Пока Леонид готовится к своему первому открытому уроку по нашему курсу «Администратор Linux», мы продолжаем рассказывать про загрузку ядра Linux-а.
Поехали!
Понимание работы системы, функционирующей без сбоев — подготовка к устранению неизбежных поломок
Древнейшая шутка в области ПО с открытым исходным кодом — заявление, что “код документирует сам себя”. Опыт показывает, что чтение исходного кода похоже на прослушивание прогнозов погоды: разумные люди все равно выйдут на улицу и посмотрят на небо. Ниже приводятся советы для проверки и изучения загрузки систем Linux с помощью знакомых инструментов отладки. Анализ процесса загрузки системы, которая работает хорошо, готовит пользователей и разработчиков к устранению неизбежных сбоев.
С одной стороны, процесс загрузки на удивление прост. Ядро операционной системы (kernel) запускается однопоточно и синхронно на одном ядре (core), что может показаться понятным даже жалкому человеческому уму. Но как запускается само ядро ОС? Какие функции выполняют initrd (диск в оперативной памяти для начальной инициализации) и загрузчики? И постойте, почему всегда горит светодиод в Ethernet-порте?

Читайте дальше, чтобы получить ответы на эти и некоторые другие вопросы; код описанных демо и упражнений также доступен на GitHub.
Начало загрузки: состояние OFF
Wake-on-LAN
Состояние OFF означает, что у системы нет питания, верно? Кажущаяся простота обманчива. Например, светодиод Ethernet горит даже в этом состоянии, потому что в вашей системе включен wake-on-LAN (WOL, пробуждение по [сигналу из] локальной сети). Убедитесь, написав:
$# sudo ethtool <interface name>Где вместо может быть, например, eth0 (ethtool находится в пакетах Linux с тем же названием). Если «Wake-on» в выводе показывает g, удаленные хосты могут загрузить систему, отправив MagicPacket. Если вы не хотите удаленно включать свою систему сами и давать такую возможность другим, отключите WOL в системном BIOS меню, или с помощью:
$# sudo ethtool -s <interface name> wol dПроцессор, отвечающий на MagicPacket, может быть Baseboard Management Controller’ом (BMC) или частью сетевого интерфейса.
Intel Management Engine, Platform Controller Hub и Minix
BMC — не единственный микроконтроллер (MCU), который может “слушать” номинально выключенную систему. В системах x86_64 есть программный пакет Intel Management Engine (IME) для удаленного управления системами. Широкий спектр устройств, от серверов до ноутбуков, обладают технологией, которая обладает таким функционалом, как KVM Remote Control или Intel Capability Licensing Service. Согласно собственному инструменту Intel, в IME есть непропатченные уязвимости. Плохие новости — отключить IME сложно. Траммелл Хадсон (Trammell Hudson) создал проект me_cleaner, стирающий некоторые наиболее вопиющие компоненты IME, например, встроенный веб-сервер, но в то же время есть шанс, что использование проекта превратит систему, на которой он запущен, в кирпич.
Прошивка IME и программа System Management Mode (SMM), которая следует за ней на загрузке, основаны на операционной системе Minix и запускаются на отдельном процессоре Platform Controller Hub, а не основном ЦП системы. Затем SMM запускает на основном процессоре программу Universal Extensible Firmware Interface (UEFI), о которой писали уже не раз. Группа Coreboot начала в Google захватывающе амбициозный проект Non-Extensible Reduced Firmware (NERF), цель которого — заменить не только UEFI, но и ранние компоненты пользовательского пространства Linux, например, systemd. А пока мы ждем результатов, пользователи Linux могут приобрести ноутбуки от Purism, System76 или Dell, на которых IME отключен, плюс, можем надеяться на ноутбуки с 64-битным ARM процессором.
