
В прошлых двух статьях я рассказал об особенностях форматов данных звуковой подсистемы современных игр. Чтобы не утомлять читателей, перейду к несколько другой теме. Какой бы движок не использовала игра, ей нужно где-то хранить ресурсы и извлекать их оттуда в нужный момент. Иногда ресурсы в архиве имеют как идентификатор, так и читабельное имя файла. Но существует довольно много движков, где имён у файлов нет, а есть только хеш. Как же в таком случае можно что-то разобрать в ресурсах?
Рассмотрим это на примере довольно редкого движка bitsquid. Он простой и компактный, но, тем не менее, имеет все необходимые для современных игр возможности. В прошлом году bitsquid вместе с его разработчиком был куплен компанией Autodesk, и теперь они собираются скрестить его с Maya и сделать свой собственный игровой движок, который, как они обещают, будет чем-то невероятным.
Чтобы любой желающий мог сам посмотреть на процесс, воспользуемся демо-версией игры The showdown Effect, которая к тому же совсем небольшого размера (около 250МБ). Зайдя в папку content, в которой, очевидно, и находятся все ресурсы, обнаруживаем там пару десятков файлов вот с такими замечательными именами:
038bbacc4ce89296 0d42c15e8f2b473f 171e8b0d2241eb79 406c3644bd95237a 44bcc04093e5c506 680514e023d37cd5 71eec7a172194fe5 9229959b09a3b4be 9e13b2414b41b842 a6db0de7cf227dfe a9956e471d528263 ac5c2f0670e5d674 b5af853949550001
Должно быть это файлы пакетов/архивов с ресурсами. Откроем один из них и посмотрим, что там внутри. А там на протяжении всего файла не видно ни таблиц, ни текстов, ни каких-то осмысленных чисел — сплошная мешанина байтов:
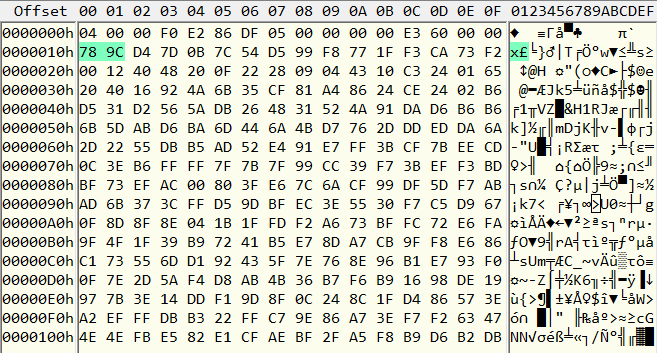
Это обычно означает, что все данные зашифрованы и/или запакованы. В данном случае почти в самом начале комбинация байт 78 9C (выделены зеленым) однозначно говорит, что данные сжаты zlib. Попробуем для начала распаковать файл «вручную». Для этого применим offzip — утилиту, которая просто пытается распаковать любые последовательности байт внутри файла, как если бы они были упакованы zip или zlib, сколько бы их ни было в файле и в какой последовательности.
Выполняем следующую команду: offzip -a 9e13b2414b41b842 unp 0
Опция -a здесь означает, что надо попытаться найти в файле все сегменты, сжатые zlib, а не рассматривать файл как единственный сжатый блок. «unp» — папка для распаковки (её нужно предварительно создать). «0» — начальное смещение, то есть искать с самого начала файла.
