Как вы думаете, кто лучше настроит PostgreSQL — DBA или ML алгоритм? И если второй, то пора ли нам задуматься, чем заняться, когда нас заменят машины. Или до этого не дойдет, и важные решения все-таки должен принимать человек. Наверное, уровень изоляции и требования к устойчивости транзакций должны оставаться в ведении администратора. Но индексы уже скоро можно будет доверить машине определять самостоятельно.

Энди Павло на HighLoad++ рассказал про СУБД будущего, которые можно «потрогать» уже сейчас. Если пропустили это выступление или предпочитаете получать информацию на русском языке — под катом перевод выступления.
Речь пойдет о проекте университета Карнеги-Меллона, посвященном созданию автономных СУБД. Под термином «автономный» подразумевается система, которая может автоматически развертывать, настраивать, конфигурировать себя без какого-либо вмешательства человека. Возможно, потребуется около десяти лет, чтобы разработать что-то подобное, но именно этим заняты Энди и его студенты. Конечно, для создания автономной СУБД необходимы алгоритмы машинного обучения, однако, в этой статье сосредоточимся только на инженерной стороне темы. Рассмотрим, как проектировать программное обеспечение, чтобы сделать его автономным.
О спикере: Энди Павло доцент университета Карнеги-Меллона, под его руководством создаётся «самоуправляемая» СУБД PelotonDB, а также ottertune, помогающий тюнить конфиги PostgreSQL и MySQL с помощью машинного обучения. Энди и его команда сейчас настоящие лидеры в области самоуправляемых баз данных.
Причина, по которой мы хотим создать автономную СУБД, очевидна. Управление данными средствами СУБД это очень дорогой и трудоемкий процесс. Средняя зарплата DBA в США примерно 89 тысяч долларов в год. В переводе на рубли получается 5,9 миллионов рублей в год. Эту по-настоящему крупную сумму вы платите людям за то, чтобы они просто присматривали за вашим программным обеспечением. Около 50% общих затрат на использование БД занимает оплата работы таких администраторов и сопутствующего персонала.
Когда речь заходит о действительно больших проектах, таких как мы обсуждаем на HighLoad++ и в которых используются десятки тысяч баз данных, сложность их структуры выходит за рамки человеческого восприятия. Все подходят к решению этой проблемы поверхностно и пытаются добиться максимальной производительности, вкладывая минимальные усилия в настройку системы.
Идея автономных СУБД не нова, их история берет начало в 1970-х, когда впервые начали создаваться реляционные базы данных. Тогда их называли самоадаптируемыми базами данных (Self-Adaptive Databases), и с их помощью пытались решить классические проблемы проектирования баз данных, над которыми люди бьются и по сей день. Это выбор индексов, разбиение и построение схемы БД, а также размещение данных. На тот момент были разработаны инструменты, которые помогали администраторам баз данных развернуть СУБД. Эти инструменты, фактически, работали так же, как и их современные аналоги работают сегодня.
Администраторы отслеживают запросы, исполняемые приложением. Затем они передают этот стек запросов в алгоритм настройки, который строит внутреннюю модель того, как приложение должно использовать базу данных.
Если вы создаете инструмент, который помогает автоматически выбирать индексы, то строите диаграммы, из которых видно, как часто идут обращения к каждой колонке. Затем передаете эту информацию в алгоритм поиска, который просмотрит множество различных расположений — попытается определить, какие из колонок можно индексировать в БД. Алгоритм будет использовать модель внутренних стоимостей, чтобы показать, что этот конкретный даст лучшую производительность по сравнению с другими индексами. Затем алгоритм выдаст предложение, какие изменения в индексах надо внести. В этот момент самое время поучаствовать человеку, рассмотреть данное предложение и, не только решить, является ли оно правильным, но и выбрать подходящее время для его внедрения.

Администраторы БД должны знать, как используется приложение, когда наблюдается падение активности пользователей. Например, в воскресенье в 3:00 утра самый низкий уровень запросов к базе данных, поэтому в это время можно перезагрузить индексы.
Как я уже говорил, все инструменты проектирования того времени работали одинаково — это очень старая проблема. Научный руководитель моего научного руководителя еще в 1976 году написал статью об автоматическом выборе индекса.
В 1990-е годы люди, по сути, работали над той же проблемой, только название сменилось с адаптивных на самонастраивающиеся БД.
Алгоритмы стали немного лучше, инструменты стали немного лучше, но на высоком уровне они работали также, как и ранее. Единственной компанией, которая находилась в авангарде движения самонастраивающихся систем, была Microsoft Research с их проектом автоматического администрирования. Они разработали по-настоящему замечательные решения, и в конце 90-х, начале 00-х снова представили набор рекомендаций по настройке их БД.
Ключевая идея, которую выдвинула компания Microsoft, отличалась от той, что была в прошлом — вместо того, чтобы инструментам настройки поддерживать свои собственные модели, они фактически просто повторно использовали модель стоимостей оптимизатора запросов, помогающую определить выгоду от одного индекса на фоне другого. Если вдуматься, это имеет смысл. Когда нужно знать, действительно ли один индекс сможет ускорить запросы, то не имеет значения, насколько он велик, если оптимизатор его не выберет. Поэтому используется оптимизатор, чтобы выяснить, выберет ли он что-то на самом деле.

В 2007 году Microsoft Research опубликовала статью, в которой изложена ретроспектива исследований за десять лет. И в ней хорошо освещены все сложные задачи, возникшие на каждом отрезке пути.
Еще одна задача, на которую обратили внимание в эру самонастраивающихся баз данных: как сделать автоматическую настройку регуляторов. Регулятор базы данных — это какой-то параметр конфигурации, который меняет поведение системы базы данных во время выполнения. Например, параметр, который присутствует почти у каждой базы данных — это размер буфера. Или, например, можно управлять такими параметрами, как политики блокировки, периодичность очистки диска и тому подобное. Из-за значительного роста сложности регуляторов СУБД в последние годы эта тема становится актуальной.
Чтобы показать, как плохо обстоят дела, приведу обзор, который сделал мой студент, изучив множество релизов PostgreSQL и MySQL.
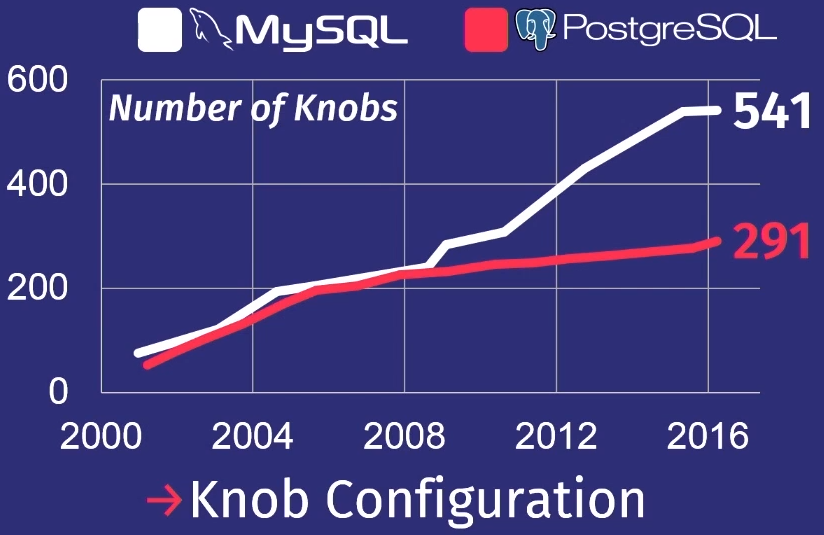
Конечно, не все регуляторы на самом деле управляют процессом исполнения задачи. Некоторые, например, содержат пути к файлам или сетевые адреса, поэтому их может настроить только человек. Но несколько десятков из них действительно могут влиять на производительность. Ни один человек не может удержать столько в голове.
Дальше мы попадаем в эру 2010-х, в которой и находимся по сей день. Я называю её эрой облачных баз данных. За это время была проделана большая работа по автоматизации развертывания большого количества баз данных в облачной среде.
Главное, что беспокоит крупных поставщиков облачных систем, это способы размещения арендатора или миграции с одной на другую. Как определить, сколько ресурсов понадобится каждому арендатору, а затем попытаться распределить их по машинам, так чтобы максимизировать производительность или соответствовать SLA с минимальными затратами.
Amazon, Microsoft и Google решают эту задачу, но в основном на операционном уровне. Только с недавнего времени поставщики облачных услуг стали задумываться о необходимости настройки отдельных систем баз данных. Эта работа не видна обычным пользователям, но она определяет высокий уровень компании.
Почему сегодня у нас не может быть по-настоящему автономной системы самоуправления? Для этого есть три причины.

Во-первых, все эти инструменты, кроме распределения нагрузки у поставщиков облачных услуг, носят лишь консультативный характер. То есть на основе вычисленного варианта человек должен вынести окончательное, субъективное решение, насколько такое предложение является правильным. Более того, нужно еще некоторое время наблюдать за работой системы, чтобы решить, остается ли принятое решение верным по мере развития сервиса. А затем применить знания к своей собственной внутренней модели принятия решений в будущем. Так можно поступить для одной БД, но не для десятков тысяч.
Следующая проблема заключается в том, что любые меры — это только реакция на что-то. Во всех примерах, которые мы рассмотрели, работа идет с данными о прошедшей рабочей нагрузке. Возникает проблема, записи о неё передаются в инструмент, и он говорит: «Да, я знаю, как решить эту проблему». Но решение касается только проблемы, которая уже произошла. Инструмент не прогнозирует будущие события и соответственно не предлагает подготовительных действий. Человек может это сделать, и делает это вручную, а инструменты такого делать не могут.
Последняя причина в том, что ни в одном из решений нет передачи знаний. Вот что я имею ввиду: для примера возьмем инструмент, который работал в одном приложении на первом экземпляре базы данных, если поместить его в еще одно такое же приложение на еще одном экземпляре базы данных, он мог бы на основе полученных знаний при работе с первой базе данных помочь настроить вторую базу данных. В действительности все инструменты начинают работу с нуля, им нужно заново получить все данные о происходящем. Человек же работает совсем по-другому. Если я знаю, как настроить одно приложение определенным образом, я смогу увидеть те же паттерны и в другом приложении и, возможно, настроить его гораздо быстрее. Но ни один из этих алгоритмов, ни один из этих инструментов до сих пор не работает таким образом.
Почему я уверен, что настало время изменений? Ответ на этот вопрос примерно такой же, как и на вопрос, почему стали популярны супермассивы данных или машинное обучение. Оборудование становится более качественным: увеличиваются производственные ресурсы, растет емкость хранилищ, увеличивается мощность аппаратного обеспечения, что ускоряет вычисления для обучения моделей машинного обучения.
Нам стали доступны продвинутые программные средства. Раньше нужно было быть экспертом по MATLAB или низкоуровневой линейной алгебре, чтобы написать некоторые алгоритмы машинного обучения. Теперь у нас есть Torch и Tenso Flow, которые делают ML доступным, и, конечно, мы научились лучше понимать данные. Люди знают, какие именно данные могут понадобиться для принятия решений в будущем, поэтому не отбрасывают так много данных, как раньше.
Цель наших исследований состоит в том, чтобы замкнуть этот круг в автономных СУБД. Мы можем, как и предыдущие инструменты, предлагать варианты решений, но вместо того, чтобы полагаться на человека — правильным ли является решение, когда конкретно нужно его развернуть, — алгоритм сделает это автоматически. А затем с помощью обратной связи будет учиться и со временем становиться лучше.
Я хочу рассказать о проектах, на которыми мы сейчас работаем в Университете Карнеги-Меллона. В них мы подходим к задаче двумя разными способами.
В первом — OtterTune — мы ищем способы настраивать база данных, рассматривая их как черные ящики. То есть способы настроить существующие СУБД, не контролируя внутреннюю часть системы, и наблюдая только за ответной реакцией.
Во проекте Peloton речь идет о создании новых баз данных с нуля, с чистого листа, с учетом того, что система должна работать автономно. Какие регулировки и алгоритмы оптимизации нужно заложить — что невозможно применить к существующим системам.
Рассмотрим оба проекта по порядку.
Проект по регулировке существующих систем, который мы разработали, называется OtterTune.
Представьте, что база данных настраивается как служба. Идея состоит в том, что вы загружаете метрики времени выполнения тяжелых операций БД, съедающих все ресурсы, а в ответ приходит рекомендуемая конфигурация регуляторов, которая, по нашему мнению, увеличит производительность. Это может быть время задержки, пропускная способность или любая другая характеристика, которую вы укажете — мы постараемся найти оптимальный вариант.

