На простом примере рассмотрим создание буквально за несколько минут собственного бессерверного автомасштабируемого REST API с разбором кейса — получения списка для ресурса.
Интересно? Тогда заходим под кат!

(Источник)
Вместо вступления
Для разбора примера использовать какие-либо базы данных не будем, вместо этого нашим источником информации будет обычный текстовый файл на AWS S3.
- Итак, предположим, что на AWS S3 у нас есть текстовый файл с заголовками и некий процесс пишет в него информацию.
- Мы создадим облачный API, который по GET запросу с переданным параметром будет возвращать в виде ответа JSON коллекции.
- При этом, в зависимости от сложности задач и, как следствие, повышенных требований к вычислительной мощности ресурсов, не придется об этом заботиться, т.к. сервис полностью автомасштабируемый. А это означает, что не нужно никакого администрирования, выделения серверов и управления ими, просто загружаем свой код и запускаем его.
Архитектура разрабатываемой системы

Используемые компоненты Amazon Web Services:
- Amazon S3 — объектное хранилище, которое позволяет хранить практически неограниченные объемы информации;
- AWS Identity and Access Management (IAM) — сервис, предоставляющий возможности безопасного управления доступом к сервисам и ресурсам AWS. Используя IAM, можно создавать пользователей AWS и группы, управлять ими, а также использовать разрешения, чтобы предоставлять или запрещать доступ к ресурсам AWS;
- AWS Lambda — сервис, позволяющий запускать код без резервирования и настройки серверов. Все вычислительные мощности автоматически масштабируются под каждый вызов. Плата взимается на основе количества запросов к функциям и их продолжительности, т.е. времени, в течение которого исполняется код.
Уровень бесплатного доступа (Free tier) предполагает 1 млн. запросов в месяц бесплатно и 400К Гб-с. Поддерживаемые языки: Node.js, Java, C#, Go, Python, Ruby, PowerShell
. Будем использовать Python:
- Библиотека boto3 — это AWS SDK для Python, позволяющий взаимодействовать с различными сервисами Amazon;
- Amazon API Gateway — полностью управляемый сервис для разработчиков, предназначенный для создания, публикации, обслуживания, мониторинга и обеспечения безопасности API в любых масштабах. Помимо возможности использования нескольких версий одного и того же API (stages) с целью отладки, доработки и тестирования, сервис позволяет создавать бессерверные REST API при помощи AWS Lambda. Lambda выполняет код в высокодоступной вычислительной инфраструктуре, устраняя необходимость в распределении и масштабировании серверов, а также в управлении ими.
Уровень бесплатного доступа (Free tier) для HTTP/REST API включает один миллион вызовов API в месяц в течение 12 месяцев
Подготовка данных
В качестве источника информации для формирования ответов по REST-запросу GET будет применяться текстовый файл с табуляцией в качестве разделителей полей. Информация сейчас не имеет большого значения для данного примера, но для дальнейшего использования API я выгрузил из торгового терминала Quik таблицу текущих торгов по облигациям, номинированным в российских рублях, сохранил в файле bonds.txt и поместил этот файл в специально созданный бакет AWS S3.
Примерный вид полученной информации такой, как показано на рисунке ниже:

Далее, необходимо написать функцию, которая будет считывать информацию из файла bonds.txt, парсить ее и выдавать по запросу. С этим прекрасно справится AWS Lambda. Но сначала необходимо будет создать новую роль, которая позволит созданной Lambda-функции считывать информацию из бакета, расположенного в AWS S3.
Создание роли для AWS Lambda
- В консоли управления AWS переходим в сервис AWS IAM и далее в закладку «Роли», нажимаем на кнопку «Create role»;
Добавление новой Роли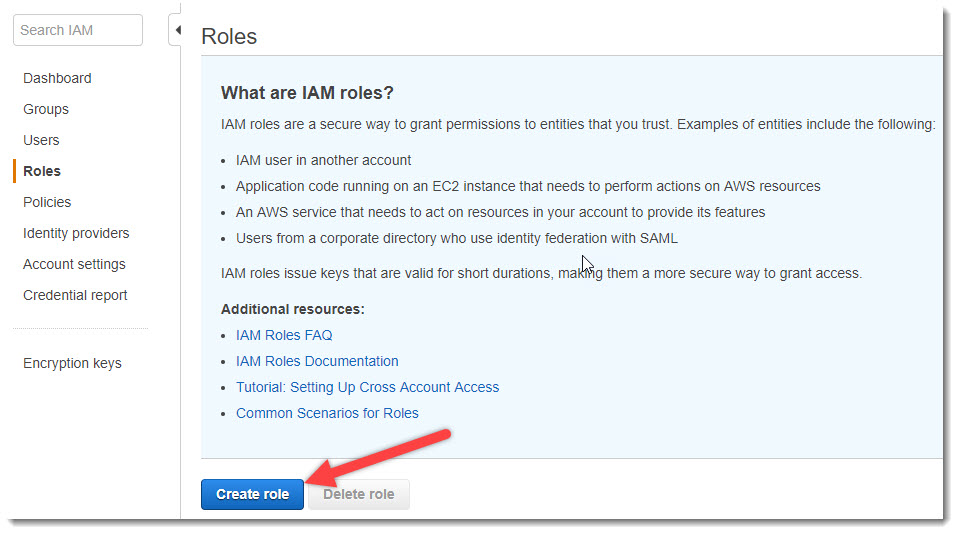
- Роль, которую мы сейчас создадим, будет использоваться сервисом AWS Lambda для чтения информации с AWS S3. Поэтому, на следующем шаге выбираем «Select type of trusted» --> «Aws Service» и «Choose the service that will use this role» --> «Lambda» и нажимаем на кнопку «Next: Permissions»
Роль для сервиса Lambda
- Теперь необходимо задать политики доступа к ресурсам AWS, которые будут использоваться во вновь созданной роли. Т.к. список политик достаточно внушителен, используя фильтр для политик укажем к нем «S3». В результате чего получим отфильтрованный список применительно к сервису S3. Отметим чекбокс напротив политики «AmazonS3ReadOnlyAccess» и нажмем на кнопку «Next: Tags».
