Потому что так написано в книжках или так говорят авторитетные личности? Какие ВАШИ проблемы решает тот или иной подход/паттерн?
Даже то, что на первый взгляд кажется очевидным, порой бывает очень сложно объяснить. А иногда, в попытке объяснения, приходит понимание того, что очевидные мысли были и вовсе ошибочны.
Давайте попробуем взять какой-нибудь пример и изучить на нем эти вопросы со всех сторон.
Игрушечный город
Виртуальный город
SOLID как много в этом слове …
Предметная область
Презентационная логика
Сохранение состояния
Многослойность
2-tier
N-tier
2 как 3
Сервисы
Инструменты
Теория и практика
Итог
Игрушечный город
Давайте представим небольшой игрушечный город. Он состоит из ряда строений, через него проходит несколько дорог. По дорогам перемещаются машины и ходят люди. Движение регулируют светофоры. Все происходящее в городе подчинено определенным правилам и всем этим многообразием можно управлять.
Людей и машины можно перемещать, светофоры переключать, менять время дня и ночи и т.п… С этим городом одновременно могут взаимодействовать несколько человек. Они могут или просто наблюдать, или что-то делать, заставляя город меняться. Все это прекрасно существует, но наступает момент, когда появляется необходимость перенести игрушечный город в виртуальный мир.
Те люди, которые взаимодействовали с городом напрямую, теперь поудобнее уселись в свои кресла и уставились в темные мониторы, сжав в одной руке мышку, а другую положив на клавиатуру, в ожидании того момента, когда все оживет и виртуальный город засияет своими красками перед их глазами. Но для того чтобы это произошло, предстоит пройти долгий путь.
Виртуальный город
Для начала нужно сделать самое главное – создать модель нашего виртуального города. Хоть это может и показаться чем-то простым, на самом деле, в этом кроется большинство проблем и сложностей. Но начинать все равно надо, так что приступим.
Наша цель – описать модель города в виртуальном виде. Для этого мы возьмем любой популярный объектно-ориентированный язык высокого уровня. Использование такого языка предполагает использование объектов в качестве основных кирпичиков для создания виртуальной модели города.
Конечно, можно просто описать всю модель в одном объекте, но это чревато только лишней сложностью и запутанностью. Когда все «свалено» в одно место и непонятно как перемешано, становится трудно понимать, что вообще происходит и тем более вносить какие-либо изменения. Поэтому, чтобы сделать проще и не запутаться в получившейся программе, мы разобьем описание нашего города на небольшие отдельные части.
В качестве таких частей мы возьмем то, что легко отделяется друг от друга при взгляде на наш реальный город — отдельные объекты этого города (дом культуры, красная БМВ на перекрестке, Петрович, бегущий по своим делам). Описание каждого объекта в виртуальном мире представляет собой описание его свойств (цвет, модель, название, расположение и т.п.). Чтобы не повторяться и не описывать одинаковые свойства для похожих объектов каждый раз, мы выделим группу таких свойств и назовем их типом объекта. Хорошими кандидатами являются такие общие типы, как машина, дом, человек и т.п. Они позволят сосредоточить в себе описание основных свойств. А различные виды машин, например, будут дополнять базовый тип «машина» своим уникальным набором свойств, создавая целый набор новых типов. Такие новые типы по отношению к исходным типам называются наследниками. А сам процесс создание нового типа, на основе существующего — наследованием.
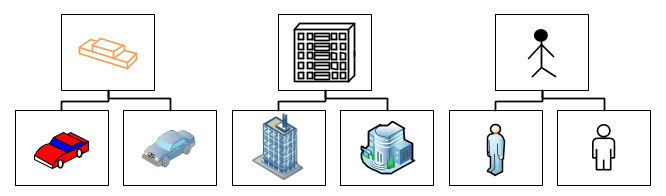
Все созданные нами типы объектов будут представлять модель нашего города.
После этого просто создадим экземпляры этих типов для каждого существующего в городе объекта и заполним их его уникальными значениями.
И вот вроде бы все расставлено по своим местам, группа машин стоит на перекрестке в ожидании зеленого сигнала светофора, девочка Юля — в ожидании своего лифта, и даже вода застыла в трубах огромного небоскреба. Мы наполнили нашу модель состоянием, повторив состояние нашего реального города за какой-то определенный момент времени.
Но, если мы внимательно посмотрим на наш реальный город, то мы увидим, что он постоянно меняется. Все изменения его состояния представляют собой изменения значения свойств различных объектов, появление новых объектов или исчезновение старых. Вот светофор переключился и поменял значение свойства «Текущий сигнал светофора» с красного на зеленый. Вот лифт поменял значение свойства «Этаж» со второго на первый и значение свойства «Открыты ли двери» с да на нет.
Значит для того чтобы наш город ожил, наша программа должна уметь менять состояние модели, а это значит — уметь менять свойства различных объектов, добавлять новые объекты или удалять старые, т.е. обладать поведением.
Для этого добавим в программу все возможные действия в нашем городе. Каждое такое действие можно описать в виде процедуры изменения свойств какого-либо объекта или группы объектов. После описания всех этих процедур становится видно, что их количество достаточно велико. Чтобы упростить поддержку и изменения всех доступных процедур их стоит разбить на группы. Недолго думая, можно сгруппировать такие процедуры по однотипности их действий, получив таким образом набор классов, каждый из которых будет отвечать за набор схожих действий.
Вроде бы, теперь все разделено и выглядит очень даже неплохо, но есть одно «но». Описание свойств наших объектов полностью отделено от процедур, которые эти свойства меняют и превращают нашу модель в анемичную модель. При таком разделении совершенно непонятно, как могут меняться свойства того или иного объекта. А если изменение одного свойства должно быть связано с изменением других свойств или зависит от значения других свойств, то это знание о внутреннем устройстве объекта придется продублировать во всех процедурах, меняющих это свойство. Чтобы избежать этих проблем мы не будем группировать процедуры по действиям, а разложим эти процедуры по тем типам, свойства которых они меняют.
Благодаря этому, для публичного доступа можно будет оставить только используемые другими свойства и методы, скрыв знания о внутреннем устройстве объекта. Такой процесс сокрытия внутренних принципов работы называется инкапсуляция. Например, мы хотим переместить лифт на несколько этажей. Для этого нужно проверить состояние дверей – открыты или закрыты, запустить и остановить двигатель и т.п. Вся эта логика будет просто скрыта за действием «переместиться на этаж». В итоге получается, что тип объекта представляет собой набор свойств и процедур, меняющих эти свойства.
Некоторые процедуры могут иметь одинаковый смысл, но быть связанными с различными объектами. Например, процедура «издать звуковой сигнал» есть и у красной BMW и у синих жигулей. И хоть внутри они могут быть выполнены совершенно по-разному, они несут в себе один и тот же смысл.
Так как у нас уже есть общий тип «машина», мы можем поместить процедуру «издать звуковой сигнал» туда. Если логика такого поведения у всех одна, то там же ее можно будет и определить. Это упростит производные типы и избавит от дублирования кода. Но если вдруг, в производных типах логика такого поведения будет отличаться, то ее можно легко поменять с помощью переопределения поведения. Такая возможность называется полиморфизмом.
Абстракция, наследование, инкапсуляция и полиморфизм – это те прелести ООП, следуя которым можно создавать более гибкий дизайн. В довесок к ним существует некоторый набор принципов, цель которых такая же – помочь создать более гибкий дизайн.
SOLID как много в этом слове …
SOLID – аббревиатура общеизвестных принципов объектно-ориентированного дизайна. В этой аббревиатуре их скрыто пять, по одному на каждую букву.
Single Responsibility Principle (принцип единственной ответственности) — у каждого объекта должна быть только одна причина для изменения.
Для того, чтобы в каждой комнате каждого дома можно было использовать и интернет, и электричество — была создана единая розетка с разъемами для интернет-провода и электрического провода.
public class Socket
{
private PowerWire _powerWire;
private EthernetWire _ethernetWire;
public Socket(PowerWire powerWire, EthernetWire ethernetWire)
{
_powerWire = powerWire;
_ethernetWire = ethernetWire;
}
...
}
Для работы такой розетки необходимо было подводить интернет-провод и электрический провод. И, казалось бы, нет ничего страшного в том, что не во всех розетках всегда используется и интернет, и электричество, зато компактно и удобно. Но все становится не таким удобным, когда наступает пора изменений.
Сначала появились квартиры и даже целые здания, в которых был не нужен интернет. Совсем. Но для того, чтобы наши розетки могли в них работать, пришлось протягивать интернет-провода и туда, что только увеличило стоимость работ, не принеся никакой пользы.
