
Сегодня одним из главных препятствий на пути внедрения машинного обучения в бизнес является несовместимость метрик ML и показателей, которыми оперирует топ-менеджмент. Аналитик прогнозирует увеличение прибыли? Но ведь нужно понять, в каких случаях причиной увеличения станет именно машинное обучение, а в каких — прочие факторы. Увы, но довольно часто улучшение метрик ML не приводит к росту прибыли. К тому же иногда сложность данных такова, что даже опытные разработчики могут выбрать некорректные метрики, на которые нельзя ориентироваться.
Давайте рассмотрим, какие бывают метрики ML и когда их целесообразно использовать. Разберём типичные ошибки, а также расскажем о том, какие варианты постановки задачи могут подойти для машинного обучения и бизнеса.
ML-метрики: зачем их так много?
Метрики машинного обучения весьма специфичны и часто вводят в заблуждение, показывая
Какие задачи чаще всего решаются с помощью машинного обучения? В первую очередь это регрессия, классификация и кластеризация. Первые две — так называемое обучение с учителем: есть набор размеченных данных, на основе какого-то опыта нужно предсказать заданное значение. Регрессия — это предсказание какого-то значения: например, на какую сумму купит клиент, какова износостойкость материала, сколько километров проедет автомобиль до первой поломки.
Кластеризация — это определение структуры данных с помощью выделения кластеров (например, категорий клиентов), причём у нас нет предположений об этих кластерах. Этот тип задач мы рассматривать не будем.
Алгоритмы машинного обучения оптимизируют (вычисляя функцию потерь) математическую метрику — разность между предсказанием модели и истинным значением. Но если метрика представляет собой сумму отклонений, то при одинаковом количестве отклонений в обе стороны эта сумма будет равна нулю, и мы просто не узнаем о наличии ошибки. Поэтому обычно используют среднюю абсолютную (сумма абсолютных значений отклонений) или среднюю квадратичную ошибку (сумма квадратов отклонений от истинного значения). Иногда формулу усложняют: берут логарифм или извлекают квадратный корень из этих сумм. Благодаря этим метрикам можно оценить динамику качества вычислений модели, но для этого полученный результат нужно с чем-то сравнить.
C этим не возникнет сложностей, если уже есть построенная модель, с которой можно сравнить полученные результаты. А что если вы в первый раз создали модель? В этом случае часто используют коэффициент детерминации, или R2. Коэффициент детерминации выражается как:
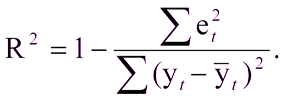
Где:
R^2 — коэффициент детерминации,
et^2 — средняя квадратичная ошибка,
yt — верное значение,
yt с крышкой — среднее значение.
Единица минус отношение средней квадратичной ошибки модели к средней квадратичной ошибке среднего значения тестовой выборки.
То есть коэффициент детерминации позволяет оценить улучшение предсказания моделью.
Иногда бывает, что ошибка в одну сторону неравнозначна ошибке в другую. Например, если модель предсказывает заказ товара на склад магазина, то вполне можно ошибиться и заказать чуть больше, товар дождётся своего часа на складе. А если модель ошибётся в другую сторону и закажет меньше, то можно и потерять покупателей. В подобных случаях используют квантильную ошибку: положительные и отрицательные отклонения от истинного значения учитываются с разными весами.
В задаче классификации модель машинного обучения распределяет объекты по двум классам: уйдет пользователь с сайта или не уйдет, будет деталь бракованной или нет, и т.д. Точность предсказания часто оценивают как отношение количества верно определенных классов к общему количеству предсказаний. Однако эту характеристику редко можно считать адекватным параметром.

Рис. 1. Матрица ошибок для задачи предсказания возвращения клиента
Пример: если из 100 застрахованных за возмещением обращаются 7 человек, то модель, предсказывающая отсутствие страхового случая, будет иметь точность 93%, не имея никакой предсказательной силы.
