Если вы читали предыдущие статьи, то знаете о моём новом увлечении низкоуровневым программированием. Я написал несколько статей о программировании на ассемблере для
x86_64 Linux и в то же время начал погружаться в исходный код ядра Linux.Мне очень интересно разобраться, как работают низкоуровневые штуки: как программы запускаются на моём компьютере, как они расположены в памяти, как ядро управляет процессами и памятью, как работает сетевой стек на низком уровне и многое другое. Итак, я решил написать еще одну серию статей о ядре Linux для архитектуры x86_64.
Обратите внимание, что я не профессиональный разработчик ядра и не пишу код ядра на работе. Это всего лишь хобби. Мне просто нравятся низкоуровневые вещи и интересно в них копаться. Поэтому если заметите какую-то путаницу или появилятся вопросы/замечания, свяжитесь со мной в твиттере, по почте или просто создайте тикет. Буду благодарен.
Все статьи публикуются в репозитории GitHub, и если что-то не так с моим английским или содержанием статьи, не стесняйтесь отправить пулл-реквест.
Обратите внимание, что это не официальная документация, а просто обучение и обмен знаниями.
Необходимые знания
- Понимание кода на C
- Понимание кода ассемблера (синтаксис AT&T)
Во всяком случае, если вы только начинаете изучать такие инструменты, я постараюсь что-то объяснить в этой и следующих статьях. Окей, с вступлением закончили, пора погрузиться в ядро Linux и низкоуровневые вещи.
Я начал писать эту книгу во времена ядра Linux 3.18, и многое могло измениться с тех пор. Если есть изменения, я буду соответственно обновлять статьи.
Волшебная кнопка включения, что дальше?
Хотя это статьи о ядре Linux, мы пока не дошли до него — по крайней мере, в этом параграфе. Как только вы нажмете волшебную кнопку питания на своём ноутбуке или настольном компьютере, он начинает работать. Материнская плата посылает сигнал к блоку питания. После получения сигнала он обеспечивает компьютеру необходимое количество электроэнергии. Как только материнская плата получает сигнал «Питание в норме», то пытается запустить CPU. Тот сбрасывает все оставшиеся данные в своих регистрах и устанавливает предопределённые значения для каждого из них.
У процессоров 80386 и более поздних версий после перезагрузки должны быть такие значения в регистрах CPU:
IP 0xfff0 CS selector 0xf000 CS base 0xffff0000
Процессор начинает работать в реальном режиме. Давайте немного вернемся назад и попытаемся понять сегментацию памяти в этом режиме. Реальный режим поддерживается на всех x86-совместимых процессорах: от 8086 до современных 64-разрядных процессоров Intel. В процессоре 8086 используется 20-битная шина адресов, то есть он может работать с адресным пространством
0-0xFFFFF или 1 мегабайт. Но у него есть только 16-битные регистры с максимальным адресом 2^16-1 или 0xffff (64 килобайта).Сегментация памяти нужна для использования всего доступного адресного пространства. Вся память делится на небольшие сегменты фиксированного размера по
65536 байт (64 КБ). Поскольку с 16-битными регистрами мы не можем обратиться к памяти выше 64 КБ, был разработан альтернативный метод.Адрес состоит из двух частей: 1) селектор сегмента с базовым адресом; 2) смещение от базового адреса. В реальном режиме базовым адресом селектора сегмента является
селектор сегмента * 16. Таким образом, чтобы получить физический адрес в памяти, нужно умножить часть селектора сегмента на 16 и добавить к нему смещение:Физический адрес = Селектор сегмента * 16 + СмещениеНапример, если у регистра
CS:IP значение 0x2000:0x0010, то соответствующий физический адрес будет таким:>>> hex((0x2000 << 4) + 0x0010)
'0x20010'Но если взять селектор наибольшего сегмента и смещение
0xffff:0xffff, то получается адрес:>>> hex((0xffff << 4) + 0xffff)
'0x10ffef'то есть
65520 байт после первого мегабайта. Поскольку в реальном режиме доступен только один мегабайт, 0x10ffef становится 0x00ffef с отключенной линией A20.Хорошо, теперь мы немного знаем о реальном режиме и адресации памяти в этом режиме. Вернемся к обсуждению значений регистров после сброса.
