В HTTP/2 появилась компрессия стандартных заголовков, но тело URI, Cookie, значения User-Agent по-прежнему могут составлять десятки килобайт и требуют токенизации, поиска и сравнения подстрок. Задача становится критичной, если HTTP-парсер должен обрабатывать интенсивный злонамеренный трафик. Стандартные библиотеки предоставляют обширный инструментарий обработки строк, но у HTTP-строки есть своя специфика. Именно для этой специфики разработан HTTP-парсер Tempesta FW. Его производительность в несколько раз выше по сравнению с современными Open Source решениями и превосходит быстрейшие из них.
Александр Крижановский (krizhanovsky) основатель и системный архитектор Tempesta Technologies, эксперт в области высокопроизводительных вычислений в Linux/x86-64. Александр расскажет об особенностях структуры HTTP-строк, объяснит, почему стандартные библиотеки плохо подходят для их обработки, и представит решение Tempesta FW.
Под катом: как HTTP Flood превращает ваш HTTP-парсер в узкое место, проблемы x86-64 с branch mispredictions, кэшированием и не выровненной памятью на типичных задачах HTTP-парсера, сравнение FSM с прямыми переходами, оптимизация GCC, автовекторизация, strspn()- и strcasecmp()-like алгоритмы для HTTP-строк, SSE, AVX2 и фильтрация инъекционных атак с использованием AVX2.
В Tempesta Technologies мы разрабатываем софт на заказ: специализируемся в сложных областях, связанных с высокой производительностью. Особенно гордимся разработкой ядра первой версии WAF компании Positive Technologies. Web Application Firewall (WAF) — это HTTP-proxy: он занимается очень глубоким анализом HTTP-трафика на предмет атак (Web и DDoS). Мы написали для него первое ядро.
Кроме консалтинга мы разрабатываем Tempesta FW — это Application Delivery Controller (ADC). О нем и поговорим.
Application Delivery Controller — это HTTP-proxy c расширенной функциональностью. Но я расскажу о функции, которая связана с безопасностью — о фильтрации DDoS и Web-атак. Также упомяну об ограничениях, а работу и функции покажу с примерами кода.

Tempesta FW встроена в ядро Linux TCP/IP Stack. Благодаря этому и ряду других оптимизаций, он очень быстрый — может обрабатывать 1,8 млн запросов в секунду на дешевом железе. Это в 3 раза быстрее Nginx на топовой нагрузке и также быстро, если сравнивать с kernel bypass approach.
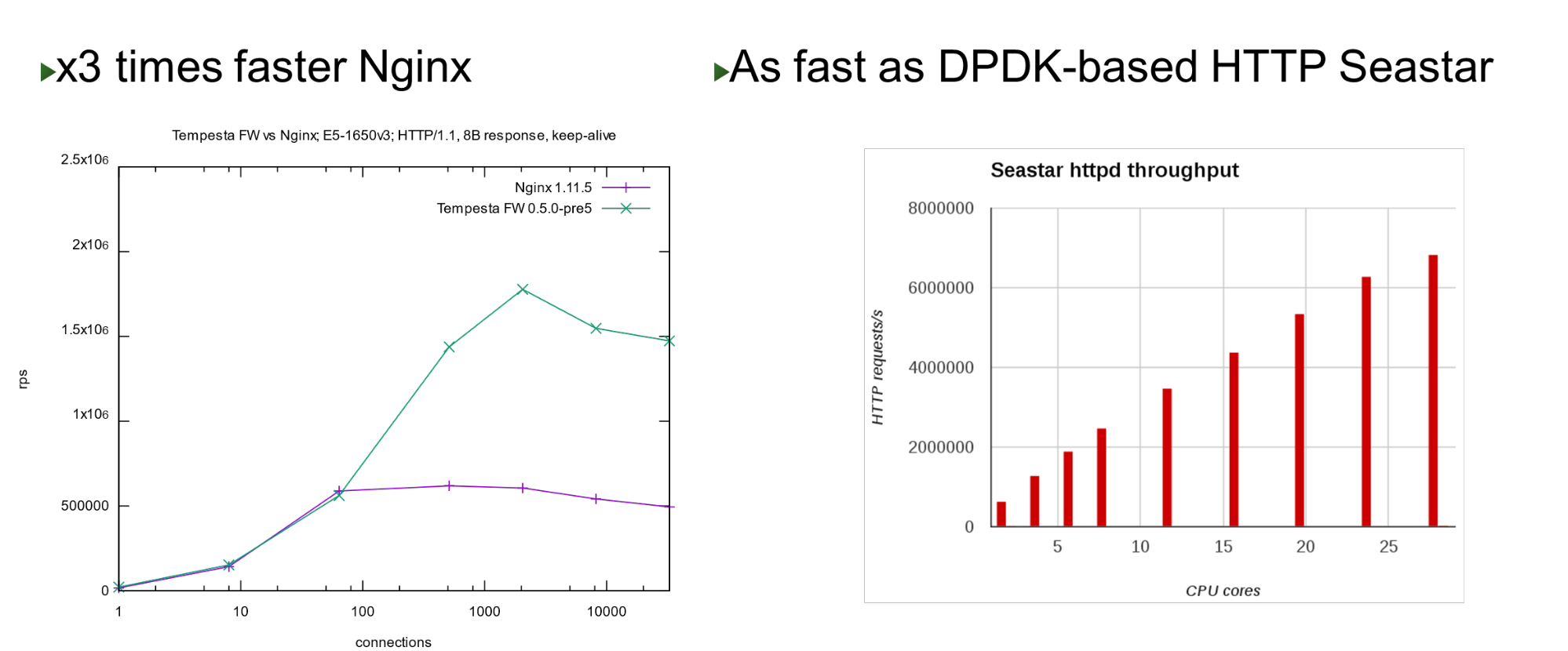
На небольшом количестве ядер он показывает схожую производительность с проектом Seastar, который используется в ScyllaDB (написан на DPDK).
Проект родился тогда же, когда мы приступили к работе над PT AF — в 2013 году. Этот WAF базировался на одном популярном Open Source HTTP-акселераторе. Nginx, HAProxy, Varnish или Apache Traffic — это хорошие HTTP-акселераторы: отлично доставляют контент, кэшируют, модифицируют, но ни один из них не предназначен для массивной обработки и фильтрации трафика.
Поэтому мы подумали, что если есть файрвол сетевого уровня, почему бы не продолжить эту идею и встроиться в качестве файрвола прикладного уровня в TCP/IP стек? Собственно, получился Tempesta FW — гибрид HTTP-акселератора и файрвола.
Примечание: Nginx будет использоваться в докладе как пример, потому, что это простой и популярный веб-сервер. Вместо него мог быть любой другой Open Source HTTP-сервер.
Посмотрим на наш HTTP-запрос (HTTP/(1,~2))
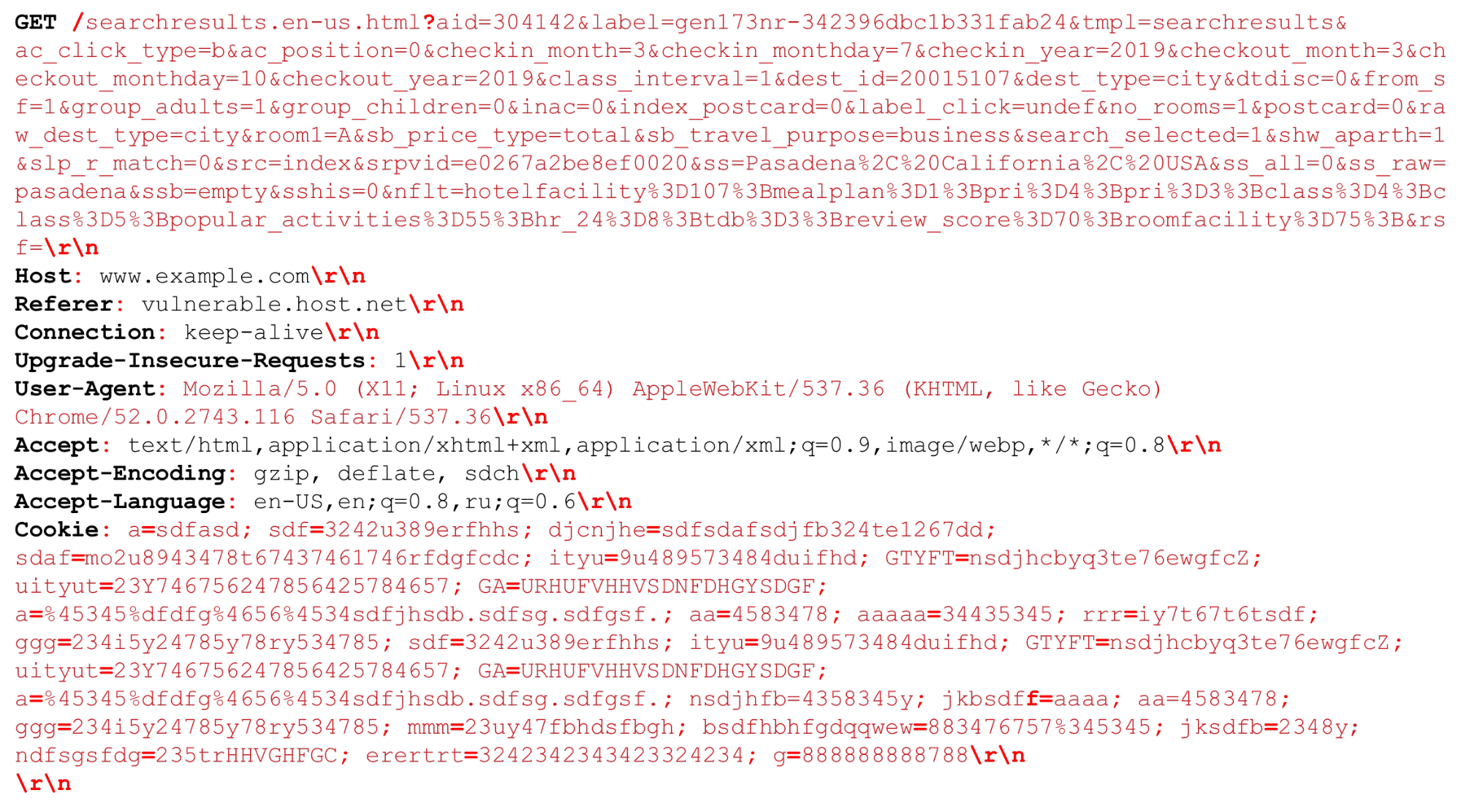
У нас может быть очень большой URI. Красным жирным выделены разделители, которые важны в момент разбора HTTP. Выделю особенности: большие строки по несколько килобайт, а также разные разделители, например, дополнительные «точка с запятой», которые нам нужно парсить, или последовательность "\r\n".
Немного о HTTP/2 тоже нужно сказать.
HTTP/2 — это смесь строк и двоичных данных. Этот микс относится больше к оптимизации пропускной способности соединения, чем к экономии ресурсов сервера.
HTTP/2 в HPACK использует динамическую таблицу. Первый запрос от клиента не оптимизирован, его нет в таблице. Вы его должны распарсить, чтобы он добавился в таблицу. Если к вам приходит HTTP/2 DDoS, это будет как раз тот случай. В нормальном случае HTTP/2 — это бинарный протокол, но вы все равно должны парсить текст: текстовые имена заголовков, данные.
Huffman-кодировка. Это простая кодировка, но Huffman чудовищно тяжело быстро запрограммировать для сжатия: Huffman-кодировка пересекает границу байта, нельзя пользоваться векторными расширениями и нужно идти по байтам. Не получится быстро обрабатывать данные по 32 или по 16 байт.
Cookie, User-Agent, Referer, URI могут быть очень большими. Сначала снимаете Huffman, потом отдаете в обычный HTTP-парсер, такой же, как в HTTP/1. Хотя это разрешено RFC, куки не рекомендуется сжимать, потому что это конфиденциальные данные — нельзя отдавать атакующему информацию об их размере.
Медленная HTTP-обработка. Все HTTP-серверы сначала декодируют HTTP/2 и потом отдают эти строки в HTTP/1-парсер, которым уже пользуется HTTP/1.
В чем проблема с парсингом HTTP/1?
Вредоносный трафик нацелен на самую медленную (самую слабую) часть процесса. Поэтому, если мы хотим сделать фильтр, то должны обращать внимание на медленные части, чтобы они тоже работали быстро.
Посмотрим на nginx-профиль под HTTP-flood. Отключаем access log, чтобы не тормозила файловая система. Когда запрашивается даже обычная индексная страница, парсер поднимается в top'е.
Слева — «Flat profile». Интересно, что в нем самая горячая точка ненамного тяжелее, чем следующая, а после нее профиль ровно спускается. Это значит, например, что оптимизация первой функции в два раза не поможет значительно улучшить производительность. Именно поэтому мы не стали оптимизировать тот же Nginx, а сделали новый проект, который улучшит производительность всего «хвоста» профиля.
Обычно у нас есть цикл (
Входим в цикл (1) и смотрим текущее состояние (check state). Переходим на поступившие данные (символ

