
1. НЕ внедряйте инструмент мониторинга
Если ИТ-подразделения получат только инструмент мониторинга, эффективный и востребованный мониторинг не возникнет сам собой. Вместо того чтобы заниматься внедрением системы мониторинга, попытайтесь подойти к созданию мониторинга ИТ-инфраструктуры как к организации процесса.
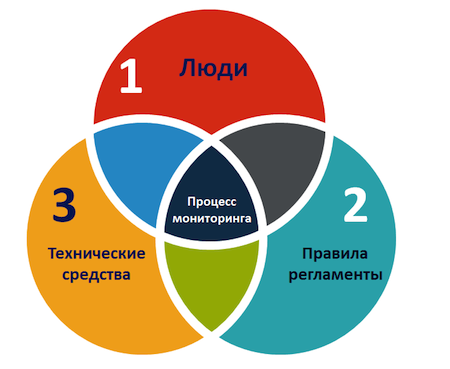
Что я понимаю под процессом мониторинга? Процесс мониторинга — это совокупность человеческих ресурсов, технических средств и организационных мер, направленных на решение задач, которые компания ставит перед мониторингом в процессе эксплуатации ИТ-инфраструктуры. Особенно хочу отметить, что люди и правила в данном определении важны не меньше, а скорее даже больше, нежели технические средства.
Вот несколько типичных примеров названий проектов по мониторингу, в которых я когда-то участвовал. Название проекта в большинстве случаев точно отражает результат, который хотел получить заказчик:
- Внедрение системы управления и эксплуатации корпоративной телекоммуникационной сети
- Создание системы мониторинга ИТ-инфраструктуры
- Разработка системы управления и эксплуатации интернет-контура
- Внедрение системы мониторинга коммутационного оборудования ОАО
- Создание системы управления информационными технологиями
- Создание программно-аппаратного комплекса системы управления и мониторинга ИТ-инфраструктуры
Компании концентрируются на технических средствах и чаще всего приносят в жертву остальные две составляющие — человеческие ресурсы и организационные меры. В итоге инструмент появляется, а четкое понимание, кто и как этим инструментом должен пользоваться — нет.
Естественно, в любом проекте внедрения системы мониторинга в той или иной степени присутствует и ролевая модель, и сопроводительная документация. Но как правило, эта документация носит формальный характер и не помогает ИТ-подразделениям отвечать на вопросы, возникающие при работе с системой.
2. Интегратор НЕ сделает за вас всей работы
Обычно для проектов, связанных с мониторингом, крупные и средние компании привлекают специалистов из компаний-интеграторов. В процессе обследования инфраструктуры интеграторы полагаются на свой опыт знаний и решения проблем. Но далеко не факт, что это именно то, что требуется компании. Никто не знает тонкостей проблем, связанных с эксплуатацией ИТ-инфраструктуры, лучше, чем специалисты компании.
Поэтому я рекомендую перед привлечением стороннего подрядчика самостоятельно определить проблемы, которые компания хочет решить с помощью мониторинга. Например:
- неравномерное распределение нагрузки на виртуальную инфраструктуру;
- высокое количество аварий в ИТ-инфраструктуре;
- высокая степень загрузки высококвалифицированных специалистов выполнением простых задач;
- низкий уровень доступности корпоративных сервисов;
- большое количество звонков на первую линию;
- длительное время с момента возникновения аварии до ее обнаружения;
- необходимость оптимизации работы системных администраторов;
- низкая производительность ИТ-инфраструктуры;
- отсутствие достоверных данных о ресурсах ИТ-инфраструктуры;
- отсутствие инструментов предупреждения аварий.
