У нас в Malwarebytes мы переживаем бешеный рост и с тех пор, как я присоединился к компании около года назад в Кремниевой Долине, одной из моих основных обязанностей было проектирование и разработка архитектур нескольких систем для развития быстрорастущей компании и всей необходимой инфраструктуры для поддержки продукта, который используют миллионы людей каждый день. Я работал в индустрии антивирусов более 12 лет в нескольких разных компаниях, и знаю, насколько сложными получаются в итоге эти системы, из-за колоссальных объемов данных, с которыми приходится иметь дело ежедневно.
Что интересно, так это то, что последние 9 лет или около того, вся разработка веб-бекендов, с которой я сталкивался, осуществлялась на Ruby on Rails. Не поймите меня неправильно, я люблю Ruby on Rails и я верю, что это великолепная среда, но через некоторое время вы привыкаете мыслить о разработке систем в стиле Ruby, и вы забываете, насколько эффективной и простой ваша архитектура могла бы быть, если бы вы задействовали мультипоточность, параллелизм, быстрое исполнение и эффективное использование памяти. Много лет я писал на C/C++, Delphi и C#, и я начал осозновать насколько менее сложными вещи могут быть, если вы выбрали правильный инструмент для дела.
Как Главный Архитектор, я не любитель холиваров о языках и фреймворках, которые так популярны в сети. Я верю, что эффективность, продуктивность и поддерживаемость кода зависят в основном от того, насколько простым вы сможете построить ваше решение.
Проблема
Работая над одной из частей нашей системы сбора анонимной телеметрии и аналитики, перед нами стояла задача обрабатывать огромное количество POST-запросов от миллионов клиентов. Веб-обработчик должен был получать JSON-документ, который может содержать коллекцию данных (payload), которые, в свою очередь нужно сохранить на Amazon S3, чтобы наши map-reduce системы позже обработали эти данные.
Традиционно мы бы посмотрели в сторону worker-уровневной (worker-tier) архитектуры, и использовали такие вещи, как:
- Sidekiq
- Resque
- DelayedJob
- Elasticbeanstalk Worker Tier
- RabbitMQ
- и так далее
И установили бы 2 разных кластера, один для веб фронтенда, и другой для воркеров (workers), чтобы можно было масштабировать фоновые задачи.
Но с самого начала наша команда знала, что мы должны написать это на Go, посколько на этапе обсуждения мы уже понимали, что эта система должна будет справляться с огромным траффиком. Я использовал Go около 2 лет, и мы разработали несколько систем на нём, но ни одна из них не работала пока с такими нагрузками.
Мы начали с создания нескольких структур, чтобы описать данные запроса, которые будут приниматься в POST-запросах, и метод для загрузки их на наш S3-бакет.
type PayloadCollection struct {
WindowsVersion string `json:"version"`
Token string `json:"token"`
Payloads []Payload `json:"data"`
}
type Payload struct {
// [redacted]
}
func (p *Payload) UploadToS3() error {
// the storageFolder method ensures that there are no name collision in
// case we get same timestamp in the key name
storage_path := fmt.Sprintf("%v/%v", p.storageFolder, time.Now().UnixNano())
bucket := S3Bucket
b := new(bytes.Buffer)
encodeErr := json.NewEncoder(b).Encode(payload)
