
Мне всегда было интересно, как устроен Хабр изнутри, как построен workflow, как выстроены коммуникации, какие применяются стандарты и как тут вообще пишут код. К счастью, такая возможность у меня появилась, ведь недавно я стал частью хабракоманды. На примере небольшого рефакторинга мобильной версии попробую ответить на вопрос: каково это — работать тут фронтом. В программе: Node, Vue, Vuex и SSR под соусом из заметок о личном опыте в Хабре.
Первое, что нужно знать о команде разработки — нас мало. Мало — это три фронта, два бэка и техлид всея Хабра — Баксли. Есть, конечно, ещё тестировщик, дизайнер, три Вадима, чудо-веник, маркетологиня и прочие Бумбурумы. Но непосредственных контрибьюторов в сорцы Хабра всего шесть. Такое встречается довольно редко — проект с многомиллионной аудиторией, который снаружи выглядит как гигантский энтерпрайз, на деле больше похож на уютный стартап с максимально плоской организационной структурой.
Как и многие другие IT-компании, Хабр исповедует идеи Agile, практику CI и вот это вот всё. Но по моим ощущениям, Хабр как продукт развивается скорее волнообразно, чем непрерывно. Так несколько спринтов подряд мы усердно что-то кодим, проектируем и перепроектируем, ломаем что-то и чиним, резолвим тикеты и заводим новые, наступаем на грабли и стреляем себе в ноги, чтобы наконец релизнуть фичу в прод. А затем наступает некоторое затишье, период перепланировки, время делать то, что находится в квадранте «важно-несрочно».
Как раз о таком «межсезонном» спринте и пойдет речь ниже. На этот раз в него попал рефакторинг мобильной версии Хабра. На нее вообще в компании возлагают большие надежды, и в перспективе она должна заменить собой весь зоопарк инкарнаций Хабра и стать универсальным кроссплатформенным решением. Когда-нибудь тут появится и адаптивная верстка, и PWA, и оффлайн-режим, и пользовательская кастомизация, и много чего интересного.
Ставим задачу
Как-то раз на рядовом стендапе, один из фронтов рассказал о проблемах в архитектуре компонента комментариев мобильной версии. С этой подачи мы организовали микро-совещание в формате групповой психотерапии. Каждый по очереди говорил, где у него болит, всё фиксировали на бумаге, сочувствовали, понимали, разве что никто не хлопал. На выходе получился список из 20 проблем, который ясно давал понять, что мобильный Хабр должен проделать еще долгий и тернистый путь к успеху.
Меня беспокоила прежде всего эффективность использования ресурсов и то, что называется smooth interface. Каждый день на маршруте «дом-работа-дом» я видел как мой старенький телефон отчаянно пытается отобразить 20 заголовков в ленте. Выглядело это примерно так:

Что здесь происходит? Если кратко, то сервер отдавал HTML страницу всем одинаково, вне зависимости залогинен пользователь или нет. Затем загружается клиентский JS и заново запрашивает необходимые данные, но уже с поправкой на авторизацию. То есть фактически мы делали одну и ту же работу дважды. Интерфейс мерцал, а пользователь загружал добрую сотню лишних килобайт. В подробностях все выглядело еще более жутко.
