В 2015 году мы начали создавать централизованный сервис мониторинга. Причем все ограничивалось не только внедрением. Нужно было проработать множество регламентов, инструкций, а также взаимоотношения между подразделениями Сбертеха в рамках мониторинга. В этом посте я подробно расскажу, как мы выбирали платформу, по каким принципам все создавали и что в итоге у нас получилось.

Основные цели и идеология проекта
Вот какие цели мы преследовали в проекте:
- Получение достоверных данных о размерах и составе IT-инфраструктуры;
- Оптимизация использования ИТ-мощностей;
- Снижение затрат на поддержку и эксплуатацию IT-инфраструктуры сред разработки и тестирования;
- Поддержка IT-инфраструктуры в готовности к разработке и проведению испытаний;
- Оперативное информирование специалистов о неполадках в работе тестовых сред;
- Аудит соответствия окружений тестовых сред и промышленных АСМ — не очень типичная для нас задача;
- Сбор данных для отчетов по результатам тестирования, обеспечение измерения критических параметров на всех этапах тестирования.
Забегая вперед, могу сказать, что все цели в той или иной степени уже выполнены к настоящему моменту. И некоторые сопутствующие проблемы мониторинг тоже помог решить.
Помимо целей, мы сформулировали принципы, идеологию, которой придерживались по ходу всего проекта:
- Удовлетворенность пользователя — один из главных показателей работы мониторинга. На конференции ITSMf 2017 я рассказывал о мониторинге ИТ-инфраструктуры, и пятое НЕ в том докладе звучит так: «НЕ заставляйте ваших сотрудников работать с системой мониторинга». Смысл в том, чтобы мотивировать, а не обязывать. Достигается это за счет правильно выстроенных KPI. В начале работы сервиса такие KPI могут еще не появиться. Тем не менее, очень важно с первых дней работы мониторинга начать приносить пользу потенциальным заказчикам.
- Минимум времени на доработки. Для этого мы используем элементы Agile. Они помогают максимально быстро предоставлять новые функции и получать от заказчиков обратную связь.
- Открытость системы как для доработок, которая выражается в создании единого бэклога, запросы в который может писать любой сотрудник, так и в плане предоставления информации — наш сервис позволяет получить информацию о конфигурации мониторинга, которая, как правило, скрыта.
- Высокая степень интеграции в повседневную работу. В приоритете у нас стоит реализация функциональности, необходимой пользователям на ежедневной основе. Это помогло в относительно короткие сроки популяризовать сервис мониторинга внутри компании.
Выбор системы мониторинга
Практически во всех проектах, где я участвовал, рано или поздно всплывала таблица со сравнением функциональности различных систем, в которой какой-то конкретной системе отдавалось очевидное преимущество.
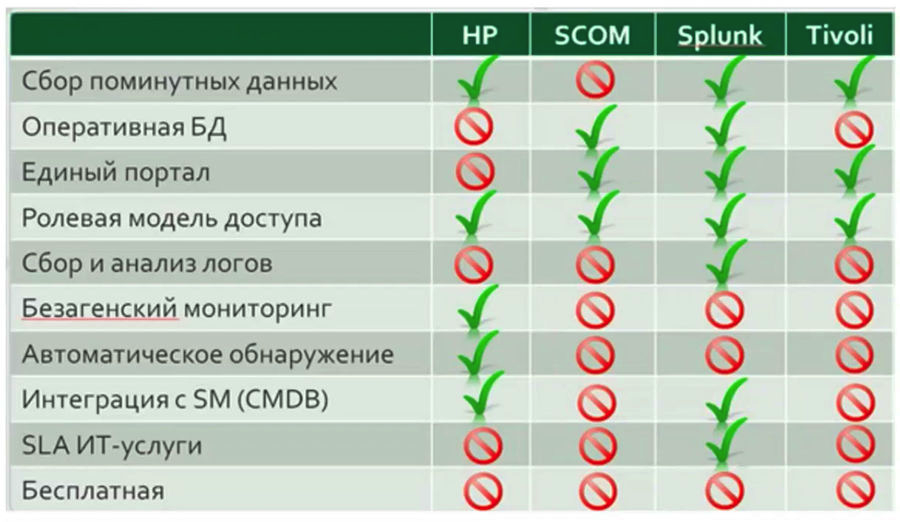
На мой взгляд, до непосредственного начала работы с сервисом мониторинга такой сравнительный анализ делать нельзя, и уж тем более не стоит принимать решение о выборе того или иного решения, исходя из этого анализа. До тех пор, пока система в вашей компании не проработает хотя бы на протяжении небольшого промежутка времени, нельзя однозначно судить о том, какие конкретно функции именно в вашей компании будут востребованы. Такие таблицы могут отлично помочь, если вы по каким либо причинам хотите сменить систему мониторинга.
Сравнение с другими инсталляциями Zabbix
Можно много говорить о том, как сравнить размер нескольких инсталляций систем мониторинга, но все выбранные для этого характеристики, на мой взгляд, довольно субъективны. Чтобы у вас появилось более точное представление о размере нашей инсталляции, я решил привести примеры аналогичных сервисов в других компаниях, о которых представители Zabbix рассказывали на конфереции Highload.
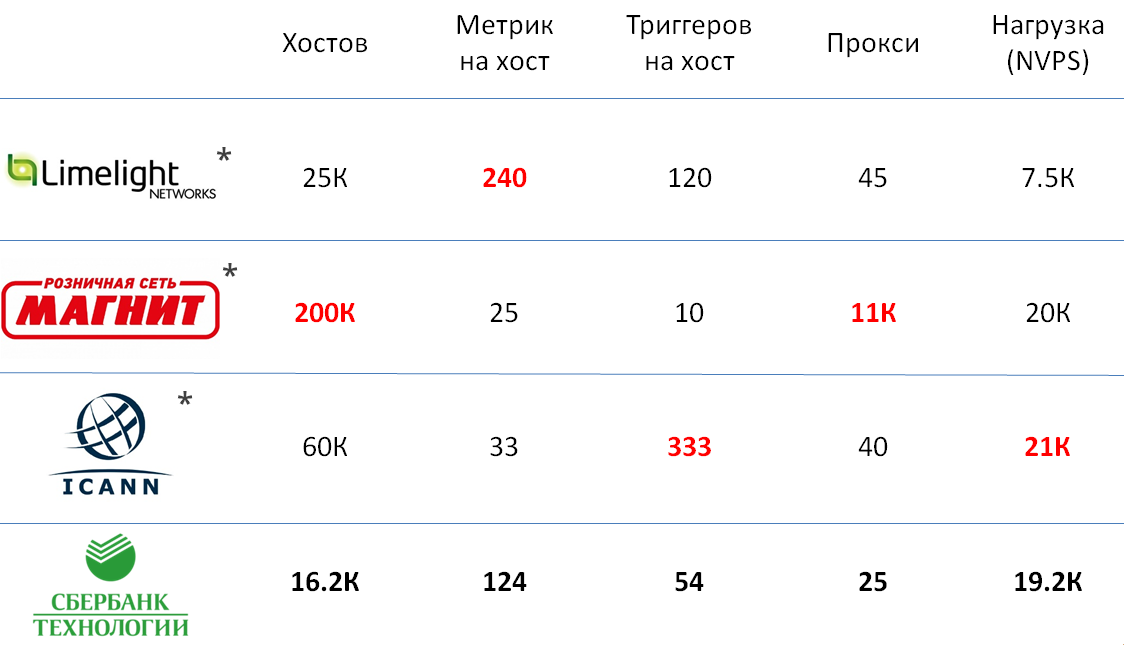
Как видите, инстанс Zabbix в Сбертехе не сильно уступает крупнейшим инсталляциям, а по суммарной нагрузке идет вровень с ними.
