TL;DR: GitHub://PastorGL/AQLSelectEx.
Однажды, ещё не в студёную, но уже зимнюю пору, а конкретно пару месяцев назад, для проекта, над которым я работаю (нечто Geospatial на основе Big Data), потребовалось быстрое NoSQL / Key-Value хранилище.
Терабайты исходников мы вполне успешно прожёвываем при помощи Apache Spark, но схлопнутый до смешного объёма (всего лишь миллионы записей) конечный результат расчётов надо где-то хранить. И очень желательно хранить таким образом, чтобы его можно было по ассоциированным с каждой строкой результата (это одна цифра) метаданным (а вот их довольно много) быстро найти и отдать наружу.
Форматы хадуповского стека в этом смысле малопригодны, а реляционные БД на миллионах записей тормозят, да и набор метаданных не столь фиксированный, чтобы хорошо ложиться в жёсткую схему обычной РСУБД — PostgreSQL в нашем случае. Нет, она нормально поддерживает JSON, но с индексами у неё на миллионах записей всё равно проблемы. Индексы пухнут, таблицу становится надо партиционировать, и начинается такая морока с администрированием, что нафиг-нафиг.
Исторически в качестве NoSQL на проекте использовали MongoDB, но монга со временем показывает себя всё хуже и хуже (особенно в плане стабильности), поэтому постепенно вывели из эксплуатации. Быстрый же поиск более современной, быстрой, менее глючной, и вообще лучшей альтернативы привёл к Aerospike. У многих бигдатнутых ребят она в фаворе, и я решил проверить.
Тесты показали, что, действительно, сохраняются данные в сторидж прямиком из спарковского джоба со свистом, а поиск по многим миллионам записей происходит заметно быстрее, чем в монге. Да и памяти она ест поменьше. Но выяснилось одно «но». Клиентское API у аэроспайка — сугубо функциональное, а не декларативное.
Для записи в сторидж это не важно, потому что всё равно все типы полей каждой результирующей записи приходится по месту в самом джобе определять — и контекст не теряется. Функциональный стиль тут к месту, тем более что под спарк по-другому писать код и не выйдет. А вот в веб-морде, которая должна выгружать результат во внешний мир, и является обычным веб-приложением на спринге, уже куда логичнее было бы из пользовательской формочки формировать стандартный SQL SELECT, в котором было бы полным полно AND и OR — сиречь, предикатов, — в условии WHERE.
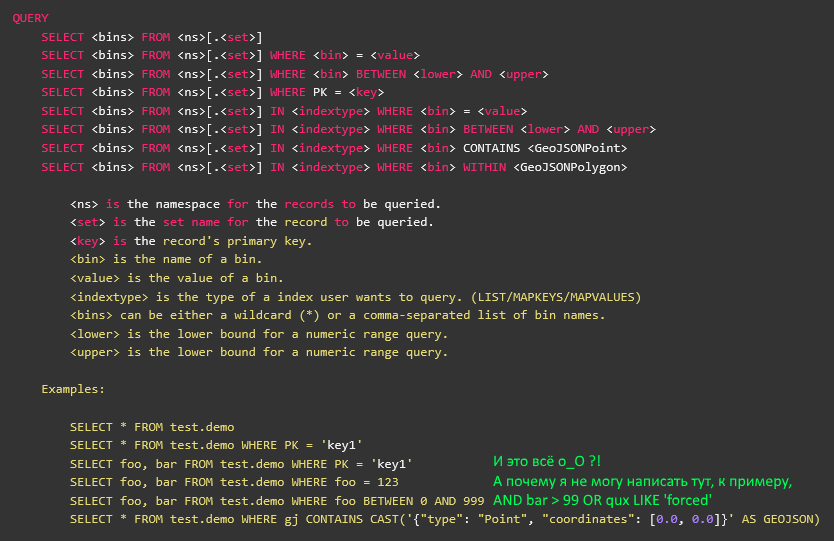
Поясню разницу на таком синтетическом примере:
SELECT foo, bar, baz, qux, quux
FROM namespace.set WITH (baz!='a')
WHERE
(foo>2 AND (bar<=3 OR foo>5) AND quux LIKE '%force%')
OR
NOT (qux WITHIN CAST('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}' AS GEOJSON)— это и читаемо, и относительно понятно, какие записи хотел получить кастомер. Если такой запрос кинуть в лог прям как есть, его потом и для отладки вручную дёрнуть можно будет. Что очень удобно при разборе всяких странных ситуаций.
