Сверточные нейронные сети
Для начала немного теории. Что такое свертка? Мы не будем на этом останавливаться подробно, так как про это написана уже тонна материалов, но все-таки кратко пробежаться стоит. Есть красивая визуализация от Стэнфорда, которая позволяет ухватить суть:
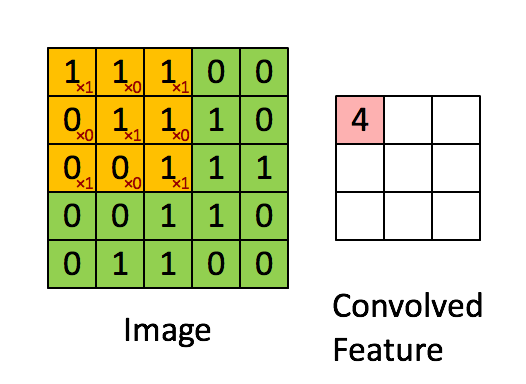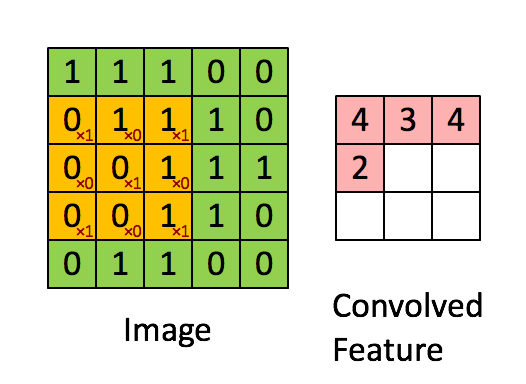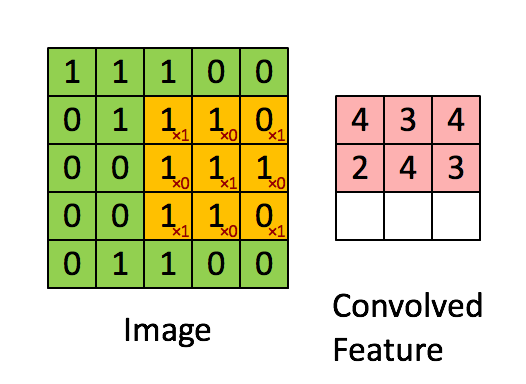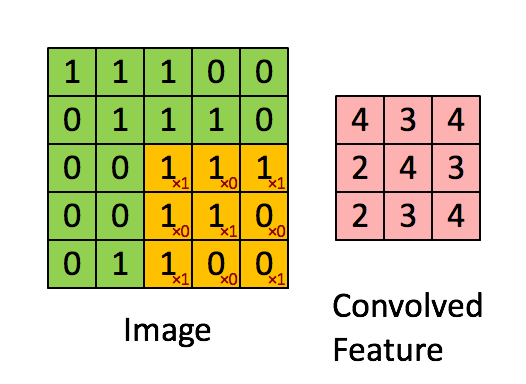
Источник
Надо ввести базовые понятия, чтобы потом мы понимали друг друга. Окошко, которое ходит по большой матрице называется фильтром (в англоязычном варианте kernel, filter или feature detector, так что можно встретить переводы и кальки этих терминов не пугайтесь, это все одно и то же). Фильтр накладывается на участок большой матрицы и каждое значение перемножается с соответствующим ему значением фильтра (красные цифры ниже и правее черных цифр основной матрицы). Потом все получившееся складывается и получается выходное (“отфильтрованное”) значение.
Окно ходит по большой матрице с каким-то шагом, который по-английски называется stride. Этот шаг бывает горизонтальный и вертикальный (хотя последний нам не пригодится).
Еще осталось ввести важный концепт канала. Каналами в изображениях называются известные многим базовые цвета, например, если мы говорим о простой и распространенной схеме цветового кодирования RGB (Red — красный, Green — зеленый, Blue — голубой), то там предполагается, что из трех этих базовых цветов, путем их смешения мы можем получить любой цвет. Ключевое слово здесь — “смешение”, все три базовых цвета существуют одновременно, и могут быть получены из, например, белого света солнца с помощью фильтра нужного цвета (чувствуете, терминология начинает обретать смысл?).