if encodeErr != nil {
return encodeErr
}
// Everything we post to the S3 bucket should be marked 'private'
var acl = s3.Private
var contentType = "application/octet-stream"
return bucket.PutReader(storage_path, b, int64(b.Len()), contentType, acl, s3.Options{})
}Решение “в лоб” с помощью Go-рутин
Изначально мы взяли простейшее наивное решение POST-обработчика, просто стараясь распараллелить обработку с помощью простой go-рутины:
func payloadHandler(w http.ResponseWriter, r *http.Request) {
if r.Method != "POST" {
w.WriteHeader(http.StatusMethodNotAllowed)
return
}
// Read the body into a string for json decoding
var content = &PayloadCollection{}
err := json.NewDecoder(io.LimitReader(r.Body, MaxLength)).Decode(&content)
if err != nil {
w.Header().Set("Content-Type", "application/json; charset=UTF-8")
w.WriteHeader(http.StatusBadRequest)
return
}
// Go through each payload and queue items individually to be posted to S3
for _, payload := range content.Payloads {
go payload.UploadToS3() // <----- DON'T DO THIS
}
w.WriteHeader(http.StatusOK)
}Для средних нагрузок, такой подход будет работать для большинства людей, но он быстро показал себя неэффективным в большем масштабе. Мы ожидали, что запросов будет много, но, когда мы выкатили первую версию в продакшн, то поняли что ошиблись на порядки. Мы совершенно недооценили количество траффика.
Подход выше плох по нескольким причинам. В нём нет способа контролировать, сколько горутин мы запускаем. И поскольку мы получали 1 миллион POST-запросов в минуту, этот код, конечно, быстро падал и крашился.
Пробуем снова
Мы должны были найти другой путь. С самого начала мы обсуждали, что нам нужно уменьшить время обработки запроса до минимума и тяжелые задачи делать в фоне. Разумеется, это то, как вы должны это делать в мире Ruby on Rails, иначе у вас заблокируются все доступные веб-обработчики, и неважно, используете ли вы puma, unicorn или passenger (Только давайте не обсуждать тут JRuby, пожалуйста). Значит мы должны были бы использовать общепринятые решения для таких задач, такие как Resque, Sidekiq, SQS, и т.д… Этот список большой, так как существует масса способов решить нашу задачу.
И нашей второй попыткой было создание буферизированного канала, в котором мы могли поместить очередь задач, и загружать их на S3, а так как мы можем контролировать максимальное количество объектов в нашей очереди, и у нас есть куча RAM, чтобы держать все в памяти, мы решили, что будет достаточно просто буферизировать задачи в канале очереди.
var Queue chan Payload
func init() {
Queue = make(chan Payload, MAX_QUEUE)
}
func payloadHandler(w http.ResponseWriter, r *http.Request) {
...
// Go through each payload and queue items individually to be posted to S3
for _, payload := range content.Payloads {
Queue <- payload
}
...
}А затем, собственно, чтобы вычитывать задачи из очереди и обрабатывать их, мы использовали что-то подобное этому коду:
func StartProcessor() {
for {
select {
case job := <-Queue:
job.payload.UploadToS3() // <-- STILL NOT GOOD
}
}
