Продолжаем тему, которую начали рассматривать в первой части. Сегодня поговорим о сетевых соединениях и целевых серверах, представим возможные варианты и опции планирования инфраструктуры для оптимального восстановления Instant VM Recovery. Итак, добро пожаловать под кат.
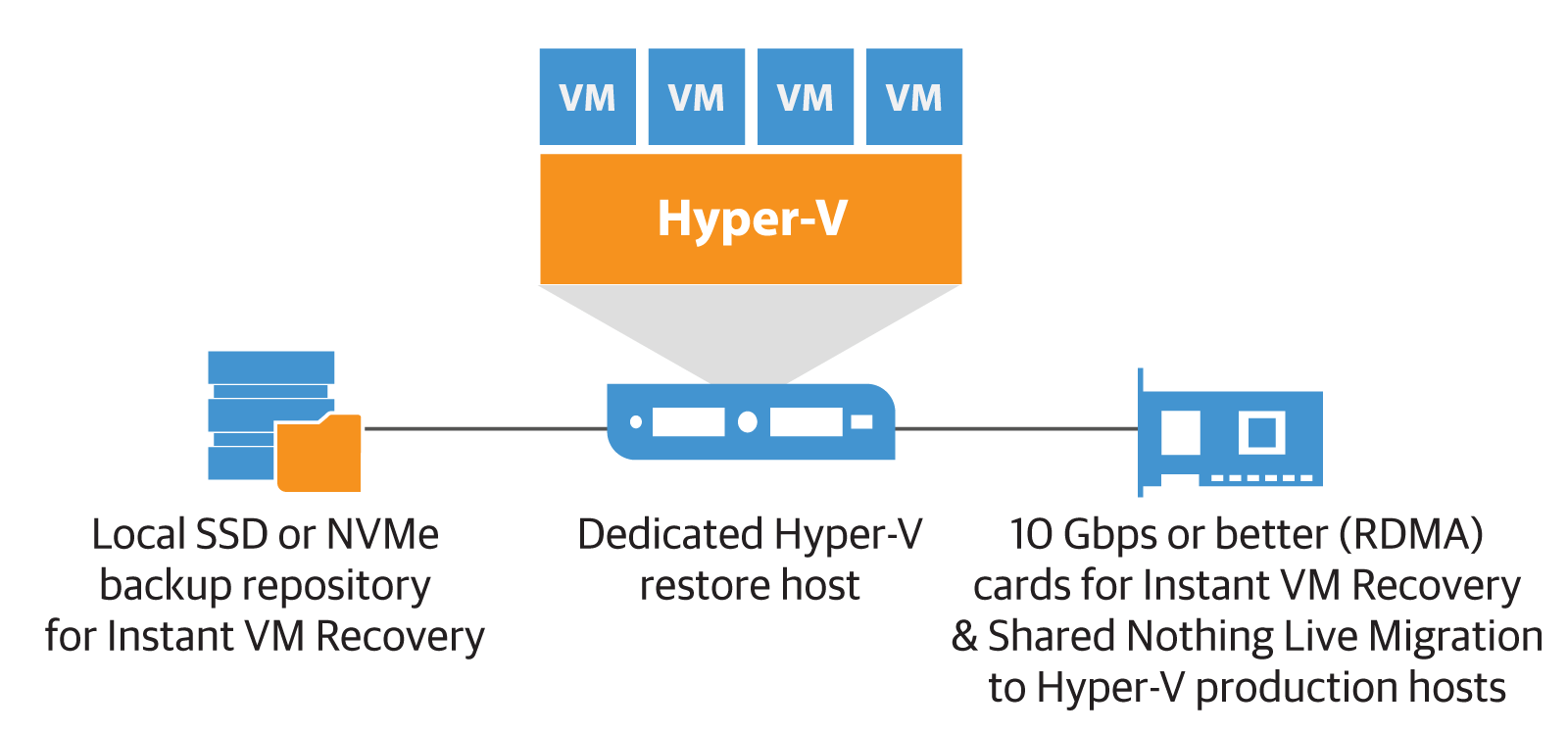
Конечно, хорошо иметь канал с пропускной способностью 10 Гбит\сек, по которому выполняется передача данных при бэкапе. Впрочем, для восстановления из резервной копии подойдет и канал поскромнее, но рекомендуется использовать NIC teaming с LACP либо SMB Multichannel, или еще какой-то вариант с агрегацией пропускной способности. Можно задействовать, например, порты LOM в варианте 4x1 Гбит\сек. Такая конфигурация рекомендуется для соединения «несколько исходных устройств – 1 целевое устройство резервного копирования», то есть при подключении «много к одному». (Аналогично, параллельное восстановление с одного хранилища бэкапов на целевые устройства -как правило, это те же исходные, с которых выполнялось резервное копирование- представляет собой подключение «один ко многим».)
