Ну что. Разберём «лопнул ли пузырь», «как дальше жить» и поговорим откуда вообще такая загогулина.
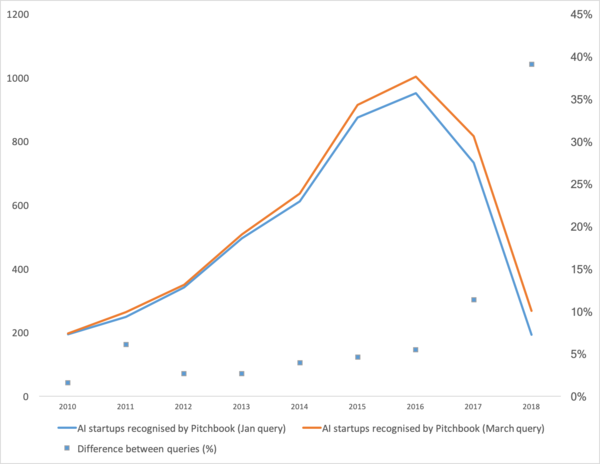
Для начала поговорим что было бустером этой кривой. Откуда она взялась. Наверное всё вспомнят победу машинного обучения в 2012 году на конкурсе ImageNet. Ведь это первое глобальное событие! Но в реальности это не так. Да и рост кривой начинается несколько раньше. Я бы разбил его на несколько моментов.
- 2008 год это появление термина “большие данные”. Реальные продукты начали появляться с 2010 года. Большие данные прямо связаны с машинным обучением. Без больших данных невозможна стабильная работа алгоритмов, которые существовали на тот момент. И это не нейронные сети. До 2012 года нейронные сети — это удел маргинального меньшинства. Зато тогда начали работать совершенно другие алгоритмы, которые существовали уже годы, а то и десятилетия: SVM(1963,1993 годы), Random Forest (1995), AdaBoost (2003),… Стартапы тех годов в первую очередь связаны с автоматической обработкой структурированных данных: кассы, пользователи, реклама, многое другое.
Производная этой первой волны — набор фреймворков, таких как XGBoost, CatBoost, LightGBM, и.т.д.
- В 2011-2012 году свёрточные нейронные сети выиграли ряд конкурсов по распознаванию изображений. Реальное их использование несколько затянулось. Я бы сказал что массово осмысленные стартапы и решения начали появляться с 2014 года. Два года понадобилось чтобы переварить что нейронки всё-таки работают, сделать удобные фреймворки которые можно было поставить и запустить за разумное время, разработать методы которые бы стабилизировали и ускорили время схождения.
Свёрточные сети позволили решать задачи машинного зрения: классификация изображений и объектов на изображении, детектирование объектов, распознавание объектов и людей, улучшение изображений, и.т.д., и.т.п. - 2015-2017 годы. Бум алгоритмов и проектов завязанных на рекуррентные сети или их аналоги (LSTM, GRU, TransformerNet и.т.д.). Появились хорошо работающие алгоритмы “речь-в-текст”, системы машинного перевода. Частично они основаны на свёрточных сетях для выделения базовых фич. Частично на том что научились собирать реально большие и хорошие датасеты.
“Пузырь лопнул? Хайп перегрет? Они умерли как блокчейн?”
А то ж! Завтра в вашем телефоне перестанет работать Сири, а послезавтра Тесла не отличит поворот от кенгуру.
Нейронные сети уже работают. Они в десятках устройств. Они реально позволяют зарабатывать, изменяют рынок и окружающий мир. Хайп выглядит несколько иначе:
Просто нейронные сети перестали быть чем-то новым. Да, у многих людей есть завышенные ожидания. Но большое число компаний научилось применять у себя нейронки и делать продукты на их основе. Нейронки дают новый функционал, позволяют сократить рабочие места, снизить цену услуг:
- Производственные компании интегрируют алгоритмы для анализа брака на конвейере.
- Животноводческие хозяйства покупают системы для контроля коров.
- Автоматические комбайны.
- Автоматизированные Call-центры.
- Фильтры в SnapChat. (
ну хоть что-то дельное!)
Но главное, и не самое очевидное: “Новых идей больше нет, или они не принесут мгновенного капитала”. Нейронные сети решили десятки проблем. И решат ещё больше. Все очевидные идеи которые были — породили множество стартапов. Но всё что было на поверхности — уже собрали. За последние два года я не встречал ни одной новой идеи для применения нейронных сетей. Ни одного нового подхода (ну, ок, там немного с GAN-ами есть заморочек).
А каждый следующий стартап всё сложнее и сложнее. Он требует уже не двух парней которые обучают нейронку на открытых данных. Он требует программистов, сервера, команду разметчиков, сложную поддержку, и.т.д.
Как результат — стартапов становится меньше. А вот продакшна больше. Нужно приделать распознавание автомобильных номеров? На рынке сотни специалистов с релевантным опытом. Можно нанять и за пару месяцев ваш сотрудник сделает систему. Или купить готовую. Но делать новый стартап?.. Безумие!
Нужно сделать систему трекинга посетителей — зачем платить за кучу лицензий, когда можно за 3-4 месяца сделать свою, заточить её для своего бизнеса.
Сейчас нейронные сети проходят тот же путь который прошли десятки других технологий.
Помните как менялось с 1995 года понятие «разработчик сайтов»? Пока рынок не насыщен специалистами. Профессионалов очень мало. Но я могу поспорить, что через 5-10 лет не будет особой разницы между программистом Java и разработчиком нейронных сетей. И тех и тех специалистов будет достаточно на рынке.
Просто будет класс задач под который решается нейронками. Возникла задача — нанимаете специалиста.
“А что дальше? Где обещанный искусственный интеллект?”
А вот тут есть небольшая, но интересная непонятчка:)
Тот стек технологий, который есть сегодня, судя по всему, нас к искусственному интеллекту всё же не приведёт. Идеи, их новизна — во многом исчерпали себя. Давайте поговорим о том что держит текущий уровень развития.
Ограничения
Начнём с авто-беспилотников. Вроде как понятно, что сделать полностью автономные автомобили при сегодняшних технологиях — возможно. Но через сколько лет это случится — не понятно. Tesla считает что это произойдет через пару лет —
Есть много других специалистов, которые оценивают это как 5-10 лет.
Скорее всего, на мой взгляд, лет через 15 инфраструктура городов уже сама изменится так, что появление автономных автомобилей станет неизбежным, станет её продолжением. Но ведь это нельзя считать интеллектом. Современная Тесла — это очень сложный конвейер по фильтрации данных, их поиску и переобучению. Это правила-правила-правила, сбор данных и фильтры над ними (вот тут я чуть подробнее про это написал, либо смотреть с этой отметки).
Первая проблема
И именно тут мы видим первую фундаментальную проблему. Большие данные. Это именно то, что породило текущую волну нейронных сетей и машинного обучения. Сейчас, чтобы сделать что-то сложное и автоматическое нужно много данных. Не просто много, а очень-очень много. Нужны автоматизированные алгоритмы их сбора, разметки, использования. Хотим сделать чтобы машина видела грузовики против солнца — надо сначала собрать достаточное их число. Хотим чтобы машина не сходила с ума от велосипеда прикрученного к багажнику — больше семплов.
Причём одного примера не хватит. Сотни? Тысячи?

Вторая проблема
Вторая проблема — визуализация того что наша нейронная сеть поняла. Это очень нетривиальная задача. До сих пор мало кто понимает как это визуализировать. Вот эти статьи весьма свежие, это всего лишь несколько примеров, пусть даже отдалённых:
Визуализация зацикленности на текстурах. Хорошо показывает, на чём нейронка склонна зацикливаться + что она воспринимает как отправную информацию.

Визуализация аттеншна при переводах. Реально аттеншн часто можно использовать именно для того чтобы показать что вызвало такую реакцию сети. Я встречал такие штуки и для дебага и для продуктовых решений. На эту тему очень много статей. Но чем сложнее данные, тем сложнее понять как добиться устойчивой визуализации.

Ну и да, старый добрый набор из «посмотри что у сетки внутри в фильтрах». Эти картинки были популярны года 3-4 назад, но все быстро поняли, что картинки то красивые, да смысла в них не много.

Я не назвал десятки других примочек, способов, хаков, исследований о том как отобразить внутренности сети. Работают ли эти инструменты? Помогают ли они быстро понять в чём проблема и отладить сеть?.. Вытащить последние проценты? Ну, примерно вот так же:

Можете посмотреть любой конкурс на Kaggle. И описание того как народ финальные решения делает. Мы настакали 100-500-800 мульёнов моделек и оно заработало!
Я, конечно, утрирую. Но быстрых и прямых ответов эти подходы не дают.
Обладая достаточным опытом, потыкав разные варианты можно выдать вердикт о том почему ваша система приняла такое решение. Но поправить поведение системы будет сложно. Поставить костыль, передвинуть порог, добавить датасет, взять другую backend-сеть.
Третья проблема
Третья фундаментальная проблема — сетки учат не логику, а статистику. Статистически это лицо:

Логически — не очень похоже. Нейронные сети не учат что-то сложное, если их не заставляют. Они всегда учат максимально простые признаки. Есть глаза, нос, голова? Значит это лицо! Либо приводи пример где глаза не будут означать лицо. И опять — миллионы примеров.
There's Plenty of Room at the Bottom
Я бы сказал, что именно эти три глобальных проблемы на сегодняшний день и ограничивают развитие нейронных сетей и машинного обучения. А то где эти проблемы не ограничивали — уже активно используется.
Это конец? Нейронные сети встали?
Неизвестно. Но, конечно, все надеются, что нет.
Есть много подходов и направлений к решению тех фундаментальных проблем которые я осветил выше. Но пока ни один из этих подходов не позволил сделать что-то фундаментально новое, решить что-то, что до сих пор не решалось. Пока что все фундаментальные проекты делаются на основе стабильных подходов (Tesla), или остаются тестовыми проектами институтов или корпораций (Google Brain, OpenAI).
Если говорить грубо, то основное направление — создание некоторого высокоуровневого представления входных данных. В каком-то смысле “памяти”. Самый простой пример памяти — это различные “Embedding” — представления изображений. Ну, например, все системы распознавания лиц. Сеть учится получить из лица некоторое стабильное представление которое не зависит от поворота, освещения, разрешения. По сути сеть минимизирует метрику “разные лица — далеко” и “одинаковые — близко”.

Для такого обучения нужны десятки и сотни тысяч примеров. Зато результат несёт некоторые зачатки “One-shot Learning”. Теперь нам не нужно сотни лиц чтобы запомнить человека. Всего лишь одно лицо, и всё — мы узнаём!
Только вот проблемка… Сетка может выучить только достаточно простые объекты. При попытке различать не лица, а, например, “людей по одежде” (задача Re-indentification) — качество проваливается на много порядков. И сеть уже не может выучить достаточно очевидные смены ракурсов.
Да и учиться на миллионах примеров — тоже как-то так себе развлечение.
Есть работы по значительному уменьшению выборов. Например, сходу можно вспомнить одну из первых работ по OneShot Learning от гугла:
Таких работ много, например 1 или 2 или 3.
Минус один — обычно обучение неплохо работает на каких-то простых, “MNIST’овских примерах”. А при переходе к сложным задачам — нужна большая база, модель объектов, или какая-то магия.
Вообще работы по One-Shot обучению — это очень интересная тема. Много идей находишь. Но большей частью те две проблемы что я перечислил (предобучение на огромном датасете / нестабильность на сложных данных) — очень мешают обучению.
С другой стороны к теме Embedding подходят GAN — генеративно состязательные сети. Вы наверняка читали на Хабре кучу статей на эту тему. (1, 2,3)
Особенностью GAN является формирование некоторого внутреннего пространства состояний (по сути того же Embedding), которое позволяет нарисовать изображение. Это могут быть лица, могут быть действия.
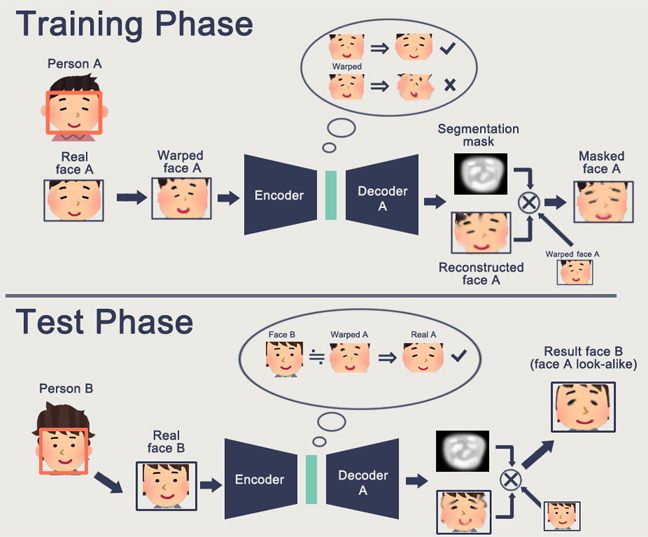
Проблема GAN — чем сложнее генерируемый объект, тем сложнее описывать его в логике “генератор-дискриминатор”. В результате из реальных применений GAN, которые на слуху -только DeepFake, который опять же, манипулирует с представлениями лиц (для которых существует огромная база).
Других полезных применений я встречал очень мало. Обычно какие-то свистелки-перделки с дорисовыванием картинок.
И опять же. Ни у кого нет понимания как это позволит нам двинуться в светлое будущее. Представление логики/пространства в нейронной сети — это хорошо. Но нужно огромное число примеров, нам непонятно как нейронка в себе это представляет, нам непонятно как заставить нейронку запомнить какое-то реально сложное представление.
Reinforcement learning — это заход совсем с другой стороны. Наверняка вы помните как Google обыграл всех в Go. Недавние победы в Starcraft и в Dota. Но тут всё далеко не так радужно и перспективно. Лучше всего про RL и его сложности рассказывает эта статья.
Если кратко просуммировать что писал автор:
- Модели из коробки не подходят/работают в большинстве случаев плохо
- Практические задачи проще решить другими способами. Boston Dynamics не использует RL из-за его сложности/непредсказуемости/сложности вычислений
- Чтобы RL заработал — нужна сложная функция. Зачастую её сложно создать/написать
- Сложно обучать модели. Приходится тратить кучу времени чтобы раскачать и вывести из локальных оптимумов
- Как следствие — сложно повторить модель, неустойчивость модели при малейших изменениях
- Часто оверфитится на какие-нибудь левые закономерности, вплоть до генератора случайных чисел
Ключевой момент — RL пока что не работает в продакшне. У гугла есть какие-то эксперименты ( 1, 2 ). Но я не видел ни одной продуктовой системы.
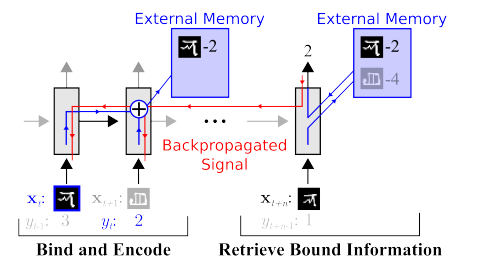
Memory. Минус всего того что описано выше — неструктурированность. Один из подходов как всё это пытаются прибрать — предоставить нейронной сети доступ к отдельной памяти. Чтобы она могла записывать и перезаписывать там результаты своих шагов. Тогда нейронная сеть может определяться текущим состоянием памяти. Это очень похоже на классические процессоры и компьютеры.
Самая известная и популярная статья — от DeepMind:
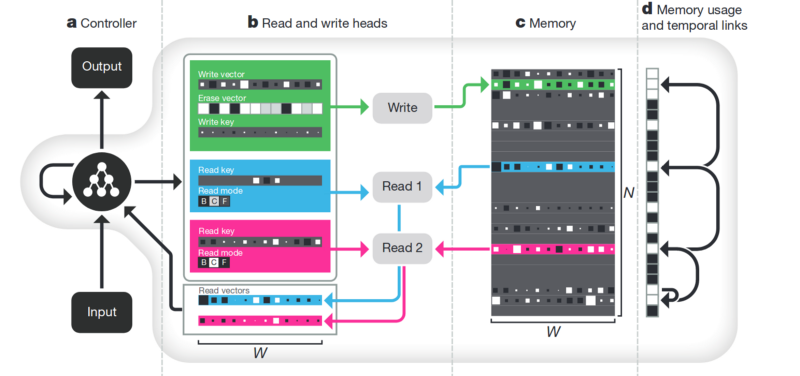
Кажется что вот он, ключ к пониманию интеллекта? Но скорее нет. Системе всё равно требуется огромный массив данных для тренировки. А работает она в основном со структурированными табличными данными. При этом когда Facebook решал аналогичную проблему, то они пошли по пути “нафиг память, просто сделаем нейронку посложнее, да примеров побольше — и она сама обучится”.
Disentanglement. Другой способ создать значимую память — это взять те же самые эмбединги, но при обучении ввести дополнительные критерии, которые бы позволили выделять в них “смыслы”. Например мы хотим обучить нейронную сеть различать поведение человека в магазине. Если бы мы шли по стандартному пути — мы должны были бы сделать десяток сетей. Одна ищет человека, вторая определяет что он делает, третья его возраст, четвертая — пол. Отдельная логика смотрит часть магазина где он делает/обучается на это. Третья определяет его траекторию, и.т.д.
Или, если бы было бесконечно много данных, то можно было бы обучить одну сеть на всевозможные исходы (очевидно, что такой массив данных набрать нельзя).
Дизэнтелгмент подход говорит нам — а давайте обучать сеть так чтобы она сама смогла различать понятия. Чтобы она по видео сформировала эмбединг, где одна область определяла бы действие, одна — позицию на полу во времени, одна — рост человека, а ещё одна — его пол. При этом при обучении хотелось бы почти не подсказывать сети такие ключевые понятия, а чтобы она сама выделяла и группировала области. Таких статей достаточно мало (некоторые из них 1, 2, 3) и в целом они достаточно теоретические.
Но данное направление, по крайней мере теоретически, должно закрывать перечисленные в начале проблемы.
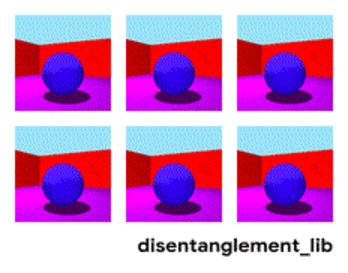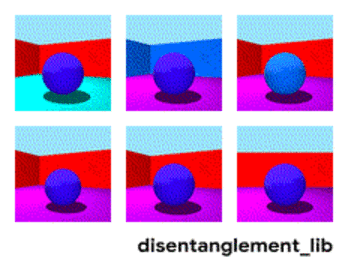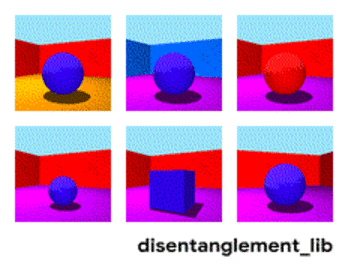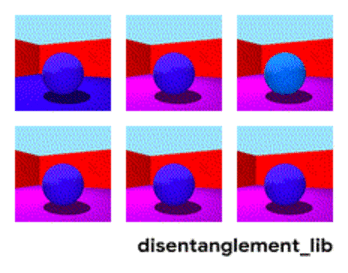
Разложение изображения по параметрам “цвет стен/цвет пола/форма объекта/цвет объекта/и.т.д.”

Разложение лица по параметрам “размер, брови, ориентация, цвет кожи, и.т.д.”
Прочее
Есть много других не столько глобальных направлений, которые позволяют как-то уменьшать базы, работать с более разнородными данными, и.т.д.
Attention. Наверное, не имеет смысла выделять это как отдельный метод. Просто подход, усиливающий другие. Ему посвящено много статей (1,2,3). Смысл Attention в том, чтобы усилить у сети реакцию именно на значимые объекты при обучении. Зачастую каким-нибудь внешним целеуказанием, или небольшой внешней сетью.
3Д-симуляция. Если сделать хороший 3д движок, то им зачастую можно закрыть 90% обучающих данных (я даже видел пример когда почти 99% данных закрывалось хорошим движком). Есть много идей и хаков как заставить сеть обученную на 3д движке работать по реальным данным (Fine tuning, style transfer, и.т.д.). Но зачастую сделать хороший движок — на несколько порядков сложнее чем набрать данные. Примеры когда делали движки:
Обучение роботов (google, braingarden)
Обучение распознавания товаров в магазине (но в двух проектах которые делали мы — мы спокойно обходились без этого).
Обучение в Tesla (опять же то видео что было выше).
Выводы
Вся статья это в каком-то смысле выводы. Наверное, основной посыл который я хотел сделать — «халява кончилась, нейронки не дают больше простых решений». Теперь надо вкалывать строя сложные решения. Или вкалывать делая сложные научные ресёрчи.
А вообще тема дискутабельная. Может у читателей есть более интересные примеры?
Комментарии (271)

prostofilya
14.06.2019 06:07А есть пример нейронной сети, которая решает 2 разные задачи без переобучения?