Политики для Роли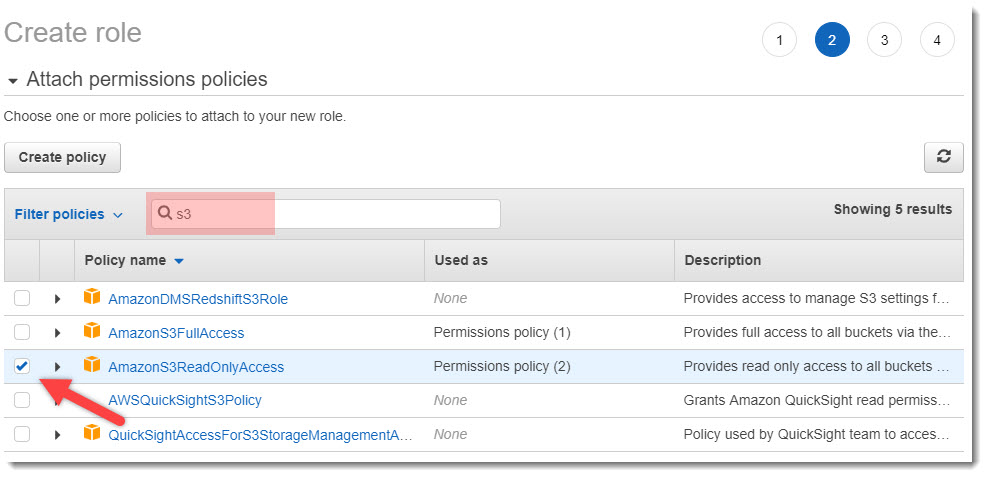
- Шаг (Add tags (optional)) – необязательный, но при желании можно указать теги для Роли. Мы этого делать не будем и перейдем к следующему шагу – Preview. Здесь необходимо задать наименование роли – «ForLambdaS3-ReadOnly», добавить описание и нажать на кнопку «Create role».
Наименование Роли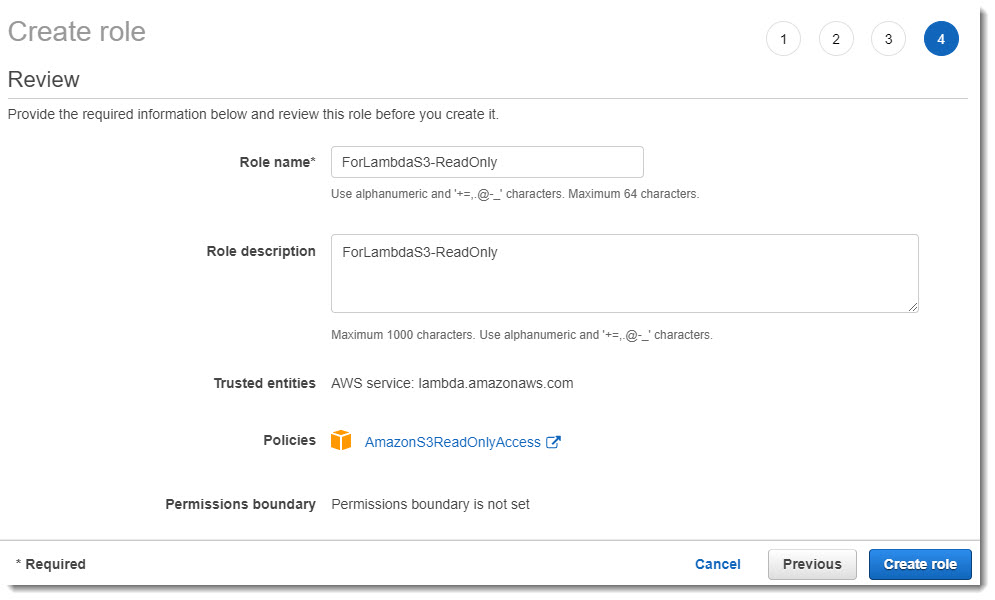
Все, роль создана и мы можем ее использовать в дальнейшей работе.
Создание новой функции в AWS Lambda
- Переходим в сервис AWS Lambda и нажимаем на кнопку «Create function»:
Создание функции
Заполняем все поля как показано на скриншоте ниже:
- Name – «getAllBondsList»;
- Runtime – «Python 3.6»
- Role – «Choose an existing role»
- Existing role – здесь выбираем ту роль, которую мы создали выше — ForLambdaS3-ReadOnly
Наименование и выбор роли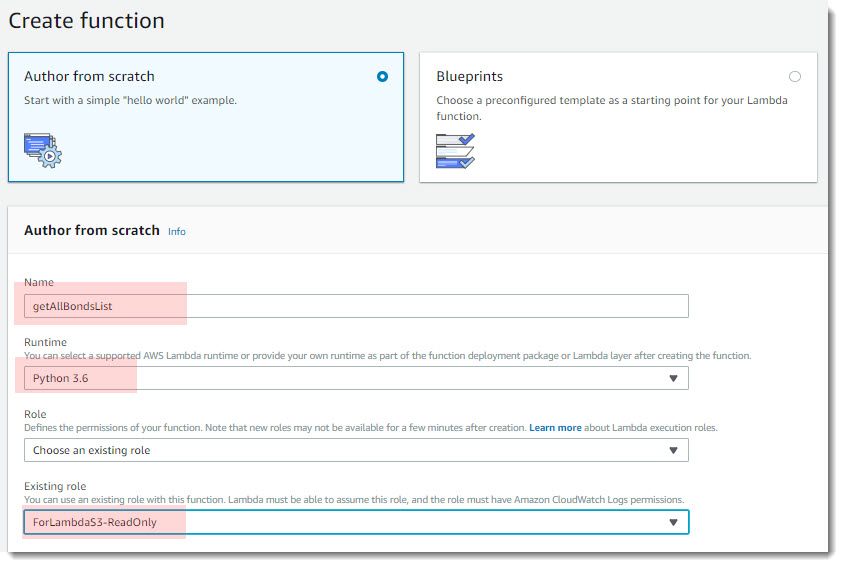
- Остается только написать код функции и проверить ее работоспособность на различных тестовых запусках. Необходимо отметить, что основным компонентом любой Lambda-функции (если используете Python) является библиотека boto3:
import boto3 s3 = boto3.resource('s3') bucket = s3.Bucket('your-s3-bucket') obj = bucket.Object(key = 'bonds.txt') response = obj.get()
Основная идея нашей Python-функции следующая:
- Открыть файл bonds.txt;
- Считать заголовки столбцов;
- Разбить записи постранично (10 коллекций в нашем случае);
- Выбрать нужную страницу;
- Смаппить название столбцов и записей;
- Выдать результат в виде коллекций.
