Это последний доклад с шестого Гипербатона, который мы опубликуем на Хабре. Григорий Сапунов из Intento поделился подходом к оценке качества сервисов облачного машинного перевода, рассказал о результатах оценки и главных отличиях между доступными сервисами.
— Меня зовут Григорий Сапунов, я расскажу про ландшафт сервисов облачного машинного перевода. Мы измеряем этот ландшафт уже больше года, он очень динамичен и интересен.

Расскажу, что он собой представляет, почему полезно понимать, что там происходит, про доступные решения, которых довольно много, про сравнение стоковых моделей, предобученных моделей машинного перевода, про кастомизированные модели, которые начали активно появляться в последний год, и приведу свои рекомендации по выбору моделей.
Машинный перевод стал очень полезным средством, который помогает автоматизировать множество разных задач. Он заменяет человека только в некоторых темах, но как минимум может сильно сократить расходы. Если надо переводить много описаний товаров или отзывов на большом веб-сервисе, то человек здесь просто не способен справиться с большим потоком, а машинный перевод реально хорош. И на рынке уже много готовых решений. Это какие-то предобученные модели, их часто называют стоковыми, и модели с доменной адаптацией, которая сильно развивается в последнее время.
При этом создавать свое решение машинного перевода достаточно сложно и дорого. Современные технологии машинного перевода, нейросетевой машинный перевод, требует очень много всего, чтобы взлететь внутри. Нужны таланты, которые будут этим заниматься, нужно много данных, чтобы это обучить, и время, чтобы этим заниматься. Кроме того, нейросетевой машинный перевод требует сильно больше машинных ресурсов, чем предыдущие версии машинных переводов типа SMT или rule-based.
При этом машинный перевод, который доступен в облаке, очень разный. И правильный выбор машинного перевода позволяет вам сильно упростить жизнь, сэкономить время, деньги и в конце концов решить вашу задачу или не решить. Разброс по качеству, по reference-based-метрикам, которые мы измеряем, может быть в четыре раза.

При этом по ценам разброс может быть вообще в 200 раз. Это совершенно ненормальная ситуация. Сервисы более-менее одного качества могут отличаться в 200 раз. Это простой способ для вас сэкономить или потратить лишние деньги.
При этом сервисы ощутимо отличаются по продуктовым характеристикам. Это может быть поддержка форматов, поддержка файлов, наличие batch-режима или его отсутствие, это максимальный объем текста, который сервис может перевести за один раз, и много всего другого. И все это нужно понимать, когда выбираете сервис. Если выберете не тот сервис, то либо придется переделывать, либо вы не получите качество, которое хотели бы получить. В итоге это сводится к тому, что вы быстрее выводите что-то на рынок, экономите деньги, обеспечиваете лучшее качество вашему продукту. Или не обеспечиваете.

Сравнить эти сервисы, чтобы понять, что именно вам подходит, долго и дорого. Если заниматься этим самостоятельно, вы должны интегрироваться со всеми сервисами облачного машинного перевода, написать эти интеграции, заключить договоры, сначала устроить раздельный биллинг, проинтегрироваться со всеми. Дальше прогнать через все эти сервисы какие-то свои данные, оценить. Это запретительно дорого. Бюджет такого проекта может превысить бюджет основного проекта, ради которого вы это делаете.
Так что это важная тема, но самостоятельно ей заниматься сложно, и мы в этом месте хорошо помогаем понять, что к чему.

На рынке есть спектр технологий. Практически все сервисы перешли к нейросетевому машинному переводу или какому-то гибриду. Есть еще количество статистических машинных переводчиков на рынке.
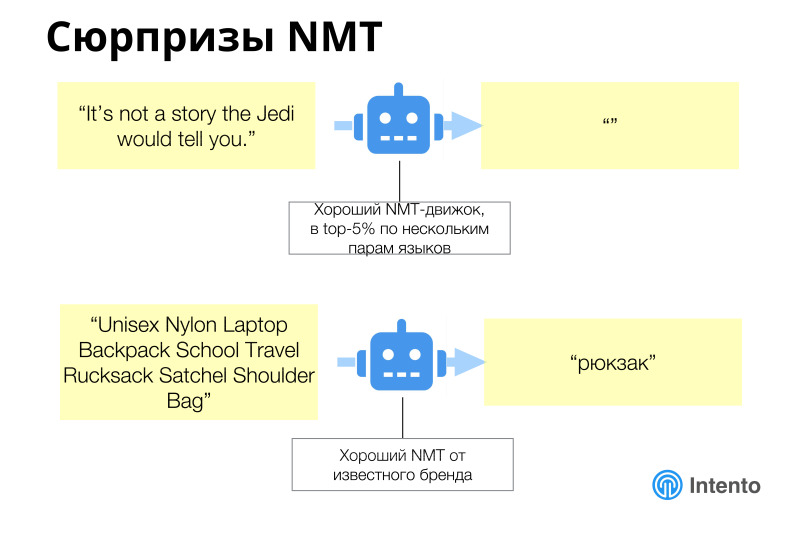
У каждого есть свои особенности. НМТ вроде как более современная хорошая технология, но тоже бывают свои тонкости.
В целом нейросетевой машинный перевод работает лучше, чем предыдущие модели, но за ним тоже надо следить, бывают совершенно неожиданные результаты. Как истинный Йода он может промолчать, выдать пустой ответ на какую-то строку, и надо уметь это поймать и понять, что на ваших данных он себя так ведет. Или замечательный пример из e-commerce, когда большое описание товара было отправлено в машинный перевод, а он просто сказал, что это рюкзак и всё. И это было стабильное поведение этого машинного сервиса, который хороший и отлично работает на общих данных, новостных данных. Но на этой конкретной области e-commerce работает плохо. И вам нужно это понимать, нужно на своих данных прогнать все эти сервисы, чтобы выбрать тот, который под ваши данные подходит лучше всего. Это не тот сервис, который будет работать лучше на новостях или чем-то еще. Это тот, который на вашем конкретном кейсе должен сработать лучше. Это надо понять в каждом конкретном случае.

Есть много уровней кастомизации. Нулевой уровень — ее отсутствие. Есть стоковые модели пре-тренированные, это все те, которые развернуты в облаке сейчас у разных провайдеров. Есть вариант с полностью кастомизированными моделями на своих корпусах, когда вы, условно, делаете заказ в какой-то компании, которая занимается машинным переводом, она под вас, на ваших данных с нуля тренирует модель. Но это долго, дорого, требует больших корпусов. Есть крупный провайдер, который за такой эксперимент с вас возьмет 5000 долларов, цифры такого порядка. Вещи, которые дорого попробовать. И это вам ничего не гарантирует. Вы можете обучить модель, а она окажется хуже, чем имеющаяся на рынке, и деньги выкинуты на ветер. Это две крайние опции. Либо стоковая модель, либо кастомизированная на вашем корпусе.
Есть промежуточные случаи. Есть глоссарии, очень хорошая вещь, которая помогает улучшить текущие модели машинного перевода. И есть доменная адаптация, что сейчас активно развивается, некий transfer learning, что угодно, что скрывается за этими словами, которая позволяет обучить некую общую модель или даже специальную модель дообучить на ваших данных, и качество такой модели будет лучше, чем просто общая модель. Это хорошая технология, она работает, сейчас в стадии активного развития. Следите за ней, я про нее дальше расскажу.

Есть еще одно важное измерение, поднимать у себя или использовать облако. В этом месте есть популярное заблуждение, люди до сих пор думают, что сервисы облачного машинного перевода, если вы ими пользуетесь, будут брать ваши данные и обучать на них свои модели. Это уже неправда последние год-два. Все крупные сервисы отказались от этого, у них в terms of service явно прописано, что мы не используем ваши данные для обучения своих моделей. Это важно. Это снимает кучу барьеров на пути адаптации облачного машинного перевода. Сейчас можно безопасно пользоваться этими сервисами и быть уверенными, что сервис не будет использовать ваши данные для тренировки своих моделей, и он не станет вам конкурентом со временем. Это безопасно.
Это первое преимущество облаков по сравнению с тем, что было еще два года назад.
Второе преимущество, если будете развертывать нейросетевой перевод у себя внутри, вам нужно довольно тяжелую инфраструктуру поднимать с графическими ускорителями для обучения всех этих нейросетей. И даже после обучения для inference все равно нужно использовать высокопроизводительные графические карты, чтобы это работало. Получается дорого. Стоимость владения таким решением реально большая. И компания, которая не собирается профессионально предоставлять API на рынок, не нужно этим заниматься, нужно взять готовый сервис облачный и этим пользоваться. В этом месте у вас экономия по деньгам, по времени и есть гарантия неиспользования ваших данных для нужд сервиса.
Про сравнение.

Этой темой мы занимаемся давно, полтора года проводим регулярное измерение качества. Мы выбрали автоматические референсные метрики, они позволяют массировано это делают, и получать некие доверительные интервалы. Мы более-менее знаем, на каком количестве данных метрики качества устаканиваются, и можно делать адекватный выбор между разными сервисами. Но надо помнить, что метрики автоматические и человеческие дополняют друг друга. Автоматические метрики хороши для того, чтобы провести предварительный анализ, выбрать места, на которые особенно стоит обратить внимание людям, и дальше лингвистам или доменным экспертам посмотреть на эти варианты перевода и выбрать то, что вам подходит.