}Честно говоря, я понятия не имею, о чём мы тогда думали. Это, видимо, было поздней ночью, с кучей выпитых Red-Bull-ов. Этот подход не дал нам никакого выигрыша, мы просто обменяли плохую конкурентность на буферизированный канал и это просто откладывало проблему. Наш синхронный обработчик очереди загружал лишь одну пачку данных на S3 за единицу времени, и поскольку частота входящих запросов была намного больше возможности обработчика загружать их на S3, наш буферизированный канал очень быстро достигал своего лимита и блокировал возможность добавлять в очередь новые задачи.
Мы молча проигнорировали проблему и запустили обратный отсчет краха нашей системы. Время отклика (latency) увеличивалось по наростающей уже через несколько минут после того, как мы задеплоили эту глючную версию.
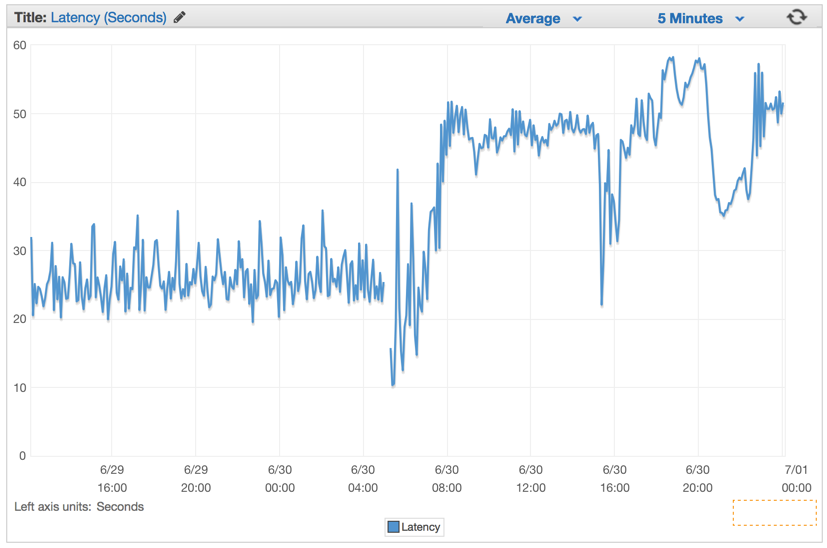
Лучшее решение
Мы решили использовать популярный паттерн работы с каналами в Go, чтобы создать двухуровневую систему каналов, одна — для работы с очередью каналов, другую для контроля за количеством обработчиков задач, работающих с очередью одновременно.
Идея была в том, чтобы распараллелить загрузку на S3, контролируя этот процесс, чтобы не перегрузить машину и не упираться в ошибки соединения с S3. Поэтому мы выбрали Job/Worker паттерн. Для тех, кто знаком с Java, C#, etc, считайте это Go-способом реализации Worker Thread-Pool, используя каналы.
var (
MaxWorker = os.Getenv("MAX_WORKERS")
MaxQueue = os.Getenv("MAX_QUEUE")
)
// Job represents the job to be run
type Job struct {
Payload Payload
}
// A buffered channel that we can send work requests on.
var JobQueue chan Job
// Worker represents the worker that executes the job
type Worker struct {
WorkerPool chan chan Job
JobChannel chan Job
quit chan bool
}
func NewWorker(workerPool chan chan Job) Worker {
return Worker{
WorkerPool: workerPool,
JobChannel: make(chan Job),
quit: make(chan bool)}
}
// Start method starts the run loop for the worker, listening for a quit channel in
// case we need to stop it
func (w Worker) Start() {
go func() {
for {
// register the current worker into the worker queue.
w.WorkerPool <- w.JobChannel
select {
case job := <-w.JobChannel:
// we have received a work request.
if err := job.Payload.UploadToS3(); err != nil {
log.Errorf("Error uploading to S3: %s", err.Error())
}
case <-w.quit:
// we have received a signal to stop
return
}
}
}()
}
// Stop signals the worker to stop listening for work requests.
func (w Worker) Stop() {
go func() {
w.quit <- true
}()
}Мы изменили наш хендлер запросов так, чтобы он создавал объект типа Job с данными, и отправлял его в канал JobQueue, чтобы далее его подхватывали обработчики задач.
func payloadHandler(w http.ResponseWriter, r *http.Request) {
if r.Method != "POST" {
w.WriteHeader(http.StatusMethodNotAllowed)
return
}
// Read the body into a string for json decoding
var content = &PayloadCollection{}
err := json.NewDecoder(io.LimitReader(r.Body, MaxLength)).Decode(&content)
if err != nil {
w.Header().Set("Content-Type", "application/json; charset=UTF-8")
w.WriteHeader(http.StatusBadRequest)
return
}
// Go through each payload and queue items individually to be posted to S3
for _, payload := range content.Payloads {
// let's create a job with the payload
work := Job{Payload: payload}
// Push the work onto the queue.
JobQueue <- work
}
w.WriteHeader(http.StatusOK)