Преимущества Zabbix
Во второй половине 2017 года мы проводили пилот Zabbix для мониторинга ПРОМ-инфраструктуры. Тогда же мы сформулировали ряд качественных критериев, которые мы относим к безусловным преимуществам Zabbix:
- Open-source. Неограниченные возможности для обработки и кастомизации.
- Открытость механизма и источника сбора метрик. В коммерческих энтерпрайз-решениях многие метрики бывают непонятны — различные боттл-неки, утечки памяти, которые зачастую не может объяснить даже техническая поддержка вендора. У Zabbix такой проблемы нет — всегда можно четко сказать, как он собирает те или иные метрики. Таким образом, доверие к системе со стороны системных администраторов повышается.
- Относительная легкость масштабирования — прежде всего, за счет введения дополнительных прокси-серверов, на которые можно перенести часть нагрузки. В случае достижения предела производительности одного инстанса есть возможность поднять второй и объединить оба под одной системой визуализации (Grafana).
- Классный API — на мой взгляд, это одно из главных преимуществ Zabbix. Качественный, проработанный и понятный API открывает огромные возможности для интеграции со смежными системами, автоматизации и пр.
- Мониторинг динамических объектов — мелочь, а приятно. В Zabbix этот мониторинг прост и интуитивно понятен, позволяет очень быстро добиться хороших результатов. Динамические объекты — это любые объекты, которые появляются и исчезают на серверах в течение срока службы: файловые системы, сетевые интерфейсы, и другие. Поэтому возникает потребность в том, чтобы автоматизировать постановку и снятие этих объектов с мониторинга.
- Сравнительно малое количество компонентов. В коммерческих решениях каждый компонент — это отдельная подсистема с собственной базой, которую нужно отдельно устанавливать. А Zabbix — это единая система, в которой сосредоточены сразу все способы мониторинга: агентский, безагентский, сетевой и другие — всего 14 типов.
- Визуализация данных с Grafana. Интеграция с Grafana дает возможность строить графики и создавать действительно удобные дашборды.
- Наличие мониторинга доступности IT-услуг. В Zabbix есть встроенная подсистема, которая умеет подсчитывать доступность IT-услуг для дальнейшего использования в SLA.
- Гибкость создания метрик и их пороговых значений. Здесь Zabbix имеет широкие возможности для настройки сложных метрик мониторинга:
– прежде всего это создание вычисляемых метрик: на основе нескольких простых метрик вычисляется одна сложная.
– доступна предобработка значения метрик — это когда вы, например, загружаете в Zabbix какой-то большой массив данных, а потом, перед тем как положить в базу конкретную метрику, Zabbix анализирует массив и вытаскивает именно те данные, которые вы хотите сохранить в виде метрики.
– мастер-метрики. Существует возможность собрать массив данных по объекту за один опрос в одну большую метрику, а затем использовать ее как источник данных для других метрик. Это позволяет уменьшить количество запросов и синхронизировать сбор всех метрик по времени.
- Возможность внутреннего мониторинга. Zabbix, как open source продукт, имеет проблемы с производительностью. Однако продуманная система внутреннего мониторинга помогает достаточно быстро справляться с этими проблемами.
Недостатки Zabbix
Справедливости ради не могу не упомянуть об основных, на мой взгляд, недостатках Zabbix. Из них тоже можно составить приличный список:
- Низкая степень автоматизации работы с бэкендом. Оговорюсь, что у меня не было возможности поэкспериментировать со всеми вариантами СУБД. В качестве бэкенда Zabbix в нашей компании используется СУБД Oracle. Массовые операции могут занимать более часа — например, обновление или изменение метрик, которое привязано к большому количеству объектов (15 тысяч узлов сети).
- Отсутствие встроенных средств управления агентами мониторинга. В коммерческих продуктах такие средства имеются. В Zabbix этого пока нет. Нет даже обновления инструментария на агентов. Конечно, все можно сделать самостоятельно, но лучше бы получить эти возможности «из коробки».
- Пока что низкая проработка мониторинга доступности IT-услуг. Здорово, что мониторинг есть, но его нужно еще дорабатывать. Сейчас не предусмотрена возможность как-либо ограничить доступ пользователей к каким-либо отдельным частям сервисно-ресурсной модели (далее СРМ). Если дерево СРМ большое, веб-интерфейс начинает тормозить. И возможности для кастомизации вычисления доступности в данной подсистеме пока что низкие.
- Долгие обновления. Последнее обновление базы данных заняло у нас порядка восьми часов. В это время сервис мониторинга был недоступен. Как вариант, можно запросить скрипты в поддержке и провести апдейт отдельно.
- Скромная функциональность встроенной подсистемы визуализации. Grafana решает эту проблему, однако встроенная визуализация пока что оставляет желать лучшего.
- Встроенный мониторинг СУБД (ODBC). Дело в том, что такой мониторинг открывает у Zabbix отдельное подключение при каждом опросе метрики. И если база у вас большая (с большим количеством собираемых метрик), то пул соединений в ней может переполниться и база перестанет отвечать на запросы, в том числе для целевых систем. В Zabbix есть альтернативный инструмент мониторинга (например, DBforBIX), но настраивать его для большого количества объектов — занятие достаточно трудоемкое. Плюс для этого нужно писать отдельную автоматизацию.
- Недостаточная гибкость инвентаризации IT-инфраструктуры. С одной стороны, приятно что она есть. С другой — выглядит она как отдельная вкладка у любого объекта мониторинга, на которой расположен жестко заданный набор полей инвентаризации с жестко заданными именами. Чтобы что-то изменить, нужно уже лезть в исходный код фронтенда. Невозможно также изменить количество этих полей и размеры — есть риск что-то сломать в ходе ближайшего обновления.
- Отсутствие автоматизации построения карт сетей. Для сравнения можно привести HP OpenView Network Node Manager, который отлично умеет строить карты сетевой топологии в автоматическом режиме. В Zabbix все придется строить вручную. Возможно, по этой причине данная функциональность у нас практически не востребована.
- Недостаточная гибкость ролевой модели. В Zabbix предусмотрено всего четыре роли пользователя с жестко фиксированными возможностями. Кроме того, отсутствует возможность «из коробки» ограничить доступ пользователей к API Zabbix. То есть если пользователь имеет доступ к фронтенду, то он автоматически имеет доступ и к API. У нас это приводило к тому, что пользователи неумелыми запросами серьезно нагружали систему. Кроме того, нет возможности дать пользователю доступ, например, к чтению метрик без доступа, к редактированию настроек объекта мониторинга.
Архитектура системы
Теперь несколько слов о количественных показателях и архитектуре нашей системы.
