Сегодня мы расскажем читателям Хабра о двух важных технологических изменениях в переводчике Яндекс.Браузера. Во-первых, перевод выделенных слов и фраз теперь использует гибридную модель, и мы напомним, чем этот подход отличается от применения исключительно нейросетей. Во-вторых, нейронные сети переводчика теперь учитывают структуру веб-страниц, об особенностях которой мы также расскажем под катом.
Гибридный переводчик слов и фраз
В основе первых систем машинного перевода лежали словари и правила (по сути, написанные вручную регулярки), которые и определяли качество перевода. Профессиональные лингвисты годами работали над тем, чтобы вывести всё более подробные ручные правила. Работа эта была столь трудоемкой, что серьезное внимание уделялось лишь наиболее популярным парам языков, но даже в рамках них машины справлялись плохо. Живой язык – очень сложная система, которая плохо подчиняется правилам. Ещё сложнее описать правилами соответствия двух языков.
Единственный способ машине постоянно адаптироваться к изменяющимся условиям – это учиться самостоятельно на большом количестве параллельных текстов (одинаковые по смыслу, но написаны на разных языках). В этом заключается статистический подход к машинному переводу. Компьютер сравнивает параллельные тексты и самостоятельно выявляет закономерности.
У статистического переводчика есть как достоинства, так и недостатки. С одной стороны, он хорошо запоминает редкие и сложные слова и фразы. Если они встречались в параллельных текстах, переводчик запомнит их и впредь будет переводить правильно. С другой стороны, результат перевода бывает похож на собранный пазл: общая картина вроде бы понятна, но если присмотреться, то видно, что она составлена из отдельных кусочков. Причина в том, что переводчик представляет отдельные слова в виде идентификаторов, которые никак не отражают взаимосвязи между ними. Это не соответствует тому, как люди воспринимают язык, когда слова определяются тем, как они используются, как соотносятся с другими словами и чем отличаются от них.