}Во время инициализации сервера мы создаем Dispatcher и вызываем Run() чтобы создать пул воркеров (pool of workers) и начать слушать входящие задачи в JobQueue.
dispatcher := NewDispatcher(MaxWorker)
dispatcher.Run()Ниже приведён наш код реализации диспатчера:
type Dispatcher struct {
// A pool of workers channels that are registered with the dispatcher
WorkerPool chan chan Job
}
func NewDispatcher(maxWorkers int) *Dispatcher {
pool := make(chan chan Job, maxWorkers)
return &Dispatcher{WorkerPool: pool}
}
func (d *Dispatcher) Run() {
// starting n number of workers
for i := 0; i < d.maxWorkers; i++ {
worker := NewWorker(d.pool)
worker.Start()
}
go d.dispatch()
}
func (d *Dispatcher) dispatch() {
for {
select {
case job := <-JobQueue:
// a job request has been received
go func(job Job) {
// try to obtain a worker job channel that is available.
// this will block until a worker is idle
jobChannel := <-d.WorkerPool
// dispatch the job to the worker job channel
jobChannel <- job
}(job)
}
}
}Заметьте, что мы указываем количество обработчиков, которые будут запущены и добавлены в пул. Поскольку мы использовали Amazon Elasticbeanstalk для этого проекта и докеризированное Go-окружение, и всегда старались следовать двенадцатифакторной методологии, чтобы конфигурировать наши системы в продакшене, то мы читаем эти значения из переменных окружения. Таким образом мы можем контролировать количество обработчиков и максимальный размер очереди, чтобы быстро подтюнить эти параметры без редеплоя всего кластера.
var (
MaxWorker = os.Getenv("MAX_WORKERS")
MaxQueue = os.Getenv("MAX_QUEUE")
)Мгновенный результат
Сразу же после того, как мы задеплоили последнее решение, мы увидели, что время отклика упало до незначительных цифр и наша возможность обрабатывать запросы выросла радикально.
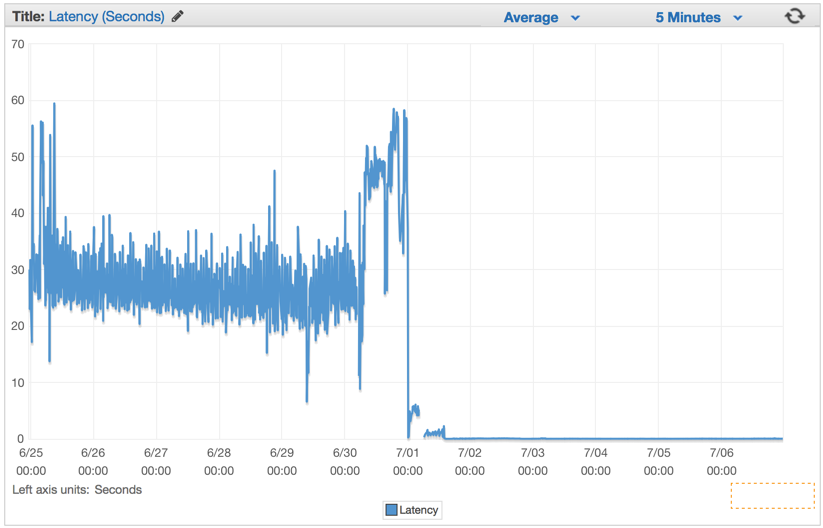
Через несколько минут после разогрева Elastic Load Balancer-ов, мы увидели что наше ElasticBeanstalk приложение обрабатывает порядка 1 миллиона запросов в минуту. У нас есть обычно несколько часов утром, когда пики трафика достигают более 1 миллиона запросов в минуту.
Как только мы задеплоили новый код, количество необходимых серверов значительно упало, со 100 до примерно 20 серверов.
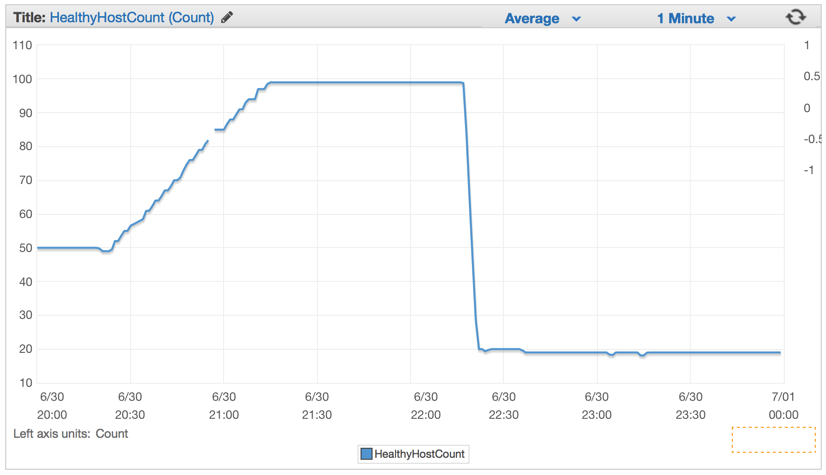
После того, как мы настроили наш кластер и настройки авто-масштабирования, мы смогли уменьшить их количество еще больше — до 4-х EC c4.large инстансов и Elastic Auto-Scaling запускал новый инстанс, если использование CPU превышало 90% в течении 5 минут.
Выводы
Я глубоко уверен, что простота всегда побеждает. Мы могли создать сложную систему с кучей очередей, фоновыми процессами, сложным деплоем, но вместо всего этого мы решили воспользоваться силой авто-масштабирования ElasticBeanstalk и эффективностью и простотой подхода к конкурентности, которую Golang даёт из коробки.
Не каждый день вы видите кластер из всего 4х машин, которые даже слабее, чем мой нынешний Macbook Pro, обрабатывающие POST-запросы, пишущие на Amazon S3 бакет 1 миллион раз каждую минуту.
Всегда есть правильный инструмент для задачи. И для тех случаев, когда ваша Ruby on Rails система нуждается в более мощном веб-обработчике, выйдите немного из экосистемы ruby для более простых, при этом более мощных решений.
Комментарии (52)