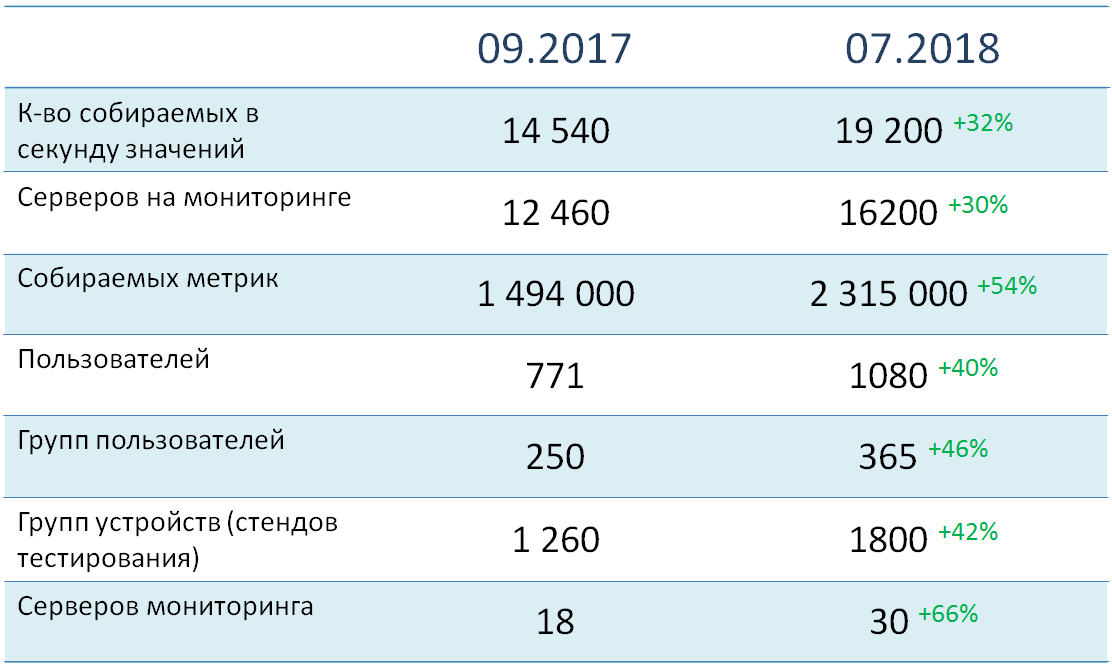
На мониторинге в данный момент находится больше 16 тысяч объектов (в основном, серверов), с которых суммарно собирается почти два с половиной миллиона метрик. Их суммарная нагрузка на систему — около 19 тысяч значений в секунду. Все объекты мониторинга распределены по более чем 1800 группам устройств, подавляющее большинство которых соответствует конкретным тестовым средам. На данный момент в системе зарегистрировано больше 1000 пользователей, которые разделены на 365 функциональных групп.
Как видите, мы уделяем довольно большое внимание распределению устройств и пользователей по группам. Это позволяет значительно увеличить точность оповещений от нашего сервиса.
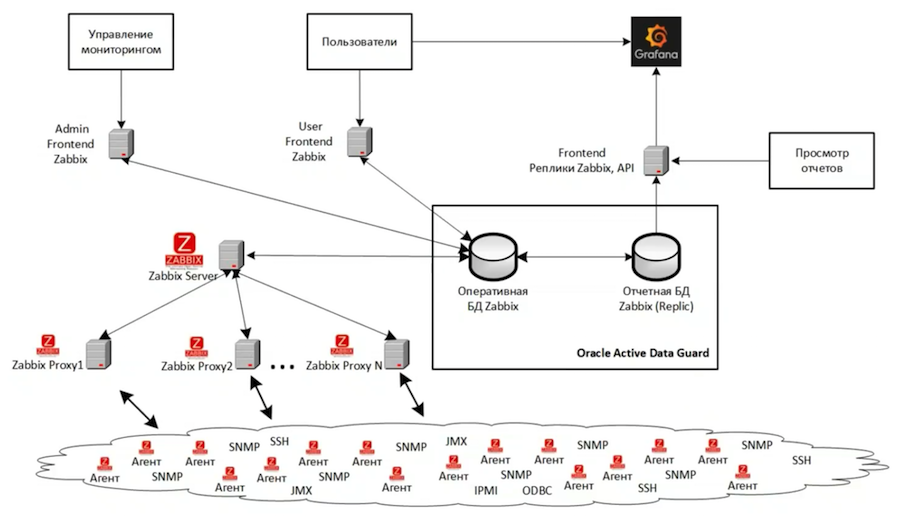
Всего у нас три инстанса Zabbix. На схеме представлена архитектура самого большого из них, который мониторит основную IT-инфраструктуру разработки и тестирования. Еще один инстанс наблюдает за инфраструктурой мониторинга. И третий инстанс у нас используется для целей разработки и тестирования новых инструментов мониторинга. Вся структура основного инстанса у нас виртуализирована на базе VMWare. Вообще, по возможности лучше не использовать никакую систему виртуализации, потому что искать и решать проблемы производительности в случае виртуальной инфраструктуры на порядок сложнее.
Бэкенд основан на Oracle Active Data Guard и состоит из двух баз — основной и реплики. Фронтенда у нас три:
- Для административных задач — он настроен для выполнения тяжелых, сложных и долговременных операций, которые сильно нагружают сервер;
- Пользовательский — с более жесткими настройками, не позволяющими пользователям слишком сильно перегружать основную систему мониторинга;
- Для отчетности — он смотрит на реплику и был адаптирован, чтобы взаимодействовать с read-only базами. К нему подключается Grafana, обеспечивающая качественную визуализацию данных мониторинга.
Особенности реализации
В этом рассказе я решил не заострять внимание на базовой функциональности, которая реализована практически в любом мониторинге — фиксация аварий, сбор информации о производительности или доступности ИТ-систем. Сосредоточусь на отличительных особенностях нашего сервиса.
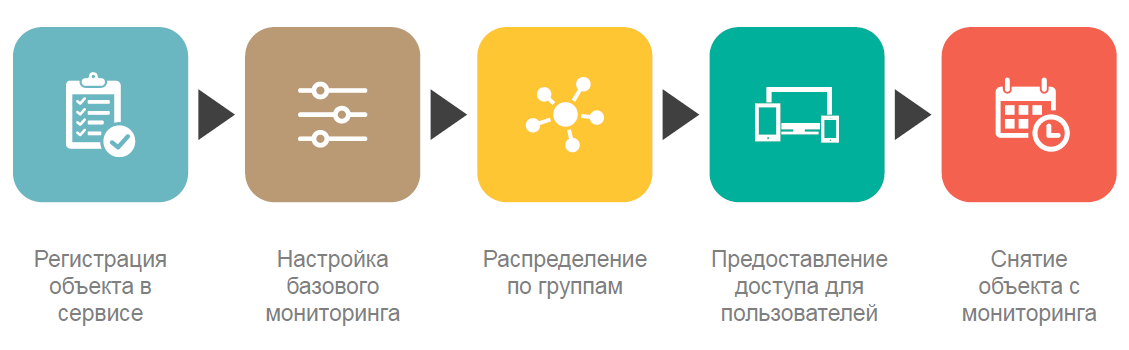
К таким особенностям в первую очередь относится высокая степень автоматизации типовых задач. Мы практически не тратим время на постановку серверов на мониторинг, предоставление доступа к результатам мониторинга, а сосредоточены, в основном, на развитии сервиса и добавлении в него новых нестандартных возможностей. В этом нам сильно помогает более 200 скриптов автоматизации, разработанных с момента ввода сервиса мониторинга в опытную эксплуатацию.
Но перед тем, как зарегистрировать агента в Zabbix, его еще нужно поставить. Как я писал выше, одним из недостатков Zabbix я вижу отсутствие инструментов управления агентами мониторинга. Поэтому для установки агентов у нас организован отдельный job в рамках наших DevOps процессов. На рисунке ниже приведена схема установки агента.