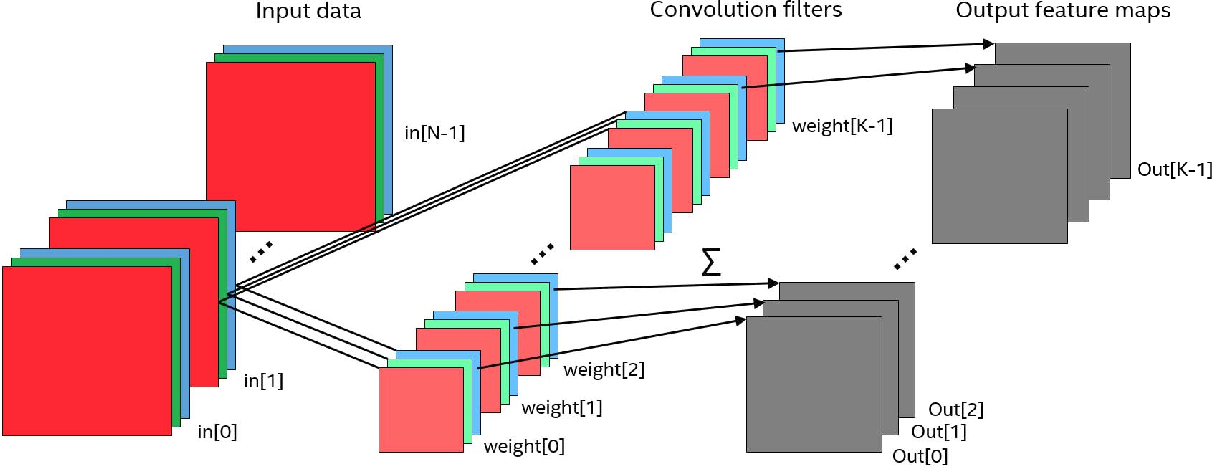
И вот получается, что у нас есть изображение, в нем есть каналы и по нему с нужным шагом ходит наш фильтр. Осталось понять — что собственно делать с этими каналами? С этими каналами мы делаем с следующее — каждый фильтр (то есть матрица небольшого размера) накладывается на исходную матрицу одновременно на все три канала. Результаты же просто суммируются (что логично, если разобраться, в конце концов каналы — это наш способ работать с непрерывным физическим спектром света).
Нужно упомянуть еще одну деталь, без которой понимание дальнейшего будет затруднено: открою вам страшную тайну, фильтров в сверточных сетях гораздо больше. Что значит гораздо больше? Это значит, что у нас существует n фильтров выполняющих одну и ту же работу. Они ходят с окном по матрице и что-то рассматривают. Казалось бы, зачем делать одну работу два раза? Одну да не одну — из-за различной инициализации фильтрующих матриц, в процессе обучения они начинают обращать внимание на разные детали. К примеру один фильтр смотрит на линии, а другой на определенный цвет.

Источник: cs231n
Это визуализация разных фильтров одного слоя одной сети. Видите, что они смотрят на совершенно разные особенности изображения?
Все, мы вооружены терминологией для того, чтобы двигаться дальше. Параллельно с терминологией мы разобрались, как работает сверточный слой. Он является базовым для сверточных нейронных сетей. Есть еще один базовый слой для CNN — это так называемый pooling-слой.
Проще всего его объяснить на примере max-pooling. Итак, представьте, что в уже известном вам сверточном слое матрица фильтра зафиксирована и является единичной (то есть умножение на нее никак не влияет на входные данные). А еще вместо суммирования всех результатов умножения (входных данных по нашему условию), мы выбираем просто максимальный элемент. То есть мы выберем из всего окна пиксель с наибольшей интенсивностью. Это и есть max-pooling. Конечно, вместо функций максимум может быть другая арифметическая (или даже более сложная) функция.