Расскажу про то, какие есть системы на рынке, как мы это все анализировали, как они соотносятся по ценам, и расскажу про наши результаты анализа, что важно здесь в качестве, и что за пределами качества тоже важно при выборе сервиса.

В первую очередь, есть уже большое количество облачных сервисов машинного перевода, мы рассматривали только те, в которых есть предобученные модели, которые можно взять и начать использовать, и у них есть публичное API.
Есть еще какое-то количество сервисов, у которых нет публичного API или они разворачиваются внутри, мы их не рассматриваем в нашем исследовании. Но даже среди этих сервисов их уже большое количество, мы измеряем и оцениваем 19 таких сервисов. Практика показывает, средний человек знает нескольких лидеров рынка, а про остальных не знает. А они есть, и они местами хорошие.

Мы взяли популярность языков по вебу и разбили их на четыре группы. Самые популярные, больше 2% сайтов, менее популярные и еще менее. Есть четыре группы языков, по которым мы дальше анализируем, и из всего этого сосредотачиваемся на первой группе, самые популярные языки, и немножко на второй.
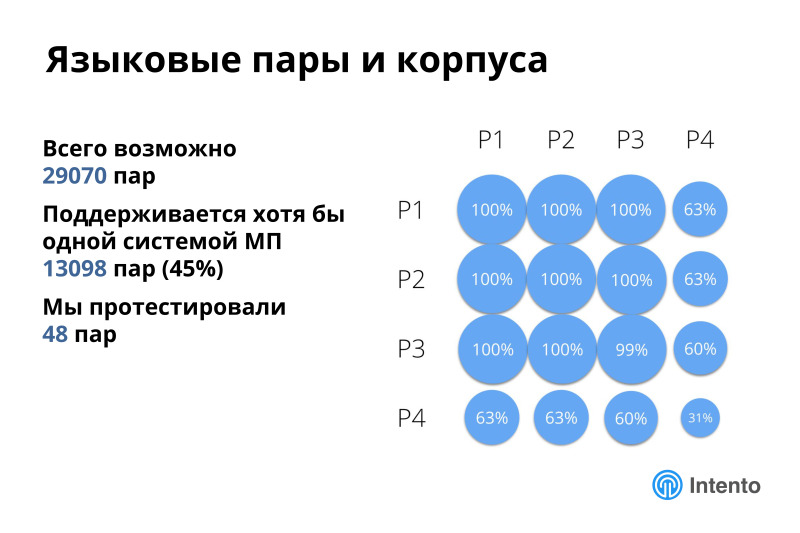
Поддержка внутри первых трех групп практически 100%. Если вам нужен язык не супер экзотический, то вы его получите из облака. А если нужна экзотическая пара, может оказаться, что какой-то из языков не поддерживается никаким сервисом машинного облачного перевода. Но даже при всех ограничениях, примерно половина всех возможных пар поддерживается. Это неплохо.

Из всего этого мы протестировали 48 пар, составили такую матрицу, выбрали в первую очередь английский и все языки первой группы, частично языки внутри первой группы, и немножко английский и языки второй группы. Это более-менее покрывает типовые сценарии использования, но за пределами остается много всего другого интересного. Эти пары мы оценили, поизмеряли и расскажу, что там происходит. Полный репорт есть по ссылке, он бесплатный, мы его регулярно обновляем, буду вас агитировать пользоваться этим.
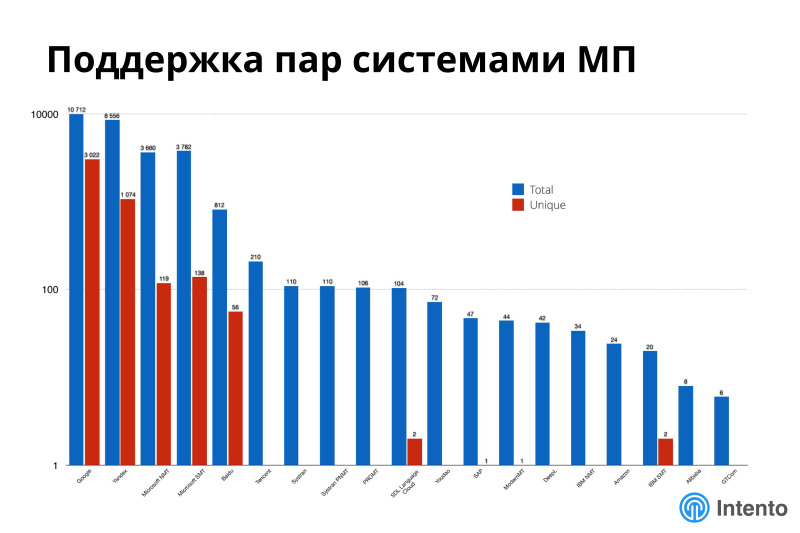
На этом графике не видно цифр и осей, но это про поддержку различных языков разными системами машинного перевода. По оси Х разные системы машинного перевода, по оси Y в логарифмической шкале количество поддерживаемых пар вообще и уникальных. По этой картинке красный — уникальный, синий — все. Видно, что если у вас очень экзотическая комбинация языков, может оказаться, вам в силу уникальности надо использовать семь разных провайдеров, потому что только один из них поддерживает очень специфическую пару, которая вам нужна.

Для оценки качества мы выбрали новостные корпуса, general domain корпуса. Это не гарантирует, что на ваших конкретных данных из другой области ситуация будет такая же, скорее всего не такая же, но это хорошая демонстраций, как вообще подходить к такому исследованию, как для себя выбрать правильный подходящий вам сервис. Покажу на примере новостных областей. Это легко переносится на любую другую вашу область.

Мы выбрали метрику hLEPOR, это примерно то же самое, что и BLEU, но по нашему интуитивному ощущению она дает лучшее впечатление, как сервисы между собой соотносятся. Для простоты считайте, что метрика от 0 до 1, 1 — полное соответствие некоему референсному переводу, 0 — полное несоответствие. hLEPOR лучше дает интуитивное ощущение, что значит разница в 10 единиц по сравнению с BLEU. Про метрику можно отдельно почитать, в методологии исследования все описано. Это нормальная метрика, прокси-метрика, не идеальная, но хорошо передает суть.

Разница в ценах колоссальная. Мы составили матрицу, за какую цену можно получить перевод 1 млн символов. Можете скачать и посмотреть, разница колоссальна, от 5 долларов до 1000 долларов за миллион символов. Выбор неправильного сервиса просто поднимаем вам затраты колоссально, или выбор правильного может помочь очень сильно сэкономить в этом месте. Рынок непрозрачен, нужно понимать, что чего стоит и где какое качество. Держите в голове эту матрицу. Сложно сопоставить все сервисы, по цене, цены часто не очень прозрачные, политика не очень понятна, есть какие-то грейды. Это все сложно, эта таблица помогает принять решение.
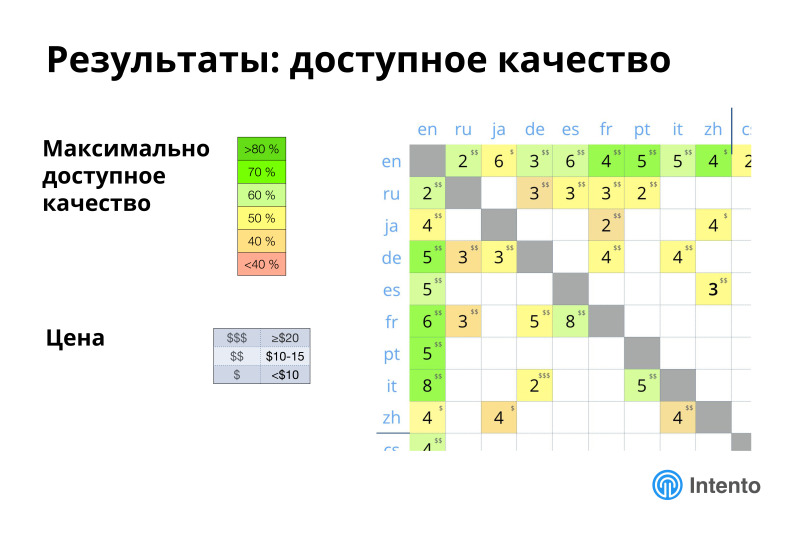
Результаты своего анализа мы свели в такие забавные картинки. На этой картинке отражено, какое максимально доступное качество есть по тем парам, которые мы измеряли, чем более зеленые — тем более высокое качество доступно, какова конкуренция в этих парах, есть ли вообще из чего выбирать, условно, где-то 8 провайдеров обеспечивают это максимально доступное качество, где-то всего 2, и есть еще значок доллара, это про цену, за которую вы получаете максимальное качество. Разброс большой, где-то дешево можно получить приемлемое качество, где-то оно не очень приемлемое и дорогое, возможны разные комбинации. Ландшафт сложный, нет одного супер игрока, который везде лучше во всем, дешев, хорош и так далее. Везде есть выбор, и везде его нужно совершать разумно.