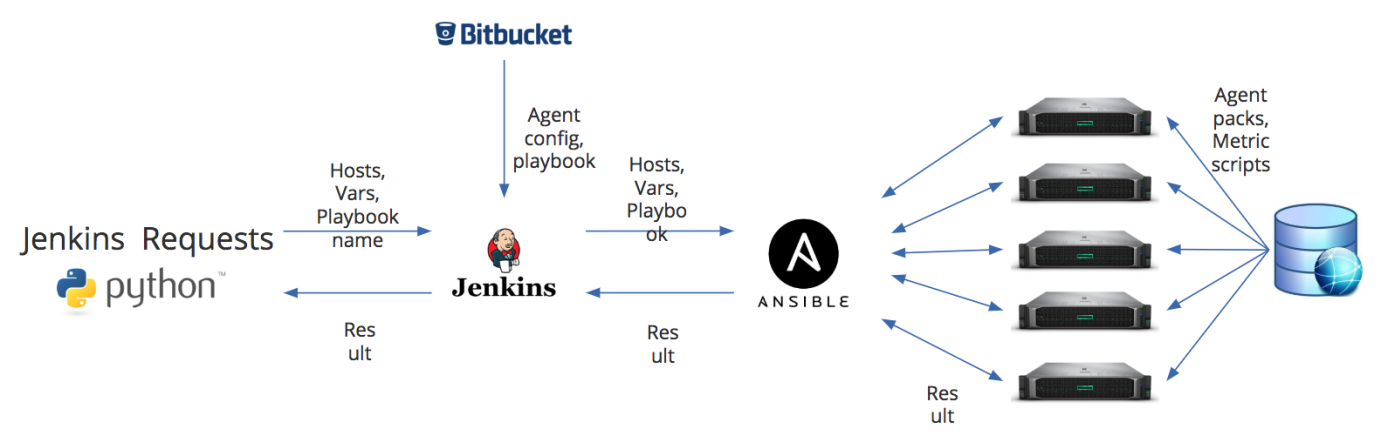
У нас есть две основные точки входа. Это либо скрипт на Python — он через REST API передает в job Jenkins информацию о хостах, на которые нужно установить или обновить агента, список дополнительных переменных, а также имя playbook, который нужно запускать на Ansible. Либо дефолтные данные могут идти из Bitbucket. Но в Jenkins они могут быть полностью заменены в соответствии с теми переменными, которые мы передали. И это нам помогает, например, обновлять агенты, которые мониторятся разными прокси-серверами. Особенность нашего процесса в том, что конфиг агента Zabbix формируется практически на лету.
Отчетность
Уже на старте работ по проекту стало ясно, что стандартные средства отчетности, предусмотренные инструментарием Zabbix, не позволят реализовать все наши потребности. В связи с этим на базе микросервисной архитектуры была реализована отдельная подсистема отчетности, которая существенно расширяет возможности базовых отчетов мониторинга. Сейчас у нас функционирует уже больше двадцати отчетов. Вот некоторые примеры вместе с реализуемыми целями:

Оповещения
На протяжении всей работы сервиса у нас эволюционировали почтовые оповещения. Вот как они выглядят на данный момент:
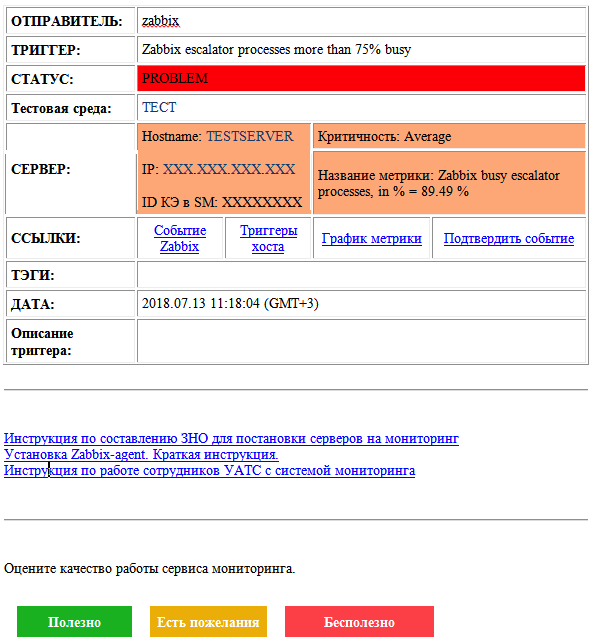
Здесь есть как информация о проблеме и ее статусе, так и об объекте мониторинга. Имеются ссылки на связанные метрики и события, поле для описания проблемы, ссылки на инструкции и форма обратной связи. По более критичным авариям у нас, разумеется, есть еще и рассылка в виде SMS.
Такие информативные оповещения позволили минимизировать общение большей части наших пользователей с самим Zabbix. Достаточно получения этой самой почтовой рассылки. Мы хорошо сгруппировали пользователей — на 1080 человек приходится 365 групп. Поэтому рассылка получается довольно-таки точечной — и, соответственно, не надоедливой. Многие наши пользователи практически забыли, что у нас есть, собственно, Zabbix — они пользуются рассылкой и системой визуализации Grafana.
Интеграция с процессами управления
Проект изначально предполагал интеграцию мониторинга с некоторыми нашими процессами управления IT-инфраструктурами. Если сервис мониторинга зафиксировал аварию, можно создать по ней тикет — для тех команд, которые больше работают с Jira. Для сервисных подразделений существует возможность создавать инциденты в HP Service Manager:

На базе Zabbix также была разработана и автоматизирована методика оптимизации утилизации IT-инфраструктуры. Оптимизируются три основных параметра: объем CPU, оперативной памяти и жестких дисков. Работает эта методика на базе скользящего среднего и 90-процентного перцентиля. На основании этой методики любой объект или сервер входит в одну из трех категорий: недозагруженный, загруженный оптимально, перегруженный.
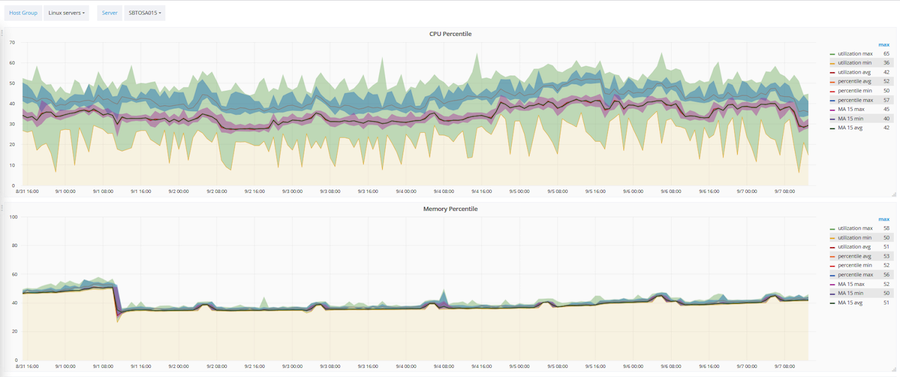
Выше показано, как эта методика применяется к конкретному серверу. Розовый коридор — значение скользящего среднего. Широкий зеленый коридор — сырые данные. А голубой — это 90-процентный перцентиль.
Интеграция с конфигурационной базой данных позволила автоматизировать большую часть задач, связанных с предоставлением доступа и построением сервисно-ресурсной модели. Благодаря этой интеграции был разработан набор отчетов для аудита соответствия реальной инфраструктуры тому, как она описывается в системах учета. То есть мы можем сравнить, как инфраструктура числится у нас в системах учета, с тем, какой она является на самом деле.
