В прошлой статье я описал использование когортного анализа для выяснения причин динамики клиентской базы. Сегодня пришло время поговорить про трюки подготовки данных для когортного анализа.
Легко рисовать картинки, но для того, чтобы они считались и отображались правильно “под капотом” нужно проделать немало работы. В этой статье мы поговорим о том, как реализовать когортный анализ. Я расскажу про реализацию при помощи Excel, а в другой статье при помощи R.
Хотим мы этого или нет, но по факту Excel это инструмент анализа данных. Более “высокомерные” аналитики будут считать, что это слабый и не удобный инструмент. С другой стороны по факту сотни тысяч людей делают анализ данных в Excel и в этом отношении он легко побьет R / python. Конечно, когда мы говорим о advances analytics и машинном обучении, мы будем работать на R / python. И я был бы за то, чтобы большая часть аналитики делалась именно этими инструментами. Но стоит признать факты, в Excel обрабатывают и представляют данные подавляющее большинство компаний и именно этим инструментом пользуются обычные аналитики, менеджеры и product owners. Вдобавок Excel трудно победить в части простоты и наглядности процесса, т.к. вы мастерите свои расчеты и модельки буквально руками.
И так, как же нам сделать когортный анализ в Excel? Для того, чтобы решать подобные задачи нужно определить 2 вещи:
Какие данные у нас в начале процесса
Как должны выглядеть наши данные в конце процесса.
Чтобы собрать когортный анализ нам не будет достаточно только оборотный данных по датам и подразделениям. Нам нужны данные на уровне отдельных клиентов. В начале процесса нам понадобится:
Календарная дата
Id клиента
Дата регистрации клиента
Объем продаж этого клиента в эту календарную дату
Первая сложность, которую предстоит преодолеть — это получить эти данные. Если у вас правильное хранилище, то они уже должны быть у вас. С другой стороны, если пока реализовали только запись данных о совокупных продажах по дням, то данные по клиентам у вас есть только на “проде”. Для когортного анализа вам придется реализовать ETL и сложить в ваше хранилище данные в разрезе клиентов, иначе у вас ничего не выйдет. И лучше всего если вы разделите “прод” и аналитику в разные базы, т.к. У аналитических задач и задач функционирования вашего продукта разные цели конкуренция за ресурсы. Аналитикам нужны быстрые агрегаты и расчеты на по многим пользователям, продукту нужно быстро обслужить конкретного пользователя. Об организации хранилища я напишу отдельную статью.
Итак, вы имеете стартовые данные:

Первое, что нам нужно сделать это преобразовать их в “лесенки”. Для этого нужно над этой таблицей построить сводную таблицу, по строкам — дата регистрации, по столбцам — календарная дата, в качестве значений — кол-во id клиентов. Если вы верно извлекли данные, то у вас должен получится вот такой треугольник/лесенка:
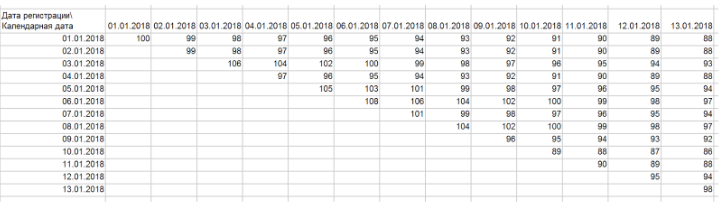
В целом лесенка это наш когортный график, в котором каждая строка отображает динамику отдельной когорты. Клиенты во времени в этой отображении двигаются только внутри одной строки. Таким образом динамика когорты отображает развитие отношений с группой клиентов пришедший в один период времени. Часто для удобства и без потери качества, можно объединить когорты в “блоки” строк. Например, вы можете сгруппировать их по неделям и месяцам. Точно так же вы можете сгруппировать и колонку, т.к. Возможно ваш темп развития продукта не требует детализации до дней.
На основе этой лесенки вы можете влоб построить график из моей статьи (я правда указывал, что сгруппировал несколько строк в одну, чтобы когорт было поменьше):
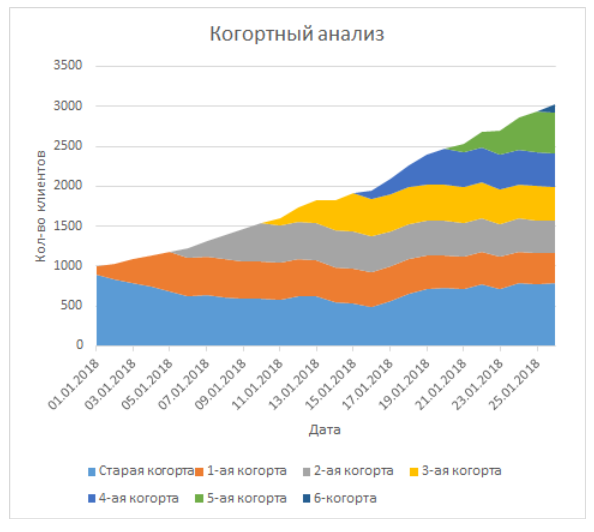
Это график с накопительными областями, где каждый ряд — это строка, по горизонтали даты.
