
Fluent — семейство спецификаций, реализаций и практик для локализации, разработанной Mozilla. Сейчас она применяется в браузере Firefox. Используя Fluent, переводчики могут писать более естественные переводы на родном языке. Сегодня мы представляем спецификацию формата файлов Fluent версии 1.0. Приглашаем разработчиков переводческих инструментов попробовать его и рассказать о ваших впечатлениях.
Какие проблемы решает Fluent
Браузер Firefox поддерживает около сотни языков, и это бросает разработчикам вызов с точки зрения локализации. Многие проблемы сложно решить используя традиционные подходы. В локализации ПО доминирует принцип разметки переводов «один к одному» с исходным текстом. Грамматика исходного языка (в случае с Mozilla — английского) накладывает серьёзные ограничения на доступность выразительных средств при переводе.
Рассмотрим следующее сообщение, которое появляется, когда пользователь пытается закрыть окно Firefox с несколькими вкладками.
tabs-close-warning-multiple = You are about to close {$count} tabs. Are you sure you want to continue?Сообщение отображается только в том случае, если вкладок 2 или больше. В английском языке, слово tab будет всегда во множественном числе — tabs. Англоязычного разработчика устроит такое сообщение. Оно звучит корректно для любых значений $count.
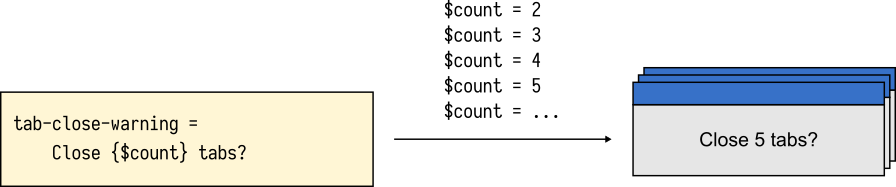
В английском языке для всех значений $count достаточно одного варианта сообщения.
Многие же переводчики заметят, что слово tab может принять разные формы в зависимости от значения $count.
В традиционном подходе к локализации, ответственность за корректную обработку сообщения будет лежать на переводчиках. Они должны учитывать, что в других языках может существовать несколько множественных форм слова, даже если в английском она всего одна. Чем больше языков будет поддерживать приложение, тем серьёзнее будет становиться проблема.
- В некоторых языках существительные обладают родом, что потребует изменения прилагательных и причастий. Во французском слова connecte, connectee, connectes и connectees переводятся на английский как connected.
- Руководство по стилю может требовать использования определённых терминов в зависимости от платформы, на которой работает ПО. В английской версии Firefox, например, Settings используется на платформе Windows, а Preferences — на других системах, чтобы соответствовать стандартам, принятым в этих системах. В японском разница может быть ещё интереснее: от операционной системы зависит выбор система письма для некоторых компьютерных терминов.
- Контекст и целевая аудитория приложения может требовать дополнительных модификаций текста. Англоязычное приложение для работы с бухгалтерским учётом может использовать форматирование цифр отличное от того, что используют на обычных сайтах в интернете. Но в других языках такое разделение может быть необязательным.
Существует множество грамматических и стилистических вариаций, которые нельзя напрямую сопоставить между двумя языками. Поддержка всех этих нюансов с помощью традиционного подхода может быть затруднительной. В некоторых языках придётся идти на компромиссы, в других вообще не будет подходящего решения.
Асимметричная локализация
Fluent меняет распределение ролей в локализации. Вместо того, чтобы требовать от разработчиков учитывать все возможные нюансы всех языков, Fluent старается держать тексты на исходном языке в максимально простой форме.
Мы делаем возможным передачу грамматики и стиля других языков независимо от исходного текста. Всё происходит изолированно. То, что один язык может использовать более продвинутую логику в локализации, не влияет на другие языки перевода. Каждая локализация в программе сама решает, насколько сложным должен быть текст перевода.