Загрузчики
Что помимо запуска забагованного шпионского ПО делает загрузочная прошивка? Задача загрузчика — предоставить только что включенному процессору необходимые ресурсы для запуска операционной системы общего назначения вроде Linux. Во время включения нет не только виртуальной памяти, но и DRAM до момента поднятия ее контроллера. Затем загрузчик включает источники питания и сканирует шины и интерфейсы, чтобы найти образ ядра и корневую файловую систему. Популярные загрузчики, например, U-Boot и GRUB, обладают поддержкой как распространенных интерфейсов вроде USB, PCI и NFS, так и других более специализированных встроенных устройств, таких как NOR- и NAND-flash. Загрузчики также взаимодействуют с аппаратными устройствами безопасности, например, Trusted Platform Module (TPM), чтобы установить цепочку доверия с начала загрузки.

Запуск загрузчика U-boot в песочнице на сервере сборки.
Популярный загрузчик с открытым исходным кодом U-Boot поддерживается системами от Raspberry Pi до устройств Nintendo, автомобильных плат и Chromebook’ов. Системный журнал отсутствует, а если что-то идет не так, может не быть даже консольного вывода. Чтобы облегчить отладку, команда U-Boot предоставляет песочницу для тестирования патчей на хосте сборки или даже в системе Непрерывной Интеграции. На системе, где установлены обычные инструменты для разработки вроде Git и GNU Compiler Collection (GCC), разобраться в песочнице U-Boot не составит труда.
$# git clone git://git.denx.de/u-boot; cd u-boot
$# make ARCH=sandbox defconfig
$# make; ./u-boot
=> printenv
=> help
Вот и все: вы запустили U-Boot на x86_64 и можете тестировать каверзные фичи, например, переразбиение фиктивных запоминающих устройств, манипуляцию секретными ключами на базе TPM и горячее подключение (hotplug) USB-устройств. Песочница U-Boot может быть одноэтапной в рамках отладчика GDB. Разработка с использованием песочницы в 10 раз быстрее, чем тестирование путем перезаписи загрузчика на плату, плюс, “кирпичную” песочницу можно восстановить нажатием Ctrl+C.
Запуск ядра
Снабжение загружающегося ядра
По завершении своих задач, загрузчик выполнит переключение на код ядра, которое он загрузил в основную память, и начнет его исполнение, передав все параметры командной строки, которые уточнил пользователь. Какой программой является ядро? file /boot/vmlinuz показывает, что это bzImage. В дереве источников Linux есть инструмент extract-vmlinux, который можно использовать для распаковки файла:
$# scripts/extract-vmlinux /boot/vmlinuz-$(uname -r) > vmlinux
$# file vmlinux
vmlinux: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically
linked, stripped
Ядро представляет собой Executable and Linking Format (ELF) бинарный файл, как и программы пользовательского пространства Linux. Это значит, что мы можем использовать команды из пакета binutils, такие как readelf, чтобы его изучить. Сравните, например, такие выводы:
$# readelf -S /bin/date
$# readelf -S vmlinux
Список разделов в бинарных файлах по большей части аналогичен.
