
Не так давно компания Pure Storage анонсировала новую функциональность ActiveCluster – active/active метрокластер между хранилищами данных. Это технология синхронной репликации, при которой логический том растянут между двумя хранилищами и доступен на чтение/запись на обоих. Эта функциональность доступна с новой версией прошивки Purity//FA 5 и является абсолютно бесплатной. Также Pure Storage пообещали, что настройка растянутого кластера никогда не была еще такой простой и понятной.
В данной статье мы расскажем про ActiveCluster: из чего состоит, как работает и настраивается. Отчасти статья является переводом официальной документации. Помимо этого, мы поделимся опытом тестирования его на отказоустойчивость в VMware-окружении.
Конкурентные решения
Представленная функциональность не является чем-то инновационным, аналогичные решения есть у большинства крупных производителей СХД: Hitachi GAD (Global Active Device), IBM HyperSwap, HPE 3PAR Peer Persistance, Fujitsu Storage Cluster, Dell Compellent Live Volume, Huawei HyperMetro.
Однако мы решили выделить некоторые плюсы ActiveCluster по сравнению с конкурентными решениями:
- Не требует дополнительных лицензий. Функциональность доступна «из коробки».
- Простое управление репликацией (мы попробовали — это действительно удобно и просто).
- Облачный медиатор (Quorum device). Не требует наличия третьей площадки и развертывания на ней кворум сервера.
Обзор ActiveCluster
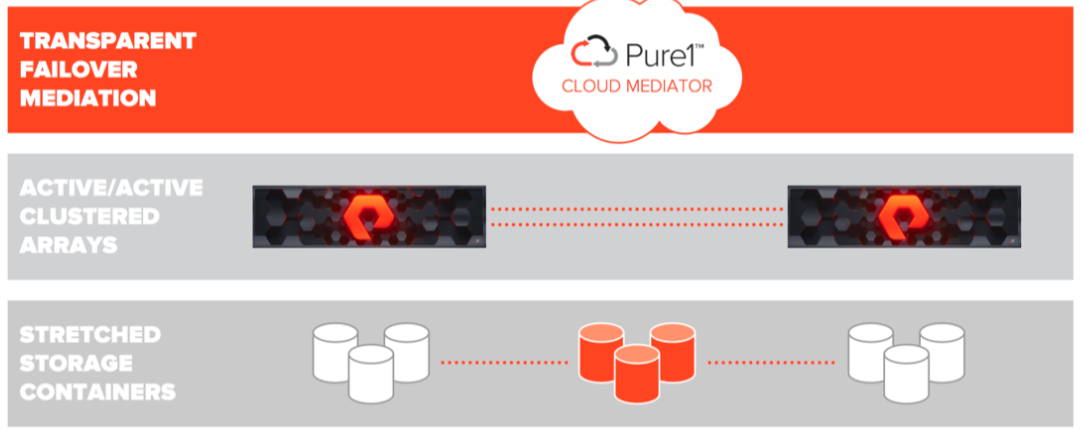
Рассмотрим компоненты, из которых состоит ActiveCluster:
- Transparent Failover Mediation. Cloud Mediator – это кворум сервер/устройство, которое принимает решение, какой из массивов продолжит работать и предоставлять доступ к данным, а какой должен прекратить работу в случае различных сбоев.
- Active/Active Clustered Arrays – массивы PureStorage с настроенной синхронной репликацией между ними. Предоставляют доступ к консистентной копии данных как с одного массива, так и с другого.
- Stretched Storage Containers – контейнеры, содержащие объекты, которые должны реплицироваться между двумя массивами.
В ActiveCluster появились новые объекты – Pods. Pod – это контейнер, содержащий другие объекты. Если между двумя массивами существует репликационный канал, то в pod можно добавить несколько массивов и тогда все объекты в этом pod будут реплицироваться между массивами. Растянутыми pod`ами можно управлять с любого массива.
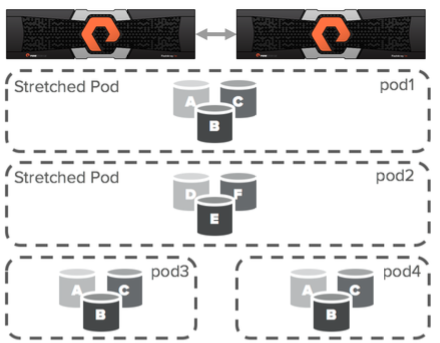
Pod может содержать volumes, snapshots, protection groups и другую конфигурационную информацию. Pod функционирует как consistency group, то есть гарантирует согласованный порядок записи томов в одном pod.