К примеру, посмотрим на перевод сообщения о закрытии вкладок на чешский. Слово panel (вкладка) должно принимать одну из двух форм: panely для количества вкладок 2, 3 и 4, и panelu для всех остальных значений.
tabs-close-warning-multiple = {$count ->
[few] Chystate se zavrit {$count} panely. Opravdu chcete pokracovat?
*[other] Chystate se zavrit {$count} panelu. Opravdu chcete pokracovat?
}Fluent даёт переводчикам возможность писать грамматически верные предложения и свободно использовать выразительные средства своего языка. Благодаря Fluent, чешский перевод использует правильные множественные формы для любых возможных значений $count.
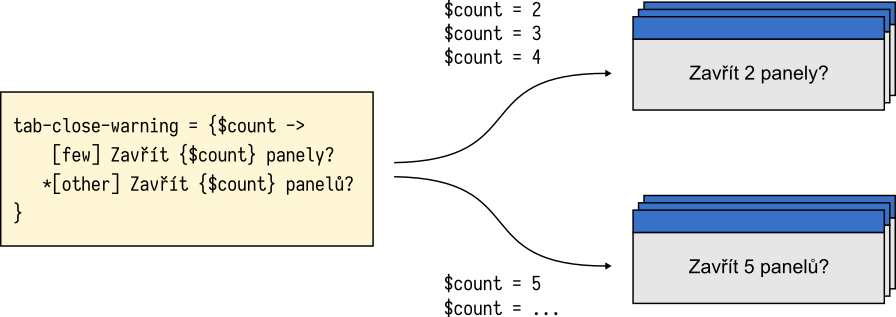 В чешском языке, при значениях $count равным 2, 3 и 4, существительному требуется особая множественная форма.
В чешском языке, при значениях $count равным 2, 3 и 4, существительному требуется особая множественная форма.В то же время, в исходный текст или код не требуется вносить никаких изменений. Логика в чешской локализации никак не влияет на все остальные локализации программы. Во французском языке это предложение будет таким же простым, как и английское:
tabs-close-warning-multiple =
Vous etes sur le point de fermer {$count} onglets.
Voulez-vous vraiment continuer ?Концепция асимметричной локализации является ключевой инновацией Fluent, которая стала возможной благодаря опыту Mozilla в разработке многоязычного ПО на протяжении 20 лет. Многие ключевые идеи для Fluent были позаимствованы из MessageFormat от ICU (International Component for Unicode) и из формата XLIFF.
На первый взгляд, Fluent походит на другие решения для локализации, которые позволяют использовать варианты слов для множественных существительных и слов с грамматическим полом. В отличие от них, Fluent использует целостный подход к локализации. Fluent развивает эти идеи, определяя синтаксис для всего текстового файла, где хранятся переводы, и разрешая ссылаться из одних сообщений на другие.
Термины и ссылки
Файл Fluent может содержать в себе множество сообщений, каждое из которых переведено на язык переводчика. Сообщения могут ссылаться на другие сообщения внутри того же файла, или на сообщения из других файлов. Во время выполнения, Fluent объединяет файлы в наборы (bundles), и ссылки разрешаются внутри этого набора.
Ссылка на сообщения — это мощный инструмент для поддержки единообразия переводов. Однажды определённый перевод может многократно использоваться в других переводах. Fluent поддерживает специальный тип сообщения под названием термин (term), хорошо подходящий для многократного использования. Идентификатор термина всегда начинается с чёрточки.
-sync-brand-name = Аккаунт FirefoxПосле определения, термин -sync-brand-name может использоваться из других сообщений как переменная, всегда возвращая корректный текст. Термины помогают внедрить единообразие согласно руководству стилей. К примеру, их можно изменять для особого брендирования неофициальных сборок или бета-релизов.
sync-dialog-title = {-sync-brand-name}
sync-headline-title =
{-sync-brand-name}: The best way to bring
your data always with you
sync-signedout-account-title =
Подключитесь с помощью {-sync-brand-name}Использование термина напрямую в середине предложения может вызвать проблемы во флективных языках, или в языках с другими правилами капитализации текста. Значение термина можно определить в нескольких аспектах в зависимости от контекста. Рассмотрим следующее определение термина -sync-brand-name на итальянском.