Не будем уделять много времени самому коду функции и технической реализации, здесь все довольно просто и полный код доступен в моем GitHub.
for i in range(0, len(lines_proc)): d = dict((u''.join(key), u''.join(value)) for (key, value) in zip(headers, lines_proc[i].split("\t"))) response_body.append(d) return { 'statusCode': 200, 'page' : num_page, 'body': response_body }
Вставим код (или напишем свой :) ) в блок «Function code» и нажимаем на кнопку «Save» в правом верхнем углу экрана.
Вставка кода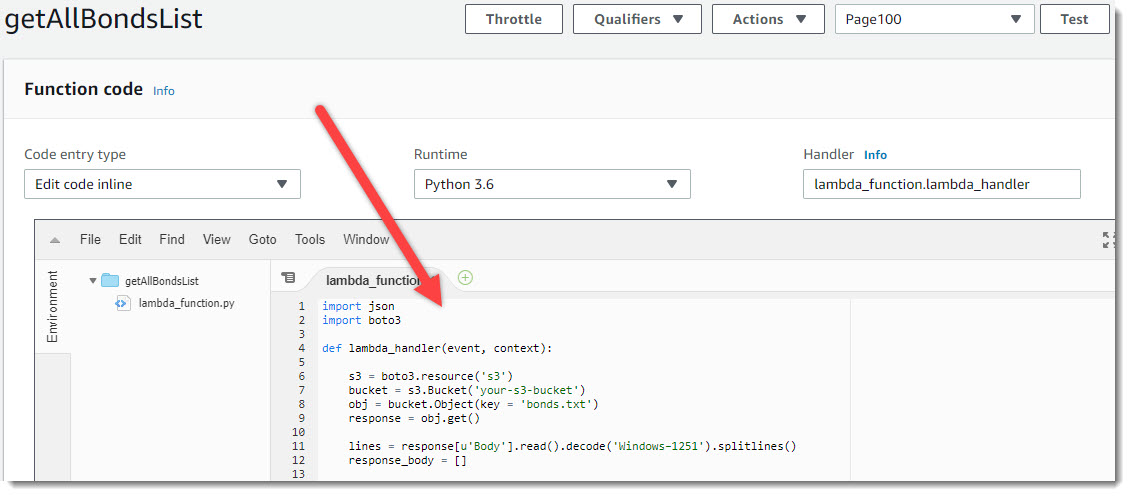
- Создание тестовых событий. После вставки кода, функция доступна для запуска и тестирования. Нажмем на кнопку «Test» и создадим несколько тестовых событий: запуск функции lambda_handler с разными параметрами. А именно:
- Запуск функции с параметром 'page': '100';
- Запуск функции с параметром 'page': '1000000';
- Запуск функции с параметром 'page': 'bla-bla-bla';
- Запуск функции без параметра 'page'.
Тестовое событие Page100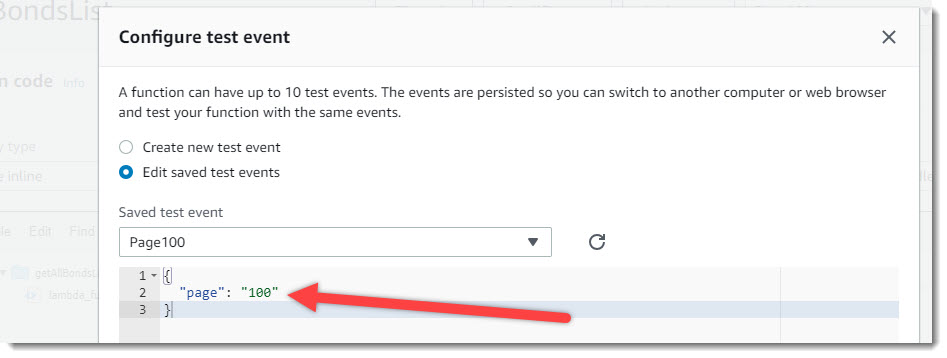
Запуск созданной функции с передачей тестового события page == 100. Как видно из скриншота ниже, функция успешно отработала, возвратила статус 200 (OK), а также набор коллекций, который соответствуют сотой странице разделенных данных при помощи пагинации.
Запуск тестового события Page100
Для чистоты эксперимента запустим другое тестовое событие – «PageBlaBlaBla». В этом случае функция возвращает результат с кодом 415 и комментарий, что необходимо проверить корректность переданных параметров:
Тестовое событие PageBlaBlaBla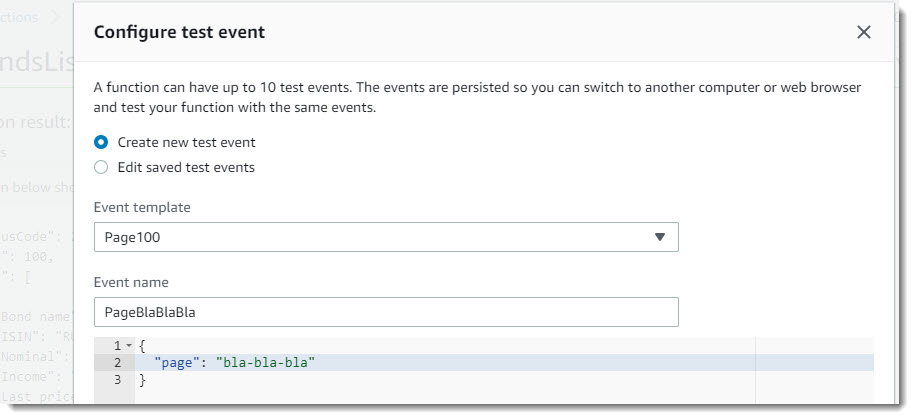
Запуск события PageBlaBlaBla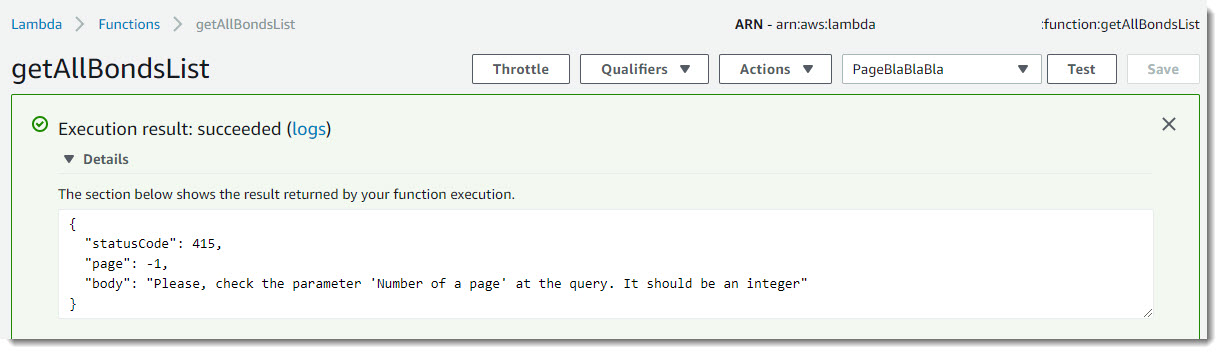
Создание API
После того как протестированы все остальные кейсы и есть понимание того, что Lambda-функция работает так, как мы этого ожидаем, приступаем к созданию API. Создадим точку доступа к созданной выше Lambda-функции и дополнительно установим защиту от нежелательных запусков при помощи API Key.