Например, можно настроить несколько заданий резервного копирования с нескольких хостов Hyper-V / LUNs сохранять бэкапы на одно и то же целевое хранилище. Если у вас 10 таких хостов с общей пропускной способностью канала 4x1 Гбит\сек, то при наличии пайпа на 10Гбит\сек на целевом устройстве это вполне адекватная конфигурация.
В случае, когда СХД резервного копирования – это SMB share, очень даже неплохо работает многоканальность (она может быть дополнена SMB Direct, если у вас настроены NICs с поддержкой RDMA). Сейчас такие возможности поддерживаются во многих развертываниях кластеров Hyper-V. Однако компонент решения Veeam, отвечающий за передачу данных (data mover), пока умеет задействовать SMB Multichannel и SMB Direct (опять же, при настроенных NICs с поддержкой RDMA) только в сценарии, когда для бэкапа ВМ, хранящихся на SMB File share, вы используете off-host proxy. Эти Veeam Data Movers работают, соответственно, на off-host backup proxy и на репозитории. Такой сценарий подробно описан тут.
Еще важный момент: при использовании Windows NIC teaming в режиме работы Switch independent mode передача данных разрешена от всех участников, а получение — только от одного. Если вы хотите получить оптимальную пропускную способность в обоих направлениях для одного процесса, то не надо использовать LACP. Но в таком варианте нужно обеспечить выполнение нескольких восстановлений на один и тот же хост.
Как видим, агрегирование пропускной способности несет с собой ряд ограничений и не полностью идентично наличию одного хорошего канала. В любом случае нужно отталкиваться от планируемых сценариев использования.
Суммируя: в зависимости от вашей инфраструктуры можно использовать Windows NIC teaming в LACP либо режим Switch Independent mode / SMB Multichannel. Последний вариант полезен, если вы работаете с SMB file share и хотите задействовать SMB Direct (не забудьте про особенности работы, указанные выше).
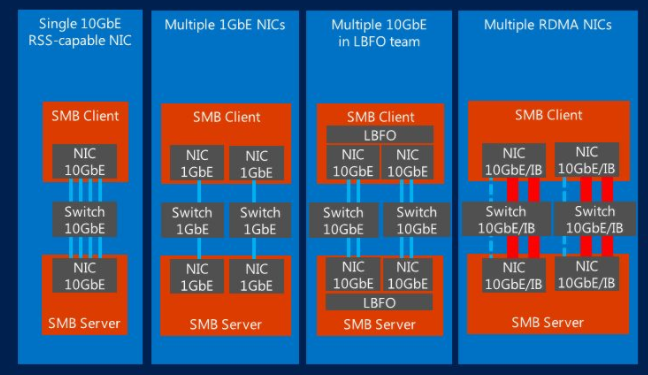
Высокая пропускная способность и небольшая задержка нужны, чтобы в ходе Instant VM Recovery обеспечить наилучшую производительность при монтировании виртуальных дисков, при доступе к данным и при их копировании.
Можно выполнять несколько операций восстановления одновременно и при этом не прекращать работу заданий резервного копирования. То есть, опять-таки, при наличии приличного канала основную роль играют вычислительный ресурс и СХД. Если все это грамотно рассчитано для резервного копирования, то и восстановление будет эффективным.
Рассмотрим несколько вариантов, из которых, вполне возможно, вы подберете оптимальные для себя.
Даже если у вас высокопроизводительная СХД с кэшированием чтения\записи или настроен уровень 1, то, как говорилось в предыдущем посте, нужно быть внимательным, чтобы не допустить переполнения. В противном случае будут затронуты производственные ВМ. А это может произойти, например, если вы пытаетесь записывать на СХД большие объемы данных как можно быстрее – так бывает при миграции СХД. Мы стараемся при таких операциях избегать использования СХД 1-го уровня. Аналогичные соображения относятся и к восстановлению ВМ большого размера.