-sync-brand-name = {$capitalization ->
*[uppercase] Account Firefox
[lowercase] account Firefox }Благодаря ассиметричной природе Fluent, переводчик на итальянский может определить две формы для написания бренда. Вариант с верхним регистром (по умолчанию) подходит для самостоятельного использования или для использования в начале предложения. Вариант в нижнем регистре может быть запрошен путём передачи параметра капитализации, когда термин используется внутри большого предложения.
sync-dialog-title = {-sync-brand-name}
sync-headline-title =
{-sync-brand-name}: il modo migliore
per avere i tuoi dati sempre con te
# Явный запрос варианта в нижнем регистре.
sync-signedout-account-title =
Connetti il tuo {-sync-brand-name(capitalization: "lowercase")}Определение нескольких вариантов термина — это удобный приём, который позволяет соответствовать грамматическим правилам множества языков. В следующем примере, польский переводчик может использовать склонения для построения правильного предложения в сообщении sync-signedout-account-title.
-sync-brand-name = {$case ->
*[nominative] Konto Firefox
[genitive] Konta Firefox
[accusative] Kontem Firefox
}
sync-signedout-account-title =
Zaloguj do {-sync-brand-name(case: "genitive")}Fluent позволяет внедрять сложную логику языковых конструкций там, где это необходимо. В то же время, просто перевод остаётся простым. Fluent не добавляет сложной реализации в простые конструкции.
sync-signedout-caption = Take Your Web With You
sync-signedout-caption = Il tuo Web, sempre con te
sync-signedout-caption = Zabierz swoja siec ze soba
sync-signedout-caption = So haben Sie das Web uberall dabei.Fluent Syntax
Сегодня мы объявляем о первом стабильном релизе Fluent Syntax. Это спецификация формата файла для хранения переводов, а так же бета-релиз парсеров на JavaScript, Python и Rust.
На примерах выше вы увидели, что из себя представляет синтаксис Fluent. Он создан быть понятным для людей с небольшими техническими познаниями, и позволяет делать проверку и редактирование текста с минимальным количеством ошибок. Восстановление после ошибки является важным моментом: один неверный перевод не сломает весь файл или прилегающие к нему переводы. Комментарии пригодятся для передачи контекста конкретного сообщения или целой группы. Переводы могут занимать несколько строк, что облегчает работу и разметку больших фрагментов текста.
Файлы Fluent можно открыть в любом текстовом редакторе, что снижает порог вхождения для разработчиков и локализаторов. Формат уже поддерживается открытой платформой для перевода ПО Pontoon от Mozilla.
 Fluent Playground — это песочница для тестирования Fluent прямо в браузере.
Fluent Playground — это песочница для тестирования Fluent прямо в браузере.Подробности о синтаксисе можно узнать из материала Fluent Syntax Guide (англ). Формальное определение можно найти в материале Fluent Syntax specification (англ). А если вы хотите просто попробовать Fluent, используйте Fluent Playground — онлайновый редактор со сниппетами, которыми можно поделиться.
Обратная связь
Firefox является основным фактором развития Fluent. В Firefox уже используется более 3000 сообщений Fluent. Миграция на Fluent началась в прошлом году, и сейчас идёт полным ходом. Формат Fluent показал себя стабильным и гибким решением для сложных интерфейсов, вроде страницы настроек Firefox. Он так же используется на множестве веб-страниц Mozilla, таких как Firefox Send и Common Voice.
Мы считаем, что Fluent — это отличный выбор для приложений, в которых важны простота и скорость выполнения, но в то же время требующих отображения элементов интерфейса в зависимости от множества переменных. В частности, Fluent помогает создавать естественные предложения на разных языках в ограниченном пространстве мобильных интерфейсов; в информационно-насыщенных платформах социальных медиа; и в играх для передачи игровой статистики и объяснения механики игроку.