- Переходим в сервис AWS API Gateway. Нажимаем на кнопку «Create API», задаем имя API – «getAllBondsList»
Создание нового API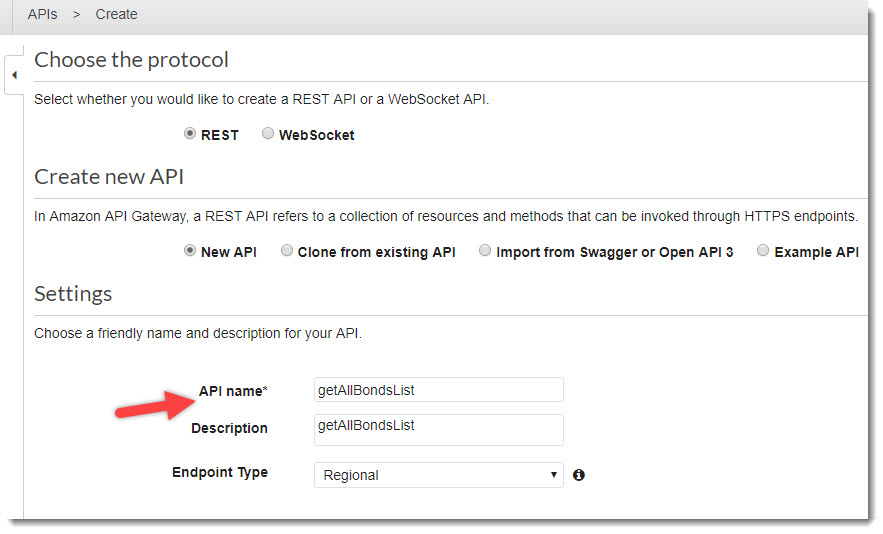
- Добавляем метод GET вновь созданному API. Для этого выбираем Actions --> Create method, в появившемся раскрывающемся списке выбираем метод GET и нажимаем на галочку
Новый метод GET
Далее, укажем что в методе GET будет использоваться наша Lambda-функция getAllBondsList. Выбираем ее и нажимаем на кнопку Save.
Привязка Lambda-функции
- Проведем деплой нашего API, получив тем самым URL-адрес для вызова API.
Нажимаем Actions --> Deploy API, и далее, Deployment stage --> New Stage
Существует возможность развертывать API в разные стадии и называть эти стадии можно как угодно (например, DEV/QA/PROD). Мы развернем сразу в PROD.
Deploy API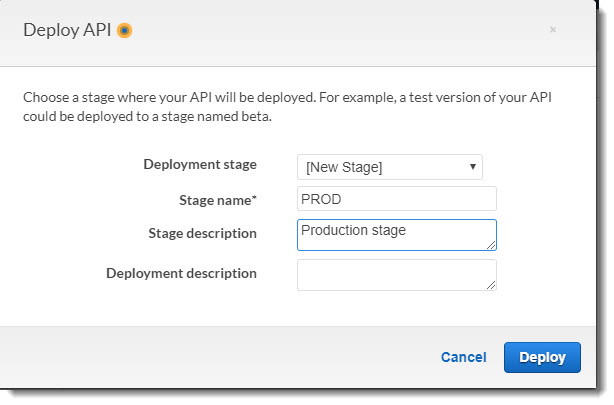
После деплоя будет доступна ссылка на запуск вновь созданного API. Перейдем по этому URL в адресной строке браузера (или выполним команду curl в терминале) — получим вызов API и, как следствие, запуск Lambda-функции:
URL-адрес API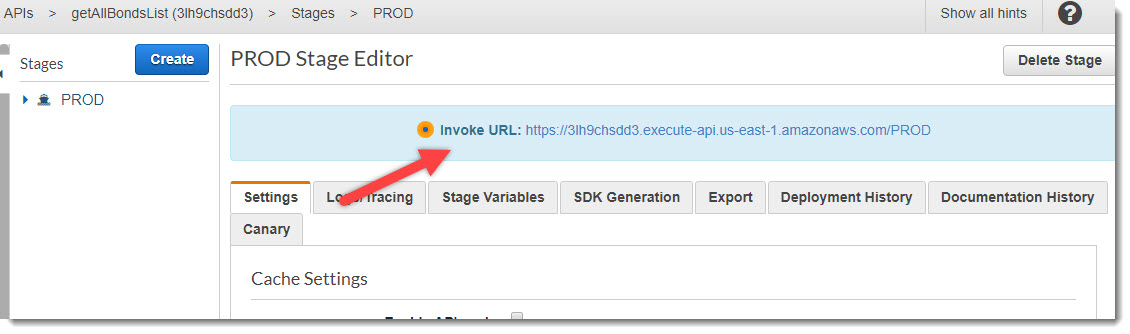
Для демонстрации работы AWS API Gateway я буду использовать приложение Postman. В нем можно достаточно комфортно отлаживать и тестировать работу API.