ActiveCluster: схемы доступа хостов к массивам
Доступ хостов к данным может быть настроен двумя моделями доступа: uniform и non-uniform. В uniform модели каждый хост на обеих площадках имеет доступ к обоим массивам на чтение/запись. В non-uniform модели каждый хост имеет доступ только к локально расположенному массиву на чтение/запись.
Uniform-модель доступа
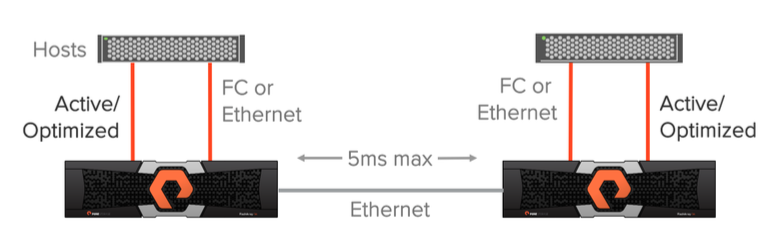
Uniform-модель доступа к данным может использоваться в окружениях, где для соединения хостов с массивами используется Fibre Channel или Ethernet (iSCSI) и между массивами используется Ethernet-соединение (10g) для репликации. В данной конфигурации хост имеет доступ к данным через оба массива: как через локальный, так и через удаленный. Это решение поддерживается только при максимальной задержке между массивами по каналам репликации в 5 мс.

Схема выше иллюстрирует логические пути от хостов до массивов, а также канал репликации между массивами в схеме доступа Uniform. Предполагается, что данные доступны обоим хостам вне зависимости от того, на какой площадке они находятся. Важно понимать, что пути до локального массива будут иметь меньшую задержку, чем до удаленного.
Оптимизация производительности при использовании Uniform-модели
Для лучшей производительности ввода/вывода при использовании active/active синхронной репликации хост не должен использовать пути до удаленного массива. Для примера рассмотрим представленную ниже картинку. Если «VM 2A» будет выполнять операцию записи на том «A», используя массив «Array A», то эта операция записи повлечет за собой двойную задержку передачи данных через канал репликации, а также задержку от хоста до удаленного массива.
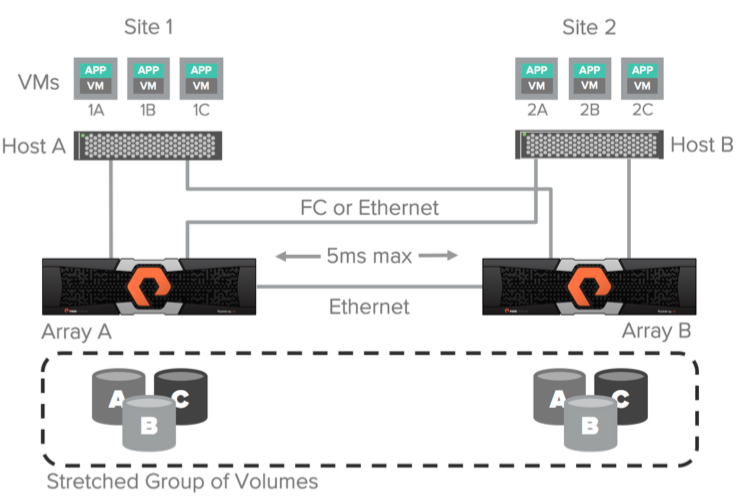
Предлагаю разобрать более подробно. Предположим, что задержка по каналу репликации между массивами у нас 3ms. В случае соединения «Host B» <-> «Array B» задержка 1ms. А в случае «Host B» <-> «Array A» – 3ms. Команда записи будет отправлена от хоста «VM 2A» на удаленную площадку к массиву «Array A» с задержкой в 3ms. Далее команда записи будет отправлена через канал репликации на массив «Array B» с задержкой в 6ms (3ms + 3ms). После этого ответ об успешной записи будет отправлен обратно от массива «Array B» к массиву «Array A» через канал репликации (6ms + 3ms = 9ms). Далее ответ об успешной записи будет отправлен обратно на хост “VM 2A” (9ms + 3ms = 12ms). Итого мы получаем задержку в 12ms на операцию записи в случае использования удаленного массива. Если посчитаем точно по такому же принципу использование локального массива – то получим 8ms.