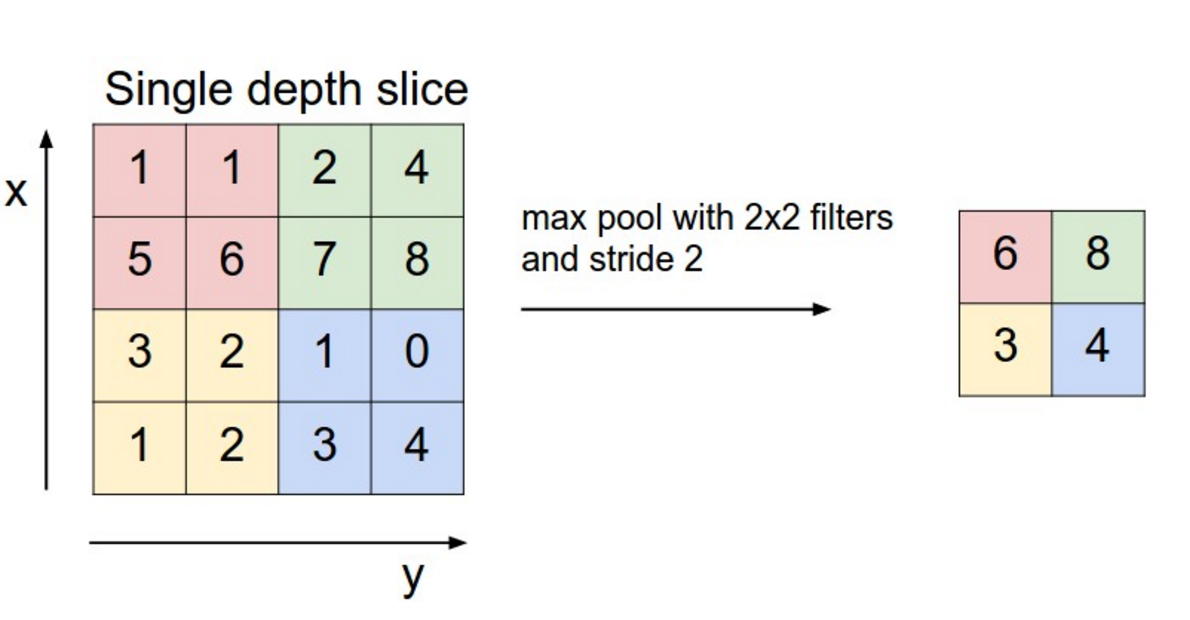
Источник: cs231n
В качестве дальнейшего чтения по этому поводу я рекомендую пост Криса Ола (Chris Olah).
Все вышеназванное — это хорошо, но без нелинейности у нейронных сетей не будет так необходимого нам свойства универсального аппроксиматора. Соответственно, надо сказать пару слов про них. В рекуррентных и полносвязных сетях бал правят такие нелинейности, как сигмоида и гиперболический тангенс.