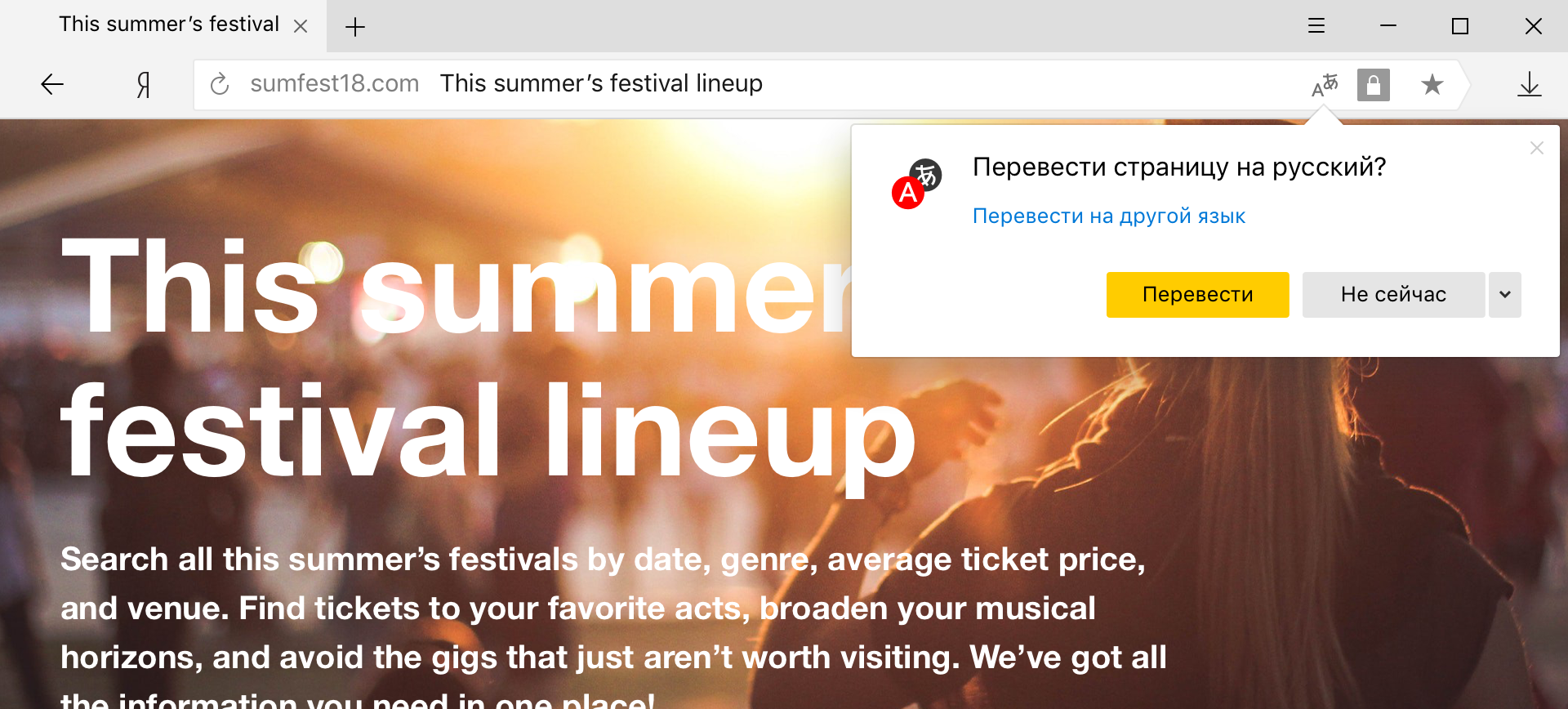
Решить эту проблему помогает нейронные сети. Векторное представление слов (word embedding), применяемое в нейронном машинном переводе, как правило, сопоставляет каждому слову вектор длиной в несколько сотен чисел. Векторы, в отличие от простых идентификаторов из статистического подхода, формируются при обучении нейронной сети и учитывают взаимосвязи между словами. Например, модель может распознать, что, поскольку «чай» и «кофе» часто появляются в сходных контекстах, оба эти слова должны быть возможны в контексте нового слова «разлив», с которым, допустим, в обучающих данных встретилось лишь одно из них.
Однако процесс обучения векторным представлениям явно более статистически требователен, чем механическое запоминание примеров. Кроме того, непонятно, что делать с теми редкими входными словами, которые недостаточно часто встречались, чтобы сеть могла построить для них приемлемое векторное представление. В этой ситуации логично совместить оба метода.
С прошлого года Яндекс.Переводчик использует гибридную модель. Когда Переводчик получает от пользователя текст, он отдаёт его на перевод обеим системам — и нейронной сети, и статистическому переводчику. Затем алгоритм, основанный на методе обучения CatBoost, оценивает, какой перевод лучше. При выставлении оценки учитываются десятки факторов — от длины предложения (короткие фразы лучше переводит статистическая модель) до синтаксиса. Перевод, признанный лучшим, показывается пользователю.
Именно гибридная модель теперь используется в Яндекс.Браузере, когда пользователь выделяет для перевода конкретные слова и фразы на странице.
Этот режим особенно удобен для тех, кто в целом владеет иностранным языком и хотел бы переводить лишь неизвестные слова. Но если, к примеру, вместо привычного английского вы встретите китайский, то здесь без постраничного переводчика обойтись будет трудно. Казалось бы, отличие лишь в объеме переводимого текста, но не всё так просто.
