Ввод в эксплуатацию намечен на 2021 год.
На прошлой неделе компания Fujitsu рассказала о технических характеристиках чипа A64FX, который ляжет в основу новой «машины». Расскажем подробнее о чипе и его возможностях.

/ фото Toshihiro Matsui CC / Японский суперкомпьютер K computer
Технические характеристики A64FX
Ожидается, что вычислительные возможности Post-K почти в десять раз превысят показатели самого мощного из существующих суперкомпьютеров IBM Summit (по данным за июнь 2018).
Подобной производительностью суперкомпьютер обязан чипу A64FX на архитектуре Arm. Этот чип состоит из 48 ядер для проведения вычислительных операций и четырех ядер для управления ими. Все они равномерно разделены на четыре группы — Core Memory Groups (CMG).
Каждая группа имеет 8 МБ L2-кеша. Он связан с контроллером памяти и интерфейсом NoC («сеть на кристалле»). NoC соединяет между собой различные CMG c контроллерами PCIe и Tofu. Последний отвечает за связь процессора с остальной системой. У контроллера Tofu имеется десять портов с пропускной способностью в 12,5 ГБ/с.
Схема чипа выглядит следующим образом:
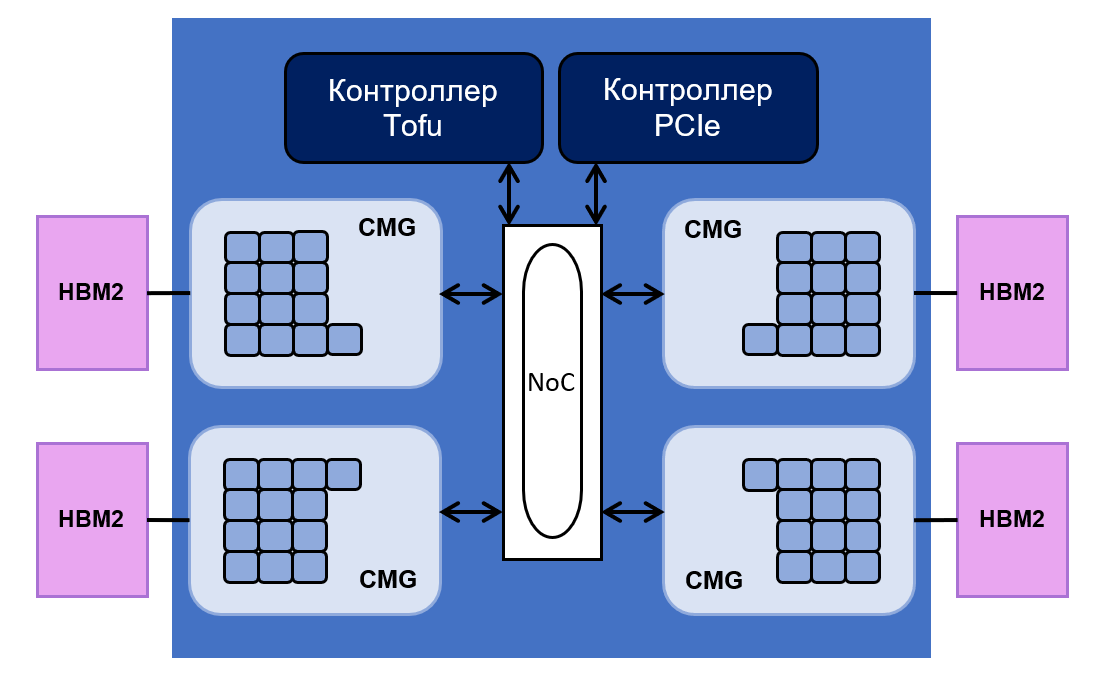
Суммарный объём памяти HBM2 у процессора составляет 32 гигабайта, а её пропускная способность равняется 1024 ГБ/с. В компании Fujitsu говорят, что производительность процессора на операциях с плавающей точкой достигает 2,7 терафлопс для 64-битных операций, 5,4 терафлопс — для 32-битных и 10,8 терафлопс — для 16-битных.