Потом появилось требование, что розетки должны быть оборудованы дополнительным проводом для заземления и из-за этого пришлось менять ВСЕ розетки, в том числе и те, которые использовались только для интернета. Был проделан большой объем работы, который мог бы быть меньше, если бы не затрагивались розетки, используемые только для интернета.
public class Socket
{
private PowerWire _powerWire;
private EthernetWire _ethernetWire;
private GroundWire _groundWire;
public Socket(PowerWire powerWire, EthernetWire ethernetWire, GroundWire groundWire)
{
_powerWire = powerWire;
_ethernetWire = ethernetWire;
_groundWire = groundWire;
}
...
}
Но последней каплей стало требование — поменять для всех интернет-розеток интернет-провод на новый стандарт. А так как вообще все розетки являются одновременно еще и интернет-розетками – то пришлось опять менять ВСЕ. Хотя объем работ мог бы быть гораздо меньше, так как количество розеток, используемых для интернета, в разы меньше количества всех розеток.
public class Socket
{
private PowerWire _powerWire;
private SuperEnthernetWire _superEnthernetWire;
private GroundWire _groundWire;
public Socket(PowerWire powerWire, SuperEthernetWire superEthernetWire, GroundWire groundWare)
{
_powerWire = powerWire;
_superEnthernetWire = superEnthernetWire;
_groundWare = groundWare;
}
...
}
Во всех случаях был проделан совершенно лишний объем работы из-за того, что в одном объекте было совмещено сразу несколько, совершенно не связанных обязанностей. И у каждой из этих обязанностей была своя, отдельная причина для изменения.
Чтобы избежать таких проблем — розетка должна была быть разделена на две, независимые друг от друга, части – электрическую розетку и интернет-розетку:
public PowerSocket
{
private PowerWire _powerWire;
private GroundWare _groundWare;
public PowerSocket(PowerWire powerWire, GroundWare groundWare)
{
_powerWire = powerWire;
_groundWare = groundWare;
}
...
}
public class EthernetSocket
{
private SuperEthernetWire _superEthernetWire;
public EthernetSocket (SuperEthernetWire _superEthernetWire)
{
_superEthernetWire = superEthernetWire;
}
...
}
А в тех случаях, когда действительно была бы нужна и электрическая и интернет-розетка можно было бы использовать агрегацию:
public PowerEthernetSocket
{
private PowerSocket _powerSocket;
private EthernetSocket _ethernetSocket;
public PowerEthernetSocket (PowerSocket powerSocket, EthernetSocket ethernetSocket)
{
_powerSocket = powerWire;
_ethernetSocket = ethernetSocket;
}
...
}
Open-closed principle (принцип открытости-закрытости) – объекты должны быть закрыты для модификаций, но открыты для расширений.
Для оповещения людей о важной информации в центре города, на самом оживленном перекресте был установлен большой экран. На нем отображался текст сообщений, приходящих из различных источников.
public class Message
{
public string Text { get; set; }
}
public class BigDisplay
{
public void DisplayMessage(Message message)
{
PrintText(message.Text);
}
public void PrintText(string text)
{
...
}
}
Спустя какое-то время появился новый вид сообщений — сообщения, содержащие дату. И для таких сообщений на экране было необходимо отображать и дату и текст. Доработку можно было выполнить различными способами.
1. Создать новый тип, производный от типа «сообщение», добавить ему атрибут «дата» и поменять процедуру отображения сообщений.
public class Message
{
public string Text { get; set; }
}
public class MessageWithDate : Message
{
public DateTime Date { get; set; }
}
...
public void DisplayMessage(Message message)
{
if (message is MessageWithDate)
PrintText(message.Date + Message.Text)
else
PrintText(message.Text);
}
Но такой способ плох тем, что придется менять поведение всех типов, которые каким-либо образом выводят сообщение. И если в дальнейшем появится еще какой-то новый, особый тип сообщений — все придется менять еще раз.
2.Добавить свойство «дата» в тип «сообщение» и поменять способ получения текста, чтобы получилось так:
public class Message
{
private string _text;
public string Text
{
get
{
if(Date.HasValue)
return Date.Value + _text;
else
return _text;
}
set { _text = value; }
}
public DateTime? Date { get; set; }
}
Но, во-первых, такой способ плох тем, что нам приходится менять основной тип и добавлять в него поведение, которое свойственно не всем сообщениям, из-за чего появляются лишние проверки. Во-вторых, при появлении нового типа сообщения нам придется создавать еще один атрибут, который будет не у всех сообщений, и добавлять лишние проверки в код. В-третьих, теперь отсутствует способ получения текста сообщения без даты для сообщений с датами. И в случае такой необходимости — текст сообщения придется выковыривать.
3. Сразу записывать дату в текст сообщения, чтобы вообще не создавать никакого нового типа и не менять способа отображения сообщения на экране. Но такой способ плох тем, что в тех местах, где от сообщения нужно будет получить только дату — сначала придется определять, содержит ли это сообщение дату вообще, а потом вычленять ее из текста сообщения.
Если следовать принципу открытости-закрытости, можно избежать всех этих проблем и пойти четвертым путем:
public class Message
{
public string Text { get; set; }
public virtual string GetDisplayText()
{
return Text;
}
}
public class MessageWithDate : Message
{
public DateTime Date { get; set; }
public override string GetDisplayText()
{
return Date + Text;
}
}
...
public void DisplayMessage(Message message)
{
PrintText(message.GetDisplayText());
}
При таком подходе нам не нужно менять базовый тип «сообщение» — он будет оставаться закрытым. В то же время он будет открытым для расширения его возможностей. Помимо этого, пропадут все проблемы, свойственные другим подходам.
Liskov substitution principle (принцип подстановки Барбары Лисков) — функции, которые используют базовый тип, должны иметь возможность использовать подтипы базового типа, не зная об этом.
После добавления в программу типа «велосипед» пришло время добавить еще один тип – «мопед». Мопед — он же как велосипед, только еще лучше. Значит велосипед отлично подойдет в качестве базового типа для мопеда. Сказано-сделано, и в программе появился еще один тип «мопед» — производный от типа «велосипед».
public class Bicycle
{
public int Location;
public void Move (int distance) { ... }
}
public class MotorBicycle : Bicycle
{
public int Fuel;
public override void Move(int distance)
{
if (fuel == 0)
return;
...
fuel = fuel – usedFuel;
}
}
Но по сравнению с велосипедом, у мопеда есть одна неприятная особенность – если бензин кончается, то мопед уже не может двигаться. И эту неприятную особенность пришлось учесть в коде. Учли, а значения придавать не стали – на то у нас и производный тип, чтобы учитывать всякие специфические особенности.
Так как мопед быстрее чем велосипед, то при возможности он стал использоваться в программе там, где раньше использовался велосипед. Но, в один прекрасный день программа зависла намертво. Поиск ошибки был долог и мучителен, т.к. проблема повторялась периодически и случайным образом. Опустим описание бессонных ночей и сразу перейдем к виновнику всех бед – методу, который перемещал велосипедиста между двумя, далеко расположенными друг от друга точками:
public void LongJourney (int to, Biker biker, Bicycle bicycle)
{
while(bicycle.location < to)
{
int distance = to - bicycle.location;
if (distance > 1000)
distance = 1000;
bicycle.move(distance);
biker.sleep();
}
}
Когда в метод вместо велосипеда передавался мопед с недостаточным количеством бензина, он зависал навсегда из-за того, что мопед не продвигался ни на сантиметр, даже если такое действие вызывали явно. Чтобы исправить эту проблему — можно было бы сделать так, конечно:
public void LongJourney (int to, Biker biker, Bicycle bicycle)
{
while(bicycle.location < to)
{
int distance = to - bicycle.location;
if (distance > 1000)
distance = 1000;
if (bicycle is MotorBicycle && bicycle.Fuel == 0)
FillFuel((MotorBicycle)bicycle);
bicycle.move(distance);
biker.sleep();
}
}
public void FillFuel(MotorBicycle motorBicycle)
{
...
}
Но тогда внесение таких изменений потребовало бы изменения большого числа процедур, что, во-первых, долго, во-вторых, чревато тем, что это можно забыть и такая забывчивость приведет к очередным неуловимым проблемам. Помимо этого, добавление таких условий являлось бы утечкой абстракции. А в случае появления еще какого-либо фактора, влияющего на поведение, все эти сложности только удвоились бы.
На самом деле, изначальная проблема кроется в том, что мопед не является разновидностью велосипеда, не смотря на всю свою внешнюю схожесть. Поэтому попытки привести их к общему знаменателю не привели ни к чему хорошему. Для мопеда пришлось сделать отдельный, независимый от велосипеда тип, и учесть это во всех нужных процедурах.