Переходим в конец

… и снова ищем состояние в инструкции внутри
Когда уже присвоили переменной

Несколько слов о парсере nginx и его окружении.
Nginx работает с обычным API сокетов — данные, которые поступают на адаптер, копируются в user space. В результате у нас есть большой чанк данных, в котором ищем то, что нужно.
Nginx использует алгоритм, который работает за два прохода: сначала ищет длину, потом проверяет. На первом шаге он сканирует строку на токены, ищет первый токен («пробный»). На втором — токенизирует, проверяет конец запроса (
«Get» всегда находится в одном чанке данных. Tempesta FW работает с zero-copy. Это значит, что данные могут приходить с совершенно произвольным размером: по 1 байту или по 1000 байт. Этот «механизм» нам не подходит.
Посмотрим, как работает
Lookup table. Слева — типичный пример enum: начинаем с 0, потом последовательные метки, 26 констант, а дальше некоторый код, который это все обрабатывает. Справа код, который генерирует компилятор.

Сначала сравниваем переменную
Получается двойное разыменовывание памяти: если мы получили секретные данные, то по байтам находим адрес в массиве и переходим по этому указателю. Важно знать, что в жизни все еще хуже, чем в примере — для lookup table компилятор генерирует код сложнее, в случае сценария для Spectre-атаки.
Бинарный поиск. Следующий кейс —

Справа видим последовательное сравнение, переход на адрес и продолжение сравнения — бинарный поиск идет по коду.
HTTP-парсер nginx. Посмотрим, что такое state machine nginx. В ней 9 килобайт кода — это в три раза меньше, чем кэш первого уровня на машине, на которой запускались бенчмарки (как и на большинства x86-64 процессоров).
Парсер заголовков nginx
Мы же должны строго проверять имена и значения заголовков из соображений безопасности.
Наша state machine на порядок мощнее: мы делаем валидацию заголовков по RFC и сразу, в парсере, почти все обрабатываем. Если в nginx 80 состояний, то у нас — 520, и их становится больше. Если бы мы прогоняли на
У нас zero-copy I/O — чанки разного размера могут резать данные в разных местах. разные чанки могут резать наши данные. В zero-copy I/O, например, «GET» может (редко) встречаться как «GET», «GE» и «T» или «G», «E» и «T», поэтому нужно хранить состояние между порциями данных. Мы практически убираем затраты на I/O, но в профиле взлетает вверх — все плохо. Большой HTTP-парсер одно из самых критичных мест в проекте.
Что делать, чтобы улучшить эту ситуацию?
Первое, что мы делаем — используем не цикл, а прямые переходы по меткам (

Мы кодируем каждое наше состояние меткой в
Недостаток: когда мы хотим перейти на следующее состояние, то сразу должны оценить, есть ли у нас еще доступные данные (потому что zero-copy I/O). Тело условия
В случае больших state machine, для
Заменяем

У GCC есть стандартное расширение, которое может помочь. Берем имя метки (здесь это
Посмотрим, что из этого получается.
На маленьком количестве состояний кодогенератор прямых переходов даже немного медленнее, чем обычный
Примечание: код Tempesta сложнее, чем в примерах. На GitHub есть все бенчмарки, чтобы вы посмотрели все в деталях. Оригинальный код парсера доступен по ссылке (основной HTTP-парсер). Кроме него, в Tempesta FW есть парсеры поменьше, которые используют FSM попроще.
В state machine мы много переходим по коду, поэтому (ожидаемо) будет много branch mispredictions. Выполним «профайлинг» по branch-misses prediction:
На большой state machine в 406 состояний мы тратим 38% времени на обработку переходов в
Дальше посмотрим на профилирование обоих типов state machine по эвентам L1 instruction cache miss — почти 30 килобайт для
Кажется, что если мы не помещаемся в кэш, должно быть очень много кэш-промахов для такой state machine. Но нет, их в 2 раза меньше. Все потому, что кэш работает лучше: мы последовательно работаем с кодом и успеваем подтянуть данные из старших кэшей.
Когда мы программируем код state machine на

Слева — это то, что мы запрограммировали: сначала парсим методы
Это происходит потому, что компилятор не понимает, как к нам приходят данные. Он распределяет код в соответствии со своей картиной прекрасного кода. Чтобы он располагал код в правильном порядке, мы должны использовать компиляторный барьер.
Компиляторный барьер — это пустышка ассемблера, через которую компилятор не будет менять порядок. Просто расставив такие барьеры, мы улучшили производительность на 4%.
Раз компилятор не располагает данные так, как мы хотим, то сделаем profiler guided optimization (оптимизацию под управлением профилировщика). Profiler guided optimization (PGO) — общее количество выборок, а не последовательность вызовов. Например, URI получает больше выборок, чем анализ метода, поэтому расположит код обработки URI перед обработкой метода.
Как это работает? Напишем код, запустим на нем бенчмарки, отдадим результат профайлинга компилятору, и он сгенерирует оптимальный код для наших нагрузок. Но проблема в том, что он просто компилирует самые горячие участки кода, но не отслеживает зависимость по времени. Если самый большой в нагрузке URI, то это и будет самое горячее место. URI поднимется в топ функции, а PGO не покажет, что перед URI всегда находится имя метода. Соответственно, PGO не работает.
Что же работает?

На картинке показано начало парсинга метода, конец и барьер. Мы совершенно не ожидали увидеть код за барьером. Кажется, такого быть не должно — мы же поставили барьер.
Но что происходит в реальности? Компилятор видит
Чтобы такого не было, GCC предлагает следующее расширение: это атрибуты

Здесь мы соглашаемся с тем, что
Посмотрим на оптимизацию компилятора. Первое, что приходит в голову, использовать не O2, а O3 — должно быть быстрее. Но это не так — O3 иногда генерирует код хуже.

O3 — это набор некоторых оптимизаций. Если добавить их к O2 по отдельности, мы получим разные варианты: некоторые оптимизации помогают, некоторые мешают. Для нашего конкретного кода мы выбираем только те оптимизации, которые генерируют код лучше. Оставляем лучший результат — здесь 1,820 секунд относительно 1,838 и 1,858.
Зеленым выделены некоторые опции — это автовекторизация.
Пример цикла из гайда GCC.
Если у нас есть некоторый переменный массив, который повторяется, мы можем оптимизировать цикл — разложить на векторы. По умолчанию на третьем уровне оптимизации -O3 включается автовекторизация: GCC генерирует векторный код где может. Но не весь код можно автоматически векторизовать (даже если он векторизуем в принципе).
Мы можем включить опцию GCC
Делаем небольшой хак, как в nginx: не парсим строки по байтам, а вычисляем
Мы знаем, что если
Тогда попробуем выравнивать
Но оказывается, что такой подход работает хуже:
Если коротко: есть разница между изолированным, неоптимизируемым, кодом бенчмарка и inlined кодом парсера, который теряет оптимизацию из-за большего объема кода. В профайлинге никаких пенальти не было.
Примечание: подробное обсуждение того, почему так происходит в нашей задаче, можно почитать на GitHub.
Например, это нормальный URI:

Если вы достаточно привередливы к отелю, зайдете на Booking и зададите какие-то фильтры, получите URI больше килобайта.
У nginx стоит достаточно массивная машина парсинга на
Еще один URI: /redir_lang.jsp?lang=foobar%0d%0aContent-Length:%200%0d
%0a%0d%0aHTTP/1.1%20200%20OK%0d%0aContent-Type:%20text/
html%0d%0aContent-Length:%2019%0d%0a%0d%0aShazam</
html>.
Он выглядит как первый, но в нем есть инъекция. Придется достаточно много поковыряться, чтобы это понять.
Проведем тест: возьмем первый URI, скормим wrk, натравим на nginx и увидим, что парсинг nginx становится очень горячим.