А теперь посмотрим на обращение к предикатному API в функциональном стиле:
Statement reference = new Statement();
reference.setSetName("set");
reference.setNamespace("namespace");
reference.setBinNames("foo", "bar", "baz", "qux", "quux");
reference.setFillter(Filter.stringNotEqual("baz", "a"));
reference.setPredExp(// 20 expressions in RPN
PredExp.integerBin("foo")
, PredExp.integerValue(2)
, PredExp.integerGreater()
, PredExp.integerBin("bar")
, PredExp.integerValue(3)
, PredExp.integerLessEq()
, PredExp.integerBin("foo")
, PredExp.integerValue(5)
, PredExp.integerGreater()
, PredExp.or(2)
, PredExp.and(2)
, PredExp.stringBin("quux")
, PredExp.stringValue(".*force.*")
, PredExp.stringRegex(RegexFlag.ICASE)
, PredExp.and(2)
, PredExp.geoJSONBin("qux")
, PredExp.geoJSONValue("{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}")
, PredExp.geoJSONWithin()
, PredExp.not()
, PredExp.or(2)
);Вот же стена кода, да ещё и в обратной польской нотации. Нет, я всё понимаю, что стековая машина проста и удобна для реализации с точки зрения программиста самого движка, но ломать голову и писать предикаты в RPN из клиентского приложения… Я лично не хочу думать за вендора, я хочу чтобы мне, как потребителю этого API, было удобно. А предикаты даже с вендорским расширением клиента (концептуально похожим на Java Persistence Criteria API) писать неудобно. И по-прежнему нету читаемого SELECT в логе запросов.
Вообще, SQL и был придуман для того, чтобы писать на нём критериальные запросы на птичьем языке, приближенном к естественному. Так, спрашивается, какого лешего?
Погодите, что-то тут не то… На КДПВ же скриншот из официальной документации аэроспайка, на котором вполне себе описан SELECT?
Да, описан. Вот только AQL — это сторонняя утилита, написанная задней левой ногой в тёмную ночь, и заброшенная вендором три года назад во времена предыдущей версии аэроспайка. Никакого отношения к клиентской библиотеке она не имеет, хоть и писана на жабе — в том числе.
Версия трёхлетней давности не имела предикатного API, и потому в AQL нет поддержки предикатов, а всё, что после WHERE — это на самом деле обращение к индексу (вторичному или первичному). Ну, то бишь, ближе к расширению SQL типа USE или WITH. То есть, нельзя просто так взять исходники AQL, разобрать на запчасти, и использовать в своём приложении для предикатных вызовов.
Вдобавок, как я уже сказал, писана она в тёмную ночь задней левой ногой, и на ANTLR4 грамматику, которой AQL парсит запрос, без слёз смотреть невозможно. Ну, на мой вкус. Я почему-то люблю, когда декларативное определение грамматики не перемешано с кусками жабного кода, а там заварена весьма крутая лапша.
Что ж, к счастью, я тоже вроде как умею в ANTLR. Правда, давно уже не брал в руки шашку, и последний раз писал ещё под третью версию. Четвёртая — она намного приятнее, потому что кому захочется писать ручной обход AST, если всё написали до нас, и в наличии имеется нормальный визитор, потому приступим.
В качестве базы возьмём синтаксис SQLite, и попробуем выкинуть всё ненужное. Нам требуется только SELECT, и ничего более.
grammar SQLite;
simple_select_stmt
: ( K_WITH K_RECURSIVE? common_table_expression ( ',' common_table_expression )* )?
select_core ( K_ORDER K_BY ordering_term ( ',' ordering_term )* )?
( K_LIMIT expr ( ( K_OFFSET | ',' ) expr )? )?
;
select_core
: K_SELECT ( K_DISTINCT | K_ALL )? result_column ( ',' result_column )*
( K_FROM ( table_or_subquery ( ',' table_or_subquery )* | join_clause ) )?
( K_WHERE expr )?