Главное, что есть нового в проекте OtterTune — возможность использовать данные предыдущих сессий настройки и повысить эффективность следующих сессий. Например, берем конфигурацию PostgreSQL, в которой есть приложение, которое мы никогда раньше не видели. Но если оно обладает определенными характеристиками или использует базу данных так, как базы данных, которые мы уже видели в наших приложениях, то мы уже знаем, как настроить и это приложение более эффективно.
На более высоком уровне алгоритм работы заключается в следующем.
Допустим, есть целевая БД: PostgreSQL, MySQL, или VectorWise. Необходимо установить контроллер в том же домене, который будет выполнять две задачи.
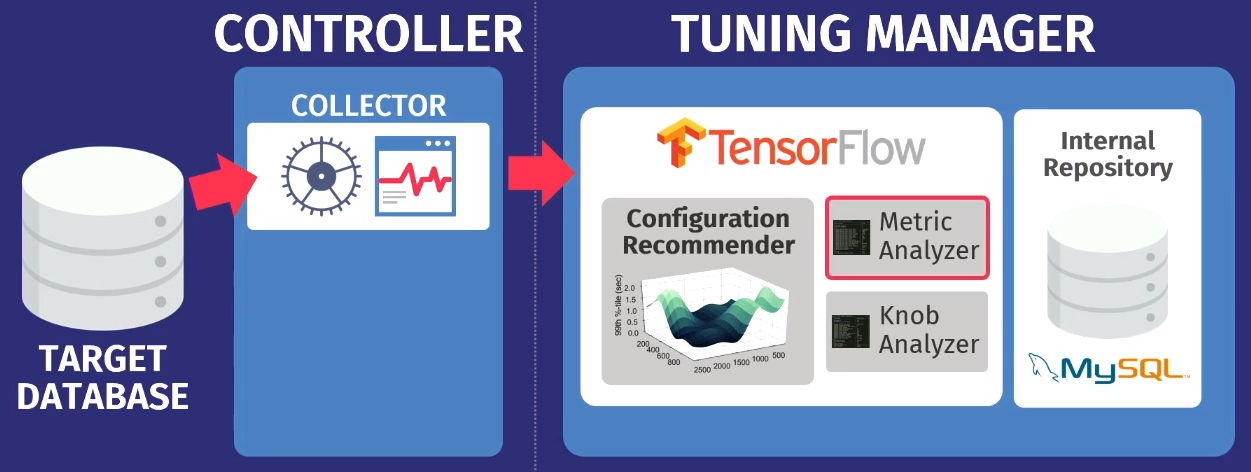
Первую выполняет так называемый коллектор — инструмент, который собирает данные о текущей конфигурации, т.е. метрики времени выполнения запросов от приложений к БД. Данные, собранные коллектором, загружаем в Tuning Manager — службу настройки. При этом не важно, работает ли БД локально или в облаке. После загрузки данные сохраняются в нашем собственном внутреннем репозитории, в котором хранятся все когда-либо сделанные тестовые сессии настройки.
Прежде чем выдать рекомендации, нужно выполнить два этапа. Во-первых, нужно посмотреть на метрики времени выполнения и выяснить, какие из них на самом деле важны. На примере ниже показатели, которые возвращает MySQL но команде
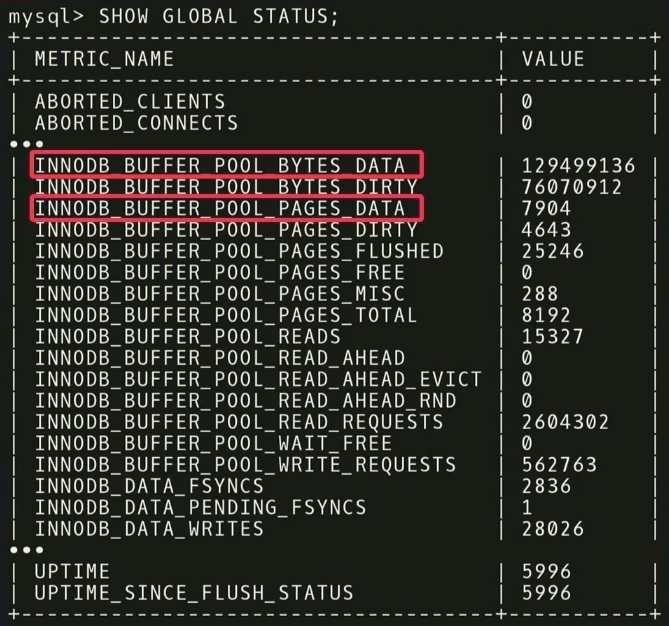
Например, есть две метрики:
На втором этапе делаем то же самое, только в отношении регуляторов. В MySQL 500 регуляторов, и, конечно, не все из них действительно значимы, а для разных приложений важны разные из них. Нужно провести еще один статистический анализ, чтобы выяснить, какие регуляторы действительно повлияют на целевую функцию.
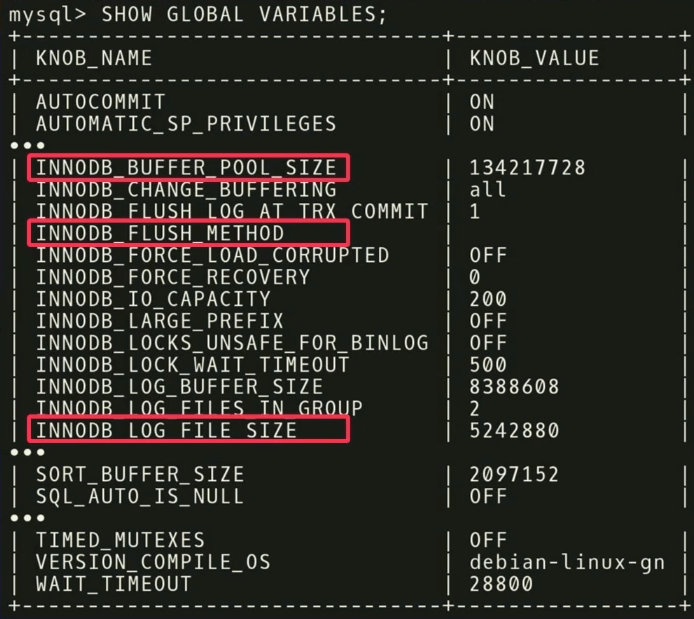
На нашем примере мы выяснили, что три регулятора
Есть и другие интересные моменты, связанные с регуляторами. На скриншоте есть регулятор с именем
После анализа данные передаются в наш конфигурирующий алгоритм, использующий модель гауссовского процесса — довольно старый метод. Вы, вероятно, слышали о глубоком обучении, мы делаем нечто похожее, но без глубоких сетей. Мы используем GPflow — пакет для работы с моделями гауссовского процесса, разработанный в России на основе TensorFlow. Алгоритм выдает рекомендацию, которая должна улучшить целевую функцию; эти данные передаются обратно агенту установки, работающему внутри контроллера. Агент применяет изменения, выполняя сброс — к сожалению, придется перезапустить базу данных — и затем процесс повторяется снова. Собирается еще некоторые метрики времени выполнения, передаются в алгоритм, осуществляется анализ возможности улучшения и повышения производительности, выдается рекомендация, и так далее, снова и снова.
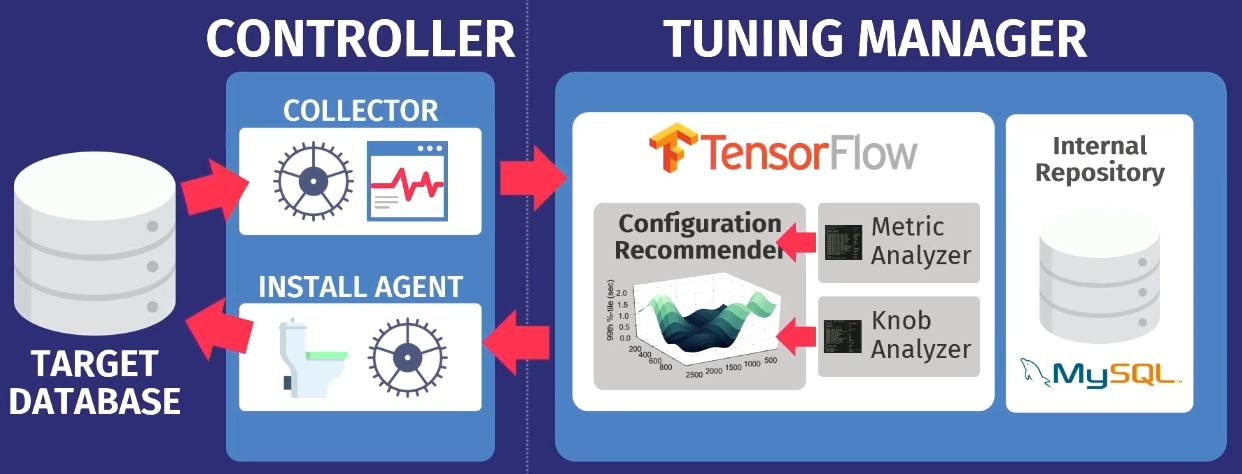
Ключевая особенность OtterTune заключается в том, что в качестве входных данных алгоритмам нужна только информация о метриках времени выполнения. Нам не нужно видеть ваши данные и пользовательские запросы. Нам просто нужно отслеживать операции чтения и записи. Это весомый аргумент — данные, принадлежащие вам или вашим клиентам, не будут раскрыты третьим лицам. Нам не нужно видеть никакие запросы, алгоритм работает, основываясь только на метриках времени выполнения, потому что дает рекомендации для регуляторов, а не для физического проектирования.
Посмотрим на работу демоверсии OtterTune. На сайте проекта, запустим Postgres 9.6, и будем нагружать систему тестом TPC-C. Начнем с начальной конфигурации PostgreSQL, которая разворачивается при установке на Ubuntu.