Нейросетевой переводчик веб-страниц
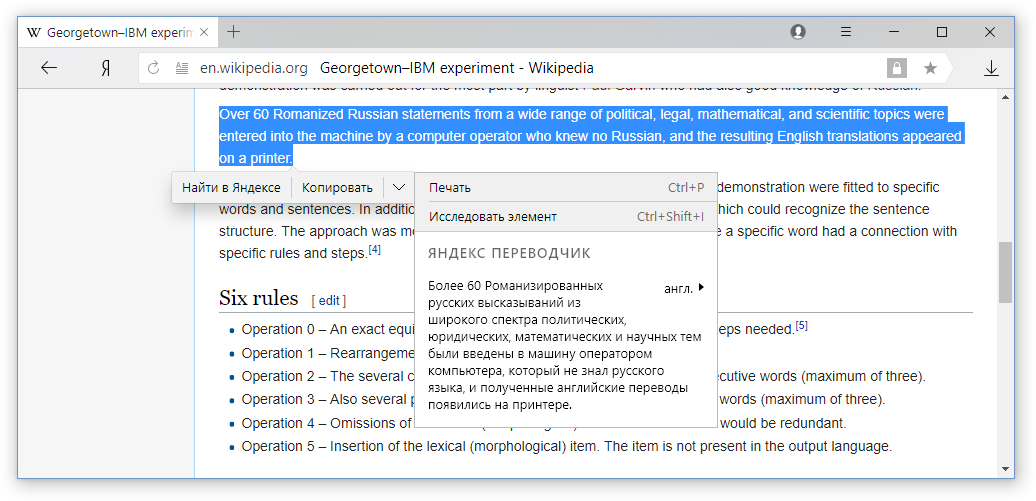
Со времён Джорджтаунского эксперимента и практически до наших дней все системы машинного перевода обучались переводить каждое предложение исходного текста по отдельности. В то время как веб-страница – это не просто набор предложений, а структурированный текст, в котором есть принципиально разные элементы. Рассмотрим основные элементы большинства страниц.
Заголовок. Обычно яркий и крупный текст, который мы видим сразу при заходе на страницу. Заголовок часто содержит суть новости, поэтому важно перевести его правильно. Но сделать это сложно, потому что текста в заголовке мало и без понимания контекста можно допустить ошибку. В случае с английским языком всё ещё сложнее, потому что англоязычные заголовки часто содержат фразы с нетрадиционной грамматикой, инфинитивы или даже пропускают глаголы. Например, Game of Thrones prequel announced.
Навигация. Слова и фразы, которые помогают нам ориентироваться на сайте. Например, Home, Back и My account вряд ли стоит переводить как «Дом», «Спина» и «Мой счёт», если они расположены в меню сайта, а не в тексте публикации.
Основной текст. С ним всё проще, он мало отличается от обычных текстов и предложений, которые мы можем найти в книгах. Но даже здесь важно обеспечивать консистентность переводов, то есть добиваться того, чтобы в рамках одной веб-страницы одни и те же термины и понятия переводились одинаково.
Для качественного перевода веб-страниц недостаточно использовать нейросетевую или гибридную модель – необходимо учитывать ещё и структуру страниц. А для этого нам нужно было разобраться со множеством технологических трудностей.
Классификация сегментов текста. Для этого мы опять же используем CatBoost и факторы, основанные как на самом тексте, так и на HTML-разметке документов (тэг , размер текста, числа ссылок на единицу текста, ...). Факторы достаточно разнородные, поэтому именно CatBoost (основанный на градиентном бустинге) показывает лучшие результаты (точность классификации выше 95%). Но одной классификации сегментов недостаточно.
Перекос в данных. Традиционно алгоритмы Яндекс.Переводчика обучаются на текстах из интернета. Казалось бы, это идеальное решение для обучения переводчика веб-страниц (иными словами, сеть учится на текстах той же природы, что и у тех текстов, на которых мы собираемся её применять). Но как только мы научились отделять друг от друга различные сегменты, мы обнаружили интересную особенность. В среднем на сайтах контент занимает примерно 85% всего текста, а на заголовки и навигацию приходится всего по 7.5%. Вспомним также, что сами заголовки и элементы навигации по стилю и грамматике заметно отличаются от остального текста. Эти два фактора в совокупности приводят к проблеме перекоса данных. Нейронной сети выгоднее просто игнорировать особенности этих весьма бедно представленных в обучающей выборке сегментов. Сеть обучается хорошо переводить только основной текст, из-за чего страдает качество перевода заголовков и навигации. Чтобы нивелировать этот неприятный эффект, мы сделали две вещи: к каждой паре параллельных предложений мы приписали в качестве метаинформации один из трёх типов сегментов (контент, заголовок или навигация) и искусственно подняли концентрацию двух последних в тренировочном корпусе до 33% за счёт того, что стали чаще показывать обучающейся нейросети подобные примеры.