InfiniteCode
08.07.2015 06:01+3Когда задача стоит загрузить данные от клиентов на S3, желательно использовать Pre-signed URL. Тогда не будет проблемы с узким горлышком и ожиданием пока выполнится загрузка — все делается клиентом, а на сервере остается только логика и «оркестровка» этого процесса. Весь трафик упадет на плечи Амазона.

affka
08.07.2015 06:54+2Интересно, смог бы справиться с такой задачей (и таким же успехом) Node.js, не рассматривали его как вариант?

AterCattus
09.07.2015 10:04+1Довелось мигрировать одну систему с node.js на go. Теоретически, можно бы написать… Если очень коротко, то нода не справлялась.

robert_ayrapetyan
08.07.2015 07:07+192к запросов \ сек на ядро, для системы, которая просто сохраняет данные в базу, не очень впечатляет.

orcy
08.07.2015 17:21+2Как рекламе в банках или где-нибудь еще:
Только у нас миллион* запросов в минуту!!!
____
* на 4 серверах**
** каждый сервер с 2-х ядерным CPU
monah_tuk
09.07.2015 08:04Если пойти дальше, то 10^6/60 = 16666.(6) запросов в секунду, т.е., по сути, проблему C10K смогли решить 3 серверами.

mikhanoid
08.07.2015 08:08-5(semantic-nazi-on Рутина в русском языке совсем не то же самое, что и routine в английском. Хотя, вроде как, оба слова происходят от французского «дорожка», но в русском это обыденность, повседневность, закостенелость и прочее, а в английском — стандартная процедура или даже именно компьютерная подпрограмма. Когда Вы пишете Go-рутина, то это читается как Go-обыденность. Хрень какая-то, а не термин. Что мешает переводить как Go-процедура?)

divan0 Автор
08.07.2015 08:16+5Есть термин goroutine, в русскоязычном сообществе используется «горутина», и в данном случая я просто следую оригиналу — где автор пишет «Go routine» вместо «goroutine» (что выглядит как некая игра слов), я перевожу как «Go рутина» соответственно.
«Go-процедура» — это совсем промт-стайл будет ) Тогда уже «горутина» будет удачнее, имхо.mikhanoid
08.07.2015 08:52-4IMHO, это просто от безграмотности сообщества (no offence). Вместо того, чтобы подумать, какому русскому термину соответствует название, просто берётся калька. Чем гопрограмма, как предлагает neolink, хуже? Гопроцедура, гофункция. Но рутина вообще не к месту. Горутина вместо гопрограммы (гофункции, гопроцедуры) — это то же самое, что и «дорожная карта» вместо нормального слова «план».

nsinreal
08.07.2015 10:27+5Goprogram & goroutine -> Гопрограмма & гопрограмма. Ненавижу граммар-наци, вы тупые. Нельзя делать перевод в состоянии обдолбанности

batyrmastyr
14.07.2015 10:25-1А вы сами что курили, чтобы goprogram выдумать и багетить с того, что перевод несуществующего термина совпадает с переводом существующего? Надеюсь вы не из аплогетов «лучший перевод — тупая транслитерация»?