Регистр
CS состоит из двух частей: видимого селектора сегментов и скрытого базового адреса. Хотя базовый адрес обычно формируется путём умножения значения селектора сегмента на 16, но во время аппаратного сброса селектор сегмента в регистре CS получает значение 0xf000, а базовый адрес — 0xffff0000. Процессор использует этот специальный базовый адрес, пока не изменится CS.Начальный адрес формируется добавлением базового адреса к значению в регистре EIP:
>>> 0xffff0000 + 0xfff0
'0xfffffff0'Мы получаем
0xfffffff0, что на 16 байт ниже 4 ГБ. Эта точка называется вектором сброса. Это расположение в памяти, где CPU ждёт первую инструкцию для выполнения после сброса: операцию перехода (jmp), которая обычно указывает на точку входа BIOS. Например, если посмотреть исходный код coreboot (src/cpu/x86/16bit/reset16.inc), мы увидим: .section ".reset", "ax", %progbits
.code16
.globl _start
_start:
.byte 0xe9
.int _start16bit - ( . + 2 )
...Здесь мы видим код операции (опкод)
jmp, а именно 0xe9, и адрес назначения _start16bit - ( . + 2).Мы также видим, что раздел
reset составляет 16 байт, и он компилируется для запуска с адреса 0xfffff0 (src/cpu/x86/16bit/reset16.ld):SECTIONS {
/* Trigger an error if I have an unuseable start address */
_bogus = ASSERT(_start16bit >= 0xffff0000, "_start16bit too low. Please report.");
_ROMTOP = 0xfffffff0;
. = _ROMTOP;
.reset . : {
*(.reset);
. = 15;
BYTE(0x00);
}
}Теперь запускается BIOS; после инициализации и проверки оборудования BIOS необходимо найти загрузочное устройство. Порядок загрузки сохраняется в конфигурации BIOS. При попытке загрузки с жёсткого диска BIOS пытается найти загрузочный сектор. На дисках с разметкой разделов MBR загрузочный сектор хранится в первых 446 байтах первого сектора, где каждый сектор равен 512 байтам. Последние два байта первого сектора —
0x55 и 0xaa. Они показывают BIOS, что это загрузочное устройство.Например:
;
; Примечание: этот пример написан в синтаксисе ассемблера Intel x86
;
[BITS 16]
boot:
mov al, '!'
mov ah, 0x0e
mov bh, 0x00
mov bl, 0x07
int 0x10
jmp $
times 510-($-$$) db 0
db 0x55
db 0xaaСобираем и запускаем:
nasm -f bin boot.nasm && qemu-system-x86_64 boot QEMU получает команду использовать двоичный файл
boot, который мы только что создали как образ диска. Так как двоичный файл, сгенерированный выше, удовлетворяет требованиям загрузочного сектора (начало в 0x7c00 и завершение магической последовательностью), то QEMU будет рассматривать двоичный файл как главную загрузочную запись (MBR) образа диска.Вы увидите:
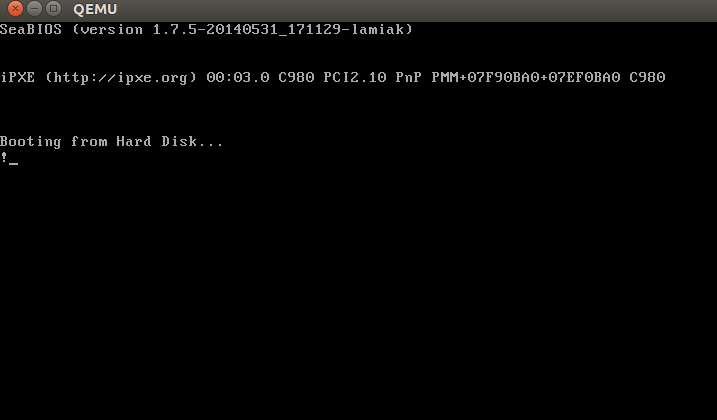
В этом примере мы видим, что код выполняется в 16-битном реальном режиме и начинается с адреса
0x7c00 в памяти. После запуска он вызывает прерывание 0x10, которое просто печатает символ !; заполняет оставшиеся 510 байт нулями и заканчивается двумя волшебными байтами 0xaa и 0x55.Двоичный дамп можно посмотреть утилитой
objdump:nasm -f bin boot.nasm
objdump -D -b binary -mi386 -Maddr16,data16,intel boot Конечно, в реальном загрузочном секторе — код для продолжения процесса загрузки и таблица разделов вместо кучи нулей и восклицательного знака :). С этого момента BIOS передаёт управление загрузчику.