Сервис мониторинга на базе Zabbix выступает у нас также в качестве средства автоматизации и поставщика данных для управления доступностью. В нем отслеживается доступность средств тестирования, а также возможность учета технологических окон.
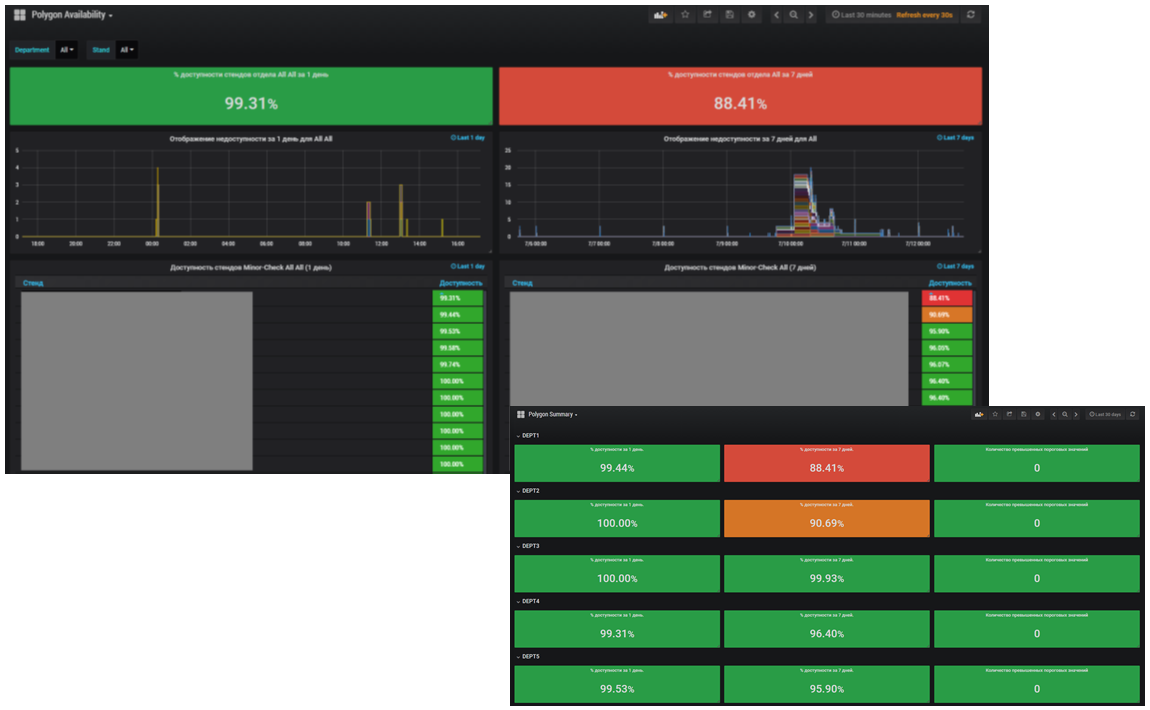
На базе этой функциональности мы недавно закончили разработку подсистемы, которая отслеживает доступность полигонов тестирования. Мониторинг ведется как в разрезе стендов тестирования, так и в разделе отделов. Вычисляется пока усредненное значение за один день и за семь дней.
Итоги проекта
Как я упоминал раньше, одним из важных критериев функционирования сервиса является удовлетворенность пользователей. С 2017 года мы начали собирать обратную связь:
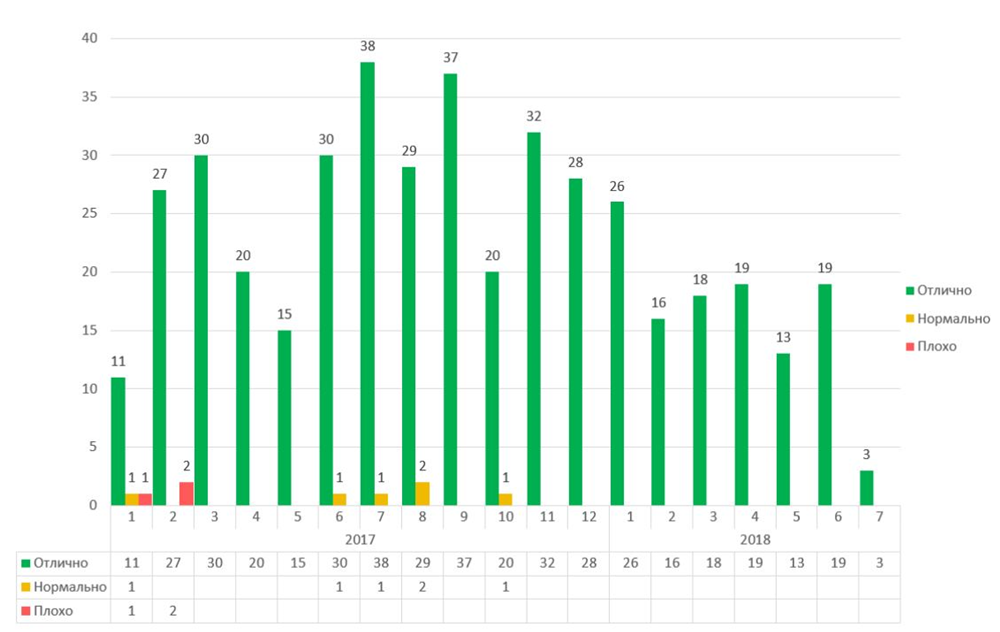
На этом графике можно увидеть стабильно высокую удовлетворенность сотрудников компании сервисом мониторинга начиная с 2017 года.
В рамках проекта мониторинга была разработана структура и правила наполнения базы знаний по мониторингу, куда входят:
- Регламенты работы с сервисами мониторинга
- Правила составления заявок на доступ
- Инструкции по расширению функционала мониторинга
- Описание возможностей сервиса мониторинга
- Информация об отчетах, которые можно получить
- Описание процессов реагирования на аварии
Чтобы упростить работу с системой мониторинга, недавно мы начали запись видеокурсов. В итоге практически 70% обращений пользователей закрывается отправкой им соответствующих ссылок на статьи или видео из базы знаний. Это существенно снизило нагрузку по консультированию, которая у специалистов по мониторингу, как известно, очень большая.
Одним из побочных эффектов внедрения централизованного сервиса стал массовый отказ подразделений Сбертеха от локальных средств мониторинга в течение 2016 года. Это позволило высвободить небольшую часть ресурсов подразделений. Отмечу, что отказ от локальных систем проходил на добровольной основе и решение подразделениями принималось исходя из преимуществ, которые дает сервис централизованного мониторинга.