Получаем следующее:
+------------+-----+----------------------------+----------------------+ | hex_offset | ... | zip -> unzip size / offset | spaces before | info | +------------+-----+----------------------------+----------------------+ 0x00000010 24803 -> 65536 / 0x000060f3 _ 16 8:7:28:0:1:441d52d8 0x000060f7 21186 -> 65536 / 0x0000b3b9 _ 4 8:7:28:0:1:74fe0bf1 0x0000b3bd 16694 -> 65536 / 0x0000f4f3 _ 4 8:7:28:0:1:4bdbbd7f 0x0000f4f7 17028 -> 65536 / 0x0001377b _ 4 8:7:28:0:1:4cae9920 0x0001377f 16200 -> 65536 / 0x000176c7 _ 4 8:7:28:0:1:aa6b718e 0x000176cb 14445 -> 65536 / 0x0001af38 _ 4 8:7:28:0:1:e190c104 [поскипано...] 0x04ec0fb4 17108 -> 65536 / 0x04ec5288 _ 4 8:7:28:0:1:952f8201 0x04ec528c 17139 -> 65536 / 0x04ec957f _ 4 8:7:28:0:1:373c403f 0x04ec9583 22442 -> 65536 / 0x04eced2d _ 4 8:7:28:0:1:8e95fe5c 0x04eced31 4215 -> 65536 / 0x04ecfda8 _ 4 8:7:28:0:1:93e0ac5a - 1483 valid compressed streams found - 0x04d7e61c -> 0x05cb0000 bytes covering the 98% of the file
Как видим, 98% содержимого файла распаковалось в кучу сегментов по 64кБ каждый. Проанализировав их содержимое, можно заметить, что они представляли из себя единое целое — один большой файл, который был просто порезан на кусочки по 64кБ и затем сжаты по отдельности zlib-ом. В принципе могло быть и наоборот — каждый исходный ресурс сжат отдельно и потом все они слеплены в один большой файл. Но в нашем случае файл один, поэтому распаковать его можно такой командой:
offzip -a -1 9e13b2414b41b842 unp 0
Опция -1 означает, что все обнаруженные распакованные сегменты нужно соединить. В итоге мы получаем распакованный файл, который опять же надо изучить. Помотав его туда-сюда, можно обнаружить, что внутри имеются и lua-скрипты, и звуки, и текстуры, теперь уже несжатые, но слепленные все вместе.
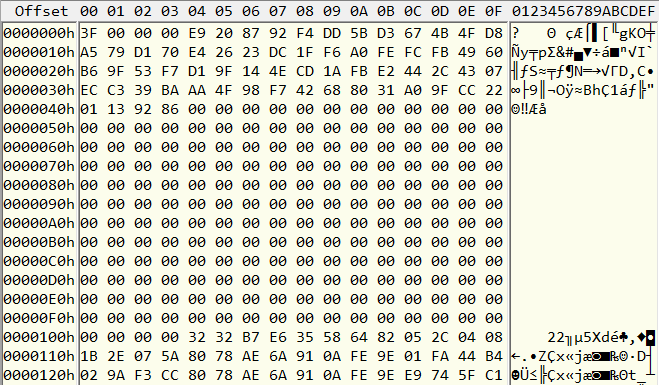
Наша задача — разделить файл на отдельные ресурсы, притом желательно каким-то образом узнать их названия. Обратимся к началу файла. Здесь у нас что-то непонятное, потом много нулей, и потом видимо начинается какая-то таблица. Похоже что строки в ней имеют длину 16 байт, причем интересно, правая половина всегда разная, а в левой половине наблюдаются повторяющиеся числа (выделены зеленым). Заметим также, что название самого файла иногда повторяется внутри него в одной из строчек.
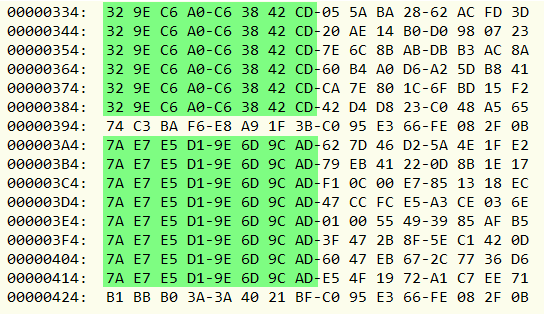
Далее, оказывается, что последняя строка в таблице почему-то такая же, как первая. К тому же, если посмотреть несколько файлов, похоже, что первое число в них — это как раз число строк таблицы (правда, минус один). Сопоставив все эти данные, можно заключить, что это таблица, где записаны имена ресурсов в виде хеша, отдельно имя ресурса и его тип. А последняя строка — это уже не таблица, а информация о первом ресурсе, где в начале видимо как раз идёт его хеш, а потом должны быть размер, другие параметры, и сам файл. Чтобы убедиться в этом, поищем остальные числа в файле, и, конечно же, они находятся, причём именно в той последовательности, как идут в таблице.