Итак, ядро должно запустить другие ELF бинарники Linux… Но как запускаются программы пользовательского пространства? В функции
main(), верно? Не совсем.Перед запуском функции
main() программам необходим контекст выполнения, включая heap- (куча) и stack- (стек) память, плюс, файловые дескрипторы для stdio, stdout и stderr. Программы пользовательского пространства получают эти ресурсы из стандартной библиотеки (glibc для большей части Linux систем). Рассмотрим следующие:$# file /bin/date
/bin/date: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically
linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32,
BuildID[sha1]=14e8563676febeb06d701dbee35d225c5a8e565a,
strippedУ бинарных файлов ELF есть интерпретатор, также как у скриптов Bash и Python. Но его не нужно уточнять через
#!, как в скриптах, потому что ELF — собственный формат Linux. Интерпретатор ELF снабжает бинарный файл всеми необходимыми ресурсами с помощью вызова _start() — функции, доступной в исходном пакете glibc, который можно изучить через GDB. У ядра, очевидно, нет интерпретатора, и оно должно снабжать себя самостоятельно, но как? Исследование запуска ядра с GDB дает ответ на этот вопрос. Для начала, установите пакет отладки ядра, в котором содержится неурезанная версия
vmlinux, например, apt-get install linux-image-amd64-dbg. Или скомпилируйте и установите из какого-то источника собственное ядро, например, следуя инструкциям из отличной Debian Kernel Handbook. gdb vmlinux, за которым следует info files, показывает ELF раздел init.text. Укажите старт выполнения программы в init.text с помощью l *(address), где address — шестнадцатеричный старт init.text. GDB укажет, что ядро x86_64 запускается в файле ядра arch/x86/kernel/head_64.S, где мы найдем функцию сборки start_cpu0() и код, который явно создает стек и распаковывает zImage перед вызовом функции x86_64 start_kernel(). 32-битные ядра ARM имеют схожий arch/arm/kernel/head.S. start_kernel() не зависит от архитектуры, поэтому функция находится в init/main.c ядра. Можно сказать, что start_kernel() является настоящей main() функцией Linux.От start_kernel() до PID 1
Манифест оборудования ядра: таблицы ACPI и деревья устройств
При загрузке ядру необходима информация об оборудовании помимо типа процессора, для которого оно было скомпилировано. Инструкции в коде дополнены конфигурационными данными, которые хранятся отдельно. Существует два основных метода хранения данных: деревья устройств (Device Tree) and ACPI таблицы. Ядро узнает из этих файлов, какое оборудование нужно запускать на каждой загрузке.
Для встроенных устройств дерево устройств (ДУ) является манифестом установленного оборудования. ДУ — файл, который компилируется в одно время с исходником ядра и обычно находится в /boot вместе с
vmlinux. Чтобы посмотреть, что находится в бинарном дереве устройств на ARM устройстве, просто воспользуйтесь командой strings из пакета binutils в файле, имя которого соответствует /boot/*.dtb, так как dtb означает бинарный файл дерева устройств (Device-Tree Binary). ДУ можно изменить, отредактировав JSON-подобные файлы, из которых оно состоит, и перезапустив специальный dtc компилятор, предоставляющийся с исходником ядра. ДУ — статический файл, чей путь обычно передается ядру загрузчиками в командной строке, но в последние годы был добавлен оверлей дерева устройств, где ядро может динамически подгружать дополнительные фрагменты в ответ на hotplug-события после загрузки.Семейство x86 и многие ARM64 устройства бизнес-уровня используют альтернативный механизм Advanced Configuration and Power Interface (ACPI, усовершенствованный интерфейс управления конфигурацией и питанием). В отличие от ДУ, информация ACPI хранится в виртуальной файловой системе
/sys/firmware/acpi/tables, которая создается ядром на запуске через обращение к встроенному ПЗУ. Для чтения ACPI таблиц воспользуйтесь командой acpidump из пакета acpica-tools. Вот пример:
ACPI таблицы на ноутбуках Lenovo готовы к Windows 2001.
Да, ваша Linux система готова к Windows 2001, если захотите ее установить. В ACPI есть как методы, так и данные, в отличие от ДУ, который больше похож на язык описания аппаратуры. Методы ACPI продолжают быть активными и после загрузки. Например, если запустить команду acpi_listen (из пакета apcid), а затем закрыть и открыть крышку ноутбука, увидим, что функционал ACPI продолжал работать все это время. Временная и динамическая перезапись таблиц ACPI возможна, но для постоянного изменения потребуется взаимодействие с меню BIOS на загрузке или перепрошивка ПЗУ. Вместо таких сложностей, возможно вам стоит просто установить coreboot, замену прошивки с открытым исходным кодом.