ActiveCluster позволяет использовать ALUA (Asymmetric Logical Unit Access), для предоставления путей до локальных хостов как active/optimized и предоставления путей до удаленных хостов как active/non-optimized. Оптимальный путь определяется для каждой связки host <-> volume устанавливая опцию preferred array. Таким образом, не важно на каком из хостов работает ваше приложение или виртуальная машина, хост всегда будет знать какой массив для него локальный (имеет оптимальные пути), а какой удаленный (имеет не оптимальные пути).
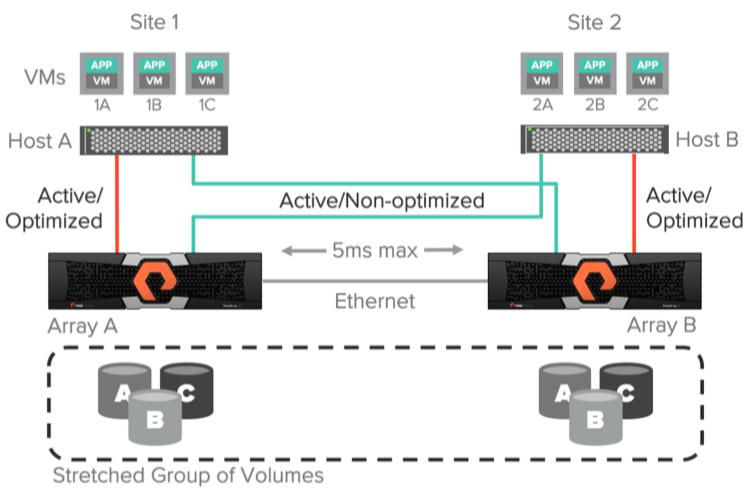
Используя ActiveCluster, можно конфигурировать действительно active/active датацентры, не заботясь о том, на какой площадке работает ваша виртуальная машина или приложение. Все операции чтения/записи всегда будут идти через локальный для хоста массив.
Non-uniform модель доступа
Модель доступа Non-uniform также используется в окружениях, где для соединения хостов с массивами используется Fibre Channel или Ethernet (iSCSI). В данной модели хосты имеют доступ только к локальному массиву и не имеют доступа к удаленному массиву. Данное решение также предполагает использование репликационных соединений между массивами с задержкой не более 5ms.
Плюсы и минусы этих моделей доступа
Модель доступа Uniform обеспечивает более высокий уровень отказоустойчивости, так как выход из строя одного массива не повлечет за собой рестарт виртуальных машин или приложений, использовавших этот массив, – доступ к данным будет продолжен через другой. Конечно данная модель предполагает работающий и настроенный мультипасинг (multipathing) на стороне хостов, который распределял бы запросы ввода/вывода по active/optimized путям и по active/non-optimized в случае, когда первые недоступны.
В случае использования модели Non-uniform хосты имеют доступ только к локальному массиву и, соответственно, только по active/optimized путям. В случае выхода из строя локального массива все виртуальные машины или приложения потеряют доступ к данным на этой площадке и будут перезапущены (например, средствами VMware HA) на другой площадке, используя доступ к данным через другой массив.
Настройка Active Cluster
Ребята из Pure Storage заявляют об очень простой, интуитивной настройке ActiveCluster. Что же, давайте посмотрим. Настройка производится в 4 шага:
Шаг 1: Соединение двух Flash массивов.
Соединяем наши массивы двумя каналами Ethernet 10Gb/s и через GUI настраиваем тип соединения как Sync Replication.

Шаг 2: Создание и растягивание pod.
Для создания pod мы будем использовать CLI (через GUI тоже можно). Команда purepod используется для создания и «растягивания» pod. Как мы уже говорили ранее, pod – это контейнер, который создан для упрощения управления в active/active среде. Pod определяет, какие объекты должны синхронно реплицироваться между массивами. Управлять растянутыми pod’ами и объектами в них можно с любого из массивов. Pod может содержать в себе тома, снапшоты, клоны, протекшен группы и другую конфигурационную информацию.
Создаем pod на массиве Array A:
arrayA> purepod create pod1Растягиваем pod на Array B:
arrayA> purepod add --array arrayB pod1Теперь любые тома, снапшоты или клоны, помещенные в этот pod, будут автоматически реплицироваться между массивами «Array A» и «Array B».
Шаг 3: Создание томов
На любом из массивов создаем том vol1 размеров 1TB и помещаем его в pod1:
> purevol create --size 1T pod1::vol1Вместо создания тома мы можем переместить любой уже имеющийся том в pod1 и он начнет реплицироваться.