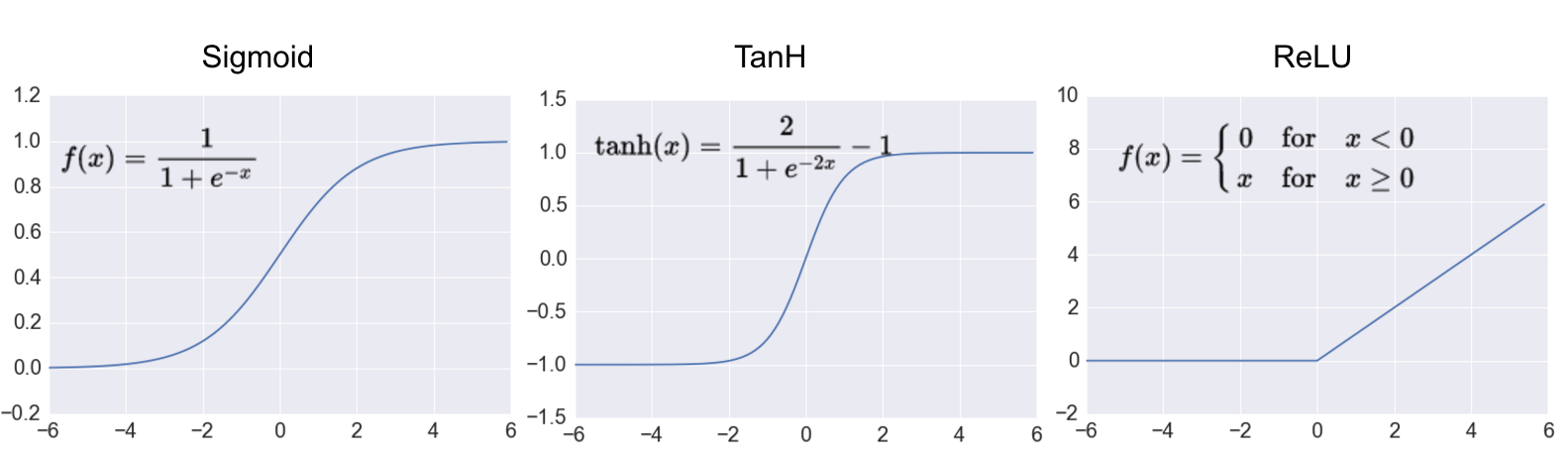
Источник
Это хорошие нелинейные гладкие функции, но они все-таки требуют существенных вычислений по сравнению с той, которая правил бал в CNN: ReLU — Rectified Linear Unit. По-русски ReLU принято называть линейным фильтром (вы еще не устали от использования слова фильтр?). Это простейшая нелинейная функция, к тому же не гладкая. Но зато она вычисляется за одну элементарную операцию, за что ее очень любят разработчики вычислительных фреймворков.
Ладно, мы с вами уже обсудили сверточные нейронные сети, как устроено зрение и всякое такое. Но где же про тексты, или я вас бессовестно обманывал? Нет, я вас не обманывал.
Применение сверток к текстам

Вот эта картинка практически полностью объясняет, как мы работает с текстом с помощью CNN. Непонятно? Давайте разбираться. Прежде всего вопрос — откуда у нас возьмется матрица для работы? CNN же работают с матрицами, не так ли? Здесь нам нужно вернуться немного назад и вспомнить, что такое embedding (по этому поводу есть отдельная статья).
Если вкратце, embedding — это сопоставление точки в каком-то многомерном пространстве объекту, в нашем случае — слову. Примером, возможно, самым известным такого embedding является Word2Vec. У него кстати есть семантические свойства, вроде
word2vec(“king”) - word2vec(“man”) + word2vec(“woman”) ~= word2vec(“queen”). Так вот, мы берем embedding для каждого слова в нашем тексте и просто ставим все вектора в ряд, получая искомую матрицу.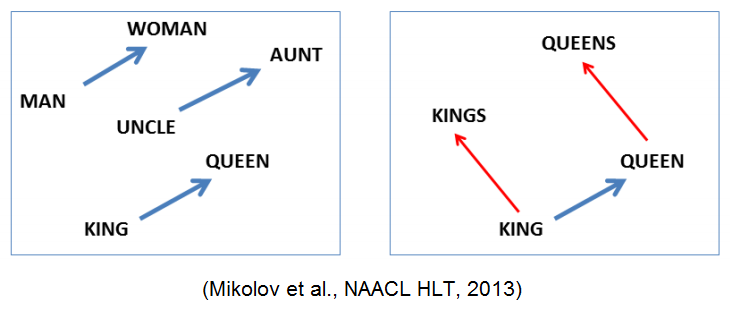
Теперь следующий шаг, матрица — это хорошо, и она вроде бы даже похожа на картинку — те же два измерения. Или нет? Подождите, у нас в картинке есть еще каналы. Получается, что в матрице картинки у нас три измерения — ширина, высота и каналы. А здесь? А здесь у нас есть только ширина (на заглавной картинке раздела матрица для удобства отображения транспонирована) — это последовательность токенов в предложении. И — нет, не высота, а каналы. Почему каналы? Потому что embedding слова имеет смысл только полностью, каждое отдельное его измерение нам ни о чем не скажет.