Для начала запустим TPC-C тест на пять минут, соберем необходимые метрики времени выполнения, загрузим их в службу OtterTune, получим рекомендации, применим изменения и затем повторим процесс. Вернемся к этому позже. Система базы данных работает на одном компьютере, служба Tensor Flow — на другом, и подгружает данные сюда.
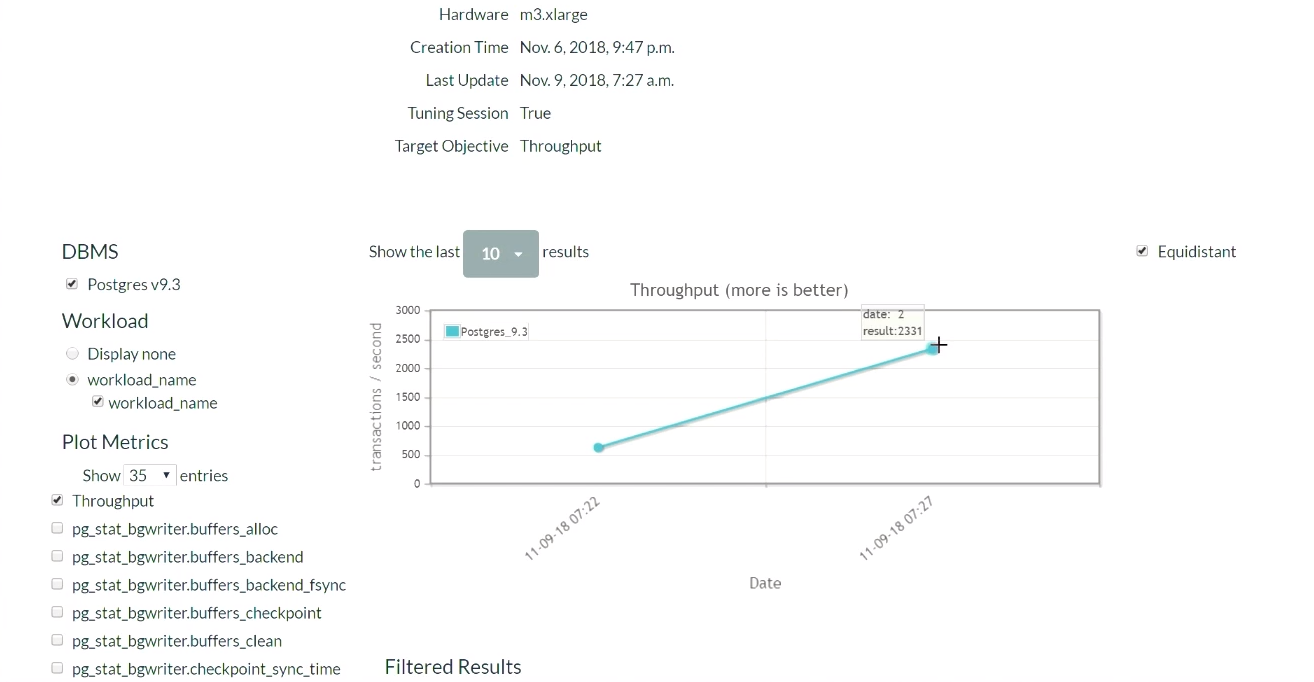
Через пять минут обновим страницу (демонстрация этой части результатов начинается в этот момент). Когда мы только начали, в конфигурации по умолчанию для PostgreSQL, происходило 623 транзакции в секунду. Затем, после получения рекомендации и однократного применения изменений, количество транзакций увеличилось до 2300 в секунду. Стоит признать, что эта демонстрация запускалась уже несколько раз, поэтому в системе уже есть набор ранее собранных данных. Вот почему решение находится настолько быстро. Что бы произошло, если в системе не было таких ранее собранных данных? Данный алгоритм является своего рода пошаговой функцией, и постепенно он добрался бы до такого уровня.

Через некоторое время и пять итераций лучший результат стал 2600. Мы прошли путь от 600 транзакций в секунду, и смогли достичь значения в 2600. Небольшое падение появилось из-за того, алгоритм решил попробовать другой способ настройки регуляторов, после того как достиг неплохих результатов. Результат был с запасом, поэтому большого падения производительности не случилось. Получив негативный результат, алгоритм перенастроился и начал искать другие способы регулирования.
Сделаем вывод, что не следует опасаться запуска плохой стратегии в работу, потому что алгоритм будет исследовать пространство решений и примерять различные конфигурации, для достижения условий соглашения SLA. Хотя всегда можно настроить сервис, чтобы алгоритм выбирал только улучшающие решения. И со временем вы будете получать все лучшие и лучшие результаты.
А теперь вернемся к теме нашего разговора. Расскажу об уже имеющихся результатах из статьи, опубликованной в Sigmod. Мы настраивали MySQL и PostgreSQL для TPC-C с помощью OtterTune, с целью повышения пропускной способности.
Сравним конфигурации этих СУБД, разворачиваемые по умолчанию при первой установке на Ubuntu. Далее, запустим несколько опенсорсных скриптов настройки, которые можно взять у Percona и некоторых других консалтинговых фирм, работающих с PostgreSQL. Эти скрипты используют эвристические процедуры, вроде правила, что для своего аппаратного обеспечения вы должны выставить определенный размера буфера. Также у нас есть конфигурация от Amazon RDS, в которой уже есть преднастройки от Amazon для оборудования, на котором вы работаете. Затем сравним это с результатом ручной настройки дорогостоящих DBA, но с условием, что у них есть 20 минут и возможность выставлять какие угодно параметры. А последним этапом запустим OtterTune.
Для MySQL видно, что конфигурация по умолчанию сильно отстает, скрипты работают немного лучше, RDS еще немного лучше. В данном случае лучший результат показал администратор базы данных — ведущий администратора MySQL из Facebook.
OtterTune проиграл человеку. Но дело в том, что есть некий регулятор, который отключает синхронизацию очистки журнала, и для Facebook это не принципиально. Однако, мы запретили доступ к этому регулятору OtterTune, потому что алгоритмы не знают, согласны ли вы потерять последние пять миллисекунд данных. На наш взгляд, это решение должен принимать человек. Возможно, Facebook согласен с такими потерями, мы этого не знаем. Если мы настроим этот регулятор таким же образом, то сможем конкурировать с человеком.
В случае с PostgreSQL скрипты настройки работают хорошо. RDS справляется немного хуже. Но, стоит отметить, что показатели OtterTune в этот превзошли человека. На гистограмме показаны результаты, полученные после того, как БД настроил главный эксперт по PostgreSQL судебной системы Висконсина. В этом примере OtterTune смог найти оптимальный баланс между размером файла журнала и размером буферного пула, уравновешивая объем памяти, используемый этими двумя компонентами, и обеспечивая наилучшую производительность.
Основной вывод — в службе OtterTune используются такие алгоритмы и машинное обучение, что мы можем достичь той же или лучшей производительности, по сравнению с очень-очень дорогостоящими DBA. И это касается не только одного экземпляра базы данных, мы можем масштабировать работу до десятков тысяч экземпляров, потому что это просто программное обеспечение, просто данные.
Второй проект, о котором я хотел бы рассказать, называется Peloton. Это совершенно новая система данных, которую мы строим с нуля в Карнеги-Меллон. Мы называем ее самоуправляемая СУБД.
Идея состоит в том, чтобы выяснить, какие изменения в лучшую сторону можно сделать, если контролировать весь программный стек. Как сделать настройки лучше, чем может OtterTune, за счет знания о каждом фрагменте системы, обо всем программном цикле.

Как это будет работать: мы интегрировали компоненты машинного обучения с подкреплением в систему базы данных, и можем наблюдать все аспекты ее поведения во время выполнения, а затем давать рекомендации. И мы не ограничиваемся рекомендациями по настройке регуляторов, как это происходит в службе OtterTune, мы хотели бы выполнять весь стандартный набор действий, о которых я говорил ранее: выбор индексов, выбор схем разбиения, вертикальное и горизонтальное масштабирование, и т.д.
Название системы Peloton скорее всего еще изменится. Я не знаю как в России, но у нас в США, термин «peloton» означает «бесстрашный» и «финишный», а на французском языке он значит «взвод». Но в США есть велотренажерная компания Peloton, у которой очень много денег. Каждый раз, когда появляется упоминание о них, например открытие нового магазина, или новая реклама по ТВ, все мои друзья пишут мне: «Смотри, они украли твою идею, украли твое название». В рекламе показаны красивые люди, которые ездят на своих велотренажерах, и мы попросту не можем с этим конкурировать. А недавно Uber анонсировали новый планировщик ресурсов под названием «Peloton», поэтому мы больше не можем так называть свою систему. Но нового названия у нас пока нет, поэтому в этом рассказе я все же буду использовать текущую версию имени.
Рассмотрим, как работает эта система на высоком уровне. Для примера возьмем целевую базу данных, повторюсь, это наше программное обеспечение, это то, с чем мы работаем. Мы собираем ту же историю рабочей нагрузки, что я показывал ранее. Отличие в том, что мы собираемся генерировать модели прогнозирования, которые позволят нам предсказать, какими будут циклы рабочей нагрузки в будущем, какими будут требования рабочей нагрузки в будущем. Вот почему мы называем эту систему самоуправляемой СУБД.
Беспилотный автомобиль смотрит перед собой и может увидеть, что расположено перед ним на дороге, может предсказать, как добраться до места назначения. Таким же образом работает и автономная система баз данных. Вы должны иметь возможность смотреть в будущее и делать заключение, как будет выглядеть рабочая нагрузка через неделю или через час. Затем мы передаем эти спрогнозированные данные в компонент планирования — мы называем его мозгом — работающий на Tensor Flow.
Процесс перекликается с работой AlphaGo из Лондона в рамках проекта Google Deep Mind, на верхнем уровне все это работает по похожему сценарию: применяется поиск по дереву методом Монте-Карло, результатом поиска являются различные действия, которые нужно выполнить для достижения желаемой цели.
Схему работы примерно определяет следующий алгоритм:

Не стоит постоянно прибегать к метафоре беспилотного автомобиля, но именно так они и работают. Это называется горизонтом планирования.
Посмотрев на горизонт на дороге, мы ставим себе воображаемую точку, до которой нужно добраться, а затем начинаем планировать последовательность действий, чтобы достичь этой точки на горизонте: ускориться, замедлиться, повернуть налево, повернуть направо и т.д. Затем мы мысленно откидываем все действия кроме первого, которые нужно совершить, выполняем его, а после повторяем процесс снова. Беспилотники прогоняют такой алгоритм 30 раз в секунду. Относительно баз данных такой процесс протекает немного медленней, но сама идея остается той же.
Мы решили создать нашу собственную систему баз данных с нуля, а не строить что-то поверх PostgreSQL или MySQL, потому что, если честно, они слишком медленны по сравнению с тем, что мы хотели бы сделать. PostgreSQL прекрасен, я люблю его и использую в своих курсах в университете, но на создание индексов уходит слишком много времени, потому что все данные идут с дисков.
В аналогиях с автомобилями автономную СУБД на PostgreSQL можно сравнить с беспилотной фурой. Фура сможет распознать собаку впереди на дороге и объехать ее, но не если она выбежала на проезжую часть прямо перед машиной. Тогда столкновение неизбежно, потому что фура недостаточно маневренная. Мы решили создать систему с нуля, чтобы иметь возможность как можно быстрее применять изменения и выяснять, какова правильная конфигурация.
Сейчас мы решили первую проблему и опубликовали статью о комбинации глубокого обучения и классической линейной регрессии для автоматического выбора и прогнозирования рабочих нагрузок.
Но есть б?льшая проблема, для которой у нас пока нет хорошего решения — каталоги действий. Вопрос состоит не в том, как выбрать действия, потому что ребята из Microsoft уже сделали это. Вопрос в том, как определить, является ли одно действие лучше другого, с точки зрения того, что происходит перед развертыванием и после развертывания. Как обратить действие, если индекс, созданный по команде человека, окажется не оптимальным, как можно отменить это действие и указать причину отмены. Кроме этого, существует целый ряд других задач с точки зрения взаимодействия нашей собственной системы с внешним миром, для которых у нас пока нет решения, но мы работаем над ними.
К слову, расскажу занимательную историю, об одной известной компании, занимающейся базами данных. У этой компании был инструмент автоматического выбора индекса, и у инструмента была проблема. Один клиент постоянно отменял все индексы, которые инструмент рекомендовал и применял. Эта отмена происходила настолько часто, что инструмент завис. Он не знал, какова должна быть дальнейшая стратегия поведения, потому что любое решение, предлагаемое человеку, получало отрицательную оценку. Когда разработчики обратились к клиенту и спросили: «Почему вы отменяете все рекомендации и предложения по индексам?», клиент ответил, что ему просто не нравились их названия. Люди — глупые, но приходится иметь с ними дело. И для этой проблемы у меня пока также нет решения.
Учитывая два разных подхода к созданию автономных систем баз данных, поговорим теперь о том, как спроектировать СУБД, чтобы она была автономной.
Остановимся на трех темах:
Еще раз вернемся к ключевым точкам: система баз данных должна предоставлять правильную информацию алгоритмам машинного обучения для последующего принятия лучших решений. Количество бесполезных данных, которые мы передаем, должно быть уменьшено для увеличения скорости получения ответов.
Я уже говорил, что любой регулятор, требующий от человека оценочного суждения, в автономных компонентах должен быть отмечен как запрещенный. Необходимо отметить этот параметр в настройках
Алгоритм может обнаружить, что при отключении синхронизации в журнале скорость работы значительно возрастет, и применит такое изменение, однако, это может быть неверным решением в вашем проекте.
Что касается регуляторов, которые должны настраиваться автоматически, нужны дополнительные метаданные о том, как алгоритмы могут изменять такие регуляторы.
Сюда относятся такие параметры как:
Для разных интервалов значений желательно задавать алгоритму диапазон, который он может использовать. Если на машине мало памяти, то логично увеличивать значение регулятора интервалами по 10 килобайт, но при работе на машине с большим объемом памяти, возможен шаг увеличения по 10 гигабайт. Таким образом сокращается пространство решений, и это позволяет алгоритмам быстрее сходиться к ответу.
Необходимо как-то пометить каждый регулятор, который ограничен аппаратными ресурсами. Есть нюансы, однако, сделать это нужно. Например, нужно ограничить общий объем памяти, который могут использовать приложения или системы баз данных, чтобы он не превышал общий доступный объем памяти.
Проблема в том, что иногда имеет смысл заложить избыточное обеспечение, как, например с ядрами процессора. Как алгоритм в реальности будет работать с этим, мы просто еще не знаем. Но хотим иметь возможность оперировать метаданными о том, что скажем, этот регулятор относится к памяти, этот — к диску и так далее. Потому что тогда мы сможем понять, в рамках каких диапазонов нужно оставаться.
Мы считаем, что нужно убрать все регуляторы, которые могут настраивать сами себя, если такие есть. Такой проблемы не возникает у программного обеспечения с открытым исходным кодом, она больше относится к вендроскому ПО.
Допустим, в процессе работы обнаруживается дополнительный внешний фактор, не учтенный в алгоритмах машинного обучения. Значит нужно построить новые модели с его учетом, что само по себе является дополнительной рабочей нагрузкой: мы не можем заранее узнать, что вернет запрос и, нужно снова строить модели, которые предсказывали бы, что будет происходить дальше. Если у вас в системе есть что-то вроде регуляторов с автоматической самонастройкой от Oracle, то они могут менять свои значения когда им вздумается, и вы не можете смоделировать это заранее.

Повторюсь, такая модель поведения наблюдается только в коммерческой сфере, и для сохранения автономности все подобные регуляторы должны быть отключены или удалены.
Что касается метрик, мы хотим раскрыть аппаратные возможности, лежащие в основе системы баз данных. Речь идет о возможностях процессора, скорости памяти, скорости диска, скорости сети и тому подобного. Должно присутствовать что-то вроде внутреннего каталога, или информационной схемы, которая показывала бы, как выглядит процессор. Причина простая: когда вы разворачиваете PostgreSQL на определенной машине и на аппаратных средствах то оптимальной будет одна конфигурация регуляторов, а при использовании более мощного оборудования оптимальная конфигурация регуляторов может сильно отличаться.

Предоставляя информацию об аппаратных средствах нашим алгоритмам, можно задействовать методы машинного обучения и экстраполировать, чего можно добиться на этом компьютере, а чего на другом компьютере.
Если существуют какие-либо подкомпоненты, которые можно настраивать, вы должны быть уверены, что для каждого отдельного компонента предоставлены все правильные метрики. Для примера, рассмотрим пример плохой системы, в которой этого должным образом не происходит. Я говорю о RocksDB, известной как MyRocks на MySQL.
RocksDB позволяет настраивать разные семейства колонок. Можно определить несколько семейств колонок на таблицу, а затем для каждого семейства настроить параметры индивидуально. Чтобы выяснить, правильно ли настраивается семейство, нужно посмотреть на метрики и понять, как на самом деле использовалось аппаратное обеспечение. Нужно сделать запрос к информационной схеме RocksDB, чтобы получить статистику по семействам колонок.

Для определения производительности СУБД, важно не отображение семейств колонок и того, как можно их настроить, а количество операций чтения и записи, выполняемые системой. Но MyRocks не показывает такой информации по семействам колонок. Единственный способ получить эту информацию — взглянуть на глобальную статистику семейства колонок:

В коммерческой сфере дела обстоят немного лучше, чем в компаниях, которые используют open source. Последние хоть и улучшают этот аспект от релиза к релизу, но до сих пор никто не достиг идеала.
Помимо очевидного времени простоя, проблема состоит в том, что нужно смоделировать продолжительность времени простоя. В MySQL есть регулятор, с помощью которого устанавливается размер файла журнала. И в зависимости текущего и будущего значения, будет меняться время простоя. Если размер файла журнала в данный момент составляет 5 Гб, и я меняю значение на 10 Гб, я смогу начать работать сразу после перезапуска системы, потому что фактический размер файла не меняется. Но если нужно поменять 5 Гб на один, то время простоя увеличится — на сжатие файла уйдет много времени.
Необходимо смоделировать весь этот процесс, и таким образом все больше времени уходит на принятие изменений. По этой причине мы собираем нашу систему с нуля — PostgreSQL не позволяет делать этого.
Уведомления — очень важный элемент работы. Вам нужно знать, что происходит в моделях. Например, что работа замедлилась, потому что сейчас строится индекс, или же потому, что только что построенный индекс оказался не оптимальным.
Сложности также возникают при горизонтальном масштабировании рабочей нагрузки. При увеличении нагрузки система замедлится, но с этим все равно нужно работать — в будущем системе предстоит соответствовать уровню SLA. На данный момент мы еще не знаем, как будем решать этот вопрос.
И последнее, о чем я хочу поговорить. Как вы знаете, многие системы данных работают в реплицируемых средах для достижения высокой доступности. Поэтому естественно желание выгодно использовать дополнительные ресурсы, чтобы собирать больше данных для обучения. Для этого необходимо, чтобы реплики отличались и имели разные конфигурации.

Предположим, вы работаете в системе с одной мастер-БД и двумя репликами, и решаете задачу выбора индексов. На мастере выбран отличный индекс, но в репликах можно попробовать другие индексы, вдруг какой-то окажется лучше, чем в мастере. Представим, что индекс, найденный в первой реплике, оказался действительно лучшим — он выдает производительность выше, чем на индексе в мастер-БД, соответственно, можно переместить его и дальше использовать на мастере.
Однако не стоит забывать, что бывает, что на репликах могут быть конфигурации, не способные удовлетворить требования приложения к рабочей нагрузке.
Допустим, на второй реплике используется индекс с менее хорошими показателями. Это плохо, потому что, если мастер выйдет из строя, нужно будет переключиться на такую реплику, и мы получим 5-ти минутную задержку. Все это выливается в downtime, а вся идея о высокой доступности системы теряется.
Чтобы избежать потерь, нужно на раннем этапе признать конфигурацию неликвидной, и либо откатить ее, отключить и перезапустить, вернув на правильную конфигурацию, либо просто отменить действие и попытаться нагнать упущенное как можно скорее. Поскольку известно, что ни одна СУБД не позволяет иметь различные конфигурации на уровне, о котором мы здесь говорим, работу необходимо производить в среде, основанной на машинном обучении.
Я собираюсь закончить свой доклад критикой в сторону Oracle. В 2017 году Oracle заявили, что выпустили первую в мире СУБД с самоуправлением. Ларри Эллисон, генеральный директор и основатель Oracle, вышел на сцену и сказал, что «это самое важное, что корпорация Oracle сделала за 20 лет».