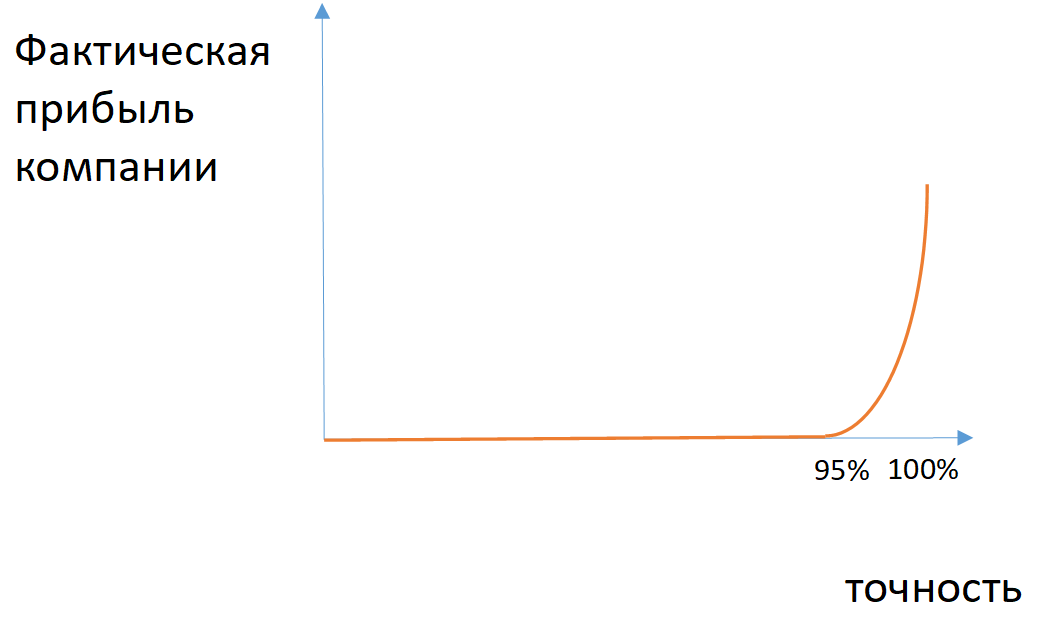
Рис. 2. Пример зависимости фактической прибыли компании от точности модели в случае разбалансированных классов
Для каких-то задач можно применить метрики полноты (количество правильно определенных объектов класса среди всех объектов этого класса) и точности (количество правильных определенных объектов класса среди всех объектов, которые модель отнесла к этому классу). Если необходимо учитывать одновременно полноту и точность, то применяют среднее гармоническое между этими величинами (F1-мера).
С помощью этих метрик можно оценить выполненное разбиение по классам. При этом многие модели предсказывают вероятность отношения модели к определенному классу. С этой точки зрения можно изменять порог вероятности, относительно которого элементы будут присваиваться к одному или другому классу (например, если клиент уйдёт с вероятностью 60 %, то его можно считать остающимися). Если конкретный порог не задан, то для оценки эффективности модели можно построить график зависимости метрик от разных пороговых значений (ROC-кривая или PR-кривая), взяв в качестве метрики площадь под выбранной кривой.
Рис. 3. PR-кривая
Бизнес-метрики
Выражаясь аллегорически, бизнес-метрики — это слоны: их невозможно не заметить, и в одном таком «слоне» может уместиться большое количество «попугаев» машинного обучения. Ответ на вопрос, какие метрики ML позволят увеличить прибыль, зависит от улучшения. По сути, бизнес-метрики так или иначе привязаны к увеличению прибыли, однако нам почти никогда не удаётся напрямую связать с ними прибыль. Обычно применяются промежуточные метрики, например:
- длительность нахождения товара на складе и количество запросов товара, когда его нет в наличии;
- количество денег у клиентов, которые собираются уйти;
- количество материала, которое экономится в процессе производства.
Когда речь идёт об оптимизации бизнеса с помощью машинного обучения, всегда подразумевается создание двух моделей: предсказательной и оптимизационной.
Первая сложнее, её результаты использует вторая. Ошибки в модели предсказания вынуждают закладывать больший запас в модели оптимизации, поэтому оптимизируемая сумма уменьшается.
Пример: чем ниже точность предсказания поведения клиентов или вероятности промышленного брака, тем меньше клиентов удаётся удержать и тем меньше объём сэкономленных материалов.
Общепринятые метрики успешности бизнеса (EBITDA и др.) редко получается использовать при постановках задач ML. Обычно приходится глубоко изучать специфику и применять метрики, принятые в той сфере, в который мы внедряем машинное обучение (средний чек, посещаемость и т.д.).