Также крайне полезно будет еще на первых этапах организации мониторинга зафиксировать метрики, которые будут оценивать проблемы в количественном выражении, и собрать статистику по этим метрикам. В результате мы получим информацию о состоянии функционирования ИТ-инфраструктуры до организации процесса мониторинга. А после внедрения мониторинга сможем контролировать, как организация повлияла на изменение этих показателей. Примерами таких метрик могут быть:
- среднее количество инцидентов, зафиксированное за отчетный период;
- среднее время простоя ключевых сервисов;
- средний % доступности ИТ-инфраструктуры;
- средний % утилизации инфраструктуры;
- количество обращений на первую линию за отчетный период;
- среднее время с момента возникновения инцидента до его обнаружения;
Чем лучше будут проработаны метрики, характеризующие основные проблемы эксплуатации ИТ-инфраструктуры, тем большего их улучшения удастся достичь в ходе мониторинга. Постоянное вычисление этих метрик должно стать неотъемлемой частью процесса. С определенной периодичностью необходимо пересматривать формулы их расчета. Так вы сможете своевременно реагировать на изменения в развитии ИТ-инфраструктуры, ее качественном и количественном составе. Целесообразно использовать эти метрики в качестве KPI при оценке эффективности работы подразделений сопровождения ИТ-инфраструктуры.
3. НЕ путайте мониторинг и администрирование ИТ-инфраструктуры
Квалифицированные специалисты — одна из трех ключевых составляющих эффективного процесса мониторинга. Иногда в целях экономии, особенно в процессе внедрения, компании пытаются возложить сопровождение и развитие системы мониторинга на системных администраторов, занимающихся эксплуатацией ИТ-инфраструктуры. А вот если для поддержки мониторинга выделить отдельную структуру (специалиста), это значительно повысит качество работы сервиса. Мониторинг будет для этих сотрудников основной, а не побочной деятельностью, так что они будут гораздо больше заинтересованы в его успешности и востребованности.
В обязанности подразделения (специалиста) по мониторингу, помимо прочих, должны входить следующие функции:
- администрирование комплекса систем мониторинга;
- создание новых метрик мониторинга;
- корректировка пороговых значений мониторинга;
- разработка новых инструментов мониторинга;
- исполнение запросов пользователей;
- формирование отчетности;
- развитие процесса мониторинга ИТ в целом.
Даже если у вас конфигурированием мониторинга будет совместно заниматься несколько ИТ-подразделений, все равно должна быть отдельная структура — центр экспертизы в отношении всего, что касается мониторинга. Это поможет предотвратить дублирующие трудозатраты и оперативно разрешать любые конфликтные ситуации, которые при совместном администрировании рано или поздно возникнут.
4. НЕ рассчитывайте, что ваши подчиненные будут использовать мониторинг, если вы сами этого не делаете
Бывает, руководитель, затеявший внедрение мониторинга в компании, дает необходимые распоряжения, выделяет средства, заключает договор с интегратором и на этом заканчивает работу с мониторингом. И зря, ведь чтобы мониторинг был эффективным, он должен быть в том или ином виде востребован на всех уровнях корпоративной иерархии. Как только сервисом мониторинга станет пользоваться руководитель, это автоматически станет обязательным и для всех его подчиненных.

5. НЕ заставляйте сотрудников работать с системой мониторинга
Рано или поздно внедрение системы мониторинга завершается, и начинается ее эксплуатация. Иногда это сопровождается распоряжением: всем ИТ-подразделениям начать работу с системой. Как правило, прямое принуждение не приносит положительных результатов. Максимум, чего можно добиться — формального исполнения в минимально необходимом объеме.
Мониторинг будет положительно воспринят в том случае, если он будет помогать каждому подразделению решать свои задачи. Если подразделения эксплуатации ИТ не начинают использовать мониторинг, это может говорить о том, что цели внедрения мониторинга были поставлены неверно. Или о том, что цели внедрения не совпадают с целями ИТ-подразделений.
Мотивируйте подразделения компании использовать результаты мониторинга, а не обязывайте это делать. Хорошим вариантом такой мотивации будет создание для каждого подразделения ключевых показателей на базе метрик, описывающих проблемы эксплуатации ИТ-инфраструктуры в количественном выражении. Их примеры я приводил выше.