Такая несправедливость немного разозлила меня. Не то, чтобы я хотел получить от них признание, но, по крайней мере, они могли бы сказать, что такая идея возникла у нас намного раньше. Мы представили статью на конференции CIDR за несколько месяцев до того, как они опубликовали свои идеи. Я послал Ларри электронное письмо, в котором написал: «Эй, я видел твое объявление, но было немного обидно, что ты ничего не сказал о нас. Конечно, мы некоторое время не работали над этим проектом, но как ты можешь говорить, что Oracle стал первым в мире в этой области?» Он не ответил на мое письмо, это нормально — он никогда не отвечает на мои письма.
Однако, давайте разберем и посмотрим, чем на самом деле является система, представленная Oracle. По их словам, пять ключевых идей делают систему автономной.
Первое, это автоматическое оптимизированное исправление — довольно хорошая штука, но я бы не назвал это самоуправлением, потому что суть всего лишь в том, что при выпуске свежей версии изменения вносятся без каких-либо простоев.
Следующие три идеи — автоматическое индексирование, восстановление и масштабирование. По сути, это те же инструменты, о которых я говорил ранее, пришедшие из эпохи самоснастройки в 2000-х годах. Те же инструменты, которые Oracle сделал десять лет назад, запускаемые сейчас в управляемой среде. К ним применимы те же ограничения, о которых я говорил ранее: это реакционные меры, отсутствие трансферного обучения — нет возможности получить знания из какого-либо действия или изменения для последующего улучшения.
Поэтому я утверждаю, что такая система не является самоуправляемой. Мы можем поспорить о том, что для СУБД означает термин самоуправление, но это довольно философский вопрос.
Пятый пункт — автоматическая настройка запросов. Если вы знакомы с литературой по базам данных, там это называется адаптивной обработкой запросов. Основная идея заключается в следующем: возьмем сложный запрос с множеством JOIN. Пропустим через оптимизатор и получим план выполнения запроса. После запуска оптимизированного запроса в работу возможны сомнения в качестве оптимизации. Если такое происходит нужно перестать работать с таким запросом, вернуться к оптимизатору и запросить новый план. А затем нужно продолжить с места остановки или перезапустить запрос с лучшим планом.
Идея не нова и не является разработкой Oracle. Microsoft в 2017 году анонсировала SQL Server, оснащенный той же функцией. У IBM DB2 в начале 00-х было нечто похожее, под названием «LEO» — оптимизатор обучения. И даже раньше, в 1970-х, именно так работал оптимизатор запросов Ingres. Он обрабатывал кортежи данных, потому что тогда не было возможности делать JOIN, и работал с таблицами, насчитывающими около сотни кортежей. Поэтому для того времени идея была применима.
В завершение хотелось бы сказать, что я думаю, что достичь автономности СУБД станет возможно в ближайшее десятилетие. Понадобится много исследований, многие проблемы не решены, и над ними еще нужно поработать. То, чем мы занимаемся, довольно увлекательно.
Всем тем, кто работает с такими системами, я хочу дать напутствие — каждый раз, когда вы добавляете новую функцию, вы должны четко понимать, как эта функция будет управляться машиной. Не думайте, что найдется человек, который знает, как настроить регулятор для любого приложения. Всегда следует думать, как будет обрабатываться информация, как будет происходить перезапуск системы и т.п., если параметрам будет управлять ПО.
Энди Павло на HighLoad++ рассказал про СУБД будущего, которые можно «потрогать» уже сейчас. Если пропустили это выступление или предпочитаете получать информацию на русском языке — под катом перевод выступления.
Речь пойдет о проекте университета Карнеги-Меллона, посвященном созданию автономных СУБД. Под термином «автономный» подразумевается система, которая может автоматически развертывать, настраивать, конфигурировать себя без какого-либо вмешательства человека. Возможно, потребуется около десяти лет, чтобы разработать что-то подобное, но именно этим заняты Энди и его студенты. Конечно, для создания автономной СУБД необходимы алгоритмы машинного обучения, однако, в этой статье сосредоточимся только на инженерной стороне темы. Рассмотрим, как проектировать программное обеспечение, чтобы сделать его автономным.
О спикере: Энди Павло доцент университета Карнеги-Меллона, под его руководством создаётся «самоуправляемая» СУБД PelotonDB, а также ottertune, помогающий тюнить конфиги PostgreSQL и MySQL с помощью машинного обучения. Энди и его команда сейчас настоящие лидеры в области самоуправляемых баз данных.
Причина, по которой мы хотим создать автономную СУБД, очевидна. Управление данными средствами СУБД это очень дорогой и трудоемкий процесс. Средняя зарплата DBA в США примерно 89 тысяч долларов в год. В переводе на рубли получается 5,9 миллионов рублей в год. Эту по-настоящему крупную сумму вы платите людям за то, чтобы они просто присматривали за вашим программным обеспечением. Около 50% общих затрат на использование БД занимает оплата работы таких администраторов и сопутствующего персонала.
Когда речь заходит о действительно больших проектах, таких как мы обсуждаем на HighLoad++ и в которых используются десятки тысяч баз данных, сложность их структуры выходит за рамки человеческого восприятия. Все подходят к решению этой проблемы поверхностно и пытаются добиться максимальной производительности, вкладывая минимальные усилия в настройку системы.
Можно сэкономить круглую сумму, если настроить СУБД на уровне приложения и окружения, чтобы обеспечить максимальную производительность.
Самоадаптируемые БД, 1970–1990
Идея автономных СУБД не нова, их история берет начало в 1970-х, когда впервые начали создаваться реляционные базы данных. Тогда их называли самоадаптируемыми базами данных (Self-Adaptive Databases), и с их помощью пытались решить классические проблемы проектирования баз данных, над которыми люди бьются и по сей день. Это выбор индексов, разбиение и построение схемы БД, а также размещение данных. На тот момент были разработаны инструменты, которые помогали администраторам баз данных развернуть СУБД. Эти инструменты, фактически, работали так же, как и их современные аналоги работают сегодня.
Администраторы отслеживают запросы, исполняемые приложением. Затем они передают этот стек запросов в алгоритм настройки, который строит внутреннюю модель того, как приложение должно использовать базу данных.
Если вы создаете инструмент, который помогает автоматически выбирать индексы, то строите диаграммы, из которых видно, как часто идут обращения к каждой колонке. Затем передаете эту информацию в алгоритм поиска, который просмотрит множество различных расположений — попытается определить, какие из колонок можно индексировать в БД. Алгоритм будет использовать модель внутренних стоимостей, чтобы показать, что этот конкретный даст лучшую производительность по сравнению с другими индексами. Затем алгоритм выдаст предложение, какие изменения в индексах надо внести. В этот момент самое время поучаствовать человеку, рассмотреть данное предложение и, не только решить, является ли оно правильным, но и выбрать подходящее время для его внедрения.
Администраторы БД должны знать, как используется приложение, когда наблюдается падение активности пользователей. Например, в воскресенье в 3:00 утра самый низкий уровень запросов к базе данных, поэтому в это время можно перезагрузить индексы.
Как я уже говорил, все инструменты проектирования того времени работали одинаково — это очень старая проблема. Научный руководитель моего научного руководителя еще в 1976 году написал статью об автоматическом выборе индекса.
Самонастраивающиеся БД, 1990–2000
В 1990-е годы люди, по сути, работали над той же проблемой, только название сменилось с адаптивных на самонастраивающиеся БД.
Алгоритмы стали немного лучше, инструменты стали немного лучше, но на высоком уровне они работали также, как и ранее. Единственной компанией, которая находилась в авангарде движения самонастраивающихся систем, была Microsoft Research с их проектом автоматического администрирования. Они разработали по-настоящему замечательные решения, и в конце 90-х, начале 00-х снова представили набор рекомендаций по настройке их БД.
Ключевая идея, которую выдвинула компания Microsoft, отличалась от той, что была в прошлом — вместо того, чтобы инструментам настройки поддерживать свои собственные модели, они фактически просто повторно использовали модель стоимостей оптимизатора запросов, помогающую определить выгоду от одного индекса на фоне другого. Если вдуматься, это имеет смысл. Когда нужно знать, действительно ли один индекс сможет ускорить запросы, то не имеет значения, насколько он велик, если оптимизатор его не выберет. Поэтому используется оптимизатор, чтобы выяснить, выберет ли он что-то на самом деле.
В 2007 году Microsoft Research опубликовала статью, в которой изложена ретроспектива исследований за десять лет. И в ней хорошо освещены все сложные задачи, возникшие на каждом отрезке пути.
Еще одна задача, на которую обратили внимание в эру самонастраивающихся баз данных: как сделать автоматическую настройку регуляторов. Регулятор базы данных — это какой-то параметр конфигурации, который меняет поведение системы базы данных во время выполнения. Например, параметр, который присутствует почти у каждой базы данных — это размер буфера. Или, например, можно управлять такими параметрами, как политики блокировки, периодичность очистки диска и тому подобное. Из-за значительного роста сложности регуляторов СУБД в последние годы эта тема становится актуальной.
Чтобы показать, как плохо обстоят дела, приведу обзор, который сделал мой студент, изучив множество релизов PostgreSQL и MySQL.
За последние 15 лет число регуляторов у PostgreSQL возросло в 5 раз, а у MySQL — в 7 раз.
Конечно, не все регуляторы на самом деле управляют процессом исполнения задачи. Некоторые, например, содержат пути к файлам или сетевые адреса, поэтому их может настроить только человек. Но несколько десятков из них действительно могут влиять на производительность. Ни один человек не может удержать столько в голове.
Облачные БД, 2010–…
Дальше мы попадаем в эру 2010-х, в которой и находимся по сей день. Я называю её эрой облачных баз данных. За это время была проделана большая работа по автоматизации развертывания большого количества баз данных в облачной среде.
Главное, что беспокоит крупных поставщиков облачных систем, это способы размещения арендатора или миграции с одной на другую. Как определить, сколько ресурсов понадобится каждому арендатору, а затем попытаться распределить их по машинам, так чтобы максимизировать производительность или соответствовать SLA с минимальными затратами.
Amazon, Microsoft и Google решают эту задачу, но в основном на операционном уровне. Только с недавнего времени поставщики облачных услуг стали задумываться о необходимости настройки отдельных систем баз данных. Эта работа не видна обычным пользователям, но она определяет высокий уровень компании.
Подводя итог 40-летним исследованиям баз данных с автономными и неавтономными системами, можно сделать выводы, что этой работы все же недостаточно.
Почему сегодня у нас не может быть по-настоящему автономной системы самоуправления? Для этого есть три причины.
Во-первых, все эти инструменты, кроме распределения нагрузки у поставщиков облачных услуг, носят лишь консультативный характер. То есть на основе вычисленного варианта человек должен вынести окончательное, субъективное решение, насколько такое предложение является правильным. Более того, нужно еще некоторое время наблюдать за работой системы, чтобы решить, остается ли принятое решение верным по мере развития сервиса. А затем применить знания к своей собственной внутренней модели принятия решений в будущем. Так можно поступить для одной БД, но не для десятков тысяч.