bolk
08.07.2015 11:46+9«IMHO», «no offence», «semantic-nazi-on»? Вы какой-то ненастоящий граммар-наци.

neolink
08.07.2015 08:46+4если брать за аналогию coroutine, то гопрограмма. Но транслитерация (горутина) звучит лучше

youlose
08.07.2015 09:02При чём тут Ruby on rails вообще непонятно, ребята сделали воркер для передачи json объектов в S3 и даже разбалансировали не средствами Go, для этого рельсы как бы и не нужны совсем. И я сомневаюсь что такая большая разница будет для такой задачи, они просто не умеют (или просто не хотят) работать с Ruby, а лучше работают с Go, так бы и писали сразу.
P.S. И ещё, у них же такая нагрузка не из пустоты появилась, потому разумно что на таких нагрузках можно (а может быть и нужно) переходить с Ruby на что-то менее удобное, но более производительное.

Pryada
08.07.2015 10:43Объясните, пожалуйста, этот кусок:
func (d *Dispatcher) Run() { // starting n number of workers for i := 0; i < d.maxWorkers; i++ { worker := NewWorker(d.pool) worker.Start() } go d.dispatch() }
Откуда взялся d.pool? В структуре Dispatcher его нет.divan0 Автор
08.07.2015 10:48Скорее всего, подразумевался d.WorkerPool — код, наверняка, подчищался/упрощался для статьи, потому пролезли ошибки.

lair
08.07.2015 11:09+1Но с самого начала наша команда знала, что мы должны написать это на Go, посколько на этапе обсуждения мы уже понимали, что эта система должна будет справляться с огромным траффиком.
Pet technology, оно же Architecture as Requirements.
dblokhin
08.07.2015 11:58-1Третий вариант, точно такой же как и второй, только с небольшим допущением:
func StartProcessor() { for { select { case job := <-Queue: // job.payload.UploadToS3() // <-- STILL NOT GOOD go job.payload.UploadToS3() } } }
Тогда не будет блокировки основного цикла, ожидающего следующего Job. Так и работает 3 вариант.

tangro
08.07.2015 15:23+2Я правильно понял, что ребята с четвёртой попытки написали обычный пул воркеров с диспетчеризацией сообщений, который в C#/Java/C++ + boost можно было взять из коробки и не пыхтеть?
divan0 Автор
08.07.2015 15:34-6Почти )
Если ребята написали этот пул с третьей попытке на Go, угадайте, как бы выглядело их «не пыхтеть» на C++/boost.
GamePad64
08.07.2015 15:59+6Собственно, создаём пул:
boost::asio::io_service ios;
Добавляем задачи:
ios.post(&routine1); // routine -- это обычный указатель на функцию ios.post(&routine2); ios.post(&routine3); ...
Запускаем в несколько потоков:
std::thread t1(&boost::asio::io_service::run, &ios); std::thread t2(&boost::asio::io_service::run, &ios); ios.run();
Завершаем выполнение:
t1.join(); t2.join();divan0 Автор
08.07.2015 16:08-3Миллион OS-тредов != миллион горутин.
tangro
08.07.2015 16:31+4так и не надо миллион ос-потоков, создаём сколько надо, а задачи по ним распределятся сами
neolink
08.07.2015 17:09ну а в итоге то что?
ну есть в бусте это. ребята вон сами написали, в гугле ещё косой десяток вариантов пула воркеров на го, некоторые даже как пакеты оформлены.monah_tuk
09.07.2015 08:15Кстати, а почему их и не использовали? И в чём проблема использование готового, хорошо-отлаженного решения?
ЗЫ в 11 стандарт у Asio протиснуться не получилось, пробуется в 17.neolink
09.07.2015 10:25+2потому что задача стоит не сделать абстрактный пул потоков который 2 хелло ворда отправляет.
им приходят http запросы они это парсят и отправляют в S3.
но вопрос не в бусте, да если хорошенько посидеть на си это можно сделать ну раза в 2 быстрее точно, но вот где бы эти ребята взяли такого человека не понятно и сколько бы он это писал, а потом это всё отлаживал, когда оно нефига не по тому что не успевает, а потому что где-то free нет, где-то race и т.п. падает.
а тут выпил редбула, посидел вечерок и в продакшен
divan0 Автор
09.07.2015 13:32-1А вы вправду не понимаете, почему народ в своё время массово стал переходить с C++/Java на Ruby/Python и прочие решения, даже в ущерб производительности?
divan0 Автор
09.07.2015 13:34А вообще, автор статьи, конечно, тупил много ) Но в этом и прелесть статьи, по-моему, что автор не стыдится своих ошибок, и описывает шаг за шагом. Желание написать своё решение, а не искать готовые, видимо было вызвано по той же причине, по которой он не захотел использовать готовые инструменты (не языка, а технологии, описанные в статье).
divan0 Автор
09.07.2015 13:38Ребят, ну если вы тут пытаетесь доказать, что разработка многопоточных архитектур на C++/boost — это легко, просто и надежно, без надобности нарабатывать 5+ лет опыта и читать талмуды, то что-то вы важное упускаете.
Я писал многопоточный софт на boost и писал на Go — и это просто небо и земля. Пробовать обе технологии, или привязаться лишь к одной и её пропагандировать — это уже ваш выбор.