Здесь мы нарисовали лучшие системы по этим языковым парам. Видно, что лучшей системы нет одной, разные сервисы лучше на разных парах в этой конкретной области — новости, в других областях ситуация изменится. Где-то Google хорош, где-то хорош Deepl, это свежий европейский переводчик, про который мало кто знает, это небольшая компания, которая успешно борется с Google и побеждает его, реально хорошее качество. На русско-английской паре Яндекс стабильно хорошо. Amazon недавно появился, подключил русский язык и другие, и он тоже неплох. Это свежие изменения. Год назад многого из этого не было, было меньше лидеров. Сейчас ситуация очень динамическая.
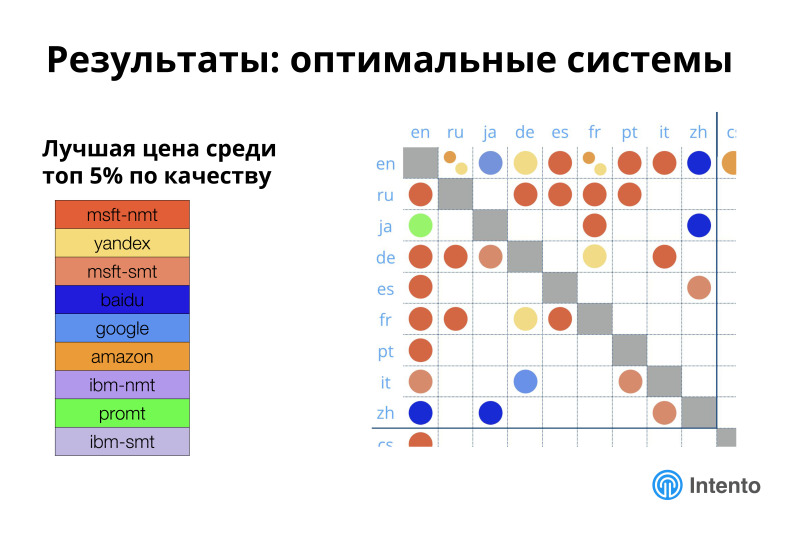
Знать лучшую систему не всегда важно. Чаще важно знать оптимальную систему. Если посмотреть на топ 5% систем по этому качеству, то среди этого топ 5% есть наиболее дешевая, дающая это хорошее качество. В этом месте ситуация ощутимо другая. Google уходит из этого сравнения, очень сильно поднимается Microsoft, становится больше Яндекса, Amazon еще больше вылезает, появляются более экзотические провайдеры. Ситуация становится другая.
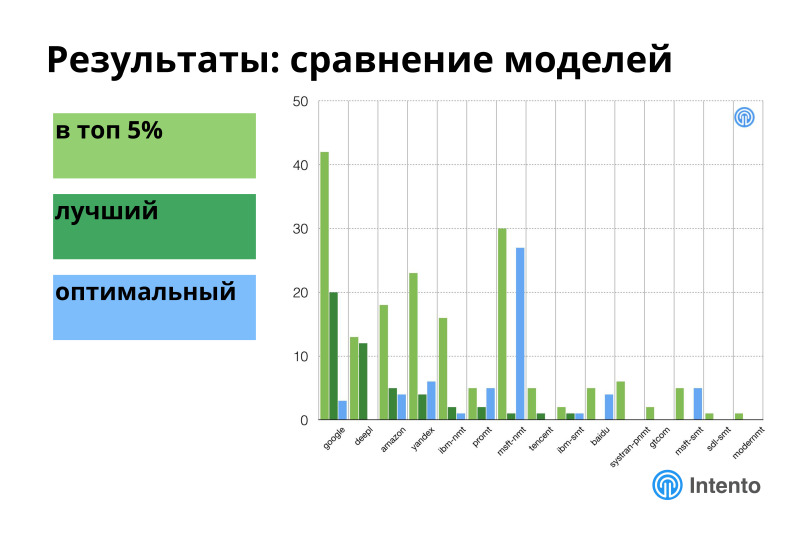
Если посмотреть на всех провайдеров машинного перевода, по горизонтали — разные провайдеры, по вертикали — как часто провайдер оказывается в одном из этих топов, то в топе 5% оказывается почти каждый из них рано или поздно. Лучшими из них для каких-то конкретных измеренных пар являются 7 провайдеров, оптимальными тоже 7. Это значит, что если у вас есть какой-то набор языков, на который вам нужно переводить, и вы хотите обеспечить максимальное или оптимальное качество, вам одного провайдера недостаточно, вам нужно подключать портфолио этих провайдеров, и тогда у вас будет максимальное качество, максимальная эффективность по деньгам и так далее. Нет одного игрока, который лучше. Если у вас сложные задачи, нужно много разных пар, вам прямая дорога к тому, чтобы использовать разных провайдеров, это лучше, чем использовать кого-то одного.
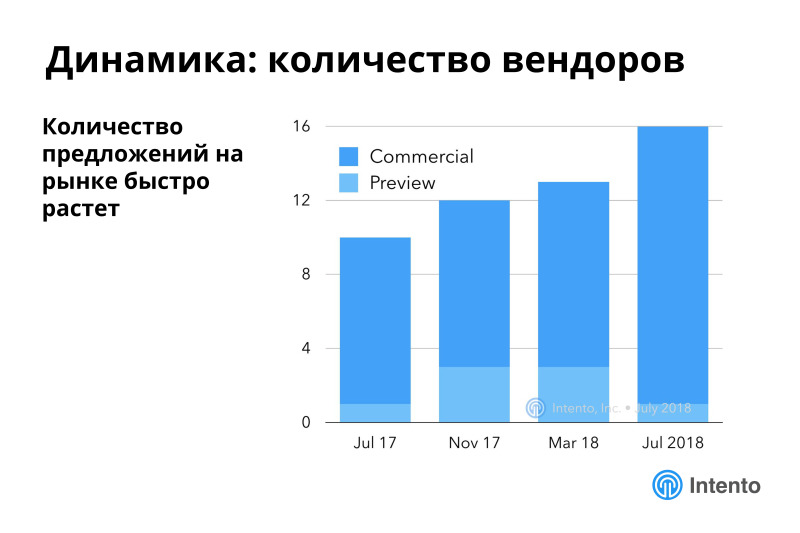
Рынок очень динамичен, количество предложений растет быстро. Мы начали измерять в начале 17-го года, свежий бенчмарк опубликовали в июле. Количество доступных сервисов растет, кто-то из них до сих пор в превью, у них нет публичного прайсинга, они в какой-то альфе или бете, которую вроде можно использовать, но условия еще не очень понятны.
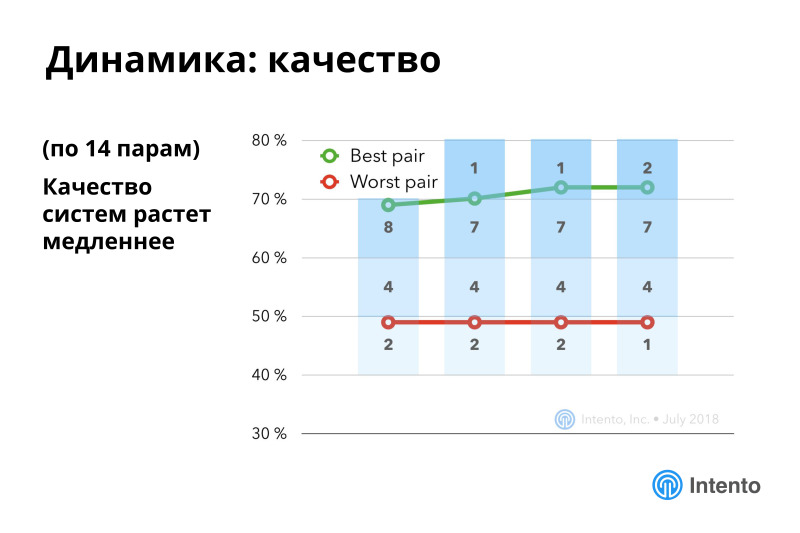
Качество растет медленнее, но тоже растет. Основной интерес происходит внутри конкретных языковых пар.
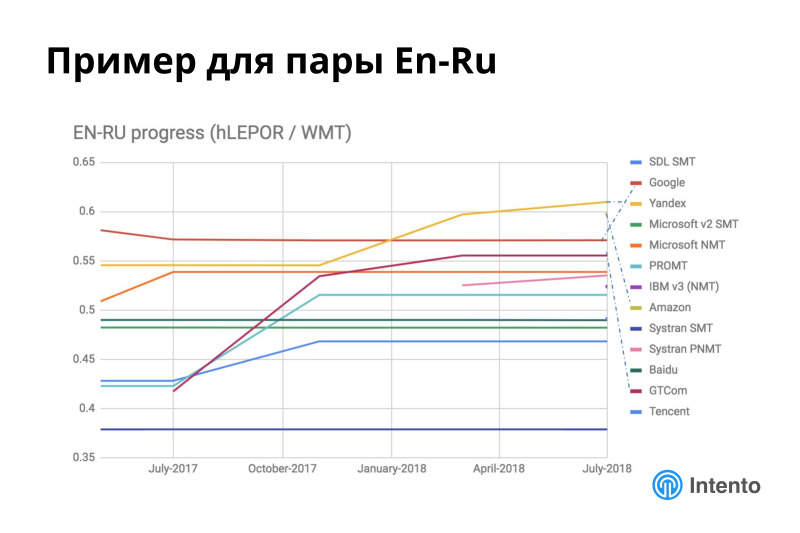
Например, ситуация внутри английско-русской языковой пары очень динамичная. Яндекс за последние полгода очень сильно повысил свое качество. Появился Amazon, он справа одной точкой представлен, он тоже идет недалеко за Яндексом. Неплохо прокачался провайдер GTCom, которого почти никто не знает, это китайский провайдер, он хорошо переводит с китайского на английский и русский, и английский — русский тоже неплохо обрабатывает.
Похожая картина происходит более-менее на всех языковых парах. Везде что-то меняется, постоянно появляются новые игроки, меняется их качество, модели переобучаются. Вы видите, тут есть стабильные провайдеры, качество которых не меняется. В этом случае стабильные — это скорее мертвые, потому что есть другие нестабильные, качество которых более-менее улучшается. Это хорошая история, улучшаются они практически постоянно.
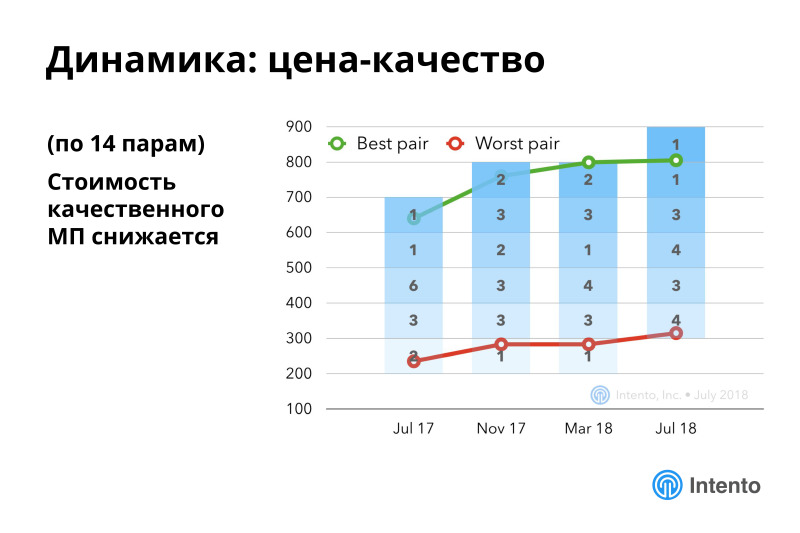
Если посчитать более сложную метрику про цену-качество, то здесь есть стабильные улучшения. Это значит, что стоимость качественного машинного перевода постоянно снижается, с каждым месяцем, с каждым годом вам доступен все более качественный машинный перевод за меньшие деньги. Это хорошо.