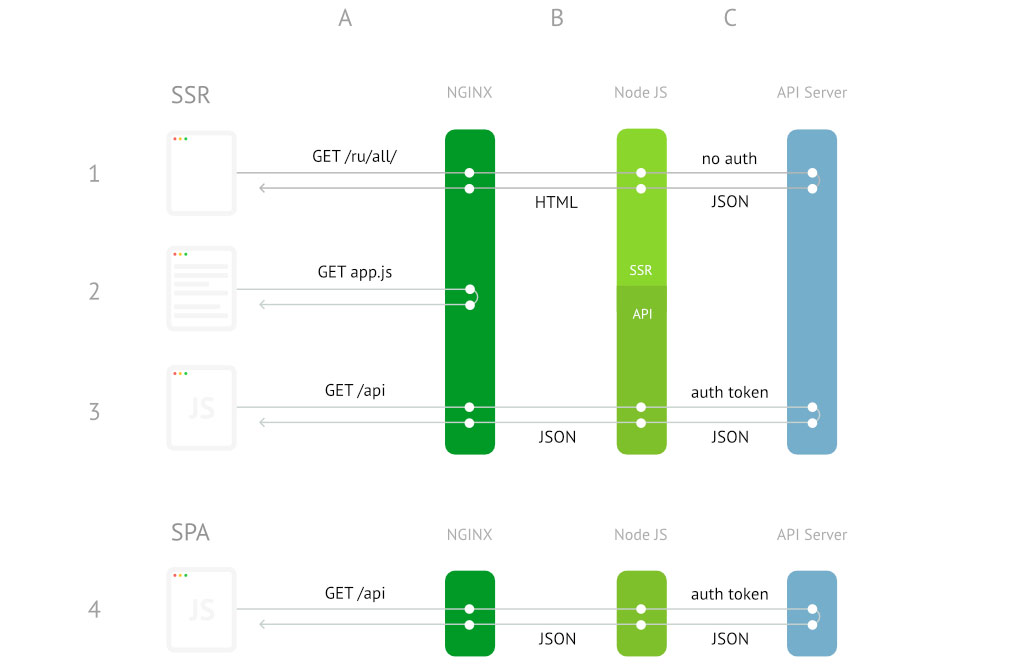
Нашу архитектуру того времени очень точно описал один из пользователей Хабра:
Мобильная версия — дерьмо. Говорю как есть. Ужасное сочетание SSR вместе с CSR.
Мы вынуждены были это признать, как бы печально это ни было.
Я прикинул варианты, поставил себе тикет в «Джире» с описанием на уровне «сейчас плохо, сделай норм» и широким мазками декомпозировал задачу:
- переиспользовать данные,
- минимизировать количество перерисовок,
- исключить дубли запросов,
- сделать процесс загрузки более очевидным.
Переиспользуем данные
В теории server-side rendering призван решить две задачи: не страдать от ограничений поисковых систем по части индексирования SPA и улучшить метрику FMP (неизбежно ухудшив TTI). В классическом сценарии, который окончательно сформулировали в Airbnb в 2013 году (еще на Backbone.js), SSR — это то же самое изоморфное JS-приложение, запущенное в среде Node. Сервер просто отдает в качестве ответа на запрос сгенерированную верстку. Затем происходит регидрация на стороне клиента, и дальше все работает без перезагрузок страницы. Для Хабра, как и для многих других ресурсов с текстовым наполнением, серверный рендеринг — критически важный элемент построения дружественных отношений с поисковиками.
Несмотря на то, что с момента появления технологии прошло уже более шести лет, и за это время в мире фронтэнда утекло действительно много воды, для многих разработчиков эта идея все еще покрыта завесой тайны. Мы не остались в стороне, и выкатили в прод Vue-приложение с поддержкой SSR, упустив одну маленькую деталь: мы не прокинули initial state на клиент.
Почему? Точного ответа на этот вопрос нет. То ли не хотели увеличивать размер ответа от сервера, то ли из-за букета других архитектурных проблем, то ли просто не взлетело. Так или иначе прокинуть state и переиспользовать все, что делал сервер, кажется вполне целесообразным и полезным делом. Задача на самом деле тривиальная — state просто инжектится в контекст выполнения, и Vue автоматически добавляет его к сгенерированной верстке в качестве глобальной переменной:
window.__INITIAL_STATE__. Одна из возникших проблем — невозможность преобразовать в JSON цикличные структуры (circular reference); решалось простой заменой таких структур на их плоские аналоги.
Кроме того, имея дело с UGC-контентом следует помнить, что данные следует преобразовывать в HTML-entities, для того, чтобы не сломать HTML. Для этих целей мы используем he.
