, хотя доклад был хороший.

Vitter
29.06.2015 21:33+2вообще вы странно считали.
Взял пример из 1 таблицы — количество ключевых слов.
Го — 25
правда, не подсчитано количество ключевых слов-операторов.
А их в Го — 48.
В Хаскеле действительно 55, но вместе с операторами.
То есть 28 ключевых слов + 27 ключевых слов-операторов.
Так что будьте внимательными при построении таблицdivan0 Автор
30.06.2015 13:24А, да? Нет, операторы я не хотел учитывать, конечно же.
Вообще, уже понял, что было ошибкой считать «побольше языков». Изначально хотел сравнить только группу из 4-5 императивных языков, которые я рассматриваю, как универсальные кроссплатформенные языки для серверного софта — C++, Go, Python, Java, Ruby, но потом решил, что появится масса вопросов «А где язык X?» и решил добавить и остальные, тем более, что это было относительно просто.
stepanp
05.07.2015 21:31+3Вот почему на хабре по С++, Rust, C#, Java и т.п. как правило серьезные статьи по делу, а про Swift, Go и наверное JS большинство статей состоят из сплошной воды и восхищения языком?
stepanp
05.07.2015 21:38+3Типа «смотрите какой swift офигенный, потому что в нем split и форматирование строк есть», «50 хаков на моем любимом js, первым из которых записан тернарный оператор» или «херня ваш rust, вот есть Go его сделали в гугле, поэтому он клевый и простой а еще потому что про него меньше вопросов задают на stack overflow»



Trueteller
Т.е. по всем трем методикам выходит, что разработка на C в 3-7 раз проще, чем разработка на C#.
Вы согласны с этим тезисом или как можете объяснить это соотношение?
divan0 Автор
Сложно ответить — я не пишу на C#, и мне самому интересно послушать версии, насколько показатели по нему кореллируют или нет с реальными ощущениями. Подозреваю, что в третьем случае, у C# такой «отрыв» из-за того, что он больше в энтерпрайзе используется, и не особо в open-source сообществе.
Nagg
Ну вот вы вроде сами понимаете, что отношение кол-ва репозиториев на гитхабе к кол-ву вопросов на SO очень и очень слабо коррелирует с сложностью языка, возможно даже слабее чем отношение популяции канадских бобров к средней зарплате в РФ.
divan0 Автор
Конечно мне знаком принцип «correlation doesn't imply causation», но логика этого сравнения озвучена — при прочих равных, более сложный язык будет вызывать больше вопросов. Хотя понимаю, что там факторов, которые дают погрешность в ± 100% — целая пачка.
В любом случае — это лучшее, что я придумал на тему «как использовать социальные данные для приблизительной оценки сложности языков».
Nagg
Объективно говоря, C# как язык — это java 8 + пяток простых сахарных помогалок. Многие сходяться во мнении, что экосистема явы имеет более высокий порог вхождения, чем C#. Ну а тут, судя по графику, C# сложнее java в почти 4 раза.
divan0 Автор
Смотрите, идея в том, что одним числом рассчитать и оценить сложность нельзя, поэтому я беру 3 методики, которые косвенно кореллируют со сложностью языка, и составляю картинку по ним. Наверное стоило, как результат, сделать разбитие на группы сложности, чтобы не вводить в заблуждение и не было придирок конкретно к отдельным графикам…
lair
Показатели по C# вообще никак не коррелируют с реальными ощущениями. Я писал на JS, на C++, имел некий контакт со Scala и Java — так что нет, сравнительные показатели в ваших графиках критики ощущениями не выдерживают.
divan0 Автор
Кстати, «два вопроса для критиков» я специально для вас написал ) Ответьте, если не сложно )
lair
В данной статье так и не определен термин «сложность», поэтому что-то предложить здесь сложно.
Во-первых, для трех методик можно говорить и о банальном совпадении. Во-вторых, первая и вторая методика коррелируют друг с другом безотносительно того, показывают они сложность, или нет.
А теперь немножко об (формальных) ошибках в ваших методиках.
Вот вы говорите, что в JS 41 ключевое слово, а в C# — 79. Но вы не учитываете несколько занятных вещей. Во-первых, JS указывает каждое слово один раз (несмотря на различное поведение), а C# — столько раз, сколько различных семантик у него есть. Во-вторых, в списке ключевых слов C# есть type aliases и два оператора, которые учитывать тоже некорректно.