Если на предыдущем обычном индексном запросе было видно, что парсер уже в топе, здесь становится еще горячее.
Что особенного есть у строк HTTP? Разные разделители
Они работают медленно. Посмотрим бенчмарки и поймем, что в них не так.
Есть несколько парсеров.
Nginx — простейший парсер, синтаксический анализатор Он строго проверяет соответствие RFC. Есть еще парсеры PicoHTTPParser (H2O) и Cloudflare. Они быстрее обрабатывают данные, но могут пропустить символы, которые недопустимы по RFC.
PCMESTRI. В парсерах используется несколько разных подходов. Первый — это инструкция PCMESTRI, которая используется в Pico-парсере.
Задаем диапазоны (ranges) в инструкции. К сожалению, мы можем загрузить либо 16 символов, либо 8 диапазонов. Если диапазон состоит всего из одного символа — просто повторяем. Из-за этого ограничения Pico-парсер не может полностью проверить соответствие RFC, потому что в данном месте у RFC больше 8 диапазонов.

Загружаем алфавит в регистр, загружаем строку, исполняем инструкцию. На выходе быстро видим — есть совпадение или нет.
AVX2 — подход CloudFlare. CloudFlare-парсер с помощью AVX2 обрабатывает за раз 32 байта строки, вместо 16 байт у Pico-парсера. В CloudFlare лучше парсинг, потому что его перевели его на AVX2.

Проверяем все символы до пробела по таблице ASCII, все символы больше 128 и берем диапазон между ними. Простой код работает быстро.
Сравним PCMESTRI и AVX2. Для нас актуальный лимит — 1500. Это максимальный размер пакета, который к нам приходит. Видим, что AVX2-код на больших данных работает намного быстрее, чем Pico-парсер. Но работает медленнее на маленьких данных, потому что в AVX2 инструкции тяжелее.

Сравним с
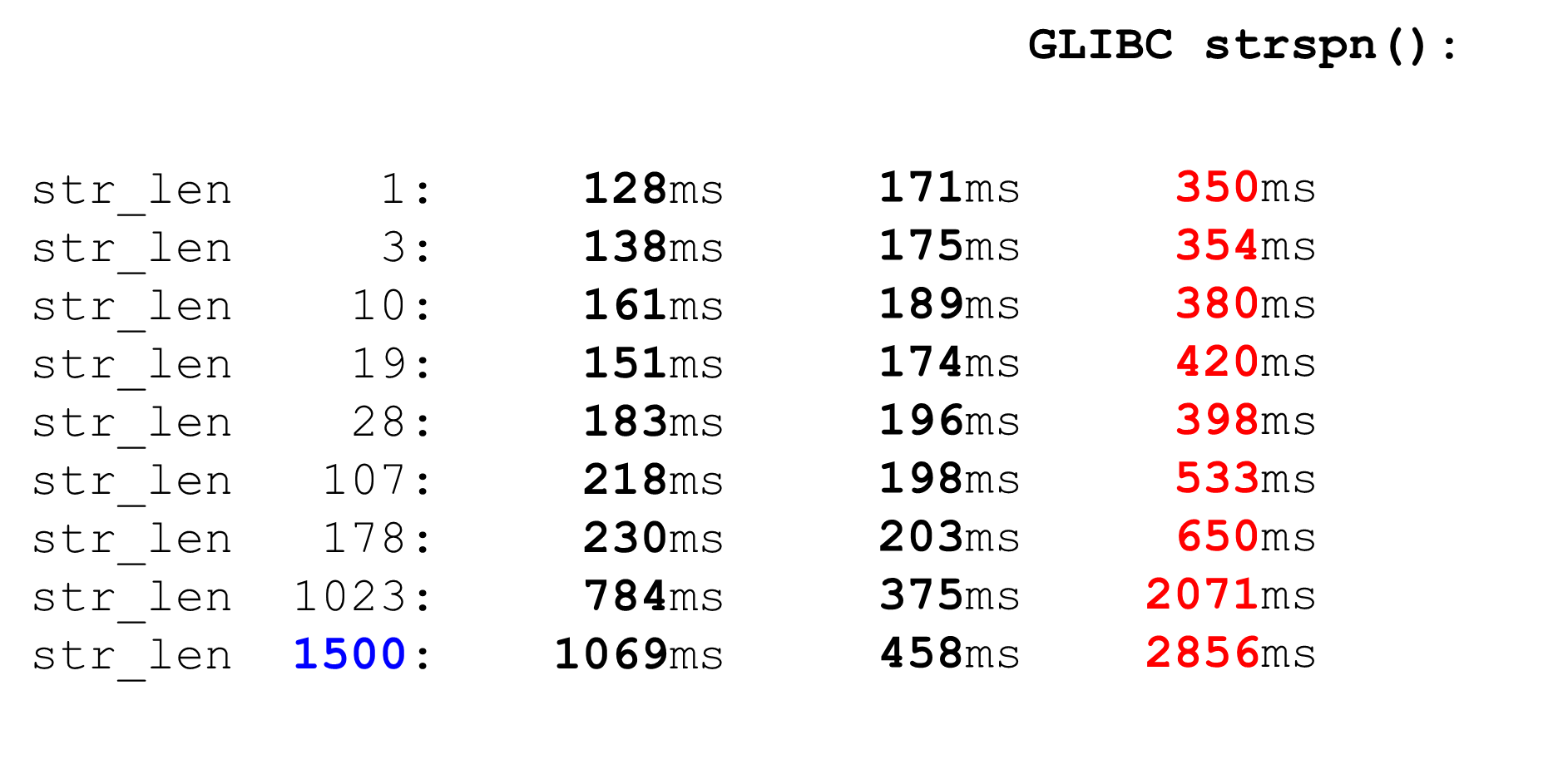
Наш парсер по скорости как эти два. На маленьких данных он такой же быстрый, как Pico-парсер, на больших — как CloudFlare. При этом он не пропускает недопустимые символы.

Как устроен парсер? Мы, как nginx, определяем массив байт и по нему проверяем входные данные — это пролог функции. Здесь мы работаем только с короткими сроками, используем
Основная петля и большой хвост. В основном цикле обработки мы делим данные: если они достаточно длинные, обрабатываем по 128, 64, 32 или по 16 байт. Имеет смысл обрабатывать по 128: мы параллельно используем несколько каналов процессора (несколько pipeline) и суперскалярность процессора.
Хвост. Конец функции похож на начало. Если у нас меньше 16 байт, то обрабатываем по 4 байта в цикле, а потом не больше 3 байт в конце.
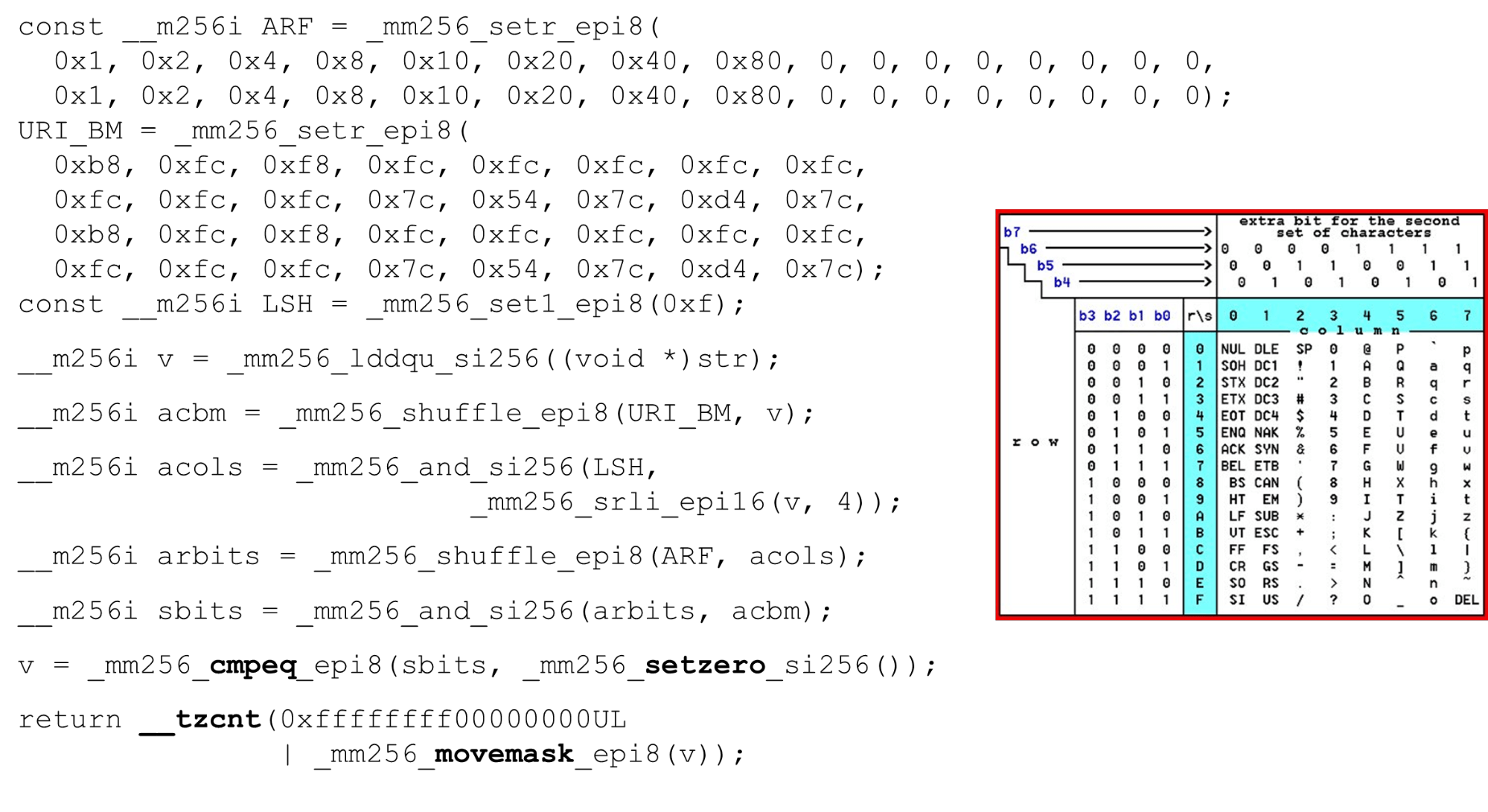
Загружаем битовые маски и данные — это основной алгоритм основного тела функции. Мы представляем таблицу ASCII (как на картинке) по 16 строк и 8 столбцов. Сначала кодируем наши строки таблицы в первом регистре URI BM: первую и вторую строку.
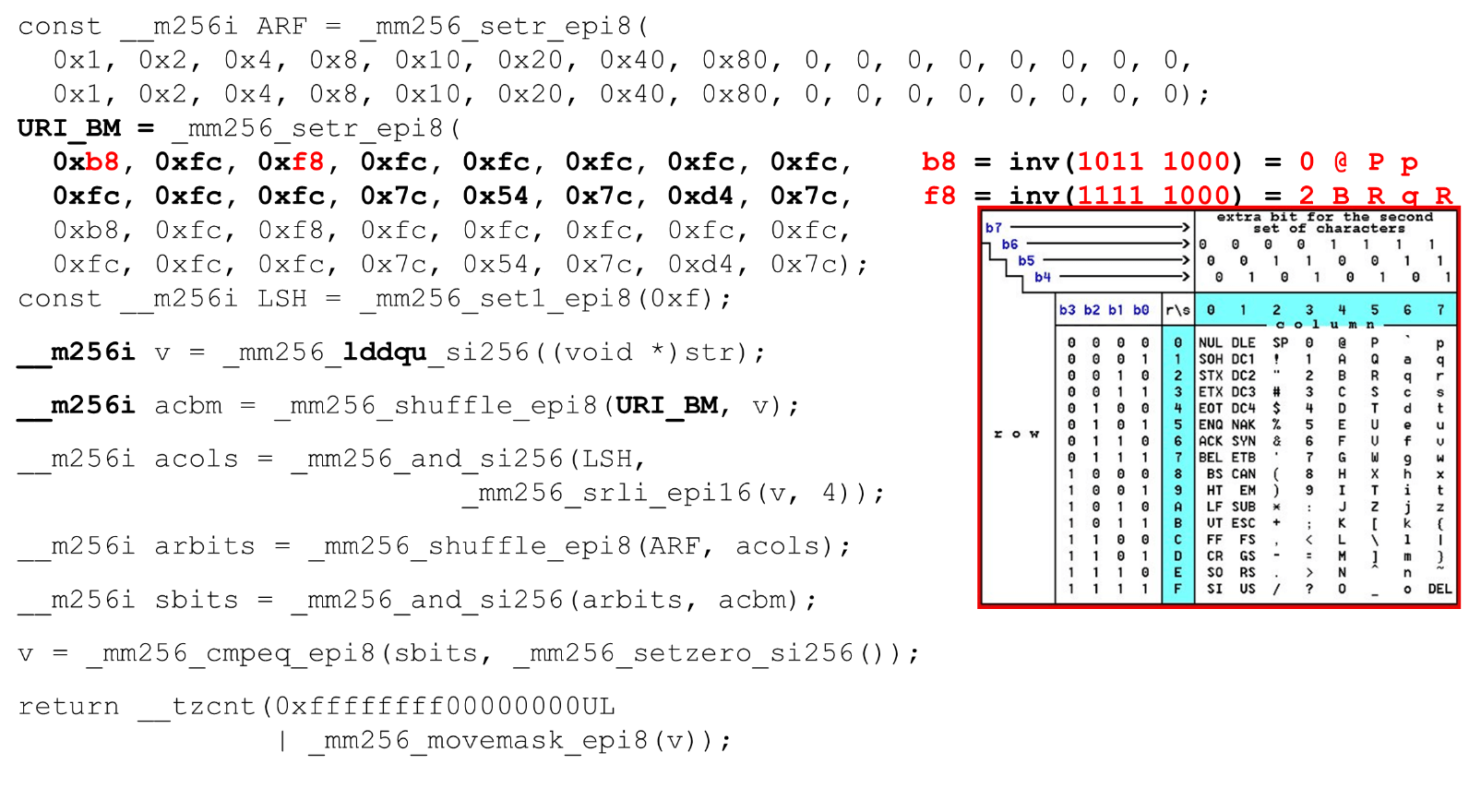
Актуальные символы, которые мы допускаем, это
Кодируем в обратном порядке: начинаем с 0, первый служебный символ недопустим, а потом единицы — то, что допустимо.
Расставляем битовые маски ASCII. Например, на вход приходит строка