Трудности перевода
По иронии судьбы удобнее всего оптимизировать модели с помощью метрик, которые трудно понять представителям бизнеса. Как площадь под ROC-кривой в модели определения тональности комментария соотносится с конкретным размером выручки? С этой точки зрения перед бизнесом встают две задачи: как измерить и как максимизировать эффект от внедрения машинного обучения?
Первая задача проще в решении, если у вас есть ретроспективные данные и при этом остальные факторы можно нивелировать или измерить. Тогда ничто не мешает сравнить полученные значения с аналогичными ретроспективными данными. Но есть одна сложность: выборка должна быть репрезентативна и при этом максимально похожа на ту, с помощью которой мы апробируем модель.
Пример: нужно найти самых похожих клиентов, чтобы выяснить, увеличился ли у них средний чек. Но при этом выборка клиентов должна быть достаточно большой, чтобы избежать всплесков из-за нестандартного поведения. Эту задачу можно решить с помощью предварительного создания достаточно большой выборки похожих клиентов и на ней проверять результат своих усилий.
Однако вы спросите: как перевести выбранную метрику в функцию потерь (минимизацией которой и занимается модель) для машинного обучения. С наскока эту задачу не решить: разработчикам модели придётся глубоко вникнуть в бизнес-процессы. Но если при обучении модели использовать метрику, которая зависит от бизнеса, качество моделей сразу вырастает. Скажем, если модель предсказывает, какие клиенты уйдут, то в роли бизнес-метрики можно использовать график, где по одной оси отложено количество уходящих, по мнению модели, клиентов, а по другой оси — общий объём средств у этих клиентов. С помощью такого графика бизнес-заказчик может выбрать удобную для себя точку и работать с ней. Если с помощью линейных преобразований свести график к PR-кривой (по одной оси точность, по второй полнота), то можно оптимизировать площадь под этой кривой одновременно с бизнес-метрикой.

Рис. 4. Кривая денежного эффекта
Заключение
Прежде чем ставить задачу для машинного обучения и создавать модель, нужно выбрать разумную метрику. Если вы собираетесь оптимизировать модель, то в качестве функции ошибок можно использовать одну из стандартных метрик. Обязательно согласуйте с заказчиком выбранную метрику, её веса и прочие параметры, преобразовав бизнес-метрики в модели ML. По длительности это может быть сравнимо с разработкой самой модели, но без этого не имеет смысла приступать к работе. Если привлечь математиков к изучению бизнес-процессов, то можно сильно уменьшить вероятность ошибок в метриках. Эффективная оптимизация модели невозможна без понимания предметной области и совместной постановки задачи на уровне бизнеса и статистики. И уже после проведения всех расчётов вы сможете оценить полученную прибыль (или экономию) в зависимости от каждого улучшения модели.
Николай Князев, руководитель группы машинного обучения «Инфосистемы Джет»
Комментарии (16)

DDudko
15.08.2018 15:38Пример: если из 100 застрахованных за возмещением обращаются 7 человек, то модель, предсказывающая отсутствие страхового случая, будет иметь точность 93%, не имея никакой предсказательной силы.
Это как? Как статистические 93% (7 обращений на 100 случаев) превратились в точность предсказывающей модели? Что это за модель?
И про отсутствие предсказательной силы, хорошо бы раскрыть. Если метеорит упадет с вероятностью 0,01%, то с точность в 99,9% он не упадет прямо сейчас. Или у вас какое-то другое определение предсказательности?JetHabr Автор
15.08.2018 16:11Точность (Accuracy) определяется как отношение верных ответов модели к общему числу ответов модели.
Есть модель, которая просто для всех людей предсказывает, что они не обратятся за страховым случаем (константая модель). Эта модель для 100 человек предсказала, что они не обратятся. Она была верной в 93 случаях – 93 человека и правда не обратились, таким образом, точность составила 93/100 = 93%.
В примере с метеоритом в постановке задачи не раскрываете период, за который считается вероятность, поэтому непонятно, откуда появляется прямо сейчас.JetHabr Автор
16.08.2018 16:18Вот у нас есть мультиклассификатор, черный такой ящик. Мы не знаем, что в нем — то ли OVR, то ли OVO, то ли дерево решений, то ли сетка. На входе — данные, на выходе — классификация. Так как же его внутренность влияет на метрики? (ну кроме возможности-невозможности смотреть на вероятности и их кривые
Вопрос в том, что вы подаете на обучение. Пример: есть три класса 1, 2 и 3, при этом класс 2 — это белый шум, куда по ошибке входят элементы и из 1го и 3го класса. В этом случае, строя классификатор 1 vs 3 (обучая только на элементах 1го и 3его класса), вы получаете условно «хорошие» значения метрик, а добавляя элементы класс 2 в классификатор, ухудшаете все метрики и классификатор выглядит плохим.