( K_GROUP K_BY expr ( ',' expr )* ( K_HAVING expr )? )?
| K_VALUES '(' expr ( ',' expr )* ')' ( ',' '(' expr ( ',' expr )* ')' )*
;
expr
: literal_value
| BIND_PARAMETER
| ( ( database_name '.' )? table_name '.' )? column_name
| unary_operator expr
| expr '||' expr
| expr ( '*' | '/' | '%' ) expr
| expr ( '+' | '-' ) expr
| expr ( '<<' | '>>' | '&' | '|' ) expr
| expr ( '<' | '<=' | '>' | '>=' ) expr
| expr ( '=' | '==' | '!=' | '<>' | K_IS | K_IS K_NOT | K_IN | K_LIKE | K_GLOB | K_MATCH | K_REGEXP ) expr
| expr K_AND expr
| expr K_OR expr
| function_name '(' ( K_DISTINCT? expr ( ',' expr )* | '*' )? ')'
| '(' expr ')'
| K_CAST '(' expr K_AS type_name ')'
| expr K_COLLATE collation_name
| expr K_NOT? ( K_LIKE | K_GLOB | K_REGEXP | K_MATCH ) expr ( K_ESCAPE expr )?
| expr ( K_ISNULL | K_NOTNULL | K_NOT K_NULL )
| expr K_IS K_NOT? expr
| expr K_NOT? K_BETWEEN expr K_AND expr
| expr K_NOT? K_IN ( '(' ( select_stmt
| expr ( ',' expr )*
)?
')'
| ( database_name '.' )? table_name )
| ( ( K_NOT )? K_EXISTS )? '(' select_stmt ')'
| K_CASE expr? ( K_WHEN expr K_THEN expr )+ ( K_ELSE expr )? K_END
| raise_function
;Хмм… Таки и в одном только SELECT многовато лишнего. И если от лишнего избавиться достаточно просто, то есть и ещё одна нехорошая вещь относительно самой структуры получающегося пути обхода.
Конечная цель — оттранслироваться в предикатное API с его RPN и подразумеваемой стековой машиной. А тут атомарное expr никак не способствует подобному преобразованию, потому что подразумевает обычный разбор слева направо. Да ещё и рекурсивно определённое.
То бишь, получить наш синтетический пример мы можем, но читаться он будет именно как написан, слева направо:
(foo>2 И (bar<=3 ИЛИ foo>5) И quux ПОХОЖ_НА '%force%') ИЛИ НЕ(qux В_ПОЛИГОНЕ('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}')В наличии скобочки, определяющие приоритет разбора (значит, потребуется мотаться туда-сюда по стеку), а также некоторые операторы ведут себя как вызовы функций.
А нужна нам такая вот последовательность:
foo 2 > bar 3 <= foo 5 > ИЛИ И quux ".*force.*" ПОХОЖ_НА И qux "{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}" В_ПОЛИГОНЕ НЕ ИЛИБрр, жесть, бедный мозг, которым такое читать. Зато без скобок, нет никаких роллбэков и непоняток с порядком вызова. И как нам перевести одно в другое?
И тут в бедном мозге происходит чпок! — здрасте, это же классический Shunting Yard от многоув. проф. Дейкстры! Обычно, таким околобигдатовским шаманам, как я, алгоритмы не нужны, потому что мы просто переводим уже написанные дата-сатанистами прототипы с питона на жабу, и потом долго и нудно тюним перфоманс полученного решения чисто инженерными (== шаманскими) методами, а не научными.
Но тут вдруг стало нужно и знание алгоритма. Или хотя бы представление об оном. К счастью, не весь университетский курс был за прошедшие годы забыт, и коли уж я помню про стековые машины, то и про связанную с ними алгоритмику тоже что-то ещё могу раскопать.
Окей. В грамматике, заточенной под Shunting Yard, SELECT на верхнем уровне будет выглядеть так:
select_stmt
: K_SELECT ( STAR | column_name ( COMMA column_name )* )
( K_FROM from_set )?
( (K_USE | K_WITH) index_expr )?
( K_WHERE where_expr )?
;
where_expr
: ( atomic_expr | OPEN_PAR | CLOSE_PAR | logic_op )+
;
logic_op
: K_NOT | K_AND | K_OR
;
atomic_expr
: column_name ( equality_op | regex_op ) STRING_LITERAL
| ( column_name | meta_name ) ( equality_op | comparison_op ) NUMERIC_LITERAL
| column_name map_op iter_expr
| column_name list_op iter_expr
| column_name geo_op cast_expr
;То бишь, токены, соответствующие скобкам — значимые, а рекурсивного expr быть не должно. Вместо него будет куча всяких частных чё_нибудь_expr, и все — конечные.