ID столбцов для входных данных. Дальше располагаем колонки таблицы ASCII в другом регистре. Потом мы «пересечем» регистры колонок и строк, и получим соответствие: наш символ или нет.
Поскольку колонки — это старшие 4 бита от байта, мы сдвигаемся влево. У AVX есть смещение только по 2 байта, поэтому сначала смещаем байт, потом n с нашей маской, чтобы получить только значимые биты.

Располагаем столбцы ASCII. Запускаем второй shuffle, перемещаем колонку по нужным позициям. В обоих случаях байт входных данных из последней колонки, поэтому на первой и второй позиции получаем одну и ту же колонку.
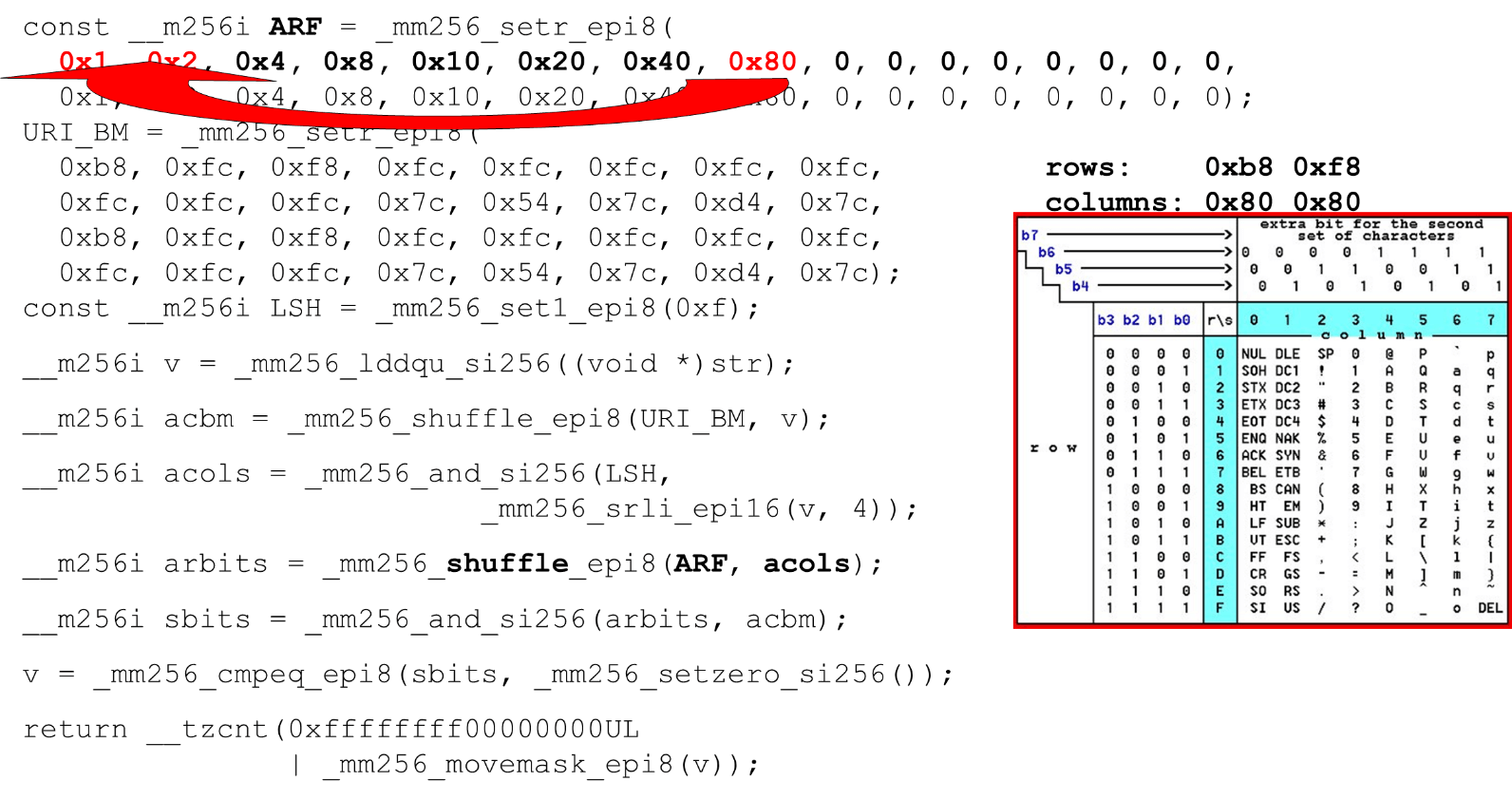
Пересечение колонок и строк масок. Делаем

Подсчитываем в конце количество нулей. Собираем это все из вектора в
Настраиваем алфавиты. Работая с таблицей ASCII, получаем дешевую фичу: используем статические таблицы, но ничто не мешает спрашивать пользователя, какой алфавит доступен для URI, имен и значений разных заголовков. В HTTP запросе URI и в заголовке используется 8 алфавитов (плюс-минус) для парсинга одного HTTP запроса. Эти таблицы можем загружать в этот же код и сравнивать по одному алфавиту, заданному пользователем, допустимый URI. Если нет — по-другому.
Несколько кейсов, когда это может быть полезно.
SSRF-атака с BlackHat'17(«A New Era of SSRF»):
RCE-атака: «perform effective command injection attacks like», BSides'16:
Relative Path Overwrite. Последний кейс — то, что было у Google в 2016 году. В URI приехали фигурные скобки, двоеточия —
Это достаточно тривиальный код. Мы тоже сравниваем строки по 32 байта, по два массива.
Приводим регистр только одной строки, потому что во второй мы запрограммировали константы в нашем парсере в нижнем регистре. Поскольку у нас сравнения знаковые, вычитаем по 128 из каждого байта (трюк из Hacker's Delight).
Также мы сравниваем диапазон допустимого символа: можем ли приводить регистр для этой строки или нет, это буква или нет. В момент проверки этого диапазон вместо двух сравнений от a до z можем использовать только одно сравнение (трюк из Hacker's Delight) и переместиться в константу.
Tempesta намного быстрее GLIBC, даже новой версии (18 или 19). Код

Мы используем векторные расширения процессора — они доступны в ядре. Векторные инструкции обрабатываются FPU модулем процессора. Это не основной модуль процессора, не основные регистры, но достаточно объемные.
Поэтому в Linux есть оптимизация. Если мы идем из ядра в user space и обратно, то не сохраняем контекст FPU регистров (XMM, YMM, ZMM): меняем контекст только регистров основного модуля процессора. Предполагается, что ядро ОС не работает с векторным расширением процессора. Но если вам это необходимо, например, для криптографии, можете это делать, но должны использовать
Это собственные макросы, которые сохраняют и восстанавливают состояние модуля процессора, который отвечает за векторные регистры. Это достаточно медленные ресурсы.
Перед бенчмарками сохранения и восстановления контекста FPU, пара слов о векторных операциях. Почему иногда есть смысл работать с ассемблером? Иногда GCC генерирует неоптимальный код. Проблема в том, что на старых моделях процессоров значительное пенальти от перехода кода с SSE на AVX. У GCC есть новый ключ
Нужно использовать эту инструкцию, только если вы работаете со старым кодом, который был скомпилирован для SSE какой-то третьей стороной. Это не наш случай и мы можем безопасно выкинуть эту инструкцию.
У нас есть автовекторизация в процессоре. Это значит, что в любом user space коде будут векторные операции.