От start_kernel() до пользовательского пространства
Код в
init/main.c, на удивление, легко читается и, как ни странно, до сих пор носит оригинальный копирайт Линуса Торвальдса (Linus Torvalds) из 1991-1992. Строки, найденные в dmesg | head запущенной системы, в основном берут начало из этого исходного файла. Первый ЦП зарегистрирован системой, глобальные структуры данных инициализированы, один за другим поднимаются планировщик, обработчики прерываний (IRQs), таймеры и консоль. Все timestamp’ы до запуска timekeeping_init() равны нулю. Эта часть инициализации ядра синхронная, то есть исполнение происходит только в одном потоке. Функции не выполняются до тех пор, пока не будет завершена и возвращена последняя из них. В результате, вывод dmesg будет полностью воспроизводимым даже между двумя системами, до тех пор пока они обладают одинаковыми ДУ или ACPI таблицами. Linux ведет себя также как операционная система реального времени (RTOS, real-time operating system), запущенная на MCU, например, QNX или VxWorks. Эта ситуация сохраняется в функции rest_init(), которая вызывается start_kernel() в момент ее завершения.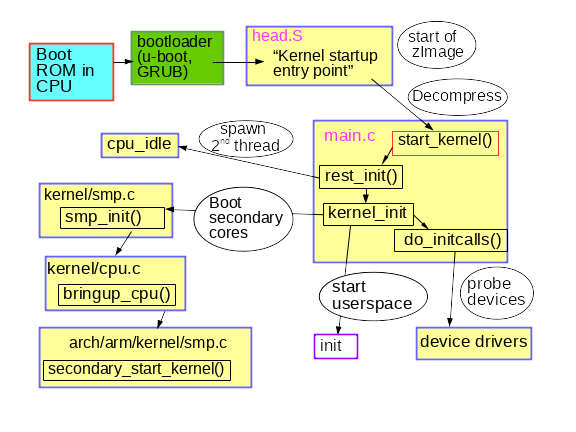
Краткое описание раннего процесса загрузки ядра
Скромно названный
rest_init() создает новый поток, который запускает kernel_init(), который в свою очередь вызывает do_initcalls(). Пользователи могут следить за работой initcalls, добавив initcalls_debug в командную строку ядра. В результате вы будете получать сущность dmesg каждый раз при запуске функции initcall. initcalls проходит через семь последовательных уровней: early, core, postcore, arch, subsys, fs, device и late. Самая заметная для пользователей часть initcalls — определение и установка периферийных устройств процессора: шины, сеть, хранилище, дисплеи, и так далее, сопровождающиеся загрузкой их модулей ядра. rest_init() также создает второй поток в загрузочном процессоре, который начинается с запуска cpu_idle(), пока планировщик распределяет его работу.kernel_init() также устанавливает симметричную мультипроцессорность (symmetric multiprocessing, SMP). В современных ядрах найти этот момент в выводе dmesg можно по строчке «Bringing up secondary CPUs...». SMP затем делает “горячее подключение” ЦП, что означает, что оно управляет его жизненным циклом с помощью стейт-машины условно похожей на те, что используются в устройствах вроде автоопределяющихся USB карт памяти. Система управления питанием ядра часто выключает отдельные ядра (core), и пробуждает их по мере необходимости, чтобы один и тот же hotplug код ЦП раз за разом вызывался на незанятой машине. Посмотрите на то, как система управления питанием вызывает hotplug ЦП с помощью инструмента BCC под названием offcputime.py.Обратите внимание, что код в
init/main.c почти закончил исполнение в момент запуска smp_init(). Процессор загрузки завершил большую часть разовой инициализации, которую другим ядрам (core) повторять не нужно. Тем не менее, потоки должны быть созданы для каждого ядра (core), чтобы на каждом управлять прерываниями (IRQs), workqueue, таймерами и событиями питания. К примеру, посмотрите на потоки процессоров, которые обслуживают softirqs и workqueues, с помощью команды ps -o psr.$\# ps -o pid,psr,comm $(pgrep ksoftirqd)
PID PSR COMMAND
7 0 ksoftirqd/0
16 1 ksoftirqd/1
22 2 ksoftirqd/2
28 3 ksoftirqd/3
$\# ps -o pid,psr,comm $(pgrep kworker)
PID PSR COMMAND
4 0 kworker/0:0H
18 1 kworker/1:0H
24 2 kworker/2:0H
30 3 kworker/3:0H
[ . . . ]где поле PSR означает “процессор”. Каждое ядро (core) должно иметь собственные таймеры и cpuhp обработчики hotplug.