Шаг 4: Презентация тома на хост.
Еще раз отметим, что ActiveCluster – это настоящее active/active решение, которое позволяет читать и писать на один и тот же логический том, используя оба массива.
Создаем хост и презентуем том vol1 этому хосту:
> purehost create --preferred-array arrayA --wwnlist <WWNs оf ESX-1 >
> purehost connect --vol pod1::vol1 ESX-1Прошу обратить внимание, что мы указываем опцию –preferred-array которая означает, что пути с массива «ArrayA» будут для этого хоста оптимальными (active/optimized).
Это все! Теперь ESX-1 имеет доступ к тому vol1 через оба массива «ArrayA» и «ArrayB». Быстро и просто, неправда ли?
Дополнительно проверим состояние медиатора. Мы используем облачный медиатор Pure, для доступа к нему массивы должны иметь выход в интернет. Если политика безопасности не позволяет этого сделать, то есть возможность скачать и развернуть локальный медиатор.
purepod list --mediator
Name Source Mediator Mediator Version Array Status Frozen At Mediator Status
pod1 - purestorage 1.0 Array-A online – online
Array-B online - online Функциональное тестирование ActiveCluster в среде VMware
Перед нами стояла задача функционального тестирования связки двух Flash Array//m20 в конфигурации ActiveCluster и VMware (2 ESX хоста) в части обеспечения отказоустойчивой работы виртуальных машин. Мы эмулировали наличие двух площадок, на каждой из которой был ESX-хост и Flash Array. Использовалась версия VMware 6.5 U1 и версия Pure//FA 5.0.1.
У нас были следующие критерии успеха:
- Эмулируемые отказы дискового массива не приводят к перебою в работе виртуальных машин.
- Эмулируемые отказы ESX-сервера позволяют автоматически (средствами VMware HA) запустить виртуальные машины на другом ESX сервере.
- Эмулируемые отказы площадки (массив + esx-сервер) позволяют автоматически (средствами VMware HA) запустить виртуальные машины на другой площадке.
- Проверить работу vMotion в конфигурации с VMware + ActiveCluster.
Схема нашего стенда представлена ниже:

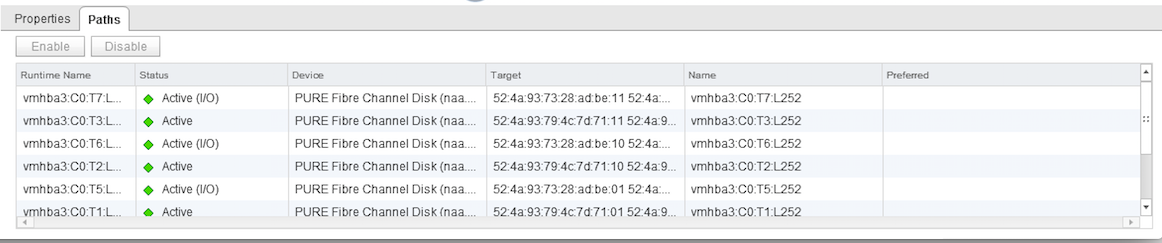
Между массивами m20 #1 и m20 #2 был собран ActiveCluster с использованием репликационного канала на 10 Гбит/с. На одном массиве был создан pod, а затем растянут добавлением в него второго массива. На обоих массивах создан том размером 200GB и добавлен в растянутый pod, тем самым запустив репликацию этих томов между массивами. Реплицируемый том был презентован обоим ESX-хостам по схеме Uniform access с конфигурацией preferred array для хост-групп. Для хоста ESX1 preferred array был m20 #1, а для ESX2 соответственно m20 #2. Таким образом со стороны ESX-хостов пути до датасторов были active (I/O optimized) до локального массива и active (non-optimized) до удаленного.
Эмуляция отказа дискового массива
Для тестирования была проинсталлирована виртуальная машина с Windows 2012 r2. Файлы ВМ располагались на общем датасторе на растянутом томе с Pure Storage. Также в эту ВМ был презентован еще один диск на 100GB с этого же датастора, на который мы запустили синтетическую нагрузку средствами IOmeter. Отмечу, что у нас не было цели замерять производительность, нам необходимо было сгенерировать любую I/O активность, чтобы при наших тестированиях отловить моменты, когда SCSI команды чтения/записи могли подвиснуть при переключении путей до массивов.