Примечание: как объясняется выше, CPU находится в реальном режиме; где вычисление физического адреса в памяти происходит следующим образом:
Физический адрес = Селектор сегмента * 16 + СмещениеУ нас только 16-битные регистры общего назначения, а максимальное значение 16-битного регистра
0xffff, поэтому на самых больших значениях результат будет:>>> hex((0xffff * 16) + 0xffff)
'0x10ffef'где
0x10ffef равно 1 МБ + 64 КБ - 16 байт. В процессоре 8086 (первый процессор с реальным режимом) 20-битная адресная линия. Поскольку 2^20 = 1048576, то фактически доступная память составляет 1 МБ.В целом адресация памяти реального режима выглядит следующим образом:
0x00000000 - 0x000003FF – таблица векторов прерываний реального режима 0x00000400 - 0x000004FF - область данных BIOS 0x00000500 - 0x00007BFF - не используется 0x00007C00 - 0x00007DFF - наш загрузчик 0x00007E00 - 0x0009FFFF - не используется 0x000A0000 - 0x000BFFFF - память Video RAM (VRAM) 0x000B0000 - 0x000B7777 - видеопамять монохромного режима 0x000B8000 - 0x000BFFFF - видеопамять цветного режима 0x000C0000 - 0x000C7FFF - Video ROM BIOS 0x000C8000 - 0x000EFFFF - теневая область (BIOS Shadow) 0x000F0000 - 0x000FFFFF - системный BIOS
В начале статьи написано, что первая инструкция для процессора находится по адресу
0xFFFFFFF0, что намного больше 0xFFFFF (1 МБ). Как CPU получить доступ к этому адресу в реальном режиме? Ответ в документации coreboot:0xFFFE_0000 - 0xFFFF_FFFF: 128 килобайт ROM транслируются в адресное пространство В начале выполнения BIOS находится не в RAM, а в ROM.
Загрузчик
Ядро Linux можно загружать разными загрузчиками, такими как GRUB 2 и syslinux. В ядре есть протокол загрузки, который определяет требования к загрузчику для реализации поддержки Linux. В данном примере мы работаем с GRUB 2.
Продолжая процесс загрузки, BIOS выбрал загрузочное устройство и передал управление загрузочному сектору, выполнение начинается с boot.img. Из-за ограниченного объёма это очень простой код. Он содержит указатель для перехода к основному образу GRUB 2. Тот начинается с diskboot.img и обычно хранится сразу после первого сектора в неиспользуемом пространстве перед первым разделом. Приведённый выше код загружает в память остальную часть образа, который содержит ядро GRUB 2 и драйверы для обработки файловых систем. После этого выполняется функция grub_main.
Функция
grub_main инициализирует консоль, возвращает базовый адрес для модулей, устанавливает корневое устройство, загружает/парсит конфигурационный файл grub, загружает модули и т.д. В конце выполнения она переводит grub в нормальный режим. Функция grub_normal_execute (из исходного файла grub-core/normal/main.c) завершает последние приготовления и показывает меню для выбора операционной системы. Когда мы выбираем один из пунктов меню grub, запускается функция grub_menu_execute_entry, которая выполняет команду grub boot и загружает выбранную ОС.Как указано в протоколе загрузки ядра, загрузчик должен прочитать и заполнить некоторые поля заголовка установки ядра, который начинается со смещения
0x01f1 от кода установки ядра. Это смещение указано в скрипте линкера. Заголовок ядра arch/x86/boot/header.S начинается с: .globl hdr
hdr:
setup_sects: .byte 0
root_flags: .word ROOT_RDONLY
syssize: .long 0
ram_size: .word 0
vid_mode: .word SVGA_MODE
root_dev: .word 0
boot_flag: .word 0xAA55Загрузчик должен заполнить этот и остальные заголовки (которые помечены только как тип
write в протоколе загрузки Linux, как в данном примере) значениями, которые получил из командной строки или рассчитал во время загрузки. Сейчас мы не будем подробно останавливаться на описаниях и пояснениях для всех полей заголовка. Позже обсудим, как ядро их использует. Описание всех полей см. в протоколе загрузки.Как видим в протоколе загрузки ядра, память будет отображаться следующим образом:
| Защищённый режим ядра |
100000 +------------------------+
| Отображение I/O |
0A0000 +------------------------+
| Зарезерв. для BIOS | Как можно больше оставить свободным
~ ~
| Командная строка | (также может находиться за отметкой X+10000)
X+10000 +------------------------+
| Стек/куча | Для использования кодом реального режима ядра
X+08000 +------------------------+
| Установка ядра | Код реального режима ядра
| Загрузочный сектор ядра| Легаси-загрузочный сектор ядра
X +------------------------+
| Загрузчик | <- Точка входа 0x7C00 загрузочного сектора
001000 +------------------------+
| Зарезерв. для MBR/BIOS |
000800 +------------------------+
| Обычно использ. MBR |
000600 +------------------------+
| Использ. только BIOS |
000000 +------------------------+
Итак, когда загрузчик передаёт управление ядру, оно начинается с адреса:
X + sizeof (KernelBootSector) + 1где
X — адрес загрузочного сектора ядра. В нашем случае X равен 0x10000, как видно в дампе памяти:
Загрузчик перенёс ядро Linux в память, заполнил поля заголовка, а затем перешёл на соответствующий адрес памяти. Теперь мы можем перейти непосредственно к коду установки ядра.