Первое тестирование APIКопируем URL со стадии PROD в Postman и посылаем запрос GET нашему API:
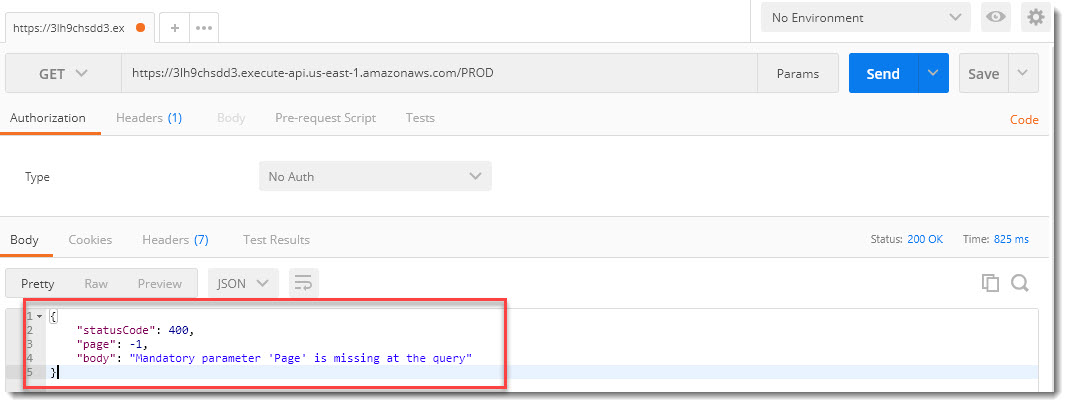
Кажется, что-то пошло не так… запрос GET вернул JSON-ответ с кодом 400 и подсказкой, что не задан параметр Page в запросе вызова API. Добавим поддержку параметров запроса к API.
- Поддержка переданных параметров в запросе.
Возвращаемся в настройки GET запроса и переходим в шаг Method Request.
Method Request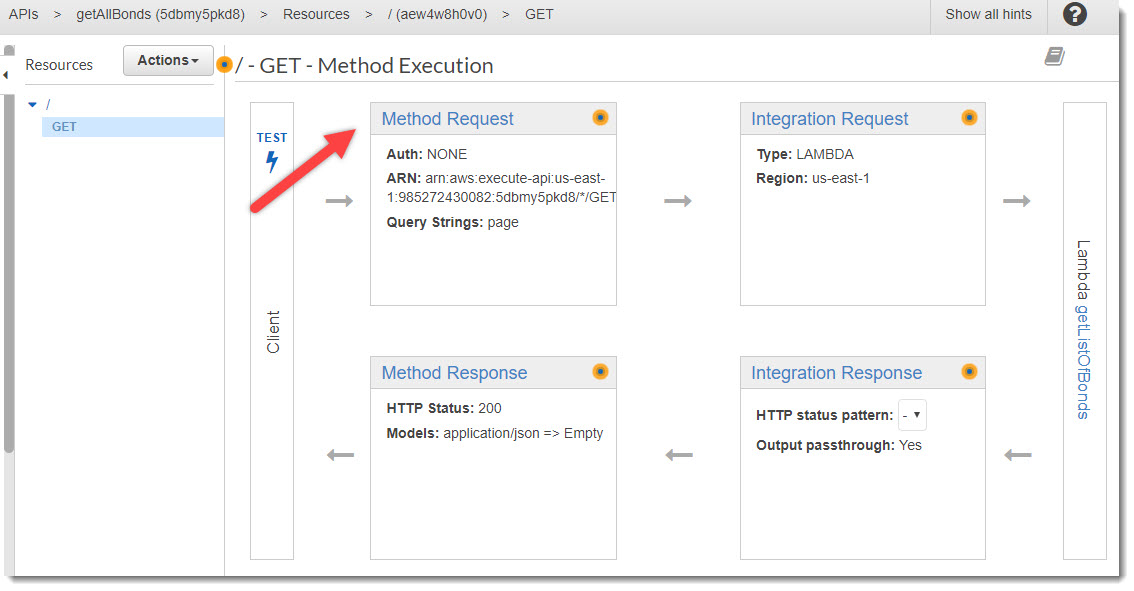
В детальных настройках Method Request необходимо раскрыть блок URL Query String Parameters и добавить новый параметр «page» и сделать его обязательным (Required):
Добавление параметра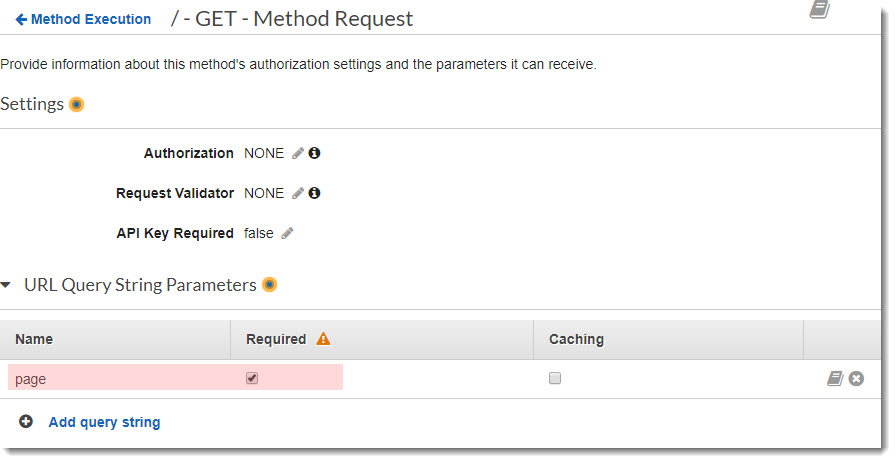
Возвращаемся на страницу Method Execution и переходим в Integration Request. Спускаемся в самый низ страницы и раскрываем блок «Mapping Templates». Выбираем «When there are no templates defined (recommended)», в поле Content-Type следует указать application/json и нажать на галочку. Прокручиваем страницу ниже и в текстовом поле вводим код, как указано на картинке ниже. После этого нажимаем на кнопку Save.
Method Request
Предварительно сделав деплой API, проверяем еще раз, но уже с передачей параметра «page»:

Это успех! Теперь запрос отработал успешно и вернул нам коллекции, содержащиеся на десятой странице! Ура! - Осталось только защитить наш API от нежелательных посягательств извне.
Для этого необходимо настроить работу API таким образом, чтобы при обращении он требовал секретный ключ, который передается в header.
Перейдем в API Keys и создадим новую связку API ключей — KeyForBondsList.
API Keys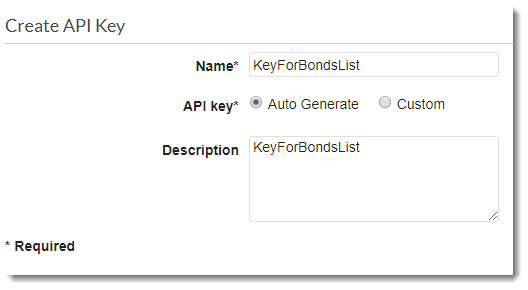
После того как API Key будет успешно создан, необходимо указать, что API getAllBondsList должен требовать обязательной передачи API ключа в заголовке запроса. И привязать конкретный ключ KeyForBondsList к API getAllBondsList.