6. НЕ концентрируйтесь на проверке функциональности системы мониторинга во время ее испытаний
После разработки системы мониторинга происходят ее испытания и затем — опытная эксплуатация. Здесь становится актуальным наше очередное «не». В той или иной степени я сталкивался с этой проблемой в каждом проекте.
Если внедрение инструмента мониторинга выполняет сторонняя организация, важно, чтобы специалисты компании активно участвовали в формировании методов тестирования системы на этапах приемочных испытаний и опытной эксплуатации. Во время испытаний необходимо сконцентрироваться именно на том, действительно ли инструмент помогает достичь поставленных перед мониторингом целей и задач.
Приведем примеры использования метрик для итоговых испытаний:
- Оптимизация утилизации ИТ-инфраструктуры. На основе отчетов системы мониторинга можно принимать однозначные и мотивированные решения относительно оптимальной утилизации и более рационального распределения ИТ-инфраструктуры.
- Снижение количества аварий в ИТ-инфраструктуре. Мониторинг ИТ-инфраструктуры должен давать как можно больше правильных сигналов и как можно меньше ложных. Проверить это можно, собрав статистику процентного соотношения сигналов от системы мониторинга, которые действительно сообщают об аварийном состоянии компонентов ИТ-инфраструктуры и привели к реакции по устранению причин аварии.
- Снижение загрузки высококвалифицированных специалистов выполнением простых задач. Проверка полноты и детальности выстроенной в системе ролевой модели, а также полноты ее наполнения информацией о структурных подразделениях компании, анализ правил эскалации оповещений в случае, если система их предусматривает. Полезно будет также определить процентное соотношение сигналов, которые попадают целевым адресатам, и сравнить это значение с целевыми показателями.
- Повышение уровня доступности корпоративных сервисов. Сравнение показателей доступности корпоративных сервисов, определенных системой мониторинга, с фактическими показателями доступности за отчетный период, которые определены альтернативными методами. Сюда же можно отнести проверку полноты и детальности списка метрик, используемых при определении доступности корпоративных сервисов, пороговых значений этих метрик и настройки оповещений на целевые группы сопровождения корпоративных сервисов.
- Проверка качества ИТ-услуг, предоставляемых внешним подрядчиком. Проверка того, что метрики мониторинга предоставляемых сервисов максимально покрывают параметры из SLA, подписанного с внешним подрядчиком. На основе их данных можно однозначно говорить о выполнении подрядчиком условий SLA.
- Инвентаризация ИТ-инфраструктуры. Проверка полноты инвентаризационной информации, собираемой системой мониторинга, и соответствие ее требованиям и задачам инвентаризации; проверка качества и удобства использования инвентаризационных отчетов, выдаваемых системой мониторинга.
- Проактивное предупреждение аварий. Сравнение статистики по количеству аварий за отчетный период до начала использования системы мониторинга и после ввода ее в опытную эксплуатацию; сравнение этих значений с целевыми показателями.
С одной стороны, проверить это все довольно сложно — нужно сначала определить способ вычисления этих метрик, а затем накопить по ним статистику. Но с другой стороны, эти метрики можно будет использовать не только в процессе испытаний мониторинга, но и заложить в будущем в системе мотивации ИТ-подразделений, занимающихся эксплуатацией.
Проверка же базовой функциональности — например, появления в системе мониторинга аларма в случае отключения питания у коммутатора — сама по себе не дает никакого представления о том, что система будет справляться с поставленными перед ней задачами. Такая проверка лишь покажет, что система в принципе работает.
7. Мониторинг НЕ начнет приносить пользу, пока вы не начнете работать с ним и адаптировать его под свои потребности
Это «не» относится к этапу эксплуатации системы после завершения внедрения. Здесь крайне важно понимать, что без правильно выстроенного процесса мониторинга и его актуализации, данные в системе начнет устаревать сразу после завершения работ по его внедрению.
К моменту ввода в промышленную эксплуатацию должны быть по возможности решены все организационные вопросы, связанные с обслуживанием системы и функционированием мониторинга, правилами ее использования, разграничения ответственности и поддержки. Также должны быть определены правила и порядок разрешения проблем, которые будут возникать во время работы. Отсутствие этих правил — главная причина, по которой мониторинг перестает работать и начинает деградировать после завершения активной фазы работы интегратор.