Начало этапа установки ядра
Наконец-то мы в ядре! Хотя технически оно ещё не запущено. Сначала часть установки ядра должна кое-что настроить, в том числе декомпрессор и некоторые вещи с управлением памятью. После всего этого она распакует настоящее ядро и перейдёт к нему. Выполнение установки начинается в arch/x86/boot/header.S с символа _start.
На первый взгляд это может показаться немного странным, так как перед ним есть несколько инструкций. Но давным-давно у ядра Linux был собственный загрузчик. Теперь же если запустить, например,
qemu-system-x86_64 vmlinuz-3.18-generic вы увидите:

Собственно, файл
header.S начинается с магического числа MZ (см. скриншот дампа выше), текста сообщения об ошибке и заголовка PE:#ifdef CONFIG_EFI_STUB
# "MZ", MS-DOS header
.byte 0x4d
.byte 0x5a
#endif
...
...
...
pe_header:
.ascii "PE"
.word 0Он нужен для загрузки операционной системы с поддержкой UEFI. Его устройство рассмотрим в следующих главах.
Фактическая точка входа для установки ядра:
// header.S line 292
.globl _start
_start:Загрузчик (grub2 и другие) знает об этой точке (смещение
0x200 от MZ) и переходит прямо к ней, хотя header.S начинается с раздела .bstext, где находится текст сообщения об ошибке://
// arch/x86/boot/setup.ld
//
. = 0; // current position
.bstext : { *(.bstext) } // put .bstext section to position 0
.bsdata : { *(.bsdata) }Точка входа установки ядра:
.globl _start
_start:
.byte 0xeb
.byte start_of_setup-1f
1:
//
// rest of the header
//Здесь мы видим код операции
jmp (0xeb), который переходит к точке start_of_setup-1f. В нотации Nf, например, 2f ссылается на локальную метку 2:. В нашем случае это метка 1, которая присутствует сразу после перехода, и она содержит остальную часть заголовка setup. Сразу после заголовка установки мы видим раздел .entrytext, который начинается с метки start_of_setup.Это первый фактически выполняемый код (кроме предыдущих инструкций перехода, конечно). После того, как часть установки ядра получает управление от загрузчика, первая инструкция
jmp находится по смещению 0x200 от начала реального режима ядра, то есть после первых 512 байт. Это можно увидеть как в протоколе загрузки ядра Linux, так и в исходном коде grub2:segment = grub_linux_real_target >> 4;
state.gs = state.fs = state.es = state.ds = state.ss = segment;
state.cs = segment + 0x20;В нашем случае ядро загружается по адресу
0x10000. Это означает, что после запуска установки ядра регистры сегментов будут иметь следующие значения:gs = fs = es = ds = ss = 0x10000
cs = 0x10200После перехода к
start_of_setup ядро должно сделать следующее:- Убедиться, что все значения регистров сегментов одинаковы
- При необходимости настроить правильный стек
- Настроить bss
- Перейти к коду C в arch/x86/boot/main.с
Посмотрим, как это реализовано.