В коде на жабе, который имплементирует визитор для этого дерева, дела обстоят чуточку более по-наркомански — в строгом соответствии с алгоритмом, который сам обрабатывает висящие logic_op и балансирует скобки. Приводить выдержку я не буду (посмотрите на ГХ самостоятельно), но приведу следующее соображение.
Становится понятно, почему авторы аэроспайка не стали заморачиваться поддержкой предикатов в AQL, и забросили его три года назад. Потому что оно строго типизированное, а сам аэроспайк преподносится как schema-less сторидж. И вот так просто взять и распотрошить запрос из голого SQL без заранее заданной схемы нельзя. Упс.
Но мы-то ребята прожжённые, а, главное, наглые. Нужна схема с типами полей, значит будет схема с типами полей. Тем более, что в клиентской библиотеке уже есть все нужные определения, просто их надо подцепить. Хотя кода понаписать под каждый тип пришлось немало (см. по той же ссылке, с 56 строки).
Теперь же инициализируемся...
final HashMap FOO_BAR_BAZ = new HashMap() {{
put("namespace.set0", new HashMap() {{
put("foo", ParticleType.INTEGER);
put("bar", ParticleType.DOUBLE);
put("baz", ParticleType.STRING);
put("qux", ParticleType.GEOJSON);
put("quux", ParticleType.STRING);
put("quuux", ParticleType.LIST);
put("corge", ParticleType.MAP);
put("corge.uier", ParticleType.INTEGER);
}});
put("namespace.set1", new HashMap() {{
put("grault", ParticleType.INTEGER);
put("garply", ParticleType.STRING);
}});
}};
AQLSelectEx selectEx = AQLSelectEx.forSchema(FOO_BAR_BAZ);… и вуаля, теперь наш синтетический запрос просто и понятно дёргается из аэроспайка:
Statement statement = selectEx.fromString("SELECT foo,bar,baz,qux,quux FROM namespace.set WITH (baz='a') WHERE (foo>2 AND (bar <=3 OR foo>5) AND quux LIKE '%force%') OR NOT (qux WITHIN CAST('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}' AS GEOJSON)");А уж для преобразования формочки с веб-морды в сам запрос мы заюзаем давно написанную в веб-морде тонну кода… когда до проекта дойдёт наконец дело, а то заказчик пока что отложил его на полку. Обидно, блин, почти неделю времени потратил.
Надеюсь, потратил я его с пользой, и библиотечка AQLSelectEx окажется кому-нибудь нужна, а сам подход — чуть более приближенным к реальности учебным пособием, чем другие статьи с хабра, посвящённые ANTLR.
Комментарии (41)

sshikov
13.01.2019 15:50>Форматы хадуповского стека в этом смысле малопригодны
В смысле, чтобы GEOJSON что-ли хранить и по нему запросы произвольные писать?PastorGL
13.01.2019 19:09В том смысле, чтобы дописывать в сторидж результаты обсчёта новых порций, и забирать потом из веб-морды по запросу ко всем накопленным на момент запроса.
sshikov
13.01.2019 19:12Ну, дописывать-то например можно в HBase, без особых проблем. Эту проблему он вам решит, особенно на таких объемах.
PastorGL
13.01.2019 19:26Можно, но мы живём в AWS. Там HBase держать вариантов немного. Либо в перманентном кластере EMR (дорого, неудобно), либо в S3 (медленно, опять неудобно, и есть ещё специфические болячки из-за асинхронности S3). Под NoSQL нужна одна виртуалка достаточных размеров, что сильно проще в администрировании.
musicriffstudio
13.01.2019 20:23+3реляционные БД на миллионах записей тормозят
ну вот, например, этот сайт использует реляционную бд.
Тут миллионы комментариев и вс> показывает мгновенно, если зайти в собственный профиль — отфильтрует статьи/комментарии и покажет краткую статистику.
Тоже мгновенно.gecube
13.01.2019 23:02-1Тут используется наверняка адищенские схемы шардирования.