Минимизируем перерисовки
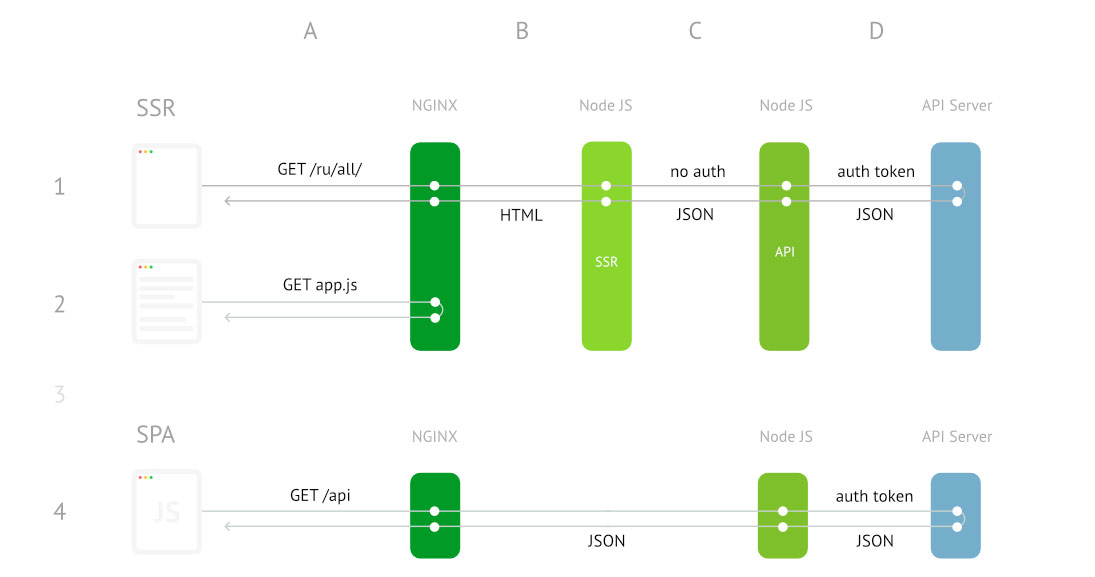
Как видно из схемы выше, в нашем случае один инстанс Node JS выполняет две функции: SSR и «прокси» в API, где как раз происходит авторизация пользователя. Это обстоятельство делает невозможным авторизацию в момент исполнения JS-кода на сервере, так как нода однопоточная, а функция SSR синхронная. То есть сервер просто не может отправлять запросы сам на себя, пока коллстэк чем-то занят. Получилось так, что state мы прокинули, но интерфейс не переставал дергаться, так как данные на клиенте следовало обновить с учетом пользовательской сессии. Нужно было научить наше приложение класть в initial state правильные данные с учетом логина пользователя.
Решений проблемы нашлось всего два:
- цеплять авторизационные данные к межсерверным запросам;
- разбить слои Node JS в два отдельных инстанса.
Первое решение требовало использовать глобальные переменные на сервере, а второе растягивало сроки реализации задачи как минимум на месяц.
Как сделать выбор? Хабр часто двигается по пути наименьшего сопротивления. Неформально здесь существует некое общее стремление сокращать до минимума цикл от идеи до прототипа. Модель отношения к продукту чем-то напоминает постулаты booking.com, с той лишь разницей, что Хабр куда более серьезно относится к пользовательскому фидбеку и доверяет принятие подобных решений тебе как разработчику.
Следуя этой логике и своему собственному желанию побыстрее решить проблему, я выбрал глобальные переменные. И, как это часто случается, за них рано или поздно приходится платить. Мы заплатили почти сразу: поработали в выходные, разгребли последствия, написали post mortem и начали делить сервер на две части. Ошибка была очень глупой, а баг с ее участием воспроизводился непросто. И да, за такое стыдно, но так или иначе, спотыкаясь и кряхтя, мой PoC с глобальными переменными все же вышел в продакшн и вполне успешно работает в ожидании переезда на новую «двухнодную» архитектуру. Это был важный шаг, ведь формально цель была достигнута — SSR научился отдавать полностью готовую к использованию страницу, а UI стал намного более спокойным.