Итак, все готово: тестовая ВМ работает на ESX1, хост ESX1 использует оптимальные пути до массива m20 #1 для операций ввода/вывода. Мы идем в серверную и отрубаем по питанию массив m20 #1 и наблюдаем за IOmeter в ВМ. Никакого прерывания в вводе/выводе не происходит. Смотрим состояние путей до датастора: пути до m20 #1 в состоянии dead, пути до m20 #2 перешли в состояние active (I/O). Тест проводился несколько раз с немного разными входными данными, но результат всегда был успешным. Тест считаем успешно пройденным.
P.S. После включения массива m20 #1 пути переключились обратно на него, то есть на локальную для этого ESX-хоста площадку.
Эмуляция отказа ESX-хоста
Этот тест не очень интересный, так как мы, по сути, проверяем не Pure Storage, а работу VMware HA. Мы в любом случае ожидали downtime для ВМ и последующее ее воскрешение кластером на другом ESX хосте.
В общем, мы сходили в серверную и дернули по питанию хост ESX1. VMware HA отработал штатно, и наша ВМ успешно поднялась на хосте ESX2. Тест считаем успешным.
Эмуляция отказа всей площадки
По сути, это первый и второй тест, проводимые одновременно. И в любом случае это downtime для виртуальной машины, так как мы отключаем ESX хост. Исходные данные такие же, как и в первом тесте: ВМ работает на ESX1, хост ESX1 использует для ввода/вывода массива m20 #1, в ВМ запущен IOmeter для синтетической нагрузки на массив.
Мы идем в серверную и отключаем питание у ESX1 и m20 #1. Наблюдаем. В течении 1-2 минут VMware HA поднимает виртуальную машину на ESX2, пути на ESX2 в состоянии dead для m20 #1 и в состоянии active (I/O) для массива m20 #2. Тест считаем успешным.
Проверка работоспособности vMotion в конфигурации ActiveCluster
Весьма формальный тест. Нам необходимо было проверить, что он работает и нет никаких подводных камней. Погоняли vMotion как на включенной виртуальной машине, так и на выключенной, со сменой датастора и без, никаких проблем не выявлено. Тест успешно пройден.
Заключение
Технология синхронной репликации уже не нова и есть практически у каждого крупного вендора СХД, но Pure Storage выделяются среди них тем, что не требуют дополнительных лицензий на ее использование, которые зачастую могут составлять немалую часть от стоимости самой СХД. Также ребята из Pure вывели на новый уровень удобство управлением репликацией, теперь не требуется изучение множества десятков страниц документации для того, чтобы её настроить, а весь процесс интуитивно понятен. Для повышения собственных компетенций и в рамках организации Proof of Concept мы проводим различные тестирования как у себя, так и у заказчиков. Вместе с дистрибьютором OCS (второй массив мы взяли у них), мы развернули первый в России Pure Storage ActiveCluster, на котором проводили тестирования.
Сергей Сурнин, эксперт Сервисного центра компании «Инфосистемы Джет»
Комментарии (30)

KorP
23.05.2018 12:59аналогичные решения есть у большинства крупных производителей СХД
Как же NetApp то забыли?
Спасибо за статью.HKG
23.05.2018 13:36Если вы имеете в виду NetApp MetroCluster, то этот продукт больше соответствует классичейской синхронной репликации. Так как данные доступны на чтение/запись только на одном массиве.
В статье же перечислены технологии которые позволяют выполнять операции чтения/записи через любой массив в кластере, в любой момент времени.Smasher
23.05.2018 16:19+1C NetApp MetroCluster данные читаются локально, они доступны на обеих площадках. Это можно менять опцией. Запись же идёт по оптимальному пути, используется ALUA, и синхронно попадает на вторую площадку. Да в один момент времени LUN доступен для записи только на одной площадке. Зато с точки зрения надежности позволяет избавиться от решения проблемы когерентности записи данных. Для приложений всё прозрачно. В случае c Pure ActiveCluster надо не забывать о том, что эту проблему необходимо решать на уровне приложений. При одновременной записи в одни блоки в LUNе на разных площадках "побеждает" тот, кто записал последни.
HKG
23.05.2018 16:46Совершенно верно. В таких решениях как ActiveCluster, когда LUNы доступны на запись на обеих площадках, необходим контроль со стороны хостов за порядком записи на эти LUNы. Для этого прекрасно подходят кластерные файловые системы, такие как VMFS, Veritas CFS, OCFS и другие.