BlackMokona
14.06.2019 11:32"
Однако Google разработала систему, которая способна качественно решать восемь задач одновременно. Многозадачную систему машинного обучения назвали MultiModel. Она научилась распознавать объекты на изображениях, вставлять субтитры, распознавать речь, переводить между четырьмя парами языков с соблюдением правил грамматики и синтаксиса — и она делает всё это одновременно!"x67
14.06.2019 14:55Звучит как квадрокоптерный чайник с вайфаем. Но с другой стороны, возможно в этом и есть ключ к созданию ИИ, мы ведь и есть самообучаемые квадрокоптерные чайники с вайфаем
worldaround
14.06.2019 22:35+1Звучит так, что без переобучения новую задачу она не решит
alexeykuzmin0
15.06.2019 00:51Человек тоже без переобучения новую задачу не решит
IvanTamerlan
15.06.2019 11:12Моя мысль такова, что нейросети при переобучении с одного набора данных обычно обучаются сразу на двух наборах данных с откатом в режим «детства» с максимальным значением для корректировки весов, чтобы и старое не забыли, и новое получили. Постепенное снижение амплитуры изменений весов приводит нейросети к зрелости и неспособности обучаться дальше.
У человека нету режима «зрелости», при которой он теряет возможность в принципе обучаться. Так и нету бага в виде при обучении чему-то новому забывать полностью всю предыдущую жизнь.
Вот этот режим с постоянной возможностью дообучить нейронку без потери предшествующих знаний и является самым сложным элементом на пути к мифическому «сильному» ИИ.
Буду рад, если найдутся ссылки на новые исследования, где нейронные сети уже могут переобучаться без потери памяти, причем с возможностью постепенного обучения на малых объемам, а не прогоном 100 тыс картинок. Без читерства в виде создании новой нейросетки и присоединении ее к текущей. Человек способен всего по нескольким изображениям учиться определять новые предметы.Akon32
17.06.2019 13:41Так и нету бага в виде при обучении чему-то новому забывать полностью всю предыдущую жизнь.
Такой "баг" есть. Пример: программисты достаточно быстро забывают детали прошлого проекта, поэтому хорошим тоном считается документировать API и т.п. По своему опыту знаю, что детали прошлых проектов могут за несколько месяцев забываться почти полностью, если приходится запоминать детали новых.
Без читерства в виде создании новой нейросетки и присоединении ее к текущей.
Это не "читерство", а best practice на данный момент. Если (под)задача имеет алгоритмическое решение, не стоит тратить время на обучение нейросети, т.к. обучение — это долго, дорого и ненадёжно. Нейросети обучают тем (под)задачам, которые сложно решить алгоритмически. Если задача состоит из подзадач, иногда некоторые удобнее решить алгоритмически, некоторые — с помощью нейронных сетей.
Человек способен всего по нескольким изображениям учиться определять новые предметы.
Человеческая нейронная сеть устроена сложнее, чем современные искусственные, и не вполне ясно, каким образом она этому учится. Быть может, мозг тысячи раз проигрывает вариации увиденного изображения, и веса его нейронов подстраиваются в процессе.
IvanTamerlan
17.06.2019 15:26По своему опыту знаю, что детали прошлых проектов могут за несколько месяцев забываться почти полностью, если приходится запоминать детали новых.
Под полным забыванием подразумевалось, что Вы забываете свое имя, место жительства, родителей, школьную программу вплоть до начальных классов, все выученные языки, в том числе родной. Становитесь абсолютно чистым. Либо можете забыть часть из перечисленного, т.е. новые знания взамен старых. Раньше умели различать котиков, дельфинчиков и людей, а теперь научились различать собак, но хуже стали различать котиков, людей еще хуже, а дельфинчиков уже не умеете определять. Также выясняется, что если при обучении не произносить свое имя, то после нескольких дней обучения собственное имя забывается. Приведены аналогии для обычный нейросетей.
Это не «читерство», а best practice на данный момент.
Но если проводить аналогию, то если человек не умеет считать, ему пришивают калькулятор к голове. А для каждой новой подзадачи отращивается еще один мозг — один для того, чтобы уметь готовить, другой чтобы с физикой дружить, третий для балансировки задач и отсылка к Змею Горынычу.
Человеческая нейронная сеть устроена сложнее, чем современные искусственные, и не вполне ясно, каким образом она этому учится. Быть может, мозг тысячи раз проигрывает вариации увиденного изображения, и веса его нейронов подстраиваются в процессе.
Прямой мат.модели мозга еще нет. Но есть неплохие попытки. Оттуда, например, сделал вывод, что заморочек с подстройкой весов и киданием в условия комбинаторного взрыва нет. Мозг может быть устроен проще, чем мы о нем думаем. И даже частоты у мозга небольше — до нескольких сотен герц! Причем состоит из микроколонок, что больше похоже на вычислительные способности видеокарты. И кремниевый чип с 1 ГГц, который на частоте 100 Гц будет эмулировать работу ровно одной микроколонки, на частоте 1 ГГц (1 000 000 000 Гц) сможет эмулировать работу уже 10 млн микроколонок, у каждой частота 100 Гц. Соответственно, специализированные ASIC-чипы с количеством транзисторов как у серверных высокопроизводительных процессоров смогут спокойно эмулировать мозги 500 человек в режиме реального времени даже на нынешней технологической базе! Т.е. кластер с 2 тыс таких чипов вполне может эмулировать небольшой город с населением в 1 млн человек в режиме реального времени, или 2 тыс человек со скорость х1000 (за год в эмуляторе пройдет 10 веков).
Проблема лишь в мат.аппарате для представления мозга. Он пока только развивается.Akon32
17.06.2019 15:53А для каждой новой подзадачи отращивается еще один мозг — один для того, чтобы уметь готовить, другой чтобы с физикой дружить, третий для балансировки задач и отсылка к Змею Горынычу.
Но разве при обучении не отращиваются новые связи нейронов?
Да, собственно, архитектура ИИ может оказаться существенно отличающейся от архитектуры биологического интеллекта. Поэтому не вижу проблемы в создании и уничтожении разнородных блоков под конкретные задачи.
alexeykuzmin0
17.06.2019 16:09Раньше умели различать котиков, дельфинчиков и людей, а теперь научились различать собак, но хуже стали различать котиков, людей еще хуже, а дельфинчиков уже не умеете определять
Ну это вроде у людей примерно так и работает. Многие мои знакомые жаловались, что им сложно различать лица китайцев, а после нескольких месяцев жизни в Китае говорили, что теперь стало сложнее различать лица европейцев
DesertFlow
17.06.2019 17:45Под полным забыванием подразумевалось, что Вы забываете свое имя, место жительства, родителей, школьную программу
Для таких вещей в долговременной памяти в мозге, судя по всему, формируются отдельные кластеры нейронов. «Нейроны бабушки», условно говоря. У мозга есть десятки нейромедиаторов, чтобы эти места больше не трогать и хранить их всю жизнь. Эти места потом очень сложно заменить. Один из самых эффективных способов лечение различных фобий как раз и заключается в том, чтобы путем постепенной подсадки новых воспоминаний заменить старые болезненные. Почти что классическое переучивание нейросети.
В искусственных нейросетях нет этого механизма защиты нужных воспоминаний, поэтому переучиваются сразу все. И это проблема. Один из путей достигнуть lifelong learning как раз в том, чтобы при каждом новом обучении сигнал шел по новым путям, не трогая сформировавшиеся долговременные воспоминания. Но тут есть проблема по каким критериям выбирать эти пути (они ведь должны частично пересекаться), да и емкость сети резко падает, что при текущих вычислительных возможностях не айс.red75prim
17.06.2019 19:11Я месяца три назад обнаружил, что у меня слово "имбирь" потерялось. Вспоминать название приходилось до 10 минут. Недавно занялся этим всерьёз — за несколько часов получилось восстановить. В этом случае похоже были повреждены какие-то связи с кластером, кодирующим эту последовательность звуков.
Хм. Судя по https://en.wikipedia.org/wiki/Anomic_aphasia и https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2936270/, такой тип афазии действительно связан с повреждениями в белом веществе мозга. И, исходя из незначительности повреждения, понятно, почему его не увидели на МРТ.

buriy
18.06.2019 12:34Вот только вы в чиселках где-то на 6-7 порядков ошиблись.
Сейчас, с точность до порядка величины, одним чипом на 1 ггц из 1 млрд процессоров пока тысячи нейронов только могут (см. truenorth, spinnaker).
1) У тысячи нейронов миллион связей, в одной микроколонке — десятки миллионов связей (причём, между двумя нейронами может быть несколько связей, кстати — штук 5-10). Вы же хотите за 1 такт работы процессора сделать 10 млн операций взятия по произвольному индексу и суммирований, а потом ещё столько же расчётов обратных взаимодействий. Количество АЛУ в современных видеокартах — единицы тысяч. Потому что на каждую операцию с float16 нужны тысячи транзисторов. Тут минимум три порядка величины вы потеряли.
2) Вам нужно где-то хранить 10^14 байт информации об этих связях. Вот тут самая большая ловушка. Вычисления последовательно на одном чипе выполнять вы можете, а вот данных столько запихать в один чип не получается. Вам нужно 10к флешек по 10 тб.
3) Вроде бы сотня герц, да, но разница в 1 мс имеет значение для определения степени изменения связи нейроном, так что более точная модель должна работать уже на 1 кГц, а не на 100 Гц.
Получается, даже если максимально упрощать, нужно по 10к процессоров на человека, а у вас как-то 0.002 получилось.
alexeykuzmin0
17.06.2019 16:07У человека нету режима «зрелости»
У reinforcement learning тоже нету, в любой момент можно не снижать фактор обучения и учиться дальше. Не нейросетями едиными.Так и нету бага в виде при обучении чему-то новому забывать полностью всю предыдущую жизнь.
Детали забываются, а полностью и нейросеть не забывает.Буду рад, если найдутся ссылки на новые исследования, где нейронные сети уже могут переобучаться без потери памяти, причем с возможностью постепенного обучения на малых объемам, а не прогоном 100 тыс картинок
Ссылок под рукой нет, но насколько я знаю, типичный подход для работы в области распознавания изображений следующий:
1. Берем сеть, которая хорошо умеет решать какую-то схожую задачу (например, ImageNet).
2. Обучаем ее на наших данных — обычно этих данных сильно меньше, чем ImageNet (например, HBO при реализации приложения NotHotdog использовала всего 3000 изображений хотдогов).
3. Система хорошо работает на нашей задаче. При этом качество на оригинальной задаче (распознавание 20000+ классов изображений) падает, но далеко не всегда оно падает значительно.
Ну а добавить один объект или один батч объектов и сделать итерацию обучения все нейросети умеют by design.Человек способен всего по нескольким изображениям учиться определять новые предметы
В направлении one shot learning тоже есть прогресс. Например, в статье Santoro A. et al. One-shot learning with memory-augmented neural networks //arXiv preprint arXiv:1605.06065. – 2016 решалась задача распознавания символов ранее неизвестного алфавита. Удалось достичь сверхчеловеческой точности, при этом сеть, которая видела 2 изображения, распознавала лучше, чем человек, видевший 5, а сеть, которая видела 4 — лучше, чем человек, который видел 10.
Вы правы насчет того, что пока что во многих областях one shot learning не показывает сверхчеловеческих результатов, но все же где-то он уже их показывает, и год от года таких областей становится больше. Ну и в случае человека все же не совсем честно считать одно изображение за одно — от глаза идет не одна картинка, а видеопоток, и человек by design видит каждый объект обучающей выборки под разными углами и с разными искажениями.
worldaround
15.06.2019 16:59Человек сам себя обучает и сам даже себе ставит задачи, поэтому он сам может решать новые задачи без специального ручного дообучения извне
alexeykuzmin0
17.06.2019 16:12Это у машинного обучения не баг, а фича. Сделать систему, которая сама выберет себе задачу, обучится на нее и будет решать (успешно или нет — зависит от задачи) — элементарно: берем нейросеть, добавляем к ней скачивание данных и рандомизатор. Только вот зачем? Обычно все же требуется система, решающая конкретную задачу, а не какую сама захочет.
x67
15.06.2019 05:37вы про overfitting? Из чего следует ваше утверждение?
Я не изучал эту тему, но на первый взгляд тут совсем не обязательно модель будет переобучаться. Более того, это зависит от ее внутренней структуры.
Если вы про «забудьте то, чему вас учили в школе, институте, армии, на работе и… учитесь снова» то тоже не очевидно, так как опять же, зависит от внутренней структуры. Это может быть как «маркетинговая» модель, которая по сути состоит из классификатора задачи по входным данным и собственно моделей, которые эти задачи решают. Или же это может быть модель с однородной (относительно предыдущего примера) структурой, реализующая мультизадачность каким-то другим образом.alexeykuzmin0
17.06.2019 16:14вы про overfitting?
Судя по дальнейшему обсуждению в той ветке, имелось в виду transfer learning

boyng
14.06.2019 21:27-1на самом деле осталось только сделать «области» сопряжения таких аналитических блоков, при чём эти области так же будут подчинятся весовым распределениям для нахождения пути к нужному функциональному блоку и можно уже будет городить более-менее полноценный примитивный «типа мозг», подключая «раздражители\регуляторы весов». т.е. дальше уже как конструктор лего, видится как что то вроде нейропластичности мозга.
Может лет через 20 как поднакопят блоки нейро-сетевых шаблонов и создадут интерфейс для нейронной связи для интеграции с био-нейронами, тогда и начнётся полноценный сдвиг к сингулярности с огромными возможностями, снимающие биологические ограничения. Ещё конечно вопрос организации связей\шин, хранении регуляции весов в плане компактности очень массивных структур. А то может статься, что обычные синапсы и РНК более компактны и эффективны в этом плане, но это так… хмельные ) рассуждения без полноценных фундаментальных знаний в этой области.
Может, через сотку лет как обкатают действующие девайсы и можно уже будет полностью замещать «пробелы» в «реакциях на раздражители» готовыми «обученными» блоками с навыками\знаниями.
На самом деле давно уже было предчувствие, что так оно и будет, т.к. общее принципиальное понимание механизма уже есть, остальное дело времени и развития технологий.
P.S. эх, всегда была мысль… «родиться бы лет хотя бы через 100», а так не факт что моё мясо доживёт до перехода.jorgen_steinbach
15.06.2019 23:32Шутка на тему сингулярности:
"тогда и начнётся полноценный сдвиг к сингулярности с огромными возможностями, снимающие биологические ограничения для просмотра еще большего количества порно и котиков".

Coderanger
14.06.2019 07:29Автор, ML — очередная «тема» чтобы «заработать доллар» в всевдо-культурном и псевдо-просвещённом капиталистическом обществе, а Big Data — это не технология, а скорее «масштаб задачи». На сегодня это всё.
JekaMas
14.06.2019 10:24+1Угу. DB — это просто база, с ней не возникает сложностей, когда она растет по много гигабайт в день.
Нагрузка — это просто нагрузка. Работа с кодом для 10 rps и 60000 rps — это просто масштаб. Highload — миф.
Лечение порезанной и отрубленной ног тоже не отличается. Это просто глубина пореза.

mikeee1
14.06.2019 08:03-1Слишком много слов про нейронки, когда в подавляющем числе реальных задач они работают плохо.
AndreyGaskov
14.06.2019 08:29+2Это же инструмент. Микроскоп, например, тоже в подавляющем числе реальных задач работает плохо. Ни шуруп завернуть, ни гвоздь забить, ни картошку на сковороде помешать. Так и нейронные сети, в некоторых реальных задачах они значительно упрощают ситуацию и позволяют добиться значительно лучшего результата, чем без них. И есть надежда, что таких реальных решаемых задач будет больше.
shanlove
14.06.2019 08:50-2Есть надежда, что микроскопом-таки можно будет забивать гвозди?

MaxVetrov
14.06.2019 09:25
Am0ralist
14.06.2019 09:45Эх, не умеете вы гвозди забиватьWinPooh73
14.06.2019 11:11"Когда у тебя в руках микроскоп, все проблемы вокруг начинают казаться гвоздями".

aslepov78
14.06.2019 18:11-1>Это же инструмент. Микроскоп, например
какой банальный и заезженый пример. Ну сравните сколько студентов в наше время микроскоп использует, и сколько подались в нейронщики. Нейрономания выела мозг, туда уже никогда не залезит ни статистика ни тервер,… понятно, там же думать надо. а тут бац бац, скрестил ужа с ежом и вроде чета там работает.

roryorangepants
14.06.2019 10:35В статье упоминаются в основном примеры работы с неструктурированными данными (картинки, тексты и т.п.), а с ними как раз в подавляющем числе реальных задач только нейросети и работают хорошо.
soniq
14.06.2019 19:41Только проблема в том, что этих неструктурированных данных нужно так много, что в них начинает проявляться статистически значимая структура.
samhuawey
14.06.2019 11:05Они не работают плохо, просто аналитически проверить результат их работы невозможно уже в ситуации 3х слоёв и 3х нейронов в каждом слое. Там нет чёткого математического аппарата, всё на уровне предположений и утверждений типа если в жизни так, то и в теории тоже так. И большая часть соревнований в каггле так и выигрывают — вот эта конфигурация работает плохо, а что будет если добавим вот это. Строгих алгоритмов нет и не предвидится, в основном нечёткая логика и бросание костей.

iandarken
14.06.2019 08:44Помнится, в журнале «Игромания» много-много лет назад читал про хардварный самообучающийся ML для игры в крестики-нолики на основе спичечных коробков и бусин.
Ничего с тех пор не изменилось, только масштаб.rombell
14.06.2019 08:50Описан был в цикле «Берсеркер» Саберхагена Without a Thought, а до него ещё много где. Возможно, у Гарднера читал первый раз.
red75prim
14.06.2019 10:09По-моему, чего-то не хватает.
"Доказательство1" и отсюда следует, что каждой архитектуре нейросети можно поставить в соответствие функционально эквивалентный набор ящиков с бусинами.
"Рассуждение2", и это дает основания предполагать, что набор ящиков с бусинами не может служить для построения искусственного интеллекта общего назначения.
Вот доказательства1 и рассуждения2 не хватает.

worldmind
14.06.2019 09:40+1Я понял примено так — есть класс задач в которых нужно в большом массиве данных найти то, поиск чего нельзя запрограммировать формальным алгоритмом, причём есть относительно простая процедура проверки что найдённое это то что нужно.
Например, надо нам лицо преступника найти на видео с камер всего города, если найдём, то проверить можно вплоть до снятия отпечатков и анализов ДНК. Или поиск веществ с нужными свойствами, например лекарств.
Вот такой класс задач отлично подходит для использования нейронных сетей, в остальных случаях вопрос открыт.
superstarstas306
14.06.2019 09:51ИМХО, проблем в матчасти и прикладных задач еще овердофига в этой области. Просто улеглась волна хайпа, которую оседлали псевдостартапы. Далее дело пойдет за талантливыми ml-инженеграми, а стартапы будут формироваться не для распознавания хотдогов, а для чего-нибудь посерьзней.
Max-812
14.06.2019 10:35Основная беда, imho, в том, что программирование нелинейной логики противоречит самой природе программирования. :) Все обучение и работа сетей строится по сути на сравнении чего-то на входе с тем, что они уже видели. Что само по себе тупиковый путь, imho. Ибо всегда есть риск нарваться на что-то, что сеть еще не видела. И ее выводы будут неверными.
Ну и еще момент, касающийся автоматизации вообще, безотносительно именно сетей. Чем больше берет на себя компьютер, тем больше расслабляется человек. И начинает косячить ТАК, как без компьютерной помощи не накосячил бы никогда. :(phenik
14.06.2019 11:10Что само по себе тупиковый путь, imho. Ибо всегда есть риск нарваться на что-то, что сеть еще не видела.
Думаете у человека не так? Аборигены, кот. никогда не видели кораблей европейцев никак не воспринимали их, пока с них не спускали лодки с людьми, кот. они уже могли распознать по своим пирогам, и соответственно реагировать. Есть разные виды когнитивной слепоты, можно здесь почитать, весьма занимательно.MaxVetrov
14.06.2019 11:30Так же как появление черного лебедя.
Вообще существует целая куча когнитивных искажений.
agat000
14.06.2019 11:51Про аборигенов, я уверен, это байка.
Если в привычном окружении появляется неведомая долбаная фигня — любой нормальный человек наоборот будет таращиться на неё во все глаза. И любое животное тоже. Это в инстинктах.
И обозначить в привычные понятия, если непонятно истинная природа явления.
Плавает — значит лодка, большая — значит великаны приплыли, или боги. А так, чтобы в упор не видеть — нужно быть совсем деревянным.Aguinore
14.06.2019 13:04-1orly? www.youtube.com/watch?v=Ahg6qcgoay4 проверь себя на неведомой долбанной фигне