В конечном счете архитектура SSR-CSR мобильной версии ведет вот к такой картине:
?
Исключаем дубли запросов
После проделанных манипуляций, первоначальный рендер страницы перестал провоцировать эпилепсию. Но дальнейшее использование Хабра в режиме SPA все ещё вызывало недоумение.
Так как основу user flow составляют переходы вида список статей > статья > комментарии и обратно, важно было оптимизировать расход ресурсов этой цепочки в первую очередь.
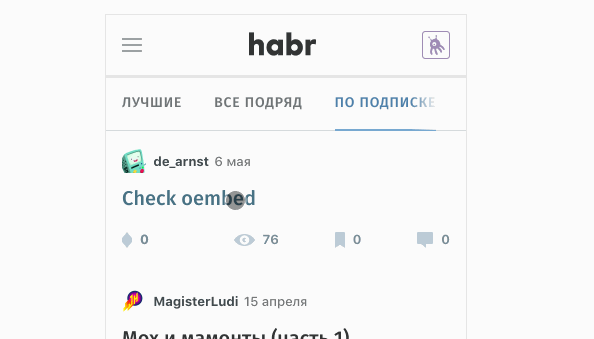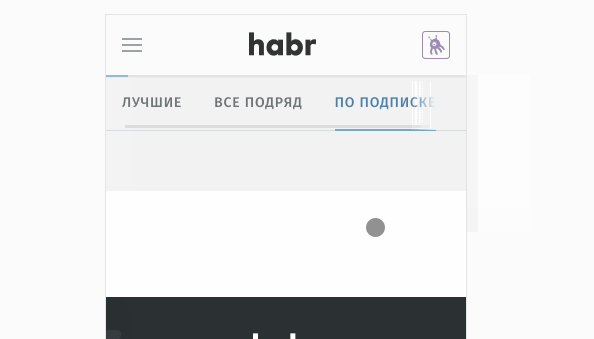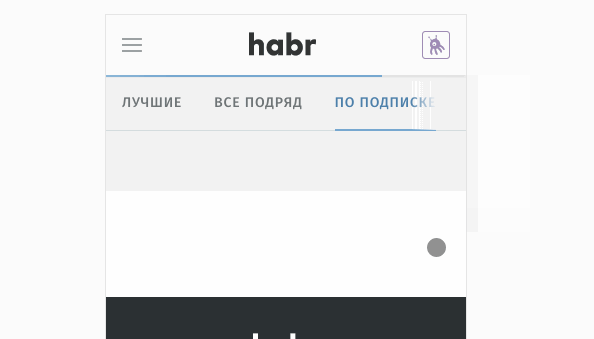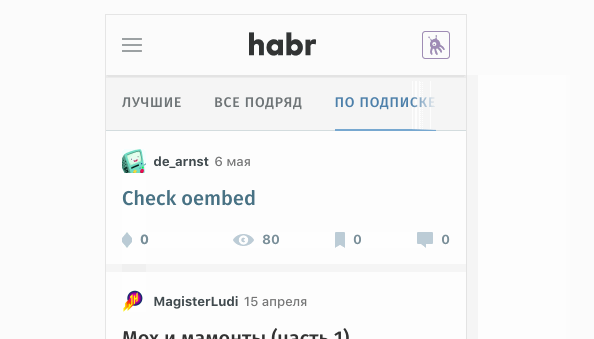
Глубоко копать не пришлось. На скринкасте выше видно, что приложение перезапрашивает список статей при свайпе назад, причём во время запроса мы статьи не видим, значит предыдущие данные куда-то исчезают. Выглядит все так, будто компонент списка статей использует локальный стейт и теряет его на destroy. На самом же деле, приложение использовало глобальный стейт, но архитектура Vuex была построена «в лоб»: модули привязаны к страницам, которые в свою очередь привязаны к роутам. Причем все модули «одноразовые» — каждый следующий заход на страницу переписывал модуль целиком:
ArticlesList: [
{ Article1 },
...