Следующая проблема заключается в том, что любые меры — это только реакция на что-то. Во всех примерах, которые мы рассмотрели, работа идет с данными о прошедшей рабочей нагрузке. Возникает проблема, записи о неё передаются в инструмент, и он говорит: «Да, я знаю, как решить эту проблему». Но решение касается только проблемы, которая уже произошла. Инструмент не прогнозирует будущие события и соответственно не предлагает подготовительных действий. Человек может это сделать, и делает это вручную, а инструменты такого делать не могут.
Последняя причина в том, что ни в одном из решений нет передачи знаний. Вот что я имею ввиду: для примера возьмем инструмент, который работал в одном приложении на первом экземпляре базы данных, если поместить его в еще одно такое же приложение на еще одном экземпляре базы данных, он мог бы на основе полученных знаний при работе с первой базе данных помочь настроить вторую базу данных. В действительности все инструменты начинают работу с нуля, им нужно заново получить все данные о происходящем. Человек же работает совсем по-другому. Если я знаю, как настроить одно приложение определенным образом, я смогу увидеть те же паттерны и в другом приложении и, возможно, настроить его гораздо быстрее. Но ни один из этих алгоритмов, ни один из этих инструментов до сих пор не работает таким образом.
Почему я уверен, что настало время изменений? Ответ на этот вопрос примерно такой же, как и на вопрос, почему стали популярны супермассивы данных или машинное обучение. Оборудование становится более качественным: увеличиваются производственные ресурсы, растет емкость хранилищ, увеличивается мощность аппаратного обеспечения, что ускоряет вычисления для обучения моделей машинного обучения.
Нам стали доступны продвинутые программные средства. Раньше нужно было быть экспертом по MATLAB или низкоуровневой линейной алгебре, чтобы написать некоторые алгоритмы машинного обучения. Теперь у нас есть Torch и Tenso Flow, которые делают ML доступным, и, конечно, мы научились лучше понимать данные. Люди знают, какие именно данные могут понадобиться для принятия решений в будущем, поэтому не отбрасывают так много данных, как раньше.
Цель наших исследований состоит в том, чтобы замкнуть этот круг в автономных СУБД. Мы можем, как и предыдущие инструменты, предлагать варианты решений, но вместо того, чтобы полагаться на человека — правильным ли является решение, когда конкретно нужно его развернуть, — алгоритм сделает это автоматически. А затем с помощью обратной связи будет учиться и со временем становиться лучше.
Я хочу рассказать о проектах, на которыми мы сейчас работаем в Университете Карнеги-Меллона. В них мы подходим к задаче двумя разными способами.
В первом — OtterTune — мы ищем способы настраивать база данных, рассматривая их как черные ящики. То есть способы настроить существующие СУБД, не контролируя внутреннюю часть системы, и наблюдая только за ответной реакцией.
Во проекте Peloton речь идет о создании новых баз данных с нуля, с чистого листа, с учетом того, что система должна работать автономно. Какие регулировки и алгоритмы оптимизации нужно заложить — что невозможно применить к существующим системам.
Рассмотрим оба проекта по порядку.
OtterTune
Проект по регулировке существующих систем, который мы разработали, называется OtterTune.
Представьте, что база данных настраивается как служба. Идея состоит в том, что вы загружаете метрики времени выполнения тяжелых операций БД, съедающих все ресурсы, а в ответ приходит рекомендуемая конфигурация регуляторов, которая, по нашему мнению, увеличит производительность. Это может быть время задержки, пропускная способность или любая другая характеристика, которую вы укажете — мы постараемся найти оптимальный вариант.
Главное, что есть нового в проекте OtterTune — возможность использовать данные предыдущих сессий настройки и повысить эффективность следующих сессий. Например, берем конфигурацию PostgreSQL, в которой есть приложение, которое мы никогда раньше не видели. Но если оно обладает определенными характеристиками или использует базу данных так, как базы данных, которые мы уже видели в наших приложениях, то мы уже знаем, как настроить и это приложение более эффективно.
На более высоком уровне алгоритм работы заключается в следующем.
Допустим, есть целевая БД: PostgreSQL, MySQL, или VectorWise. Необходимо установить контроллер в том же домене, который будет выполнять две задачи.
Первую выполняет так называемый коллектор — инструмент, который собирает данные о текущей конфигурации, т.е. метрики времени выполнения запросов от приложений к БД. Данные, собранные коллектором, загружаем в Tuning Manager — службу настройки. При этом не важно, работает ли БД локально или в облаке. После загрузки данные сохраняются в нашем собственном внутреннем репозитории, в котором хранятся все когда-либо сделанные тестовые сессии настройки.
Прежде чем выдать рекомендации, нужно выполнить два этапа. Во-первых, нужно посмотреть на метрики времени выполнения и выяснить, какие из них на самом деле важны. На примере ниже показатели, которые возвращает MySQL но команде
SHOW_GLOBAL_STATUS на InnoDB. Не все из них полезны для нашего анализа. Известно, что в машинном обучении большое количество данных не всегда хорошо. Потому что тогда требуется еще больше данных, чтобы отделить зерна от плевел. Как и в этом случае, важно избавиться от сущностей, которые на самом деле не имеют значения.Например, есть две метрики:
INNODB_BUFFER_POOL_BYTES_DATA и INNODB_BUFFER_POOL_PAGES_DATA. Фактически, это одна и та же метрика, но в разных единицах измерения. Можно провести статистический анализ, увидеть, что метрики сильно коррелируют, и сделать вывод, что использовать для анализа обе избыточно. Если отбросить одну из них, уменьшится размерность задачи обучения и сократится время получение ответа.На втором этапе делаем то же самое, только в отношении регуляторов. В MySQL 500 регуляторов, и, конечно, не все из них действительно значимы, а для разных приложений важны разные из них. Нужно провести еще один статистический анализ, чтобы выяснить, какие регуляторы действительно повлияют на целевую функцию.
На нашем примере мы выяснили, что три регулятора
INNODB_BUFFER_POOL_SIZE, FLUSH_METHOD и LOG_FILE_SIZE оказывают наибольшее влияние на производительность. За их счет снижается время задержки для транзакционной рабочей нагрузки.Есть и другие интересные моменты, связанные с регуляторами. На скриншоте есть регулятор с именем
TIMED_MUTEXES. Если обратиться к рабочей документации MySQL, в разделе 45.7 будет указано, что этот регулятор устарел. Но алгоритм машинного обучения не умеет читать документацию, поэтому не знает об этом. Он знает, что есть регулятор, который можно включить или выключить, и потребуется много времени, чтобы понять, что это ни на что не влияет. Но можно провести расчёты заранее и выяснить, что регулятор ничего не делает, и не тратить время на его настройку.После анализа данные передаются в наш конфигурирующий алгоритм, использующий модель гауссовского процесса — довольно старый метод. Вы, вероятно, слышали о глубоком обучении, мы делаем нечто похожее, но без глубоких сетей. Мы используем GPflow — пакет для работы с моделями гауссовского процесса, разработанный в России на основе TensorFlow. Алгоритм выдает рекомендацию, которая должна улучшить целевую функцию; эти данные передаются обратно агенту установки, работающему внутри контроллера. Агент применяет изменения, выполняя сброс — к сожалению, придется перезапустить базу данных — и затем процесс повторяется снова. Собирается еще некоторые метрики времени выполнения, передаются в алгоритм, осуществляется анализ возможности улучшения и повышения производительности, выдается рекомендация, и так далее, снова и снова.
Ключевая особенность OtterTune заключается в том, что в качестве входных данных алгоритмам нужна только информация о метриках времени выполнения. Нам не нужно видеть ваши данные и пользовательские запросы. Нам просто нужно отслеживать операции чтения и записи. Это весомый аргумент — данные, принадлежащие вам или вашим клиентам, не будут раскрыты третьим лицам. Нам не нужно видеть никакие запросы, алгоритм работает, основываясь только на метриках времени выполнения, потому что дает рекомендации для регуляторов, а не для физического проектирования.
Посмотрим на работу демоверсии OtterTune. На сайте проекта, запустим Postgres 9.6, и будем нагружать систему тестом TPC-C. Начнем с начальной конфигурации PostgreSQL, которая разворачивается при установке на Ubuntu.
Для начала запустим TPC-C тест на пять минут, соберем необходимые метрики времени выполнения, загрузим их в службу OtterTune, получим рекомендации, применим изменения и затем повторим процесс. Вернемся к этому позже. Система базы данных работает на одном компьютере, служба Tensor Flow — на другом, и подгружает данные сюда.
Через пять минут обновим страницу (демонстрация этой части результатов начинается в этот момент). Когда мы только начали, в конфигурации по умолчанию для PostgreSQL, происходило 623 транзакции в секунду. Затем, после получения рекомендации и однократного применения изменений, количество транзакций увеличилось до 2300 в секунду. Стоит признать, что эта демонстрация запускалась уже несколько раз, поэтому в системе уже есть набор ранее собранных данных. Вот почему решение находится настолько быстро. Что бы произошло, если в системе не было таких ранее собранных данных? Данный алгоритм является своего рода пошаговой функцией, и постепенно он добрался бы до такого уровня.
Через некоторое время и пять итераций лучший результат стал 2600. Мы прошли путь от 600 транзакций в секунду, и смогли достичь значения в 2600. Небольшое падение появилось из-за того, алгоритм решил попробовать другой способ настройки регуляторов, после того как достиг неплохих результатов. Результат был с запасом, поэтому большого падения производительности не случилось. Получив негативный результат, алгоритм перенастроился и начал искать другие способы регулирования.
Сделаем вывод, что не следует опасаться запуска плохой стратегии в работу, потому что алгоритм будет исследовать пространство решений и примерять различные конфигурации, для достижения условий соглашения SLA. Хотя всегда можно настроить сервис, чтобы алгоритм выбирал только улучшающие решения. И со временем вы будете получать все лучшие и лучшие результаты.
А теперь вернемся к теме нашего разговора. Расскажу об уже имеющихся результатах из статьи, опубликованной в Sigmod. Мы настраивали MySQL и PostgreSQL для TPC-C с помощью OtterTune, с целью повышения пропускной способности.
Сравним конфигурации этих СУБД, разворачиваемые по умолчанию при первой установке на Ubuntu. Далее, запустим несколько опенсорсных скриптов настройки, которые можно взять у Percona и некоторых других консалтинговых фирм, работающих с PostgreSQL. Эти скрипты используют эвристические процедуры, вроде правила, что для своего аппаратного обеспечения вы должны выставить определенный размера буфера. Также у нас есть конфигурация от Amazon RDS, в которой уже есть преднастройки от Amazon для оборудования, на котором вы работаете. Затем сравним это с результатом ручной настройки дорогостоящих DBA, но с условием, что у них есть 20 минут и возможность выставлять какие угодно параметры. А последним этапом запустим OtterTune.
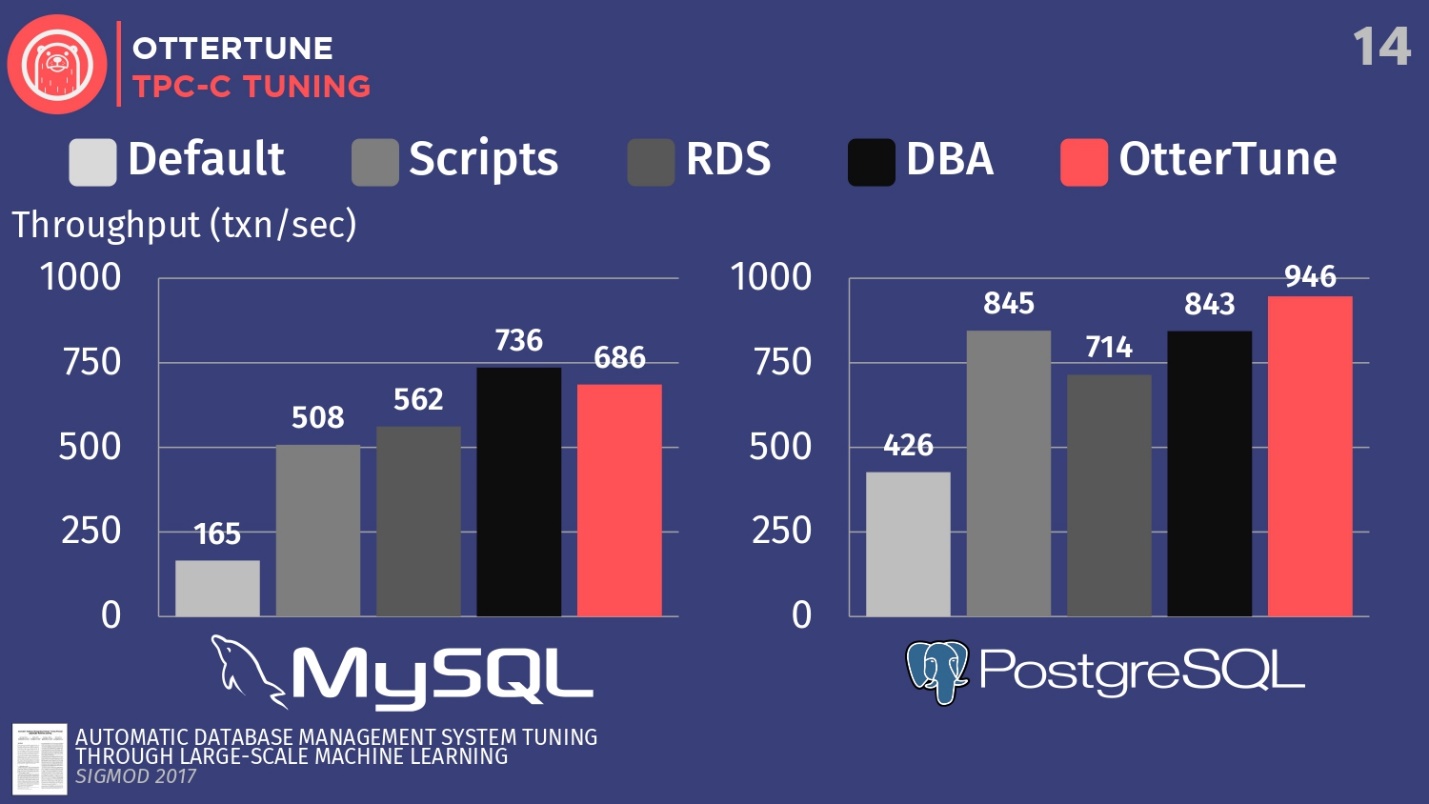
Для MySQL видно, что конфигурация по умолчанию сильно отстает, скрипты работают немного лучше, RDS еще немного лучше. В данном случае лучший результат показал администратор базы данных — ведущий администратора MySQL из Facebook.