Любые два процесса в системе используют векторные расширения процессора. Когда ваш процесс идет в ядро и обратно, вы не тратите время на сохранение и восстановление векторного состояния процессора. Но если переключаетесь из одного user space в другой (context switch), то кроме того, что там инвалидируются кэши первого уровня, еще и плохо работает модуль context switch на FPU begin/end. Операция достаточно дорогая — микробенчмарк.
В микробенчмарках всегда все драматизировано, но операция получается очень дорогая. Поэтому в user space переключать контекст долго. В ядре у нас нет переключения контекста, поэтому все быстро. Мы сохраняем и восстанавливаем векторный процессор только один раз на достаточно большой набор пакетов.
В начале, я показывал вариант lookup table для оптимизации switch-кода: долгий процесс, enum, компилируем switch-таблицу в массив и идем по двойному разыменовыванию указателя, перескакивающему по этому массиву. Это сценарий для Spectre-атаки, которая эксплуатирует спекулятивное исполнение.
У Google есть хорошая статья, как сейчас устроено двойное разыменовывание указателей в современных компиляторах (с начала 2018 года). Работает оно не очень хорошо. Если раньше в регистре хранился некоторый адрес и мы переходили по этому адресу, то теперь у нас другой код.
Как работает? Мы «вызываем» функцию на l1, процесс переходит на эту метку и мы делаем хак: как бы возвращаемся из функции (которой нет), но переписываем адрес возврата. Когда мы делаем инструкцию
Следующая относительно новая атака — Meltdown. Она специфична только для user space процессов. Очень болезненная — это чтение памяти ядра из пространства пользователя. Атаку предотвращает Kernel Pate Table Isolation (KPTI), который компилируется в новых ядрах по умолчанию. Но KPTI очень дорог, до 30-40% деградации производительности (по замерам MariaDB).
Это связано с тем, что у вас больше нет оптимизации lazy TLB: адресное пространство ядра и процессора полность разделяется в разных таблицах страниц (раньше lazy TLB держал маппинг пространства ядра таблице страниц каждого процесса). Для user space это болезненно, а для Tempesta FW, полностью работающей в ядре — нет.
Несколько полезных ссылок:
Александр Крижановский (krizhanovsky) основатель и системный архитектор Tempesta Technologies, эксперт в области высокопроизводительных вычислений в Linux/x86-64. Александр расскажет об особенностях структуры HTTP-строк, объяснит, почему стандартные библиотеки плохо подходят для их обработки, и представит решение Tempesta FW.
Под катом: как HTTP Flood превращает ваш HTTP-парсер в узкое место, проблемы x86-64 с branch mispredictions, кэшированием и не выровненной памятью на типичных задачах HTTP-парсера, сравнение FSM с прямыми переходами, оптимизация GCC, автовекторизация, strspn()- и strcasecmp()-like алгоритмы для HTTP-строк, SSE, AVX2 и фильтрация инъекционных атак с использованием AVX2.
В Tempesta Technologies мы разрабатываем софт на заказ: специализируемся в сложных областях, связанных с высокой производительностью. Особенно гордимся разработкой ядра первой версии WAF компании Positive Technologies. Web Application Firewall (WAF) — это HTTP-proxy: он занимается очень глубоким анализом HTTP-трафика на предмет атак (Web и DDoS). Мы написали для него первое ядро.
Кроме консалтинга мы разрабатываем Tempesta FW — это Application Delivery Controller (ADC). О нем и поговорим.
Application Delivery Controller
Application Delivery Controller — это HTTP-proxy c расширенной функциональностью. Но я расскажу о функции, которая связана с безопасностью — о фильтрации DDoS и Web-атак. Также упомяну об ограничениях, а работу и функции покажу с примерами кода.
Производительность
Tempesta FW встроена в ядро Linux TCP/IP Stack. Благодаря этому и ряду других оптимизаций, он очень быстрый — может обрабатывать 1,8 млн запросов в секунду на дешевом железе. Это в 3 раза быстрее Nginx на топовой нагрузке и также быстро, если сравнивать с kernel bypass approach.
На небольшом количестве ядер он показывает схожую производительность с проектом Seastar, который используется в ScyllaDB (написан на DPDK).
Проблема
Проект родился тогда же, когда мы приступили к работе над PT AF — в 2013 году. Этот WAF базировался на одном популярном Open Source HTTP-акселераторе. Nginx, HAProxy, Varnish или Apache Traffic — это хорошие HTTP-акселераторы: отлично доставляют контент, кэшируют, модифицируют, но ни один из них не предназначен для массивной обработки и фильтрации трафика.
Поэтому мы подумали, что если есть файрвол сетевого уровня, почему бы не продолжить эту идею и встроиться в качестве файрвола прикладного уровня в TCP/IP стек? Собственно, получился Tempesta FW — гибрид HTTP-акселератора и файрвола.
Примечание: Nginx будет использоваться в докладе как пример, потому, что это простой и популярный веб-сервер. Вместо него мог быть любой другой Open Source HTTP-сервер.
HTTP
Посмотрим на наш HTTP-запрос (HTTP/(1,~2))
У нас может быть очень большой URI. Красным жирным выделены разделители, которые важны в момент разбора HTTP. Выделю особенности: большие строки по несколько килобайт, а также разные разделители, например, дополнительные «точка с запятой», которые нам нужно парсить, или последовательность "\r\n".
Немного о HTTP/2 тоже нужно сказать.
Особенности HTTP/2
HTTP/2 — это смесь строк и двоичных данных. Этот микс относится больше к оптимизации пропускной способности соединения, чем к экономии ресурсов сервера.
HTTP/2 в HPACK использует динамическую таблицу. Первый запрос от клиента не оптимизирован, его нет в таблице. Вы его должны распарсить, чтобы он добавился в таблицу. Если к вам приходит HTTP/2 DDoS, это будет как раз тот случай. В нормальном случае HTTP/2 — это бинарный протокол, но вы все равно должны парсить текст: текстовые имена заголовков, данные.
Huffman-кодировка. Это простая кодировка, но Huffman чудовищно тяжело быстро запрограммировать для сжатия: Huffman-кодировка пересекает границу байта, нельзя пользоваться векторными расширениями и нужно идти по байтам. Не получится быстро обрабатывать данные по 32 или по 16 байт.
Cookie, User-Agent, Referer, URI могут быть очень большими. Сначала снимаете Huffman, потом отдаете в обычный HTTP-парсер, такой же, как в HTTP/1. Хотя это разрешено RFC, куки не рекомендуется сжимать, потому что это конфиденциальные данные — нельзя отдавать атакующему информацию об их размере.
Медленная HTTP-обработка. Все HTTP-серверы сначала декодируют HTTP/2 и потом отдают эти строки в HTTP/1-парсер, которым уже пользуется HTTP/1.
В чем проблема с парсингом HTTP/1?
- Надо быстро программировать state machine.
- Надо быстро обрабатывать последовательные строки.
Вредоносный трафик нацелен на самую медленную (самую слабую) часть процесса. Поэтому, если мы хотим сделать фильтр, то должны обращать внимание на медленные части, чтобы они тоже работали быстро.
Nginx-профиль
Посмотрим на nginx-профиль под HTTP-flood. Отключаем access log, чтобы не тормозила файловая система. Когда запрашивается даже обычная индексная страница, парсер поднимается в top'е.
| % | symbol name |
| 1,5719 | ngx_http_parse_header_line |
| 1,0303 | ngx_vslprintf |
| 0,6401 | memcpy |
| 0,5807 | recv |
| 0,5156 | ngx_linux_sendfile_chain |
| 0,4990 | ngx_http_limit_req_handler |
Как кодируются обычные HTTP-парсеры
Обычно у нас есть цикл (
while), который бежит по строке, и две переменные: состояния (state) и текущих данных (str_ptr).Входим в цикл (1) и смотрим текущее состояние (check state). Переходим на поступившие данные (символ
'b') и реализуем некоторую логику. Переходим на второе состояние (2).Переходим в конец
switch (3) — это уже второй переход относительно начала нашего кода и, возможно, второй промах в кэше инструкций. Дальше идем на начало while (4), съедаем следующий символ…… и снова ищем состояние в инструкции внутри
case 2:.Когда уже присвоили переменной
state значение 2, мы могли просто перейти на следующую инструкцию. Но вместо этого еще раз поднялись наверх и еще раз спустились. Мы «нарезаем круги» по коду вместо того, чтобы просто спуститься вниз. Нормальные парсеры так не делают, например, Ragel генерирует парсер с прямыми переходами.HTTP-парсер Nginx
Несколько слов о парсере nginx и его окружении.
Nginx работает с обычным API сокетов — данные, которые поступают на адаптер, копируются в user space. В результате у нас есть большой чанк данных, в котором ищем то, что нужно.
Nginx использует алгоритм, который работает за два прохода: сначала ищет длину, потом проверяет. На первом шаге он сканирует строку на токены, ищет первый токен («пробный»). На втором — токенизирует, проверяет конец запроса (
Get) и запускает switch, по размеру токена.for (p = b->pos; p < b->last; p++) {
...
switch (state) {
...
case sw_method:
if (ch == ' ') {
m = r->request_start;
switch (p - m) { // switch on token length!
case 3:
if (ngx_str3_cmp(m, 'G', 'E', 'T', ' ')) {
...
}
if ((ch < 'A' || ch > 'Z') && ch != '_' && ch != '-')
return NGX_HTTP_PARSE_INVALID_METHOD;
break;
...«Get» всегда находится в одном чанке данных. Tempesta FW работает с zero-copy. Это значит, что данные могут приходить с совершенно произвольным размером: по 1 байту или по 1000 байт. Этот «механизм» нам не подходит.
Посмотрим, как работает
switch в GCC.GCC
Lookup table. Слева — типичный пример enum: начинаем с 0, потом последовательные метки, 26 констант, а дальше некоторый код, который это все обрабатывает. Справа код, который генерирует компилятор.
Сначала сравниваем переменную