Хорошо, разобрались с матрицей, теперь дальше про свертки. Получается, что свертка у нас может ходить только по одной оси — по ширине. Поэтому для того, чтобы отличить от стандартной свертки, ее называют одномерной (1D convolution).
И сейчас уже практически все понятно, кроме загадочного Max Over Time Pooling. Что это за зверь? Это уже обсуждавшийся выше max-pooling, только примененный ко всей последовательности сразу (то есть ширина его окна равна всей ширине матрицы).
Примеры использования сверточных нейронных сетей для текстов

Сверточные нейронные сети хороши там, где нужно увидеть кусочек или всю последовательность целиком и сделать какой-то вывод из этого. То есть это задачи, например, детекции спама, анализа тональности или извлечения именованных сущностей. Разбор статей может быть сложен для вас, если вы только что познакомились с нейронными сетями, этот раздел можно пропустить.
В работе [2] Юн Ким (Yoon Kim) показывает, что CNN хороши для классификации предложений на разных датасетах. Картинка, использованная для иллюстрации раздела выше — как раз из его работы. Он работает с Word2Vec, но можно и работать непосредственно с символами.
В работе [3] авторы классифицируют тексты исходя прямо из букв, выучивая embedding для них в процессе обучения. На больших датасетах они показали даже лучшие результаты, чем сети, работавшие со словами.
У сверточных нейронных сетей есть существенный недостаток, по сравнению с RNN — они могут работать только со входом фиксированного размера (т.к. размеры матриц в сети не могут меняться в процессе работы). Но авторы вышеупомянутой работы [1] смогли решить эту проблему. Так что теперь и это ограничение снято.
В работе [4] авторы классифицируют тексты исходя прямо из символов. Они использовали набор из 70 символов для того чтобы представить каждый символ как one-hot вектор и установили фиксированную длину текста в 1014 символа. Таким образом, текст представлен бинарной матрицей размером 70x1014. Сеть не имеет представления о словах и видит их как комбинации символов, и информация о семантической близости слов не предоставлена сети, как в случаях заранее натренированных Word2Vec векторов. Сеть состоит из 1d conv, max-pooling слоев и двух fully-connected слоев с дропаутом. На больших датасетах они показали даже лучшие результаты, чем сети, работавшие со словами. К тому же этот подход заметно упрощает preprocessing шаг что может поспособствовать его использованию на мобильных устройствах.
В другой работе [5] авторы пытаются улучшить применение CNN в NLP использованием наработок из компьютерного зрения. Главные тренды в компьютерно зрении в последнее время это увеличивание глубины сети и добавление так называемых skip-связей (e.g., ResNet) которые связывают слои которые не соседствуют друг с другом. Авторы показали что те же принципы применимы и в NLP, они построили CNN на основе символов с 16-размерными embedding, которое учились вместе с сетью. Они натренировали сети разной глубины (9, 17, 29 и 49 conv слоёв) и поэкспериментировали со skip-связями, чтобы выяснить, как они влияют на результат. Они пришли к выводу, что увеличение глубины сети улучшает результаты на выбранных датасетах, но производительность слишком глубоких сетей (49 слоев) ниже чем умеренно глубоких (29 слоев). Применение skip-связей привел к улучшению результатов сети из 49 слоев, но все равно не превзошел показатель сети с 29 слоями.