Из коробки из ни в одной из «классических» БД типа Postgres и Mysql я не помню.
И как только Вы на это коммититесь, то приходится самому реализовывать транзакционность уже в распределенной среде, синхронизацию реплик etc.
Эту проблему решают NewSQL решения, но многие пока не дозрели до них.musicriffstudio
13.01.2019 23:09+1адищенские схемы шардирования
как звучит-то, а!
Нет, обычные несколько табличек с индексами и связями. Никакого колдунства.gecube
14.01.2019 00:40-1Ну, так расскажите про свои ноу-хау, про нагрузку, про используемые технологические решения…
Это ж ведь правда очень интересно.
Реально сталкиваюсь с недостатком подобной информации, что и приводит к неверным ожиданиям от технологий, и, что хуже — к неверному их применениюmusicriffstudio
14.01.2019 01:41+2так нет никаких ноухау.
Миллионы записей это обычная нагрузка для типового склсервера на типовом серверном железе. Что и подтверждает быстрая безперебойная работа сайта хабр.ком.
gecube
14.01.2019 10:32ну, опять. Я со всей душой, и опять набегают минусаторы…
К Вам, musicriffstudio. Вы вообще пока, знаете… создаете впечатление… некомпетентного человека. Вы же понимаете, что проблема не только и не сколько в кол-ве записей в базе. А в нагрузке — какие запросы (insert/update/delete) и в каком количестве прилетают. Условно — миллион просмотров страницы — это уже миллион селектов (минимум!). Я уж не говорю, про особенности типа VACUUM у Постгреса или то, что WAL всегда пишется в один поток (т.е. мы всегда блокируемся, когда у нас транзакционность и не забываем про уровни изоляции). Поэтому — да, миллион записей это немного. И, да, это ничего не значит в контексте нашей беседы.
И еще — коли уж миллион записей — типовая нагрузка, то чего тормозят всякие дешевые vpsочки с личными хостингами на друпале и вордпрессе?
Я, конечно, понимаю, что можно устроить хайлоад на ровном месте, но ведь инженерия заключается в том, чтобы это предотвратить.
И еще — хабр это же ведь не только странички и пользователя. Это как минимум несколько разных проектов, с общими кусками (типа базы юзеров), с разной нагрузкой (причем еще вопрос какой, но точно не 10rps). И как эта кухня устроена внутри — снаружи абсолютно неясно.mayorovp
14.01.2019 10:46+1В данном случае впечатление некомпетентного человека создаете именно вы. Да, разумеется, проблема в операциях, а не в количестве записей! Так почему же вы продолжаете доказывать, что миллионы записей представляют хоть какую-то проблему?
И еще — коли уж миллион записей — типовая нагрузка, то чего тормозят всякие дешевые vpsочки с личными хостингами на друпале и вордпрессе?
Предположу, что там мегарасширяемый код с кучей плагинов. Подобные архитектуры плохо дружат с любыми СУБД.
eefadeev
14.01.2019 12:29+2Зря вы начали ломать «прекрасный новый мир» в голове любителя современных решений…
vlanko
14.01.2019 13:13Мускул на старых машинах и простых фреймворках быстро крутит 40миллионов строк. Другие технологии нужны, когда у вас терабайтные базы (да и то, Microsoft SQL Server осиливает 30 ТБ)
PastorGL
14.01.2019 13:1840 миллионов в нашем случае это всего десятка три построенных карт. А надо держать порядка сотен в год. Мало.
Cim
14.01.2019 13:35Что такое «40 миллионов строк»? Что такое «быстро крутит»? Пожалуйста, объективные метрики и требования в студию.
Писать в 40-миллионную таблицу ума много не надо — это быстро. Но получение данных — иная задача. Делаете SELECT, а в ответ получаете: ой, я пошел искать перебором т.к. индекс слишком большой.
Есть какие-то задачи и какие-то требования. Сделать форум на сто миллионов комментариев и хранить их в MySQL можно. Особенно, если эти комментарии редко меняются: взял добавил кеширования, и количество SQL-запросов уменьшилось до нуля.
А теперь представьте, что у вас задача — делать выборки в реальном времени под самые разные запросы. Для аналитики или чего-то схожего. Или для графиков, которые клиент хочешь видеть в самых разных комбинациях масштаба и диапазона, где кеширование не применить т.к. кеш станет больше, чем данные.musicriffstudio
14.01.2019 14:01опять это «теперь представьте». Вот конкретный сайт в котором можно примерно оценить обьем, нагрузку и посмотреть аналитику.