state в регистре EAX с константой. Дальше представляем все метки в виде последовательного массива указателей по 8 байт (lookup table). На этой инструкции переходим по смещению в этом массиве — это двойное разыменовывание указателей. Снизу справа код, на который мы перешли из этой таблицы.Получается двойное разыменовывание памяти: если мы получили секретные данные, то по байтам находим адрес в массиве и переходим по этому указателю. Важно знать, что в жизни все еще хуже, чем в примере — для lookup table компилятор генерирует код сложнее, в случае сценария для Spectre-атаки.
Бинарный поиск. Следующий кейс —
switch не с последовательными константами, а с произвольными. Код тот же, но теперь GCC не может скомпилировать такой большой массив и использовать константы в качестве индекса массива. Он переходит на бинарный поиск.Справа видим последовательное сравнение, переход на адрес и продолжение сравнения — бинарный поиск идет по коду.
HTTP-парсер nginx. Посмотрим, что такое state machine nginx. В ней 9 килобайт кода — это в три раза меньше, чем кэш первого уровня на машине, на которой запускались бенчмарки (как и на большинства x86-64 процессоров).
$ nm -S /opt/nginx-1.11.5/sbin/nginx
| grep http_parse | cut -d' ' -f 2
| perl -le '$a += hex($_) while (<>); print $a'
9220
$ getconf LEVEL1_ICACHE_SIZE
32768
$ grep -c 'case sw_' src/http/ngx_http_parse.c
84Парсер заголовков nginx
ngx_http_parse_header_line () — простой токенизатор. Он ничего не делает со значениями заголовков и их именами, а просто складывает токены HTTP-заголовков в хэш. Если вам нужно какое-то значение заголовка — просканируйте таблицу заголовков и повторите анализ.Мы же должны строго проверять имена и значения заголовков из соображений безопасности.
Tempesta FW: строгая валидация HTTP-строк
Наша state machine на порядок мощнее: мы делаем валидацию заголовков по RFC и сразу, в парсере, почти все обрабатываем. Если в nginx 80 состояний, то у нас — 520, и их становится больше. Если бы мы прогоняли на
switch, то он был бы в 10 раз больше.У нас zero-copy I/O — чанки разного размера могут резать данные в разных местах. разные чанки могут резать наши данные. В zero-copy I/O, например, «GET» может (редко) встречаться как «GET», «GE» и «T» или «G», «E» и «T», поэтому нужно хранить состояние между порциями данных. Мы практически убираем затраты на I/O, но в профиле взлетает вверх — все плохо. Большой HTTP-парсер одно из самых критичных мест в проекте.
$ grep -c '__FSM_STATE\|__FSM_TX\|__FSM_METH_MOVE\|__TFW_HTTP_PARSE_' http_parser.c
520
7.64% [tempesta_fw] [k] tfw_http_parse_req
2.79% [e1000] [k] e1000_xmit_frame
2.32% [tempesta_fw] [k] __tfw_strspn_simd
2.31% [tempesta_fw] [k] __tfw_http_msg_add_str_data
1.60% [tempesta_fw] [k] __new_pgfrag
1.58% [kernel] [k] skb_release_data
1.55% [tempesta_fw] [k] __str_grow_tree
1.41% [kernel] [k] __inet_lookup_established
1.35% [tempesta_fw] [k] tfw_cache_do_action
1.35% [tempesta_fw] [k] __tfw_strcmpspnЧто делать, чтобы улучшить эту ситуацию?
Прямые переходы FSM
Первое, что мы делаем — используем не цикл, а прямые переходы по меткам (
go to). Такпоступают нормальные генераторы парсеров, например, Ragel.Мы кодируем каждое наше состояние меткой в
switch и меткой языка C с таким же именем. Каждый раз, когда мы хотим перейти, мы находим метку в switch или обращаемся напрямую из кода к этому же состоянию. Первый раз мы идем через switch, а потом уже внутри него переходим сразу на нужную метку.Недостаток: когда мы хотим перейти на следующее состояние, то сразу должны оценить, есть ли у нас еще доступные данные (потому что zero-copy I/O). Тело условия
for копируется на каждое состояние: вместо одного условия в обычной switch-driven FSM, у нас их 500 — по числу состояний. Генерировать код на каждое состояние не здорово.В случае больших state machine, для
for с большим switch внутри, GTC тоже повторяет условие for несколько раз внутри кода.Заменяем
switch прямыми переходами. Следующая оптимизация — не используем switch и переходим на прямые переходы по сохраненным адресам метов. Мы хотим сразу перейти на нужную точку, как только зашли в функцию. GCC позволяет это делать.У GCC есть стандартное расширение, которое может помочь. Берем имя метки (здесь это
from) и присваиваем ее адрес некоторой C-переменной через двойной амперсанд (&&). Теперь можем сделать прямой переход инструкцией jmp на адрес этой метки с помощью goto.Посмотрим, что из этого получается.
Производительность прямых переходов
На маленьком количестве состояний кодогенератор прямых переходов даже немного медленнее, чем обычный
switch. Но для больших state machine производительность увеличивается в два раза. Если state machine небольшая, лучше пользоваться обычным switch.$ grep -m 2 'model name\|bugs' /proc/cpuinfo
model name : Intel(R) Core(TM) i7-6500U CPU @ 2.50GHz
bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf
$ gcc --version|head -1
gcc (GCC) 8.2.1 20181105 (Red Hat 8.2.1-5)
States Switch-driven automaton Goto-driven automaton
7 header_line: 139ms header_line: 156ms
27 request_line: 210ms request_line: 186ms
406 big_header_line: 1406ms goto_big_header_line: 727msПримечание: код Tempesta сложнее, чем в примерах. На GitHub есть все бенчмарки, чтобы вы посмотрели все в деталях. Оригинальный код парсера доступен по ссылке (основной HTTP-парсер). Кроме него, в Tempesta FW есть парсеры поменьше, которые используют FSM попроще.
Почему прямые переходы могут быть медленнее
В state machine мы много переходим по коду, поэтому (ожидаемо) будет много branch mispredictions. Выполним «профайлинг» по branch-misses prediction:
perf record -e branch-misses -g ./http_benchmark
406 states: switch - 38% on switch(),
direct jumps - 13% on header value parsing
7,27 states: switch - <18% switch(), up to 40% for()
direct jumps – up to 46% on header & URI parsingНа большой state machine в 406 состояний мы тратим 38% времени на обработку переходов в
switch. На state machine с прямыми переходами горячие точки — это парсинг строки. В парсинг строки в каждом состоянии входят проверки условия конца строки: условие for в state machine на switch.perf stat -e L1-icache-load-misses ./http_benchmark
Switch-driven automaton Goto-driven automaton
big FSM code size: 29156 49202
L1-icache-load-misses: 4M 2MДальше посмотрим на профилирование обоих типов state machine по эвентам L1 instruction cache miss — почти 30 килобайт для
switch и 50 килобайт для прямых переходов (больше, чем кэш первого уровня инструкции).Кажется, что если мы не помещаемся в кэш, должно быть очень много кэш-промахов для такой state machine. Но нет, их в 2 раза меньше. Все потому, что кэш работает лучше: мы последовательно работаем с кодом и успеваем подтянуть данные из старших кэшей.
Компилятор меняет порядок кода
Когда мы программируем код state machine на
go to, то сначала мы располагаем состояния, которые будут вызваны первыми при получении данных: HTTP-метод, URI, а потом HTTP-заголовки. Кажется логичным, что код будет загружаться в кэш процессора последовательно, сверху вниз, так же, как мы идем по данным. Но это совершенно не так. Если заглянуть в ассемблерный код, то увидим удивительные вещи.Слева — это то, что мы запрограммировали: сначала парсим методы
GET и POST, потом где-то далеко внизу маловероятный метод UNLOCK. Поэтому мы ожидаем увидеть в начале ассемблера парсинг GET и POST, а потом уже UNLOCK. Но все совершенно наоборот: GET в середине, POST в конце, а UNLOCK сверху.Это происходит потому, что компилятор не понимает, как к нам приходят данные. Он распределяет код в соответствии со своей картиной прекрасного кода. Чтобы он располагал код в правильном порядке, мы должны использовать компиляторный барьер.
Компиляторный барьер — это пустышка ассемблера, через которую компилятор не будет менять порядок. Просто расставив такие барьеры, мы улучшили производительность на 4%.
STATE(sw_method) {
... // the most frequent states
MATCH(NGX_HTTP_GET, "GET ");
MATCH(NGX_HTTP_POST, "POST");
__asm__ __volatile__("": : :"memory");
... // many other states
// Improbable states
METH_MOVE(Req_MethU, 'N', Req_MethUn);
METH_MOVE(Req_MethUn, 'L', Req_MethUnl);
METH_MOVE(Req_MethUnl, 'O', Req_MethUnlo);
METH_MOVE(Req_MethUnlo, 'C', Req_MethUnloc);
METH_MOVE_finish(Req_MethUnloc, 'K', NGX_HTTP_UNLOCK)Компонуем код по-своему
Раз компилятор не располагает данные так, как мы хотим, то сделаем profiler guided optimization (оптимизацию под управлением профилировщика). Profiler guided optimization (PGO) — общее количество выборок, а не последовательность вызовов. Например, URI получает больше выборок, чем анализ метода, поэтому расположит код обработки URI перед обработкой метода.
Как это работает? Напишем код, запустим на нем бенчмарки, отдадим результат профайлинга компилятору, и он сгенерирует оптимальный код для наших нагрузок. Но проблема в том, что он просто компилирует самые горячие участки кода, но не отслеживает зависимость по времени. Если самый большой в нагрузке URI, то это и будет самое горячее место. URI поднимется в топ функции, а PGO не покажет, что перед URI всегда находится имя метода. Соответственно, PGO не работает.
Req_Method: {
if (likely(PI(p) == CHAR4_INT('G', 'E', 'T', ' '))) {
...
goto Req_Uri;
}
if (likely(PI(p) == CHAR4_INT('P', 'O', 'S', 'T'))) {
...
goto Req_UriSpace;
}
goto Req_Meth_SlowPath;
}
... // other methods: POST, PUT etc.
Req_Uri:
... // URI processing
Req_Meth_SlowPath:
...Что же работает?
likely/unlikely макросы (для кода ядра Linux, в user space доступны интринзики GCC __builtin_expect()). Они говорят, какой код расположить ближе. Например, likely сообщает, что тело запроса должно находиться сразу за if. Тогда предвыборка кода (prefetching процессора) выберет этот код и все будет быстро.На картинке показано начало парсинга метода, конец и барьер. Мы совершенно не ожидали увидеть код за барьером. Кажется, такого быть не должно — мы же поставили барьер.