За созданием Post-K следят редакторы ресурса Top500, которые составляют список самых мощных вычислительных систем. По их оценке, для достижения производительности в один эксафлопс в суперкомпьютере используют более 370 тыс. процессоров A64FX.
В устройстве впервые применят технологию векторного расширения под названием Scalable Vector Extension (SVE). Она отличается от других SIMD-архитектур тем, что не ограничивает длину векторных регистров, а задает для них допустимый диапазон. SVE поддерживает векторы длиной от 128 до 2048 бит. Так любую программу можно запустить на других процессорах, поддерживающих SVE, без необходимости перекомпиляции.
При помощи SVE (так как это SIMD-функция) процессор может одновременно проводить вычисления с несколькими массивами данных. Вот пример одной из таких инструкций для функции NEON, которая использовалась для векторных вычислений в других архитектурах процессоров Arm:
vadd.i32 q1, q2, q3Она складывает четыре 32-битных целых числа из 128-битного регистра q2 с соответствующими числами в 128-битном регистре q3 и пишет результирующий массив в q1. Эквивалент этой операции на языке C выглядит так:
for(i = 0; i < 4; i++) a[i] = b[i] + c[i];Дополнительно SVE поддерживает функцию автовекторизации. Автоматический векторизатор анализирует циклы в коде и, если возможно, сам использует векторные регистры для их выполнения. Это повышает производительность кода.
Например, функция на C:
void vectorize_this(unsigned int *a, unsigned int *b, unsigned int *c)
{
unsigned int i;
for(i = 0; i < SIZE; i++)
{
a[i] = b[i] + c[i];
}
}
Она будет скомпилирована следующим образом (для 32-битного процессора Arm):
104cc: ldr.w r3, [r4, #4]!
104d0: ldr.w r1, [r2, #4]!
104d4: cmp r4, r5
104d6: add r3, r1
104d8: str.w r3, [r0, #4]!
104dc: bne.n 104cc <vectorize_this+0xc>
Если же задействовать автовекторизацию, то выглядеть это будет так:
10780: vld1.64 {d18-d19}, [r5 :64]
10784: adds r6, #1
10786: cmp r6, r7
10788: add.w r5, r5, #16
1078c: vld1.32 {d16-d17}, [r4]
10790: vadd.i32 q8, q8, q9
10794: add.w r4, r4, #16
10798: vst1.32 {d16-d17}, [r3]
1079c: add.w r3, r3, #16
107a0: bcc.n 10780 <vectorize_this+0x70>
Здесь происходит загрузка SIMD-регистров q8 и q9 с данными из массивов, на которые указывают r5 и r4. После чего инструкция vadd складывает по четыре 32-битных целых значения за раз. Это увеличивает объем кода, но так обрабатывается гораздо больше данных за каждую итерацию цикла.
Кто еще создает эксафлопсные суперкомпьютеры
Созданием эксафлопсных суперкомпьютеров занимаются не только в Японии. Например, работы также ведутся в Китае и США.
В Китае создают Тяньхэ-3 (Tianhe-3). Его прототип уже тестируется в Национальном суперкомпьютерном центр в Тяньцзине. Финальную версию компьютера планируется закончить в 2020 году.

/ фото O01326 CC / Суперкомпьютер Тяньхэ-2 — предшественник Тяньхэ-3
{kind=link}
В основе Тяньхэ-3 лежат китайские процессоры Phytium. Устройство содержит 64 ядра, имеет производительность в 512 гигафлопс и пропускную способность памяти в 204,8 ГБ/с.
Работающий прототип создан и для машины из серии Sunway. Он тестируется в Национальном суперкомпьютерном центре в Цзинане. По словам разработчиков, на компьютере сейчас функционирует около 35 приложений — это биомедицинские симуляторы, приложения для обработки больших данных, и программы для изучения климатических изменений. Ожидается, что работа над компьютером будет завершена в первой половине 2021.