С момента начала полноценной работы в 2016 году сервис оказывает большую помощь системным администраторам. Хотя размеры ИТ-инфраструктуры продолжают линейно расти, отдел администрирования пока не нуждается в расширении. И это не в последнюю очередь заслуга системы мониторинга. С ее помощью мы также смогли стабилизировать рост числа заявок, приходящих отделу системного администрирования от смежных подразделений
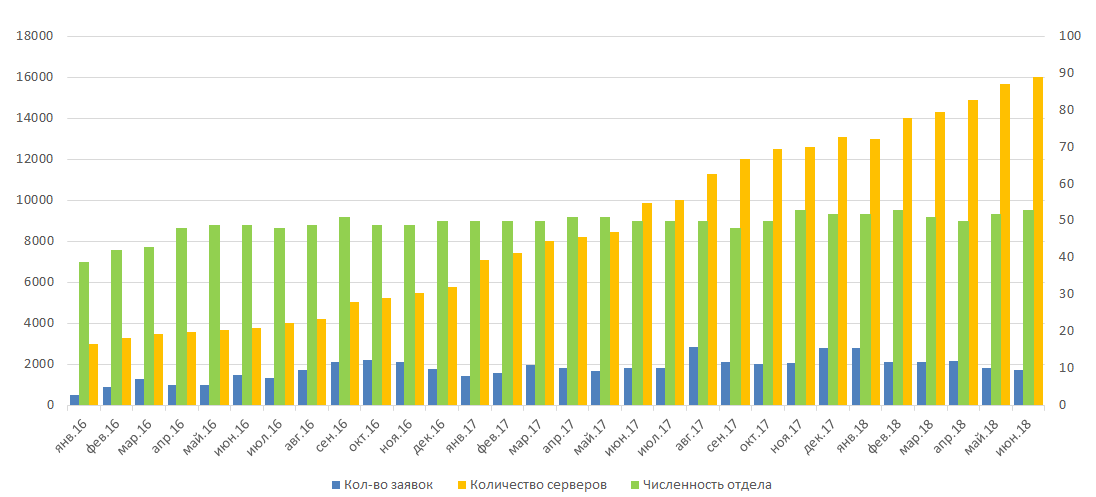
В результате оптимизации КТС в 2016 году и ее автоматизации на базе сервиса мониторинга, удалось высвободить и распределить в пулы подразделений большое количество неиспользуемых ресурсов: 600 ядер CPU, почти 7,5 терабайт оперативной памяти и порядка 50 терабайт дискового пространства.
Комментарии (35)

Mikuhairo
22.08.2018 05:28Как вы делали интеграцию с HP SM и Jira? Какие проблемы при этом решали?
Мы думали сделать, но отказались от этой идеи и тикеты об авариях проходят через человека.sperr0w Автор
22.08.2018 09:34Для интеграции с JIRA использовали питоновский модуль JIRA. В нем создавали тикет. Проблемы могут появиться из за составления тикета для отправки внутри скрипта. Формат зависит от workflow в Jira, который использует проект (переход тикетов из одного статуса в другой и т.д.) при изменении этого workflow, скрипт отправки нужно корректировать.
Да, еще проблема была с автоматическим закрытием тикета в JIRA, так как где-то нужно было хранить соответствия номера тикета и события в Zabbix, на основании которого этот тикет был создан. Для этого использовали небольшую базу SQLite.
Для интеграции с HP SM, для нас сделали Web сервис (WSDL). В скрипте мы готовили XML c с описанием инцидента и подавали на вход этому сервису.
В скрипте использовали библиотеку suds.
Проблемы были, в основном, организационного характера и были связаны с коммуникациями.
Meklon
22.08.2018 09:19По Jira интеграции очень интересно, да. И еще вопрос — вы не собирали с помощью Zabbix данные по установленному софту и его версиям? Если данные не закрытые — какое у вас приблизительное соотношение Linux/Windows на серверах, которые мониторятся Zabbix?
sperr0w Автор
22.08.2018 09:42Скажем так, Linux на 14% больше, чем Windows.
Я думаю, если сообщество проявит интерес к тому, как организован мониторинг ИТ-инфраструктуры у нас в компании, я продолжу публиковать статьи, где буду описывать наиболее интересные моменты относительно того, как работает наш сервис.sperr0w Автор
22.08.2018 10:00И еще вопрос — вы не собирали с помощью Zabbix данные по установленному софту и его версиям?
Да, конечно собираем. Если почитать внимательнее основные цели проекта, то там присутствует: «Аудит соответствия окружений тестовых сред и промышленных АСМ». Это как раз в том числе про соответствие версий софта в проме и тестовых средах. Кроме того, в разделе отчетность я явно указал наличие отчета «о соответствии версий ППО в стенде для сравнения с конфигурацией промышленных сред».
onlinehead
22.08.2018 10:31В целом интересно было почитать, спасибо за статью.
Но некоторые моменты меня смутили, вроде восьмичасового простоя при обновлении при полной недоступности мониторинга.
Восемь часов простоя при обновлении выглядит как фатальный неустранимый недостаток и повод отказаться от подобной системы и уехать на что-нибудь другое.
Почему это вообще не стало причиной отказа от использования Zabbix?
Есть же, к примеру, Sensu как мониторинг, есть специальные стораджи для метрик вроде InfluxDB и Graphite (даже он прекрасно выдержит 20krps на современном железе с SSD), которые, кроме на порядок большей нагрузки, умеют еще и в различные выборки, запросы и агрегирование гибкое (в Graphite можно еще и свои функции написать, благо python).
Для inventory тоже множество решений различных, даже в рамках configuration management утилит. Не знаю есть ли что-то подобное для Ansible, но для Puppet есть специальный модуль который все собирает.sperr0w Автор
22.08.2018 10:53Восьмичасовой простой возник лишь один раз. Кроме того, как я уже сказал, мы нашли решение для этой проблемы в будущем (обновление базы напрямую SQL скриптами, не через сервер приложений), поэтому это не стало причиной отказа. Если бы это был мониторинг ПРОМ-а, такой проблемы у нас не возникло бы (протестировали бы обновление на полноценном клоне базы и выявили бы все проблемы на этапе тестирования).
По поводу вопроса выбора альтернативы — считаю этот вопрос риторическим. Существует огромное количество разных инструментов мониторинга, каждый со своими болезнями. Какие то чуть лучше мониторят одну часть инфраструктуры, другие чуть лучше другую. Zabbix вполне сбалансированный инструмент, который пригоден для мониторинга большой инфраструктуры и я пока что не вижу причин от него отказываться. Во всяком случае, лично для меня сейчас проблема долгого обновления больших шаблонов — проблема намного более серьезная, нежели проблема времени обновления базы.
Кроме того, я считаю, что 80% успеха мониторинга лежит в организационной плоскости и создании эффективного процесса, а не в выборе инструмента.
На следующей неделе я планирую опубликовать статью, в которой опишу основные моменты организации процесса мониторинга.
sperr0w Автор
22.08.2018 11:00Основные проблемы, которые возникали перед нами за последние 4 года работы с Zabbix, мы так или иначе успешно решали. Причем, несмотря на шестилетний опыт работы с Enterprice решениями для мониторинга от HP (ныне MicroFocus), я сомневаюсь, что я смог бы так же успешно справиться с этими проблемами на стеке их мониторинга.
onlinehead
22.08.2018 11:48Кроме того, я считаю, что 80% успеха мониторинга лежит в организационной плоскости и создании эффективного процесса, а не в выборе инструмента.
Это безусловно, тут я с вами совершенно согласен.
Основные проблемы, которые возникали перед нами за последние 4 года работы с Zabbix, мы так или иначе успешно решали. Причем, несмотря на шестилетний опыт работы с Enterprice решениями для мониторинга от HP...
Я понимаю, что вы сравниваете с другим Enterprise решением и наверно в сравнении с ним Zabbix действительно лучше.
Я все это написал просто к тому, что сталкивался с ним неоднократно и он на столько со скрипом решает некоторые задачки: банальная годовая выборка с агрегацией, чтобы посмотреть глобальные тенденции дается его базе очень тяжело, а ведь еще есть динамическое создание, для которых нужны шаблоны, без которых совсем все плохо и все равно придется их настраивать, но все это больно и неудобно (вы это уже упоминали как раз), реализация многих концепций вроде динамической балансировки приложений по доступным нодам тоже малореальна и т.п.