Multi-task learning. Поскольку теперь мы умеем разделять тексты на веб-страницах на три класса сегментов, может показаться естественной идеей обучать три отдельные модели, каждая из которых будет справляться с переводом своего типа текстов – заголовков, навигации или контента. Это действительно работает неплохо, однако ещё лучше работает схема, при которой мы обучаем одну нейросеть переводить сразу все типы текстов. Ключ к пониманию лежит в идее mutli-task learning (MTL): если между несколькими задачами машинного обучения имеется внутренняя связь, то модель, которая учится решать эти задачи одновременно, может научиться решать каждую из задач лучше, чем узкопрофильная специализированная модель!
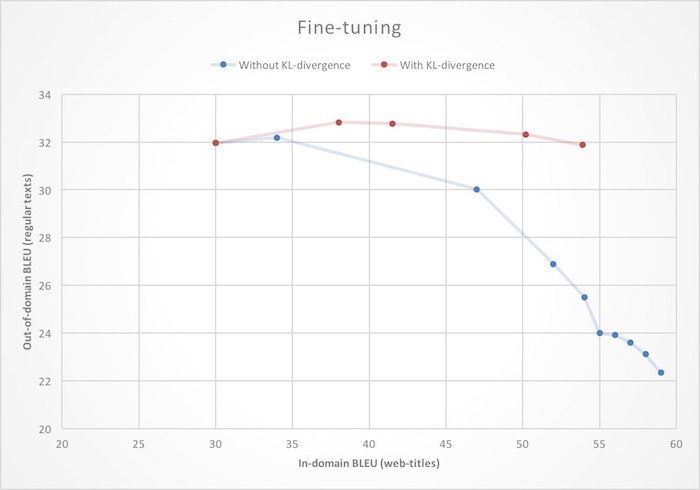
Fine-tuning. У нас уже был весьма неплохой машинный перевод, поэтому было бы неразумно обучать новый переводчик для Яндекс.Браузера с нуля. Логичнее взять базовую систему для перевода обычных текстов и дообучить её для работы с веб-страницами. В контексте нейросетей это часто называют термином fine-tuning. Но если подойти к этой задаче в лоб, т.е. просто инициализировать веса нейронной сети значениями из готовой модели и начать учить на новых данных, то можно столкнуться с эффектом доменного сдвига: по мере обучения качество перевода веб-страниц (in-domain) будет расти, но качество перевода обычных (out-of-domain) текстов будет падать. Чтобы избавиться от этой неприятной особенности, при дообучении мы накладываем на нейросеть дополнительное ограничение, запрещая ей слишком сильно менять веса по сравнению с начальным состоянием.
Математически это выражается добавлением слагаемого к функции потерь (loss function), представляющего из себя расстояние Кульбака—Лейблера (KL-divergence) между распределениями вероятностей порождения очередного слова, выдаваемыми исходной и дообучаемой сетями. Как можно видеть на иллюстрации, это приводит к тому, что рост качества перевода веб-страниц больше не приводит к деградации перевода обычного текста.
Полировка частотных фраз из навигации. В процессе работы над новым переводчиком мы собрали статистику по текстам различных сегментов веб-страниц и увидели интересное. Тексты, которые относятся к элементам навигации, достаточно сильно стандартизированы, поэтому часто представляют из себя одни и те же шаблонные фразы. Это настолько мощный эффект, что больше половины всех встречающихся в интернете навигационных фраз приходится на всего лишь 2 тысячи самых частотных из них.