Мы будем рады услышать мнение о Fluent от разработчиков или вендоров. Fluent разрабатывается как стандарт будущего, поэтому мы приглашаем всех попробовать его и рассказать, с какими ещё проблемами вы сталкиваетесь в работе. С вашей помощью мы сможем усовершенствовать Fluent для работы на множестве платформ и в множестве ситуаций.
Мы открыты для конструктивной критики. Узнать больше о Fluent можно на сайте проекта. Если вам есть что рассказать, свяжитесь с нами на Fluent Discourse.
Комментарии (40)

worldmind
22.04.2019 15:21+1Я от локализации далёк, но интересовался когда-то, проблема-то типовая, но те решения что были не производили впечатления хороших, каковыми должны быть решения для типовой проблемы.
А это выглядит похожим на нормальное.
GCU
23.04.2019 15:23Очень похоже на синтаксический сахар для MessageFormat из ICU
worldmind
23.04.2019 15:29Возможно, разве это плохо?
GCU
23.04.2019 16:39Это лучше чем было, перенос части языкозависимой логики формирования текстов на сторону переводчиков требует или полноценной поддержки инструментами для перевода (CAT вроде Trados или MemoQ) или знаний со стороны переводчика.
Увы, ICU MessageFormat не удалось этого добиться за более чем десяток лет своего существования, но может Fluent повезёт больше…

bm13kk
22.04.2019 15:39Честно говоря не понял чем оно лучше symfony подхода symfony.com/doc/current/translation.html
Более того, симфони богаче тем что можно использовать диапазоны чисел.
mayorovp
22.04.2019 15:49Там в сообщении можно использовать согласование только с одним числительным. Плюс сам выбор между trans и transChoise почему-то должен делать программист, а не переводчик.

valery1707
22.04.2019 15:57transChoiseуже признан устаревшим с версии4.2.
Но программист должен передавать количество параметром вtrans.mayorovp
22.04.2019 16:01А документацию-то ещё не поправили...
Да и новая реализация не радует: если я правильно ее понял, то числительное с которым будет согласование, обязано называться
%count%. А это тоже должен переводчик решать.
bm13kk
22.04.2019 19:331 Как ответили ниже уже смержили методы.
2 Это хорошо что только одно перечисление. Как программист я хочу разбивать целое на куски. Вместо того чтобы городить лапшку из нескольких кусков и многомерную матрицу всех вариантов.
3 Более детально про разбиение. Это плохо напимано именно в той странице что я сослался. Но в симфони в переводе можно кроме переменных использовать другие переводы.
```
%user_link% has send you %message_link%
```
Где %user_link% и %message_link% другие ключи к переводу. Или другие микро твиг файлы, или макросы.mayorovp
22.04.2019 19:57+1Это хорошо что только одно перечисление. Как программист я хочу разбивать целое на куски. Вместо того чтобы городить лапшку из нескольких кусков и многомерную матрицу всех вариантов.
Как программисту, вам вообще не надо этим заниматься.
Разбиение текста на куски неспециалистом может привести к тому, что отдельные куски станут непереводимы. Или они будут переводимы, но будут идти в неправильном порядке.
Кстати, обратная проблема тоже существует. Так, на stackoverflow фраза "about", как выяснилось, имеет три разных перевода...
bm13kk
22.04.2019 20:26> Как программисту, вам вообще не надо этим заниматься.
Это невозможно. Как минимум надо передать переменные в систему перевода.
Обратное (только программист переводит) так же невозможно. Поэтому вся система эффективна только при условии совместной работы.
То есть я за развитие переводов — как отдельной ветки разработки с отдельными тулами и сервисами. Есть гораздо больше проблем, чем мы обсудили. Например, имя — может быть ссылкой, и код вылезет внутрь системы переводов. Поэтому выход файрфокса в эту сферу я только приветствую.