Выравнивание регистров сегментов
Прежде всего ядро проверяет, что регистры сегментов
ds и es указывают на один и тот же адрес. Затем очищает флаг направления с помощью инструкции cld: movw %ds, %ax
movw %ax, %es
cldКак я писал ранее, grub2 по умолчанию загружает код установки ядра по адресу
0x10000, а cs по адресу 0x10200, потому что выполнение начинается не с начала файла, а с перехода сюда:_start:
.byte 0xeb
.byte start_of_setup-1fЭто смещение на
512 байт от 4d 5a. Также необходимо выровнять cs с 0x10200 до 0x10000, как и все остальные регистры сегментов. После этого устанавливаем стек: pushw %ds
pushw $6f
lretwЭта инструкция помещает на стек значение
ds, за ним следуют адрес метки 6 и инструкция lretw, которая загружает адрес метки 6 в регистр счётчика команд и загружает cs со значением ds. После этого у ds и cs будут одинаковые значения.Настройка стека
Почти весь этот код — часть процесса подготовки окружения для языка C в реальном режиме. Следующий шаг — проверить значение регистра
ss и создать корректный стек, если значение ss неверное: movw %ss, %dx
cmpw %ax, %dx
movw %sp, %dx
je 2fЭто может инициировать три разных сценария:
- у
ssдопустимое значение0x1000(как у всех остальных регистров, кромеcs) - у
ssнедопустимое значение, и флагCAN_USE_HEAPустановлен (см. ниже) - у
ssнедопустимое значение, и флагCAN_USE_HEAPне установлен (см. ниже)
Рассмотрим все сценарии по порядку:
- У
ssдопустимое значение (0x1000). В этом случае мы переходим к метке 2:
2: andw $~3, %dx
jnz 3f
movw $0xfffc, %dx
3: movw %ax, %ss
movzwl %dx, %esp
stiЗдесь мы устанавливаем выравнивание регистра
dx (который содержит значение sp, указанное загрузчиком) по 4 байтам и проверяем на нуль. Если он равен нулю, то помещаем в dx значение 0xfffc (выровненный по 4 байтам адрес перед максимальным размером сегмента 64 КБ). Если он не равен нулю, то продолжаем использовать значение sp, заданное загрузчиком (0xf7f4 в нашем случае). Затем помещаем значение ax в ss, что сохраняет правильный адрес сегмента 0x1000 и устанавливает правильный sp. Теперь у нас есть правильный стек:
- Во втором сценарии
ss != ds. Сначала помещаем значение _end (адрес конца кода установки) вdxи проверяем поле заголовкаloadflags, используя инструкциюtestb, чтобы проверить, можно ли использовать кучу. loadflags — это заголовок битовой маски, который определяется следующим образом:
#define LOADED_HIGH (1<<0)
#define QUIET_FLAG (1<<5)
#define KEEP_SEGMENTS (1<<6)
#define CAN_USE_HEAP (1<<7)и, как указано в протоколе загрузки:
Имя поля: loadflags
Это поле является битовой маской.
Бит 7 (запись): CAN_USE_HEAP
Установите этот бит равным 1, чтобы указать, что значение
heap_end_ptr допустимо. Если это поле пусто, будет отключена
часть функциональности установки. Если установлен бит
CAN_USE_HEAP, то в dx ставим значение heap_end_ptr (которое указывает на _end) и добавляем к нему STACK_SIZE (минимальный размер стека 1024 байта). После этого переходим к метке 2 (как в предыдущем случае) и делаем правильный стек.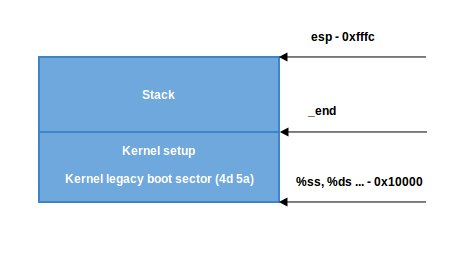
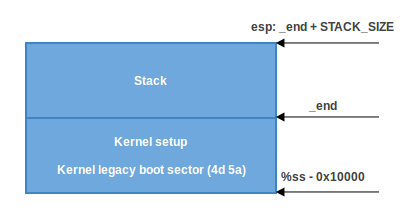
- Если
CAN_USE_HEAPне установлен, просто используем минимальный стек от_endдо_end + STACK_SIZE:
Настройка BSS
Нужны ещё два шага, прежде чем перейти к основному коду C: это настройка области BSS и проверка «волшебной» подписи. Сначала проверка подписи:
cmpl $0x5a5aaa55, setup_sig
jne setup_badИнструкция просто сравнивает setup_sig с магическим числом 0x5a5aaa55. Если они не равны, сообщается о неустранимой ошибке.
Если магическое число совпадает и у нас есть набор правильных регистров сегментов и стек, то осталось лишь настроить раздел BSS перед переходом к коду C.