Мы, конечно же, воспользовались этим и отдали несколько тысяч самых частотных фраз и их переводов на верификацию нашим переводчикам, чтобы быть абсолютно уверенными в их качестве.
External alignments. К переводчику веб-страниц в Браузере было ещё одно важное требование – он не должен искажать разметку. Когда тэги HTML располагаются вне предложений или на их границах, никаких проблем не возникает. Но если внутри предложения есть, например, two underlined words, то в переводе мы хотим видеть “два подчёркнутых слова”. Т.е. в результате перевода должны выполняться два условия:
- Подчёркнутый фрагмент в переводе должен соответствовать именно подчёркнутому фрагменту в исходном тексте.
- Согласованность перевода на границах подчёркнутого фрагмента не должна нарушаться.
Для того чтобы обеспечить такое поведение, мы сначала переводим текст как обычно, а затем с помощью статистических моделей пословного выравнивания определяем соответствия между фрагментами исходного и переведённого текстов. Это помогает понять, что именно нужно подчеркнуть (выделить курсивом, оформить как гиперссылку, ...).
Intersection observer. Мощные нейросетевые модели перевода, которые мы натренировали, требуют заметно больше вычислительных ресурсов на наших серверах (как CPU, так и GPU), чем статистические модели предыдущих поколений. При этом пользователи далеко не всегда дочитывают страницы до конца, поэтому отправка всего текста веб-страниц в облако выглядит излишней. Чтобы сэкономить серверные ресурсы и пользовательский трафик мы научили Переводчик использовать Intersection Observer API, чтобы отправлять на перевод только тот текст, который отображается на экране. За счёт этого нам удалось снизить расход трафика на перевод более чем в 3 раза.
Несколько слов об итогах внедрения нейросетевого переводчика с учётом структуры веб-страниц в Яндекс.Браузер. Для оценки качества переводов мы используем метрику BLEU*, которая сравнивает переводы, выполненные машиной и профессиональным переводчиком, и оценивает качество машинного перевода по шкале от 0 до 100%. Чем ближе машинный перевод к человеческому, тем выше процент. Обычно пользователи замечают изменение качества при росте метрики BLEU хотя бы на 3%. Новый переводчик Яндекс.Браузера показал рост почти на 18%.

Машинный перевод – одна из самых сложных, горячих и исследуемых задач в области технологий искусственного интеллекта. Это обусловлено и её чисто математической привлекательностью, и её востребованностью в современном мире, где каждую секунду в интернете создаётся невероятное количество контента на всевозможных языках. Машинный перевод, который ещё совсем недавно вызывал в основном смех (вспомним гуртовщиков мыши), в наши дни помогает пользователям преодолевать языковые барьеры.
До идеального качества ещё далеко, поэтому мы будем продолжать движение на переднем краю технологий в этом направлении, чтобы пользователи Яндекс.Браузера могли выходить за рамки, к примеру, рунета и находить полезный для себя контент в любой точке интернета.
Комментарии (29)

foxyrus
03.07.2018 10:04Такой перевод работает только в Яндекс Браузер?
TheShestov
04.07.2018 12:01поддерживаю вопрос. я попробовал поискать в расширения хрома — но нашел только 3 авторских плагина. не знаю какие технологии они используют и доступен ли «новый» переводчик для всех (чтобы использовать его в ПО), поэтому не рискнул ставить.
Обращение к авторам: мы можем использовать отечественный переводчик в хроме? :)
igruh
03.07.2018 11:01Переводы текстов из Википедии автоматизированным системам даются довольно легко ввиду очевидных причин — стремление делать текст простым и понятным рядовому пользователю. А вот попробуем орешек по-сложнее —
сайт Формулы1Перевод:
Стратегия шарить на Гран-При Австрии оставил их звезда водитель шарить, прежде чем оба автомобиля Mercedes DNF'D впервые с Испании 2016. Но это анализ и обучение, а не взаимные обвинения, что команда теперь должна все исправить, говорит директор команды Mercedes Тото Вульф.