Тогда ваша взвешенная сумма ошибок — это (FN/(TP+FN))+(FP/(FP+TN)),
Не совсем — я имел ввиду, что просто количество ошибок это:
(FN+FP)/(TP+FN+FP+TN),
а взвешенное (w1*FN+w2*FP)/(TP+FN+FP+TN)
(ну, кроме OVR/OVO, но про это мы уже говорили)?
Кроме OVR и OVO, мы, например, можем обобщить и рассматривать один подмножества классов против других подмножеств классов в структуре. Например, сначала определить 1+2 vs 3+4 и или 1 vs 3+4 и 2 vs 3+4, — тут вопрос, какие классификаторы будут иметь большую точность и какими имеет смысл пользоваться. Если рассматривать крайнюю дилемму, то OVO – мало шума, но и мало данных для обучения (не используются другие сэмплы), OVR – много данных, но и может быть много шума, поэтому имеет смысл часто поподбирать именно какие подмножества классов против каких хорошо различаются.lair
16.08.2018 22:00Вопрос в том, что вы подаете на обучение.
Так и это не зависит от того, что там внутри.
Пример: есть три класса 1, 2 и 3, при этом класс 2 — это белый шум, куда по ошибке входят элементы и из 1го и 3го класса.
Эээ, а зачем нам такой второй класс? Давайте говорить о нормальных примерах, где все классы имеют смысл.
Не совсем — я имел ввиду, что просто количество ошибок это:
"Начинай сначала". Вот вы говорили, что для мультикласса можно взять "взвешенную сумму ошибочных предсказаний". Как, бишь, вы ее считаете?
Кроме OVR и OVO, мы, например, можем обобщить и рассматривать один подмножества классов против других подмножеств классов в структуре.
Получили решающее дерево. И? Как это на метрики-то повлияло?
JetHabr Автор
17.08.2018 11:32Эээ, а зачем нам такой второй класс? Давайте говорить о нормальных примерах, где все классы имеют смысл.
К сожалению, не все классы всегда хорошо разделимы, и встречаются классы, которые больше и хуже разделимы. И добавление более плохого класса ухудшает качество описанным способом. Крайний пример с шумом был приведен, чтобы продемонстрировать мысль, но вы перед началом задачи не знаете какой класс шумный, а какой нет, и это еще надо выяснять, например, описанным способом.
Получили решающее дерево. И? Как это на метрики-то повлияло?
Это влияет на постановку задачи: что от чего различается и это, естественно, определяет метрики. Непонятно, какого влияния вы ожидаете.lair
17.08.2018 11:35И добавление более плохого класса ухудшает качество описанным способом.
"Качество" — это не метрика. Какую метрику ухудшает "добавление плохого класса"?
Это влияет на постановку задачи: что от чего различается и это, естественно, определяет метрики.
Еще раз говорю: задача поставлена в виде "у нас есть четыре класса, нам надо различать в них". Мы же про метрики, понятные для бизнеса, да?
DDudko
17.08.2018 13:23До точности, еще дойдем.
Вы написали пример:
Пример: если из 100 застрахованных за возмещением обращаются 7 человек, то модель, предсказывающая отсутствие страхового случая, будет иметь точность 93%, не имея никакой предсказательной силы.
Про точность тут ничего не сказано (вернее она 100%, т.к. говорим о свершившемся факте). Значит либо посылки не верные, либо выводы.
Есть модель, которая просто для всех людей предсказывает, что они не обратятся за страховым случаем (константая модель). Эта модель для 100 человек предсказала, что они не обратятся. Она была верной в 93 случаях – 93 человека и правда не обратились, таким образом, точность составила 93/100 = 93%.
Вы повторили мои слова, в вашем примере ничего этого нет.
Николай, для человека, который использует статистические методы, вы крайне небрежны в формулировах
almaredan
15.08.2018 16:12Имеется в виду модель, которая всегда возвращает отсутствие страхового случая. Автор немного плохо сформулировал.