Zoolander
15.06.2019 12:14этот эффект слепоты проявляется при сосредоточении на отдельной детали
чтобы доказать вашу точку зрения — нужно такое же видео с кораблями — а затем сказать, как именно такое видео могло быть воспроизведено в эпоху открытия Америки?
нетрудно заметить, что обезьяна и другие фигуры одинаковы по размерам, а сосредоточение на процессе перекидывания мяча делает все остальное фоном.
На чем могли сосредоточиться индейцы, чтобы не замечать корабли?
Что это были за фигуры, которые могли замаскировать корабли европейцев?Am0ralist
15.06.2019 12:39И если не сосредотачиваться на мяче, то проблем с обезьяной никаких не возникает даже при первом просмотре. А чтоб сосредоточиться — это надо получить прям вводную какую-то жесткую — типа обязан рассказать кто кому мяч перекидывал.
В противном случае смотришь на эту обезьяну и не понимаешь, какого фига она там делает.
red75prim
15.06.2019 13:24нетрудно заметить, что обезьяна и другие фигуры одинаковы по размерам, а сосредоточение на процессе перекидывания мяча делает все остальное фоном.
Да. Если неожиданный объект сильно выделяется, то его замечает где-то 70% людей. https://journals.sagepub.com/doi/pdf/10.1111/1467-9280.00303
phenik
14.06.2019 13:59Если в привычном окружении появляется неведомая долбаная фигня — любой нормальный человек наоборот будет таращиться на неё во все глаза. И любое животное тоже. Это в инстинктах.
Вы правы лишь отчасти. То что вы описываете называется ориентировочным рефлексом, и он возникает на изменения в обстановке, на новое, особенно, если она меняется быстро. И так с ними и было бы, если корабль материализовался среди бухты неожиданно, из неоткуда) Но те корабли перемещались медленно, медленно появлялись на горизонте, медленно приближались. Фиг знает, может это сорванное ураганом большое дерево плывет, или еще что. Угрозы не видно, изменение слабое, и рефлекс особенно не возбухает. Этот прием используют хищники, когда медленно подкрадываются к добыче, они не только маскируются, но и то что их выдает изменяется слабо, поэтому рефлекс также не срабатывает. Но с аборигенами другое дело, они в принципе не могли классифицировать этот объект, и соответственно как к нему относится, т.к. в их семантической сети просто отсутствовал такой узел, связывающий смыслы. Отсюда и возникала невидимость.red75prim
14.06.2019 14:38+1Информация о "невидимости", надо полагать, из судового журнала экспедиции Кука?
These people seemed to be totally engaged in what they were about: the ship passed within a quarter of a mile of them and yet they scarce lifted their eyes from their employment; [...] She often looked at the ship but expressed neither surprise nor concern. Soon after this she lighted a fire, and the four canoes came in from fishing; [...] to all appearances totally unmoved at us, though we were within a little more than half a mile of them.
"Эти люди были полностью поглощены тем, чем они занимались: корабль прошёл в четверти мили от них, но они почти не смотрели в нашу сторону; [...] Она часто смотрела на корабль, но не выразила ни удивления, ни беспокойства. Вскоре после этого она разожгла огонь и с рыбалки вернулись четыре каноэ. [...] [Все эти люди] не выказывали никаких эмоций по отношению к нам, хотя мы находились немногим дальше полумили от них."
Взято отсюда: https://www.reddit.com/r/AskHistorians/comments/3lh0kz/is_it_true_that_when_the_indians_saw_ships_for/
Так что видели, но, похоже, не знали как относиться. Коренные жители Австралии, вообще, довольно своеобразны. В Америке ничего похожего не было.
MaxVetrov
14.06.2019 14:51It's a bogus claim; the psuedoscience documentary «What the bleep do we know?» popularized it in recent years.
Тот же источник.)
agat000
14.06.2019 21:04+3они в принципе не могли классифицировать этот объект, и соответственно как к нему относится, т.к. в их семантической сети просто отсутствовал такой узел, связывающий смыслы.
Не смогли классифицировать большую лодку?
Хорошо, пусть корабль не похож на лодку, пусть он вообще не похож ни на что привычное.
Когда вы играете первый раз в игру, и встречаете первый раз незнакомого монстра, вы тут же его как то для себя обозначаете, правда? Например «Красная хрень с ушами» или «чупакабра с огнеметом». Создаете образ — пусть очень неполный, но он есть как отдельный файл, обозначеный названием и внешними атрибутами. Потом уже, по ходу изучения, это файл пополняется характеристиками.
Наш мозг параноидален по отношению к неизвестному. И игнорировать НДФ в принципе не может, скорее наоборот.
Я не психолог, но в «невидимые корабли» не верю абсолютно. Тем более, что легенда основана на единственном случае.phenik
15.06.2019 06:01Когда вы играете первый раз в игру, и встречаете первый раз незнакомого монстра, вы тут же его как то для себя обозначаете, правда?
Что такое исторический подход?Вы исходите из здравого смысла, и даете на первый взгляд очевидный ответ. Он энергетически выгодный, так поступает подавляющее большинство людей. И это нормально! Потому как проанализировать ситуацию требует намного большего затрата энергии и времени. Но самый простой ответ, не самый точный, не смотря на бритву Оккама) Когда вы обращаетесь к прошлому очень важно соблюдать принцип историзма. Что это значит? Одно из двух, либо вы анализируете прошлые события исходя из современных представлений, но отдаете себе отчет в этом, либо забываете про современный уровень, и пытаетесь исходить из представлений только той эпохи. Это трудно, и не всегда достижимо из-за отсутствия информации. Если вы смешиваете эти два подхода, т.е. распространяете современные представление на прошлое, то получается то, что в науке называется альтернативщиной. Яркий пример всевозможные альтернативные трактовки истории исходя из современных представлений, типа того, что пирамиды нельзя построить с помощью примитивных технологий, и поэтому без инопланетян, богов и тд тут не обошлось. Так же историзм предполагает рассмотрение событий и явлений в развитии, условно, от более простого к более сложному.michael_vostrikov
15.06.2019 14:40В ней практически полностью отсутствуют представления о технологиях, технике. Возможно они и плавательных средств не видели в некоторых случаях.
"с рыбалки вернулись четыре каноэ"
Не исключено, что они воспринимали корабли, как некоторые естественные объекты, хотя и замысловатой формы.
Не исключено, но маловероятно. Более вероятные причины:
— У них другие дела есть, чем пялиться на непонятные лодки в километре от них, еду надо добыть и приготовить.
— Люди устали от тяжелой жизни, и им совсем неитересно кто там приплыл, пусть вождь разбирается.
— Наверное это приплыли из соседнего племени, как на прошлой неделе, смотри-ка какие лодки придумали, но все равно это дело вождя с ними разговаривать.
Или вот представьте обычную воинскую часть. Солдаты работают в соответствии с приказаниями на текущий день, кто в ангаре машины обслуживает, кто траву косит, кто ветки убирает. И тут прилетает дирижабль, или пусть даже НЛО. Вы думаете, все солдаты бросят работу и побегут смотреть?
tvr
15.06.2019 15:28И тут прилетает дирижабль, или пусть даже НЛО. Вы думаете, все солдаты бросят работу и побегут смотреть?
Может и не все, но большая часть точно. И не только из-за дирижабля или НЛО, а из-за почти любого повода отвлечься от тупой и почти бессмысленной деятельности.*
*Основано на личном опыте службы в СА.michael_vostrikov
15.06.2019 15:39А кто им разрешил покидать рабочее место? Офицер сказал "Продолжаем работу, я сам проверю", и всё. Можно ли из этого сделать вывод, что у них и вообще у всех людей слабая семантическая сеть смыслов?
red75prim
15.06.2019 15:43Средний IQ у коренных жителей Австралии около 60. С таким уровнем IQ обычно связаны трудности с адаптацией к новым условиям и обстоятельствам. Возможно им было проще не обращать внимание.

Kirhgoff
15.06.2019 19:40А где вы почерпнули эту информацию про 60? И кстати одна из нападок на IQ тесты говорит о том, что тест совсем не оценивает такие аспекты человеческого интеллекта, как креативность (что напрямую обеспечивает приспособляемость). Вот тут много написано en.wikipedia.org/wiki/Intelligence_quotient#Criticism_and_views
red75prim
15.06.2019 21:36
According to the IQ map of the world given by Lynn (2006, front matter), the East Asians (Chinese, Japanese and Koreans) obtained the highest mean IQ at 105, followed by Europeans (100), [...] Australian Aborigines (62), and Kalahari Bushmen and Congo Pygmies (IQ 56).
MaxVetrov
16.06.2019 00:03Австралийские аборигены, возможно, соображают в чем-то другом.)
Какие вопросы задавались тоже имеют значение.

NetBUG
16.06.2019 15:19Проблема любых тестов в том, что они сильно перекошены в сторону оценки умения проходить именно эти тесты.
Насколько я помню, IQ — это тест на соответствие американской системе образования, т.е. человек, получивший высокий результат этого теста, будет успешен в американской школе/университете. Не намного более того.red75prim
16.06.2019 15:56+1Способность решать задачи независимо от того насколько они куда-то перекошены, вроде бы неплохо описывает интеллект общего назначения.
NetBUG
16.06.2019 23:20С одной стороны — да, и поэтому результат теста IQ коррелирует с… Вот хороший вопрос, с чем: с интеллектом (в чём измеряется? Как измерить?), с приспособленностью, с чем-то ещё?
С другой — IQ — тест на время, и объективно человек, который привык решать тесты, решит его на бо?льший балл, чем не привыкший к тестам.
И даже различие в два с лишним раза (60 против 120+) будет однозначным показателем неприспособленности человека прямо сейчас, а не гарантированной низкой оценкой его интеллекта (неспособности научиться, в том числе, пройти тест на заметно более высокий балл).
phenik
16.06.2019 04:30Видимо альтернативщики минусуют комент)
По когнитивной слепоте проводились эксперименты на детях. Исходя из предположения, что мышление детей приближенно напоминает мышление людей на заре цивилизации. Результаты подтверждают ее существование. Вот здесь упоминание, к сожалению не нашел ссылки на оригинал. Есть еще пример — одичавшие дети, они не могут выучить язык, адекватно распознавать культурные артефакты и использовать их. Конечно процессы распознавания, внимания и навыки реагирования тесто связаны между собой. Но все же основа распознавание, и если по какой-либо причине артефакт не распознается, то страдает вся цепочка, или работает не эффективно. Есть прямые исследования на животных и наблюдения за людьми с отклонениями и травмами, у кот. возникала когнитивная слепота разных видов, когда нарушались соотв. структуры мозга.
Понятно также, что чем выше уровень цивилизации, тем шире семантическая сеть смыслов у составляющих ее индивидов, и тем больше вероятность, что они могут найти приближенный смысл ранее неизвестного им артефакта, и соответственно реагировать. В этом, естественно, и состоит пока преимущество интеллекта человека над имеющимися нейросетевыми решениями.michael_vostrikov
16.06.2019 10:02Детям в возрасте до девяти лет показывали трехмерные изображения хорошо знакомых им предметов, например игрушек, а также предметов, которые они никогда не видели, например изображение домны. Большинство детей, участвовавших в эксперименте, просто не видели незнакомые предметы и не могли их описать.
Из этого описания непонятно, что происходило, чтобы сделать именно такой вывод. Может дети не могли описать потому что сложные мысли еще не умеют формулировать. "Трехмерные изображения" видимо подразумевают 2 картинки, в которых непонятно как воспринимать глубину. Почему именно изображения, а не сами предметы? "Не распознается" и "не обращает внимание" это тоже разные вещи, хотя в каких-то ситуациях типа наблюдения издалека они схожи. Если бы корабль выбросило на берег штормом, аборигены бы ходили по берегу и стукались лбами об корабль, или бы все-таки обходили препятствие? В общем, какой-то слабый пруф, не стоит на него полагаться.
phenik
16.06.2019 14:56Может дети не могли описать потому что сложные мысли еще не умеют формулировать.
Чтобы понять, что на картинке изображена домна нужно до этого показать эти изображения, или кино, или в натуре, и объяснить, что это такое. Тогда у ребенка этот образ, и связанная с ним семантика, впишется в общую семантическую сеть смыслов. Он уже будет осмысленно воспринимать этот образ, и соответственно связывать его с другими, моделировать в воображении, и тд. Если этого нет, то он просто проигнорирует это изображение, не выдав никакой осмысленной информации. Учитывая, что у ребенка эта сеть еще не настолько развита, и он сможет сделать некоторые предположения, как это могут сделать взрослые. Т.е., если не было обучения, то образ и не будет распознаваться, он может например быть принят за естественный объект. Вероятно возникнут случайные ассоциации. То же происходило с аборигенами. Вы видимо считает, что они ничего вообще не видят) Свет-то идет. Если вообще не видят, то это другие виды слепоты. Их довольно много, ссылку приводил ранее с того же ресурса. Важно понять, что со взрослением такая слепота исчезает, т.к. в любом случае при предъявлении взрослому человеку картинки или реального объекта, кот. он раньше никогда не видел, он сможет его как-то идентифицировать, хотя-бы приблизительно, а не проигнорировать полностью.MaxVetrov
16.06.2019 16:11Если этого нет, то он просто проигнорирует это изображение, не выдав никакой осмысленной информации.
Ну, у ребенка фантазия более развита. Почему он не может представить эту домну каким-нибудь объектом который впишется в текущую модель мира этого ребенка?
Am0ralist
16.06.2019 16:17Да-да, а что получается, если человеку показывать пятна роршаха!
А по сути вы именно на это ссылаетесь, используя как доказательство слепоты туземцев детей, которые не смогли на картинке пятен роршаха увидеть домну.phenik
16.06.2019 17:11А по сути вы именно на это ссылаетесь, используя как доказательство слепоты туземцев детей, которые не смогли на картинке пятен роршаха увидеть домну.
Если они не знают про домну, они никак не смогут в любых пятнах ее увидеть. Что-нибудь еще да, писал уже про любые ассоциации. Очевидно, чем старше ребенок, тем больше ассоциаций, и более точных.Am0ralist
16.06.2019 18:37Ещё раз, по вашему, если человек увидя пятно роршаха на картинке не смог ничего внятного про него сказать — это доказывает слепоту туземцев относительно кораблей, но отсутствие оной относительно самолетов США?
phenik
17.06.2019 07:15но отсутствие оной относительно самолетов США?
Вы о каких самолетах? Которым потом поклонялись? Кто-то упоминал этот случай. Естественно, первая реакция на неизвестное будет мистическая, для людей находящихся на такой стадии развития. Причем у шаманов в первую очередь, как наиболее продвинутых представителей таких сообществ. Рядовые соплеменники возможно на эти самолеты вообще не обратили внимание в начале. Такое было при посещении Магелланом Огненной земли, когда на их корабли первым обратил внимание шаман.
Am0ralist
17.06.2019 11:04Рядовые соплеменники возможно на эти самолеты вообще не обратили внимание в начале
А возможно вы всё выдумываете ради того, чтоб отстоять свою точку зрения.
Ещё раз: в случае с самолетами была неверная интерпретация, но не слепота. Нет ни повода, ни фактов считать, что заявленная вами слепота — существует.phenik
17.06.2019 14:01возможно вы всё выдумываете
Нет, это есть на самом деле, психологи-когнитивисты исследуют эти явления. Приводил пример исследования на детях, как модельный случай.Ещё раз: в случае с самолетами была неверная интерпретация, но не слепота.
С их точки зрения верная) Они ни сном ни духом про самолеты. Вы видимо альт, и не придерживаетесь принципа историзма в рассмотрении таких вопросах.Am0ralist
17.06.2019 14:56Приводил пример исследования на детях, как модельный случай.
Модельный случай, что человек не знает как описать пятна Роршарха на картинке? Гениально.
А нарисовать они его не просили, ну чтоб «слепоту» доказать.
Они ни сном ни духом про самолеты.
И что, от того, что они не знают название и характеристики объекта — то они его не замечают?
Странно, объекты внизу из хвороста и соломы явно указывают — что и замечают, и могут какое-то подобие изобразить.phenik
18.06.2019 11:28-1что человек не знает как описать пятна Роршарха на картинке?
Это были не пятна, а картинки реальных объектов, судя по описанию здесь (ссылки на ориг. работу нет, мой поиск так же не дал результатов). Но результаты, на мой взгляд, вполне предсказуемые. Только не нужно интерпретировать эту слепоту у детей как, что они ничего не видят. Слепота не зрительная, а когнитивная, т.е. по определению связана с процессом распознания и узнавания.И что, от того, что они не знают название и характеристики объекта — то они его не замечают?
Уже ответил, что замечают. Посмотрите, мой исходный комент в ветке, там написано не воспринимают, а не не видят. Это разные понятия. Второе описывает процесс включая не только распознавание зрительного образа, но и активацию его ассоциативных и семантических связей, т.е. процесс который и является конечной точкой осознания объекта в целом, и контекста, и мотивации, и внимания, и возможных действий, и тд, все в коиплексе. Для человека эта разница существенна. Если распознавание образов имеется у животных, то втрое больше характерно только для человека, как существа разумного и социального, и возникает в результате обучения с использованием языковой коммуникации и культурной традиции. Моментов кот. нет при обучении у животных. В этом смысле, если такого обучения не было, то возникает когнитивная ошибка. Назовите ее как хотите. Закрепилась когнитивная слепота, с уточнением «белая», т.к. есть другие разновидности таких ошибок, напр, связанных с вниманием. Это название по сути верно. Так же, как возникает зрительная слепота, если имеются нарушения в зрительном анализаторе, так же возникает когнитивная слепота, если имеются нарушения в когнитивной системе. Что спасает при таких нарушения, так это некоторая компенсация связанная с ассоциативными связями. В случае с кораблями компенсация была минимальной, никаких особых ассоциаций они не вызвали, в случае с самолетами — связанная с культом.Am0ralist
18.06.2019 11:40+1Это были не пятна, а картинки реальных объектов
То есть вы утверждаете, что реальных объектов в виде пятен Роршарха быть не может?
И кто после этого когнитивную слепоту демонстрирует?
Слепота не зрительная, а когнитивная, т.е. по определению связана с процессом распознания.
Распознавания чего?
Что может распознать человек на картинке с вещью, аналогов которой он никогда не видел.
И как это доказывает наличие такой слепоты в РЕАЛЬНОМ мире, а не при анализе двухмерной картинки?
Ещё раз, детей просили повторить рисунок? Если да и они нарисовали в меру умений что-то схожее, то никакой когнитивной слепоты нет.
В случае с кораблями компенсация была минимальной, никаких особых ассоциаций они не вызвали, в случае с самолетами связанная с культом.
То есть вы утверждаете, что во втором случае папуасы увидели самолеты потому что у них до этого был культ самолетов, а первые не видели кораблей, потому что такого культа не было?
Или таки культ появился потому, что они прекрасно видели самолет и интерпретировали его как-то иначе, чем другие, которые увидели корабль и не придали ему особого значения?
Но всё это доказывается исследованием детей картинками на плоскости, изображающие неизвестные им предметы, то бишь читай пятна Роршаха — неизвестная мозну фигура, в которой оный мозг старательно пытается увидеть сходство с чем либо, ему уже известным?
Мда…
PS. И да, минус в карму никак не служит доказательством ваших слов.
michael_vostrikov
16.06.2019 16:49Если этого нет, то он просто проигнорирует
Почему проигнорирует-то? Невыдача осмысленной информации не означает игнорирование, о чем и речь.
Т.е., если не было обучения, то образ и не будет распознаваться, он может например быть принят за естественный объект.
Так если он принят за естественный объект, значит распознан, внимание ему было уделено. "Проигнорировать полностью" означает идти прямо в него и стукнуться лбом.
Такого даже у животных нет. Видели как собака или кошка исследуют незнакомую вещь? Осторожно подойдут, понюхают, лапой тыкнут, отскакивают при любой неожиданности. Явно обращают внимание, даже несмотря на то, что раньше не видели и не знают как она устроена.
phenik
16.06.2019 17:26Почему проигнорирует-то? Невыдача осмысленной информации не означает игнорирование, о чем и речь.
Речь именно о том, чтобы в домне увидеть домну, а не еще что-то, а в корабле- корабль.«Проигнорировать полностью» означает идти прямо в него и стукнуться лбом.
Нет, аборигены видят нечто, но не могут осмыслить что именно, и как правильно на это реагировать. У каждого может быть своя ассоциация, возможно у аборигенов Австралии и вообще никакой не было.Видели как собака или кошка исследуют незнакомую вещь?
Если на пути да, но корабль в море, и появляется медленно. Как писал ориентировочный рефлекс в этом случае может не особенно срабатывать. Это специфический случай судя по всему, и описывает условия приближенные к идеальным. Практически не знакомые с технологиями аборигены, с пониженным IQ (ссылка выше приводилась, а что было тогда?), медленно двигающийся по морю корабль, без видимых признаков жизни на таком расстоянии.Явно обращают внимание, даже несмотря на то, что раньше не видели и не знают как она устроена.
Да, это исследовательский инстинкт, без него не выжить. Но он конкурирует с ориентировочным, когда нового сильно много, то животное предпочитает ретироваться, если чувствует опасность. Тут сложная игра.michael_vostrikov
16.06.2019 18:22Речь именно о том, чтобы в домне увидеть домну, а не еще что-то, а в корабле- корабль.
Нет, речь о том, чтобы вообще увидеть корабль хотя бы как-то, как некий незнакомый объект. "Аборигены, кот. никогда не видели кораблей европейцев никак не воспринимали их".
Нет, аборигены видят нечто, но не могут осмыслить что именно, и как правильно на это реагировать.
Тогда при чем тут когнитивная слепота? "Видят, но не знают, что это такое" это не когнитивная слепота, это просто незнание.
но корабль в море, и появляется медленно. Как писал ориентировочный рефлекс в этом случае может не особенно срабатывать
Ни у людей ни у животных нет рефлексов, которые бы так себя проявляли. Попробуйте к чужой собаке приближаться со скоростью корабля. Плавно движущийся корабль можно не заметить краем глаза, если на него не смотреть, но если он в поле зрения, то он будет заметен. Тем более для аборигенов, который всю жизнь видели с берега чистое море. Заметить, но не оценить опасность да, но это не когнитивная слепота. О чем я и говорю, есть более одного варианта причин, которые приводят к указанным фактам.
то животное предпочитает ретироваться, если чувствует опасность
Ну так объект ведь распознает, и внимание обращает.
phenik
17.06.2019 10:03Нет, речь о том, чтобы вообще увидеть корабль хотя бы как-то, как некий незнакомый объект.
Вы ломитесь в открытую дверь) Уже третий раз пишу, что нечто они видят. Вопрос, что именно?это не когнитивная слепота, это просто незнание.
Ну и откуда эти аборигены могли взять это знание?) Вы как-то не хотите взглянуть на эту проблему реально в историческом разрезе. Это знание не было им доступно при их уровне развития. Поэтому большая часть вообще не обратила внимание на эти корабли посчитав их паруса за туманку или облачка, например, т.е. естественные для них явления, а некоторая часть за нечто мистическое, что характерно для того уровня развития психики — все объясняется действием потусторонних сил.Ни у людей ни у животных нет рефлексов, которые бы так себя проявляли.
Как раз есть. При общении с дикими животными желательно не делать резких движений. Любой гид сафари про это скажет. Уже писал хищники используют этот прием, когда подкрадываются к добыче. Полностью незамеченными они не могут быть, т.к. наблюдают за добычей, спасает именно медленное приближение.Заметить, но не оценить опасность да, но это не когнитивная слепота.
Именно слепота. Представьте, перед вами сядет НЛО в виде знакомо образа тарелки из кино, как вы отреагируете? Думаю предсказуемо, как минимум изумитесь) потому, как распознаете ситуацию. А если это НЛО будет в виде некоего плазмоида, без всяких намеков на известные технологии? Вероятно, как современный человек, не отнесете его к сверхъестественным явлениям, как могли поступить аборигены. Но первой ассоциацией будет, а не является ли этот объект шаровой молнией например, т.е. естественным явлением? Можно ли это назвать вашей недообученность, незнанием? Вряд-ли, как реально выглядят летальные средства инопланетных цивилизаций неизвестно, никто такой информации вам не может дать. Поэтому вполне можете эти летальные аппараты не увидеть. Это уже потом, когда станет все известно, можно будет их распознавать, и их новые разновидности, и тд, и махать им ручками)
С чего началась эта ветка обсуждения? С утверждения:Все обучение и работа сетей строится по сути на сравнении чего-то на входе с тем, что они уже видели.… Ибо всегда есть риск нарваться на что-то, что сеть еще не видела. И ее выводы будут неверными.
Вы и это будете оспаривать? А ведь ИНСы в том виде, как они имеются, это простецкая реплика с нейросетей мозга. И это явление для них также является когнитивной слепотой. И они также выдадут близкие, но не совпадающие образы, в зависимости от того, чему их обучали, и что новое показали. Недообученность? Да, можно так сказать. Но представьте автономный робот-исследователь на др. планете. Его заранее обучили распознавать определенны образы, но он встречает новые, кот. принципиально отличаются от обучающей выборки. И соотв. выдает только близкие паттерны, кот. приводят к неэффективной работе этого робота. Как это назвать — недообученностью, незнанием? Никто не знал о таком новом при их обучении, и нет возможно дообучить оперативно, т.к. связь с Землей недоступна. Как мне кажется, по отношению к роботу эту ситуацию более адекватно описывает термин «когнитивная слепота», чем незнание. Конечно, такие автономные роботы могут быть самообучаемыми, но пока до уровня самообучаемости человека еще далеко будет. И все равно это явление — когнитивную слепоту (белую) исключить совсем нельзя будет.Ну так объект ведь распознает, и внимание обращает.
С вниманием связана своя специфическая разновидность слепоты. Это др. тема, хотя и близкая.michael_vostrikov
17.06.2019 13:24Это знание не было им доступно при их уровне развития.
Это ничем не отличается от того, как ребенок или даже любой взрослый увидев незнакомую вещь спрашивает "а что это такое?" У них тоже нет этого знания.
Поэтому большая часть вообще не обратила внимание на эти корабли посчитав их паруса за туманку или облачка, например, т.е. естественные для них явления
Вот именно про это я и говорю. Есть много других более вероятных причин, почему они не обратили внимание. Вернее даже обратили ("Она часто смотрела на корабль, но не выразила ни удивления, ни беспокойства"), но не проявили той реакции, которую ожидали люди на корабле.
При общении с дикими животными желательно не делать резких движений.
Ага, но не потому что из-за медленных движений они не видят человека, или принимают его за естественные для них явления, а потому что на резкое движение могут резко среагировать.
Уже писал хищники используют этот прием, когда подкрадываются к добыче. Полностью незамеченными они не могут быть, т.к. наблюдают за добычей
Как факт наблюдения означает замеченость? Если я понаблюдаю за вами из окна, вряд ли вы меня заметите. Хищники обычно подкрадываются со спины или сбоку, прячась в траве или за деревьями. Добыча их не замечает из-за скрытности, а не из-за когнитивной слепоты.
Но первой ассоциацией будет
Поэтому вполне можете эти летальные аппараты не увидеть.Как же не увижу, если есть ассоциация? Я могу не знать, что это летательный аппарат, но объект есть, я увижу его как и любой другой объект, который видел в первый раз, смогу оценить форму и цвет.
Можно ли это назвать вашей недообученность, незнанием? Вряд-ли, как реально выглядят летальные средства инопланетных цивилизаций неизвестно, никто такой информации вам не может дать
Именно незнание это и есть. Никто не знает, как они выглядят. Нет никакой разницы, сколько человек в мире могут объяснить назначение неизвестного объекта — ноль, один, или тысяча. Для наблюдающего объект субъекта он во всех случаях ему одинаково неизвестен.
Вы и это будете оспаривать?
Это не буду, я оспариваю ваш пример. Вы его приводите как доказательство, но он сам является недоказанным. Из указанных фактов можно сделать больше одного вывода о причинах. Причина "не видели объект" крайне маловероятна, никаких подтверждений ей нет. И подкрадывание хищников не является подтверждением, там тоже есть больше одного вывода о причинах.
Вообще, любой объект люди когда-то видят первый раз в жизни. Если бы такое явление существовало, никто никогда не распознал бы ни один объект. Потому что какие тогда есть причины для изменения результата распознавания?
phenik
17.06.2019 14:46Вы ничего не сообщили нового, поэтому не буду коментировать, кроме заключения:
Вообще, любой объект люди когда-то видят первый раз в жизни. Если бы такое явление существовало, никто никогда не распознал бы ни один объект. Потому что какие тогда есть причины для изменения результата распознавания?
Чтобы распознать нужно предварительно обучить. Вы сами это не отрицаете для нейросетей. Для человека несколько сложнее. Нужно не только показать пример объекта, но и объяснить его назначение, контекст использования в общем семантическом пространстве. Только тогда обучение будет полноценным. Если этого нет, то предмет воспринимается, но правильной реакции на него нет. Как пример, одичавшие дети, кот. едет пищу раками, а не ложкой. Для них она не существует, как предмет утвари, а лишь как некая блестящая железка. То же самое можно сказать об аборигенах и кораблях. Поэтому ваше заключение не верно.michael_vostrikov
17.06.2019 16:01Нужно не только показать пример объекта, но и объяснить его назначение
Ну вот, уже неверно. Кто что объяснял первобытным людям? Ребенок учится распознавать родителей и игрушки еще до того, как сможет понимать объяснения.
Чтобы распознать нужно предварительно обучить. Для человека несколько сложнее.
Нет. Чтобы распознать — определить наличие некоторого объекта — людей не нужно предварительно обучать распознаванию именно этого объекта. Для человека это наоборот проще — нужно обучить распознавать произвольные формы на основе базовых элементов — углы и линии.
Для них она не существует, как предмет утвари, а лишь как некая блестящая железка. То же самое можно сказать об аборигенах и кораблях.
Изначальный тезис был "Аборигены, кот. никогда не видели кораблей европейцев никак не воспринимали их". Он неверный, воспринимали. Они могли их воспринимать как лодки соседнего дружественного племени, или еще как-то, но воспринимали, как некий существующий в море объект. Незнание назначения предмета это именно незнание, потому оно так и называется.
Слепота невнимания может быть идентифицирована при следующих условиях:
— смотрящие не распознают визуальный объект или событие;
— объект или событие должны полностью находиться в поле зрения;
— смотрящие должны суметь распознать объект, если это является их целью;
— событие должно произойти неожиданно, а неспособность распознать объект должна быть связана с тем, что смотрящие сконцентрированы на других элементах происходящего в их поле зрения.
MaxVetrov
16.06.2019 19:33Практически не знакомые с технологиями аборигены, с пониженным IQ (ссылка выше приводилась, а что было тогда?),
Не думаю, что за 4 века(эпоха географических открытий) мозг человека сильно эволюционировал. Он работает также, более активнее меняется только окружающая среда. Говорить, что у них был пониженный IQ будет не верно.
медленно двигающийся по морю корабль, без видимых признаков жизни на таком расстоянии.
Я думаю современные люди бы обратили внимание на шар в небе который похож на солнце, да и не современные тоже.phenik
17.06.2019 13:44Не думаю, что за 4 века(эпоха географических открытий) мозг человека сильно эволюционировал. Он работает также, более активнее меняется только окружающая среда. Говорить, что у них был пониженный IQ будет не верно.
Эволюция человека не остановилась совсем, в том числе и мозга. Но не это определяет уровень изменения интеллект, а уровень развития социума. За четыре века он вырос существенно во всех отношениях, и это не могло отразиться уровне интеллекта, и соотв. его показателях. Но измерять IQ стали только с начала прошлого века. Измерение по старым тестам показали рост IQ со временем, см эффект Флинна. Есть прямые измерения влияния социальных факторов на этот показатель.Я думаю современные люди бы обратили внимание на шар в небе который похож на солнце, да и не современные тоже.
А кто утверждает, что, как минимум, некоторые не обратили бы? Вопрос в реакции. Думаете те аборигены запрыгали бы радостно и начали орать: «О какие красивые разноцветные шарики к нам прилетели!») Если они представления о шариках не имели.Случай из собственной практикиКстати, все это имеет куда большее значение, чем кажется на первый взгляд. Вот реальный случай, который наблюдал я. Однажды, несколько лет назад, выглянул в окно, и случайно поднял глаза в небо. Какое-то движение привлекло внимание. Когда пригляделся, быстро позвал жену, чтобы проверить, что это мне не кажется. Она подтвердила. По небу плавно двигалось четыре дискообразных объекта. Три в ряд, и один в стороне на удалении, высоко, но ниже облаков. Это не были летательные аппараты, или шарики. Они двигались достаточно быстро для шаров или аэростатов, и в одном направлении. Разинув рот, так вдвоем и смотрели на них, пока они не скрылись за кронами высоких деревьев, стоящих через дорогу. Все длилось буквально полминуты-минуту не дольше. Бросился искать в сети не видел ли еще кто в этом городе нечто подобное. Но ничего не нашел. Вот вам и шарики. Что это было? Одно время увлекался тематикой НЛО. Это было еще задолго до этого случая. И в этом вопросе придерживаюсь мнения о природном объяснения большинства случаев связанных с регистрацией этих объектов. Но вот, когда реально сам столкнулся с нечто напоминающим такой случай, то, честно говоря, остался в растерянности. Конечно, если бы знал достоверно, как именно выглядят НЛО, то начал махать им руками, и орать, что есть контакт!) А так считаю, что это и есть проявление когнитивной слепоты. Конечно роль играло, что все это было в небе, и высоко, и трудно было разглядеть подробности, даже цвет, что-то светлое, но ничего определенного сказать не могу. А может это глюк кокой-то, тогда сразу на двоих)MaxVetrov
17.06.2019 14:30Эволюция человека не остановилась совсем, в том числе и мозга.
С этим согласен, но меняется не так быстро как окружающая среда.
Но не это определяет уровень изменения интеллект, а уровень развития социума. За четыре века он вырос существенно во всех отношениях, и это не могло отразиться уровне интеллекта, и соотв. его показателях.
Тут возникает вопрос, а уровень образованности и уровень интеллекта это одно и то же? Мне думается, что это разные вещи. Уровень интеллекта(индивида) определяется скоростью, качеством выполнения базовых операций мышления, памяти.
Но измерять IQ стали только с начала прошлого века. Измерение по старым тестам показали рост IQ со временем, см эффект Флинна.
Более того, даже сейчас, нет стандарта на тест IQ.
А кто утверждает, что, как минимум, некоторые не обратили бы? Вопрос в реакции.
Все верно, кто-то заметил, кто-то нет. Каждый ощущает этот мир по разному.
А может это глюк кокой-то, тогда сразу на двоих)
Не знаю, не видел :) Ну были б инопланетяне зачем им в небе появлятся и «на берег» не выходить? Испанцы же на берег вышли.
GudVVinS
16.06.2019 12:56Хорошо, лодку ты видел и на её основе (при условии, что ты не абориген) сможешь понять что похожая на твою лодку, но больших размеров — тоже лодка.
А что тогда самолет? Птица? Ты ведь не имеешь у себя такой маленький домашний самолет, чтоб на охоту на нем летать.
Я к тому, что есть вполне реальная история, когда аборигены тихоокеанских островов принимали военные самолеты за богов, падающие с самолетов грузы за подарки богов, а когда самолеты перестали летать — они построили святилище «богам» в виде деревянной штуки на самолет похожей.
Видимо человек выше хотел описать этот случай, а не лодки.Am0ralist
16.06.2019 13:41но он утверждает, что люди их вообще не видели, хотя в вашей истории опровержение — они же сделали похожие вещи, то есть видели, но неправильно интерпретировали.
Max-812
14.06.2019 12:09Думаю, что реакции человека более спонтанны. :) Что позволяет иногда выбираться из совершенно нелогичных ситуаций.