В этой статье я перечислил именно те конкурентные продукты, которые позволяют выполнять запись на обе площадки в один момент времени и выполнять Transperent Failover (то есть хост не замечает потерю LUNa в случается выхода из строя одной СХД, теряется только часть путей до LUNа). NetApp MetroCluster ни хуже, ни лучше, у него другая идеология работы, поэтому я его не включал в этот перечень конкурентных продуктов.Smasher
23.05.2018 17:10выполнять Transperent Failover (то есть хост не замечает потерю LUNa в случается выхода из строя одной СХД, теряется только часть путей до LUNа)
Что без проблем позволяет сделать MetroCluster. И Dell EMC VPLEX.Включать продукты в список по критерию деталей реализации — странный подход. Клиент решает проблему, а не покупает конкретную реализацию технического решения.
HKG
23.05.2018 18:03На сколько мне известно, в случае выхода из строя одной площадки (одной СХД NetApp), хост на какое то время теряет доступ к дискам. NetApp`у нужно время что бы поднять SVM на другой площадке, плюс поднять и залогинить все WWNы в фабрику, после чего хост восстановит доступ к лунам. Если у вас есть другая информация — прошу подкрепить ее документаций или failover-тестами.
DellEMC VPLEX не является СХД, это виртуализатор в первую очередь.Smasher
23.05.2018 18:10Всё это происходит быстрее, чем сработает таймаут на стороне хоста.
То есть если мы говорим о решении, которе должно обеспечивать RTO, RPO = 0, то MetroCluster подходит под это определение.
Клиент не покупает СХД в вакууме, он покупает решение.
HKG
24.05.2018 00:03+1Всё это происходит быстрее, чем сработает таймаут на стороне хоста
Предложите это клиенту при покупке NetApp и зафиксируйте в договоре :)
Сам NetApp заявляет, что MetroCluster обеспечивает RPO Zero и RTO under 120 seconds.
Пруф — www.netapp.com/us/products/backup-recovery/metrocluster-bcdr.aspx
Solaris и Linux по дефолту имеют 60 секунд scsi timeout.
VMware вроде 140 секунд, виртуальные машины вероятно переживут такое пропадание дисков, приложения которые работают в ВМ — вряд ли.
То есть в большинстве случаев, мы получим простой бизнеса.
Вот и главное отличие этих решений, в случае active/active кластеров, такой как Pure Storage ActiveCluster — резервная площадка всегда готова, что бы принять нагрузку на себя. И здесь действительно RTO&RPO = Zero.
Есть еще аргументы в пользу NetApp MetroCluster? Или теперь понятно почему его нет в списке конкурентных решений?Smasher
24.05.2018 03:32Solaris и Linux по дефолту имеют 60 секунд scsi timeout.
Который невозможно поменять? Так себе аргумент
То есть в большинстве случаев, мы получим простой бизнеса.
Предлагаю рассказывать эти байки клиентам, которые успешно используют MetroCluster последние 10+ лет и не имеют простоя бизнеса из-за проблем с хранилищем.
Сам NetApp заявляет, что MetroCluster обеспечивает RPO Zero и RTO under 120 seconds.
NetApp аккуратен в своих заявлениях, даже маркетинговых.
Клиенты более 10 лет используют решение, простоев не имеют. В том числе клиенты в России. Всё проверяется тестированием на реальных задачах.HKG
24.05.2018 15:35Solaris и Linux по дефолту имеют 60 секунд scsi timeout.
Который невозможно поменять? Так себе аргумент
С вашим подходом, можно выкрутить таймаут в 120+ секунд и заявить, что СХД обеспечивает Transperent Failover! Ведь ОС не заметит пропадание дисков… Но вот любое приложение может заметить и отвалиться… И тут вы скажите подкрутить таймаут в приложении, верно? Пусть тоже подождет 120 секунд :) Но ведь, это означет, что все пользователи приложения теперь тоже должны подождать 120 секунд… А если это крупный банк или ритейл компания, где каждая транзакция или каждый клиент на счету. Как ни говори, а это простой бизнеса. Ваш подход — подкрутить таймауты, не серьезен.
Еще раз повторюсь, в статье описаны решения, которые обеспечивают RTO&RPO = 0. MetroCluster таким не является (ссылка выше).
Я очень рад за клиентов которые успешно внедрили и используют MetroCluster. Означает, что это решение полностью покрывает их потребности и SLA.Smasher
24.05.2018 20:43За какое время происходит переключение путей в растянутой FC фабрике? По вашей логике, если это значение >0, то никто не обеспечивает RTO=0.