Помимо цен и качества есть огромный пласт вопросов, которые тоже важны при выборе конкретного провайдера. Это всякие продуктовые фичи, поддержки html, xml, поддержка хитрых и не очень форматов, bulk-режим, автоопределение языка — популярная тема, поддержка глоссариев, кастомизация, надежность сервиса. И еще то, что мы называем счастьем разработчика, по ссылке потом можно прочитать, что мы имеем в виду.
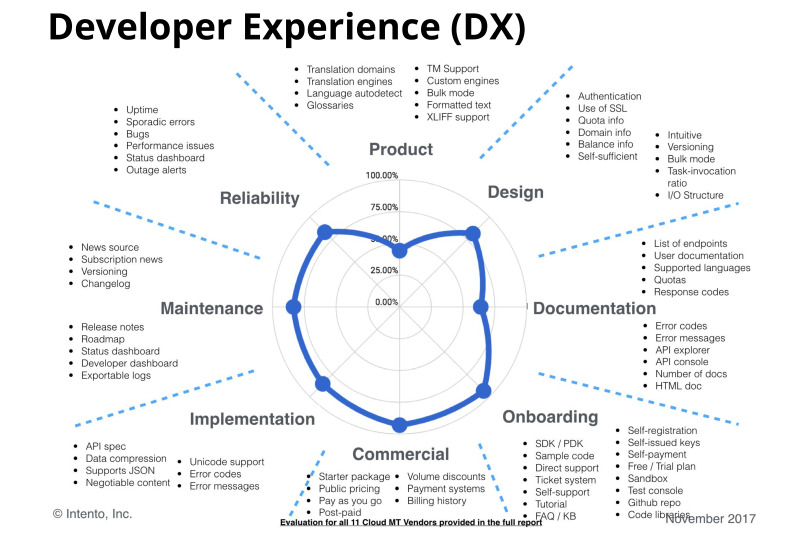
Это для создания машинного бедствия. Под DX мы понимаем огромное количество всяких разных аспектов, включая наличие хорошей документации, понятные коды и сообщения об ошибках, соответствие стандартам HTTP, наличие некоего плейграунда, чтобы динамически поиграть с API, наличие удобного биллинга и много всего другого, что очень сильно влияет на принятие решения о том, стоит использовать конкретный сервис или нет. Если разработчик чертыхается, подключая новую API, то это плохой сигнал. Разработчик может сказать, что нам это не надо, и по факту некоторые API просто сложно использовать для конкретных задач, потому что они чего-то не поддерживают из нужного вам. Это важный аспект.
Это пример диаграммы по одному из реальных сервисов, который сравнительно неплох на фоне других. У многих других сервисов эта диаграмма ближе к нулю собирается, часто нет нормальной документации, нет SDK, непонятно, как с биллингом работать, невозможно выгружать данные об использовании сервиса и много всего другого. Поддержки нет нормальной. Это сложная тема.
Недавно мы столкнулись с замечательным сервисом, который вроде как публичный, а документация на API доступна после подписания NDA. Есть много странных случаев. По факту это некий фактор принятия решений. Знайте про него, он в какой-то момент может всплыть.
Это была часть про стоковые модели, которые есть на рынке. Надеюсь, я передал общие ощущения, что рынок динамичные, есть много игроков и нет одного суперлидера. Каждый лучше в чем-то одном, и вам скорее всего придется собирать портфолио провайдеров, если вы хотите переводить на много разных языков.
Вторая интересная тема — кастомизированные модели, которые начали появляться сравнительно недавно. Мы начали измерения этих кастомизированных моделей, скоро выпустим репорт, а сейчас расскажу предварительные результаты этого измерения.

Сейчас уже многие сервисы поддерживают какую-то кастомизацию. Это могут быть некие глоссарии, это может быть дообучение на вашем датасете, и провайдеров много. В первую очередь, сколько-то топовых, типа Google, Microsoft, IBM, сколько-то более экзотических, и часть, про которые мало кто знает, но они тоже позволяют это делать.