Хорошо, теперь осталось разобрать формат записей и попытаться угадать захешированные названия. В принципе может быть так, что игра обращается к ресурсам уже по хешу, и исходных названий в ней не осталось, в таком случае названий мы не найдём. Но к счастью, чаще всего их можно найти, угадать, или вычислить по коду или скриптам. Кстати, насчет скриптов: мы уже видели, что здесь используется lua, значит, скорее всего, расширение для таких файлов будет «lua». Вид используемого хеша можно определить по наличию в коде известных констант. Например, в FNV используется число 0x811C9DC5. Если же применяется собственный алгоритм, он обычно простой, типа сложения со сдвигом, но найти его в коде будет уже не так просто.
Я уже было собрался искать 0x811C9DC5, но решил для начала погуглить, и оказалось, что разработчик bitsquid у себя в блоге как-то рассказывал о преимуществах хеша murmur64. Как у любого хеша, у murmur есть разные версии, но 64-битный — это как раз 8 байтов, как в нашей таблице. Исходный код нашелся здесь. Скомпилируем его и попробуем посчитать хеш строки «lua». Правда, мы не знаем, чему равен seed, поэтому пока попробуем взять ноль.
Получаем murmur64 от «lua» = A14E8DFA2CD117E2
Это число как раз часто встречается в нашем файле! Поздравляем, теперь мы знаем, как игра считает хеш. Если бы seed не был нулём, пришлось бы опять-таки смотреть или отлаживать код, чтобы это узнать. Это может быть константа, или длина текстовой строки, а вообще это может быть что угодно. Например, первый символ, склеенный с длиной строки.
Ну хорошо, мы знаем одно из расширений, неужели теперь придётся по одному угадывать все остальные? Возможно, бывает и так. Но давайте попробуем поискать где-то их список, так сказать, в открытом виде. Он может быть в одном из lua-скриптов, или прямо в исполняемом файле, как в данном случае:
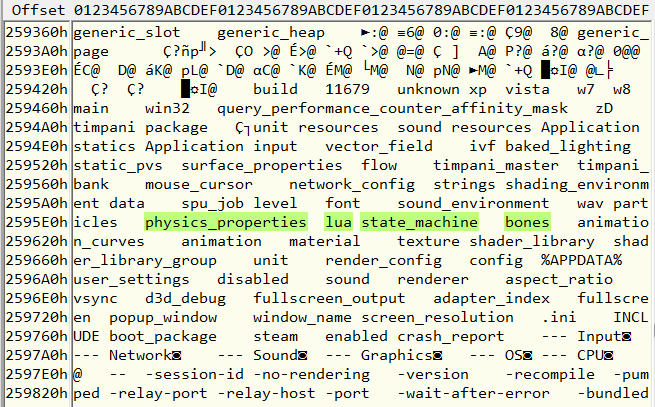
В середине я выделил строки, которые точно являются типами ресурсов. Но где этот список начинается, и где кончается? Это можно определить экспериментально.
Попробуем для примера murmur64 от «unit» = E0A48D0BE9A7453F
И действительно, такой код есть. Вроде бы очевидное название, но угадать его с первого раза было бы не так просто. А звуковые банки так вообще называются «timpani_bank», вот уж ни за что не угадал бы.
Итак, теперь мы знаем все типы ресурсов (расширения файлов), но как узнать их имена? Они могут быть в ресурсах или в коде. Посмотрим например .ini файл, который лежит рядом с архивами.
boot_package = "resource_packages/boot"
boot_script = "scripts/boot/boot"
pdxigs = {
game_name = "Showdown"
game_version = "1.0.0"
server_url = "http://xxxxxxxx.xxxxxxxxxxxxx.com/xxxx"
}
steam = {
notification_position = "bottom-left"
}
timpani = "content/sounds/shoot"
Вот и первая зацепка — загрузочный пакет называется «resourse_packages/boot». Посчитаем хеш этой строки — 9E13B2414B41B842, он есть в нашем списке. В нём наряду с другими файлами содержится загрузочный скрипт
«scripts/boot/boot» = BBF3D6DD1B2AC672.