Чуть сложнее логика для реализации графика “потоков”. Для потоков мы должны сделать некоторые дополнительные вычисления. В логике потоков каждый клиент прибывает в различных состояниях:
- Новый — любой клиент, у кого разница между датой регистрации и календарной дате <7 дней
- Реактивированный — любой клиент, кто уже не новый, но в прошлом календарном месяце не генерировал выручку
- Действующий — любой клиент, кто не новый, но в в календарном месяце генерировал выручку
- Ушедший — любой клиент, кто не генерирует выручку 2 месяца подряд
Во-первых вам стоит в компании закрепить эти определения, чтобы вы могли корректно реализовать эту логику и автоматически рассчитывать состояния. Эти 4 определения имеют далеко идущие последствия в целом и для маркетинга. Ваши стратегии по привлечению, удержанию и возвращению будут базироваться на том, в каком состоянии вы считаете находится клиент. А если вы начнете внедрять модели машинного обучения в прогнозировании ухода клиентов, то определения станут вашим краеугольным камнем успешности этих моделей. Вообще про организацию работы и важность аналитической методологии я напишу отдельную статью. Выше я привел просто пример того, какими могут быть эти определения.
В Excel вам нужно создать дополнительную колонку, куда вписать описанную выше логику. В нашей случае нам придется “попотеть”. У нас есть 2 типа критериев:
- Разница между датой регистрацией и календарной датой — эти данные есть у каждой строки и тут просто нужно ее посчитать (вычитание дат в Excel просто дает разницу в днях)
- Данные о выручке в текущем и прошлом месяце. Эти данные нам не доступны в строке. Более того, с учетом того, что в нашей таблице не гарантирован порядок, то вы не можете точно сказать, где у вас данные по другим дням месяца для этого клиента.
Решить проблему 2 типа критериев можно 2 способами:
- Попросите сделать это в базе данных. SQL позволяет при помощи аналитической функции вычислить для каждого клиента сумму выручки за текущий и прошлый месяц (для текущего месяца SUM(revenue) OVER (PARTITION BY client_id, calendar_month, а потом LAG, чтобы получить смещение по прошлому месяцу):
- В экселе вам придется реализовать это так:
- Для текущего месяца: СУММЕСЛИ(), критериями будет id клиента и месяц ячейки календарного дня
- Для прошлого месяца: СУММЕСЛИ(), критериями будет id клиента и месяц ячейки календарного дня минус ровно 1 календарный месяц. При этом обращу внимание, что вы должны вычесть именно календарный месяц, а не 30 дней. Иначе вы рискуете получить смазанную картину из-за неодинакового числа дней в месяцах. Также используйте функцию ЕСЛИОШИБКА, чтобы заменить ошибочные значения для клиентов у кого не было прошлого месяца.
Добавив колонки выручки текущего месяца, прошлого месяца вы можете построить вложенное условие ЕСЛИ, учитывающие все факторы (разницу дат и суммы выручки в текущем/прошлом месяце):
ЕСЛИ( разница дат <7; “новый”;
ЕСЛИ( И (выручка прошлого месяца = 0; выручка текущего месяца > 0); “реактивация”;
ЕСЛИ( И (выручка прошлого месяца > 0; выручка текущего месяца > 0); “действующий”
ЕСЛИ( И (выручка прошлого месяца = 0; выручка текущего месяца = 0); “ушедший”; “ошибка”))))
“Ошибка” нужна тут только для контроля, что вы не ошиблись в записи. Логика критериев состояний MECE (https://en.wikipedia.org/wiki/MECE_principle), т.е. Если все сделано правильно, то каждому будет проставлено одно состояние из 4-х
У вас должно получится вот так:

Теперь эту таблицу можно пересобрать при помощи сводной таблицы в таблицу для построения графика. Вам нужно трансформировать ее в таблицу:
Календарная дата (колонки)
Состояние (строки)
Кол-во id клиентов (значения в ячейках)
Далее мы просто должны на основе данных построить диаграмму столбчатую диаграмма с накоплениями, по оси Х календарная дата, ряды это состояния, кол-во клиентов это высота столбцов. Вы можете поменять порядок состояний на графике, изменив порядок рядов в меню “выбрать данные”. В итоге мы получим такую картину:
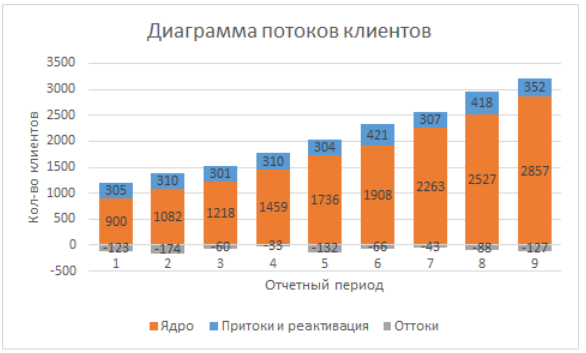
Теперь мы можем приступать к интерпретации и анализу.