Или вот вы говорите, что по тегу C# на SO 812 тысяч вопросов. Однако стоит открыть произвольный, как выяснится, что единственное, чем он связан с C# — это то, что на нем написан код, а вся суть вопроса к языку отношения не имеет. И таких там большинство, это я вам говорю как человек, который на этот тег подписан.
senia
Я писал на множестве языков, в том числе несколько лет на C#, затем несколько лет на Java, попутно использую JS и считаю, что имею весьма не плохое знание Scala.
Нет. C# не сложен. Он не должен выделяться. Единственное мое объяснение: он популярен для коммерческой разработки, но не популярен для open source проектов.
Вообще 3 точки: C, Java и C# дискредитируют все методы оценки.
Да и оценивать сложность языка бесполезно. Стоит оценивать сложность разработки на языке, а это уже оценка вместе с экосистемой и только на одинаковом спектре задач.
divan0 Автор
Да, про C# на последнем графике тоже такое объяснение вижу.
Не соглашусь. Пусть и с погрешностью, но «сложность разработки на языке» кореллирует со «сложностью языка», которую, по косвенным признакам, я тут и пытался обрисовать.
А про одинаковый спектр задач — уже тут в комментариях постил, посмотрите сравнение по задачам из Rosetta Code — там тоже интересные результаты: arxiv.org/pdf/1409.0252v4.pdf
senia
И что же мы имеем по метрикам?
divan0 Автор
Ну, я в посте написал, что на каждую критику жду ответа на два вопроса :) Потому что мне всё же интересно, какими ещё косвенными методами можно оценивать сложность.
Функциональные языки вообще не хотел добавлять, потому что первые две методики работают лишь на похожих императивных языках.
senia
clojure настолько же императивный, как и все остальные.
И настолько же ФП, как и C#, JS, java8 и scala. +- погрешность. Например в scala есть typeclass.
И уж точно не сравнится с haskell.
И я уже обосновал вам, что по первой методике вы похожих не выбрали. Существенная часть ключевых слов scala относится к системе типов (те самые дженерики), еще часть — к ФП. Где тут похожесть с go?
1. Формальный критерий субъективной оценки? Нет уж, спасибо. Можно посмотреть скорость разработки схожих задач схожими командами и скорость «выгорания» людей при работе с языком, но у нас нет такой возможности.
2. как можно объяснить достаточно очевидную корелляцию результатов у всех трех методик
divan0 Автор
Насчет второго — это всё же другое ) Все таки таблицы взяты не с потолка, а из четких соображений о том, что эти цифры могут в той или мере кореллировать со сложностью. А в вашем примере просто график, в котором топорно подогнаны шкалы, чтобы изобразить трендинг. :)
Clojure — императивный язык?
senia
у вас — топорно подогнаны метрики и выборка языков. См. clojure.
Можно конечно предположить, что причина в корреляции между спектром применения и полнотой языка (первые 2 метрики) и коммерческой успешностью (последняя), но я бы поостерегся делать столь далеко идущие выводы.
Внезапно, правда? Более того, он не следит на сайдэффектами, так что по некоторым определениям он не ФП (как и все здесь, кроме haskell).
senia
Так, на всякий случай: Clojure — императивный язык?
areht
> б) как можно объяснить достаточно очевидную корелляцию результатов у всех трех методик, если они несостоятельны и их результаты — результат случайного распределения?
Есть такая штука как KPI. Её легко измерить начальнику(иначе она бессмысленна), её легко «подогнать» подчинённому.
Люди хотели язык упростить — повыкидывали концепции и ключевые слова. KPI вы успешно измерили.
Упростился ли язык от того, что можно писать
value = «12345» + (string)6789
а не
value = «12345» + 6789
— нет. В первом случае надо помнить про волшебное слово, а во втором — держать в голове правила, по которым произойдёт конкатенация (или сложение?).
А «string.Format(»{0}{1}", «12345», 6789)" вообще в БНФ не попадает
Поэтому у вас по «сложности» проигрывают языки с развитой статической системой типов.
> Пусть и с погрешностью, но «сложность разработки на языке» кореллирует со «сложностью языка», которую, по косвенным признакам, я тут и пытался обрисовать.
Пока вы не дали определения «сложности языка» тут бесполезно соглашаться или нет.
Вы слона по хвосту оцениваете.
Это не придираясь к диванной аналитике по мелочам, типа что потерялись всякие codeplex.