Наконец, к началу промышленной эксплуатации системы мониторинга должны быть подготовлены регламенты, в которых будут сформулированы основные правила работы внутри процесса мониторинга:
- кто и как будет работать с системой;
- кто несет ответственность за поддержание системы в актуальном состоянии;
- кто имеет право корректировки пороговых значений метрик;
- каким образом происходит создание новых метрик;
- в каких случаях должны создаваться новые метрики;
- в какой срок происходит создание новых метрик;
- что должно происходить в случае, если система мониторинга зафиксировала аварию;
- кто и как на эту аварию должен реагировать;
- кто несет ответственность за функционирование системы мониторинга;
- как будут разрешаться конфликты, связанные с появлением ложных или с отсутствием верных сигналов.
Заключение
Я очень надеюсь, что, прочитав мою статью, вы не найдете ситуаций, похожих на то, что происходит в вашей компании. В случае, если в вашей компании мониторинг только начинает свое развитие, информация об этих семи главных, на мой взгляд, ошибках в процессе внедрения мониторинга поможет вам создать эффективный процесс, который принесет стабильность в работу вашей ИТ-инфраструктуры.
Комментарии (17)

rdbkzn
12.09.2018 12:06Наверное, вы правы: для «сбербанка» интегратор не сможет выполнить работу сотрудников «сбербанка».
Молоток не способен забивать гвозди фактом своего наличия.
А где практические рекомендации ? Или текст применим только для заказчиков размера сбербанка?rjhdby
12.09.2018 13:05+1Собственно в статье даны довольно неплохие практические рекомендации. Только это не рекомендации по настройке zabbix, а рекомендации по настройке процесса.
klauss_z
12.09.2018 13:23Практическая часть была в прошлом материале автора, про развитие мониторинга в Сбертехе — habr.com/company/sberbank/blog/420731
sperr0w Автор
13.09.2018 00:14Для описания организации процесса все довольно конкретно. Считаю, что рекомендации применимы для любой компании, которая хочет организовать мониторинг, приносящий реальную пользу.
amarao
12.09.2018 14:15Все разы, когда я имел дело с запуском мониторинга чего-либо в продакшен, основной проблемой был не сам мониторинг, а два извечных вопроса:
* Кто это читает?
* Кто это исправляет и как он знает что фиксить?
Главной драмой мониторинга является то, что лучше всего проблемы может диагностировать techlead или его аналог. Но обычно это человек, который меньше всего хочет получать сообщения «на сервере srv3455 у диска /dev/sdzb появились сбойные сектора» в час ночи.
А дальше мы вообще заканчиваем с мониторингом (как ИТ) и начинаем с организационной работой. Откуда саппорт знает, что надо делать в этой ситуации? Кто саппорт научил, кто следит за актуальностью этих знаний и их воспроизводимостью при текучке кадров?
И из абстрактной задачи «predictive monitoring» мы получаем практическую дилемму «надо бы сотрудников подешевле — значит, кто-то за них, заранее, должен знать все сценарии отказа» VS «надо набрать толковых людей, которые разберутся».
На практике получается смешанный подход, и документация и практики (схемы что где как менять и что делать) нарабатываются со временем.
Более того, из моего опыта, за вычетом пары-тройки тривиальных сценариев, попытка придумать сценарии до реальных отказов чаще всего приводит к тому, что сценарии есть, но в жизни всё не так как запланировано.sperr0w Автор
13.09.2018 00:18См. Седьмое НЕ из моей статьи. Там как раз про это.
amarao
13.09.2018 12:48«кто и как» не раскрыто. Т.е. «кто» — кого назначат, «как» — в соответствии с должностными обязанностями (поддерживать работоспособность информационных систем Компании). Типа, вопрос закрыт.