Oracle RAC по умолчанию имеет значение disktimeout = 200 секундам. Как с этим жить фанатам RTO= абсолютному 0?
Например, есть крупный банк в России, который имеет 5 метрокластеров. Банк частный. Сколько бы метрокластеров они купили, если бы первый не обеспечил им RTO=0?
HKG
25.05.2018 11:13За какое время происходит переключение путей в растянутой FC фабрике? По вашей логике, если это значение >0, то никто не обеспечивает RTO=0.
Вы вообще представляете как работает FC SAN и Multipathing на хостах? :)
За переключение путей отвечает хост (точнее multipating software). В случае пропадания СХД из SAN, multipathing мгновенно отрабатывает это событие (современные multipath решения умеют смотреть в SAN). Исключение составляют события, когда СХД остается в SAN фабрике, но по каким то причинам «не отвечает» на scsi команды, обычно такое может происходить из за высокой нагрузки на СХД или на SAN. В таком случае на хостах срабатывают таймауты. Никакой разницы при переключении путей между растянутой SAN и локальной — нет.
В статье описан тест, когда мы по питанию отключали одну из СХД. Никакого прерывания в вводе/выводе не происходило, ни на секунду. Multipathing мгновенно отрабатывал это событие и переключал активные пути на резервную СХД.
Oracle RAC по умолчанию имеет значение disktimeout = 200 секундам. Как с этим жить фанатам RTO= абсолютному 0?
Опять вас не понимаю. В случае выхода из строя одной из СХД, multipathing мгновенно отрабатывает (см. тесты в статье) и резервная СХД уже готова принять на себя ввод/вывод, никакие таймауты на хостах не срабатывают и не важно какие значения они имеют.
kolayshkin
25.05.2018 12:54Да в один момент времени LUN доступен для записи только на одной площадке. Зато с точки зрения надежности позволяет избавиться от решения проблемы когерентности записи данных. Для приложений всё прозрачно
Если в NetApp MetroCluster нет необходимости смотреть за когерентностью кеша, то как же данные будут идеинтичны на обоих площадках? Или гарантирована потеря части данных, в случае если кто-нибудь в активный массив гвоздь забъёт?
murzics
23.05.2018 16:03Есть ли другие способы репликации?
Меня одного смущает, что хост подключается к схд по протоколу FC со скоростью 16 Гбит, а репликацию между контроллерами осуществляет через ethernet со скоростью 10 Гбит?ximik13
23.05.2018 19:28Чисто в теории, на удаленную площадку передаются только операции write. В нормальной режиме работы я сомневаюсь, что у вас процент записи по потоку превысит значение в 50% от общего потока ввода\вывода. Ну и All Flash СХД обычно используются как первичный сторадж под большую транзакционную нагрузку, т.е. в принципе сомнительно, что вы сможете при этом забить по потоку даже 10G интерфейс.
И предложенный способ репликации на самом деле самое лучшее, что может быть на рынке с текущим уровнем развития технологий (по крайней мере из того как описаны принципы работы у Pure), да еще и предлагается вендором "бесплатно". Какой еще более надежный способ репликации вы бы хотели увидеть? :)
Ну и не надо забывать что метро-кластер не равно резервное копирование.
murzics
23.05.2018 22:36Не стоит забывать что система m20 имеет до 6 портов FC на скорости 16 Гбит каждый. Умножаем это все на 2 контроллера и получаем теоретический максимальный поток с хостов 192 Гбит. Для того чтобы порт репликации (10 Гбит) не справился, достаточно будет всего 6% нагрузки, что вполне возможно. Pure надо было использовать 40GbE, или даже 100GbE.
ximik13
24.05.2018 10:13Вы не ответили про другие более надежные способы репликации, которые вы хотели бы видеть или видели на СХД.
Про 40G и 100G согласен только отчасти. Тут еще вопрос в распространенности сетевого оборудования и готовности существующих каналов связи к таким подключениям.
Вы зря упираете на максимальную пропускную способность :). Для СХД важнее показатели по транзакционной нагрузке (IOPS) и времени отклика (ms). Но если уж вы хотите приравнять все к пропускной способности каналов, то попробуйте поделить например 2GB/s (гигабайта) на 8KB (килобайт). Получите вполне приличную цифру в IOPS, и это только для операций записи, которые нужно передавать на удаленный массив. Много вы видели даже средних инсталляций, где суммарная транзационная нагрузка c хостов превышает хотя бы 100к IOPS?