В нём внутри ссылки на другие скрипты, например, «scripts/boot/boot_common». В этом коммоне, в свою очередь, есть множество строк, в том числе
«resource_packages/base_game_resources» = 0D42C15E8F2B473F
Видимо это название пакета, где содержатся основные ресурсы игры. Проверим — действительно есть такой. Так постепенно можно теоретически найти все числа. Естественно, это делается не вручную, а пишутся программы или скрипты, ведь в средней игре несколько десятков или даже сотен тысяч ресурсов. Процесс разгадывания иногда затягивается надолго, и всё равно зачастую в итоге остаются некоторое количество безымянных файлов. Тем не менее, большинство имён обычно удаётся найти, после чего составляется список, который используется при распаковке ресурсов и модификации игры.
Итак, предположим, мы нашли все названия, и теперь ресурсы у нас имеют осмысленные имена и расширения. Вернёмся к формату файла.
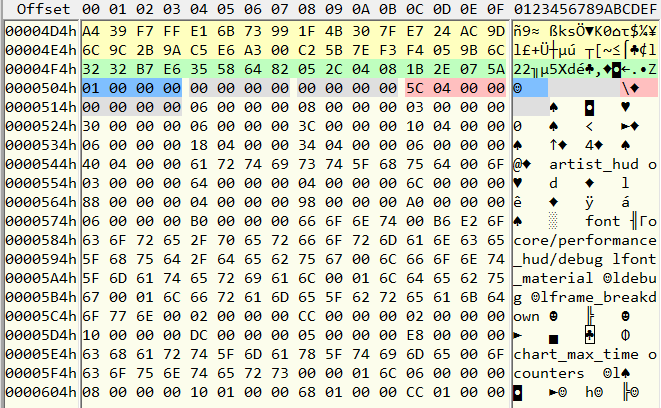
После таблицы — списка хешей (выделена желтым) начинаются отдельные записи для всех ресурсов. Как мы уже выяснили, первая строчка (выделена зеленым) — это имя и тип ресурса. Здесь 82645835E6B73232 = «config», правую часть (имя) мы пока не знаем. Попробуем угадать, что же идёт дальше. По всей видимости, тут у нас несколько 32-битных чисел. Сначала единичка, потом два ноля, дальше еще одно число (выделено розовым), похожее на размер, и еще один ноль. Неизвестно, что это, но у всех файлов эти числа именно такие. Потом начинается собственно содержимое ресурса. Проверим его длину. Прибавим размер 045С к смещению, где начинается запись, 0518, получим 0974.
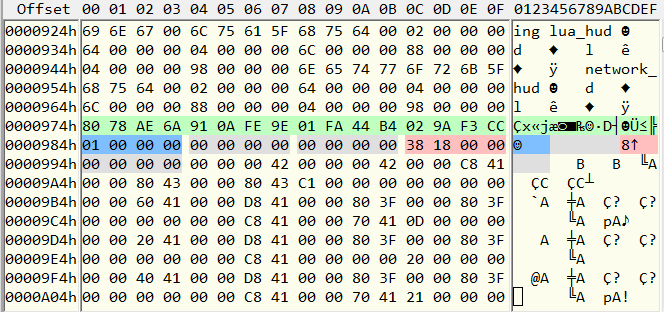
Да, действительно, здесь уже следующий хеш. 9EFE0A916AAE7880 = это «font», далее всё то же самое, что в первой записи и длина фонта — 1838. Далее идёт сам фонт, он начинается большой серией плавающих чисел, их тоже обычно легко видно невооружённым глазом. Например 42000000 — это 32, 41С80000 — это 25, и конечно 3F800000 — самое часто встречающееся в игровых файлах плавающее число — это 1.
Вроде бы формат записей в архиве мы разобрали. Похоже, единственное, что у нас есть для каждого ресурса, это его размер. Странно, что нет смещения, ну, бывает и так. Остальные числа — нули, возможно, они что-то значат, но нам это неизвестно. Проверим на всякий случай последнюю запись, прибавив длину последнего ресурса к адресу его начала. Получаем 4ECFDA0 — это как раз общая длина файла. Похоже, в конце больше ничего нет, значит можно приступать к написанию программы распаковки. Она будет читать файл пакета и разделять его на ресурсы. Если хеш имеется в нашем списке — сохранять файлы с правильным именем, если нет — в качестве имени берётся сам хеш.