Раздел BSS используется для хранения статически выделенных неинициализированных данных. Linux тщательно проверяет, что эта область памяти обнулилась:
movw $__bss_start, %di
movw $_end+3, %cx
xorl %eax, %eax
subw %di, %cx
shrw $2, %cx
rep; stoslПервым делом начальный адрес __bss_start перемещается в
di. Затем адрес _end + 3 (+3 для выравнивания по 4 байтам) перемещается в cx. Регистр eax очищается (с помощью инструкции xor), вычисляется размер раздела bss (cx-di) и он помещается в cx. Затем cx делится на четыре (размер «слова») и многократно используется инструкция stosl, сохраняя значение еах (нуль) в адрес, указывающий на di, автоматически увеличивая di на четыре и повторяя это до тех пор, пока сх не достигнет нуля). Чистый эффект этого кода заключается в том, что нули записываются во все слова в памяти от __bss_start до _end: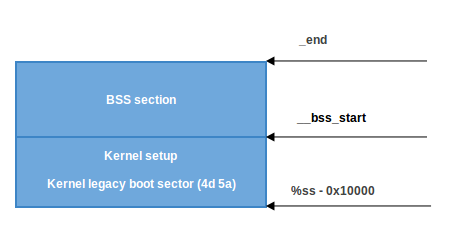
Переход к main
Вот и всё: у нас есть стек и BSS, так что можно перейти к функции
main() C: calll mainФункция
main() находится в arch/x86/boot/main.c. О ней поговорим в следующей части.Вывод
Это конец первой части об устройстве ядра Linux. Если у вас есть вопросы или предложения, свяжитесь со мной в твиттере, по почте или просто создайте тикет. В следующей части мы увидим первый код на C, который выполняется при установке ядра Linux, реализацию подпрограмм памяти, таких как
memset, memcpy, earlyprintk, раннюю реализацию и инициализацию консоли и многое другое.Ссылки
Комментарии (21)

myxo
03.11.2018 16:35+4Это замечательно, но ведь перевод первых нескольких глав уже существует.
proninyaroslav.gitbooks.io/linux-insides-ru/content/Booting/linux-bootstrap-1.html
Bombus
03.11.2018 20:43+2Теперь запускается BIOS; после инициализации и проверки оборудования BIOS необходимо найти загрузочное устройство. Порядок загрузки сохраняется в конфигурации BIOS.
А можно чуть подробнее раскрыть фразу «Теперь запускается BIOS»? Кто это делает? Кто выполняет настройку оборудования с указанными в биосе параметрами? Это делает:
— процессор биоса (есть ли такой)?
— центральный процессор выполняет код записанный в биосе?
— пресловутая Intel Management Engine?khim
04.11.2018 03:57+2Чтобы подробно объяснить как всё происходит придётся написать пару книг, сравнимых с тем, которую мы тут обсуждаем.
Лучше вернуться на 30 лет назад и посмотреть на то, как стартовал какой-нибудь Compaq Deskpro: включили процессор, выставили ему CS, как описано в статье и начали исполнять код. Всё.
В современном же мире у вас в компьютере десяток (а то и не один) процессоров, у каждого своя прошивка, часть загружается из основной памяти, часть нет, часть «заводится» BIOS'ом, часть, наоборот, стартует до него… в общем масса бурной деятельности, которая, для ващей убедительности ещё и нифига не документирована (то есть буквально: от Intel приходят бинарные блобы на несколько мег, про которые сказано, что их нужно в ваш BIOS внинковать и позвать в определённый момент… что точно они делают — документация умалчивает).
Так что если ваша цель — не потратить несколько лет на разборки с этими механизмами, а загрузить какую-нибудь OS… то лучше сделать вид, что мы вернулись в 1980е и у нас простой и бесхитростный 80386й «под капотом».CodeRush
04.11.2018 10:43+1Так что если ваша цель — не потратить несколько лет на разборки с этими механизмами, а загрузить какую-нибудь OS… то лучше сделать вид, что мы вернулись в 1980е и у нас простой и бесхитростный 80386й «под капотом».
Лучше не надо, потому что те механизмы, которые делают современный ПК похожим на 80386 — это такое хтоническое чудовище, что с ними лучше не сталкиваться никогда. UEFI имеет в разы более простой интерфейс с прошивкой, и лучше изучить один раз код Linux EFI stub, или любого минимального EFI-загрузчика, и забыть про этот легаси-ад навсегда.khim
05.11.2018 00:23Не видел никаких «более простых интерфейсов с прошивкой», увы. Сам по себе EFI — это куча безумно сложного кода, решающего простую задачу. То, что с ним приходится общаться — как по мне, так скорее проблема, чем достоинство. И да — «хтоническое чудовище» имеет место быть, но вот только от способа загрузки это особо не зависит.