Не надо никуда ходить.
Если есть какой-то другой набор требований или условий — не надо выдумывать. Надо взять и сделать тестовое решение и проверить на требуемых обьемах.Cim
14.01.2019 14:20Так и статья не про Хабр. И не про то, что «наш постгрес не смог 40 миллионов записей, поэтому мы взяли <что-то-для-бигдаты>». На Хабре и приложениях такого рода можно решить половину проблем кешированием и денормализацией данных.
На хабре достаточно много данных, но всё еще слишком мало, чтобы это стало проблемой. И такой входящий поток, что можно шардировать как угодно и вводить новую ноду в кластер раз в пятилетку, и практически не иметь проблем с инфраструктурой.
Задача автора была сильно сложнее.
Cim
14.01.2019 12:15+1Миллионы миллионам рознь. Плюс иногда можно намазать кеширование.
У нас постгрес сделал «ой» на 100 миллионах записей под наши конкретные требования. Решение проблемы требовало бы шардирования, но посколько 100 миллионов записей — это нагрузка за неделю, то рисовать (и затем поддерживать) новые шарды каждую неделю как-то было бы не весело. Выбрали другую, колоночную, базу — наш формат данных и типы запросов подходили под не-реляционное хранилище прекрасно.
AnyKey80lvl
14.01.2019 01:31Вот же мучаются люди без Vertica! Бесплатно до 1тб данных и 3 узлов в кластере. Ваша задача отлично решается с помощью flex tables.
mayorovp
14.01.2019 08:25И все-таки, чем вам не угодил рекурсивный expr? Получить постфиксную форму из уже построенного AST можно тривиально.
PastorGL
15.01.2019 01:59Можно, не спорю. Но чем плохо попрактиковаться с альтернативными подходом?
mayorovp
15.01.2019 06:34А задача была «попрактиковаться» или разобрать запрос? Если первое, то я не понимаю зачем вообще использовать ANTLR. Если второе — то имеет смысл поручить всю работу ANTLR.
PastorGL
15.01.2019 10:25Не понимаю сути вашей претензии, если честно. Что именно не так, по-вашему, я сделал с ANTLR?
Если хотите быть конструктивным, киньте ссылку на пример кода, который считаете правильным, вместо того, чтобы ворчать.mayorovp
15.01.2019 12:09Кинуть ссылку я не могу — у меня под рукой нет antlr. Но, судя по документации, он умеет справляться с тем рекурсивным форматом которого вы почему-то испугались.
Например, если дать ему вот такое выражение:
a * b + c * d, то будет построено вот такое дерево:
+ / / * * / \ / a b c d
Теперь это дерево нужно всего лишь правильно рекурсивно обойти, чтобы получить постфиксную запись.

PastorGL Автор
16.01.2019 01:08См. ответ на следующий комментарий, но, BTW, синтаксическое дерево как таковое мне вообще не нужно, и уж тем более я не собираюсь его обходить. Мне нужен визитор, который ANTLR строит по дереву, или место, где произошла ошибка разбора, если дерево построить нельзя.
mayorovp
15.01.2019 12:46Ну вот вот код на C#:
class Program : SQLiteBaseVisitor<bool> { public override bool VisitParameter(SQLiteParser.ParameterContext context) { Push(context.id.Text); return false; } public override bool VisitBinary(SQLiteParser.BinaryContext context) { foreach (var expr in context.expr()) Visit(expr); Push(context.op.Text); return false; } // ... }
Входная строка:
a*b - (c+d)/e
Выходная последовательность:a b * c d + e / -
Замечу, что мне даже не пришлось добавлять отдельное правило для скобок — antlr справился за меня. Ну, в реальном коде будут еще обработчики для унарных операций, для литералов и для LIKE/NOT LIKE.
Все равно же получается намного проще чем вы сделали!
PastorGL Автор
15.01.2019 23:28Возможно я вас огорчу, но такое решение не подходит под все условия задачи.