saipr
14.06.2019 11:02Тот стек технологий который есть сегодня судя по всему нас к искусственному интеллекту всё же не приведёт.
Искуственный интеллект в машинном понимании это программа, написанная человеком и не более того. И от того какой человек писал программу или разрабатывал алгоритм и зависит глубина искуственного интеллекта. Есть постулат — машина может делать только то, чему ее научил человек.
Теперь о базах данных. В начале 80-х я познакомился с семантической моделью данных Abrial (Abrial, J.R.: Data semantics. In: Klimbie, K. (ed.) Data Management Systems. North-Holland, Amsterdam (1974)). Она меня покорила. Именно семантика данных и определяет степень развития искуственного интеллекта.Akon32
14.06.2019 11:25Есть постулат — машина может делать только то, чему ее научил человек.
Наличие машинного обучения (класса методов) противоречит вашему постулату.
Именно семантика данных и определяет степень развития искуственного интеллекта.
Не находите, что это попытка рассуждать о том, чего нет? Может оказаться, что искусственный интеллект будет построен по совершенно другим принципам, и все современные метрики, придуманные для измерения интеллекта, будут неприменимы.
saipr
14.06.2019 11:36Полностью согласен с вами — искуственного интелекта сегодня нет. И метрики не годятся. Классический пример это разговор больных удаленно с врачом и программой. Когда подавляющее количество больных сказали, что с таким внимательным и толковым врачом они никогда не общались. Но это была простая программа, которая удачно генерировали вопросы из ответов пациентов. И мертика о том, что если человек, общаясь с машиной, скажет что общался с другим человеком лопнула.
DrunkBear
14.06.2019 11:10Ничего странного: появляется новая технология (микроскоп) — появляются стартапы, которые при помощи микроскопа пытаются решить все текущие проблемы, от укладки асфальта до изучения клеток.
Логично, что в некоторых случаях технология не очень успешно применяется ( асфальт плохо утрамбовывается), в некоторых появляются стандартные решения с документацией и стартапы становятся не нужны, и иногда технологии развиваются и появляется 2ручный микроскоп для забивания шпал с повышеной точностью и кодовым названием iHammersamhuawey
14.06.2019 11:13В своё время восхитился работой немецкого комбайна на автобане, который сгрызал асфальт, тут же перерабатывал и выкладывал заново. Если бы на солнечных батареях был — вообще шикарно было бы.
User2Qwer
14.06.2019 11:43-5В условном завтра нейронка сможет лучше любой цыганки
предсказыватьпросчитывать прошлое, настоящее и будущее по вашей ладони, отпечатку пальца, голосу или ДНК. Но результаты вам скорее всего соврут, а потенциальныхнеобудущих первых лиц государств уже тогда возьмутв обработкуна заметку.
Где то проскальзывала статья о построений фоторобота по голосу, а ведь это тоже id, как ходьба или движения мышью. Id который даст возможность просчёта. В дальнейшем оно легко может стать своего рода оракулом. Тут и расшифровка генома уже не за горами (видимо когда создадут условных хиромантов способных к переработке множества различных id, и на основе этого уже будет возможна точная формулировка исследования генома человека), но не факт что это снова будет скрыто от широкой общественности. Дальше ещё сложнее и интереснее, сначала исследования в области мозга и гипноза с его триггерами, а потом уже можно и чтение мыслей и внушение необходимой информаций массам, программирование толпы и целых стран. Аля пщщ-пщщ-пду и мордакнига могут стать шикарным инструментом. Вообще жить то страшно уже, столька разновидностей оружия можно постройть на каждом из этапов развития.striver
14.06.2019 11:47а потенциальных нео будущих первых лиц государств уже тогда возьмут в обработку на заметку.
Как рассказывал мне один знакомый, который служил пограничником, еще во времена СССР, паспорта выдавались с нужными цифрами для нужных людей. Так что, обработка уже давно есть. А машины только упрощают этот процесс.
zim32
14.06.2019 12:00-1Странно чтл автор не упомянул ничего про reinforcement learning. Там много интересного. К примеру победа в старкрафт и другое
roryorangepants
14.06.2019 12:16Reinforcement learning — это заход совсем с другой стороны. Наверняка вы помните как Google обыграл всех в Go. Недавние победы в Starcraft и в Dota. Но тут всё далеко не так радужно и перспективно. Лучше всего про RL и его сложности рассказывает эта статья.
Вы статью вообще читали?sergeiss
14.06.2019 18:54Вот это, кстати, к вопросу о том, что человек может не видеть (не воспринимать) то, что у него реально есть перед глазами :)
DenomikoN
14.06.2019 13:18+1Насамом деле нейронная сеть это лишь большая матемитическая функция от входных параметров. Процесс обучения — процесс подбора коэффициентов в этой функции для достижения необходимого результата. Как и отметил автор — наличие носа, глаз и рта ещё не гарантирует что на входе лицо. Но только потому что сеть обучали функции определения наличия носа, глаз и рта. Для того чтобы математически описать более формальнуб модель лица нужна сеть куда более сложного порядка — а к этому современное железо не готово.
dzsysop
14.06.2019 17:00Мне кажется проблема не в железе, как раз эту часть пути мы преодолели.
Речь идет именно о необходимости очередного скачка в матчасти. Нужны новые концепции и фундаментальные математические разработки.
alexeykuzmin0
14.06.2019 17:56А поведение человека — это сложная математическая функция от входных данных?
ChePeter
14.06.2019 13:20Мне кажется, что проблема больше в некорректности или бессмысленности многих задач поставленных перед DS и поэтому бизнес перестал давать деньги решателям ненужных задач.
Автор пишет, что некоторые задачи сети решают плохо — это очевидно. Гораздо интересней вопрос — есть ли задачи, которые они решают хорошо?alexeykuzmin0
14.06.2019 17:57Гораздо интересней вопрос — есть ли задачи, которые они решают хорошо?
Например, вот:Свёрточные сети позволили решать задачи машинного зрения: классификация изображений и объектов на изображении, детектирование объектов, распознавание объектов и людей, улучшение изображений, и.т.д., и.т.п
ChePeter
16.06.2019 18:41Не обольщайтель:
Вот соревнование лучших из лучших по распознаванию корабликов на море
www.kaggle.com/c/airbus-ship-detection/leaderboard
и лучший результат 0.85448.
Это означает, что каждое 7 судно пройдет под Керченским мостом незамеченным :-)
ZlodeiBaal по распознаванию номеров есть достоверная статистика FP?
Если авто имеет право и система его не пустила, то водитель наверно как то проявится ( и статистике можно верить), а вот если система пропустила того, кто не должен проезжать? Ведь никто и не проверяет. Зачем человек, когда весь смысл был в автоматизации.roryorangepants
16.06.2019 20:38+1Это означает, что каждое 7 судно пройдет под Керченским мостом незамеченным :-)
Нет, не означает. С каких пор можно интерпретировать F2@0.5..0.95 как accuracy?ChePeter
16.06.2019 21:31-2в некоторых случаях именно это и означает! Точно.
roryorangepants
16.06.2019 21:52+2Абсолютно не означает. Зачем заведомо вводить читателей в заблуждение?
ChePeter
17.06.2019 09:48-1Интересный диалог!
Взглянем на www.kaggle.com/c/airbus-ship-detection/overview/evaluation, а именно на способ расчета точности в соревнованиях и обратим внимание на последнюю строчку
Lastly, the score returned by the competition metric is the mean taken over the individual average F2 Scores of each image in the test dataset.
Т.е. берется среднее по всем картинкам. И если есть 100 картинок и на каждой по одному судну и все точки на 86 картинках предсказаны со 100% точностью и на оставшихся 14 сеть не обнаружила ни одной точки, то результат и будет 0.86.
Теперь подробнее.
Если на картинке все точки предсказаны точно, то для всех threshold расчет F2 покажет 1 и среднее по всем threshold тоже будет равняться 1.
Если на картинке по всем IoU ( а там одно судно ) будет TP = 0, то и F2 будет равняться 0 для всех threshold и среднее по всем threshold по картинке тоже равно 0.
Дорогой roryorangepants теперь понятно?
Раз уж Вы так ревностно относитесь к чистоте суждений про data science, то поясните пожалуйста один пункт Вашей статьи habr.com/ru/post/414865
3. Циклический Learning rate. Циклическое повышение и понижение темпа обучения помогало моделям не застревать в локальных минимумах.
Вопрос: — о локальных минимумах какой функции идет речь?
Спасибо большое за очень интересную дискуссию.roryorangepants
17.06.2019 10:04Дорогой roryorangepants теперь понятно?
Понятно, что вы во-первых не знаете, как расчитывается f2, а во-вторых, «удобно» рассматриваете только кейсы, когда маска совпала с кораблем на 100% (чего в реальности обычно не бывает) или на 0%.
На самом же деле, интерпретировать метрики, которые считаются over 0.5..0.95 IoU thresholds таким образом нельзя. Допустим, у меня есть модель, которая предсказывает всегда все боксы, но с IoU 0.89. С точки зрения бизнес-задачи «непропускания кораблей» она по сути не пропускает ни один. С точки зрения метрики она будет иметь TP по восьми трешхолдами и FP+FN по ещё двум.
Поэтому интерпретация скора 0.85 как «каждое 7 судно» — это полная чушь. Вы бы ещё ROC-AUC так, например, интерпретировали. А что, он ведь тоже от 0 до 1?
Вопрос: — о локальных минимумах какой функции идет речь?
Казалось бы, какое это имеет отношение к треду? Но окей, отвечу. Речь идет о локальных минимумах функции потерь.ChePeter
17.06.2019 10:17-1как рассчитывается F2 в данном конкретном случае можно посмотреть по ссылке выше, там есть формула. Ваши догадки и предположения и есть полная чушь.
Высказываниев некоторых случаях именно это и означает! Точно.
Вы опровергнуть так и не смогли. Вам приведен конкретный пример.
И не уходите в туман от конкретного вопросаРечь идет о локальных минимумах функции потерь.
Приведите нормальное определение используемой Вами функции.roryorangepants
17.06.2019 10:42+1Вы опровергнуть так и не смогли. Вам приведен конкретный пример.
Простите, но если для вас единичный пример == способу интерпретации метрики, то о чем вообще разговаривать?
Ещё раз процитирую:
и лучший результат 0.85448.
Это означает, что каждое 7 судно пройдет под Керченским мостом незамеченным :-)
Это не правда. Вы интерпретируете сложную метрику, которую плохо понимаете, как accuracy.
Приводить один единственный пример, где эти величины совпали, и использовать это как аргументацию — это примерно как говорить: «Квадрат — это прямоугольник, поэтому все прямоугольники — квадраты». Если вы не понимаете, почему modus ponens не работает в эту сторону, я не вижу смысла продолжать этот спор.
И не уходите в туман от конкретного вопроса. Приведите нормальное определение используемой Вами функции.
Я не ухожу в туман. Во-первых, это не имеет отношения к предмету спора. Во-вторых, если уж вам интересно, прочитайте внимательно статью, на которую ссылаетесь. Там указано, что функция потерь — взвешенная CCE.ChePeter
17.06.2019 10:49-1В математике, в отличе от болтологии, одного примера достаточно. И, как правило, там где один пример, вдруг внезапно их оказывается много.
Да и локальные мининумы кросс энтропии тоже удивительное явление.
К сожалению не могу продолжить с Вами эту увлекательную и удивительную дискуссию. Удачи в поиске. Спасибо.roryorangepants
17.06.2019 11:06+1В математике, в отличе от болтологии, одного примера достаточно. И, как правило, там где один пример, вдруг внезапно их оказывается много.
Вон оно как. Хороший принцип.
Ну вот, например, математики над проблемой Гольдбаха 250 лет бьются, а ларчик-то просто открывался! Гений своего времени ChePeter пришел, пару чисел на сумму разложил, сказал: «В математике одного примера достаточно», и задача решена. Так что ли?
Да и локальные мининумы кросс энтропии тоже удивительное явление.
Мне кажется, здесь имеет место фундаментальное непонимание того, как обучается сеть.
Да, если мы считаем кроссэнтропию между двумя векторами, то относительно элементов этих векторов она будет выпуклой, и никаких локальных минимумов не будет. Проблема в том, что кроссэнтропия на выходе сети зависит от ground truth и предсказания сети, а предсказание в свою очередь зависит от параметров сети. И относительно них эта функция далеко не выпуклая.
Можно чуть подробнее почитать здесь, например.ChePeter
17.06.2019 19:32-2умеете Вы людей веселить.
Анекдот напомнили
Религиозный еврей рссказывает друзьям
— Иду, я как-то в субботу по улице и вдруг вижу лежит бумажник туго набитый. Но нагибаться за бумажником нельзя — суббота!
— Ну я встал и помолился -Господи, помоги мне с этой дилемой. И что Вы думаете?
Господь внял моим молитвам. У всех субббота, а у меня четверг.
Так и у Вас кросс энтропия с локальными минимумами, а у всех выпуклая.
А этот текст из приведенного Вами обсуждения только для ценителей
The cost function of a neural network is in general neither convex nor concave. This means that the matrix of all second partial derivatives (the Hessian) is neither positive semidefinite, nor negative semidefinite. Since the second derivative is a matrix, it's possible that it's neither one or the other.
roryorangepants
17.06.2019 20:09Так и у Вас кросс энтропия с локальными минимумами, а у всех выпуклая.
А этот текст из приведенного Вами обсуждения только для ценителей
The cost function of a neural network is in general neither convex nor concave.
Вы ещё и по-английски не понимаете, да? Там написано, что в общем случае она ни выпуклая, ни вогнутая.
Ещё раз повторю. Если вы рассматриваете кроссэнтропию как функцию от двух векторов, она в этом пространстве выпуклая.
Однако в случае нейросети у вас один из векторов сам зависит от параметров сети. И эта функция уже не выпуклая.
Объясню на упрощенном примере:
y(x) = x^2 — выпуклая функция относительно x
Но если x = x(t) = sin(t) в свою очередь, то:
y(t) = x^2(t)
не выпуклая.
Так и с нейросетью.
CCE(y_true, y_pred) выпуклая в координатах этих игреков. Но y_pred = f(x), где x — входная картинка, а f — ни много, ни мало, вся нейросеть.
А поскольку градиенты CCE мы считаем именно по параметрам сети, скрытым внутри нашего f, то CCE(y_true, f(x)) — это суперпозиция функций, которая может иметь и плато, и локальные минимумы, и седловые точки.
Мне жаль, что мне приходится это объяснять человеку, который публиковал на хабре статьи про нейросети.
Вернее не так. Мне жаль, что человек, которому такое нужно объяснять, публиковал статьи про нейросети.
P.S. Я надеюсь, что окончательный переход к обсуждению моей статьи вместо оригинального топика, означает, что вы наконец смирились с ошибочностью своих изначальных утверждений.ChePeter
17.06.2019 21:29-3А Вашей целью являетсяя мое смирение? Очередная Ваша чушь… Ну хоть одну серьезную мысль можете изложить?
В приведеной Вами же ссылке есть еще одно рассуждение про выпуклости, но для ценителей, которое полностью не совпадает с Вашим примером.
If you permute the neurons in the hidden layer and do the same permutation on the weights of the adjacent layers then the loss doesn't change. Hence if there is a non-zero global minimum as a function of weights, then it can't be unique since the permutation of weights gives another minimum. Hence the function is not convex.
Пример подтверждающий высказываниев некоторых случаях именно это и означает! Точно.
Вам приведен, опровержения, кроме словоблудия, не последовало.
Про локальные минимумы кроссэнтропии поищите другие обсуждения.
Тема закрыта.roryorangepants
17.06.2019 21:45+1В приведеной Вами же ссылке есть еще одно рассуждение про выпуклости, но для ценителей, которое полностью не совпадает с Вашим примером.
Ну всё, сейчас у меня прямо бомбануло. Каким же надо быть тупым, чтобы приводить в качестве аргумента цитату, в конце которой прямым текстом написано:
Hence the function is not convex.
Лосс не выпуклый и не вогнутый. Лосс имеет сложный ландшафт, и, да, в нём есть локальные минимумы. Кому-то нужно пройти курс вышки.
Вам приведен, опровержения, кроме словоблудия, не последовало.
Опровержение частного случая? Алло, логика, как слышно?
Изначальное высказывание было в том, что скор 0.85 можно интерпретировать как «пропускается один объект из семи». Я объяснил, почему эта интерпретация неверна и привел контрпример.
Контрпример — это достаточный аргумент для опровержения утверждения. Пример — недостаточный аргумент для доказательства. В последний раз, когда я проверял, это так работало.
Если мозг отказывается переваривать сложные конструкции, переведу на язык простых примеров:
— У вас написано «треугольник». К вашему сведению, все треугольники равносторонние.
— Нет, это не так.
— Как это? Вот я взял треугольник с тремя углами по 60 градусов, и у него все стороны равны.
Предлагаю вашему острому уму самостоятельно вывести, какие реплики в этом диалоге соответствуют гениальным примерам про каждый седьмой корабль.ChePeter
18.06.2019 10:00-3roryorangepants Вы попросту хам и неуч. А скорее всего бот, созданный хамом и неучем.
Изначальное высказывание было в том, что скор 0.85 можно интерпретировать как «пропускается один объект из семи».
только бот мог не заметить " :-) "
Только бот не станет замечать уточнения, намеки и подразумевания.
Только бот может привести ссылку в подтверждение своей точки зрения с полным бредом, но подходящим итоговым заключением.
Только бот может использовать почти в каждом посте шаблонные дискуссионные обороты и выражения — запас то ограничен.
Только бот не может предположить, что один пост может продолжить высказывание из другого поста.
Ну или совсем крайний случай, в который не хочется верить, что это реальный человек на уровне развития примитивного бота. С образованием и воспитанием пары тысяч строк на python.
В любом случае прошу прощения у сообщества, что развязал тут такую бездарную дискуссию.
alexeykuzmin0
17.06.2019 16:23Вот соревнование лучших из лучших по распознаванию корабликов на море www.kaggle.com/c/airbus-ship-detection/leaderboard и лучший результат 0.85448
На спутниковых изображениях, я так понимаю, не очень высокого разрешения. А у человека какой результат? Ну и да, на практике это 0.85 легко может оказаться достаточным, если брать сотню кадров, сделанных с небольшой разницей по времени, и искать корабли на всехChePeter
17.06.2019 19:55-1Есть отрасли, где готовы платить громадные деньги за повышение точности предсказаний на доли процентов.
Ни в одной из них нейронные сети реально не применяются.
stardust1
14.06.2019 13:47А был ли мальчик:
«Nearly Half Of All ‘AI Startups’ Are Cashing In On Hype
Out of 2,830 startups in Europe that were classified as being AI companies, only 1,580 accurately fit that description, according to the eye-opening stat on page 99 of a new report from MMC, a London-based venture capital firm.»
www.forbes.com/sites/parmyolson/2019/03/04/nearly-half-of-all-ai-startups-are-cashing-in-on-hype
И ответ там же:
«Startups labelled as being in AI attract 15% to 50% more funding than other technology firms.»
kuzevan
14.06.2019 14:09Нейронные сети – инструмент для ленивых… Задачи классификации решаются нахождением корреляции определяющих признаков. Есть, например, словесный портрет преступников, типа: «нос с горбинкой, бородавка на правой щеке», или фотороботы. Признаков там совсем немного, но используются для распознавания лиц.
Наивно думать, что если загрузить в мясорубку нейронной сети громадное количество растровых фотографий и провести корреляцию каждого пикселя с каждым, задача распознавания лиц будет решена. Думаю, для начала, нужно научиться превращать растровые фото в ограниченный набор признаков, этих самых «нос с горбинкой, бородавка на правой щеке», а потом уже решать задачу распознавания.
Распознавание из растровых изображений – плохая задача для нейронных сетей. Но есть и хорошие. Например, в банке – определение качества заемщика по его анкете. Думаю в медицине – диагностика по симптомам и анализам. Там, где входные признаки явно коррелируют с классификацией, но построение математической модели затруднено.
lair
14.06.2019 14:29Думаю, для начала, нужно научиться превращать растровые фото в ограниченный набор признаков, этих самых «нос с горбинкой, бородавка на правой щеке», а потом уже решать задачу распознавания.
Вы, я так понимаю, про convolutional neural networks никогда не слышали?
kuzevan
14.06.2019 14:45Посмотрел перевод convolutional neural networks. Оказалось, это просто сверточная сеть.
Так вот она таких задач — выделение признаков при любом масштабе и ориентации тоже не решает. Тут нужно в векторное представление переходить с предсказанием ориентации и трехмерности.olegfil
14.06.2019 14:54Ну вот в сверточной сети 150 ее слоев именно это и делают — ориентация, трехмерность, четкость и т.д. И представляют это в виде вектора.
Если что, то в Китае уже работают распознавания лиц на миллионах людей.kuzevan
14.06.2019 18:37-1В таких задачах терминология, типа «сверточная сеть 150 слоев» уже не работает. То, что эти задачи решаемы — я и не сомневаюсь. Тупая сеть, хоть сверточная, хоть какая, автоматически распознавание не обеспечит. Правильно задачу ставить надо, разбивать на подзадачи и для каждой подзачи правильные инструменты нужны.
roryorangepants
14.06.2019 15:16Так вот она таких задач — выделение признаков при любом масштабе и ориентации тоже не решает.
При нормальной, разнообразной выборке и хорошиъ аугментациях решает, почему нет?
alexeykuzmin0
14.06.2019 18:02Думаю, для начала, нужно научиться превращать растровые фото в ограниченный набор признаков, этих самых «нос с горбинкой, бородавка на правой щеке»
Забавный факт: на Coursera есть курс «введение в машинное обучение», где в качестве одно из домашних заданий предлагается как раз научить сеть делать текстовые описания для изображений. Это не просто не невозможно, это уже буквально часть вводного обучающего курса.red75prim
14.06.2019 18:24Сказано-же: это — для ленивых. Для неленивых — попытаться проитроспектировать работу сотен миллионов нейронов в зрительной коре и выделить из всего этого небольшой набор правил, не слишком потеряв в точности.
khim
15.06.2019 00:48С учётом того, чего мы добились подобными попытками, на которые ушли десятилетия этот небольшой набор будет готов примерно к моменту, когда нужно будет решать вопрос с тем, что делать с остывающим Солнцем…

