Всем известно, что резервное копирование затевается для того, чтобы можно было восстановить работу системы после сбоя или повреждения данных. Конечно, здесь важна скорость — ведь чем быстрее происходит восстановление, тем меньше простои и убытки для бизнеса. Для ситуаций, когда необходимо максимально быстро возобновить работу виртуальной машины, инженеры Veeam и разработали функциональность мгновенного восстановления Instant VM Recovery. Она весьма популярна среди пользователей, и сегодня мы предлагаем вашему вниманию несколько полезных советов для планирования соответствующей инфраструктуры.
Итак, добро пожаловать под кат.
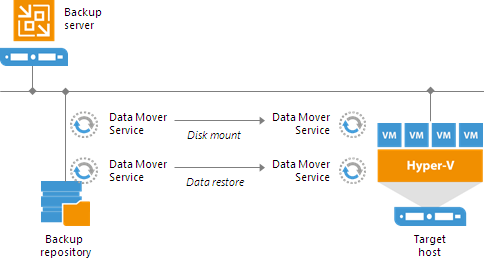
Для тех, кто еще не знаком с возможностями Instant VM Recovery, есть довольно подробное описание в документации на русском языке, в частности, вот такое определение:
Технология мгновенного восстановления виртуальных машин (Instant VM Recovery) позволяет за несколько секунд запустить виртуальную машину прямо из сжатой и дедуплицированной резервной копии, которая хранится в репозитории.
Далее в руководстве описан базовый сценарий использования.
Если ваша инфраструктура не очень велика, и вы планируете восстанавливать небольшое число ВМ в случае необходимости, то знания базового сценария вполне достаточно.
Однако среди реальных сценариев использования Instant VM Recovery встречаются и весьма крупные инфраструктуры, в которых нужно было восстановить работу критичных сервисов после повреждения СХД, а в каких-то — после вирусной атаки. Даже если резервные копии не повреждены (благодаря хранению на отдельной системе, как велит правило «3-2-1»), восстановление может идти довольно долго. Поэтому при планировании таких сценариев IT-специалисты ставят целью обеспечить высокую скорость за счет параллельного восстановления нескольких ВМ, а также соблюдение установленнной последовательности восстановления.
Причем все это должно работать быстрее и обходиться дешевле, чем плата за ключ дешифрования по итогу атаки вируса-шифровальщика. (Да-да, всё упирается во «время-деньги».) Естественно, нужно защитить от возможных атак резервные копии, хранящиеся на диске. Специалисты рекомендуют применять многофакторную аутентификацию для доступа к репозиториям.
Или, допустим, вы являетесь провайдером услуг, предоставляя в пользование потребителям сотни, а то и тысячи ВМ. Тут счет машинам, которые может понадобиться восстановить в мгновение ока, пойдет уже как минимум на десятки. И здесь, конечно, не обойтись без планирования и подготовки. Ведь необходимо будет не просто быстро поднять все необходимые машины из бэкапа, но и обеспечить достаточную производительность этих машин, и при этом постараться свести к минимуму влияние на ресурсы производственной инфраструктуры. Так, высокую скорость можно обеспечить при восстановлении с аппаратных снимков SAN Snapshots, созданных с учетом работы приложений и реплицируемых между массивами или сохраняемых на другие носители (например, на магнитную ленту).
В целом же при проектировании инфраструктуры во главе угла должен быть баланс, нацеленный на оптимизацию как процесса бэкапа, так и процесса восстановления.
Конечно, мы всегда стремимся обеспечить максимально быстрое восстановление ВМ и их работу без большой потери производительности или влияния на другие машины. Для этого нужно:
Конечно, в идеале для мгновенного восстановления нужно держать резервные копии на скоростной СХД, с хорошим каналом передачи данных. Но это недешевое удовольствие, поэтому обычно более старые бэкпы хранят на СХД попроще и подешевле. Можно использовать SAN попроще, S2D. Главное – хранить на СХД с достаточно высокой производительностью самые свежие бэкапы. Это могут быть четыре последних бэкапа за прошедшие сутки, и т.п. – все зависит от требований и политик организации. Если есть необходимость, то можно использовать и SSD, и даже NVMe.
Нужно понимать, что пока вы «поднимаете» машину, с этой СХД не только будут читаться данные восстанавливаемой ВМ, но работающие задания будут продолжать записывать бэкапы на эту же СХД. Вот почему так важна ее производительность.
В компании среднего размера используется бюджетный вариант СХД, организовано несколько уровней хранения:
Если скорость чтения-записи и величина задержки (latency) СХД при этих операциях вас устраивают, можно добавить репозитории к SAN. Если нет, то можно наращивать количество репозиториев по мере необходимости, т.е. выполнять горизонтальное масштабирование.