Interface segregation principle (принцип разделения интерфейсов) — клиенты не должны зависеть от методов, которые они не используют.
Для придания большей реалистичности было добавлено одно интересное поведение. Если в неположенном месте, на дороге, появлялся человек, то транспортное средство, которому он помешал — должно было остановиться и посигналить. Для этого был реализован метод:
public void CheckIntersect(Car car, People[] people)
{
...
if (Intersect(car, people))
{
car.Stop();
car.Beep();
}
}
public bool Intersect(Car car, People[] people)
{
...
}
Поведение было проверено и все было хорошо до тех пор, пока в системе не появился велосипед и не сбил человека, выбежавшего на шоссе. И это не удивительно, ведь проверку столкновения и автоматическую остановку сделали только для автомобилей.
Первой же безумной идеей могло быть стать желание сделать велосипед производным типом от типа «машина», чтобы его можно было легко подставлять в такие методы, без их изменения. Ведь если приглядеться повнимательнее, в процедуре используются только такие действия машины, которые есть и у велосипеда, и ничего страшного не произойдет. Но это только в этом методе. Если такой странный производный тип передать в какую-нибудь другую процедуру, использующую что-нибудь машинно-специфичное, то такая процедура обязательно сломается.
Второй безумной идеей могло бы стать желание создать отдельную процедуру для проверки столкновения велосипеда с человеком. Но тогда получится, что вся логика будет продублирована. И более того, придется создавать для каждого нового транспортного средства отельную процедуру. Это получится совсем не гибко.
Но, если в процедуре проверки столкновения используются только такие два действия, которые есть у любого транспортного средства, зачем передавать в метод какой-то конкретный тип?
Мы можем определить контракт, который должен соблюдать тип, который можно использовать в этом методе и реализовать его во всех транспортных средствах.
public interface IVehicle
{
...
void Stop();
void Beep();
}
public class Car : IVehicle { ... }
public class Bycycle : IVehicle { ... }
public void CheckIntersect(IVehicle vehicle, People[] peoples)
{
...
if (Intersect(vehicle, peoples))
{
vehicle.Stop();
vehicle.Beep();
}
}
public bool Intersect(IVehicle vehicle, People[] people)
{
...
}
Тогда, в такой метод можно будет передать любой существующий вид транспортного средства и любой вид, который появится в дальнейшем, при соблюдении им условий контракта.
Dependency Inversion Principle (принцип инверсии зависимостей) — абстракции не должны зависеть от деталей. Детали должны зависеть от абстракций.
В нашем городе существует система оповещения новостей. Система получает важные новости и транслирует их через систему динамиков города.
public class NotifySystem
{
private SpeakerSystem _speakerSystem = new SpeakerSystem();
public void NotifyOnWarning(string message)
{
_speakerSystem.Play(message);
}
}
Все работает прекрасно, но требованиям свойственно меняться. Теперь мы должны иногда передавать сообщения не через систему динамиков, а через мобильные телефоны, отправляя их в виде смс. Конечно, мы можем сделать еще один объект для отправки уведомлений о сообщениях через смс, но для этого придется дублировать большую часть логики. Чтобы этого избежать — мы пойдем другим путем. Системе оповещения, в принципе, все равно как ее сообщения будут отображаться. Самое главное – это их отправка. Поэтому, мы можем сделать так:
public class NotifySystem
{
private IMessageDelivery _messageDelivery;
public public NotifySystem(IMessageDelivery messageDelivery)
{
_messageDelivery = messageDelivery;
}
public void NotifyOnWarning(string message)
{
_messageDelivery.SendMessage(message);
}
}
Мы просто объявим интерфейс системы доставки сообщений, которую мы будем использовать, внутри системы оповещения. А реализация этого интерфейса ляжет на плечи тех, кто захочет пользоваться системой оповещения. По сути, мы создаем некий шаблон поведения, который позволяем расширить так, как удобно потребителю.
— А можно было бы просто не заморачиваться всеми этими принципами и писать код как получится?
— Конечно!
— И все равно все бы так же работало?
— Естественно!
— Для чего же тогда нужно использовать все эти сложности в виде ООП, ООД? Если я не буду думать обо всех этих сложностях — я гораздо быстрее напишу программу! А чем быстрее напишу, тем лучше!
— Если программа достаточно проста, а ее дальнейшее развитие, доработка или исправление ошибок не предвидится, то все это, в принципе, и не нужно. Но! Если программа сложная, планируется ее доработка и поддержка, то применение всех этих «лишних сложностей» будет напрямую влиять на самое главное – на количество потраченных ресурсов, требуемых для доработок и поддержки, а это значит – на стоимость.
Все эти правила, шаблоны, парадигмы объединяет одна основная мысль – сделать код модульным, гибким, легко расширяемым и устойчивым к изменениям. Изменение поведения таких маленьких, слабосвязанных модулей, как правило, стоит дешевле, чем изменения поведения большого модуля, в котором все смешано в кучу.
Предметная область
— Запомни, если плохой алгоритм будет стоить тебе тысячу, то плохая архитектура будет стоить тебе миллион.
Тем не менее, все, что было описано выше – это, в основном, решение проблем технических. О том, что такое ООП, ООД, какие плюсы у них есть и как их использовать расписано уже десятки лет назад. Достаточно вбить пару ключевых слов, например, SOLID и получить кучу пояснительной информации.
Если проблема достаточно общая и требует для своего решения какой-нибудь алгоритм, то, скорее всего, он тоже уже есть — достаточно только протянуть руку. Пару запросов в поисковике, например, «посчитать вагоны, сцепленные по кругу, решение» и сотни результатов перед вами.
Но вот для того, чтобы правильно разделять логику на модули и сервисы — одних технических знаний недостаточно, и поисковик тут уже никак не поможет. Нужно хорошее понимание предметной области, а с этим уже проблемы, так как надо прикладывать много сил для изучения чего-то, совершенно с программированием не связанного. Поэтому разработчики больше любят решать технические проблемы, отдавая решение бизнес-проблем на откуп аналитиков. Но аналитикам неизвестно внутреннее устройство программы, которое отражает не структуру бизнеса, а представления разработчика об этой структуре. И чем дальше это представление от реальности, тем сложнее эту структуру будет менять для соответствия изменениям, произошедшим в бизнесе.
Это связано в том числе и с двойной интерпретацией задачи. Сначала аналитик пытается понять то, что нужно добавить или изменить в приложении, общаясь с бизнес-пользователями. Затем эти знания он пытается своими словами передать разработчику. В результате, истина может искажаться и все эти искажения могут вылиться в не самую подходящую структуру программы.
Пользователь высказал пожелание о том, что в комнаты домов днем должен попадать дневной свет так, чтобы все было видно. Разработчик, недолго думая, выдолбил в стене круглую дыру и проверил — оказалось, что света все еще недостаточно. Тогда разработчик выдолбил еще две дыры рядом и опять проверил. Убедившись, что света достаточно, разработчик решил, что задача выполнена. По этому принципу дыры были выдолблены во всех домах. Требования были соблюдены.
Но лето кончилось и наступила зима, а вместе с ней и холода. Злой пользователь прибежал и стал ругаться на то, что в комнатах стало ужасно холодно. При выяснении причин стало ясно, что из-за дыр, выдолбленных под солнечный свет, в комнату попадает много холодного воздуха с улицы и она промерзает. После выяснений обстоятельств оказалось, что пользователь хотел обычное окно, но какие-то требования забыл упомянуть он, а что-то по-своему передал аналитик, и получилось то, что получилось. Так как все промерзло – решать проблему пришлось на ходу, времени на разработку хороших окон и переделку дыр под окна в зимний период уже не было. Поэтому было принято решение обойтись «костылем» и заделать дыры полиэтиленом. Такой способ помог избавиться от сильного промерзания и позволил оставить солнечный свет днем. Но кто знает, сколько новых проблем неполное понимание изначальных требований еще принесет…
Для того, чтобы решить эту проблему между всеми участниками разработки должно выработаться общее, одинаковое представление о том, что происходит и что для чего нужно. Для этого существует целый подход – Domain Driven Design, целью которого как раз и является выработка общего понимания и общей терминологии (общего языка) среди всех участников разработки.
Плохое понимание модели приводит к тому, что разработчик старается заниматься тем, что ему ближе и понятнее – решением технических проблем. В том числе и решением бизнес-проблем чисто техническим способом. А в случае отсутствия технических проблем — их изобретением и их же героическим решением. Все это будет приводить только к появлению странных, малопонятных конструкций в программе. С другой стороны, это может быть осознанным выбором, если разработчик следует Ipoteka Driven Development.