],
PageArticle: { ArticleFull1 },
Итого, у нас был модуль ArticlesList, который содержит в себе объекты типа Article и модуль PageArticle, который являлся расширенной версией объекта Article, cвоего рода ArticleFull. По большому счету, данная реализация ничего ужасного в себе не несет — это очень просто, можно даже сказать наивно, но предельно понятно. Если выпилить обнуление модуля при каждой смене роута, то с этим можно даже жить. Однако переход между лентами статей, к примеру /feed > /all, гарантированно выбросит все, что связано с персональной лентой, так как у нас всего один ArticlesList, в который нужно положить новые данные. Это снова нас приводит к дублированию запросов.
Собрав в кучу все, что удалось раскопать по теме, я сформулировал новую структуру стейта и представил ее коллегам. Обсуждения были продолжительными, но в итоге аргументы «за» перевесили сомнения, и я приступил к реализации.
Логика решения лучше всего раскрывается за два этапа. Сначала мы пытаемся отвязать модуль Vuex от страниц и привязать напрямую к роутам. Да, данных в сторе станет немного больше, геттеры станут чуть сложнее, но мы не будем грузить статьи по два раза. Для мобильной версии, это, пожалуй, самый сильный аргумент. Получится примерно так:
ArticlesList: {
ROUTE_FEED: [
{ Article1 },
...
],
ROUTE_ALL: [
{ Article2 },
...
],
}
Но что если списки статей могут пересекаться между несколькими роутами и что, если мы хотим переиспользовать данные объекта Article для отрисовки страницы поста, превратив его в ArticleFull? В этом случае, более логичным было бы использование такой структуры:
ArticlesIds: {
ROUTE_FEED: [ '1', ... ],
ROUTE_ALL: [ '1', '2', ... ],
},
ArticlesList: {
'1': { Article1 },
'2': { Article2 },
...
}
ArticlesList здесь — это просто некое хранилище статей. Всех статей, которые были загружены в течение пользовательской сессии. Мы относимся к ним максимально бережно, ведь это трафик, который, возможно, был загружен через боль где-нибудь в метро между станциями, и мы совершенно точно не хотим причинить пользователю эту боль снова, заставив его грузить данные, которые он уже загрузил. Объект ArticlesIds является просто массивом айдишников (как бы «ссылок») на объекты Article. Такая структура позволяет не дублировать общие для роутов данные и переиспользовать объект Article при рендере страницы поста посредством мержа в него расширенных данных.
Вывод списка статей стал также более прозрачным: компонент-итератор перебирает массив с айдишниками статей и отрисовывает компонент тизера статьи, передавая Id в качестве пропса, а дочерний компонент в свою очередь достает нужные данные из ArticlesList. При переходе на страницу публикации, мы достаем уже имеющуюся дату из ArticlesList, делаем запрос на получение недостающих данных и просто добавляем их к существующему объекту.
Почему этот подход лучше? Как я писал выше, такой подход бережнее по отношению к загружаемым данным и позволяет переиспользовать их. Но помимо этого он открывает дорогу некоторым новым возможностям, которые отлично вписываются в такую архитектуру. Например, поллинг и подгрузка статей в ленту по мере их появления. Мы можем просто сложить свежие посты в «хранилище» ArticlesList, сохранить отдельный список новых айдишников в ArticlesIds и уведомить пользователя об этом. При нажатии на кнопку «Показать новые публикации», мы просто вставим новые Id в начало массива текущего списка статей и все будет работать почти магическим образом.