И наконец, как запускается пользовательское пространство? Ближе к концу,
kernel_init() ищет initrd, который может может запустить процесс init от его имени. Если его нет, ядро самостоятельно исполняет init. Зачем тогда может быть нужен initrd?Раннее пользовательское пространство: кто заказывал initrd?
Помимо дерева устройств еще один путь к файлу, опционально предоставляемый ядру на загрузке, принадлежит
initrd. initrd часто находится в /boot вместе с bzImage файлом vmlinuz в x86, или вместе с похожим uImage и деревом устройств для ARM. Список содержимого intrd можно посмотреть с помощью инструмента lsinitramfs, который является частью пакета initramfs-tools-core. initrd образ дистрибутива содержит минимальные каталоги /bin, /sbin и /etc, а также модули ядра и файлы в /scripts. Все должно выглядеть более-менее знакомым, так как initrd по большей части похож на упрощенную корневую файловую систему Linux. Такое сходство немного обманчиво, так как почти все исполняемые файлы в /bin и /sbin внутри ramdisk’а — симлинки на бинарный файл BusyBox, что делает директории /bin и /sbin в 10 раз меньше, чем в glibc. Зачем пытаться создавать
initrd, если единственное, что он делает — загружает некоторые модули и запускает init в обычной корневой файловой системе? Рассмотрим зашифрованную корневую файловую систему. Расшифровка может зависеть от загрузки модуля ядра, хранящегося в /lib/modules корневой файловой системы… и, ожидаемо, в initrd. Крипто-модуль может быть статически скомпилирован в ядро, а не загружен из файла, но есть несколько причин отказаться от этого. Например, статическая компиляция ядра с модулями может сделать его слишком большим, чтобы вместить в доступном хранилище, или же статическая компиляция может нарушать условия лицензии программного обеспечения. Неудивительно, драйвера хранилища, сети и HID (human input devices) также могут быть представлены в initrd — по сути, любой код, который не является обязательной частью ядра, необходимой для монтирования корневой файловой системы. Также в initrd пользователи могут хранить собственный код ACPI таблиц.
Веселье с rescue shell и кастомным initrd.
initrd также отлично подходит для тестирования файловых систем и устройств хранения данных. Положите инструменты для тестирования в initrd и запустите тесты из памяти, а не из тестируемого объекта.Наконец, когда
init работает, система запущена! Поскольку вторичные процессоры уже работают, машина стала асинхронным, выгружаемым, непредсказуемым и высокопроизводительным существом, которое мы все знаем и любим. Действительно, ps -o pid,psr,comm -p показывает, что процесс init пользовательского пространства больше не запущен на загрузочном процессоре. Итог
Процесс загрузки Linux звучит запретно, с учетом количества затронутого ПО, даже на простейшем встроенном устройстве. С другой стороны, процесс загрузки довольно прост, так как излишняя сложность, вызванная вытесняющей многозадачностью, RCU и состоянием гонки, здесь отсутствует. Обращая внимание только на ядро и PID 1, можно упустить из виду большую работу, проделанную загрузчиками и вспомогательными процессорами для подготовки платформы к запуску ядра. Ядро, безусловно, отличается от других программ Linux, но применение инструментов для работы с другими бинарными файлами ELF поможет лучше понять его структуру. Изучение работоспособного процесса загрузки подготовит к сбоям, возможным в будущем.
THE END
Ждём ваши комментарии и вопрос, как обычно, или тут, или на нашем открытом уроке, где отдуваться будет Леонид.