Но пришла пора заканчивать небольшое путешествие по принципам ООД и другим отвлеченным темам и возвращаться к программе. После добавления бизнес-логики к нашей модели, у нас получился уже не просто снимок застывшего города, а его полноценная модель. Модель, состояние которой можно легко менять так же, как и состояние реальной модели.
Презентационная логика
Несмотря на все наши успехи, пользователи продолжают нетерпеливо ждать перед погасшим монитором. Мы создали модель нашего города, вдохнули в него жизнь, описав логику его изменения, проделав тем самым очень важный объем работы. Теперь нам осталось дать возможность пользователям «увидеть» то, что мы сделали. Для этого нам нужно научить наше приложение взаимодействовать с пользователями. Во-первых, пользователь хочет смотреть, что происходит с его городом, как двигаются машинки, как загораются ночные окна, как куда-то спешат люди. А во-вторых, он хочет влиять на город — переключать светофор, менять день на ночь, создавать новые дома и т.п.
Но охватить всю картинку целиком возможно только в простых случаях. Если наша модель сложная, то отобразить ее целиком на экране, а уж тем более понять, становится не просто сложно, а практически невозможно. Самый лучший способ борьбы со сложностью – это разделение на более простые части, как мы и поступим. Мы будем отображать состояние нашей модели по частям. Самое главное – это правильно определить эти части. Каждая такая часть должна быть по возможности самодостаточной. Самодостаточной для понимания какой-то полезной информации или для принятия какого-либо нужного решения об изменении. Итак, мы поделим наше состояние на части в соответствии с пользовательскими задачами и попробуем отобразить их пользователю.
Например, мы хотим регулировать светофор на перекресте. Для этого нам не нужно знать какие дома стоят вокруг, где работают или живут люди, которые ждут зеленый сигнал светофора или то, что происходит на другом конце города. Все, что нам нужно для принятия решения — это информация о перекресте и о том, что на нем находится. Сколько машин и на каких полосах стоит, сколько людей стоит в ожидании на пешеходном переходе и какой сигнал у светофора. Перекресток в разрезе этой задачи — это корневой объект, с которым связаны другие объекты (машины, светофор, люди). В случае другой задачи, например, управления всего транспортного потока города, наш перекресток будет всего лишь частью другого корневого объекта – транспортной инфраструктуры всего города.
Отображая состояние перекрестка на экране пользователя, по сути, мы показываем его «фотографию» на момент обращения к программе, давая пользователю возможность изучить ее и принять решение. Пользователь может изучить эту «фотографию» со всех ракурсов и узнать для себя что-нибудь полезное. Опираясь на эти знания, он может принять решение об изменении состояния модели. Для этого он может, например, переключить сигнал светофора. Конечно, наша фотография может быть не застывшей, а анимированной. Периодически меняться и отображать произошедшие изменения. Но все равно не будет никаких гарантий, что отображается самое последнее состояние.
В процессе переноса реальной модели в виртуальную – она превратилась в обезличенный набор параметров и их значений. И этот набор данных можно крутить и трансформировать, как только душе угодно. Поэтому наш перекресток, как и любую другую часть нашей модели, можно отобразить огромным числом различных способов. И далеко не все из них будут удобны пользователю. Это удобство будет выражаться в скорости и качестве принятия решения пользователем.
Например, состояние нашего перекрестка мы можем отобразить на экране в виде нескольких списков. В одном мы перечислим все машины, которые на нем сейчас находятся, в другом — людей, которые стоят на переходах. Помимо списков на экране будет изображен набор переключателей, отображающих сигнал светофора и несколько текстовых полей с названием и координатами перекрестка.
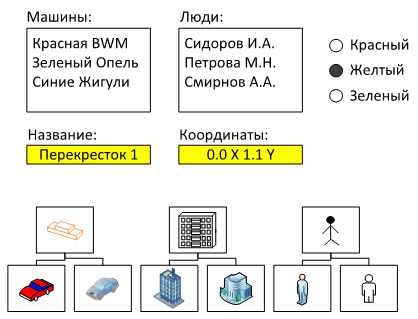
Или же, мы может отобразить перекресток в более удобном для человека виде – нарисовать его так же, как он выглядит в реальной модели, расставить на нем машинки и человечков, нарисовать светофор. Где-нибудь в углу отобразить мини-карту города, значком обозначив расположение перекрестка. Очевидно, что во втором случае восприятие состояния будет гораздо более удобным и быстрым. Хотя в обоих случаях на экране отображены одни и те же данные.
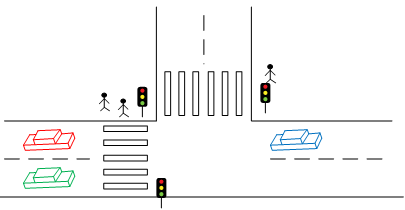
Так же и с остальной частью программы – очень важно не просто отобразить данные пользователю на экране, а сделать это максимально удобным и понятным для него способом.
А если взять что-нибудь, типа Microsoft HoloLens, то вообще можно отображать наш виртуальный город так же, как он выглядел в реальности или даже еще удобнее.
Сохранение состояния
После нескольких часов непрерывной работы пользователь, с радостью от проделанной работы, откидывается на спинку стула.
— Уффф – произносит усталый пользователь.
— Чпок – отвечают ему пробки и свет в мониторе гаснет.
В глазах разработчика появляется вселенская грусть. Ничего не подозревающий пользователь включает свет обратно и запускает компьютер. Запустив свой виртуальный город — пользователь видит, что все что он успел сделать – пропало. Город выглядит точно так же, как и в момент первого запуска …
Конечно же, наш мир далек от совершенства и компьютеры не могут работать непрерывно. Помимо этого, оперативной памяти компьютера тоже может быть недостаточно для того, чтобы удержать в памяти все состояние модели. Поэтому сохранение состояния способом, который умеет переживать выключения компьютера, является важной составляющей большинства программ. А так как все объекты нашей модели не меняются одновременно, мы вообще можем держать ее всегда в сохраненном состоянии и восстанавливать из сохраненного состояния небольшими частями, для просмотра или внесения нужных изменений. После чего можем спокойно сохранять новое состояние обратно.
Существуют различные способы сохранения состояния: можно хранить его в файле, придумав какой-нибудь формат, можно записывать на диск или флешку, можно использовать специальные системы хранения данных. Наиболее распространенным способом на текущий момент является использование для этого баз данных. Самыми популярными из них на сегодняшний день являются реляционные базы данных.
Не будем изобретать велосипед и решим проблему сохранения состояния модели при помощи РСУБД. Помимо удобства сохранения и извлечения данных, она предоставляет дополнительные полезные возможности, такие как, контроль целостности данных, который реализуется с помощью различных ограничений. Так же, база данных защищает от различных сбоев в момент сохранения, не давая возможности записать изменившееся состояние лишь частично, тем самым приводя его в поломанное состояние.
В базе данных вся информация хранятся в таблицах. Как правило, для каждого типа объекта существует своя таблица. А для каждого свойства объекта в этой таблице существует колонка. Значит, для того, чтобы сохранить экземпляр какого-либо типа — нам нужно создать для него соответствующую таблицу, с соответствующим набором колонок.
Описав всю необходимую структуру таблиц, мы, наконец-то, можем сохранить наше состояние в базе данных, чтобы не переживать о его сохранности. Но для этого нам нужно научить наше приложение использовать эти таблицы для сохранения и загрузки состояния. Для этого мы возьмем готовый инструмент в виде ORM и опишем сопоставление между типами и таблицами в базе данных. Хотя в случае, когда типов не так уж и много или использовать сторонний инструмент не хочется или не представляется возможным, существуют и другие способы.
Еще одним интересным способом сохранения является хранение не самого состояния модели, а описания действий, которые это состояние поменяли. Это напоминает redo-лог в базах данных или запись шахматной партии, в виде последовательности ходов. Такой подход называется event sourcing.
— Слушай. Получается, что создавая структуры для хранения данных, добавляя к ним ограничения, триггера, связи между таблицами и т.п. мы дублируем бизнес-ограничения, которые уже есть в модели, на сервере приложения?
— Получается, что так.
— Выходит, что мы все время учимся тому, что дублировать – это плохо, а тут рррраз и надублировали. Хммм….
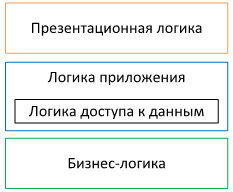
Многослойность
Так как мы аккуратно создавали нашу программу и старались не смешивать различные действия, то, в итоге, у нас выделилось несколько разных слоев логики.