FanKiLL
08.07.2015 15:31Я немного не понял, у низ Queue это обычный chan как и было раньше, как он превратился в poll «воркеров»
и почему они не использовали встроенный в go golang.org/pkg/container/heap к примеру.
Optik
08.07.2015 19:02+9Один вопрос — как человек, не осознающий что для десятка тысяч запросов в секунду нужен выделенный пул потоков, стал архитектором?
divan0 Автор
09.07.2015 13:40Думаю тут разгадка во фразе «мы очень недооценили количество входящих вопросов».
Optik
09.07.2015 20:59После первого фейла уже масштаб проблемы должен был прояснить головы. Решение же типовое безотносительно языков и фреймворков, это первое что в голову должно прийти. Люди банально не понимали как работает выбранный инструмент (особенно печально, что после 2х лет использования).
Эта статья должна быть предупреждением для бизнеса, о качестве кадров и иметь соответствующий заголовок.

matiouchkine
09.07.2015 12:30+1> Но с самого начала наша команда знала, что мы должны написать это на Go, посколько на этапе обсуждения мы уже понимали, что эта система должна будет справляться с огромным траффиком.
Ну да, естественно, ведь Эрланг, например, совсем не для этого придуман и вылизан. До 15-9 Go не доберется никогда, но великие архитекторы с самого начала знают, что писать нужно на нем.divan0 Автор
09.07.2015 13:45+3Фраза эта да, кривовато звучит. Думаю, на деле он хотел сказать, что они хотели попробовать для этого проекта Go, вместо Ruby (как я понял, это их основной стек был), потому что нужна была большая нагрузка.
А по поводу обожание Эрланга — Go не собирается никуда добираться. Он уже и сейчас дает людям возможность быстро получать качественный результат, с которым легко и приятно работать. Это единственное, что важно в конечном итоге.matiouchkine
09.07.2015 14:43-4Я не знаю, что вы понимаете под «обожанием», но все же просто: нужно 15-9, concurrency и реальное время — это эрланг. Можно подвинуться в этом, и получить скорость разработки — руби. Если вдруг архитектор не пальцем деланый — эликсир.
А если нужно командой рукожопых джуниоров быренько запилить что-то похожее на надежный сервис — вот тут у Го самая ниша. Из которой выбраться ему не суждено.divan0 Автор
09.07.2015 15:12+2Это ваш взгляд. В Google уже 3+ млн строк кода на Go, включая многие ключевые сервисы.
Go очень сильно берет низким порогом входа, это правда. Я, кстати, считаю это одним из минусов Эрланга — если бы освоить эрланг у меня заняло пару вечеров, как и Go, я бы конечно так или иначе попробовал Эрланг где-нибудь в pet projects. А читать кучу книг и тратить месяцы, просто чтобы узнать — хорошая технология или нет — я просто не могу. И это не оправдание, это реалии — интересных технологий пруд пруди, и время входа тут очень сильное конкурентное преимущество (но не единственное, конечно же).
dblokhin
09.07.2015 15:15+1Скажите, что такое «15-9»?
matiouchkine
09.07.2015 15:53+1Эрланг доказал в продакшене «девять девяток», то есть 99.9999999% reliability. Elixir — пятнадцать.
Это значит, в целом, что если бизнесу нужен этот показатель, то бизнес как бы прибит гвоздями к эликсиру (у эрланга действительно высоковат порог входа, мы не можем зависеть от того, найдется ли в городе заезжий эрлангист).