Примечание: Старайтесь не использовать один и тот же массив СХД для продакшена и бэкапов, дабы минимизировать риск потери данных из-за ошибок во встроенном ПО.
Используется Storage Spaces Direct, обеспечивающий высокую доступность, а также несколько целевых систем с ReFS Multi-Resilient Volumes, обеспечивающих защиту данных и чётность с зеркальным ускорением (mirror-accelerated parity). Можно выполнить настройку таким образом, чтобы «горячие» (самые свежие) данные зеркалировались на SSD перед тем, как стать «холодными», т.е. данными, которые долежали нетронутыми до часа Х и перешли во «вторую категорию свежести». «Холодные» данные переезжают на уровень хранения попроще (подешевле). В таком варианте заложены возможности как для горизонтального, так и для вертикального масштабирования.

Строим инфраструктуру резервного копирования, исходя из того, что нам нужен 2-й уровень хранения только для тех ВМ, которые требуют максимально быстрого бэкапа и восстановления.
Для этого можно задействовать пару дисковых СХД на 2TB SSD/NVMe, куда будут вести запись задания бэкапа с достаточно малым количеством хранимых точек восстановления. Затем эти бэкапы будут уезжать на СХД попроще и подешевле – для длительного хранения.
Можно использовать разные либо одни и те же репозитории. В любом случае удобно будет задействовать задания переноса резервных копий Veeam Backup Copy.

В любом случае на тот уровень, куда пишут непосредственно задания резервного копирования, будет приходиться приличная нагрузка, поэтому нужно обеспечить высокую производительность при записи, и желательно на подольше.
Так, если у вас имеется СХД типа AFA с 60 SDD для производственных ВМ, то для них вы можете использовать MLC, поскольку операции чтения-записи будут распределены по всем дискам. Но если ее планируется использовать как первый уровень хранения бэкапов и, соответственно, для восстановления Instant VM Recovery, то имейте в виду, что нагрузка будет постоянно приходиться на малое число дисков, и ресурс может исчерпаться довольно быстро.
В следующий раз мы рассмотрим, что следует учесть при планировании сетевых подключений и целевой системы – той, на которую будет выполняться восстановление.
Итак, добро пожаловать под кат.
Для тех, кто еще не знаком с возможностями Instant VM Recovery, есть довольно подробное описание в документации на русском языке, в частности, вот такое определение:
Технология мгновенного восстановления виртуальных машин (Instant VM Recovery) позволяет за несколько секунд запустить виртуальную машину прямо из сжатой и дедуплицированной резервной копии, которая хранится в репозитории.
Далее в руководстве описан базовый сценарий использования.
Зачем это планировать и оптимизировать?
Если ваша инфраструктура не очень велика, и вы планируете восстанавливать небольшое число ВМ в случае необходимости, то знания базового сценария вполне достаточно.
Однако среди реальных сценариев использования Instant VM Recovery встречаются и весьма крупные инфраструктуры, в которых нужно было восстановить работу критичных сервисов после повреждения СХД, а в каких-то — после вирусной атаки. Даже если резервные копии не повреждены (благодаря хранению на отдельной системе, как велит правило «3-2-1»), восстановление может идти довольно долго. Поэтому при планировании таких сценариев IT-специалисты ставят целью обеспечить высокую скорость за счет параллельного восстановления нескольких ВМ, а также соблюдение установленнной последовательности восстановления.
Причем все это должно работать быстрее и обходиться дешевле, чем плата за ключ дешифрования по итогу атаки вируса-шифровальщика. (Да-да, всё упирается во «время-деньги».) Естественно, нужно защитить от возможных атак резервные копии, хранящиеся на диске. Специалисты рекомендуют применять многофакторную аутентификацию для доступа к репозиториям.
Или, допустим, вы являетесь провайдером услуг, предоставляя в пользование потребителям сотни, а то и тысячи ВМ. Тут счет машинам, которые может понадобиться восстановить в мгновение ока, пойдет уже как минимум на десятки. И здесь, конечно, не обойтись без планирования и подготовки. Ведь необходимо будет не просто быстро поднять все необходимые машины из бэкапа, но и обеспечить достаточную производительность этих машин, и при этом постараться свести к минимуму влияние на ресурсы производственной инфраструктуры. Так, высокую скорость можно обеспечить при восстановлении с аппаратных снимков SAN Snapshots, созданных с учетом работы приложений и реплицируемых между массивами или сохраняемых на другие носители (например, на магнитную ленту).
В целом же при проектировании инфраструктуры во главе угла должен быть баланс, нацеленный на оптимизацию как процесса бэкапа, так и процесса восстановления.