А на самом деле его даже не начинали раскрывать.sperr0w Автор
13.09.2018 16:17+1Вопрос регламентов очень сильно завязан на специфику и орг структуру конкретной компании. Не существует универсальных рецептов. В 7 пункте я лишь хочу подчеркнуть, что правила, регламенты, инструкции и прочее должны существовать к моменту начала работы системы. Любые, пусть даже не оптимальные регламенты лучше, чем их их полное отсутствие.
rjhdby
13.09.2018 16:50Единственно надо понимать, что эти инструкции и регламенты не должны быть отлиты в граните. Они должны постоянно улучшаться и меняться, подстраиваясь под текущие реалии.
sperr0w Автор
13.09.2018 20:09Да, конечно. В том числе к этих регламентных должно быть зафиксировано порядок и периодичность их пересмотра.
amarao
13.09.2018 18:11вот в этом месте у нас и разногласия. Если у вас регламенты уже есть, то они не о том, что случилось.
Точнее, можно иметь регламент о том, кто пишет клиенту «извините, ваших данных больше нет», но если мы про техническую часть (как чинить? какие сервера можно ребутать, какие нет? Можно ли накатывать бэкап базы и по каким случаям?), то регламенты «заранее» нифига хорошего не сделают. Можно прогнать несколько искусственных аварий, но мой опыт говорит, что они не похожи на аварии настоящие.
Так что алгоритм тут другой — в пусконаладке и тестовом внедрении ответственные люди (архитекторы) участвуют в разборах полётов, и эти разборы и становятся основой для мониторинга. Дальше в продакшене каждый раз, когда непонятно что делать, это исправляют «самые умные», а по итогам второй раз такое уже исправляет линейный персонал по готовой инструкции.
Готовые инструкции заранее никто написать не может. Я не найду ссылку, но где-то было математическое исследование тьюринг-полных машин, где было показано, что пространство ошибок для программы всегда имеет большую мощность (!) чем пространство документированных состояний. (вывод: даже если можно полностью описать как оно должно работать, невозможно полностью описать как оно может сломаться).AntoniusFirst
13.09.2018 19:45Некоторое, что можно загнать в регламент — можно и автоматизировать.
Если причины известной проблемы рандомные, но примерно известно где копать, к системе алертинга/мониторинга привязывается база знаний/CMDB, которая обогащает события специальным полем с описанием «где копать и кому звонить, если раскопать не получилось». В более простом случае, в событие автоматически добавляется информация с телефоном ответственного.sperr0w Автор
13.09.2018 20:56Собственно, у нас как раз такая интеграция с CMDB и реализована. См. Предыдущую статью.
sperr0w Автор
13.09.2018 20:52В этой компании до внедрения сервиса мониторинга никогда аварий не происходило? Или их не решали никак?
Сомневаюсь.
Вот "самые умные" должны сесть и оформить в виде регламентов свое видение того, кто и что должен делать в случае, если мониторинг зафиксировал аварию (с учетом опыта решения проблем, которые были до...). А потом эти регламенты дорабатывать на основе ситуаций, когда в процессах взаимодействия произошёл сбой.
rjhdby
Это «НЕ», фактически, предполагает, что сотрудники сами дойдут до понимания, что мониторинг им нужен. К сожалению, процесс этого понимания может быть крайне болезненным и убыточным для компании. Так что как бы ни хотелось следовать этому принципу, но какими-то базовыми метриками(доступность, CPU, RAM, FS) таки необходимо заставлять пользоваться всех администраторов.
sperr0w Автор
Не правильно заставлять. Не правильно. Если создать такие условия, что подразделениям будет выгодно пользоваться системой мониторинга, они сами начнут ее использовать. Самый банальный пример. Поставьте в kpi подразделения целевой показатель по количеству критических аварий. И аварии эти считайте по системе мониторинга. В этом случае подразделения очень быстро сами, добровольно запросят оповещения, которые предвещают критические аварии. Это и есть мотивация в моем понимании.
rjhdby
И произойдет это, скорее всего, после былинного отказа, когда бизнес потеряет деньги, а сопровождение девственность.