Перейдем опять в настройки GET запроса в Method Request и сменим параметр API Key Required с false на true. Теперь API будет требовать передачи API Key.
API Key Required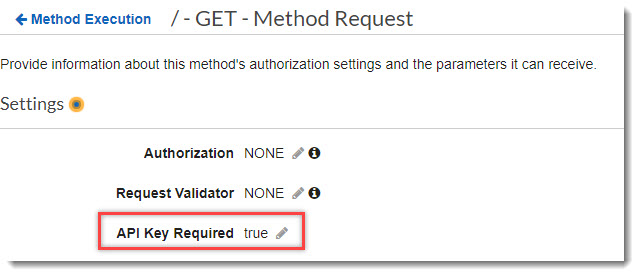
Переходим в Usage Plan и создадим новый план использования API.
Во-первых, дадим ему имя и описание, а во-вторых, здесь же можно задать лимиты на запуск API, например, не чаще чем один запуск в секунду и т.д.
Создание Usage Plan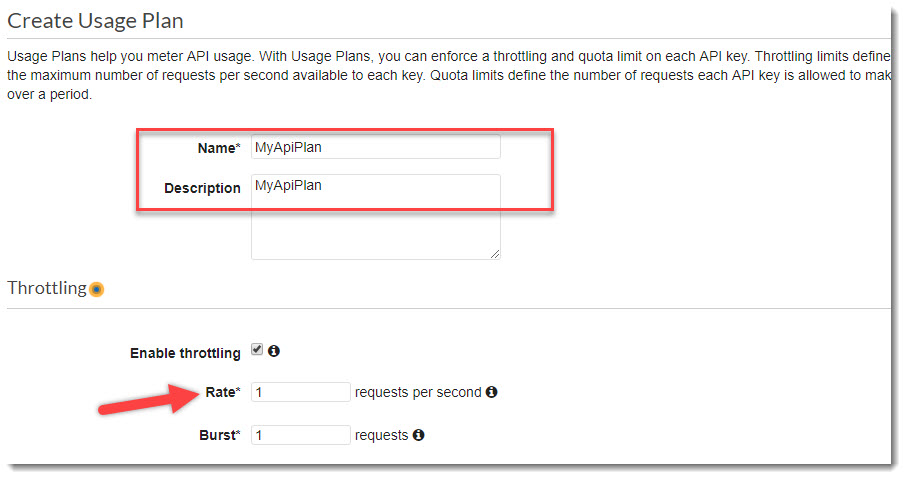
Нажимаем на Next и переходим к следующей странице, где необходимо связать стадии API с планом пользования:
Привязка стадии к Usage Plan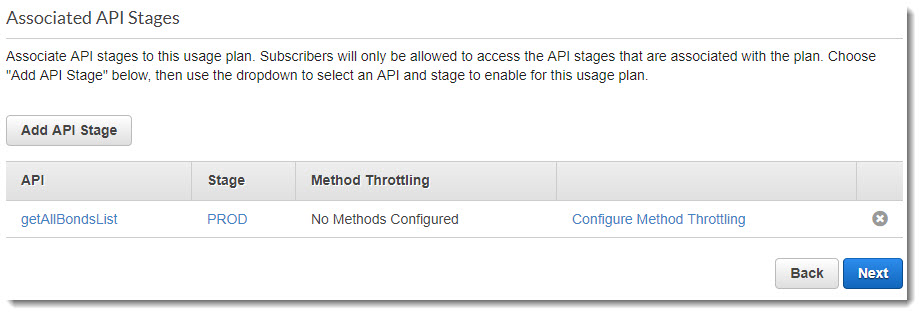
На следующей странице привязываем API Keys к плану использования API. Нажимаем на кнопку Add API Keys to Usage Plan и находим по названию созданные API Keys на предыдущих шагах:
Привязка API Keys к Usage Plan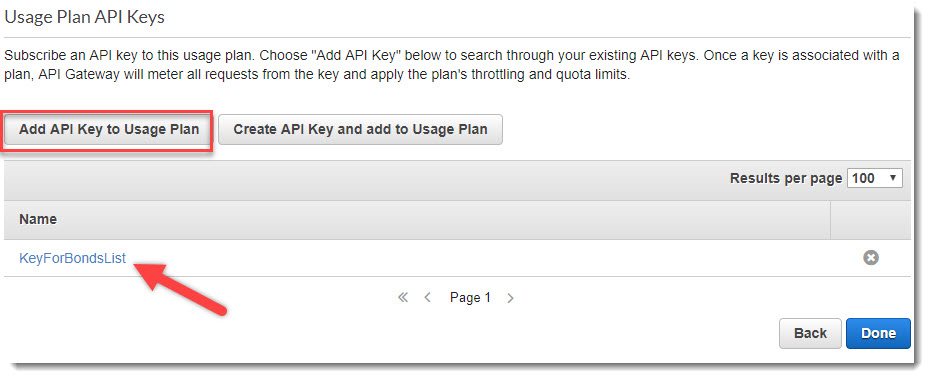
Выполнив деплой и запустив еще раз вызов GET нашего API мы получаем ответ: «Forbidden», т.к. в заголовке запроса отсутствует API Key:
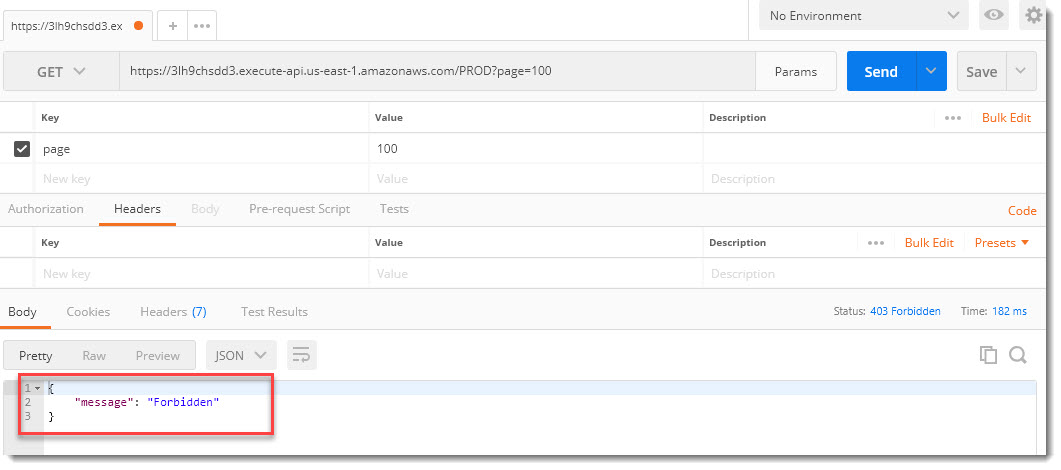
Попробуем добавить его, скопировав из API Keys --> KeyForBondsList --> API key --> Show и вставим в соответствующий раздел запроса с ключом «x-api-key»:
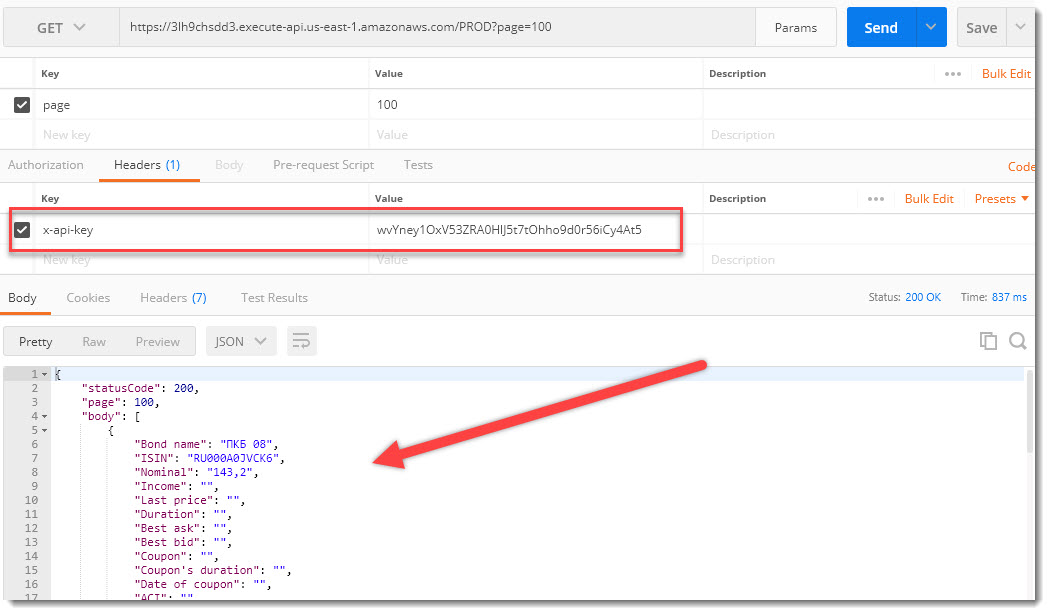
Все получилось! На этот раз запрос возвращает данные без каких-либо проблем, вызов API безопасный и защищен от злоумышленников секретным ключом API Key.
Выводы и итоги
В этой статье мы рассмотрели создание бессерверного автомасштабируемого REST API с применением облачных сервисов Amazon. Статья получилась не самой маленькой по объему, но я старался максимально подробно объяснить весь процесс создания API и скомпоновать всю последовательность действий.
Уверен, что после одного-двух повторений описанных в статье действий, Вы сможете поднимать свои облачные API за 5 минут и даже быстрее.
Благодаря своей относительной простоте, дешевизне и мощности сервис AWS API Gateway раскрывает перед разработчиками широкие возможности для использования в работе и в коммерческих проектах. Для закрепления теоретического материала данной статьи, попробуйте оформить бесплатную годовую подписку Amazon Web Services и проделать самостоятельно вышеуказанные шаги по созданию REST API.
По любым вопросам и предложениям, с удовольствием готов пообщаться. Жду Ваших комментариев к статье и желаю успехов!
Комментарии (24)

maxzh83
08.01.2019 17:34Бессерверный REST API
Сильно напрягает термин «бессерверный». Если вы реализуете не всю серверную логику, это не значит, что сервера нет.I_v_g Автор