Что касается Соединённых штатов, то американцы планируют создать свой эксафлопсный компьютер к 2021 году. Проект называется Aurora A21, и над ним работают Аргоннская национальная лаборатория Министерства энергетики США, а также компании Intel и Cray.
В этом году исследователи уже отобрали десять проектов для программы Aurora Early Science Program, участники которой смогут первыми воспользоваться новой высокопроизводительной системой. Среди них оказались программы по созданию карты нейронов мозга, изучению темной материи и разработке симулятора ускорителя частиц.
Эксафлопсные компьютеры сделают возможным построение сложных моделей для исследований, поэтому создания таких машин ожидают многие научные проекты. Один из самых амбициозных — Human Brain Project (HBP), цель которого заключается в создании полной модели человеческого мозга и исследовании нейроморфных вычислений. Как говорят ученые из HBP, применение новым эксафлопсным системам найдется с первых же дней их существования.
Чем мы занимаемся в ИТ-ГРАД: • IaaS • PCI DSS хостинг • Облако ФЗ-152
Материалы из нашего блога о корпоративом IaaS:
- Бессерверные вычисления в облаке — тренд современности или необходимость?
- Как разместить 100% инфраструктуры в облаке IaaS-провайдера и не пожалеть об этом
- Облачные технологии в финансовой сфере: опыт российских компаний
Комментарии (17)

GeMir
28.08.2018 09:01+1Контроллер Tofu — элегантный реверанс в сторону места разработки. Не без чувства юмора создатели.
dim2r
28.08.2018 09:46В 90х годах когда учился, один преподаватель хотел привести в универ из Германии мега-компьютер с 1Гб ОЗУ и потреблением в 13 киловат. Через 10 лет такие мощности уже были в топовых ноутбуках. Но тогда не верилось совсем. Подождем, может еще на нашем веку будут ноутбуки с экзафлопсами. :)
Jamdaze
28.08.2018 14:26Ждать можно сколько угодно, но размеры атомов от этого не уменьшаться. Нет ни каких предпосылок для ещё одного экспоненциального удешевления микропроцессоров.
Например ситуация с видеокартами\памятью, вроде бы и новые техпроцессы вводятся и нанометры уменьшаются а цена только растёт.beeruser
28.08.2018 14:50«нанометры уменьшаются», но цена транзистора перестала падать после 20нм техпроцесса.
beeruser
28.08.2018 14:11У вас примеры используют NEON, который является чисто SIMD набором.
Зачем фантазировать, когда SVE выглядит иначе.
SVE использует z-регистры и предикаты.
developer.arm.com/-/media/developer/developers/hpc/white-papers/a-sneak-peek-into-sve-and-vla-programming.pdf?revision=c702475b-6325-41a2-b3d3-d9f244028841
Berkof
29.08.2018 11:33Будущее нужно приближать, приятно что кто-то этим занимается… Плохо, что не мы.
А есть ли смысл использовать такие процессоры в более приземлённых задачах? Ну, скажем, в веб серверах или хостах виртуализации для очень дешёвых и простых виртуалок?beeruser
29.08.2018 17:33Fujitsu хочет коммерциализировать эту разработку. Поэтому они перешли со SPARC на ARM.
Greendq
Интересно, сколько будет потреблять всё это чудо? Гигаватты?
oldbie
При такой стомости создания это вообще имо волнует только в контексте проектирования системы охлаждения.
А мне вот интересно какие перспективы открвывает такой компьютер, какие недоступные ранее задачи он сможет решать.
vanxant
Увы, не так много. В заявленной области типичные алгоритмы имеют сложность O(n4), если сильно повезёт/извратнуться — O(n3). Т.е. подняли вычислительную мощь в 10 раз — повысили точность либо размеры симуляции в 1.5-2 раза. По аналогии — это как переход с FullHD на 4К. Хороший, бодрый эволюционный шаг, но никаких революций не произойдёт.
coctic
Считается, что одна установка такого класса должна потреблять не более 20 МВт. Ну может чуть превысят порог. Но не гигаватты.