Как здесь мы сравниваем? Мы выбрали одну специальную область, биомед, под него стоковых моделей не очень много, область со специальной терминологией. Выбрали пару английский — немецкий, просто потому что нам легче было датасет собрать под эту пару. И попробовали пообучать эти модели на разных обучающих выборках от 10 тыс. до 1 млн предложений. Сделали тестовый датасет из 2 тыс. предложений, по нашим измерениям на 2 тыс. предложений метрика устаканивается и можно адекватно сравнивать разные сервисы. 50 предложений недостаточно.
Мы выбрали метрику hLEPOR, и дальше обучаем всех этих провайдеров нашими датасетами, измеряем качество на нашем тестовом датасете, а заодно измеряем качество стоковых моделей на этом датасете, чтобы понять, какой бейслайн, какой референс поинт в этом месте. Покажу, как меняется качество и какое получается при тренировке. В этом месте важный аспект — стоимость владения этими моделями. Про это мы отдельно в репорте расскажем, когда все это соберем вместе. Но тут ситуация усложняется, у вас есть затраты на тренировку моделей, какое-то время и деньги на тренировку, не везде прозрачные. Есть стоимость поддержки этой модели и стоимость ее использования, у разных сервисов она разная. Из этих трех компонентов складывается стоимость владения, это важный аспект, его надо посчитать перед тем, как переходить на кастомный движок. Это существенное отличие от стоковых моделей.
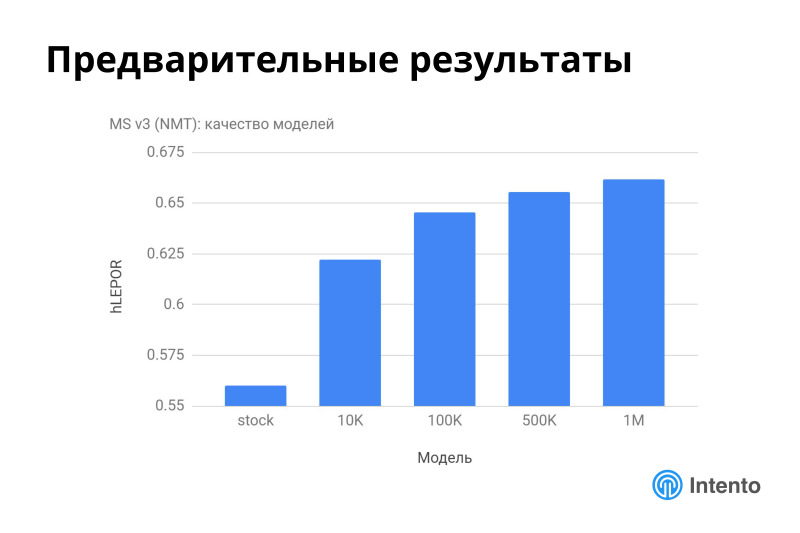
Предварительные результаты показывают, что это действительно работает. Вот пример на Microsoft, на 3 версии его API. Стоковая модель на биомеде работает довольно плохо, но это нормальная история, нельзя считать, что Microsoft худший. Он работает хорошо на типовых доменах. Под этот домен, видимо, он не обучался. Это нормальная история вовремя понять, что под ваш домен стоковая модель не работает, зато достаточно всего 10 тыс. предложений и Microsoft начинает хорошо работать на вашем конкретном домене. И последовательно увеличивая датасет, вы это качество еще увеличиваете. Это хорошая история, он быстро адаптировался, это можно использовать.
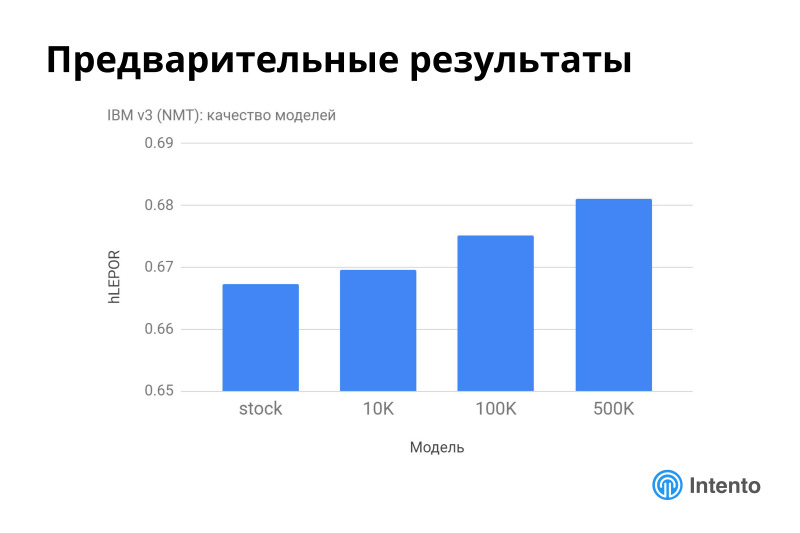
IBM, стоковая модель неплохо работает из коробки, но дообучением ее тоже можно поднять качество. Это это неплохо, качество нормально растет. Улучшение даже на 2% — это хорошее улучшение.
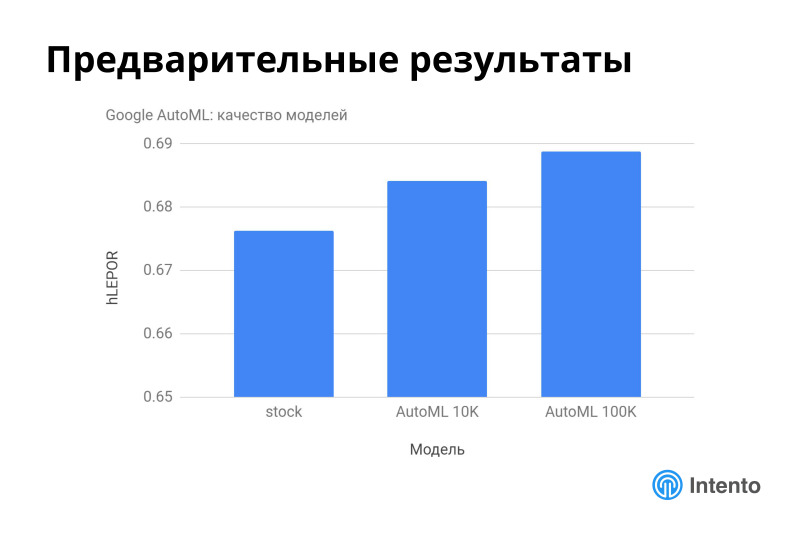
Google AutoML недавно запущенный тоже неплохо работает, стоковая модель сама по себе неплохого качества оказалась на этом конкретном датасете, а обучение моделей на 10 или 100 тыс. предложениях улучает качество.
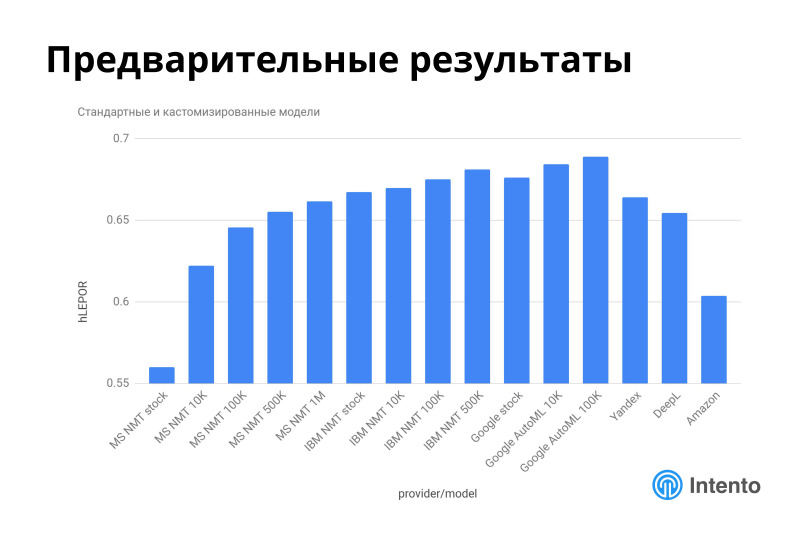
Если все это нарисовать на одной картинке, есть Microsoft, есть Google, есть какое-то количество стоковых моделей — Яндекс, Deepl, Amazon, стоковый Google, стоковый Microsoft. И видно, в данном конкретном случае это интересный кейс. Как принимать решения в подобной ситуации? Нужно понять, что на вашей предметной области какая-то стоковая модель плоха, но какая-то может оказаться хорошей. Яндекс, Google и Deepl, оказывается, из коробки на биомеде работают довольно здорово, и даже превышают качество некоторых обученных моделей. Это интересно. Если вы это в самом начале исследования поймете, то можно на этом остановиться и использовать стоковую модель. Это здорово.
С другой стороны, это дает вам некую нижнюю границу качества, относительно которой дальше можно оценивать улучшения и понимать, стоят они тех денег или не стоят, которые вы собираетесь за них заплатить. И последовательное увеличение размеров обучающих датасетов неплохо прокачивает эти модели. Можно получать более высокое качество, в целом есть стабильное улучшение качества сервиса в зависимости от того, сколько данных вы в него отправили. И помните, это только ваши данные, сервис не будет их использовать для обучения своих общий моделей. Это существенное отличие. Это до сих пор не устоялось в головах, но это произошло. Можно безопасно отправлять данные, и сервис не будет с вами конкурировать в перспективе.
Как вообще подходить осознанно к выбору движка облачного машинного перевода для ваших конкретных задач?

Подготовьте тестовый корпус. Без него сравнивать сложно. Можно с лингвистами сравнивать, но это дорогой труд, он трудновоспроизводим.
Как только вы подготовили тестовый корпус, сравните стоковые модели на рынке. Может оказаться, что какая-то из них уже вам подходит. Так бывает. Мы обнаруживали, что конкретные сервисы хорошо из коробки работают, например, на юридических документах или еще на каких-то. Их можно использовать сразу и не обучать специальные модели, просто надо найти свой движок, который обучался на данных, похожих на ваши. Либо они подойдут, либо зададут нижнюю планку по качеству, относительно которой дальше будете сравнивать либо заказные решения, с которыми к вам кто-то придет, либо другие облачные, которые вы будете дообучать. Это хорошая история — знать свой бейслайн.
Подготовьте глоссарий и какой-то тренировочный корпус, обучающую выборку, если можете. И если вы можете потратить усилия на сбор таких дата-сетов, то разумно попробовать адаптируемые модели. Они либо подойдут, либо зададут планку для подрядчика, который вам будет делать совсем кастомное решение. В любом случае, это, скорее всего, увеличит вам общее качество. А дальше выбор за вами. Дальше чисто экономика — стоит это увеличение качества денег, которые вы будете за него платить, или не стоит.