Комментарии (8)

jcmvbkbc
06.10.2018 02:01Помимо дерева устройств еще один путь к файлу, опционально предоставляемый ядру на загрузке, принадлежит initrd
Нифига не путь к файлу, а сам файл — загружается загрузчиком так же, как и образ ядра, и адрес по которому он был загружен передаётся ядру при старте.
jcmvbkbc
06.10.2018 02:27ядро x86_64 запускается в файле ядра arch/x86/kernel/head_64.S, где мы найдем функцию сборки start_cpu0() и код, который явно создает стек и распаковывает zImage перед вызовом функции x86_64 start_kernel().
Всё смешалось в этом предложении. Ссылка указывает в arch/x86/boot/compressed/head_64.S, а в тексте — arch/x86/kernel/head_64.S. Это разные файлы, работающие в разное время. Первый работает сначала, он выполняет распаковку vmlinux. Он не является частью vmlinux, а добавляется в bzImage вместе с упакованным vmlinux. Второй является частью vmlinux. В нём находится код, выполняемый всеми процессорами при старте. start_cpu0 находится именно в нём.
gre
07.10.2018 08:20CodeRush jcmvbkbc Xalium
Может быть напишите корректную статью — что в 2018 году происходит при загрузке компьютера? :)CodeRush
07.10.2018 08:42+1У меня есть таковая от 2013 года, и только про самые первые шаги. Вообще посоветую вот эту статью, в которой авторы занимаются оптимизацией скорости загрузки, хотя она и не про «что происходит», а про «какого хрена так медленно», но и нужный вам вопрос тоже освещен неплохо.
BiosUefi
08.10.2018 10:02>>возможно вам стоит просто установить coreboot,
особенно для того железа которое не поддерживается, но даже если и поддерживается то «не про вашу честь».
Помницца обрадовался что Menlow было в списке поддерживаемых, начал ковырять, СМС код отсутствует, видео ROM отсутствует, инициализация памяти отсутствует, в коде прямые ошибки валящие инициализацию (переход из CAR в свежеинициализированную RАM).
В статье, каждые пять строк претендуют как минимум на отдельную статью.
А коль набежит стая о хомячков, то писать комменты милостливо позволят раз в сутки.
CodeRush
Практически все, что здесь написано — не выдерживает никакой критики, извините. Просто по порядку первые несколько вещей:
Это не программный пакет, а аппаратно-программный комплекс.Которые были пропатчены сразу же.
Треммелл не имеет отношения к этому проект, а создал его итальянский студент Никола Корна.
PCH — это северный мост, и на отдельном процессоре запускается только прошивка ME, а SMM — это режим основного процессора x86, и код, работающий в нем, не имеет никакого отношения к Minix.
Буллшит, UEFI — это не программа, а интерфейс, а SMM к UEFI вообще отношения не имеет, и тем более не реализует его. Запускается при старте не UEFI, а PI/AGESA, и первый код SMM стартует значительно позже, в фазе DXE.
Вот это все — вовсе не задача загрузчика. Задача загрузчика — считать с диска ядро ОС, распаковать его, отобразить в память и передать ему управление. Все описанное в цитате делается прошивкой, в задачи которой, кроме инициализации железа, входит еще и предоставление интерфейса для загрузчиков, абстрагирующего их от оборудования. Одним из таких интерфейсов как раз и является UEFI, пришедший на смену более старому интерфейсу BIOS Interrupt Call.
Дальше читать не стал, прошу пардону. К переводчику претензий особых не имею, а автору посоветую
идти в жопупочитать нормальных книг и самому сначала понять, как система работает, а не звон слушать очередной, тем более ретранслировать его в виде подобных статей.Xalium
Перед этим есть предложение «Что помимо запуска забагованного шпионского ПО делает загрузочная прошивка?». Свалили в кучу прошивку и загрузчик.
CodeRush
При этом оно в главе про загрузчики, ага.
Про шпионское ПО я даже комментировать не стал, потому что там ничего другого, кроме как послать по вектору еще раз, в голову не приходит. Фанаты — они фанаты и есть, им сколько не рассказывай, почему так, а не иначе — все равно останешься махровым проприетарщиком, продавшимся капиталистам за корзину печенья.