А если бизнесу это как бы не особо надо, как, например, гуглу и/или автору статьи — сойдет и руби, если уметь программировать, конечно.neolink
09.07.2015 16:51а что значит доказал в продакшене? по отдельно взятому софту для банкомата у которого считали время online?
да у ерланга в целом есть заточки под стояние надолго, но вот сам язык содержит много ограничений, и в конечном счете все упирается в программистов и то что получилось у эриксона не факт что получится у конкретно взятой команды.
И да сколько у вас девяток и как вы их считали (доступность полной функциональности сервиса или просто что сервис был как бы запущен) ну и что за проектmatiouchkine
09.07.2015 17:00Вас в гугле забанили?
stackoverflow.com/questions/8426897/erlangs-99-9999999-nine-nines-reliability
Мы сами никак не считали, мы взлетели больше года назад и с тех пор не было ни одного отказа.
У нас эликсир, не чистый эрланг. На нем писать проще и приятней, чем на руби. Хот релоад, прекомпиляция кода, нативный код ?? AST туда-сюда и воркеры. Но это ни при чем же, если отказ транзакции приводит к тому, что теперь курс вдвое больше и разница из своего кармана — выучишь и эрланг.
Проект FX, подробнее не могу.neolink
09.07.2015 17:32+1> Вас в гугле забанили?
а вы мой комментарий точно прочитали? я про AXD301 как бы и писал.
и это ничего не доказывает кроме того что ерланг был 20 лет назад и то что есть одна success story. Кстати это по ссылке тоже написано.
И какая история про эликсир с 15 девятками?
> Мы сами никак не считали
ок… а откуда такой снобизм тогда?
> нативный код ?? AST туда-сюда
а в beam jit появился? или это что-то от энтузиастов
> если отказ транзакции
что-то не понятно, это вы сейчас latency на обработку имели ввиду?
в целом традиционно ерланг хорошо справляется с перекидыванием небольших сообщений (смс, rabbitmq) и т.п. он под маршрутизацию (правда голоса) и создавался.
но я не уверен что он 69гб хипа переварит

gto
14.07.2015 10:57+2Когда-то, в далёком 2005, был на экскурсии на одном заводе. Там в бухгалтерии бежал серверок написаный на паскале. Его как в 94 запустили, так он и бежал 11 лет без единого сбоя или перезагрузки. Так что, по вашей логике, паскаль круче. Доказано в продакшене.
matiouchkine
14.07.2015 11:03+1Да, по моей логике (и по любой другой логике тоже) паскаль круче (для той конкретной задачи, которую решал этот серверок.)
Возможно, кто-то мог сравниться с паскалем на том конкретном сервере, но лучше, чем «бежал 11 лет без единого сбоя или перезагрузки» показателя не бывает. Это если вам ехать надо.
Если шашечки — тогда, конечно, есть куда более эзотерические варианты.

hlamer
14.07.2015 18:03Насколько я понял суть работы Dispatcher, он:
1. Берет задачу из JobQueue
2. Берет доступный воркер из WorkerPool
3. Шлет задачу воркеру в JobChannel
А почему воркеры не могут напрямую читать задачи из JobQueue?
M0sTH8
Стоит заметить, что последнее решение можно сильно упростить, убрав создание горутины на каждый диспатч запрос. Это уменьшит количество работы для сборщика мусора в разы.