Другая важная особенность CNN в компьютерном зрении это возможность использования весов сети натренированной на одном большом датасете (типичный пример — ImageNet) в других задачах компьютерного зрения. В работе [6] авторы исследуют применимость этих принципов в задаче классификации текстов с помощью CNN с word embedding. Они изучают, как перенос тех или иных частей сети (Embedding, conv слои и fully-connected слои) влияет на результаты классификации на выбранных датасетах. Они приходят к выводу что в NLP задачах семантическая близость источника на котором заранее тренировалась сеть играет важную роль, то есть сеть, натренированная на рецензиях к фильмам, будет хорошо работать на другом датасете с кинорецензиями. К тому же они отмечают, что использование тех же embedding для слов увеличивает успех трансфера и рекомендуют не замораживать слои, а дотренировывать их на целевом датасете.
Практический пример
Давайте на практике посмотрим, как сделать sentiment analysis на CNN. Мы разбирали похожий пример в статье про Keras, поэтому за всеми деталями я отсылаю вас к ней, а здесь будут рассмотрены только ключевые для понимания особенности.
Прежде всего на понадобится концепция Sequence из Keras. Собственно, это и есть последовательность в удобном для Keras виде:
x_train = tokenizer.texts_to_sequences(df_train["text"])
x_test = tokenizer.texts_to_sequences(df_test["text"])
x_val = tokenizer.texts_to_sequences(df_val["text"])Здесь
text_to_sequences — функция, которая переводит текст в последовательность целых чисел путем а) токенизации, то есть разбиения строки на токены и б) замены каждого токена на его номер в словаре. (Словарь в этом примере составлен заранее. Код для его составления в полном ноутбуке.)Далее получившиеся последовательности нужно выровнять — как мы помним CNN пока не умеют работать с переменной длиной текста, это пока не дошло до промышленного применения.
x_train = pad_sequences(x_train, maxlen=max_len)
x_test = pad_sequences(x_test, maxlen=max_len)
x_val = pad_sequences(x_val, maxlen=max_len)После этого все последовательности будут либо обрезаны, либо дополнены нулями до длины
max_len. А теперь, собственно самое важное, код нашей модели:
model = Sequential()
model.add(Embedding(input_dim=max_words, output_dim=128, input_length=max_len))
model.add(Conv1D(128, 3))
model.add(Activation("relu"))
model.add(GlobalMaxPool1D())
model.add(Dense(num_classes))
model.add(Activation('softmax'))Первым слоем у нас идет
Embedding, который переводит целые числа (на самом деле one-hot вектора, в которых место единицы соответствует номеру слова в словаре) в плотные вектора. В нашем примере размер embedding-пространства (длина вектора) составляет 128, количество слов в словаре max_words, и количество слов в последовательности — max_len, как мы уже знаем из кода выше.После embedding идет одномерный сверточный слой
Conv1D. Количество фильтров в нем — 128, а ширина окна для фильтров равна 3. Активация должна быть понятна — это всеми любимый ReLU.После ReLU идет слой
GlobalMaxPool1D. «Global» в данном случае означает, что он берется по всей длине входящей последовательности, то есть это ни что иное, как вышеупомянавшийся Max Over Time Pooling. Кстати, почему он называется Over Time? Потому что последовательность слов у нас имеет естественный порядок, некоторые слова приходят к нам раньше в потоке речи/текста, то есть раньше по времени.Вот какая модель у нас получилась в итоге:

На картинке можно заметить интересную особенность: после сверточного слоя длина последовательности стала 38 вместо 40. Почему так? Потому что мы с вами не разговаривали и не применяли padding, технику, позволяющую виртуально «добавить» данных в исходную матрицу, чтобы светка могла выйти за ее пределы. А без этого свертка длины 3 с шагом равным 1 сможет сделать по матрице шириной 40 только 38 шагов.
Ладно, что же у нас получилось в итоге? На моих тестах этот классификатор дал качество 0.57, что, конечно, немного. Но вы легко сможете улучшить мой результат, если приложите немного усилий. Дерзайте.
P.S.: Спасибо за помощь в написании этой статьи Евгению Васильеву somesnm и Булату Сулейманову khansuleyman.