Можно порекомендовать восстанавливаться на отдельные LUNы с различными профайлами. Восстановленные ВМ затем можно не торопясь смигрировать на производственные CSV. Для обеспечения высокой доступности (high availability) можно задействовать кластер, используя Storage live migration (функционал миграции СХД «вживую»). Естественно, надо ориентироваться на производительность вашего массива СХД.
Еще один сценарий восстановления в продакшен, довольно эффективный: использование хоста Hyper-V с локальной СХД на SSD или NVMe. Размер дискового пространства зависит от того, сколько ВМ вы хотите восстанавливать за определенный промежуток времени и насколько эти ВМ велики.
По идее, вам вряд ли потребуется восстанавливать всех и вся, так что данная конфигурация должна получиться довольно экономичной по стоимости. Например, можно использовать по одному SSD в каждом из узлов кластера или лишь в нескольких, или вообще только в одном. Чем больше SSD/NVMe вы используете, тем более бюджетными они могут быть, при этом поддерживая достаточно эффективное распределение нагрузки по хостам. На завершающем этапе процедуры мгновенного восстановления виртуальные машины можно спокойно перенести на производственные CSV, задействуя все тот же функционал Storage live migration.
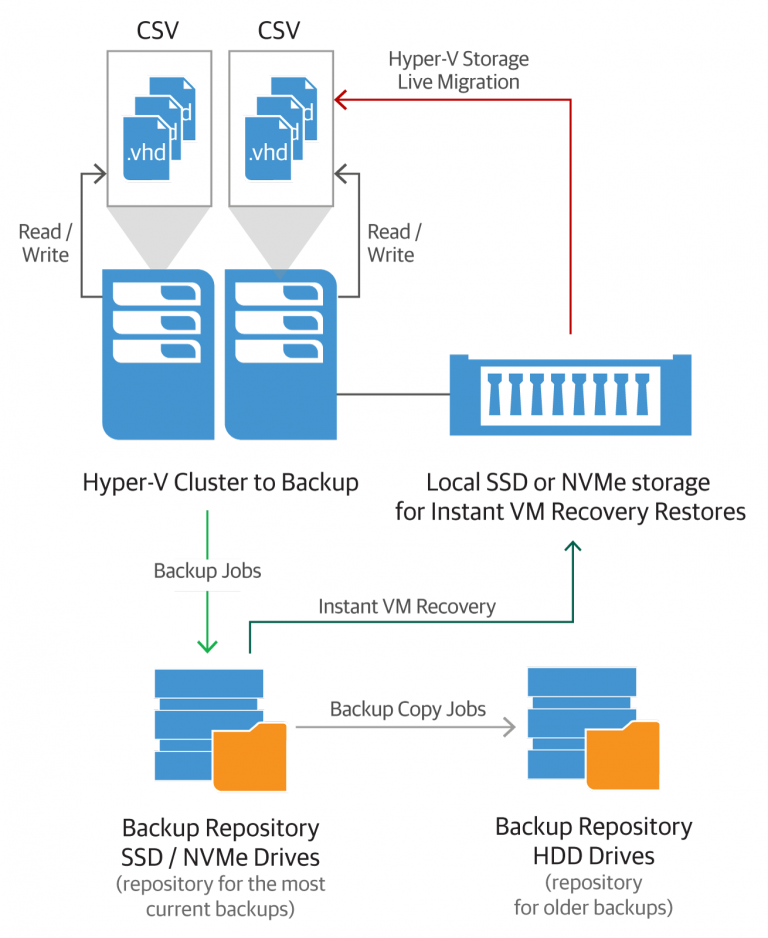
На схеме показан вариант планирования инфраструктуры. Разумеется, можно комбинировать вышеописанные подходы на ваше усмотрение.
В таком варианте мы выделяем один или несколько хостов конкретно для поддержки восстановления. Это позволяет избежать возможного дефицита ресурсов и влияния на работу продакшен-хостов в кластере. Можно использовать диски NVMe. Рекомендуем предварительно протестировать возможности восстановления в такой конфигурации, чтобы понять, насколько хватает ресурсов.
Если планируется увеличение их потребления, то для заключительной миграции восстановленных машин в продакшен можно использовать так называемую миграцию без разделения ресурсов Shared Nothing Live Migration. (Для этого придется задать дополнительные настройки безопасности.) Что же касается сетевых ресурсов, то можно задействовать, например, SMB Multichannel и возможности SMB Direct для миграции на CSV/Live Migration / S2D Hyper-V.