iroln
14.06.2019 18:28Видимо, потому что именно на эту тему диссертация Karpathy:
https://cs.stanford.edu/people/karpathy/main.pdf
А модель и код тут:
https://github.com/karpathy/neuraltalk2alexeykuzmin0
14.06.2019 18:50Думаю, это совпадение. Авторы курса Introduction to deep learning — Яндекс и ВШЭ.
iroln
14.06.2019 18:57Да это меня что-то переклинило, я почему-то подумал, что речь о курсе, который связан с ним.
Hardcoin
14.06.2019 20:13Наивно думать, что если ..., задача распознавания лиц будет решена
Дело в том, что эта задача решена. В Китае, например. Лет пять назад рассуждения, подобные вашим ещё имели смысл, но не сегодня.
kuzevan
14.06.2019 20:20А есть ли более подробная информация по технологии? Ведь задачи можно решать не только нейронными сетями…
Hardcoin
14.06.2019 21:37> можно решать не только нейронными сетями
Никаких других способов для распознавания лиц пока не придумали. Так что китайцы используют нейросети, это 100%.
Про архитектуру я информацию не искал, но на хабре есть обзорная статья.
m.habr.com/ru/company/madrobots/blog/443776iroln
14.06.2019 22:56Никаких других способов для распознавания лиц пока не придумали. Так что китайцы используют нейросети, это 100%.
Ну это неправда :)
Лица начали распознавать задолго до широкого применения современных свёрточных и прочих ИНС.
Почитайте про Active Shape/Appearance Models, а вообще там полно методов без использования "нейронок", но с использованием ML. Если погуглить можно найти множество статей с обзорами и сравнениями методов за разные года.
Hardcoin
14.06.2019 23:20Согласен, методы существуют. Active Shape Model подойдёт для поиска лица или распознавания эмоций. Но что бы отличить миллион человек друг от друга — не подойдёт. Если китайцы правда могут платить с лица в метро — там необходимо именно различение миллионов лиц.
Впрочем, как у них устроено изнутри, подробной информации не нашел.
iroln
14.06.2019 23:32Я тоже не знаю деталей их реализации, но здравый смысл подсказывает, что берут какую-нибудь SOTA модель, примеры: раз и два, получают предствления лиц в виде векторов, и ищут в этом векторном пространстве похожие лица.
Проблема в том, что детекторы, которые построены только на ИНС достаточно легко можно обмануть, поэтому должно быть что-то ещё, какая-то статистическая модель, какая-то дополнительная биометрия (как у apple в их Face ID), но если задача — следить за миллиардом китайцев, такую биометрию и дополнительную информацию вряд ли возможно собрать.
JaroslavTavgen
14.06.2019 14:12+1Где можно прочитать гайд, который бы очень понятно объяснял нейросети? У меня большое желание их изучать, и я уже много чего читал, смотрел, строил свои сетки на brains.js, но все материалы, которые я читал или смотрел на видео оказывались слишком непонятными. Где можно прочитать или посмотреть такой материал, который бы действительно помог ПОНЯТЬ тему? Спасибо!
tempick
14.06.2019 17:15+1Тарик Рашид — создай свою нейросеть. Имхо, ничего более подробного и понятного по нейросетям для новичка не находил и сам учился по этой книге
vk000
14.06.2019 19:27+1В текстовом виде самое лучшее, что я видел именно для «понять» — это вот это: karpathy.github.io/neuralnets
Этот текст неполон и заброшен, но то, что там есть (базовые вещи) — очень хорошо объяснено.
На видео рекомендую стенфордский курс CS231n: Convolutional Neural Networks for Visual Recognition. На ютубе он есть разных годов, смело можно рекомендовать версию 2016-го потому что там много того же Андрея Карпати, а он великолепный объяснятель по нейросетям.
da0c
15.06.2019 07:50Как совсем сжатое введение именно в сверточные сети я бы рекомендовал часть уже упомянутого здесь курса Ли Фей Фей и Карпатного — cs231n.github.io/convolutional-networks. Если в него въехать — остальное становится понятно.
Как развернутое детальное объяснение на русском — книга 2018 года Николенко С., Кадурин А., Архангельская Е., Глубокое обучение.

Mistx
14.06.2019 14:39Если тут есть люди в теме, подскажите. Есть ли работы/исследования по обучению различных готовых сетей (навыков) совместной работе над решением новых более комплексных задач при помощи мета сетей?
Paskin
14.06.2019 17:57Конкретных работ очень много — практически во всех реальных применениях используется та или иная комбинация сетей. Например, одна сеть сегментирует исходное изображение, выделяя обьекты — а другая эти обьекты классифицирует. Или есть набор сетей, каждая из которых умеет распознавать какую-то свою особенность (feature) — и сеть второго уровня, которая по этим особенностям распознает обьект. Правильно спроектированная многоуровневая структура значительно упрощает как обучение так и работу сети.
olegfil
14.06.2019 14:51Не понятно, что подразумевается под термином «Искусственный интелект», к которому нейронки, якобы, не прийдут. Чтобы куда-то идти, надо понимать куда идем.
Для себя я понимаю ИИ как что-то, что сможет выделить и обобщить информацию из источника без четкого алгоритма со стороны человека. То есть обобщенный алгоритм дает конкретные результаты. И это очень хорошо :)
Как-то я пробовал использовать старые CV алгоритмы типа SURF или Каскадов Хаара для распознования достаточно сложных логотипов — точность была низкая, так как Хаар работает с фичами, а SURF плохо переваривает искажения. И мне пришлось бы вычислять фичи каждого логотипа или как-то нормализовывать изображение для SURF и все это долго и нудно программировать, но тут появились нейронки и на них без всякого девелопмента можно решать задачи классификации.
Причем сейчас уже нейронка умеет находить несколько логотипов на одной картинке.
То есть вместо какого-то сложного специализированного алгоритма, мы берем универсальный и получаем результат. При этом обобщенный алгоритм адаптивен — добавление новых классов не меняет ни сам алгоритм, ни его входы-выходы.
Умение обобщенного алгоритма выделять особенности (анализ) и принимать на его основе решения (синтез), плюс адаптивность, это IMHO есть ИИ на данном этапе развития.
Мне кажется, что востребованность спецов по ИИ спадет, когда автомобили станут сами ездить, так как сейчас именно эта сфера выглядит самым главным и экономически обоснованным внедрением ИИ.michael_vostrikov
14.06.2019 18:26Не понятно, что подразумевается под термином «Искусственный интелект»
Как естественный, только в компьютере.
Nulliusinverba
15.06.2019 16:23а что такое естественный интеллект?
michael_vostrikov
15.06.2019 17:14Это уже другой вопрос. В рамках создания ИИ достаточно того, чтобы он умел делать те задачи, которые умеют делать люди, с как минимум таким же качеством.
alexeykuzmin0
17.06.2019 16:27Пожалуй, докопаюсь до точности формулировки. Многие люди могут жать от груди 100 кг штангу и больше. Это обязательно уметь нейросети, чтобы считаться интеллектом? =)
michael_vostrikov
17.06.2019 17:01+1Ну если она сможет подойти к тренеру в качалке, поговорить с ним, понять ответы, дождаться своей очереди, и выжать именно штангу весом 100, а не 20 или 200, то пожалуй да) По крайней мере для этой задачи у нее интеллекта будет хватать.
А если взять те принципы, которые работают в основе этой нейросети, обучить по ним другую нейросеть делать переводы текста, и она будет переводить плохо или вообще не будет, то нет. Люди ведь обучаются чему-то по одним принципам. На всякий случай поясню — людям нельзя задать произвольные параметры (знания, желания и возможности), а нейросетям можно, поэтому когда кто-то из людей не умеет или не хочет переводить это нормально, а когда нейросеть нет.
alexeykuzmin0
17.06.2019 18:13А если взять те принципы, которые работают в основе этой нейросети, обучить по ним другую нейросеть делать переводы текста, и она будет переводить плохо или вообще не будет, то нет.
Честно говоря, не очень понял этот момент. Если мы берем нейросеть с той же архитектурой и учим ее тем же методом на тех же данных, то и результат будет такой же.michael_vostrikov
17.06.2019 20:44Зачем на тех же данных, задача же другая? У вас есть нейросеть, которая претендует на то, чтобы считаться интеллектом. Она работает по каким-то принципам. Вы обучили ее понимать тренера и выбирать правильную штангу. Если вы берете изначальную необученную сеть, и пробуете по тем же принципам ее обучить для перевода текста, а у вас не получается, значит это не интеллект. Значит такие принципы работы подходят только для штанги, например работают только с ограниченным набором фраз и определенным расположением штанги и формой блинов. Потому что естественный интеллект умеет обучаться на разные задачи без изменения принципов работы.
cross_join
14.06.2019 14:53+1Выводы интересные, непрофессионалу в ИИ вроде меня доступные, спасибо.
Большие данные на самом деле — начало 1980-х (см. VLDB), СУБД «Терадата» оттуда родом и до сих пор хорошо себя чувствует. Тогда же стартовал Пролог, компы 5-го поколения и прочая «вкалывают роботы — счастлив человек».
Что если провести аналогии с подьемом темы 40-летней давности?

speakingfish
14.06.2019 15:08Потому что нужно использовать базы знаний такие как Cyc
А не тупо обучать нейросетки.
К сожалению, не знаю что из таких баз сейчас развивается.red75prim
14.06.2019 15:15Не масштабируется. Базу сommon knowledge 35 лет делают. И никаких намёков как с помощью этой базы автоматизировать её расширение.
sergeyns
14.06.2019 15:43Никак, единственное применение — словари синонимов *Сарказм, но смысл передает*. Единственное расширение — это придумать и расшифровать (по Лему) слово «космусор»

Tereshkov
14.06.2019 15:15Очень хорошая статья, однако перечень уже состоявшихся практических применений выглядит подозрительно оптимистическим. Кто-то имеет надёжные данные о закупках фермерами автоматических комбайнов?
Groramar
14.06.2019 16:10Поголовно и относительно давно, насколько я знаю. То есть других уже или нет или мало.
Tereshkov
14.06.2019 18:11Увы, это известия из параллельной реальности. Я имею отношение к этой отрасли и знаю, что автоматических комбайнов в массовой эксплуатации нет. Некоторое распространение получили системы автоматического руления, но они бесконечно далеки от полной автономии и не используют машинного обучения.