Про метеорит (да и про страховку) правильнее говорить не упадет (не обратиться за возмещением) в течении некоторого срока (да-да, прям как у Яндекса с дождями в погоде)DDudko
17.08.2018 13:33Автор не «немного плохо сформулировал», а никак не сформулировал. Не понятно на кого рассчитана статья. Ввел r2, дал определение из учебника, но никаких выводов и следствий не привел. Просто:
То есть коэффициент детерминации позволяет оценить улучшение предсказания моделью.
И как позвольте спросить? Или это статья для людей разбирающихся, тогда зачем формулу давал? Кстати, классическая формула проще.
А зачем, позвольте спросить, нужна модель, которая «всегда возвращает отсутствие». Зачем нам такая модель, которая всегда дает один ответ?lair
17.08.2018 18:06А зачем, позвольте спросить, нужна модель, которая «всегда возвращает отсутствие». Зачем нам такая модель, которая всегда дает один ответ?
Для сравнения метрик. Это, на самом деле, удобно, в начале разработки какого-нибудь алгоритма иметь рядом результаты "наивных" предикторов (константного и рандомного). Если "наш" алгоритм показывает (релевантные) метрики хуже, чем наивные алгоритмы — он бесполезен.
DDudko
17.08.2018 13:37Пример: нужно найти самых похожих клиентов, чтобы выяснить, увеличился ли у них средний чек. Но при этом выборка клиентов должна быть достаточно большой, чтобы избежать всплесков из-за нестандартного поведения. Эту задачу можно решить с помощью предварительного создания достаточно большой выборки похожих клиентов и на ней проверять результат своих усилий.
А также учитывать множество внешних факторов, которые не будут учтены. Например, спящий перед входом бездомный.
Но если при обучении модели использовать метрику, которая зависит от бизнеса, качество моделей сразу вырастает.
Какую метрику? Метрика зависящая от бизнеса… т.е. бизнес это переменная, а метрика функция от нее зависящая? Как интересно
lair
Precision-recall-f-score в их стандартном определении — это все хорошо и мило, когда у вас бинарная классификация. Но как посчитать их же, когда у вас мульти-класс? В частности, в наивном определении, внезапно, precision оказывается строго равным recall.
JetHabr Автор
Вопросы с мультиклассом — это отдельная интересная область. Ее можно решать и как One vs. All, и как взвешенную сумму ошибочных предсказаний, и как (если) эти классы можно упорядочить, и как регрессию и прочие подходы.
На практике наиболее интересным и жизнеспособным для бизнеса является выделение множеств классов, которые хорошо или плохо отличимы друг от друга. Например, если мы говорим о поведении пользователя на сайте, то можно отличать человека который больше никогда не придет на сайт, от человека который зайдет завтра, но вводя третий класс: люди которые зайдут через 3 дня, но не зайдут завтра, мы теряем точность, т.к. этот третий класс перемешивается с обоими по сходным признакам.
lair
Простите, а почему у вас в одном ряду стоит методология решения (OVR) и метрика оценки (кстати, что вы складываете в "сумме ошибочных предсказаний"?)?
И как это на метрики влияет? Предположим, в бизнес-задаче есть четыре класса, из них два друг от друга плохо отличимы — что дальше?
JetHabr Автор
Методология решения определит и метрики, которые можно демонстрировать. Сумма ошибочных предсказаний – это сумма sampl'ов в которых была допущена ошибка. Не очень понятен вопрос.
Это сводит нашу задачу мультиклассификации к задаче бинарной классификации, и дальше метрики уже можно выбрать исходя их этой задачи.
lair
Эм, это как? Вот у нас есть мультиклассификатор, черный такой ящик. Мы не знаем, что в нем — то ли OVR, то ли OVO, то ли дерево решений, то ли сетка. На входе — данные, на выходе — классификация. Так как же его внутренность влияет на метрики? (ну кроме возможности-невозможности смотреть на вероятности и их кривые)
Да так, люди разное считают за ошибки.
Давайте теперь сведем задачу бинарной классификации к двуклассовой задаче (правда, смешно звучит)? Тогда ваша взвешенная сумма ошибок — это (FN/(TP+FN))+(FP/(FP+TN)), оно же false negative rate + false positive rate, правильно? Или я где-то ошибся?
Повторюсь: в бизнес-задаче — четыре класса. Все их надо друг от друга отличать. Как вы сведете эту задачу к бинарной классификации (ну, кроме OVR/OVO, но про это мы уже говорили)?