Другое дело что в конкретно этом примере был забыт многолетний програмисткий опыт костылей. Вместо того, чтобы городить новое «самое лучшее решение» нужны стандарты и АПИ для обьединение старых тулов и новых подходов.mayorovp
22.04.2019 21:32+1Это невозможно. Как минимум надо передать переменные в систему перевода.
Ну так передайте их. Переменные и id сообщения. И на этом ответственность программиста заканчивается — в этом и вся прелесть предложенного решения.
bm13kk
23.04.2019 13:15Возьмем пример выше.
Программит американец делает сайт и сообщение «Dana posted 5 photos». Для американца надо передать 2 переменные — имя и количество фоток. Он закрывает и забывает.
Спустя время подтягивается русская локализация. И тут хоп — не хватает данных. Надо еще передать пол Даны. И опять создается тикет. И итерация разработки.
А потом приходит японская локализация — и надо уже возраст передать…
Ну не заканчивается ответственность программиста. Ни одна система интернализации не учитывает всех ньансов. Их все надо допиливать в процессе. Причем именно в процесса. Заранее проанализировать почти невозможно.mayorovp
23.04.2019 13:38А теперь сравниваем предложенный подход и классический.
Предложенный.
Переводчик на русский: нам нужен пол пользователя.
Программист: ок.
Переводчик на японский: а нам нужен ещё и возраст.
Программист: ок.
Классический.
Переводчик на русский: нам нужен пол пользователя.
Программист: ок.
Переводчик на русский: нет, нам нужен choice по полу пользователя.
Программист: но выбор уже занят количеством.
Переводчик на русский: придумай что-нибудь, пол реально нужен.
Программист: ну хорошо, сделаю три разных сообщения.
Переводчик на японский: а мне нужен возраст.
Программист: да вы издеваетесь! Это мне что, мега-матрицу придётся делать?
Переводчик на японский: но возраст-то нужен.
Программист: ну ладно, уговорили…
Переводчик на русский: эй, почему слетел перевод? Почему столько новых дубликатов у уже переведенных строк?

wtigga Автор
23.04.2019 04:14+1Когда программист сам разбивает на куски, начинается ужас. Ладно, если сейчас в UI только пять языков романской группы. А когда там их 18, то программист не в состоянии предусмотреть все возможные проблемы.
В этом и прелесть: если нет ресурсов/специалистов, переводим «в лоб». Если есть спец на конкретную локаль — у него полная свобода действий в оптимизации строки под нужды его языка, не нужно лишний раз дёргать разработчика.bm13kk
23.04.2019 13:28Я там выше написал, что даже с узким специалистом все равно будет моменты обратной связи и технической доработки.

vyo
22.04.2019 16:32По сравнению с классическим gettext некоторые преимущества вроде и есть, но до совершенства пока далеко. Если честно, мне всё-таки полюбилось встраивание сообщений а не их id в текст.
mayorovp
22.04.2019 16:39+1А переводчики Stack Overflow от встраивания сообщений в текст программы — плюются: после любого мелкого исправления английского текста фразу надо переводить заново.
GCU
23.04.2019 14:54По-хорошему переводить её заново всё равно придётся, просто старый перевод может висеть довольно долго (и не всегда это правильно). Мелкие правки неплохо закрывает fuzzy, ну и можно держать английские тексты как перевод (en.po) и править мелочи там, не трогая код.
mayorovp
23.04.2019 14:57Что хорошего в том, чтобы переводить фразу заново при изменении опечатки в оригинале или новомодной замены his на them? Русской перевод от этого не меняется.
GCU
23.04.2019 15:52Увы, тот факт что русский перевод не меняется — совершенно не означает что переводы на другие языки тоже меняться не будут — особенно в случае новомодной замены his на them. Точно так же никто не гарантирует того, что опечатка никак не повлияла на переводы.
mayorovp
23.04.2019 16:17Заменить his на them переводчики на другие языки могут и независимо от английского перевода. С опечатками — то же самое.