Вы парсите абстрактное дерево как абстрактное дерево, а мой случай — он вообще-то конкретный. То предикатное API, которое я обёртываю в SELECT — типизированное, и набор допустимых операций для каждого типа свой. Если бы я использовал ваш вариант (впрочем, во времена ANTLR v3 я бы тоже такой заюзал, потому что другого и не было), мне пришлось бы добавлять дополнительную логику для каждого типа предиката где-то после разбора.
А тут я её пишу прямо по месту, в контексте конкретного чё_нибудь_expr.
Общая сложность в итоге вышла бы ровно такая же, так что спорить тут на самом деле не о чем :)mayorovp
16.01.2019 08:38Я не увидел в вашем методе exitWhere_expr никакой особой обработки типизированных предикатов, это в чистом виде реализация алгоритма сортировочной станции. Всё что вы там делаете — это переупорядочиваете ноды и складываете их в контейнер predExpStack.
В моём варианте на выходе получается точно такой же predExpStack, только пишется мой вариант гораздо проще вашего.
ToSHiC
15.01.2019 20:46Если у вас всё же не совсем абстрактный JSON, а данные, пусть и с большим, но фиксированным количеством колонок — то попробуйте clickhouse.yandex.
igor_suhorukov
Респект за труды! Подобный опыт с sql подобными выражениями и мы проходили на oracle coherence.
Но если трезво взглянуть на задачу, данные в ваших объемах можно было бы легко поместить в CitusDB или Greenplum например, где полноценный SQL и column oriented storage и кластеризуется при потребности. Да и Geenplum дружит с PostGIS расширением. Обе базы MPP, так что мороки с пухнущими индексами не должно быть.
sshikov
И прям с индексами на JSON/GEOJSON колонки?
igor_suhorukov
В MPP системах индексы редко используют. Greenplum я не использовал, но CitusDB позволяет создавать GIST индексы по шардам.
sshikov
Я так понимаю, вопрос именно в том, чтобы искать по geojson (во всяком случае, у меня в похожем проекте возникали именно такие задачи), а индекс по json это немножко не тоже самое, что обычный, это скорее похоже на полнотекстовый поиск.
igor_suhorukov
Тогда Greenplum+PostGIS или CrateDB
sshikov
Нам вообще хватило PostGIS в конечном итоге, так как результатов было еще чуть меньше, чем тут описывается.
gecube
Вопрос в том насколько ГринПлам сейчас актуален. Учитывая, что он на древнем движке Постгрес. У нас из-за при его тестировании под конкретную задачу были затык с переносом экстеншенов из более свежей ванильной версии постгрес. И, да, в наших задачах greenplum никакого серьезного прироста скорости не дал. Хотя брался за задачу пилота спец по Postgres/GreenPlum.
Ещё неясны перспективы greenplum в связи с усилением позиций clickhouse.
Мне лично Greenplum не понравился помимо всего вышеописанного, какой-то вымороченной инструкцией по установке, как будто из 90-х. Докеры? Оркестрация? Все мимо.
igor_suhorukov
Намного актуальнее мегапопулярного Amazon Redshift, который основан на PostgreSQL 8.0.2. Действительно, произвольные расширения ванильного постгреса так легко не поставить на распределенные версии PostgreSQL. Но там и другой планировщик и другая схема хранения данных на диске.
CitusDB почти не накладывает ограничений на версию PostgreSQL и расширения. И предоставляется как сервис на AWS.
Clickhouse нишевый инструмент, который не может делать объединения между шардированными таблицами и поддержда SQL сильно ограничена. Clickhouse скорее конкурент Apache Druid, Apache Pinot.
Друг занимается администрированием Greenplum, могу узнать как он справляется. К тому же есть вариант хостить его в Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform (GCP)
PastorGL
Зачем пытаться использовать надстроенное РСУБД как NoSQL, если можно сразу использовать NoSQL? И на запись оно в разы быстрее получается, и вообще мороки меньше. Аэроспайк до 2 млрд. записей на инстанс — это поставил и забыл. Нам этого лимита надолго хватит.
igor_suhorukov
Ответ обычно прост — записывать быстро, а вот извлекать и искать не удобно. Потому и появляются обычно свои парсеры и надстройки, когда извлекать нужно не по ключу и т.п. Потом оказывается что кода с NoSQL больше чем с SQL, часто разработка повторяет что что уже давно реализовано в объектно-реляционных MPP СУБД.