Литература
[1] Bai, S., Kolter, J. Z., & Koltun, V. (2018). An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arxiv.org/abs/1803.01271
[2] Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP 2014), 1746–1751.
[3] Heigold, G., Neumann, G., & van Genabith, J. (2016). Neural morphological tagging from characters for morphologically rich languages. arxiv.org/abs/1606.06640
[4] Character-level Convolutional Networks for Text Classification. Xiang Zhang, Junbo Zhao, Yann LeCun arxiv.org/abs/1509.01626
[5] Very Deep Convolutional Networks for Text Classification. A Conneau, H Schwenk, L Barrault, Y Lecun arxiv.org/abs/1606.01781
[6] A Practitioners’ Guide to Transfer Learning for Text Classification using Convolutional Neural Networks. T Semwal, G Mathur, P Yenigalla, SB Nair arxiv.org/abs/1801.06480
Комментарии (22)

ivodopyanov
10.04.2018 15:19Самое вкусное, что было в области применения CNN к NLP — это seq2seq и ASR на сверточных сетях от Facebook.

madrugado Автор
10.04.2018 15:56Это довольно сложные модели их не так просто рассказать людям, не знакомым с областью. Хотя я согласен, что они очень интересны.
Относительно convolutional seq2seq я бы еще добавил, что lua Torch имплементация устарела, лучше использовать PyTorch: github.com/facebookresearch/fairseq-py
Относительно ASR мое мнение, что даже интереснее TTS в виде более раннего WaveNet от DeepMind. Но тогда надо было бы рассказывать про padding, dilated convolutions и прочие более сложные вещи, которые для вводной статьи слишком сложны.

sebres
10.04.2018 16:26+2Статья замечательная, чего мне не хватило, это собственно…
ссылки на оригинал.
Укажите пожалуйста, что это, хоть и обрезаный (с отступлениями, вытяжками со стороны и т.д.), но всё же перевод… А то не красиво как-то выходит.
sshmakov
10.04.2018 17:26-2Вот еще одна ссылка на оргинал (предыдущая мне недоступна).
sebres
10.04.2018 17:40+1Ну это как раз малая часть (и Denny Britz на её первоначальный вариант от 2014 года ссылается)…
Из статьи же Брица, той что на WildML за 2015 год, практически 70-80% (если не больше).
предыдущая мне недоступна
А WildML нынче в реестре? Поискал в блэклисте — говорит вроде нет… Если все же — сочувствую...
madrugado Автор
10.04.2018 17:35-2это не перевод, я ее читал, когда писал, по картинкам у нас частичное пересечение (хотя картинки стенфордские), в остальном статьи разные
sebres
10.04.2018 17:52Вы серьёзно?.. Ну-ну.
When we hear about Convolutional Neural Network (CNNs), we typically think of Computer Vision. CNNs were responsible for major breakthroughs in Image Classification and are the core of most Computer Vision systems today…
Когда мы слышим о сверточных нейронных сетях (CNN), мы обычно думаем о компьютерном зрении. CNN лежали в основе прорывов в классификации изображений...И т.д. и т.п.
Вы правда думаете, что изменением пары фраз и заместив 20-30% можно "обмануть" человека бегло читающего по английски?
Молодой человек, это называется — плагиат.
Но хоть мораль — дело общественное, совесть всё таки — дело каждого.
Так что я вам ничего доказывать не собираюсь, оставайтесь при своем мнении.madrugado Автор
10.04.2018 18:01-2коллега, вы ведете себя некорректно, докажите с цифрами, что это плагиат, по совпадению одного предложения вы делаете далеко идущий вывод

mephistopheies
10.04.2018 18:49паренек, иди почитай что такое плагиат и критерии плагиата, потом можем обсудить тут все формально, а пока сплошные набросы без какой либо конкретики, уровень церковно-приходской школы

slonopotamus
10.04.2018 22:17Чего это без конкретики? Приведен вполне конкретный пример.
mephistopheies
11.04.2018 08:22-1с вашей то кармой на этом сайте лучше вообще не участвовать в серьезных дискуссиях

khdavid
11.04.2018 11:18-1Ребят, а что такое NLP? Мне на ум сразу приходит нейро-лингвистическое программирование. Читаю статью, в введении ничего не написано, потом сразу к математике. В общем, не смог дочитать.