Да, мне кажется просто наши инфраструктуры выглядят совсем по-разному и именно поэтому я Zabbix последние лет 7 воспринимаю как что-то, от чего все равно придется избавляться.
Кстати, а на проде тоже Zabbix, или вы поддерживаете разные системы мониторинга для разных сред?sperr0w Автор
22.08.2018 13:48банальная годовая выборка с агрегацией
В условиях нашей компании такая выборка по всей инфраструктуре это уже BigData. И решать такую задачу нужно соответствующими средствами. Кстати, у нас реализованы инструменты экспорта данных из базы Zabbix в NoSQL. Там эти данные специалисты Capacity Management могут крутить так как им нужно. IMHO это не задача сервиса мониторинга.
а ведь еще есть динамическое создание, для которых нужны шаблоны, без которых совсем все плохо и все равно придется их настраивать, но все это больно и неудобно
Звучит как-то по Prometheus-овски. Zabbix в том числе устраивает нас потому, что хотя у меня и есть претензии к его ролевой модели, с помощью неё удается поддерживать сервис на 1000+ пользователей. И именно эта ролевая модель не дает грузить в базу все подряд (как это происходит в некоторых других инструментах мониторинга. Но опять же, это мое личное мнение.
Еще раз повторюсь, в любой компании есть своя специфика. Прежде всего, подход к мониторингу зависит от того, как в принципе в компании реализован цикл разработки, тестирования и сопровождения в проме систем. Скажем так, если бы каждую систему на протяжении всего жизненного цикла (в том числе в ПРОМ-е) сопровождала бы одна независимая от других команда, то инструментом мониторинга точно был бы не Zabbix.
hMartin
22.08.2018 11:49Оперативное информирование специалистов о неполадках в работе тестовых сред;
Чистая правда, вот только мне приходила вся инфа о неполадках всех тестовых контуров, а я хотел только мои сервера. Сказали, что так нельзя и junk забивался очень быстро.
Я так понимаю Заббикс единый инструмент технического мониторинга? Бизнес события у нас выгребал Splunksperr0w Автор
22.08.2018 12:16Сказали, что так нельзя и junk забивался очень быстро: Что — то мне подсказывает, что вы общаетесь с командой мониторинга банка, а не с нашей командой. Мы вам такого сказать не могли. Всем, кто озаботился настройкой оповещений, мы помогли сделать их максимально полезными.
Наш сервис — единственный централизованный сервис мониторинга тестовых сред. Насколько мне известно, других централизованных инструментов мониторинга в СБТ нет.
hMartin
22.08.2018 13:14Что — то мне подсказывает, что вы общаетесь с командой мониторинга банка, а не с нашей командой
Да, вполне возможно, настраивали давно
Наш сервис — единственный централизованный сервис мониторинга тестовых сред
В ЕФС было распоряжение от ЦСПС с приемкой бизнес событий мониторинга через Splunk. НТ тоже производили с подключением этого добра, там даже команда отдельная есть, которая спланк сопровождает.sperr0w Автор
22.08.2018 13:20ЕФС — это далеко не все тестовые среды.
Предлагаю дальнейшую дискуссию по этому поводу вести за рамками комментариев к данной статье.
igor_kuznetsov
22.08.2018 11:52SCOM не используете вообще?
sperr0w Автор
22.08.2018 12:16SCOM использовался в банке, но насколько я знаю, сейчас обсуждается уход от SCOM в связи с его низкой производительностью. Наша команда никаких других инструментов, кроме Zabbix не поддерживает.
igor_kuznetsov
24.08.2018 09:57Понятно, ну, сбер не первая компания которая не осилила его настройку
sperr0w Автор
24.08.2018 13:34Я бы выразился немного по-другому: Сберу хватило ума перестать прикладывать усилия к тому, чтобы заставить работать SCOM и он обратил внимание на другие, более отзывчивые и простые в настройке инструменты мониторинга. Я совсем не хочу обидеть ни SCOM, ни тех, кто его использует. Просто по моему мнению, этот инструмент не очень подходит для нашей компании.
slava_k
22.08.2018 14:30Спасибо за за статью и что делитесь опытом.
Вы как-то дублируете сбор критически важных метрик (доступность, целостность сети) на уровне сервисов? Второй/отдельный Zabbix? Возможно, полностью автономная параллельная система на другом софте? Следите ли (и если да — то с помощью чего) за работоспособностью самого сервиса сбора метрик?sperr0w Автор
22.08.2018 15:06Как я уже писал выше, у нас работает три инстанса Zabbix.
Один из них как раз и дублирует мониторинг критически важных для компании сервисов (в том числе, на нем развернут и «мониторинг мониторинга»). Этот инстанс намного меньше чем инстанс мониторинга тестовых сред, а потому работает он значительно стабильнее (нагрузка на нем порядка 200 НВПС).
Если вам интересно, я могу попробовать описать наш внутренний мониторинг (графики и метрики, по которым мы диагностируем проблемы на Zabbix) в отдельном посте.slava_k
22.08.2018 16:08Да, было бы интересно как именно мониторите сам Zabbix (нагруженный) — жизнеспособность агентов на целевых хостах, работоспособность внутренностей сервера сборки данных и прочее. Какие с этим были проблемы, как разрешались. Спасибо.
Zelenoglazko
22.08.2018 18:31+1к интересующимся, расскажите пожалуйста про проблемы Zabbix и их анализ
sperr0w Автор
22.08.2018 16:46Под конфигурационной базой данных в данном случае имели в виду базу HP Service Manager. Интеграцию написали сами.
nanshakov
22.08.2018 18:38Как много времени заняло внедрение? На что потратили больше всего времени?
sperr0w Автор
23.08.2018 09:05Как много времени заняло внедрение?
Сложно сказать, так как активное развитие сервиса продолжается все время и сейчас его даже больше, чем было год или два назад и надеюсь. Не уверен, что для сервиса мониторинга вообще возможно такое понятие, как «окончание внедрения».
На что потратили больше всего времени?
Опять же, в связи со спецификой нашей инфраструктуры и в частности инфраструктуры, на которой работает наш сервис, много времени за последние четыре года приходилось тратить оптимизацию производительности (если в о технических моментах). Наверное, чуть позже я опишу мощности, которые задействованы в нашем сервисе. К примеру, 19000 НВПС нам удалось достичь на 8 ядрах (на основном сервере приложений), без SSD, High-End или чего-либо в этом роде.
Если говорить об организационных моментах, самым сложным было добиться популярности нашего сервиса в компании, так как наших заказчиков никто не заставлял работать именно с нашим сервисом.
Sleuthhound
22.08.2018 19:02Спасибо за интересную статью.
Расскажите пожалуйста как вы осуществляете мониторинг базы данных в забиксе? Ведь из коробки он совершенно не предназначен для этого. Мониторить базы через ODBC — это смерти подобно. Другие наколенные решения (скрипты, доп. программы и z-модули), например для Oracle — это zbxora, для Pg — libzbxpgsql, для MySQL (думаю у вас нет его) — нет ничего достойного.
Спасибо.sperr0w Автор
23.08.2018 09:13Нам удалось добиться от ODBC более менее стабильной работы. Сильно помогли в этом мастер-метрики. Так что сейчас мы продолжаем использовать именно ODBC, благо процесс постановки на мониторинг баз почти полностью автоматизирован.