Мерседес, в команде, чтобы победить в Формуле-1 После 2014 гибридной эры, были виновны три Льюиса Хэмилтона, связанных с безопасностью или виртуальной машины безопасности ошибок в этом сезоне, не сумев столкнуть его для новых шин в Австралии, Китае и теперь в Австрии во время этих гонок были нейтрализованы.
Оригинал:
A strategy fumble at the Austrian Grand Prix left their star driver fuming, before both Mercedes cars DNF’d for the first time since Spain 2016. But it’s analysis and learning, not recriminations, that the team now need to put things right, says Mercedes Team Principal Toto Wolff.
Mercedes, the team to beat in Formula 1’s post-2014 hybrid era, have now been guilty of three Lewis Hamilton-related Safety or Virtual Safety Car errors this season, having failed to pit him for new tyres in Australia, China and now Austria while those races were being neutralised.kukutz
03.07.2018 11:50+1А чем вы переводили? В Яндекс.Браузере несколько другой результат:
Стратегия возиться на Гран-При Австрии оставила своего звездного водителя дымящимся, прежде чем оба автомобиля Mercedes DNF'D впервые с Испании 2016 года. Но это анализ и обучение, а не взаимные обвинения, что команде теперь нужно все исправить, говорит директор команды Mercedes Тото Вольфф.
Mercedes, команда, победившая в гибридной эре Формулы-1 После 2014 года, теперь виновна в трех ошибках, связанных с безопасностью или виртуальной безопасностью автомобилей Льюиса Хэмилтона в этом сезоне, не сумев столкнуть его с новыми шинами в Австралии, Китае и теперь Австрии, пока эти гонки были нейтрализованы.
Тоже не идеал, но получше вроде.igruh
03.07.2018 12:03Да, действительно чуть лучше в плане согласования членов предложения. Я использовал Яндекс.Переводчик, т.к. ставить Яндекс.Браузер только ради этого теста не хотелось. Странно, что разница вообще есть.
Popadanec
03.07.2018 23:32Гугл, перевод через браузер:
Стратегия, пробивавшаяся на Гран-при Австрии, оставила свой звездный водитель дымящим, прежде чем оба автомобиля Mercedes DNF'd впервые после Испании 2016 года. Но это анализ и обучение, а не взаимные обвинения, что команде сейчас нужно все исправить, говорит Mercedes Руководитель команды Тото Вольф.
«Мерседес», команда, которая обыграла гибридную эру Формулы-1 в 2014 году, теперь виновна в трех ошибках безопасности в области безопасности или виртуальной безопасности в Льюисе Хэмилтоне в этом сезоне, не сумев нанести удар по новым шинам в Австралии, Китае и Австрии эти расы были нейтрализованы.
TheShestov
04.07.2018 12:07а у меня на translate.yandex.ru уже отличающийся вариант:
Стратегия промаха на Гран-При Австрии оставила своего звездного водителя дымящимся, прежде чем оба автомобиля Mercedes DNF впервые с Испании 2016 года. Но это анализ и изучение, а не взаимные обвинения, что команде теперь нужно все исправить, говорит директор команды Mercedes Тото Вольфф.
Mercedes, команда, которая победила в гибридной эре Формулы-1 После 2014 года, теперь виновна в трех ошибках безопасности Льюиса Хэмилтона или виртуальной безопасности в этом сезоне, не сумев столкнуть его за новые шины в Австралии, Китае и теперь Австрии, пока эти гонки нейтрализуются
viktprog
03.07.2018 12:05+1«в Австралии, Китае и Австрии эти расы были нейтрализованы.» — Google Translate
tundrawolf_kiba
03.07.2018 13:40+1«в Австралии, Китае и Австрии эти расы были нейтрализованы.» — Google Translate
Прямо какой-то XCOM или SCP.