Чем мы в этом месте можем помочь? Многим. У нас есть отчеты по сравнению систем машинного перевода, по ссылке опубликован последний отчет и есть все предыдущие. Мы стараемся их делать примерно раз в квартал, они бесплатные, читайте их, там есть много деталей. Он сильно более детализирован по сравнению с тем, что я сегодня рассказывал.
Скоро мы выпустим отчет по кастомизированным моделям, где подробнее распишем, как сервисы соотносятся по качеству после обучения и чего это все стоит. У нас есть единое API ко всем сервисам машинного перевода. Достаточно одной интеграции, чтобы пользоваться всеми лучшими сервисами, доступными на рынке. У нас есть SDK под NodeJS, под .NET, есть CLI. А кроме того, скоро будет API, который можно будет использовать для оценки качества моделей. Вы сможете загрузить свои данные и прогнать их через выбранных провайдеров. Посчитайте метрики, отгрузите нам результирующие данные, мы выберем лучшую модель. Этот процесс хорошо автоматизируется, можно будет гораздо дешевле и проще выбрать то, что подходит под ваш конкретный кейс, и начать этим пользоваться — через нас или самостоятельно.
Скоро у нас будут web tools для перевода. Не все люди, которые пользуются машинным переводом, хотят писать интеграции, работать даже с одним API. Это понятная история. Можно будет через браузер попробовать разные сервисы, понять, кто для вашего случая лучший и пользоваться им.
Основные выводы такие, что единого лидера нет. Не ждите одного супер-рейтинга, который скажет, что один провайдер лучше всех. Это не так. Часто нужно собирать портфолио провайдеров, чтобы обеспечить максимальное качество. Качество всех стоковых моделей улучшается постоянно. Надо за этим следить, чтобы понять, что появился сервис или лучше по качеству, чем у вас, или более оптимальный по деньгам. Рынок машинного перевода становится более фрагментированным, появляются провайдеры или модели, обученные на специальных корпусах, более эффективные, чем общие провайдеры. Помните Deepl? Это интересный провайдер, который сумел обучиться на своих уникальных данных и побить Google во многих языковых парах.
Кроме того, помните, что сейчас, имея свои уникальные данные, вы можете натренировать свои модели в облачных сервисах и пользоваться ими. Качество, скорее всего, будет гораздо лучше, чем у дефолтных моделей, и точно лучше, чем у неправильно выбранных моделей. Спасибо.
— Меня зовут Григорий Сапунов, я расскажу про ландшафт сервисов облачного машинного перевода. Мы измеряем этот ландшафт уже больше года, он очень динамичен и интересен.
Расскажу, что он собой представляет, почему полезно понимать, что там происходит, про доступные решения, которых довольно много, про сравнение стоковых моделей, предобученных моделей машинного перевода, про кастомизированные модели, которые начали активно появляться в последний год, и приведу свои рекомендации по выбору моделей.
Машинный перевод стал очень полезным средством, который помогает автоматизировать множество разных задач. Он заменяет человека только в некоторых темах, но как минимум может сильно сократить расходы. Если надо переводить много описаний товаров или отзывов на большом веб-сервисе, то человек здесь просто не способен справиться с большим потоком, а машинный перевод реально хорош. И на рынке уже много готовых решений. Это какие-то предобученные модели, их часто называют стоковыми, и модели с доменной адаптацией, которая сильно развивается в последнее время.
При этом создавать свое решение машинного перевода достаточно сложно и дорого. Современные технологии машинного перевода, нейросетевой машинный перевод, требует очень много всего, чтобы взлететь внутри. Нужны таланты, которые будут этим заниматься, нужно много данных, чтобы это обучить, и время, чтобы этим заниматься. Кроме того, нейросетевой машинный перевод требует сильно больше машинных ресурсов, чем предыдущие версии машинных переводов типа SMT или rule-based.
При этом машинный перевод, который доступен в облаке, очень разный. И правильный выбор машинного перевода позволяет вам сильно упростить жизнь, сэкономить время, деньги и в конце концов решить вашу задачу или не решить. Разброс по качеству, по reference-based-метрикам, которые мы измеряем, может быть в четыре раза.
При этом по ценам разброс может быть вообще в 200 раз. Это совершенно ненормальная ситуация. Сервисы более-менее одного качества могут отличаться в 200 раз. Это простой способ для вас сэкономить или потратить лишние деньги.
При этом сервисы ощутимо отличаются по продуктовым характеристикам. Это может быть поддержка форматов, поддержка файлов, наличие batch-режима или его отсутствие, это максимальный объем текста, который сервис может перевести за один раз, и много всего другого. И все это нужно понимать, когда выбираете сервис. Если выберете не тот сервис, то либо придется переделывать, либо вы не получите качество, которое хотели бы получить. В итоге это сводится к тому, что вы быстрее выводите что-то на рынок, экономите деньги, обеспечиваете лучшее качество вашему продукту. Или не обеспечиваете.
Сравнить эти сервисы, чтобы понять, что именно вам подходит, долго и дорого. Если заниматься этим самостоятельно, вы должны интегрироваться со всеми сервисами облачного машинного перевода, написать эти интеграции, заключить договоры, сначала устроить раздельный биллинг, проинтегрироваться со всеми. Дальше прогнать через все эти сервисы какие-то свои данные, оценить. Это запретительно дорого. Бюджет такого проекта может превысить бюджет основного проекта, ради которого вы это делаете.
Так что это важная тема, но самостоятельно ей заниматься сложно, и мы в этом месте хорошо помогаем понять, что к чему.
На рынке есть спектр технологий. Практически все сервисы перешли к нейросетевому машинному переводу или какому-то гибриду. Есть еще количество статистических машинных переводчиков на рынке.
У каждого есть свои особенности. НМТ вроде как более современная хорошая технология, но тоже бывают свои тонкости.
В целом нейросетевой машинный перевод работает лучше, чем предыдущие модели, но за ним тоже надо следить, бывают совершенно неожиданные результаты. Как истинный Йода он может промолчать, выдать пустой ответ на какую-то строку, и надо уметь это поймать и понять, что на ваших данных он себя так ведет. Или замечательный пример из e-commerce, когда большое описание товара было отправлено в машинный перевод, а он просто сказал, что это рюкзак и всё. И это было стабильное поведение этого машинного сервиса, который хороший и отлично работает на общих данных, новостных данных. Но на этой конкретной области e-commerce работает плохо. И вам нужно это понимать, нужно на своих данных прогнать все эти сервисы, чтобы выбрать тот, который под ваши данные подходит лучше всего. Это не тот сервис, который будет работать лучше на новостях или чем-то еще. Это тот, который на вашем конкретном кейсе должен сработать лучше. Это надо понять в каждом конкретном случае.
Есть много уровней кастомизации. Нулевой уровень — ее отсутствие. Есть стоковые модели пре-тренированные, это все те, которые развернуты в облаке сейчас у разных провайдеров. Есть вариант с полностью кастомизированными моделями на своих корпусах, когда вы, условно, делаете заказ в какой-то компании, которая занимается машинным переводом, она под вас, на ваших данных с нуля тренирует модель. Но это долго, дорого, требует больших корпусов. Есть крупный провайдер, который за такой эксперимент с вас возьмет 5000 долларов, цифры такого порядка. Вещи, которые дорого попробовать. И это вам ничего не гарантирует. Вы можете обучить модель, а она окажется хуже, чем имеющаяся на рынке, и деньги выкинуты на ветер. Это две крайние опции. Либо стоковая модель, либо кастомизированная на вашем корпусе.
Есть промежуточные случаи. Есть глоссарии, очень хорошая вещь, которая помогает улучшить текущие модели машинного перевода. И есть доменная адаптация, что сейчас активно развивается, некий transfer learning, что угодно, что скрывается за этими словами, которая позволяет обучить некую общую модель или даже специальную модель дообучить на ваших данных, и качество такой модели будет лучше, чем просто общая модель. Это хорошая технология, она работает, сейчас в стадии активного развития. Следите за ней, я про нее дальше расскажу.
Есть еще одно важное измерение, поднимать у себя или использовать облако. В этом месте есть популярное заблуждение, люди до сих пор думают, что сервисы облачного машинного перевода, если вы ими пользуетесь, будут брать ваши данные и обучать на них свои модели. Это уже неправда последние год-два. Все крупные сервисы отказались от этого, у них в terms of service явно прописано, что мы не используем ваши данные для обучения своих моделей. Это важно. Это снимает кучу барьеров на пути адаптации облачного машинного перевода. Сейчас можно безопасно пользоваться этими сервисами и быть уверенными, что сервис не будет использовать ваши данные для тренировки своих моделей, и он не станет вам конкурентом со временем. Это безопасно.
Это первое преимущество облаков по сравнению с тем, что было еще два года назад.
Второе преимущество, если будете развертывать нейросетевой перевод у себя внутри, вам нужно довольно тяжелую инфраструктуру поднимать с графическими ускорителями для обучения всех этих нейросетей. И даже после обучения для inference все равно нужно использовать высокопроизводительные графические карты, чтобы это работало. Получается дорого. Стоимость владения таким решением реально большая. И компания, которая не собирается профессионально предоставлять API на рынок, не нужно этим заниматься, нужно взять готовый сервис облачный и этим пользоваться. В этом месте у вас экономия по деньгам, по времени и есть гарантия неиспользования ваших данных для нужд сервиса.