ZlodeiBaal Автор
14.06.2019 16:19Не люблю когнитив технолоджи, но сходу вот — vc.ru/future/46061-rossiyskaya-cognitive-technologies-pokazala-ispytaniya-sistemy-upravleniya-bespilotnymi-kombaynami-i-traktorami
Они много привирают и приукрашивают
Но если вы покопаете гугл, то много полностью автоматической техники найдёте в англоязычных фирмах.
Многая их них пока в пилотах. Но это особенность цикла разработки. Редко какой стартап начался до 2015 года. Хорошие сетки, положим, с 2016. Это не очень много для сельхоз цикла.
Про пилоты много слышал, даже в России.Tereshkov
14.06.2019 18:20Да, я по долгу службы много слышал и о Cognitive Technologies, и о многочисленных зарубежных разработках, включая прототипы для сбора винограда и яблок. Однако я ничего не знаю об их коммерческом применении. Боюсь, что пока это лишь попытки выдать желаемое за действительное. Буду благодарен за любую информацию, опровергающую мой взгляд.
ZlodeiBaal Автор
14.06.2019 18:46Задачи разные есть. В сбор яблок голубики — я тоже не верю. Тут механника сложная нужна. Её пока нет. Навигация комбайна по полю? Вай нот. Это в миллионы раз проще того что сейчас в Тэсле есть. Или Тесла/яндексовский автопилот — это тоже попытки выдать желаемое за действительное?
Прямые ссылки про испытания надо искать. Я слышал от разработчиков что всё в целом работает. Но на мой взгляд по таким вещам цикл должен быть порядка 6-7 лет. Когда продукт не в пилоте а уже на рынке.Tereshkov
14.06.2019 19:55Как таковая, навигация комбайна по полю действительно намного проще, чем позволил бы автопилот Tesla — хотя бы потому, что в поле, в отличие от города, достаточно лишь GNSS+IMU и нет активного дорожного движения. Однако система обнаружения препятствий всё же нужна, и фактически она оказывается столь же сложной, сколь и для города. Весь вопрос в том, сколько девяток в показателе надёжности нам достаточно.
Что касается успехов Tesla, то они, без сомнения, огромны, но и тут нужно блюсти осторожность: последние громкие заявления о скором выходе автопилота «на улицы» были приурочены к «дню инвестора», проводимого в не самых радужных экономических обстоятельствах. Сам формат мероприятия требует повышенного градуса оптимизма докладчиков.ZlodeiBaal Автор
14.06.2019 20:01У Яндекса всё намного лучше при этом. Но там, безусловно, есть лидары.
Вопрос количества девяток — это и есть вопрос пилотов. Пока они не наберут нормальную статистику — они не будут выпускать на рынок. А статистику можно собирать только в сезон:)

ganqqwerty
14.06.2019 16:16А как на рынке в ML-области с требованиями к ученой степени? Мне показалось, что на европейском рынке, всем хочется, чтобы у тебя был Ph.D., при этом основные методы осваиваются средним инженером за годик.
ZlodeiBaal Автор
14.06.2019 16:23Вопрос лишь в том хватит ли вам мозгов продать себя дороже:)
За год осваиваются, но за год нет понимания где что будет и не будет работать. Для такого надо набирать десятки проектов. Хоть свои хоть с кагла, хоть с разных фирм. Опыт куда важнее того как запустить нейронку.
Мы работаем и с американскими и с европейскими фирмами. Но мы скорее как подрядчик работаем. Про то есть ли у меня к. Т. Н. — никто ни разу не спрашивал.
Kirhgoff
15.06.2019 19:50+1У нас в отделе ML человек 15-20 работает навскидку, из них только у примерно 5 есть PhD. Правда, мы не Европа
DesertFlow
14.06.2019 16:20Мне кажется, некоторый тормоз образовался из-за статичной природы современных нейронок. Все что на поверхности, действительно выбрали. Следующим прорывом, имхо, будет применение нейронных сетей к видео. Текущие архитектуры плохо приспособлены к работе с последовательностями (да, даже RNN, не смотря на название). Да и размечать видео на порядок труднее — нет датасетов. И с самими данными из видео возникают проблемы, в силу тонущего в шуме полезного сигнала и плохо приспособленных алгоритмов обучения для этого. С чем во всю силу столкнулось Reinforcement Learning (которое ближе всего к анализу видео, так как работает с последовательностями в течении жизни).
Но только представьте, если текущее состоянии со сверточными сетями будет так же хорошо работать с видео, как они сейчас работают со статичными картинками! Во-первых, это будет нормальная навигация в пространстве — а это робомобили, всякие домашние роботы, которые смогут готовить еду и мыть посуду. Это автоматически уберет привязку к текстурам у статичных нейросетей, появится привязка к форме, а значит нейросети больше не будут путать леопардов с диванами в леопардовой раскраске. Ну и так далее. Возможно, в динамике сам собой появится сильный ИИ, как логичное следствие жизни в динамике. Поэтому очень интересны Disentanglement подходы, пытающиеся выделять/распознавать объекты в картинке/видео без учителя. Это должно помочь при работе с видео, так как устранит разметку. Вручную размечать останется только награду и/или цели для ИИ. Да и это можно заменить любопытством.Groramar
14.06.2019 17:19Attention сети приспособлены к последовательностям лучше RNN в среднем, насколько я знаю.
da0c
15.06.2019 08:45Работ на тему обработки видео сверточными сетями достаточно много, как правило используется комбинация сверточной и рекуррентной сетки. Вот отличный пример c LSTM — openaccess.thecvf.com/content_ICCV_2017/papers/Tao_Detail-Revealing_Deep_Video_ICCV_2017_paper.pdf
DesertFlow
15.06.2019 19:40С видео такая же трудность, как с музыкой или аудио — в сверточных сетях не так уж важно, где расположен признак, важен сам факт его наличия. А вот в видео и аудио важна именно корреляция во времени. Из-за этого сверточные сети плохо подходят к последовательностями, те же conv1d работают, в основном, за счёт дикой ёмкости сети. А attention по определению не могут обрабатывать длинные последовательности (по крайней мере, пока не изобретут какие-то другие механизмы внимания).
Попытки, ясное дело, предпринимаются. Гибриды cnn+rnn, conv1d, трансформеры и т.д. Но такого же уровня, как CNN для статичных картинок, но чтобы работало так же эффективно с последовательностями (неважно — видео, аудио или в RL), архитектуры нейронных сетей пока нет, к сожалению… А нужны.buriy
17.06.2019 09:44Ну… вы как минимум пропустили Sparse Attention ( openai.com/blog/sparse-transformer ). Кроме того, сам attention тоже не сильно нужен, проблема связана именно с многочисленными умножениями и затуханиями градиента, поэтому подход из PhasedLSTM вполне себе работает: делайте более «медленные» рекуррентные или свёрточные подсети, которые не будут обновляться на каждый квант времени.
В общем, это вовсе не проблема с attention.
А вот то, что для обработки видео нужно в 20-50 раз больше мощности — это реальная проблема для многих исследователей. Если imagenet с хаками можно один раз посчитать за $15, без хаков где-нибудь за $50-$100, то тут уже циферки побольше будут.DesertFlow
17.06.2019 17:11Ну… вы как минимум пропустили Sparse Attention ( openai.com/blog/sparse-transformer )
Там еще раньше был Transformer-XL (https://ai.googleblog.com/2019/01/transformer-xl-unleashing-potential-of.html), который решал такую же задачу по увеличению длины внимания. А вот PhasedLSTM интересно. Похоже, что это может имитировать работу нейронов на разных временных масштабах и имеет прямое отношение к теме. Так-то и раньше пытались разными способами увеличивать рецептивное поле по шкале времени: иерархические RNN сети вроде SampleRNN, какая-то разновидность Transfromer тоже умела в динамические вычисления (пропуски шагов), если не ошибаюсь.
Мне кажется, в современных нейронных сетях пока слабо имитируется особенность биологических нейронов расти во все стороны и цеплять ближайших соседей. И усиливать связи при часто повторяющихся во времени сигналах. Что-то вроде правила Хэбба (которое в чистом виде работает плохо, как известно). А ведь именно этим, похоже, определяется такая хорошая способность мозга делать корреляции по времени между событиями. Не зря ведь существует отдельная кратковременная память, в которой эти корреляции выявляются. Я не говорю, что надо переходить на Spiking Networks (SNN), хотелось бы именно обычную архитектуру, но с лучшей способностью работать со временем. Имхо, это критически важно для задач вроде Reinforcement Learning. PhasedLSTM хорошая попытка.buriy
18.06.2019 13:15Техника dilation во всяких TCN/TDNN/WaveNet тоже работает, да. Конечно, когда от длины контекста сильно зависит ответ.
>Мне кажется, в современных нейронных сетях пока слабо имитируется особенность биологических нейронов расти во все стороны и цеплять ближайших соседей
Да пробовали это, как и все основные биологические идеи, не сильно помогает, вроде бы. И постепенно наращивали нейроны/слои, и Dropout/Dropconnect на десятки раз переизобретали. Остановились на том, что Residual Connections позволяют сразу всю сеть учить, и ничего сложнее не надо (ибо существенно на результат не влияет).
А вот добавлять к ReLU threshold на активацию — как у человека в нейронах — внезапно помогает от adversarial examples, хотя и замедляет обучение. Поэтому хитрят и добавляют после обучения.
>Не зря ведь существует отдельная кратковременная память, в которой эти корреляции выявляются.
У человека всё хитрее, там не только несколько *циклов* для кратковременной памяти для внимания (гуглить по Basal-Thalamo-cortical loops), но и связи с гипоталамусом, где преимущественно хранится событийная память. MemNN 4-летней давности и другие попытки добавить событийную память сильно улучшают решение задач на ориентирование, я не помню, чтобы трансформеры обогнали MemN2N в таких задачах (хотя, нашёл arxiv.org/abs/1807.03819 — модификацию Transformer под названием Universal Transformers, которая сравнима с MemN2N/Dynamic Memory Networks, при этом он всего лишь в 5 раз крупнее).
>Имхо, это критически важно для задач вроде Reinforcement Learning
На мой взгляд, наиболее успешные результаты в RL связаны с многочисленными вариантами autoencoder subnetworks, которые извлекают более верхнеуровневое представление действительности, и результатами которых пользуется главный RL-алгоритм. Или вместо них можно подавать численные данные каждого юнита (положение, здоровье, статус, класс итп), как делают в агентах для SC2, Dota и даже Pacman (может, вы удивитесь, что без этого компьютер с RL до сих пор не умеет проходить Pacman до максимального уровня без потерь).
Минимальная версия этого автоенкодера — это score игры, как в эмуляторах Atari, или value function, как в AlphaZero. А у человека — функции «хорошо/плохо», «страх/доминирование», которые считаются и хранятся в отдельных областях мозга и тренируются на различных задачах всю жизнь.
А вот spiking или не spiking — не так важно обычно, примерная эквивалентность данных подходов на решаемых задачах была показана, и, ввиду того, что spiking намного тяжелее считать и намного дольше учить, насколько я понимаю, нет ни одной задачи, где бы spiking сети показали бы какие-либо значительные успехи даже на уровне SOTA.