Бизнес-логика
Это та часть логики программы, которая отвечает за изменение состояния нашей модели. Она описывает условия, которые должны соблюдаться для совершения изменения и сами изменения. Ей известна и доступна только модель.
Презентационная логика
Это та логика программы, которая отвечает за отображение состояния модели и доступных действий пользователю. Ей известна модель, которую нужно отобразить и бизнес-логика, которую можно вызвать.
Логика доступа к данным
Это та логика программы, которая знает, как сохранять и загружать состояние модели. Ей известна модель и то, как ее можно заполнить данными из базы данных.
Логика приложения
Это та логика, которая связывает все воедино, как клей. Ей известно и о бизнес-логике, и о логике доступа к данным, и о презентационной логике. Она объединяет их, помогает им и налаживает друг с другом взаимодействие.
Соблюдение такого разделения упрощает изменения приложения. Чем меньше слоям известно друг о друге и чем больше их логики скрыто друг от друга, тем проще их менять. Ведь, по сути, какая разница презентационной логике, где и как хранится состояние модели? И наоборот, какая разница логике хранения данных, где и как отображаются эти данные на интерфейсе? Ведь способов их отображения может быть несколько и они могут очень сильно отличаться друг от друга. В то же время модели все равно, как приложение сохраняет ее состояние или как это состояние отображается на экране. Только изменение модели или бизнес-логики может затронуть другие слои, так как они являются центральной частью программы.
2-tier
— Эй! – крикнул один пользователь другому. – Ты же должен был добавить новое здание в этом месте!
— Так я его и добавил, вот, посмотри. – ответил второй первому.
— Действительно… – почесал в затылке первый. — Странно, что я его не вижу у себя.
— Ничего странного, – ответил им разработчик. – ведь у каждого из вас своя база данных, т.е., по сути, у каждого свой собственный город.
— А зачем нам каждому свой город? – спросили раздраженные пользователи. – ведь он у нас был один, общий и мы хотим один, общий.
В глазах разработчика снова появилась вселенская грусть.
Для того, чтобы видеть изменения друг друга — пользователи должны работать с одним и тем же состоянием модели. Так как состояние нашей модели хранится в базе данных, это означает то, что пользователи должны использовать общую базу данных. Как правило, она располагается на отдельном компьютере, к которому программы всех пользователей имеют доступ.
Теперь одновременно несколько пользователей могут смотреть и менять одно и то же состояние модели. Но, появилась другая проблема – проблема конкурентного доступа. Ее можно решить различными способами. Наиболее распространенный способ – блокировка ресурсов для единоличного доступа перед внесением в них изменений, чем мы и воспользуемся. Для этого придется внимательно изучить всю программу и понять, в каких местах нам нужно добавить блокировки.
Хорошо, если задача требует блокировки малого числа ресурсов на короткий промежуток времени. Плохо, когда приходится блокировать большое число ресурсов и делать это продолжительное время. В таких случаях можно попробовать применить другой подход.
После физического разделения программы на два компьютера — у нас получилась клиент-серверная (двухзвенная) архитектура.
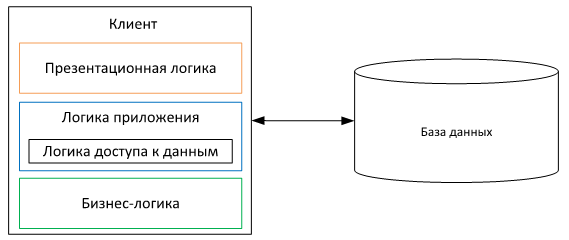
Это физическое разделение прибавляет дополнительные технические проблемы. Во-первых, сетевые соединения могут обрываться, и это будет являться дополнительной точкой отказа. Это надо будет учитывать при разработке приложения, чтобы правильно обрабатывать ошибки обрыва сети или недоступности сервера.
Во-вторых, передача данных по сети требует больше времени и это тоже надо учитывать. С одной стороны, для ускорения получения данных, данные могут кэшироваться на клиенте. С другой стороны, изменения могут отправляться не постоянно, а накапливаться в рамках задачи и отправляться один запросом.
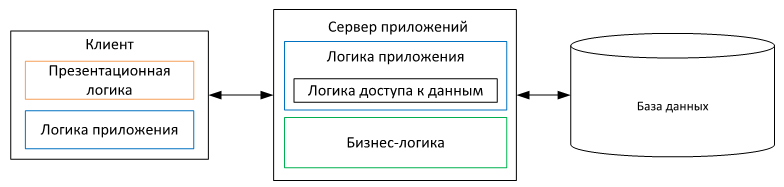
N-tier
— А мне бы еще нормально с планшета управлять городом, а то там такие сложные вычисления, что я засыпаю раньше, чем он что-то посчитает, пока я на работу еду из дома. – попросил один из пользователей.
— А мне нужно, чтобы некоторые новые пользователи имели доступ не ко всем действиям. – сказал другой пользователь.
В глазах разработчика появился уже знакомый взгляд…
Для решения новых проблем придется перенести бизнес-логику программы с пользовательского компьютера на отдельный, специально выделенный для этого компьютер, который обычно называют сервером приложений.
Наше аккуратное разделение логики на слои сыграло нам на руку. Презентационная логика и бизнес-логика и так были уже достаточно разделены, так что тут осталось только физически разделить их и создать дополнительную логику приложения для их взаимодействия. Наш толстый клиент, который содержал в себе бизнес-логику, значительно «похудел» и стал тонким клиентом.
К минусам, как и в случае клиент-серверного подхода, добавятся возможные сетевые проблемы и замедление скорости работы приложения за счет физического разделения бизнес-логики и презентационной логики. Помимо этого, к минусам можно отнести то, что внесение изменений станет более сложным, т.к. будет затрагивать больше кода, в том числе и того, который нужен для передачи данных между сервером приложений и клиентом.
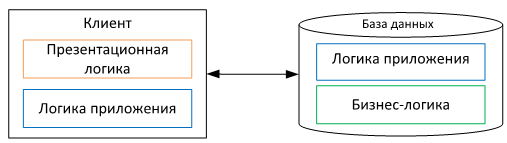
2 как 3
На самом деле, для решения проблем, перечисленных выше, не обязательно иметь трехзвенную архитектуру. Решить эти проблемы можно и в двухзвенной архитектуре, переместив бизнес-логику в базу данных, тем самым оставив клиент тонким. У такого подхода есть как свои плюсы, так и свои минусы.
Из плюсов хочется отметить — отсутствие физического разделения бизнес-логики и состояния модели, что может положительно сказаться как на скорости работы, так и на отказоустойчивости. Из минусов хочется отметить то, что самое главное в базе данных – это умение сохранять и извлекать данные, а не поддерживать бизнес-логику. Поэтому возможности языков, используемых в базах данных, уступают по возможностям современным высокоуровневым языкам. Помимо этого, отсутствует нормальная возможность использования большого разнообразия различных фреймворков. Все это сказывается на возможности и стоимости написания гибкого кода.
Другим минусом является возможность масштабирования. Масштабировать сервера приложений под высоконагруженные операции проще, нежели чем базы данных. Учитывая эти аспекты, получается то, что использование для бизнес-логики отдельного звена в качестве сервера приложений зачастую будет дешевле, чем содержание ее в базе данных.
Сервисы
— У нас тут вчера сломалось управление транспортом в городе и из-за этого не работала вся программа. – начал один из пользователей, – Но, с управлением транспорта никак не связано управление электроэнергией или водопроводной системой – продолжил он. – Можно как-нибудь сделать так, чтобы возможность их использования не зависела от проблем в несвязанных с ними областях? – спросил пользователь в итоге.
— У меня тоже есть просьба – продолжил другой пользователь – Можно сделать так, чтобы для обновления различных возможностей программы не нужно было бы ждать довольно долго обновления всей программы? – спросил он.
Потратив достаточно времени в самом начале и хорошо поняв предметную область, мы смогли выделить группу сервисов. Например, сервис управления светофорами, сервис управления электроэнергией или даже сервис управления зданиями. Все эти сервисы являются частью нашего виртуального города, но между собой они связаны достаточно мало, а зачастую, не связаны вовсе. Поэтому код программы был написан так же, с разбивкой на сервисы. Чтобы этого достичь — мы выделили необходимый для каждого сервиса публичный набор методов, спрятав все остальное. Таким образом, мы превратили наш сервис в «черный ящик». Этого легко удалось достичь, используя различные средства языка, такие как: модификаторы доступа методов, интерфейсы, абстрактные классы и т.п.