Про сравнение.
Этой темой мы занимаемся давно, полтора года проводим регулярное измерение качества. Мы выбрали автоматические референсные метрики, они позволяют массировано это делают, и получать некие доверительные интервалы. Мы более-менее знаем, на каком количестве данных метрики качества устаканиваются, и можно делать адекватный выбор между разными сервисами. Но надо помнить, что метрики автоматические и человеческие дополняют друг друга. Автоматические метрики хороши для того, чтобы провести предварительный анализ, выбрать места, на которые особенно стоит обратить внимание людям, и дальше лингвистам или доменным экспертам посмотреть на эти варианты перевода и выбрать то, что вам подходит.
Расскажу про то, какие есть системы на рынке, как мы это все анализировали, как они соотносятся по ценам, и расскажу про наши результаты анализа, что важно здесь в качестве, и что за пределами качества тоже важно при выборе сервиса.
В первую очередь, есть уже большое количество облачных сервисов машинного перевода, мы рассматривали только те, в которых есть предобученные модели, которые можно взять и начать использовать, и у них есть публичное API.
Есть еще какое-то количество сервисов, у которых нет публичного API или они разворачиваются внутри, мы их не рассматриваем в нашем исследовании. Но даже среди этих сервисов их уже большое количество, мы измеряем и оцениваем 19 таких сервисов. Практика показывает, средний человек знает нескольких лидеров рынка, а про остальных не знает. А они есть, и они местами хорошие.
Мы взяли популярность языков по вебу и разбили их на четыре группы. Самые популярные, больше 2% сайтов, менее популярные и еще менее. Есть четыре группы языков, по которым мы дальше анализируем, и из всего этого сосредотачиваемся на первой группе, самые популярные языки, и немножко на второй.
Поддержка внутри первых трех групп практически 100%. Если вам нужен язык не супер экзотический, то вы его получите из облака. А если нужна экзотическая пара, может оказаться, что какой-то из языков не поддерживается никаким сервисом машинного облачного перевода. Но даже при всех ограничениях, примерно половина всех возможных пар поддерживается. Это неплохо.
Из всего этого мы протестировали 48 пар, составили такую матрицу, выбрали в первую очередь английский и все языки первой группы, частично языки внутри первой группы, и немножко английский и языки второй группы. Это более-менее покрывает типовые сценарии использования, но за пределами остается много всего другого интересного. Эти пары мы оценили, поизмеряли и расскажу, что там происходит. Полный репорт есть по ссылке, он бесплатный, мы его регулярно обновляем, буду вас агитировать пользоваться этим.
На этом графике не видно цифр и осей, но это про поддержку различных языков разными системами машинного перевода. По оси Х разные системы машинного перевода, по оси Y в логарифмической шкале количество поддерживаемых пар вообще и уникальных. По этой картинке красный — уникальный, синий — все. Видно, что если у вас очень экзотическая комбинация языков, может оказаться, вам в силу уникальности надо использовать семь разных провайдеров, потому что только один из них поддерживает очень специфическую пару, которая вам нужна.
Для оценки качества мы выбрали новостные корпуса, general domain корпуса. Это не гарантирует, что на ваших конкретных данных из другой области ситуация будет такая же, скорее всего не такая же, но это хорошая демонстраций, как вообще подходить к такому исследованию, как для себя выбрать правильный подходящий вам сервис. Покажу на примере новостных областей. Это легко переносится на любую другую вашу область.
Мы выбрали метрику hLEPOR, это примерно то же самое, что и BLEU, но по нашему интуитивному ощущению она дает лучшее впечатление, как сервисы между собой соотносятся. Для простоты считайте, что метрика от 0 до 1, 1 — полное соответствие некоему референсному переводу, 0 — полное несоответствие. hLEPOR лучше дает интуитивное ощущение, что значит разница в 10 единиц по сравнению с BLEU. Про метрику можно отдельно почитать, в методологии исследования все описано. Это нормальная метрика, прокси-метрика, не идеальная, но хорошо передает суть.
Разница в ценах колоссальная. Мы составили матрицу, за какую цену можно получить перевод 1 млн символов. Можете скачать и посмотреть, разница колоссальна, от 5 долларов до 1000 долларов за миллион символов. Выбор неправильного сервиса просто поднимаем вам затраты колоссально, или выбор правильного может помочь очень сильно сэкономить в этом месте. Рынок непрозрачен, нужно понимать, что чего стоит и где какое качество. Держите в голове эту матрицу. Сложно сопоставить все сервисы, по цене, цены часто не очень прозрачные, политика не очень понятна, есть какие-то грейды. Это все сложно, эта таблица помогает принять решение.
Результаты своего анализа мы свели в такие забавные картинки. На этой картинке отражено, какое максимально доступное качество есть по тем парам, которые мы измеряли, чем более зеленые — тем более высокое качество доступно, какова конкуренция в этих парах, есть ли вообще из чего выбирать, условно, где-то 8 провайдеров обеспечивают это максимально доступное качество, где-то всего 2, и есть еще значок доллара, это про цену, за которую вы получаете максимальное качество. Разброс большой, где-то дешево можно получить приемлемое качество, где-то оно не очень приемлемое и дорогое, возможны разные комбинации. Ландшафт сложный, нет одного супер игрока, который везде лучше во всем, дешев, хорош и так далее. Везде есть выбор, и везде его нужно совершать разумно.
Здесь мы нарисовали лучшие системы по этим языковым парам. Видно, что лучшей системы нет одной, разные сервисы лучше на разных парах в этой конкретной области — новости, в других областях ситуация изменится. Где-то Google хорош, где-то хорош Deepl, это свежий европейский переводчик, про который мало кто знает, это небольшая компания, которая успешно борется с Google и побеждает его, реально хорошее качество. На русско-английской паре Яндекс стабильно хорошо. Amazon недавно появился, подключил русский язык и другие, и он тоже неплох. Это свежие изменения. Год назад многого из этого не было, было меньше лидеров. Сейчас ситуация очень динамическая.
Знать лучшую систему не всегда важно. Чаще важно знать оптимальную систему. Если посмотреть на топ 5% систем по этому качеству, то среди этого топ 5% есть наиболее дешевая, дающая это хорошее качество. В этом месте ситуация ощутимо другая. Google уходит из этого сравнения, очень сильно поднимается Microsoft, становится больше Яндекса, Amazon еще больше вылезает, появляются более экзотические провайдеры. Ситуация становится другая.
Если посмотреть на всех провайдеров машинного перевода, по горизонтали — разные провайдеры, по вертикали — как часто провайдер оказывается в одном из этих топов, то в топе 5% оказывается почти каждый из них рано или поздно. Лучшими из них для каких-то конкретных измеренных пар являются 7 провайдеров, оптимальными тоже 7. Это значит, что если у вас есть какой-то набор языков, на который вам нужно переводить, и вы хотите обеспечить максимальное или оптимальное качество, вам одного провайдера недостаточно, вам нужно подключать портфолио этих провайдеров, и тогда у вас будет максимальное качество, максимальная эффективность по деньгам и так далее. Нет одного игрока, который лучше. Если у вас сложные задачи, нужно много разных пар, вам прямая дорога к тому, чтобы использовать разных провайдеров, это лучше, чем использовать кого-то одного.
Рынок очень динамичен, количество предложений растет быстро. Мы начали измерять в начале 17-го года, свежий бенчмарк опубликовали в июле. Количество доступных сервисов растет, кто-то из них до сих пор в превью, у них нет публичного прайсинга, они в какой-то альфе или бете, которую вроде можно использовать, но условия еще не очень понятны.
Качество растет медленнее, но тоже растет. Основной интерес происходит внутри конкретных языковых пар.
Например, ситуация внутри английско-русской языковой пары очень динамичная. Яндекс за последние полгода очень сильно повысил свое качество. Появился Amazon, он справа одной точкой представлен, он тоже идет недалеко за Яндексом. Неплохо прокачался провайдер GTCom, которого почти никто не знает, это китайский провайдер, он хорошо переводит с китайского на английский и русский, и английский — русский тоже неплохо обрабатывает.
Похожая картина происходит более-менее на всех языковых парах. Везде что-то меняется, постоянно появляются новые игроки, меняется их качество, модели переобучаются. Вы видите, тут есть стабильные провайдеры, качество которых не меняется. В этом случае стабильные — это скорее мертвые, потому что есть другие нестабильные, качество которых более-менее улучшается. Это хорошая история, улучшаются они практически постоянно.
Если посчитать более сложную метрику про цену-качество, то здесь есть стабильные улучшения. Это значит, что стоимость качественного машинного перевода постоянно снижается, с каждым месяцем, с каждым годом вам доступен все более качественный машинный перевод за меньшие деньги. Это хорошо.
Ссылка со слайда
Помимо цен и качества есть огромный пласт вопросов, которые тоже важны при выборе конкретного провайдера. Это всякие продуктовые фичи, поддержки html, xml, поддержка хитрых и не очень форматов, bulk-режим, автоопределение языка — популярная тема, поддержка глоссариев, кастомизация, надежность сервиса. И еще то, что мы называем счастьем разработчика, по ссылке потом можно прочитать, что мы имеем в виду.