Запускаем программу — и она успешно распаковывает кучу файлов из нашего пакета. Проверим их содержимое. Текстуры действительно получились корректными DDS-файлами, звуки проигрываются как обычные OGG, остальные файлы (например, модели юнитов) хотя и имеют какой-то особый формат, тоже выглядят правдоподобно.
Воодушевленные успехом, начинаем распаковку всех остальных файлов. И тут нас ожидает Unhandled Exception. Практически все файлы распаковались, кроме нескольких. Так обычно и бывает. Среди тысяч файлов обязательно найдётся один-два, упакованных как-нибудь нестандартно, или с дополнительными параметрами. Посмотрим, что не так с этими файлами. Оказывается, единичка после хеша была неспроста. В этом файле здесь не единичка, а семёрка. Мало того, при распаковке других игр, сделанных на том же движке, оказалось, что и нули там тоже не всегда нули. Но и это ещё не всё. Есть один файл, структура которого, кажется, вообще нарушена. При попытке найти в нём очередной ресурс оказывается, что оставшегося куска файла не хватает для ресурса такой длины.
Посмотрим запись об этом конкретном ресурсе. Вроде бы всё правильно: хеш, после него единичка, два нуля, потом размер. Как же так? Может быть, файл неправильно распаковался? Ну-ка, попробуем ещё раз. Возможно, в мелькании сотен строк вывода offzip мы что-то не заметили?
0x0286c4e2 65196 -> 65536 / 0x0287c38e _ 4 8:7:28:0:1:340433a1 0x0287c392 65242 -> 65536 / 0x0288c26c _ 4 8:7:28:0:1:27dce3e7 0x0288c270 65415 -> 65536 / 0x0289c1f7 _ 4 8:7:28:0:1:b9bd6cd0 . 0x028cac59.................... - zlib Z_DATA_ERROR, the data in the file is not in zip format or uses a different windowBits value (-z). Try to use -z -15 0x028cc207 65533 -> 65536 / 0x028dc204 _ 196624 8:7:28:0:1:54aa0921 0x028dc208 65513 -> 65536 / 0x028ec1f1 _ 4 8:7:28:0:1:c4b3abd4 0x028fc1f9 65533 -> 65536 / 0x0290c1f6 _ 65544 8:7:28:0:1:890356ae 0x0290c1fa 65534 -> 65536 / 0x0291c1f8 _ 4 8:7:28:0:1:934a442c 0x0292c200 65496 -> 65536 / 0x0293c1d8 _ 65544 8:7:28:0:1:c21356fb 0x0293c1dc 65521 -> 65536 / 0x0294c1cd _ 4 8:7:28:0:1:5bf3ea59 0x0294c1d1 65514 -> 65536 / 0x0295c1bb _ 4 8:7:28:0:1:d7c697a0
Да, действительно, какая-то проблема. Именно в этом файле присутствуют сегменты, которые не распаковались. Кстати, что это за ресурс такой? Посмотрим содержимое файла по смещению 0x028cac59, или чуть раньше.
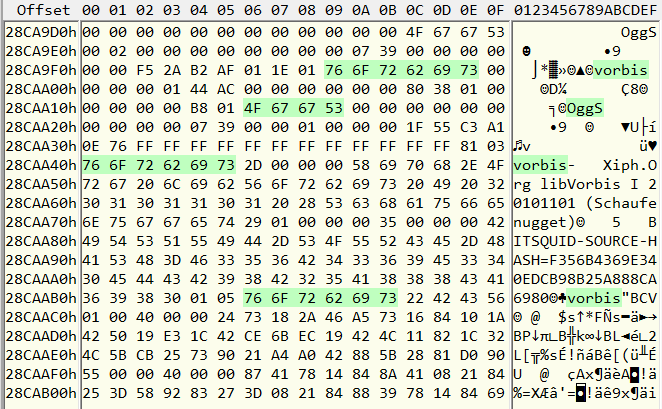
А это как раз «timpani_bank». Ну конечно! Ведь ogg-поток может содержать настолько хаотичный поток битов, что zlib просто не может его сжать, в итоге из 92-МБ файла несколько 64-кбайтных сегментов после сжатия получились даже больше, чем 64к. Видимо разработчики резонно решили, что в таком случае нет смысла их сжимать, и поместили в архив прямо как было. Поэтому offzip не смог найти там заветные байты 78 9C, и в итоге просто пропустил их при распаковке.