Благодаря слабой связанности — в большинстве случаев все эти сервисы можно менять независимо друг от друга. Но, т.к. физически все эти сервисы являются одной программой, такие изменения нельзя независимо установить клиенту. Если сервис меняется достаточно часто, и такие изменения нужно как можно раньше устанавливать клиенту, это становится не очень удобно. Появляется вынужденная зависимость от других сервисов, которую хотелось бы избежать.
Чтобы справится с этой проблемой, мы физически разделили программу на несколько частей. Таким физическим разделением может являться выделение сервисов в различные файлы (библиотеки). Это позволило разбить программу на несколько файлов – основной запускаемый файл и набор библиотек.
С помощью такого физического разделения появляется возможность независимого обновления сервисов, представляющее простую замену библиотеки сервиса. Несмотря на то, что сервисы стали физически разделены, они продолжают использовать общую логику приложения, что достаточно удобно, и живут в одном процессе — что позволяет использовать все возможности единого приложения. Помимо этого, такое явное разделение позволяет некоторым разработчикам работать только над определенным сервисами.
Для того, чтобы избежать «падения» всей программы, добавим в программу механизм обработки различных ошибок, возникающих при работе сервисов, который позволит программе оставаться работоспособной даже если какой-то сервис сбоит.
Но, если такой устойчивости будет недостаточно, можно разделить сервисы на разные процессы. Для этого придется доработать логику приложения для поддержки межпроцессного взаимодействия каким-либо удобным способом.
К плюсам такого подхода можно так же отнести — возможность использования для каждого отдельного сервиса своего набора технологий. Что, безусловно, является отличной приманкой для разработчиков. Но, в таком случае пропадет взаимозаменяемость разработчиков, что может стать недостатком.
К минусам такого подхода, как и в похожих случаях, можно отнести проблемы, связанные с уменьшением скорости взаимодействия, а так же, возможные перебои в передаче данных между процессами. Так же, еще можно добавить и то, что при разделении бизнес-логики появляются дополнительные проблемы в виде необходимости поддержки целостности данных в задачах, затрагивающих сразу несколько сервисов, например, с помощью распределенных транзакций.
— Слушай, а что всё так носятся с этими микросервисами?
— Разработчики думают, что физически разделив бизнес-логику, смогут писать слабосвязанные, легкозаменяемые устойчивые модули.
— Как будто им раньше что-то мешало…
Любое физическое разделение решает одни технические проблемы, но взамен привносит проблемы другие. Решать изначальные технические проблем, безусловно, надо, но всегда стоит подумать, превысит ли выгода от их решения недостаток от появления новых проблем.
Каждый раз, когда происходит физическое разделение частей программы, необходимо реализовывать инфраструктурную прослойку, которая будет скрывать это разделение. Да, с технической точки зрения создание такой инфраструктуры — это, безусловно, интересная чисто техническая задача, поэтому программисты с радостью берутся за нее. Но если это толком не решает никаких проблем, то это лишь увеличивает стоимость и сложность программы, не принося никакой выгоды.
Инструменты
-А зачем, вместо того, чтобы сделать нормальный запрос к БД, он вытягивает обе таблицы на сервер приложения, затем героически объединяет их и фильтрует результат для получения необходимых данных?
— Когда у тебя в руках только молоток, все задачи кажутся гвоздями.
Языки, библиотеки, фреймворки, утилиты – это все то, чем пользуется разработчик в процессе работы. Все это нужно для максимального снижения стоимости решения технических проблем, оставляя больше времени для решения уникальных для проекта проблем бизнеса. Поэтому правильный выбор инструментов важен, так как напрямую влияет на производительность труда. Грубо говоря, можно что-то полдня выпиливать пилой, а можно взять электролобзик — вжик и готово!
Так как инструменты бывают разные и предназначены для разных целей – их правильное применение не менее важно. Забивать гвозди ломом, конечно, можно (и это будет удобнее, чем кулаками), но все-таки, не так легко и удобно, как молотком.
Но, среди разработчиков существует один очень плохой синдром под названием – «Not invented here». Его смысл в том, что вместо того, чтобы взять какой-либо готовый инструмент для решения определенного круга задач, разработчики начинают изобретать свой. Наиболее сильно это может проявляться в желании создания своей платформы.
Так как создание таких инструментов — задача чисто техническая и какого-либо понимания предметной области бизнеса для этого не нужно, разработчики с удовольствием любят этим заниматься. Но, когда разработчик нацелен на решение бизнес-проблем — он наоборот, с радостью упрощает себе жизнь сторонними инструментами.
Теория и практика
В теории, теория и практика одно и тоже. На практике — нет.
В теории, конечно, все красиво, но на практике все совсем не так. Недостаток технических знаний, знаний предметной области, времени или людей – все это ведет к появлению нежелательных проблем в коде и влияет на качество программы.
В реальности разработчики часто стоят перед компромиссом между качеством и скоростью. Попытка угодить заказчику и уложиться в срок заставляет делать все наспех. Это, в итоге, дает обратный эффект. Спешное решение проблем заставляет создавать плохие решения, которые, в итоге, накапливаются как большой снежный ком, пытаясь похоронить под собой весь проект. Из-за них поддержка и исправление начинают стоить еще дороже, что только усугубляет проблему, особенно в объяснениях заказчику, почему стоимость однотипных изменений стала стоить дороже.
Такие плохие решения практически неизбежны в любом проекте, поэтому очень важно находить время на рефакторинг.

Итог
В конечном итоге, все упирается в деньги. Чем дешевле стоимость разработки и поддержки, тем выгоднее создавать программу. Поэтому все подходы/инструменты/шаблоны/парадигмы и т.п. нацелены на одно – удешевления процесса разработки и поддержки.
Но разработка — это в том числе и творческий процесс. К решению одной и той же задачи можно прийти невероятно большим количеством путей, у каждого из которых будут свои плюсы и минусы.
И только от разработчика зависит насколько хорошим будет этот путь. Поэтому в разработке программ люди — это главный и самый важный ресурс.
Комментарии (33)

alan008
20.07.2015 13:56>>межпроцессорное взаимодействие
полагаю, имелось в виду межпроцессное
За статью спасибо, хоть и капитанство, но практически полностью совпадает с моим видением того, что в целом представляет из себя разработка любой системы.
konsoletyper
20.07.2015 14:12+5За статью спасибо, хоть и капитанство
Беда в том, что многие, прочитав такие статьи, согласно кивнут, но пойдут и продолжат по-прежнему писать код как придётся, не руководствуясь описанными принципами. Надо почаще мыть мозг разработчикам на эту тему, авось рано или поздно задумаются, может, что-то они делают не так.alan008
22.07.2015 21:59+5>>продолжат писать код как придется
Мне кажется, самое страшное в этой ситуации не то, что разработчики не знают того, что описано в статье. Страшно то, что они это знают, но это никак не помогает им становиться лучше, потому что все эти решения нужно не только знать (что они вот такие хорошие бывают) но и уметь их правильно готовить (причем по свОему для каждой комбинации платформы/языка/фреймворка, да что уж лукавить — даже для каждой отдельно выбранной архитектуры приложения). То что я знаю, из чего состоит вкусный борщ, вероятно, позволит мне отличить невкусный борщ от вкусного, но вряд ли сильно мне поможет вкусный борщ сварить. Вот это тревожит.

ApInvent Автор
20.07.2015 14:42полагаю, имелось в виду межпроцессное
Да, верно — имелось ввиду именно это. Хотел поправить и пропустил. Благодарю.

Vilyx
20.07.2015 13:58-1Автор, вы слишком много аспектов попытались описать в одной статье. ООП, декомпозиция предметной области, проектирование, шаблоны проектирования бизнес приложений, каждая из этих тем может потянуть минимум на небольшую книгу. И было бы здорово перенять положительный опыт и рисовать классы и методы в UML.
ApInvent Автор
20.07.2015 14:35+2Автор, вы слишком много аспектов попытались описать в одной статье. ООП, декомпозиция предметной области, проектирование, шаблоны проектирования бизнес приложений каждая из этих тем может потянуть минимум на небольшую книгу.
Описание всех этих аспектов, пускай и в компактном виде, но в одном месте — было одной из целей данной статьи.
И было бы здорово перенять положительный опыт и рисовать классы и методы в UML.
Спасибо за замечание, учту на будущее.

onegreyonewhite
20.07.2015 14:51-1Спасибо! Очень интересно и красочно описана тема. Возьму за пример вашу статью, когда буду помогать изучать ООП своим подопечным.
жаль кармы не хватает, чтобы «плюсануть» публикацию.