Во первых строках — производительность
Конечно, мы всегда стремимся обеспечить максимально быстрое восстановление ВМ и их работу без большой потери производительности или влияния на другие машины. Для этого нужно:
- Быстро выполнять операцию чтения с СХД резервных копий. Чем быстрее СХД, с которой делается восстановление, тем лучше производительность восстанавливаемой ВМ.
- Иметь хороший скоростной канал передачи данных. Пропускная способность — рекомендуется 10 Гбит/c или выше.
- Иметь достаточно быструю целевую систему для восстановления (это может быть та, с которой делались бэкапы). Целевая СХД должна иметь такую производительность, чтобы поддерживать все операции чтения-записи у восстановленной ВМ на то время, пока вы не финализировали процесс (читаем про заключительные шаги в документации).
Подбираем СХД резервных копий с учетом планируемого восстановления Instant VM Recovery
Конечно, в идеале для мгновенного восстановления нужно держать резервные копии на скоростной СХД, с хорошим каналом передачи данных. Но это недешевое удовольствие, поэтому обычно более старые бэкпы хранят на СХД попроще и подешевле. Можно использовать SAN попроще, S2D. Главное – хранить на СХД с достаточно высокой производительностью самые свежие бэкапы. Это могут быть четыре последних бэкапа за прошедшие сутки, и т.п. – все зависит от требований и политик организации. Если есть необходимость, то можно использовать и SSD, и даже NVMe.
Нужно понимать, что пока вы «поднимаете» машину, с этой СХД не только будут читаться данные восстанавливаемой ВМ, но работающие задания будут продолжать записывать бэкапы на эту же СХД. Вот почему так важна ее производительность.
Пример 1
В компании среднего размера используется бюджетный вариант СХД, организовано несколько уровней хранения:
- на уровне 1 (небольшой емкости) хранятся самые свежие бэкапы – это т.н. «highly available repository», то есть репозиторий, обеспечивающий высокую доступность.
- более старые бэкапы перемещаются на уровень 2 (емкостью побольше) – это т.н. «non-highly available repository», то есть обеспечивающий доступность не очень высокую, а просто удовлетворительную.
Если скорость чтения-записи и величина задержки (latency) СХД при этих операциях вас устраивают, можно добавить репозитории к SAN. Если нет, то можно наращивать количество репозиториев по мере необходимости, т.е. выполнять горизонтальное масштабирование.
Примечание: Старайтесь не использовать один и тот же массив СХД для продакшена и бэкапов, дабы минимизировать риск потери данных из-за ошибок во встроенном ПО.
Пример 2
Используется Storage Spaces Direct, обеспечивающий высокую доступность, а также несколько целевых систем с ReFS Multi-Resilient Volumes, обеспечивающих защиту данных и чётность с зеркальным ускорением (mirror-accelerated parity). Можно выполнить настройку таким образом, чтобы «горячие» (самые свежие) данные зеркалировались на SSD перед тем, как стать «холодными», т.е. данными, которые долежали нетронутыми до часа Х и перешли во «вторую категорию свежести». «Холодные» данные переезжают на уровень хранения попроще (подешевле). В таком варианте заложены возможности как для горизонтального, так и для вертикального масштабирования.
Пример 3
Строим инфраструктуру резервного копирования, исходя из того, что нам нужен 2-й уровень хранения только для тех ВМ, которые требуют максимально быстрого бэкапа и восстановления.
Для этого можно задействовать пару дисковых СХД на 2TB SSD/NVMe, куда будут вести запись задания бэкапа с достаточно малым количеством хранимых точек восстановления. Затем эти бэкапы будут уезжать на СХД попроще и подешевле – для длительного хранения.
Можно использовать разные либо одни и те же репозитории. В любом случае удобно будет задействовать задания переноса резервных копий Veeam Backup Copy.
В любом случае на тот уровень, куда пишут непосредственно задания резервного копирования, будет приходиться приличная нагрузка, поэтому нужно обеспечить высокую производительность при записи, и желательно на подольше.
Так, если у вас имеется СХД типа AFA с 60 SDD для производственных ВМ, то для них вы можете использовать MLC, поскольку операции чтения-записи будут распределены по всем дискам. Но если ее планируется использовать как первый уровень хранения бэкапов и, соответственно, для восстановления Instant VM Recovery, то имейте в виду, что нагрузка будет постоянно приходиться на малое число дисков, и ресурс может исчерпаться довольно быстро.
В следующий раз мы рассмотрим, что следует учесть при планировании сетевых подключений и целевой системы – той, на которую будет выполняться восстановление.
Что еще почитать и посмотреть
- Мгновенное восстановление виртуальной машины – раздел руководства пользователя (на русском языке)
- Мгновенное восстановление ВМ в картинках (на англ.языке)
- Статья на Хабре о подборе СХД для резервного копирования