Никакого флага/признака для отличия сжатых и несжатых сегментов в структуре файла нет, значит игра поступает просто: если сегмент имеет размер меньше б4к — значит он упакован, если же ровно 64к — то нет. Однако и тут не всё так просто. Были случаи (в другой игре, на другом движке), когда после упаковки сегмента его длина оставалась точно равной 64к. И вот тут уже никак не определить, сжатый он или нет. Хотя вероятность такого совпадения очень мала, это тоже придётся учитывать.
Вот так, постепенно, сравнивая и анализируя файлы, чаще всего можно разобрать формат данных, даже не прибегая к отладке кода. Не буду вдаваться в подробности, как определить, что это была за семёрка, и что это были за нули, которые не всегда нули, ведь всех особенностей формата на одном примере всё равно не разгадать. А если найдутся другие игры, которые их используют — тогда и будем разбираться.
monah_tuk
Изумительно. Сигнатуру gzip в мемориз. И за offzip спасибо.
naum
Боюсь, что стоит удалить из мемориза теперь, у zlib'а никогда не было сигнатуры, это потоковое сжатие без каких-то враппов для формата, а тем более magic'а по оффсету 0. Если автор пояснит почему наличие 78 9C гарантирует zlib (deflate?) — будет круто.
naum
Oops, дико лоханулся и посыпаю головую пеплом. Конкретно у zlib'а 0x78 первым байтом (Compression Method and flags по RFC) идет в большинстве случаев. Во втором байте контроль первого + уровень компрессии.
78 9C — Default Compression
78 DA — Best Compression
monah_tuk
Да, я тоже полез разбираться. Сразу для gzip, пусть будет: stackoverflow.com/questions/13112604/find-gzip-start-and-end
DonkeyHot
stackoverflow.com/questions/9050260/what-does-a-zlib-header-look-like
demp
Разработчики bitsquid недавно начали публиковать серию статей про хранение данных:
Maccimo
А не было ли попыток этот процесс автоматизировать, создать некое подобие IDA Pro для работы с файлами неизвестных форматов?
ID_Daemon Автор
Не слышал о таких, и думаю это невозможно. Существуют автоматические определители звуковых файлов, или архивов, как в этом случае. Но все они основаны на наличии стандартных заголовков, а это лишь меньшая часть работы с «неизвестными» форматами.
Maccimo
Полностью автоматически разобрать произвольный формат конечно же невозможно.
Но можно:
— сравнить несколько файлов предположительно одного типа и вычислить сигнатуру, поле содержащее размер файла, по полю с размером файла — endianness;
— посчитать энтропию, сообразить, что файл скорее всего запакован и попытаться найти упакованные фрагменты, как вы это сделали при помощи offzip;
— попытаться определить регулярные структуры (вектры, таблицы, и т.п.)
— автоматически сгенерировать дамперы, а для архивов — упаковщики/распаковщики;
— и, наконец, закончив автоматический анализ, дать возможность реверс-инженеру вручную обработать полученные данные. Примерно как в IDA Pro мы можем нажатием 'u' отменить интерпретацию какого-то фрагмента в качестве кода и пометить его, например, как строку.
Иными словами — автоматизировать рутину и объединить кучу утилит командной строки в одном интерфейсе.
ID_Daemon Автор
Сейчас посмотрел несколько последних проектов, такое ощущение, что ни разу не было никакой рутинной работы, всё время что-то новое.
Я допускаю, что можно сделать какую-то автоматизацию, но всё равно потом почти в каждом случае придется переделывать вручную, то есть мне кажется, количество ручной работы не уменьшится.
ValdikSS
www.synalysis.net
bitbucket.org/haypo/hachoir/wiki/Home
И еще Advanced hex editor и 010 умеют создавать структуры файлов.
ID_Daemon Автор
Если не ошибаюсь, с помощью этих программ можно лишь вручную смоделировать структуру файлов. То есть вручную задать шаблон, где будет длина файла, таблица смещений, и т.д. Вопрос же был, как я понял, об автоматическом анализе неизвестного формата. Здесь нужен искусственный интеллект.