Самой большой проблемой на данный момент является то, что невозможно в прототипах элементов данных (далее ЭД) разведки использовать в качестве мастер-метрики использовать обычный ЭД из шаблона. Такой функционал значительно снизил бы количество сессий, который мониторинг создает к базе. Но и использование мастер-метрики внутри разведки по каждому Tablespace уже снизило количество создаваемых сессий примерно в 3 раза.
У нас запланировано основательное тестирование инструментария DBforBIX, но руки до этого пока что не дошли. Решающим при окончательном выборе будет возможность полной автоматизации процесса постановки на мониторинг, так как баз, которые нужно мониторить у нас очень много.
iddqda
23.08.2018 09:57Спасибо, интересно
Но вот такой вопрос, навеянный цифрой 1500 тестовых сред и затем слайдом с Магнитом, в котором указано 11К прокси:
А не приходила мысль на 1500 тестовых сред создавать 1500 инстансов заббиксов, локальных для каждой тестовой среды? Так же как вы раскатываете zabbix-агентов, тем же ансиблом можно автоконфигурить и раскатывать и zabbix-server-а
В каждом таком инстансе будут свои пользователи со своими метриками от своей тестовой среды. Требования по производительности инстанса минимальны. Можно развернуть на виртуалке или даже в докере.
Конечно, главный Zabbix для мониторинга непосредственно железа и крутых отчетов останется, но нагрузка и количество пользователей радикально уменьшится. А насколько проще будет чистить базу от разобранных тестовых средsperr0w Автор
23.08.2018 10:42А не приходила мысль на 1500 тестовых сред создавать 1500 инстансов заббиксов
Можно привести очень много причин того, почему это делать не стоит. Приведу лишь некоторые:
- Появится полторы тысячи виртуалок/контейнеров Zabbix (по крайней мере у нас в компании, на тестовом стенде нельзя держать никакой сторонний софт, так что под каждый инстанс Zabbix придется резервировать отдельные ресурсы)
- Каждой команде придется держать экспертизу по мониторингу.
- Каждая команда неизбежно будет тратить ресурсы на разработку примерно одних и тех же метрик мониторинга. В рамках компании это КОЛОССАЛЬНОЕ КОЛИЧЕСТВО ресурсов. Одним из плюсов нашего сервиса является то, что в моем подразделении сосредоточена подавляющая часть экспертизы мониторинга компании (мы так или иначе в курсе всех активностей, связанных с мониторингом в Сбертехе и банке). И сейчас, спустя 4 года, если к нам обращаются с просьбой о разработке того или иного функционала, мы можем ответить, что «это уже было в Симсонах». Если же это действительно что-то новое, мы сразу ведем разработку так, чтобы новый инструмент затем можно было тиражировать на все среды тестирования, где это возможно. Мы также сразу информируем потенциальных потребителей о появлении нового функционала и т.д.
- Мы не избавляемся от централизованного инстанса, иначе не получим целостной картины состояния инфраструктуры.
- И еще много много всего.
Я бы рассмотрел возможность подобной идеологии (инструментом, скорее всего, был бы не Zabbix) только в том случае, если каждая АС поддерживается совершенно независимой командой от начала и до конца (и нет каких то сервисных подразделений, которые занимаются администрированием всей инфраструктуры в целом). — Об этом я уже написал в одном из комментариев.iddqda
23.08.2018 11:251. серверный истанс не обязан стоять именно на тех же серверах, что и тестовые среды. можно все инстансы собрать на отдельную ферму и в отдельную подсеть и в облако, да куда угодно. А в zabbix-agent-ы разных сред добавить к параметру ServerName, кроме вашего центрального сервера, FQDN инстанса соответствующего среде
2. А кто же те 1000 пользователей вашего централизованного забикса. Они если сейчас не эксперты, то для них мало что изменится. Ну url будут другой писать.
3. Администровать все инстансы будет по прежнему ваше подразделение
4. Конечно его необходимо оставить. Я об этом прямо написал
5. Вот тут согласен :)
И это… я не настаиваю, просто в последнее время начал смотреть на различные ИТ решения под углом: «А насколько это решение масштабируется?»
sperr0w Автор
23.08.2018 11:34У нас в данный момент нет необходимости поднимать полторы тысячи инстансов Zabbix. Нас полностью устраивают те три инстанса, что есть сейчас.
Cayp
Можете ли вы рассказать подробнее о методике/алгоритме отнесения серверов к категории недозагруженный/загруженный оптимально/ перегруженный?
sperr0w Автор
Базовый интервал сбора метрик в нашем сервисе принят в 60 секунд.
В Zabbix для каждого сервера вычисляются метрики 15-ти минутного скользящего среднего (далее MA15) и 90% перцентиля* (далее PCT90) для каждого из трех параметров: CPU Utilization, RAM Utilization, Disk Utilization — по каждому разделу.
Для MA15 базовый интервал сбора — 60 секунд (на то оно и скользящее)
Для PCT90 интервал сбора — 15 минут, данная метрика менее ресурсоёмкая.
Далее отдельными метриками в Zabbix же вычисляем суточные максимумы для MA15 и PCT90: MA15_1DMAX и PCT90_1DMAX
В итоге, получаем 30 значений в месяц для каждой из метрик.
Анализ мы ведем на промежутке 3-х месяцев: анализируем по 90 значений каждой метрики MA15_1DMAX и PCT90_1DMAX.
Из этих 90 значений отбрасываем одно наибольшее:
1) Пытаемся избежать попадания в выборку случайного повышения нагрузки
2) Не берем в расчет нагрузку, которая за три месяца возникала всего один раз
Из оставшихся 89 значений выбираем наибольшее по обеим метрикам. Назовем полученные два значения MA15_90DMAX и PCT90_90DMAX (не забываем, что на самом деле это не максимум, а «второй» максимум — первый мы исключили из выборки).
Для нашей инфраструктуры тестовых сред** мы определили следующие целевые показатели:
оптимальная загруженность: 60-80%
недозагруженность: < 60%
перегруженность: > 80%
Далее сравниваем MA15_90DMAX и PCT90_90DMAX с целевыми показателями и категоризируем каждый сервер по каждому из ресурсов (CPU, RAM, HDD).
Теперь пару слов о том, почему используем оба параметра MA15 и PCT90, а не какой то один. Если говорить очень кратко, то каждый сервер использует ресурсы по-разному и тестирование на серверах проходят разные. Некоторые могут быть стабильно утилизированы — для таких серверов более показательна MA15. Другие сервера интенсивно работают лишь небольшой промежуток времени, а остальное время простаивают.
Базовой для нас является все-таки MA15, но если показания MA15 и PCT 90 сильно различаются, то приходится проводить более детальный анализ.
Ближайшим развитием этой методики мы видим профилирование серверов по типу нагрузки. Считаю, что в перспективе это позволит серьезно оптимизировать распределение виртуалок по гипервизорам и обеспечить стабильность работы даже в условиях значительной переподписки. Но до реализации данной методики руки пока что не дошли, хотя из полученных данных уже ясно, что эта работа принесет положительные результаты.
* все приведенные в данном описании метрики определены именно для нашей инфраструктуры и для нашей компании. Далеко не факт, что для вас подойдет именно 15-ти минутное усреднение или именно 90% перцентиль. Мы, например, делали пилотный проект и выбирали примерно из 20 комбинацией перцентиля и разных интервалов усреднения
** для ПРОМ-а эта методика требует доработок, так как специфика работы и нагрузки ПРОМ систем отличается от тестовых сред кардинально.