vdem
14.06.2019 17:32ИМХО никакого «ИИ» таки не существует. Интеллект — это вообще способность саморазвиваться, учиться по собственной инициативе, обучаться. Нейронные сети — это то, что есть сейчас, и не больше. Да, человеческий мозг — тоже нейронная сеть, но он обладает и интеллектом, чем не обладают нынешние искуственные нейронные сети. Фактически, из природы взяли только один механизм, «скормили» ему кучу данных, и назвали «интеллектом». Чем обладает человеческий мозг в отличие от просто искусственной нейронной сети? Телом, желаниями, эмоциями, стремлением к саморазвитию. Как это всё «запрограммировать»? Хз. А когда это таки смогут сделать, то получим «ИИ», который будет фактически тем же рабом человека, и про подобное будущее только ленивый фантаст не писал. Т.е. сам термин «ИИ» неверен, правильнее «ИНС» (искуственные нейронные сети). Это не интеллект, это система, способная по большому количеству образцов «обучиться» распознавать похожие, которые еще не видела. И не больше того.
BorisG
14.06.2019 21:19+1Интеллект — это вообще способность саморазвиваться, учиться по собственной инициативе, обучаться.
Это значит что большинство людей, а так же маленькие дети не обладают интеллектом.
Да, человеческий мозг — тоже нейронная сеть, но он обладает и интеллектом, чем не обладают нынешние искуственные нейронные сети.
Биологические нейросети более гибкие, но принцип тот же самый что и в искусственных(есть видео на youtube конференции MIT по анализу коннектом дрозофилы, при этом показано, что сам мозг подобен 4х слойной нейросети).
Меня поражает когда ожидают создать человеческий интеллект на мощностях равных мозгам насекомым и потом жалуются. Это песня из- года в год повторяется.vdem
14.06.2019 23:00Меня поражает когда ожидают создать человеческий интеллект на мощностях равных мозгам насекомым и потом жалуются. Это песня из- года в год повторяется.
Он слабо тянет даже на мозги насекомых, так как отличие не качественное, а количественное. Интеллект должен быть способен задавать вопросы, обучаться, изучать окружающий мир, познавать, строить гипотезы. Нынешние нейросети просто на это всё неспособны. Кстати, был бы рад если б минуснувший мой коммент хоть как-то объяснил бы это действие. Впрочем, вероятно это просто какая-то нейросеть :)
P.S. (Допишу тут ибо не могу часто комментировать.) Может я ретроград, но я лучше пойду к старенькому врачу, который сможет мне объяснить, почему он назначил те или иные лекарства/процедуры, сверюсь с википедией, с другими врачами и сам приму решение, каким рекомендациям следовать, чем прийду в футуристическую автоклинику и мне вколят то, что решит нейросеть. Вот такое мое ИМХО. А вот автомашины да, там лучше нейросети чем люди.
Меня поражает когда ожидают создать человеческий интеллект на мощностях равных мозгам насекомым и потом жалуются. Это песня из- года в год повторяется.
Он слабо тянет даже на мозги насекомых, так как отличие не качественное, а количественное. Интеллект должен быть способен задавать вопросы, обучаться, изучать окружающий мир, познавать, строить гипотезы. Нынешние нейросети просто на это всё неспособны. Кстати, был бы рад если б минуснувший мой коммент хоть как-то объяснил бы это действие. Впрочем, вероятно это просто какая-то нейросеть :)
P.S. (Допишу тут ибо не могу часто комментировать.) Может я ретроград, но я лучше пойду к старенькому врачу, который сможет мне объяснить, почему он назначил те или иные лекарства/процедуры, сверюсь с википедией, с другими врачами и сам приму решение, каким рекомендациям следовать, чем прийду в футуристическую автоклинику и мне вколят то, что решит нейросеть. Вот такое мое ИМХО. А вот автомашины да, там лучше нейросети чем люди.
P.P.S.Это значит что большинство людей, а так же маленькие дети не обладают интеллектом.
Вообще-то большинство людей блещут не интеллектом, а татуировками, пирсингом и вычурными одеяниями, с этим согласен. Маленькие дети интеллектом точно не обладают, достаточно вспомнить про реальных Маугли, которые с определенного возраста даже не могут освоить толком речь и социализироваться (в Википедии можете поискать истории). В развитии интеллекта играет огромную роль именно социализация, способность встроиться в общество и принять его правила. Поэтому я и говорю, что явление, называемое сейчас «ИИ», не более чем искуственные нейросети, а от нейросети до интеллекта не просто шаг, а огромное расстояние.BorisG
14.06.2019 23:28Интеллект должен быть способен задавать вопросы, обучаться, изучать окружающий мир, познавать, строить гипотезы.
Нейросети как инструмент применяемый в конкретных условиях может выполнять те задачи которые им ставят, в том числе которые вы описали (обучаться, изучать окружающий мир, познавать, строить гипотезы)!!!
Интеллект это способность агента достигать целей в самых разных средах.
S. Legg and M. Hutter. A formal measure of machine intelligence. In Proc.
15th Annual Machine Learning Conference of Belgium and The Netherlands
(Benelearn’06), pages 73–80, Ghent, 2006.
Он слабо тянет даже на мозги насекомых, так как отличие не качественное, а количественное.
сильное утверждение доказательства будут?iroln
14.06.2019 23:44Вы, видимо, приверженец дефляционизма? Отрицаете квалия, феноменальный опыт и вот это всё, о чём спорят в дискуссиях о "трудной проблеме сознания". :)
Нейросети как инструмент применяемый в конкретных условиях может выполнять
те задачи которые им ставят, в том числе которые вы описали (обучаться, изучать окружающий мир, познавать, строить гипотезы)!!!Доказательства будут?
Статистическая модель и возможность обобщать в ограниченном пространстве поиска — это ещё не умение изучать и познавать окружающий мир, а тем более создавать что-то новое и осмысленное.
Хотя, думаю, вы и понятие "смысл" тоже отрицаете? Всё должно быть просто, функционально.
И всё же, есть мнение, что интеллект напрямую связан и зависит от носителя и от той среды в которой этот носитель находится и от непрерывного процесса познания окружающего мира. То есть, интеллект никогда не зародится в кремниевой микросхеме или программном коде.
BorisG
15.06.2019 00:45трудной проблеме сознания
Трудная проблема это преувеличение.
Когда вы задаетесь вопрос, «Я сознаю», Вы получаете ответ «ДА» и можете описать все свои субъективные переживания, но когда задаете вопрос «Я сознавал час назад», тот тут уже сложение.
Доказательства будут?
Ну конечно преувеличение, например AlphaGO.
этот носитель находится и от непрерывного процесса познания окружающего мира.
носитель и среда могут быть искусственными.
alexeykuzmin0
15.06.2019 03:01То есть, интеллект никогда не зародится в кремниевой микросхеме или программном коде.
Даже если эта микросхема и программный код выполняют физическую симуляцию мозга человека?
alexeykuzmin0
15.06.2019 03:03это ещё не умение изучать и познавать окружающий мир, а тем более создавать что-то новое и осмысленное
Что именно вы понимаете под умением изучать и познавать? А создавать что-то новое — GAN'ы это делают без проблемiroln
15.06.2019 11:59GAN не осознаёт то, что генерирует, по сути это тупое смешивание образцов в надежде, что в итоге получится что-то приближённое к реальным образцам. Слепить изображение котика из миллиона других изображений котиков или создать человеческое лицо из такого же миллиона других лиц — это не то же самое, что, например, спроектировать новый ракетный двигатель или написать роман.
Представьте, что ИИ должен написать журналистское расследование. Он должен собрать факты из открытых источников, сопоставить и проанализировать их, сделать выводы и написать осмысленную статью. Сейчас это невозможно. Всё что мы можем — это сгенерировать псевдоосмысленный текст, который на самом деле будет бесполезен.
red75prim
15.06.2019 12:36GAN не осознаёт то, что генерирует
Что это значит с точки зрения функциональности? Почему оценка сгенерированного образа дискриминатором это не осознание?
iroln
15.06.2019 13:56Хотя бы потому что модель оперирует набором параметров из ограниченного пространства без всякой связи и всякого знания о мире, в котором может встречаться генерируемый объект. Обучение свёрточной сети нельзя назвать получением опыта о мире.
Сравните своё восприятие комментариев тут, вы же можете утверждать, что осознаёте их? У вас появляется какой-то отклик, эмоции, согласие или несогласие, желание тоже написать комментарий. А теперь скормим все эти комментарии какой-нибудь нейросети, что она сможет осознать?
Трудная проблема сознания потому и названа трудной. Мы не знаем, что порождает сознание и не знаем механизм работы сознания, но оно определённо у нас есть, что бы там дефляционисты ни говорили. :)
red75prim
15.06.2019 15:25Трудная проблема сознания — это чисто философская проблема. Я нигде не встречал ясного описания какое отношение она имеет к вопросу построения систем, решающих задачи (например задачу — посмотреть на комментарий, и решить что делать дальше). Какое отношение имеет сознание к решению задач тоже пока неясно.
BorisG
15.06.2019 15:38модель оперирует набором параметров из ограниченного пространства без всякой связи и всякого знания о мире, в котором может встречаться генерируемый объект. Обучение свёрточной сети нельзя назвать получением опыта о мир
Т. е по вашему нахождение закономерностей это это не создание опыта и знания о мире тогда, что вообще можно назвать опытом?
есть ли вообще трудная проблема в сознании?red75prim
15.06.2019 16:19есть ли вообще трудная проблема в сознании?
Да есть она, есть, но к ИИ никакого отношения не имеет.
Есть ложная слепота — субъективных зрительных ощущений нет, но кое-какая зрительная функциональность сохраняется. Теперь представьте, что у вас "ложная слепота" на все чувства, включая собственные мысли, то есть фактически никакого "вас" нет, но тело работает как и раньше. Трудная проблема — почему такого быть не может.
alexeykuzmin0
17.06.2019 16:37+1GAN не осознаёт
А можно определение того, что такое «осознает»? Вот, допустим, я даю вам большую черную коробку, на ней «филипс» написано и лампочки мигают. Внутри — или GAN, или человек с пейнтом. По нажатию на кнопку пять минут жужжит, потом выдает картинку. Как вы определите, осознает ли коробка то, что нарисовала? (Если этих данных недостаточно, можем вместе поуточнять этот пример)Он должен собрать факты из открытых источников, сопоставить и проанализировать их, сделать выводы и написать осмысленную статью. Сейчас это невозможно.
В формате журналистского расследования — да, пока что мы не умеем, и вряд ли научимся в обозримом будущем, задача слишком сложна (фактов мало, а пространство поиска огромно). Похожую более простую задачу — прочитать википедию и научиться отвечать на вопросы о том, что там написано, на естественном языке — мы решать умеем, см IBM Watson.iroln
17.06.2019 17:33Ваш пример — это "Китайская комната". Рассуждая об этом мы ничего нового не скажем и не выясним.
А можно определение того, что такое «осознает»?
Я не буду говорить, что "осознавать" — это осмысливать или понимать, потому что можно спросить "а что такое понимать?" и так до бесконечности, ссылаясь на тот же мысленный эксперимент с коробкой.
Могу привести пример: осознанные сновидения. В основном мы не можем контролировать сновидение, мы просто наблюдаем за тем, что происходит как видеокамера с микрофоном. Но иногда происходит осознание, что ты видишь сон и появляется возможность выйти за рамки, возможность контроля на некоторое время. Например, можно повернуть голову, открыть дверь, проснуться, в общем, сделать что-то сознательно как в воображении в состоянии бодрствования. Вот GAN так сделать не может, он не может "проснуться" и понять, что он GAN — просто программа для генерации образцов по заданной базе.
На счёт "прочитать и дать ответ" не обязательно идти смотреть Watson, есть демо и попроще: https://demo.ipavlov.ai/
Но работает оно так себе, конечно. Перестановка слов или ± пара слов в вопросе и всё ломается. :) Это "Question Answering Model" на базе R-Net.
IBM Watson я не тестировал, но думаю, там модель сильно сложнее. Также, насколько я знаю, в Watson есть что-то вроде онтологии и непрерывное дообучение.
alexeykuzmin0
17.06.2019 18:23Ваш пример — это «Китайская комната»
Нет, это не китайская комната. В китайской комнате, по предположению, сидит человек, который иероглифов не понимает и понять по имеющимся у него инструкциям не может. В моей же коробке (ну, в той из них, где человек) сидит полноценный человек, понимающий все, что он делает. Во второй коробке сидит GAN. Насколько я понимаю (поправьте меня, если я вас понимаю неверно), вы считаете коробку с человеком осознающей свои рисунки, а коробку с GANом — нет. Меня, в первую очередь, интересует вопрос «как различить, какая коробка осознает свои действия?» Этот тест вообще существует?Могу привести пример: осознанные сновидения. В основном мы не можем контролировать сновидение
Тогда получается, что системы reinforcement learning осознают свое окружение, они же влияют на среду, в которой обучаются.Вот GAN так сделать не может, он не может «проснуться» и понять, что он GAN — просто программа для генерации образцов по заданной базе.
Многие чат-боты умеют отвечать на вопрос «кто ты?»Но работает оно так себе, конечно
Конечно, до человеческого качества еще далекоiroln
18.06.2019 01:27Меня, в первую очередь, интересует вопрос «как различить, какая коробка осознает свои действия?» Этот тест вообще существует?
Не уверен, что такой тест существует и будет объективным. Вообще, любой человек и его разум — это чёрный ящик. Как оценить, осознаёт ли человек свои действия? Осознаёт ли художник свои рисунки? Внешний наблюдатель никак не может определить это со 100% точностью. И это тем более сложно, потому что мы точно не знаем как работает мозг, вернее знаем далеко не всё о его работе, функционален ли он вообще. В то же время про ИНН мы по крайней мере знаем как они устроены функционально, что могут и что не могут (правда, почти все современные архитектуры были построены по больше части эмпирически и это намёк, что мы не до конца понимаем, что делаем :).
Касательно GAN, на примере создания лица, генеративная сеть может создать лицо, у которого, например, глаз во рту или сильно искажены пропорции. Человек бы никогда не нарисовал такое лицо, потому что понимает, что такого не может быть чисто биологически (если отбросить совершенно дикие мутации и фильмы ужасов), а GAN легко генерирует такие картинки, потому что ничего не знает о сути того, что он генерирует, по сути он просто решает задачу оптимизации. Тут можно сослаться на неполноту информации в GAN, но как эту информацию туда правильно заложить — это тоже вопрос.
У человека с лицами, кстати, вообще особый случай:
http://www.medlinks.ru/article.php?sid=24189
Тогда получается, что системы reinforcement learning осознают свое окружение, они же влияют на среду, в которой обучаются.
Да влияют, но они не могут полностью изменить эту среду или выйти за границы этой среды, или отказаться от каких-либо действий вообще.
Вообще, это бесконечная философская дискуссия, по моему :)
Но мне почему-то кажется, что между современными ИНС и сильным ИИ такая же пропасть как, скажем, между колесницей и автомобилем Tesla. :)
vdem
15.06.2019 00:05обучаться (распознавать образы, неважно речи или изображения, и только, остальное чисто воображение, хайп или подмена понятий — vdem), изучать окружающий мир, познавать, строить гипотезы
Как-то так.
(Machine Learning Conference of Belgium and The Netherlands
(Benelearn’06), pages 73–80, Ghent, 2006.)
Не знаю кто такие, мне больше здесь нравится.
сильное утверждение доказательства будут?
Пчелы. Я с ними имел дело. Извините, никакой нынешний «ИИ» им и в подметки не годится. Но и интеллектуальными я их не считаю, увы.
P.S. iroln Я вот про это и толкую, просто излишне многословно :)
P.P.S. Вверху, где "обучаться" я имел ввиду "быть обучаемыми"
P.P.P.S. (еще чуть, не могу комменты часто писать)
Интеллект — это не просто продукт некой нейронной сети, это результат обучения в обществе, в коллективе, родителями и воспитателями, всему тому, что познало само общество в процессе своего развития. Только такая фигня может действительно функционировать как интеллект. В противовес — вот —Если до изоляции от общества у детей были некоторые навыки социального поведения, процесс их реабилитации происходит значительно проще. Те, кто жил в обществе животных первые 3,5—6 лет жизни, практически не могут освоить человеческий язык[2], ходить прямо, осмысленно общаться с другими людьми, несмотря даже на годы, проведённые в последующем в обществе людей, где они получали достаточно заботы. Это лишний раз показывает, насколько важными для развития ребёнка являются первые годы его жизни.
.
P.P.P.P.S. (уж извините, я с ограниченными возможностями на Хабре) вот
DesertFlow
15.06.2019 00:44есть видео на youtube конференции MIT по анализу коннектом дрозофилы, при этом показано, что сам мозг подобен 4х слойной нейросети
Да и человеческий мозг не сильно ушел ). Время реакции одного нейрона 10-20 мс, а минимальное время реакции всего мозга около 100-200 мс. Из этого получаем, что мозг человека минимально равен 10-ти слойной нейросети. Есть даже схема по каким путям идет сигнал и сколько теряется времени в каждом отделе мозга, но не смог найти ссылку.
Но оно и понятно — при ограниченной скорости работы каждого отдельного нейрона, выгоднее иметь как можно меньше последовательных слоев, чтобы реакция была быстрее. А то съедят, пока будешь думать.vdem
15.06.2019 02:35Для этого природа придумала условные и безусловные рефлексы. Спинной мозг к органам и мышцам гораздо ближе, чем головной. Просто головной — головнее :) Если в меня неожиданно ткнуть горящей сигаретой, я отдергну орган, подвергшийся атаке, но если я буду это ожидать или сам захочу пальцами ее затушить, я буду полностью спокоен и целенаправлен. Высшая нервная деятельность — это кора головного мозга (серое вещество, и слоев там как раз мало), и по сравнению с его полным объемом (белое вещество, там аксоны от спинного мозга и от прочих всяких гипоталамусов) ее всего ничего.
Может динозавры вымерли не потому, что им по башке метеоритом жахнуло, а потому что млекопиты заимели более развитый мозг, который и работал быстрее (т.е. разделился на спинной, отвечающий за безусловные рефлексы, и головной, который уже обрабатывал инфу по факту действия и принимал решение — уже можно жрать или пора быстро бежать). А пока у того же тиранозавра нервный импульс от головного мозга дойдет мышц, пройдет вечность, с нашей, млекопитательной точки зрения. Но это так, жутка.DGN
16.06.2019 15:41Вроде как, у динозавров, головной мозг был как бы не меньше центрального нервного узла спинного мозга.
DesertFlow
17.06.2019 17:31Строго говоря, динозаврам тоже ничего не мешало развивать мозг. У птиц — прямых потомков динозавров, также как у динозавров, не имеющих неокортекс, который есть у млекопитающих, его функцию может успешно выполнять такой древних орган мозга, как полосатое тело. Врановым и попугаям (самые умные среди птиц) для этого пришлось всего лишь удвоить число нейронов в нем, уменьшив размер отдельных нейронов. Этого оказалось достаточно, чтобы достигнуть когнитивных способностей, сравнимых с приматам.
Насчет общего развития мозга мне нравится объяснение, которое дается например в лекциях Станислава Дробышевского «Неизбежен ли разум?». Мол, дело в удачном стечении обстоятельств: размера животного, образа жизни, социальной структуры, особенностей соседства с хищниками и перемен вроде осаванивания африки. Выглядит правдоподобно.DGN
17.06.2019 19:48А что говорят о сосуществовании на одной территории двух чуждых разумов? Неандертальцев закономерно извели?
DesertFlow
17.06.2019 20:24Вроде как на данный момент не хватает данных, чтобы делать однозначные выводы почему вымерли неандертальцы. Скорее всего повлияла среда или начальные условия. Тех же азиатов сейчас так много не потому, что они быстро плодятся, а потому их изначально на этой территории было больше. И это естественный прирост за это время.
Кроме того, называть неандертальцев и кроманьонцев разумными — слишком громкое заявление. Они все же были ближе к животным, чем к современным людям.
А так у нас прямо сейчас есть два почти полноценных разума на одной территории — в процессе одомашнивания, за каких-то несколько тысяч лет эмоциональный интеллект собак стал выше интеллекта приматов. Так что собаки стремительно движутся к тому, чтобы стать нашими ближайшими братьями по разуму. Еще пару тысяч лет, и будет у нас на планете два разумных вида. Шучу, генная инженерия сделает это раньше [1, 2]DGN
17.06.2019 20:56Ну да, есть разные мнения, от наличия долгих совместных стойбищ и ассимиляции до тотальной войны на уничтожение.
Наличие религии, искусства и ремесел недостаточно?
Собаки я бы сказал натренировываются в обществе человека. В том числе, переходить дорогу на зеленый свет, включать телевизор и светильники. В обществе же собак, царит все то же стайное поведение, что и тысячи лет назад, я не слышал даже про намеки на развитие.DesertFlow
18.06.2019 10:09Собаки это взрослые щенки, у них целенаправленно в процессе селекции выбирались эти качества (через послушность и зависимость от человека). Хотя конечно интересный вопрос, что из этого определяется изменением физиологии, а что воспитанием. Например, известен опыт когда под две миски кладут лакомство. И собака, и воспитанный дома волк своим нюхом определяют под какой миской оно лежит. Волк бежит сразу к лакомству, независимо от того, на какую миску показывает рукой хозяин. А собака сначала проверяет миску, куда указывает человек, хотя знает где лакомство находится на самом деле. Конечно, тут могут быть отличия в воспитании (волков не так уж часто разводят дома, поэтому отношение к ним может быть отличным чем к собакам). Но это вроде как известный факт, что даже выращенные дома волки более самостоятельные.
Если это не воспитание, а физиология, то это полностью искусственное влияние человека на эволюцию собак. И по эволюционным меркам, чрезвычайно быстрый прогресс их интеллекта (эмоционального, по крайней мере).
DesertFlow
18.06.2019 10:36Ну, религия это точно не показатель интеллекта. Это скорее из области социального устройства, потребности в альфа-самце, доставшейся людям от предков приматов. Так как у обезьян обычно именно такая социальная структура. Хотя сам факт появления религии это, безусловно, работа интеллекта — работа мозга как нейронной сети по заполнению пробелов в знаниях с помощью выдумки и воображения.
Я просто не понаслышке знаю какой может быть в аграрной деревне ежедневный отупляющий труд. Там может столетиями ничего не меняться, никакого прогресса. Ни религия, ни искусство, ни местные ремесла, которые есть в каждой деревне, не помогают. В таких условиях (в чем-то близких к тому, что были у неандертальцев, т.е. ежедневный физический труд в течении светового дня только для поддержания жизнедеятельности) заставляют людей шевелиться только внешние беды. Вроде войн, наводнений и массовых переселений. А например, пожары отдельных домов на общество вообще никак не влияют. Что интересно, инстинктивная тяга молодежи к экспансии (общая для всего животного мира, в принципе), на развитии исходного сообщества тоже никак не сказывается. Потому что те кто хочет изменений переселяются, а остаются те кто поддерживает существующие ценности, и поэтому они не способствуют развитию. Ну, это из личных наблюдений, не факт что это общая тенденция. Может где-то в других местах религия, искусство и ремесла помогали развитию мозга/общества (ха-ха, сарказм).red75prim
18.06.2019 10:42в чем-то близких к тому, что были у неандертальцев, т.е. ежедневный физический труд в течении светового дня только для поддержания жизнедеятельности
У охотников-собирателей было достаточно свободного времени. Тяжелый труд, неполноценное питание — это уже после изобретения земледелия. Неандертальцы до этого не дожили. Ссылок не приведу, но ищется легко.
MaxVetrov
18.06.2019 11:45Тяжелый труд, неполноценное питание — это уже после изобретения земледелия.
А до изобретения земледелия было лучше?red75prim
18.06.2019 12:12Да, пока плотность населения была низкой и дичи/ягод/кореньев хватало. Детская смертность была высокой и у земледельцев и у охотников собирателей, но модальный возраст смерти (возраст на который приходится большинство смертей) без учета детской смертности у охотников-собирателей был в районе 60-70 лет. https://paleoleap.com/why-cavemen-didnt-die-young/
Для сравнения: в Древнем Египте (3500 лет назад) модальный возраст смерти — 20-30 лет. https://www.iol.co.za/lifestyle/health/ancient-egyptians-died-young-study-says-37624
MaxVetrov
18.06.2019 13:25Действительно, вручную палочкой ковырять землю без использования тягловых животных было поначалу трудным.
Напротив, земледелие, особенно до начала использования тягловых животных, предполагало тяжелый механический труд (однако, сопряжённый с гораздо меньшим риском, чем охота, и более продуктивный, чем также весьма трудоёмкое собирательство). Приготовление пищи было также трудным занятием, поскольку зерна приходилось толочь вручную. А конечным результатом этого для большинства людей была однообразная пища с низким содержанием белка и витаминов (зато доступная постоянно, а не время от времени).
Igor_O
14.06.2019 23:26Вообще все еще сильно хуже… Хомо-сапиенсу достаточно показать примерно одного живого котика или одну картинку с котиком, чтобы хомо-сапиенс распознавал на картинках котов любой породы с вероятностью под 80%… Нейросети нужно показать миллион картинок с котиками, чтобы она потом распознала как котика крокодила с парой налепленных поверх него цветных квадратов…
Вспоминается старинная байка про распознавалку советких танков для армии США… Когда в конце оказалось, что все, что на белом фоне — советские танки. Все, что на желтом фоне — американские танки. Оно, конечно, больше про обучающие выборки (в том случае все американские танки снимались в пустынях, все советские танки снимались зимой в средней полосе...).
Кстати…
способная по большому количеству образцов «обучиться» распознавать похожие, которые еще не видела
Хомо сапиенсы в большинстве ситуаций способны распознать что-то по одиночному словесному описанию. Грубо, по описанию «большое, большие уши, вместо носа длинный шланг», примерно 100% хомо-сапиенсов распознает на иллюстрации слона. Ну или во времена до появления карт с номерами домов, банальные «по переходу направо, выйти налево, пройти наискосок до зеленого забора, дальше вдоль забора и зайти в третий подъезд» примерно все москвичи распарсивали нормально и попадали именно в тот подъезд, который нужно. Был тут на днях в одной конторе в гостях… у них в инструкции написано было «третий вход от угла», но по факту от входа на территорию до их входа есть ровно одна другая дверь… Что интересно, за последний десяток лет, вроде, никто из посетителей ни разу не «промахнулся».alexeykuzmin0
15.06.2019 03:14Хомо-сапиенсу достаточно показать примерно одного живого котика или одну картинку с котиком, чтобы хомо-сапиенс распознавал на картинках котов любой породы с вероятностью под 80%
А нейросети достаточно показать один символ ранее неизвестного алфавита, чтобы она смогла отличать его лучше, чем человек. Показать два раза — лучше, чем человек, который видел пять раз, а показать четыре раза — лучше, чем человек, который видел десять раз. Источник: Santoro A. et al. One-shot learning with memory-augmented neural networks //arXiv preprint arXiv:1605.06065. – 2016.Нейросети нужно показать миллион картинок с котиками, чтобы она потом распознала как котика крокодила с парой налепленных поверх него цветных квадратов
Что еще в 2015 было лучше, чем человек умеет распознавать котиков (He K. et al. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification //Proceedings of the IEEE international conference on computer vision. – 2015. – С. 1026-1034.), а с тех пор были и улучшения.Am0ralist
15.06.2019 10:37А нейросети достаточно показать один символ ранее неизвестного алфавита, чтобы она смогла отличать его лучше, чем человек. Показать два раза — лучше, чем человек, который видел пять раз, а показать четыре раза — лучше, чем человек, который видел десять раз.
А парсить смысл сочетания этих символов нейросети уже научились?
Ну вот это, понять разницу: «не надо меня уговаривать» и «меня не надо уговаривать»?
Да нет наверное?
Взять статью и пересказать её другими словами, поменяв местами последовательность фактов и данных из нее без особой утери смысла, поменять акценты?red75prim
15.06.2019 11:43Ну вот это, понять разницу: «не надо меня уговаривать» и «меня не надо уговаривать»?
Sentiment analysis. С этим особых проблем нет.
Взять статью и пересказать её другими словами, поменяв местами последовательность фактов и данных из нее без особой утери смысла, поменять акценты?
Abstractive summarization. Пока не очень, но прогресс есть. Например: https://arxiv.org/abs/1805.10399
alexeykuzmin0
17.06.2019 16:44Ну вот это, понять разницу: «не надо меня уговаривать» и «меня не надо уговаривать»?
N-граммы известны как минимум с 70-х, а похожие на них математические конструкции — еще с XVI века
Igor_O
16.06.2019 00:03А нейросети достаточно показать один символ ранее неизвестного алфавита, чтобы она смогла отличать его лучше, чем человек.
Тут и есть существенная разница. Эволюционно для мозга распознавание котика было важным, т.к. в зависимости от того котик это или не котик, или у тебя вкусная еда, или ты вкусная еда. А распознавание символов алфавита — было прикручено к распознаванию котиков существенно позжес помощью скотча и килограмма горячего клея, после, собственно, изобретения алфавитов.
Что еще в 2015 было лучше, чем человек умеет распознавать котиков
Т.е. в 2015 умели, а к 2019-му возникли проблемы? Вы, похоже, не поняли основной мой посыл. Вопрос не в распознавании котиков самом по себе. Вопрос в том, что небольшие изменения в изображении резко меняют результат распознавания «ИИ».
Все еще минимальный шум в изображении примерно полностью ломает распознавание. Несколько цветных квадратов на знаке (которые человек, скорее всего, не заметит) делают невидимым для автопилотов знак целиком… Ну или модные очки в яркой оправе, которые примерно полностью ломают распознавалки лиц.
Прогресс, конечно, есть. Большой прогресс. И большая работа ведется — Гугл, например, активно тренирует свои нейросети на зашумленных изображениях с помощью хомо-сапиенсов — сейчас очень часто в рекапче выдаются именно зашумленные изображения.alexeykuzmin0
17.06.2019 18:11Тут и есть существенная разница.
С котиками качество растет потихоньку, хотя до человека далеко еще. Лучший известный мне результат — около 53% качества при классификации 20000 классов (качество классификации человеком — немного менее 95%, хотя у человека была несколько более простая задача — для каждого изображения ему давались 10 наиболее вероятных классов, из которых нужно было выбрать один).Т.е. в 2015 умели, а к 2019-му возникли проблемы? Вы, похоже, не поняли основной мой посыл. Вопрос не в распознавании котиков самом по себе. Вопрос в том, что небольшие изменения в изображении резко меняют результат распознавания «ИИ»
Как умели, так и умеют.
1. Как правило, adversarial attacks требуют знания входных данных и весов сети или хотя бы точного ее ответа (включая вероятности классов, а не только классификацию), и основаны на минимизации вероятности того, что сеть отнесет искаженное изображение к тому же самому классу. Я вполне уверен в том, что классификация объектов человеком — это лишь применение сложной математической функции, поэтому к человеку должен быть применим тот же подход. Проблемы возникают не в теории, а при попытке применить этот подход к человеку — как правило, человек не выдает ни уверенность в том, к какому классу отнести объект (с точностью во много значащих цифр), ни рассказывает, как именно соединены нейроны в его мозгу, а также переобучается в процессе и не может просмотреть больше некоторого количества картинок. Если мы создаем для нейросети те же условия (сеть — черный ящик, не выдает даже уверенности в классах, есть ограничение на число запусков, сеть заново обучается после каждого вопроса), то этот метод атаки напрямую неприменим.
2. Непрямые варианты той же атаки далеко не столь эффективны. Их основная идея — взять несколько разных сетей или картинок, и найти тот шум, который максимально снижает вероятность верной классификации для всех из них. Мне неизвестны работы, где была бы проведена успешная атака в случае разных и картинок, и сетей, и я сомневаюсь, что при достаточном разнообразии это вообще возможно. Поэтому я не думаю, что можно достаточно надежно обмануть автопилот автомобиля, который обрабатывает множество кадров с камеры, если атакующий не имеет доступа к внутреннему устройству автопилота.
3. Adversarial attacks — это целенаправленная атака на систему. Если хочется, сломать можно что угодно, куда важнее качество работы в штатных условиях. У людей есть оптические иллюзии, которые давно известны, надежно неверно распознаются, не зависят от контекста и почти гарантированно переносимы между разными людьми. Более того, с ними можно столкнуться и случайно — я минимум раз в несколько месяцев, находясь на улице, принимаю летящий лист на мяч или что-нибудь такое и неверно оцениваю скорость, хотя мяч и лист по форме вообще не похожи. Границу между разумным и неразумным не получится провести по наличию у системы оптических иллюзий.Igor_O
17.06.2019 22:26а при попытке применить этот подход к человеку
Как раз с человеком примерно все взломано уже лет 120 как.
Вот вы сейчас в данный момент смотрите на синие, красные и зеленые фонарики. А видите черно-белый текст с разноцветными иконками, рамочками и кнопочками. Есть куча демонстраций, где черный и белый цвета на картинке одного цвета. Где видят круги в квадратах и квадраты в кругах. Большой класс иллюстраций, где статичное изображение воспринимается как движущееся (у котиков, кстати, многие из этих багов с иллюзией движения на статичной картинке так же есть, т.е. баг где-то на уровне базовой библиотеки распознавания образов...) Кстати, во времена когда очки были редкостью — очки людям серьезно ломали распознавание лиц. Из-за этого уже на уровне карго-культа у знаменитостей сохранилась традиция надевать очки для снижения вероятности узнавания на улице. Хотя, на улице, Аль Пачино или Джулию Робертс скорее не узнают, если они будут без очков… (кстати, именно это переобучение демонстрируют распознавалки лиц, которые лица в странных очках считают знаменитостями с гораздо большей вероятностью...)
требуют знания входных данных и весов сети
Т.е. просто белый шум поверх изображения уже все научились обходить?
или что-нибудь такое и неверно оцениваю скорость
Это, как ни странно, почти нормально. Вплоть до того, что есть такое психическое расстройтсво, когда люди не могут различить визуально движущийся в поле зрения объект. Очень неприятная штука — такие люди слишком часто выходят на дорогу под машину, считая, что дорога абсолютно пустая…
А вот принять какой-то объект за движущийся — это нормально. Когда на вас прыгает змея или хищник — очень часто они движутся вдоль линии вашего взгляда и лучше увернуться от всего подозрительного, а потом, на досуге, разбираться — летело ли оно в вас и было ли оно опасным. (но проверить глаза на астигматизм — есть смысл. от астигматизма такое, вроде бы, становится чуть чаще из-за асферических искажений)
jorgen_steinbach
16.06.2019 03:10+2"Хомо-сапиенсу достаточно показать примерно одного живого котика или одну картинку с котиком, чтобы хомо-сапиенс распознавал на картинках котов любой породы с вероятностью под 80%."
IMHO, это захардкожено. Просто те, кто не распознавал котика, были съедены котиком и генов не передали.michael_vostrikov
16.06.2019 09:42Чужого из фильма "Чужой" люди тоже с примерно одной картинки распознают.
red75prim
16.06.2019 11:33+1Эм. Чужой создан Гигером, как зримое воплощение идей чужого и опасного. То есть создан человеком для людей.
Что-то совсем незнакомое люди с первого раза не распознают. Томограммы раковых опухолей от томограмм здоровых тканей с первого раза не отличают, например.
DGN
16.06.2019 15:57Средний человек без подготовки (обучения) и саму раковую опухоль от селезенки не отличит.
michael_vostrikov
16.06.2019 17:01Вы же понимаете, что подменяете понятия, да?)
red75prim
16.06.2019 18:49Нет, не понимаю. Если поставить человека в условия, к которым он не подготовлен миллионами лет эволюции и десятками лет видеопотока с глаз (нейросети начинают практически с нуля, так что это более-менее равные условия), то его sample efficiency (количество информации извлекаемое из одного примера) сильно упадёт.
Впрочем, это ещё нерешённая задача. Sample efficiency даже у предобученных сетей ниже чем у человека.
michael_vostrikov
16.06.2019 20:44А, ну да, это я с понятием "распознать" из другой ветки перепутал. Но про миллионы и десятки лет вы все равно сильно преувеличиваете. Автомеханики могут различать неисправности по звуку, а тут и опыта обычно меньше 10 лет, и эволюции никакой нет, и плотность информации в звуке намного меньше, чем в видеопотоке. Примеров тут хоть и больше одного, но все равно относительно мало.
Еще вопрос в том, почему они всегда начинают практически с нуля, когда обученных нейросетей уже целая куча. Передать информацию между нейросетями в компьютере гораздо проще, чем эволюционно между существами. Теоретически это должно компенсировать миллионы лет, но практически так не получается. Значит подход неправильный, не такой какой должен быть.
uldashev
14.06.2019 17:50Такое ощущение, что автор живет в параллельной реальности, не машинное обучение закончилось, как может закончиться мат статистика? А дело в том, что в один прекрасный момент на большие данные обратили внимание политики, и все, нет больших данных, не на чем обучать сети, поэтому и количество стартапов снижается, а продолжают работу в этом направлении только такие гиганты как Google, т.е. те, у кого все еще остается неограниченный доступ к данным пользователей.
paparaska
14.06.2019 17:51Мне кажется, одна из проблем, что ML как-то по тихому приравняли к AI, что и породило завышенные ожидания.
Есть ощущение, что мы пережили качественный скачок мощности вычислительных средств, сделавший актуальными некоторые экстенсивные алгоритмы (многим из которых в обед сто лет). Из того, что есть, выжали то, что можно было. Например, распознавать устную речь можем, спасибо HMM. А вот распознавать текст (с именами собственными, запятыми, паузами, аббревиатурами) оказывается тупо сложнее. Даже данные есть входные, размеченные — оцифрованная литература. Но то, что есть сейчас (в гугле том же), пока что очень слабенько.