Но что происходит в реальности? Компилятор видит
likely условие — наиболее вероятно, что мы войдем в тело условия и там перейдем на безусловный переход на метку Req_Uri. Получается, что код, который находится после нашего условия не обрабатывается в «hot path». Компилятор двигает код под меткой за if, несмотря на барьер, потому что соблюдается условие горячего кода.Чтобы такого не было, GCC предлагает следующее расширение: это атрибуты
hot и cold для меток. Они говорят какая метка горячая (наиболее вероятная), а какая холодная (менее вероятная).Здесь мы соглашаемся с тем, что
GET вероятнее POST и оставляем для него likely. Под условие поднимается обработка URI, а POST уходит ниже. Весь другой код для наименее вероятных state machine остается внизу, потому что метка холодная.Неоднозначный -O3
Посмотрим на оптимизацию компилятора. Первое, что приходит в голову, использовать не O2, а O3 — должно быть быстрее. Но это не так — O3 иногда генерирует код хуже.
O3 — это набор некоторых оптимизаций. Если добавить их к O2 по отдельности, мы получим разные варианты: некоторые оптимизации помогают, некоторые мешают. Для нашего конкретного кода мы выбираем только те оптимизации, которые генерируют код лучше. Оставляем лучший результат — здесь 1,820 секунд относительно 1,838 и 1,858.
Зеленым выделены некоторые опции — это автовекторизация.
Автовекторизация
Пример цикла из гайда GCC.
int a[256], b[256], c[256];
void foo () {
for (int i = 0; i < 256; i++)
a[i] = b[i] + c[i];
}Если у нас есть некоторый переменный массив, который повторяется, мы можем оптимизировать цикл — разложить на векторы. По умолчанию на третьем уровне оптимизации -O3 включается автовекторизация: GCC генерирует векторный код где может. Но не весь код можно автоматически векторизовать (даже если он векторизуем в принципе).
Мы можем включить опцию GCC
-fopt-info-vec-all, которая показывает, что было векторизовано, а что нет. Получаем, что для нашего бенчмарка ничего не векторизуется, но код все равно генерируется хуже. Поэтому векторизация работает не всегда: иногда она замедляет код. Но мы всегда можем посмотреть, что векторизовалось, а что нет, и выключить векторизацию, если нужно.Выравнивание: как сравнить строку с GET?
Делаем небольшой хак, как в nginx: не парсим строки по байтам, а вычисляем
int и сравниваем им строки.#define CHAR4_INT(a, b, c, d) ((d << 24) | (c << 16) | (b << 8) | a)
if (p == CHAR4_INT('G', 'E', 'T', ' ')))
// we have GET as methodМы знаем, что если
int не выровнен, то он замедляется в 2-3 раза. Мы написали маленький бенчмарк, который это доказывает.$ ./int_align
Unaligned access = 6.20482
Aligned access = 2.87012
Read four bytes = 2.45249Тогда попробуем выравнивать
int. Будем смотреть, если адрес int выровненный, то сравниваем по int, если нет — по байтам. (((long)(p) & 3)
? ((unsigned int)((p)[0]) | ((unsigned int)((p)[1]) << 8)
| ((unsigned int)((p)[2]) << 16) | ((unsigned int)((p)[3]) << 24))
: *(unsigned int *)(p));Но оказывается, что такой подход работает хуже:
full request line: no difference
method only: unaligned - 214ms
aligned - 231ms
bytes - 216msЕсли коротко: есть разница между изолированным, неоптимизируемым, кодом бенчмарка и inlined кодом парсера, который теряет оптимизацию из-за большего объема кода. В профайлинге никаких пенальти не было.
Примечание: подробное обсуждение того, почему так происходит в нашей задаче, можно почитать на GitHub.
Почему нам важны строки HTTP?
Например, это нормальный URI:
Если вы достаточно привередливы к отелю, зайдете на Booking и зададите какие-то фильтры, получите URI больше килобайта.
У nginx стоит достаточно массивная машина парсинга на
switch/case. Она работает не очень быстро. Кроме того, в случае Tempesta FW, нам нужно не просто распарсить URI, но и проверить его на наличие инъекций.case sw_check_uri:
if (usual[ch >> 5] & (1U << (ch & 0x1f)))
break;
switch (ch) {
case '/':
r->uri_ext = NULL;
state = sw_after_slash_in_uri;
break;
case '.':
r->uri_ext = p + 1;
break;
case ' ':
r->uri_end = p;
state = sw_check_uri_http_09;
break;
case CR:
r->uri_end = p;
r->http_minor = 9;
state = sw_almost_done;
break;
case LF:
r->uri_end = p;
r->http_minor = 9;
goto done;
case '%':
r->quoted_uri = 1;
...Еще один URI: /redir_lang.jsp?lang=foobar%0d%0aContent-Length:%200%0d
%0a%0d%0aHTTP/1.1%20200%20OK%0d%0aContent-Type:%20text/
html%0d%0aContent-Length:%2019%0d%0a%0d%0aShazam</
html>.
Он выглядит как первый, но в нем есть инъекция. Придется достаточно много поковыряться, чтобы это понять.
Проведем тест: возьмем первый URI, скормим wrk, натравим на nginx и увидим, что парсинг nginx становится очень горячим.
Если на предыдущем обычном индексном запросе было видно, что парсер уже в топе, здесь становится еще горячее.
8.62% nginx [.] ngx_http_parse_request_line
2.52% nginx [.] ngx_http_parse_header_line
1.42% nginx [.] ngx_palloc
0.90% [kernel] [k] copy_user_enhanced_fast_string
0.85% nginx [.] ngx_strstrn
0.78% libc-2.24.so [.] _int_malloc
0.69% nginx [.] ngx_hash_find
0.66% [kernel] [k] tcp_recvmsgЧто особенного есть у строк HTTP? Разные разделители
' : ' и ' , ', и даже конец строк, который может быть, как двухбайтный \r\n, так и однобайтный \n, о чем говорил вначале. Нет 0-терминации C-строк — в целях безопасности мы хотим аккуратнее проверять, что нам приходит. У нас есть две стандартные функции, которые помогают в парсере.strspn: проверяет алфавит, доступные символы в строке, динамически компилирует допустимый алфавит, хотя он известен на этапе компиляции программы.strcasecmp(). Нет необходимости в преобразовании регистра для сравненияxсFoo:. В большинстве случаев дляstrcasecmp()требуется только соответствие / несоответствие, а знать позицию в строке не нужно.
Они работают медленно. Посмотрим бенчмарки и поймем, что в них не так.
Быстрые парсеры
Есть несколько парсеров.
Nginx — простейший парсер, синтаксический анализатор Он строго проверяет соответствие RFC. Есть еще парсеры PicoHTTPParser (H2O) и Cloudflare. Они быстрее обрабатывают данные, но могут пропустить символы, которые недопустимы по RFC.
PCMESTRI. В парсерах используется несколько разных подходов. Первый — это инструкция PCMESTRI, которая используется в Pico-парсере.
Задаем диапазоны (ranges) в инструкции. К сожалению, мы можем загрузить либо 16 символов, либо 8 диапазонов. Если диапазон состоит всего из одного символа — просто повторяем. Из-за этого ограничения Pico-парсер не может полностью проверить соответствие RFC, потому что в данном месте у RFC больше 8 диапазонов.
Загружаем алфавит в регистр, загружаем строку, исполняем инструкцию. На выходе быстро видим — есть совпадение или нет.
AVX2 — подход CloudFlare. CloudFlare-парсер с помощью AVX2 обрабатывает за раз 32 байта строки, вместо 16 байт у Pico-парсера. В CloudFlare лучше парсинг, потому что его перевели его на AVX2.
Проверяем все символы до пробела по таблице ASCII, все символы больше 128 и берем диапазон между ними. Простой код работает быстро.
Сравним PCMESTRI и AVX2. Для нас актуальный лимит — 1500. Это максимальный размер пакета, который к нам приходит. Видим, что AVX2-код на больших данных работает намного быстрее, чем Pico-парсер. Но работает медленнее на маленьких данных, потому что в AVX2 инструкции тяжелее.
Сравним с
strspn. Если мы решим использовать strspn — все становится хуже, особенно на больших данных. В «боевом» парсере нельзя использовать strspn.Tempesta matcher быстрее и точнее
Наш парсер по скорости как эти два. На маленьких данных он такой же быстрый, как Pico-парсер, на больших — как CloudFlare. При этом он не пропускает недопустимые символы.
Как устроен парсер? Мы, как nginx, определяем массив байт и по нему проверяем входные данные — это пролог функции. Здесь мы работаем только с короткими сроками, используем
likely, потому что branch misprediction для коротких строк болезненнее, чем для длинных. Выносим этот код наверх. У нас есть ограничение в 4 из-за последней строчки — мы должны написать достаточно мощное условие. Если будем обрабатывать больше 4 байт, то условие будет тяжелее, а код медленнее.static const unsigned char uri_a[] __attribute__((aligned(64))) = {
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
...
// Branch misprediction is more crucial for short strings
if (likely(len <= 4)) {
switch (len) {
case 0:
return 0;
case 4:
c3 = uri_a[s[3]];
// fall through to process other chars
case 3:
c2 = uri_a[s[2]];
case 2:
c1 = uri_a[s[1]];
case 1:
c0 = uri_a[s[0]];
}
return (c0 & c1) == 0 ? c0 : 2 + (c2 ? c2 + c3 : 0);
}Основная петля и большой хвост. В основном цикле обработки мы делим данные: если они достаточно длинные, обрабатываем по 128, 64, 32 или по 16 байт. Имеет смысл обрабатывать по 128: мы параллельно используем несколько каналов процессора (несколько pipeline) и суперскалярность процессора.
for ( ; unlikely(s + 128 <= end); s += 128) {
n = match_symbols_mask128_c(__C.URI_BM, s);
if (n < 128)
return s - (unsigned char *)str + n;
}
if (unlikely(s + 64 <= end)) {
n = match_symbols_mask64_c(__C.URI_BM, s);
if (n < 64)
return s - (unsigned char *)str + n;
s += 64;
}
if (unlikely(s + 32 <= end)) {
n = match_symbols_mask32_c(__C.URI_BM, s);
if (n < 32)
return s - (unsigned char *)str + n;
s += 32;
}
if (unlikely(s + 16 <= end)) {
n = match_symbols_mask16_c(__C.URI_BM128, s);
if (n < 16)
return s - (unsigned char *)str + n;
s += 16;
}Хвост. Конец функции похож на начало. Если у нас меньше 16 байт, то обрабатываем по 4 байта в цикле, а потом не больше 3 байт в конце.
while (s + 4 <= end) {
c0 = uri_a[s[0]];
c1 = uri_a[s[1]];
c2 = uri_a[s[2]];