Всё отличие, в сущности — используя интерфейсы прошлого века вы общаетесь как бы с чем-то простым и бесхитростным (хотя на самом деле нет), а общаясь с EFI — вы с самого начала отказываетесь от идеи контролировать что-либо.CodeRush
05.11.2018 01:04Мы, мне кажется, друг друга не понимаем.
"Положите загрузчик на диск по вот этому пути, сделайте в нем функцию EFIAPI efi_main(EFI_HANDLE Handle, EFI_SYSTEM_TABLE *SystemTable), которую вам прошивка и вызовет" — это вот, на мой взгляд, в разы проще спецификации multiboot, прерываний этих номерных, карты памяти e820 и прочего EBDA.
EFI — это интерфейс, а сложным он стал от того, что оборудование стало сложным, плюс вагон особенностей реализации наконец-то решили стандартизировать.
От способа загрузки чудовищность зависит напрямую, с EFI-загрузкой нам доступны все сервисы и возможности прошивки с человеко-понятном виде, с нормальными именами, со спецификацией открытой. А с легаси — кривая эмуляция на IoTrap-ах, трамплины в 16-битный режим и обратно, и прочие костыли для совместимости с седой древностью, которые теперь приходится заводить через жертвоприношения.
Если ваша ОС нормально работает с EFI-загрузкой — ей и пользуйтесь, а CSM отключайте — от него на современном железе одни проблемы.khim
05.11.2018 04:47Понимаете, есть разная «простота». «Положите загрузчик на диск» — это то, что сегодня принято называть. «простотой», когда «легковесный фреймворк» состоит из десятков тысяч файлов, в которых полностью не разбирается никто.
Я же говорю про другую простоту — когда полное описание всей системы занимает осмысленный размер и понятно из чего она состоит. Да, описание карты памяти e820 может быть и выглядит не так красиво, как «понятные» интерфейсы EFI — но разбор его можно написать даже в машинном коде, а на ассемблере — так вообще запросто. А вот чтобы взаимодействовать с EFI — вам нужна масса весьма сложного кода, который, от того, что вы его скачали с сайта и запустили «не глядя» проще не становится.
Что касается CSM — то тут согласен, но не потому что EFI прост, а BIOS сложен (всё ровно наоборот), а потому что CSM — это не BIOS! Это куча… добра, которая пытается эмулировать простую вещь (BIOS) поверх другой, ещё более сложной кучи… добра. В результате получаем чудесный гибрид, который ещё сложнее и глючнее, чем EFI, но при этом ещё и ограниченнее!CodeRush
05.11.2018 05:50А вот чтобы взаимодействовать с EFI — вам нужна масса весьма сложного кода, который, от того, что вы его скачали с сайта и запустили «не глядя» проще не становится.
Не нужна там никакая масса кода, все взаимодействие идет через EFI_SYSTEM_TABLE, которая по факту обыкновенная таблица указателей на функции. Ничего хитрого в работе с EFI нет, и взаимодействовать с ним можно и в машинном коде, и на ассемблере, и на чем угодно. Придется узнать немного о формате PE, и соглашении о вызовах Microsoft x64, и о том, что зачем нужен ExitBootServices(), но это все значительно проще, чем BIOS Interrupt Call с его магическими номерами, магическими адресами, нереальным режимом, управлением адресной линией А20, ресетом через порт клавиатуры и ручным пробросом VGA через мосты.
Вы, мне кажется, смотрите на GNU EFI SDK или EDK2 и думаете, что они необходимы и без них с EFI нельзя договориться. Если так — вы ошибаетесь.
Мне очень нравится идея концептуальной простоты, но реализации таковой не выдерживают, к сожалению, столкновения с реальностью, начальством и отделом маркетинга, и потому либо не существуют, либо не используются. Приходится ехать на том, что есть, и на вот этом ехать с EFI значительно веселее, чем без него, на мой взгляд.
CodeRush
05.11.2018 06:12Я перечитал два раза, и думаю, что понял наконец, о чем речь. Вам, видимо, не нравится тот факт, что EFI пытается абстрагировать сложность оборудования от пользователя, и делает это громадным количеством кода, который вам бы не хотелось запускать, а он все равно запускается и повлиять на это крайне не просто.