Да, миграция СХД (Storage live migration) – процесс не самый быстрый, это минус. Но есть и плюс – ваши виртуальные машины восстановлены и в ходе этого процесса продолжают работать.
Конечно, каждый выбирает предпочтительные варианты в зависимости от того, что является в конкретной инфраструктуре наиболее узким местом (исходный сервер, целевой сервер, сетевые ресурсы). Более того, вполне возможно, что тщательная проработка потребуется лишь для планирования восстановления наиболее критичных ВМ или для тех потребителей, которые оплатят такой сервис.
В любом случае главной целью всегда будет максимально быстрое выполнение восстановления.
После этого уже можно спокойно выполнить миграцию на СХД кластера, обеспечив высокую доступность и отказоустойчивость. И, конечно, виртуальным машинам должна быть обеспечена защита в виде резервного копирования\репликации на тот случай, если в какой-то момент их снова понадобится восстановить.
Про сетевые соединения
Конечно, хорошо иметь канал с пропускной способностью 10 Гбит\сек, по которому выполняется передача данных при бэкапе. Впрочем, для восстановления из резервной копии подойдет и канал поскромнее, но рекомендуется использовать NIC teaming с LACP либо SMB Multichannel, или еще какой-то вариант с агрегацией пропускной способности. Можно задействовать, например, порты LOM в варианте 4x1 Гбит\сек. Такая конфигурация рекомендуется для соединения «несколько исходных устройств – 1 целевое устройство резервного копирования», то есть при подключении «много к одному». (Аналогично, параллельное восстановление с одного хранилища бэкапов на целевые устройства -как правило, это те же исходные, с которых выполнялось резервное копирование- представляет собой подключение «один ко многим».)
Например, можно настроить несколько заданий резервного копирования с нескольких хостов Hyper-V / LUNs сохранять бэкапы на одно и то же целевое хранилище. Если у вас 10 таких хостов с общей пропускной способностью канала 4x1 Гбит\сек, то при наличии пайпа на 10Гбит\сек на целевом устройстве это вполне адекватная конфигурация.
В случае, когда СХД резервного копирования – это SMB share, очень даже неплохо работает многоканальность (она может быть дополнена SMB Direct, если у вас настроены NICs с поддержкой RDMA). Сейчас такие возможности поддерживаются во многих развертываниях кластеров Hyper-V. Однако компонент решения Veeam, отвечающий за передачу данных (data mover), пока умеет задействовать SMB Multichannel и SMB Direct (опять же, при настроенных NICs с поддержкой RDMA) только в сценарии, когда для бэкапа ВМ, хранящихся на SMB File share, вы используете off-host proxy. Эти Veeam Data Movers работают, соответственно, на off-host backup proxy и на репозитории. Такой сценарий подробно описан тут.
Еще важный момент: при использовании Windows NIC teaming в режиме работы Switch independent mode передача данных разрешена от всех участников, а получение — только от одного. Если вы хотите получить оптимальную пропускную способность в обоих направлениях для одного процесса, то не надо использовать LACP. Но в таком варианте нужно обеспечить выполнение нескольких восстановлений на один и тот же хост.
Как видим, агрегирование пропускной способности несет с собой ряд ограничений и не полностью идентично наличию одного хорошего канала. В любом случае нужно отталкиваться от планируемых сценариев использования.
Суммируя: в зависимости от вашей инфраструктуры можно использовать Windows NIC teaming в LACP либо режим Switch Independent mode / SMB Multichannel. Последний вариант полезен, если вы работаете с SMB file share и хотите задействовать SMB Direct (не забудьте про особенности работы, указанные выше).
Высокая пропускная способность и небольшая задержка нужны, чтобы в ходе Instant VM Recovery обеспечить наилучшую производительность при монтировании виртуальных дисков, при доступе к данным и при их копировании.
Можно выполнять несколько операций восстановления одновременно и при этом не прекращать работу заданий резервного копирования. То есть, опять-таки, при наличии приличного канала основную роль играют вычислительный ресурс и СХД. Если все это грамотно рассчитано для резервного копирования, то и восстановление будет эффективным.
Рекомендации для целевых устройств
Рассмотрим несколько вариантов, из которых, вполне возможно, вы подберете оптимальные для себя.