Делаем загрузку приятнее
Вишенкой на торте рефакторинга стала концепция скелетонов, которая делает процесс загрузки контента на медленном интернете чуть менее отвратительным. Никаких дискуссий на этот счет не было, путь от идеи до прототипа занял буквально два часа. Дизайн нарисовался практически сам, и мы научили наши компоненты рендерить незатейливые, едва-мерцающие div-блоки во время ожидания данных. Субъективно такой подход к лоадингу действительно уменьшает количество гормонов стресса в организме пользователя. Скелетон выглядит так:
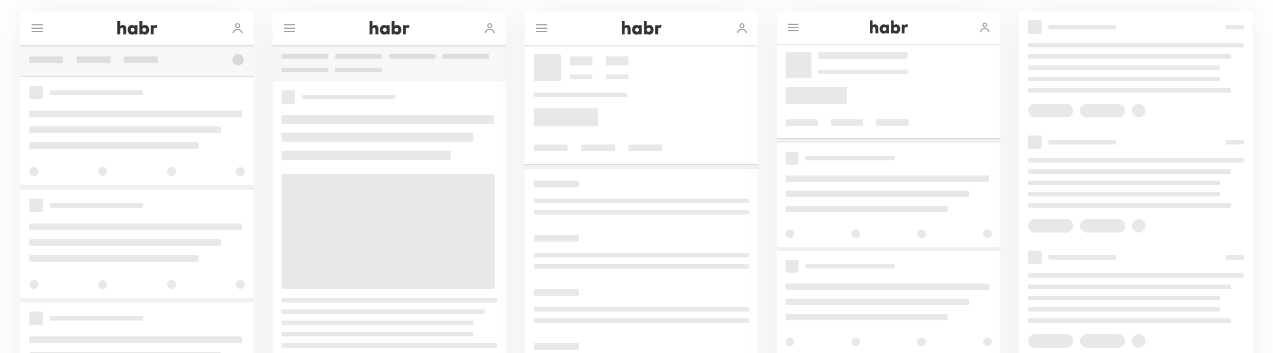
Хабралоадинг
Рефлексируем
Я полгода работаю в Хабре и знакомые по-прежнему спрашивают: ну что, как тебе там? Хорошо, комфортно — да. Но есть кое-что, что отличает эту работу от других. Я работал в командах, которые были абсолютно равнодушны к своему продукту, не знали и не понимали, кто их пользователи. А здесь все по-другому. Тут чувствуешь ответственность за то, что делаешь. В процессе разработки фичи, ты частично становишься ее оунером, принимаешь участие во всех продуктовых встречах, связанных с твоим функционалом, вносишь предложения и сам принимаешь решения. Делать продукт, которым ежедневно пользуешься сам, очень круто, а писать код для людей, которые, возможно, разбираются в этом лучше тебя — просто невероятное ощущение (no sarcasm).
После релиза всех этих изменений мы получили позитивный фидбэк, и это было очень и очень приятно. Это вдохновляет. Спасибо! Пишите еще.
Напомню, что после глобальных переменных мы решились на смену архитектуры и выделение проксирующего слоя в отдельный инстанс. «Двухнодная» архитектура уже добралась до релиза в виде публичного бета-тестирования. Сейчас любой желающий может переключиться на нее и помочь нам сделать мобильный Хабр лучше. На сегодня все. С удовольствием отвечу на все ваши вопросы в комментариях.
Andrew_Pinkerton
Спасибо, всегда было интересно узнавать подробности о том как устроен Хабр, и как он развивается.
inzeppelin подскажите, в чем созданы схемы? Например вот эта:
inzeppelin Автор
Просто нарисованы в графическом редакторе, магии нет, к сожалению.
perfect_genius
Сворачивании веток комментариев даже в плане нет что ли?
AngReload
Они уже писали что это в планах. Но похоже что конкретных сроков нет.
hMartin
а что за модель монитора? какой-то он необычно квадратный и толстый)
baragol
Это, кажется, старенький Apple Cinema
Boomburum
Да, 24" Apple Cinema :) Хотя в остальном в офисе доминируют Делл-ы.
illo
Ты ошибся, это 30 дюймовая Apple Cinema ))
Boomburum
Точно, 30. 24 у меня дома такая же )
OtshelnikFm
«24 у меня дома» — уже))
nemilya
Мобильный хабр на Vue — это круто. Изучаю понемногу его, было бы интересно услышать про опыт использования vuejs
inzeppelin Автор
Принято. Будем стараться писать больше технических деталей.
newday
не рассматривали Nuxt.js?
inzeppelin Автор
Серверная архитектура проектировалась довольно давно. Наверное в те времена Nuxt не выглядел достаточно убедительно, а может были и другие причины. В любом случае, сейчас ничего такого не планируем. Если у вас есть опыт переезда Express > Nuxt, расскажите, пожалуйста. Очень интересно будет почитать.
newday
опыта переезда нет, но там все достаточно просто, и ваши вопросы с initial state и дублированием запросов там решены из коробки.