MaximChistov
03.07.2018 13:52Может подскажете, почему ваш переводчик совсем не может переводить сайты с эстонского на английский?
www.postimees.ee как примерkukutz
03.07.2018 14:04Я только что попробовал в Яндекс.Браузере, переводит.
MaximChistov
03.07.2018 14:19А у меня не переводит:
kukutz
03.07.2018 17:18Пока не получилось. Можете рассказать подробности? Какая в точности у вас версия браузера? Какая версия и локаль ОС?
MaximChistov
04.07.2018 10:46Зарепортил issue только что через ваш инструмент в браузере для этого, этого хватит? Могу еще в лс указанный там имейл скинуть
amarao
03.07.2018 18:15Заголовки сложны даже для человека.
Feds charge Man after FCC boss Ajit Pai's kids get death threat over net neutrality axe vote
DNS ad-hocracy in peril as ICANN advisors mull root server shakeup (глагол? Какой такой глагол?)
Software delays, lack of purpose means Microsoft’s “Andromeda” may never arrive
'Coding' cockup blamed for NHS cough-up of confidential info against patients' wishes
Mikel John Obi told father had been kidnapped hours before World Cup match
(последнее я даже сам не смог перевести пока не прочитал тизер — (Mikel John Obi was told that his father had been kidnapped and would be killed if he reported anything – just hours before he led Nigeria into their final World Cup group phase tie against Argentina.)
sshikov
03.07.2018 20:03Operations available on Datasets are divided into transformations and actions. Transformations are the ones that produce new Datasets, and actions are the ones that trigger computation and return results. Example transformations include map, filter, select, and aggregate (groupBy). Example actions count, show, or writing data out to file systems.
Доступные наборы данных подразделяются на преобразования и действия. Преобразования-это преобразования, которые создают новые наборы данных, а действия-те, которые запускают вычисления и возвращают результаты. К примерам преобразований относятся map, filter, select и aggregate (groupBy). Примеры действий count, show или запись данных в файловые системы.
Operations available on Datasets -> Доступные наборы данных — серьезно?
На сугубо техническом тексте все еще уныло. Термины и аббревиатуры полностью сносят ему башку.QtRoS
03.07.2018 23:24Для сравнения Google Translate
Операции, доступные в наборах данных, делятся на преобразования и действия. Преобразования — это те, которые создают новые наборы данных, а действия — это те, которые вызывают результаты расчета и возврата. Примеры преобразований включают в себя карту, фильтр, выбор и агрегат (groupBy). Примеры действий подсчитывают, показывают или записывают данные в файловые системы.
sshikov
04.07.2018 19:23Хм. Знаете, местами тут лучше, но проблема с терминами налицо — никто не просил переводить названия методов :(
Frankenstine
04.07.2018 12:16Заголовок часто содержит суть новости, поэтому важно перевести его правильно
Как показывает практика, 99% заголовков не соответствует статьям, даже если их не то что переводили, а и просто сочиняли живые люди-журнализды :)
mike1
04.07.2018 12:50Спасибо за статью! А была ли на хабре статья про сам переход Яндекс.Переводчика на нейросети? Правда ли, что используется RNN? Некоторые источники, например vc.ru/32616-mashinnyy-perevod-ot-holodnoy-voyny-do-glubokogo-obucheniya, об этом пишут.
maedv
Очень хорошее качество перевода, иногда даже лучше переводных хабра-статей, спасибо Яндексу
exehoo
Пожалуй, это самое толковое нововведение Яндекса за последние годы.
achekalin
Вот еще кто-то скрестит новый Я-Переводчик и все те источники, откуда «редакторы» Хабра свою нетлетку тянут — и получим сайт, где то же будет появляться, но на три дня раньше, чем на Хабре. Ой!
kryvichh
Чтобы самим не копаться в горах нетленок, я доверяю редакторам Хабра в их выборе самых интересных и свежих статей.
achekalin
Так иногда у них такое выходит из-под пера, что… Ну, нетленку-то пишут первоисточники, а что редакторы создают — это не нетленку-то, а мумифицированные останки!