Вариант 1: Восстановление на хосты Hyper-V и напрямую на LUN в производственную инфраструктуру
Даже если у вас высокопроизводительная СХД с кэшированием чтения\записи или настроен уровень 1, то, как говорилось в предыдущем посте, нужно быть внимательным, чтобы не допустить переполнения. В противном случае будут затронуты производственные ВМ. А это может произойти, например, если вы пытаетесь записывать на СХД большие объемы данных как можно быстрее – так бывает при миграции СХД. Мы стараемся при таких операциях избегать использования СХД 1-го уровня. Аналогичные соображения относятся и к восстановлению ВМ большого размера.
Можно порекомендовать восстанавливаться на отдельные LUNы с различными профайлами. Восстановленные ВМ затем можно не торопясь смигрировать на производственные CSV. Для обеспечения высокой доступности (high availability) можно задействовать кластер, используя Storage live migration (функционал миграции СХД «вживую»). Естественно, надо ориентироваться на производительность вашего массива СХД.
Вариант 2: Восстановление на хосты Hyper-V с локальными дисками SSD/NMVe
Еще один сценарий восстановления в продакшен, довольно эффективный: использование хоста Hyper-V с локальной СХД на SSD или NVMe. Размер дискового пространства зависит от того, сколько ВМ вы хотите восстанавливать за определенный промежуток времени и насколько эти ВМ велики.
По идее, вам вряд ли потребуется восстанавливать всех и вся, так что данная конфигурация должна получиться довольно экономичной по стоимости. Например, можно использовать по одному SSD в каждом из узлов кластера или лишь в нескольких, или вообще только в одном. Чем больше SSD/NVMe вы используете, тем более бюджетными они могут быть, при этом поддерживая достаточно эффективное распределение нагрузки по хостам. На завершающем этапе процедуры мгновенного восстановления виртуальные машины можно спокойно перенести на производственные CSV, задействуя все тот же функционал Storage live migration.
На схеме показан вариант планирования инфраструктуры. Разумеется, можно комбинировать вышеописанные подходы на ваше усмотрение.
Вариант 3: Восстановление на выделенные хосты Hyper-V с локальными дисками SSD/NVMe
В таком варианте мы выделяем один или несколько хостов конкретно для поддержки восстановления. Это позволяет избежать возможного дефицита ресурсов и влияния на работу продакшен-хостов в кластере. Можно использовать диски NVMe. Рекомендуем предварительно протестировать возможности восстановления в такой конфигурации, чтобы понять, насколько хватает ресурсов.
Если планируется увеличение их потребления, то для заключительной миграции восстановленных машин в продакшен можно использовать так называемую миграцию без разделения ресурсов Shared Nothing Live Migration. (Для этого придется задать дополнительные настройки безопасности.) Что же касается сетевых ресурсов, то можно задействовать, например, SMB Multichannel и возможности SMB Direct для миграции на CSV/Live Migration / S2D Hyper-V.
Да, миграция СХД (Storage live migration) – процесс не самый быстрый, это минус. Но есть и плюс – ваши виртуальные машины восстановлены и в ходе этого процесса продолжают работать.
В заключение
Конечно, каждый выбирает предпочтительные варианты в зависимости от того, что является в конкретной инфраструктуре наиболее узким местом (исходный сервер, целевой сервер, сетевые ресурсы). Более того, вполне возможно, что тщательная проработка потребуется лишь для планирования восстановления наиболее критичных ВМ или для тех потребителей, которые оплатят такой сервис.
В любом случае главной целью всегда будет максимально быстрое выполнение восстановления.
После этого уже можно спокойно выполнить миграцию на СХД кластера, обеспечив высокую доступность и отказоустойчивость. И, конечно, виртуальным машинам должна быть обеспечена защита в виде резервного копирования\репликации на тот случай, если в какой-то момент их снова понадобится восстановить.
KorP
А почему везде фигурирует Hyper-V? Для Vmware какие то другие варианты рекомендуются?
ISE73
Скорее нет, чем да. В обеих статьях идет речь про инфраструктуру — она скорее всего будет у вас одинакова что для Hyper-V, что для Vmware.
KorP
Так я по этому и решил уточнить этот момент.
polarowl Автор
Для разнообразия, так сказать:) Для VMware уже и так есть в большом количестве и примеры, и рекомендации, и лучшие практики, начиная аж с Veeam Backup & Replication 7.0. Типовые же варианты инфраструктур и сценарии использования, как правило, сходные для обеих платформ.