c3 = uri_a[s[3]];
if (!(c0 & c1 & c2 & c3)) {
n = s - (unsigned char *)str;
return !(c0 & c1) ? n + c0 : n + 2 + (c2 ? c2 + c3 : 0);
}
s += 4;
}
c0 = c1 = c2 = 0;
switch (end - s) {
case 3:
c2 = uri_a[s[2]];
case 2:
c1 = uri_a[s[1]];
case 1:
c0 = uri_a[s[0]];
}
n = s - (unsigned char *)str;
return !(c0 & c1) ? n + c0 : n + 2 + c2;Загружаем битовые маски и данные — это основной алгоритм основного тела функции. Мы представляем таблицу ASCII (как на картинке) по 16 строк и 8 столбцов. Сначала кодируем наши строки таблицы в первом регистре URI BM: первую и вторую строку.
Актуальные символы, которые мы допускаем, это
0 @ P p и 2 B R q R. Кодируются они так: b8 = inv(1011 1000) = 0 @ P p, f8 = inv(1111 1000) = 2 B R q R.Кодируем в обратном порядке: начинаем с 0, первый служебный символ недопустим, а потом единицы — то, что допустимо.
Расставляем битовые маски ASCII. Например, на вход приходит строка
"pr": первый символ из первой строки ASCII, второй из второй строки. Запускаем инструкцию shuffle, которая перемешивает наши закодированные строки таблицы в соответствии с порядком этих символов во входных данных.ID столбцов для входных данных. Дальше располагаем колонки таблицы ASCII в другом регистре. Потом мы «пересечем» регистры колонок и строк, и получим соответствие: наш символ или нет.
Поскольку колонки — это старшие 4 бита от байта, мы сдвигаемся влево. У AVX есть смещение только по 2 байта, поэтому сначала смещаем байт, потом n с нашей маской, чтобы получить только значимые биты.
Располагаем столбцы ASCII. Запускаем второй shuffle, перемещаем колонку по нужным позициям. В обоих случаях байт входных данных из последней колонки, поэтому на первой и второй позиции получаем одну и ту же колонку.
Пересечение колонок и строк масок. Делаем
and («пересекаем» колонки со столбцами) и получаем, что входные данные допустимы — результат and от пересечения колонки и строк не нулевой.Подсчитываем в конце количество нулей. Собираем это все из вектора в
int и возвращаем на выход — достаточно просто.Настраиваем алфавиты. Работая с таблицей ASCII, получаем дешевую фичу: используем статические таблицы, но ничто не мешает спрашивать пользователя, какой алфавит доступен для URI, имен и значений разных заголовков. В HTTP запросе URI и в заголовке используется 8 алфавитов (плюс-минус) для парсинга одного HTTP запроса. Эти таблицы можем загружать в этот же код и сравнивать по одному алфавиту, заданному пользователем, допустимый URI. Если нет — по-другому.
Атаки
Несколько кейсов, когда это может быть полезно.
SSRF-атака с BlackHat'17(«A New Era of SSRF»):
http://foo@evil.com:80@google.com/ — маловероятный символ амперсанда. В некоторых приложениях он используется, в некоторых нет. Но если у вас не используется, можете исключить из допустимого алфавите и атака будет заблокирована.RCE-атака: «perform effective command injection attacks like», BSides'16:
User-Agent: ...;echo NAELBD$((26+58))$echo(echo NAELBD)NAELBD.... User-Agent — статический хедер, но есть случаи RCE-атаки, когда приходит некоторый shell с нетипичными символами для User-Agent. Защищаемся исключая знак доллара.Relative Path Overwrite. Последний кейс — то, что было у Google в 2016 году. В URI приехали фигурные скобки, двоеточия —
.../gallery?q=%0a{}*{background:red}/..//apis/howto_guide.html. Это маловероятные символы, которые можно исключить из алфавита.strcasecmp()
Это достаточно тривиальный код. Мы тоже сравниваем строки по 32 байта, по два массива.
__m256i CASE = _mm256_set1_epi8(0x20);
// Hacker’s Delight for signed comparison: -0x80 for both operands
__m256i A = _mm256_set1_epi8('A' – 0x80);
__m256i D = _mm256_set1_epi8('Z' - 'A' + 1 – 0x80);
// Hacker’s Delight: 'a' <= v <= 'z' to
// v - ('a' – 0x80) < 'z' - 'a' + 1 - 0x80
__m256i sub = _mm256_sub_epi8(str1, A);
__m256i cmp_r = _mm256_cmpgt_epi8(D, sub);
__m256i lc = _mm256_and_si256(cmp_r, CASE);
__m256i vl = _mm256_or_si256(str1, lc);
__m256i eq = _mm256_cmpeq_epi8(vl, str2);
return ~_mm256_movemask_epi8(eq);Приводим регистр только одной строки, потому что во второй мы запрограммировали константы в нашем парсере в нижнем регистре. Поскольку у нас сравнения знаковые, вычитаем по 128 из каждого байта (трюк из Hacker's Delight).
Также мы сравниваем диапазон допустимого символа: можем ли приводить регистр для этой строки или нет, это буква или нет. В момент проверки этого диапазон вместо двух сравнений от a до z можем использовать только одно сравнение (трюк из Hacker's Delight) и переместиться в константу.
Производительность strcasecmp()
Tempesta намного быстрее GLIBC, даже новой версии (18 или 19). Код
strcasecmp() тоже использует AVX, но не вторую версию. С AVX2 получается быстрее, поэтому у Tempesta код быстрее.FPU в ядре Linux
Мы используем векторные расширения процессора — они доступны в ядре. Векторные инструкции обрабатываются FPU модулем процессора. Это не основной модуль процессора, не основные регистры, но достаточно объемные.
Поэтому в Linux есть оптимизация. Если мы идем из ядра в user space и обратно, то не сохраняем контекст FPU регистров (XMM, YMM, ZMM): меняем контекст только регистров основного модуля процессора. Предполагается, что ядро ОС не работает с векторным расширением процессора. Но если вам это необходимо, например, для криптографии, можете это делать, но должны использовать
fpu_begin и fpu_end для сохранения и восстановления контекста FPU регистров:__kernel_fpu_begin_bh();
memcpy_avx(dst, src, n);
__kernel_fpu_end_bh();
Это собственные макросы, которые сохраняют и восстанавливают состояние модуля процессора, который отвечает за векторные регистры. Это достаточно медленные ресурсы.
AVX и SSE
Перед бенчмарками сохранения и восстановления контекста FPU, пара слов о векторных операциях. Почему иногда есть смысл работать с ассемблером? Иногда GCC генерирует неоптимальный код. Проблема в том, что на старых моделях процессоров значительное пенальти от перехода кода с SSE на AVX. У GCC есть новый ключ
vzeroupper — используйте его, чтобы он не генерировал эту инструкцию vzeroupper, которая очищает регистры и убирает это пинальти.Нужно использовать эту инструкцию, только если вы работаете со старым кодом, который был скомпилирован для SSE какой-то третьей стороной. Это не наш случай и мы можем безопасно выкинуть эту инструкцию.
FPU
У нас есть автовекторизация в процессоре. Это значит, что в любом user space коде будут векторные операции.
Любые два процесса в системе используют векторные расширения процессора. Когда ваш процесс идет в ядро и обратно, вы не тратите время на сохранение и восстановление векторного состояния процессора. Но если переключаетесь из одного user space в другой (context switch), то кроме того, что там инвалидируются кэши первого уровня, еще и плохо работает модуль context switch на FPU begin/end. Операция достаточно дорогая — микробенчмарк.
В микробенчмарках всегда все драматизировано, но операция получается очень дорогая. Поэтому в user space переключать контекст долго. В ядре у нас нет переключения контекста, поэтому все быстро. Мы сохраняем и восстанавливаем векторный процессор только один раз на достаточно большой набор пакетов.
Intelpocalypse
В начале, я показывал вариант lookup table для оптимизации switch-кода: долгий процесс, enum, компилируем switch-таблицу в массив и идем по двойному разыменовыванию указателя, перескакивающему по этому массиву. Это сценарий для Spectre-атаки, которая эксплуатирует спекулятивное исполнение.
У Google есть хорошая статья, как сейчас устроено двойное разыменовывание указателей в современных компиляторах (с начала 2018 года). Работает оно не очень хорошо. Если раньше в регистре хранился некоторый адрес и мы переходили по этому адресу, то теперь у нас другой код.
jmp *%r11
call l1
l0: pause
lfence
jmp l0
l1: mov %r11, (%rsp)
retКак работает? Мы «вызываем» функцию на l1, процесс переходит на эту метку и мы делаем хак: как бы возвращаемся из функции (которой нет), но переписываем адрес возврата. Когда мы делаем инструкцию
call, на стеке располагаем адрес возврата, текущий адрес, переписываем нужным содержимым регистра и переходим на l1. Но процессор, когда работает его prefetcher, видит, что здесь функция, а дальше барьер. Соответственно, все будет медленно — он бросает prefetching и мы избавляемся от уязвимости Spectre. Код получается медленный, производительность падает на 15%.Следующая относительно новая атака — Meltdown. Она специфична только для user space процессов. Очень болезненная — это чтение памяти ядра из пространства пользователя. Атаку предотвращает Kernel Pate Table Isolation (KPTI), который компилируется в новых ядрах по умолчанию. Но KPTI очень дорог, до 30-40% деградации производительности (по замерам MariaDB).
Это связано с тем, что у вас больше нет оптимизации lazy TLB: адресное пространство ядра и процессора полность разделяется в разных таблицах страниц (раньше lazy TLB держал маппинг пространства ядра таблице страниц каждого процесса). Для user space это болезненно, а для Tempesta FW, полностью работающей в ядре — нет.
Несколько полезных ссылок:
Мы приняли решение перенести конференцию Saint HighLoad++ с апреля на август или сентябрь этого года. Но чтобы не останавливать наше профессиональное общение, 6 апреля проведём мини-онлайн-конференцию (бесплатную для всех, у кого есть билеты на Saint HighLoad++) и надеемся, что Александр Крижановский расскажет нам о механике web акселерации.
Так же мы поступим с PHP Russia: 13 мая небольшой онлайн, офлайн осенью. А вот для трех других конференций — KnowledgeConf, РИТ++ и TechLead Conf — создаем новый продукт в онлайне. Следите за нами в рассылке или соцсетях, расскажем, что и как сработает.