08.01.2019 18:28Инструменты, которые используются в статье, Amazon в официальной документации позиционирует как «бессерверные», и каждый раз указывает на это как на преимущество: AWS Lambda — бессерверный сервис вычислений, AWS API Gateway — бессерверные автомасштабируемые API.
Рекомендую для краткого ознакомиться здесь:
Так же у AWS достаточно подробная документация с примерами.maxzh83
08.01.2019 20:09У меня не к вам претензия, а к маркетологам. Они создают новые термины, чтобы поменять мышление конечного пользователя в нужную им сторону. На самом деле сервера как были так и есть, просто они в облаке (еще один прекрасный термин) Amazon и ты этот сервер
не контролируешьне замечаешь.Stas911
09.01.2019 16:02Зачем потребителю сервиса вообще об этом знать, если он к этому отношения не имеет от слова «совсем»? Вы, когда газом дома пользуетесь, много знаете о магистральных газовых делах?
trapwalker
09.01.2019 22:20+1Постойте, что не так? Лямбда-подход существенно отличается от классического и тут не о чем спорить. Тот факт, что сервер так или иначе какой-то всё же есть от вас тоже никто не скрывает. Ну наивно же. Вполне разумное желание дать концепции и подходу в целом какое-то «имя». Чем плохо называть его бессерверным я не понимаю.
Это как сказать, что облачные решения harwareless. Понятно, что железо там где-то в кишочках амазона есть, но оно не стоит в вашем датацентре, не нуждается в ТО, в смазке, в охлаждении, в замене кулеров, в обновлении… В этом же смысле это бессерверное решение. Вы не оперируете понятием сервер в некотором аспекте, в котором раньше оперировали.
Тот же stateless не избаляет же вас от любых состояний во всех смыслах. Вы придеритесь ещё, что прога либо работает, либо нет, и это уже состояние.
Не обижайте маркетологов за это. Они где угодно нагрешили, но не тут. Просто вы придираетесь. Понимайте бессерверное, как новый уровень абстракции.
vdem
09.01.2019 15:25Сильно напрягает и слово «бессерверный». Вроде бы всегда было «безсерверный».
I_v_g Автор
09.01.2019 15:54+1Думаю, есть смысл немного освежить в памяти вот какое правило определения букв в приставках:
Приставки Без-/Бес-
Примеры широкого использования формулировки «бессерверный»:
Википедия
Amazon
trapwalker
09.01.2019 22:39+1Не знаю… меня бы «безсерверный» напрягло бы. Если дофига читать в детстве, то можно, к примеру, получать двойки в школе по русскому за лень учить правила, но пятёрки на диктантах за «инстинктивную» грамотность из-за гигабайтов прочитанного текста. Читаешь Азимова и Хайнлайна, а нейроночка-то в голове тренируется сама собой.