GCU
23.04.2019 17:07Вопрос ответственности.
Могут как заменить, так и не заменить — это вполне в компетенции переводчиков. Я категорически против того, чтобы эту ответственность забирать у переводчиков — менять текст и решать, что переводчикам об этом знать не обязательно(ведь русский перевод же не изменится).
Фактически разработчик меняя текст берёт на себя ответственность за использование старых переводов, а в его ли это компетенции?mayorovp
23.04.2019 17:13Вот именно, это в компетенции переводчиков. Так зачем же принудительно заставлять обновлять перевод?
GCU
23.04.2019 17:34Не понимаю, откуда взялось «принудительно заставлять обновлять»?
1 Я писал про fuzzy, которым можно «закрыть» изменения старым переводом
2 Потом этот fuzzy всё равно переводчики будут смотреть, и возможно даже что-то переведут
3 Скрывать любые пусть даже мелкие правки от переводчиков нет смысла
mayorovp
22.04.2019 19:58Вот, вспомнил ещё последствия классического подхода gettext: на stackoverflow фраза "about", как выяснилось, имеет три разных перевода. Без доработок со стороны программистов её нормально перевести было невозможно.
GCU
23.04.2019 15:14В gettext есть msgctx, в чём проблема то была?
Доработки со стороны программистов всё равно останутся, передавать переводчикам контекст всё равно придётся, число, пол и т.д.mayorovp
23.04.2019 15:21+1Проблема в том, что потребовалось несколько итераций исправления перевода чтобы понять, почему вдруг пункт «О сайте» появился на странице профиля участника и что делает кнопка «Об участнике» на странице метки.
GCU
23.04.2019 16:13Что это «последствия классического подхода gettext» на мой взгляд неудачная формулировка (gettext имеет стандартное решение этой проблемы), так как и в Fluent это точно так-же решается передачей различного контекста (id или параметра). Да, если его уже передавали — то в Fluent это решится лишь переводом, а если нет — последствия аналогичны.
mayorovp
23.04.2019 16:19Дело тут не в способах решения, а в самом подходе. При gettext-подходе сообщения переводятся как есть, и только при обнаружении конфликтов им проставляются контексты.
В предложенном подходе заменившие контексты идентификаторы назначаются всем сообщениям изначально.GCU
23.04.2019 17:21На практике конфликты достаточно редки и повторное использование вполне оправдано, при генерации в .po файле можно перечислить все файлы с указанием строк, где msgid использовался и это помогает определить — допустимо ли повторное использование или нужно разделить по контексту.
Автоматически раздавая всем вхождениям уникальный контекст получаем 100500 «OK» и «Cancel» на перевод и перевод каждого нового «OK» оплачивается отдельно :)wtigga Автор
23.04.2019 17:23Автоматически раздавая всем вхождениям уникальный контекст получаем 100500 «OK» и «Cancel» на перевод и перевод каждого нового «OK» оплачивается отдельно :)
Эм, нормальные перводчики/агентства используют для повторов другую ставку при определённом совпадении (вплоть до 0-20% при 100% match).GCU
23.04.2019 17:44Я про них и писал :), но не всегда можно получить нулевую ставку.
Кроме того бесплатный 100% match как правило означает что на контекст переводчик тупо забивает, что и было изначальной проблемой.
GCU
23.04.2019 15:46gettext хорошо решает задачу сбора строк в перевод по исходному коду проекта, изменение, добавление, удаление. Fluent же вообще к этим задачам не относится, поэтому их нельзя сравнивать целиком.
Как формат Fluent гораздо мощнее .po
P.S. В .po даже есть msgid_plural, но его не называли «Концепцией асимметричной локализации — ключевой инновацией»

express
Определенно им нужно сменить рукописный шрифт в логотипе.