Так что на мой взгляд решение от Pure вполне претендует на свое место в сегменте компаний, которые доросли уже до двух площадок, но не доросли еще до дорогих энтерпрайзных решений.
navion
23.05.2018 16:08Оно совместимо с VVOLs?
HKG
24.05.2018 00:34К сожалению нет. Вот, что пишут на этот счет Pure:
ActiveCluster is not compatible with VVOLs at this time
Думаю в следующих версиях firmware возможность использования VVOLs будет добавлена.
Без ActiveCluster, работа с VVOLs поддерживается.
ximik13
23.05.2018 19:34Интересно как реализовано подключение контроллеров массивов между площадками. Сама схема и логика работы (контроллер1 площадка1 в контроллер1 площадка2 или как?). Что произойдет например, если отваляться линки репликации только от одного контроллера одного массива? Оба массива будут лететь на одном
крылекотроллере или это как-то по другому отрабатывается.HKG
24.05.2018 16:07Репликационные порты массивов должны быть подключены через коммутатор (прямое подключение array1ctl0 <-> array2ctl0 не поддерживается). Каждому репликационному порту назначается собственный IP адрес, таким образом каждый видит каждого. В случае выхода из строя контроллера на первой площадке, ничего не изменится для второй.
ximik13
24.05.2018 16:46Т.е. в случае выхода из строя контроллера на первой площадке, данные записанные на второй площадке буду с обоих контроллеров "пихаться" в живой контроллер на первой. Все верно? Или все таки все POD переедут на один контроллер на второй площадке?
Куда будет писать данные живой контроллер на первой площадке? В один контроллер на второй? Вообще в нормально режиме как выбирается контроллер, которому передать данные на удаленной площадке?
Сборка метро кластера возможна, если заказчик не хочет давать массивам выход в интернет и нет возможности подключить облачный Cloud Mediator?
Как отработает кластер split-brain, если обе площадки работают, но пропала связь с Cloud Mediator и оборвались каналы репликации?
HKG
24.05.2018 17:08Т.е. в случае выхода из строя контроллера на первой площадке, данные записанные на второй площадке буду с обоих контроллеров «пихаться» в живой контроллер на первой. Все верно? Или все таки все POD переедут на один контроллер на второй площадке?
Куда будет писать данные живой контроллер на первой площадке? В один контроллер на второй? Вообще в нормально режиме как выбирается контроллер, которому передать данные на удаленной площадке?
К сожалению у меня нет ответа на данный вопрос. Это внутренние алгоритмы работы и они нигде не описаны.
Сборка метро кластера возможна, если заказчик не хочет давать массивам выход в интернет и нет возможности подключить облачный Cloud Mediator?
Возможна. Он может работать и без медиатора, только в таком случае возможна ситуация split-brain. Pure предоставляют возможность скачать медиатор в виде OVA образа и развернуть локально на площадке.
Как отработает кластер split-brain, если обе площадки работают, но пропала связь с Cloud Mediator и оборвались каналы репликации?
Если связь с медиатором и каналы репликации оборвались одновременно, то ввод/вывод будет заблокирован на обеих СХД. Только администратор сможет вручную выбрать, какая из СХД продолжит работать.
В случае если сначала оборвался канал репликации, то медиатор выберет, какая из СХД продолжит работать, а какая перейдет в состояние readonly. Затем, если оборвется связь до медиатора, уже ничего не произойдет и доступ к данным будет продолжен через одну из СХД.
Pinkkoff
24.05.2018 12:48Статья очень крутая, Сергей, спасибо!
Как я понимаю, у IBM это умеет только SVC и продукты на её (или его) основе. Их новомодные флеши A9000 и A9000R умеют какой-то hyper-swap, но то ли это?HKG
25.05.2018 13:21Спасибо!
Новые линейки IBM Storwize и Flashsystem по сути несут в себе весь функционал SVC. HyperSwap это feature этих СХД, которая по сути является аналогом ActiveCluster. Я немного почитал про HyperSwap и судя по документации там тоже поддерживается режим работы active/active, когда чтение/запись возможна на любую из СХД.
DonAlPAtino
25.05.2018 10:59Эмуляции отказа сети между двумя датацентрами не хватает. Это же самое интересное!
HKG
25.05.2018 13:06Тестировали тоже, к сожалению забыли об этом в статье упомянуть. В случае обрыва сети между ЦОДами, медиатор выбирал одну из СХД, которая продолжит работать. Вот кстати failover сценарии из документации по ActiveCluster.

mikkisse
Отличная статья. Спасибо!