novikovag
11.04.2018 13:26-1Всегда поражался, какой удобный инструмент эти нейронные сети, ими можно разводить лохов, пилить гранты, писать котоламповые статьи и особо не напрягаться. Весь кампутервижин ими засрали, теперь до языков добрались. Ну это понятно, маняматикам нужно показать свою значимость, но мусор типа seq2seq или сабжа ничего кроме улыбки не вызывает.

svboobnov
11.04.2018 14:02В этих наших интернетах опять кто-то неправ. Посмотрите на пару обычных соображений:
- Если нейросети применяют, значит, они выгоднее, чем разработанные вручную алгоритмы.
- Если вакансии на должности программиста-аналитика или data-scientist'а появляются, значит, ML используется в бизнесе.
- Ну, и система автоматического «развода лохов» (поиск заёмщиков, классификация потребителей рекламы) работает без перерывов, без выходных и никогда не уйдёт в декрет.

svboobnov
11.04.2018 13:54Спасибо! Статья понравилась. Пояснения кратки и ясны, легче будет разобраться мне, как неспециалисту.
zodiak
Расскажите как, если не сложно.
madrugado Автор
Это уже довольно сложный материал, и я не стал его включать в основную статью.
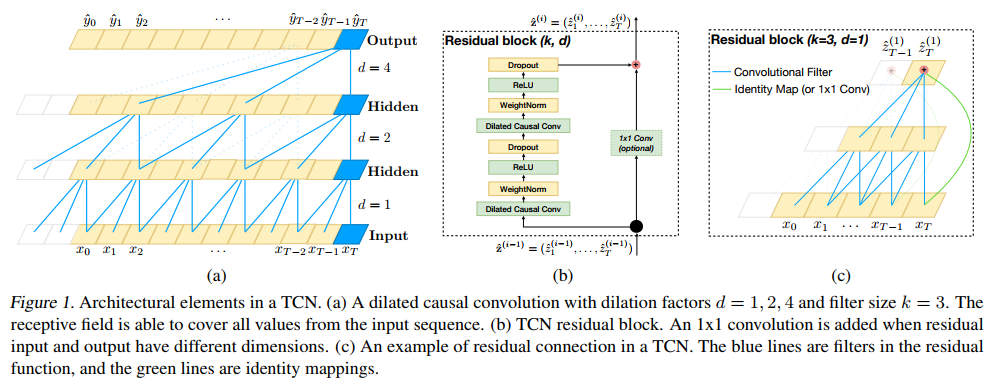
Чтобы ответить вам на вопрос, нужно рассказать несколько дополнительных вещей:
1) Residual connection — это способ проброса гридиентов в глубину, напрямую, когда мы «добавляем ко входу», то есть вход остается неизменным, а наш смысловой блок просто делает какую-то добавку. В сверточных нейронных сетях (типа ResNet) принято делать именно блоки, из которых строится сеть, а не отдельные сверточные слои.
2) Cвертка 1x1 — это специальный вид свертки, кторый интегрирует все каналы в одно значение, оставляя размер матрицы неизменным. Здесь он используется в качестве обработки входа, чтобы можно было совместить разное число каналов на входе и выходе residual-блока.
Авторы в своей сети используют так называемые fully-convolutional сети, т.е. размер матрицы, с которой они работают остается постоянным. Используя трюк с 1x1-conv и residual connection, они добиваются большой глубины, не теряя возможности варьировать обработку по ширине. Тут важно отметить, что они строят сеть так, чтобы нигде не делают изменения ширины матрицы, именно это позвояет им работать с матрицами переменной ширины.