АПИ реализуется (переносится в вашем случае) через механизм server middleware, остальное (сам рендеринг и логика фронта) посредством маппинга файловой структуры SFC в vue-router, так же привязывается vuex.
Впрочем все это хорошо задокументировано и снабжено множеством примеров
skymal4ik
Релизы приложения выходят очень редко, по крайней мере в Apple Store. Не знаете, с чем связан такой цикл выпуска?
Мне, как пользователю было бы приятнее немного чаще получать апдейты с исправлением багов (привет, Twitter syndication) и новыми функциями (сворачивание веток, возможность просмотра статьи во время написания комментария и т.д.).
В любом случае спасибо за отличное и лёгкое приложение, по пути на работу с утра постоянно читаю.
Boomburum
Мобильное приложение, к сожалению, больше не поддерживается.
PavelBelyaev
У меня 50 Мегабит и смартфон вроде свежий гэлэкси с8, достаточно мощный. Но хабр этот скелетон показывает секунды 3-4 при пагинации, в бета, в старой версии было раз в 20 быстрее отрисовка, без всяких анимаций в стиле — сейчас я эти квадратики заменю на текст...
inzeppelin Автор
Вы имеете в виду, что медленная бета, которая доступна сейчас для тестирования? Или в 20 раз быстрее было пол года назад?
PavelBelyaev
Да, бетка, в мобильном браузере, но отключил бету и тоже самое.
Просто всеобщая тенденция такая, недавно заметил с компа что и на сайте dns-shop и в интернет-банке тинькофф, если раньше за доли секунды на обычном html+css отрисовывалось, глазом не заметить, то сейчас оно примерно так же быстро грузится, но первоначально отрисовывается с пустыми квадратиками, а потом по таймауту что-ли через 2-3 секунды эти квадратики заполняются данными. Это издержки реактивных интерфейсов или такая анимация заложена разработчиками, чтобы было красиво?
inzeppelin Автор
Квадратики рисуем, чтобы чем-то развлечь пользователя в момент ожидания данных с сервера. Специально для красоты конечно их не показываем.
В остальном, вы правы, реактивные интерфейсы содержат чаще всего много логики. За это нужно платить. Но мы только в начале пути. Уверен, все стабилизируется, и мы найдём правильный баланс между функциональностью и производительностью.
mSnus
Все это заставляет грустить о старом добром AJAX+jQuery. Все равно тут нет каких-то #самостоятельных# компонентов типа отдельного окна чата, самообновляющейся ленты новостей и так далее. Раньше возврат к ленте новостей прекрасно кешировался бы броузером, а комментарии не менее прекрасно подгружались бы прямо под статьей по мере надобности, при этом нижние бы грузились, пока пользователь ещё читает верхние…
А сейчас, середине 2019го, показать статический текст и подгрузить комментарии под ним — проблема! Как-то это не укладывается в голове. Я понимаю, когда новые задачи требуют новых решений, но когда надо просто отобразить немного текста ...
inzeppelin Автор
Все так. Я с вами согласен. Некоторые даже говорят, мол, «пора валить из фронтенда», но мы пока держимся, настроены оптимистично, верим в законы диалектики и здравый смысл.
В качестве развлечения, хочу вам предложить вот такой «привет» из 2008-го :)
Construct
Я не совсем понял из статьи, а зачем запросы к API проходят через Node, а не идут напрямую к API-серверу?
inzeppelin Автор
Основная функция API Node — авторизация запросов пользователей