Throwable
20.07.2015 15:01-1Все это полезно и хорошо, но:
Но! Если программа сложная, планируется ее доработка и поддержка, то применение всех этих «лишних сложностей» будет напрямую влиять на самое
Миф, цитируемый разводилами-теоретиками недалеким менеджерам. До сих пор не доказана эффективность разработки с ООП перед процедурным подходом. Кроме того, имеется множество авторитетных мнений за то, что ООП является скорей антипаттерном и в реальной жизни лишь усложняет проектирование и разработку, заставляя концентрироваться на абстрактных вещах, не имеющих отношения к решаемой задаче.
Расцвет ООП начался в эпоху оконных интерфейсов, где иерархическая модель однотипных визуальных компонентов с наследованием и инкапсуляцией поведения (отрисовка, реакция на ввод) хорошо вписывалась в предлагаемую парадигму. В реальных задачах концепты ООП становятся рудиментарными.
— Миллионы приложений используют реляционную модель и живут счастливо без всякого наследования в своей предметной области. Приложение в 99% случаев работает с конкретной сущностью, нежели абстрактным надклассом.
— Инкапсуляция становится бесполезной, когда изменения состояния затрагивает сразу много объектов, и когда зависимости одни от других нетривиальны и не вписываются в иерархическую схему. Пример: бильярдный стол с шарами и физикой. Каждый шар хранит и изменяет состояние. Инкапсулировать физику отскоков в шары невозможно, поскольку шар ничего не знает о других.
— Переопределяя очередной метод в большой иерархии, программист не может быть уверен, что не нарушит деятельность объекта на каком-то уровне.
Trueteller
20.07.2015 15:29Я тоже стал думать в эту сторону. Автор начинает с того, что предлагает задуматься над причиной принятия наших решений, а потом без всяких раздумий выбирает ООП как концепцию.
В то же время, существует (и поддерживается многими) мнение, что ООП-моделирование в классическом понимании красиво в теории, но создает огромное количество проблем на практике. А также существуют другие подходы, такие как функциональное программирование, пытающиеся преодолеть эти ограничения.
Понятно, что с таким разбором статья получилась бы совсем большой. Но стоило хотя бы отметить существование выбора.ApInvent Автор
20.07.2015 15:47+2Я тоже стал думать в эту сторону. Автор начинает с того, что предлагает задуматься над причиной принятия наших решений, а потом без всяких раздумий выбирает ООП как концепцию.
Понятно, что с таким разбором статья получилась бы совсем большой. Но стоило хотя бы отметить существование выбора.
Действительно, мысли раскрыть эту тему были — но, прикинув объем, я решил эту тему не затрагивать. Так можно было бы углубляться до бесконечности. Поэтому за основу была взята наиболее популярная, на мой взгляд, концепция.
В то же время, существует (и поддерживается многими) мнение, что ООП-моделирование в классическом понимании красиво в теории, но создает огромное количество проблем на практике. А также существуют другие подходы, такие как функциональное программирование, пытающиеся преодолеть эти ограничения.
Мне кажется, что ООП и ФП не противостоят друг другу, они о разных вещах. Можно одинаково успешно пользоваться и тем и другим.
Я думаю, это могло бы быть хорошей темой для отдельной статьи.
konsoletyper
20.07.2015 16:50+1А также существуют другие подходы, такие как функциональное программирование, пытающиеся преодолеть эти ограничения.
ФП не пытается преодолеть «ограничения», введёнными ООП, т.к. появилось оно на 20 лет раньше и никак не могло чего-либо знать об этих «ограничениях». Контекст применения ФП несколько другой, им удобно делать обработку данных, но вот там, где у нас много состояния, ФП создаёт лишние сложности. Просто иногда там, где лучше было бы задачу решать с точки зрения ФП, её начинают решать с помощью ООП и сильно обламываются. Обратное, кстати, тоже случается.
gandjustas
20.07.2015 17:19ФП это очень обобщенное понятие. Современное (практическое) ФП появилось только в языках OCaml и Haskell. То есть примерно в то же время, что и ООП. И если бы в C++ основной упор не был сделан на ООП, а на ФП, то мы бы сейчас писали на совсем других языках.
Кстати товарищ Степанов еще 25 лет назад в ФП увидел бОльший потенциал и спроектировал STL для C++ в функциональном стиле. Но не помогло.
Так что последние 25 лет ФП как раз догонял ООП, ичсх таки догнал, потому что ООП уперся в потолок выразительности, а ФП все еще есть куда расти.
ApInvent Автор
20.07.2015 15:36+4Миф, цитируемый разводилами-теоретиками недалеким менеджерам. До сих пор не доказана эффективность разработки с ООП перед процедурным подходом. Кроме того, имеется множество авторитетных мнений за то, что ООП является скорей антипаттерном и в реальной жизни лишь усложняет проектирование и разработку, заставляя концентрироваться на абстрактных вещах, не имеющих отношения к решаемой задаче.
Серебряной пули вообще не существует. Для каждой задачи лучше всего подходит какой-то свой набор инструментов.
— Миллионы приложений используют реляционную модель и живут счастливо без всякого наследования в своей предметной области. Приложение в 99% случаев работает с конкретной сущностью, нежели абстрактным надклассом.
Я и не говорил, что они будут жить грустно или не будут работать. Я говорил, что у всего есть своя стоимость. И в зависимости от задач, стоимость применения ООП или реляционного подхода будет отличаться.
— Инкапсуляция становится бесполезной, когда изменения состояния затрагивает сразу много объектов, и когда зависимости одни от других нетривиальны и не вписываются в иерархическую схему. Пример: бильярдный стол с шарами и физикой. Каждый шар хранит и изменяет состояние.
Если Вы считаете, что она здесь не нужна, то стоит применить тот подход, который на Ваш взгляд будет наилучшим. Я обеими руками за то, чтобы подходы и инструменты применялись разумно, а не бездумно.
— Переопределяя очередной метод в большой иерархии, программист не может быть уверен, что не нарушит деятельность объекта на каком-то уровне
На мой взгляд, ООП в данном случае вообще ни при чем. Так же можно сказать и про то, что программист может поменять процедуру и не быть уверенным в том, что все будет работать хорошо. Тут проблема явно в другом.gandjustas
20.07.2015 16:22-2На мой взгляд, ООП в данном случае вообще ни при чем. Так же можно сказать и про то, что программист может поменять процедуру и не быть уверенным в том, что все будет работать хорошо. Тут проблема явно в другом.
Как раз в этом. Контракты класса не присутствуют явно в коде, а наследование создает сильную связь между, которая заставляет производные выполнять контракт базового класса.
Поэтому возникает сразу две проблемы:
1) Изменения в наследнике могут нарушить контракт
2) Изменения в базовых классах могут нарушить логику наследников (проблема хрупкого базового класса).
Для второго даже придуман принцип OCP, который говорит нам, что как только мы начали использовать класс нельзя больше вносить изменений в его контракт (привет итерационное проектирование).
С процедурами чуть лучше. Можно явно отследить кто процедуру вызывает. Кроме того нет простого способа подменить одну процедуру другой по месту вызова, кроме ручной реализации виртуальных методов. Поэтому проблема хрупкого базового класса отсутствует, также как отсутствует проблема соблюдения LSP.ApInvent Автор
20.07.2015 16:40Тоже самое можно сказать и про процедурный подход — если поменять логику работы процедуры, которая используется в других процедурах, то они так же могут поломаться.
Тут просто существует общая проблема изменения поведения кода, который уже где-то используется.gandjustas
20.07.2015 16:44-3Еще раз: вызовы процедур — явные. Вызовы виртуальных методов классов — нет. Более того, у вас может и не быть исходников классов, от которых вы наследуетесь (ага OCP). А вот как заставить код в другом модуле вызвать мою процедуру, да еще и без моего ведома — понятия не имею
ApInvent Автор
20.07.2015 16:57Я не понимаю, как Ваш комментарий связан с проблемой изменения существующего поведения, на основе которого реализовано другое поведение.
Если Вы используете чужую процедуру, исходного кода которой у Вас нет и полагаетесь на ее поведение, что произойдет если ее поведение поменяется? У Вас ничего не поломается все равно?gandjustas
20.07.2015 17:31-2ОК, не понимаете. Давайте с примерами.
сlass Base { public void Public() { this.Internal(); } protected abstract void Internal(); } class Derived: Base { int x = 0; protected override void Internal() { x++; } }
Предположим что авторы классов Base и Derived — разные.
Потом автор меняет метод Base.Public() на такой:
public void Public() { this.Internal(); this.Internal(); }
Такие изменения очень часто ломают поведение производного класса. Это называется хрупким базовым классом.
А теперь другой сценарий. Вносят такие изменения в код:
class Derived: Base { int x = 0; protected override void Internal() { if(x++==100) throw new Exception(); } }
При этом код, вызывающий Base.Public, выглядит примерно так:
try { b.Public(); } catch (InvalidOperationException e) { //some code }
Это нарушение LSP, которое очень легко допустить из-за неявных контрактов.