Эдакий лайфхак, если позволите.
akdes
08.01.2019 18:05+1Спасибо за статью.
Небольшая ремарка: насколько я помню, лямбда всё же имеет ограничение по кол. запросов, что не маловажно при её концепции… А то было у меня..., думаю, нафига мне сервер, возьму лямбду, и пусть она кипитится милион раз в день. А фигушки, там есть свой порог…
I_v_g Автор
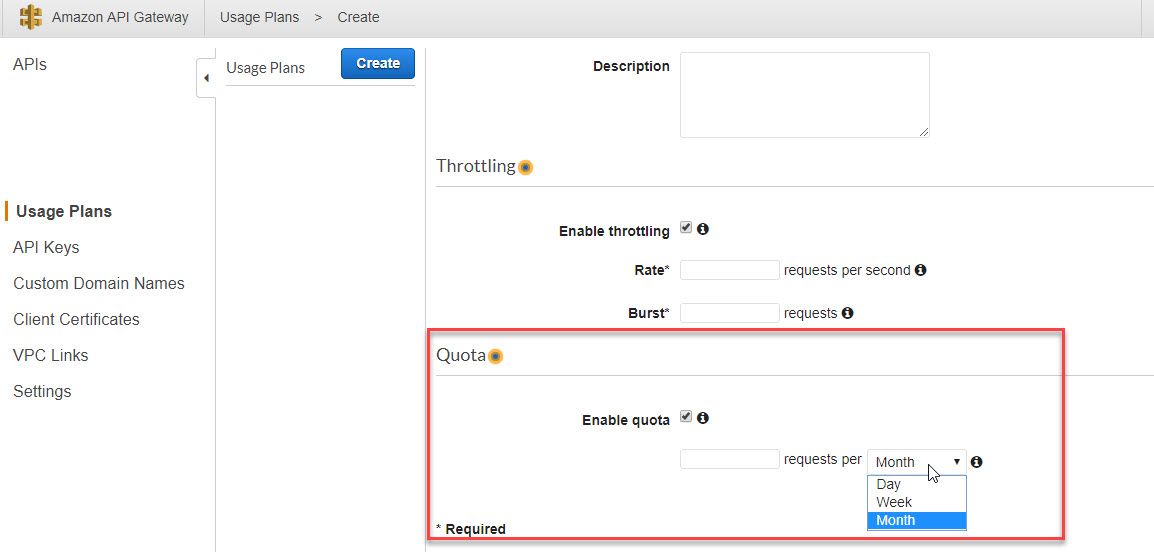
08.01.2019 18:15Вы использовали Лямбду совместно с API Gateway? Дело в том, что у вызова API Gateway могут быть заданы ограничения по количеству запусков в день/неделю/месяц:
akdes
08.01.2019 18:19нет, я лишь хотел сказать, что Лямбда не решает проблему, когда речь идёт о бешенном количестве запросов. Кажется лимит в 1000 запросов за секунду — крыжка. Когда я услышал о лямбде, думал, ну всё, сношу 10 XL Instance и бегу на лямбду…
I_v_g Автор
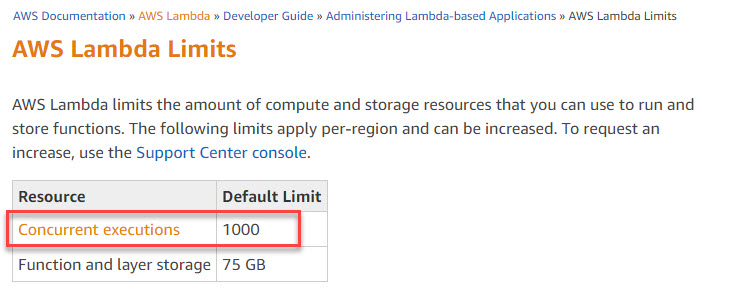
08.01.2019 18:47Все правильно, у Лямбды (как у любого другого сервиса Amazon) есть некоторые ограничения (AWS Lambda Limits) по умолчанию — 1000 параллельных запусков. Для увеличения лимита — необходимо обратиться в поддержку с просьбой об увеличении лимита сервиса в конкретном регионе.
ilyapirogov
08.01.2019 18:50+1Это искусственный лимит, который можно увеличить по запросу в службу поддержки. Такие лимиты есть для всех сервисов AWS и почти все их можно увеличить при необходимости. Созданы они были, как я понимаю, для защиты от фрода или попыток целенаправленно съесть все ресурсы AWS.
docs.aws.amazon.com/lambda/latest/dg/limits.html
PhoenixUA
09.01.2019 12:22Поддерживаемые языки: Node.js, Java, C#, Go, Python
Что-то устарела у них документация.
11.09.2018 — Today we are excited to release support for PowerShell Core 6.0Angerslave
09.01.2019 12:45Через Lambda Layers можно практически любой язык теперь подключить, например, PHP:
aws.amazon.com/blogs/apn/aws-lambda-custom-runtime-for-php-a-practical-example
I_v_g Автор
09.01.2019 12:53В защиту актуальности документации Amazon :)
AWS Lambda Runtimes
Благодарю за внимательность!
Angerslave
Мне показалось или весь файл дёргается с S3 до пагинации? Это в лучше случае неэффективно (по времени и data transfer), в худшем при разрастании файла и нагрузка бюджет будет расти очень быстро, а в какой-то момент лямбда начнёт падать из-за недостатка памяти. Ну и завернуть бы всё хотя бы в CloudFormation, чтобы действительно за 5 минут разворачивать.
I_v_g Автор
Основная идея статьи — это дать представление как можно создавать облачный API используя сервисы Amazon AWS API Gateway, без привязки к какой-либо конкретной реализации это API. Если Вы обратили внимание, то в статье упомянуто, что информация для текущих целей не столь важна.
Ps. Вы правы, пагинация выдаваемой информации из базы данных, наверное, смотрелась бы более эффектно, но цель статьи, еще раз повторюсь, показать простоту процесса создания автомасштабируемого API.
Буду благодарен, если Вы поделитесь более эффективным способом считывания информации из текстового файла :)
Stas911
Check S3 select: aws.amazon.com/blogs/aws/s3-glacier-select
I_v_g Автор
Большое спасибо за ссылку! Очень интересно!