OtterTune проиграл человеку. Но дело в том, что есть некий регулятор, который отключает синхронизацию очистки журнала, и для Facebook это не принципиально. Однако, мы запретили доступ к этому регулятору OtterTune, потому что алгоритмы не знают, согласны ли вы потерять последние пять миллисекунд данных. На наш взгляд, это решение должен принимать человек. Возможно, Facebook согласен с такими потерями, мы этого не знаем. Если мы настроим этот регулятор таким же образом, то сможем конкурировать с человеком.
Этот пример показывает, как мы стараемся быть консервативными в том, что окончательное решение должен принимать человек. Потому что существуют определенные аспекты баз данных, о которых алгоритм ML не догадывается.
В случае с PostgreSQL скрипты настройки работают хорошо. RDS справляется немного хуже. Но, стоит отметить, что показатели OtterTune в этот превзошли человека. На гистограмме показаны результаты, полученные после того, как БД настроил главный эксперт по PostgreSQL судебной системы Висконсина. В этом примере OtterTune смог найти оптимальный баланс между размером файла журнала и размером буферного пула, уравновешивая объем памяти, используемый этими двумя компонентами, и обеспечивая наилучшую производительность.
Основной вывод — в службе OtterTune используются такие алгоритмы и машинное обучение, что мы можем достичь той же или лучшей производительности, по сравнению с очень-очень дорогостоящими DBA. И это касается не только одного экземпляра базы данных, мы можем масштабировать работу до десятков тысяч экземпляров, потому что это просто программное обеспечение, просто данные.
Peloton
Второй проект, о котором я хотел бы рассказать, называется Peloton. Это совершенно новая система данных, которую мы строим с нуля в Карнеги-Меллон. Мы называем ее самоуправляемая СУБД.
Идея состоит в том, чтобы выяснить, какие изменения в лучшую сторону можно сделать, если контролировать весь программный стек. Как сделать настройки лучше, чем может OtterTune, за счет знания о каждом фрагменте системы, обо всем программном цикле.
Как это будет работать: мы интегрировали компоненты машинного обучения с подкреплением в систему базы данных, и можем наблюдать все аспекты ее поведения во время выполнения, а затем давать рекомендации. И мы не ограничиваемся рекомендациями по настройке регуляторов, как это происходит в службе OtterTune, мы хотели бы выполнять весь стандартный набор действий, о которых я говорил ранее: выбор индексов, выбор схем разбиения, вертикальное и горизонтальное масштабирование, и т.д.
Название системы Peloton скорее всего еще изменится. Я не знаю как в России, но у нас в США, термин «peloton» означает «бесстрашный» и «финишный», а на французском языке он значит «взвод». Но в США есть велотренажерная компания Peloton, у которой очень много денег. Каждый раз, когда появляется упоминание о них, например открытие нового магазина, или новая реклама по ТВ, все мои друзья пишут мне: «Смотри, они украли твою идею, украли твое название». В рекламе показаны красивые люди, которые ездят на своих велотренажерах, и мы попросту не можем с этим конкурировать. А недавно Uber анонсировали новый планировщик ресурсов под названием «Peloton», поэтому мы больше не можем так называть свою систему. Но нового названия у нас пока нет, поэтому в этом рассказе я все же буду использовать текущую версию имени.
Рассмотрим, как работает эта система на высоком уровне. Для примера возьмем целевую базу данных, повторюсь, это наше программное обеспечение, это то, с чем мы работаем. Мы собираем ту же историю рабочей нагрузки, что я показывал ранее. Отличие в том, что мы собираемся генерировать модели прогнозирования, которые позволят нам предсказать, какими будут циклы рабочей нагрузки в будущем, какими будут требования рабочей нагрузки в будущем. Вот почему мы называем эту систему самоуправляемой СУБД.
Основная идея работы самоуправляемой СУБД схожа с идеей работы автомобиля с автоматическим управлением.
Беспилотный автомобиль смотрит перед собой и может увидеть, что расположено перед ним на дороге, может предсказать, как добраться до места назначения. Таким же образом работает и автономная система баз данных. Вы должны иметь возможность смотреть в будущее и делать заключение, как будет выглядеть рабочая нагрузка через неделю или через час. Затем мы передаем эти спрогнозированные данные в компонент планирования — мы называем его мозгом — работающий на Tensor Flow.
Процесс перекликается с работой AlphaGo из Лондона в рамках проекта Google Deep Mind, на верхнем уровне все это работает по похожему сценарию: применяется поиск по дереву методом Монте-Карло, результатом поиска являются различные действия, которые нужно выполнить для достижения желаемой цели.
Схему работы примерно определяет следующий алгоритм:
- Исходными данными является набор требуемых действий, например, удаление индекса, добавление индекса, вертикальное и горизонтальное масштабирование, и тому подобное.
- Происходит генерация последовательности действий, которая в итоге приводит к достижению максимум целевой функции.
- Отбрасываются все критерии, кроме первого, и изменения применяются.
- Система смотрит на получившийся эффект, затем процесс повторяется снова и снова.
Не стоит постоянно прибегать к метафоре беспилотного автомобиля, но именно так они и работают. Это называется горизонтом планирования.
Посмотрев на горизонт на дороге, мы ставим себе воображаемую точку, до которой нужно добраться, а затем начинаем планировать последовательность действий, чтобы достичь этой точки на горизонте: ускориться, замедлиться, повернуть налево, повернуть направо и т.д. Затем мы мысленно откидываем все действия кроме первого, которые нужно совершить, выполняем его, а после повторяем процесс снова. Беспилотники прогоняют такой алгоритм 30 раз в секунду. Относительно баз данных такой процесс протекает немного медленней, но сама идея остается той же.
Мы решили создать нашу собственную систему баз данных с нуля, а не строить что-то поверх PostgreSQL или MySQL, потому что, если честно, они слишком медленны по сравнению с тем, что мы хотели бы сделать. PostgreSQL прекрасен, я люблю его и использую в своих курсах в университете, но на создание индексов уходит слишком много времени, потому что все данные идут с дисков.
В аналогиях с автомобилями автономную СУБД на PostgreSQL можно сравнить с беспилотной фурой. Фура сможет распознать собаку впереди на дороге и объехать ее, но не если она выбежала на проезжую часть прямо перед машиной. Тогда столкновение неизбежно, потому что фура недостаточно маневренная. Мы решили создать систему с нуля, чтобы иметь возможность как можно быстрее применять изменения и выяснять, какова правильная конфигурация.
Сейчас мы решили первую проблему и опубликовали статью о комбинации глубокого обучения и классической линейной регрессии для автоматического выбора и прогнозирования рабочих нагрузок.
Но есть б?льшая проблема, для которой у нас пока нет хорошего решения — каталоги действий. Вопрос состоит не в том, как выбрать действия, потому что ребята из Microsoft уже сделали это. Вопрос в том, как определить, является ли одно действие лучше другого, с точки зрения того, что происходит перед развертыванием и после развертывания. Как обратить действие, если индекс, созданный по команде человека, окажется не оптимальным, как можно отменить это действие и указать причину отмены. Кроме этого, существует целый ряд других задач с точки зрения взаимодействия нашей собственной системы с внешним миром, для которых у нас пока нет решения, но мы работаем над ними.
К слову, расскажу занимательную историю, об одной известной компании, занимающейся базами данных. У этой компании был инструмент автоматического выбора индекса, и у инструмента была проблема. Один клиент постоянно отменял все индексы, которые инструмент рекомендовал и применял. Эта отмена происходила настолько часто, что инструмент завис. Он не знал, какова должна быть дальнейшая стратегия поведения, потому что любое решение, предлагаемое человеку, получало отрицательную оценку. Когда разработчики обратились к клиенту и спросили: «Почему вы отменяете все рекомендации и предложения по индексам?», клиент ответил, что ему просто не нравились их названия. Люди — глупые, но приходится иметь с ними дело. И для этой проблемы у меня пока также нет решения.
Проектирование автономной СУБД
Учитывая два разных подхода к созданию автономных систем баз данных, поговорим теперь о том, как спроектировать СУБД, чтобы она была автономной.
Остановимся на трех темах:
- как осуществить настройку регуляторов,
- как собрать внутренние метрики,
- как осуществить проектирование действий.
Еще раз вернемся к ключевым точкам: система баз данных должна предоставлять правильную информацию алгоритмам машинного обучения для последующего принятия лучших решений. Количество бесполезных данных, которые мы передаем, должно быть уменьшено для увеличения скорости получения ответов.
Я уже говорил, что любой регулятор, требующий от человека оценочного суждения, в автономных компонентах должен быть отмечен как запрещенный. Необходимо отметить этот параметр в настройках
PG_SETTINGS или в любом другом файле конфигурации, чтобы запретить алгоритму обращение к данному регулятору.В отношении таких параметров, как пути к файлам, уровни изоляции, требования устойчивости транзакций и т.д. решения должен принимать человек, а не алгоритм.
Алгоритм может обнаружить, что при отключении синхронизации в журнале скорость работы значительно возрастет, и применит такое изменение, однако, это может быть неверным решением в вашем проекте.
Что касается регуляторов, которые должны настраиваться автоматически, нужны дополнительные метаданные о том, как алгоритмы могут изменять такие регуляторы.
Сюда относятся такие параметры как:
- Диапазон значений. От минимума до максимума, если речь идет о числовых переменных, или наборы значений для переменных перечислимых типов.
- Булевы флаги для включения и отключения опций. Если у вас есть регуляторы, отвечающие за включение и отключение опций, не следует использовать значения -1 или 0, лучше сделать отдельный булевый флаг.
- Работа с диапазонами значений, особенно это касается переменных интервалов. Например, требуется установить некоторый размер буфера. Если речь идет о 64-битной переменной, то вы можете установить диапазон от 0 или 264. Но не все отдельные значения из этого интервала имеют смысл, или дают новую информацию для алгоритма.
Для разных интервалов значений желательно задавать алгоритму диапазон, который он может использовать. Если на машине мало памяти, то логично увеличивать значение регулятора интервалами по 10 килобайт, но при работе на машине с большим объемом памяти, возможен шаг увеличения по 10 гигабайт. Таким образом сокращается пространство решений, и это позволяет алгоритмам быстрее сходиться к ответу.
Необходимо как-то пометить каждый регулятор, который ограничен аппаратными ресурсами. Есть нюансы, однако, сделать это нужно. Например, нужно ограничить общий объем памяти, который могут использовать приложения или системы баз данных, чтобы он не превышал общий доступный объем памяти.
Проблема в том, что иногда имеет смысл заложить избыточное обеспечение, как, например с ядрами процессора. Как алгоритм в реальности будет работать с этим, мы просто еще не знаем. Но хотим иметь возможность оперировать метаданными о том, что скажем, этот регулятор относится к памяти, этот — к диску и так далее. Потому что тогда мы сможем понять, в рамках каких диапазонов нужно оставаться.