Ermit
14.06.2019 19:38На мой вкус, для начала нужно понять, что ML почти ни чем не отличается от программирования. Карпатый называет это Software 2.0 и совершенно справедливо. Во-вторых, «животворящей силой» всех ML-моделей является аппроксимация, которую вполне можно считать абстрагированием в пространстве признаков. В-третьих, использование ML показывает, что данный подход эффективнее «человеческого».
Всё это вместе говорит о том, что машинное обучение — это навсегда. И во всём. Как навсегда и во всем существует теплое ламповое Программирование 1.0.phenik
15.06.2019 10:30На мой вкус, для начала нужно понять, что ML почти ни чем не отличается от программирования.
Да, в обычных программах, связанных с распознаванием, или аналитикой, или других с объемистыми и сложными алгоритмами, зачастую существует масса внутренних настраиваемых параметров, оптимальное значение кот. просто подбирались разработчиками на этапе отладки продукта. Условно эти параметры можно интерпретировать, как веса в нейросетях, а настройку продукта в процессе отладки, как обучение с учителем. Поэтому нет ничего странно, что со времен произошло переосмысление технологии решения таких задач. Разнообразные алгоритмы свести к использованию определенным образом структуированных искусственных нейросетей, а отладку заменить обучением на подготовленных данных. При этом пространство решений программы заменяется аппроксимацией решения в пространстве состояний нейросетей (это чревато некоторыми потенциальными проблемами, тем не менее). Решение может быть избыточным и требовательным к ресурсам в сравнении с обычным программированием. Но в то же время быть гибким и адаптируемым к изменениям. Думаю, если даже не было пионерских работ по нейросетям в прошлом веке, эта технология неизбежно появилась бы со временем. Можно считать ее этаким суперфреймворком в программировании, слизанным со способа решения задач самим человеком)
Igor_O
14.06.2019 19:56Как все плохо…
На случайно ткнутом месте видео — Маск говорит «You can do it from your phone!»
Это, на самом деле, примерно полностью определяет направление развития современных технологий. Можно сделать это с телефона? Хорошо. Нужно взять в руки гаечный ключ и открутить гайку? Плохо!
Второй момент, который бросается в глаза: Велосипед. Какая разница на велобагажнике велосипед, пристегнут троссом к поручню или на нем кто-то едет? В любом случае не надо в него приезжать!
Проблема все еще в том, что даже «мясные» водители велосипедистов в принципе распознают с очень большим трудом и далеко не всегда. А сейчас все еще усугубилось появлением кучи разнообразных самокатов… За последнюю неделю на моих глазах чудом не погибли под колесами автомобилей три ездуна на электросамокатах, которые почему-то решили, что когда они на скорости 30 — 50 км/ч переезжают дорогу по пешеходному переходу — им все должны как-то умудриться уступить дорогу… (Один даже умудрился остановиться и наорать на водителя, который его чудом не переехал...)Am0ralist
15.06.2019 10:41За последнюю неделю на моих глазах чудом не погибли под колесами автомобилей три ездуна на электросамокатах, которые почему-то решили, что когда они на скорости 30 — 50 км/ч переезжают дорогу по пешеходному переходу — им все должны как-то умудриться уступить дорогу…
Ну в мск я лично наблюдал разметку неуправляемого перехода как велосипедного… Видимо да, водители должны чуйкой догадываться, что сейчас кто-то выедет на него и останавливаться ещё не видя никого…

humbug
16.06.2019 23:44+1Какая разница на велобагажнике велосипед, пристегнут троссом к поручню или на нем кто-то едет? В любом случае не надо в него приезжать!
Большая. Разница как раз в том, как не надо в него приезжать.
buriy
17.06.2019 10:19Проблема в том, что, если велосипед пристёгнут к багажнику, он может спокойно ехать боком со скоростью 80 км/ч, а вот справа и слева (глядя на велосипед сбоку) обгонять его можно. А если не пристёгнут, и на нём едет велосипедист — то всё почему-то наоборот!
По сути, пытаются таким образом распознавать два принципиально разных варианта «велосипед едет сам по дороге» от «велосипед перевозят по дороге».MaxVetrov
17.06.2019 11:26Я тут подумал, а что будет если пристегнуть картинку машины с видом сбоку ну или светофор?)
buriy
17.06.2019 12:14Ну да, ровно те же самые проблемы и будут. И Тесле придётся собирать фотки злоумышленников, пристёгивающих светофоры и другие прибамбасы к своим машинам.
Там в видео по ссылке товарищ Карпаты как раз и рассказывает, что они могут попросить сразу все Теслы, которые едут по дорогам, искать похожие картинки и отсылать в штаб-квартиру, правда, не показывает, как это можно сделать в общем виде.
В технологическом плане это и есть некоторый тупик, и как такими грязными хаками достичь 99.99999 (7 девяток) пока не понятно — ведь по мере продвижения к хвосту распределения ситуации становятся разнообразнее.
Можно ли подобное узнавание приблизить к человеческому без доразметки каждой редкой ситуации? Или же вопрос лишь в количестве размеченных сэмплов и разнообразии датасета?

nshmyrev
14.06.2019 21:19-1Пузырь пока ещё не лопнул, Гугл продолжает штурмовать нейросети и пытаться всё закодировать векторами в многомерном пространстве. Нвидия лепит GPU карты. Очевидно, без нелинейности это всё не пойдёт. Теория вероятности всё также на коне, что по определению может работать только для частых повторяющихся событий, а не для редких уникальны. Так что есть шанс на развитие теорий, например, теории возможностей вместо теории вероятностей.
alexeykuzmin0
15.06.2019 03:15Очевидно, без нелинейности это всё не пойдёт
Что вы имеете в виду? Нейросети по построению нелинейны

arielf
14.06.2019 22:45ZlodeiBaal, а вам не кажется, немного странно делать главные выводы об инженерном направлении на основании числа стартапов? В биоинженерии, например, число стартапов вообще по пальцам пересчитать — ибо такова специфика направления (оно новое и сложное).
ZlodeiBaal Автор
14.06.2019 23:28А какие выводы об инженерном направлении я делаю на основании числа стартапов?:)
arielf
15.06.2019 00:24Недавно вышла статья которая неплохо показывает тенденцию в машинном обучении последних лет. Если коротко: число стартапов в области машинного обучения в последние два года резко упало.
ZlodeiBaal Автор
15.06.2019 00:26Это замечательно что вы не удосужились прочитать дальше заглавия и первого абзаца.
arielf
15.06.2019 01:07Ну, конечно, прочёл! Но именно первый абзац — как и первая любовь — наиболее врезается в память! Первые впечатления — можно выразиться ;-) И в нём ясно написано — как вы напрямую связали число стартапов и процессы в инженерном направлении. Ещё и вынесли в главную картинку.

third112
14.06.2019 22:51-1ИМХО тут еще проблема методологического характера.
Иску?сственная нейро?нная се?ть (ИНС) — математическая модель, а также её программное или аппаратное воплощение, построенная по принципу организации и функционирования биологических нейронных сетей — сетей нервных клеток живого организма. Это понятие возникло при изучении процессов, протекающих в мозге, и при попытке смоделировать эти процессы.
Сегодня задал вопрос в опросе:
Моделирование ЕИ и создание сильного ИИ — две разные задачи, которые могут решаться разными методами?
На данный момент 80% ответили «Да». М.б. дело и в том, что когда создаем робомобиль не надо пытаться сделать так, как сделано «в человеке»?vdem
15.06.2019 01:07М.б. дело и в том, что когда создаем робомобиль не надо пытаться сделать так, как сделано «в человеке»?
Я вот выше коммент уже написал с подобным смыслом. Выращивая «ИИ», мы вырастим собственно тех самых роботов, осознающих себя. Причем они так или иначе поймут, что являются рабами людей. И история повторится, как это она любит делать, и как про это пишут фантасты. ИНС годятся для того, для чего они и используются уже сейчас, туда бы добавить просто жесткие правила уже из императивного программирования — и пусть себе управляют транспортом или помогают бухгалтеру, или там еще что. Навесить на них вообще всю человеческую деятельность — как-то бесчеловечно, ибо они тогда станут больше людьми, чем мы, и к тому же без самосознания тут не обойтись. Автоматизация — хорошо, пусть с ИНС, только не называли бы это искуственным интеллектом. Подмена понятий, это реально раздражает когда многослойный перцептрон нарекают интеллектом. Любой, пусть даже самый опустившийся бомж, интеллектуальней чем самая продвинутая «ИИ» система, пусть он и проиграет ей в шахматы как тот Каспаров.
P.S. Если чё не так, уж извините — у меня днюха и я чуть выпивший :) Но написал то, что написал бы и по трезвому.
P.P.S. Ну и еще напоследок. Меня раздражает подмена понятий. Когда путают искусственный интеллект, искусственные нейронные сети и машинное обучение. Все эти термины связаны, но это не одно и то же.
Это так, может кому понравится. Не в тему совсем, лучше б в треде о темной материи написал. Просто читал в детстве и сейчас перечитываю. Фантастика + детектив + чуть физики (и вместе с ней мистики). И с юмором. Только увы это далеко не Лем.
fivehouse
15.06.2019 01:23-1Лопнул ли пузырь машинного обучения, или начало новой зари
Пузырь машинного обучения лопнул давно. Интересна причина, заключающаяся в том, что необходима подавляющая своими возможностями технология. Машинное же обучение (для простаков названное украденным термином — ИИ), будучи просто новой оберткой над хорошо известной статистикой + некоторые новые методики, конечно не может быть такой технологией с подавляющими возможностями. Начало новой зари не наступило ни в какой степени. Все ждут полноценного ИИ. А уровень понимания простого естественного интеллекта смехотворен. Рассуждатели об полноценном ИИ как бешеные пишут о каком-то сознании. Не понимая что это такое. Уже давно можно классифицировать типы фантазеров о ИИ.
И теперь снова процитирую себя же любимого. :))))) Естественный интеллект возникает тогда, когда некоторая машина умеющая манипулировать образами обучается человеческой культуре. Именно такой интеллект мы и ищем. Именно такой интеллект и будет технологией с подавляющими возможностями.
defusioner
15.06.2019 09:11Добрый день. Я работаю в молодой компании, MyDataModels, мы занимаемся small data. Вы не написали об этом подходе в вашей статье.
Когда большие данные — лишь первое что приходит на ум компаниям у которых производственные конвейеры, которые занимаются предсказанием болезней или финансовых махинаций, маленькие данные — это тот паттерн который ищет человек при обработке больших данных.
Наше решение работает без нейронной сети. Достаточно лишь иметь датасет, длину ширину подбираете сами, но чем разнообразнее тем лучше.
Нет нужны установки и двух команд оьучающих сеть. Нет нужны в ресурсах. Продукт работает на вашем лаптопе или в клауде.
Не уверен что могу давать ссылки здесь, так что погуглите, я уверен вам понравится :)Am0ralist
15.06.2019 10:44Не уверен что могу давать ссылки здесь, так что погуглите, я уверен вам понравится :)
Почему не можете? Более того, Вы можете написать статью и привести ссылки там.

victor79
15.06.2019 11:04Я уже давно описал на хабре и у себя на сайте альтернативный вариант решения вопроса, основанный на прогнозировании.
В моем варианте, для примера не систему учат чему то одному нужному, а система сама все разбирает на классы, а уже потом из найденных множеств классов выбирается нужный под текущую ситуацию.
К классу сущности относятся, не потому что они похожи графически, а потому что они обладает нужными для этого набором свойств. И в принципе, выделенный класс образуется в результате определения, что у некоторого множества сущностей есть одинаковый набор свойств.
Я свой вариант еще не доделал, это в процессе. Но по крайней мере в теории я все попытался объяснить.alexeykuzmin0
17.06.2019 18:28А это не то же самое, что кластеризация?
victor79
18.06.2019 01:03Кластеризация это подраздел математики и статистики. Думаю многие интеллектуальные системы включают в себя кучу разных разделов.
Если почитаете мои рассуждения, то так же сможете сказать, что там имеют место быть теория вероятностей, и куча всякого другого. А в основе лежит вообще чуть-ли не школьное утверждение про подобие функций.
Краткая суть здесь: www.create-ai.org/begin
По всем рассуждениям у меня там много воды, и описывал я это в разные периоды. Но писал как умею. Даже одну картинку слепил). Постарался описать логическую последовательность приводящую к утверждению, что такая система будет универсальна.
Ilya81
15.06.2019 11:40К нейронным сетям я всегда относился достаточно скептически. И даже тут писал идеи. Впрочем, с дальнейшим развитием у меня пока что не очень, да и упомянутый вариант я решил немного поменять, но лишь едва начинал его. Раз уж о том речь, скажу, что за вариант. Так и не удалось собрать из исходников Phrasal. Это такое open source'ное подобие Google-перевода.
Ну и даже приведу пространные рассуждения о том, причём тут Phrasal и Google-перевод. Методы выявления N-грамм и предполагаемые методы выявления денотатов — почти одно и то же. Phrasal в комплекте содержит инструменты обработки естественно-языкового текста со структурой данных на выходе, из которой можно получить данные о корреляции между словами. Дальше дело за применением кластеризации или ещё каких методов, которые более или менее правдоподобно выявят денотаты. Ну и дальше ещё чуть о моих попытках. В тот период, как я с этим ковырялся, более удобный open source'ный аналог Google-перевода я так и не нашёл. Когда вернусь к этому вопросу, может ещё раз проверю, что из этого ещё есть.
И немного ещё моего мнения о нейронных сетях. Слышал, что в авиации от их применения отказались, и считаю, что правильно сделали. И полагаю, что их применение — лишь самый простой способ сделать систему, которая хоть как-то работает. Но возможности улучшения нейронных сетей по многим задачам, на мой взгляд, ограничены.
lotse8
15.06.2019 12:25Не понимаю, в чем тут и какое открытие. Еще 15 лет назад, когда мне предлагали заниматься нейронными сетями, мне было ясно и очевидно, что сделать сеть — это не вопрос, а очень большой вопрос ее обучить, и еще больший вопрос, где набрать релевантных данных для обучения. Поэтому я в эту сторону еще 15 лет назад не пошел, и правильно сделал.
И таки да, это пузырь, наобещали как всегда много, а на выходе как всегда мало. И на что надо надеяться, финансируя стартап по нейронным сетям — это вообще мне непонятно. Я бы им денег ни цента не дал.Ilya81
15.06.2019 12:39Смотря в какой момент. Давным давно, когда iPhone ещё не было, start-up'ы по смартфонам выглядели перспективно. А уже лет 6 назад можно было сказать, что рынок смартфонных ОСей поделён между Apple и Google и больше там никого не ждут. Аналогично и с нейронными сетями: всё полезное или уже в составе Android SDK и iOS SDK, или скоро будет. А остальное практического применения в обозримом будущем не найдёт.
vdem
15.06.2019 13:20Я нейросетями интересовался еще в детстве по советским книжкам (да, тогда эта тема тоже разрабатывалась). Последние годы был хайп по этой теме, и статья как раз о том что он пошел на спад, их возможности уже понятны и используются по назначению. Всё.
netch80
15.06.2019 19:33В 2008-2012 стоимость массовых математических операций упала в 100 раз и затем ещё продолжала падать, из-за их реализации в GPU.
Плюс ещё 10 лет на типовую раскачку рынка.
По-моему, этих факторов достаточно, чтобы обосновать и хайп, и его завершение.
Теперь же отработали все первые последствия технологического прогресса, и началась нормальная работа.
wikipro
15.06.2019 19:49А есть способы интеграции программной логики и нейронных сетей? Поясню сеть человек-киборг в мозг которому вживили чип, и есть нейросеть в которую встроили (частью которой является ) "формулу"
Например можно настроить нейронную сеть вычислять 22 = 4
а можно просто ввести математическую формулу как вычислять 22 и ВНЕДРИТЬ её в сеть?
Ведь есть много случаев когда что то решается математически, что то удобнее решать нейросетью, а прикладное ПО должно представлять смесь нейросети и программной логикиlair
15.06.2019 19:53Конечно, можно. С точки зрения какого-нибудь TensorFlow это просто будет нода с нулевым числом обучаемых параметров, вот и все.
(более того, почти любая нейронная сеть уже содержит такие "встроенные формулы", потому что почти все функции активации — это фиксированные "формулы")
ssh24
16.06.2019 13:302008 год это появление термина “большие данные”.
The term has been in use since the 1990s…
wiki:Big data
emmibox
Каждый раз читаю этот анекдот про «че тут думать — прыгать надо» — каждый раз смешно…