Альтернатив тут несколько, но выстрелить может, на мой взгляд, только одна — LinuxBoot, который сейчас развивают Google и Facebook. Там ребята выкинули из EFI весь верхний уровень (тот самый Extensible Firmware Interface) и заменили его ядром Linux, которое основную систему затем загружает kexec'ом без всяких интерфейсов, и умирает после этого практически без следа.
Идея отличная и работает замечательно, но для загрузки произвольной ОС (которой нужен ACPI, к примеру) не подходит, а если начать подводить — снова получится EFI, и далеко не факт, что во второй раз получится лучше.
CodeRush
04.11.2018 10:22+1Чуть подробнее.
Прямо от ресет-вектора выполняется так называемая прошивка или firmware (firm она потому, что это ровно между hard и soft). Выполняется она на том же центральном процессоре, что и все остальное (начинается исполнение с одного конкретного ядра, обычно нулевого, которое называют BootStrap Processor, а все остальные ядра ничего не делают, пока не получат специальное SIPI-прерывание). Код прошивки исполняется прямо из ПЗУ, подключенного к одной из простых шин — LPC/SPI/eSPI, а затем копируется в ОЗУ после того, как это самое ОЗУ удасться найти и проинициализировать (процесс этот называется тренировкой, memory training).
По сути своей, прошивка состоит из двух относительно независимых слоев, нижний из которых занимается инициализацией конкретного оборудования (процессора, памяти, шин), абсолютно необходимого для верхнего слоя и ОС, и верхнего, который реализует интерфейс к этой самой ОС, и которым ОС пользуется для своих собственных целей. Само слово BIOS (т.е. базовая система ввода-вывода) — оно именно про интерфейс (который полностью называется BIOS Interrupt Call, т.к. использует программные прерывания практически для всего), а UEFI уже и называется именно интерфейсом.
Intel Management Engine — это отдельный процессор со своей собственной прошивкой (хранящейся обычно на том же ПЗУ, что и основная), стартующий раньше центрального и исполняющий различные сервисные задачи, которые на центральном процессоре исполнять по разным причинам не удобно.
Тов. khim прав в том, что тут надо книги писать и не одну, и одной Beyond BIOS тут не обойдешься, потому что она исключительно про одну (хоть и популярную) реализацию верхнего уровня прошивок для современных архитектур.
Кроме UEFI/TianoCore можно посмотреть на coreboot/Intel FSP/AMD AGESA/U-boot (это реализации именно нижнего уровня), а для верхнего — LinuxBoot и SeaBIOS.
johovich
04.11.2018 07:11Вот уж точно, что все относительно. Я делаю на Си структуру данных trie и считал это низким уровнем. :-)
rmjke
04.11.2018 11:400x000B8000 — 0x000BFFFF — видеопамять цветного режима
Если мне не изменяет память, то эти адреса относятся к текстовому режиму.vdem
04.11.2018 15:48Текстовый, 4 страницы 80x25. Память графических режимов (вернее, отображение видеопамяти в оперативку) по умолчанию с 0x000A0000, 64 Kb для реального режима (чтоб в высоких разрешениях работать, надо через int 10h переключать банки памяти). Игрался с этим еще в школе, Turbo Pascal + Assembler :)

icbook
04.11.2018 20:33+1Не факт, что на платформах начиная с «х686» (условно), вот так легко и просто выполнится первая инструкция по адресу 0xfffffff0. Даже в рамках firmware-букваря стоит заметить, что аппаратные платформы давно уже не являются классическими х86 в полном смысле этого слова.
khim
05.11.2018 00:26А какие есть ещё альтернативы? Всегда после включения должен выполняться какой-то известный адрес. Как иначе? И если уж исторически он расположен по адресу 0xfffffff0 — то куда и зачем его вдруг переносить?
CodeRush
05.11.2018 01:12Если коротко — Intel ACM, который процессор еще до ресет-вектора найдет через FIT, проверит его подпись при помощи МЕ, и затем исполнит, а он уже передаст управление на legacy reset vector, или сразу на SEC core.
Нужно это для организации root-of-trust для verified boot и measured boot, загрузки микрокода из FIT, и других задач, с которыми нужно закончить до начала исполнения пользовательского кода, но которые при этом нельзя выполнить на МЕ.
Вот тут @matrosov хорошо написал про ACM и BootGuard, почитайте если интересно.
saipr
Да, такую бы статью на заре Minix !