Оба случая с большим трудом реализуемы в функциональном подходе.ApInvent Автор
20.07.2015 18:49За примеры, конечно, спасибо, но к чему они? Я изначально сказал то, что проблема изменения поведения кода, который кем-то используется, существует не только в ООП и является общей проблемой. Да, в ООП есть ситуации, когда эта проблема может быть более острой, но это никак не противоречит моим словам. Я же не пытаюсь доказать Вам, что ООП это единственно правильный подход, в котором нет проблем. Как я уже упоминал выше — серебряной пули нет, и везде есть свои плюсы и минусы.
В случае функционального подхода можно представить иерархию функций:
let func1 f = let func2 f = let funcX f = f + 1 funcX f; func2 f; printfn "%i" (func1 1)
И предположить, что функция funcX сделана другим автором, который потом берет и меняет ее поведение на:
let funcX f = f - 1
В этом случае у нас тоже может все поломаться и без всякого ООП.gandjustas
20.07.2015 19:54-4Вы же сами видите, что в варианте ФП связи явные, а в ООП — неявные. Вот и проблем в ООП больше.
Вы же не думаете что нарушения LSP и «хрупкий базовый класс» это чьи-то выдумки? Это реальные проблемы, с которыми сталкиваются люди. Аналогичных проблем в ФП не видно. Не факт, что их нет, но их мало.
Да, в ООП есть ситуации, когда эта проблема может быть более острой, но это никак не противоречит моим словам.
Это вы сейчас так говорите, а в статье ни слова.ApInvent Автор
20.07.2015 21:14+3Это вы сейчас так говорите, а в статье ни слова.
Можете считать отсылкой к этому текст о том, что инструменты бывают разные и для разных целей нужно применять свои. Если уж более подробно описывать минусы ООП, то нужно описывать минусы и плюсы и других подходов, и все это делать на хороших примерах, чтобы было хорошо понятно всем. А это большая, интересная тема, но для отдельной статьи.
Вы же сами видите, что в варианте ФП связи явные, а в ООП — неявные. Вот и проблем в ООП больше.
Если переопределяется метод базового класса, то должно быть очевидно, что такой метод может где-то использоваться и полагаться на то, что это не так совершенно неправильно. Т.е. если в случае с ФП нужно поискать — используется ли функция где-нибудь или нет, то в случае с переопределенными методами даже искать ничего не надо — нужно просто считать, что они точно где-то используются. Получится та же проблема, что и в случае изменения поведения функции, которая используется другими функциями.
Если это не брать в расчет и бездумно что-то менять, то не стоит удивляться, что что-то ломается. По-Вашему получается, что если болгаркой отпилить палец, то виновата болгарка.gandjustas
20.07.2015 22:03-1Если переопределяется метод базового класса, то должно быть очевидно, что такой метод может где-то использоваться и полагаться на то, что это не так совершенно неправильно.
Вопрос не в том используется или нет, а в том — как используется и меняется ли использование со временем. Второй вопрос особенно болезненный. Потому что не менять контракт класса — еще пол-беды. Но по сути даже внутреннюю реализацию базового класса менять нельзя, если активно используется наследование и виртуальные методы.
Именно поэтому во фреймворках довольно мало используется наследование. Массово — только в UI на десктопе.

Iceg
21.07.2015 00:36+8Напишите, пожалуйста, об этом статью. Плюсы и минусы ООП, ПП и ФП. Примеры и рекомендации, когда какой подход использовать. Какие задачи лучше решаются тем или иным подходом.
Пост увидит гораздо большее количество людей, чем ваши коментарии — значит, свою позицию вы донесёте до более широкой аудтории, да и многие, вероятно, захотят её с вами обсудить, что вам и требуется.
konsoletyper
21.07.2015 07:43+2Именно поэтому во фреймворках довольно мало используется наследование. Массово — только в UI на десктопе.
Наследование реализации, может, и редко. А наследование (расширение) интерфейса — вполне себе безобидная штука.gandjustas
21.07.2015 09:36-1Реализация интерфейса классом называется наследованием только по историческому недоразумению. Более того интерфейсы вообще не требуют ООП, например в хаскеле и go интерфейсы есть, а классов, наследования и полиморфизма (в смысле ооп) нет.
gandjustas
20.07.2015 16:42-2Статья обо всем и ни о чем. Прочитал аж два раза — непонятно какие выводы должен сделать читатель.
На справочник не тянет, слишком поверхностное и безапелляционное изложение.
На учебник тоже не тянет, слишком несвязные куски.
Похоже на краткую выборку из книг:
1) «Объектно-ориентированный анализ и проектирование» Буча
2) «Agile Software Development, Principles, Patterns, and Practices» Мартина
3) «АКПП» Фаулера
4) «DDD» Эванса
Но без ссылок на сами книги.ApInvent Автор
20.07.2015 16:57+5К сожалению, написать статью так, чтобы каждый нашел для себя что-то новое и интересное, затрагивая большой круг тем, да еще и в компактном виде, наверное, нереально.
Жаль, что это статья не смогла Вам угодить. Надеюсь, в какой-нибудь другой раз все будет иначе.
Iceg
21.07.2015 00:20+2Пока дочитал только до динамиков, но мне нравится.
Придирки к автору на тему ООП vs ФП непонятные какие-то. Статья вроде как об ООП, что прямо указано в заголовке. Это как раньше в каждый пост про винду сбегались линуксоиды (и наоборот :)), так теперь модно похоливарить в постах об объектно-ориентированном программировании про функциональное?)

Temirkhan
21.07.2015 05:36+2Наконец-то. Теперь я могу сказать, что понимаю, зачем нужны SOLID-принципы и как они работают. Автор, у Вас прекрасное «ассоциативно-абстрактное» мышление. Keep it up

misha_shar53
21.07.2015 06:19+1ООП это инструмент им надо уметь пользоваться и знать где. ФП другой инструмент и к нему те же требования. Конечно плохо когда язык (Java) навязывает выбор инструмента, демонстрируя одновременно недостатки такого подхода (классовые методы вместо функциональных программ). Я думаю что негативная оценка ООП возникла от его бездумного применения. Концепции ООП я считаю прорывными в ИТ отрасли они очень полезны. С ними связана целая эпоха в программировании и это уже не выбросить. Но применять его везде и всюду нельзя. ООП консервирует объекты и если они динамически меняются то для них ООП не подходит. Но почти всегда в ИТ проекте есть базовые типы стабильные сущности которые хорошо описываются классами. Для них ООП идеальный инструмент. Динамические объекты меняющие набор своих свойств должны описываться по другому. Статья очень полезная, по крайней мере для меня.

booomerang
21.07.2015 14:25+2Пользователь высказал пожелание о том, что в комнаты домов днем должен попадать дневной свет так, чтобы все было видно. Разработчик, недолго думая, выдолбил в стене круглую дыру и проверил — оказалось, что света все еще недостаточно. Тогда разработчик выдолбил еще две дыры рядом и опять проверил. Убедившись, что света достаточно, разработчик решил, что задача выполнена. По этому принципу дыры были выдолблены во всех домах. Требования были соблюдены.
Но лето кончилось и наступила зима, а вместе с ней и холода. Злой пользователь прибежал и стал ругаться на то, что в комнатах стало ужасно холодно. При выяснении причин стало ясно, что из-за дыр, выдолбленных под солнечный свет, в комнату попадает много холодного воздуха с улицы и она промерзает. После выяснений обстоятельств оказалось, что пользователь хотел обычное окно, но какие-то требования забыл упомянуть он, а что-то по-своему передал аналитик, и получилось то, что получилось. Так как все промерзло – решать проблему пришлось на ходу, времени на разработку хороших окон и переделку дыр под окна в зимний период уже не было. Поэтому было принято решение обойтись «костылем» и заделать дыры полиэтиленом. Такой способ помог избавиться от сильного промерзания и позволил оставить солнечный свет днем. Но кто знает, сколько новых проблем неполное понимание изначальных требований еще принесет…
Божественное сравнение, надо будет запомнить =)booomerang
21.07.2015 15:13+1-А зачем, вместо того, чтобы сделать нормальный запрос к БД, он вытягивает обе таблицы на сервер приложения, затем героически объединяет их и фильтрует результат для получения необходимых данных?
— Когда у тебя в руках только молоток, все задачи кажутся гвоздями.
Еще одна крылатая цитата, круто, спасибо, в копилку ))
dimonji
Хорошая статья, автору большое спасибо. Достаточно просто и грамотно.