Мы считаем, что нужно убрать все регуляторы, которые могут настраивать сами себя, если такие есть. Такой проблемы не возникает у программного обеспечения с открытым исходным кодом, она больше относится к вендроскому ПО.
Допустим, в процессе работы обнаруживается дополнительный внешний фактор, не учтенный в алгоритмах машинного обучения. Значит нужно построить новые модели с его учетом, что само по себе является дополнительной рабочей нагрузкой: мы не можем заранее узнать, что вернет запрос и, нужно снова строить модели, которые предсказывали бы, что будет происходить дальше. Если у вас в системе есть что-то вроде регуляторов с автоматической самонастройкой от Oracle, то они могут менять свои значения когда им вздумается, и вы не можете смоделировать это заранее.
Повторюсь, такая модель поведения наблюдается только в коммерческой сфере, и для сохранения автономности все подобные регуляторы должны быть отключены или удалены.
Что касается метрик, мы хотим раскрыть аппаратные возможности, лежащие в основе системы баз данных. Речь идет о возможностях процессора, скорости памяти, скорости диска, скорости сети и тому подобного. Должно присутствовать что-то вроде внутреннего каталога, или информационной схемы, которая показывала бы, как выглядит процессор. Причина простая: когда вы разворачиваете PostgreSQL на определенной машине и на аппаратных средствах то оптимальной будет одна конфигурация регуляторов, а при использовании более мощного оборудования оптимальная конфигурация регуляторов может сильно отличаться.
Предоставляя информацию об аппаратных средствах нашим алгоритмам, можно задействовать методы машинного обучения и экстраполировать, чего можно добиться на этом компьютере, а чего на другом компьютере.
Если существуют какие-либо подкомпоненты, которые можно настраивать, вы должны быть уверены, что для каждого отдельного компонента предоставлены все правильные метрики. Для примера, рассмотрим пример плохой системы, в которой этого должным образом не происходит. Я говорю о RocksDB, известной как MyRocks на MySQL.
RocksDB позволяет настраивать разные семейства колонок. Можно определить несколько семейств колонок на таблицу, а затем для каждого семейства настроить параметры индивидуально. Чтобы выяснить, правильно ли настраивается семейство, нужно посмотреть на метрики и понять, как на самом деле использовалось аппаратное обеспечение. Нужно сделать запрос к информационной схеме RocksDB, чтобы получить статистику по семействам колонок.
Для определения производительности СУБД, важно не отображение семейств колонок и того, как можно их настроить, а количество операций чтения и записи, выполняемые системой. Но MyRocks не показывает такой информации по семействам колонок. Единственный способ получить эту информацию — взглянуть на глобальную статистику семейства колонок:
ROCKSDB_BITES_READ, ROCKSDB_BITES_WRITTEN. Такая информация мало полезна для нас, потому что она агрегированная, а мы настраиваем каждое семейство отдельно. Мы не знаем, какой вклад вносит наше конкретное семейство колонок в общий результат по количеству операций чтения и записи. Нам нужно собрать много данных, чтобы затем извлечь их из агрегированного суммарного значения.Пожалуйста, запомните, что никакие действия или новые функции, которые вы добавляете в систему управления базы данных не должны требовать перезапуска системы для вступления в силу.
В коммерческой сфере дела обстоят немного лучше, чем в компаниях, которые используют open source. Последние хоть и улучшают этот аспект от релиза к релизу, но до сих пор никто не достиг идеала.
Помимо очевидного времени простоя, проблема состоит в том, что нужно смоделировать продолжительность времени простоя. В MySQL есть регулятор, с помощью которого устанавливается размер файла журнала. И в зависимости текущего и будущего значения, будет меняться время простоя. Если размер файла журнала в данный момент составляет 5 Гб, и я меняю значение на 10 Гб, я смогу начать работать сразу после перезапуска системы, потому что фактический размер файла не меняется. Но если нужно поменять 5 Гб на один, то время простоя увеличится — на сжатие файла уйдет много времени.
Необходимо смоделировать весь этот процесс, и таким образом все больше времени уходит на принятие изменений. По этой причине мы собираем нашу систему с нуля — PostgreSQL не позволяет делать этого.
Уведомления — очень важный элемент работы. Вам нужно знать, что происходит в моделях. Например, что работа замедлилась, потому что сейчас строится индекс, или же потому, что только что построенный индекс оказался не оптимальным.
Сложности также возникают при горизонтальном масштабировании рабочей нагрузки. При увеличении нагрузки система замедлится, но с этим все равно нужно работать — в будущем системе предстоит соответствовать уровню SLA. На данный момент мы еще не знаем, как будем решать этот вопрос.
И последнее, о чем я хочу поговорить. Как вы знаете, многие системы данных работают в реплицируемых средах для достижения высокой доступности. Поэтому естественно желание выгодно использовать дополнительные ресурсы, чтобы собирать больше данных для обучения. Для этого необходимо, чтобы реплики отличались и имели разные конфигурации.
Предположим, вы работаете в системе с одной мастер-БД и двумя репликами, и решаете задачу выбора индексов. На мастере выбран отличный индекс, но в репликах можно попробовать другие индексы, вдруг какой-то окажется лучше, чем в мастере. Представим, что индекс, найденный в первой реплике, оказался действительно лучшим — он выдает производительность выше, чем на индексе в мастер-БД, соответственно, можно переместить его и дальше использовать на мастере.
Однако не стоит забывать, что бывает, что на репликах могут быть конфигурации, не способные удовлетворить требования приложения к рабочей нагрузке.
Допустим, на второй реплике используется индекс с менее хорошими показателями. Это плохо, потому что, если мастер выйдет из строя, нужно будет переключиться на такую реплику, и мы получим 5-ти минутную задержку. Все это выливается в downtime, а вся идея о высокой доступности системы теряется.
Чтобы избежать потерь, нужно на раннем этапе признать конфигурацию неликвидной, и либо откатить ее, отключить и перезапустить, вернув на правильную конфигурацию, либо просто отменить действие и попытаться нагнать упущенное как можно скорее. Поскольку известно, что ни одна СУБД не позволяет иметь различные конфигурации на уровне, о котором мы здесь говорим, работу необходимо производить в среде, основанной на машинном обучении.
Oracle autonomous database
Я собираюсь закончить свой доклад критикой в сторону Oracle. В 2017 году Oracle заявили, что выпустили первую в мире СУБД с самоуправлением. Ларри Эллисон, генеральный директор и основатель Oracle, вышел на сцену и сказал, что «это самое важное, что корпорация Oracle сделала за 20 лет».
Такая несправедливость немного разозлила меня. Не то, чтобы я хотел получить от них признание, но, по крайней мере, они могли бы сказать, что такая идея возникла у нас намного раньше. Мы представили статью на конференции CIDR за несколько месяцев до того, как они опубликовали свои идеи. Я послал Ларри электронное письмо, в котором написал: «Эй, я видел твое объявление, но было немного обидно, что ты ничего не сказал о нас. Конечно, мы некоторое время не работали над этим проектом, но как ты можешь говорить, что Oracle стал первым в мире в этой области?» Он не ответил на мое письмо, это нормально — он никогда не отвечает на мои письма.
Однако, давайте разберем и посмотрим, чем на самом деле является система, представленная Oracle. По их словам, пять ключевых идей делают систему автономной.
Первое, это автоматическое оптимизированное исправление — довольно хорошая штука, но я бы не назвал это самоуправлением, потому что суть всего лишь в том, что при выпуске свежей версии изменения вносятся без каких-либо простоев.
Следующие три идеи — автоматическое индексирование, восстановление и масштабирование. По сути, это те же инструменты, о которых я говорил ранее, пришедшие из эпохи самоснастройки в 2000-х годах. Те же инструменты, которые Oracle сделал десять лет назад, запускаемые сейчас в управляемой среде. К ним применимы те же ограничения, о которых я говорил ранее: это реакционные меры, отсутствие трансферного обучения — нет возможности получить знания из какого-либо действия или изменения для последующего улучшения.
Поэтому я утверждаю, что такая система не является самоуправляемой. Мы можем поспорить о том, что для СУБД означает термин самоуправление, но это довольно философский вопрос.
Пятый пункт — автоматическая настройка запросов. Если вы знакомы с литературой по базам данных, там это называется адаптивной обработкой запросов. Основная идея заключается в следующем: возьмем сложный запрос с множеством JOIN. Пропустим через оптимизатор и получим план выполнения запроса. После запуска оптимизированного запроса в работу возможны сомнения в качестве оптимизации. Если такое происходит нужно перестать работать с таким запросом, вернуться к оптимизатору и запросить новый план. А затем нужно продолжить с места остановки или перезапустить запрос с лучшим планом.
Идея не нова и не является разработкой Oracle. Microsoft в 2017 году анонсировала SQL Server, оснащенный той же функцией. У IBM DB2 в начале 00-х было нечто похожее, под названием «LEO» — оптимизатор обучения. И даже раньше, в 1970-х, именно так работал оптимизатор запросов Ingres. Он обрабатывал кортежи данных, потому что тогда не было возможности делать JOIN, и работал с таблицами, насчитывающими около сотни кортежей. Поэтому для того времени идея была применима.
Что касается систем с самоуправлением в том виде, в котором они существуют сегодня, я бы не назвал это автономностью.
В завершение хотелось бы сказать, что я думаю, что достичь автономности СУБД станет возможно в ближайшее десятилетие. Понадобится много исследований, многие проблемы не решены, и над ними еще нужно поработать. То, чем мы занимаемся, довольно увлекательно.
Всем тем, кто работает с такими системами, я хочу дать напутствие — каждый раз, когда вы добавляете новую функцию, вы должны четко понимать, как эта функция будет управляться машиной. Не думайте, что найдется человек, который знает, как настроить регулятор для любого приложения. Всегда следует думать, как будет обрабатываться информация, как будет происходить перезапуск системы и т.п., если параметрам будет управлять ПО.
HighLoad++ не стоит на месте, мы уже пакуем чемоданы и выдвигаемся на HighLoad++ Siberia в Новосибирск. Зарубежных спикеров там не будет, но программа в 39 докладов очень сильная, не допускает повторений, а значит всем highload-разработчикам по-хорошему надо не ждать ноября и ехать с нами.
Московский HighLoad++ мы тоже начали готовить, сегодня вот проводим мозговой штурм. Если в этой статье вам не хватало подробностей про машинное обучение, то обратите внимание на UseData Conf — конференция 16 сентября, прием заявок открыт. Подпишитесь на рассылку, и будете знать обо всех наших интересностях.
Комментарии (2)

eviland
19.06.2019 14:47Простите TL;DR, мог пропустить ответ где-то в тексте.
У меня вопрос. Когда у вас в базе 5 таблиц — всё понятно. Но когда их 500 и нагрузка абсолютно разная по характеру (OLAP\OLTP), как ваша автономная СУБД (или не ваша, а от Oracle) поймёт какие запросы должны работать быстрее, а какие не так важны? У такой системы по умолчанию нет полной информации об архитектуре, ближайших и не очень планах, и что самое важное о требованиях к системе. Как она может делать мудрые решения будучи фактически слепой?
cross_join
То есть, ДБА — это те, кто делает бэкапы?
Каким образом автономная СУБД будет исправлять плохое проектирование и запросы — основной источник головной боли?