Это для создания машинного бедствия. Под DX мы понимаем огромное количество всяких разных аспектов, включая наличие хорошей документации, понятные коды и сообщения об ошибках, соответствие стандартам HTTP, наличие некоего плейграунда, чтобы динамически поиграть с API, наличие удобного биллинга и много всего другого, что очень сильно влияет на принятие решения о том, стоит использовать конкретный сервис или нет. Если разработчик чертыхается, подключая новую API, то это плохой сигнал. Разработчик может сказать, что нам это не надо, и по факту некоторые API просто сложно использовать для конкретных задач, потому что они чего-то не поддерживают из нужного вам. Это важный аспект.
Это пример диаграммы по одному из реальных сервисов, который сравнительно неплох на фоне других. У многих других сервисов эта диаграмма ближе к нулю собирается, часто нет нормальной документации, нет SDK, непонятно, как с биллингом работать, невозможно выгружать данные об использовании сервиса и много всего другого. Поддержки нет нормальной. Это сложная тема.
Недавно мы столкнулись с замечательным сервисом, который вроде как публичный, а документация на API доступна после подписания NDA. Есть много странных случаев. По факту это некий фактор принятия решений. Знайте про него, он в какой-то момент может всплыть.
Это была часть про стоковые модели, которые есть на рынке. Надеюсь, я передал общие ощущения, что рынок динамичные, есть много игроков и нет одного суперлидера. Каждый лучше в чем-то одном, и вам скорее всего придется собирать портфолио провайдеров, если вы хотите переводить на много разных языков.
Вторая интересная тема — кастомизированные модели, которые начали появляться сравнительно недавно. Мы начали измерения этих кастомизированных моделей, скоро выпустим репорт, а сейчас расскажу предварительные результаты этого измерения.
Сейчас уже многие сервисы поддерживают какую-то кастомизацию. Это могут быть некие глоссарии, это может быть дообучение на вашем датасете, и провайдеров много. В первую очередь, сколько-то топовых, типа Google, Microsoft, IBM, сколько-то более экзотических, и часть, про которые мало кто знает, но они тоже позволяют это делать.
Как здесь мы сравниваем? Мы выбрали одну специальную область, биомед, под него стоковых моделей не очень много, область со специальной терминологией. Выбрали пару английский — немецкий, просто потому что нам легче было датасет собрать под эту пару. И попробовали пообучать эти модели на разных обучающих выборках от 10 тыс. до 1 млн предложений. Сделали тестовый датасет из 2 тыс. предложений, по нашим измерениям на 2 тыс. предложений метрика устаканивается и можно адекватно сравнивать разные сервисы. 50 предложений недостаточно.
Мы выбрали метрику hLEPOR, и дальше обучаем всех этих провайдеров нашими датасетами, измеряем качество на нашем тестовом датасете, а заодно измеряем качество стоковых моделей на этом датасете, чтобы понять, какой бейслайн, какой референс поинт в этом месте. Покажу, как меняется качество и какое получается при тренировке. В этом месте важный аспект — стоимость владения этими моделями. Про это мы отдельно в репорте расскажем, когда все это соберем вместе. Но тут ситуация усложняется, у вас есть затраты на тренировку моделей, какое-то время и деньги на тренировку, не везде прозрачные. Есть стоимость поддержки этой модели и стоимость ее использования, у разных сервисов она разная. Из этих трех компонентов складывается стоимость владения, это важный аспект, его надо посчитать перед тем, как переходить на кастомный движок. Это существенное отличие от стоковых моделей.
Предварительные результаты показывают, что это действительно работает. Вот пример на Microsoft, на 3 версии его API. Стоковая модель на биомеде работает довольно плохо, но это нормальная история, нельзя считать, что Microsoft худший. Он работает хорошо на типовых доменах. Под этот домен, видимо, он не обучался. Это нормальная история вовремя понять, что под ваш домен стоковая модель не работает, зато достаточно всего 10 тыс. предложений и Microsoft начинает хорошо работать на вашем конкретном домене. И последовательно увеличивая датасет, вы это качество еще увеличиваете. Это хорошая история, он быстро адаптировался, это можно использовать.
IBM, стоковая модель неплохо работает из коробки, но дообучением ее тоже можно поднять качество. Это это неплохо, качество нормально растет. Улучшение даже на 2% — это хорошее улучшение.
Google AutoML недавно запущенный тоже неплохо работает, стоковая модель сама по себе неплохого качества оказалась на этом конкретном датасете, а обучение моделей на 10 или 100 тыс. предложениях улучает качество.
Если все это нарисовать на одной картинке, есть Microsoft, есть Google, есть какое-то количество стоковых моделей — Яндекс, Deepl, Amazon, стоковый Google, стоковый Microsoft. И видно, в данном конкретном случае это интересный кейс. Как принимать решения в подобной ситуации? Нужно понять, что на вашей предметной области какая-то стоковая модель плоха, но какая-то может оказаться хорошей. Яндекс, Google и Deepl, оказывается, из коробки на биомеде работают довольно здорово, и даже превышают качество некоторых обученных моделей. Это интересно. Если вы это в самом начале исследования поймете, то можно на этом остановиться и использовать стоковую модель. Это здорово.
С другой стороны, это дает вам некую нижнюю границу качества, относительно которой дальше можно оценивать улучшения и понимать, стоят они тех денег или не стоят, которые вы собираетесь за них заплатить. И последовательное увеличение размеров обучающих датасетов неплохо прокачивает эти модели. Можно получать более высокое качество, в целом есть стабильное улучшение качества сервиса в зависимости от того, сколько данных вы в него отправили. И помните, это только ваши данные, сервис не будет их использовать для обучения своих общий моделей. Это существенное отличие. Это до сих пор не устоялось в головах, но это произошло. Можно безопасно отправлять данные, и сервис не будет с вами конкурировать в перспективе.
Как вообще подходить осознанно к выбору движка облачного машинного перевода для ваших конкретных задач?
Подготовьте тестовый корпус. Без него сравнивать сложно. Можно с лингвистами сравнивать, но это дорогой труд, он трудновоспроизводим.
Как только вы подготовили тестовый корпус, сравните стоковые модели на рынке. Может оказаться, что какая-то из них уже вам подходит. Так бывает. Мы обнаруживали, что конкретные сервисы хорошо из коробки работают, например, на юридических документах или еще на каких-то. Их можно использовать сразу и не обучать специальные модели, просто надо найти свой движок, который обучался на данных, похожих на ваши. Либо они подойдут, либо зададут нижнюю планку по качеству, относительно которой дальше будете сравнивать либо заказные решения, с которыми к вам кто-то придет, либо другие облачные, которые вы будете дообучать. Это хорошая история — знать свой бейслайн.
Подготовьте глоссарий и какой-то тренировочный корпус, обучающую выборку, если можете. И если вы можете потратить усилия на сбор таких дата-сетов, то разумно попробовать адаптируемые модели. Они либо подойдут, либо зададут планку для подрядчика, который вам будет делать совсем кастомное решение. В любом случае, это, скорее всего, увеличит вам общее качество. А дальше выбор за вами. Дальше чисто экономика — стоит это увеличение качества денег, которые вы будете за него платить, или не стоит.
Ссылки со слайда: первая, вторая, третья, четвертая, пятая
Чем мы в этом месте можем помочь? Многим. У нас есть отчеты по сравнению систем машинного перевода, по ссылке опубликован последний отчет и есть все предыдущие. Мы стараемся их делать примерно раз в квартал, они бесплатные, читайте их, там есть много деталей. Он сильно более детализирован по сравнению с тем, что я сегодня рассказывал.
Скоро мы выпустим отчет по кастомизированным моделям, где подробнее распишем, как сервисы соотносятся по качеству после обучения и чего это все стоит. У нас есть единое API ко всем сервисам машинного перевода. Достаточно одной интеграции, чтобы пользоваться всеми лучшими сервисами, доступными на рынке. У нас есть SDK под NodeJS, под .NET, есть CLI. А кроме того, скоро будет API, который можно будет использовать для оценки качества моделей. Вы сможете загрузить свои данные и прогнать их через выбранных провайдеров. Посчитайте метрики, отгрузите нам результирующие данные, мы выберем лучшую модель. Этот процесс хорошо автоматизируется, можно будет гораздо дешевле и проще выбрать то, что подходит под ваш конкретный кейс, и начать этим пользоваться — через нас или самостоятельно.
Скоро у нас будут web tools для перевода. Не все люди, которые пользуются машинным переводом, хотят писать интеграции, работать даже с одним API. Это понятная история. Можно будет через браузер попробовать разные сервисы, понять, кто для вашего случая лучший и пользоваться им.
Основные выводы такие, что единого лидера нет. Не ждите одного супер-рейтинга, который скажет, что один провайдер лучше всех. Это не так. Часто нужно собирать портфолио провайдеров, чтобы обеспечить максимальное качество. Качество всех стоковых моделей улучшается постоянно. Надо за этим следить, чтобы понять, что появился сервис или лучше по качеству, чем у вас, или более оптимальный по деньгам. Рынок машинного перевода становится более фрагментированным, появляются провайдеры или модели, обученные на специальных корпусах, более эффективные, чем общие провайдеры. Помните Deepl? Это интересный провайдер, который сумел обучиться на своих уникальных данных и побить Google во многих языковых парах.
Кроме того, помните, что сейчас, имея свои уникальные данные, вы можете натренировать свои модели в облачных сервисах и пользоваться ими. Качество, скорее всего, будет гораздо лучше, чем у дефолтных моделей, и точно лучше, чем у неправильно выбранных моделей. Спасибо.